1. Introduction
Air pollution is a significant global issue, particularly in urban areas, where both short-term and long-term exposure to polluted air can have severe health consequences [
1]. Among the various air pollutants, particulate matter with a diameter of 2.5 microns or smaller (PM
2.5) is of particular concern. PM
2.5’s diminutive size enables it to infiltrate the respiratory system, resulting in significant health issues, including respiratory and cardiovascular disorders, and potentially premature mortality [
2]. Environmental pollution remains a major global health threat, with recent estimates from 2018 indicating that nine out of ten individuals inhale air that contains elevated levels of pollutants [
3]. Both ambient and household air pollution contribute to approximately seven million deaths globally each year, with around 2.2 million of these deaths occurring in the Western Pacific Region alone. In Vietnam, air pollution is accountable for an estimated 60,000 deaths annually [
3].
Ho Chi Minh City (HCMC), one of Vietnam’s largest and fastest expanding urban hubs, has experienced a notable rise in air pollution levels in recent years. This increase is primarily driven by metropolitan expansion, industrial growth, and a surge in road traffic [
4]. As per a report from GreenID, in the three years 2016, 2017, and 2018, the air quality index (AQI) results reveal a troubling trend, as the percentage of AQI readings categorized as unhealthy escalated from 31.1% in 2016 to 41.9% in 2017, and subsequently to 44.2% in 2018 [
5]. The declining air quality in HCMC has emerged as a critical issue for politicians, health officials, and the general populace. This issue has led to increased healthcare costs and economic burdens, necessitating urgent actions such as stricter emissions regulations, public health campaigns, and community engagement to mitigate the adverse effects and improve overall air quality. Therefore, developing effective strategies to predict PM
2.5 in HCMC is crucial.
Air pollutant concentration prediction models play a vital role in both assessing and managing air quality, offering critical insights for policymakers and environmental managers. These models are indispensable in optimizing air quality monitoring systems by providing detailed information on pollution levels, sources of pollutants, and the overall status of air quality in different regions [
6]. By predicting future pollution levels, decisionmakers can take proactive measures such as issuing early warnings, implementing public health campaigns, or enforcing stricter emission regulations to mitigate adverse environmental and health impacts. The ability to forecast air quality at specific future points allows for better preparedness and more informed decision making regarding pollution control strategies [
7].
There are two primary types of PM
2.5 concentration prediction models: knowledge-driven models and data-driven models. Knowledge-driven models, such as chemical transport models, are based on atmospheric science and require a thorough understanding of pollutant emission sources, transport mechanisms, and chemical transformations in the atmosphere. These models simulate the diffusion, transmission, and cross-regional transport of pollutants, making them highly valuable for detailed atmospheric analysis. However, they are often computationally intensive, requiring precise input data and extensive computational resources. Additionally, the complexity of atmospheric interactions and uncertainties in emission inventories can limit the accuracy of these models, particularly when dealing with real-world data that may not be as well structured as experimental conditions. In contrast, data-driven models are more practical and have become increasingly popular due to their ability to handle large datasets and generate predictions based on data characteristics. These models, which rely on statistical methods or machine learning techniques, are often more flexible and less dependent on detailed atmospheric knowledge. Data-driven approaches can be classified into three groups: statistical models, artificial intelligence (AI) models, and hybrid models that combine elements of both. AI models, in particular, have gained significant attention in recent years, driven by advancements in computational power and the Fourth Industrial Revolution. These models are known for their high accuracy and reliability in air quality prediction, as they excel at modeling complex, nonlinear phenomena and relationships between numerous exogenous variables [
8]. One of the key strengths of AI-based models is their ability to process vast amounts of data rapidly, offering significant advantages in terms of processing speed, scalability, and cost-effectiveness. AI models, such as machine learning and deep learning techniques, have the capability to impute missing data, identify hidden patterns in large datasets, and generate accurate predictions of pollution levels at specific future points. Moreover, AI models can provide spatial and temporal predictions, allowing researchers to estimate pollution levels for particular areas and times with a high degree of precision [
9]. In addition to their ability to simulate air quality, AI techniques also allow for real-time monitoring and adaptive learning, further enhancing their effectiveness in dynamic environments.
Numerous studies have proven the effectiveness of AI models in predicting air quality, specifically PM
2.5 levels. For example, Bingyue Pan (2018) employed the XGBoost algorithm to predict PM
2.5 levels in Tianjin City [
10], whereas Zamani et al. (2019) applied random forest, XGBoost, and deep learning methodologies utilizing multiplatform remote sensing information to forecast PM
2.5 levels in Tehran [
11]. Goulier et al. (2020) provided an hourly forecast of ten atmospheric pollutant levels in Münster utilizing an artificial neural network (ANN) methodology [
12], whereas Castelli et al. (2020) employed support vector regression (SVR) to anticipate pollutant and particle levels in California [
13]. Likewise, Gou et al. (2020) utilized statistical correlation evaluation and ANNs to discern relationships among the air pollution index and weather variables in Xi’an and Lanzhou [
14]. Doreswamy et al. (2020) created machine learning models to forecast PM levels of the atmospheric conditions of Taiwan [
15]. In the U.S., Zhou et al. (2020) examined several machine learning methodologies employed for air pollution prediction, with applications that span multiple regions, including high-pollution urban areas [
16]. Similarly, Chen et al. (2020) investigated how climate change influences PM
2.5 levels, using multimodel projections to assess the effectiveness of predictive models in the U.S [
17]. In Europe, Ordóñez et al. (2020) utilized multimodel simulations combined with machine learning techniques to improve air quality predictions, particularly for PM
2.5 levels, while Petetin et al. (2020) developed high-resolution forecasting models to enhance predictive accuracy across the continent [
18,
19]. In China, Zheng et al. (2021) employed deep learning models to enhance the accuracy of PM
2.5 concentration predictions, showcasing the latest advancements in air quality modeling [
20]. These recent studies underscore the global applicability of machine learning in tackling air pollution and provide a strong foundation for the methods employed in this paper for HCMC.
