1. Introduction
Dam failure-related flooding with large-scale flood inflow, infiltration, dam piping, and insufficient flood control capacity can cause unpredictable damage to people and property. Property damage and human casualties due to flooding occur worldwide. It is important to be able to provide accurate flood maps to reduce potential flood damage [
1]. On 12 February 2017, 200,000 people were evacuated from the village under Oroville dam in California due to unforeseen flooding. On 9 May 2018, the collapse of the Patel dam in Kenya caused the loss of at least 48 lives and 2000 flood victims [
2]. On 25 January 2019, the collapse of the Brumadinho tailings dam in Brazil caused 270 casualties and massive pollution due to mine waste. Experts say that the collapse of the Edenville and Sanford dams in Michigan on 21 May 2020 caused 3500 homes to be destroyed and 10,000 people to be evacuated—something which might happen once every 500 years. Therefore, it is very important to be able to prepare an expected flood map to provide basic data for an EAP (Emergency Action Plan) by analyzing the downstream consequences in case of an emergency situation at a dam. The Federal Emergency Management Agency (FEMA) actually provides 100 years of flood maps from all across the United States to be used as the basis for establishing flood insurance costs. Japan, meanwhile, operates a system for utilizing flood analysis and grid unit information, and provides disaster-related maps including flood control zones. In the case of Europe, the EU Flood Defense Directive has been established to produce flood risk maps which can be divided into pre-flood risk assessment, flood risk guidance, and flood risk management plans.
A one- or two-dimensional flood numerical model may be applied to prepare flood flooding diagrams in advance. Kim et al. [
1] linked the results of DAMBRK, which performs one-dimensional dynamic analysis, to the GIS program for flood map generation. Dang et al. [
3] simulated the natural dam break, and this research showed that important parameter for verifying the simulated and observed discharge is the time of collapse. Lodhi et al. [
4] conducted dam collapse analysis for various scenarios using DAMBRK and was able to indicate flooding patterns downstream of dams with probable maximum flood (PMF) conditions. The study indicated that the absence of a dam in a high rainfall intensity situation could lead to more serious flood damage downstream. These studies indicate that the limitations of one-dimensional flood analysis could be addressed by generation of flood maps using the GIS program. Mao et al. [
5] emphasized that the risk of flooding increases with economic growth. They carried out dam collapse analysis using the MIKE-21 program. Flood analysis was conducted using hydrological and geographical data, and the flood maps automatically drawn by the GIS program. Alvarez et al. [
6] conducted virtual dam collapse analysis with the Iber program, which enables two-dimensional flood wave analysis based on dam collapse analysis and finite volume methodology. This research also identified that topographic conditions affect the results of the model to a greater extent than other factors and suggested a method for performing dam collapse analysis in basins with insufficient data.
Predicted flood maps can be prepared using various models, and the resulting data can be used for diverse purposes. In Korea, flood maps are also produced through one-dimensional dynamic models to determine flood risk levels for urban areas that are downstream of dams. Dam collapse-related flood maps are prepared using probable maximum flood (PMF) conditions. Seoul, Korea has a high population density, so flood maps should be prepared and distributed not only for the above conditions but also for the event of dam inflow exceeding a return period of 200 years. However, creating flood maps by linking the GIS program with a dynamic model can require a lot of time for preparing input data, generating topographic data, and calculating a numerical map with the GIS program. Moreover, flood maps generated by the GIS program may indicate non-continuous flooding patterns for some low-lying areas, requiring post-processing of data. Such intensive work is time-consuming and makes it difficult to create a flood map that reflects various dam inflow scenarios.
The random forest model, which could be used for regression or classification, has been increasingly applied to flood analysis and water resource engineering. The random forest model is an ensemble model, which is advantageous for handling large amounts of data. Feng et al. [
7] conducted the urban flood mapping by using unmanned aerial vehicle remote sensing and random forest classifier model. The random forest model in this research applied to extract the flooded areas by recognizing the monitoring results of UAV. Sachdeva et al. [
8] performed the flood susceptibility mapping by using random forest model, and compared it GIS-based support vector machine. This research showed that the random forest model could be used for flood susceptibility assessment with other conventional machine learning methods. Munoz et al. [
9] used the random forest algorithm for flash-flood forecasting. The methodology in this research was applied to develop short-term prediction model for various time duration. This performance of presented model was improved by including precipitation data.
