



Short-Term Rainfall Prediction Based on Radar Echo Using an Improved Self-Attention PredRNN Deep Learning Model



Abstract
1. Introduction
2. Data and Data Processing
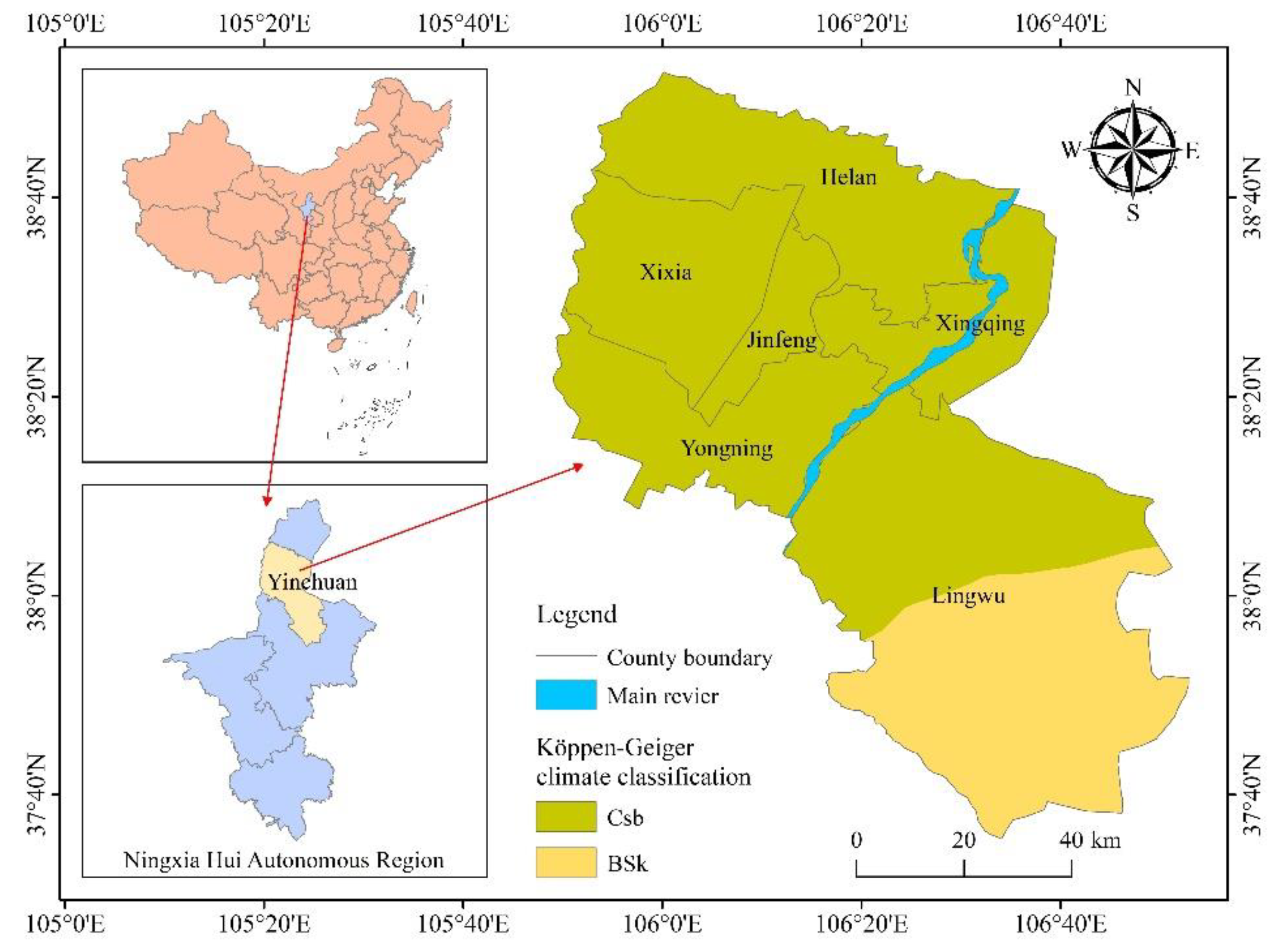
2.1. Study Area
2.2. Data Cleaning
2.3. Preparation of Dataset
3. Methodology
3.1. Problem Definition
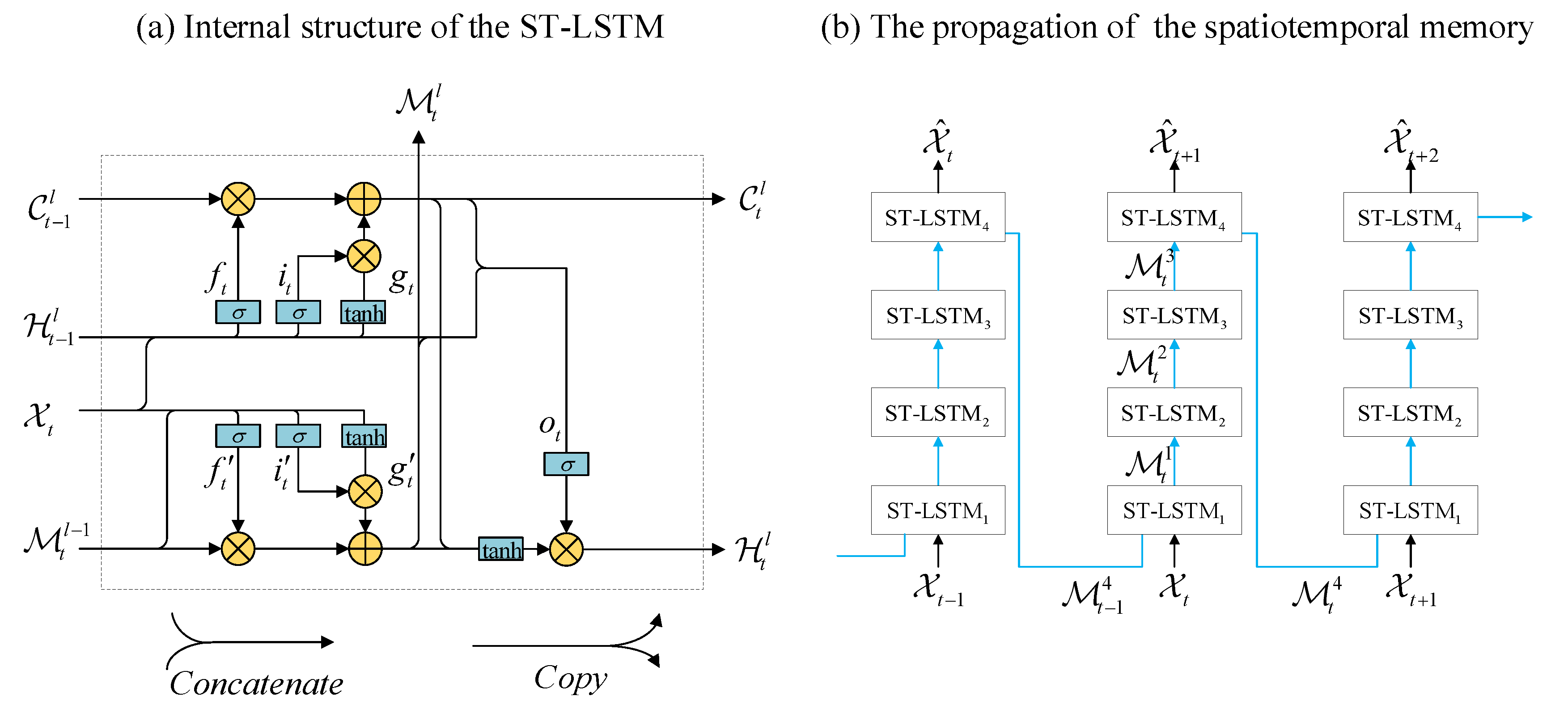
3.2. Base Model
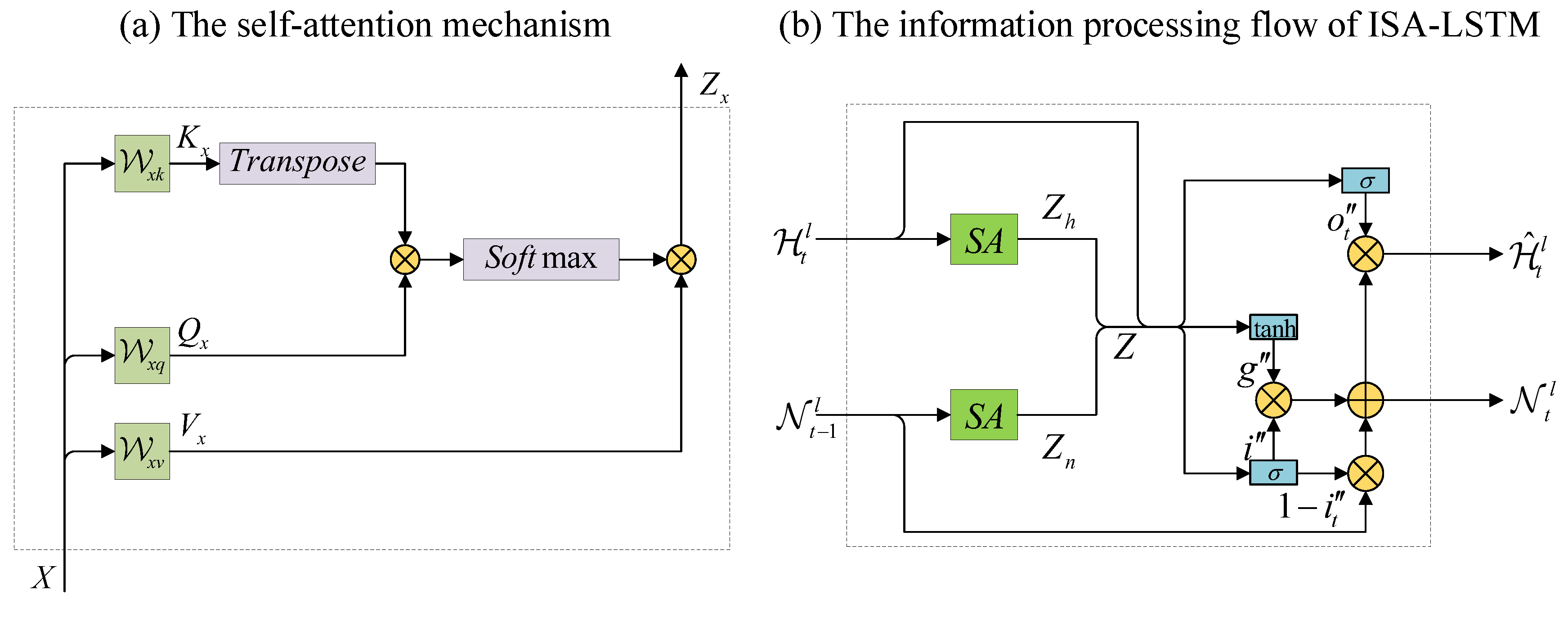
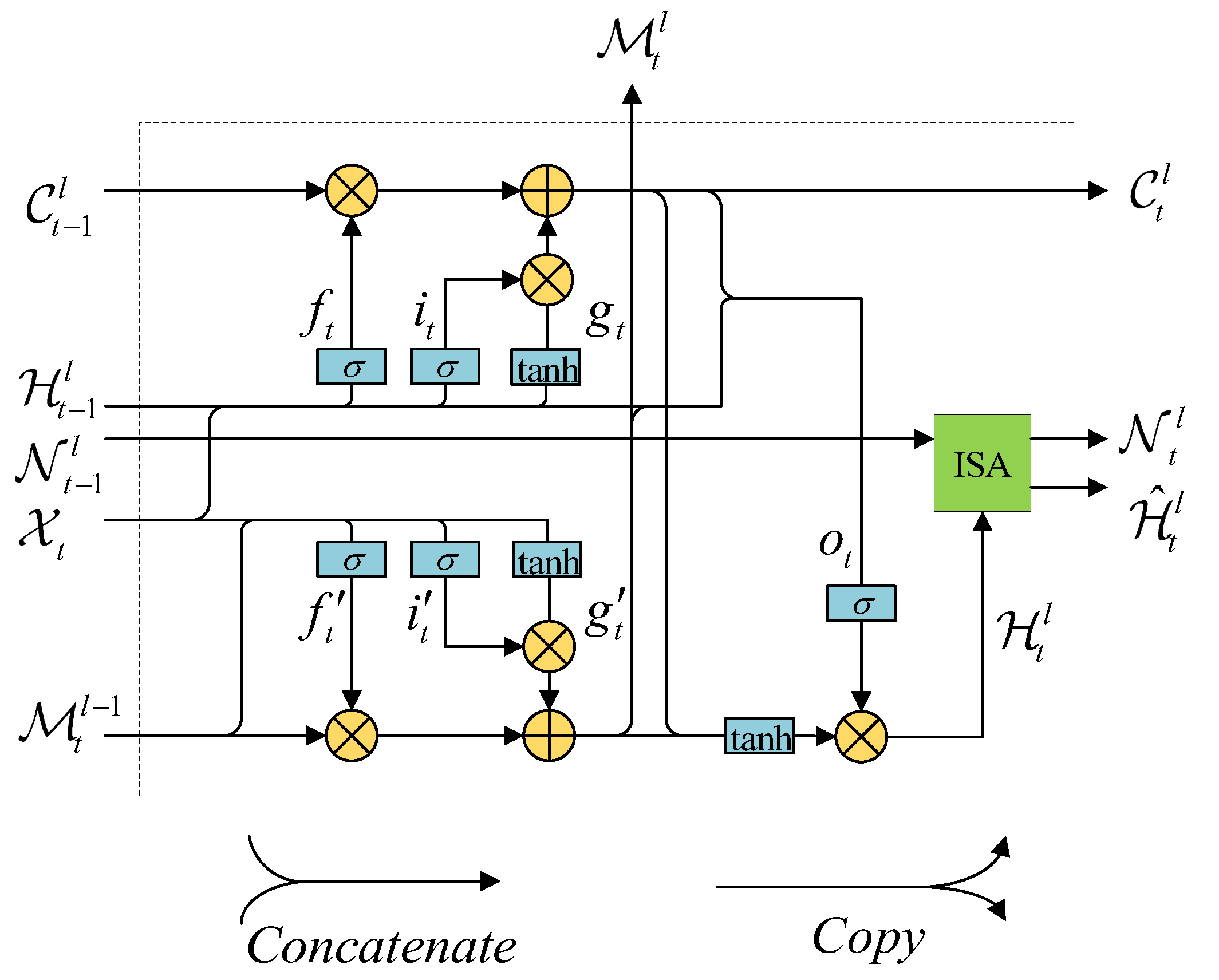
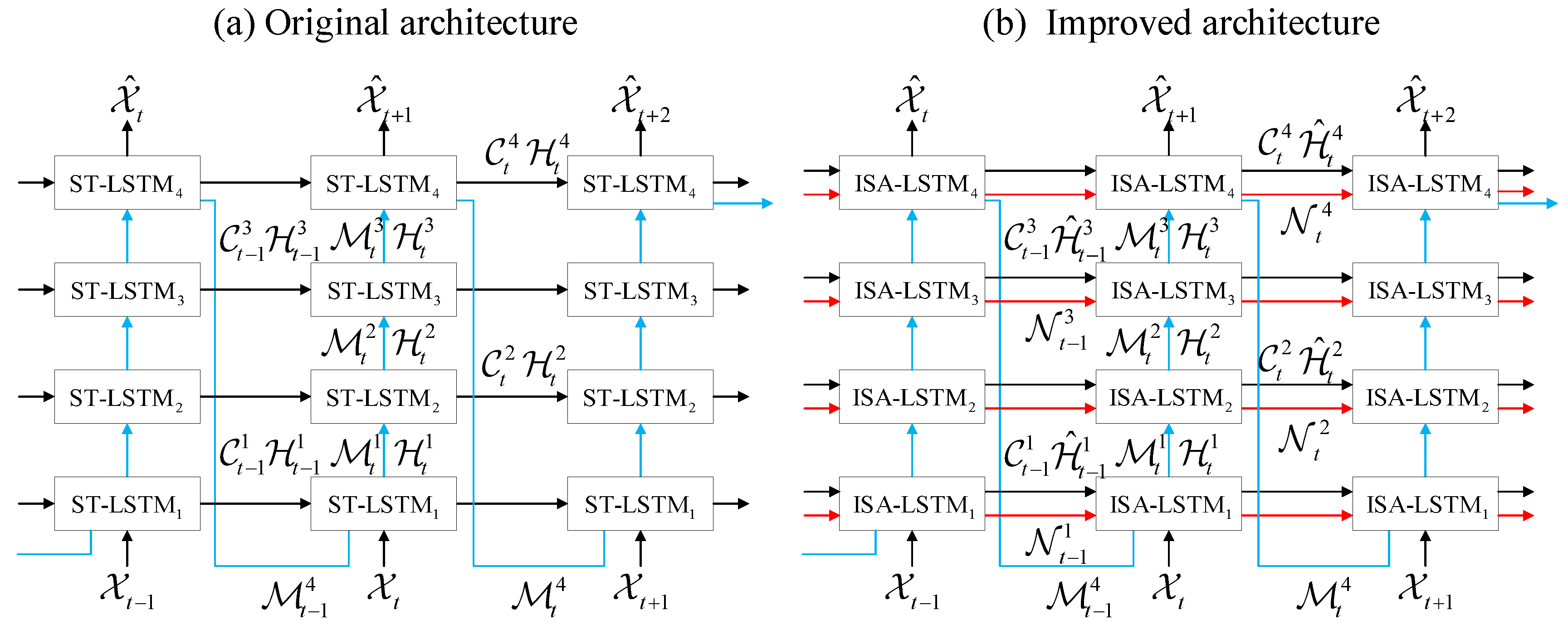
3.3. Improved Self-Attention PredRNN
3.4. Sampling Strategy
3.5. Improved Loss Function
4. Results
4.1. Implementation Details
4.2. Evaluated Algorithm
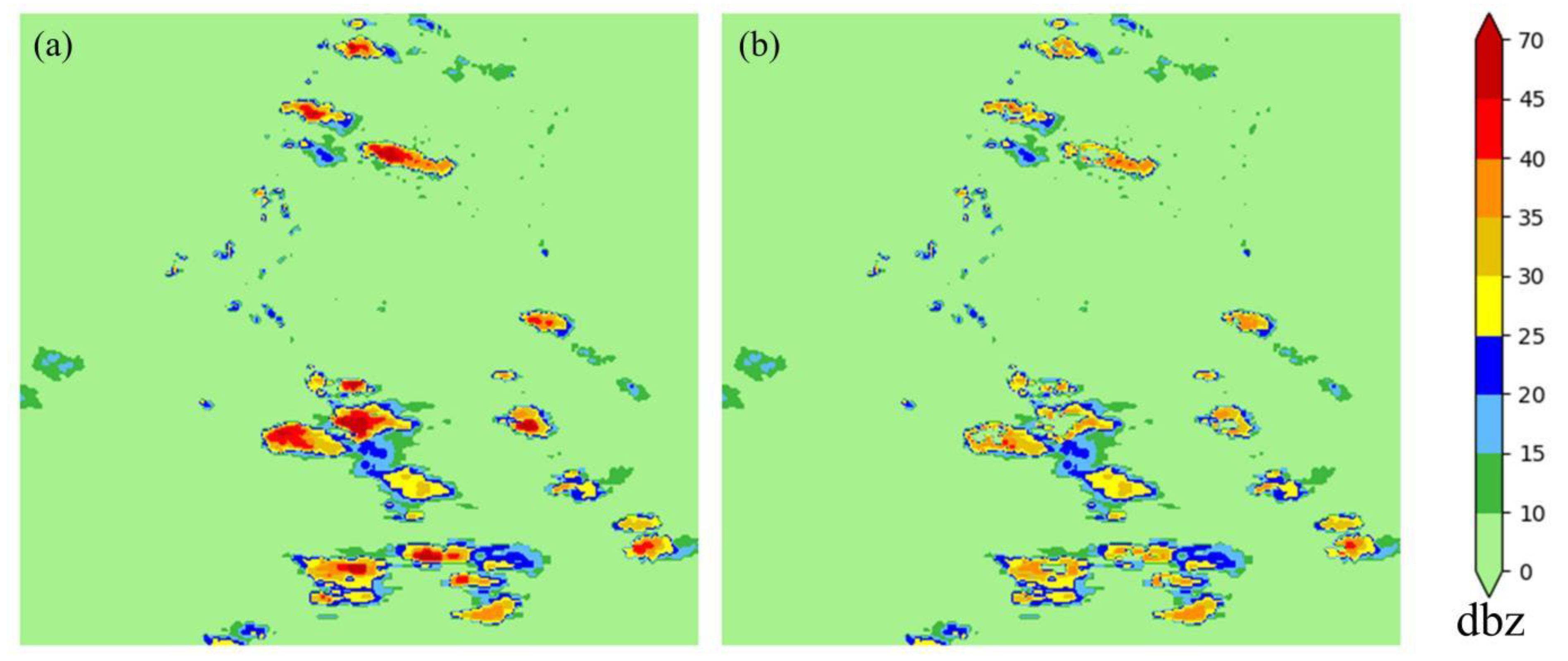
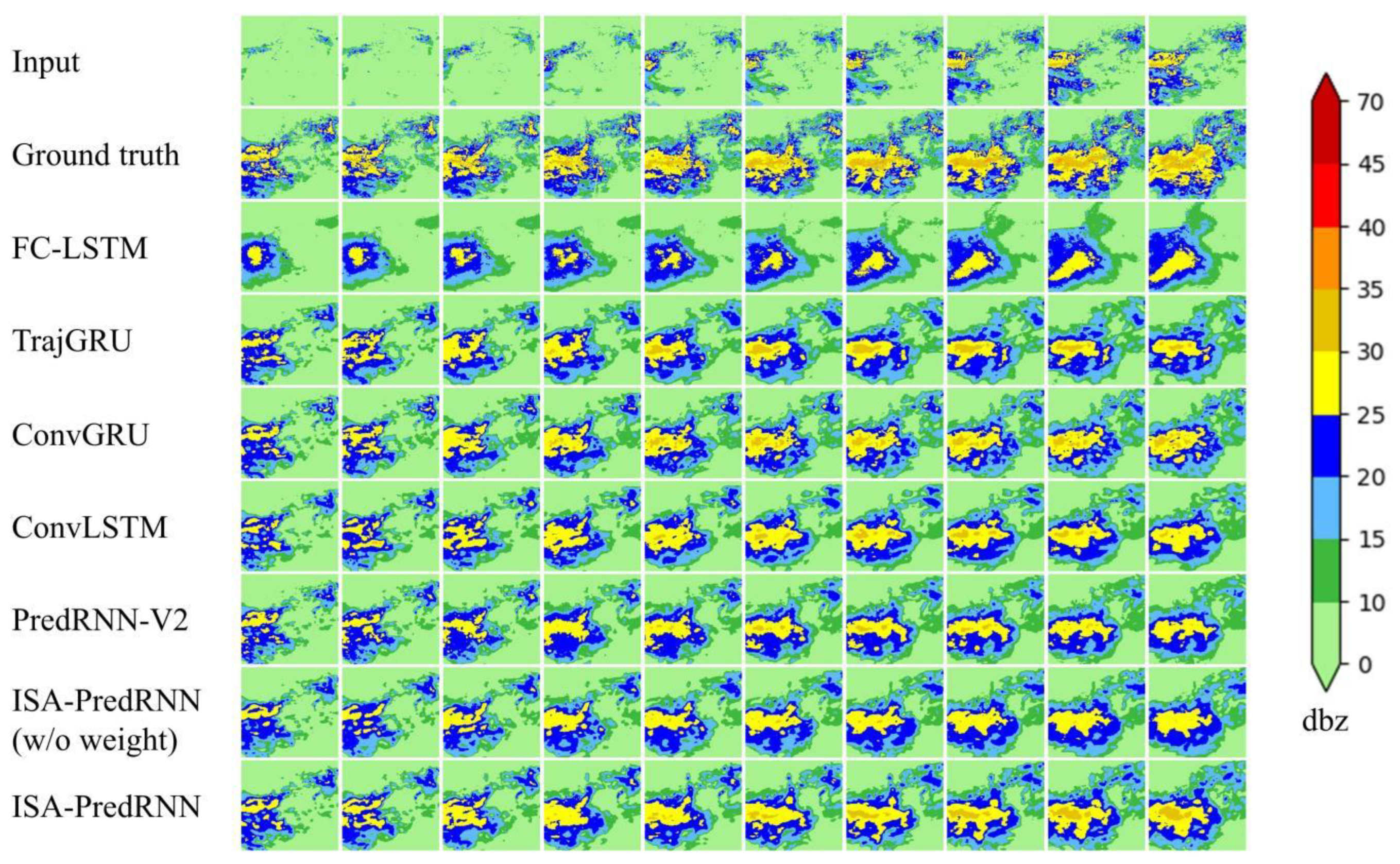
4.3. Analysis and Evaluation of Experimental Results
5. Conclusions and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dixon, M.; Wiener, G. TITAN: Thunderstorm identification, tracking, analysis, and nowcasting—A radar-based methodology. J. Atmos. Ocean. Technol. 1993, 10, 785–797. [Google Scholar] [CrossRef]
- Liang, Q.; Feng, Y.; Deng, W.; Hu, S.; Huang, Y.; Zeng, Q.; Chen, Z. A composite approach of radar echo extrapolation based on TREC vectors in combination with model-predicted winds. Adv. Atmos. Sci. 2010, 27, 1119–1130. [Google Scholar] [CrossRef]
- Zhu, J.; Dai, J. A rain-type adaptive optical flow method and its application in tropical cyclone rainfall nowcasting. Front. Earth Sci. 2021, 16, 248–264. [Google Scholar] [CrossRef]
- Yang, X.; Kuang, Q.; Zhang, W.; Zhang, G. A terrain-based weighted random forests method for radar quantitative precipitation estimation. Meteorol. Appl. 2017, 24, 404–414. [Google Scholar] [CrossRef]
