
Mind the Large Gap: Novel Algorithm Using Seasonal Decomposition and Elastic Net Regression to Impute Large Intervals of Missing Data in Air Quality Data


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
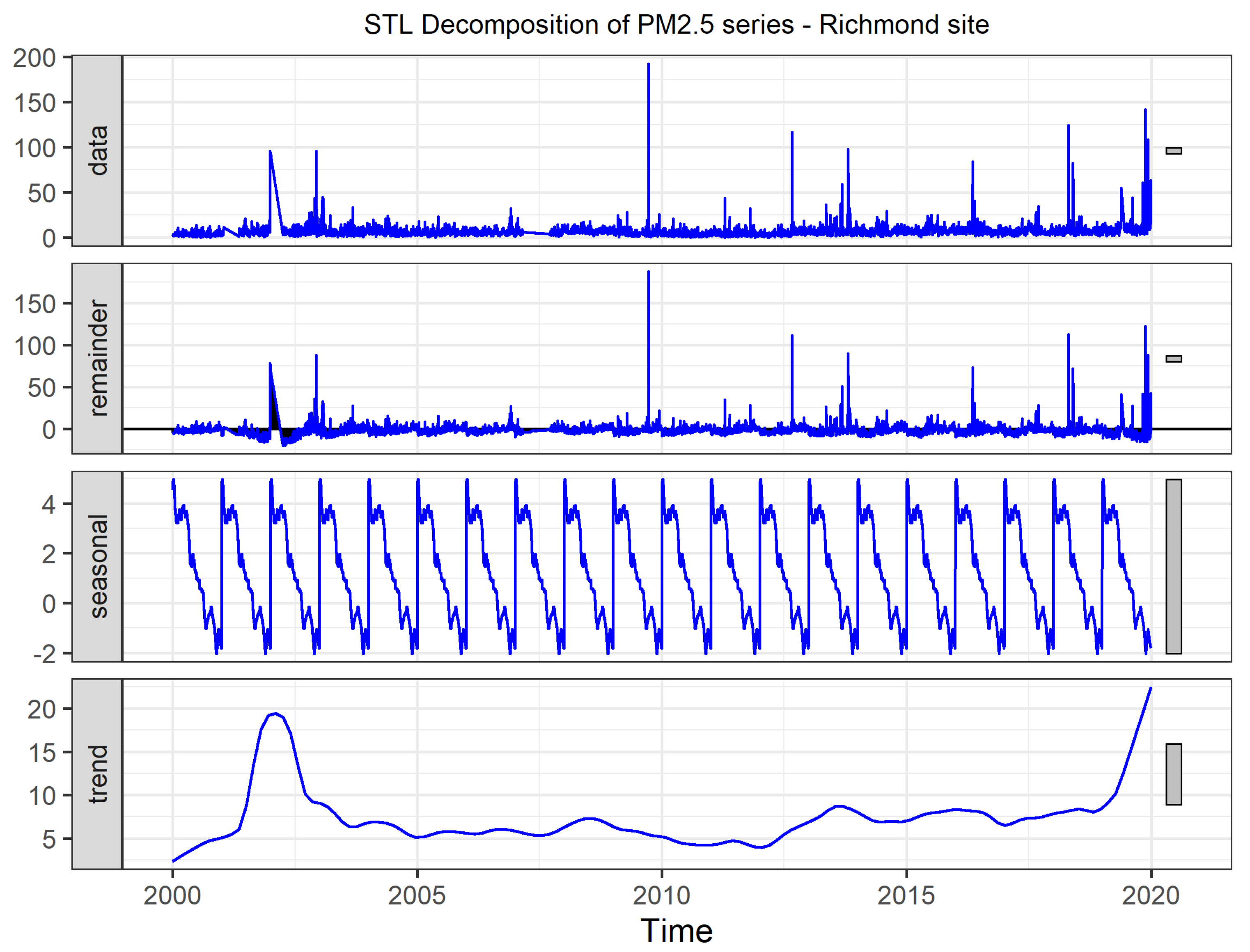
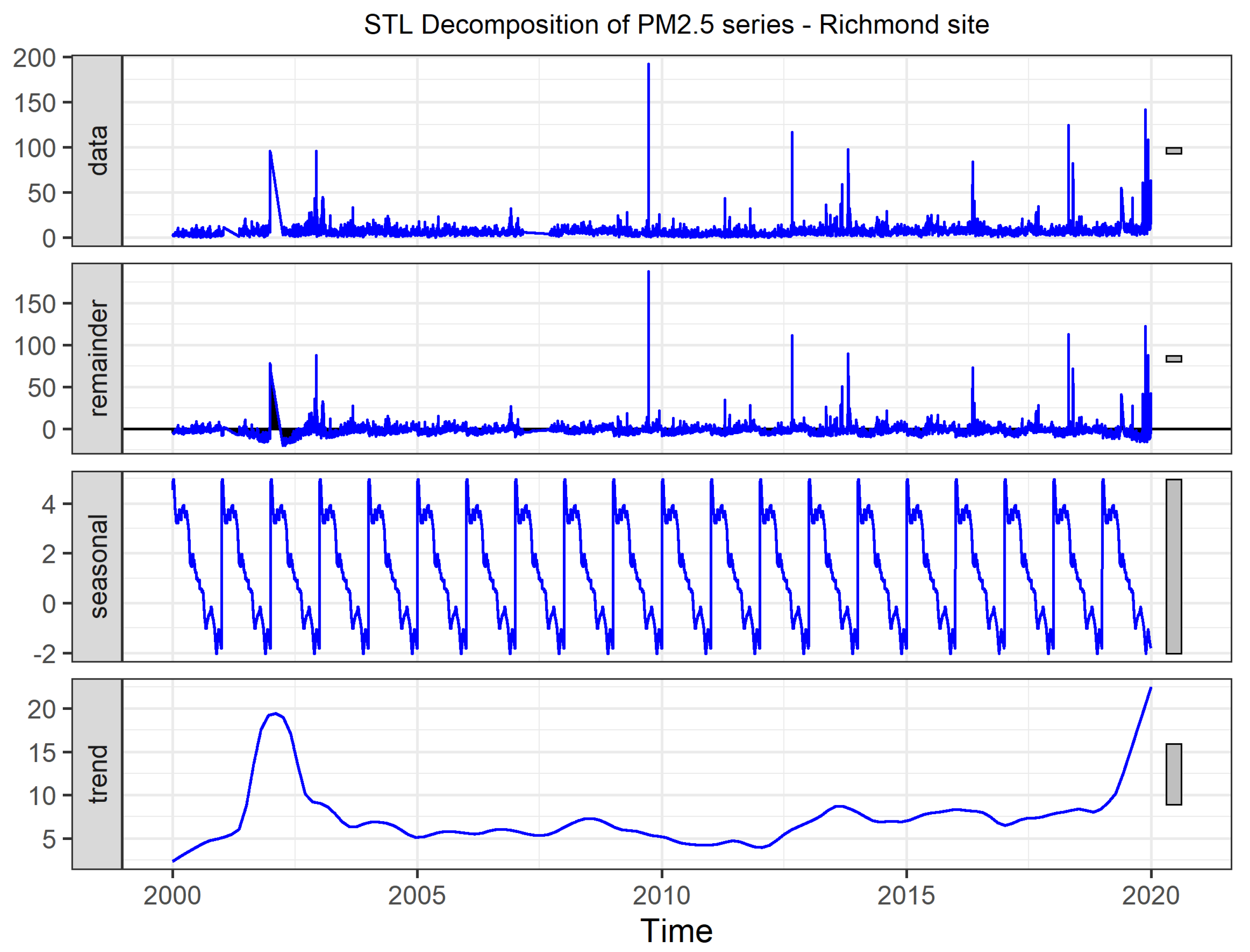
3.1. Seasonal-Trend Decomposition Procedure Based on Loess (STL)
3.2. Elastic Net Regression
