
Identification Method of Source Term Parameters of Nuclear Explosion Based on GA and PSO for Lagrange-Gaussian Puff Model
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Method Process
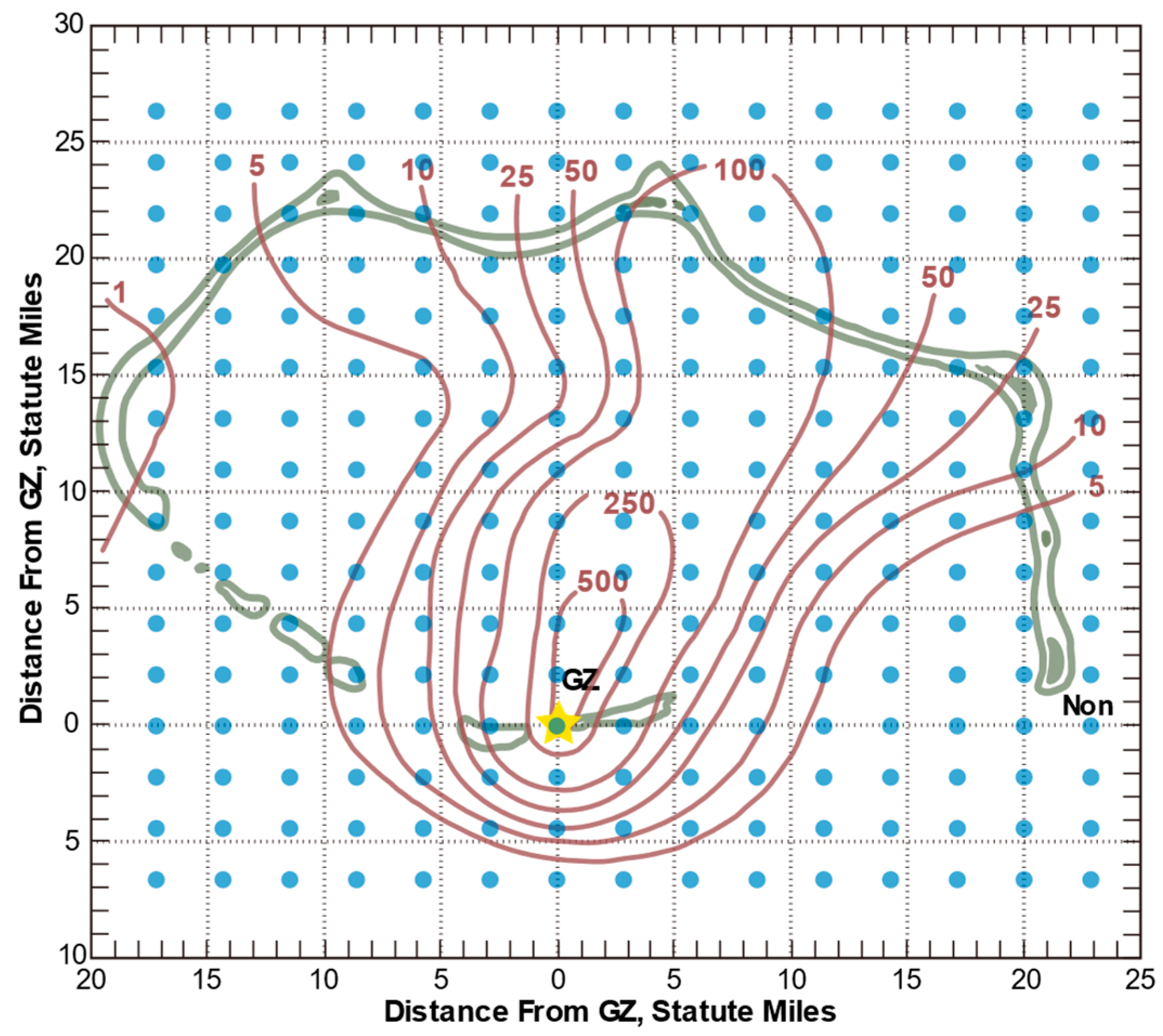
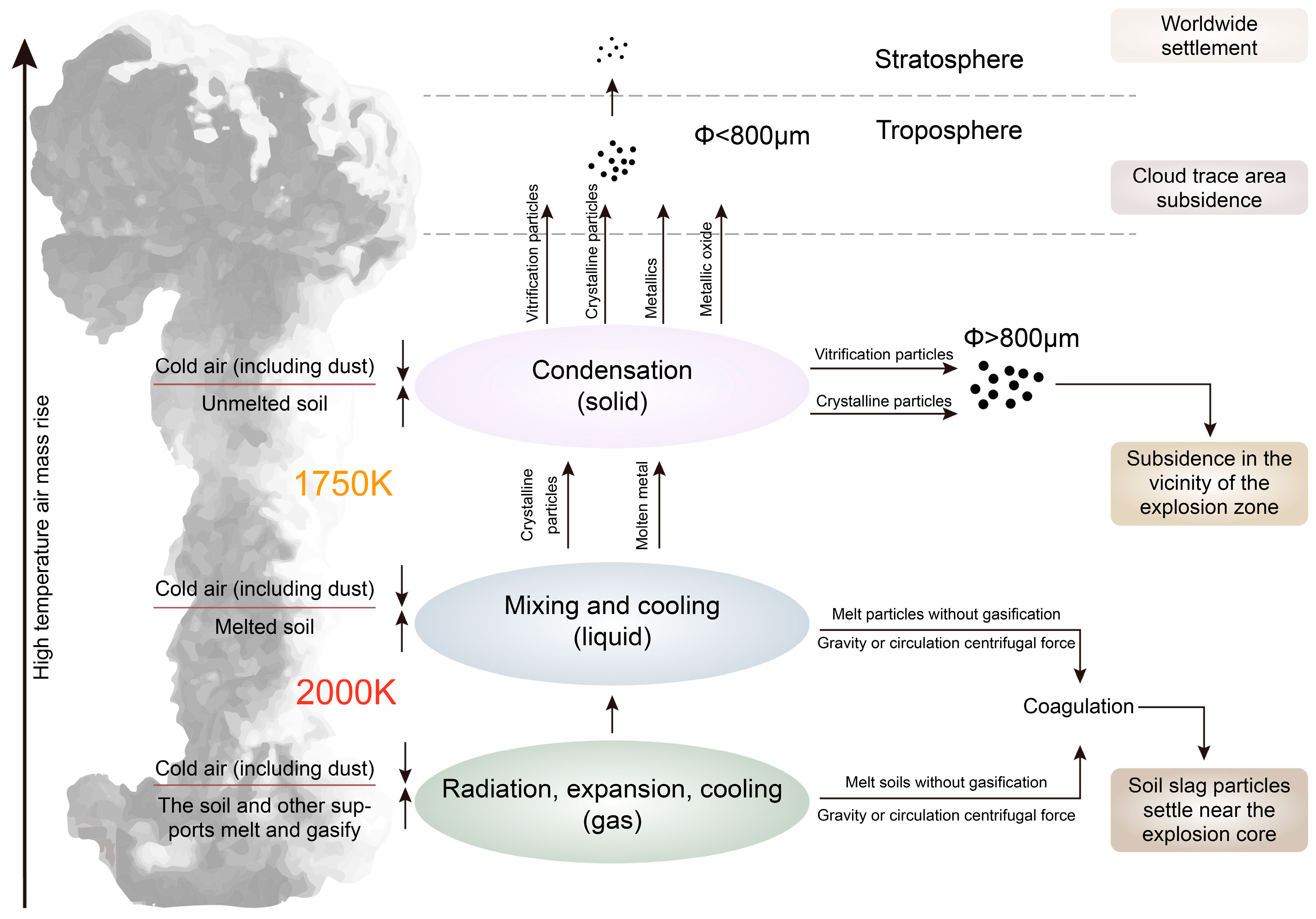
2.3. Predictive Modeling of Radioactive Particle Dispersion in Nuclear Explosions
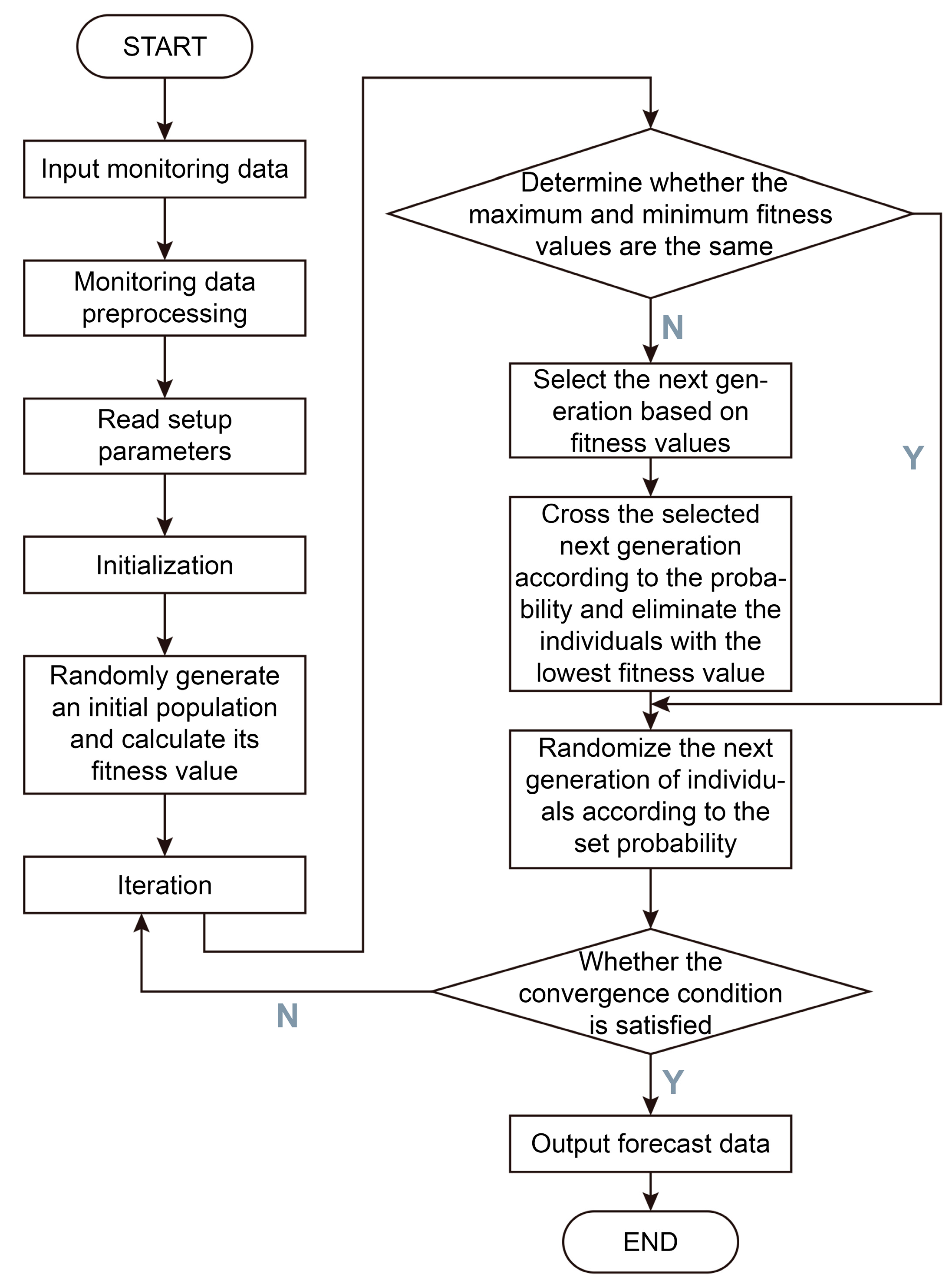
2.4. Implementation Process of GA in Nuclear Weapon Explosion Source Term Parameter Identification