- Bhuiyan, M.A.E.; Anagnostou, E.N.; Kirstetter, P.-E. A nonparametric statistical technique for modeling overland TMI (2A12) rainfall retrieval error. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1898–1902. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; Zheng, D.; Zhang, K.; Ma, Q.; Zhao, Y.; Ge, Y. Merging multiple satellite-based precipitation products and gauge observations using a novel double machine learning approach. J. Hydrol. 2021, 594, 125969. [Google Scholar] [CrossRef]
- Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; Fai, C.M.; Afan, H.A.; Ridwam, W.M.; Sefelnasr, A.; El-Shafie, A. Precipitation forecasting using multilayer neural network and support vector machine optimization based on flow regime algorithm taking into account uncertainties of soft computing models. Sustainability 2019, 11, 6681. [Google Scholar] [CrossRef]
- Chiang, Y.-M.; Hao, R.; Quan, S.; Xu, Y.; Gu, Z. Precipitation assimilation from gauge and satellite products by a Bayesian method with Gamma distribution. Int. J. Remote Sens. 2021, 42, 1017–1034. [Google Scholar] [CrossRef]
- Kolluru, V.; Kolluru, S.; Wagle, N.; Acharya, T.D. Secondary precipitation estimate merging using machine learning: Development and evaluation over Krishna river basin, India. Remote Sens. 2020, 12, 3013. [Google Scholar] [CrossRef]
- Chandriah, K.K.; Naraganahalli, R.V. RNN/LSTM with modified Adam optimizer in deep learning approach for automobile spare parts demand forecasting. Multimed. Tools Appl. 2021, 80, 26145–26159. [Google Scholar] [CrossRef]
