
Sensitivity Analysis of the Inverse Distance Weighting and Bicubic Spline Smoothing Models for MERRA-2 Reanalysis PM2.5 Series in the Persian Gulf Region



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
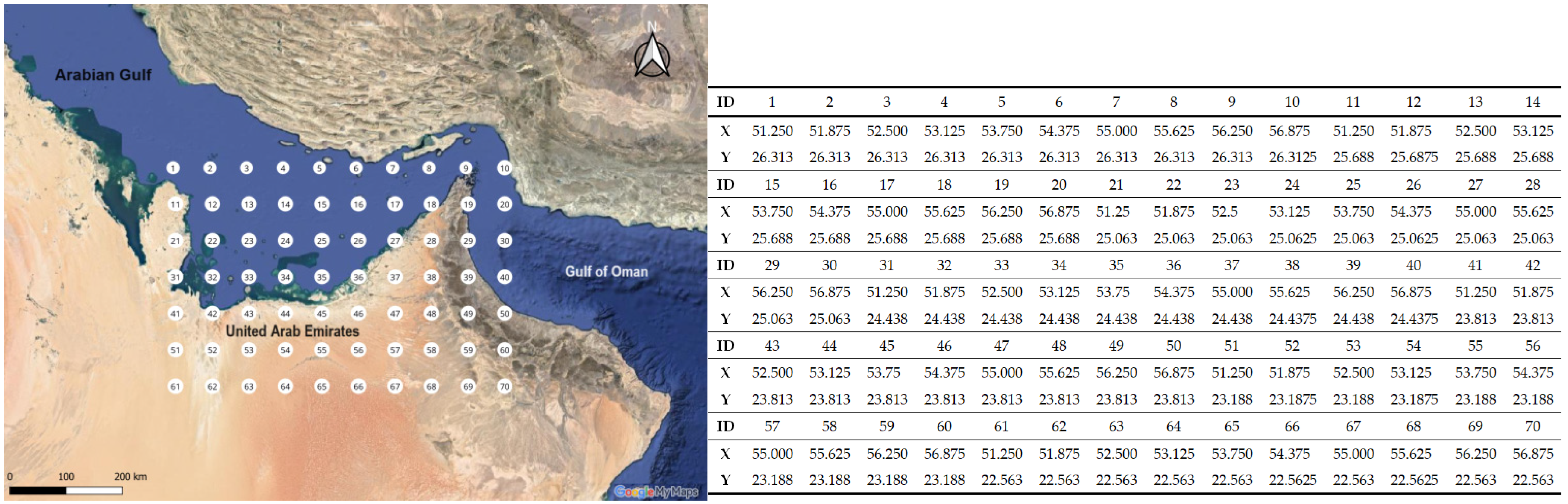
2.1. Data Series
2.2. Modeling
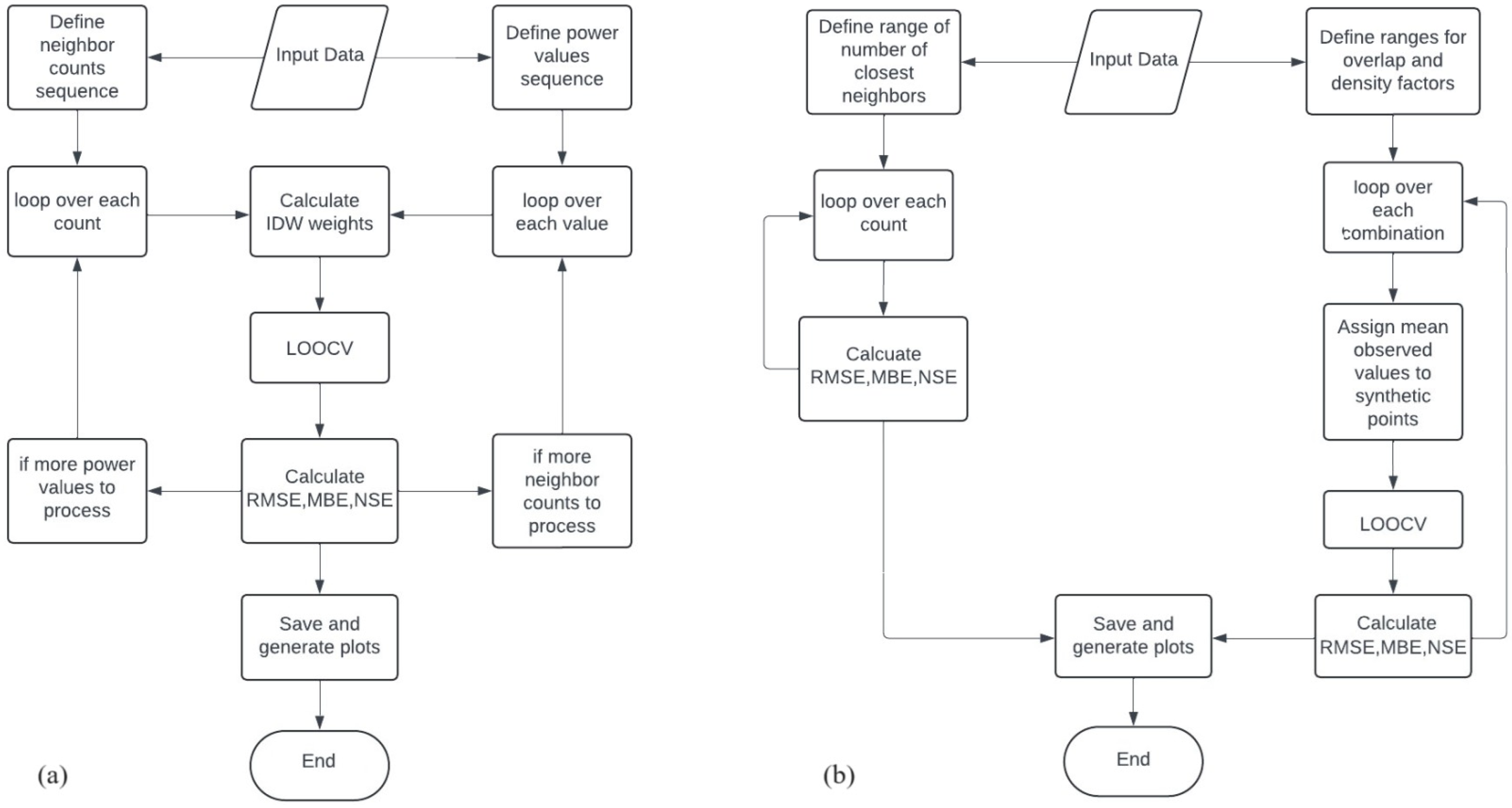
2.3. Sensitivity Analysis
- Varying the power parameter β, which determines the weight given to each data point based on its distance from the prediction site. This step involves varying β from 1 to 10 (in a sequence of 30 equidistant points);
- Consider a different number of neighbors included in the weighting process (2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 50, 60, and 70).
