The Use of Gaussian Mixture Models with Atmospheric Lagrangian Particle Dispersion Models for Density Estimation and Feature Identification


Abstract
1. Introduction
2. Method
2.1. Tracer Data
2.2. Lagrangian Atmospheric Transport and Dispersion Model
2.3. Simulations of CAPTEX
2.4. Histogram Method
2.5. Simulations of Volcanic Eruption
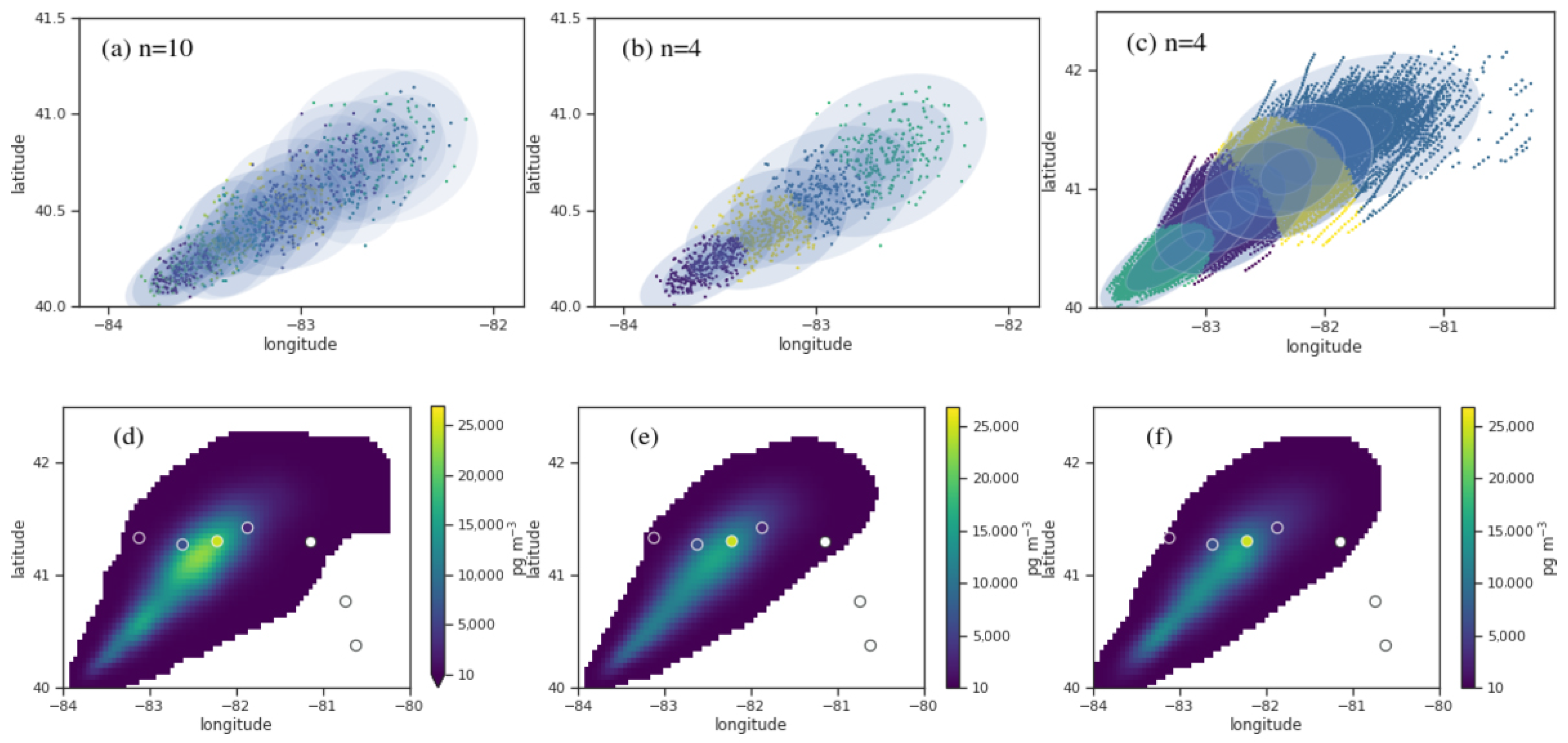
2.6. Gaussian Mixture Model
3. Results
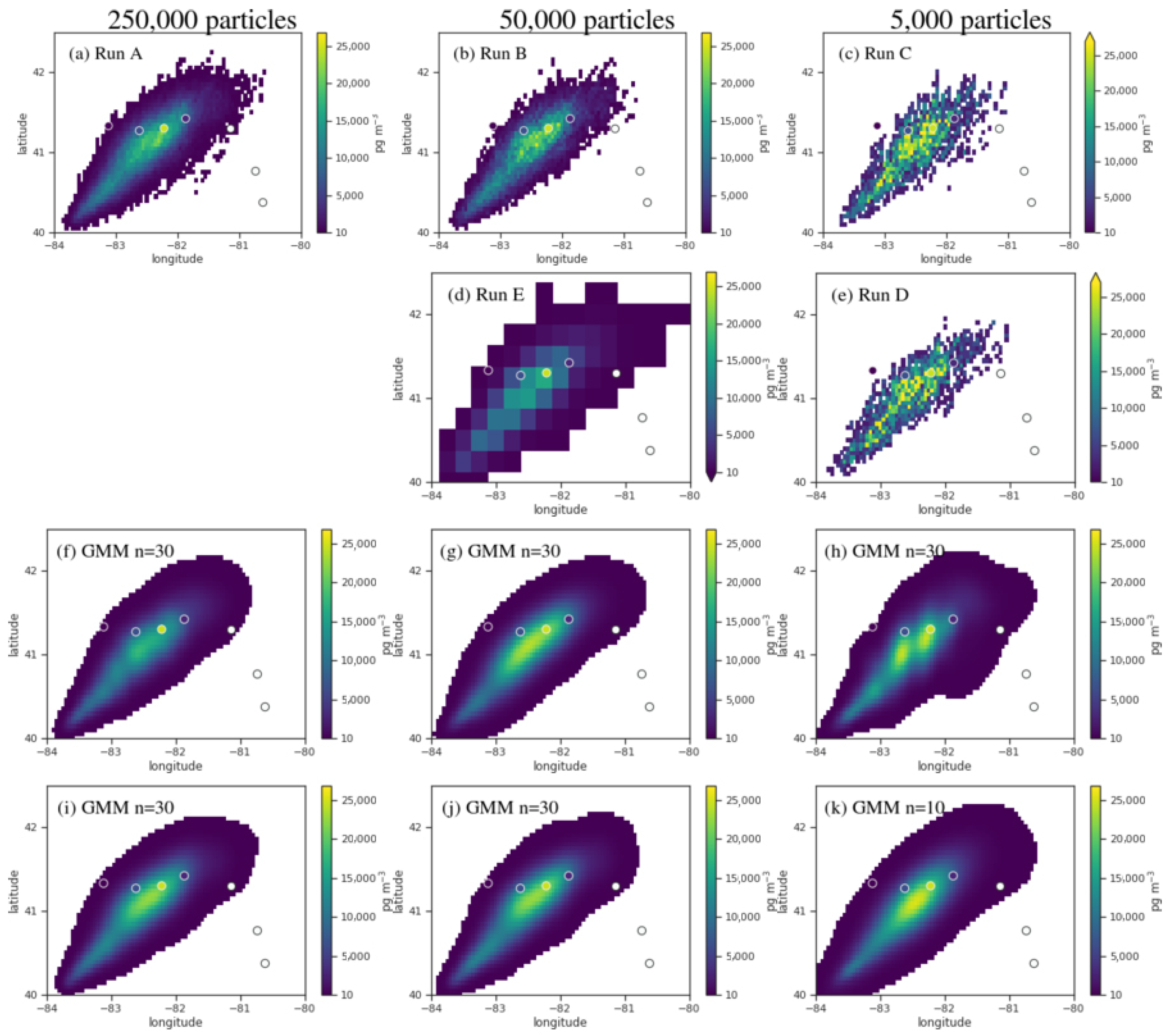
3.1. Density Reconstruction for a Tracer Experiment
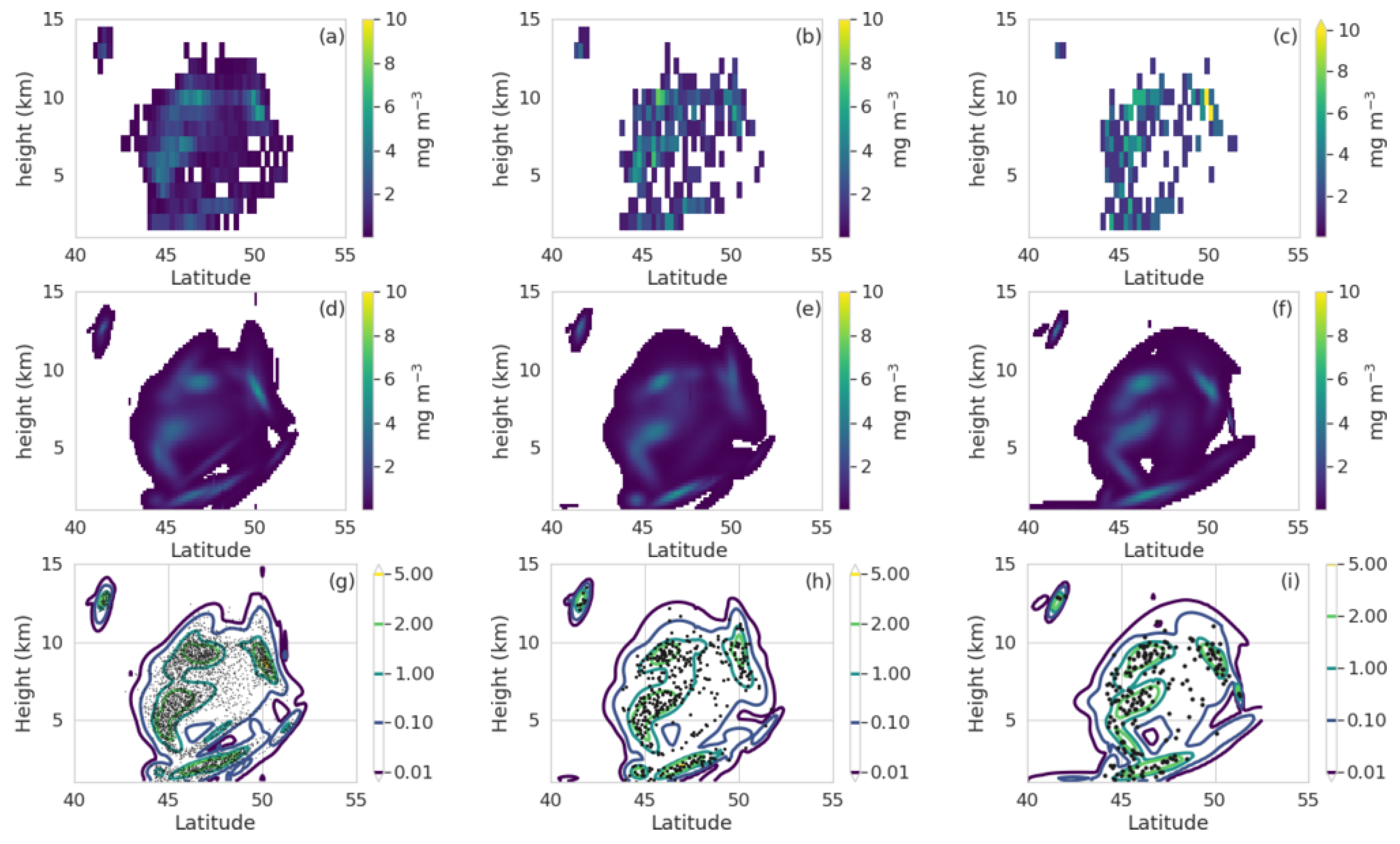
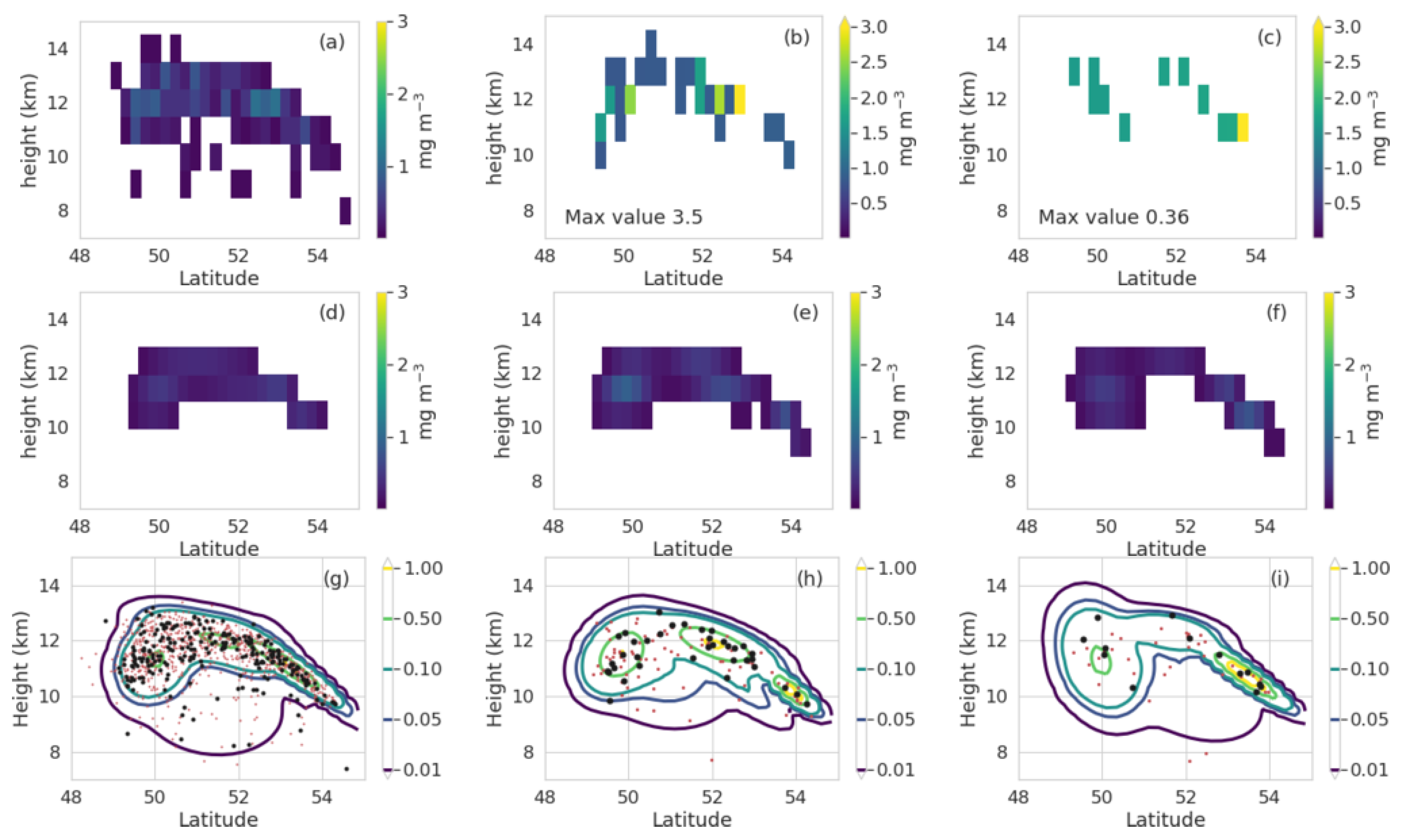
3.2. Density Reconstruction for a Volcanic Eruption
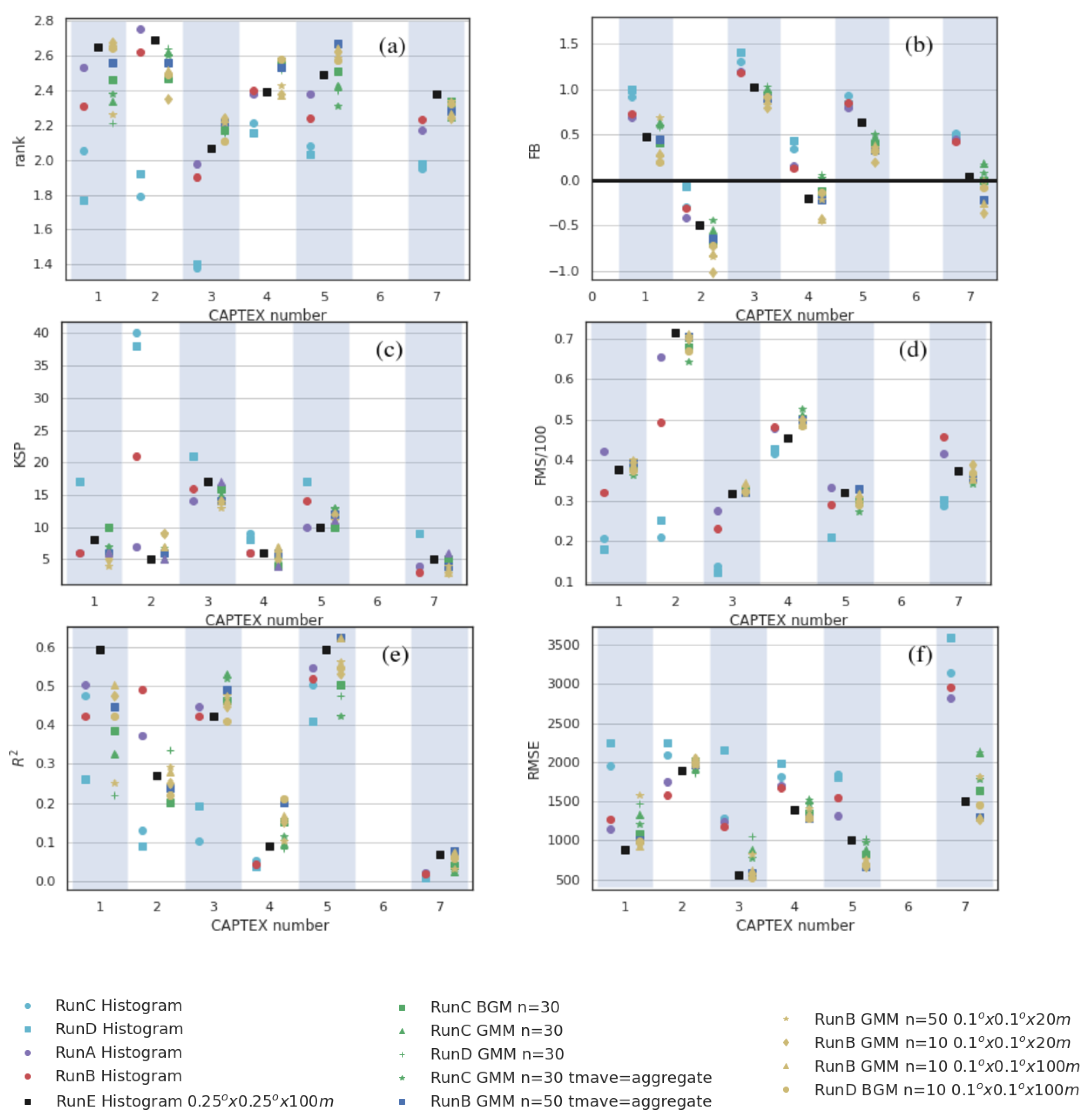
3.3. Feature Identification
3.3.1. Object Based Statistics
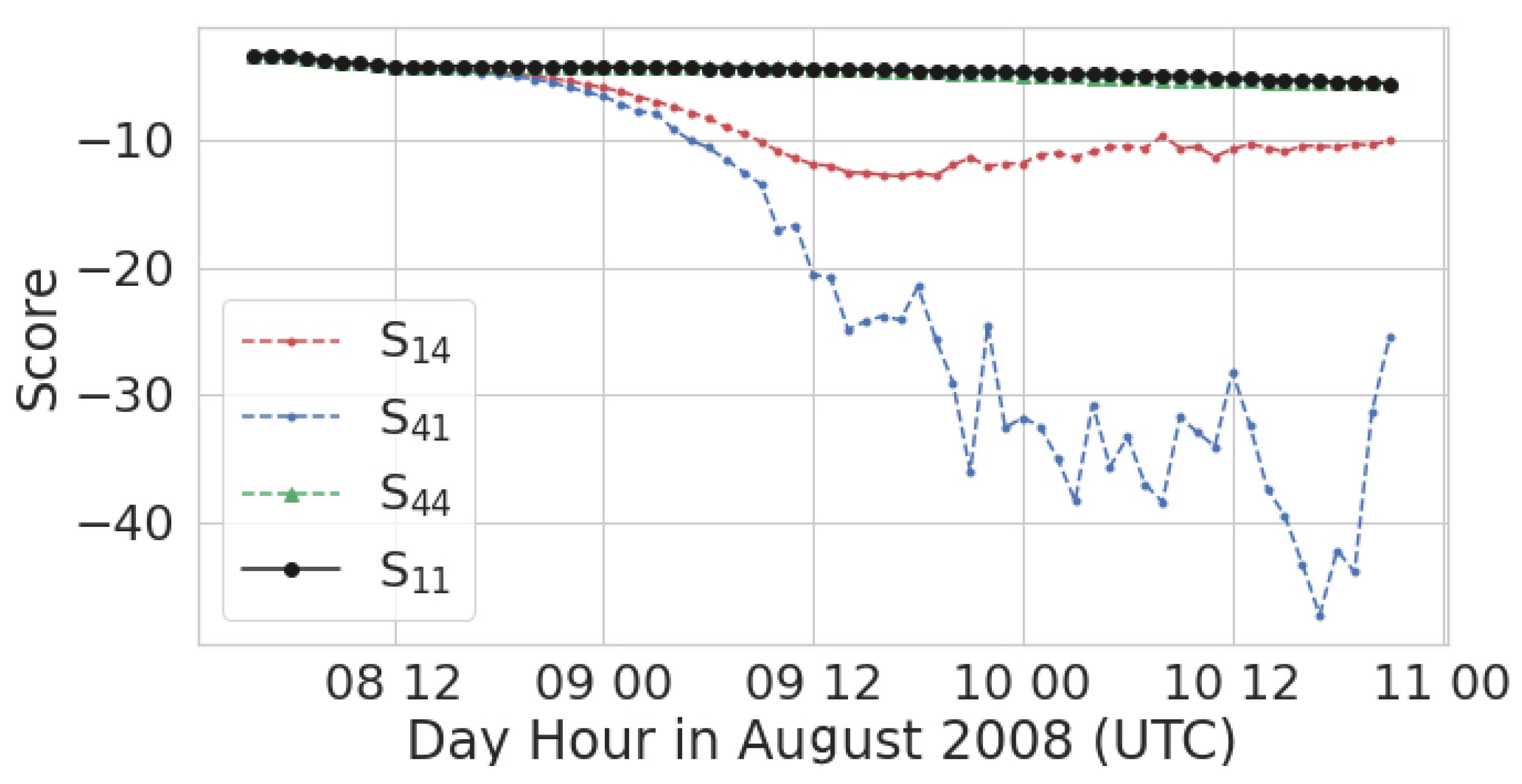
3.3.2. Identify Where and When Simulations Diverge
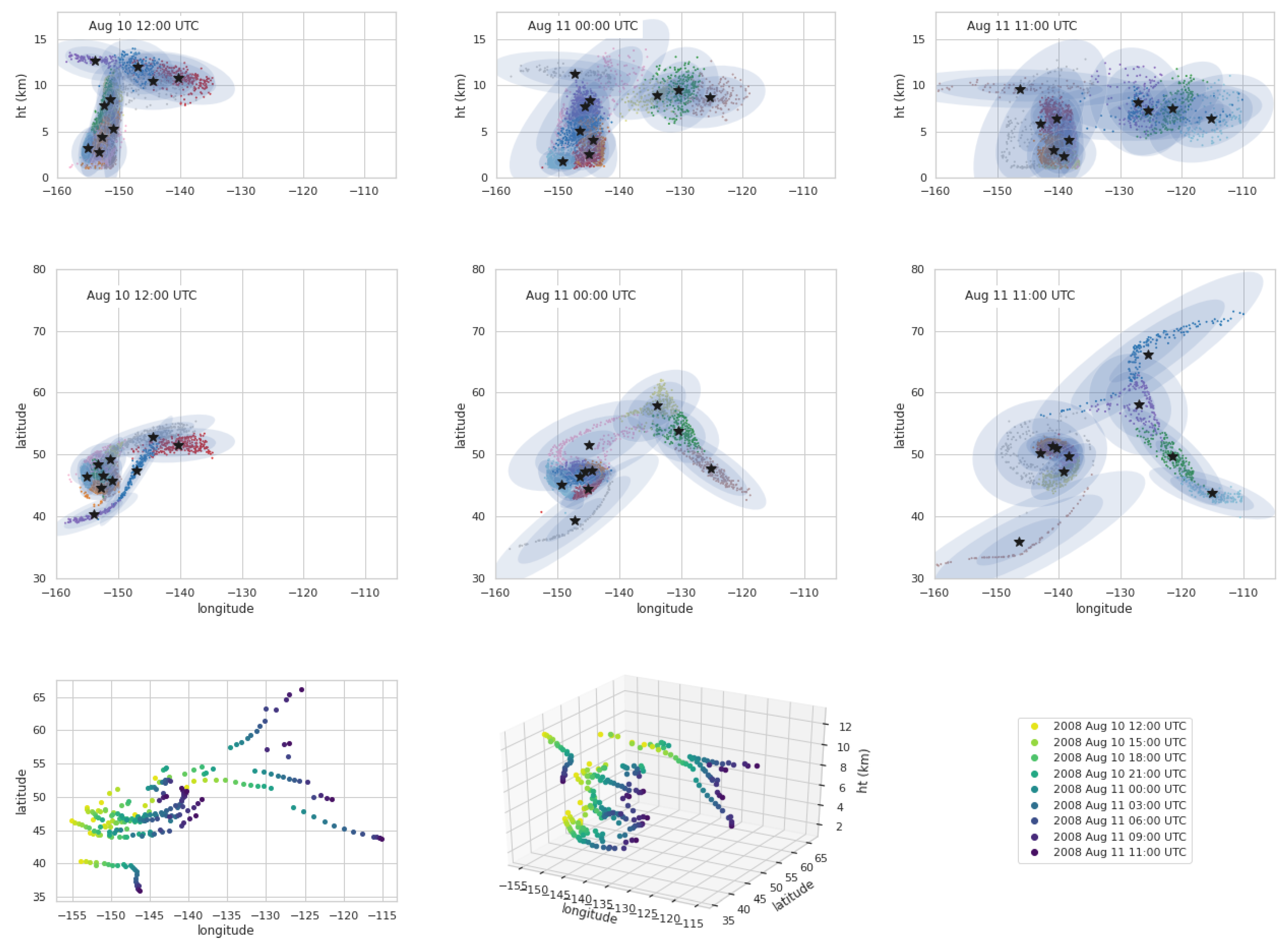
3.3.3. Feature Tracking
4. Discussion
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ARL | Air Resources Laboratory |
| BGMM | Bayesian Gaussian mixture model |
| CAPTEX | Cross Appalachian Tracer Experiment |
| GMM | Gaussian mixture model |
| HYSPLIT | Hybrid Single-Particle Langrangian Integrated Trajectory model |
| KDE | Kernel density estimator |
| LPDM | Lagrangian Particle Dispersion Model |
| probability density function | |
| n | number of Gaussians used in a fit |
| N | number of computational particles found in a defined volume |
| VAAC | Volcanic Ash Advisory Center |
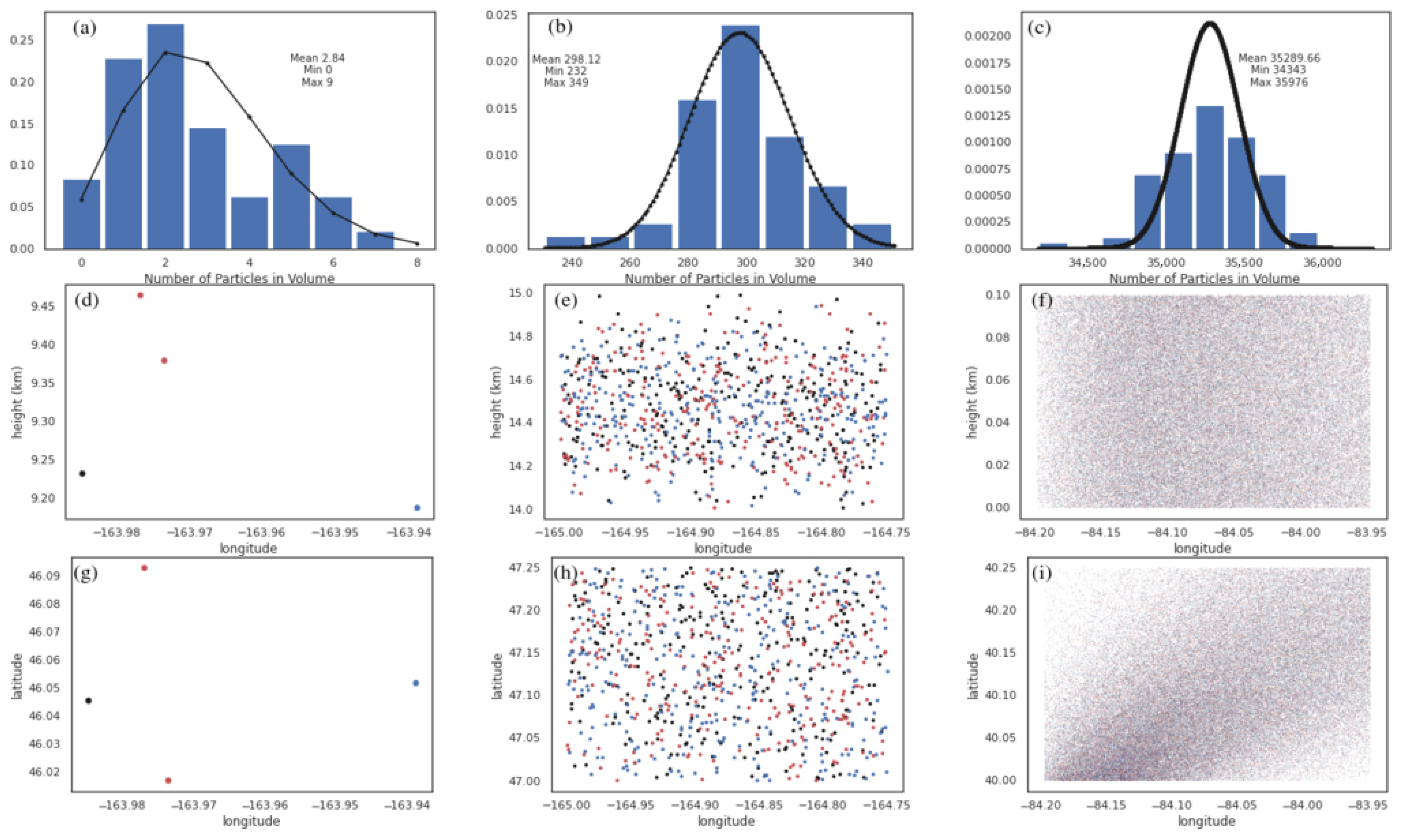
Appendix A. Shot Noise

