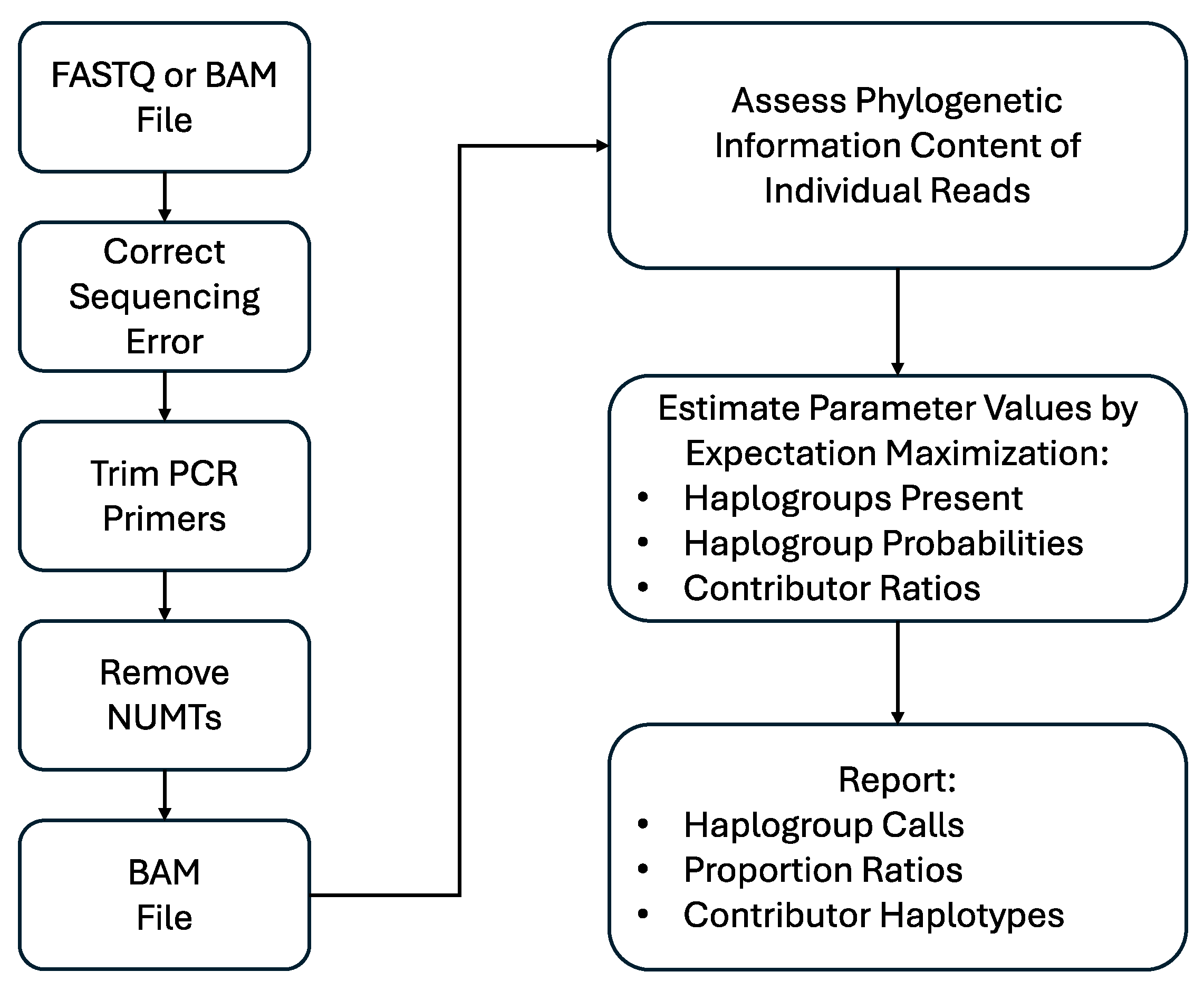
1. Introduction
The field of forensic DNA is evolving rapidly as new technologies and methods become available and are validated. With increased sensitivity and throughput capabilities, mitochondrial (mt) DNA typing has become increasingly attractive, especially for forensic investigations involving samples with limited amounts of DNA [
1], and including DNA mixtures [
2]. The historic limitation of traditional mtDNA typing has been a lower discrimination potential created by a combination of uniparental inheritance of the mitochondrial (mito) genome and limited resolution of mixtures associated with Sanger sequencing. The increased sensitivity currently achievable with massively parallel sequencing (MPS) enables accurate characterization and reporting of intrinsic, low-level sequence mitogenome variants [
3,
4,
5,
6,
7], and an advantage of uniparental inheritance is an expectation that the majority of individuals will only contribute one haplotype to a mixed sample making mtDNA an attractive aid in the assessment of mixed DNA samples [
2,
8,
9,
10].
