
Forecasting the June Ridge Line of the Western Pacific Subtropical High with a Machine Learning Method


Abstract
:1. Introduction
2. Data and Methods
2.1. Data
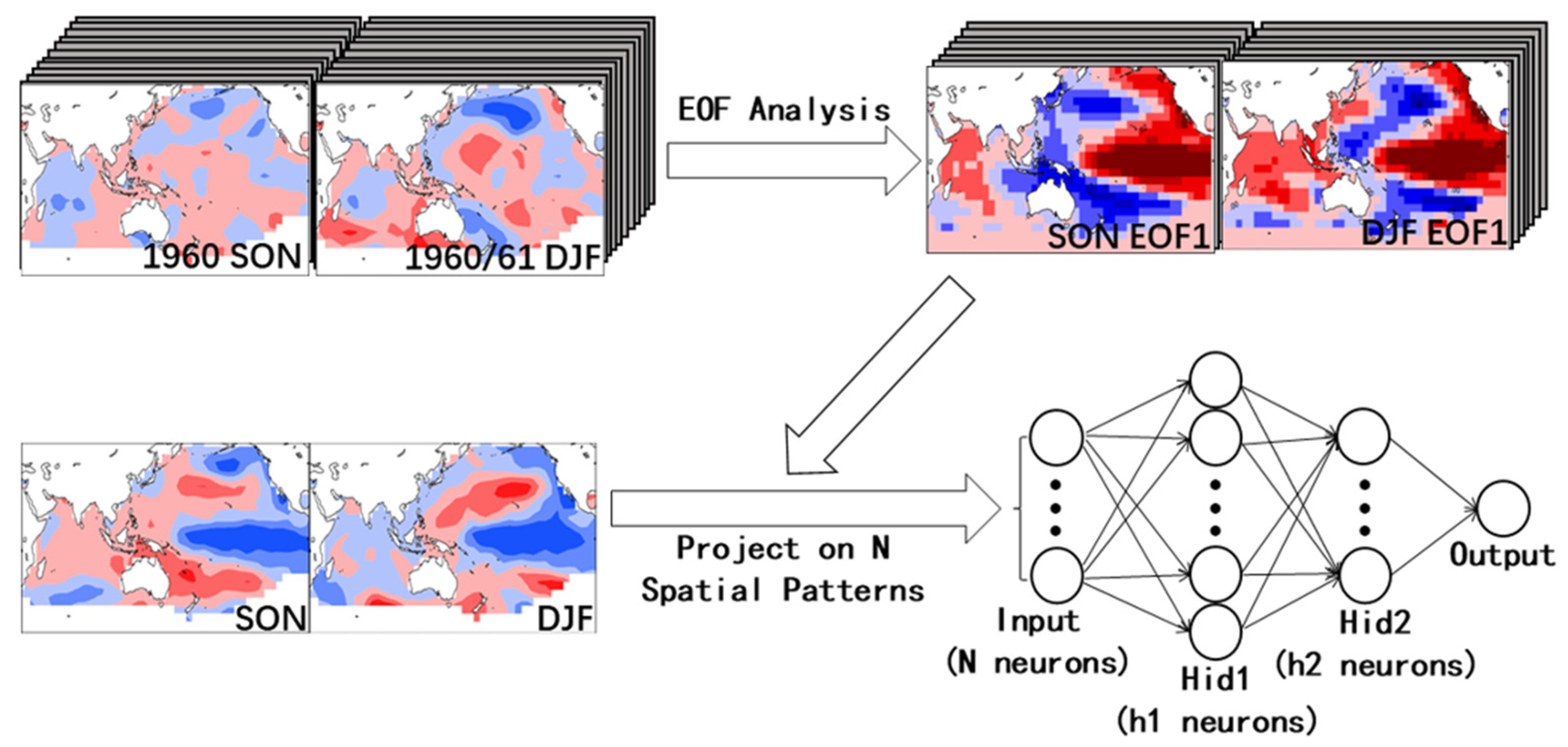
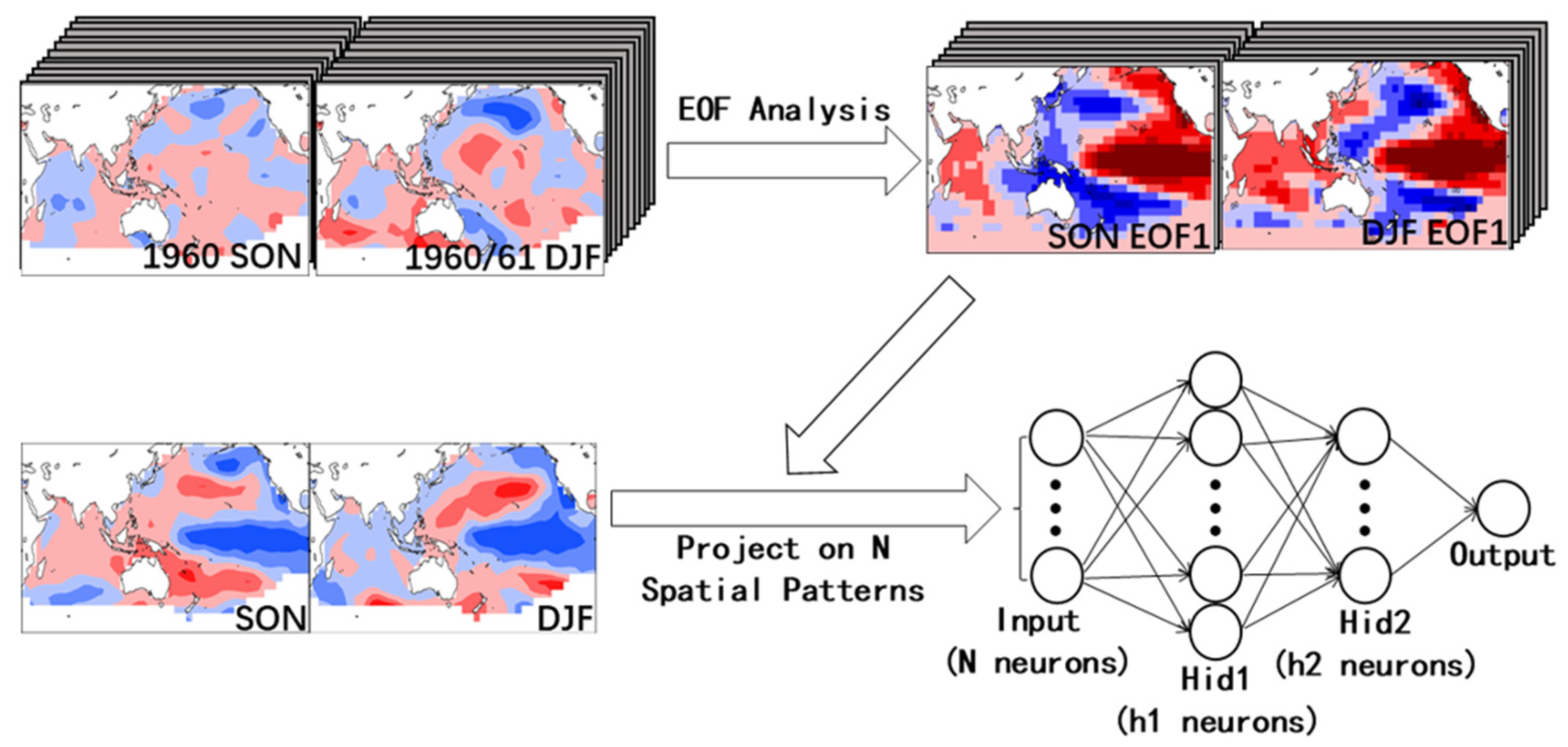
2.2. Forecast System
3. Application and Evaluation
3.1. Setting Hyperparameters
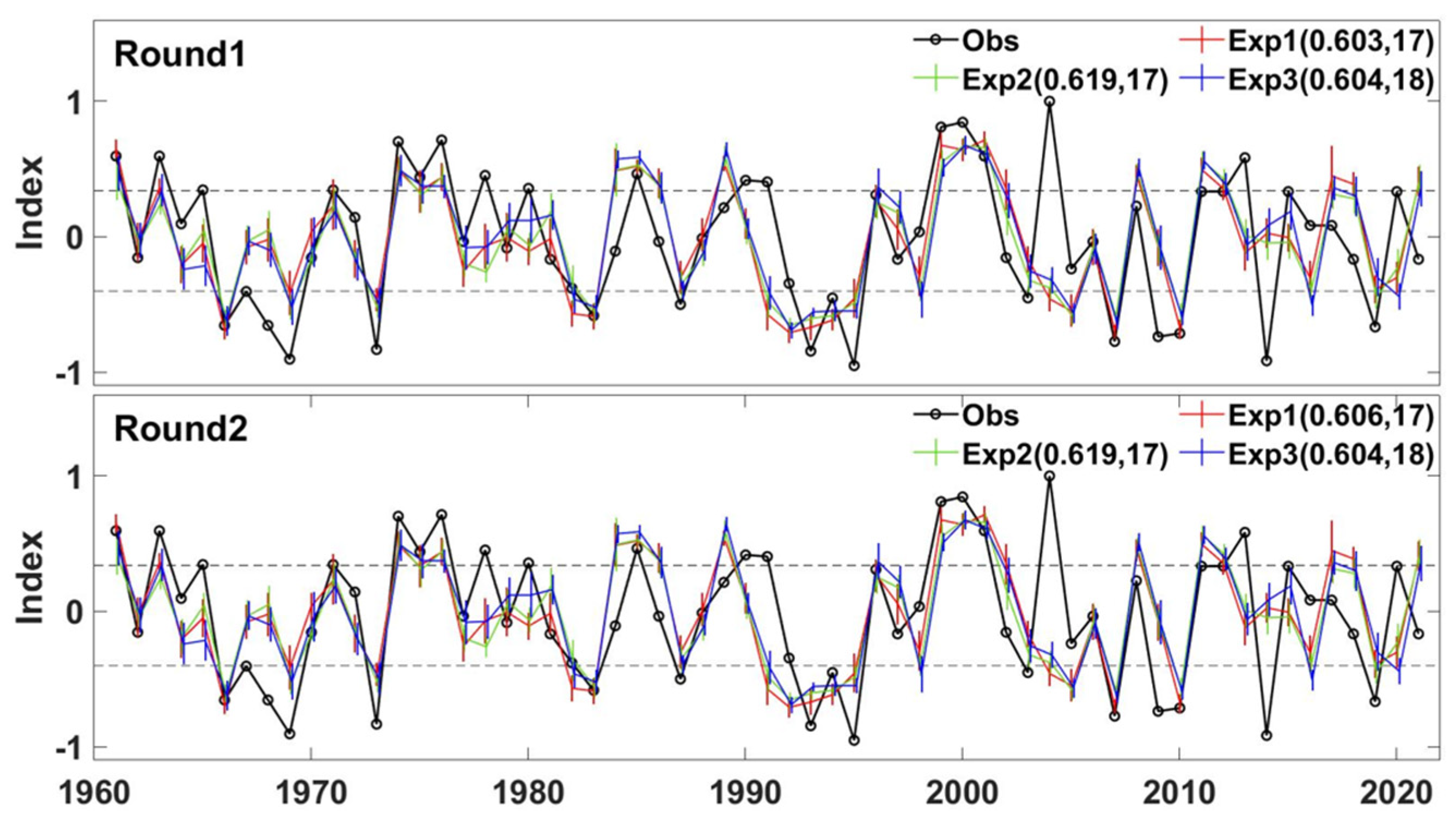
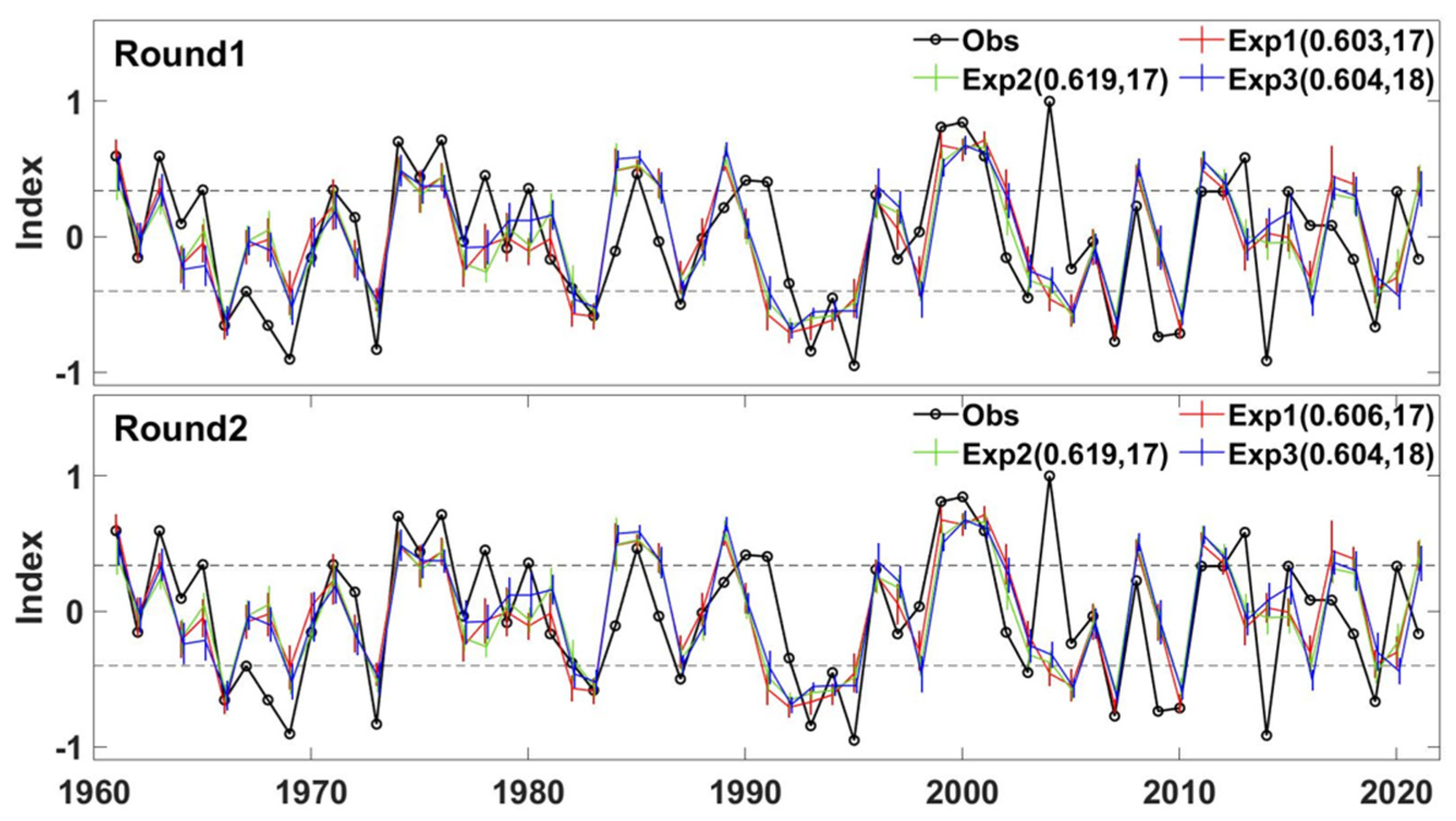
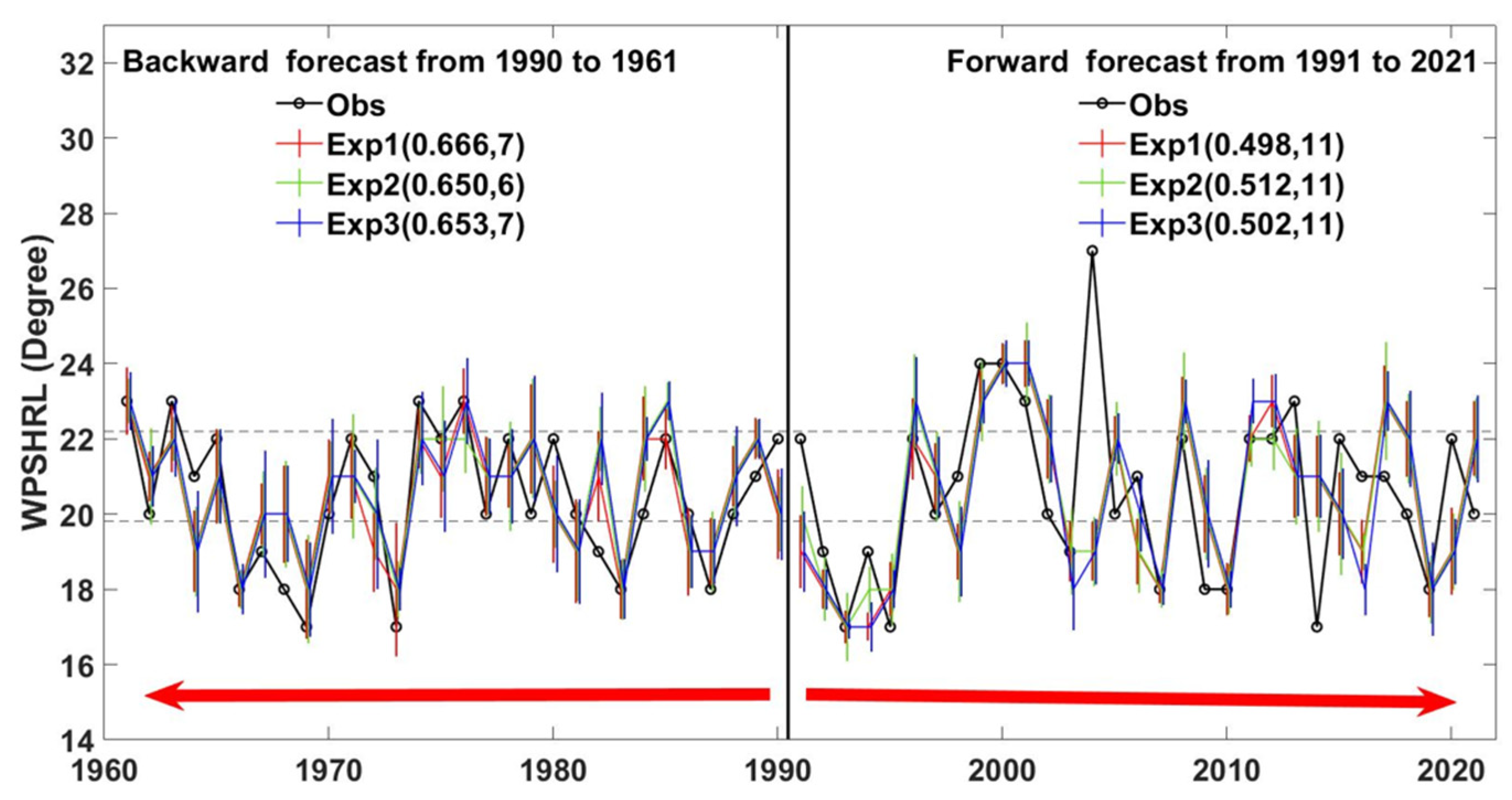
3.2. Forecast Skill
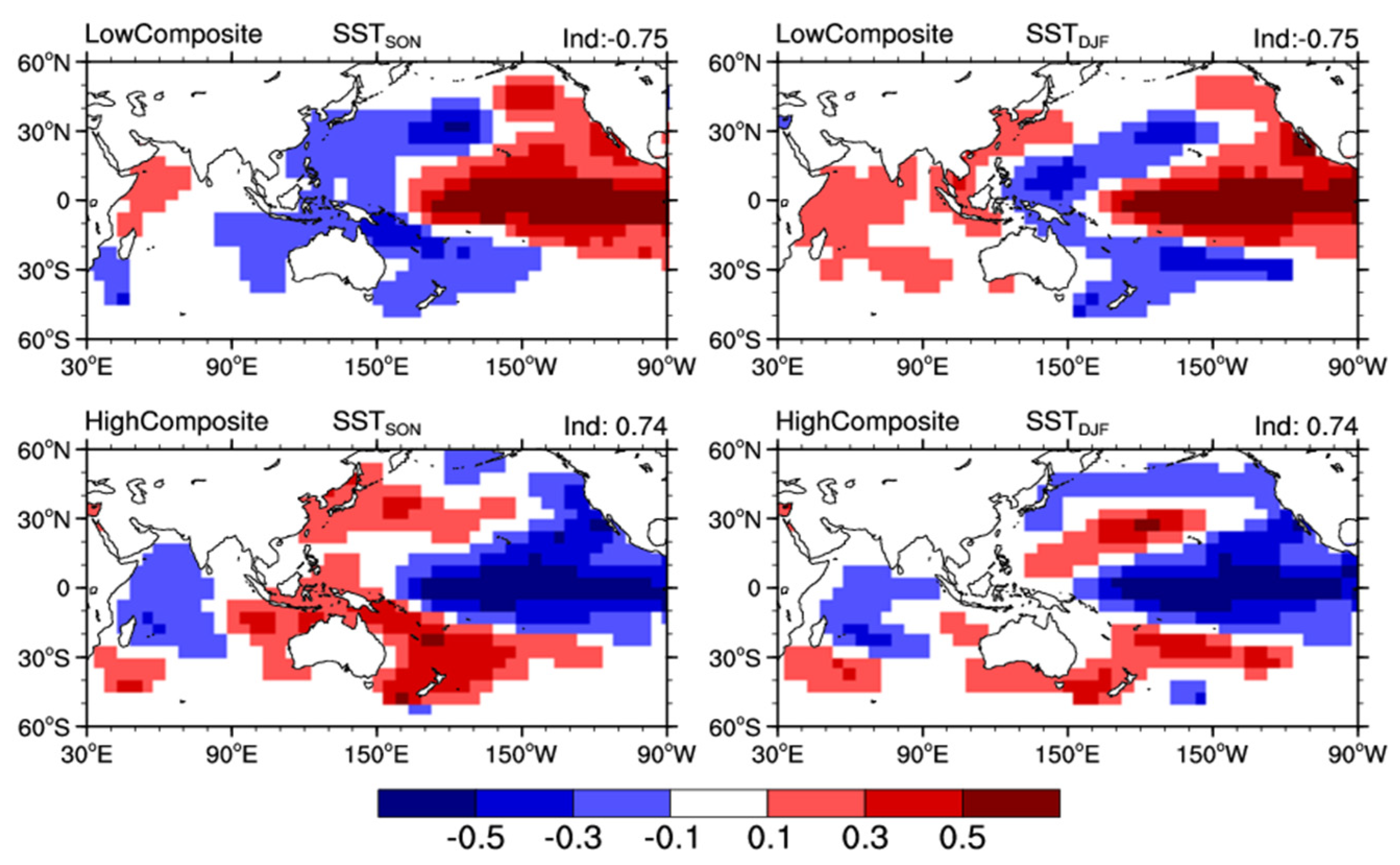
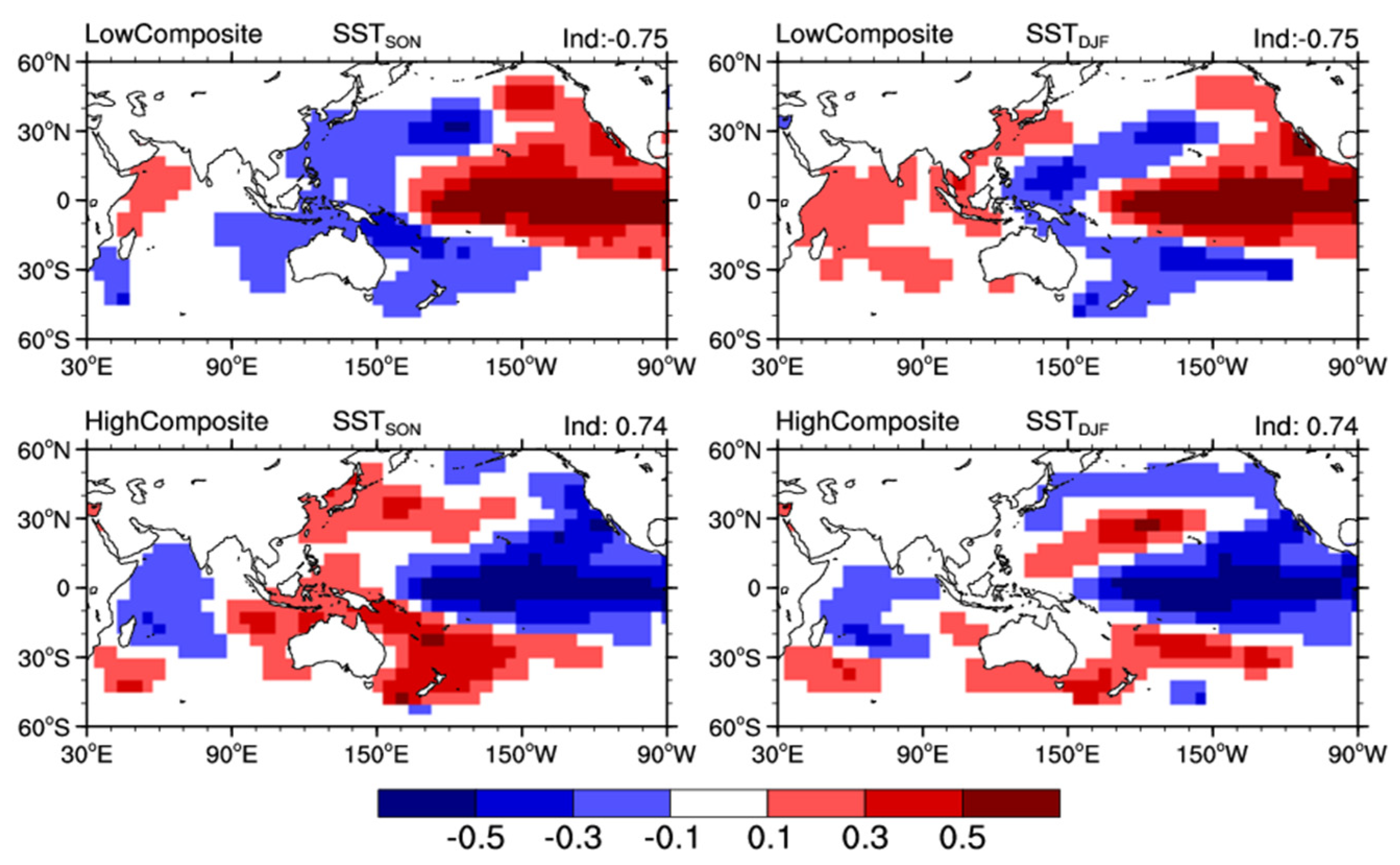
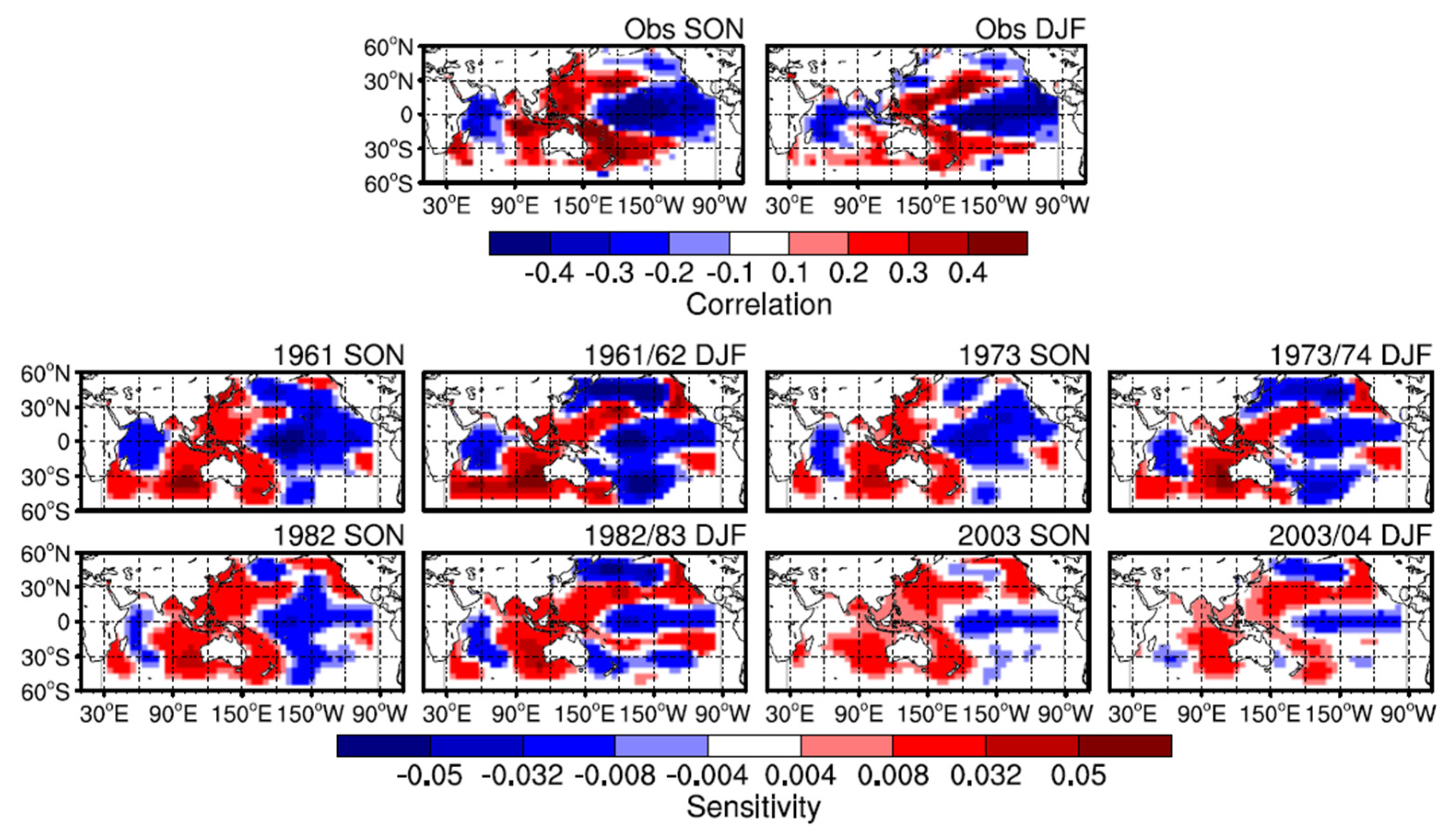
3.3. Interpretability of the Forecast System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tao, S.; Wei, J. The Westward, Northward advance of the Subtropical High over the West Pacific in Summer. J. Appl. Meteor. Sci. 2006, 17, 513–525. [Google Scholar] [CrossRef]
