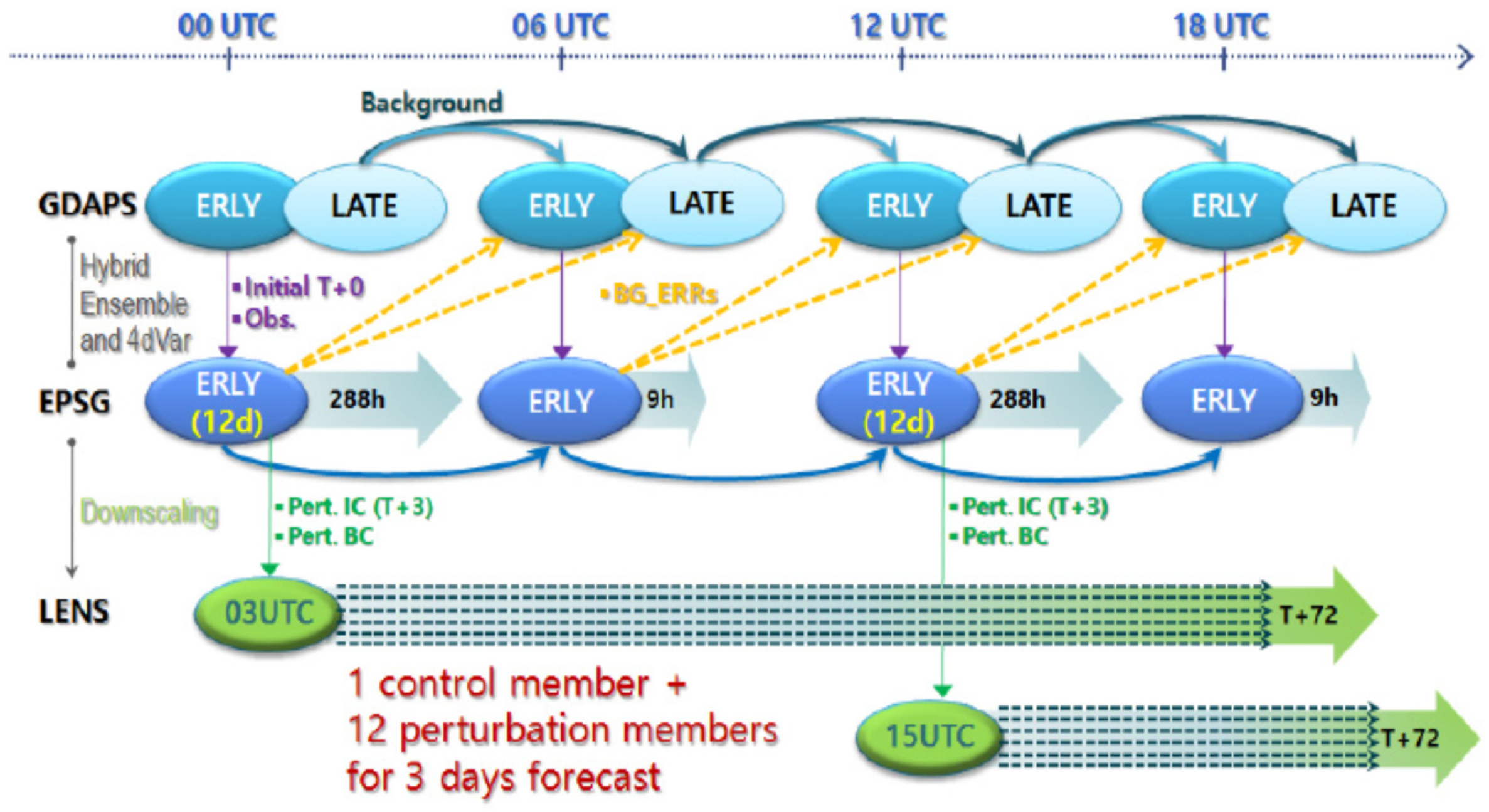
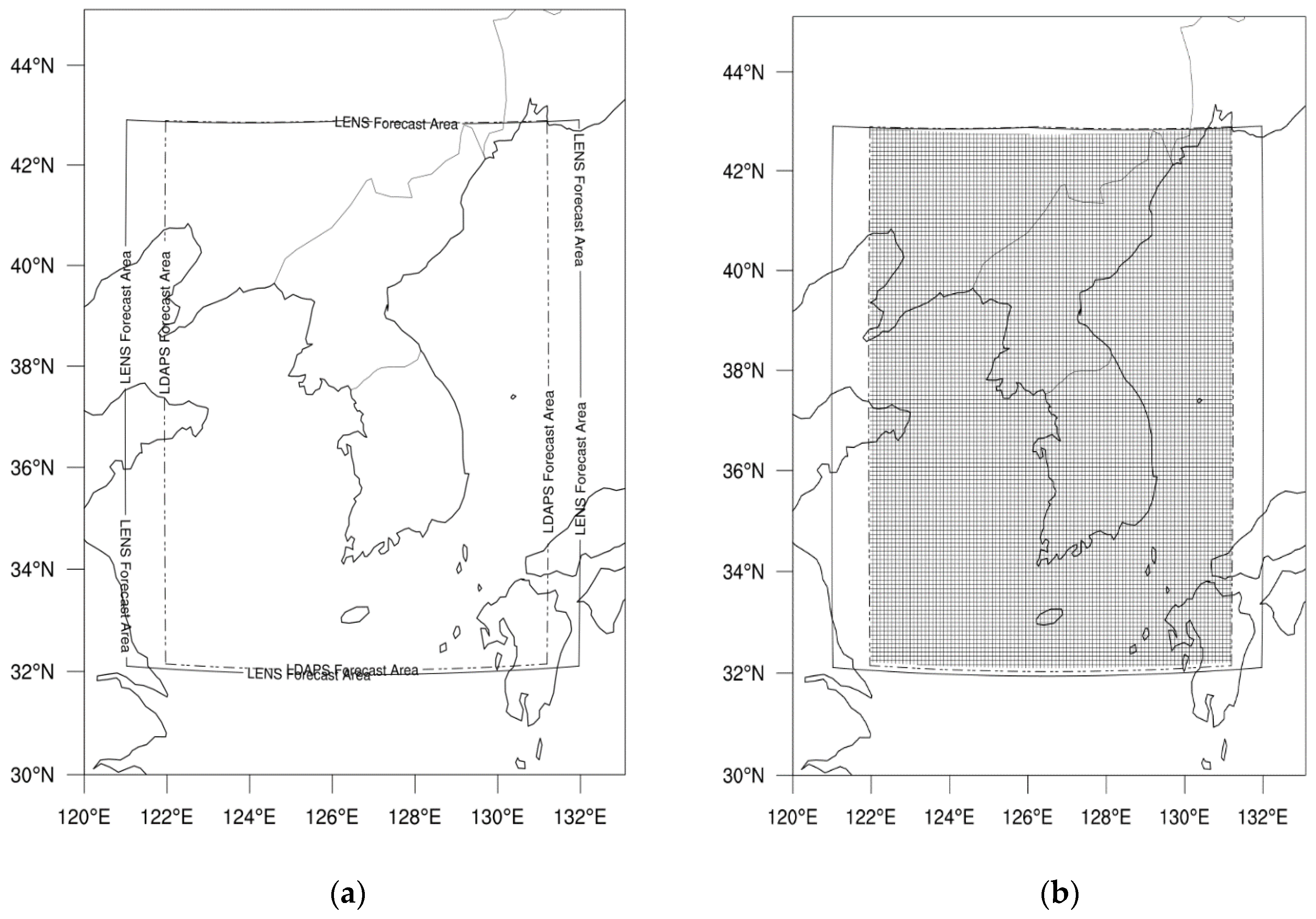
The ensemble forecasts of LLWS at intervals of 3h for lead times of 72 h (3 days) were issued twice a day at 0000 UTC (9 am local time) and 1200 UTC (9 pm local time). We focused on the LENS ensemble runs initialized at 0000 UTC. If any of the LLWS ensemble forecasts and analysis data (or both) were missing, all corresponding datasets were removed. Thereafter, the data used in the analysis were converted into seasonal data for all grid points and projection times. The verification is grid to grid.
In order to assess the reliability (or statistical consistency) of LLWS ensemble forecasts and their corresponding observations, which mean LDAPS analyses, a rank histogram [
17,
18] was used. The rank histogram is a very useful visual tool for evaluating the reliability of ensemble forecasts and identifying errors related to their mean and spread. Given a set of observations and a K-member ensemble forecasts, the first step in constructing a rank histogram is to rank the individual forecasts of a K-member ensemble from the lowest value to highest value. Next, a rank of the single observation within each group of K+1 values is determined. For example, if the single observation is smaller than all K-members, then its rank is 1. If it is greater than all the members, then its rank is K+1. For all sample of ensemble forecasts and observations, these ranks are plotted in the form of a histogram. If the rank histogram has a uniform pattern, then one may conclude that the ensemble and observation are drawn from indistinguishable distribution, whereas a non-uniform rank histogram indicates that the ensemble and observation are drawn from different distributions [
17].