3.3. Performance Measure
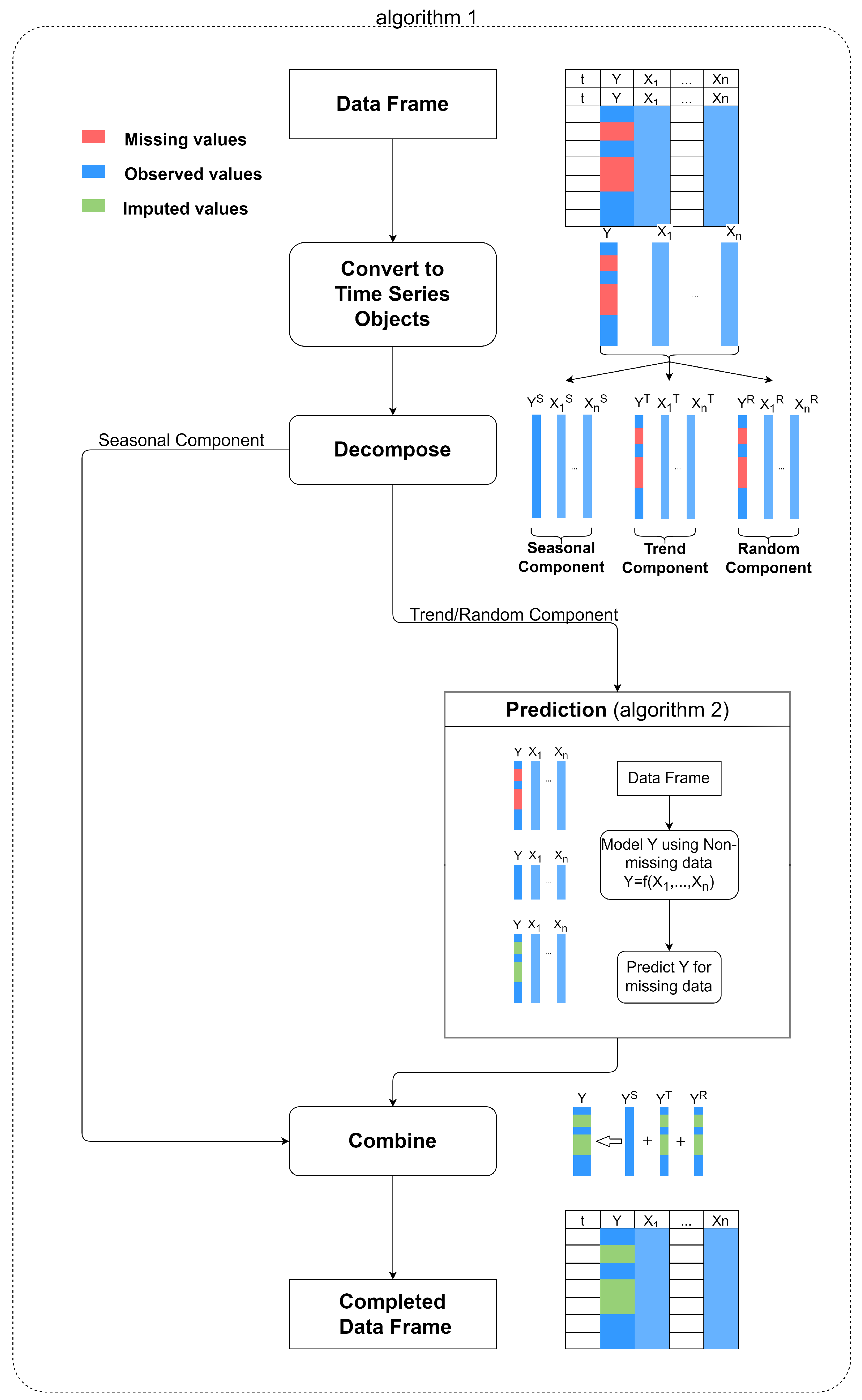
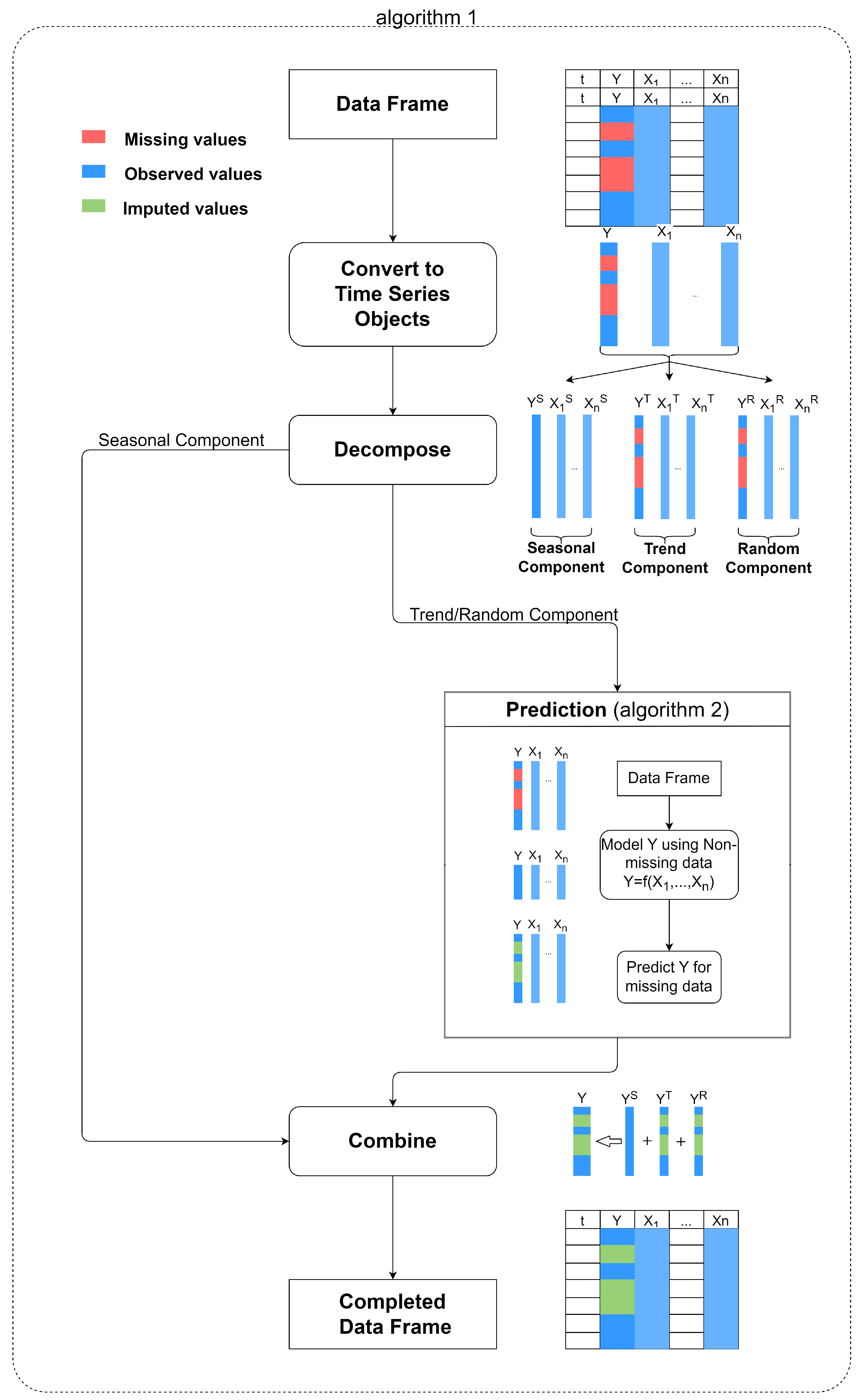
3.4. Proposed Algorithm
- Decompose all the time series (dependant and predictors) into the seasonal, trend, and random components.
- Leave out the seasonal component and impute missing values in the deseasonalised data based on an elastic net regression model.