In HCMC, PM
2.5 data are not very available, with limited research focusing on predicting PM
2.5 levels. Few studies are currently available that predict these concentrations. Vo et al. (2021) applied WRF model to predict PM
2.5 level in HCMC [
21]. Their study aimed to evaluate the prediction of PM
2.5 concentration by predicting meteorological variables using the WRF model. In addition to utilizing a limited number of meteorological factors (four variables), their study did not thoroughly address the optimization of input scenarios. Another study from Rajnish et al. (2023) built a multivariate model for predicting air quality, taking into account diverse factors like meteorological circumstances, air quality metrics, and urban spatial data, and time factors to forecast NO
2, SO
2, O
3, and CO hourly concentrations [
22]. This research attained a significant achievement in forecasting using spatially scattered data; however, the duration of data collection was relatively short, spanning only from February to December 2021. Additionally, data utilized in this investigation were gathered from monitoring stations associated with a specific research project, rather than from official, reliable, and publicly accessible government sources.
The primary objective of this research is to develop and evaluate various machine learning and deep learning algorithms for predicting PM2.5 concentrations in HCMC, using meteorological and PM2.5 data. The results from this study are expected to enhance the comprehension of the determinants affecting PM2.5 levels in this metropolis and underscore the potential of AI methodologies in alleviating air pollution and promoting public health.
2. Methodology
This section delineates the methods utilized for prediction of PM
2.5 levels in HCMC using various machine learning and deep learning algorithms. The establishment of a PM
2.5 prediction model has five key steps (
Figure 1): (1) Data processing, (2) analyzing the impact of parameters on PM
2.5, (3) designing scenarios of input datasets, (4) modeling machine learning and deep learning algorithms to predict PM
2.5, and (5) selecting the best prediction model for PM
2.5 among the developed machine learning and deep learning prediction models (
Figure 1).
