Abstract
Missing values in air quality datasets bring trouble to exploration and decision making about the environment. Few imputation methods aim at time series air quality data so that they fail to handle the timeliness of the data. Moreover, most imputation methods prefer low-missing-rate datasets to relatively high-missing-rate datasets. This paper proposes a novel missing data imputation method, called FTLRI, for time series air quality data based on the traditional logistic regression and a presented “first Five & last Three” model, which can explain relationships between disparate attributes and extract data that are extremely relevant, both in terms of time and attributes, to the missing data, respectively. To investigate the performance of FTLRI, it is benchmarked with five classical baselines and a new dynamic imputation method using a neural network with average hourly concentration data of pollutants from three disparate stations in Lanzhou in 2019 under different missing rates. The results show that FTLRI has a significant advantage over the compared imputation approaches, both in the particular short-term and long-term time series air quality data. Furthermore, FTLRI has good performance on datasets with a relatively high missing rate, since it only selects the data extremely related to the missing values instead of relying on all the other data like other methods.
1. Introduction
Air pollutants pose significant threats to public health, especially the toxicity and diseases caused by atmospheric fine particulate matter [1]. According to a survey, air pollution kills approximately 4.2 million people every year [2]. Therefore, air quality is still an issue of concern in recent years. Environmental researchers mine air quality data to uncover potential value and information, which captures user behavior [3], estimates influenza diseases [4], explores greenhouse gas emissions [5], investigates personal actions to reduce greenhouse gas emissions [6], and so on, to advise the related policy makers. However, due to problems of instrument malfunction, communication noise, and/or other unknown reasons [7], data are frequently missing. Moreover, although most air quality monitoring data are time series data, processing extensive time series environmental data with missing values is usually laborious and difficult, and sometimes unexpected failures are not detected until data are processed. Consequently, environmental databases frequently have some gaps caused by missing data [8]. It is the gap that not only seriously affects the accuracy and availability of data, but also affects the subsequent work of in-depth analysis and data mining [9]. Therefore, it is worthwhile to understand the types of data with missing values and propose an effective and robust strategy to fill time series air quality data with missing values.
In terms of the research of Rubin et al. [10], there are three types of data with missing values: Missing Completely at Random (MCAR), Missing at Random (MAR), and Not Missing at Random (NMAR). When data are MCAR, the fact that the data are missing is independent of the observed and unobserved data [10,11]. When data are MAR, the fact that the data are missing is systematically related to the observed but not the unobserved data [10,12]. When data are NMAR, the fact that the data are missing is systematically related to the unobserved data, that is, the missingness is related to events or factors that are not measured by the researcher [10,13]. Following these three categories, there are some efficient strategies to coordinate data with missing values, appropriately known as “imputation methods” [14]. Mean imputation and Median imputation are two common missing value imputation methods when data are MCAR. They are used as benchmark methods for imputing missing values in air quality datasets in many studies, such as [15,16,17,18,19]. They substitute the mean or median of the corresponding observed attribute’s values for the missing values of that attribute in a dataset, respectively [20]. However, these two simple imputation strategies lose sight of the correlation between the missing value’s own attribute and other attributes in the data points. k-nearest neighbor imputation [21] and random forest imputation [22] are two typical missing value imputation methods when data are MAR. They take into account the dependencies among different attributes of data points, and the missing value of a data point can be obtained according to other data points with complete values. In the k-nearest neighbor imputation method, the missing attribute values in a data point are replaced by the average of the corresponding attribute values of k nearest neighbors of the data point [21,23]. It has been proven that k-nearest neighbor has good imputation performance for air quality data in the literature [15,16]. Researchers [24] have proven that the imputation performance of random forest outperforms k-nearest neighbor due to its being a combination of tree predictors, where each tree depends on a random data point sampled independently [22,25]. However, an air quality monitor runs as a time series and can generate large amounts of missing data sometimes. The missing data mechanism of air quality data is generally random (MAR—missing at random) [19]. The above methods are most capable in datasets with a low missing rate, but they may provide a poor performance on a large number of discrete datasets with a relatively high missing rate [26]. Moreover, without considering that the timeliness among data points also affects data quality in a dataset, these methods may be not suitable for time series data. When processing time series datasets, these methods usually require a large number of training data points to establish a low imputation error model, because they ignore the fact that time series data points are correlated with each other over continuous time intervals, namely, the data differ less in value in short time intervals since the time corresponding to the data point is continuous. Therefore, to solve the issues of missing values in time series air quality data, it is necessary to further explore a more suitable imputation method for time series air quality data with missing values, which not only can train a higher imputation performance model with fewer air quality data, but also can achieve more efficient imputation for relatively high-missing-rate time series air quality datasets with discrete missing values.
In this paper, to achieve more efficient imputation of discrete missing values in time series air quality data, we raise a new single imputation method [18,27] called “First five last three logistic regression imputation (FTLRI)”. This method combines the traditional logistic regression with a presented “first Five & last Three” model, which can explain relationships between/among disparate attributes and extract the data points that are extremely relevant, both in terms of time and attributes, to the data point with missing values, respectively.
Since timeliness of data points in a dataset in an important factor affecting data quality [28], FTLRI uses a model of “first Five & last Three (FT)” to address that issue based on the sliding window, where “F” refers to the five data points with complete values immediately before the data point with missing values, and “T” refers to the three data points with complete values immediately after the data point with missing values in a time series dataset. Selecting the first five and the last three data points next to the data point with missing values ensures commonality of experience between data points, and the eight data points are most closely related in time to the missing value. In addition, to fully consider the correlation between different attributes in the data points, FT selects the attributes extremely related to the attribute with missing values based on the Pearson correlation. Therefore, FT emerges as a time-dependent and attribute-related model, which chooses the most appropriate, minimal amount of data to set the basis for the subsequent, most efficient missing data imputation.