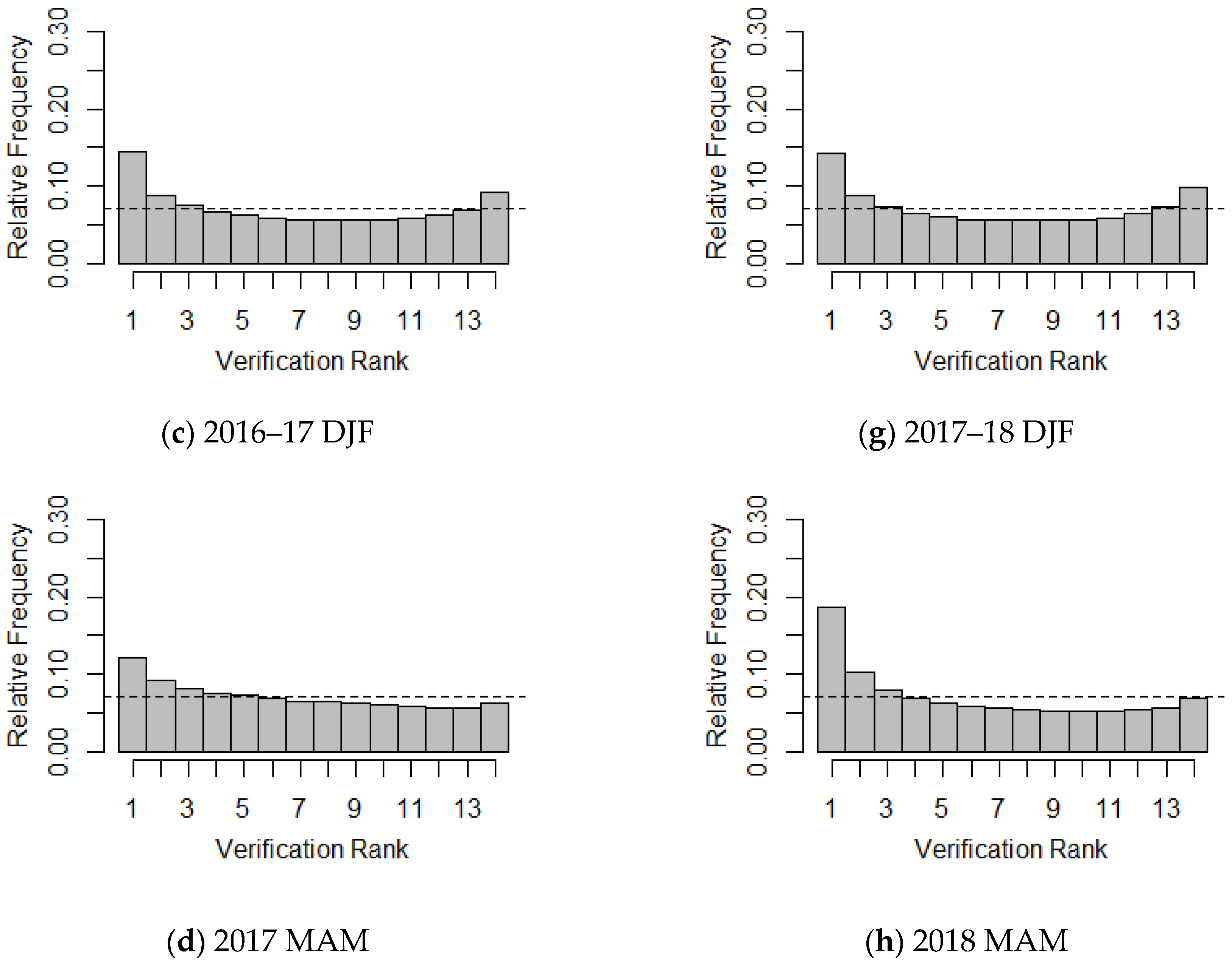
For example, a rank histogram with high (or moderate) frequency counts at both extremes, which shows a U-shaped implies the ensemble may be under-dispersive (for example
Figure 4a–d,g,h). A rank histogram with high counts near one extreme and low frequency counts near the other extreme (for example,
Figure 4h) presents a consistent bias or systematic error in the ensemble.
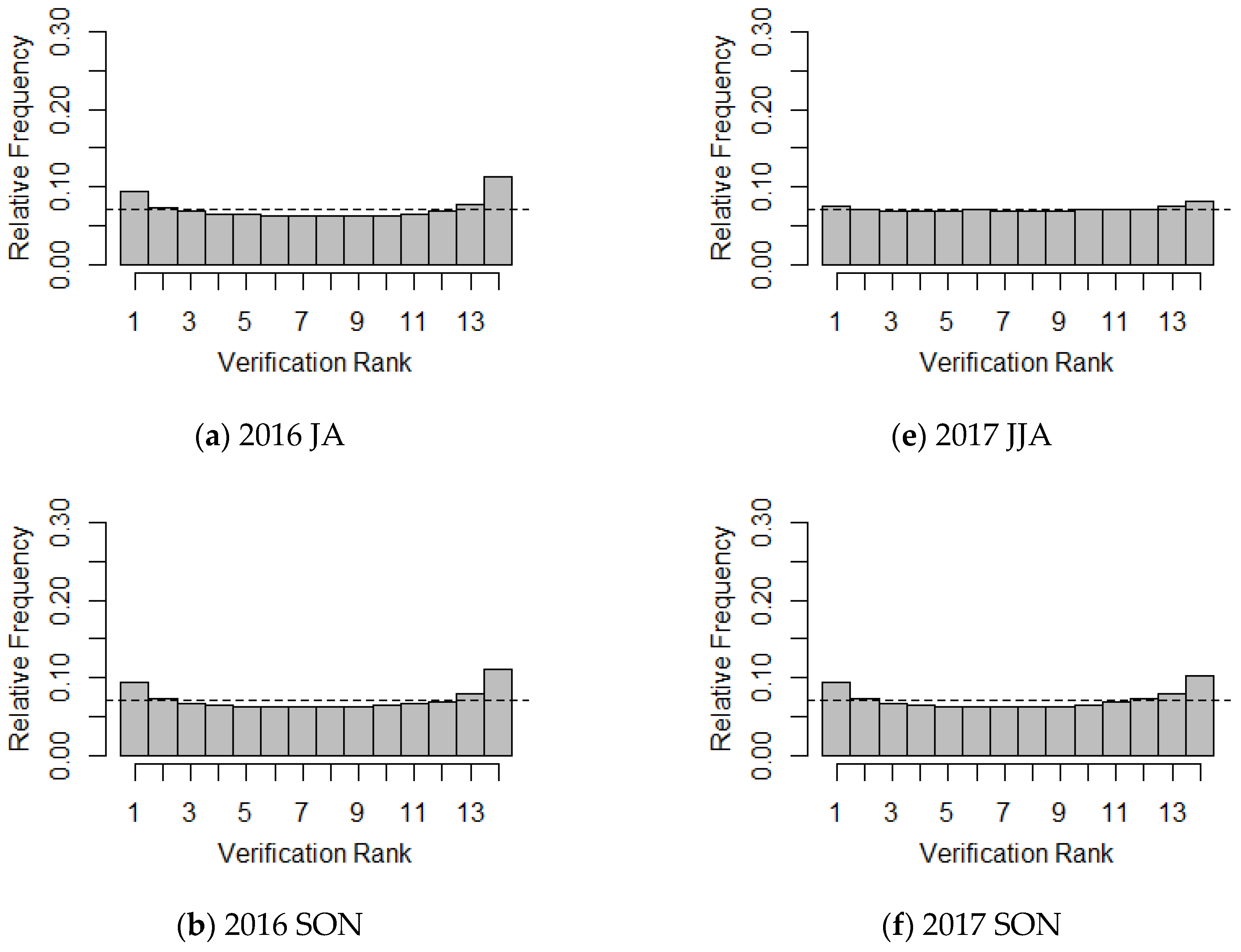
The rank histograms (RHs) for 13 ensemble forecasts and the corresponding LDAPS analyses for each season are presented in
Figure 4. In general, the RHs show similar patterns according to the seasons. For JJA and SON, the RH shows that the ensemble forecast tends to have a weak trend. For the 2016 JA and SON, the RH shows nearly similar frequency counts on both extremes, but has slightly more frequency on the right. Therefore, the LLWS ensemble forecasts have a slightly negative bias, which indicates a minor under-estimation, indicating that the LLWS ensemble forecasts are generally lower than the LDAPS analyses. However, for other seasons except 2017 JJA, the LLWS ensemble forecasts have a consistently positive bias, which implies over-estimation, in particular, the RH for the 2018 MAM has a strong positive bias compared to other seasons. The RHs for the 2017 JJA and SON do not show any skewed patterns, and it can be seen that there is almost no tendency in the two seasons. Moreover, the RHs clearly show a U-shape, except in the 2017 JJA, thus verifying that ensemble forecasts have under-dispersion, which implies that the ensemble spread is smaller than that of the corresponding LDAPS analyses, although the degree to which this was true varied seasonally. In addition, we see that about 21% of the LLWS observed data are not covered by the current LLWS ensemble forecast derived from LENS. However, the RH for the 2017 JJA has an almost uniform distribution, which indicates that the LDAPS analyses and ensemble forecasts were derived from the same distribution.
