
Atmospheric PM2.5 Prediction Using DeepAR Optimized by Sparrow Search Algorithm with Opposition-Based and Fitness-Based Learning



Abstract
:1. Introduction
2. Methods
2.1. Sparrow Search Algorithm
2.2. Sparrow Search Algorithm with Fitness-Based and Opposition-Based Learning
2.2.1. Opposition-Based Learning
- Step 1.
- Generate N individuals by random initialization, and calculate the center of gravity of N individuals. The calculation method of the center of gravity is expressed as Equation (7):
- Step 2.
- alculate the opposite position of each individual. The calculation method is shown as Equation (8);
- Step 3.
- Make sure the position of the anti-center of gravity individual within the search scope. The method is shown as Equation (9):
- Step 4.
- Calculate the fitness value of 2N individuals, and select N individuals with the best fitness as the initial individuals of the population.
2.2.2. Lévy Flight
2.2.3. Fitness-Based Learning
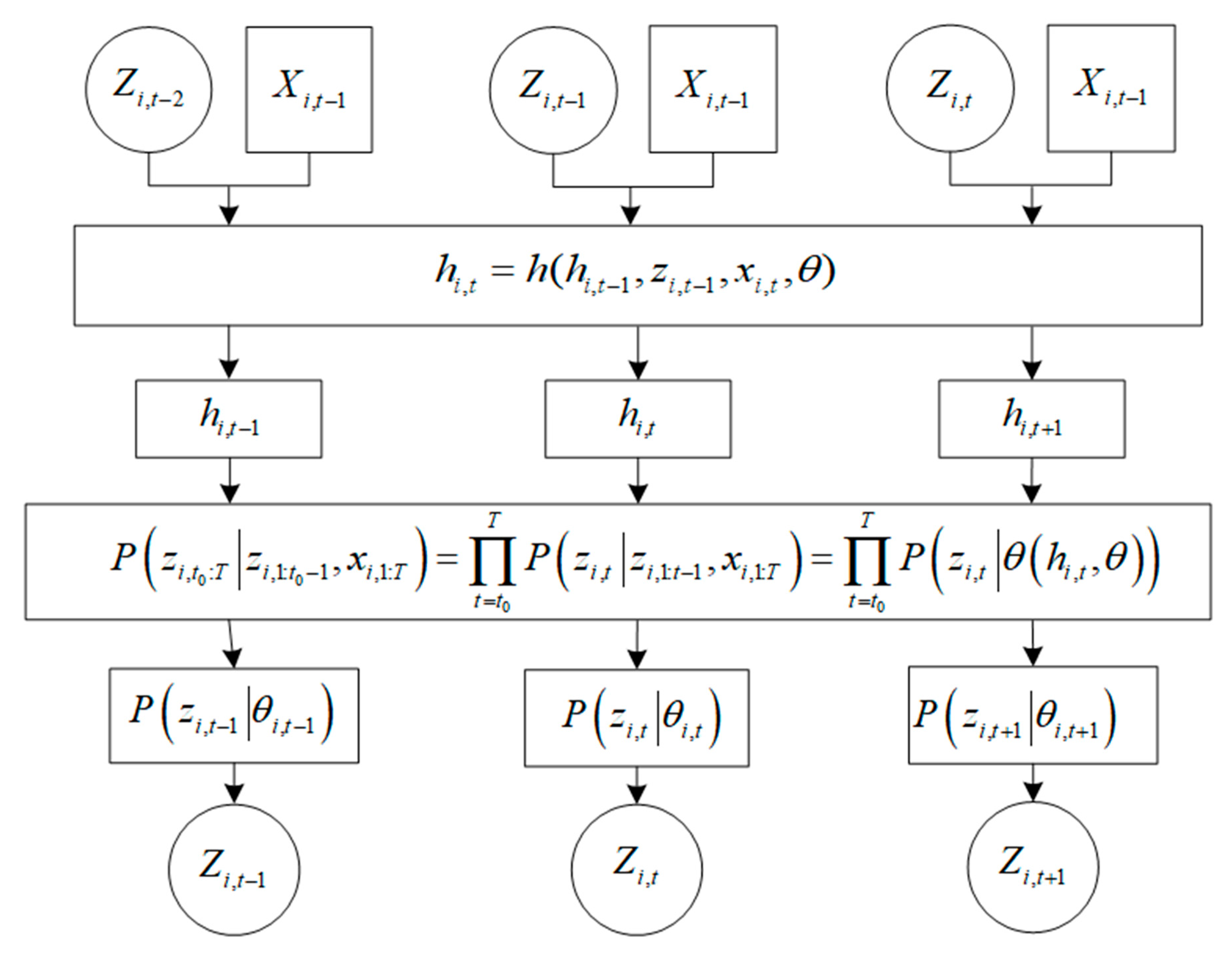
2.3. DeepAR
2.4. Framework of FOSSA–DeepAR
- Step 1.