- Liu, Y.; Hong, J.; Liu, C.; Zhang, P. Meiyu flooding of Huaihe River valley and anomaly of seasonal variation of subtropical anticyclone over the Western Pacific. Chin. J. Atmos. Sci. 2013, 37, 439–450. [Google Scholar]
- Yu, Y.; Wang, S.; Qian, Z.; Song, M.; Wang, A. Climatic linkages between SHWP position and EASM Rainy-Belts and-Areas in east part of China in summer half year. Plateau Meteor. 2013, 32, 1510–1525. Available online: http://www.gyqx.ac.cn/CN/10.7522/j.issn.1000-0534.2013.00033 (accessed on 26 February 2022).
- Wu, S.; Guo, D. Effects of East Asian summer monsoon and Western Pacific Subtropical High on summer precipitation in China. Sci. Technol. Innov. Herald. 2019, 16, 112–119. [Google Scholar] [CrossRef]
- Zhang, E.; Tang, B.; Han, Z. A long-range forecasting model for the Subtropical High using the integral multi-level recursion. J. Appl. Meteor. Sci. 1989, 4, 69–74. Available online: http://qikan.camscma.cn/article/id/19890110 (accessed on 26 February 2022).
- Dong, Z.; Zhang, R. A prediction of the Western Pacific Subtropical High based on wavelet decomposition and ANFIS model. J. Trop. Meteor. 2004, 20, 419–425. [Google Scholar] [CrossRef]
- Ren, H.; Zhang, P.; Guo, B.; Chou, J. Dynamical model of Subtropical High ridge-line section and numerical simulations with its simplified scheme. Chin. J. Atmos. Sci. 2005, 29, 71–78. [Google Scholar]