The reliability index is used to quantify the deviation of the RH from uniformity [
32]. The reliability index is defined by
, where
and
denote the number of classes in the rank histogram and the observed relative frequency in class
, respectively. If the LLWS ensemble forecasts and the corresponding LLWS observed data may have come from the same distribution, the reliability index should be zero. The reliability indexes for
Figure 4 are presented in
Table 1 and show a lack of uniformity (except in the 2017 JJA, as mentioned above). The reliability index of the 2018 MAM is greater than those of other seasons.
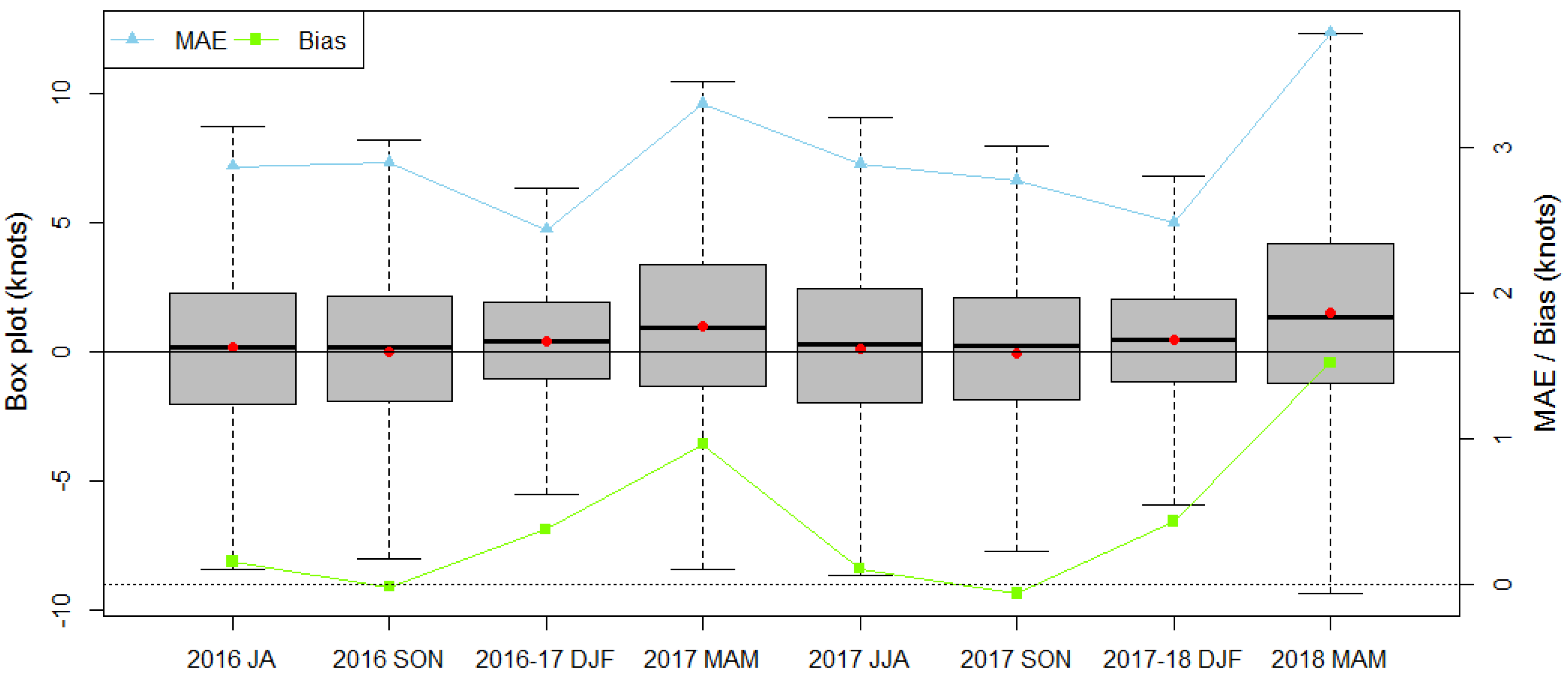
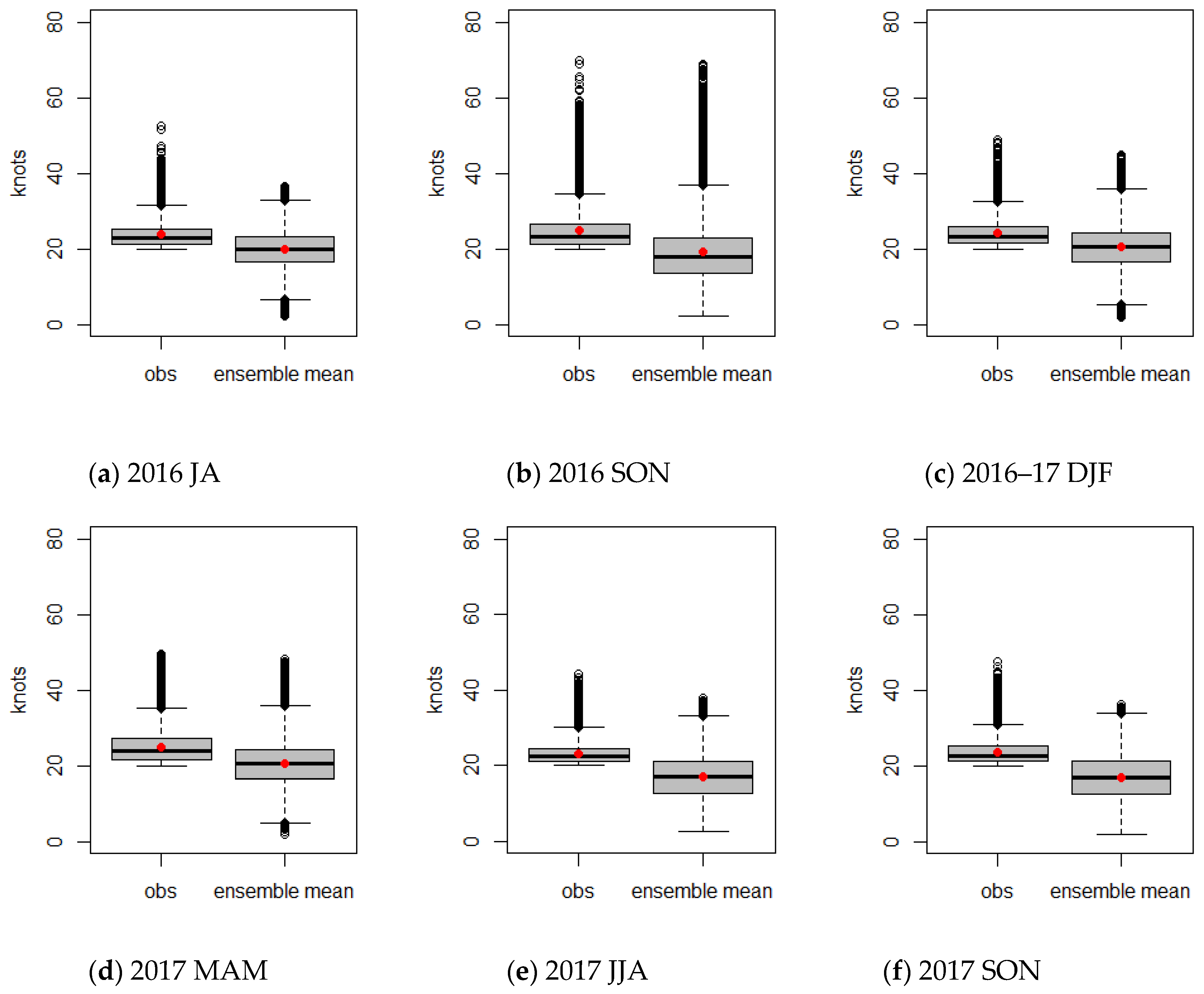
The pattern of bias according to each season is different from the results of MAE, RMSE, or CRPS, which are obtained via LLWS ensemble forecasts. Although autumn tends to have small biases, the MAE or CRPS indicate small values in winter seasons. To examine the discrepancy, box plots of the deviation between the LDAPS analyses and forecasts for each season are given in
Figure 7. The average deviation (red dot) in autumn is smaller than that in winter, but the variation of the deviations in autumn is larger than that in winter. For this reason, even if the average deviation in autumn is small, the variability of the deviations is large. Therefore, the performance skill is worse in autumn than in winter. As mentioned above, spring seasons have a strong positive bias, and the corresponding variabilities have wider ranges than they do in other seasons. This demonstrates that the prediction skill in spring is not as good as in other seasons.
