
Establishing a Real-Time Prediction System for Fine Particulate Matter Concentration Using Machine-Learning Models



Abstract
:1. Introduction
- (1)
- This study utilizes machine-learning models, including artificial neural networks, decision trees, and linear regression, to construct predictive models for PM2.5 concentration. Subsequently, the study aims to identify the most appropriate models for real-time forecasting analysis.
- (2)
- Given the uncertainty in determining the optimal model for predictions ranging from 1 to 12 h, this study seeks to develop an effective real-time prediction system. The proposed system aims to create an ensemble table for each prediction time horizon by incorporating results from diverse models. Subsequently, the system selects the most suitable prediction model for each time horizon through the ensemble table, thereby enhancing the accuracy of PM2.5 concentration predictions.
2. Methodology
2.1. Modeling Procedure
- The first step is data collection, which involves gathering meteorological and pollutant data from the air quality monitoring website (https://airtw.moenv.gov.tw/ accessed on 1 December 2022) of Taiwan’s Ministry of Environment.
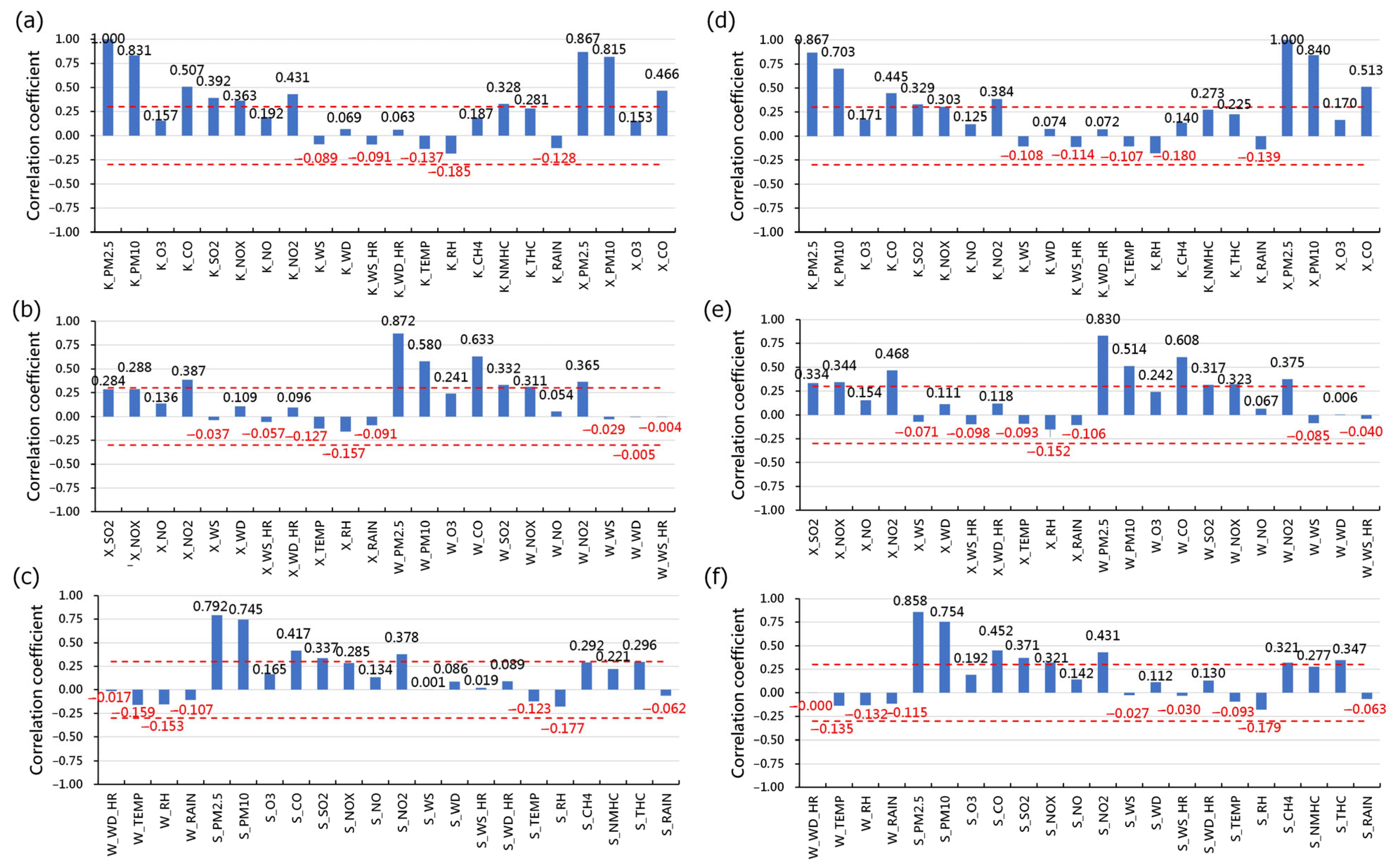
- Step two involves data filtering. In this step, all collected attribute data undergo a thorough correlation analysis with the target variable, PM2.5 concentration. The correlation analysis serves as the primary criterion for filtering attribute data. Attributes exhibiting low correlations with PM2.5 concentration are identified and, subsequently, removed during the screening process. On the other hand, attributes demonstrating high correlations are retained as input data for the models. This careful selection process aims to enhance the models’ capability to capture meaningful relationships between the input features and the target variable.
- Step three involves dataset partitioning, where all input data are divided to define the training and validation data required for model construction, as well as the testing data used after model development is completed.