- Data preprocessing. In order to avoid the gradient vanishing and gradient exploding problem, the data is standardized before training model;
- Step 2.
- Establish DeepAR model. In this study, the recurrent neural network used in DeepAR is the long short-term memory (LSTM) model. In addition, we assume that PM2.5 concentration follows a Gaussian distribution;
- Step 3.
- Optimize the initial weights of DeepAR via FOSSA. It is inefficient and unnecessary to use all samples for weight initialization due to the similarity between some samples. Therefore, the first thousand samples are used to train the initial weight of the DeepAR network. The objective function which FOSSA needs to optimize is the sum of squared errors of the samples;
- Step 4.
- Train FOSSA–DeepAR model. The samples got from the conditioning range are utilized to train FOSSA–DeepAR model. The number of iterations is set to 30;
- Step 5.
- Forecast PM2.5 concentration. The samples resulting from the prediction range will be predicted via the FOSSA–DeepAR model, then we can obtain the point and interval prediction result. In addition, the prediction results will be compared with true values.
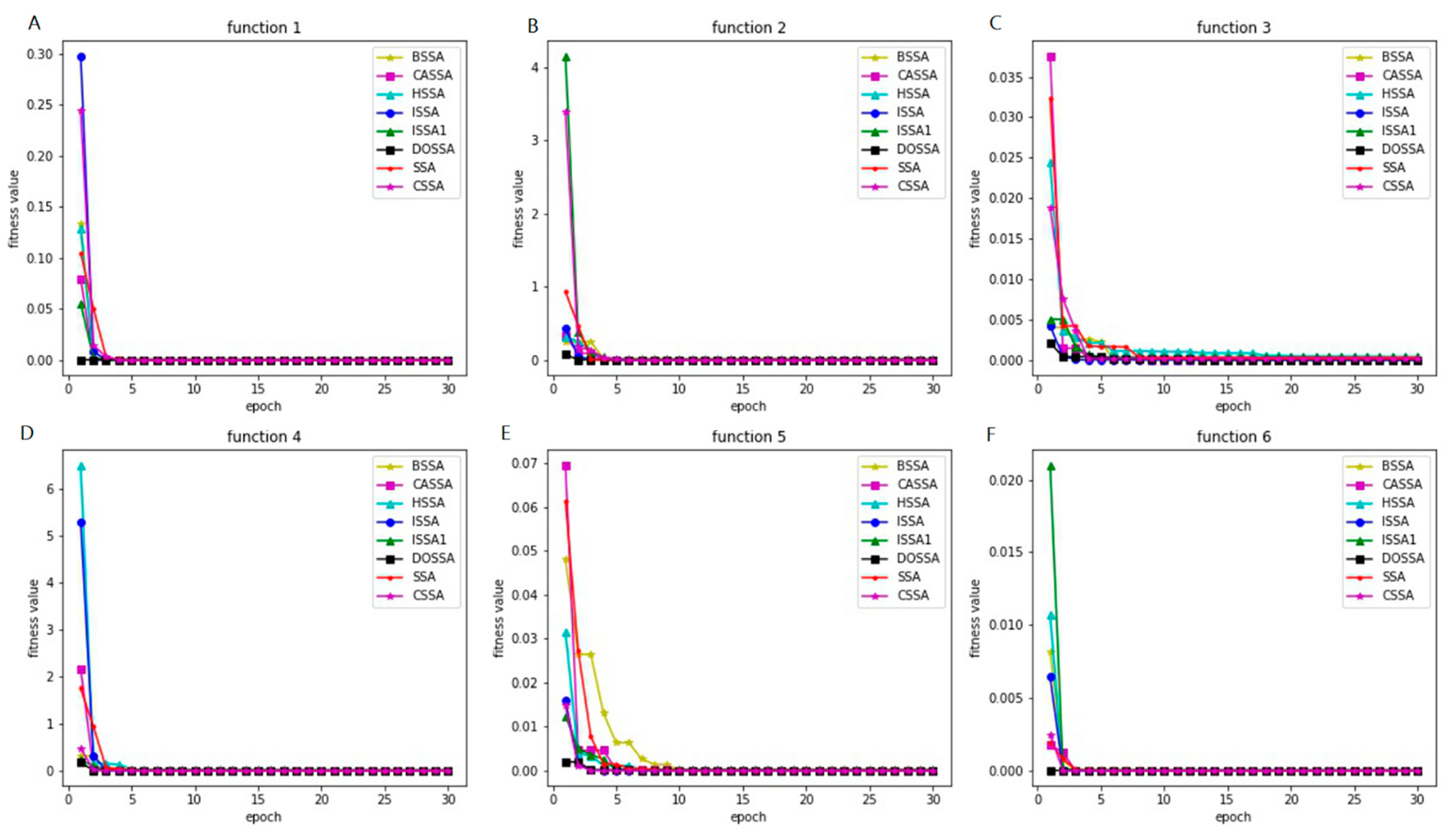
2.5. Comparison of SSA-Based Algorithms
3. Empirical Results and Analysis
3.1. Data Set and Evaluation Criteria
3.2. Results and Analysis
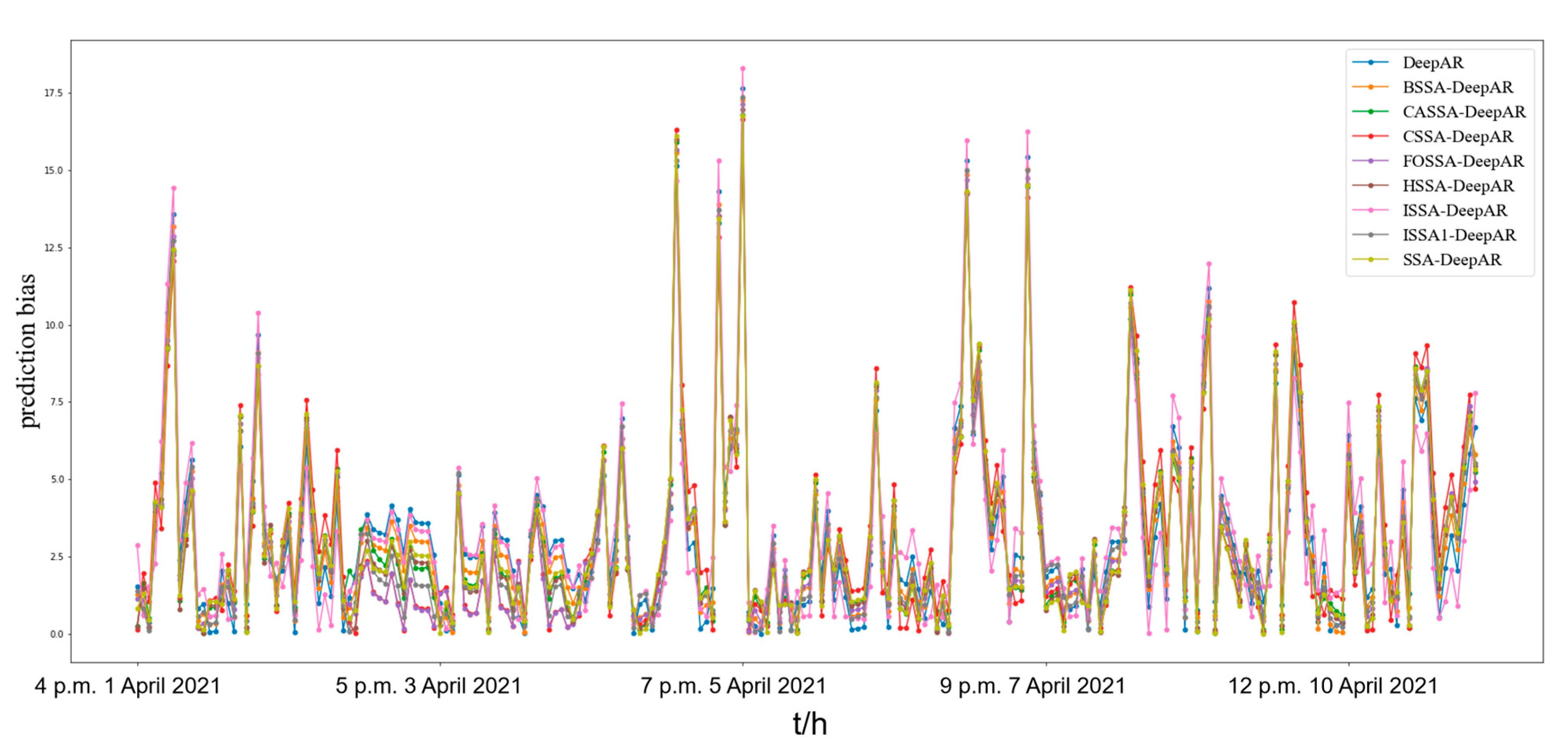
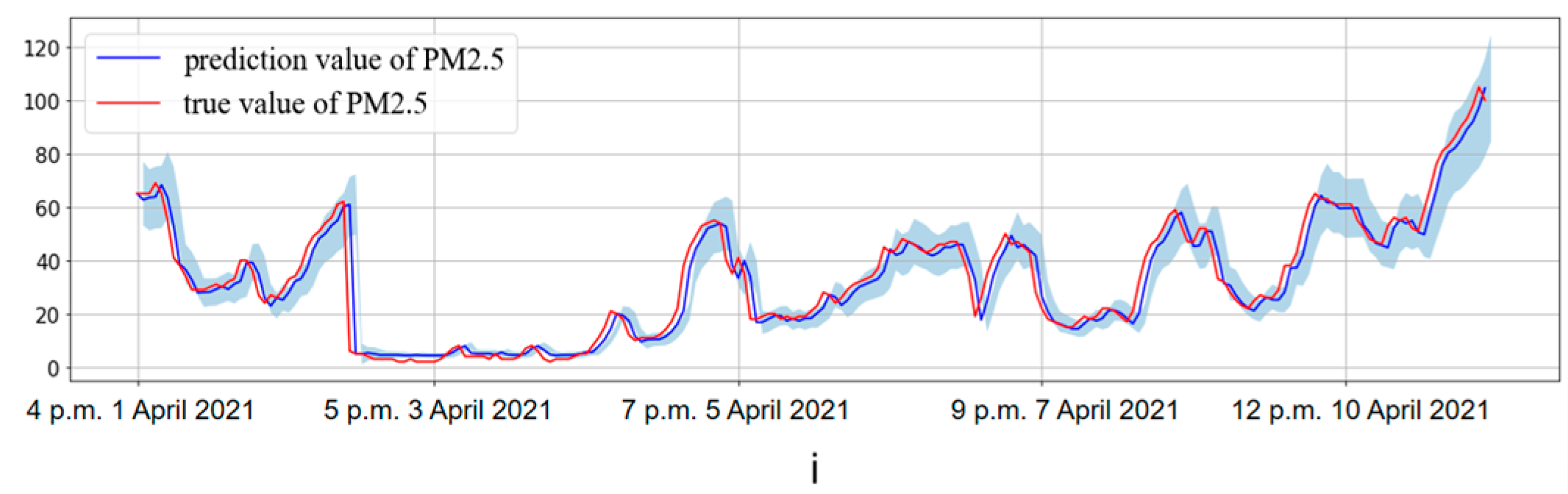
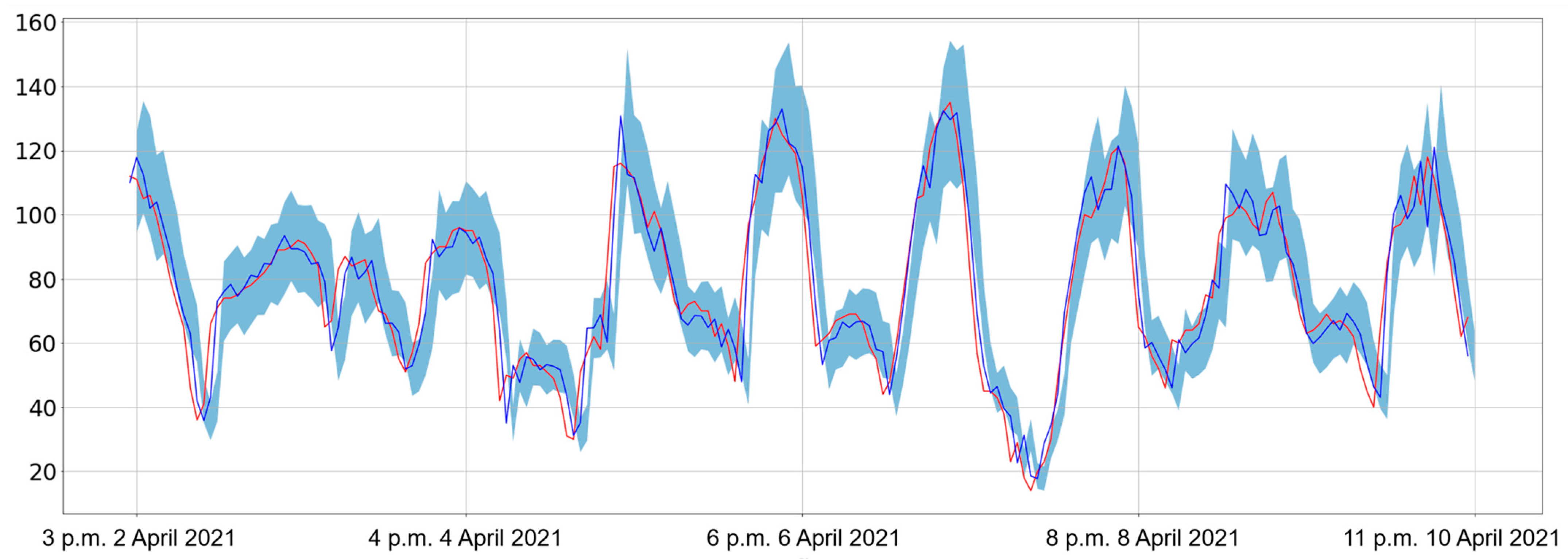
3.2.1. Prediction of PM2.5 Concentration in Beijing
3.2.2. Robustness Analysis of FOSSA–DeepAR
4. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Lin, J.; Qiu, R.; Hu, X.; Zhang, H.; Chen, Q.; Tan, H.; Lin, D.; Wang, J. Trend analysis and forecast of PM2.5 in Fuzhou, China using the ARIMA model. Ecol. Indic. 2018, 95, 702–710. [Google Scholar] [CrossRef]
- Cavieres, M.F.; Leiva, V.; Marchant, C.; Rojas, F. A Methodology for Data-Driven Decision-Making in the Monitoring of Particulate Matter Environmental Contamination in Santiago of Chile. Rev. Environ. Contam. Toxicol. 2020, 250, 45–67. [Google Scholar] [CrossRef]
- Puentes, R.; Marchant, C.; Leiva, V.; Figueroa-Zúñiga, J.; Ruggeri, F. Predicting PM2.5 and PM10 Levels during Critical Episodes Management in Santiago, Chile, with a Bivariate Birnbaum-Saunders Log-Linear Model. Mathematics 2021, 9, 645. [Google Scholar] [CrossRef]
- Jiang, F.; He, J.; Zeng, Z. Pigeon-inspired optimization and extreme learning machine via wavelet packet analysis for predicting bulk commodity futures prices. Sci. China Inf. Sci. 2019, 62, 70204. [Google Scholar] [CrossRef] [Green Version]
- Wong, P.-Y.; Lee, H.-Y.; Chen, Y.-C.; Zeng, Y.-T.; Chern, Y.-R.; Chen, N.-T.; Lung, S.-C.C.; Su, H.-J.; Wu, C.-D. Using a land use regression model with machine learning to estimate ground level PM2.5. Environ. Pollut. 2021, 277, 116846. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Sha, Y.H.; Li, Z.; Huang, Y.; Chen, W.; Chen, D.; Shen, J.; Chen, Y.; Fung, J.C. Development and application of a hybrid long-short term memory—Three dimensional variational technique for the improvement of PM2.5 forecasting. Sci. Total Environ. 2021, 770, 144221. [Google Scholar] [CrossRef]