3.1. Reliability Analysis of Forecast Probability
The forecast probability of LLWS can be generated by using a particular threshold value. Since a severe LLWS greatly impacts aviation weather forecasts, the occurrence of a severe LLWS is defined by the following threshold:
By using 13 ensemble member forecasts derived from LENS, the forecast probability of LLWS ensembles is computed as follows:
where
denotes the number of ensemble members and
denotes the number of ensemble members that are greater than 20 knots/2000 feet.
Severe LLWS events and their forecast probability, as defined in Equations (2) and (3) are calculated by using an LLWS ensemble forecast and its corresponding LDAPS analyses for each season. The distributional patterns of the LDAPS analyses and LLWS ensembles according to the presence or absence of a severe LLWS event can be analyzed by using box plots.
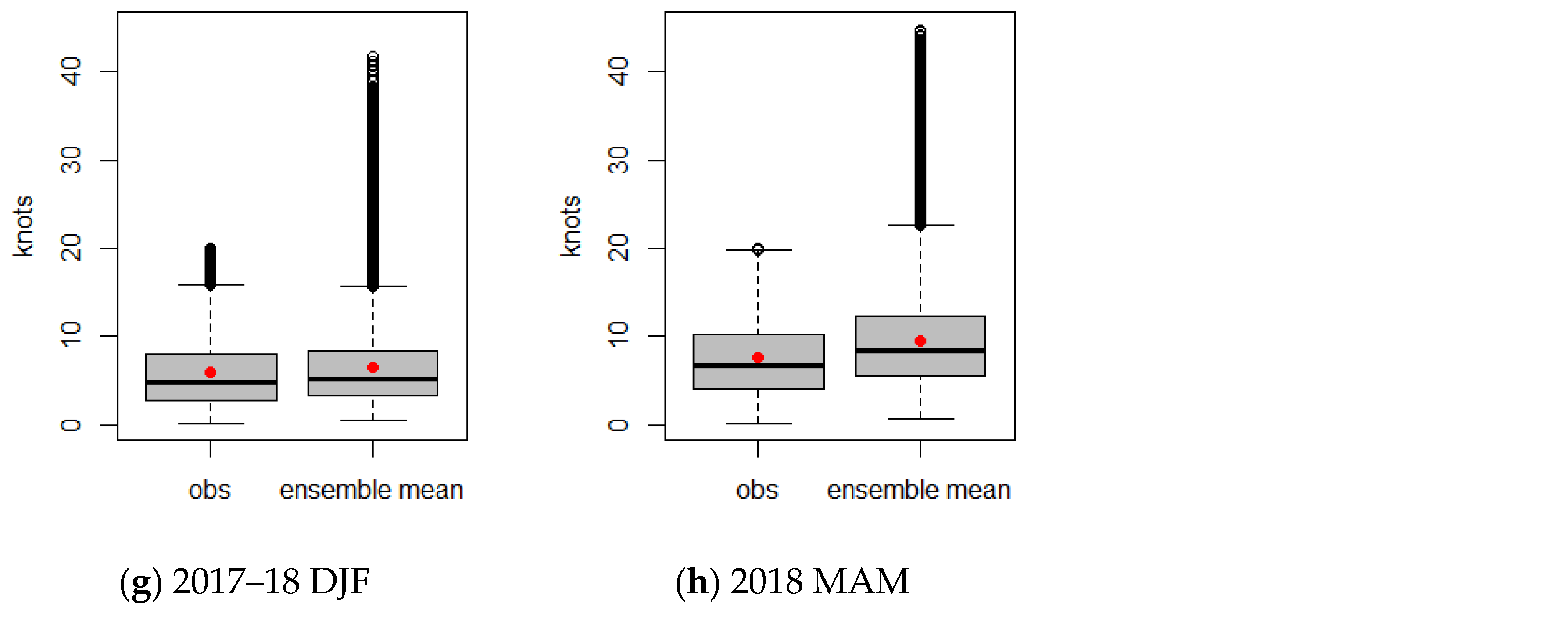
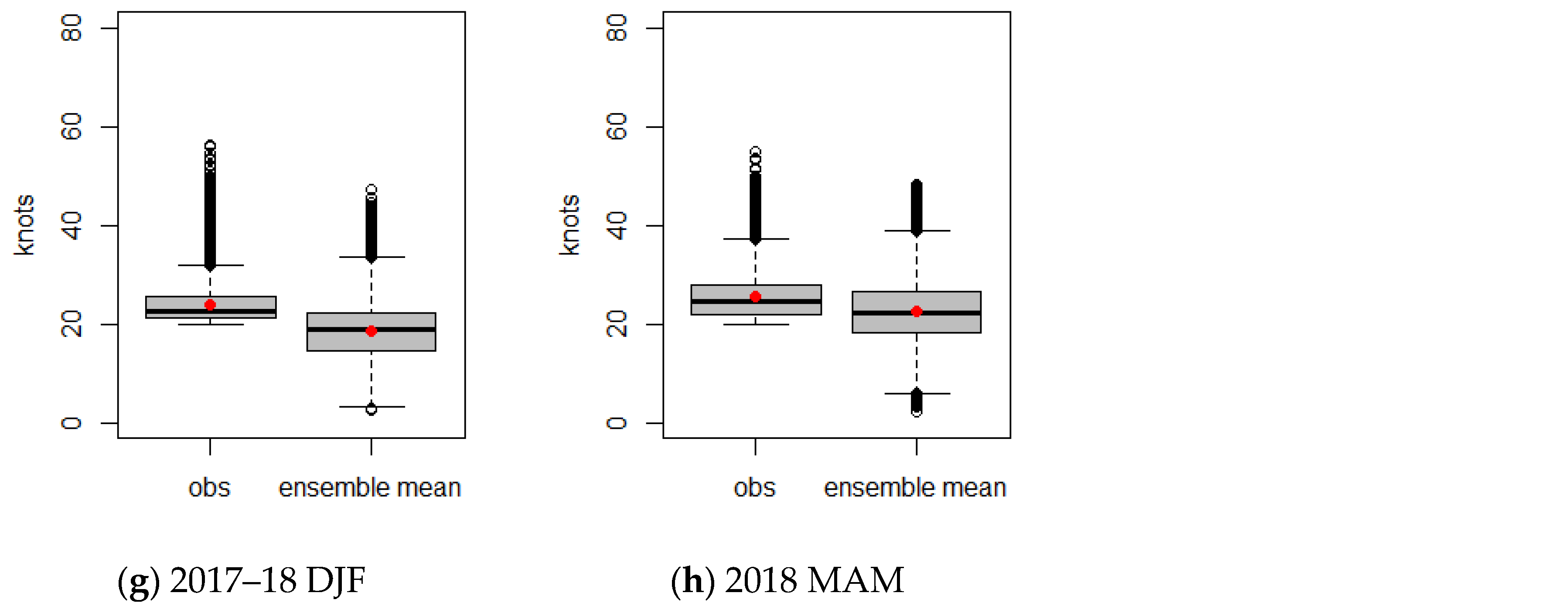
Figure 8 depicts box plots for wind speeds of the LDAPS analyses and average ensemble mean when a severe LLWS event did not occur. The distributional characteristics (mean and variation) of the observation and ensemble mean are almost similar regardless of the seasons. However, the outliers in the ensemble mean are relatively frequent compared to the LDAPS analyses. For the case of a severe LLWS in
Figure 9, the wind speeds of the LDAPS analyses and average ensemble mean show different distributional patterns. The average wind speed of the LDAPS analyses is about 24 knots, which is greater than the overall ensemble mean average and has less spread than that of the ensemble mean. On the other hand, the overall ensemble mean average is smaller than the average wind speed of the LDAPS analyses and shows a large amount of variability. This suggests that the ensemble forecasts did not simulate the LDAPS analyses well when a severe LLWS occurred. It can be seen that the prediction for a future quantity of LDAPS analyses is likely to be poorly predicted.
In general, the forecast probability of LLWS events can be assessed in terms of accuracy and reliability. The Brier score can be used to assess the accuracy and the reliability of the forecast probability is evaluated by a reliability diagram.
Forecasts are classified into two categories to produce a binary forecast: the probability of a severe LLWS event (>20 knots/2000 feet) and the probability of a non-severe LLWS (otherwise). The Brier score (BS) [
19,
20] for a data set comprising a series of forecasts and the corresponding observations is the average of the individual scores:
where
is the total number of data points,
denotes the forecast probability of the
th ensemble member forecasts and
is the corresponding observation with
for the observation of a severe LLWS event and
, otherwise. The BS is negatively oriented, with perfect forecasts exhibiting BS = 0.
