
A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation

 ,
,  and
and
Abstract
1. Introduction
2. Study Area
3. Meteorological Data
4. Methods
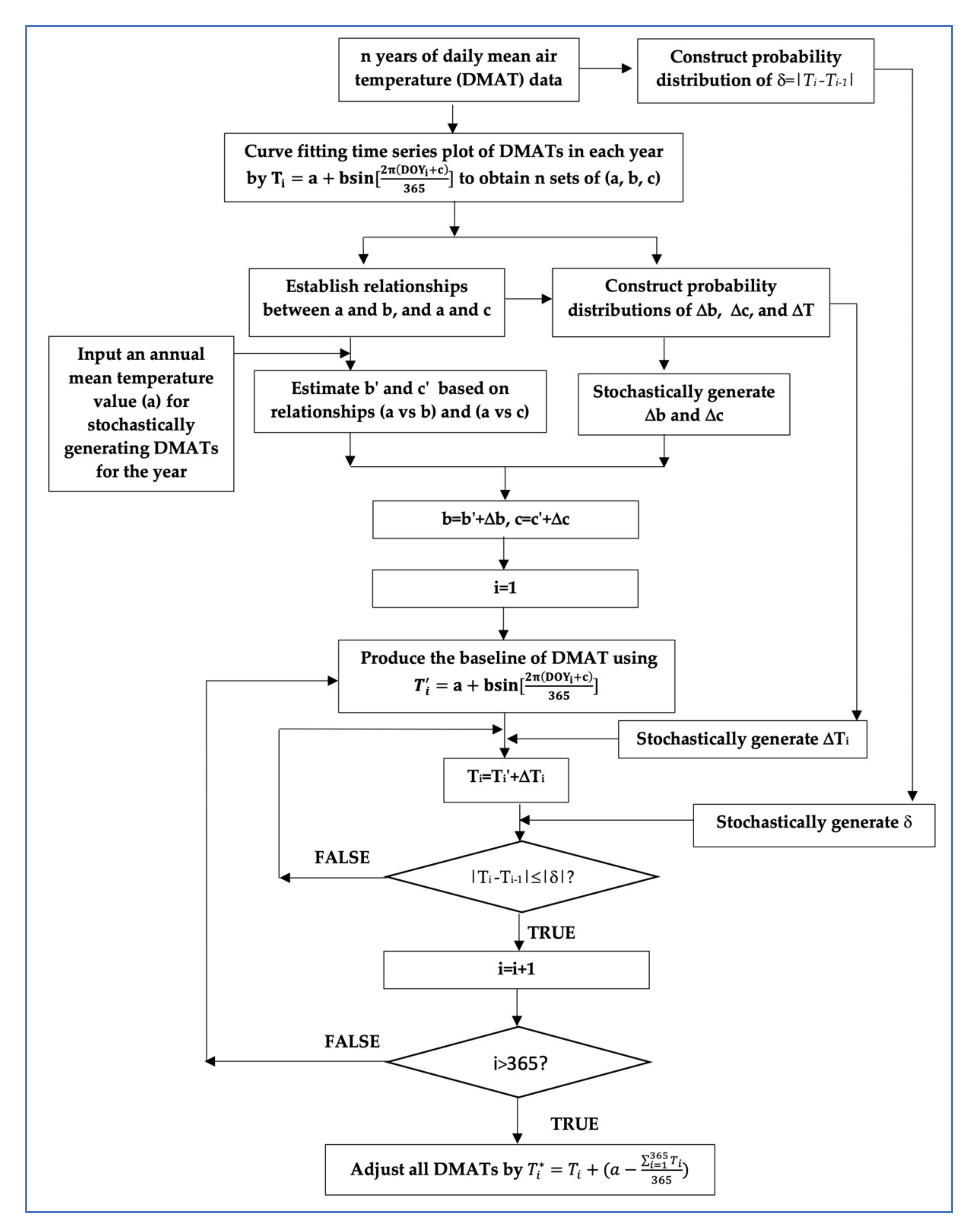
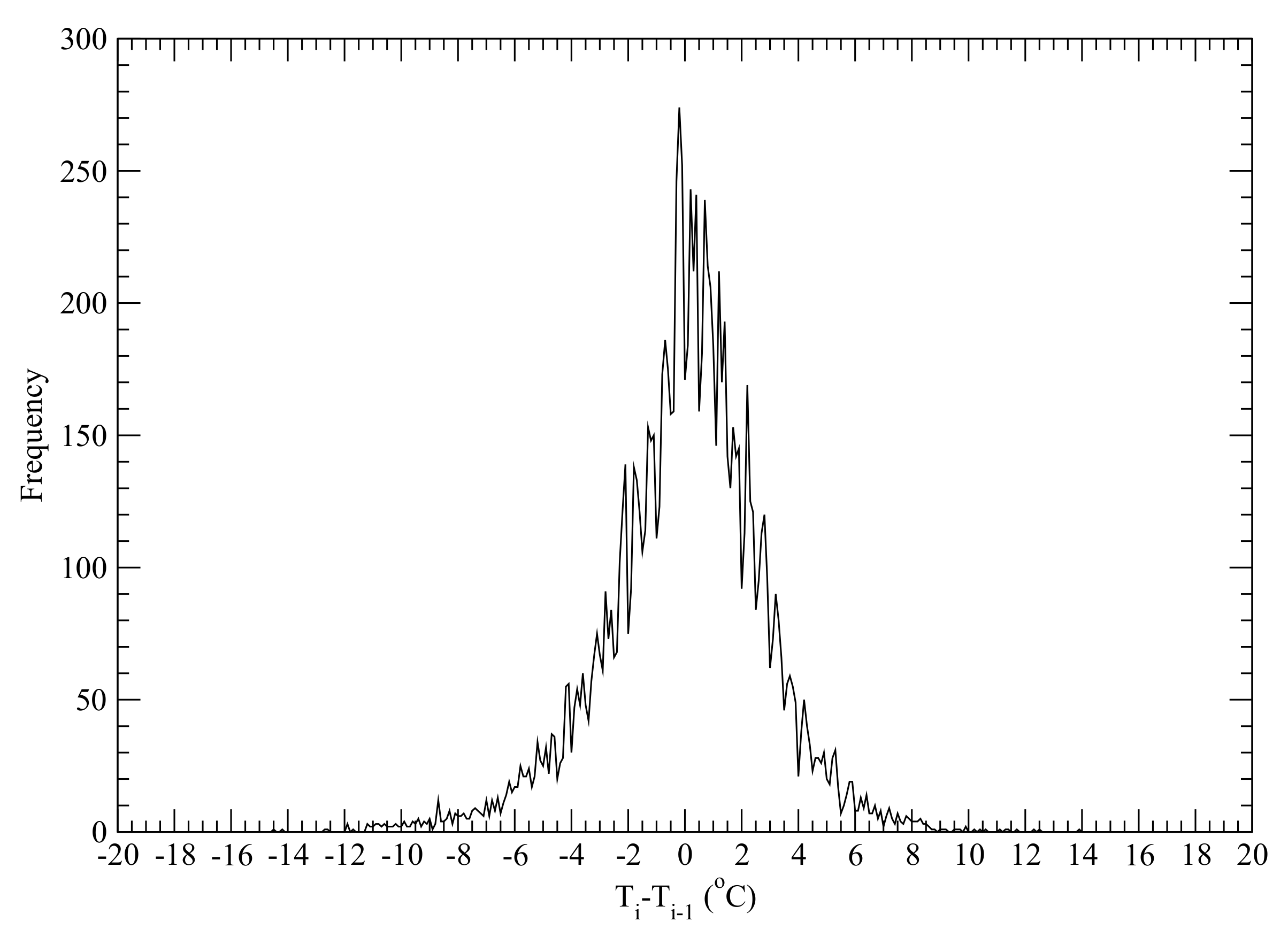
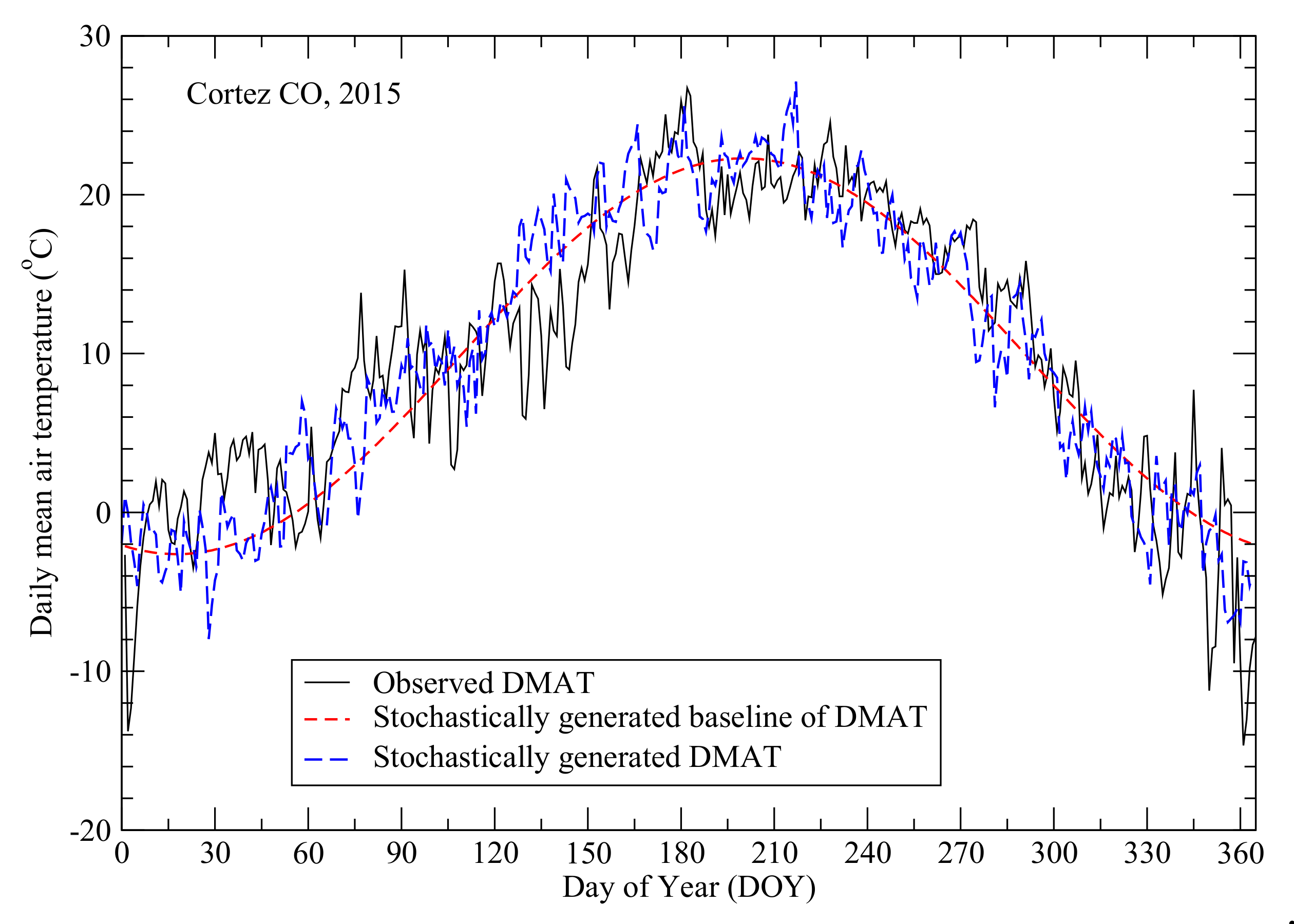
4.1. Stochastically Generating Daily Mean Air Temperature Based on Annual Mean Air Temperature
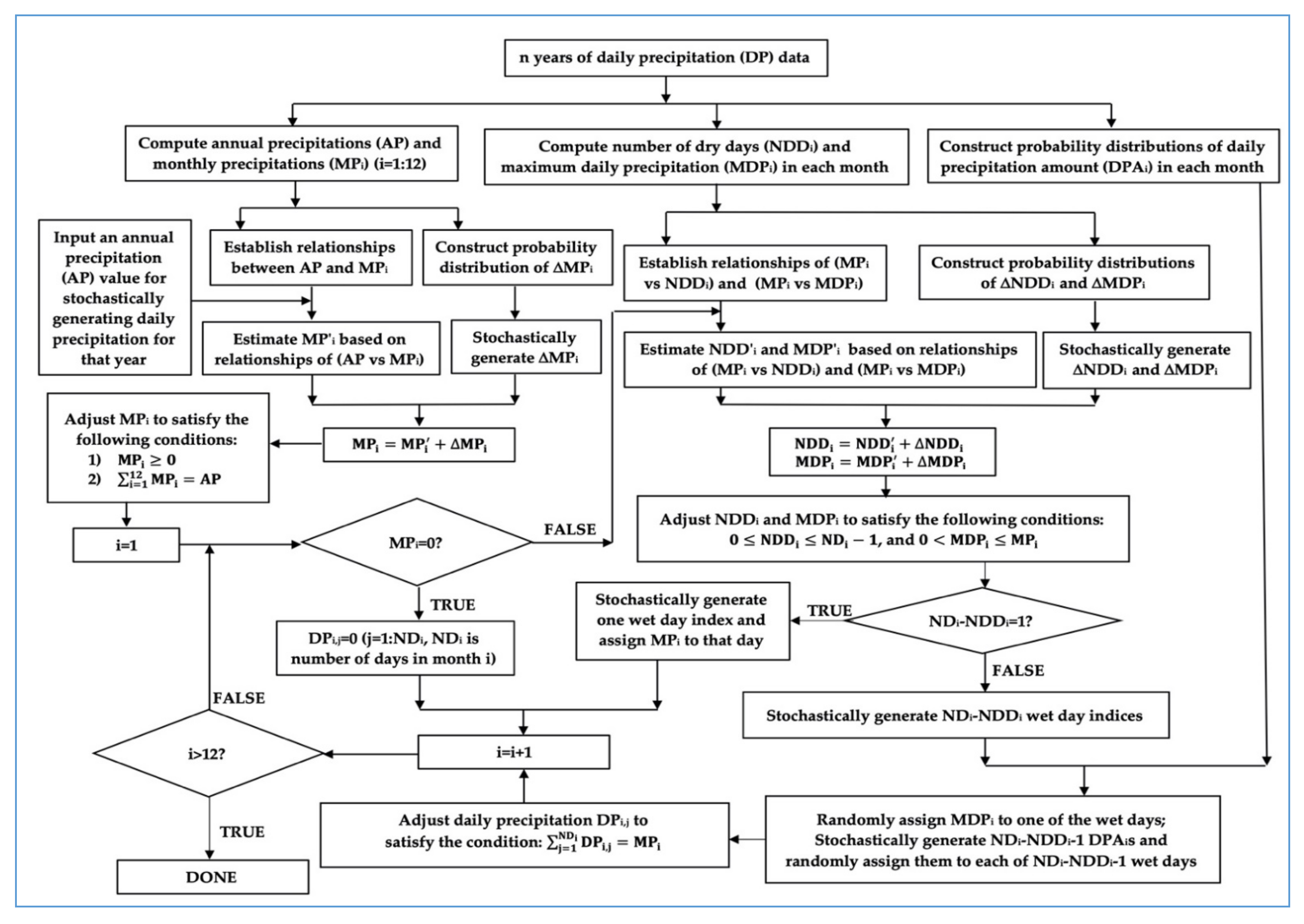
4.2. Stochastically Generating Daily Precipitation Based on Annual Precipitation