- Nazarova, A.L.; Yang, L.; Liu, K.; Mishra, A.; Kalia, R.K.; Nomura, K.-i.; Nakano, A.; Vashishta, P.; Rajak, P. Dielectric polymer property prediction using recurrent neural networks with optimizations. J. Chem. Inf. Model. 2021, 61, 2175–2186. [Google Scholar] [CrossRef]
- Jaihuni, M.; Basak, J.K.; Khan, F.; Okyere, F.G.; Sihalath, T.; Bhujel, A.; Park, J.; Lee, D.H.; Kim, H.T. A novel recurrent neural network approach in forecasting short term solar irradiance. ISA Trans. 2022, 121, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Park, M.K.; Lee, J.M.; Kang, W.H.; Choi, J.M.; Lee, K.H. Predictive model for PV power generation using RNN (LSTM). J. Mech. Sci. Technol. 2021, 35, 795–803. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv Prepr. 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Alhudhaif, A.; Polat, K.; Karaman, O. Determination of COVID-19 pneumonia based on generalized convolutional neural network model from chest X-ray images. Expert Syst. Appl. 2021, 180, 115141. [Google Scholar] [CrossRef]
- Xie, J.; Chen, S.; Zhang, Y.; Gao, D.; Liu, T. Combining generative adversarial networks and multi-output CNN for motor imagery classification. J. Neural Eng. 2021, 18, 46026. [Google Scholar] [CrossRef] [PubMed]
- Marques, S.; Schiavo, F.; Ferreira, C.A.; Pedrosa, J.; Cunha, A.; Campilho, A. A multi-task CNN approach for lung nodule malignancy classification and characterization. Expert Syst. Appl. 2021, 184, 115469. [Google Scholar] [CrossRef]
