
Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model



Abstract
:1. Introduction
2. Model
2.1. LSTM Model
2.2. LightGBM Model
2.2.1. Goss Algorithm and EFB Algorithm
2.2.2. Histogram Algorithm
2.2.3. Building the Leafwise Strategy
2.3. Weighted Combination Prediction Model Based on LSTM and LightGBM
2.3.1. An Optimal Weighted Combination Method
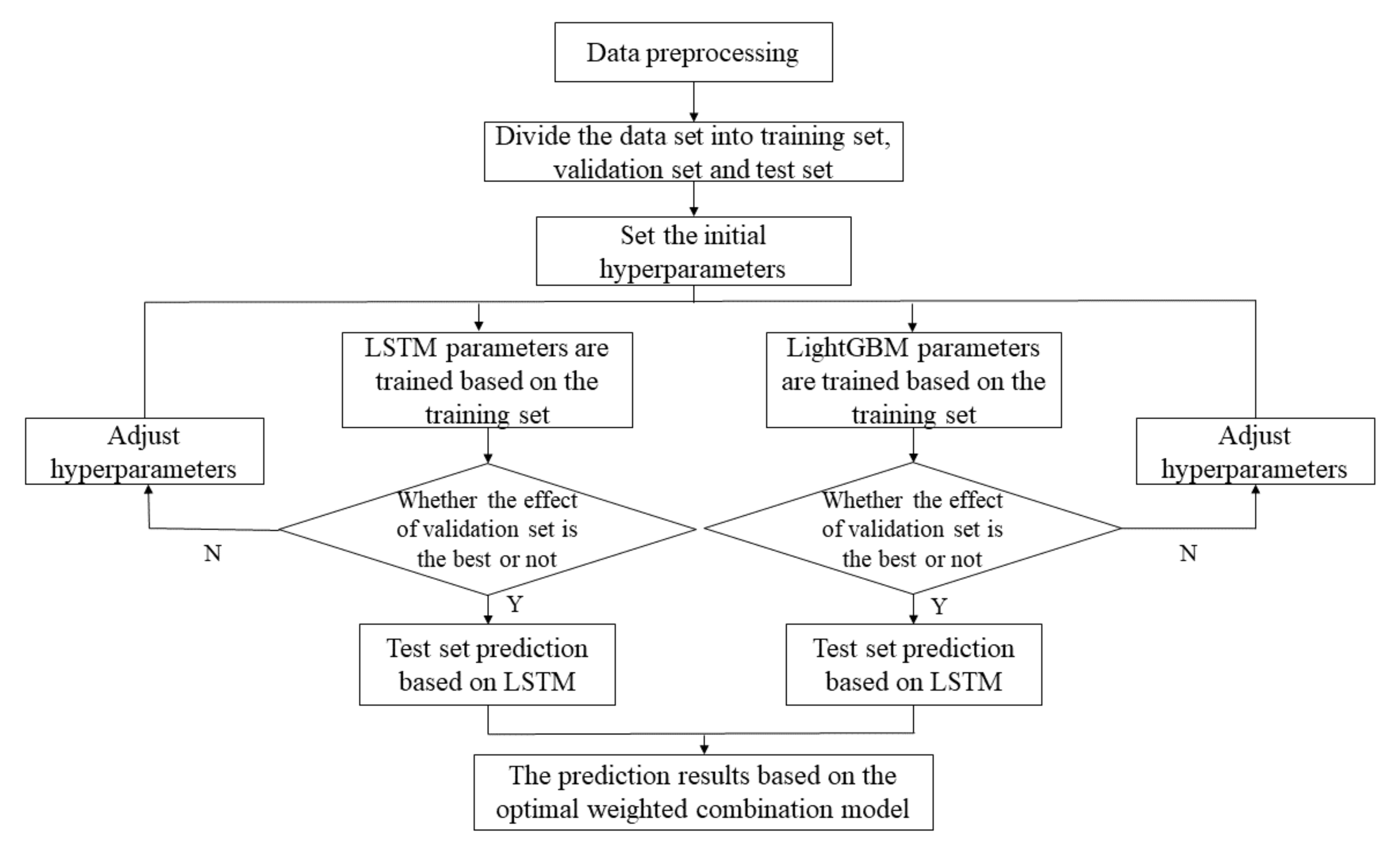
2.3.2. The Combined Forecasting Process
3. Experimental Setup and Data Processing
3.1. Experimental Environment
3.2. Data Source and Index Selection
3.3. Analysis of Influencing Factors of PM2.5 Concentration
3.3.1. Average Concentration of PM2.5 at Different Times
3.3.2. Effects of Air Particulate Matter and Meteorological Factors on PM2.5 Concentration
3.4. Data Processing and Division
3.4.1. Data Preprocessing
3.4.2. Data Set Partition and Normalization
3.5. Evaluating Indicator
4. Model Construction and Evaluation
4.1. LSTM Model
4.2. The TSLightGBM Model
4.3. LSTM-TSLightGBM Weighted Combination Model
5. Conclusions
- (1)
- The overall seasonal variation of PM2.5 concentration, from highest to lowest, shows the following pattern: winter > autumn > spring > summer. The average concentration of PM2.5 is highest in December and the lowest in August. The concentration of PM2.5 is positively correlated with the concentration of harmful particulate matter. The correlation between PM2.5 and PM10 is the highest, reaching 0.88. A certain concentration of O3 is conducive to suppressing the concentration of PM2.5, and high temperature, rainfall, and wind speed have a certain inhibitory effect on PM2.5. Meteorological factors have a small impact on PM2.5.