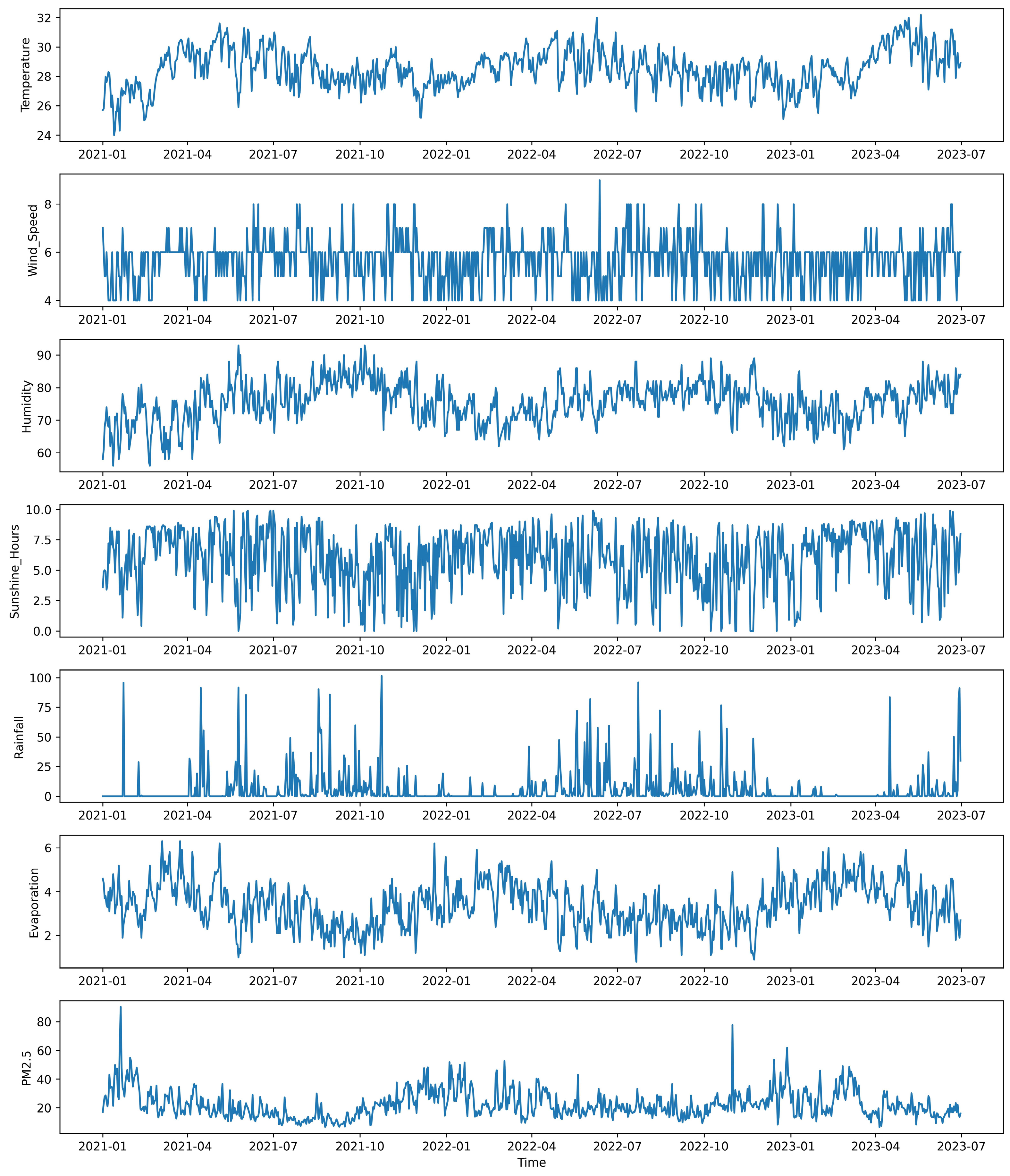
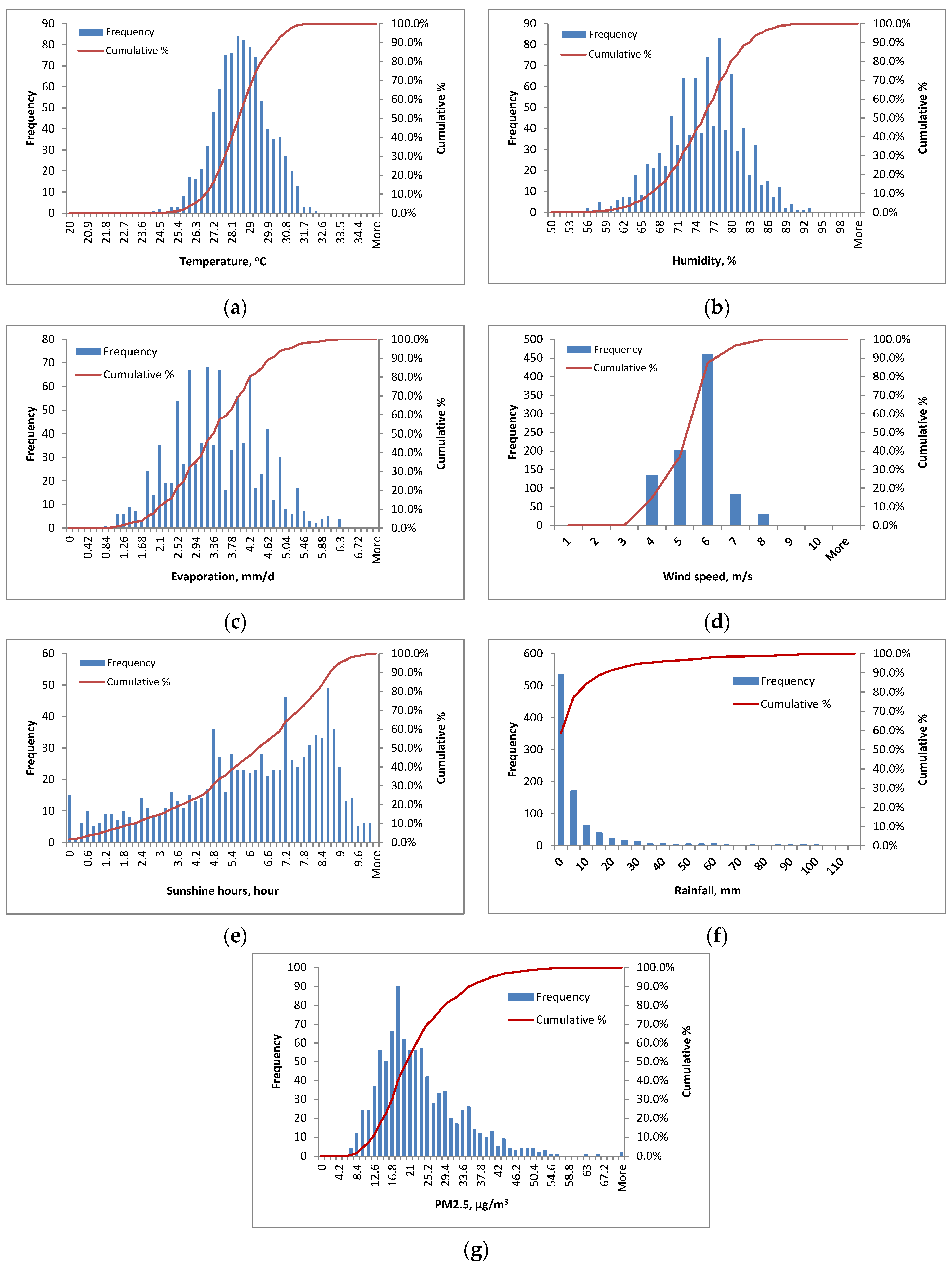
Firstly, daily data over 911 days, from 1 January 2021 to 30 June 2023, including meteorological and PM2.5 parameters in HCMC, were collected for the development of a prediction model. The meteorological data included ambient temperature, relative humidity, wind speed, rainfall, sunshine hours, and evaporation that were collected from Tan Son Hoa weather station (10.79723° N, 106.6667° E) at 236B Le Van Sy, Tan Binh District, while the PM2.5 data were obtained from the monitoring station at the U.S Consulate (10.7831° N, 106.7001° E) at 4 Le Duan street in District 1 in HCMC. These two stations are about 4 km apart as the crow flies and about 5 km apart by road. The collected data were then processed by removing unavailable data points and outliers.
Secondly, the processed data were analyzed to determine feature importance and identify the impact of the examined parameters on the objective function.
Thirdly, different sets of input data were generated to develop machine learning-based prediction models.
Fourthly, various machine learning and deep learning algorithms, including RF, XGB, SVR, ANN, GRNN, and CNN, were employed to formulate predictive models for PM2.5 in HCMC. Each algorithm employed in this work presents a distinct methodology for addressing the intricacies of PM2.5 prediction, providing varied advantages in feature selection, model training, and predictive accuracy. To evaluate the performance of these models, the dataset was split into training and testing sets. Specifically, 80% of the data were allocated for training, while the remaining 20% were designated for testing to evaluate model performance. For deep learning algorithms such as ANN and CNN, which require a validation set to monitor model training and prevent overfitting, the training data were further divided. In this case, 80% of the training data were used as sub-training data, and 20% of the training data were used for validation. This approach ensured that model training could be halted when validation performance began to decline, reducing the risk of overfitting. The remaining 20% of the dataset was consistently used as the testing set across all models to provide a final evaluation of prediction accuracy.