- Jiang, F.; Qiao, Y.; Jiang, X.; Tian, T. MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm. Atmosphere 2021, 12, 64. [Google Scholar] [CrossRef]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef]
- Jiang, F.; He, J.; Tian, T. A clustering-based ensemble approach with improved pigeon-inspired optimization and extreme learning machine for air quality prediction. Appl. Soft Comput. 2019, 85, 105827. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Clerc, M. Particle Swarm Optimization; Ashgate: Farnham, UK, 2006. [Google Scholar]
- Song, X.; Tang, L.; Zhao, S.; Zhang, X.; Li, L.; Huang, J.; Cai, W. Grey Wolf Optimizer for parameter estimation in surface waves. Soil Dyn. Earthq. Eng. 2015, 75, 147–157. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Yuan, J.; Zhao, Z.; Liu, Y.; He, B.; Wang, L.; Xie, B.; Gao, Y. DMPPT Control of Photovoltaic Microgrid Based on Improved Sparrow Search Algorithm. IEEE Access 2021, 9, 16623–16629. [Google Scholar] [CrossRef]
- Liu, G.; Shu, C.; Liang, Z.; Peng, B.; Cheng, L. A Modified Sparrow Search Algorithm with Application in 3d Route Planning for UAV. Sensors 2021, 21, 1224. [Google Scholar] [CrossRef]
- Li, A. Hybrid Sparrow Search Algorithm. Comput. Knowl. Technol. 2021, 17, 232–234. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl.-Based Syst. 2021, 220, 106924. [Google Scholar] [CrossRef]
- Liu, T.; Yuan, Z.; Wu, L.; Badami, B. Optimal brain tumor diagnosis based on deep learning and balanced sparrow search algorithm. Int. J. Imaging Syst. Technol. 2021. [Google Scholar] [CrossRef]