- (2)
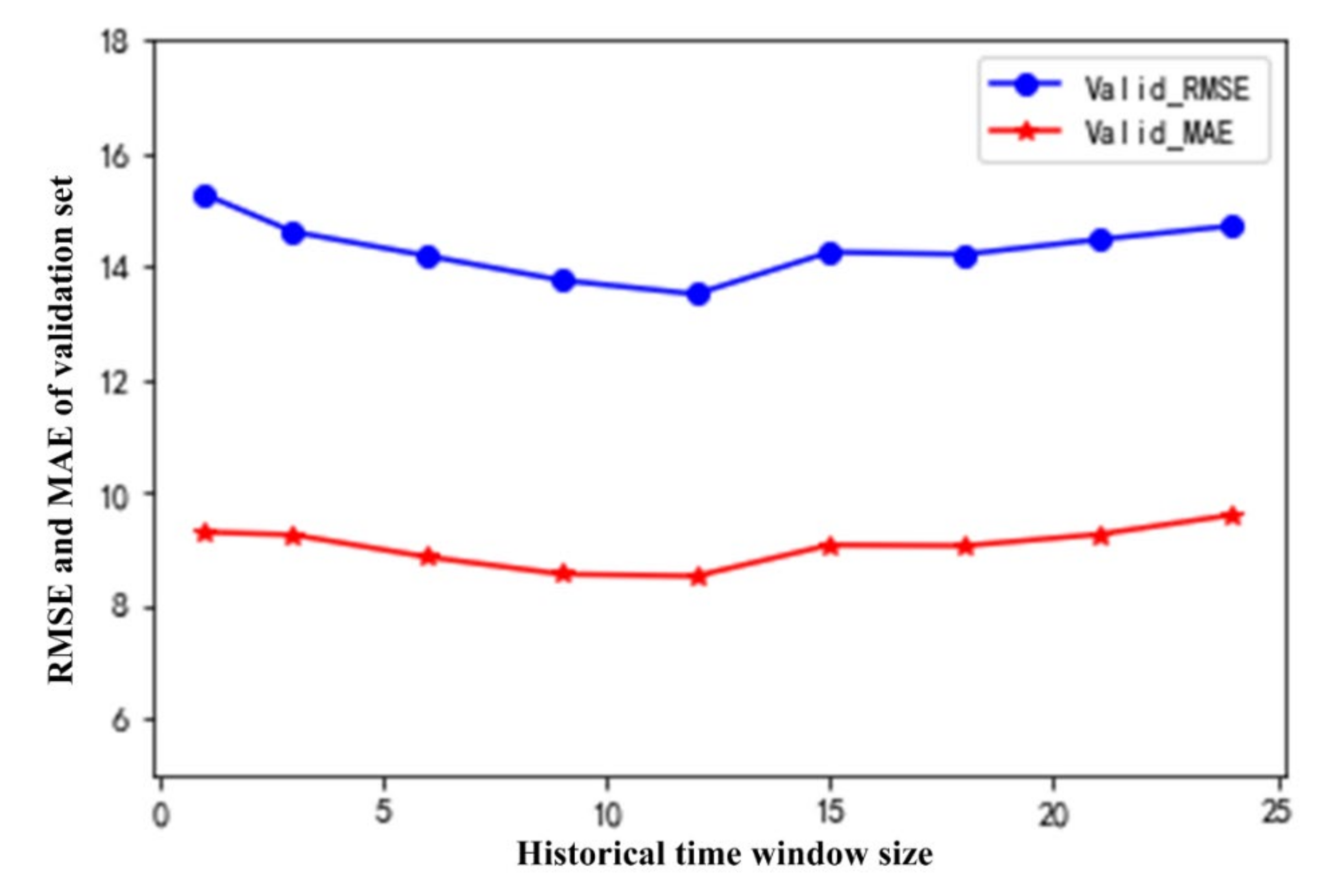
- As the PM2.5 concentration is affected by historical information, the performance of LSTM is related to the size of the time window. As the time window increases, the performance of LSTM on PM2.5 increases first and then decreases. When the time window size is 12, performance of LSTM is best. For the nontime series model, LightGBM, different feature construction methods have an impact on the performance. The TSLightGBM, which uses all the information in the time window as the input the next period of prediction, has the best performance.