5. Application of the CSWG to Stochastically Generating DMAT and DP
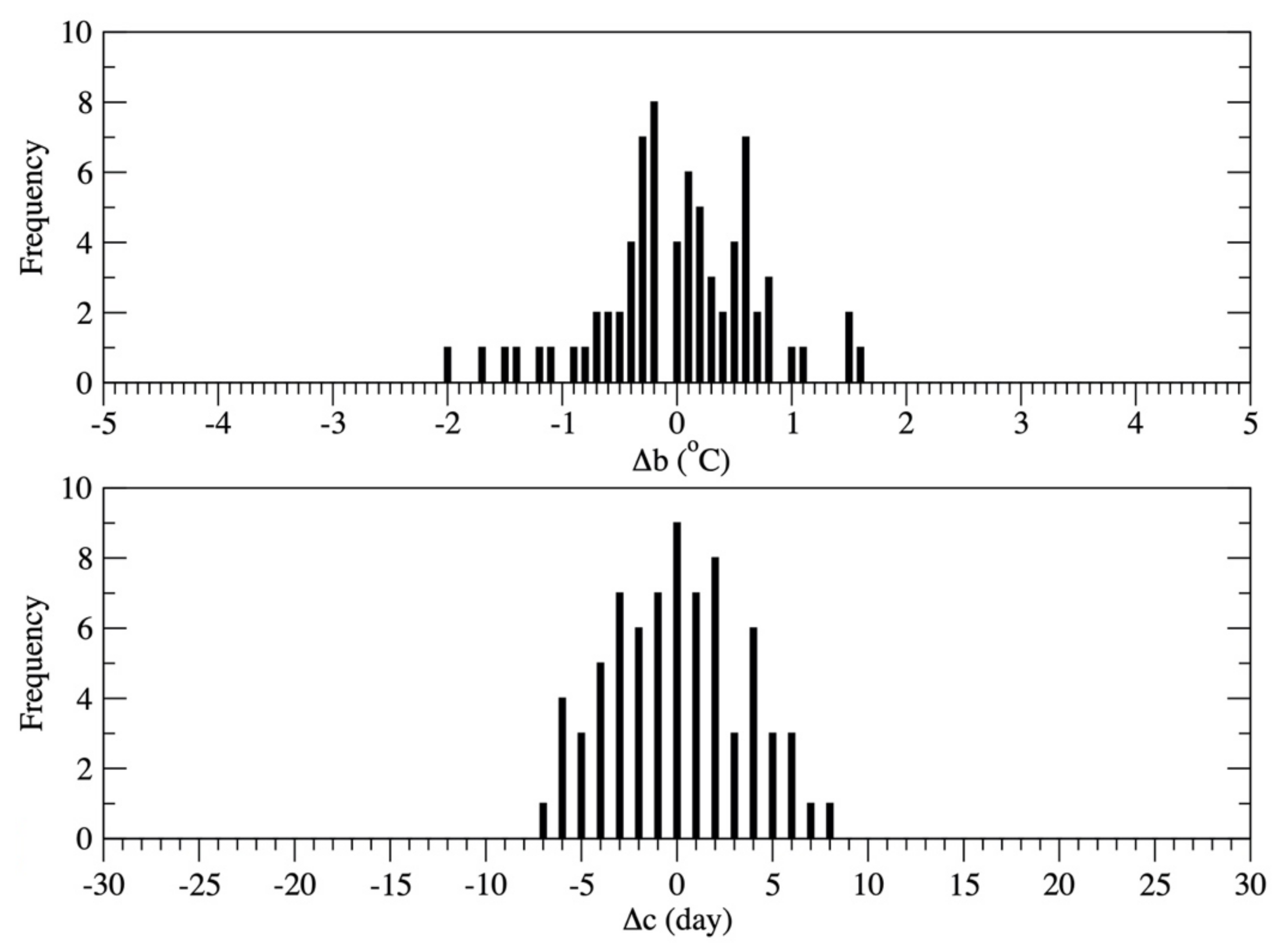
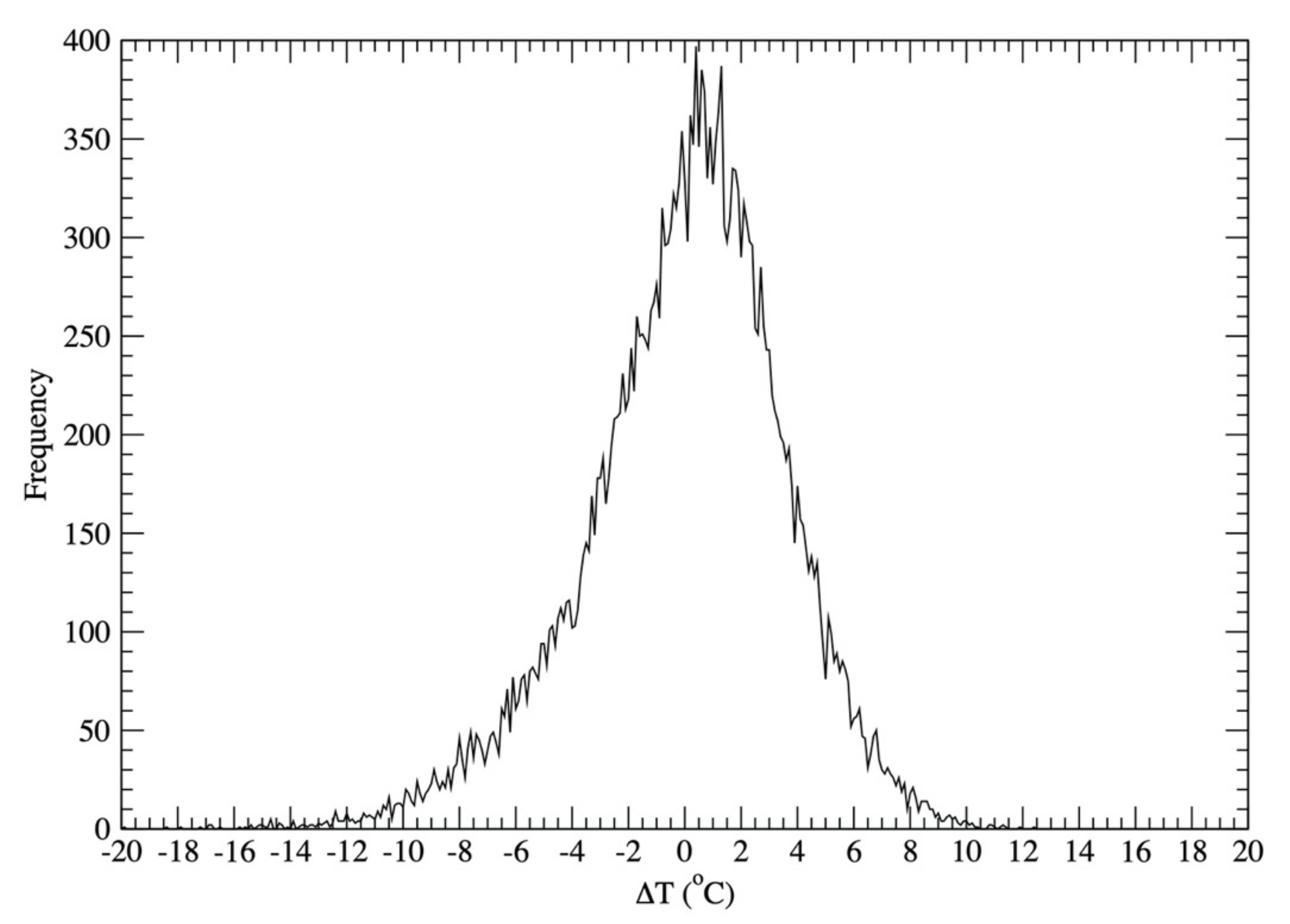
5.1. Stochastically Generating DMAT Using the CSWC
5.2. Stochastically Generating DP Using the CSWC
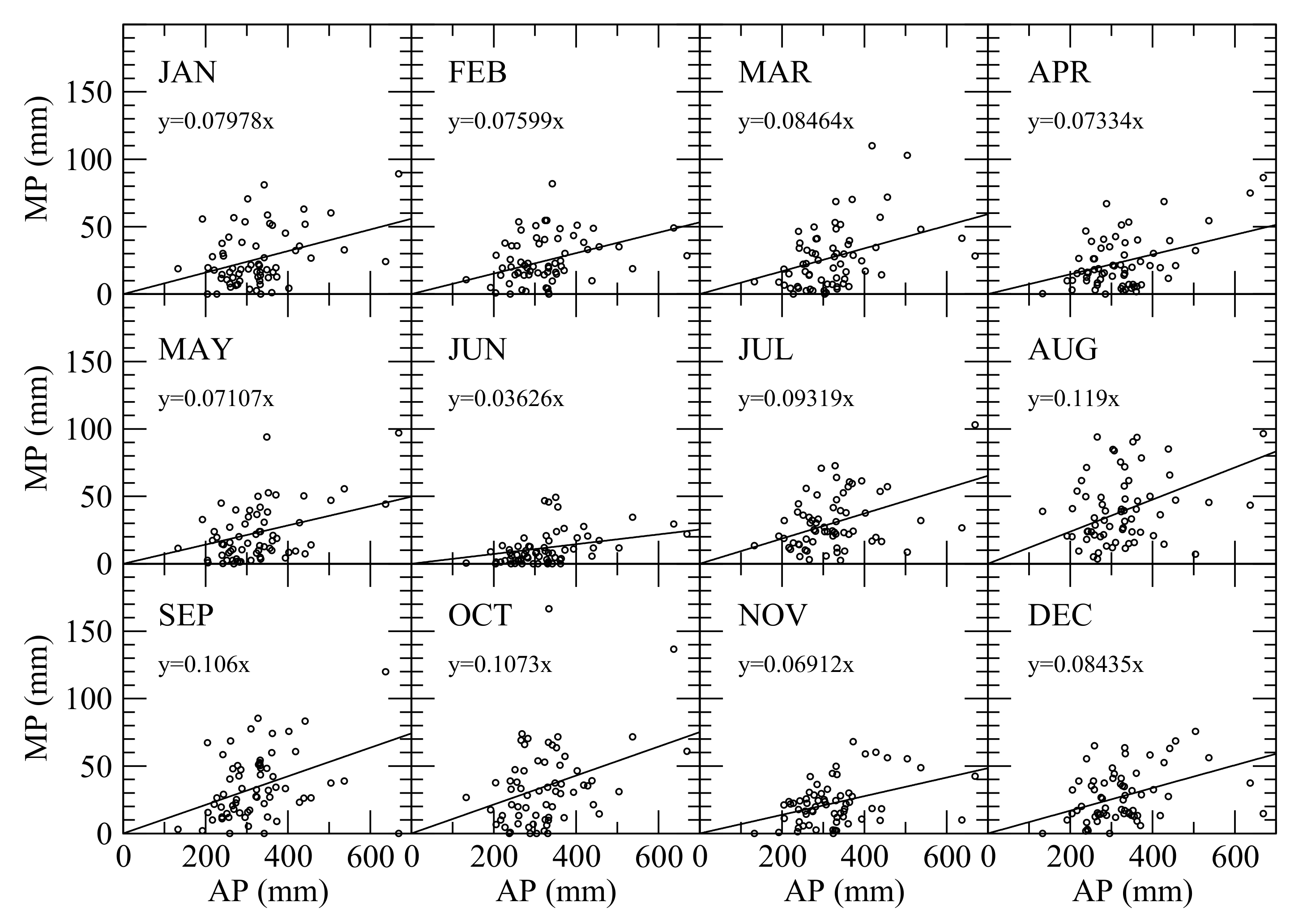
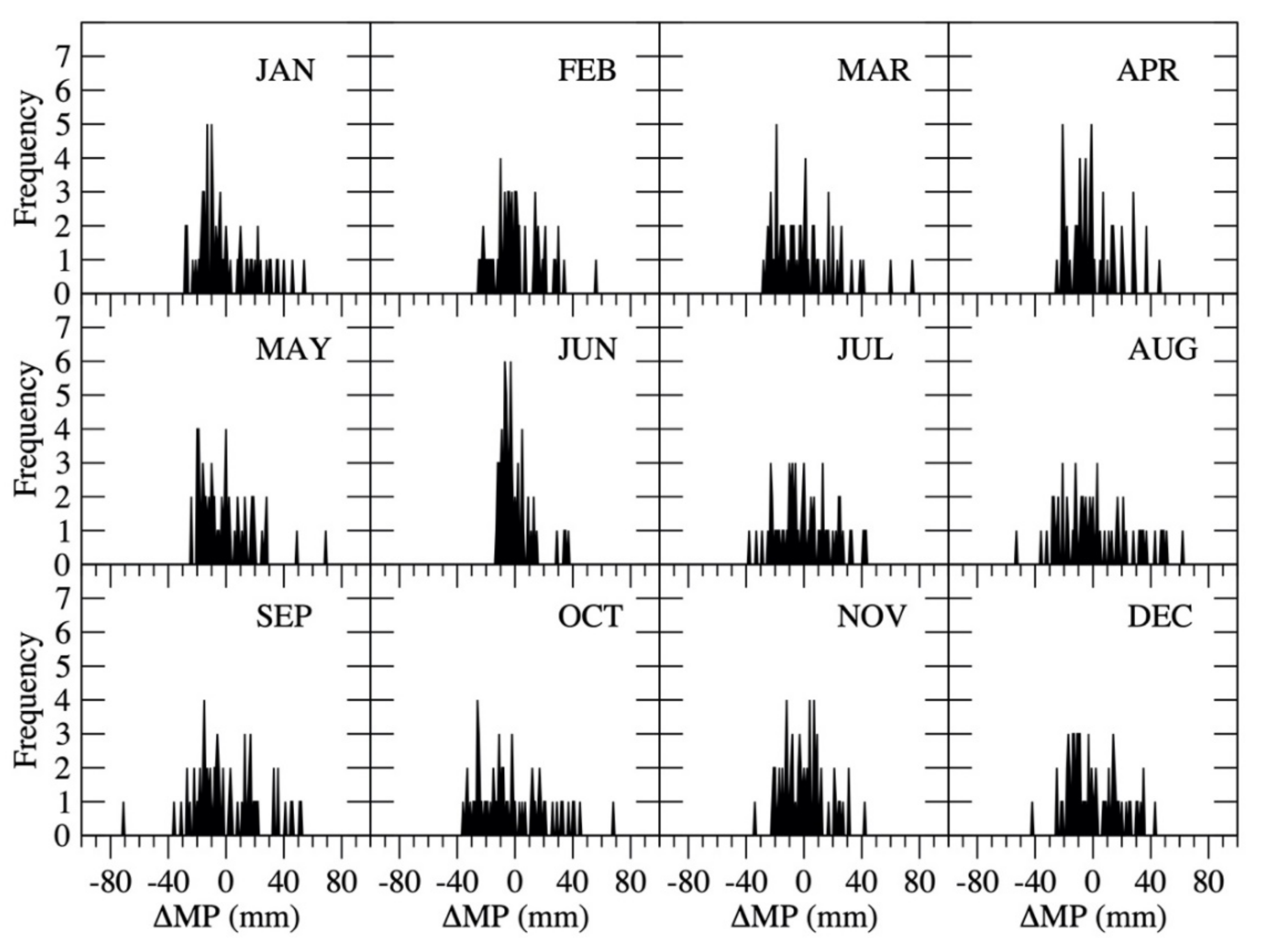
5.2.1. Estimate Monthly Precipitation from Annual Precipitation
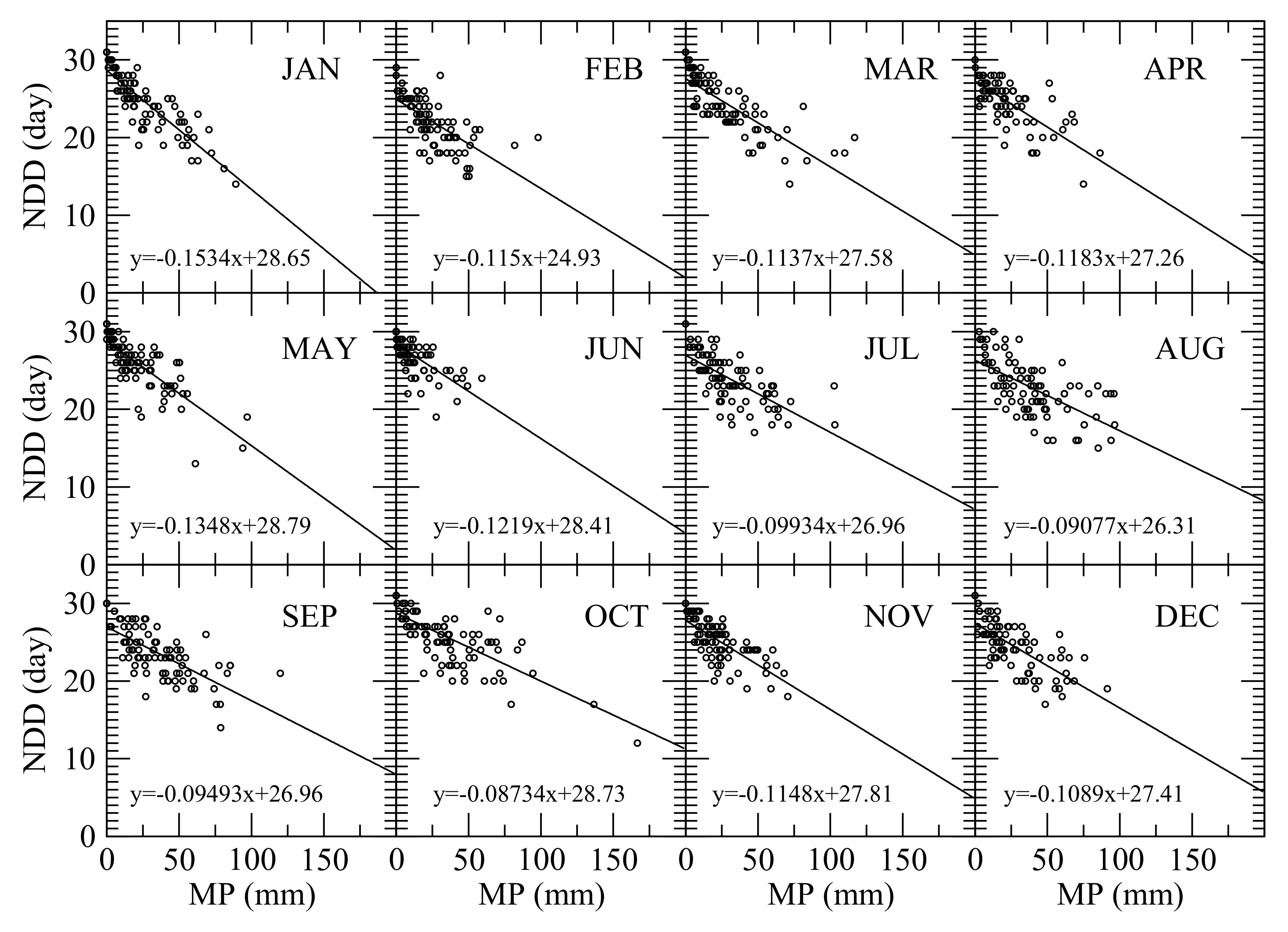
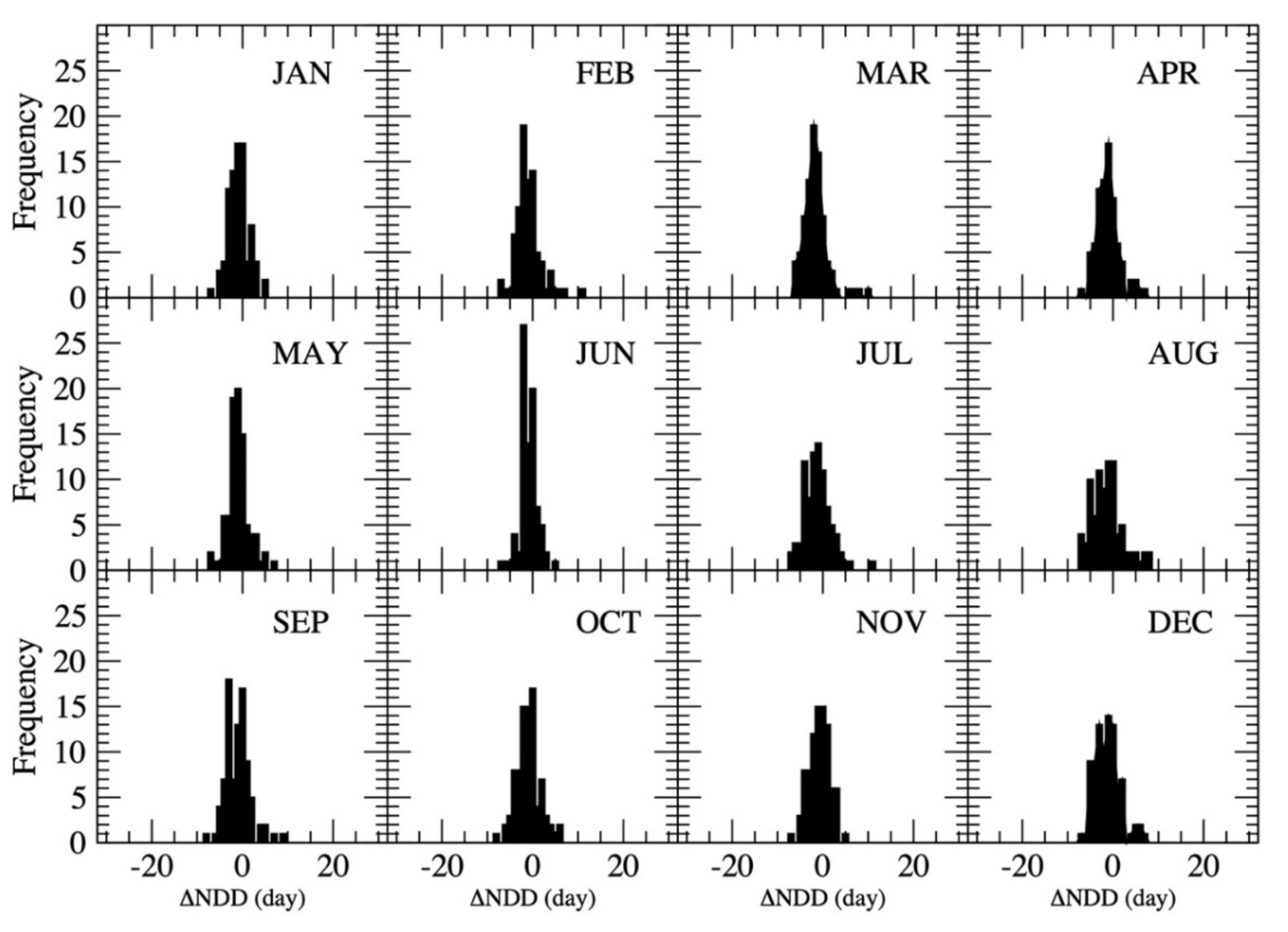