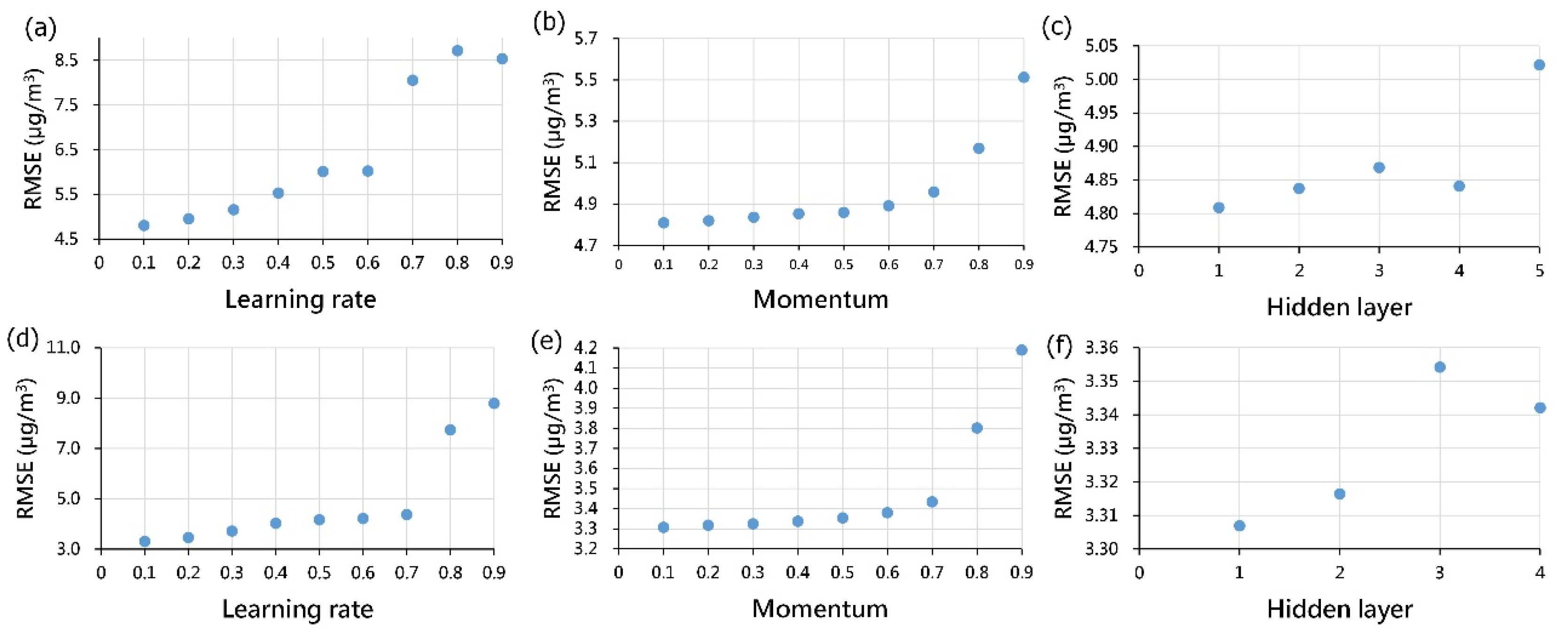
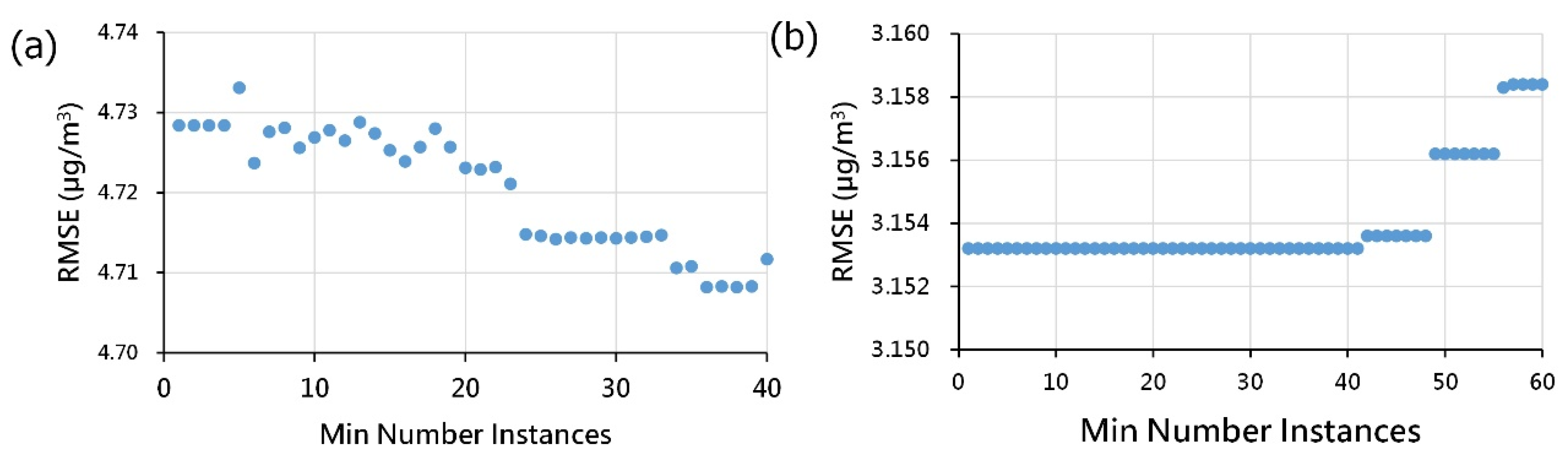
- Step four involves the crucial stage of model development, where we employ a meticulous trial-and-error approach for parameter tuning in each model. This iterative process is essential for enhancing the predictive performance of the models. Specifically, we systematically adjust model parameters based on prediction results, continuously calibrating and refining until an optimal combination is identified.
- Step five constitutes the crucial phase of performance evaluation, where the efficacy of the models is systematically assessed using a range of established evaluation metrics. This comprehensive set of metrics aims to provide a nuanced understanding of the models’ predictive capabilities. This research uses root mean squared error (RMSE), relative root mean squared error (rRMSE), mean absolute percentage error (MAPE), efficiency coefficient (CE), and correlation coefficient (r) as evaluation metrics. RMSE, rRMSE, MAPE, CE, and r are defined as follows:where n represents the total number of data points, is the ith predicted value, is the ith observed value, denotes the mean of predicted values, and represents the mean of observed values.
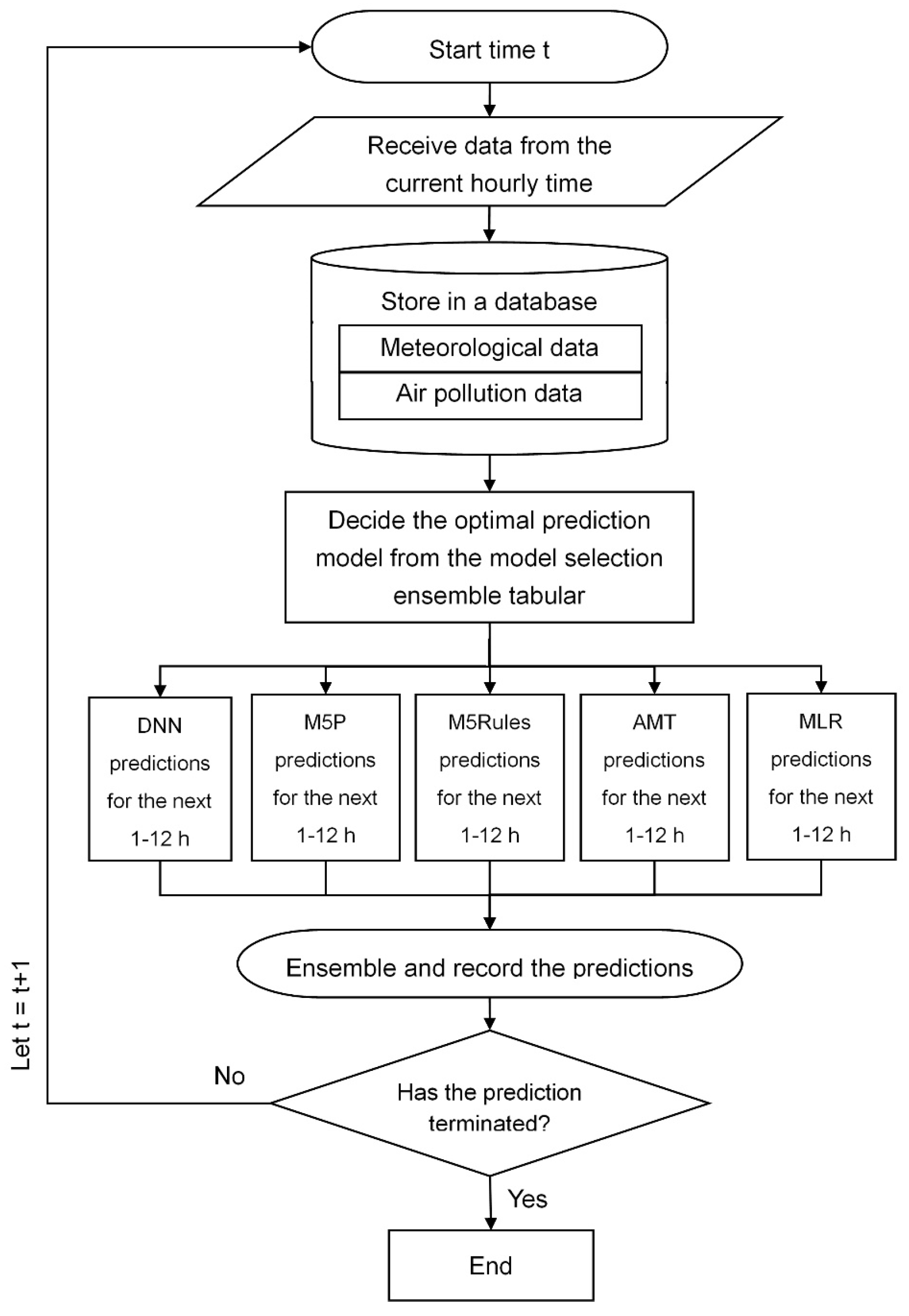
- Finally, step six involves the establishment and testing of the real-time prediction system. Based on the prediction results from various models, a model selection tabular is created to consolidate the composite real-time prediction system. This system can provide accurate predictions at different forecast horizons by selecting the best model from the selection tabular.