- Combine imputed deseasonalised data with the seasonal component and form the complete time series.
| Algorithm 1 Main Imputation Algorithm |
Input: Data frame with time index t, Dependant Y, Predictors
|
| Algorithm 2 Imputing Trend/Random component |
Input: Data frame with time index t, Dependant Y, Predictors
|
- Ridge regression with and
- Lasso regression with and
- Elastic net regression with and
3.5. Artificially Generating Missing Data
4. Experiments
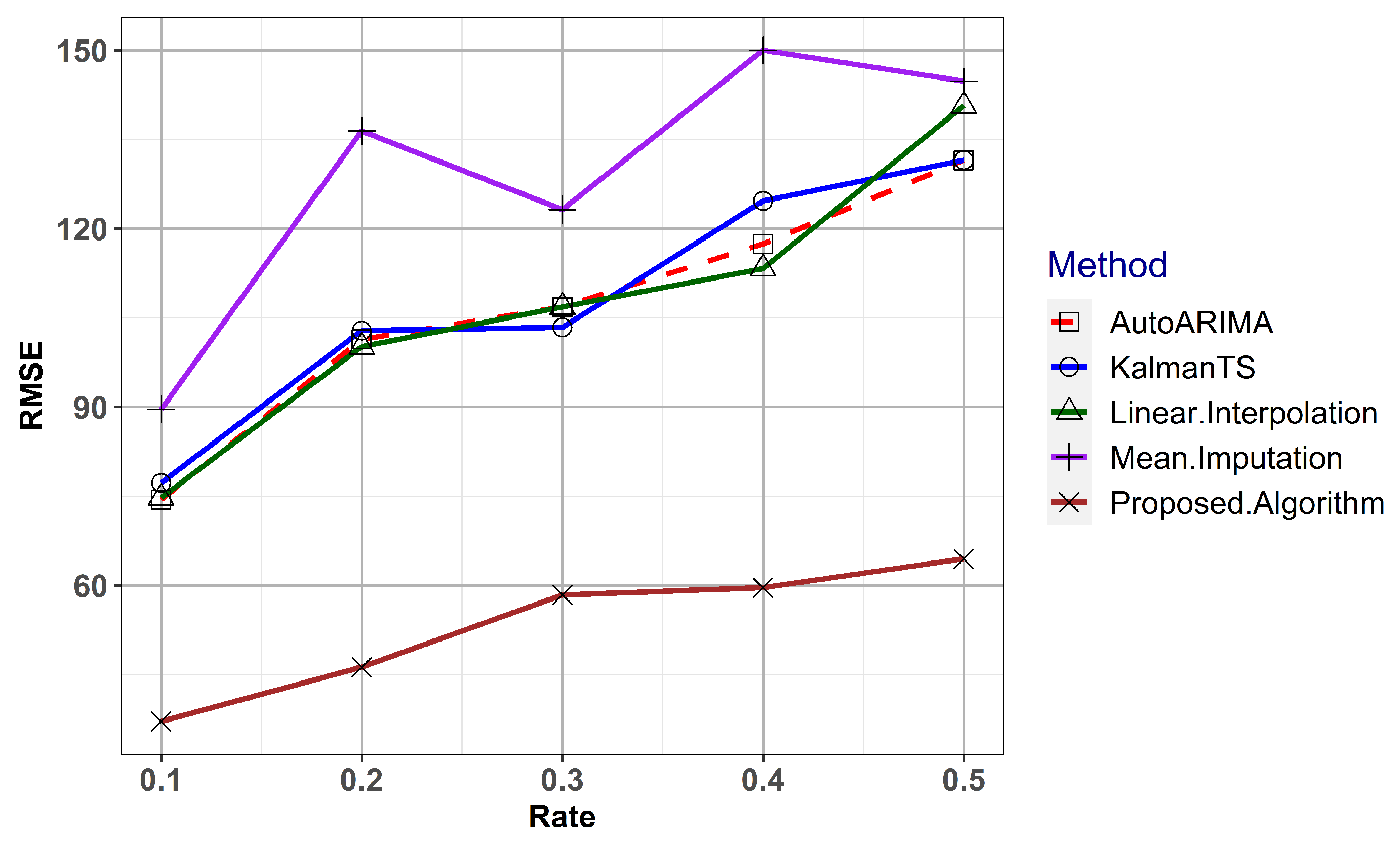
- Scenario1: Missing percentage 10% with rate 0.1
- Scenario2: Missing percentage 20% with rate 0.2
- Scenario3: Missing percentage 30% with rate 0.3
- Scenario4: Missing percentage 40% with rate 0.4
- Scenario5: Missing percentage 50% with rate 0.5
5. Results and Discussion
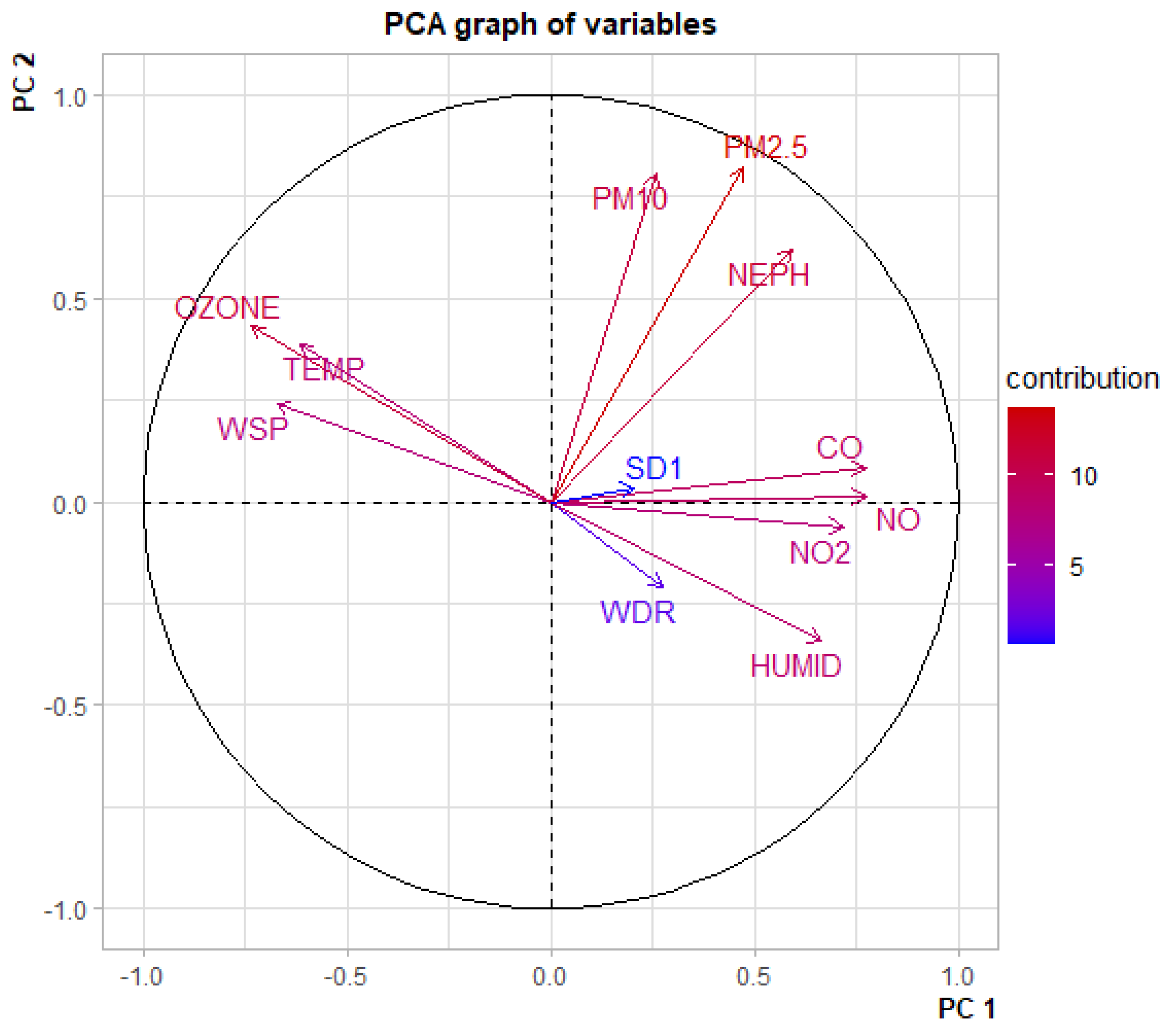
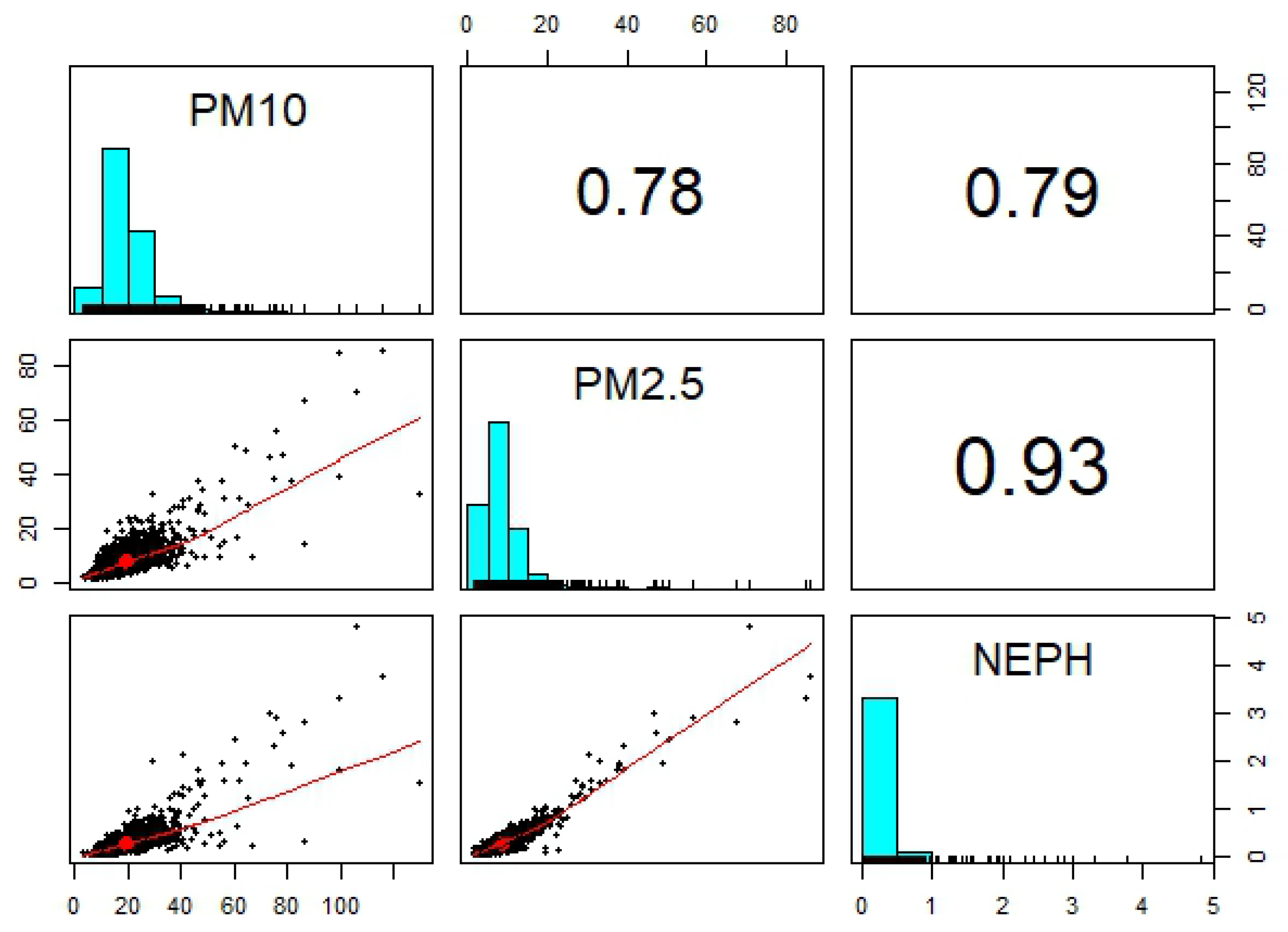
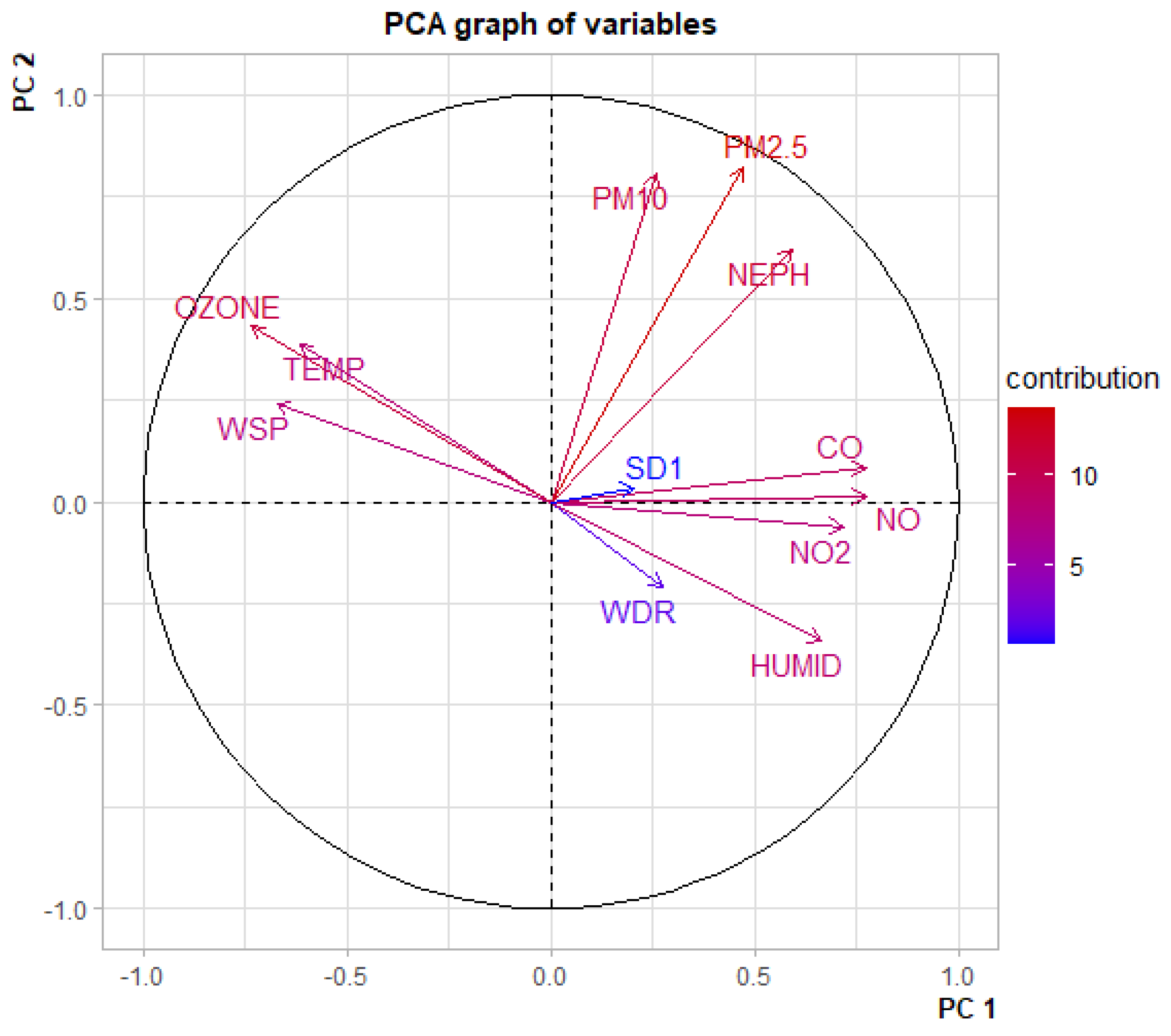
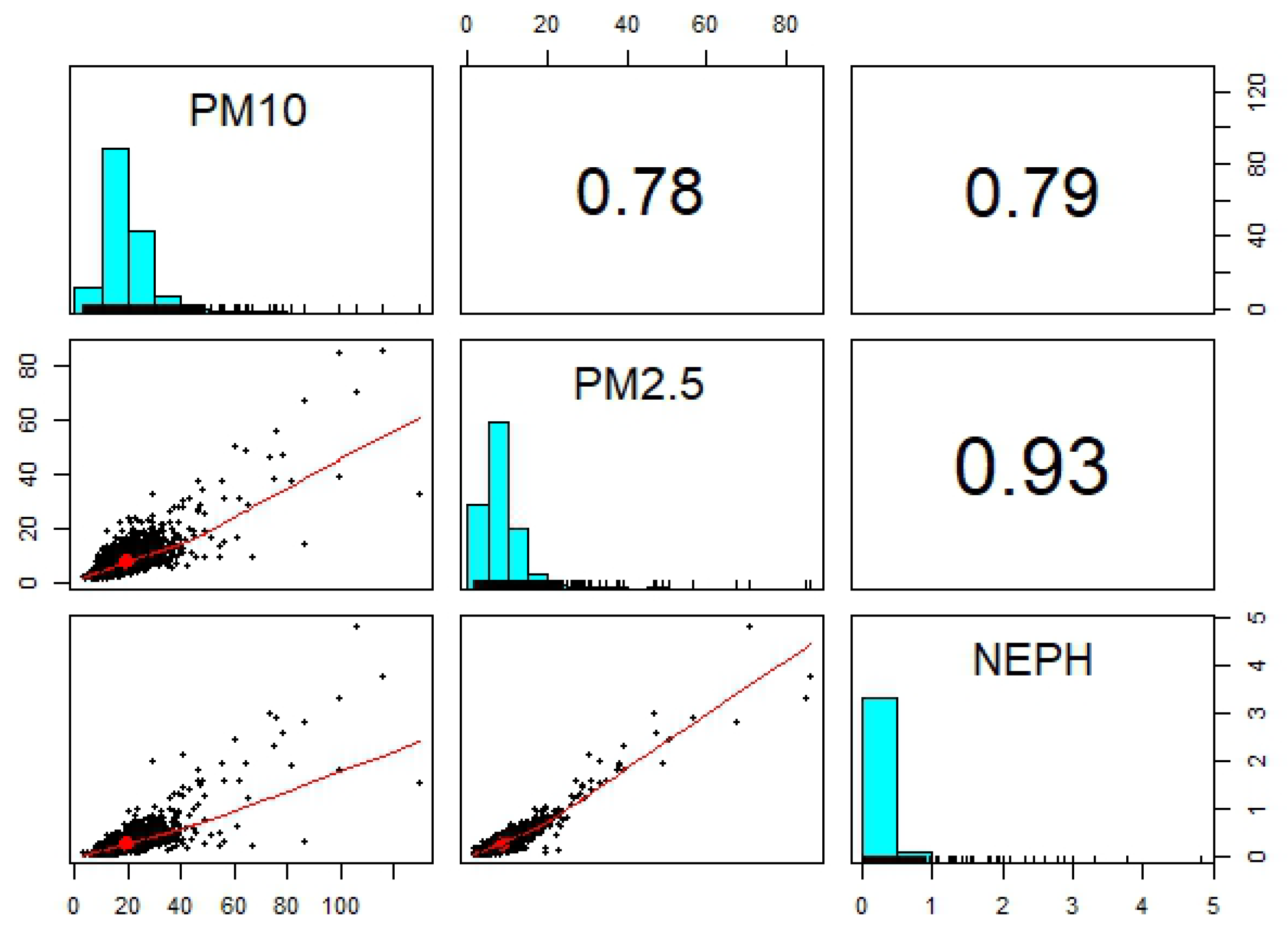
5.1. Exploratory Analysis
- CO, NO and NO are positively-correlated
- O (Ozone) and Temperature are positively correlated
- PM, PM and NEPH (a measure of visibility) are positively correlated
- Humidity is negatively correlated with O and Temperature
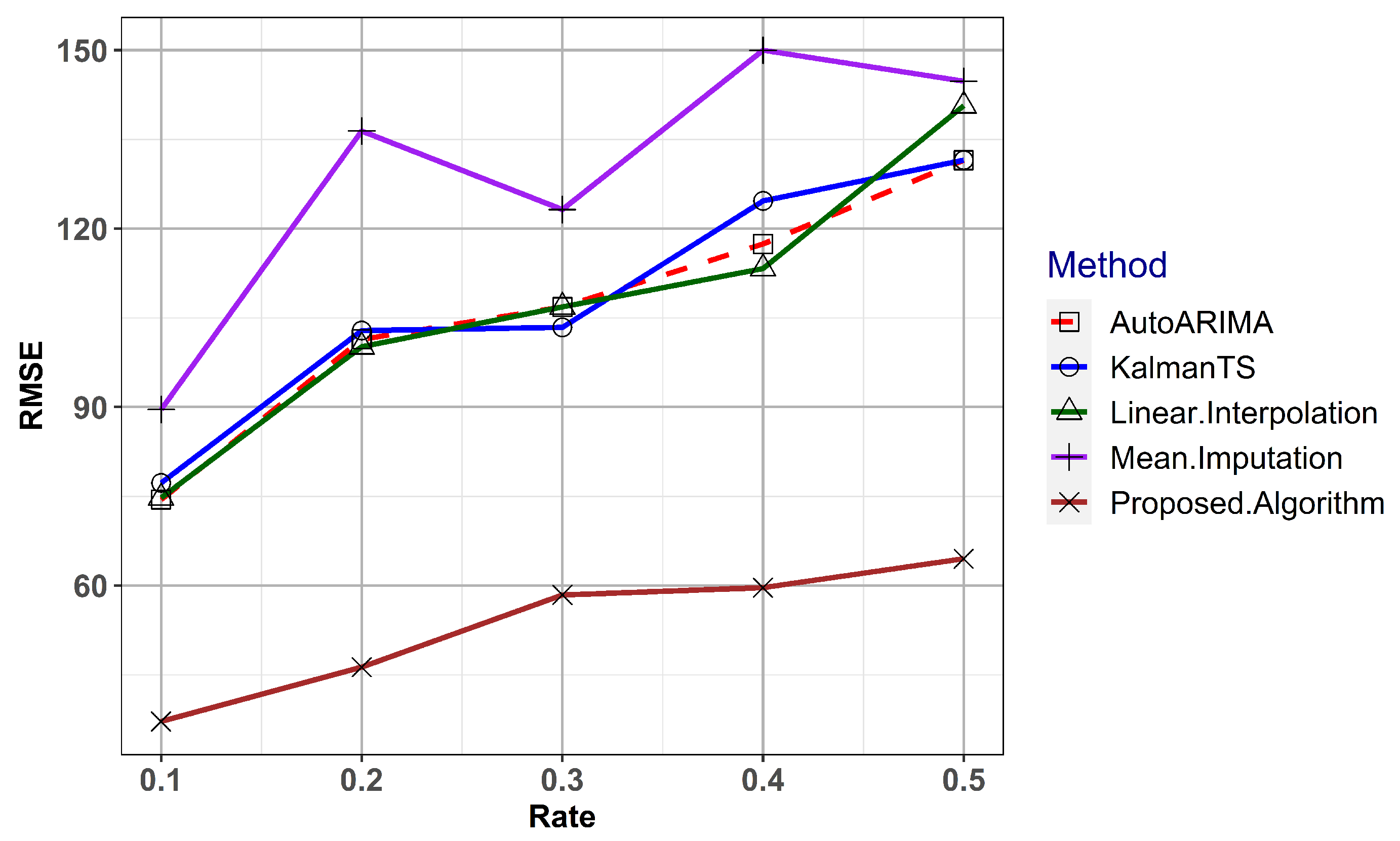
5.2. Performance Evaluation
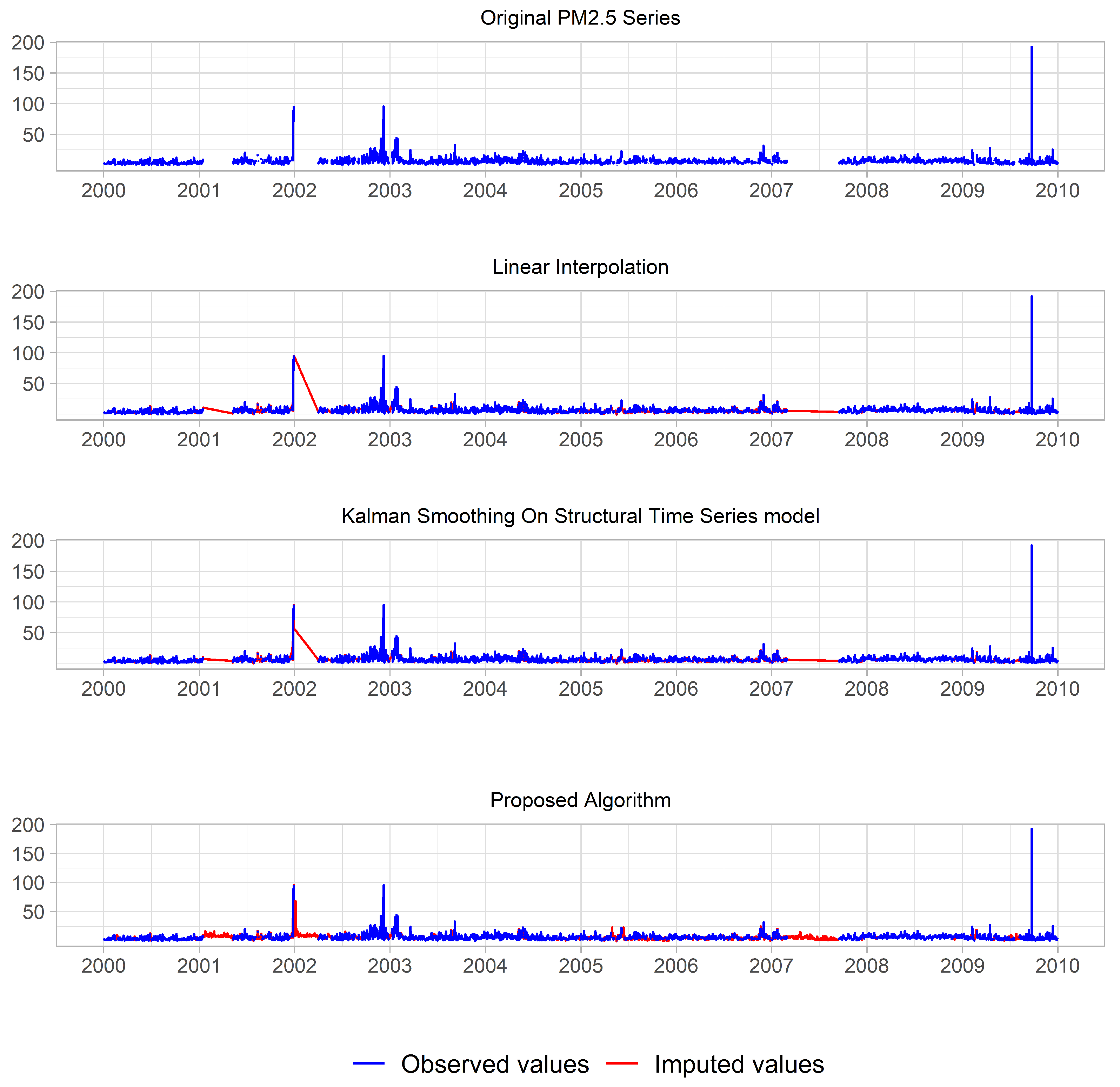
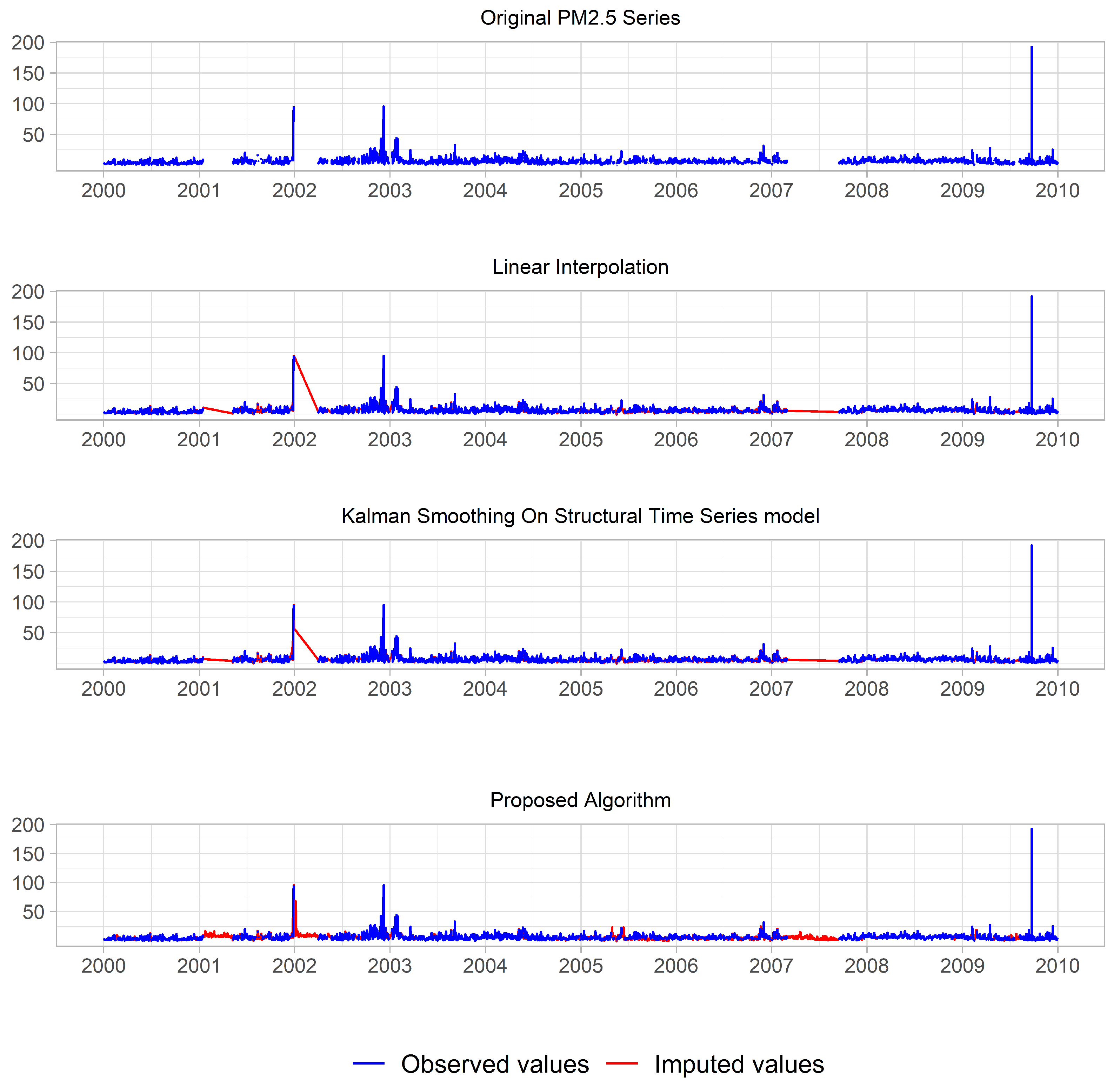
5.3. Real Application
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kalivitis, N.; Papatheodorou, S.; Maesano, C.N.; Annesi-Maesano, I. Air quality and health impacts. In Atmospheric Chemistry in the Mediterranean Region; Springer: Berlin/Heidelberg, Germany, 2022; pp. 459–486. [Google Scholar]
- Hu, W.; Mengersen, K.; McMichael, A.; Tong, S. Temperature, air pollution and total mortality during summers in Sydney, 1994–2004. Int. J. Biometeorol. 2008, 52, 689–696. [Google Scholar] [CrossRef]
- Ren, C.; Williams, G.M.; Tong, S. Does particulate matter modify the association between temperature and cardiorespiratory diseases? Environ. Health Perspect. 2006, 114, 1690–1696. [Google Scholar] [CrossRef]
- Simpson, R.; Williams, G.; Petroeschevsky, A.; Best, T.; Morgan, G.; Denison, L.; Hinwood, A.; Neville, G.; Neller, A. The short-term effects of air pollution on daily mortality in four Australian cities. Aust. N. Z. J. Public Health 2005, 29, 205–212. [Google Scholar] [CrossRef]