To further fully use correlation between continuous time and the different attributes of data points in air quality data, these eight data points with complete values selected by FT are employed in logistic regression to train a model to fill missing values effectively. Logistic regression has been widely studied recently, such as parameter estimation [29], credit scoring [30], visual detectability prediction [31], and so on, but few studies have examined the application of logistic regression to missing data, let alone its application to fill time series air quality data. Although Akbar et al. [32] indicated that random forest is more accurate than traditional logistic regression imputation for data with missing values, they did not make a detailed analysis of the two approaches. As an imputation method under the category MAR, logistic regression imputation warrants further investigation in time series air quality data with missing values for the declarative reasons. One is that logistic regression is used to explain the relationship between one dependent attribute and one or more independent attributes by estimating probabilities using a logistic regression equation in the description and analysis of data [33]. There is an interaction among the six main pollutants in the air quality data points. For example, the concentration of PM2.5 may be affected by the concentration of the other pollutants, such as SO2, CO, and NO2 [34]. The second is that logistic regression does not require high computing power, and low-performance equipment can complete the calculation [35].
To investigate the performance of FTLRI, this paper compares the three assessment indexes of FTLRI with five other classical imputation methods and a new dynamic imputation method [36] using a neural network with missing rates of 5%, 10%, 20%, and 40%, respectively, and demonstrates that the performance of FTLRI is superior to the others. Overall, the main advantages of FTLRI are as follows.
- (1)
- FTLRI is an effective time series air quality data imputation model that not only considers correlation, both in terms of time and attributes of the data points, but also legitimately utilizes logistic regression to deal with such correlation.
- (2)
- FTLRI relies on fewer training data points for each data point with missing values, including eight data points extremely relevant to the data point with missing values, to achieve a lower imputation error model compared with the other classical imputation methods.
- (3)
- FTLRI realizes accurate imputation of short-term/long-term time series air quality datasets with different missing rates by extracting the data points that are extremely relevant, both in terms of time and attributes, to the data point with missing values.
2. Materials and Methods
This section will illustrate the imputation method FTLRI proposed in this paper and the indicators to evaluate the performance of FTLRI.
2.1. A Developed FT Based on Pearson Correlation and Sliding Window
Time series air quality data are time-dependent and attribute-related. To better understand how to extract the data that are highly relevant to missing data through “first Five & last Three (FT)” in time series datasets, this subsection elaborates the developed model FT covering the Pearson correlation and a sliding window.
The Pearson correlation is employed to reveal the attributes that are highly relevant to the attribute with missing values in a time series dataset in this paper. The Pearson correlation coefficient indicates a linear relation between two attributes in a dataset, and it ranges from −1 to +1. The greater the absolute value of the correlation coefficient is, the higher the correlation degree of the two attributes in a dataset will be [37]. In this study, if the Pearson correlation coefficient between an attribute and the attribute with missing values is greater than or equal to 0.6, then the attribute is regarded as a target attribute of the attribute with missing values. It is assumed that the concentration of one pollutant at a certain time is p and the concentration of another pollutant at the same time is q in a time series air quality dataset containing n data points; then, the Pearson correlation coefficient r of the two pollutants can be expressed as Equation (1). The process of filtering the target attributes of the attribute with missing values through the Pearson correlation coefficients is first done through FT, that is, the selected target attributes through FT first are the attributes that are extremely related to the attribute with missing values.
A sliding window is employed to seek out the data points that are highly relevant in time to the data point with missing values in a time series dataset in this paper. As shown in Figure 1, assuming that the concentration of one pollutant measured at time t is X(t), a sliding window refers to a window with size w that is used to slide from the starting point of a time series air quality dataset to the end with a step length of l, and the values in the window are recorded for subsequent research when the window moves forward. The missing data in a time series dataset may lead to incomplete data in the sliding window. The proposed model FT focuses on the imputation of the missing data through the complete data in the sliding window, which are closest in time. Through the sliding window, the “first Five” data points and the “last Three” data points with complete values closest in time to the data point with missing values are found, which is required for the second step of the model FT.
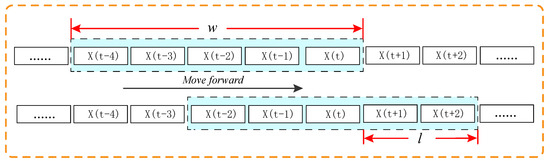
Figure 1.
The schematic of a sliding window.
Instead of depending on all the other complete data like other methods to fill missing values, FT screens out the data that are highly correlated with the missing data, both in terms of attributes and time, in a time series air quality dataset to ensure a more effective imputation later. The basic steps of FT are as follows.
Step 1.
If the Pearson correlation coefficient between an attribute and the attribute with a missing value is greater than or equal to 0.6, then this attribute is a target attribute.
Step 2.
Find the “first Five (F)” data points and the “last Three (T)” data points close in time to the data point with missing values by a sliding window based on the first step, if and only if F and T are the data points with complete values composed of target attributes and attributes with missing values in a time series air quality dataset.
In Step 2, if a data point with missing values is followed by another data point with missing values for the corresponding attribute, then the search continues until the eight data points with complete values are discovered. Thus, there are two cases for the step length l and size w of the sliding window. The first one is that the step length l and size w of the sliding window are fixed, in which the sliding window size is 9. To test the performance of the imputation method proposed in this paper under different missing rates, the step length l of the sliding window is calculated according to the number of the data points and self-defined missing rate in a time series dataset. Assuming that there are n data points in a time series air quality dataset, and the self-defined missing rate is R, the step length can be expressed as Equation (2). The second case is that the step length l and size w of the sliding window are unfixed. When one of the three data points immediately behind the data point with missing values in time has a missing value for the corresponding attribute, it will continue to look for a data point with complete values. This is the reason the size w and the step length l of the window will increase by one. Therefore, we can obtain eight data points with complete values highly relevant to the data point with missing values in time through FT, which will alter as the data point with missing values alters in a time series air quality dataset.
The data selected through FT are extremely attributively and temporally related to each missing data point. In other words, for each data point with missing values, we search for the eight highly correlated data points through FT, which is more targeted and offers the possibility for more effective imputation in the follow-up.
By training an imputation model with the eight data points from FT for each data point with missing values, we not only can overcome the obstacle of other methods that demand large volumes of training data points to build a highly effective model, but also can save the time of training, especially for low-missing-rate datasets with discrete missing values. Thus, it is worth adopting FT into the imputation of time series air quality data with discrete missing values.
2.2. Logistic Regression Imputation
Since there exists a certain relationship between missing values and complete values in data points, this section will first introduce the idea of logistic regression and then describe how logistic regression is used to fill the missing values by employing this relationship.