2.2. Model Theory
2.2.1. DNN
2.2.2. Decision Tree
- M5P
- M5Rules
- AMT
2.2.3. MLR
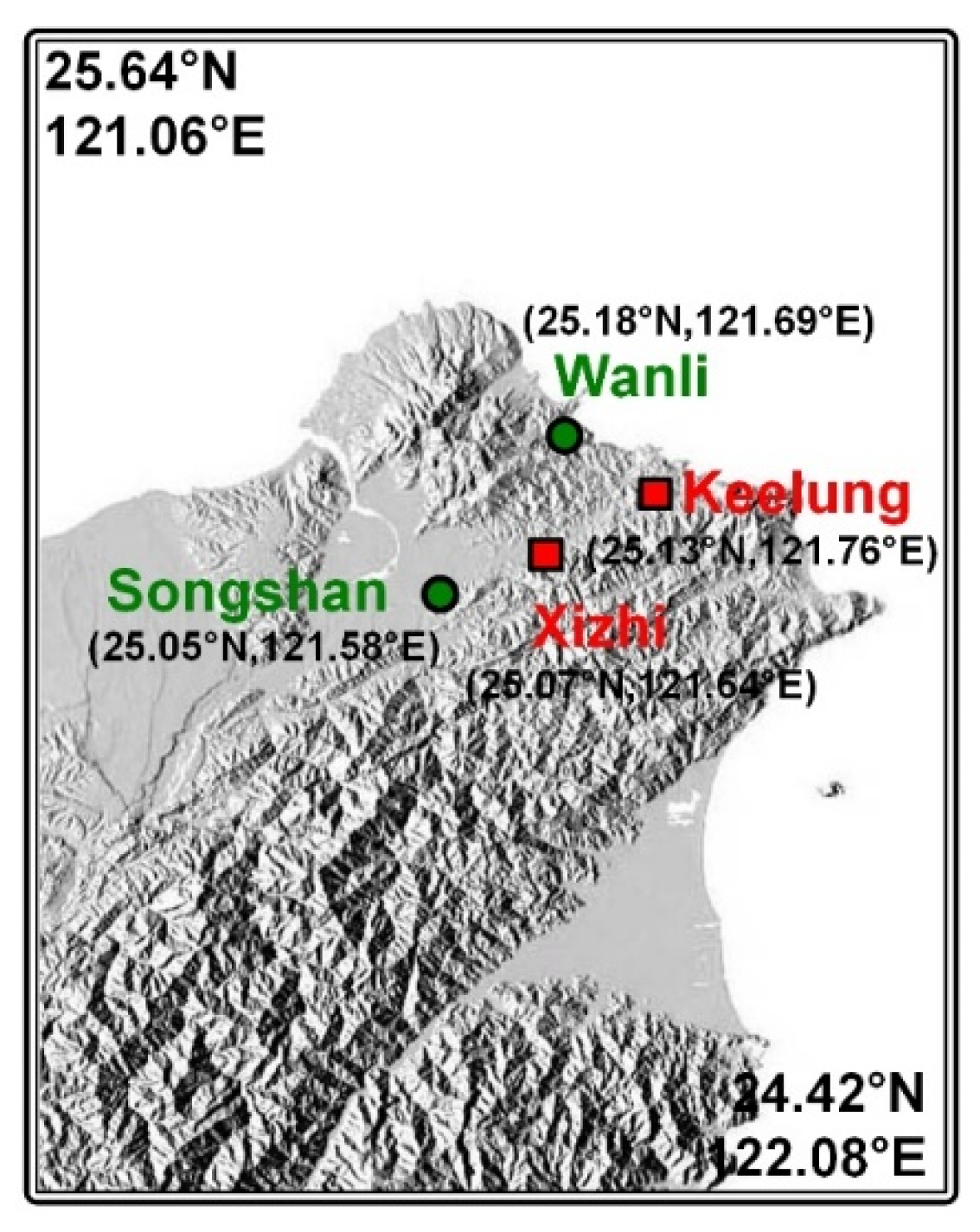
2.3. Study Area and Data
3. Model Development and Evaluation
3.1. Feature Selection
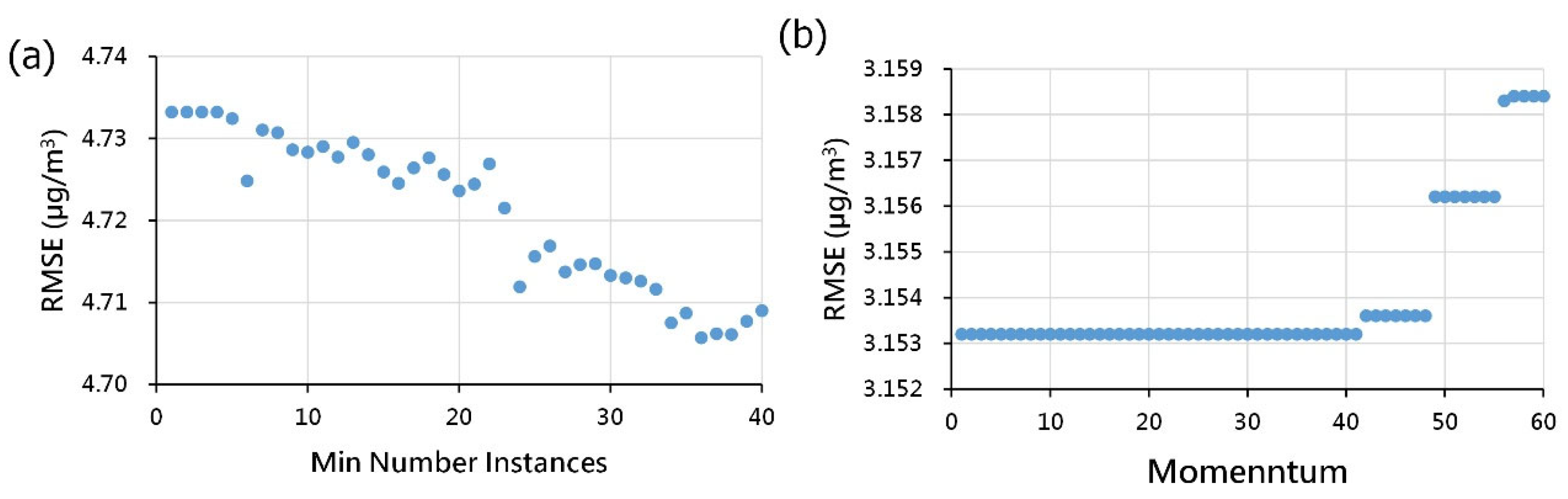
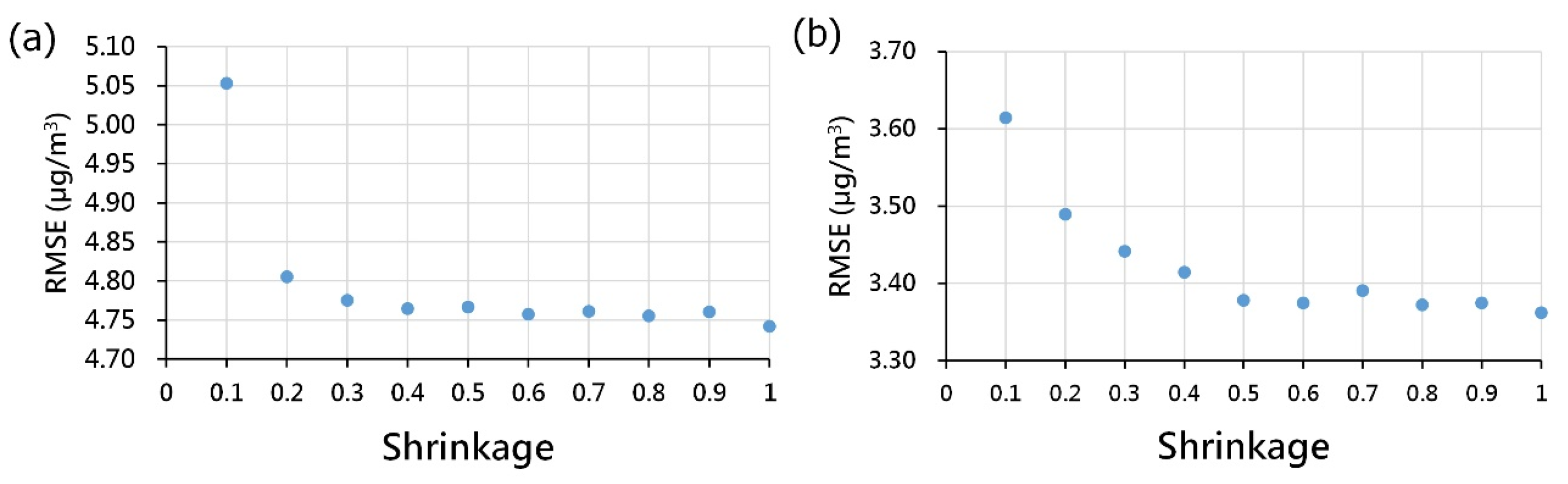
3.2. Calibration of Model Parameters
3.3. Model Testing Results
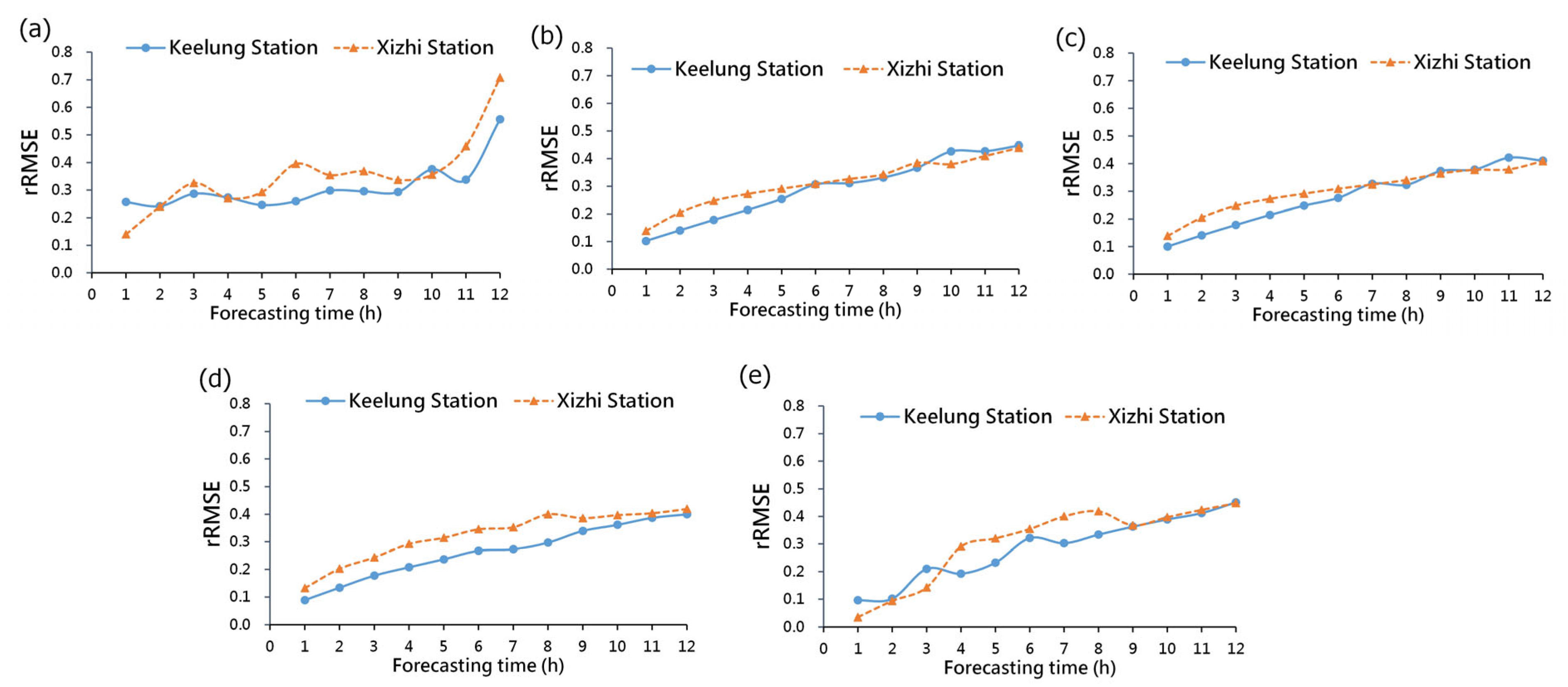
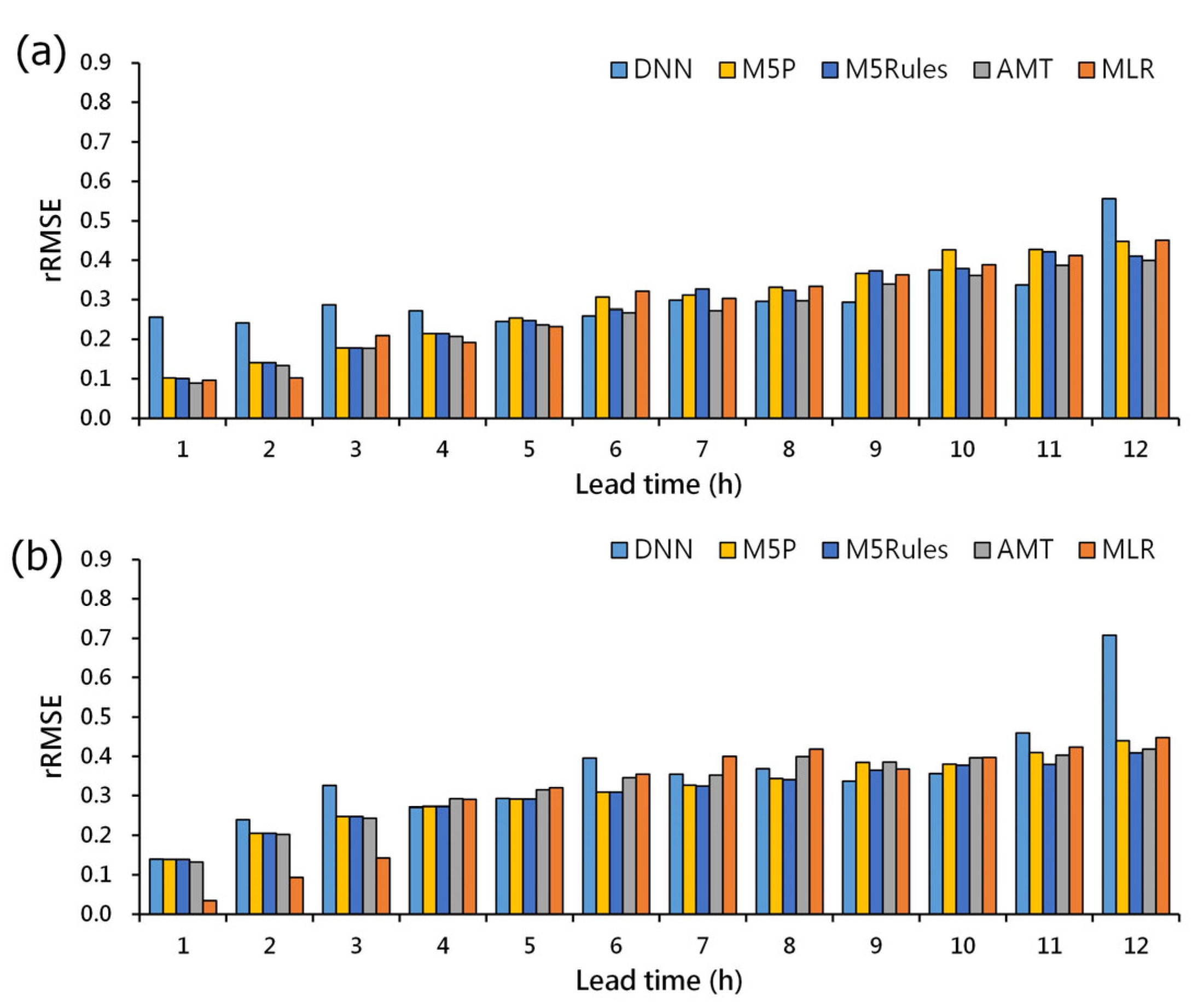
3.4. Model Comparison
4. Simulation
4.1. A Real-Time Prediction System
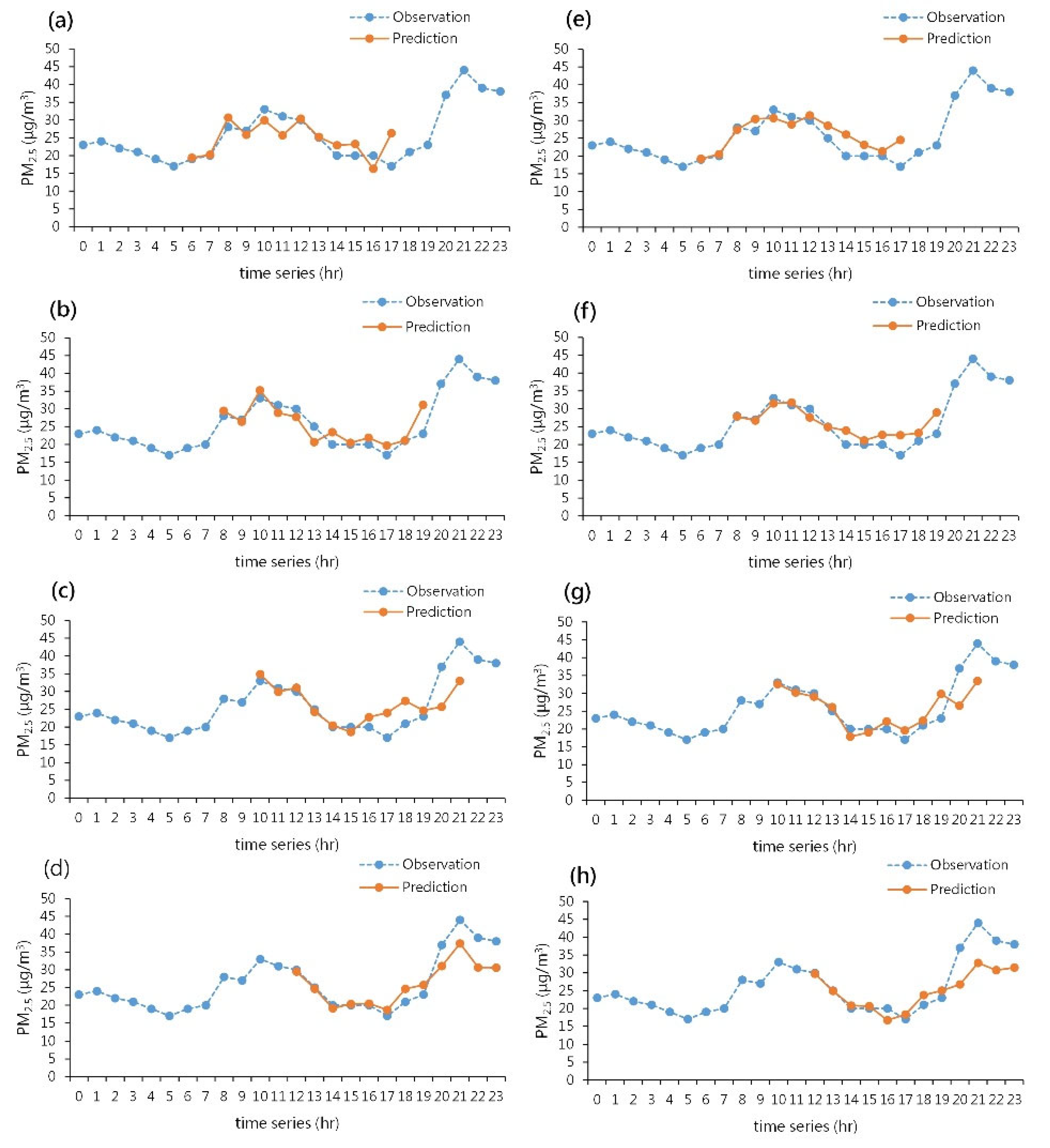
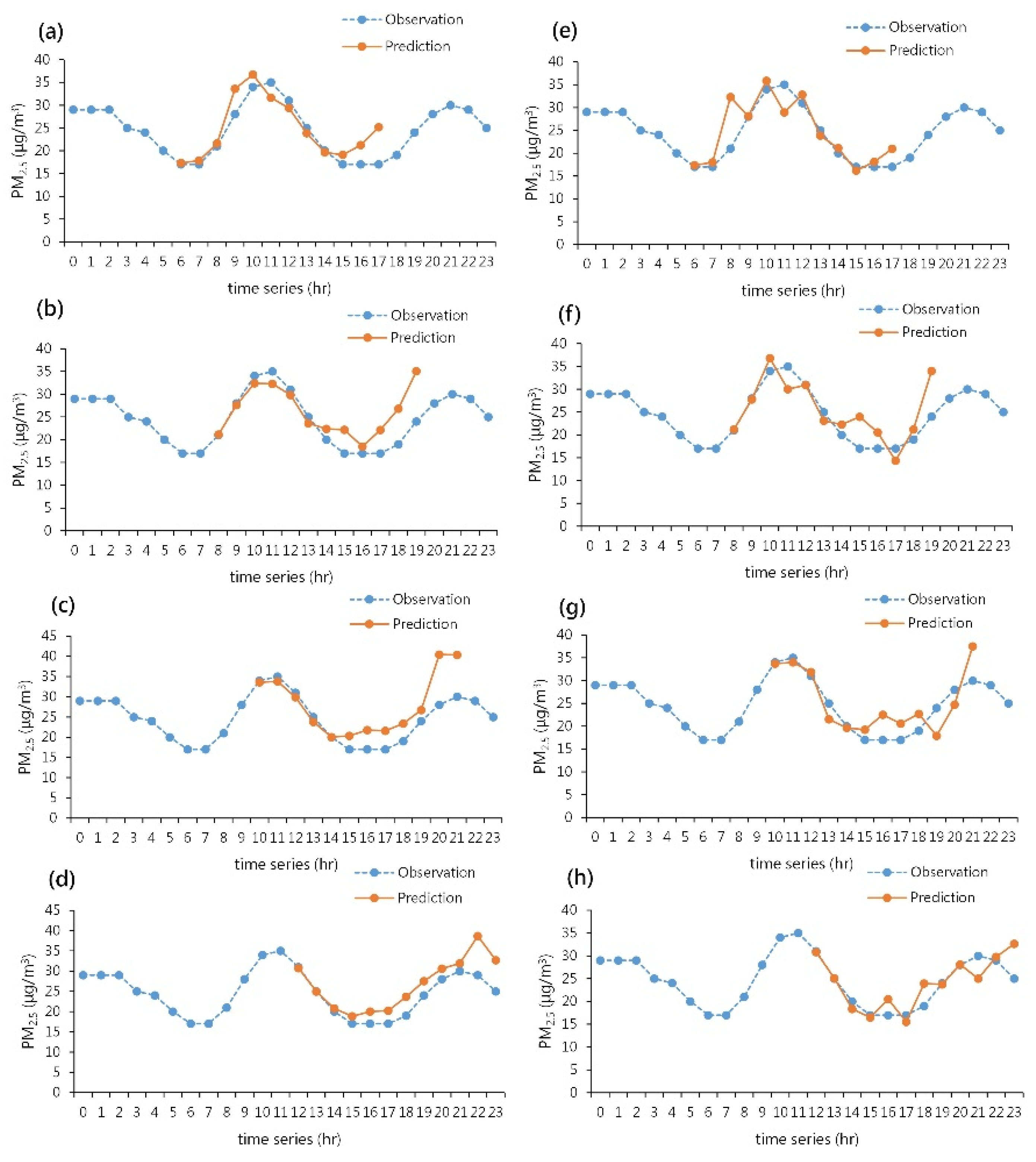
4.2. System Simulations
5. Conclusions
- (1)
- When comparing different models, it was observed that decision tree models provided a more stable predictive performance across both Keelung Station and Xizhi Station. In contrast, the DNN model exhibited larger fluctuations in error values compared to other models across various prediction time horizons. The MLR model also displayed greater fluctuations in prediction errors at Xizhi Station compared to other models. However, it is worth noting that the DNN and MLR models outperformed other models in certain time horizons, indicating that each model has its own strengths and weaknesses in prediction.
- (2)
- If the PM2.5 concentration remains above 35 μg/m3 for an extended period, there is a higher probability that the predicted results will be underestimated. The main reason for this may be the infrequent occurrence of high concentrations in historical data, causing the model to be ineffective in predicting high values.
- (3)
- At different prediction time horizons, all models performed well in predicting results for the next 3 h. However, the prediction errors began to increase for predictions in the 4 to 6 h range. For longer-term predictions covering 12 h, all models exhibited larger prediction errors. In general, as the prediction time interval increased, the prediction errors also increased, indicating that longer-term forecasts are more challenging for all models.
- (4)
- Ultimately, this study developed a real-time fine particulate matter concentration prediction system that can predict the changes in fine particulate matter concentration for the next 12 h. The system also includes hourly adjustments to the predictions. Compared to the performance of individual models, the real-time prediction system provides a more comprehensive and accurate prediction trend.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kong, S.; Li, X.; Li, L.; Yin, Y.; Chen, K.; Yuan, L.; Zhang, Y.; Shan, Y.; Ji, Y. Variation of polycyclic aromatic hydrocarbons in atmospheric PM2.5 during winter haze period around 2014 Chinese Spring Festival at Nanjing: Insights of source changes, air mass direction and firework particle injection. Sci. Total Environ. 2015, 520, 59–72. [Google Scholar] [CrossRef] [PubMed]