2.4.1. Construction of Genes and Chromosomes
2.4.2. Construction of the Fitness Function
2.4.3. Crossover, Mutation and Selection of Genetic Operators
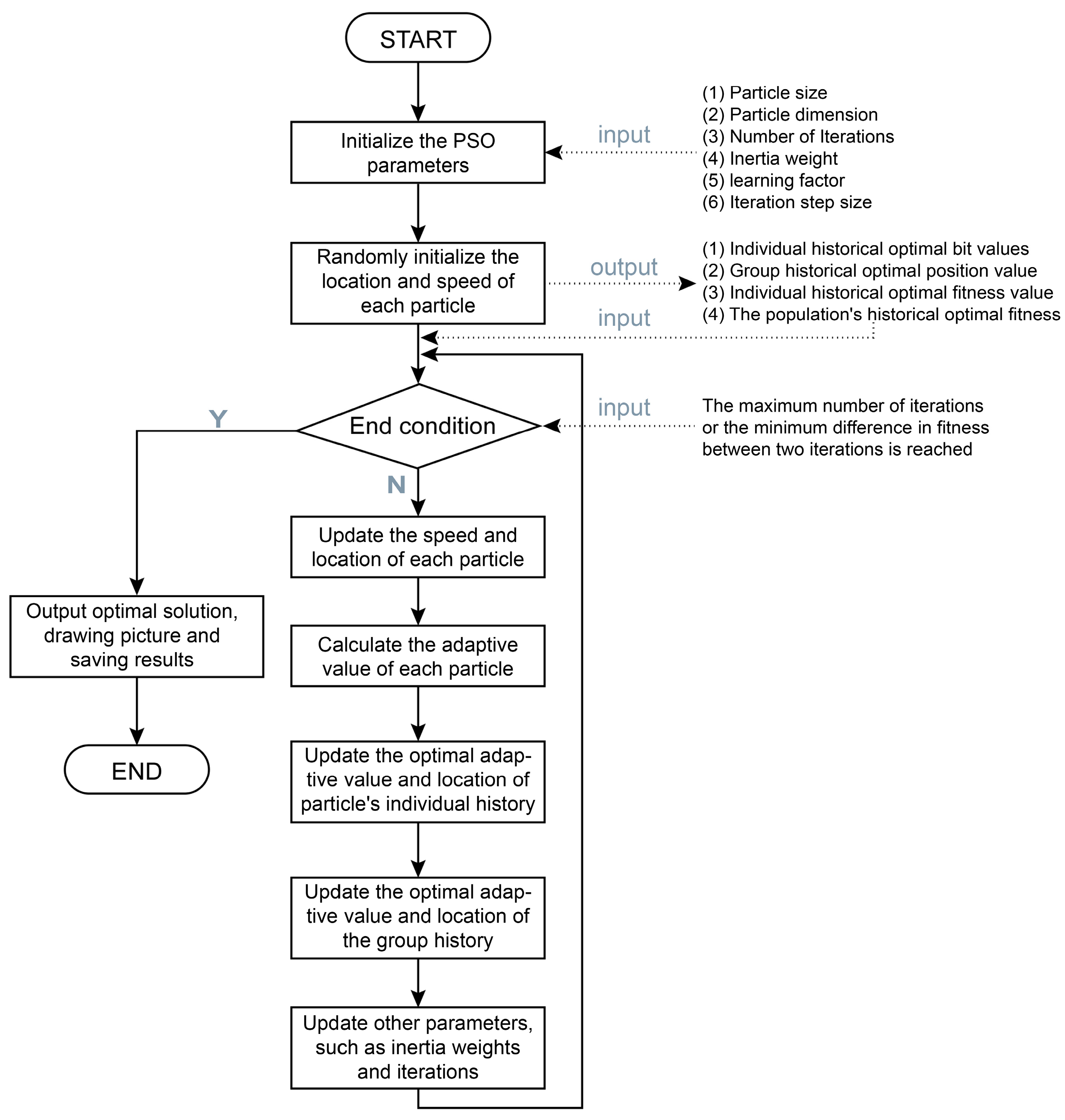
2.5. Implementation Process of PSO in Nuclear Weapon Explosion Source Term Parameter Identification
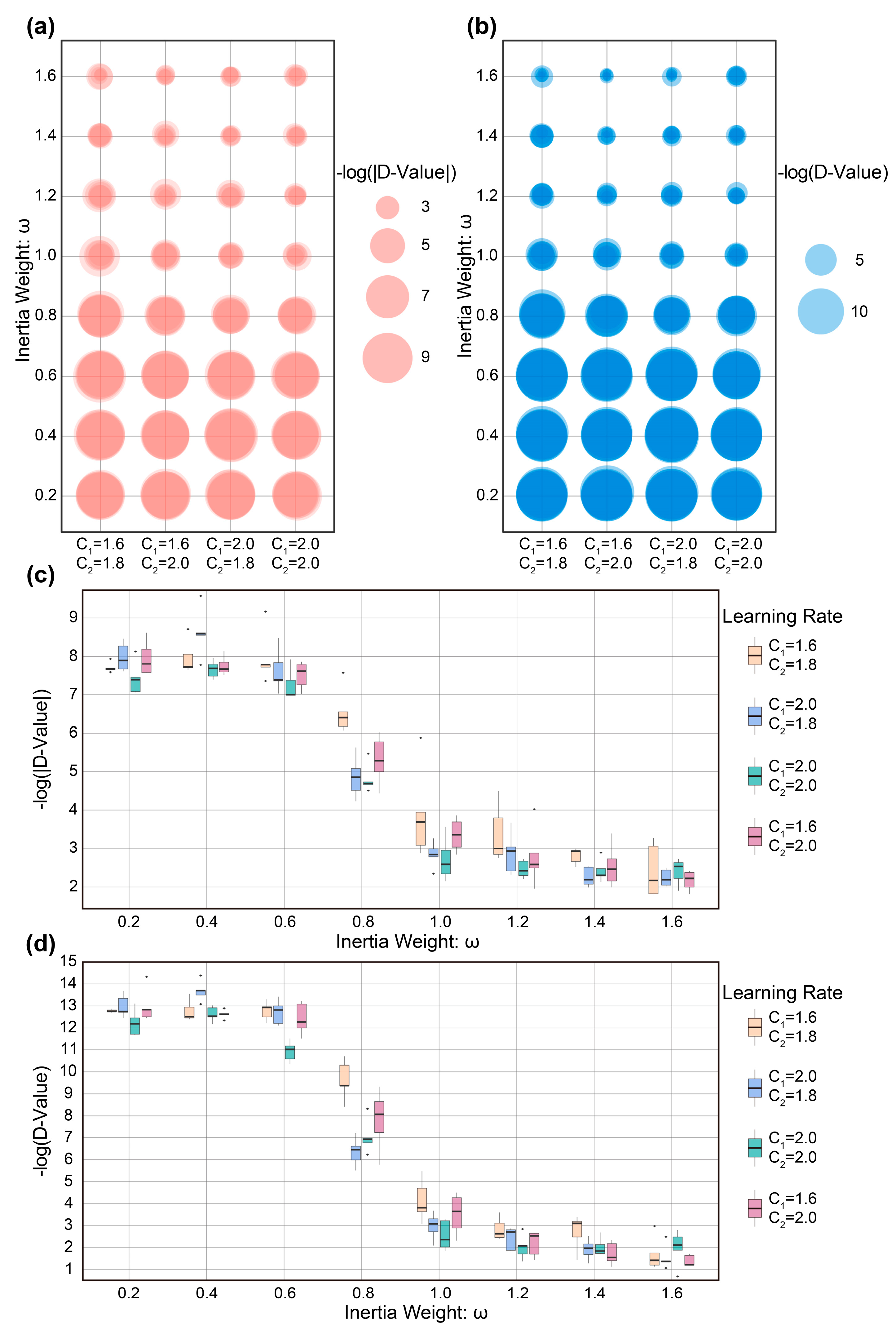
2.5.1. Parameter Selection and Optimization of PSO