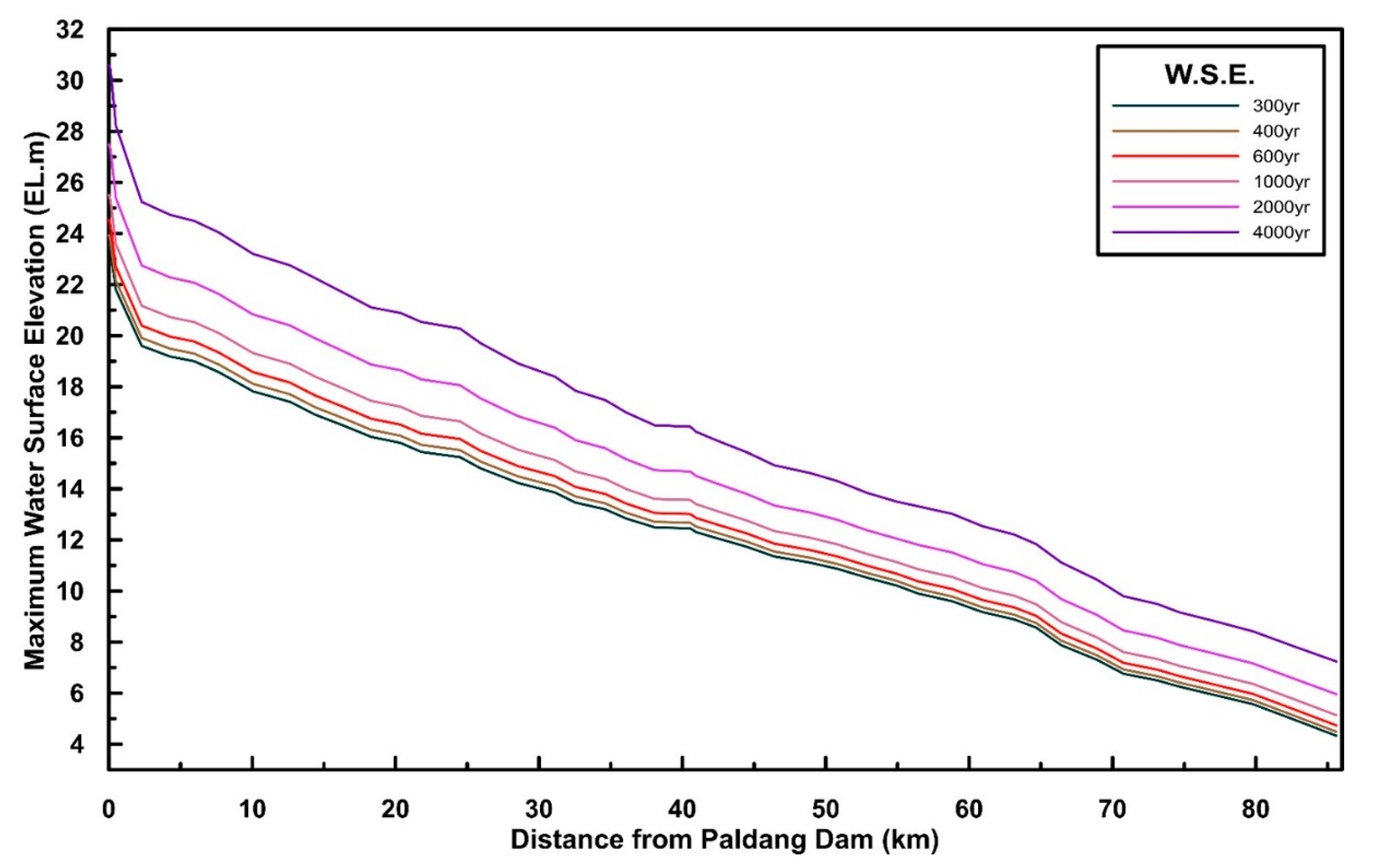
Accordingly, this study presented a technique to generate predicted flood maps rapidly when dam peak inflow (or dam inflow return period) is given along with the random forest regression technique. Flood maps for extreme condition were analyzed, and in this study, it means extensive inundation in metropolitan watersheds with the excessive discharge or collapse of dam. Since PMF (probable maximum flood) conditions were also considered, the extreme flood patterns due to climate change were analyzed with machine learning and numerical program. For random forest regression, the maximum water surface elevation for cross-sections was entered. For the rapid estimation of maximum water surface elevation for each cross-section, the log function and the spline curves were applied. The independent variable of the log function was the dam inflow return period and the dependent variable was the amount of dam inflow in cubic meter per seconds. The spline curves were generated with using maximum water surface elevation information calculated by the DAMBRK model. When any dam inflow return period was entered, the log function was used to estimate the peak inflow of the dam, and the maximum water surface elevation for each cross-section was estimated in a short time with a spline curve. Based on the maximum water surface elevation calculated by the DAMBRK model and the flood map data generated by the GIS program, the basic data for random forest regression was established. The proposed methodology aids production of large-scale flood map data, and flood risk was calculated to indicate the utilization of flood map data using the population of Seoul City and information regarding hospital and fire station accessibility. This study will enable sufficient flood data to be established in advance, as various extreme climate change-associated flood events may occur in future. The flowchart for this study is shown in
Figure 1 and
Figure 2. The random forest data for the study section shown in
Figure 1 was used for flood map prediction, and the random forest data in
Figure 2 was applied to select weights for each flood risk factor.