- The number of closest data points included in calculating the mean values for PM2.5 concentration to be assigned to the buffer points;
- The overlap and distribution of buffer points.
- The number of closest data points directly influences how the interpolation captures local spatial variations. Adjusting the number of closest points allows us to understand the balance between the local detail and the risk of incorporating noise or overfitting to local anomalies. It helps tailor the model to be sensitive to local spatial structures while maintaining general robustness;
- By experimenting with how buffer points are distributed and potentially overlap with the dataset, we are essentially modifying the model’s edge behavior and ability to extrapolate beyond the observed data domain. This can significantly affect the interpolation quality at the dataset’s boundaries, an area often prone to inaccuracies.
3. Results
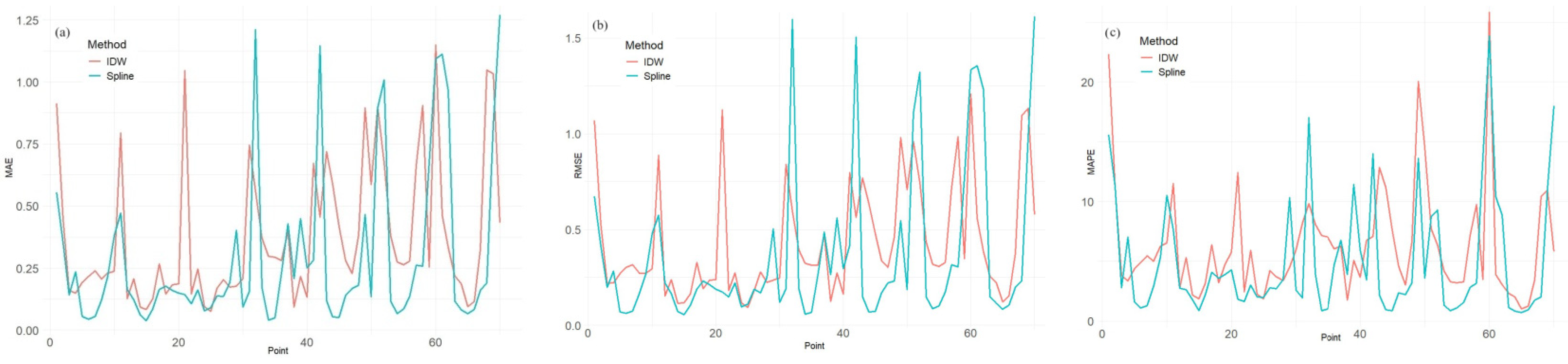
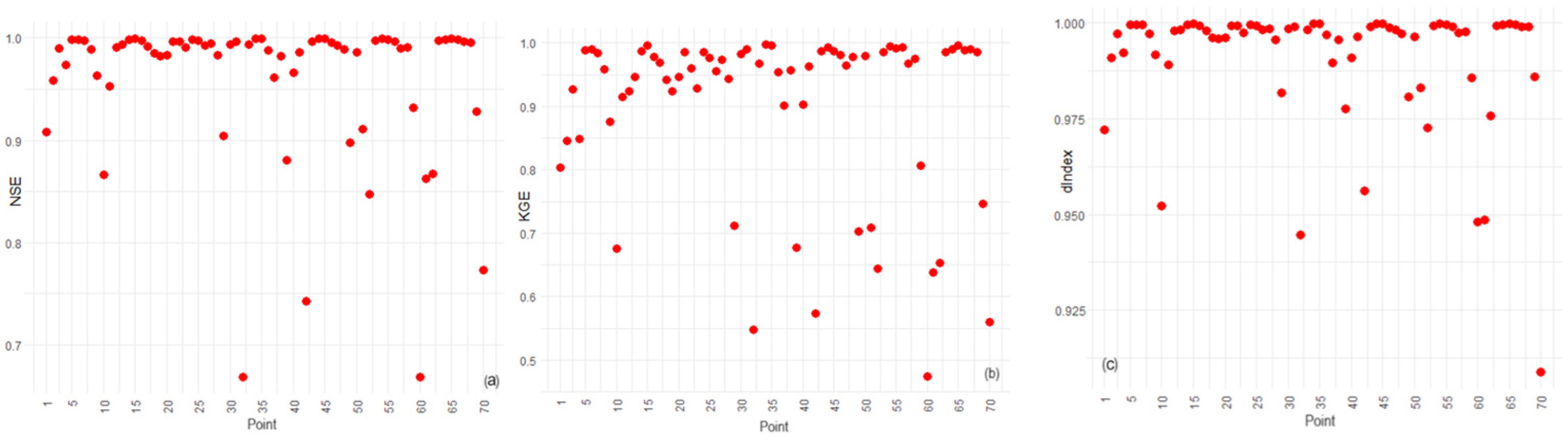
3.1. Modeling Results
3.2. Sensitivity Analysis of IDW

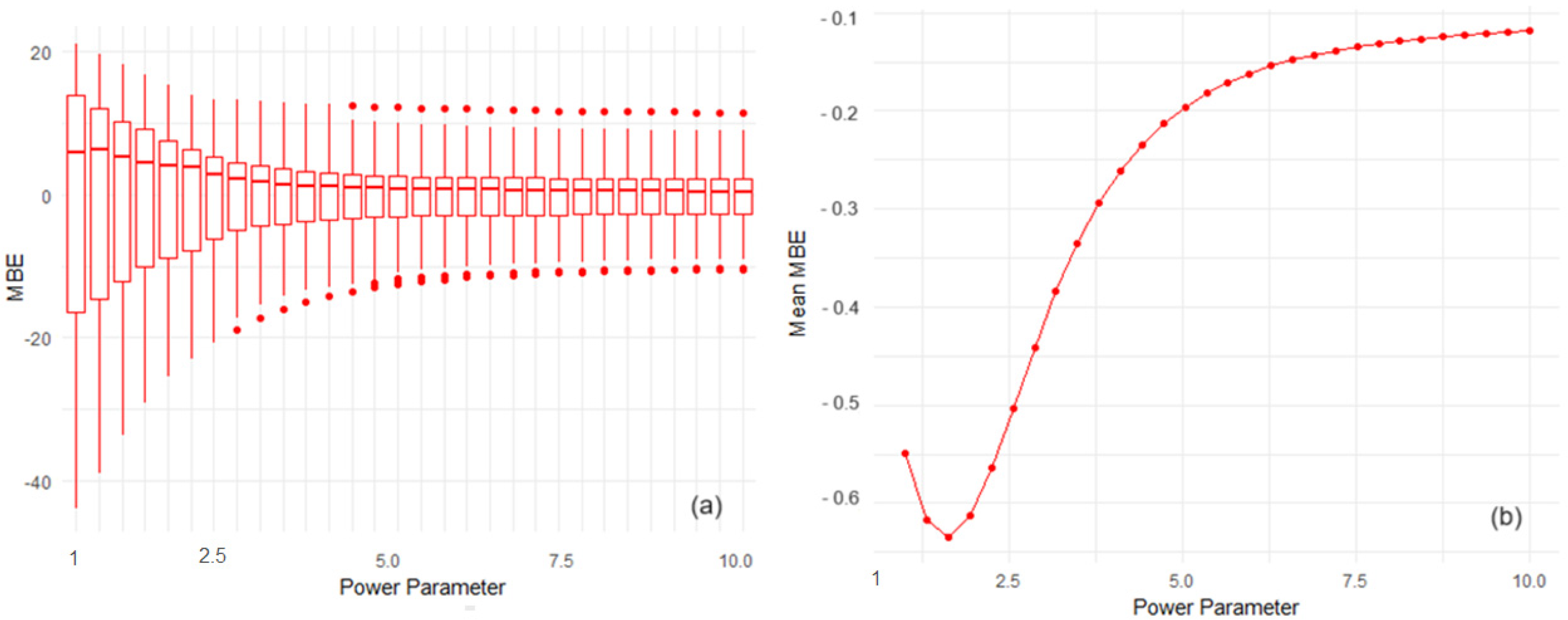
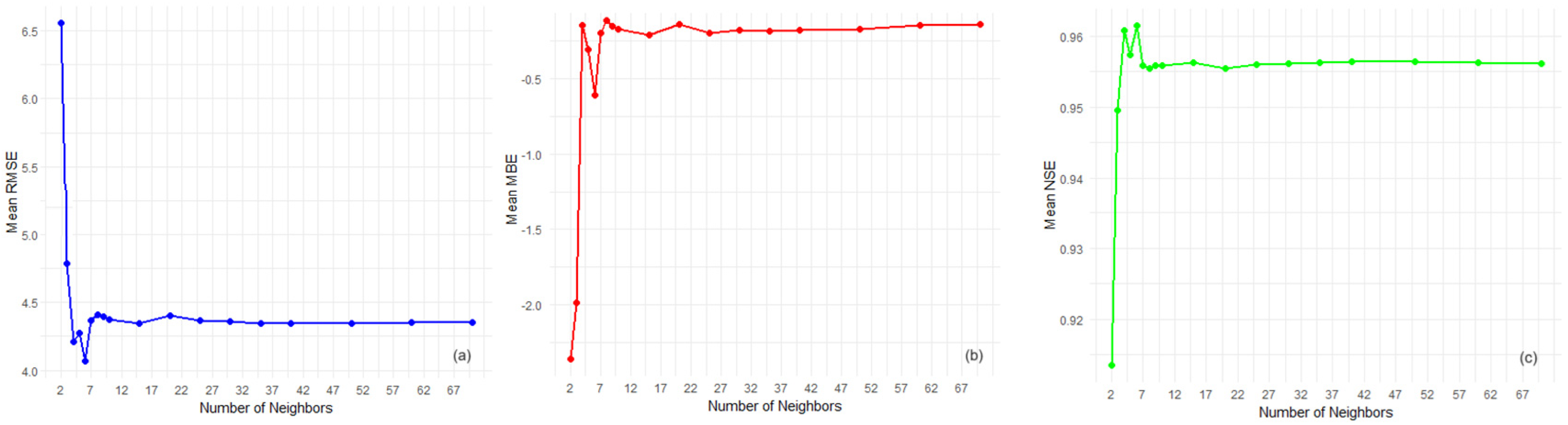