The BS can be decomposed into three additive components: reliability, resolution, and uncertainty. The components of the decomposition of the BS are as follows:
where
is the number of forecast categories,
denotes the forecast probability of a severe LLWS event in category
, the number of observations in each category is denoted by
, and the number of observations of a severe LLWS event in each category is denoted by
. The average frequency of severe LLWS observations in category k is
. The overall average frequency of the severe LLWS observations is
.
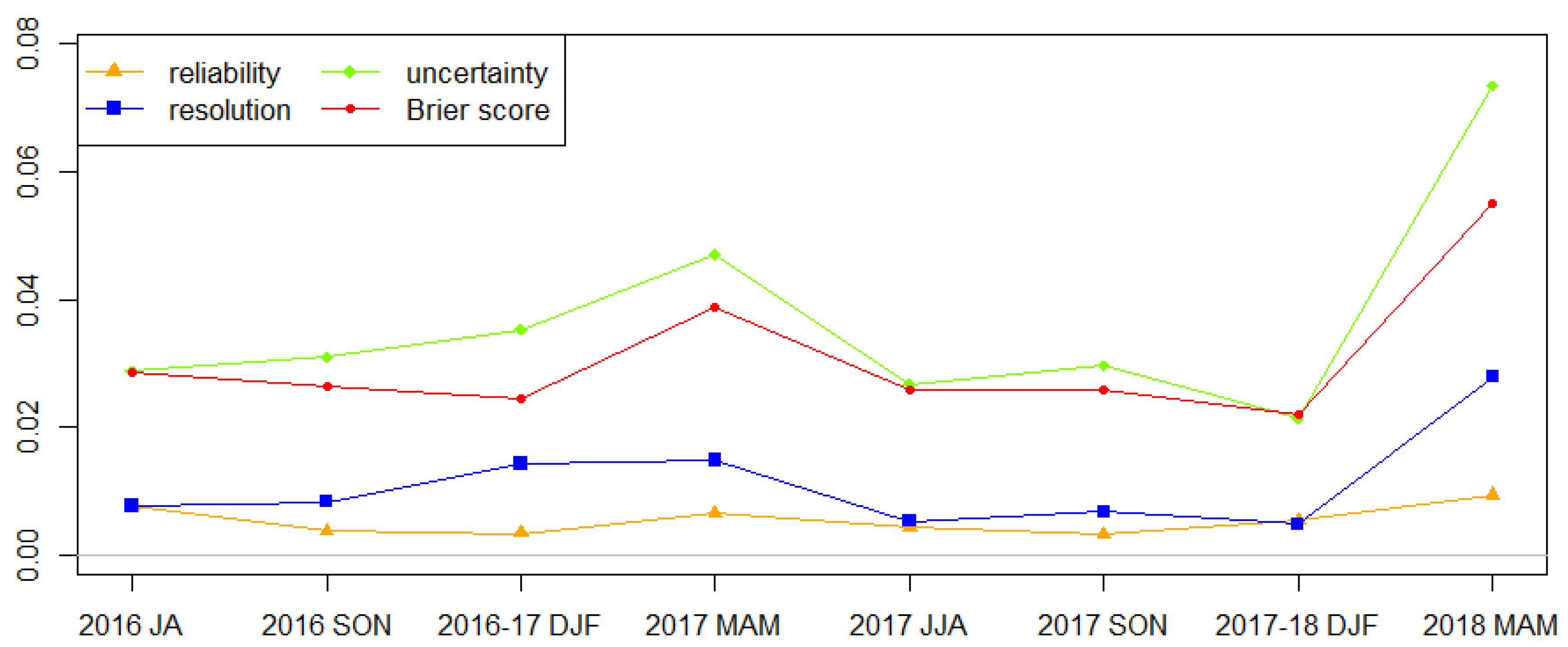
The BS, reliability, resolution, and uncertainty of the forecast probability of LLWS ensembles are described in
Figure 10. For a seasonal BS, the skill of the forecast probability is the worst in the spring season. The other seasons show similar BS values, but the performance of the forecast probability in the winter season is the best. The reason the BS is poor during the spring season is that it is heavily influenced by uncertainty rather than that by other decompositions of the BS. This is because the occurrence frequency of a severe LLWS event is higher than in other seasons, thus providing a cause of increasing uncertainty.
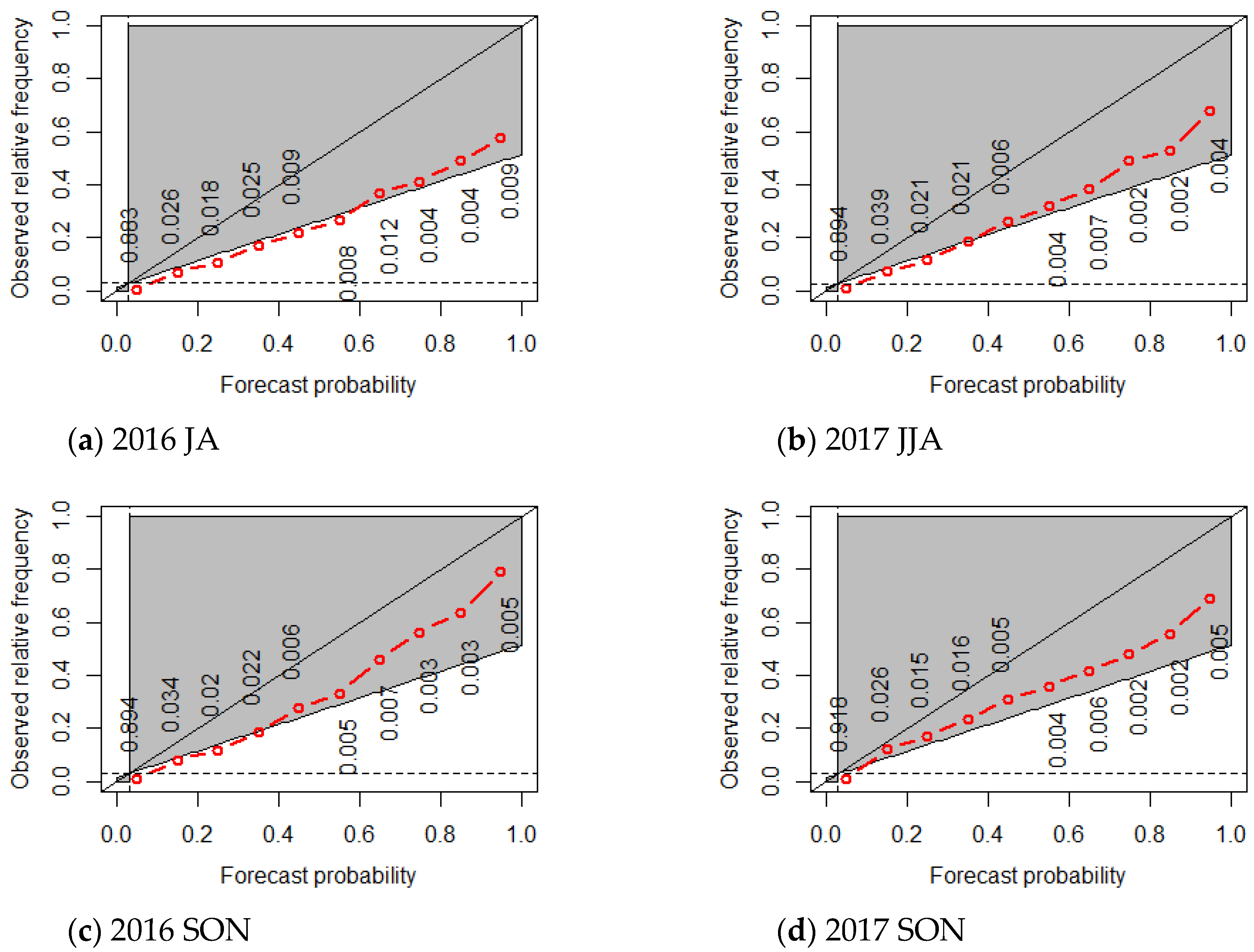
The reliability diagram is a highly useful visual tool that evaluates the reliability of the observed frequency of severe LLWS events plotted against the forecast probability of severe LLWS events [
21]. The reliability diagram shows how often a forecast probability actually occurred. For perfect reliability, the forecast probability and frequency of occurrence should be equal, and the plotted points should align on the diagonal. Thus, for example, when the forecast states an event will occur with a probability of 30%, for perfect reliability, the event should occur on 30% of the occasions for which the statement was made.
To evaluate the reliability of the forecast probability of LLWS ensembles, consider the seasonal reliability diagram given in
Figure 11. From
Figure 11, it can be seen that the reliability curve is located below the diagonal line for all seasons, which means it is over-forecasting. Comparing the two winter seasons, since the reliability curve for the 2017–2018 DJF moves away from the best line (in contrast to the 2016–2017 DJF), the reliability of the LLWS ensembles is lower in the 2017–2018 winter. This pattern is similar in other seasons.
