
Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach


 , ,
, ,  and
and
Abstract
:1. Introduction
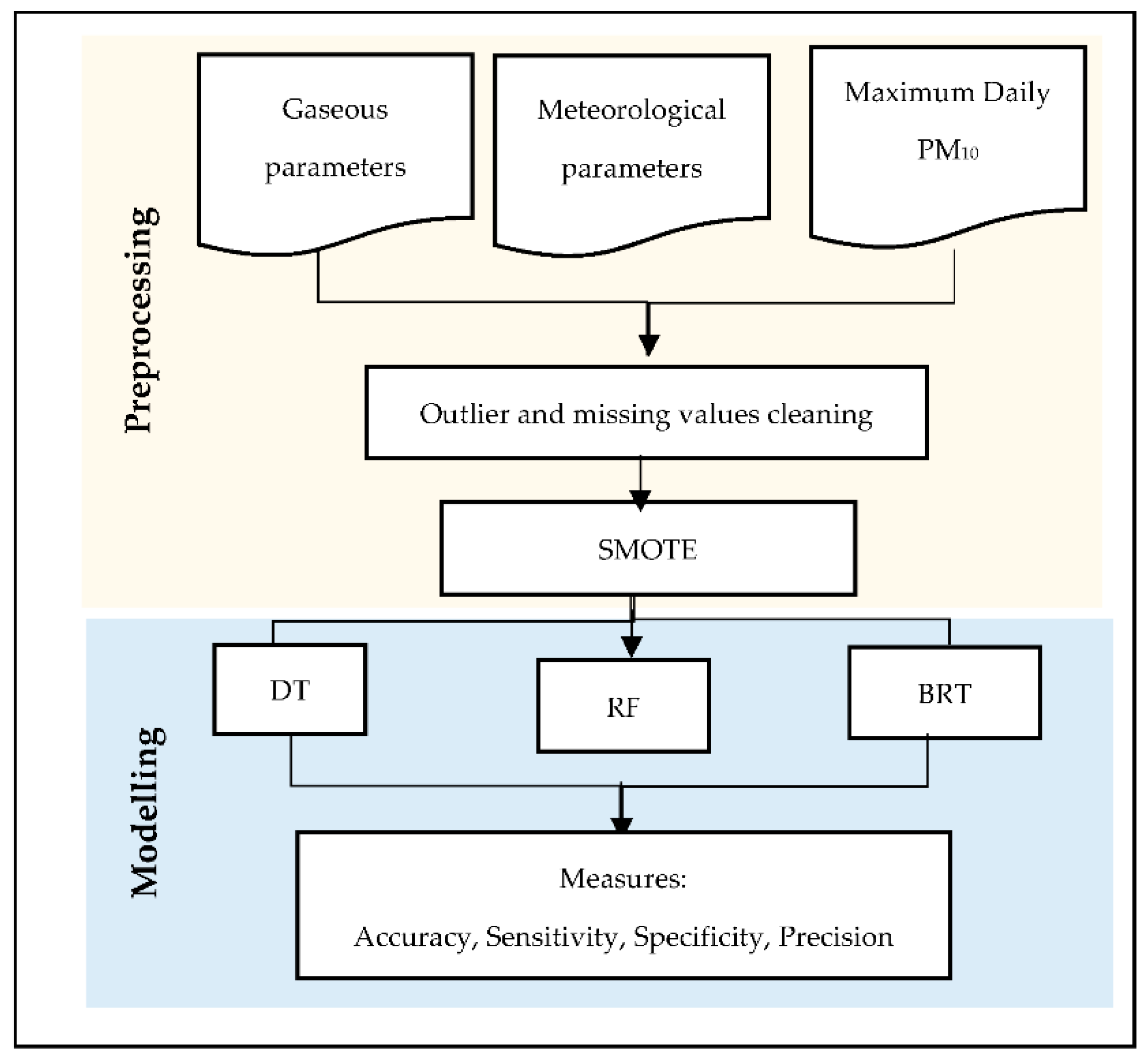
2. Materials and Methods
2.1. Study Area
2.2. Monitoring Records
2.3. Tree-Based Machine Learning Approaches