DNA mixtures have always been a part of forensic casework and have increasingly become more common in forensic investigations [
11,
12]. The observed increase in mixed DNA samples is presumably due to rapidly advancing DNA technologies with increased sensitivity along with changes in sampling strategies and methodologies [
11,
13]. An example of this advancement is the ability of laboratories to generate profile information from trace amounts of DNA collected from touched objects. The increased resolution has resulted in approximately 15% of all evidence samples containing mixtures [
14], and a retrospective study by Melton et al. [
15] evaluating 691 casework hair samples indicated that ~9% of the samples were observed to have a mixture of mtDNA sequences, including heteroplasmic sequences. When samples with observations of mixed base calls are encountered, most forensic laboratories do not interpret the results and categorize the findings as inconclusive for reporting purposes [
15]. The inability to fully identify and deconvolute mixtures is a recognized challenge when performing mtDNA analysis. As stated by the Spanish and Portuguese-Speaking Working Group of the ISFG (GHEP-ISFG) when performing a multi-laboratory study on mixture interpretation, “It is worth mentioning that mtDNA in mixture samples is not included in the evaluation of the Intercomparison Exercise program (IE). This is owed to the difficulties in interpreting mixtures from haplotype sequences from both technical and theoretical points of view.” [
16]. This clearly illustrates that analysis of mtDNA mixtures is not a routine practice, and that work in this area is needed to provide the tools necessary to conduct such analyses. In order to retain the evidentiary value of these mixed samples, forensic laboratories need the ability to deconvolute mixed mtDNA sequences which will require software and bioinformatic solutions.
A presumed mtDNA mixture is typically not easily resolved, even with an MPS approach, as reconstructing complete haplotypes from short sequencing reads requires considerable effort and is not amenable to manual techniques. In addition, the sensitivity of MPS analysis and the ability to detect low-level mixtures (1–2%) increases the observation of complicating factors including heteroplasmy in one or more of the contributors and system-associated analytical noise. While some mixtures are relatively straightforward and easy to interpret, others are complex and can be challenging to deconvolute. The past several years has seen a rise in the application of probabilistic genotyping software to short tandem repeat analysis for the interpretation of mixtures. While strides have been made in this area allowing for the deconvolution of complex mixtures, there remains a proportion of cases that cannot be fully resolved. An overview by Coble and Bright [
17], focusing on autosomal mixture interpretation using probabilistic approaches noted, “there is a strong need to apply probabilistic methods to interpreting mixtures with haploid marker systems”, such as mtDNA. To date, little work has been done to deconvolute mixtures of mtDNA sequence from MPS data [
2,
8,
18,
19]. The availability of MPS mtDNA data presents an opportunity to shift this paradigm.