Appendix B. Setting the Number of Gaussians

References
- Gerbig, C.; Korner, S.; Lin, J.C. Vertical mixing in atmospheric tracer transport models: Error characterization and propagation. Atmos. Chem. Phys. 2008, 8, 591–602. [Google Scholar] [CrossRef]
- Stohl, A.; Forster, C.; Frank, A.; Seibert, P.; Wotawa, G. Technical Note: The Lagrangian particle dispersion model FLEXPART version 6.2. Atmos. Chem. Phys. 2005, 5, 2461–2474. [Google Scholar] [CrossRef]
- De Haan, P. On the use of density kernels for concentration estimations within particle and puff dispersion models. Atmos. Environ. 1998, 33, 2007–2021. [Google Scholar] [CrossRef]
- Vitali, L.; Monforti, F.; Bellasio, R.; Bianconi, R.; Sachero, V.; Mosca, S.; Zanini, G. Validation of a Lagrangian dispersion model implementing different kernel methods for density reconstruction. Atmos. Environ. 2006, 40, 8020–8033. [Google Scholar] [CrossRef]
- Fasoli, B.; Lin, J.C.; Bowling, D.R.; Mitchell, L.; Mendoza, D. Simulating atmospheric tracer concentrations for spatially distributed receptors, updates to the Stochastic Time-Inverted Lagrangian Transport model’s R interface (STILT-R version2). J. Geophys. Res. Atmos. 2012, 117. [Google Scholar] [CrossRef]
- Chowdhury, B.; Karamchandani, P.K.; Sykes, R.I.; Henn, D.S.; Knipping, E. Reactive puff model SCICHEM: Model enhancements and performance studies. Atmos. Environ. 2015, 117, 242–258. [Google Scholar] [CrossRef]