2.3.1. Decision Tree
2.3.2. Random Forests
2.3.3. Boosted Regression Tree
2.4. Performance Measures
3. Results and Discussion
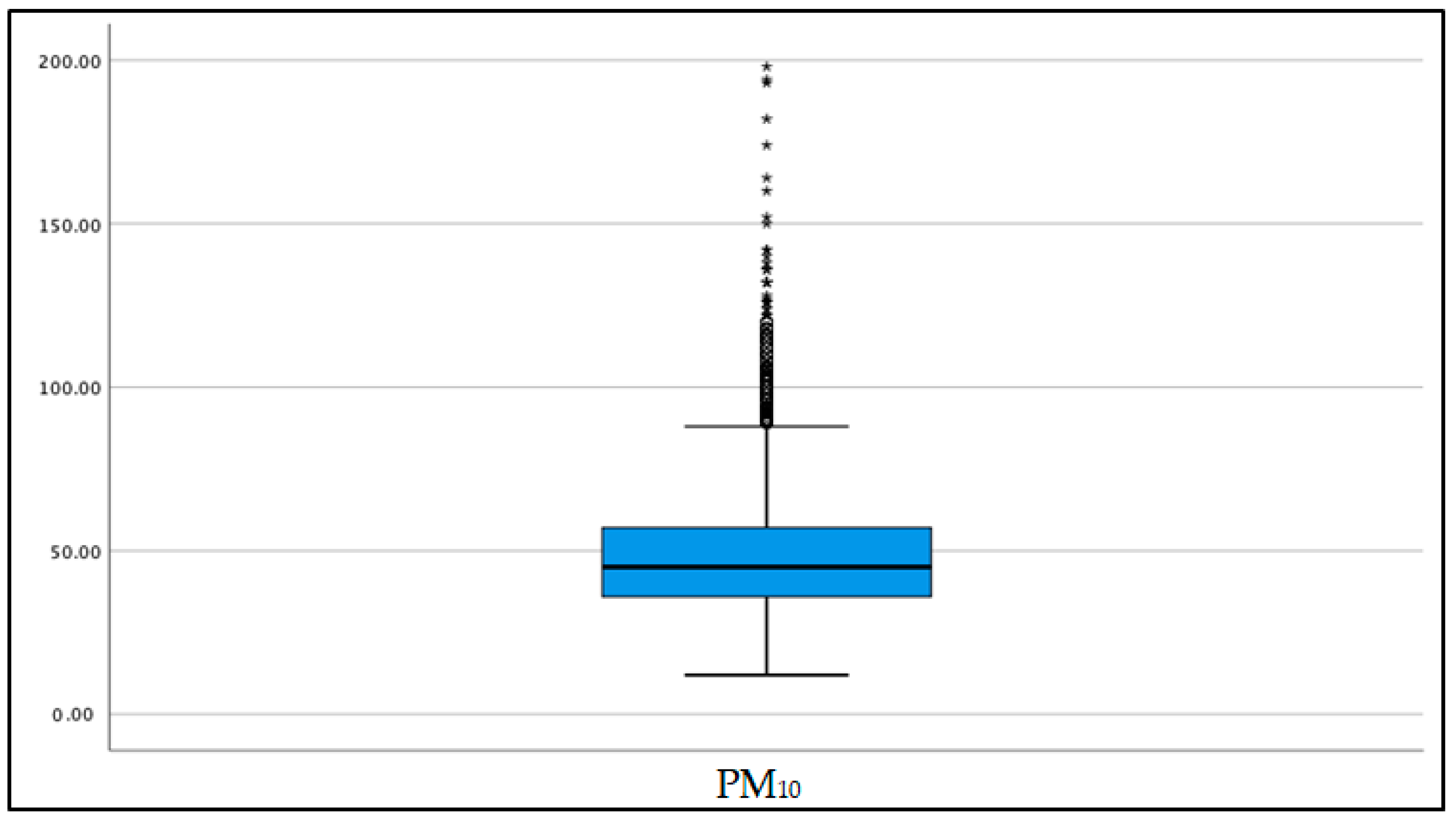
3.1. Statistical Characteristics of PM10