2.5.2. Initializing the Particle Swarm and Running the PSO Algorithm
2.6. Evaluation Method
3. Results
3.1. Results of GA in Source Term Parameter Identification
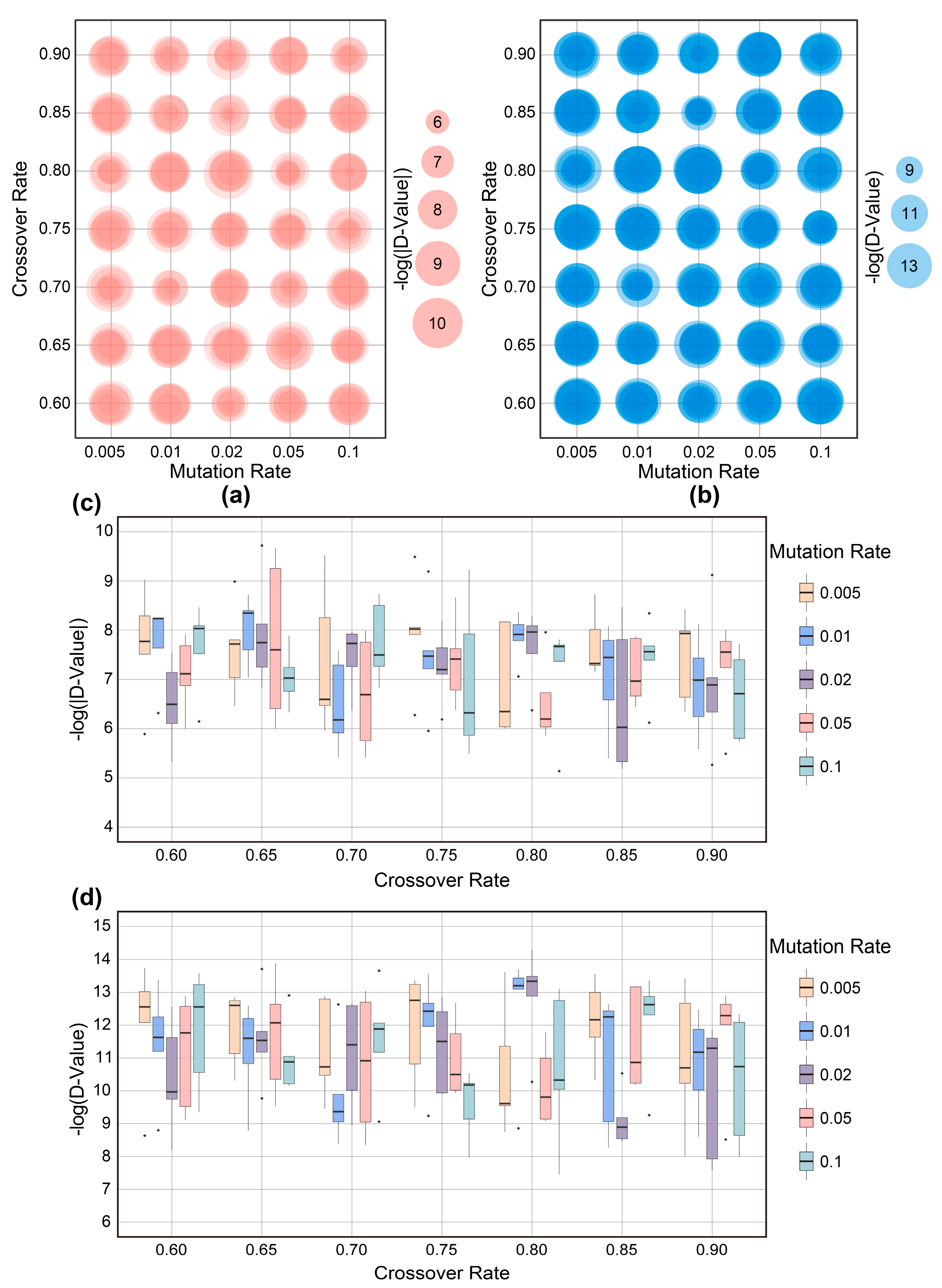
3.1.1. Selection of Genetic Operators
3.1.2. Model Parameter Optimization Results
3.1.3. Analysis of GA Results
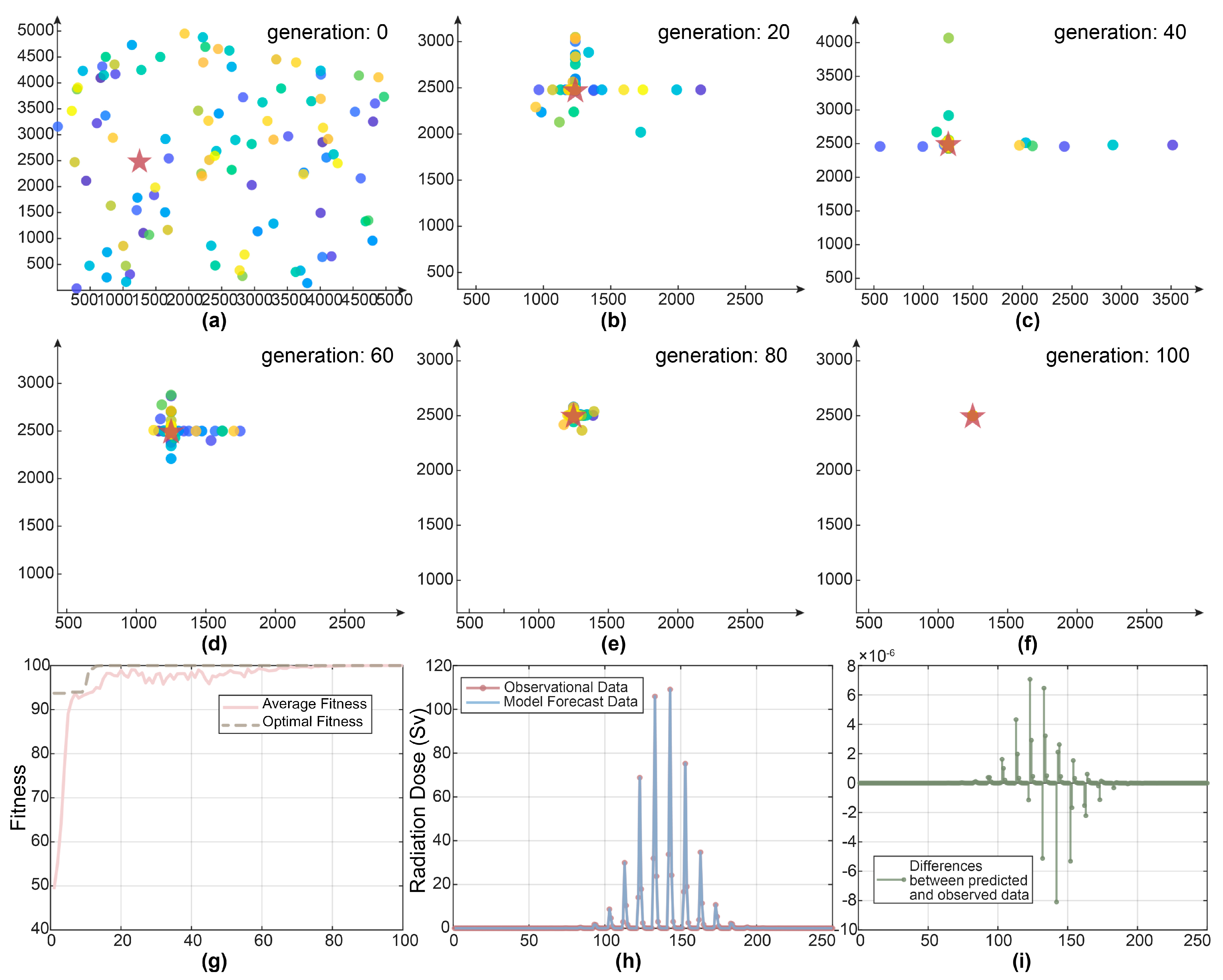
3.2. Results of PSO in Source Term Parameter Identification
3.2.1. Model Parameter Optimization Results
3.2.2. Analysis of PSO Results
3.3. Analysis and Comparison of Optimization Results for Source Term Identification
4. Discussion and Conclusions
5. Contributions and Limitations
- Neglecting model errors. The study does not discuss the model error in the Lagrange-Gaussian puff model fitting the prediction of the radioactive smoke cloud of a nuclear weapon explosion itself, and directly assumes that the measured values are equal to the predicted value of the true source term parameters input into the model. However, this error can interfere with the source term parameter identification process. The next study will try to perform an optimization search experiment using algorithms such as GA and PSO in combination with several well-established models such as DELFIC [53] or WSEG [54] so as to analyze the impact of each prediction model error on the source term parameter identification accuracy.