- Alvarez, H.A.O.; Myers, O.B.; Weigel, M.; Armijos, R.X. The value of using seasonality and meteorological variables to model intra-urban PM2.5 variation. Atmos. Environ. 2018, 182, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Tai, A.P.; Mickley, L.J.; Jacob, D.J. Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: Implications for the sensitivity of PM2.5 to climate change. Atmos. Environ. 2010, 44, 3976–3984. [Google Scholar] [CrossRef]
- Li, L.; Qian, J.; Ou, C.Q.; Zhou, Y.X.; Guo, C.; Guo, Y. Spatial and temporal analysis of Air Pollution Index and its timescale-dependent relationship with meteorological factors in Guangzhou, China, 2001–2011. Environ. Pollut. 2014, 190, 75–81. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.S.V.; Langrish, J.P.; Nair, H.; McAllister, D.A.; Hunter, A.L.; Donaldson, K.; Newby, D.E.; Mills, N.L. Global association of air pollution and heart failure: A systematic review and meta-analysis. Lancet 2013, 382, 1039–1048. [Google Scholar] [CrossRef] [PubMed]
- Srimuruganandam, B.; Nagendra, S.S. Source characterization of PM10 and PM2.5 mass using a chemical mass balance model at urban roadside. Sci. Total Environ. 2012, 433, 8–19. [Google Scholar] [CrossRef]
- Atkinson, R.W.; Fuller, G.W.; Anderson, H.R.; Harrison, R.M.; Armstrong, B. Urban ambient particle metrics and health: A time-series analysis. Epidemiology 2010, 21, 501–511. [Google Scholar] [CrossRef]
- Brauer, M.; Amann, M.; Burnett, R.T.; Cohen, A.; Dentener, F.; Ezzati, M.; Henderson, S.B.; Krzyzanowski, M.; Martin, R.V.; Van Dingenen, R.; et al. Exposure assessment for estimation of the global burden of disease attributable to outdoor air pollution. Environ. Sci. Technol. 2012, 46, 652–660. [Google Scholar] [CrossRef]
- Cheung, K.; Daher, N.; Kam, W.; Shafer, M.M.; Ning, Z.; Schauer, J.J.; Sioutas, C. Spatial and temporal variation of chemical composition and mass closure of ambient coarse particulate matter (PM10–2.5) in the Los Angeles area. Atmos. Environ. 2011, 45, 2651–2662. [Google Scholar] [CrossRef]
- Yang, F.; Tan, J.; Zhao, Q.; Du, Z.; He, K.; Ma, Y.; Duan, F.; Chen, G.; Zhao, Q. Characteristics of PM2.5 speciation in representative megacities and across China. Atmos. Chem. Phys. 2011, 11, 5207–5219. [Google Scholar] [CrossRef]
- Zhang, Y. Dynamic effect analysis of meteorological conditions on air pollution: A case study from Beijing. Sci. Total Environ. 2019, 684, 178–185. [Google Scholar] [CrossRef] [PubMed]
- Ni, X.Y.; Huang, H.; Du, W.P. Relevance analysis and short-term prediction of PM2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Anagnostopoulos, F.K.; Rigas, S.; Papachristou, M.; Chaniotis, I.; Anastasiou, I.; Tryfonopoulos, C.; Raftopoulou, P. A novel AI framework for PM pollution prediction applied to a Greek Port City. Atmosphere 2023, 14, 1413. [Google Scholar] [CrossRef]