- (3)
- Comparing LSTM-TSLightGBM with LSTM, TSLightGBM, RF, RNN, and MLP neural networks, LSTM-TSLightGBM has the smallest MAE, RMSE, and SMAPE, which demonstrates its effectiveness in processing time series data and its superiority in the hourly forecast of PM2.5.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Yu, H.; Yuan, J.; Yu, X.; Zhang, L.; Chen, W. Tracking prediction model for PM2.5 hourly concentration based on ARMAX. J. Tianjin Univ. Sci. Technol. 2017, 50, 105–111. [Google Scholar]
- Kanirajan, P.; Kumar, V.S. Power quality disturbance detection and classification using wavelet and RBFNN. Appl. Soft Comput. 2015, 35, 470–481. [Google Scholar] [CrossRef]
- Chen, S.; Wang, J.; Zhang, H. A hybrid PSO-SVM model based on clustering algorithm for short-term atmospheric pollutant concentration forecasting. Technol. Forecast. Soc. Chang. 2019, 146, 41–54. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2016, 8, 652–659. [Google Scholar] [CrossRef]
- Tsai, Y.T.; Zeng, Y.R.; Chang, Y.S. Air pollution forecasting using RNN with LSTM. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1074–1079. [Google Scholar]
- Liu, W.; Guo, G.; Chen, F.; Chen, Y. Meteorological pattern analysis assisted daily PM2.5 grades prediction using SVM optimized by PSO algorithm. Atmos. Pollut. Res. 2019, 10, 1482–1491. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J.S. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2017, 188, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Xia, L.; Gao, G.; Cheng, L. PM2.5 prediction model based on weighted KNN-BP neural network. J. Environ. Eng. Technol. 2019, 9, 14–18. [Google Scholar]
- Liu, X.; Zhao, W.; Tang, W. Forecasting Model of PM2.5 Concentration one Hour in Advance Based on CNN-Seq2Seq. J. Chin. Comput. Syst. 2020, 41, 1000–1006. [Google Scholar]
- Kow, P.Y.; Wang, Y.S.; Zhou, Y.; Kao, F.-I.; Issermann, M.; Chang, L.-C.; Chang, F.-J. Seamless integration of convolutional and back-propagation neural networks for regional multi-step-ahead PM2.5 forecasting. J. Clean. Prod. 2020, 261, 121285. [Google Scholar] [CrossRef]
- Guo, C.; Guo, W.; Chen, C.H.; Wang, X.; Liu, G. The air quality prediction based on a convolutional LSTM network. In Proceedings of the International Conference on Web Information Systems and Applications, Qingdao, China, 20–22 September 2019; Springer: Cham, Switzerland, 2019; pp. 98–109. [Google Scholar]
- Zhang, Y.; Yuan, H.; Sun, X.; Wu, H.; Dong, Y. PM2.5 Concentration Prediction Method Based on Adam’s Attention Model. J. Atmos. Environ. Opt. 2021, 16, 117. [Google Scholar]
- Weng, T.; Liu, W.; Xiao, J. Supply chain sales forecasting based on lightGBM and LSTM combination model. Ind. Manag. Data Syst. 2019, 120, 249–265. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–7 December 2017. [Google Scholar]
- Dale-Jones, R.; Tjahjadi, T. A study and modification of the local histogram equalization algorithm. Pattern Recognit. 1993, 26, 1373–1381. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T. Application of improved LightGBM model in blood glucose prediction. Appl. Sci. 2020, 10, 3227. [Google Scholar] [CrossRef]