- Kolisnik, B.; Hogan, I.; Zulkernine, F. Condition-CNN: A hierarchical multi-label fashion image classification model. Expert Syst. Appl. 2021, 182, 115195. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Wang, W.; Mao, W.; Tong, X.; Xu, G. A Novel Recursive Model Based on a Convolutional Long Short-Term Memory Neural Network for Air Pollution Prediction. Remote Sens. 2021, 13, 1284. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, R.; Wang, Y.; Yan, H.; Hong, M. Daily prediction of the arctic sea ice concentration using reanalysis data based on a convolutional lstm network. J. Mar. Sci. Eng. 2021, 9, 330. [Google Scholar] [CrossRef]
- Kreuzer, D.; Munz, M.; Schlüter, S. Short-term temperature forecasts using a convolutional neural network—An application to different weather stations in Germany. Mach. Learn. Appl. 2020, 2, 100007. [Google Scholar] [CrossRef]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.-Y.; Wong, W.-k.; Woo, W.-c. Deep learning for precipitation nowcasting: A benchmark and a new model. Adv. Neural Inf. Process. Syst. 2017, 30, 5617–5627. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Adv. Neural Inf. Process. Syst. 2017, 30, 879–888. [Google Scholar]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Yu, P.S.; Long, M. PredRNN: A recurrent neural network for spatiotemporal predictive learning. arXiv Prepr. 2021, arXiv:2103.09504. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y. Satellite image prediction relying on gan and lstm neural networks. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Singh, S.; Sarkar, S.; Mitra, P. A deep learning based approach with adversarial regularization for Doppler weather radar ECHO prediction. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5205–5208. [Google Scholar]