- Lai, K.; Xu, H.; Sheng, J.; Huang, Y. Hour-by-hour prediction model of air pollutant concentration based on EIDW-informer—A case study of Taiyuan. Atmosphere 2023, 14, 1274. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, K.; Liu, Z.; Wang, L. PM2.5 Concentration prediction based on LightGBM optimized by adaptive multi-strategy enhanced sparrow search algorithm. Atmosphere 2023, 14, 1612. [Google Scholar] [CrossRef]
- Mampitiya, L.; Rathnayake, N.; Leon, L.P.; Mandala, V.; Azamathulla, H.M.; Shelton, S.; Hoshino, Y.; Rathnayake, U. Machine learning techniques to predict the air quality using meteorological data in two urban areas in Sri Lanka. Environments 2023, 10, 141. [Google Scholar] [CrossRef]
- Corani, G. Air quality prediction in Milan: Feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Bai, Y.; Li, Y.; Wang, X.; Xie, J.; Li, C. Air pollutants concentrations forecasting using back propagation neural network based on wavelet decomposition with meteorological conditions. Atmos. Pollut. Res. 2016, 7, 557–566. [Google Scholar] [CrossRef]
- Siwek, K.; Osowski, S. Data mining methods for prediction of air pollution. Int. J. Appl. Math. Comput. Sci. 2016, 26, 467–478. [Google Scholar] [CrossRef]
- Li, C.; Zhu, Z. Research and application of a novel hybrid air quality early-warning system: A case study in China. Sci. Total Environ. 2018, 626, 1421–1438. [Google Scholar] [CrossRef]
- Mehdipour, V.; Stevenson, D.S.; Memarianfard, M.; Sihag, P. Comparing different methods for statistical modeling of particulate matter in Tehran, Iran. Air Qual. Atmos. Health 2018, 11, 1155–1165. [Google Scholar] [CrossRef]
- Wang, J.; Song, G. A deep spatial-temporal ensemble model for air quality prediction. Neurocomputing 2018, 314, 198–206. [Google Scholar] [CrossRef]
- Lee, M.; Lin, L.; Chen, C.Y.; Tsao, Y.; Yao, T.H.; Fei, M.H.; Fang, S.H. Forecasting air quality in Taiwan by using machine learning. Sci. Rep. 2020, 10, 4153. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Chen, T.; Ge, R.; Xv, F.; Cui, C.; Li, J. Prediction of PM2.5 concentration using spatiotemporal data with machine learning models. Atmosphere 2023, 14, 1517. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H. VAR-tree model based spatio-temporal characterization and prediction of O3 concentration in China. Ecotoxicol. Environ. Saf. 2023, 257, 114960. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Huang, G.; Zeng, H. Multi-objective optimal dispatch strategy for power systems with Spatio-temporal distribution of air pollutants. Sustain. Cities Soc. 2023, 98, 104801. [Google Scholar] [CrossRef]