Random forest, often known as RF, is a type of ensemble learning technique that works by creating a vast ensemble of decision trees through the training process and then displaying the average forecast of each individually constructed tree [
23]. Its ensemble structure renders it highly resilient to overfitting. The program initiates the process by generating a randomized dataset derived from the primary data. For every bootstrapped sample, a decision tree is built by selecting the best split from a randomly chosen subset of features at every node. The bootstrap aggregation technique generates multiple bootstrap samples through sampling and replacement, from which decision trees are constructed. The ultimate prediction is the mean of the forecasts from all individual trees [
24]. This study selects RF to predict PM
2.5 levels due to its superior performance across several domains, resilience to overfitting, and efficacy in situations characterized by highly nonlinear and complex relationships between features and target variables. The performance of the RF model can be regulated by tuning hyperparameters including the quantity of trees in the forest, the depth of the trees, the minimum samples required for a split, the minimum samples required for a leaf node, and the maximum possible leaf nodes [
25].
XGBoost is a powerful and scalable ensemble learning method widely used for regression and classification problems. It improves on traditional gradient boosting by optimizing the handling of regularization and model optimization [
26]. This work employs XGB to forecast PM
2.5 values by using its capacity to simulate intricate linkages and interactions in the dataset. The algorithm processes historical air quality and meteorological data, which enables it to discern patterns that affect PM
2.5 concentrations. XGB possesses numerous hyperparameters that could be adjusted to enhance performance, such as the learning rate, the ensemble size, the tree depth, the sample size for each tree, and the feature count for each tree [
27].
Support vector regression (SVR) is a type of machine learning algorithm used for regression tasks, which is derived from the support vector machine (SVM) framework [
28]. Support vector regression (SVR) is recognized for its capacity to manage high-dimensional data and to represent nonlinear relationships via kernel functions [
29]. It develops a model by transforming input data into a higher-dimensional space to facilitate linear regression analysis. SVR seeks to identify a function that diverges from the actual observed objectives by no more than a defined margin
ϵ, while simultaneously maintaining maximal flatness. This study utilizes SVR to forecast PM
2.5 concentrations in HCMC by training the model using atmospheric quality and meteorological data. The hyperparameters in SVR comprise the regularization parameter
C, the epsilon
ϵ that delineates the margin of tolerance, and the parameters linked to the selected kernel function, such as the kernel coefficient
γ for the radial basis function kernel.
Artificial neural networks (ANNs) are a category of machine learning techniques designed to emulate the architecture and functionality of the human brain [
23,
30]. An artificial neural network consists of several interconnected processing nodes, or neurons, that collaboratively execute intricate computations. The method processes a collection of input data via multiple hidden layers to obtain an output. Each neuron within the network takes input from neurons in the preceding layer and use an activation function to generate an output [
31]. The output from each neuron is subsequently transmitted to the neurons in the subsequent layer, and this process is reiterated until the output layer is reached. The design of the network, comprising the quantity of layers and the number of neurons per layer, can be tailored to improve efficiency for a certain task. Training ANNs entails modifying weights and biases of neurons to reduce a loss function, which quantifies the disparity between the expected output and observed output [
30]. This process is generally executed by backpropagation that entails calculating the gradient of the loss function concerning the weights and biases, subsequently employing it to adjust the network’s parameters. Utilizing the adaptability and efficacy of learning intricate and nonlinear relationships among variables, ANNs are employed to predict PM
2.5 levels by training the network on atmospheric conditions data, atmospheric condition datasets, and other pertinent aspects. The model acquires the ability to discern intricate patterns and relationships in the data that affect PM
2.5 values. An optimum artificial neural network design consists of a configuration of hyperparameters, such as the quantity of hidden layers, the quantity of neurons in each hidden layer, activation function, learning rate, weight constraints, and dropout rate, which produce the most accurate predictions on the validation data.
Generalized regression neural networks (GRNNs) [
32] are a category of artificial neural networks grounded in nonparametric predictive modeling. GRNNs are recognized for their rapid training capabilities and proficiency in modeling intricate correlations between input and target variables [
33]. GRNNs comprise four layers: the input layer, pattern layer, summation layer, and output layer. Each neuron in the pattern layer denotes a training example and computes a distance metric to the input. These distances are consolidated by the summation layer, which produces weighted outputs. The output layer delivers a predicted value derived from these consolidated data. The fundamental principle of GRNNs is the application of kernel regression to approximate the conditional expectation of the output variable based on the input parameter. It utilizes a radial basis function to evaluate the probability density of data points and generates predictions based on the weighted aggregation of these functions. GRNNs are adept at managing noisy and intricate datasets, making them well suited for predicting air quality, particularly PM
2.5 concentrations, which are influenced by numerous factors. The smoothing parameter (
σ) is a hyperparameter in GRNNs. The performance of the model is highly sensitive to the value of
σ, with smaller values potentially resulting in overfitting, while larger values may lead to underfitting.
A convolutional neural network (CNN) is a form of deep learning model that integrates several layers including convolutional, pooling, and fully connected layers. Convolutional layers utilize filters on input data to identify characteristics, such as edges or textures, via convolution processes. The dimensionality of data is reduced by pooling layers, which utilize maximum pooling to preserve significant features while reducing computational demands. The fully linked layers at the network’s conclusion integrate these features to generate final predictions. CNNs excel in managing large-scale and high-dimensional data, making them suitable for predicting PM2.5 levels. The convolutional layers assist in recognizing critical characteristics and trends influencing PM2.5 values. To improve the efficacy of the CNN model, essential hyperparameters like the quantity and dimensions of convolutional filters, the depth of layers, the learning rate, and the batch size will be systematically maximized. Each best-performing model is tuned to its optimal hyperparameters using a grid search method. The range for each hyperparameter is detailed in the results section for each machine learning algorithm. Optimal hyperparameters are determined using the validation dataset. This optimization process aims to find the hyperparameters that yield the minimal root mean square error (RMSE) on the validation set.