- Khan, Z.N.; Ahmad, J. Attention induced multi-head convolutional neural network for human activity recognition. Appl. Soft Comput. 2021, 110, 107671. [Google Scholar] [CrossRef]
- Wang, L.; He, Z.; Meng, B.; Liu, K.; Dou, Q.; Yang, X. Two-pathway attention network for real-time facial expression recognition. J. Real-Time Image Process. 2021, 18, 1173–1182. [Google Scholar] [CrossRef]
- Li, C.; Zhang, J.; Yao, J. Streamer action recognition in live video with spatial-temporal attention and deep dictionary learning. Neurocomputing 2021, 453, 383–392. [Google Scholar] [CrossRef]
- Kim, J.; Li, G.; Yun, I.; Jung, C.; Kim, J. Weakly-supervised temporal attention 3D network for human action recognition. Pattern Recognit. 2021, 119, 108068. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Wang, S. Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 2021, 30, 6544–6556. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.; Li, Y.; Yao, W.; Hou, L.; Sun, Q.; Chen, J. A strip steel surface defect detection method based on attention mechanism and multi-scale maxpooling. Meas. Sci. Technol. 2021, 32, 115401. [Google Scholar] [CrossRef]
- Cui, X.; Wang, Q.; Dai, J.; Xue, Y.; Duan, Y. Intelligent crack detection based on attention mechanism in convolution neural network. Adv. Struct. Eng. 2021, 24, 1859–1868. [Google Scholar] [CrossRef]
- Zhao, H.; Yang, D.; Yu, J. 3D target detection using dual domain attention and SIFT operator in indoor scenes. Vis. Comput. 2021, 38, 3765–3774. [Google Scholar] [CrossRef]