The UNT Center for Human Identification in collaboration with the Tallinn University of Technology, and a team of researchers at the Universities of California in Santa Cruz and Davis collaborating with the Children’s Hospital Oakland Research Institute (CHORI), have taken the first steps towards development of software solutions. The first group applied phased MPS data for mixture deconvolution and were able to identify the major contributor in all mixtures but had difficulties in assessing point heteroplasmy (PHP) in some samples, making it difficult to determine whether the PHP should have been assigned to the major or minor contributor [
18]. This approach showed promise but as noted by the authors, “mtDNA mixture analysis will become more effective and efficient with advances in bioinformatics pipelines”. UNT made subsequent advancements in developing pipelines using approaches focused on population and statistical phasing [
8,
9]. The mitochondrial mixture deconvolution and interpretation tool (MMDIT) is an open-source software that automates mixture deconvolution [
8], but the shiny app is tailored to data generated using the Ion S5 and Converge software (ThermoFisher, Waltham, MA, USA) making it less user-friendly for data generated on an Illumina MiSeq or other sequencing platforms. The second group developed an advanced bioinformatic approach to deconvoluting complex mtDNA mixtures from MPS data using phylogenetic information [
2]. The algorithm, Mixemt, is an opensource computer program written in Python and executed from a command line window and has been demonstrated to be effective in the deconvolution of mtDNA mixtures generated using shotgun sequencing data and a general-purpose DNA preparation kit. While the improved bioinformatic approach showed increased potential, the approach used shotgun sequencing as opposed to amplicon sequencing, the latter being more desirable and more commonly used in forensic laboratories. In addition, Mixemt utilizes a complex pipeline written in Python, requiring knowledge of command line coding. Clearly, a powerful bioinformatic approach is necessary for the deconvolution of mixtures, but in order for the approach to be widely adopted there is a need for the pipeline to be packaged in a user-friendly graphical user interface that does not require advance coding knowledge and that can use sequencing data from multiple platforms.
The principal objective of the current study was to assess a probabilistic approach to mitogenome mixture analysis that can be easily implemented as a tool in forensic laboratories. This was accomplished by combining Mixemt with a user-friendly software package, MixtureAce MT™ (NicheVision Forensics, LLC, Akron, OH, USA), to deconvolute mitochondrial mixtures using phylogenetic principles. Biological and in-silico mixtures were used to characterize the range and applicability of the new probabilistic approach.
3. Results
3.1. In-Silico Mixtures
For the two- and three-person in-silico mixtures, Mixemt was able to detect the correct haplogroups for 95% of contributors and increased to 100% when closely related (i.e., R11 detected versus the exact haplogroup of R11a) haplogroups were included. Major and minor contributors were successfully identified in all mixtures at all dilution ratios (
Figure 2).
To assess the accuracy of haplogroup contribution estimation by Mixemt in the in-silico mixtures the actual proportion of fragments subsetted to generate the mixtures was subtracted from the Mixemt estimated proportions. This resulted in negative values representing an underestimation and positive values expressing overestimation. Two-person mixtures with similar and dissimilar haplotypes were not found to be significantly different (
p = 0.98) with a range of −0.61 to 0.22 and an average of −0.07 (7% under estimation) for similar haplotypes and a range of −0.65–0.048 and an average of −0.07 for dissimilar haplotypes. Three-person mixtures were also not significantly different (
p = 0.37) and slightly more accurate on average with similar haplotypes ranging from −0.27 to 0.093 and an average of −0.055 and dissimilar mixtures ranging from −0.16 to 0.13 and averaging −0.050. Wilcoxon testing of the median values for the two- and three-person mixtures indicated that the difference was also insignificant (
p = 0.99).
Figure 3 presents the actual frequencies versus Mixemt estimated frequencies for all samples.
Spurious haplogroups were observed in the in-silico dataset with 25 spurious haplogroups identified in seven different pairs of individuals in the 2-person mixtures and 63 spurious haplogroups identified in 10 different sets of individuals in the 3-person mixtures. Due to the number of spurious haplogroups observed, analysis of the in-silico datasets was extended, reprocessing a subset of samples with spurious haplogroups in Mixemt and applying the known haplogroup function to include the contributor haplotypes in the deconvolution. Inclusion of known haplotypes resolved the spurious haplogroups.