- The Mean RMSE is inversely related to the number of neighbors, at least up to a certain point. The highest RMSE is observed when the lowest number of neighbors (m = 2) is used, indicating the least accurate predictions with a Mean RMSE of about 6.5. There is a marked improvement in the prediction accuracy as the number of neighbors increases to m = 6, where the Mean RMSE drops to its lowest value of around 4.0. Beyond m = 7, the RMSE increases slightly to approximately 4.45 and then levels off, suggesting a plateau in model performance with additional neighbors providing no significant improvement in accuracy;
- The MBE plot shows that all values are negative, implying a consistent underestimation across different numbers of neighbors. The most pronounced bias occurs at m = 2 with a Mean MBE of around −2.3. There is a sharp improvement as m increases to 4, with Mean MBE rising to about −0.12. Interestingly, there is a slight increase in bias again at m = 6 before it settles back to approximately −0.2 at m = 7 and then stabilizes. This pattern suggests that the model bias is significantly reduced as neighbors are increased from the minimum, but only up to a point, after which the benefit diminishes;
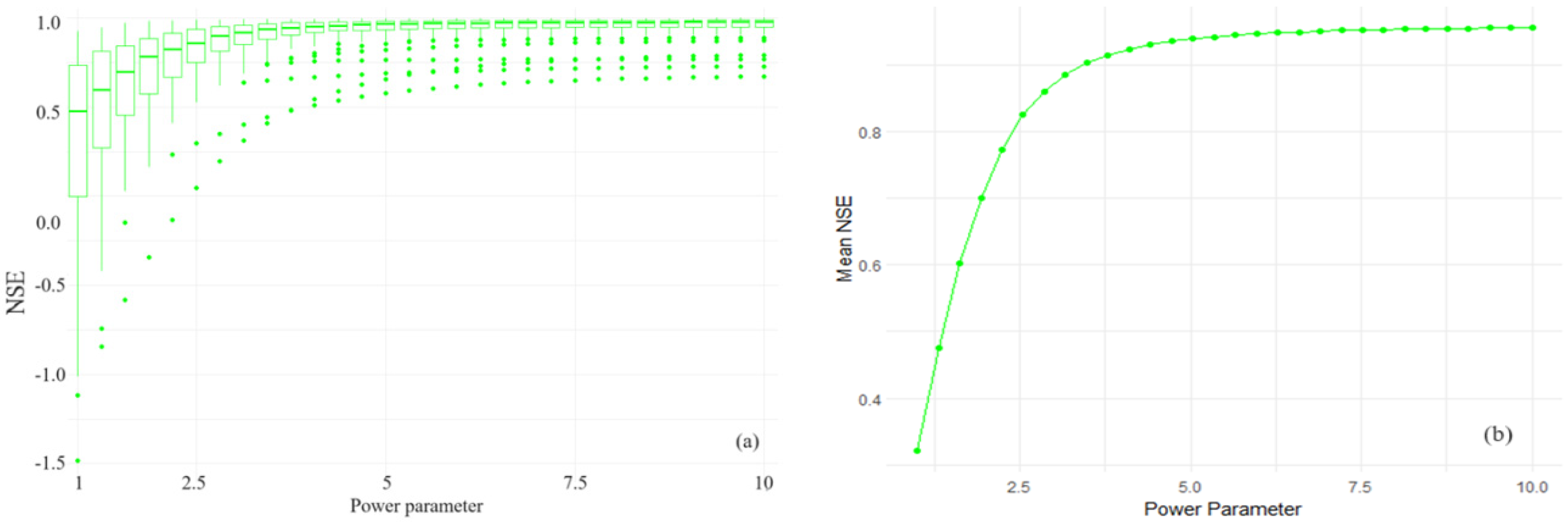
- The lowest NSE value at m = 2 indicates a poor model performance relative to the mean of the observed data. As the number of neighbors increases to m = 6, there is a significant improvement in NSE to a peak of around 0.9605, suggesting that the model’s predictive accuracy is much better. However, the subsequent drop in NSE at m = 7 and the plateau after that suggest that including more than six neighbors does not substantially capture additional variability in the data;
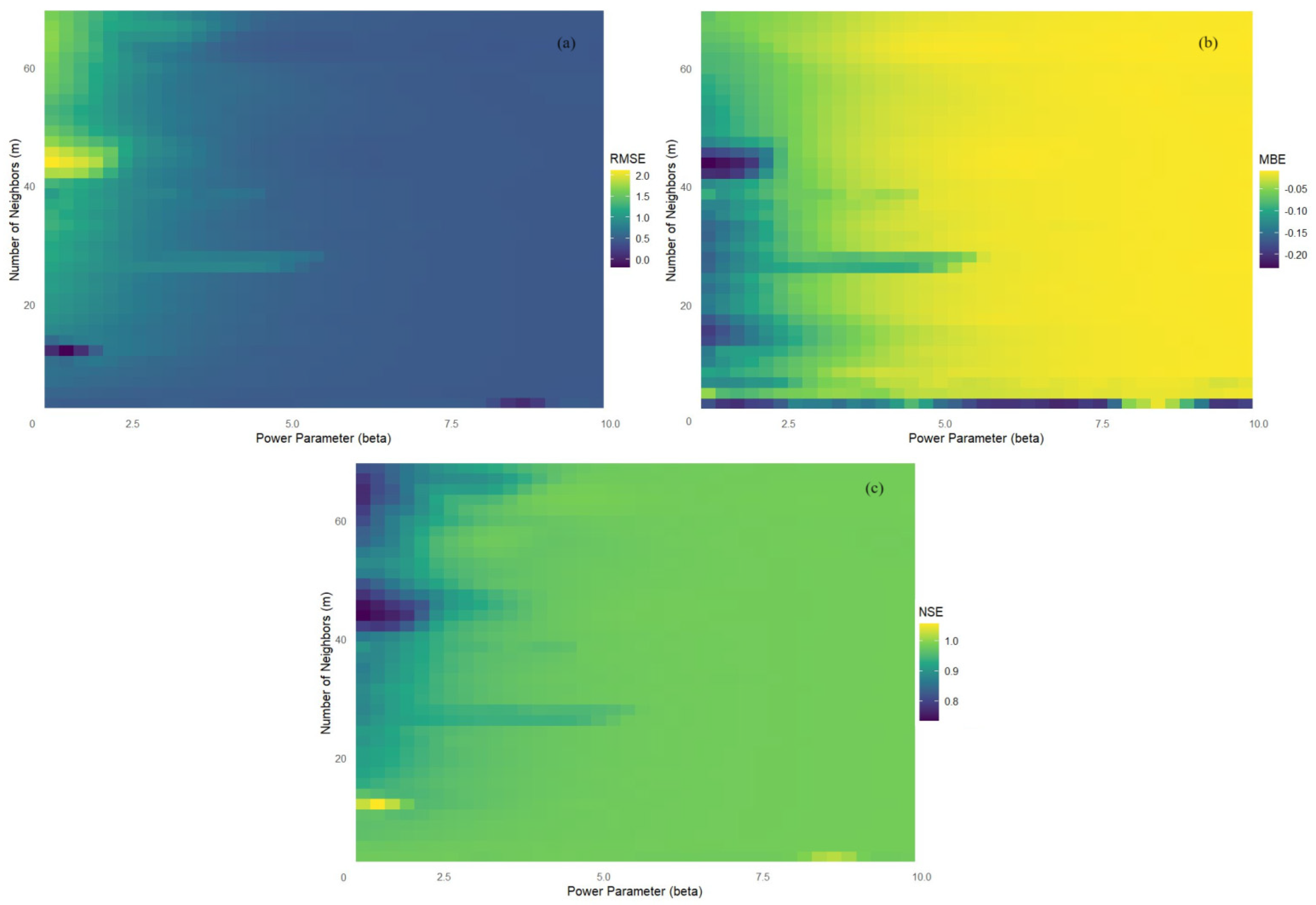
- Figure 11a indicates that for β > 2.5, RMSE does not depend on m (at least for m > 4) because, in this case, only the nearest neighbors play a significant role in interpolation. For β > 4, most MBE values are between −0.05 and 0, indicating a suitable fit of the interpolation model. NSE is almost constant as a function of both parameters (Figure 11c) when β > 4. Significant RMSE, MBE, and NBE variations on both parameters appear only for β less than 2.3 and m between 42 and 50.