- Lv, X.; Mu, X.; Zhang, J. Multi-threshold image segmentation based on improved sparrow search algorithm. Syst. Eng. Electr. 2021, 43, 318–327. [Google Scholar] [CrossRef]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Dong, M.; Wu, H.; Hu, H.; Azzam, R.; Zhang, L.; Zheng, Z.; Gong, X. Deformation Prediction of Unstable Slopes Based on Real-Time Monitoring and DeepAR Model. Sensors 2020, 21, 14. [Google Scholar] [CrossRef]
- Chen, X.; Tianfield, H.; Du, W. Bee-foraging learning particle swarm optimization. Appl. Soft Comput. 2021, 102, 107134. [Google Scholar] [CrossRef]
- Ahmadianfar, I.; Heidari, A.A.; Gandomi, A.H.; Chu, X.; Chen, H. RUN beyond the metaphor: An efficient optimization algorithm based on Runge Kutta method. Expert Syst. Appl. 2021, 181, 115079. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Zhang, L.; Niu, X. A combined forecasting model for time series: Application to short-term wind speed forecasting. Appl. Energy 2020, 259, 114137. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Range | Optimal | Dimension |
|---|---|---|---|
| 0 | 30 | ||
| 0 | 30 | ||
| 0 | 30 | ||
| 0 | 30 | ||
| 0 | 30 | ||
| 0 | 30 |
| FOSSA | SSA [10] | ISSA [14] | ISSA1 * [19] | HSSA [16] | CASSA [15] | CSSA [17] | BSSA [18] | ||
|---|---|---|---|---|---|---|---|---|---|
| Min | 0.0000 | 1.2832 | 6.5350 | 1.8723 | 4.0926 | 9.3945 | 2.6205 | 2.7542 | |
| Max | 0.0000 | 2.0067 | 7.6709 | 4.0530 | 4.9072 | 7.4786 | 1.0377 | 4.0879 | |
| Mean | 0.0000 | 1.2283 | 1.6564 | 3.1881 | 5.9980 | 7.0295 | 1.0301 | 3.9100 | |
| Std | 0.0000 | 3.2764 | 1.0734 | 7.2891 | 1.1877 | 1.6261 | 2.0642 | 8.4509 | |
| Min | 0.0000 | 3.7571 | 9.1651 | 8.3980 | 1.5489 | 2.7173 | 2.4890 | 3.0233 | |
| Max | 0.0000 | 0.0032 | 1.5011 | 0.0042 | 0.0001 | 0.0009 | 0.0027 | 0.0044 | |