- Stein, A.F.; Draxler, R.R.; Rolph, G.D.; Stunder, B.J.B.; Cohen, M.D.; Ngan, F. NOAA’S HYSPLIT ATMOSPHERIC TRANSPORT AND DISPERSION MODELING SYSTEM. Bull. Am. Meteorol. Soc. 2015, 96, 2059–2077. [Google Scholar] [CrossRef]
- Ferber, G.J.; Heffter, J.L.; Draxler, R.R.; Lagomarsino, R.; Thomas, F.L.; Dietz, R.N. Cross-Appalachian Tracer Experiment (CAPTEX-83) Final Report; NOAA Technical Memorandum ERL ARL-142; NOAA Air Resources Laboratory: Silver Spring, MD, USA, 1986. [Google Scholar]
- Hegarty, J.; Draxler, R.R.; Stein, A.F.; Brioude, J.; Mountain, M.; Eluszkiewicz, J.; Nehrkorn, T.; Ngan, F.; Andrews, A. Evaluation of Lagrangian Particle Dispersion Models with Measurements from Controlled Tracer Releases. J. Appl. Meteorol. Climatol. 2013, 52, 2623–2637. [Google Scholar] [CrossRef]
- Brown, R.M.; Leach, M.; Raynor, G.; Michael, P. Summary and Index of the Weather Documentation for the 1983 Cross-Appalachian Tracer Experiments; Informal Rep. BNL36879; Atmospheric Sciences Department, Brookhaven National Laboratory: Upton, NY, USA, 1983. [Google Scholar]
- Draxler, R.R. Evaluation of an ensemble dispersion calculation. J. Appl. Meteor. 2006, 42, 308–317. [Google Scholar] [CrossRef]
- Stohl, A.; Hittenberger, M.; Wotawa, G. Validation of the Lagrangian particle dispersion model FLEXPART against large-scale tracer experiment data. Atmos. Environ. 1998, 32, 4245–4264. [Google Scholar] [CrossRef]
- Mosca, S.; Graziani, G.; Klug, W.; Bellasio, R.; Bianconi, R. A statistical methodology for the evaluation of long-range dispersion models: An application to the ETEX exercise. Atmos. Environ. 1998, 32, 4307–4324. [Google Scholar] [CrossRef]