- Rubin, D. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Rantou, K. Missing Data in Time Series and Imputation Methods; University of the Aegean: Mytilene, Greece, 2017. [Google Scholar]
- Rubright, J.D.; Nandakumar, R.; Gluttin, J.J. A simulation study of missing data with multiple missing X’s. Pract. Assess. Res. Eval. 2014, 19, 10. [Google Scholar]
- Donders, A.R.T.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef]
- Moritz, S.; Sardá, A.; Bartz-Beielstein, T.; Zaefferer, M.; Stork, J. Comparison of different methods for univariate time series imputation in R. arXiv 2015, arXiv:1510.03924. [Google Scholar]
- Dixon, W.J. BMDP Statistical Software Manual: To Accompany the… Software Release; University of California Press: Berkeley, CA, USA, 1988. [Google Scholar]
- Little, R.J. A test of missing completely at random for multivariate data with missing values. J. Am. Stat. Assoc. 1988, 83, 1198–1202. [Google Scholar] [CrossRef]
- Nakagawa, S. Missing data: Mechanisms, methods and messages. Ecol. Stat. Contemp. Theory Appl. 2015, 81–105. [Google Scholar]
- Nakagawa, S.; Freckleton, R.P. Missing inaction: The dangers of ignoring missing data. Trends Ecol. Evol. 2008, 23, 592–596. [Google Scholar] [CrossRef]
- Chandrasekaran, S.; Zaefferer, M.; Moritz, S.; Stork, J.; Friese, M.; Fischbach, A.; Bartz-Beielstein, T. Data Preprocessing: A New Algorithm for Univariate Imputation Designed Specifically for Industrial Needs. In Proceedings of the 26 Workshop Computational Intelligence, Dortmund, Germany, 24–25 November 2016. [Google Scholar]
- Wijesekara, W.; Liyanage, L. Comparison of Imputation Methods for Missing Values in Air Pollution Data: Case Study on Sydney Air Quality Index. In Proceedings of the Future of Information and Communication Conference, San Francisco, CA, USA, 5–6 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 257–269. [Google Scholar]
- Norazian, M.N.; Shukri, Y.A.; Azam, R.N.; Al Bakri, A.M.M. Estimation of missing values in air pollution data using single imputation techniques. ScienceAsia 2008, 34, 341–345. [Google Scholar] [CrossRef]