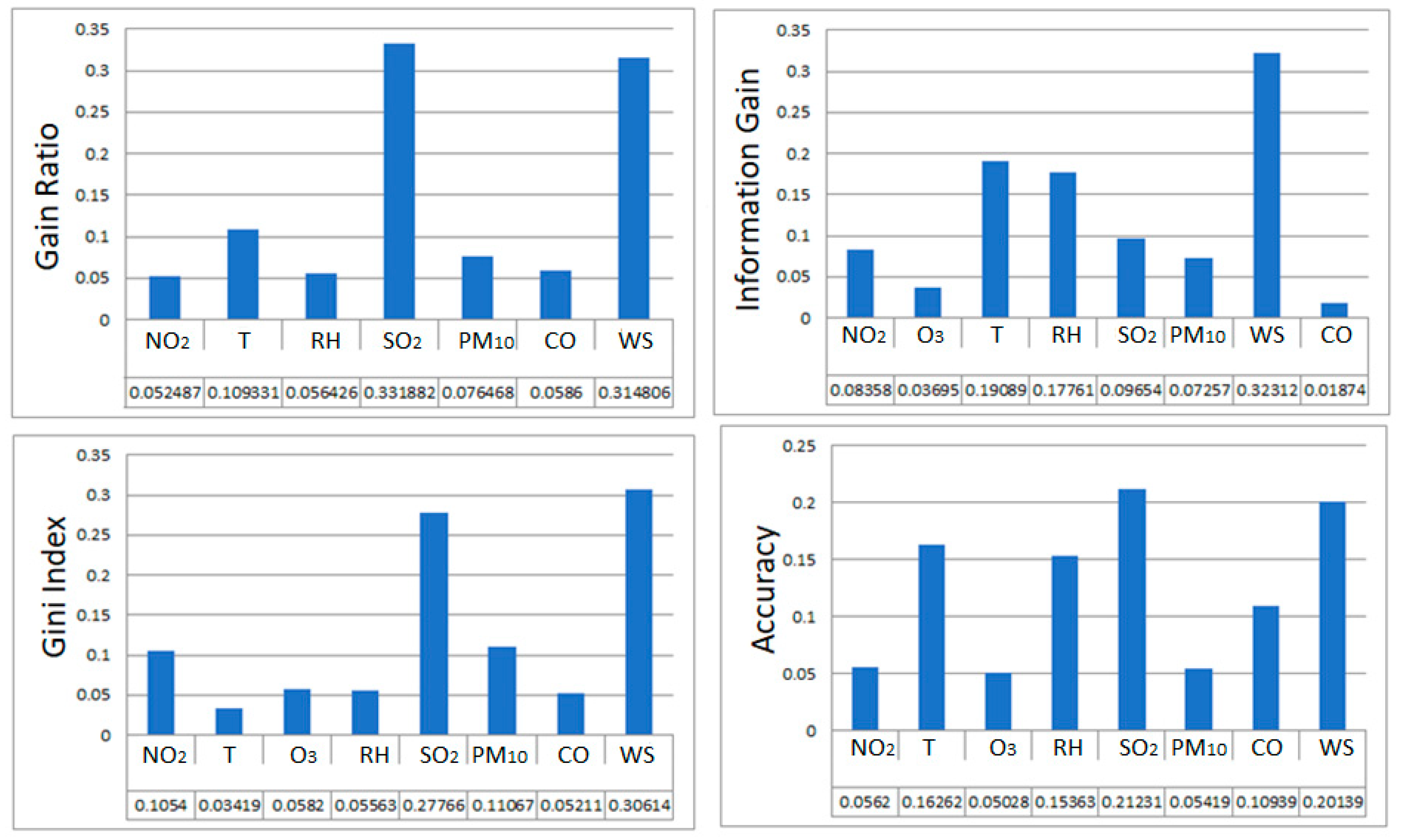
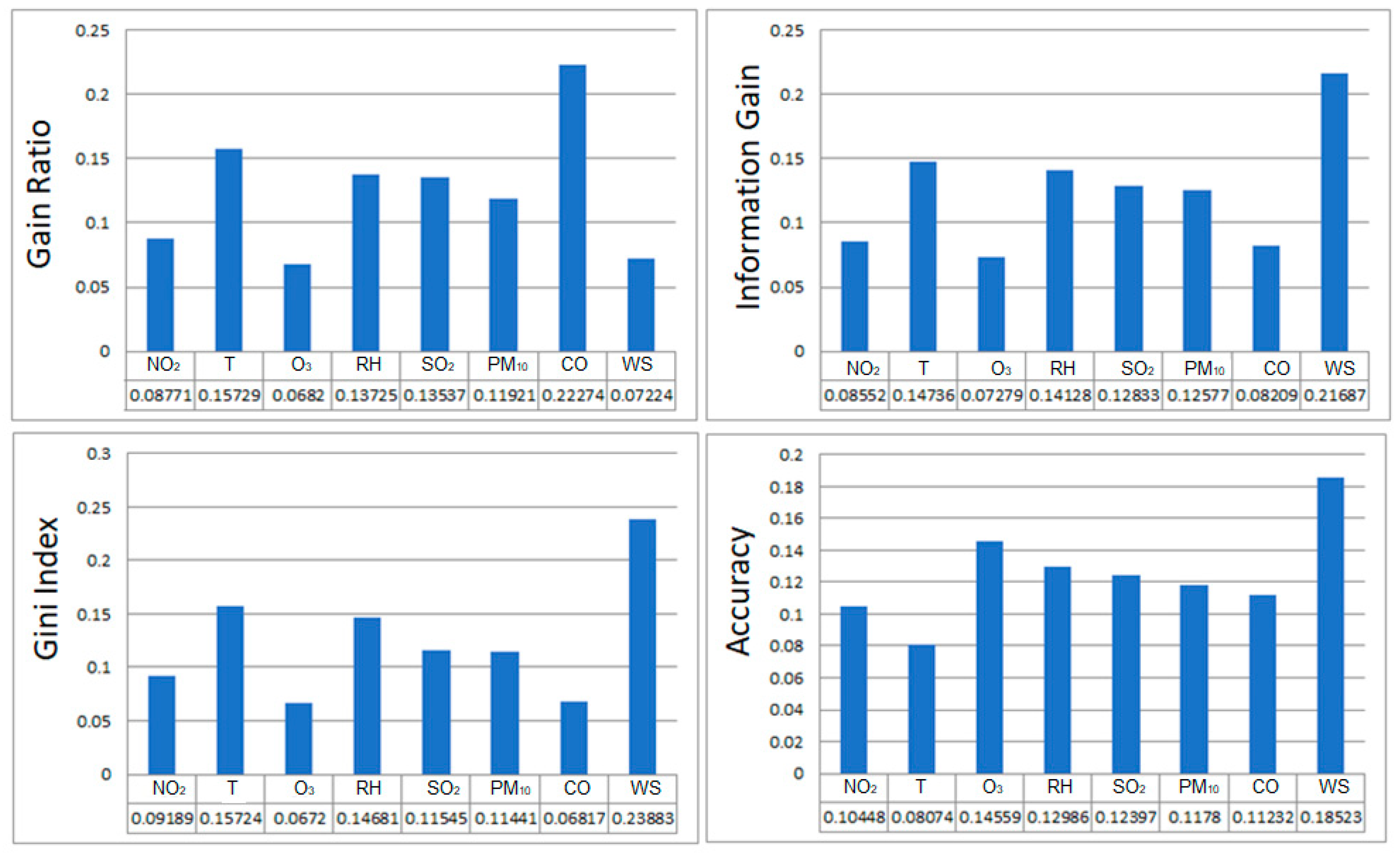
3.2. Decision Tree (DT)
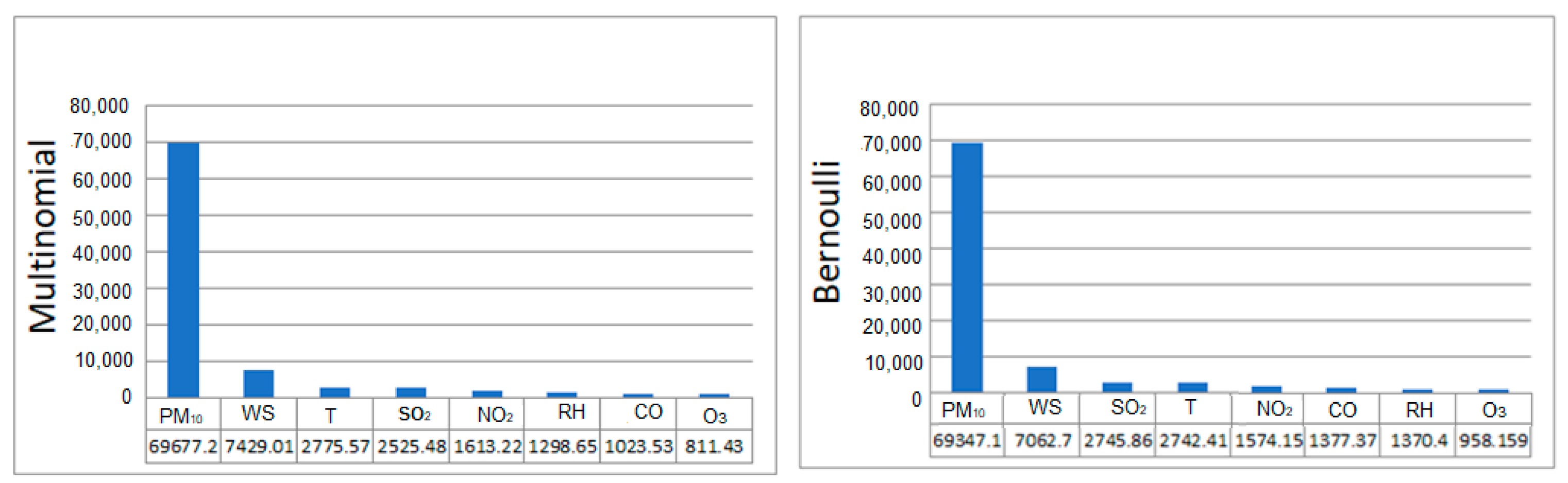
3.3. Boosted Regression Tree (BRT)
3.4. Random Forest (RF)
3.5. Performance Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Department of Environment, Malaysia. Malaysia Environmental Quality Report 2016. Available online: https://www.doe.gov.my/wp-content/uploads/2021/08/EQR-2016-AIR-TANAH.pdf (accessed on 1 January 2022).