Logistic regression includes three steps: finding a prediction function, constructing a loss function, and finding regression parameters that minimize a loss function [38,39]. The objective function of logistic regression is expressed as Equation (3).
where θ is an unknown vector of parameters to be determined, x = (x1, x2, … xd), and d denotes data point x has d attributes. The loss function reflects the degree of model prediction error. Suppose there are n data points, then the average log-likelihood loss will be Equation (4).
where y is a return variable with a value of 0 or 1. The regression parameter θ minimizes the loss function, which can be obtained by Gradient Descent [40] and Newton’s method [41] and so on. Newton’s method is adopted in this study. Newton’s method takes the second-order Taylor Formula of the function near the existing estimate of the minimum point and then finds the next estimate of the minimum point. Assuming θk is an estimate of the current minimum, then there will be Equation (5).
Supposing φ′ (θ) = 0, there will be Equation (6).
where k is the number of iterations. Equation (6) is the iterative updated equation. From Equations (5) and (6), we can see this study requires the objective function J(θ) to be second-order continuously differentiable.
This paper applies logistic regression to the imputation domain of missing values. For each data point with missing values in a time series air quality dataset, we rely on an objective regression equation to build a specific imputation model using eight corresponding highly relevant data points from FT. However, it is worth noticing that this study needs to convert the complete data of a missing attribute from continuous type into integer type since logistic regression is frequently employed to cope with classification. For example, when there are missing values in the concentration of PM2.5, we need to convert the complete values in PM2.5 into integer data before we use logistic regression to train an imputation model. That is, when using logistic regression to train an imputation model to impute continuous data, we need to preprocess the complete data of the missing attribute by scaling the complete continuous data up to a multiple of 10 to the nth power, or by other methods, to obtain integer data. Further, the integer data processed can be inputted into logistic regression to train an imputation model. Accordingly, for the missing values of the continuous attribute converted into integer type, after the imputed values are obtained through logistic regression, it is necessary to be restored to continuous type. It is the restored data that constitute the final imputation concentration values of this study.
2.3. FTLRI Based on FT and Logistic Regression
“First five last three logistic regression imputation (FTLRI)” integrates the FT proposed in Section 2.1 and the logistic regression introduced in Section 2.2 to fill the discrete missing values in a time series air quality dataset. FTLRI is inspired by the following two considerations, which are clearly shown in Figure 2. The first point is that time series data have the characteristic of autocorrelation; in other words, the attribute values of a data point are closely related to the corresponding attribute values of the other data points in a time interval. For example, the concentration value of PM2.5 is closely related to the concentration values before and after it, namely, it is not independent. The second point is that there exists a kind of cross-influence relationship among air pollutants. For example, the concentration of PM2.5 can be extremely correlated with the concentration of the other pollutants at the same time, such as CO and PM10. Exploiting highly correlated relationships to fill discrete missing values in time series air quality datasets offers higher accuracy. Instead of depending on all the other complete data like other methods to fill missing values, FTLRI depends on these two correlations to utilize FT to extract the data points that are highly relevant to each data point with missing values. FTLRI also makes full use of logistic regression to train a suitable imputation model for each data point with missing values.
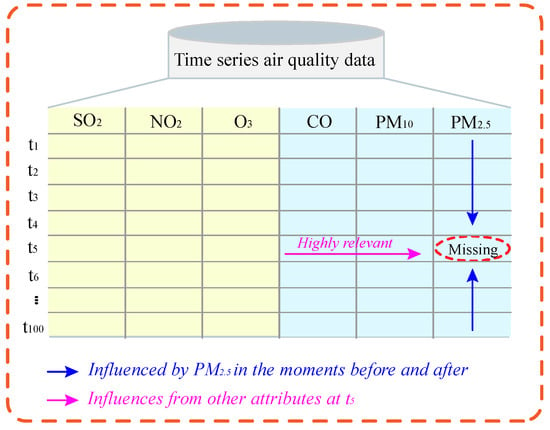
Figure 2.
The illustration of FTLRI’s ideas.
The detailed procedure of FTLRI to impute data points with missing values is outlined in Algorithm 1. The process of FTLRI starts with an incomplete time series air quality dataset, and it takes no input parameters. By calculating the Pearson correlation coefficient, Step 1 can easily access the attributes highly relevant to the missing value attributes. Step 2 is based on Step 1 to search for the first five data points and the last three data points that are strongly related to the missing value in time by FT firstly. By finding the first five data points and the last three data points, then, we rely on logistic regression to train an imputer fitted to them. Finally, the missing values can be obtained by this imputer.
| Algorithm 1 First five last three logistic regression imputation (FTLRI) |
 Output Ym |
Figure 3 illustrates the process of the imputation approach for a data point with missing values in more detail. We present only the attributes that are highly correlated with PM2.5 in this figure, including CO and PM10. In Figure 3, the missing value for the concentration of PM2.5 is finally filled with “24”. First of all, by detecting the data point with a missing value and accessing its Pearson correlation coefficient, we can discovery the corresponding “first Five” and “last Three” of the data point, which are represented on the brownish-yellow background and blue-green background colors in the figure, respectively. Next, the “first Five” and the “last Three” are employed to train a model by logistic regression, and this model is applied to obtain the missing concentration values of PM2.5 last; then, “24” is obtained.
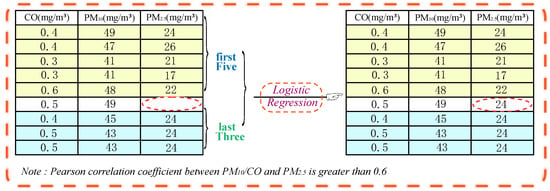
Figure 3.
An example of FTLRI.
From the detailed explanation of the process in Figure 3, we can see that, in the process of training and filling through the model, it is the corresponding “first Five” and the “last Three” adjacent to each data point with missing values that simplify the training process of the imputation model and save training time.
Instead of depending on all the other complete data points like other methods, we select these eight data points highly relevant, both in terms of time and attributes, to each data point with missing values to fill missing values, which is the key of FTLRI to train a model with lower imputation errors through logistic regression under different missing rates.
2.4. Assessment Indexes
To evaluate the performance of FTLRI, three assessment indexes are used: Mean absolute error (MAE), Root-mean-square of error (RMSE) and Mean absolute percentage error (MAPE) [42,43,44], which are shown in the following Equations (7)–(9), respectively:
where r and f are real and imputation values, respectively, and n denotes the number of a dataset with missing values.