- Ngan, F.; Stein, A.F. A Long-Term WRF Meteorological Archive for Dispersion Simulations: Application to Controlled Tracer Experiments. J. Appl. Meteorol. Climatol. 2017, 56, 2203–2220. [Google Scholar] [CrossRef]
- Crawford, A.M.; Stunder, B.J.B.; Ngan, F.; Pavolonis, M.J. Initializing HYSPLIT with satellite observations of volcanic ash: A case study of the 2008 Kasatochi eruption. J. Geophys. Res. Atmos. 2016, 121, 10786–10803. [Google Scholar] [CrossRef]
- Mastin, L.G.; Guffanti, M.; Servranckx, R.; Webley, P.; Barsotti, S.; Dean, K.; Durant, A.; Ewert, J.W.; Neri, A.; Rose, W.I.; et al. A multidisciplinary effort to assign realistic source parameters to models of volcanic ash-cloud transport and dispersion during eruptions. J. Volcanol. Geotherm. Res. 2009, 186, 10–21. [Google Scholar] [CrossRef]
- Chai, T.; Crawford, A.; Stunder, B.; Pavolonis, M.J.; Draxler, R.; Stein, A. Improving volcanic ash predictions with the HYSPLIT dispersion model by assimilating MODIS satellite retrievals. Atmos. Chem. Phys. 2017, 17, 2865–2879. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horanyi, A.; Munoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2017. [Google Scholar]
- Verbeek, J.J.; Vlassis, N.; Krose, B. Efficient greedy learning of Gaussian mixture models. Neural Comput. 2003, 15, 469–485. [Google Scholar] [CrossRef]
- Peng, W.S.; Fang, Y.W.; Zhan, R.J. A variable step learning algorithm for Gaussian mixture models based on the Bhattacharyya coefficient and correlation coefficient criterion. Neurocomputing 2017, 239, 28–38. [Google Scholar] [CrossRef]