- Cao, Z.; Yang, H.; Zhao, J.; Guo, S.; Li, L. Attention fusion for one-stage multispectral pedestrian detection. Sensors 2021, 21, 4184. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Wang, L.; Wong, D.F.; Shi, S.; Tu, Z. Context-aware self-attention networks for natural language processing. Neurocomputing 2021, 458, 157–169. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Zhang, X. Learning sentiment sentence representation with multiview attention model. Inf. Sci. 2021, 571, 459–474. [Google Scholar] [CrossRef]
- Lin, T.; Li, Q.; Geng, Y.-A.; Jiang, L.; Xu, L.; Zheng, D.; Yao, W.; Lyu, W.; Zhang, Y. Attention-based dual-source spatiotemporal neural network for lightning forecast. IEEE Access 2019, 7, 158296–158307. [Google Scholar] [CrossRef]
- Yan, Q.; Ji, F.; Miao, K.; Wu, Q.; Xia, Y.; Li, T. Convolutional residual-attention: A deep learning approach for precipitation nowcasting. Adv. Meteorol. 2020, 2020, 4812. [Google Scholar] [CrossRef]
- Sønderby, C.K.; Espeholt, L.; Heek, J.; Dehghani, M.; Oliver, A.; Salimans, T.; Agrawal, S.; Hickey, J.; Kalchbrenner, N. Metnet: A neural weather model for precipitation forecasting. arXiv Prepr. 2020, arXiv:2003.12140. [Google Scholar]
- Emerton, R.E.; Stephens, E.M.; Pappenberger, F.; Pagano, T.C.; Weerts, A.H.; Wood, A.W.; Salamon, P.; Brown, J.D.; Hjerdt, N.; Donnelly, C. Continental and global scale flood forecasting systems. Wiley Interdiscip. Rev. Water 2016, 3, 391–418. [Google Scholar] [CrossRef]
- Voyant, C.; Haurant, P.; Muselli, M.; Paoli, C.; Nivet, M.-L. Time series modeling and large scale global solar radiation forecasting from geostationary satellites data. Sol. Energy 2014, 102, 131–142. [Google Scholar] [CrossRef]