- Fewer swarm intelligence algorithms are utilized, and there are various classifications of swarm intelligence algorithms, each of which has its own advantages and disadvantages. The next study can try to use more algorithms other than GA and PSO to try to optimize the identification of nuclear weapon explosion source term parameters.
- Each algorithm itself can be further optimized. In addition to each algorithm’s parameter optimization, the next study will explore a combination of optimization of each algorithm and combine each algorithm with machine learning, neural networks and other methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Researchers: Help free the world of nuclear weapons. Nature 2020, 584, 7. [CrossRef] [PubMed]
- Colglazier, E.W. War and peace in the nuclear age. Science 2018, 359, 613. [Google Scholar] [CrossRef]
- Williams, M.; Armstrong, L.; Sizemore, D.C. Biologic, Chemical, and Radiation Terrorism Review. In StatPearls; StatPearls Publishing Copyright © 2022, StatPearls Publishing LLC.: Treasure Island, FL, USA, 2022. [Google Scholar]
- Koenig, K.L. Preparedness for terrorism: Managing nuclear, biological and chemical threats. Ann. Acad. Med. 2009, 38, 1026–1030. [Google Scholar] [CrossRef]
- Bisceglia, L.; Fateh-Moghadam, P. The prohibition of nuclear weapons: A public health priority. Lancet 2022, 400, 158–159. [Google Scholar] [CrossRef] [PubMed]
- Livingston, H.D.; Anderson, R.F. Large particle transport of plutonium and other fallout radionuclides to the deep ocean. Nature 1983, 303, 228–231. [Google Scholar] [CrossRef]
- Pittauer, D.; Tims, S.G.; Froehlich, M.B.; Fifield, L.K.; Wallner, A.; McNeil, S.D.; Fischer, H.W. Continuous transport of Pacific-derived anthropogenic radionuclides towards the Indian Ocean. Sci. Rep. 2017, 7, 44679. [Google Scholar] [CrossRef] [PubMed]
- Prăvălie, R. Nuclear weapons tests and environmental consequences: A global perspective. Ambio 2014, 43, 729–744. [Google Scholar] [CrossRef]
- Glasstone, S.; Dolan, P.J. The Effects of Nuclear Weapons; US Department of Defense: Washington, DC, USA, 1977.
- Mitsuguchi, T.; Okabe, N.; Yokoyama, Y.; Yoneda, M.; Shibata, Y.; Fujita, N.; Watanabe, T.; Saito-Kokubu, Y. (129)I/(127)I and Δ(14)C records in a modern coral from Rowley Shoals off northwestern Australia reflect the 20th-century human nuclear activities and ocean/atmosphere circulations. J. Environ. Radioact. 2021, 235–236, 106593. [Google Scholar] [CrossRef]
- Imanaka, T.; Fukutani, S.; Yamamoto, M.; Sakaguchi, A.; Hoshi, M. External radiation in Dolon village due to local fallout from the first USSR atomic bomb test in 1949. J. Radiat. Res. 2006, 47 (Suppl. A), A121–A127. [Google Scholar] [CrossRef]
- Bonnel, P.H. Acute radiation syndrome caused by ionizing radiations according to observations of victims of radioactive fallout following the explosion of a thermonuclear bomb. Rev. De Med. Nav. (Metrop. Et Outre-Mer) 1959, 14, 43–59. [Google Scholar]
- Widner, T.E.; Flack, S.M. Characterization of the world’s first nuclear explosion, the Trinity test, as a source of public radiation exposure. Health Phys. 2010, 98, 480–497. [Google Scholar] [CrossRef]
- Bergan, T.D. Radioactive fallout in Norway from atmospheric nuclear weapons tests. J. Environ. Radioact. 2002, 60, 189–208. [Google Scholar] [CrossRef] [PubMed]
- Bouville, A. Fallout from Nuclear Weapons Tests: Environmental, Health, Political, and Sociological Considerations. Health Phys. 2020, 118, 360–381. [Google Scholar] [CrossRef] [PubMed]
- Bouville, A.; Beck, H.L.; Anspaugh, L.R.; Gordeev, K.; Shinkarev, S.; Thiessen, K.M.; Hoffman, F.O.; Simon, S.L. A Methodology for Estimating External Doses to Individuals and Populations Exposed to Radioactive Fallout from Nuclear Detonations. Health Phys. 2022, 122, 54–83. [Google Scholar] [CrossRef] [PubMed]
- Drozdovitch, V.; Bouville, A.; Taquet, M.; Gardon, J.; Xhaard, C.; Ren, Y.; Doyon, F.; de Vathaire, F. Thyroid Doses to French Polynesians Resulting from Atmospheric Nuclear Weapons Tests: Estimates Based on Radiation Measurements and Population Lifestyle Data. Health Phys. 2021, 120, 34–55. [Google Scholar] [CrossRef]
- Stabilini, A.; Hafner, L.; Walsh, L. Comparison and multi-model inference of excess risks models for radiation-related solid cancer. Radiat. Environ. Biophys. 2023, 62, 17–34. [Google Scholar] [CrossRef]
- Soininen, L.; Mussalo-Rauhamaa, H. Cancer Incidence of Finnish Sami in the Light of Exposure to Radioactive Fallout. Int. J. Environ. Res. Public Health 2021, 18, 8186. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, W.; Li, X.; Yang, M.; Li, P.; Wu, Y.; Chen, X. Prediction and Analysis of Nuclear Explosion Radioactive Pollutant Diffusion Model. Pollutants 2023, 3, 43–56. [Google Scholar] [CrossRef]
- Leelőssy, Á.; Lagzi, I.; Kovács, A.; Mészáros, R. A review of numerical models to predict the atmospheric dispersion of radionuclides. J. Environ. Radioact. 2018, 182, 20–33. [Google Scholar] [CrossRef]