3. Results and Discussion
In this section, to evaluate the effectiveness of FTLRI, we ran it on time series air quality datasets collected from Lanyuan Hotel (LH), Yuzhonglanda Campus (YZ), and Biological Products Institute (BPI) in Lanzhou in 2019. For data from each different station, we selected short-term and long-term time series air quality data with different missing rates, varying between 5%, 10%, 20% and 40%, to demonstrate the feasibility of FTLRI.
3.1. Data Preparation
To verify the performance of the proposed FTLRI approach, this study took hourly concentration (mg/m3) data from Lanzhou, an old industrial city in northwest China, as benchmarks, which contained SO2, NO2, O3, CO, PM10, and PM2.5 at three stations, including LH, YZ, and BPI. Among the three stations, LH is located in Anning District, which integrates many colleges and universities, new technology, and culture, representing the main source of industrial pollution; YZ is located in the remote Yuzhong County, which expresses the background value of air quality; BPI is located in the urban area integrating commodities and housing, which reflects a high density of population and traffic pollution sources. The data came from “China Environmental Monitoring Station”, a website (http://www.cnemc.cn/ (accessed on 18 November 2020)) containing real-time measurements of concentrations of air pollutants for approximately 120 cities, embracing 600 monitoring stations. To make the study more persuasive, the study adopted the data from four different time series from March 2019, April to June 2019, July to December 2019, and the whole year of 2019 from the three above-mentioned stations and denoted them as T1, T2, T3, and T4, respectively, which is clearly shown in Table 1. Among them, time series T1 and T2 were employed to verify the performance of the imputation methods over a short term, while time series T3 and T4 were utilized to verify the performance of the imputation methods over a long term. The performance test of different imputation methods was carried out with PM2.5 as an example.

Table 1.
Notations and their explanations about data.
Prior to the experiment, all the data with missing values needed to be removed to avoid their influence on the accuracy of imputation results. In other words, the used data in this experiment were processed data with complete values [17,19]. Data information with complete values at the three different stations in the four disparate periods is shown in Table 2.
Table 2.
Data information with complete values at different stations in different time series.
3.2. Pearson Correlation Coefficient between PM2.5 and the Other Five Pollutants
Table 3 lists the Pearson correlation coefficient r between PM2.5 and SO2, NO2, O3, CO, and PM10, respectively. In Table 3, the concentrations of PM2.5 and PM10 showed a strong correlation in four different time series at the three different stations in Lanzhou in 2019, and the correlation coefficient was positive, that is, r was greater than or equal to 0.6. This may be related to their relationship, namely, PM2.5 is a kind of PM10, and they have an inclusive relationship. PM2.5 generally accounts for about 70% of PM10 [45]. In addition, the concentrations of PM2.5 also showed a strong correlation with CO in time series T3 and T4 at LH. There existed a strong correlation between PM2.5 and SO2, NO2, and CO in time series T3 at YZ and BPI, respectively. To explain this correlation, we analyzed it in terms of time of year. T3, from July to December 2019, represents the last two quarters of the four seasons in a year. At this time, the overall temperature in Lanzhou gradually decreases so that people are more likely to choose motor vehicles as transportation tools. The main pollutants emitted by motor vehicles are CO, SO2, and NO2.
Table 3.
Pearson correlation coefficient r between PM2.5 and the other five pollutants in the short-/long-term time series.
The implementation of the imputation experiment was carried out according to the Pearson correlation coefficients obtained in Table 3. We selected pollutants whose Pearson correlation coefficient with PM2.5 was greater than or equal to 0.6 to fill the missing concentration values of PM2.5 in Table 3. Specifically, at LH, the concentration values of PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T1 and T2, and the concentration values of CO and PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T3 and T4. At YZ, the concentration values of PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T1, T2, and T4, and the concentration values of SO2, NO2, CO, and PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T3. At BPI, the concentration values of PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T1, T2, and T4, and the concentration values of SO2, NO2, CO, and PM10 were employed to fill the missing concentration values of PM2.5 through different imputation methods in time series T3.
3.3. Imputation Results of Missing Concentration Values of PM2.5
In this subsection, we will fully exhibit the imputation results for the time series air quality datasets with different missing rates at the three different stations.
To make the datasets containing n data points generate different missing rates, we removed the i × l (1 ≤ i < n × R + 1) data point in the corresponding dataset according to the step length l and missing rate R in Equation (2). For simplicity in graphs and tables, Table 4 shows the different imputation methods and their corresponding abbreviations used in this experiment. The number of neighbors for k-nearest neighbor was set to eight. The parameters of the random forest and logistic regression were almost set to default in the sklearn package in Python, except for solver = “newton-cg” in the logistic regression. For dynamic imputation, we used the Adam optimizer with a learning rate of 10−3 and a mini-batch size of 32, and we terminated the training when the number of epochs reached 500 [36].
Table 4.
Abbreviations and their explanations about imputation methods.
For the missing values of PM2.5 concentration in the time series air quality dataset, we show the imputation results of the proposed method from three different perspectives. Table 5, Table 6 and Table 7 list the quantitative evaluations of the imputation results of different methods under different missing rates. Moreover, to see the imputation results of different methods more clearly, taking the missing rate of 5% as an example, Figure 4, Figure 5 and Figure 6 illustrate different methods in different time series with the bar charts of MAE, as well as the line charts of the comparison between the imputed values of relatively superior-performance methods and the real values of PM2.5 in the corresponding short-term time series T1. Finally, to comprehensively evaluate the performance of FTLRI, Figure 7, Figure 8 and Figure 9 demonstrate different methods in different time series with the box plots of the imputation errors under different missing rates.
Table 5.
Quantitative evaluation of imputation results of PM2.5 at LH under different missing rates in the short-/long-term time series.
Table 6.
Quantitative evaluation of imputation results of PM2.5 at YZ under different missing rates in the short-/long-term time series.
Table 7.
Quantitative evaluation of imputation results of PM2.5 at BPI under different missing rates in the short-/long-term time series.
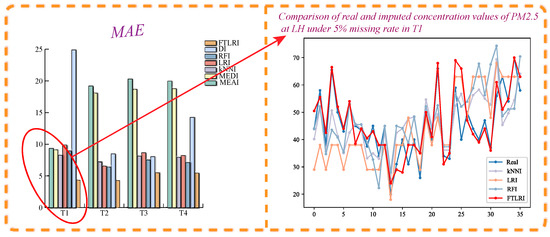
Figure 4.