- US EPA. Health and Environmental Effects of Particulate Matter (PM) 2015. Available online: https://www.epa.gov/pm-pollution/health-and-environmental-effects-particulate-matter-pm (accessed on 4 January 2022).
- Hassan, N.A.; Hashim, Z.; Hashim, J.H. Impact of climate change on air quality and public health in urban areas. Asia Pac. J. Public Health 2016, 28, 385–485. [Google Scholar] [CrossRef]
- Vinceti, M.; Malagoli, C.; Malavolti, M.; Cherubini, A.; Maffeis, G.; Rodolfi, R.; Heck, J.E.; Astolfi, G.; Calzolari, E.; Nicolini, F. Does maternal exposure to benzene and PM10 during pregnancy increase the risk of congenital anomalies? A population-based case-control study. Sci. Total Environ. 2016, 541, 444–450. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Azmi, S.Z.; Latif, M.T.; Ismail, A.S.; Juneng, L.; Jemain, A.A. Trend and status of air quality at three different monitoring stations in the Klang Valley, Malaysia. Air Qual. Atmos. Health 2010, 3, 53–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shaziayani, W.N.; Ul-Saufie, A.Z.; Ahmat, H.; Al-Jumeily, D. Coupling of Quantile Regression into Boosted Regression Trees (BRT) Technique in Forecasting Emission Model of PM10 Concentration. Air Qual. Atmos. Health 2021, 14, 1647–1663. [Google Scholar] [CrossRef]
- Byun, D.; Schere, K.L. Review of the governing equations, computational algorithms, and other components of the Models-3 Community Multiscale Air Quality (CMAQ) modeling system. Appl. Mech. Rev. 2006, 59, 51–77. [Google Scholar] [CrossRef]
- Im, U.; Markakis, K.; Unal, A.; Kindap, T.; Poupkou, A.; Incecik, S.; Yenigun, O.; Melas, D.; Theodosi, C.; Mihalopoulos, N. Study of a winter PM episode in Istanbul using the high resolution WRF/CMAQ modeling system. Atmos. Environ. 2010, 44, 3085–3094. [Google Scholar] [CrossRef]
- Hu, J.; Li, X.; Huang, L.; Ying, Q.; Zhang, Q.; Zhao, B.; Wang, S.; Zhang, H. Ensemble prediction of air quality using the WRF/CMAQ model system for health effect studies in China. Atmos. Chem. Phys. 2017, 17, 13103–13118. [Google Scholar] [CrossRef] [Green Version]
- Vongruang, P.; Wongwises, P.; Pimonsree, S. Assessment of fire emission inventories for simulating particulate matter in Upper Southeast Asia using WRF-CMAQ. Atmos. Pollut. Res. 2017, 8, 921–929. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, Y.; Ma, W.; Yu, Q.; Wang, Q.; Fu, Q.; Zhou, B.; Chen, J.; Chen, L. Evaluation and potential improvements of WRF/CMAQ in simulating multi-levels air pollution in megacity Shanghai, China. Stoch. Environ. Res. Risk Assess. 2017, 31, 2513–2526. [Google Scholar] [CrossRef]
- Zhang, H.; DeNero, S.P.; Joe, D.K.; Lee, H.H.; Chen, S.H.; Michalakes, J.; Kleeman, M.J. Development of a source oriented version of the WRF/Chem model and its application to the California regional PM 10/PM 2.5 air quality study. Atmos. Chem. Phys. 2014, 14, 485–503. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Jime, R.; Belalca, L.C. Application of WRF-Chem model to simulate PM10 concentration over Bogota. Aerosol Air Qual. Res. 2016, 16, 1206–1221. [Google Scholar] [CrossRef] [Green Version]
- Jenkins, G.S.; Gueye, M. Annual and early summer variability in WRF-CHEM simulated West African PM10 during 1960–2016. Atmos. Environ. 2022, 273, 118957. [Google Scholar] [CrossRef]
- Casallas, A.; Celis, N.; Ferro, C.; López Barrera, E.; Peña, C.; Corredor, J.; Ballen Segura, M. Validation of PM10 and PM2.5 early alert in Bogotá, Colombia, through the modeling software WRF-CHEM. Environ. Sci. Pollut. Res. 2020, 27, 35930–35940. [Google Scholar] [CrossRef] [PubMed]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled “online” chemistry within the WRF model. Atmos. Environ. 2005, 39, 6957–6975. [Google Scholar] [CrossRef]