- Cui, W.; Cao, B.; Fan, Q.; Fan, J.; Chen, Y. Source term inversion of nuclear accident based on deep feedforward neural network. Ann. Nucl. Energy 2022, 175, 109257. [Google Scholar] [CrossRef]
- Fang, S.; Dong, X.; Zhuang, S.; Tian, Z.; Zhao, Y.; Liu, Y.; Liu, Y.; Sheng, L. Inversion of 137Cs emissions following the fukushima accident with adaptive release recovery for temporal absences of observations. Environ. Pollut. 2023, 317, 120814. [Google Scholar] [CrossRef]
- Kovalets, I.V.; Efthimiou, G.C.; Andronopoulos, S.; Venetsanos, A.G.; Argyropoulos, C.D.; Kakosimos, K.E. Inverse identification of unknown finite-duration air pollutant release from a point source in urban environment. Atmos. Environ. 2018, 181, 82–96. [Google Scholar] [CrossRef]
- Lin, Y.; Mago, N.; Gao, Y.; Li, Y.; Chiang, Y.-Y.; Shahabi, C.; Ambite, J.L. Exploiting spatiotemporal patterns for accurate air quality forecasting using deep learning. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, DC, USA, 6–9 November 2018; pp. 359–368. [Google Scholar]
- Dragović, S. Artificial neural network modeling in environmental radioactivity studies–A review. Sci. Total Environ. 2022, 847, 157526. [Google Scholar] [CrossRef] [PubMed]
- Ling, Y.; Liu, C.; Shan, Q.; Hei, D.; Zhang, X.; Shi, C.; Jia, W.; Wang, J. Inversion Method for Multiple Nuclide Source Terms in Nuclear Accidents Based on Deep Learning Fusion Model. Atmosphere 2023, 14, 148. [Google Scholar] [CrossRef]
- Wang, Z.P.; Wu, H.N. Source Term Estimation with Unknown Number of Sources using Improved Cuckoo Search Algorithm. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 1075–1080. [Google Scholar]
- Cantelli, A.; D’Orta, F.; Cattini, A.; Sebastianelli, F.; Cedola, L. Application of genetic algorithm for the simultaneous identification of atmospheric pollution sources. Atmos. Environ. 2015, 115, 36–46. [Google Scholar] [CrossRef]
- Li, K.; Chen, W.; Liang, M.; Zhou, J.; Wang, Y.; He, S.; Yang, J.; Yang, D.; Shen, H.; Wang, X. A simple data assimilation method to improve atmospheric dispersion based on Lagrangian puff model. Nucl. Eng. Technol. 2021, 53, 2377–2386. [Google Scholar] [CrossRef]
- Hawthorne, H.A. Compilation of Local Fallout Data from Test Detonations 1945–1962 Extracted from DASA 1251. Volume II. Oceanic U. S. Tests; General Electric Co.: Santa Barbara, CA, USA, 1979. [Google Scholar]
- Hawthorne, H.A. Compilation of Local Fallout Data from Test Detonations 1945–1962 Extracted from DASA 1251. Volume I. Continental US Tests; General Electric Co.: Santa Barbara, CA, USA, 1979. [Google Scholar]
- Norment, H.G. DELFIC: Department of Defense Fallout Prediction System, Volume II-User’s Manual; Final Report 16 January–31 December 1979; Atmospheric Science Associates: Bedford, MA, USA, 1979. [Google Scholar]
- Du, S. A heuristic Lagrangian stochastic particle model of relative diffusion: Model formulation and preliminary results. Atmos. Environ. 2001, 35, 1597–1607. [Google Scholar] [CrossRef]
- Hurley, P.; Manins, P.; Lee, S.; Boyle, R.; Ng, Y.L.; Dewundege, P. Year-long, high-resolution, urban airshed modelling: Verification of TAPM predictions of smog and particles in Melbourne, Australia. Atmos. Environ. 2003, 37, 1899–1910. [Google Scholar] [CrossRef]
- Jung, Y.-R.; Park, W.-G.; Park, O.-H. Pollution dispersion analysis using the puff model with numerical flow field data. Mech. Res. Commun. 2003, 30, 277–286. [Google Scholar] [CrossRef]
- Stohl, A.; Forster, C.; Frank, A.; Seibert, P.; Wotawa, G. Technical note: The Lagrangian particle dispersion model FLEXPART version 6.2. Atmos. Chem. Phys. 2005, 5, 2461–2474. [Google Scholar] [CrossRef]
- Chen, N.; Xie, N.; Wang, Y. An elite genetic algorithm for flexible job shop scheduling problem with extracted grey processing time. Applied Soft Computing 2022, 131, 109783. [Google Scholar] [CrossRef]
- Rooker, T. Review of Genetic Algorithms in Search, Optimization, and Machine Learning. AI Mag. 1991, 12, 102–103. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Lipowski, A.; Lipowska, D. Roulette-wheel selection via stochastic acceptance. Physica A 2012, 391, 2193–2196. [Google Scholar] [CrossRef]
- Coello Coello, C.A.; Mezura Montes, E. Constraint-handling in genetic algorithms through the use of dominance-based tournament selection. Adv. Eng. Inform. 2002, 16, 193–203. [Google Scholar] [CrossRef]
- Henryon, M.; Sørensen, A.C.; Berg, P. Mating animals by minimising the covariance between ancestral contributions generates less inbreeding without compromising genetic gain in breeding schemes with truncation selection. Animal 2009, 3, 1339–1346. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 1944, pp. 1942–1948. [Google Scholar]
- Kennedy, J.; Eberhart, R.C.; Shi, Y. Swarm Intelligence; Morgan Kaufmann: San Francisco, CA, USA, 2001; pp. 475–495. [Google Scholar]
- Carlisle, A.; Dozier, G. An Off-the-Shelf PSO. In Proceedings of the Workshop on Particle Swarm Optimization. 2001. Available online: https://www.researchgate.net/publication/216300408_An_off-the-shelf_PSO (accessed on 1 January 2023).