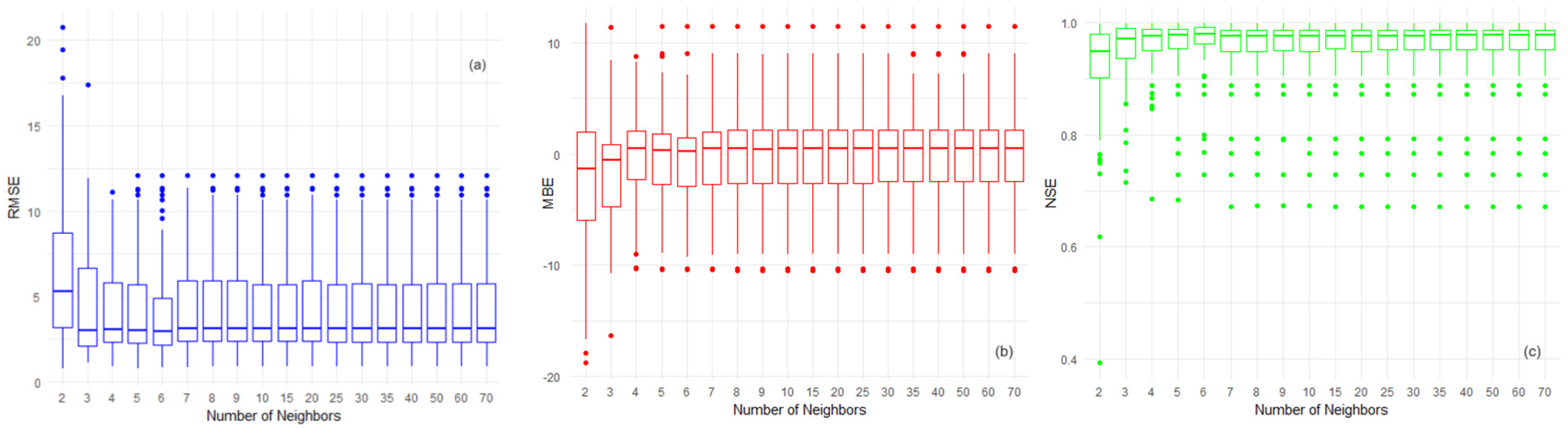
- The RMSE values (Figure 12a) tend to decrease as the number of neighbors increases, with the lowest spread (interquartile range) and the highest number of outliers at m = 6. The smallest box at this point suggests a more consistent model performance, albeit with some notable exceptions as indicated by the outliers. The largest RMSE and box size at m = 2 and fewer outliers indicate a higher average error and more significant variability. The medians being closer to the lower quartile across most boxes indicate a right-skewed distribution, with most of the data points having lower RMSE values and a few with substantially higher errors;
- The MBE boxplot (Figure 12b) indicates the presence of bias in predictions, with the most significant bias at m = 2, as demonstrated by the largest box and the median positioned toward the lower end of the range. The presence of outliers on both sides for various numbers of neighbors suggests that the model can both overestimate and underestimate to varying degrees but predominantly underestimate, as indicated by the negative means. As the number of neighbors increases beyond 6, the boxes stabilize in size, and the distribution of outliers becomes more symmetrical, suggesting a reduction in bias;
- The NSE boxplots (Figure 12c) reveal many outliers below the boxes, particularly at lower numbers of neighbors. The smallest box at m = 6 suggests the most consistent model efficiency, while the largest one at m =2 with the farthest outlier indicates the least efficient model predictions. The consistency in box size and outlier distribution for n > 6 suggests that the model efficiency does not significantly improve with more neighbors beyond this point.
3.3. BSS’ Sensitivity Analysis
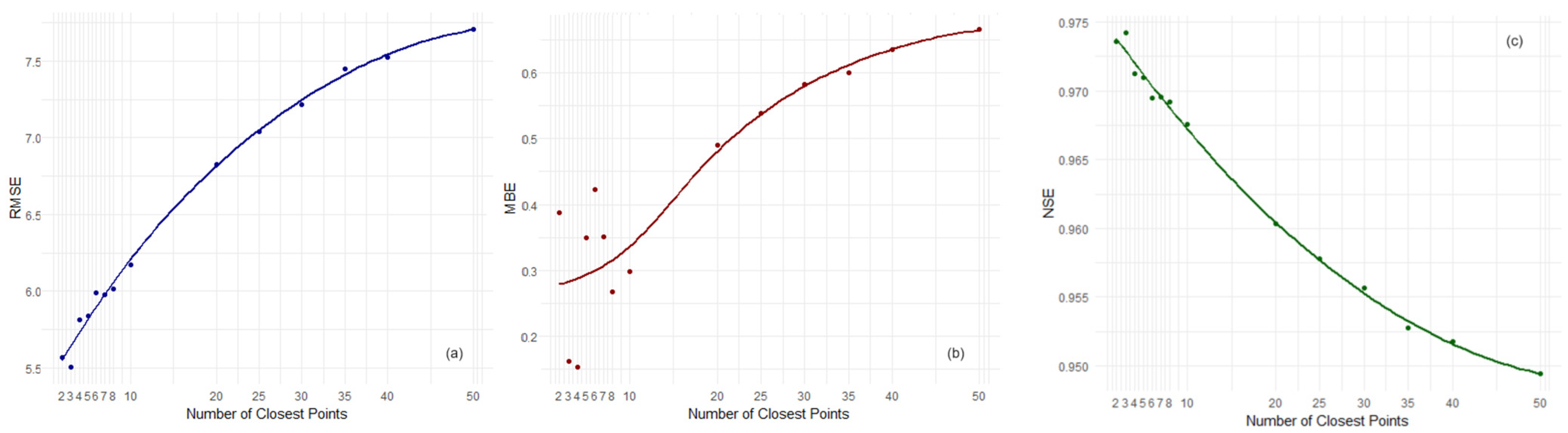
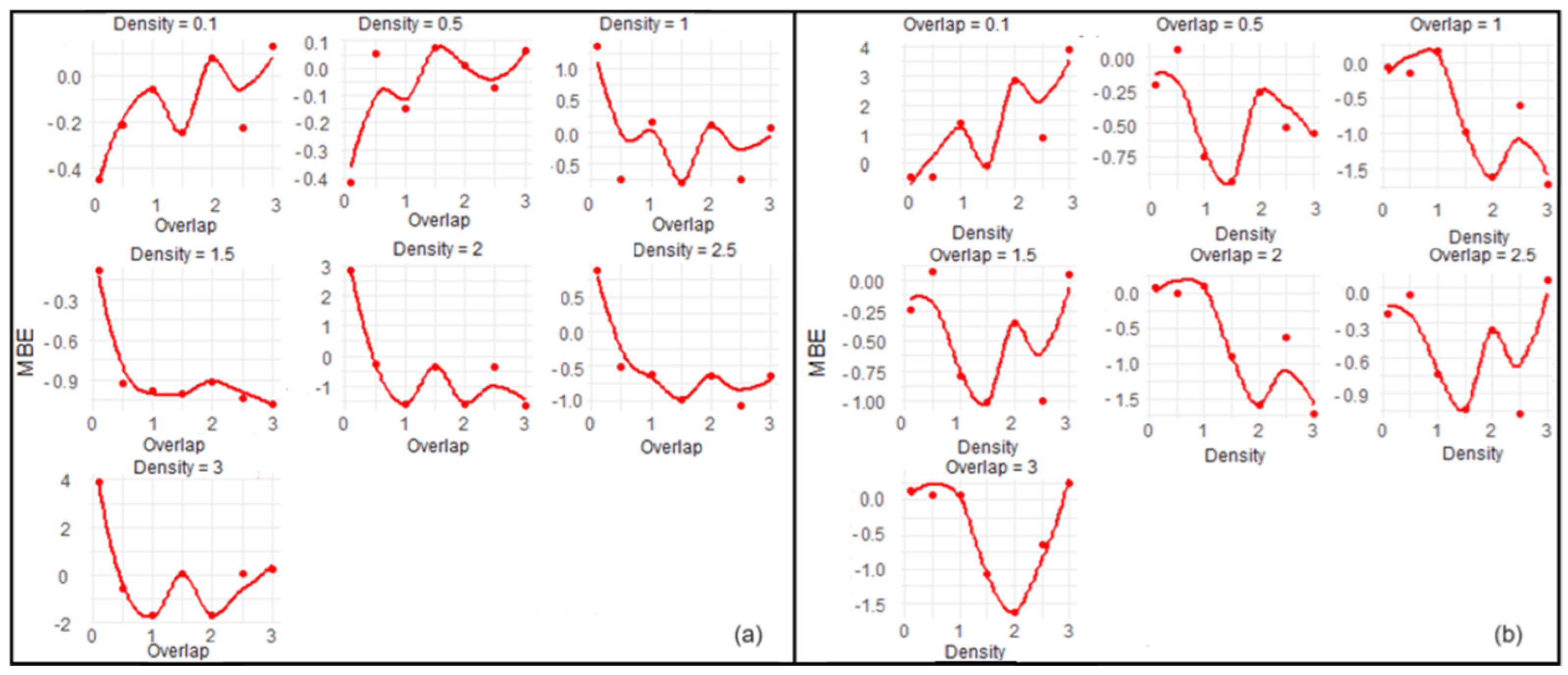
- Lower RMSE values indicate a better fit of the model to the data. Figure 14 shows that certain levels of overlap and density consistently result in lower RMSE. Specifically, a lower density often corresponds to a lower RMSE, suggesting that a denser grid of buffer points may not always lead to more accurate interpolation. However, the relationship between overlap and RMSE is not as clear-cut and appears more variable across different densities;
- The MBE value provides insight into the model’s bias, with values closer to 0 indicating less bias. Figure 15 demonstrates the variability in bias across different levels of overlap and density. It seems that the model is sensitive to these parameters, and there is no single combination that consistently minimizes bias across all levels;
- Higher NSE values suggest better model predictive power. Figure 16 shows that specific combinations lead to higher NSE. The relationship appears complex, indicating that both parameters influence the predictive accuracy in a non-linear manner.
4. Discussion
4.1. Discussion about the Sensitivity Analysis of IDW