- Balzarini, A.; Pirovano, G.; Honzak, L.; Žabkar, R.; Curci, G.; Forkel, R.; Hirtl, M.; San Jose, R.; Tuccella, P.; Grell, G.A. WRF-Chem model sensitivity to chemical mechanisms choice in reconstructing aerosol optical properties. Atmos. Environ. 2015, 115, 604–619. [Google Scholar] [CrossRef]
- Gagliardi, R.V.; Andenna, C. A Machine Learning Approach to Investigate the Surface Ozone Behavior. Atmosphere 2020, 11, 1173. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef] [Green Version]
- Myers, K.D.; Knowles, J.W.; Staszak, D.; Shapiro, M.D.; Howard, W.; Yadava, M.; Zuzick, D.; Williamson, L.; Shah, N.H.; Banda, J.M.; et al. Precision screening for familial hypercholesterolaemia: A machine learning study applied to electronic health encounter data. Lancet Digit. Heal. 2019, 1, 393–402. [Google Scholar] [CrossRef] [Green Version]
- Rosli, M.M.; Edward, J.; Onn, M.; Chua, Y.A.; Kasim, N.A.M.; Nawawi, H. Classifying Familial Hypercholesterolaemia: A Tree-based Machine Learning Approach. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 66–73. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.; Stone, C.J. Classification and Regression Trees; Wadsworth: Belmont, CA, USA, 1984. [Google Scholar]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1993. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Akiladevi, R.; Nandhini, D.B.; Nivesh, K.V.; Nivetha, P. Prediction and Analysis of Pollutant using Supervised Machine Learning. Int. J. Recent Technol. Eng. 2020, 9, 50–54. [Google Scholar]
- Giorgio, C.; Mauro, S. Air pollution prediction via multi-label classification. Environ. Model. Softw. 2016, 80, 259–264. [Google Scholar]
- Akhtar, A.; Masood, S.; Gupta, C.; Masood, A. Prediction and analysis of pollution levels in delhi using multilayer perceptron. Adv. Intell. Syst. Comput. 2018, 542, 563–572. [Google Scholar]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Elis, S.Z.N.; Ul-Saufie, A.Z.; Shaziayani, W.N.; Noor, N.M.; Zubir, N.A. Assessment of Ambient Air Pollution in Langkawi Island, Malaysia. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Kazimierz Dolny, Poland, 21–23 November 2019; Volume 551, p. 012123. [Google Scholar]
- Mohamad, N.S.; Deni, S.M.; Ul-Saufie, A.Z. Application of the First Order of Markov Chain Model in Describing the PM10 Occurrences in Shah Alam and Jerantut, Malaysia. Pertanika J. Sci. Technol. 2018, 26, 367–378. [Google Scholar]
- Paschalidou, A.K.; Karakitsios, S.; Kleanthous, S.; Kassomenos, P.A. Hourly PM10 Concentration in Cyprus through Artificial Neural Networks and Multiple Regression Models: Implications to Local Environmental Management. Environ. Sci. Pollut. Res. 2011, 18, 316–327. [Google Scholar] [CrossRef] [PubMed]
- Papanastasiou, D.K.; Kioutsoukis, M.D. Development And Assessment Of Neural Network And Multiple Regression Models In Order To Predict PM10 Levels In A Medium-Sized Mediterranean City. Water Air Soil Pollut. 2007, 182, 325–334. [Google Scholar] [CrossRef]
- Libasin, Z.; Suhailah, W.; Fauzi, W.M.; Ul-Saufie, A.Z.; Idris, N.A.; Mazeni, N.A. Evaluation of Single Missing Value Imputation Techniques for Incomplete Air Particulates Matter (PM10) Data in Malaysia. Pertanika J. Sci. Technol. 2021, 29, 3099–3112. [Google Scholar] [CrossRef]
- Department of Environment, Malaysia. Malaysia Environmental Quality Report 2019. Available online: https://www.doe.gov.my/portalv1/en/ (accessed on 10 January 2022).