The resolution is obtained from the distance between the uncertainty line and the reliability curve. If the reliability curve decreases down to the uncertainty line, the LLWS ensemble forecast has no resolution, or it indicates that the forecast cannot be distinguished from data uncertainty. The gray area in
Figure 11 is the skillful area, in which the LLWS ensemble forecast has skill, and the blank area is the area in which the LLWS ensemble forecast has no skill. For example, in the 2016 JA, if the LLWS ensemble forecast probability is lower than 60%, all the reliability curves are within the blank area, indicating that forecasts of severe LLWS events will not be skillful. For the 2017 MAM, when the forecast probability is equal to 0, the sample frequency is about 83.5%. This indicates that, of all the sample in 83.5% of the regions, no ensemble member indicated LLWS > 20 knots/2000 feet, indicating that all members predicted no severe LLWS event.
3.2. Forecast Probability Threshold Selection of LLWS
The occurrence of a severe LLWS can be categorized into four groups after a classification rule, as denoted in a 2 × 2 confusion matrix (contingency table) given in
Table 2, which contains information about the true and predicted classes.
In
Table 2, the terms positive (P) and negative (N) refer to the classifier’s prediction, and the terms true and false refer to whether that prediction corresponds to the observation. A “hit” is the number of occurrences where the forecast mean LLWS and the severe LLWS events are larger than the severe LLWS threshold. A “miss” is the number of occurrences where the forecast mean is not severe, but the observed LLWS event is severe; “false alarms” is the number of occurrence in which the forecast mean is severe, but the observed LLWS event is not severe. Several measures can be derived using the confusion matrix given in
Table 2:
where
First, we consider the forecast probability distribution obtained from 13 ensemble member forecasts to select the forecast probability threshold.
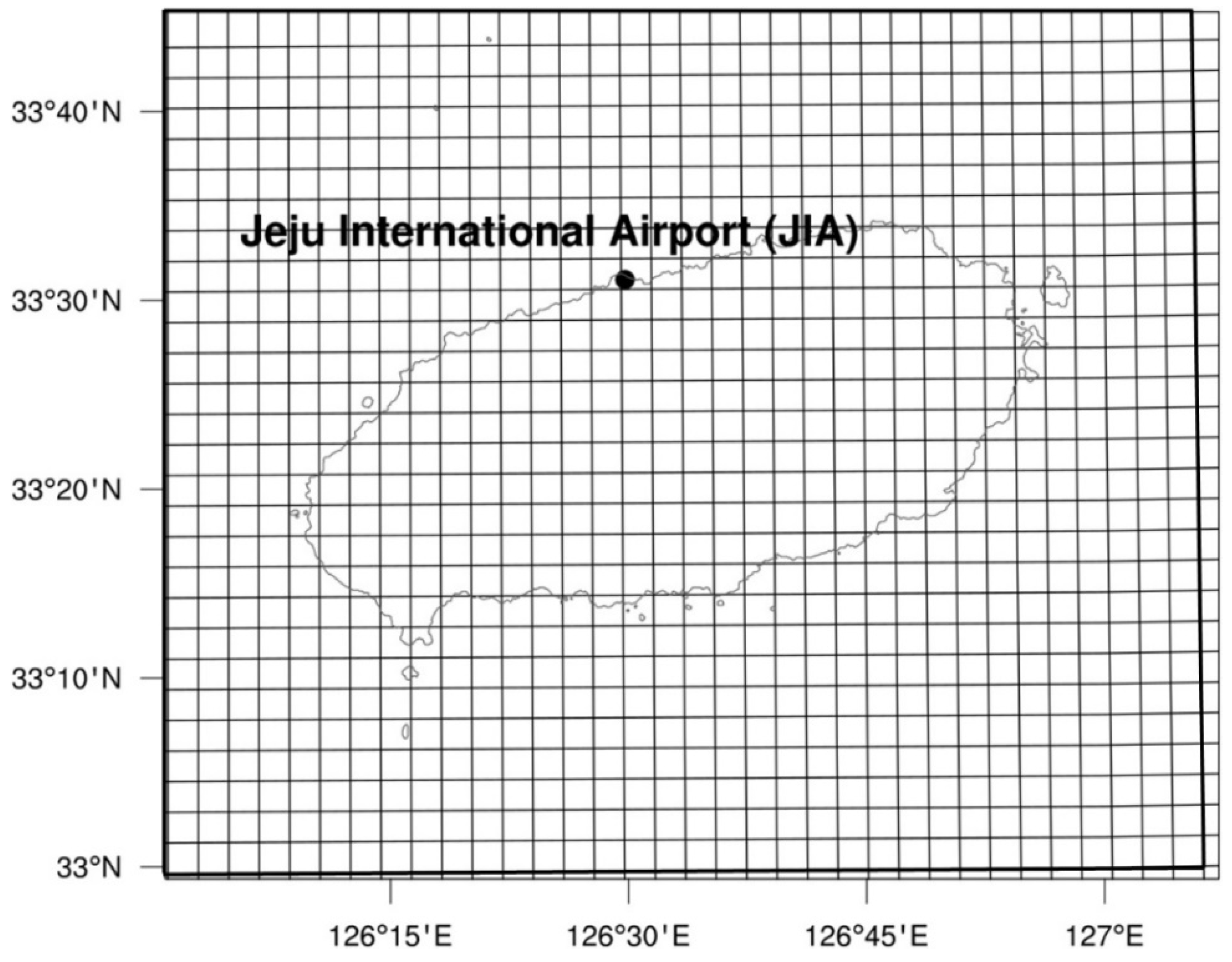
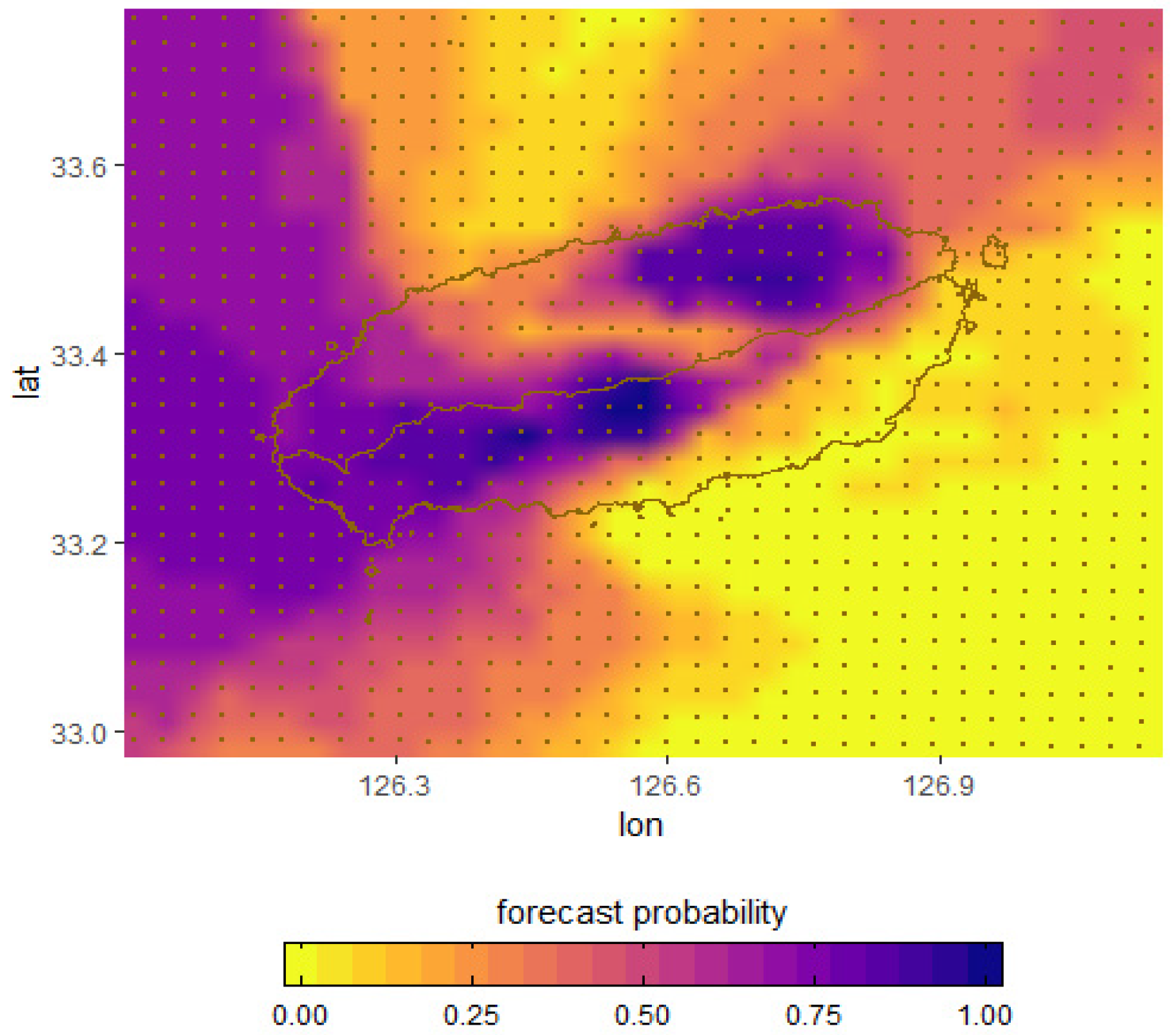
Figure 12 shows the severe LLWS probability distributions for all grid points of the Jeju area at the projection time of 24 h on 9 May 2017.