- Sensitivity to Local Conditions: Outliers may suggest that the IDW method’s performance is particularly sensitive to local spatial characteristics, such as the variability modeled underlying physical processes. This sensitivity could affect the method’s generalizability to other datasets with different spatial characteristics.
- Model Robustness and Reliability: The existence of outliers, especially if they are numerous, can call into question the robustness and reliability of the IDW method. A robust model would ideally have fewer outliers, indicating consistent performance across different settings.
- Need for Model Adjustment or Supplemental Methods: Outliers may indicate the need for additional model adjustments or the incorporation of supplemental methods to handle spatial anomalies or extreme values. They could include preprocessing steps to normalize data, remove noise, or account for non-stationarity in the data.
- Dataset Characteristics: Generalization is more feasible for datasets with similar spatial and variable characteristics;
- Outlier Management: The model’s predictability can be affected by outliers, necessitating robust outlier handling for new datasets;
- Spatial Correlation: The assumption of spatial autocorrelation inherent in IDW must hold for the target dataset;
- Parameter Reevaluation: Parameter optimization is dataset-specific and should be reevaluated for each new dataset;
- Validation: Independent validation is essential to ascertain the model’s predictive capability across datasets.
4.2. Discussion about the Sensitivity Analysis of BSS
- For minimizing RMSE, a lower density should be the choice, regardless of the overlap;
- For MBE, the least bias is observed at medium density and lower overlap levels;
- The optimal NSE values are found at lower levels of overlap across most densities, with certain exceptions at higher densities where the pattern is less clear.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nazzal, Y.; Bou Orm, N.; Bărbulescu, A.; Howari, F.; Sharma, M.; Badawi, A.; Al-Taani, A.A.; Iqbal, J.; El Ktaibi, F.; Xavier, C.M.; et al. Study of atmospheric pollution and health risk assessment. A case study for the Sharjah and Ajman Emirates (UAE). Atmosphere 2021, 12, 1442. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Dumitriu, C.S.; Ilie, I.; Barbeș, S.B. Influence of Anomalies on the Models for Nitrogen Oxides and Ozone Series. Atmosphere 2022, 13, 558. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Dumitriu, C.S.; Popescu-Bodorin, N. On the aerosol optical depth series in the Arabian Gulf region. Rom. J. Phys. 2022, 67, 814. [Google Scholar]
- Bărbulescu, A.; Barbeș, L.; Dumitriu, C.Ș. Advances in Water, Air and Soil Pollution Monitoring, Modeling and Restoration. Toxics 2024, 12, 244. [Google Scholar] [CrossRef] [PubMed]
- Inhalable Particulate Matter and Health (PM2.5 and PM10). Available online: https://ww2.arb.ca.gov/resources/inhalable-particulate-matter-and-health (accessed on 15 January 2024).