2. Research Methods
2.1. DAMBRK
The DAMBRK model is used to analyze hydrological runoff from reservoir collapse and for hydraulic routing of the flood flow downstream. A U.S. National Weather Service (NWS) dynamic flood analysis model, DAMBRK was developed by Fread [
10] in 1980s. This model was developed to allow mathematical interpretation of flood routing downstream and induction of dam discharge curves. The governing equation used in this model is a one-dimensional Saint-Venant equation designed to accommodate internal boundary conditions such as the effects of rapid varied flows, cross section changes, bridges, etc. at the downstream section. Objective values are obtained from the nonlinear weighted four-point implicit scheme equation. The downstream flow can be calculated for both subcritical and supercritical flow. Flood hydrological curves are calculated from variables such as time, size, and shape of the point of collapse. The dynamic flood routing of the DAMBRK model results in interpretation of the Saint-Venant equation, consisting of a continuous equation and a momentum equation, as the Preissmann finite differential method [
10].
In Equations (1) and (2), is the flow direction distance of the stream, is the time, is the flow rate, is the water level elevation, is the flow area, is the storage area, is the friction slope, is the loss slope due to the cross-sectional change, is lateral discharge quantity, and is the change in the amount of movement due to the rate of lateral discharge quantity. In this study, dam discharge or collapse flow rates were calculated for the various dam inflows, and the highest flood level by cross-section was calculated by performing channel routing.
2.2. Random Forest
The random forest model is a technique that uses ensemble learning to generate a number of decision trees to perform classification and regression for specific event occurrences. Although it is possible to predict desired hydrologic data using ensemble learning between different kinds of artificial neural networks, as attempted by Zhou et al. [
11], the random forest applied in this study is a model that uses a number of decision trees and aggregates each result. The random forest model is simple but offers high predictive power for conducting interpretations of natural phenomena [
12]. Important random forest parameters are max_features, bootstrap usage, and
n_estimator. The max_features parameter determines the maximum number of attributes to be used in each node. Bootstrap is an option for allowing data overlap when sampling data for each classification model. The
n_estimator is determined by the number of decision trees created in a random forest. The default value is set to 10 in this study. When the number of variables
is typically the random forest number, each split and randomly select
/3 variables to create a decision tree [
13]. The algorithm of random forest can be summarized in four stages:
(1) Extract any bootstrap sample .
(2) To determine the decision tree from the bootstrap sample, each node does not allow duplication and randomly selects the number of characteristics. Divide the nodes using characteristics that create the optimal segmentation for an objective function, such as information gain.
(3) Repeat times step (1), (2).
(4) Each decision tree’s predictions are collected, and class labels (objective values) are assigned by a majority vote.
A particular function is defined to optimize division of nodes by the most informative characteristics. A particular function that can be used in the random forest maximizes information gains in each partition. Information gain (
) can be defined as Equation (3).
where
is the property to be used for segmentation,
and
are the data set of the parent and the
th child node,
is an impurity indicator, and
is the total number of samples on the parent node and
represents the number of samples on the
th child node. The information gain is simply the difference between the impurity of the parent node and the impurity of the child node. The lower the impurity of the child node, the greater the information gain is. In this study, the parameters of random forest model, which in the scikit-learn package for python, were adjusted in automatically based on the calculation of impurity in each node.
3. Verification of the Study Area
For the purpose of flood map analysis, the Paldang dam and the Han river basin were selected as the study area. The study area for this research, including the Seoul Metropolitan, is shown in
Figure 3, and the area of the study boundary is 3140
. The city of Seoul, which has an area of 605
, is comprised of 25 administrative districts. This area has been damaged by sudden discharge from the Paldang dam during flood season and rising water surface elevation in the mainstream of the Han River.
In order to perform accurate hydraulic channel routing according to the operating conditions of the Paldang dam, it was necessary to accurately input the dam specifications into the DAMBRK program. The basin area is 23,517
and the reservoir area of the Paldang dam is 36.5
. Flood water, high water, and minimum water levels are 27.0, 25.5 and 25.0
EL.