- Zakaria, N.A.; Noor, N.M. Imputation methods for filling missing data in urban air pollution data formalaysia. Urban. Arhit. Constr. 2018, 9, 159–166. [Google Scholar]
- Junger, W.; De Leon, A.P. Imputation of missing data in time series for air pollutants. Atmos. Environ. 2015, 102, 96–104. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Wijesekara, L.; Liyanage, L. Air quality data pre-processing: A novel algorithm to impute missing values in univariate time series. In Proceedings of the 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), Virtual, 1–3 November 2021; pp. 996–1001. [Google Scholar]
- Lei, K.S.; Wan, F. Pre-processing for missing data: A hybrid approach to air pollution prediction in Macau. In Proceedings of the 2010 IEEE International Conference on Automation and Logistics, Hong Kong, China, 16–20 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 418–422. [Google Scholar] [CrossRef]
- Shahbazi, H.; Karimi, S.; Hosseini, V.; Yazgi, D.; Torbatian, S. A novel regression imputation framework for Tehran air pollution monitoring network using outputs from WRF and CAMx models. Atmos. Environ. 2018, 187, 24–33. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Xu, G.; Yao, Z.; Jia, J.; Zhang, Y. Imputation of missing data in time series for air pollutants using long short-term memory recurrent neural networks. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1293–1300. [Google Scholar]
- Lee, M.; An, J.; Lee, Y. Missing-value imputation of continuous missing based on deep imputation network using correlations among multiple iot data streams in a smart space. IEICE Trans. Inf. Syst. 2019, 102, 289–298. [Google Scholar] [CrossRef]
- Cao, W.; Wang, D.; Li, J.; Zhou, H.; Li, L.; Li, Y. Brits: Bidirectional recurrent imputation for time series. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Yoon, J.; Zame, W.R.; van der Schaar, M. Estimating missing data in temporal data streams using multi-directional recurrent neural networks. IEEE Trans. Biomed. Eng. 2018, 66, 1477–1490. [Google Scholar] [CrossRef]