- Stepanova, K.; Vavrecka, M. Estimating number of components in Gaussian mixture model using combination of greedy and merging algorithm. Pattern Anal. Appl. 2018, 21, 181–192. [Google Scholar] [CrossRef]
- Schreiber, J. Pomegranate: Fast and flexible probabilistic modeling in python. J. Mach. Learn. Res. 2018, 18, 1–6. [Google Scholar]
- Wilkins, K.L.; Watson, I.M.; Kristiansen, N.I.; Webster, H.N.; Thomson, D.J.; Dacre, H.F.; Prata, A.J. Using data insertion with the NAME model to simulate the 8 May 2010 Eyjafjallajokull volcanic ash cloud. J. Geophys. Res. Atmos. 2016, 121, 306–323. [Google Scholar] [CrossRef]
- Beckett, F.M.; Witham, C.S.; Hort, M.C.; Stevenson, J.A.; Bonadonna, C.; Millington, S.C. Sensitivity of dispersion model forecasts of volcanic ash clouds to the physical characteristics of the particles. J. Geophys. Res. Atmos. 2015, 120. [Google Scholar] [CrossRef]
- Osman, S.; Beckett, F.; Rust, A.; Snee, E. Sensitivity of Volcanic Ash Dispersion Modelling to Input Grain Size Distribution Based on Hydromagmatic and Magmatic Deposits. Atmosphere 2020, 11, 567. [Google Scholar] [CrossRef]
- Zidikheri, M.J.; Lucas, C. Using Satellite Data to Determine Empirical Relationships between Volcanic Ash Source Parameters. Atmosphere 2020, 11, 342. [Google Scholar] [CrossRef]
- Peng, J.F.; Peterson, R. Attracting structures in volcanic ash transport. Atmos. Environ. 2012, 48, 230–239. [Google Scholar] [CrossRef]