- Marković, D.M.; Marković, D.A.; Jovanović, A.; Lazić, L.; Mijić, Z. Determination of O3, NO2, SO2, CO and PM 10 measured in Belgrade urban area. Environ. Monit. Assess. 2008, 145, 349–359. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Xia, F.; Zhang, Y.; Liu, H.; Li, J.; Lou, M.; He, J.; Yan, Y.; Wang, F.; Min, M.; et al. Impact of diurnal variability and meteorological factors on the PM2. 5-AOD relationship: Implications for PM2. 5 remote sensing. Environ. Pollut. 2017, 221, 94–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Meaning | Variable | Meaning |
|---|---|---|---|
| Year | Year of this row | CO | CO concentration (μg/m3) |
| Month | Month of this row | O3 | O3 concentration (μg/m3) |
| Day | Day of this row | TEMP | Temperature (°C) |
| Hour | Hour of this row | PRES | Pressure (hPa) |
| PM2.5 | PM2.5 concentration (μg/m3) | DEWP | Dew point Temperature (°C) |
| PM10 | PM10 concentration (μg/m3) | RAIN | Precipitation (mm) |
| SO2 | SO2 concentration (μg/m3) | WD | Wind direction |
| NO2 | NO2 concentration (μg/m3) | WSPM | Wind speed (m/s) |
| Parameters | Setting |
|---|---|
| Activation function | ReLU |
| Optimization algorithm | Adam |
| Learning rate | 0.01 |
| Discard rate | 0.2 |
| Batch parameters | 32 |
| Early stop mechanism | If the MAE of the verification set drops less than 0.0005 for 15 consecutive times, training is stopped |
| T | Number of Neurons in the First Layer | Number of Neurons in the Second Layer | MAE | RMSE |
|---|---|---|---|---|
| 1 | 100 | 50 | 9.300 | 15.287 |
| 3 | 120 | 60 | 9.252 | 14.619 |
| 6 | 128 | 64 | 8.860 | 14.192 |
| 9 | 256 | 128 | 8.557 | 13.760 |
| 12 | 320 | 160 | 8.522 | 13.515 |
| 15 | 300 | 150 | 9.073 | 14.258 |
| 18 | 300 | 150 | 9.058 | 14.219 |
| 21 | 256 | 128 | 9.260 | 14.480 |
| 24 | 350 | 175 | 9.604 | 14.724 |
| Model | n_estimators | max_depth | learning_rate | MAE | RMSE |
|---|---|---|---|---|---|
| TLightGBM | 1000 | 6 | 0.01 | 12.496 | 19.570 |
| TFLightGBM | 2000 | 10 | 0.01 | 18.180 | 26.796 |
| TSLightGBM | 1000 | 10 | 0.01 | 8.153 | 13.266 |
| Model | MAE | RMSE | SMAPE |
|---|---|---|---|
| MLP | 17.853 | 28.058 | 36.974% |
| RNN | 16.846 | 27.158 | 35.487% |
| RF | 13.027 | 24.702 | 20.950% |
| LSTM | 12.918 | 23.501 | 21.271% |
| TSLightGBM | 12.278 | 23.216 | 19.936% |
| LSTM-TSLightGBM | 11.873 | 22.516 | 19.540% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Luo, Y.; Zhang, B. Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model. Atmosphere 2021, 12, 1211. https://doi.org/10.3390/atmos12091211
Jiang X, Luo Y, Zhang B. Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model. Atmosphere. 2021; 12(9):1211. https://doi.org/10.3390/atmos12091211
Chicago/Turabian StyleJiang, Xuchu, Yiwen Luo, and Biao Zhang. 2021. "Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model" Atmosphere 12, no. 9: 1211. https://doi.org/10.3390/atmos12091211
APA StyleJiang, X., Luo, Y., & Zhang, B. (2021). Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model. Atmosphere, 12(9), 1211. https://doi.org/10.3390/atmos12091211