- Liu, C.M.; Young, C.Y.; Lee, Y.C. Influence of Asian dust storms on air quality in Taiwan. Sci. Total Environ. 2006, 368, 884–897. [Google Scholar] [CrossRef]
- Misra, C.; Geller, M.D.; Shah, P.; Sioutas, C.; Solomon, P.A. Development and Evaluation of a Continuous Coarse (PM10–PM2.5) Particle Monitor. J. Air Waste Manag. Assoc. 2001, 51, 1309–1317. [Google Scholar] [CrossRef]
- Juda-Rezler, K.; Reizer, M.; Oudinet, J.P. Determination and analysis of PM10 source apportionment during episodes of air pollution in Central Eastern European urban areas: The case of wintertime 2006. Atmos. Environ. 2011, 45, 6557–6566. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, N.; Vanos, J.K.; Cao, G. Effects of synoptic weather on ground-level PM2.5 concentrations in the United States. Atmos. Environ. 2017, 148, 297–305. [Google Scholar] [CrossRef]
- Zhang, R.; Jing, J.; Tao, J.; Hsu, S.-C.; Wang, G.; Cao, J.; Lee, C.S.L.; Zhu, L.; Chen, Z.; Zhao, Y.; et al. Chemical characterization and source apportionment of PM2.5 in Beijing: Seasonal perspective. Atmos. Chem. Phys. Discuss. 2013, 13, 9953–10007. [Google Scholar]
- Hsu, C.H.; Cheng, F.Y. Synoptic weather patterns and associated air pollution in Taiwan. Aerosol Air Qual. Res. 2019, 19, 1139–1151. [Google Scholar] [CrossRef]
- De Villiers, J.; Barnard, E. Backpropagation neural nets with one and two hidden layers. IEEE Trans. Neural Netw. 1993, 4, 136–141. [Google Scholar] [CrossRef] [PubMed]
- Kwok, T.Y.; Yeung, D.Y. Constructive algorithms for structure learning in feedforward neural networks for regression problems. IEEE Trans. Neural Netw. 1997, 8, 630–645. [Google Scholar] [CrossRef] [PubMed]
- Trenn, S. Multilayer perceptrons: Approximation order and necessary number of hidden units. IEEE Trans. Neural Netw. 2008, 19, 836–844. [Google Scholar] [CrossRef] [PubMed]
- Chien, C.F.; Chen, L.F. Data mining to improve personnel selection and enhance human capital: A case study in high-technology industry. Expert Syst. Appl. 2008, 34, 280–290. [Google Scholar] [CrossRef]
- Wang, Y.; Witten, I.H. Induction of Model Trees for Predicting Continuous Classes; Working Paper 96/23; University of Waikato, Department of Computer Science: Hamilton, New Zealand, 1996. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Holmes, G.; Hall, M.; Prank, E. Generating rule sets from model trees. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Sydney, Australia, 6–10 December 1999; pp. 1–12. [Google Scholar]
- Jaakkola, H.; Thalheim, B.; Kiyoki, Y.; Yoshida, N. (Eds.) Information Modelling and Knowledge Bases XXVIII; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2017; Volume 292. [Google Scholar]
- Holmes, G.; Pfahringer, B.; Kirkby, R.; Frank, E.; Hall, M. Multiclass alternating decision trees. In Proceedings of the European Conference on Machine Learning, Helsinki, Finland, 19–23 August 2002; pp. 161–172. [Google Scholar]