| Mean | 0.0000 | 0.0007 | 7.1462 | 0.0008 | 1.8077 | 7.5227 | 0.0002 | 0.0005 | |
| Std | 0.0000 | 0.0008 | 2.8116 | 0.0009 | 2.2011 | 0.0002 | 0.0005 | 0.0010 | |
| Min | 0.0000 | 6.0371 | 4.9501 | 5.9852 | 2.6545 | 3.6010 | 1.4181 | 4.7708 | |
| Max | 0.0000 | 0.0013 | 2.2001 | 0.0016 | 0.0007 | 0.0002 | 0.0002 | 0.0010 | |
| Mean | 0.0000 | 0.0002 | 7.1001 | 0.0003 | 0.0001 | 8.9555 | 4.3154 | 0.0001 | |
| Std | 0.0000 | 0.0003 | 3.2061 | 0.0003 | 0.0002 | 3.3462 | 5.4241 | 0.0002 |
| FOSSA | SSA [10] | ISSA [14] | ISSA1 [19] | HSSA [16] | CASSA [15] | CSSA [17] | BSSA [18] | ||
|---|---|---|---|---|---|---|---|---|---|
| Min | 0.0000 | 4.9378 | 0.0000 | 5.5509 | 7.6739 | 0.0000 | 0.0000 | 2.8599 | |
| Max | 0.0000 | 0.0010 | 0.0000 | 0.0046 | 1.2333 | 0.0007 | 0.0003 | 0.0010 | |
| Mean | 0.0000 | 2.7938 | 0.0000 | 0.0003 | 8.9170 | 4.6639 | 2.6021 | 4.2719 | |
| Std | 0.0000 | 0.0001 | 0.0000 | 0.0009 | 2.6570 | 0.0001 | 7.3961 | 0.0002 | |
| Min | 4.4409 | 1.2970 | 4.4409 | 5.0758 | 5.8863 | 9.9920 | 6.2466 | 8.6839 | |
| Max | 4.44089 | 0.0025 | 4.4409 | 0.0021 | 0.0002 | 0.0001 | 0.0007 | 0.0008 | |
| Mean | 4.4409 | 0.0002 | 4.4409 | 0.0003 | 2.0866 | 1.5892 | 9.2232 | 0.0002 | |
| Std | 0.0000 | 0.0004 | 0.0000 | 0.0004 | 3.4949 | 2.8091 | 0.0001 | 0.0002 | |
| Min | 0.0000 | 1.1925 | 0.0000 | 9.9737 | 2.2204 | 0.0000 | 0.0000 | 4.7729 | |
| Max | 0.0000 | 1.8262 | 0.0000 | 1.2323 | 2.3328 | 1.4312 | 3.6241 | 1.2347 | |
| Mean | 0.0000 | 1.2497 | 0.0000 | 1.1063 | 1.4002 | 3.6135 | 2.1757 | 9.1045 | |
| Std | 0.0000 | 2.9969 | 0.0000 | 2.4449 | 3.8204 | 2.0267 | 6.2499 | 2.2412 |