Finally, after evaluating the predictive outcomes of the constructed models, the best-performing model is selected for PM
2.5 prediction in HCMC. In this study, the prediction models are evaluated using various metrics, including root mean square error (RMSE), mean absolute percentage error (MAPE), index of agreement (IOA), and normalized mean bias (NMB). These evaluation metrics are expressed as follows:
where
n is the total number of data points;
is the mean of the actual observed values;
and
are the actual observed value and predicted value for the
ith data point, respectively; RMSE measures the square root of the average squared variances between predicted and observed values; and MAPE evaluates the mean absolute percentage error between forecasted and actual values. Furthermore, the IOA quantifies the extent of model prediction inaccuracy on a scale from 0 to 1, with 1 signifying perfect concordance and 0 denoting complete discordance. IOA is formulated to address certain constraints of the coefficient of determination by offering a normalized metric of model prediction error. It considers the disparities between the anticipated and observed values, providing a more balanced measure of model performance, especially in cases with nonlinear relationships or when dealing with outliers. On the other hand, NMB measures the average discrepancy between the anticipated and observed values, normalized by the means of the observed values. It indicates the bias of the model’s predictions. Values approaching 0 signify little bias, whereas positive values denote overestimation and negative values signify underestimating.
4. Discussion
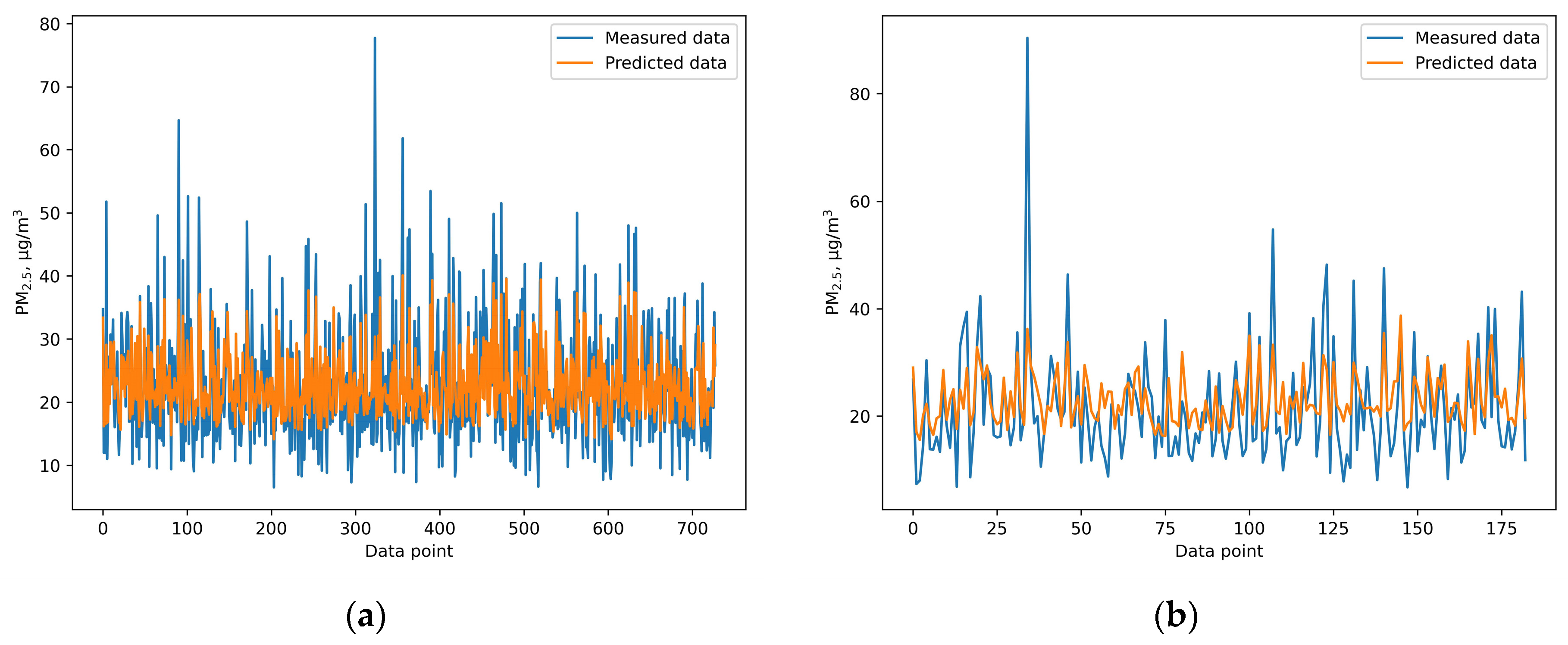
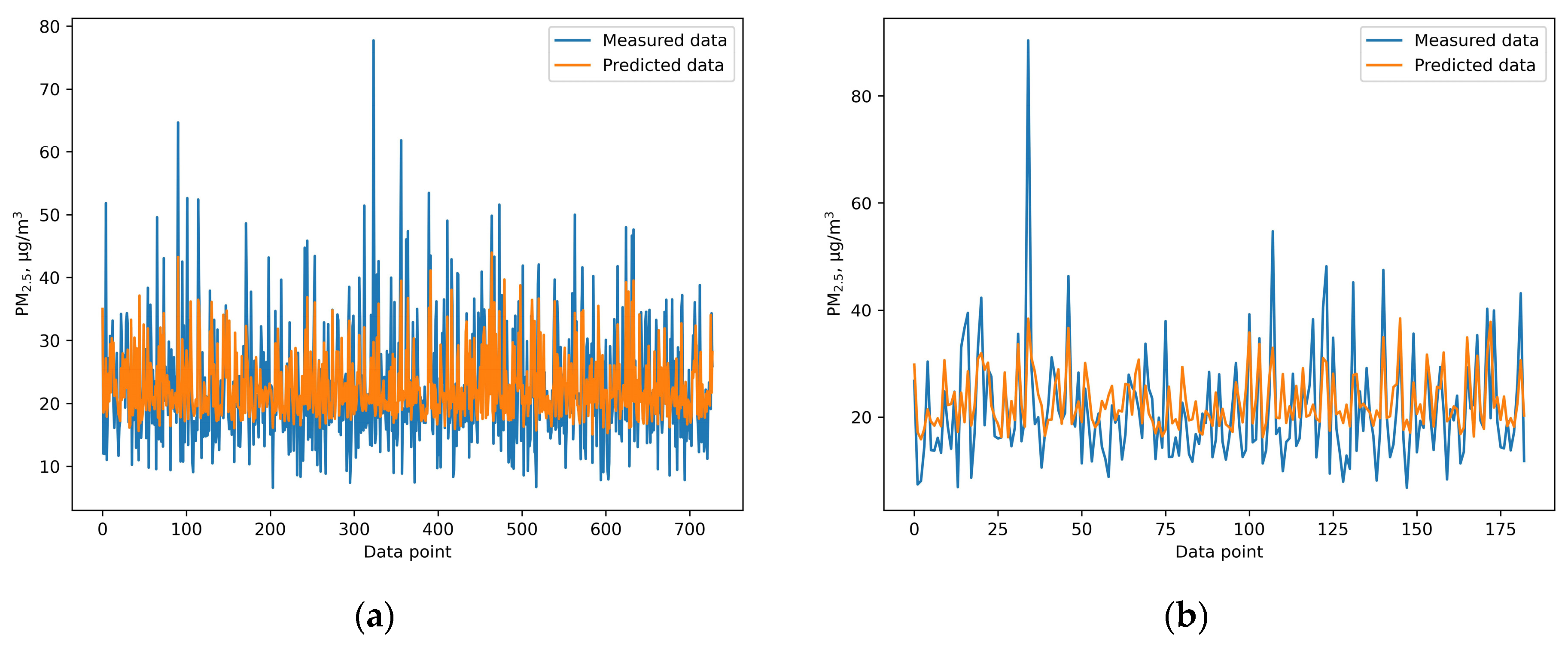
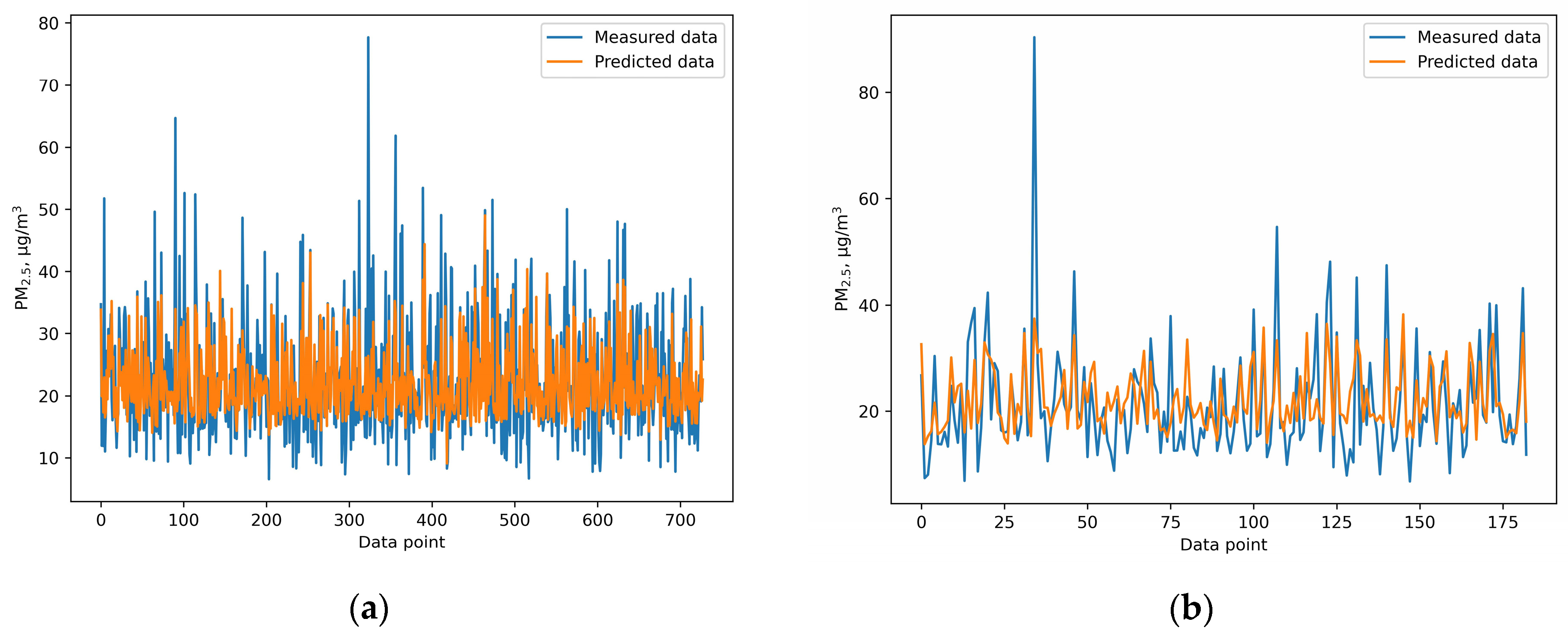
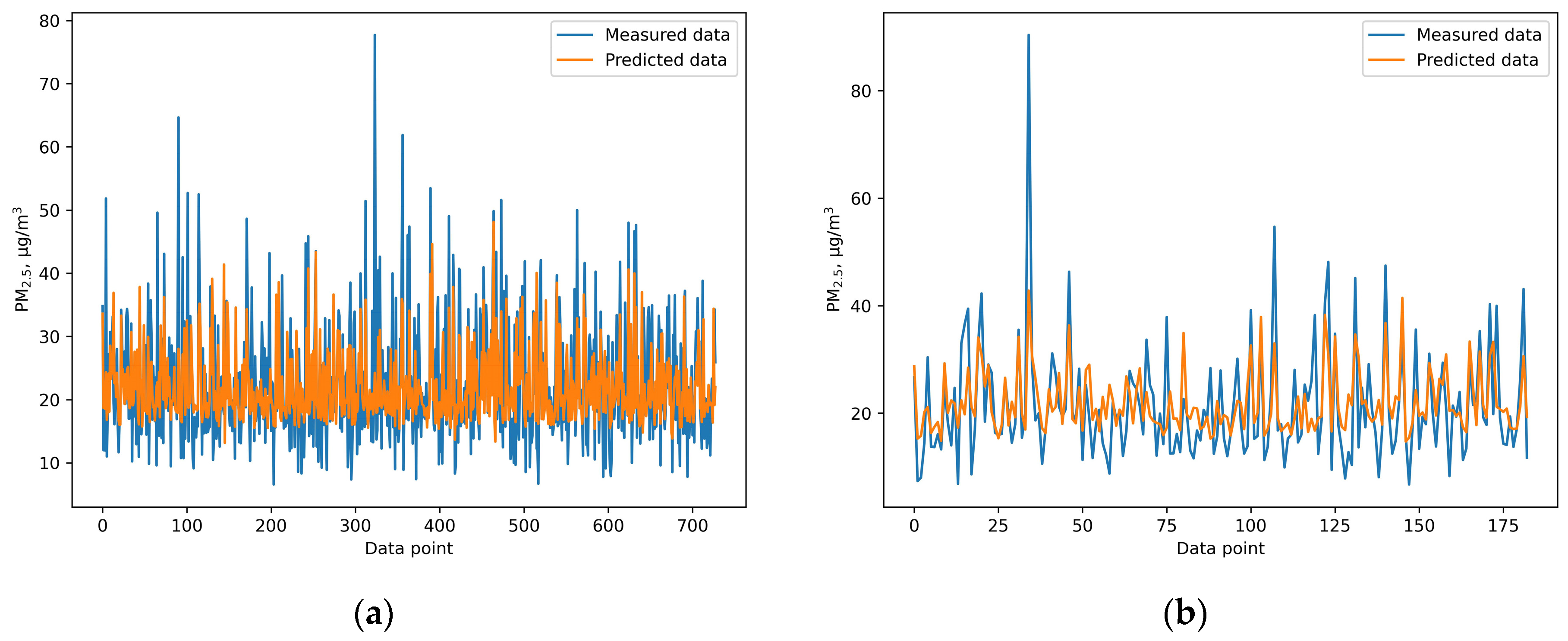
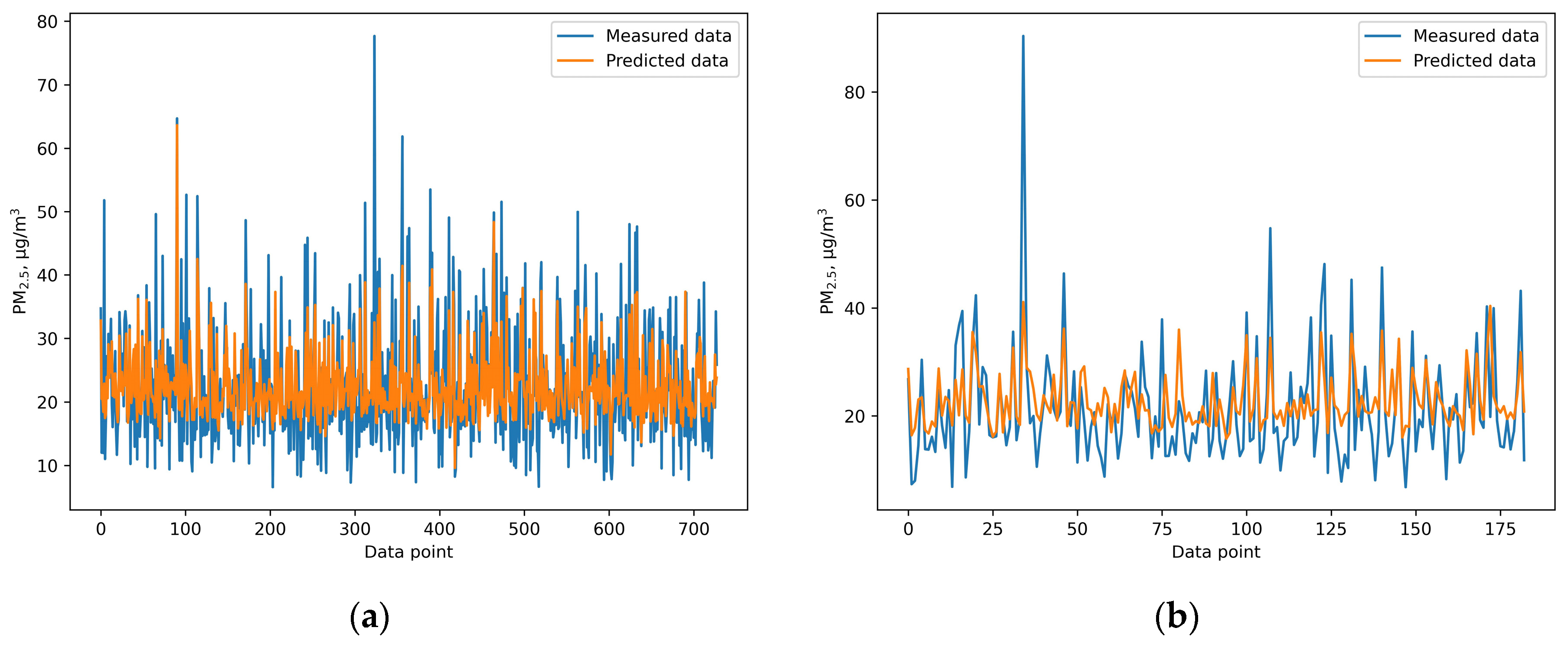
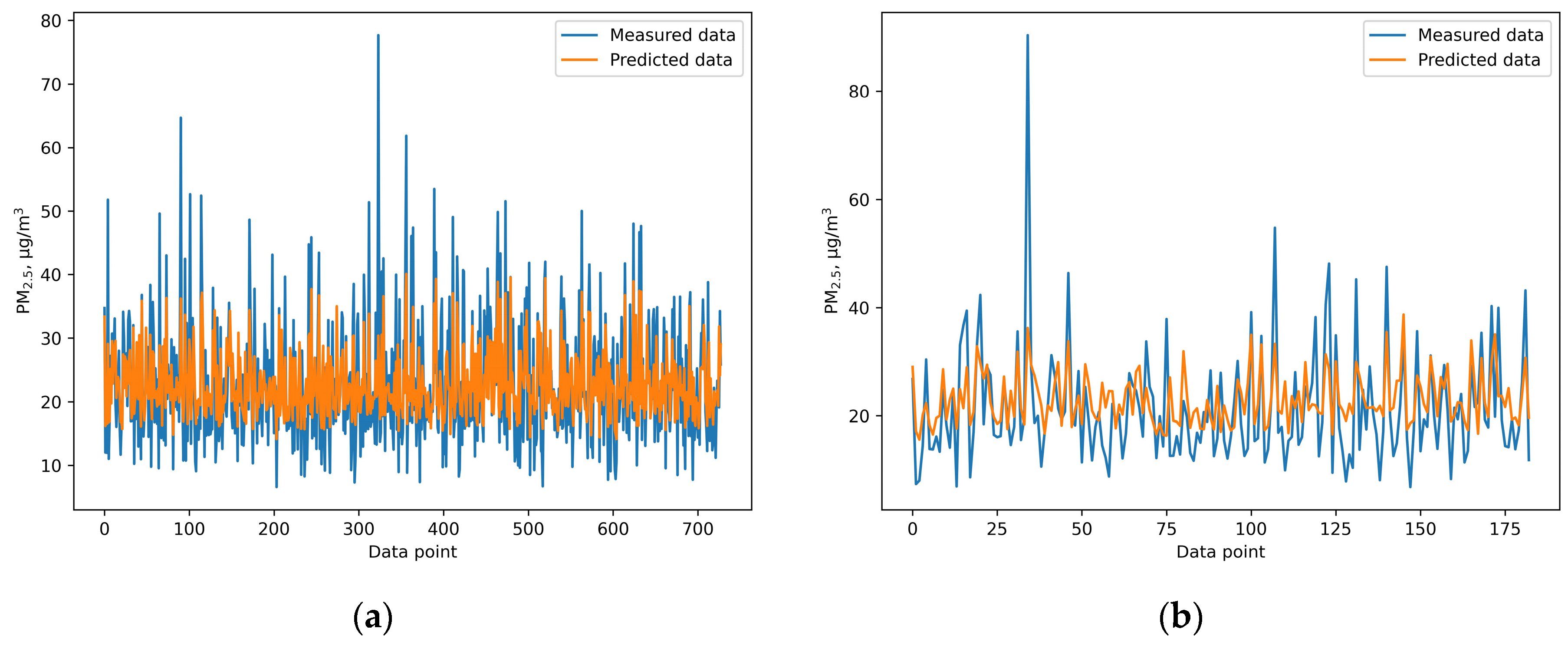
This study provides a comprehensive comparison of the performance of six different machine learning and deep learning algorithms, random forest, XGB, SVR, ANN, GRNN, and CNN, in predicting PM2.5 concentrations. Additionally, meteorological variables including temperature, humidity, wind speed, sunshine hours, rainfall, and evaporation were included to enhance the prediction accuracy. Among the models, the ANN model outperformed the others, achieving an IOA of 0.736, an RMSE of 7.978, and an NMB of 0.032 during the testing phase. These findings highlight the effectiveness of machine learning techniques in air quality prediction and highlight the importance of selecting an appropriate algorithm for predicting air pollution. This study provides valuable insights for health officials