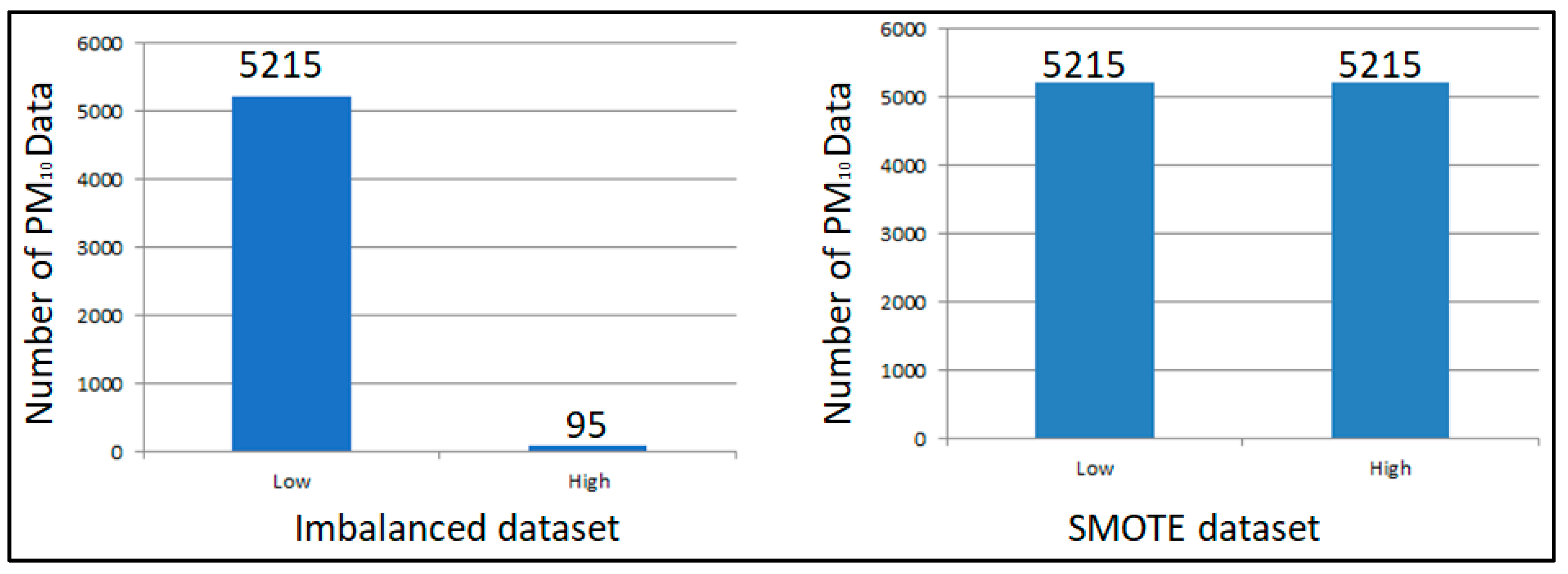
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Esfandiarpour-Boroujeni, I.; Shahini, S.M.; Shirani, H.; Mosleh, Z.; Bagheri, B.M.; Salehi, M.H. Comparison of error and uncertainty of decision tree and learning vector quantization models for predicting soil classes in areas with low altitude variations. CATENA 2020, 191, 104581. [Google Scholar] [CrossRef]
- Stafoggia, M.; Bellander, T.; Bucci, S.; Davoli, M.; Hoogh, K.D.; Donato, F.D.; Gariazzo, C.; Lyapustin, A.; Michelozzi, P.; Renzi, M.; et al. Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ. Int. 2019, 124, 170–179. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and regression by random forest. R News 2002, 2, 18–22. [Google Scholar]
- Shaziayani, W.N.; Ul-Saufie, A.Z.; Yusoff, S.A.M.; Ahmat, H.; Libasin, Z. Evaluation of boosted regression tree for the prediction of the maximum 24-hour concentration of particulate matter. Int. J. Environ. Sci. Dev. 2021, 12, 126–130. [Google Scholar] [CrossRef]
- Rosli, M.M.; Edward, J.; Onn, M. Precision screening for familial hypercholesterolaemia: A machine learning study applied to electronic health encounter data. Int. J. Adv. Comput. Sci. Appl. 2021, 9, 66–73. [Google Scholar]
- Department of Environment, Malaysia. Malaysia Environmental Quality Report 2018; Ministry of Energy, Science, Technology, Environment and Climate Change, Malaysia: Kuala Lumpur, Malaysia, 2018.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PM10 Concentration Value | Class Label |
|---|---|
| Low-level air quality with, PM10 < 100 | 1 |
| High-level air quality with, PM10 ≥ 100 | 2 |
| Prediction | Models |
|---|---|
| PM10,D+1 | PM10,D+1 ~ DT (CO (D), PM10 (D), NO2 (D), SO2 (D), O3 (D), T (D), RH (D), WS(D),) |
| PM10,D+1 ~ BRT (CO (D), PM10 (D), NO2 (D), SO2 (D), O3 (D), T (D), RH (D), WS(D),) PM10,D+1 ~ RF (CO (D), PM10 (D), NO2 (D), SO2 (D), O3 (D), T (D), RH (D), WS(D),) |
| IV | Minimum | Maximum | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|---|---|
| WS | 0.01 | 360 | 9.50 | 8.04 | 31.08 | 1346.58 |
| T | 22.89 | 37.5 | 31.36 | 2.33 | −0.63 | 0.21 |
| RH | 3.22 | 100.2 | 91.86 | 6.80 | −5.92 | 59.73 |
| SO2 | 0 | 71.4 | 0.90 | 1.54 | 19.54 | 836.04 |
| NO2 | 0 | 63 | 15.15 | 6.23 | 1.22 | 4.16 |