In
Figure 12, the yellow areas indicate that the forecast probability of a severe LLWS event is zero, and the blue areas indicate the most likely regions in which an LLWS event is over 20 knots/2000 feet. Depending on the region, the inland areas with dark blue are areas in which a severe LLWS event is more likely to occur, while other regions have different forecast probabilities for the severe LLWS. In this case, it is necessary to choose an appropriate threshold for the forecast probability to issue a severe LLWS warning for some regions. If the threshold sets to higher, the forecast confidence will increase but it will also lead to a high missing rate. On the other hand, if it is set to lower, the missing rate may be decreased, while the FAR increases. Therefore, determining a forecast probability threshold to issue severe LLWS warnings for certain regions is an important issue. For example, if the threshold is set to 100%, then all ensemble members will provide a severe LLWS forecast, and the confidence will be highest. Some regions in which a severe LLWS event actually happens, however, might be missed, but not all members will provide a severe LLWS forecast. If the threshold is set to 50%, then the missing rate may be lowered, but it may increase the FAR and the confidence level may decrease since only 50% of the members predict a severe LLWS event. Therefore, the issues with regard to the probability threshold is a very practical problem for forecasters interested in utilizing the probability information.
According to the methods of Zhou et al. [
16], we therefore select a forecast probability threshold using the ETS. Both the missing rate and FAR are related to the ETS and if both are at their lowest then the ETS will be at its highest. To select a threshold, we computed the missing rate and the FAR as well as the ETS for different forecast probabilities and selected a threshold in which both the missing rate and the FAR are their lowest and the ETS at their highest.
For each season, the missing rate, hit rate, FAR and ETS were calculated for different forecast probabilities to select a threshold of the forecast probability for each season on
grid points of Jeju at each projection time and depicted them together in one plot. For each season, we set the threshold of the forecast probability at intervals of 3 h for lead times up to 72 h.
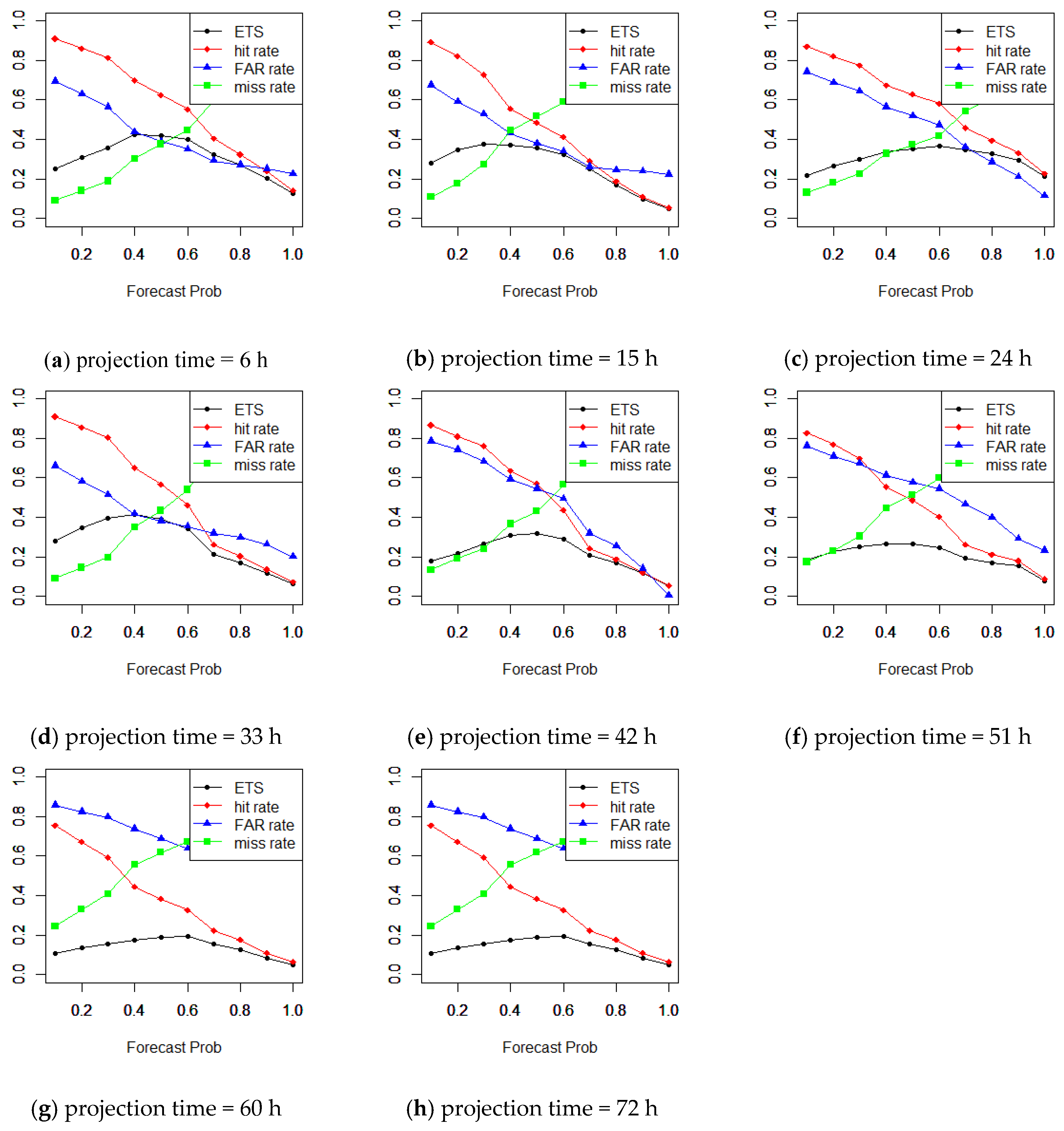
Figure 13 describes how to select a forecast probability threshold for issuing a severe LLWS. In
Figure 13, the red, blue, green and black lines denote the hit rate, FAR, missing rate, and ETS, respectively. From
Figure 13, it can be seen that the optimal forecast probability threshold is different depending on the projection times. For the projection time of 6 h, the results show that the best probability threshold is about 50%, where the ETS has a maximum point when the sum of the missing rate and the FAR is lowest. This means that the forecast probability threshold should be selected at 50% for issuing a severe LLWS warning. That is, as long as an area has a severe LLWS probability > 50%, we can be relatively confident that a severe LLWS will happen; this approach makes it most likely to miss a severe LLWS but has the lowest FAR.
For other projection times, we should select 40% at a projection time of 15 h, 60% at a projection time of 24 h, 45% at a projection time of 33 h, 55% at a projection time of 42 h, 55% at a projection time of 51 h, 60% at a projection time of 60 h and 60% at a projection time of 72 h. For other seasons, different forecast probability thresholds are obtained depending on the projection times (e.g., the 2017 MAM,
Figure 13).