- Chiritescu, R.-V.; Luca, E.; Iorga, G. Observational study of major air pollutants over urban Romania in 2020 in comparison with 2019. Rom. Rep. Phys. 2024, 76, 702. [Google Scholar]
- Dumitru, A.; Olaru, E.-A.; Dumitru, M.; Iorga, G. Assessment of air pollution by aerosols over a coal open-mine influenced region in southwestern Romania. Rom. J. Phys. 2024, 69, 801. [Google Scholar] [CrossRef]
- Gon Ryou, H.; Heo, J.; Kim, S.Y. Source apportionment of PM10 and PM2.5 air pollution, and possible impacts of study characteristics in South Korea. Environ. Pollut. 2018, 240, 963–972. [Google Scholar] [CrossRef] [PubMed]
- Arias-Pérez, R.D.; Taborda, N.A.; Gómez, D.M.; Narvaez, J.F.; Porras, J.; Hernandez, J.C. Inflammatory effects of particulate matter air pollution. Environ. Sci. Pollut. Res. 2020, 27, 42390–42404. [Google Scholar] [CrossRef] [PubMed]
- Saliba, Y.; Bărbulescu, A. A comparative evaluation of spatial interpolation techniques for maximum temperature series in the Montreal region. Rom. Rep. Phys. 2024, 76, 701. [Google Scholar]
- Popescu-Bodorin, N.; Bărbulescu, A. A ten times smaller version of CPC Global Daily Precipitation Dataset for parallel distributed processing in Matlab and R. Rom. Rep. Phys. 2024, 76, 703. [Google Scholar]
- Thangavel, P.; Park, D.; Lee, Y.C. Recent Insights into Particulate Matter (PM2.5)-Mediated Toxicity in Humans: An Overview. Int. J. Environ. Res. Public Health 2022, 19, 7511. [Google Scholar] [CrossRef] [PubMed]
- Estimate of Premature Deaths Associated with Fine Particle Pollution (PM2.5) in California Using a U.S. Environmental Protection Agency Methodology. Available online: https://archive.epa.gov/region9/mediacenter/web/pdf/pm-report_2010.pdf (accessed on 12 January 2024).
- Nazzal, Y.; Bărbulescu, A.; Howari, F.M.; Yousef, A.; Al-Taani, A.A.; Al Aydaroos, F.; Naseem, M. New insight to dust storm from historical records, UAE. Arab. J. Geosci. 2019, 12, 396. [Google Scholar] [CrossRef]
- Nazzal, Y.; Bărbulescu, A. Statistical analysis of the dust storms in the United Arab Emirates. Atmos. Resear. 2020, 231, 104669. [Google Scholar]
- How Bad Is Our Air Pollution—And How Do We Tackle It? Available online: https://www.thenationalnews.com/uae/environment/2022/09/20/explained-how-much-of-a-problem-is-air-pollution-in-the-uae/ (accessed on 20 April 2024).
- You Can Smell Petrol in the Air. 2023. Available online: https://www.hrw.org/report/2023/12/04/you-can-smell-petrol-air/uae-fossil-fuels-feed-toxic-pollution#:~:text=The%20UAE%20has%20dangerously%20high,considers%20safe%20for%20human%20health (accessed on 20 April 2024).
- OECD. Air Pollution Exposure (Indicator). 2024. Available online: https://data.oecd.org/air/air-pollution-exposure.htm#indicator-chart (accessed on 15 May 2024).
- Liu, H.; Zhang, S.; Liu, L.; Yu, J.; Ding, B. A Fluffy Dual-Network Structured Nanofiber/Net Filter Enables High-Efficiency Air Filtration. Adv. Funct. Mater. 2019, 29, 1904108. [Google Scholar] [CrossRef]
- Victor, F.S.; Kugarajah, V.; Bangaru, M.; Ranjan, S.; Dharmalingam, S. Electrospun nanofibers of polyvinylidene fluoride incorporated with titanium nanotubes for purifying air with bacterial contamination. Environ. Sci. Pollut. Res. Int. 2021, 28, 37520–37533. [Google Scholar] [CrossRef] [PubMed]
- Beaver, S.; Palazoglu, A. Influence of synoptic and mesoscale meteorology on ozone pollution potential for San Joaquin Valley of California. Atmos. Environ. 2021, 247, 118063. [Google Scholar] [CrossRef]
- Li, L.; Losser, T.; Yorke, C.; Piltner, R. Fast inverse distance weighting-based spatiotemporal interpolation: A web-based application of interpolating daily fine particulate matter PM2.5 in the contiguous U.S. using parallel programming and k-d tree. Int. J. Environ. Res. Public Health 2014, 11, 9101–9141. [Google Scholar] [CrossRef] [PubMed]
- Choi, K.; Chong, K. Modified Inverse Distance Weighting Interpolation for Particulate Matter Estimation and Mapping. Atmosphere 2022, 13, 846. [Google Scholar] [CrossRef]
- Deng, L. Estimation of PM2.5 Spatial Distribution Based on Kriging Interpolation. In Proceedings of the First International Conference on Information Sciences, Machinery, Materials and Energy, Chongqing, China, 11–13 April 2015; pp. 1791–1794. [Google Scholar]
- Diggle, P.J.; Ribeiro, P.J. Model-Based Geostatistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Lee, S.J.; Serre, M.L.; van Donkelaar, A.; Martin, R.V.; Burnett, R.T.; Jerrett, M. Comparison of geostatistical interpolation and remote sensing techniques for estimating long-term exposure to ambient PM2.5 concentrations across the continental United States. Environ. Health Perspect. 2012, 120, 1727–1732. [Google Scholar] [CrossRef]
- Wei, P.; Xie, S.; Huang, L.; Liu, L.; Tang, Y.; Zhang, Y.; Wu, H.; Xue, Z.; Ren, D. Spatial interpolation of PM2.5 concentrations during holidays in south-central China considering multiple factors. Sci. Total Environ. 2020, 740, 139761. [Google Scholar] [CrossRef]
- Oshan, T.M.; Li, Z.; Kang, W.; Wolf, L.J.; Fotheringham, A.S. Mgwr: A Python implementation of multiscale geographically weighted regression for investigating process spatial heterogeneity and scale. ISPRS Int. J. Geo-Inf. 2019, 8, 269. [Google Scholar] [CrossRef]