- Luo, Y.; Cai, X.; Zhang, Y.; Xu, J.; Yuan, X. Multivariate time series imputation with generative adversarial networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Luo, Y.; Zhang, Y.; Cai, X.; Yuan, X. E2gan: End-to-end generative adversarial network for multivariate time series imputation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3094–3100. [Google Scholar]
- Wu, Z.; Ma, C.; Shi, X.; Wu, L.; Zhang, D.; Tang, Y.; Stojmenovic, M. BRNN-GAN: Generative Adversarial Networks with Bi-directional Recurrent Neural Networks for Multivariate Time Series Imputation. In Proceedings of the 2021 IEEE 27th International Conference on Parallel and Distributed Systems (ICPADS), Beijing, China, 14–16 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 217–224. [Google Scholar]
- Miao, X.; Wu, Y.; Wang, J.; Gao, Y.; Mao, X.; Yin, J. Generative semi-supervised learning for multivariate time series imputation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 8983–8991. [Google Scholar]
- Liu, Y.; Yu, R.; Zheng, S.; Zhan, E.; Yue, Y. Naomi: Non-autoregressive multiresolution sequence imputation. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Khayati, M.; Lerner, A.; Tymchenko, Z.; Cudré-Mauroux, P. Mind the gap: An experimental evaluation of imputation of missing values techniques in time series. In Proceedings of the VLDB Endowment, Online, 31 August–4 September 2020; Volume 13, pp. 768–782. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Mazumder, R.; Hastie, T.; Tibshirani, R. Spectral regularization algorithms for learning large incomplete matrices. J. Mach. Learn. Res. 2010, 11, 2287–2322. [Google Scholar] [PubMed]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Khayati, M.; Böhlen, M.; Gamper, J. Memory-efficient centroid decomposition for long time series. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 100–111. [Google Scholar]
- Khayati, M.; Cudré-Mauroux, P.; Böhlen, M.H. Scalable recovery of missing blocks in time series with high and low cross-correlations. Knowl. Inf. Syst. 2020, 62, 2257–2280. [Google Scholar] [CrossRef]
- Balzano, L.; Chi, Y.; Lu, Y.M. Streaming pca and subspace tracking: The missing data case. Proc. IEEE 2018, 106, 1293–1310. [Google Scholar] [CrossRef]
- Zhang, D.; Balzano, L. Global convergence of a grassmannian gradient descent algorithm for subspace estimation. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; PMLR: London, UK, 2016; pp. 1460–1468. [Google Scholar]