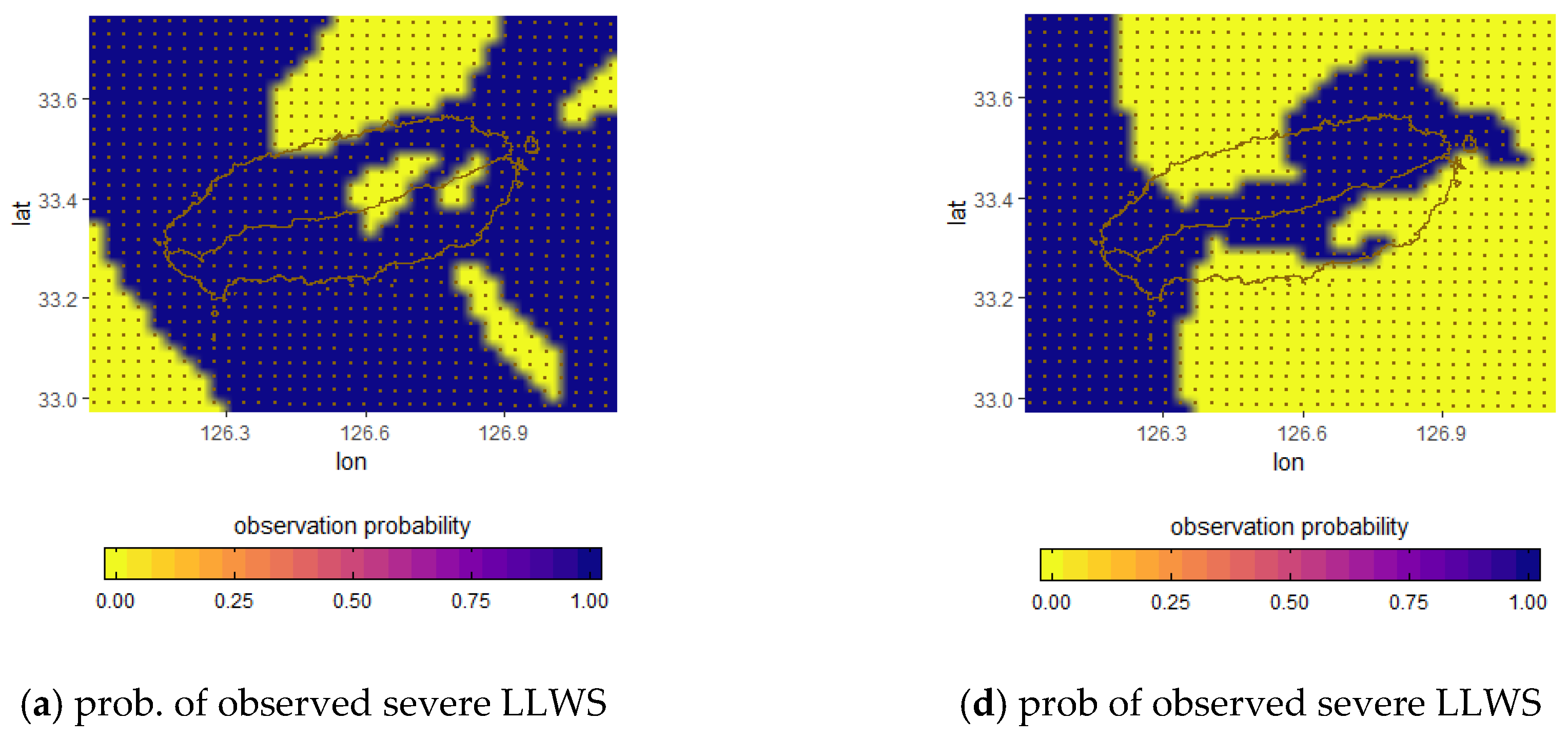
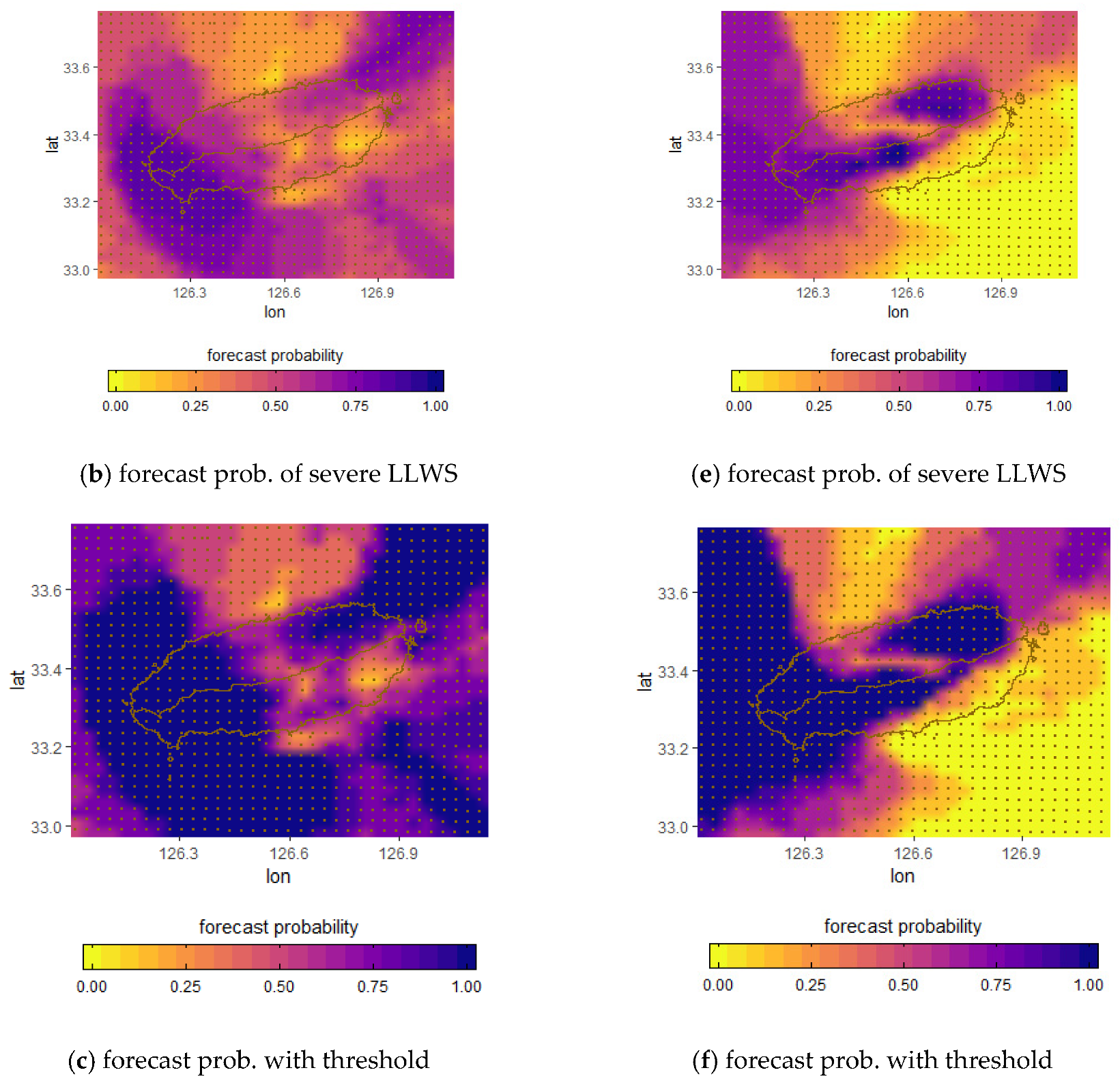
The observed probability, the forecast probability obtained from raw ensembles, and the best probability threshold for issuing a severe LLWS forecast for projection times of 60 h and 24 h on May 8 and 9, 2017 are respectively given in
Figure 14. From
Figure 14a, the probability of the observed severe LLWS has a binary value. That is, if the observed LLWS is greater than 20 knots/2000 feet, then the probability of a severe LLWS event is equal to 1 (blue region); otherwise, it is 0 (yellow region).
Figure 14b also represents the forecast probability of the LLWS ensembles defined in Equation (4). Comparing the observed probability (
Figure 14a) with the forecast probability (
Figure 14b) for the severe LLWS, the forecast probabilities are not consistent with the observed probabilities in most regions; that is, the forecast probabilities are predicted to be smaller than the observed probabilities. The forecast probability of a severe LLWS event is given in
Figure 14c when the best probability threshold is applied. In
Figure 14c, we selected 60% as the forecast probability threshold for issuing a severe LLWS warning. The forecast probability with threshold (
Figure 14c) is obtained as the forecast probability of severe LLWS (
Figure 14b) is divided by the threshold of 0.6 for all grid points. The ratio can be less than or greater than 1. If it is greater than 1, it is set to 1. The forecast probability distribution that is applied to the best probability threshold is similar to the observed probability distribution. It can be seen that regions where the forecast probability of a severe LLWS event is more than 60% are much more similar to regions where actual severe LLWS events occur compared to regions in which the threshold is not applied.
Figure 14d–f gives the probability distribution of the observed severe LLWS, the forecast probability obtained from LLWS ensembles, and the forecast probability from applying the threshold; the forecast probability threshold was set to 60%. It can be seen that the forecast probabilities obtained from LLWS ensembles are predicted to be lower than the probabilities of the observed severe LLWS events, except in some regions. This indicates that there is not a high possibility of issuing a severe LLWS warning. However, when the threshold is applied, the probability distribution of the regions where the forecast probability is greater than 60% are much more similar to those of regions in which the observed severe LLWS occurred. Therefore, we can see that the selection of a threshold plays an important role in issuing a severe LLWS warning.
We used only the hit rate, missing rate, FAR, and ETS to determine the best threshold. However, there is a limit to setting an optimal threshold using the hit rate, missing rate and FAR. If the frequency of occurrence of the observed severe LLWS events is not high, then a severe LLWS rarely occurs. In that case, any one of these rates can have a value of zero, and we cannot select a probability for which, both the missing rate and the FAR are lowest. To solve this problem, a lot of data should be provided, or as mentioned by Zhou et al. [
16], the economic factors that have an impact on the probability threshold selection rule should be considered.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}