- Zhang, R.; Wang, H.; Liu, K.; Hong, M.; Yu, D. Dynamic randomicity and complexity of Subtropical High index based on phase space reconstruction. J. Nanjing Inst. Meteor. 2007, 30, 723–729. [Google Scholar] [CrossRef]
- Wang, Y.; Teng, J.; Zhang, R.; Wan, Q.; Dong, Z.; Bai, Z. Predicting the Subtropical High index by coupling self-organizing feature map and generalized regression neural network. J. Trop. Meteor. 2008, 24, 475–482. [Google Scholar] [CrossRef]
- Fu, B.; Wang, T.; Wei, C.; Deng, Z. Testing and assessment of capabilities of day-to-day predicting of summertime West Pacific Subtropical High based on CFSv2. Guangdong Meteor. 2016, 38, 15–19. [Google Scholar] [CrossRef]
- Duan, C.; Xu, M.; Cheng, Z.; Luo, L. Evaluation on monthly prediction of Western Pacific Subtropical High by DERF2.0 model. Meteor. Mon. 2017, 43, 1267–1277. Available online: https://d.wanfangdata.com.cn/periodical/qx201710011 (accessed on 26 February 2022).
- Qian, D.; Guan, Z.; Xu, J. Prediction models for summertime Western Pacific Subtropical High based on the leading SSTA modes in the tropical Indo-Pacific sector. Trans. Atmos. Sci. 2021, 44, 405–417. [Google Scholar] [CrossRef]
- Jia, Y.; Hu, Y.; Zhong, Z.; Zhu, Y. Statistical forecast model of Western Pacific Subtropical High indices in Summer. Plateau Meteor. 2015, 34, 1369–1378. Available online: http://www.gyqx.ac.cn/CN/10.7522/j.issn.1000-0534.2014.00079 (accessed on 26 February 2022).
- Zhou, F.; Ren, H.; Hu, Z.; Liu, M.; Wu, J.; Liu, C. Seasonal predictability of primary East Asian Summer circulation patterns by three operational climate prediction models. Quart. J. Roy. Meteor. Soc. 2020, 146, 629–646. [Google Scholar] [CrossRef]
- Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability, 1st ed.; Cambridge University Press: Cambridge, UK, 2002; pp. 1–27. [Google Scholar] [CrossRef]
- Huntingford, C.; Jeffers, E.S.; Bonsall, M.B.; Christensen, H.M.; Lees, T.; Yang, H. Machine learning and artificial intelligence to aid climate change research and preparedness. Environ. Res. Lett. 2019, 14, 124007. [Google Scholar] [CrossRef] [Green Version]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- He, S.; Wang, H.; Li, H.; Zhao, J. Machine learning and its potential application to climate prediction. Trans. Atmos. Sci. 2021, 44, 26–38. Available online: http://dx.chinadoi.cn/10.13878/j.cnki.dqkxxb.20201125001 (accessed on 26 February 2022).