- Wellenzohn, K.; Böhlen, M.H.; Dignös, A.; Gamper, J.; Mitterer, H. Continuous imputation of missing values in streams of pattern-determining time series. In Proceedings of the 20th International Conference on Extending Database Technology (EDBT 2017), Venice, Italy, 21–24 March 2017. [Google Scholar]
- Ruan, W.; Xu, P.; Sheng, Q.Z.; Tran, N.K.; Falkner, N.J.; Li, X.; Zhang, W.E. When sensor meets tensor: Filling missing sensor values through a tensor approach. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 2025–2028. [Google Scholar]
- Jerrett, M.; Arain, A.; Kanaroglou, P.; Beckerman, B.; Potoglou, D.; Sahsuvaroglu, T.; Morrison, J.; Giovis, C. A review and evaluation of intraurban air pollution exposure models. J. Expo. Sci. Environ. Epidemiol. 2005, 15, 185–204. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Zhang, W.; Wang, J.; Wang, J.; Zhao, Z.; Tian, M. Short-term wind speed forecasting based on a hybrid model. Appl. Soft Comput. 2013, 13, 3225–3233. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Wang, J.; Han, T.; Kong, L. A novel hybrid approach for wind speed prediction. Inf. Sci. 2014, 273, 304–318. [Google Scholar] [CrossRef]
- Wang, J.; Qin, S.; Zhou, Q.; Jiang, H. Medium-term wind speeds forecasting utilizing hybrid models for three different sites in Xinjiang, China. Renew. Energy 2015, 76, 91–101. [Google Scholar] [CrossRef]
- Prema, V.; Rao, K.U. Time series decomposition model for accurate wind speed forecast. Renew. Wind Water Sol. 2015, 2, 1–11. [Google Scholar] [CrossRef]
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time series missing value imputation in R. R J. 2017, 9, 207. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Missing Mechanism | General | Time Series |
|---|---|---|
| MCAR | Tube containing a blood sample of an individual who is under study is broken by accident so that the blood variables cannot be measured, Questionnaire of a survey participant is lost [8] | Sensor data are recorded from a field test and sent via radio signals to be recorded. The transmission fails on random occasions due to unknown reasons [9] |