3.2. Biological Mixtures
Biological mixtures were evaluated using GeneMarker HTS (GM HTS, SoftGenetics, State College, PA, USA) and the new combined tool, MixtureAce MT™. GM HTS analysis of sequencing files from the PowerSeq panel produced an average coverage of 10,345x with an average maximum of 43,212x and an average minimum coverage of 1204x, while the Precision ID kit produced an average coverage of 3858x with an average 17,916x maximum and 74.5x minimum coverage. The proportion of the mtgenome with coverage less than 2000x was 1.8% (average) for the the PowerSeq kit and 25.7% (average) for the Precision ID kit.
Evaluation of the Precision ID dataset showed that MixtureAce MT™ was able to detect the correct haplogroups for 95% of contributors in samples with minor contribution ≥ 5%, and that the minor contributor failed to be detected in 72% of mixtures with minor frequencies of 1–2% (
Figure 4).
Spurious haplogroups were observed in the Precision ID mixtures with 7 spurious haplogroups identified in two different pairs of individuals in the 2-person mixtures and 11 spurious haplogroups identified in four different sets of individuals in the 3-person mixtures. Extended testing of the inclusion of known contributors was conducted on the Precision ID dataset, using 28 mixtures that produced spurious haplogroups and reprocessing those samples with the inclusion of two known contributors. When two known contributor haplotypes were included in the deconvolution, all spurious haplogroups were resolved and produced exact match (n = 65) or close match (n = 3) for major and minor contributors. The inclusion of known haplotype also increased the resolution of trace contributors present in all seven of the samples that had dropout of the minor contributor at 2% and in 1/8 samples with dropout at 1% minor contributor.
Evaluation of the PowerSeq dataset showed that MixtureAce MT™ was able to detect the correct haplogroups for 100% of contributors in samples with minor contribution ≥ 5%. The minor contributor failed to be detected in 83% of mixtures with minor frequencies of 1–2% (
Figure 5).
Spurious haplogroups were again observed in the PowerSeq WGM dataset with 18 spurious haplogroups identified in the same two pairs of individuals in the 2-person mixtures and 11 spurious haplogroups identified in the same 10 sets of individuals in the 3-person mixtures that were observed in the Precision ID dataset. Since the same spurious haplogroups were observed in the same samples as the Precision ID samples set, an evaluation of the inclusion of known haplotypes was not conducted on the PowerSeq mixtures.
To assess the accuracy of MixtureAce MT™ to estimate the haplogroup contributions in the biological mixtures, an independent assessment of the contributor proportions was generated using GM HTS and subtracted from the MixtureAce MT™ estimated proportions for mixture ratios ≥ 5%. This resulted in negative values representing an underestimation and positive values expressing overestimation. The accuracy the Precision ID two-person mixtures with similar haplotypes ranged from −0.25 to 0.21 with an average of −0.010 (1% under estimation) while mixtures with dissimilar haplotypes ranged from −0.15–0.15 and had an average of −0.010. The proportion estimates for the PowerSeq dataset were less accurate and tended to overestimate proportions for two-person mixtures with similar (−0.11 to 0.32, avg. 0.04) and dissimilar (−0.012 to 0.09, avg. 0.04) haplotypes. A similar result was produced for the three-person mixtures with similar (−0.12 to 0.10, avg. −0.017) and dissimilar (−0.31 to 0.22, avg. −0.034) haplotypes in the Precision ID dataset and similar (−0.097 to 0.089, avg. −0.018) and dissimilar (−0.17 to 0.068, avg. −0.026) haplotypes in the PowerSeq dataset. Wilcoxon testing indicated a statistically significant difference within the PowerSeq dataset when comparing two-person and three-person mixtures (
p = 0.00013), but did not indicate a significant difference when comparing two-person and three-person mixtures in the Precision ID dataset (
p = 0.29) or two-person similar and dissimilar haplotypes (Precision ID
p = 0.73; PowerSeq
p = 0.55), or 3-person similar and dissimilar haplotypes (Precision ID
p = 0.79, PowerSeq
p = 0.86). Comparison between the Precision ID and PowerSeq datasets also showed no significant difference (
p = 0.071).