| Model | Statistical Indicator | ||||||
|---|---|---|---|---|---|---|---|
| TIC*100 | RMSE | MAE | MAPE(%) | IFCP | IFNAW | ||
| FOSSA–DeepAR | 0.3619 | 5.6242 | 3.2011 | 18.9297 | 0.9322 | 0.8744 | 0.1108 |
| BSSA–DeepAR | 0.3710 | 5.8841 | 3.5232 | 21.0970 | 0.9258 | 0.7444 | 0.1266 |
| CASSA–DeepAR | 0.3730 | 5.7583 | 3.4411 | 23.2321 | 0.9290 | 0.7534 | 0.1236 |
| CSSA–DeepAR | 0.3647 | 5.7484 | 3.2691 | 20.4574 | 0.9300 | 0.7534 | 0.1187 |
| HSSA–DeepAR | 0.3659 | 5.7136 | 3.3003 | 22.8887 | 0.9300 | 0.7758 | 0.1312 |
| ISSA–DeepAR | 0.3667 | 5.9316 | 3.5164 | 28.6855 | 0.9246 | 0.7713 | 0.1310 |
| ISSA1–DeepAR | 0.3635 | 5.7102 | 3.3062 | 22.0377 | 0.9201 | 0.7175 | 0.1206 |
| SSA–DeepAR | 0.3686 | 5.7412 | 3.3620 | 23.6472 | 0.9294 | 0.7354 | 0.1178 |
| DeepAR | 0.3757 | 5.9485 | 3.5337 | 28.7165 | 0.9205 | 0.7265 | 0.1230 |
| Tested Model | Benchmark Model | |||||||
|---|---|---|---|---|---|---|---|---|
| BSSA–DeepAR | CASSA–DeepAR | CSSA–DeepAR | HSSA–DeepAR | ISSA–DeepAR | ISSA1–DeepAR | SSA–DeepAR | DeepAR | |
| FOSSA–DeepAR | 2.9466 (0.0032) | 7.4423 (9.8810 ) | 2.5708 (0.0101) | 4.0025 (6.2684 ) | 4.2075 (2.5816 ) | 6.6270 (3.4248 ) | 3.2962 (0.0009) | 3.0460 (0.0023) |
| BSSA–DeepAR | 0.7494 (0.4536) | 1.9894 (0.0467) | 1.8231 (0.0683) | 2.0038 (0.0451) | 1.8455 (0.0650) | 1.8861 (0.0593) | 2.1990 (0.0279) | |
| CASSA–DeepAR | 4.2459 (2.1771 ) | 1.2799 (0.2006) | 2.1025 (0.0355) | 0.1172 (0.9067) | 1.7705 (0.0766) | 4.6478 (3.3555 ) | ||
| CSSA–DeepAR | 5.4134 (6.1825 ) | 6.8126 (9.5870 ) | 3.0353 (0.0024) | 1.5721 (0.1159) | 3.0350 (0.0024) | |||