MAE of imputation results of PM2.5 at LH under 5% missing rate.
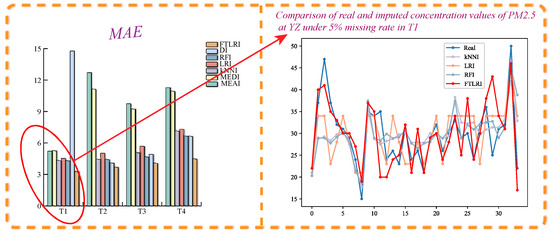
Figure 5.
MAE of imputation results of PM2.5 at YZ under 5% missing rate.
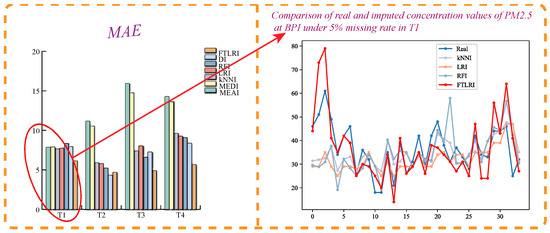
Figure 6.
MAE of imputation results of PM2.5 at BPI under 5% missing rate.
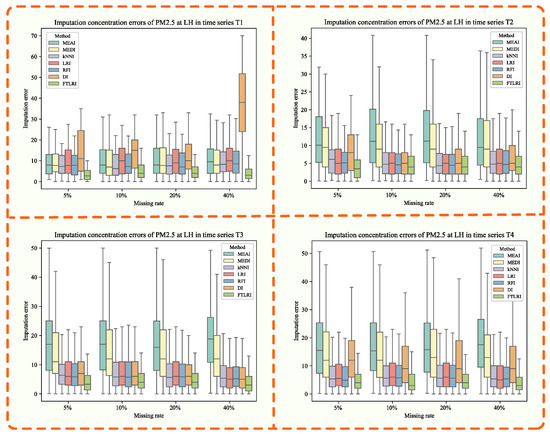
Figure 7.
Imputation concentration errors of PM2.5 generated by MEAI, MEDI, kNNI, LRI, RFI, DI, FTLRI at LH in different time series.
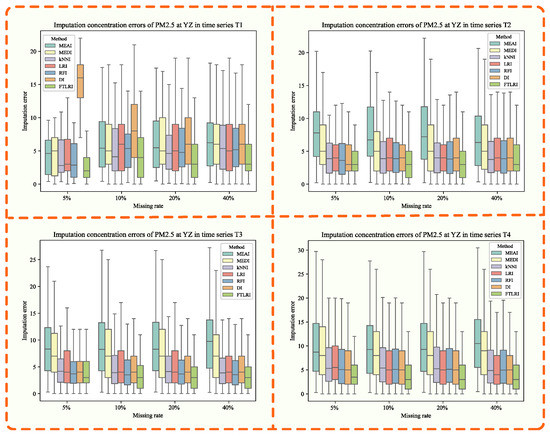
Figure 8.
Imputation concentration errors of PM2.5 generated by MEAI, MEDI, kNNI, LRI, RFI, DI, FTLRI at YZ in different time series.
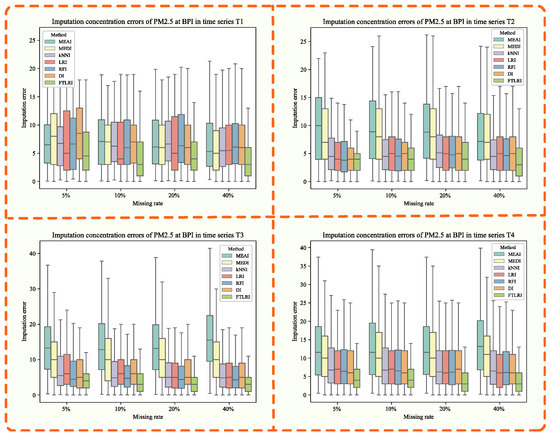
Figure 9.
Imputation concentration errors of PM2.5 generated by MEAI, MEDI, kNNI, LRI, RFI, DI, FTLRI at BPI in different time series.
3.3.1. Imputation of Missing Concentration Values of PM2.5 at LH
Table 5 shows the quantitative evaluation of the imputation results of PM2.5 in the short-term time series T1 and T2 and the long-term time series T3 and T4 under different missing rates at LH. When the missing rate was 5%, 10%, 20%, and 40%, respectively, the MAE, MSE, and MAPE of the PM2.5 imputation results obtained by FTLRI were the lowest compared with the other five classical imputation methods and the new dynamic imputation method using neural networks in both the short-term time series T1 and T2, as well as the long-term time series T3 and T4. The performance of the random forest imputation was slightly worse than that of FTLRI, ranking second among these methods. Mean imputation and Median imputation produced almost the worst results. Dynamic imputation was slightly better than Median imputation and Mean imputation, but its performance was worse than logistic regression. The imputation performance of logistic regression was unstable, and it was worse than that of the k-nearest neighbor imputation on the whole.
To see the performance of FTLRI more visually, Figure 4 clearly depicts a specific imputation effect diagram of PM2.5 with a missing rate of 5% as an example at LH. The bar chart on the left provides the diagram of the MAE obtained after PM2.5 was imputed, while the line chart on the right takes short-term time series T1 as an example to describe the values of PM2.5 imputed by the different imputation methods and the corresponding real values of PM2.5. For the graph on the right side in Figure 4, the horizontal axis represents the time frames of the missing concentrations of PM2.5 in time series T1, and the vertical axis represents the concentration values of PM2.5. Aiming at more clearly showing the imputed values and the true values of PM2.5 on the right side, we only plotted the imputation results of the four relatively superior-performance methods. As can be seen from the bar chart on the left, the assessment index MAE of the imputation results of FTLRI proposed in this paper was significantly lower than that of the other six imputation methods, in both short-term and long-term time series, which indicates that the performance of FTLRI proposed in this paper is significantly better than that of the other five classical imputation methods and the new dynamic imputation method using a neural network. As can be seen from the line chart on the right, the values imputed by FTLRI were more fitting to the corresponding real values of PM2.5 than the other four classical methods, which again shows that the imputation performance of the proposed method FTLRI in this paper stays ahead of the other imputation methods from a quantitative point of view.