5.2.2. Estimate Number of Dry Days in Each Month
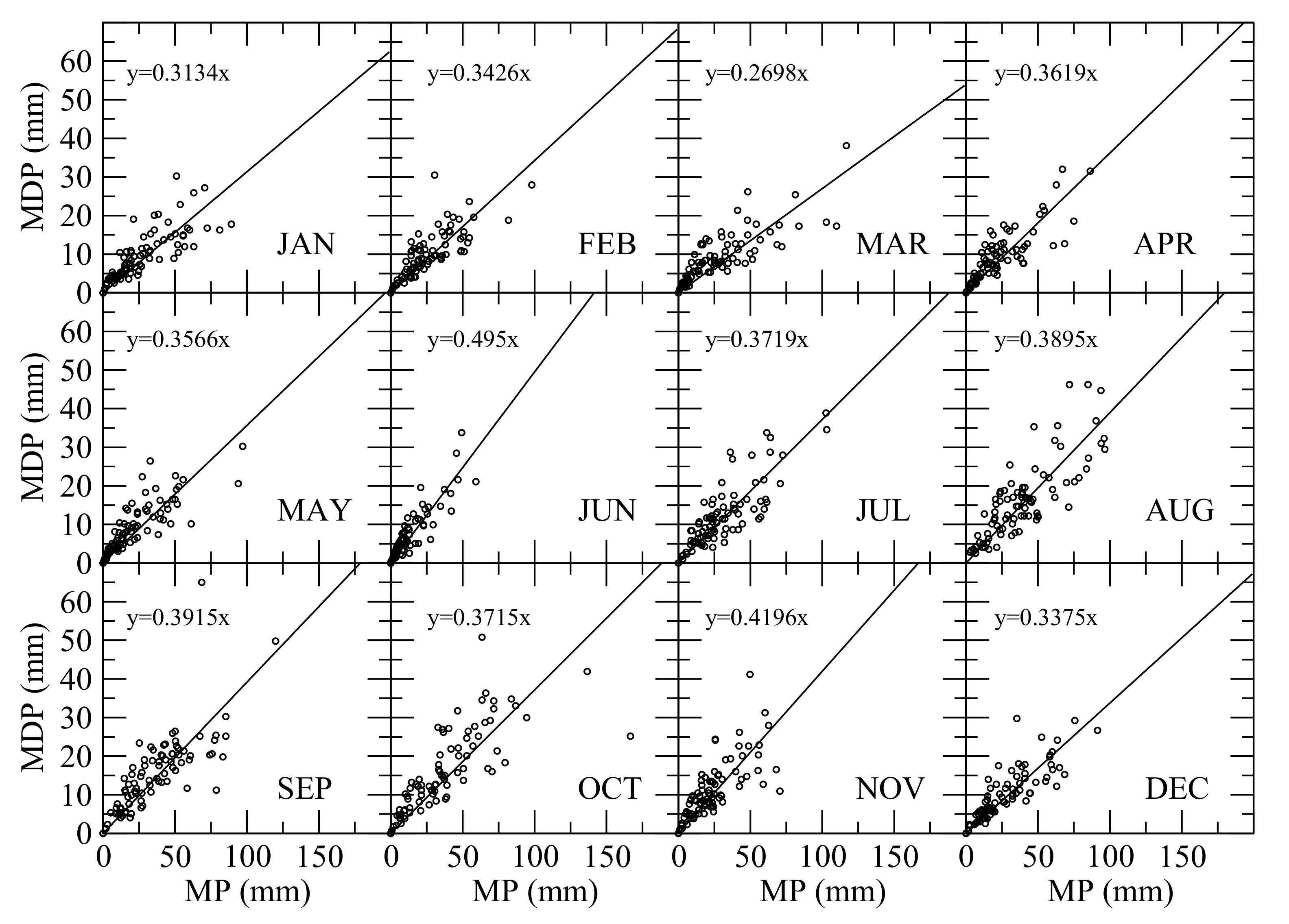
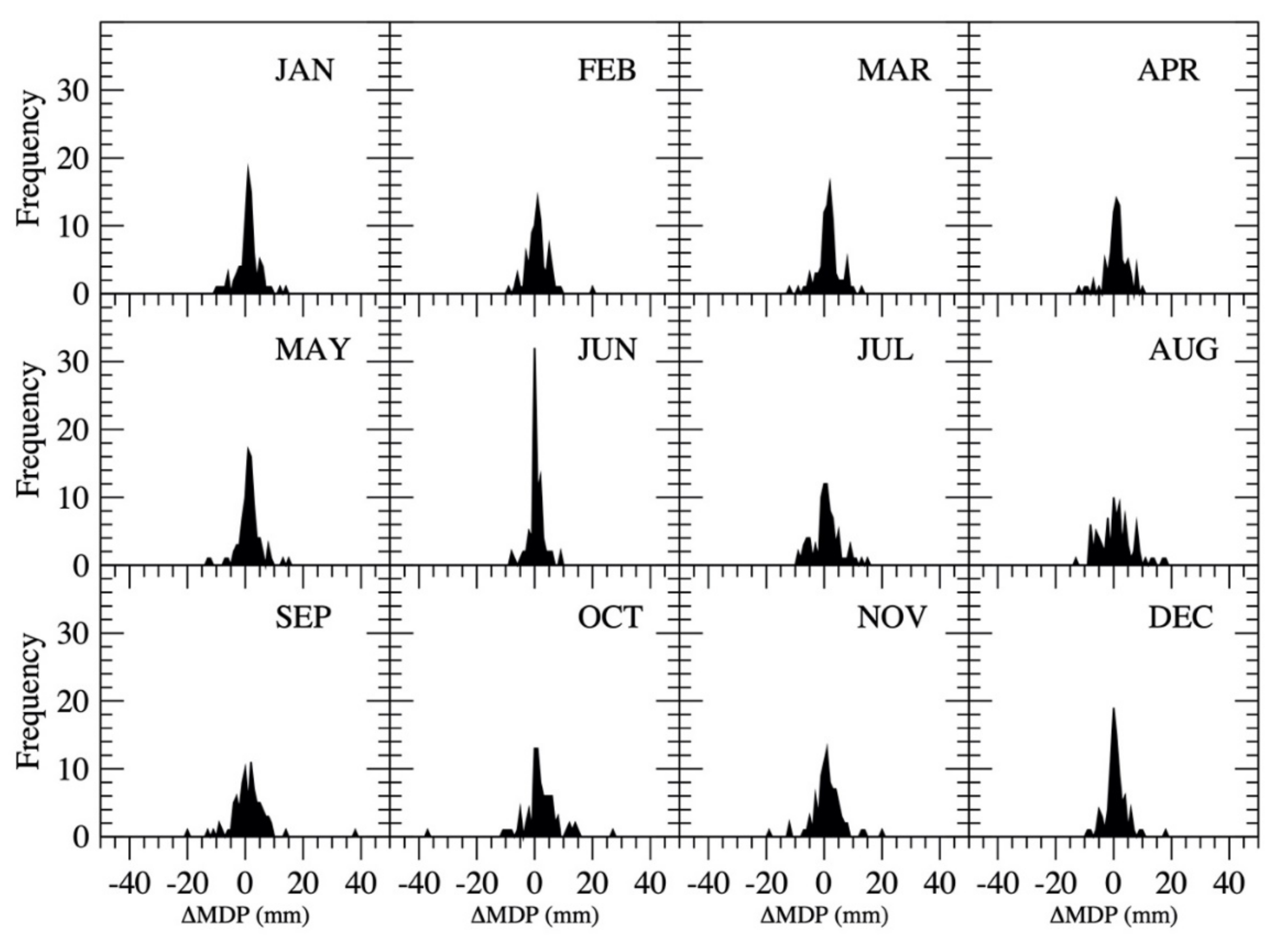
5.2.3. Estimate Maximum Daily Precipitation in Each Month
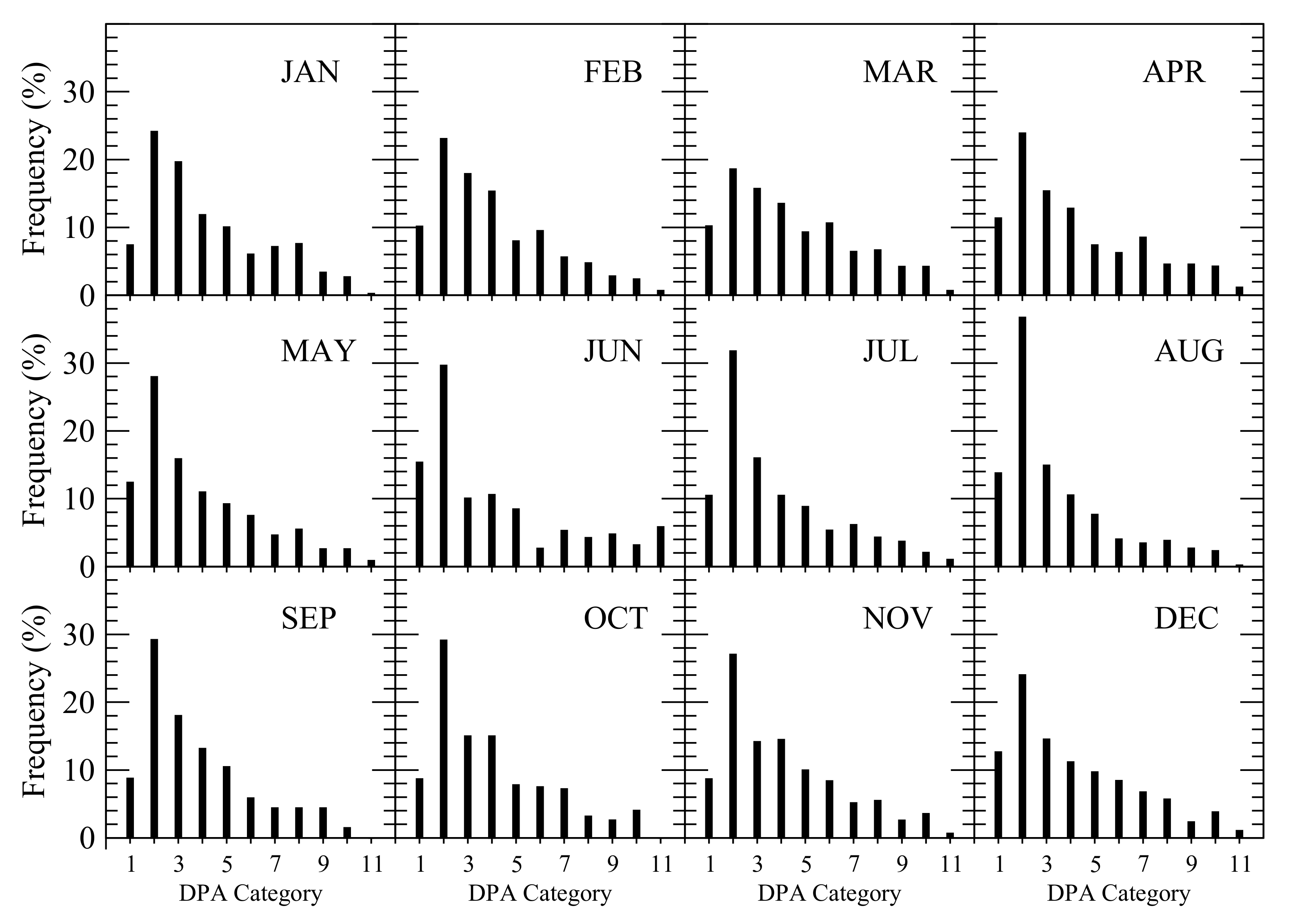
5.2.4. Construct the Probability Distribution of Daily Precipitation Amount in Each Month
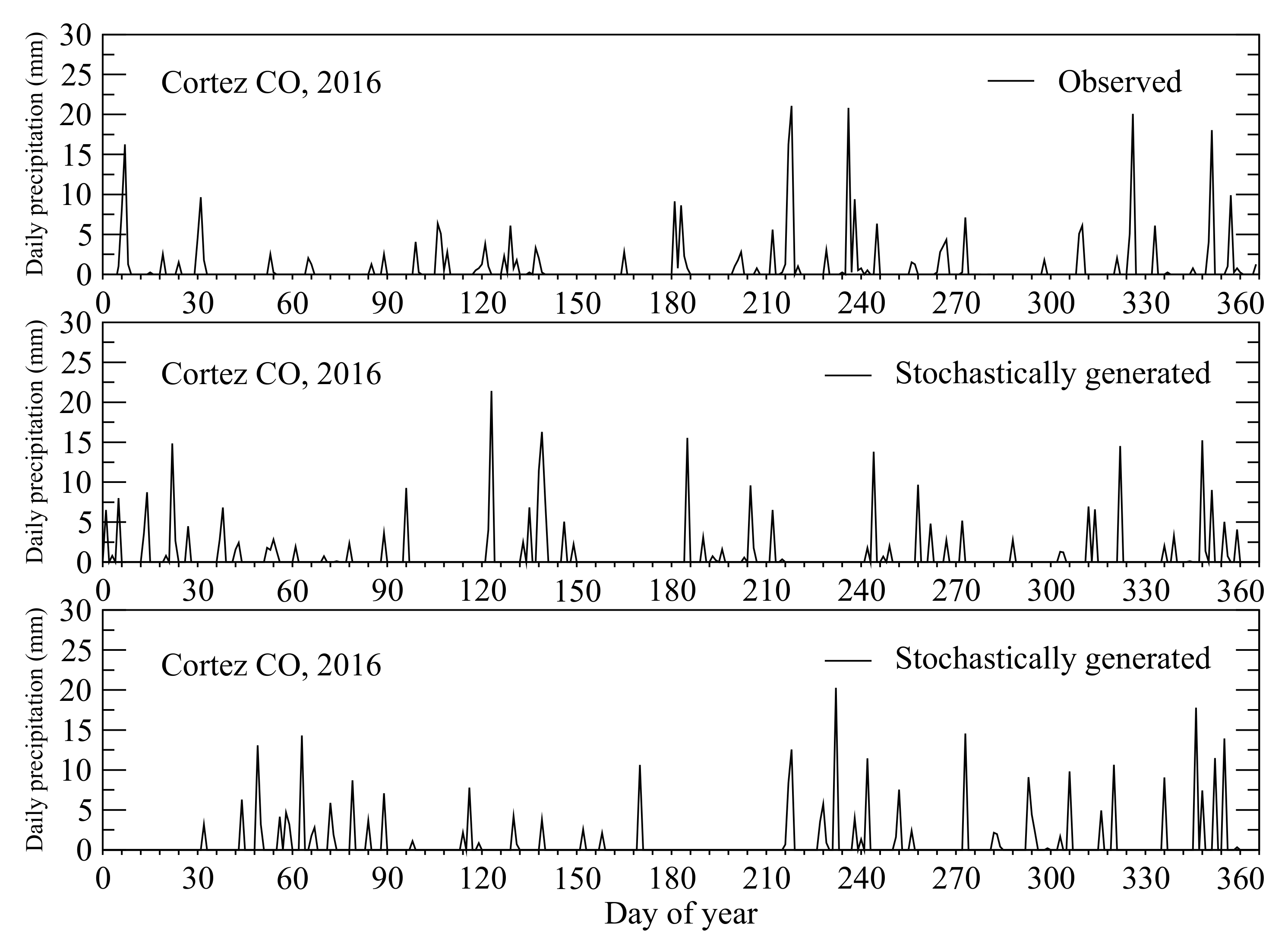
5.2.5. Stochastically Generate Daily Precipitation
- If monthly precipitation MP is zero, every day has zero precipitation in the month.
- If there is only one wet day, the precipitation amount of the wet day is equal to MP.
- If there is more than one wet day, a randomly selected wet day’s precipitation is set to be the maximum daily precipitation MDP. The precipitation amounts of other randomly selected wet days are assigned based on the probability distribution of daily precipitation category, through randomly generating an integer between 1 and 1000, and using the randomly generated integer as the array index to determine the daily precipitation amount category. If it is category 1, the daily precipitation is set to the trace rainfall (0.254 mm); otherwise, based on the daily precipitation amount range of the category defined in Table 6, a randomly generated float number within the daily precipitation amount range of the category is used.
- For each month, after all wet days are assigned a precipitation amount, total precipitation in the month is compared to the estimated MP from annual precipitation. If the difference between them is greater than a threshold (0.01 mm), precipitation amounts of all wet days are adjusted through subtracting or adding the difference divided by the number of wet days. Since each adjusted daily precipitation amount should be between trace precipitation (0.254 mm) and the maximum daily precipitation (MDP), sometimes more than two iterations are needed for adjusting daily precipitation amounts.