- Gao, Y.; Du, W.; Yan, G. Selectively-informed particle swarm optimization. Sci. Rep. 2015, 5, 9295. [Google Scholar] [CrossRef]
- Pace, F.; Santilano, A.; Godio, A. A Review of Geophysical Modeling Based on Particle Swarm Optimization. Surv. Geophys. 2021, 42, 505–549. [Google Scholar] [CrossRef]
- Yang, Y.; Yuan, H.; Li, Z.; Tsai, Y. Investigation on incompatible hazards of nitrocellulose mixed with three types of copper compounds. J. Therm. Anal. Calorim. 2023. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, X.-F.; Pan, M.-Y.; Li, P.; Tsai, Y.-T. Evaluation on algorithm reliability and efficiency for an image flame detection technology. J. Therm. Anal. Calorim. 2023. [Google Scholar] [CrossRef]
- Yang, N.; Tang, Y.; Wu, H.; Shu, C.-M.; Xing, Z.-X.; Jiang, J.-C.; Huang, A.-C. Influence evaluation of ionic liquids on the alteration of nitrification waste for thermal stability. J. Loss Prev. Process Ind. 2023, 82, 104977. [Google Scholar] [CrossRef]
- Zhu, F.; Liu, Z.; Huang, A.-C. The shaped blasting experimental study on damage and crack evolution of high stress coal seam. J. Loss Prev. Process Ind. 2023, 83, 105030. [Google Scholar] [CrossRef]
- Norment, H.G. DELFIC: Department of Defense Fallout Prediction System, Volume I-Fundamentals; Final Report 16 January–31 December 1979; Atmospheric Science Associates: Bedford, MA, USA, 1979. [Google Scholar]
- Bridgman, C.J.; Bigelow, W.S. A new fallout prediction model. Health Phys. 1982, 43, 205–218. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Term Parameters | Parameter True-Value | Gaussian Error | Error Range | Initial Source Term Parameter Range |
|---|---|---|---|---|
| Total Yield (Kt) | 110 | W = γ·Wtrue | γ∈[0.1, 10] | [11, 1100] |
| Explosive heart x coordinate | 1250 | x = xtrue + Δx | Δx∈[−1250, 3750] | [0, 5000] |
| Explosive heart y coordinate | 2500 | y = ytrue + Δy | Δy∈[−2500, 2500] | [0, 5000] |
| Average wind speed (m/s) | 6.2 | v = λ·vtrue | λ∈[0.5, 2] | [3.1, 12.4] |
| Average wind direction (°) | 191.3 | φ = φtrue + Δφ | φ∈[−20, 20] | [171.3, 211.3] |
| W (kt) | x0 (m) | y0(m) | v (m/s) | φ (°) | |
|---|---|---|---|---|---|
| Truth-value | 110 | 1250 | 2500 | 6.2 | 191.3 |
| Optimal-value | 109.5843 | 1249.9978 | 2500.0141 | 6.092 | 191.2738 |
| Accuracy Rate | 99.62% | 99.99% | 99.99% | 98.26% | 99.98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Wang, Y.; Wang, L.; Chen, X.; Huang, L.; Liu, W.; Li, X.; Yang, M.; Li, P.; Jiang, S.; et al. Identification Method of Source Term Parameters of Nuclear Explosion Based on GA and PSO for Lagrange-Gaussian Puff Model. Atmosphere 2023, 14, 877. https://doi.org/10.3390/atmos14050877
Zheng Y, Wang Y, Wang L, Chen X, Huang L, Liu W, Li X, Yang M, Li P, Jiang S, et al. Identification Method of Source Term Parameters of Nuclear Explosion Based on GA and PSO for Lagrange-Gaussian Puff Model. Atmosphere. 2023; 14(5):877. https://doi.org/10.3390/atmos14050877
Chicago/Turabian StyleZheng, Yang, Yuyang Wang, Longteng Wang, Xiaolei Chen, Lingzhong Huang, Wei Liu, Xiaoqiang Li, Ming Yang, Peng Li, Shanyi Jiang, and et al. 2023. "Identification Method of Source Term Parameters of Nuclear Explosion Based on GA and PSO for Lagrange-Gaussian Puff Model" Atmosphere 14, no. 5: 877. https://doi.org/10.3390/atmos14050877
APA StyleZheng, Y., Wang, Y., Wang, L., Chen, X., Huang, L., Liu, W., Li, X., Yang, M., Li, P., Jiang, S., Yin, H., Pang, X., & Wu, Y. (2023). Identification Method of Source Term Parameters of Nuclear Explosion Based on GA and PSO for Lagrange-Gaussian Puff Model. Atmosphere, 14(5), 877. https://doi.org/10.3390/atmos14050877