, respectively. In terms of the main specifications of Paldang Dam, the dam type is C.G.D. and its height is 29.0
. The dam elevation is 32.0
EL.
, the length is 575.0
, and the volume is 250,000
[
14]. The DAMBRK cross-section was constructed using HEC-RAS terrain information data and 1:5000 numerical map data to enable appropriate analysis of dam collapse and flood routing. A total of 44 cross-sections directly downstream of the Paldang dam were used. The roughness coefficient was entered into the DAMBRK by referring to the HEC-RAS input data and the Han River basic plan [
15].
In order to check the appropriateness of the input data and the DAMBRK cross-section, the model was verified using the actual observed inflow and observed water surface elevation. Validation was conducted on Paldang bridge and Hangang bridge, and water level data observed from 15 July to 16 July 2006 and 27 July to 28 July 2011 was used. In 2006 and 2011, flood damage was caused by rising flood water levels in the Han river. For model calibration, the river distortion factor and roughness coefficient were adjusted with trial and error method. A comparison of the water surface elevation calculated by the DAMBRK and the observed water surface elevation is shown in
Figure 4. In 2006, the mean square error (MSE) for Paldang Bridge and Hangang bridge was 0.15 m and 0.11
. In 2011, the MSE for Paldang bridge and Hangang bridge was 0.15
and 0.09
. The DAMBRK model adequately reproduced the observed water surface elevation, and the cross-section and input data used in DAMBRK was considered appropriate.
6. Discussion
Existing method could consume a lot of time for showing flood map with consideration of dam operation or collapse [
1,
2,
3,
4]. The technique proposed in this paper has the advantage of displaying a flood map faster than the previous method that using GIS program [
5]. However, there is a disadvantage that it is necessary to build a database for various flood scenarios for this purpose. This shortcoming can be solved through data processing automation that can quickly build a flood database.
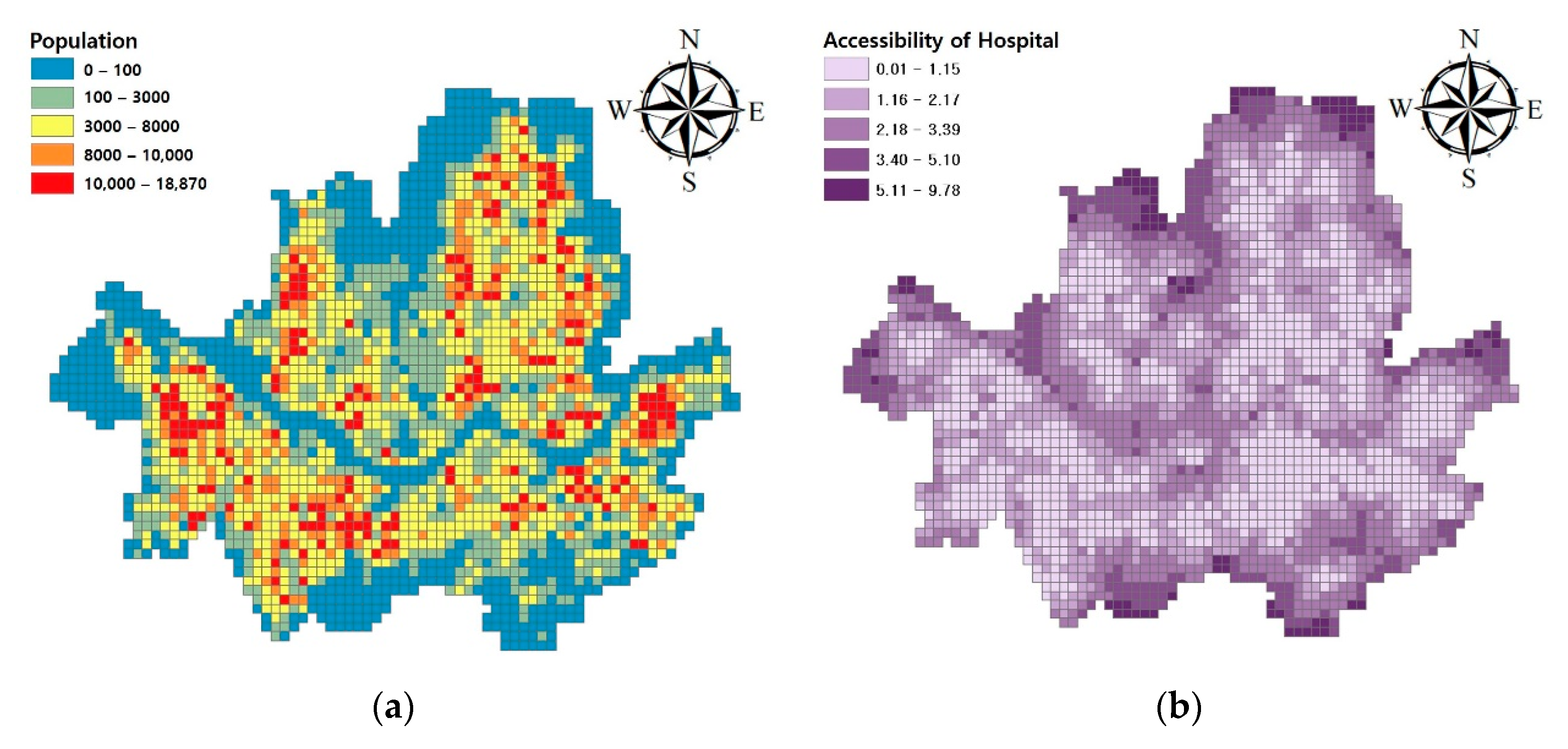
In addition, unlike previous studies, this study not only displays a flood map, but also presents a flood risk level by using flood maps that rapidly generated, population, and accessibility to hospitals and fire stations data. Previous studies appear to have performed the flood risk analysis by using various economic and topographic factors [
18,
19]. However, in this study, the flood risk that could indicate the prioritization of flood response was analyzed by simply overlapping flood map, population and accessibility data. The result of flood risk analysis in district units will be used in extreme flood situation in Seoul city.
In order to apply this technique to other watersheds, accurate stream cross-section data are required to perform the DAMBRK simulation. The enough topographic data is also needed for drawing flood map with GIS program. Since it is necessary to accurately represent the pattern of flooding in urban areas, detailed building size and height information is also required. For flood risk analysis, the population data, other data that can affect flood response are also required. Depending on the new watershed, the applied flood information and topographic data may appear differently, and meaningful prediction results should be calculated by appropriately using the data according to the characteristics of each research area.