Aiming at more intuitively comparing the imputation performance of FTLRI with the other five classical imputation approaches and the new dynamic imputation method using a neural network, Figure 7 shows the imputation errors of PM2.5 at LH in different time series under different missing rates. The imputation errors are expressed as the absolute values of the results calculated by subtracting the values imputed by different methods from the corresponding real value of PM2.5. The smaller the absolute value is, the smaller the error is, and the better the corresponding imputation methods are. The horizontal coordinate of each subplot indicates the various missing rates, and the vertical coordinate indicates the imputation errors, while the colors represent the corresponding imputation methods. As can be seen from Figure 7, the errors of FTLRI were smaller than that of the other methods, and the median lines of the box plot of FTLRI were also lower than that of the other five classical imputation methods and the new dynamic imputation method using a neural network, which further indicates that FTLRI has an advantage in missing data imputation compared with the other methods under different missing rates in both short-term and long-term time series.
From the above three perspectives, we can draw a conclusion that FTLRI has a big advantage in the missing data imputation at LH under different missing rates, and the imputation performance does not fall with the growing of missing rates and number of data points in the dataset. The cause for that phenomenon is that the imputation results of FTLRI put forward in this paper only depend on the first five and the last three complete data points, which are highly relevant to the data point with missing values in terms of time and attributes. Instead of relying on all the other complete data points, like other imputation approaches, FTLRI selects the eight data points highly correlated with the missing data point to impute the missing value, which is beneficial for imputation performance [46,47]. Therefore, the increasing of the number of data points and the changing of missing rates will not affect the performance of FTLRI, that is, FTLRI can provide superior imputation results on datasets with different missing rates and different numbers of data points.
3.3.2. Imputation of Missing Concentration Values of PM2.5 at YZ
Table 6 shows the quantitative evaluation of the imputation results of PM2.5 in the short-term time series T1 and T2 and the long-term time series T3 and T4 under different missing rates at YZ. When the missing rate was 5%, 10%, 20%, and 40%, respectively, the MAE, MSE, and MAPE of the PM2.5 imputation results obtained by FTLRI were the lowest compared with the other five classical imputation methods and the new dynamic imputation method using neural networks, in both short-term time series T1 and T2, as well as long-term time series T3 and T4, that is, the imputation performance of FTLRI was still superior to the others in both short-term and long-term time series on the whole.
Figure 5 clearly depicts a specific imputation effect diagram of PM2.5 with a missing rate of 5% as an example at YZ. The bar chart on the left provides the diagram of the MAE obtained after PM2.5 was imputed, while the line chart on the right takes short-term time series T1 as an example to describe the values of PM2.5 imputed by the four relatively superior imputation methods and the corresponding real concentration values of PM2.5. For the graph on the right side in Figure 5, the horizontal axis represents the time frames of the missing concentrations of PM2.5 in time series T1, and the vertical axis represents the concentration values of PM2.5. As can be seen from Figure 5, the proposed method FTLRI still achieved better performance than the other five classical imputation methods and the new dynamic imputation method using a neural network.
Figure 8 shows the imputation errors of PM2.5 generated by MEAI, MEDI, kNNI, LRI, RFI, DI, FTLRI at YZ in different time series under different missing rates. The horizontal coordinate of each subplot indicates the different missing rates, and the vertical coordinate indicates the imputation errors, while the colors represent the corresponding imputation methods. As can be seen from Figure 8, FTLRI still had an advantage in missing data imputation compared with the other five classical methods and the new dynamic imputation method using a neural network under different missing rates in both short-term and long-term time series.
3.3.3. Imputation of Missing Concentration Values of PM2.5 at BPI
Table 7 shows the quantitative evaluation of the imputation results of PM2.5 in the short-term time series T1 and T2 and the long-term time series T3 and T4 under different missing rates at BPI. When the missing rate was 5%, 10%, 20%, and 40%, respectively, the MAE, MSE, and MAPE of the PM2.5 imputation results obtained by FTLRI were almost the lowest compared with the other six imputation methods, in both short-term time series T1 or T2 and long-term time series T3 or T4, that is, the imputation performance of FTLRI was still superior to the others in both short-term and long-term time series on the whole.
Figure 6 clearly depicts a specific imputation effect diagram of PM2.5 with a missing rate of 5% as an example at BPI. The bar chart on the left provides the diagram of the MAE obtained after PM2.5 was imputed, while the line chart on the right takes short-term time series T1 as an example to describe the values of PM2.5 imputed by the four relatively superior imputation methods and the corresponding real values of PM2.5. As can be seen from Figure 6, the proposed method FTLRI almost achieves better performance than the other six imputation methods at BPI on the whole.
Figure 9 shows the imputation errors of PM2.5 at BPI in different time series under different missing rates. The horizontal coordinate of each subplot indicates the various missing rates, and the vertical coordinate indicates the imputation errors, while the colors represent the corresponding imputation methods. As can be seen from Figure 9, FTLRI still had an advantage in missing data imputation compared with the other five classical methods and the new dynamic imputation method using a neural network under different missing rates in both short-term and long-term time series at BPI.
Through the exploration of the PM2.5 imputation results at the above three stations under different missing rates, we can conclude that the imputation method FTLRI put forward in this paper is in a dominant position compared with the other five classical imputation methods and the new dynamic imputation method using a neural network for time series air quality datasets with discrete missing values. Specifically, for low-missing-rate time series air quality datasets with discrete missing values, FTLRI can achieve good imputation performance. Furthermore, for relatively high-missing-rate datasets, FTLRI can also achieve more accurate imputation results by using the extremely related data to the missing data instead of relying on all the other data like other methods.
3.4. Demonstrate the Reasonableness of Choosing the “First Five” Data Points and the “Last Three” Data Points in Step 2
In Step 2 of FTLRI, we searched for the highly relevant data points by selecting the first five data points and the last three data points closest to the missing value in time based on Step 1. In this subsection, we discuss the influence of the specified number of data points closest to the missing value before and after the time on the imputation performance. For convenience, the number of highly correlated data points before the time corresponding to the missing value is represented as prior, and the number of highly correlated data points after the time corresponding to the missing value is represented as rear.