- Schuurmans, J.; Bierkens, M.; Pebesma, E.; Uijlenhoet, R. Automatic prediction of high-resolution daily rainfall fields for multiple extents: The potential of operational radar. J. Hydrometeorol. 2007, 8, 1204–1224. [Google Scholar] [CrossRef]
- Hänsel, P.; Langel, S.; Schindewolf, M.; Kaiser, A.; Buchholz, A.; Böttcher, F.; Schmidt, J. Prediction of muddy floods using high-resolution radar precipitation forecasts and physically-based erosion modeling in agricultural landscapes. Geosciences 2019, 9, 401. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CSI↑ | HSS↑ | POD↑ | FAR↓ |
|---|---|---|---|---|
| FC-LSTM | 0.4771 | 0.6060 | 0.5654 | 0.2476 |
| TrajGRU | 0.6367 | 0.7489 | 0.7382 | 0.1805 |
| ConvGRU | 0.6626 | 0.7707 | 0.7598 | 0.1637 |
| ConvLSTM | 0.6625 | 0.7710 | 0.7057 | 0.1524 |
| PredRNN-V2 | 0.6879 | 0.7910 | 0.7734 | 0.1404 |
| ISA-PredRNN(w/o weight) | 0.6928 | 0.7951 | 0.7790 | 0.1391 |
| ISA-PredRNN | 0.7001 | 0.8006 | 0.7921 | 0.1435 |
| Model | CSI↑ | HSS↑ | POD↑ | FAR↓ |
|---|---|---|---|---|
| FC-LSTM | 0.2711 | 0.4075 | 0.3013 | 0.2716 |
| TrajGRU | 0.4972 | 0.6459 | 0.5685 | 0.2057 |
| ConvGRU | 0.5243 | 0.6711 | 0.5920 | 0.1807 |
| ConvLSTM | 0.5280 | 0.6748 | 0.5913 | 0.1705 |
| PredRNN-V2 | 0.5475 | 0.6916 | 0.6089 | 0.1588 |
| ISA-PredRNN(w/o weight) | 0.5659 | 0.7079 | 0.6303 | 0.1546 |
| ISA-PredRNN | 0.5812 | 0.7208 | 0.6542 | 0.1630 |
| Model | CSI↑ | HSS↑ | POD↑ | FAR↓ |
|---|---|---|---|---|
| FC-LSTM | 0.0488 | 0.0913 | 0.0506 | 0.4117 |
| TrajGRU | 0.2018 | 0.3273 | 0.2195 | 0.2922 |
| ConvGRU | 0.2343 | 0.3707 | 0.2578 | 0.2758 |
| ConvLSTM | 0.2290 | 0.3647 | 0.2467 | 0.2379 |
| PredRNN-V2 | 0.2226 | 0.3531 | 0.2368 | 0.2075 |