- Frank, E.; Mayo, M.; Kramer, S. Alternating model trees. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015; pp. 871–878. [Google Scholar]
- Freund, Y.; Mason, L. The alternating decision tree learning algorithm. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 124–133. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 821. [Google Scholar]
- Taylor, R. Interpretation of the correlation coefficient: A basic review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Mahjoobi, J.; Etemad-Shahidi, A.; Kazeminezhad, M.H. Hindcasting of wave parameters using different soft computing methods. Appl. Ocean Res. 2008, 30, 28–36. [Google Scholar] [CrossRef]
- Tso, G.K.F.; Yau, K.K.W. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Mahjoobi, J.; Etemad-Shahidi, A. An alternative approach for the prediction of significant wave heights based on classification and regression trees. Appl. Ocean. Res. 2008, 30, 172–177. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Monitoring Parameters |
|---|---|
| Keelung | AMB_TEMP, WIND_SPEED, WIND_DIREC, WS_HR, WD_HR, RAINFALL, RH, PM2.5, PM10, O3, SO2, CO, NOX, NO, NO2, THC, CH4, NMHC |
| Xizhi | AMB_TEMP, WIND_SPEED, WIND_DIREC, WS_HR, WD_HR, RAINFALL, RH, PM2.5, PM10, O3, SO2, CO, NOX, NO, NO2 |
| Wanli | AMB_TEMP, WIND_SPEED, WIND_DIREC, WS_HR, WD_HR, RAINFALL, RH, PM2.5, PM10, O3, SO2, CO, NOX, NO, NO2 |
| Songshan | AMB_TEMP, WIND_SPEED, WIND_DIREC, WS_HR, WD_HR, RAINFALL, RH, PM2.5, PM10, O3, SO2, CO, NOX, NO, NO2, THC, CH4, NMHC |
| Target Station | Selected Attributes |
|---|---|
| Keelung | PM2.5, PM10, SO2, CO, NOX, NO2, and NMHCW of Keelung Station; PM2.5, PM10, CO, and NO2 of Xizhi Station; PM2.5, PM10, SO2, CO, and NO2 of Wanli Station; PM2.5, PM10, SO2, CO, and NO2 of Songshan Station |
| Xizhi | PM2.5, PM10, SO2, CO, and NO2 of Keelung Station; PM2.5, PM10, SO2, CO, NOX, and NO2 of Xizhi Station; PM2.5, PM10, SO2, CO, NOX, and NO2 of Wanli Station; PM2.5, PM10, SO2, CO, NOX, NO2, THC, and CH4 of Songshan Station |
| Lead Time (h) | Performance | DNN | M5P | M5Rules | AMT | MLR |
|---|---|---|---|---|---|---|
| t + 1 | RMSE (μg/m3) | 5.22 | 3.99 | 3.99 | 3.99 | 4.00 |
| MAPE | 16.10 | 12.06 | 13.40 | 11.72 | 16.10 | |
| CE | 0.82 | 0.87 | 0.84 | 0.87 | 0.82 | |
| r | 0.92 | 0.91 | 0.91 | 0.91 | 0.91 | |
| t + 3 | RMSE (μg/m3) | 6.65 | 5.96 | 5.96 | 6.02 | 6.05 |
| MAPE | 19.62 | 17.74 | 18.52 | 18.87 | 19.62 | |
| CE | 0.76 | 0.82 | 0.81 | 0.77 | 0.76 | |
| r | 0.81 | 0.81 | 0.81 | 0.80 | 0.81 | |
| t + 6 | RMSE (μg/m3) | 7.18 | 7.68 | 7.49 | 7.57 | 7.63 |
| MAPE | 21.14 | 22.93 | 21.64 | 22.88 | 21.14 | |
| CE | 0.73 | 0.70 | 0.71 | 0.71 | 0.74 | |