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | annual precipitation |
| CSWG | constrainted stochastic weather generator |
| DMAT | daily mean air temperature |
| DOY | day of year |
| DP | daily precipitation |
| DPA | daily precipitation amount |
| GHCN | global historical climate network |
| GSOD | global summary of day |
| MDPi | maximum daily precipitation in month i |
| MPi | monthly precipitation in month i |
| NDi | number of day in month i |
| NDDi | numbere of dry days in month i |
References
- Jones, C.A.; Kiniry, J.R. CERES-Maize; A simulation Model of Maize Growth and Development; Texas A&M University Press: College Station, TX, USA, 1986; 194p. [Google Scholar]
- Amir, J.; Sinclair, T.R. A model of the temperature and solar-radiation effects on spring wheat growth and yield. Field Crop. Res. 1991, 28, 47–58. [Google Scholar] [CrossRef]
- Carberry, P.S.; Muchow, R.C. A simulation model of kenaf for assisting fibre industry planning in Northern Australia. III. Model description and validation. Aust. J. Agric. Res. 1992, 43, 1527–1545. [Google Scholar] [CrossRef]
- Chapman, S.C.; Hammer, G.L.; Meinke, H. A crop simulation model for sunflower. I. Model development. Agron. J. 1993, 85, 725–735. [Google Scholar] [CrossRef]
- Meinke, H.; Hammer, G.L.; Chapman, S.C. A crop simulation model for sunflower. II. Simulation analysis of production risk in a variable sub-tropical environment. Agron. J. 1993, 85, 735–742. [Google Scholar] [CrossRef]
- Dean, J.S.; Van West, C.R. Environment-behavior relationships in southwestern Colorado. In Seeking the Center Place: Archaeology and Ancient Communities in the Mesa Verde region; Varien, M., Wilshusen, R.H., Eds.; University of Utah Press: Salt Lake City, UT, USA, 2002. [Google Scholar]
- Stahle, D.W.; Cook, E.R.; Burnette, D.J.; Torbenson, M.C.A.; Howard, I.M.; Griffin, D.; Díaz, J.V.; Cook, B.I.; Williams, A.P.; Watson, E.; et al. Dynamics, Variability, and Change in Seasonal Precipitation Reconstructions for North America. J. Clim. 2020, 33, 3173–3195. [Google Scholar] [CrossRef]
- Stern, R.D.; Coe, R. A model fitting analysis of daily rainfall data. J. R. Stat. Soc. 1984, 147, 1–34. [Google Scholar] [CrossRef]
- Yang, C.; Chandler, R.E.; Isham, V.S.; Wheater, H.S. Spatial-temporal rainfall simulation using generalized linear models. Water Resour. Res. 2005, 41. [Google Scholar] [CrossRef]
- Furrer, E.M.; Katz, R. Generalized linear modeling approach to stochastic weather generators. Clim. Res. 2007, 34, 129–144. [Google Scholar] [CrossRef]
- Kim, Y.; Katz, R.W.; Rajagopalan, B.; Podestá, G.P.; Furrer, E.M. Reducing overdispersion in stochastic weather generators using a generalized linear modeling approach. Clim. Res. 2012, 53, 13–24. [Google Scholar] [CrossRef]
- Kleiber, W.; Katz, R.W.; Rajagopalan, B. Daily spatiotemporal precipitation simulation using latent and transformed Gaussian processes. Water Resour. Res. 2012, 48, 1–17. [Google Scholar] [CrossRef]
- Verdin, A.; Rajagopalan, B.; Kleiber, W.; Podesta, G.; Bert, F. A conditional stochastic weather generator for seasonal to multi-decadal simulations. J. Hydrol. 2018, 556, 835–846. [Google Scholar] [CrossRef]
- Podesta, G.; Bert, F.; Rajagopalan, B. Decadal climate variability in the Argentine Pampas: Regional impacts of plausible climate scenarios on agricultural systems. Clim. Res. 2009, 40, 199–210. [Google Scholar] [CrossRef]
- Apipattanavis, S.; Bert, F.; Podesta, G.; Rajagopalan, B. Linking weather generators and crop models for assessment of climate forecast outcomes. Agric. For. Meteorol. 2010, 150, 166–174. [Google Scholar] [CrossRef]
- Wilks, D.S.; Wilby, R.L. The weather generation game: A review of stochastic weather model. Prog. Phys. Geogr. 1999, 23, 329–357. [Google Scholar] [CrossRef]
- Gabriel, K.R.; Neumann, J. A Markov chain model for daily rainfall occurrence at Tel Aviv. Q. J. R. Meteorol. Soc. 1962, 88, 90–95. [Google Scholar] [CrossRef]
- Caskey, J.E. A Markov chain model for the probability of precipitation occurrence in intervals of various length. Mon. Weather Rev. 1963, 91, 298–301. [Google Scholar] [CrossRef]
- Stern, H. A system for automated forecasting guidance. Aust. Meteorol. Mag. 1980, 28, 141–154. [Google Scholar]
- Garbutt, D.J.; Stern, R.D.; Dennett, M.D.; Elston, J. A comparison of the rainfall climate of eleven places in West Africa using a two-part model for daily rainfall. Arch. Meteorol. Geophys. Bioclimatol. 1981, 29, 137–155. [Google Scholar] [CrossRef]
- Ahmed, J.; Bavel, C.H.M.; Hiler, E.A. Optimization of crop irrigation strategy under a stochastic weather regime: A simulation study. Water Resour. Res. 1976, 12, 1241–1247. [Google Scholar] [CrossRef]
- Delleur, J.W.; Kavvas, M.L. Stochastic models for monthly rainfall forecasting and synthetic generation. J. Appl. Meteorol. 1978, 17, 1528–1536. [Google Scholar] [CrossRef]
- Nicks, A.D.; Harp, J.F. Stochastic generation of temperature and solar radiation data. J. Hydrol. 1980, 48, 1–17. [Google Scholar] [CrossRef]
- Bruhn, J.A.; Fry, W.E.; Fick, G.W. Simulation of daily weather data using theoretical probability distributions. J. Appl. Meteorol. 1980, 19, 1029–1036. [Google Scholar] [CrossRef][Green Version]
- Larsen, G.A.; Pense, R.B. Stochastic simulation of daily climatic data. In USDA-SRS, Statistics Research Division Report, No. AGES810831; United States Department of Agriculture: Washington, DC, USA, 1981. [Google Scholar]
- Richardson, C.W.; Wright, D.A. WGEN: A Model for Generating Daily Weather Variables; ARS-8; United States Department of Agriculture, Agriculture Research Service: Washington, DC, USA, 1984; 83p.
- Hayhoe, H.N. Improvements of stochastic weather generators for diverse climates. Clim. Res. 2000, 14, 75–87. [Google Scholar] [CrossRef]
- Jones, P.G.; Thornton, P.K. MarkSim: Software to generate daily rather data for Latin America and Africa. Agron. J. 2000, 92, 445–453. [Google Scholar] [CrossRef]
- Hansen, J.W.; Mavromatis, T. Correcting low-frequency variability bias in stochastic weather generators. Agric. For. Meteorol. 2001, 109, 297–310. [Google Scholar] [CrossRef]
- Racsko, P.; Szeidl, L.; Semenov, M. A serial approach to local stochastic weather models. Ecol. Model. 1991, 57, 27–41. [Google Scholar] [CrossRef]
- Semenov, M.A.; Brooks, R.J.; Barrow, E.M.; Richardson, C.W. Comparison of the WGEN and LARS-WG stochastic weather generators in diverse climates. Clim. Res. 1998, 10, 95–107. [Google Scholar] [CrossRef]
- Semenov, M.A.; Brooks, R.J. Spatial interpolation of the LARS-WG stochastic weather generator in Great Britain. Clim. Res. 1999, 11, 137–148. [Google Scholar] [CrossRef]
- Hanson, C.L.; Cumming, K.A.; Woolhiser, D.A.; Richardson, C.W. Program for Daily Weather Simulation; US Geological Survey Water Resources Investigations: Denver, CO, USA, 1993; 443p. [Google Scholar]
- Hanson, C.L.; Cumming, K.A.; Woolhiser, D.A.; Richardson, C.W. Microcomputer Program for Daily Weather Simulations in the Contiguous United States; ARS-114; US Geological Survey Water Resources Investigations: Denver, CO, USA, 1994; 38p. [Google Scholar]
- Nicks, A.D.; Gander, A.G. Using CLIGEN to Stochastically Generate Climate Data Inputs to WEPP and Other Water Resource Models; US Geological Survey Water Resources Investigations: Denver, CO, USA, 1993; Volume 93–4018, 443p. [Google Scholar]
- Nicks, A.D.; Gander, A.G. CLIGEN: A weather generator for climate inputs to water resources and other models. In Proceedings of the Fifth International Conference on Computers in Agricuture; American Society of Agricultural Engineers: Orlando, FL, USA, 1994; pp. 903–909. [Google Scholar]