| HSSA–DeepAR | 2.0132 (0.0441) | 1.2393 (0.2152) | 3.6971 (0.0002) | 2.0012 (0.0454) | ||||
| ISSA–DeepAR | 1.6791 (0.0931) | 3.3655 (0.0008) | 2.6089 (0.0091) | |||||
| ISSA1–DeepAR | 7.4389 (1.0147 ) | 6.8539 (7.1887 ) | ||||||
| SSA–DeepAR | 3.0672 (0.0022) | |||||||
| Time Series | Statistical Indicator | ||||||
|---|---|---|---|---|---|---|---|
| TIC | RMSE | MAE | MAPE | IFCP | IFNAW | ||
| O3 in Beijing | 0.0012 | 7.9824 | 5.9910 | 0.0939 | 0.9005 | 0.8350 | 0.1996 |
| PM2.5 in Taian | 0.0013 | 14.1004 | 10.1996 | 0.3797 | 0.9182 | 0.7750 | 0.2390 |
| O3 in Taian | 0.0029 | 9.3287 | 6.1833 | 0.1993 | 0.9132 | 0.7750 | 0.2065 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, F.; Han, X.; Zhang, W.; Chen, G. Atmospheric PM2.5 Prediction Using DeepAR Optimized by Sparrow Search Algorithm with Opposition-Based and Fitness-Based Learning. Atmosphere 2021, 12, 894. https://doi.org/10.3390/atmos12070894
Jiang F, Han X, Zhang W, Chen G. Atmospheric PM2.5 Prediction Using DeepAR Optimized by Sparrow Search Algorithm with Opposition-Based and Fitness-Based Learning. Atmosphere. 2021; 12(7):894. https://doi.org/10.3390/atmos12070894
Chicago/Turabian StyleJiang, Feng, Xingyu Han, Wenya Zhang, and Guici Chen. 2021. "Atmospheric PM2.5 Prediction Using DeepAR Optimized by Sparrow Search Algorithm with Opposition-Based and Fitness-Based Learning" Atmosphere 12, no. 7: 894. https://doi.org/10.3390/atmos12070894
APA StyleJiang, F., Han, X., Zhang, W., & Chen, G. (2021). Atmospheric PM2.5 Prediction Using DeepAR Optimized by Sparrow Search Algorithm with Opposition-Based and Fitness-Based Learning. Atmosphere, 12(7), 894. https://doi.org/10.3390/atmos12070894