- Ham, Y.G.; Kim, J.H.; Luo, J.J. Deep learning for multi-year ENSO forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef]
- Geng, H.; Wang, T. Spatiotemporal model based on deep learning for ENSO forecasts. Atmosphere 2021, 12, 810. [Google Scholar] [CrossRef]
- Tangang, F.T.; Hsieh, W.W.; Tang, B. Forecasting the equatorial Pacific sea surface temperatures by neural network models. Climate Dyn. 1997, 13, 135–147. [Google Scholar] [CrossRef]
- Tangang, F.T.; Hsieh, W.W.; Tang, B. Forecasting regional sea surface temperatures in the tropical Pacific by neural network models, with wind stress and sea level pressure as predictors. J. Geophys. Res. 1998, 103, 7511–7522. [Google Scholar] [CrossRef]
- Wu, A.; Hsieh, W.W.; Tang, B. Neural network forecasts of the tropical Pacific sea surface temperatures. Neural Netw. 2006, 19, 145–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdullah, S.; Ismail, M.; Ahmed, A.N.; Abdullah, A.M. Forecasting particulate matter concentration using linear and non-Linear approaches for air quality decision support. Atmosphere 2019, 10, 667. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, CA, USA, 2016; pp. 89–223. Available online: http://www.deeplearningbook.org (accessed on 26 February 2022).
- Tran, T.; Lee, T.; Kim, J.S. Increasing Neurons or Deepening Layers in Forecasting Maximum Temperature Time Series? Atmosphere 2020, 11, 1072. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar] [CrossRef]
- Fong, R.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. arXiv 2017, arXiv:1704.03296. [Google Scholar] [CrossRef]
- Kindermans, P.J.; Schütt, K.T.; Alber, M.; Müller, K.R.; Erhan, D.; Kim, B.; Dähne, S. Learning how to explain neural networks: PatternNet and PatternAttribution. arXiv 2017, arXiv:1705.05598. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2019, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Fan, F.; Xiong, J.; Li, M.; Wang, G. On Interpretability of Artificial Neural Networks: A Survey. arXiv 2020, arXiv:2001.02522. [Google Scholar] [CrossRef]
- Belochitski, A.; Krasnopolsky, V. Robustness of neural network emulations of radiative transfer parameterizations in a state-of-the-art general circulation model. Geosci. Model Dev. 2021, 14, 7425–7437. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Gui, S.; Ji, S. Explainability in Graph Neural Networks: A Taxonomic Survey. arXiv 2021, arXiv:2012.15445. [Google Scholar] [CrossRef]
- Kaplan, A.; Cane, M.A.; Kushnir, Y.; Clement, A.C.; Blumenthal, M.B.; Rajagopalan, B. Analyses of global sea surface temperature 1856–1991. J. Geophys. Res. 1998, 103, 18567–18589. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Yan, H. Relationship between proceeding pacific sea surface temperature and Subtropical High indexes of main raining seasons. J. Trop. Meteor. 2008, 24, 483–489. [Google Scholar] [CrossRef]
- Liu, Y.; Li, W.; Ai, W.; Li, Q. Reconstruction and application of the monthly Western Pacific Subtropical High indices. J. Appl. Meteor. Sci. 2012, 23, 414–423. [Google Scholar]
- Chen, L. Interaction between the subtropical high over the north Pacific and the sea surface temperature of the eastern equatorial Pacific. Chin. J. Atmos. Sci. 1982, 6, 148–156. [Google Scholar]
- Ying, M.; Sun, S. A Study on the Response of Subtropical High over the Western Pacific the SST Anomaly. Chin. J. Atmos. Sci. 2000, 24, 193–206. [Google Scholar] [CrossRef]
- Zeng, G.; Sun, Z.; Lin, Z.; Ni, D. Numerical Simulation of Impacts of Sea Surface Temperature Anomaly upon the Interdecadal Variation in the Northwestern Pacific Subtropical High. Chin. J. Atmos. Sci. 2010, 34, 307–322. [Google Scholar] [CrossRef]
- Ong-Hua, S.; Feng, X. Two northward jumps of the summertime western pacific subtropical high and their associations with the tropical SST anomalies. Atmos. Ocean. Sci. Lett. 2011, 4, 98–102. [Google Scholar] [CrossRef] [Green Version]
- Xue, F.; Zhao, J. Intraseasonal variation of the East Asian summer monsoon in La Niña years. Atmos. Ocean. Sci. Lett. 2017, 10, 156–161. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Sun, F. Impacts of the Thermal State and the Convective Activities in the Tropical Western Warm Pool on the Summer Climate Anomalies in East Asia. Chin. J. Atmos. Sci. 1994, 18, 141–151. [Google Scholar] [CrossRef]
- Ai, Y.; Chen, X. Analysis of the correlation between the Subtropical High over Western Pacific in Summer and SST. J. Trop. Meteor. 2000, 16, 1–8. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer Feedforward Networks are Universal Approximators. Neur. Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Opper, M.; Winther, O. Gaussian Processes and SVM: Mean Field Results and Leave-One-Out. Advances in Large Margin Classifiers, 8th ed.; Smola, A.J., Bartlett, P.L., Schölkopf, B., Schuurmans, D., Eds.; MIT Press: Cambridge, CA, USA, 2000; pp. 311–326. Available online: https://www.researchgate.net/publication/40498234 (accessed on 26 February 2022).