and policymakers by demonstrating that machine learning models, especially the ANN model, can accurately predict PM2.5 concentrations. This insight is valuable for policymakers, as it can inform the implementation of effective strategies to mitigate health risks associated with PM2.5 exposure. For instance, our model could enable authorities to issue air quality alerts when PM2.5 levels are expected to rise above safe thresholds. This allows citizens to take precautionary measures, such as staying indoors or using masks on high-risk days. In addition, public health campaigns can be timed based on pollution predictions, informing residents of exposure risks and protective actions like wearing air filters or limiting outdoor activities.
Despite the promising results, this study has several limitations that should be addressed in future research. First, this study concentrates exclusively on PM2.5 levels in HCMC. A more comprehensive comprehension of air quality throughout the nation would be achieved by broadening the scope to include additional communities in Vietnam. Additionally, while machine learning and deep learning methods were applied to simulate and predict PM2.5 concentrations, the study was limited by the availability of data from a single automatic monitoring station—the U.S. Consulate station in HCMC. Consequently, the results primarily reflect PM2.5 concentration levels within the vicinity of the consulate. A larger number of standard automatic monitoring stations would enable a more generalized and representative analysis of the entire study area.
Furthermore, this study focused on predicting PM2.5 concentrations based on meteorological factors, but PM2.5 concentrations are also influenced by various other factors, such as emission sources and the presence of other air pollutants. Emission sources, including industrial zones, construction sites, and high-traffic areas, are closely related to PM2.5 concentrations. Factors such as the relative location and proximity of these sources to monitoring stations significantly impact dust concentrations. Additionally, the concentrations of other air pollutants, such as NOx, SOx, CO2, and H2S, may interact with PM2.5 concentrations. Due to data limitations, these parameters were not included in this study. Future research should find the effect of these pollutants on PM2.5 concentrations and consider integrating them into prediction models.
This study establishes a robust basis for subsequent research on PM2.5 predictions for HCMC, and its findings can contribute to the development of effective air pollution control and management strategies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}