- Dacre, H.F.; Harvey, N.J.; Webley, P.W.; Morton, D. How accurate are volcanic ash simulations of the 2010 Eyjafjallajokull eruption? J. Geophys. Res. Atmos. 2016, 121, 3534–3547. [Google Scholar] [CrossRef]
- Dacre, H.F.; Harvey, N.J. Characterizing the Atmospheric Conditions Leading to Large Error Growth in Volcanic Ash Cloud Forecasts. J. Appl. Meteorol. Climatol. 2018, 57, 1011–1019. [Google Scholar] [CrossRef]
- Gilleland, E.; Ahijevych, D.; Brown, B.G.; Casati, B.; Ebert, E.E. Intercomparison of Spatial Forecast Verification Methods. Weather Forecast. 2009, 24, 1416–1430. [Google Scholar] [CrossRef]
- Dacre, H.F. A new method for evaluating regional air quality forecasts. Atmos. Environ. 2011, 45, 993–1002. [Google Scholar] [CrossRef]
- Farchi, A.; Bocquet, M.; Roustan, Y.; Mathieu, A.; Querel, A. Using the Wasserstein distance to compare fields of pollutants: Application to the radionuclide atmospheric dispersion of the Fukushima-Daiichi accident. Tellus Ser. B-Chem. Phys. Meteorol. 2016, 68. [Google Scholar] [CrossRef]
- Harvey, N.J.; Dacre, H.F. Spatial evaluation of volcanic ash forecasts using satellite observations. Atmos. Chem. Phys. 2016, 16, 861–872. [Google Scholar] [CrossRef]
- NOAA Air Resources Laboratory. Available online: https://www.ready.noaa.gov/READY_traj_volcanoes.php (accessed on 14 December 2020).
- Eckhardt, S.; Prata, A.J.; Seibert, P.; Stebel, K.; Stohl, A. Estimation of the vertical profile of sulfur dioxide injection into the atmosphere by a volcanic eruption using satellite column measurements and inverse transport modeling. Atmos. Chem. Phys. 2008, 8, 3881–3897. [Google Scholar] [CrossRef]