| MAR | Income of an individual who is under study can be missing when the level of income is relatively high [8] | Particular sensor machine is shutdown on some weekends for maintenance the data are more likely to be missing on weekends [9] |
| MNAR | When predicting the outcome of a diagnostic test based on some patient characteristics, the test results are known for all the diseased subjects whereas unknown for a random sample of no-diseased subjects [8] | Temperature sensor fails to record values when the temperature is over 50 C [9] |
| Site | Variable | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PM | PM | NEPH | |||||||
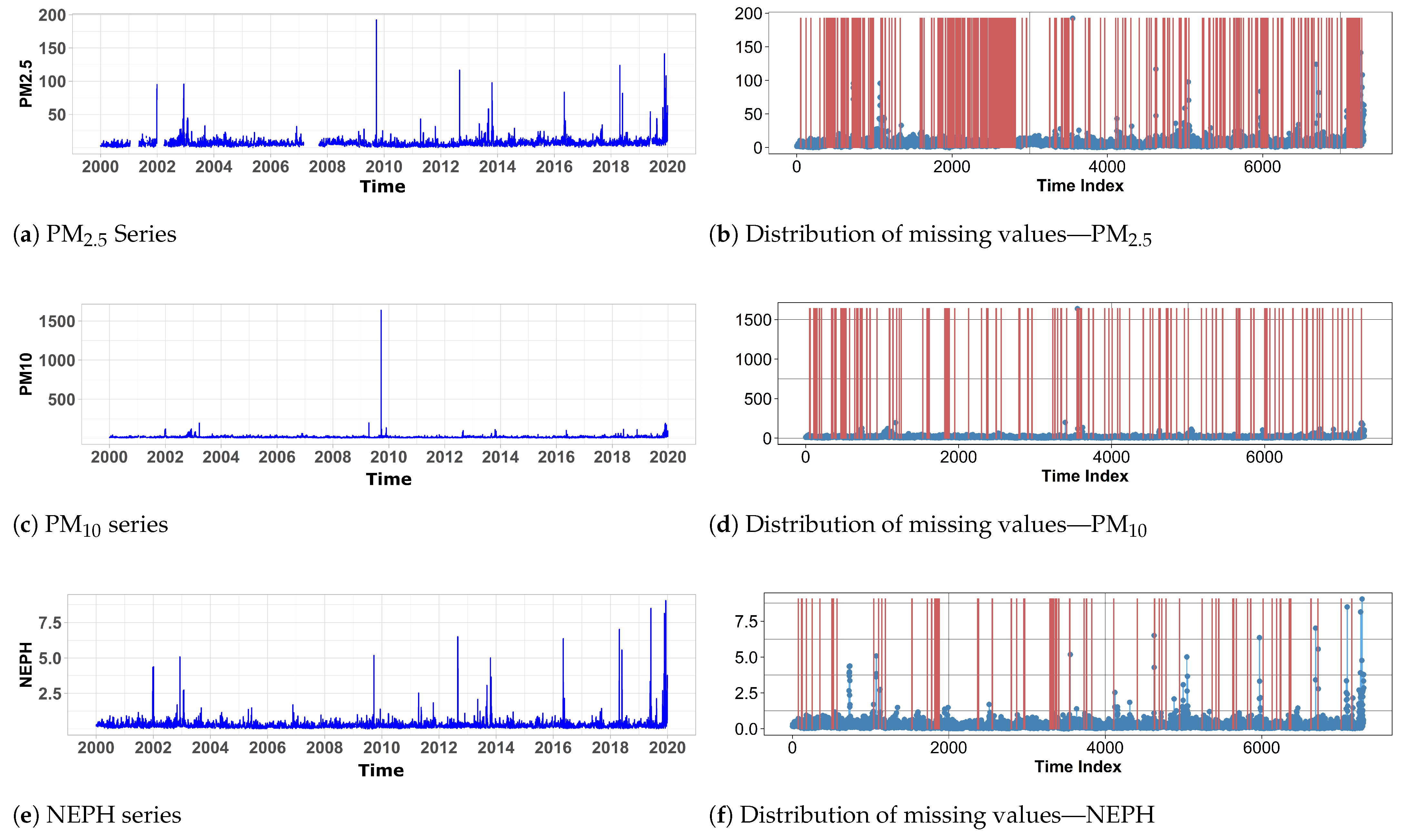
| Longest Gap | Frequent Gap | Missing Percent | Longest Gap | Frequent Gap | Missing Percent | Longest Gap | Frequent Gap | Missing Percent | |
| RICHMOND | 197 | 1 NA 179 times | 12.4 | 18 | 1 NA 63 times | 3.85 | 5 | 2 NA 28 times | 2.07 |
| BRINGELLY | 6025 | 1 NA 11 times | 83.1 | 24 | 2 NA 15 times | 3.48 | 14 | 2 NA 31 times | 3.01 |
| EARLWOOD | 83 | 1 NA 48 times | 5 | 15 | 1 NA 41 times | 3.29 | 5 | 1 NA 14 times | 1.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wijesekara, L.; Liyanage, L. Mind the Large Gap: Novel Algorithm Using Seasonal Decomposition and Elastic Net Regression to Impute Large Intervals of Missing Data in Air Quality Data. Atmosphere 2023, 14, 355. https://doi.org/10.3390/atmos14020355
Wijesekara L, Liyanage L. Mind the Large Gap: Novel Algorithm Using Seasonal Decomposition and Elastic Net Regression to Impute Large Intervals of Missing Data in Air Quality Data. Atmosphere. 2023; 14(2):355. https://doi.org/10.3390/atmos14020355
Chicago/Turabian StyleWijesekara, Lakmini, and Liwan Liyanage. 2023. "Mind the Large Gap: Novel Algorithm Using Seasonal Decomposition and Elastic Net Regression to Impute Large Intervals of Missing Data in Air Quality Data" Atmosphere 14, no. 2: 355. https://doi.org/10.3390/atmos14020355
APA StyleWijesekara, L., & Liyanage, L. (2023). Mind the Large Gap: Novel Algorithm Using Seasonal Decomposition and Elastic Net Regression to Impute Large Intervals of Missing Data in Air Quality Data. Atmosphere, 14(2), 355. https://doi.org/10.3390/atmos14020355