| r | 0.68 | 0.67 | 0.68 | 0.67 | 0.68 | |
| t + 12 | RMSE (μg/m3) | 10.28 | 9.13 | 8.89 | 8.91 | 8.98 |
| MAPE | 35.78 | 32.10 | 31.56 | 32.07 | 35.78 | |
| CE | 0.58 | 0.61 | 0.60 | 0.62 | 0.58 | |
| r | 0.54 | 0.51 | 0.53 | 0.53 | 0.53 |
| Lead Time (h) | Performance | DNN | M5P | M5Rules | AMT | MLR |
|---|---|---|---|---|---|---|
| t + 1 | RMSE (μg/m3) | 2.61 | 2.59 | 2.59 | 2.67 | 3.08 |
| MAPE | 10.63 | 10.38 | 9.72 | 9.17 | 10.63 | |
| CE | 0.87 | 0.87 | 0.86 | 0.87 | 0.87 | |
| r | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | |
| t + 3 | RMSE (μg/m3) | 5.61 | 5.21 | 5.21 | 5.35 | 5.92 |
| MAPE | 19.53 | 19.13 | 18.75 | 19.18 | 19.53 | |
| CE | 0.76 | 0.82 | 0.78 | 0.77 | 0.76 | |
| r | 0.88 | 0.88 | 0.88 | 0.87 | 0.85 | |
| t + 6 | RMSE (μg/m3) | 7.61 | 6.97 | 6.97 | 7.34 | 8.37 |
| MAPE | 25.91 | 23.45 | 25.11 | 25.98 | 25.91 | |
| CE | 0.67 | 0.71 | 0.69 | 0.69 | 0.67 | |
| r | 0.78 | 0.78 | 0.78 | 0.76 | 0.68 | |
| t + 12 | RMSE (μg/m3) | 9.93 | 9.19 | 8.84 | 9.03 | 9.86 |
| MAPE | 38.15 | 36.28 | 36.31 | 36.21 | 38.15 | |
| CE | 0.49 | 0.50 | 0.52 | 0.53 | 0.49 | |
| r | 0.65 | 0.60 | 0.64 | 0.61 | 0.60 |
| Lead Time (h) | Keelung Station | Xizhi Station |
|---|---|---|
| t + 1 | AMT | MLR |
| t + 2 | MLR | MLR |
| t + 3 | AMT | MLR |
| t + 4 | MLR | M5P, M5Rules |
| t + 5 | MLR | M5P, M5Rules |
| t + 6 | DNN | M5P, M5Rules |
| t + 7 | AMT | M5P |
| t + 8 | AMT | M5P, M5Rules |
| t + 9 | DNN | DNN |
| t + 10 | AMT | DNN |
| t + 11 | DNN | AMT |
| t + 12 | AMT | AMT |
| Lead Time (h) | Keelung Station | Xizhi Station |
|---|---|---|
| t + 1 | MLR | MLR |
| t + 2 | MLR | MLR |
| t + 3 | MLR | M5P, M5Rules |
| t + 4 | M5P, M5Rules | DNN |
| t + 5 | DNN | M5P |
| t + 6 | DNN | DNN |
| t + 7 | AMT | M5Rules |
| t + 8 | AMT | DNN |
| t + 9 | AMT | DNN |
| t + 10 | AMT | DNN |
| t + 11 | DNN | DNN |
| t + 12 | AMT | M5Rules |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.-C.; Kao, W.-J. Establishing a Real-Time Prediction System for Fine Particulate Matter Concentration Using Machine-Learning Models. Atmosphere 2023, 14, 1817. https://doi.org/10.3390/atmos14121817
Wei C-C, Kao W-J. Establishing a Real-Time Prediction System for Fine Particulate Matter Concentration Using Machine-Learning Models. Atmosphere. 2023; 14(12):1817. https://doi.org/10.3390/atmos14121817
Chicago/Turabian StyleWei, Chih-Chiang, and Wei-Jen Kao. 2023. "Establishing a Real-Time Prediction System for Fine Particulate Matter Concentration Using Machine-Learning Models" Atmosphere 14, no. 12: 1817. https://doi.org/10.3390/atmos14121817
APA StyleWei, C.-C., & Kao, W.-J. (2023). Establishing a Real-Time Prediction System for Fine Particulate Matter Concentration Using Machine-Learning Models. Atmosphere, 14(12), 1817. https://doi.org/10.3390/atmos14121817