- Stohl, A.; Prata, A.J.; Eckhardt, S.; Clarisse, L.; Durant, A.; Henne, S.; Kristiansen, N.I.; Minikin, A.; Schumann, U.; Seibert, P.; et al. Determination of time- and height-resolved volcanic ash emissions and their use for quantitative ash dispersion modeling: The 2010 Eyjafjallajokull eruption. Atmos. Chem. Phys. 2011, 11, 4333–4351. [Google Scholar] [CrossRef]
- Kristiansen, N.I.; Stohl, A.; Prata, A.J.; Bukowiecki, N.; Dacre, H.; Eckhardt, S.; Henne, S.; Hort, M.C.; Johnson, B.T.; Marenco, F.; et al. Performance assessment of a volcanic ash transport model mini-ensemble used for inverse modeling of the 2010 Eyjafjallajokull eruption. J. Geophys. Res. Atmos. 2012, 117. [Google Scholar] [CrossRef]
- Chai, T.F.; Draxler, R.; Stein, A. Source term estimation using air concentration measurements and a Lagrangian dispersion model—Experiments with pseudo and real cesium-137 observations from the Fukushima nuclear accident. Atmos. Environ. 2015, 106, 241–251. [Google Scholar] [CrossRef]
- NOAA Earth Systems Research Laboratories. Available online: https://esrl.noaa.gov/gmd/ccgg/carbontracker-lagrange (accessed on 14 December 2020).
- Webley, P.W.; Dean, K.; Peterson, R.; Steffke, A.; Harrild, M.; Groves, J. Dispersion modeling of volcanic ash clouds: North Pacific eruptions, the past 40 years: 1970–2010. Nat. Hazards 2012, 61, 661–671. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CAPTEX Simulations | |||||