| CO | 180 | 21712 | 926.37 | 475.30 | 16.44 | 689.80 |
| O3 | 0.9 | 69 | 29.21 | 10.99 | 0.23 | −0.05 |
| PM10 | 12 | 198 | 48.73 | 18.11 | 1.72 | 6.22 |
| Splitting Criteria | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| Gain ratio | 95.81 | 92.59 | 99.04 | 98.98 |
| Information gain | 96.52 | 95.78 | 97.25 | 97.21 |
| Gini index | 96.52 | 95.02 | 98.02 | 97.69 |
| Accuracy | 93.39 | 95.53 | 91.25 | 91.61 |
| Distribution | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| Multinomial | 98.12 | 97.51 | 98.72 | 98.71 |
| Bernouli | 98.12 | 97.75 | 98.66 | 98.64 |
| Splitting Criteria | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| Gain ratio | 97.03 | 94.44 | 99.62 | 99.6 |
| Information gain | 98.37 | 97.19 | 99.55 | 99.54 |
| Gini index | 98.27 | 97 | 99.55 | 99.54 |
| Accuracy | 94.5 | 96.68 | 92.33 | 92.65 |
| Models | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| DT | 96.52 | 95.78 | 97.25 | 97.21 |
| RF | 98.37 | 97.19 | 99.55 | 99.54 |
| BRT | 98.12 | 97.51 | 98.72 | 98.71 |
| Authors | Method | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|---|
| [31] | Multilayer Perceptron (MLP) | 98.1 | - | - | 98 |
| Support vector machines (SVM) | 92.5 | - | - | 92 | |
| Naïve Bayes | 91.25 | - | - | 90 | |
| [29] | Logistic Regression (LR) | 98 | 97 | 98 | 97 |
| Naïve Bayes | 97 | 98 | 97 | 93 | |
| K-nearest Neighbour (KNN) | 97 | 97 | 98 | 97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaziayani, W.N.; Ul-Saufie, A.Z.; Mutalib, S.; Mohamad Noor, N.; Zainordin, N.S. Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach. Atmosphere 2022, 13, 538. https://doi.org/10.3390/atmos13040538
Shaziayani WN, Ul-Saufie AZ, Mutalib S, Mohamad Noor N, Zainordin NS. Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach. Atmosphere. 2022; 13(4):538. https://doi.org/10.3390/atmos13040538
Chicago/Turabian StyleShaziayani, Wan Nur, Ahmad Zia Ul-Saufie, Sofianita Mutalib, Norazian Mohamad Noor, and Nazatul Syadia Zainordin. 2022. "Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach" Atmosphere 13, no. 4: 538. https://doi.org/10.3390/atmos13040538
APA StyleShaziayani, W. N., Ul-Saufie, A. Z., Mutalib, S., Mohamad Noor, N., & Zainordin, N. S. (2022). Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach. Atmosphere, 13(4), 538. https://doi.org/10.3390/atmos13040538