- Yanosky, J.D.; Paciorek, C.J.; Suh, H.H. Predicting chronic fine and coarse particulate exposures using spatiotemporal models for the Northeastern and Midwestern United States Environ. Health Perspect. 2009, 117, 522–529. [Google Scholar] [CrossRef] [PubMed]
- Saliba, Y.; Bărbulescu, A. Downscaling MERRA-2 Reanalysis PM2.5 Series over the Arabian Gulf by Inverse Distance Weighting, Bicubic Spline Smoothing, and Spatio-Temporal Kriging. Toxics 2024, 12, 177. [Google Scholar] [CrossRef] [PubMed]
- Gräler, B.; Pebesma, E.; Heuvelink, G. Spatio-Temporal Interpolation using gstat. R J. 2016, 8, 204–218. [Google Scholar] [CrossRef]
- Goudarzi, G.; Hopke, P.H.; Yazdani, M. Forecasting PM2.5 concentration using and its health effects in Ahvaz, Iran. Chemosphere 2021, 283, 131285. [Google Scholar] [CrossRef]
- Ma, J.; Ding, Y.; Cheng, J.C.P.; Jiang, F.; Wan, Z. A temporal-spatial interpolation and extrapolation method based on geographic Long Short-Term Memory neural network for PM2.5. J. Clean. Prod. 2019, 237, 117729. [Google Scholar] [CrossRef]
- Xiao, F.; Yang, M.; Fan, H.; Fan, G. An improved deep learning model for predicting daily PM2.5 concentration. Sci. Rep. 2020, 10, 20988. [Google Scholar] [CrossRef] [PubMed]
- Chae, S.; Shin, J.; Kwon, S.; Lee, S.; Kang, S.; Lee, D. PM10 and PM2.5 real-time prediction models using an interpolated convolutional neural network. Sci. Rep. 2021, 11, 11952. [Google Scholar] [CrossRef]
- Rizos, K.; Meleti, C.; Evagelopoulos, V.; Melas, D. A machine learning modelling approach to characterize the background pollution in the Western Macedonia region in northwest Greece. Atmos. Pollut. Resear. 2023, 14, 101877. [Google Scholar] [CrossRef]
- Zoras, S.; Evagelopoulos, V.; Pytharoulis, I.; Triantafyllou, A.G.; Skordas, I.; Kallos, G. Development and validation of a novel-based combination operational air quality forecasting system in Greece. Meteorol. Atmos. Phys. 2010, 106, 127–133. [Google Scholar] [CrossRef]
- Mahajan, S.; Chen, L.-J.; Tsai, T.-C. Short-Term PM2.5 Forecasting Using Exponential Smoothing Method: A Comparative Analysis. Sensors 2018, 18, 3223. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; He, W. Integrating remote sensing data with ground-based measurements to improve air quality mapping. Remote Sens. Environ. 2016, 184, 212–221. [Google Scholar]
- Shao, Y.; Ma, Z.; Wang, J.; Bi, J. Estimating daily ground-level PM2.5 in China with random-forest-based spatiotemporal kriging. Sci. Total Environ. 2020, 740, 13761. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C. Prediction of outdoor PM2.5 concentrations based on a three-stage hybrid neural network model. Atmos. Pollut. Res. 2020, 11, 469–481. [Google Scholar] [CrossRef]
- Wang, Y.; Di, Q.; Liu, Y. Hybrid deep learning model for PM2.5 prediction. Atmos. Environ. 2019, 212, 5–10. [Google Scholar]
- Chatzinikolaou, E.; Nikolopoulos, K. A hybrid statistical and machine learning model for air quality prediction. J. Environ. Manag. 2019, 237, 28–38. [Google Scholar]
- MERRA-2 tavgM_2d_aer_Nx: 2d, Monthly Mean, Time-Averaged, Single-Level, Assimilation, Aerosol Diagnostics V5.12.4 (M2TMNXAER). Available online: https://disc.gsfc.nasa.gov/datasets/M2TMNXAER_5.12.4/summary#citation (accessed on 15 May 2024).
- Gelaro, R.; McCarty, W.; Suárez, M.J.; Todling, R.; Molod, A.; Takacs, L.; Randles, C.A.; Darmenov, A.; Bosilovich, M.G.; Reichle, R.; et al. The Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2). J. Clim. 2017, 30, 5419–5454. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Modell. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Paramasivam, C.; Venkatramanan, S. Chapter 3—An Introduction to Various Spatial Analysis Techniques. In GIS and Geostatistical Techniques for Groundwater Science; Venkatramanan, S., Prasanna, M.V., Chung, S.Y., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 23–30. [Google Scholar]
- De Bohr, C. Bicubic Spline Interpolation. J. Math. Phys. 1962, XLI, 212–218. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1938, 32, 675–701. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bărbulescu, A.; Saliba, Y. Sensitivity Analysis of the Inverse Distance Weighting and Bicubic Spline Smoothing Models for MERRA-2 Reanalysis PM2.5 Series in the Persian Gulf Region. Atmosphere 2024, 15, 748. https://doi.org/10.3390/atmos15070748
Bărbulescu A, Saliba Y. Sensitivity Analysis of the Inverse Distance Weighting and Bicubic Spline Smoothing Models for MERRA-2 Reanalysis PM2.5 Series in the Persian Gulf Region. Atmosphere. 2024; 15(7):748. https://doi.org/10.3390/atmos15070748
Chicago/Turabian StyleBărbulescu, Alina, and Youssef Saliba. 2024. "Sensitivity Analysis of the Inverse Distance Weighting and Bicubic Spline Smoothing Models for MERRA-2 Reanalysis PM2.5 Series in the Persian Gulf Region" Atmosphere 15, no. 7: 748. https://doi.org/10.3390/atmos15070748
APA StyleBărbulescu, A., & Saliba, Y. (2024). Sensitivity Analysis of the Inverse Distance Weighting and Bicubic Spline Smoothing Models for MERRA-2 Reanalysis PM2.5 Series in the Persian Gulf Region. Atmosphere, 15(7), 748. https://doi.org/10.3390/atmos15070748