Figure 6 presents the GM HTS estimated proportions versus MixtureAce MT™ estimated frequencies for all samples.
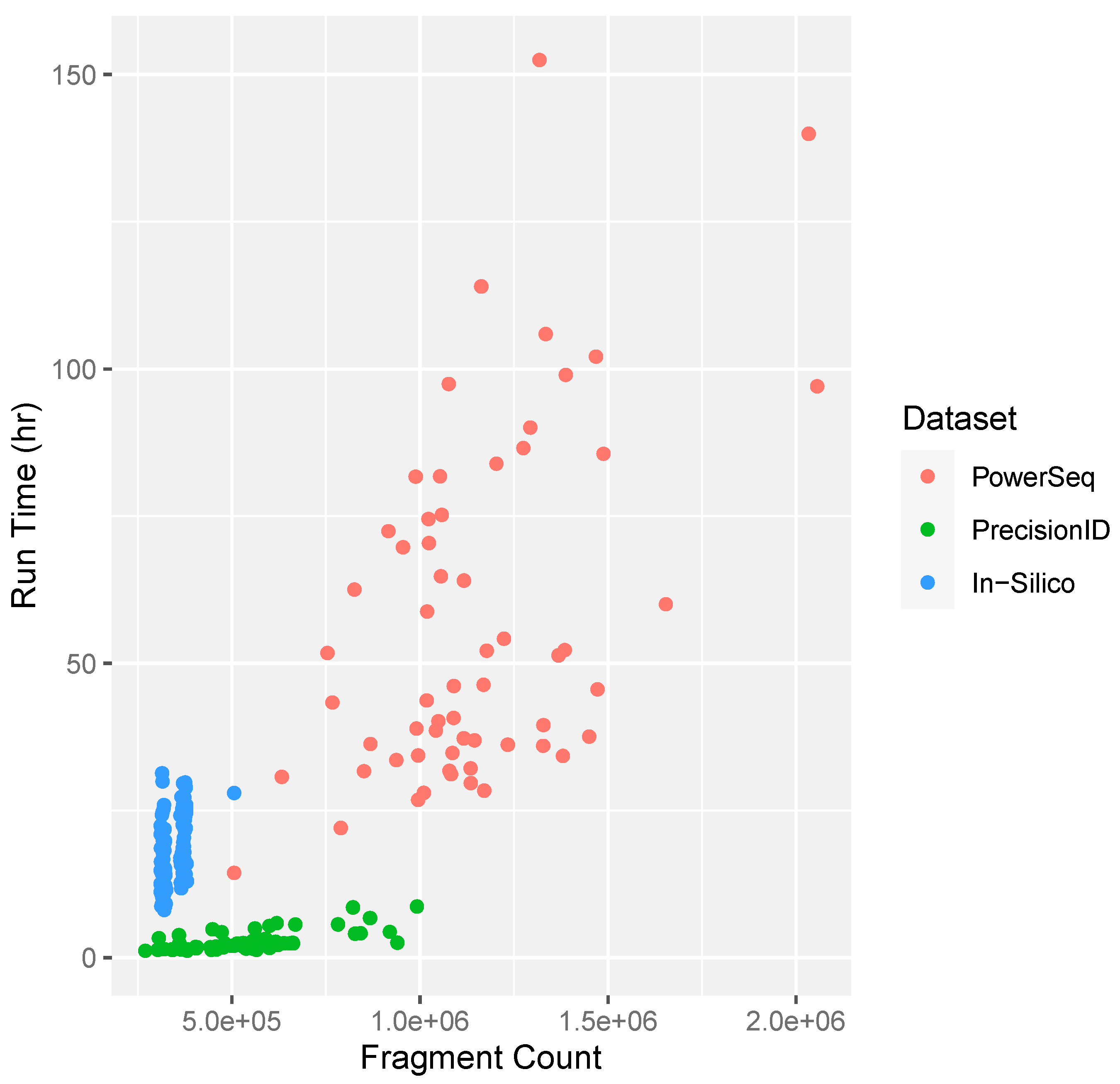
3.3. Preprocessing
One of the major drawbacks of the previously available software for mtDNA mixture deconvolution has been that implementation can be time-consuming [
10]. MixtureAce MT™ reduces confounding features such as potential NUMTs and noise which reduces the time required for the EM algorithm and heuristic filters to produce haplogroup and frequency estimates.