|---|---|---|---|---|---|
| RunID | Number of | Horizontal | Vertical | Note | |
| Particles | Resolution | Resolution | |||
| A | 250,000 | 25 m | 39 | ||
| B | 50,000 | 25 m | 196 | ||
| C | 5000 | 25 m | 1958 | ||
| D | 5000 | 25 m | SEED = −4 | 1958 | |
| E | 50,000 | 100 m | Standard run | 2 | |
| Kasatochi Simulations | |||||
| KA | 500,000 | 1 km | Reference run | 0.08 | |
| KB | 53,000 | 1 km | 0.75 | ||
| KC | 26,000 | 1 km | SEED = −4 | 1.5 | |
| KD | 26,000 | 1 km | SEED = −6 | 1.5 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crawford, A. The Use of Gaussian Mixture Models with Atmospheric Lagrangian Particle Dispersion Models for Density Estimation and Feature Identification. Atmosphere 2020, 11, 1369. https://doi.org/10.3390/atmos11121369
Crawford A. The Use of Gaussian Mixture Models with Atmospheric Lagrangian Particle Dispersion Models for Density Estimation and Feature Identification. Atmosphere. 2020; 11(12):1369. https://doi.org/10.3390/atmos11121369
Chicago/Turabian StyleCrawford, Alice. 2020. "The Use of Gaussian Mixture Models with Atmospheric Lagrangian Particle Dispersion Models for Density Estimation and Feature Identification" Atmosphere 11, no. 12: 1369. https://doi.org/10.3390/atmos11121369
APA StyleCrawford, A. (2020). The Use of Gaussian Mixture Models with Atmospheric Lagrangian Particle Dispersion Models for Density Estimation and Feature Identification. Atmosphere, 11(12), 1369. https://doi.org/10.3390/atmos11121369