By setting prior and rear from 1 to 10, respectively, to reduce time consumption, we evaluated the corresponding MAE on the benchmark datasets with different missing rates. Figure 10 illustrates the mean values of the MAE of imputation results for all the datasets under different missing rates, and the MAE of imputation results in T3 under a missing rate of 40% at BPI. The stable experimental results in Figure 10 prove that FTLRI is insensitive to prior and rear and indicate that FTLRI is a robust imputation method. Selecting the first five and the last three as a common rule of thumb basically achieved superior imputation performance. In a real application, to access a relatively desired performance, we suggest setting prior and rear from 1 to 10.
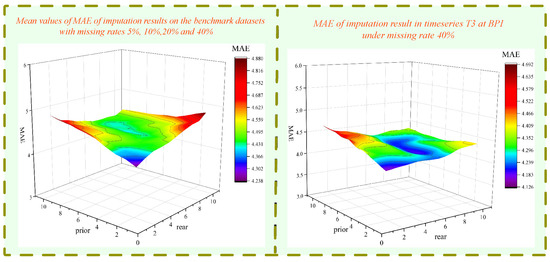
Figure 10.
The impact of different priors and rear on FTLRI imputation performance.
4. Conclusions
To accurately fill missing values in a time series air quality dataset, this paper proposes a simple but effective and robust imputation method, called FTLRI. By combining a presented model FT with logistic regression, FTLRI utilizes FT to select the data extremely related to the missing data, both in terms of time and attributes, and applies logistic regression to establish an objective regression equation to obtain the corresponding parameter vector through the selected extremely related data, then employs the parameter vector and other attribute values of the missing data point to obtain the missing value. The limitation with respect to FTLRI is that it fails to impute the missing data points effectively when there are missing values in the eight extremely related data points due to the failure to train an imputation model. In this situation, it is necessary to find another appropriate imputation approach to complete the imputation of missing values. Experiments on the time series air quality data of three different stations in Lanzhou in 2019 have shown that FTLRI can yield more favorable imputation outcomes for both the particular short-term and long-term data under different missing rates. We look forward to applying FTLRI to other time series datasets with discrete missing values, such as share prices and medical monitoring, to verify its validity in the future.
Author Contributions
Writing—original draft preparation, H.Z.; writing—review and editing, M.C.; review, Y.C.; investigation, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Gansu Key Research and Development Program (No. 21YF5GA053) and the National Natural Science Foundation of China (No. 61762057).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pang, Y.; Huang, W.; Luo, X.-S.; Chen, Q.; Zhao, Z.; Tang, M.; Hong, Y.; Chen, J.; Li, H. In-vitro human lung cell injuries induced by urban PM2.5 during a severe air pollution episode: Variations associated with particle components. Ecotoxicol. Environ. Saf. 2020, 206, 111406. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Myint, S.W. Fine resolution air quality dynamics related to socioeconomic and land use factors in the most polluted desert metropolitan in the American Southwest. Sci. Total Environ. 2021, 788, 147713. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Xia, C. Visual network analysis of the baidu-index data on greenhouse gas. Int. J. Mod. Phys. B 2021, 35, 2150115. [Google Scholar] [CrossRef]
- Kandula, S.; Shaman, J. Reappraising the utility of google flu trends. PLoS Comput. Biol. 2019, 15, e1007258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Wang, D.; Sui, P.; Long, P.; Yan, L.; Wang, X.; Yan, P.; Shen, Y.; Dai, H.; Yang, X.; et al. Effects of different agricultural organic wastes on soil GHG emissions: During a 4-year field measurement in the North China Plain. Waste Manag. 2018, 81, 202–210. [Google Scholar] [CrossRef] [PubMed]
- Wynes, S.; Nicholas, K.A. The climate mitigation gap: Education and government recommendations miss the most effective individual actions. Environ. Res. Lett. 2017, 12, 074024. [Google Scholar] [CrossRef] [Green Version]
- Li, S.-T.; Shue, L.-Y. Data mining to aid policy making in air pollution management. Expert Syst. Appl. 2004, 27, 331–340. [Google Scholar] [CrossRef]
- Picornell, A.; Oteros, J.; Ruiz-Mata, R.; Recio, M.; Trigo, M.M.; Martínez-Bracero, M.; Lara, B.; Serrano-García, A.; Galán, C.; García-Mozo, H.; et al. Methods for interpolating missing data in aerobiological databases. Environ. Res. 2021, 200, 111391. [Google Scholar] [CrossRef]
- Peng, D.; Zou, M.; Liu, C.; Lu, J. RESI: A Region-Splitting Imputation method for different types of missing data. Expert Syst. Appl. 2021, 168, 114425. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Maheswari, K.; Priya, P.P.A.; Ramkumar, S.; Arun, M. Missing Data Handling by Mean Imputation Method and Statistical Analysis of Classification Algorithm. In Proceedings of the EAI International Conference on Big Data Innovation for Sustainable Cognitive Computing, Coimbatore, India, 18–19 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 137–149. [Google Scholar]
- Ispirova, G.; Eftimov, T.; Seljak, B.K. Evaluating missing value imputation methods for food composition databases. Food Chem. Toxicol. 2020, 141, 111368. [Google Scholar] [CrossRef]
- Stead, A.D.; Wheat, P. The case for the use of multiple imputation missing data methods in stochastic frontier analysis with illustration using English local highway data. Eur. J. Oper. Res. 2020, 280, 59–77. [Google Scholar] [CrossRef]
- Pandey, A.K.; Singh, G.; Sayed-Ahmed, N.; Abu-Zinadah, H. Improved estimators for mean estimation in presence of missing information. Alex. Eng. J. 2021, 60, 5977–5990. [Google Scholar] [CrossRef]
- Zainuri, N.A.; Jemain, A.A.; Muda, N. A Comparison of Various Imputation Methods for Missing Values in Air Quality Data. Sains Malays. 2015, 44, 449–456. [Google Scholar] [CrossRef]