- Volpe, V.; Manzoni, S.; Marani, M. Leave-One-Out Cross-Validation. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011; pp. 24–45. [Google Scholar] [CrossRef]
- Dodge, J.; Ilharco, G.; Schwartz, R.; Farhadi, A.; Hajishirzi, H.; Smith, N. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv 2020, arXiv:2002.06305. [Google Scholar] [CrossRef]
- Toms, B.A.; Barnes, E.A.; Ebert-Uphoff, I. Physically interpretable neural networks for the geosciences: Applications to earth system variability. arXiv 2020, arXiv:1912.01752. [Google Scholar] [CrossRef]
- Chen, D.; Gao, S.; Chen, J.; Gao, S. The synergistic effect of SSTA between the equatorial eastern Pacific and the Indian-South China Sea warm pool region influence on the western Pacific subtropical high. Haiyang Xuebao 2016, 38, 1–15. Available online: http://dx.chinadoi.cn/10.3969/j.issn.0253-4193.2016.02.001 (accessed on 26 February 2022).
- Tsuyoshi, N. Convective Activities in the Tropical Western Pacific and Their Impact on the Northern Hemisphere Summer Circulation. J. Meteor. Soc. Jpn. Ser. II 1987, 65, 373–390. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Li, W. Influence of heat source anomaly over the western tropical Pacific on the subtropical high over East Asia and its physical mechanism. Chin. J. Atmos. Sci. 1988, 12, 107–116. [Google Scholar] [CrossRef]
- Liu, J.; Tang, Y.; Wu, Y.; Li, T.; Wang, Q.; Chen, D. Forecasting the Indian Ocean Dipole with deep learning techniques. Geophys. Res. Lett. 2021, 48, e2021GL094407. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Qian, Q.; Liang, P.; Qi, L. Advances in the Study of Intraseasonal Activity and Variation of Western Pacific Subtropical High. Meteor. Environ. Sci. 2021, 44, 93–101. [Google Scholar] [CrossRef]
- Wen, M.; He, J. Ridge Movement and Potential Mechanism of Western Pacific Subtropical High in Summer. Trans. Atmos. Sci. 2002, 25, 289–297. Available online: http://dx.chinadoi.cn/10.3969/j.issn.1674-7097.2002.03.001 (accessed on 26 February 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N\(h1, h2) | (8, 5) | (6, 5) | (6, 4) | (4, 4) | (6, 3) | (4, 3) | (3, 3) |
|---|---|---|---|---|---|---|---|
| 8 | 0.56, 14 | 0.55, 16 | 0.57, 16 | 0.57, 16 | 0.56, 17 | 0.57, 16 | 0.57, 17 |
| 10 | 0.61, 17 | 0.60, 19 | 0.62, 18 | 0.59, 18 | 0.62, 18 | 0.59, 17 | 0.61, 19 |
| 12 | 0.62, 16 | 0.56, 18 | 0.62, 17 | 0.59, 18 | 0.59, 17 | 0.61, 17 | 0.60, 16 |
| 13 | 0.65, 18 | 0.64, 18 | 0.66, 18 | 0.64, 19 | 0.65, 17 | 0.67, 18 | 0.66, 18 |
| 14 | 0.64, 14 | 0.62, 18 | 0.63, 18 | 0.61, 19 | 0.62, 17 | 0.63, 19 | 0.64, 17 |
| 16 | 0.64, 18 | 0.63, 17 | 0.62, 17 | 0.63, 17 | 0.61, 17 | 0.63, 15 | 0.61, 18 |
| 18 | 0.63, 15 | 0.61, 16 | 0.61, 13 | 0.62, 18 | 0.60, 16 | 0.61, 12 | 0.62, 18 |
| ST\(h1, h2) | (8, 5) | (6, 5) | (6, 4) | (4, 4) | (6, 3) | (4, 3) | (3, 3) |
|---|---|---|---|---|---|---|---|
| 0.28 | 0.64, 15 | 0.63, 14 | 0.64, 14 | 0.62, 17 | 0.65, 17 | 0.64, 16 | 0.65, 16 |
| 0.30 | 0.65, 15 | 0.64, 15 | 0.65, 14 | 0.62, 18 | 0.65, 18 | 0.65, 16 | 0.65, 16 |
| 0.34 | 0.66, 18 | 0.64, 16 | 0.66, 17 | 0.64, 19 | 0.65, 18 | 0.65, 18 | 0.66, 18 |
| 0.36 | 0.65, 18 | 0.64, 18 | 0.66, 18 | 0.64, 19 | 0.65, 17 | 0.67, 18 | 0.66, 18 |
| 0.38 | 0.66, 16 | 0.64, 17 | 0.66, 16 | 0.65, 18 | 0.65, 16 | 0.66, 16 | 0.65, 18 |
| 0.40 | 0.66, 15 | 0.64, 17 | 0.66, 17 | 0.65, 16 | 0.66, 18 | 0.65, 16 | 0.64, 16 |
| 0.42 | 0.67, 16 | 0.63, 18 | 0.67, 16 | 0.63, 18 | 0.64, 16 | 0.67, 15 | 0.65, 17 |
| 0.44 | 0.65, 14 | 0.61, 16 | 0.66, 15 | 0.61, 16 | 0.63, 16 | 0.66, 15 | 0.64, 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Shi, X.; Yan, H.; Jiang, Q.; Zeng, Y. Forecasting the June Ridge Line of the Western Pacific Subtropical High with a Machine Learning Method. Atmosphere 2022, 13, 660. https://doi.org/10.3390/atmos13050660
Sun C, Shi X, Yan H, Jiang Q, Zeng Y. Forecasting the June Ridge Line of the Western Pacific Subtropical High with a Machine Learning Method. Atmosphere. 2022; 13(5):660. https://doi.org/10.3390/atmos13050660
Chicago/Turabian StyleSun, Cunyong, Xiangjun Shi, Huiping Yan, Qixiao Jiang, and Yuxi Zeng. 2022. "Forecasting the June Ridge Line of the Western Pacific Subtropical High with a Machine Learning Method" Atmosphere 13, no. 5: 660. https://doi.org/10.3390/atmos13050660
APA StyleSun, C., Shi, X., Yan, H., Jiang, Q., & Zeng, Y. (2022). Forecasting the June Ridge Line of the Western Pacific Subtropical High with a Machine Learning Method. Atmosphere, 13(5), 660. https://doi.org/10.3390/atmos13050660