7. Conclusions
In this study, flood analysis was conducted using a one-dimensional flood analysis simulation and random forest modeling. To generate reliable flood data, the flood analysis model DAMBRK was validated by comparison with observed water surface elevation. The maximum water surface elevation in the Han River, flood map by dam inflow, and flood risk per district were predicted and analyzed according to the Paldang Dam inflow return period. The main findings of this study can be summarized as follows:
(1) Using the DAMBRK model, the maximum water surface elevation of each cross-section was calculated for the four inflow conditions. Under the 200, 500-year return periods and PMF conditions, flood maps were generated in conjunction with the results of DAMBRK and the ArcGIS program. Under PMF conditions, two flood maps were generated depending on whether the dam collapsed or not, indicating a wide extent of flooding and a high-water surface level under the conditions of the collapse of the Paldang Dam.
(2) Information for four flood maps was entered into the random forest model for training. The random forest regression model was trained to predict flooding patterns rapidly with consideration of any amount of dam inflow or return period. According to the conditions of peak inflow for Paldang dam, the water surface elevation was analyzed via the second and third spline curves. While it may require at least three to six hours to generate a flood map based on DAMBRK and ArcGIS analysis, prediction of a flood map through the given random forest regression model was carried out within one minute. This ability to identify flood conditions in a short period of time will help secure evacuation time and reduce damage to people and assets.
(3) Rapid estimation of maximum water surface elevation for 44 cross-sections was performed using cubic and quadratic spline curves. This process serves as an important medium for connecting input and prediction results in order to predict flood maps according to the amount of dam inflow. There are, however, some limitations to these estimated results of mapped maximum flooding in proportion to peak dam inflow due to the suggested methodology considering only the maximum discharge according to the reservoir level. Nevertheless, it is deemed appropriate for expressing the extent of extreme flooding instances.
(4) In order to indicate flood map utilization, data for human casualties, population, and accessibility to hospitals and fire stations was investigated. A method was proposed to prioritize disaster response in the event of a massive flooding based on human casualties. The analysis was performed using the calculated flood maps and predicted results. Considering casualties, the flood response priority was shown to take the order of Gangseo, Songpa, and Yeongdeungpo district. The proposed methodology is a simple one that works in conjunction with the random forest importance calculation technique but is judged to be a practical intuitive method. Suggested method has advantage of quickly determining the risk of flooding in emergency situations. If this methodology is linked to various flood maps, it is believed that flexible flood response can be achieved.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}