Figure 7 highlights the general positive correlation between fragment count and time, the influence of dissimilar and similar haplotypes within the in-silico dataset, as well as the decrease in run time for Precision ID samples that were preprocessed with MixtureAce MT™ and the PowerSeq dataset without preprocessing.
A summary of the preprocessing metrics for the Precision ID mixture dataset including input reads, read correction run time, primmer trimming run time, alignment run time, number of possible NUMTs identified, the run times for NUMT identification & removal, the number of NUMTs ultimately removed, and the total time required for preprocessing is provided in
Table 1.
3.4. Random Reduction
To further investigate the time requirements for the deconvolution process and to assess depth of coverage requirements, a subset of preprocessed biological mixture samples (
n = 14) was run with an initial average number of fragments of 800 K (mtgenome coverage of ~10 K) that were randomly reduced to various fragment counts ranging from 1.5 K to 20 K fragments per mixture. The sample subset contained similar and dissimilar haplotypes in two- and three-person mixtures at various ratios. Identifiers for the biological mixtures are structured as: contributor 1:contributor 2 and contain sample number & major haplogroup clade for each contributor with the mixture ratio given in parentheses. All mixtures tested except for 5U:10U (19:1), 7D:5U (49:1) and 4D:7D (99:1) produced correct haplogroups for the initial reduction to 20 K fragments (~215x mtgenome coverage;
Table 2). For the trace contributors at 49:1 and 99:1 the read fragments were further increased to 35 K and 50 K but still failed to identify the minor contributors. The correct identification of exact major and exact minor contributors was observed in eight of the remaining eleven samples when reduced to 10 K fragments, four samples (plus one sample with an exact major and a closely related minor haplogroup reported) at 3 K, and two samples were still producing the correct contributors when reduced to a total of 1500 read fragments per sample. Some of the mixtures continued to produce spurious haplogroups similar to the additional haplogroups reported for samples with the full complement of fragments.
4. Discussion
In this study, Mixemt was able to correctly identify the haplogroups for 95–100% of contributors in both in-silico and biological mixtures, and successfully identified the major and minor contributors in all in-silico mixture ratios and 95% of biological mixtures with minor contribution ≥ 5%. The accuracy of Mixemt to estimate haplogroup proportions closely followed the actual mixture proportions and, on average, were slightly less than the true contribution. The observations in this study on haplogroup identification and estimated proportions are similar to the findings by Vohr in the original Mixemt study, with the underestimation of proportions most likely due to the software not redistributing a portion of the fragments assigned to closely related and/or low frequency haplogroups during the evaluation of all haplogroups [
2]. Other observations in the present work differ from the Vohr study with an increased incidence of spurious or additional haplogroups and an increased level of minor dropout at higher fragment depths.