- Saeipourdizaj, P.; Sarbakhsh, P.; Gholampour, A. Application of imputation methods for missing values of PM10 and O3 data: Interpolation, moving average and K-nearest neighbor methods. Environ. Health Eng. Manag. 2021, 8, 215–226. [Google Scholar] [CrossRef]
- Schneider, T. Analysis of Incomplete Climate Data: Estimation of Mean Values and Covariance Matrices and Imputation of Missing Values. J. Clim. 2001, 14, 853–871. [Google Scholar] [CrossRef]
- Liu, X.; Wang, X.; Zou, L.; Xia, J.; Pang, W. Spatial imputation for air pollutants data sets via low rank matrix completion algorithm. Environ. Int. 2020, 139, 105713. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Davey, A. Statistical Power Analysis with Missing Data: A Structural Equation Modeling Approach; Routledge: London, UK, 2009. [Google Scholar]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomforest. R News 2002, 2, 18–22. [Google Scholar]
- Cheng, C.-H.; Chan, C.P.; Sheu, Y.-J. A novel purity-based k nearest neighbors imputation method and its application in financial distress prediction. Eng. Appl. Artif. Intell. 2019, 81, 283–299. [Google Scholar] [CrossRef]
- Hong, S.; Lynn, H.S. Accuracy of random-forest-based imputation of missing data in the presence of non-normality, non-linearity, and interaction. BMC Med. Res. Methodol. 2020, 20, 199. [Google Scholar] [CrossRef] [PubMed]
- De Freitas, A.G.M.; Minho, L.A.C.; de Magalhães, B.E.A.; Dos Santos, W.N.L.; Santos, L.S.; de Albuquerque Fernandes, S.A. Infrared spectroscopy combined with random forest to determine tylosin residues in powdered milk. Food Chem. 2021, 365, 130477. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Yuan, Z.; Chen, Y.; Shen, B.; Wu, A. An industrial missing values processing method based on generating model. Comput. Netw. 2019, 158, 61–68. [Google Scholar] [CrossRef]
- Gómez-Carracedo, M.P.; Andrade, J.M.; López-Mahía, P.; Muniategui, S.; Prada, D. A practical comparison of single and multiple imputation methods to handle complex missing data in air quality datasets. Chemom. Intell. Lab. Syst. 2014, 134, 23–33. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.M. Kamber, Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Ahmadini, A.A.H. A novel technique for parameter estimation in intuitionistic fuzzy logistic regression model. Ain Shams Eng. J. 2021, 13, 101518. [Google Scholar] [CrossRef]
- Dumitrescu, E.; Hué, S.; Hurlin, C.; Tokpavi, S. Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. Eur. J. Oper. Res. 2021, 297, 1178–1192. [Google Scholar] [CrossRef]
- Jiang, F.; Zhidong, G.; Zengshan, L.; Xiaodong, W. A method of predicting visual detectability of low-velocity impact damage in composite structures based on logistic regression model. Chin. J. Aeronaut. 2021, 34, 296–308. [Google Scholar] [CrossRef]
- Waljee, A.K.; Mukherjee, A.; Singal, A.G.; Zhang, Y.; Warren, J.; Balis, U.; Marrero, J.; Zhu, J.; Higgins, P. Comparison of imputation methods for missing laboratory data in medicine. BMJ Open 2013, 3, e002847. [Google Scholar] [CrossRef]
- Zhu, C.; Idemudia, C.U.; Feng, W. Improved logistic regression model for diabetes prediction by integrating PCA and K-means techniques. Inform. Med. Unlocked 2019, 17, 100179. [Google Scholar] [CrossRef]
- Tian, D.; Fan, J.; Jin, H.; Mao, H.; Geng, D.; Hou, S.; Zhang, P.; Zhang, Y. Characteristic and Spatiotemporal Variation of Air Pollution in Northern China Based on Correlation Analysis and Clustering Analysis of Five Air Pollutants. J. Geophys. Res. Atmos. 2020, 125, e2019JD031931. [Google Scholar] [CrossRef]
- Verma, R.; Krishan, K.; Rani, D.; Kumar, A.; Sharma, V.; Shrestha, R.; Kanchan, T. Estimation of sex in forensic examinations using logistic regression and likelihood ratios. Forensic Sci. Int. Rep. 2020, 2, 100118. [Google Scholar] [CrossRef]
- Han, J.; Kang, S. Dynamic imputation for improved training of neural network with missing values. Expert Syst. Appl. 2022, 194. [Google Scholar] [CrossRef]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Fan, Y.; Bai, J.; Lei, X.; Zhang, Y.; Zhang, B.; Li, K.C.; Tan, G. Privacy preserving based logistic regression on big data. J. Netw. Comput. Appl. 2020, 171, 102769. [Google Scholar] [CrossRef]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; De Freitas, N. Learning to learn by gradient descent by gradient descent. Adv. Neural Inf. Processing Syst. 2016, 29. [Google Scholar]
- Kelley, C.T. Solving Nonlinear Equations with Newton’s Method; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar] [CrossRef]
- Kabir, G.; Tesfamariam, S.; Hemsing, J.; Sadiq, R. Handling incomplete and missing data in water network database using imputation methods. Sustain. Resilient Infrastruct. 2020, 5, 365–377. [Google Scholar] [CrossRef]
- Niu, M.; Sun, S.; Wu, J.; Yu, L.; Wang, J. An innovative integrated model using the singular spectrum analysis and nonlinear multi-layer perceptron network optimized by hybrid intelligent algorithm for short-term load forecasting. Appl. Math. Model. 2016, 40, 4079–4093. [Google Scholar] [CrossRef]
- Hka, N.D.; Tahir, N.M.; Abd Latiff, Z.I.; Jusoh, M.H.; Akimasa, Y. Missing data imputation of MAGDAS-9’s ground electromagnetism with supervised machine learning and conventional statistical analysis models. Alex. Eng. J. 2022, 61, 937–947. [Google Scholar] [CrossRef]
- Gomišček, B.; Hauck, H.; Stopper, S.; Preining, O. Preining, Spatial and temporal variations of PM1, PM2.5, PM10 and particle number concentration during the auphep—Project. Atmos. Environ. 2004, 38, 3917–3934. [Google Scholar] [CrossRef]
- Audigier, V.; Husson, F.; Josse, J. A principal component method to impute missing values for mixed data. Adv. Data Anal. Classif. 2016, 10, 5–26. [Google Scholar] [CrossRef]
- Hasan, M.K.; Alam, M.A.; Roy, S.; Dutta, A.; Jawad, M.T.; Das, S. Missing value imputation affects the performance of machine learning: A review and analysis of the literature (2010–2021). Inform. Med. Unlocked 2021, 27, 100799. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).