- Johnson, G.L.; Hanson, C.L.; Hardegree, S.P.; Ballard, E.B. Stochastic weather simulation: Overview and analysis of two commonly used models. J. Appl. Meteorol. 1996, 35, 1878–1896. [Google Scholar] [CrossRef]
- Smith, R.E.; Schreiber, H.A. Point processes of seasonal thunderstorm rainfall 2. Rainfall depth probabilities. Water Resour. Res. 1974, 10, 418–423. [Google Scholar] [CrossRef]
- Glowacki, D.M. Living and Leaving: A Social History of Regional Depopulation in Thirteenth-Century Mesa Verde; University of Arizona Press: Tucson, AZ, USA, 2015. [Google Scholar]
- Kohler, T.A.; Varien, M.D.; Wright, A.; Kuckelman, K.A. Mesa Verde Migrations New archaeological research and computer simulation suggest why Ancestral Puebloans deserted the northern Southwest United States. Am. Sci. 2008, 96, 146–153. [Google Scholar] [CrossRef]
- Varien, M.D. Depopulation of the Northern San Juan Region. In Leaving Mesa Verde: Peril and Change in the Thirteenth-Century Southwest; Kohler, K.T., Mark, M.D., Wright, A.M., Eds.; University of Arizona Press: Tucson, AZ, USA, 2010; pp. 1–33. [Google Scholar]
- Van West, C.R. Modeling Prehistoric Agricultural Productivity in Southwestern Colorado: A GIS Approach; Washington State University Laboratory of Anthropology: Pullman, WA, USA, 1994. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | a (°C) | b (°C) | c (day) | Year | a (°C) | b (°C) | c (day) | Year | a (°C) | b (°C) | c (day) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1930 * | 8.68 | 13.26 | 259.7 | 1960 * | 9.83 | 14.15 | 253.9 | 1991 * | 8.26 | 12.66 | 253.3 |
| 1931 * | 8.97 | 13.40 | 255.4 | 1961 * | 9.70 | 13.40 | 259.2 | 1992 | 11.62 | 13.22 | 262.2 |
| 1932 * | 8.58 | 13.46 | 259.6 | 1962 * | 10.25 | 12.25 | 251.4 | 1993 | 12.19 | 12.62 | 262.3 |
| 1934 * | 10.70 | 11.31 | 260.9 | 1963 * | 10.26 | 13.35 | 253.7 | 1995 | 12.36 | 11.35 | 252.0 |
| 1936 * | 9.76 | 12.67 | 258.3 | 1964 * | 9.04 | 13.37 | 251.7 | 1997 | 8.89 | 12.48 | 257.0 |
| 1937 * | 9.01 | 13.92 | 250.7 | 1965 * | 9.49 | 11.31 | 249.0 | 1998 | 9.32 | 12.30 | 252.8 |
| 1938 * | 9.56 | 11.81 | 254.9 | 1966 * | 10.16 | 13.25 | 253.9 | 1999 | 9.32 | 11.21 | 256.1 |
| 1939 * | 9.61 | 13.03 | 253.4 | 1967 * | 9.87 | 12.33 | 255.3 | 2000 | 10.35 | 12.66 | 260.9 |
| 1940 * | 10.07 | 12.72 | 256.9 | 1968 * | 9.10 | 12.53 | 255.9 | 2001 | 9.87 | 12.70 | 258.5 |
| 1941 * | 9.35 | 10.76 | 254.8 | 1969 * | 10.24 | 12.67 | 255.0 | 2002 | 9.56 | 13.45 | 262.5 |
| 1942 * | 9.71 | 12.24 | 249.6 | 1970 * | 9.70 | 12.08 | 253.9 | 2003 | 10.23 | 12.64 | 256.5 |
| 1943 * | 11.36 | 12.33 | 258.3 | 1971 * | 9.41 | 12.81 | 258.2 | 2004 | 9.23 | 12.01 | 261.3 |
| 1944 * | 9.73 | 12.39 | 250.5 | 1972 * | 10.37 | 12.52 | 259.4 | 2005 | 9.63 | 11.44 | 256.7 |
| 1945 * | 9.55 | 12.21 | 253.1 | 1975 | 11.34 | 13.90 | 253.1 | 2006 | 9.63 | 12.46 | 263.5 |
| 1947 * | 9.97 | 12.70 | 256.7 | 1976 | 12.00 | 11.75 | 254.6 | 2007 | 9.81 | 13.20 | 258.1 |
| 1948 * | 9.66 | 12.83 | 253.7 | 1978 | 11.15 | 12.94 | 258.8 | 2008 | 8.83 | 13.16 | 254.3 |
| 1949 * | 9.56 | 13.20 | 253.4 | 1980 | 11.56 | 11.91 | 255.4 | 2009 | 9.22 | 12.60 | 261.7 |
| 1952 * | 9.86 | 13.32 | 253.3 | 1981 | 12.05 | 12.45 | 257.0 | 2010 | 9.13 | 12.79 | 255.3 |
| 1953 * | 10.25 | 12.37 | 252.5 | 1983 | 10.49 | 12.20 | 251.7 | 2011 | 9.27 | 13.32 | 258.0 |
| 1954 * | 11.27 | 11.94 | 256.6 | 1985 | 11.03 | 12.83 | 257.6 | 2012 | 10.42 | 13.11 | 259.6 |
| 1955 * | 9.40 | 12.92 | 249.8 | 1986 | 12.22 | 11.47 | 263.2 | 2013 | 9.10 | 14.26 | 260.8 |
| 1956 * | 9.92 | 12.43 | 256.6 | 1987 | 10.89 | 12.22 | 261.2 | 2014 | 10.10 | 12.06 | 256.6 |
| 1957 * | 9.83 | 10.91 | 255.1 | 1988 * | 8.94 | 13.33 | 251.7 | 2015 | 10.01 | 11.74 | 257.7 |
| 1958 * | 10.68 | 12.25 | 252.4 | 1989 * | 9.22 | 12.96 | 259.3 | 2016 | 9.83 | 12.46 | 256.2 |
| 1959 * | 10.73 | 12.53 | 256.8 | 1990 * | 9.18 | 13.01 | 257.1 |
| a vs. b | a vs. c | |
|---|---|---|
| Root Mean Square Error (RMSE) | 0.69 °C | 3.4 day |
| Correlation Coefficient (r) | 0.25 | 0.13 |
| Maximum (OBS.-EST.) | 1.16 °C | 7.5 day |
| Minimum (OBS.-EST.) | −1.96 °C | −6.9 day |
| Month | f | RMSE (mm) | r | Range of ΔMP |
|---|---|---|---|---|
| January | 0.07978 | 19.29 | 0.38 | [−28.0 mm, 54.0 mm] |
| February | 0.07599 | 16.45 | 0.26 | [−25.0 mm, 56.0 mm] |
| March | 0.08464 | 21.13 | 0.43 | [−28.0 mm, 75.0 mm] |
| April | 0.07334 | 16.71 | 0.50 | [−25.0 mm, 46.0 mm] |
| May | 0.07107 | 18.18 | 0.47 | [−24.0 mm, 69.0 mm] |
| June | 0.03626 | 11.09 | 0.41 | [−13.0 mm, 37.0 mm] |
| July | 0.09319 | 18.78 | 0.35 | [−38.0 mm, 43.0 mm] |
| August | 0.119 | 24.76 | 0.15 | [−53.0 mm, 62.0 mm] |
| September | 0.106 | 23.23 | 0.31 | [−71.0 mm, 52.0 mm] |
| October | 0.1073 | 28.22 | 0.38 | [−36.0 mm,131.0 mm] |
| November | 0.06912 | 15.02 | 0.39 | [−34.0 mm, 42.0 mm] |
| December | 0.08435 | 17.87 | 0.34 | [−42.0 mm, 43.0 mm] |
| Month | g | RMSE (day) | r | Range of ΔNDD |
|---|---|---|---|---|
| January | −0.2087 | 2.4 | 0.77 | [−7 day, 5 day] |
| February | −0.1947 | 3.0 | 0.34 | [−7 day, 11 day] |
| March | −0.1811 | 3.2 | 0.48 | [−6 day, 10 day] |
| April | −0.187 | 13.3 | 0.37 | [−7 day, 7 day] |
| May | −0.1911 | 2.6 | 0.65 | [−7 day, 7 day] |
| June | −0.1812 | 2.1 | 0.47 | [−7 day, 5 day] |
| July | −0.189 | 3.2 | 0.29 | [−7 day, 11 day] |
| August | −0.1776 | 3.7 | 0.31 | [−7 day, 8 day] |
| September | −0.1542 | 2.9 | 0.46 | [−8 day, 9 day] |
| October | −0.1293 | 2.8 | 0.62 | [−8 day, 6 day] |
| November | −0.1763 | 2.3 | 0.53 | [−7 day, 5 day] |
| December | −0.1951 | 3.1 | 0.13 | [−7 day, 7 day] |
| Month | h | RMSE (mm) | r | Range of ΔMDP |
|---|---|---|---|---|
| January | 0.3134 | 4.12 | 0.76 | [−10 mm, 14 mm] |
| February | 0.3426 | 4.13 | 0.73 | [−9 mm, 20 mm] |
| March | 0.2698 | 4.30 | 0.75 | [−12 mm, 13 mm] |
| April | 0.3619 | 3.98 | 0.80 | [−12 mm, 10 mm] |
| May | 0.3566 | 4.19 | 0.77 | [−13 mm, 15 mm] |
| June | 0.495 | 2.91 | 0.90 | [−8 mm, 9 mm] |
| July | 0.3719 | 4.79 | 0.81 | [−9 mm, 15 mm] |
| August | 0.3895 | 5.99 | 0.80 | [−13 mm, 18 mm] |
| September | 0.3915 | 6.56 | 0.75 | [−20 mm, 18 mm] |
| October | 0.3715 | 7.33 | 0.74 | [−37 mm, 27 mm] |
| November | 0.4196 | 5.20 | 0.71 | [−19 mm, 20 mm] |
| December | 0.3375 | 3.76 | 0.83 | [−9 mm, 18 mm] |
| Category | DPA Range | Category | DPA Range |
|---|---|---|---|
| 1 | DPA = 0.254 mm (trace) | 7 | 0.55 MDP ≤ DPA < 0.65 MDP |
| 2 | 0.254 mm < DPA < 0.15 MDP | 8 | 0.65 MDP ≤ DPA < 0.75 MDP |
| 3 | 0.15 MDP ≤ DPA < 0.25 MDP | 9 | 0.75 MDP ≤ DPA < 0.85 MDP |
| 4 | 0.25 MDP ≤ DPA < 0.35 MDP | 10 | 0.85 MDP ≤ DPA < 0.95 MDP |
| 5 | 0.35 MDP ≤ DPA < 0.45 MDP | 11 | 0.95 MDP ≤ DPA ≤ MDP |
| 6 | 0.45 MDP ≤ DPA < 0.55 MDP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, F.; Nagaoka, L.; Wolverton, S.; Atkinson, S.F.; Kohler, T.A.; O’Neill, M. A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation. Atmosphere 2021, 12, 135. https://doi.org/10.3390/atmos12020135
Pan F, Nagaoka L, Wolverton S, Atkinson SF, Kohler TA, O’Neill M. A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation. Atmosphere. 2021; 12(2):135. https://doi.org/10.3390/atmos12020135
Chicago/Turabian StylePan, Feifei, Lisa Nagaoka, Steve Wolverton, Samuel F. Atkinson, Timothy A. Kohler, and Marty O’Neill. 2021. "A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation" Atmosphere 12, no. 2: 135. https://doi.org/10.3390/atmos12020135
APA StylePan, F., Nagaoka, L., Wolverton, S., Atkinson, S. F., Kohler, T. A., & O’Neill, M. (2021). A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation. Atmosphere, 12(2), 135. https://doi.org/10.3390/atmos12020135