| ISA-PredRNN(w/o weight) | 0.2738 | 0.4217 | 0.2950 | 0.2055 |
| ISA-PredRNN | 0.3052 | 0.4606 | 0.3347 | 0.2252 |
| Model | Number of Layer | Number of Kernel | Kernel Size | MSE |
|---|---|---|---|---|
| FC-LSTM | 4 | 128-128-128-128 | 5 × 5 | 178.64 |
| TrajGRU | 4 | 128-128-128-128 | 5 × 5 | 106.22 |
| ConvGRU | 4 | 128-128-128-128 | 5 × 5 | 93.74 |
| ConvLSTM | 4 | 128-128-128-128 | 5 × 5 | 91.95 |
| PredRNN-V2 | 4 | 128-128-128-128 | 5 × 5 | 83.53 |
| ISA-PredRNN(w/o weight) | 4 | 128-128-128-128 | 5 × 5 | 79.93 |
| ISA-PredRNN | 4 | 128-128-128-128 | 5 × 5 | 78.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Wu, L.; Zhang, T.; Zhang, W.; Huang, J.; Wang, X. Short-Term Rainfall Prediction Based on Radar Echo Using an Improved Self-Attention PredRNN Deep Learning Model. Atmosphere 2022, 13, 1963. https://doi.org/10.3390/atmos13121963
Wu D, Wu L, Zhang T, Zhang W, Huang J, Wang X. Short-Term Rainfall Prediction Based on Radar Echo Using an Improved Self-Attention PredRNN Deep Learning Model. Atmosphere. 2022; 13(12):1963. https://doi.org/10.3390/atmos13121963
Chicago/Turabian StyleWu, Dali, Li Wu, Tao Zhang, Wenxuan Zhang, Jianqiang Huang, and Xiaoying Wang. 2022. "Short-Term Rainfall Prediction Based on Radar Echo Using an Improved Self-Attention PredRNN Deep Learning Model" Atmosphere 13, no. 12: 1963. https://doi.org/10.3390/atmos13121963
APA StyleWu, D., Wu, L., Zhang, T., Zhang, W., Huang, J., & Wang, X. (2022). Short-Term Rainfall Prediction Based on Radar Echo Using an Improved Self-Attention PredRNN Deep Learning Model. Atmosphere, 13(12), 1963. https://doi.org/10.3390/atmos13121963