The number of spurious haplogroups in both the in-silico and the biological datasets in this study were higher than what Vohr observed. This could be due to differences in a shotgun versus an amplicon sequencing approach, the differences in the number of fragments in each mixture, or differences in Mixemt settings, but is most likely due to the present study having a small amplicon size, a high number of fragments per sample, differences in contributor haplotypes and mixture combinations, and multiple contributors having haplotype differences (private mutations) from Phylotree haplogroup defining polymorphisms. Due to a low density of variants in the coding region, private mutations in the coding region are unlikely to overlap any other variant site within the same fragment, and the small size of fragments (~200 bps) generated by our sequencing protocol also reduce the chance that multiple variants will be located on the same fragment. In this study, all of the additional haplogroups belonged to the H subclade of Phylotree and resulted from the identification of 1 or 2 diagnostic variants. For example, in-silico mixture 787 (B2o), 832 (L1c2b1a’b) had additional haplogroups H3aq (1018A) and H27/H27e (11719A and 16129A) for each of the three ratios (1:1, 1:3, and 3:1). All three of these variants are contained in the haplotype of individual 832, are not associated with the haplogroup L1c2b1a’b, but are diagnostic for H3aq and H27/H27e. The Vohr study noted spurious H subclade haplogroups and saw an increase in additional haplogroups when the number of sample fragments (10 K, 20 K, and 40 K) was increased. While Vohr observed spurious H haplogroups when one of the true haplogroups (true: H1 [
2]) in a mixture was closely related to the additional haplogroup (spurious H1s and H26), this was only observed for three out of eleven 3-person in-silico combinations in our dataset. Ultimately, all of the spurious haplogroups in our datasets were resolved by adding known haplotypes during deconvolution. The addition of known haplotypes also led to resolution of the minor contributor in all of the 49:1 and in one 99:1 biological mixtures. Inclusion of known haplotype (profile) information in mixture deconvolution is a common practice in forensic cases as persons of interest are commonly known or suspected to be contributors in DNA mixtures.
The biological datasets in this study had an average of 500,000 and 1 million reads for the Precision ID and PowerSeq amplifications, respectively. With an average fragment length of 200 bps for both amplification kits, and considering 5% minor contribution, this relates to approximately 300- and 600-fold coverage, and approximately 60- and 120-fold coverage for a 1% minor contribution across the mtgenome. At this high number of fragments, for both amplification kits, the major and minor contributors were correctly identified for 5% minor contribution but only one out of 15 mixtures (10U:7D; 49:1) with a minor contribution of 1–2% was resolved. The Vohr study found that in-silico samples consisting of 3000 fragments of approximately 300 bps (~3 fold coverage for 5% minor contribution) often failed to detect contributors present at less than 10% and increasing mixtures to 10,000 fragments could resolve minor contributors at 5% (our calculation: 9-fold coverage), but required 20,000–40,000 fragments to recover 1% (our calculation: 4- to 7-fold coverage) contribution in 20 and 31 out of 50 mixtures, respectively. The reason for the differences is unclear but could be due to differences in sequencing approaches and average fragment length or differences in contributor haplotypes and combinations.
Heteroplasmy and Haplotype Reconstruction
The in-silico dataset contains nine individuals with one site, three individuals with two sites, and 19 individuals with no sites of heteroplasmy with MAFs ranging from 6.4 to 47.0%. Across all mixtures in the in-silico dataset, there was one trio of individuals (399:886:918) that had a spurious haplogroup that was possibly due to the 16093C heteroplasmic site (MAF 25.9%) in individual 886. A spurious haplogroup, H27 [
1] was reported for each of the mixture ratios for this combination of individuals. The 16093C diagnostic SNP was observed with an estimated proportion of 12.4% in the 1:1:1 mixture, 11.7% in the 1:3:3 mixture, and 12.4% in the 3:3:1 mixture. No other indications of complications due to heteroplasmy were found in the in-silico or biological datasets. The biological dataset contains two individuals with one site, three individuals with two sites, and six individuals with no sites of heteroplasmy with a MAF range of 2.4–41.1%.
Haplotype reconstruction was attempted for a small subset of samples using the MixtureAce MT™ reported diagnostic variants. The proportion of the haplotype that was able to be reconstructed ranged from ~12% for minor contributors in mixtures with highly similar haplotypes to ~65% for major contributors in mixtures with similar haplotypes and both contributors in mixtures with dissimilar haplotypes. While complete reconstruction of an individual’s haplotype is not reported by MixtureAce MT™, the reported haplogroup along with the estimated proportions (unequal proportions required) enable most samples to be fully reconstructed through manual investigation of the sequencing pileup in an alignment software.
5. Conclusions
Overall, MixtureAce MT™ effectively detects the correct contributing haplogroups and closely estimates contributor proportions in sequencing data generated from small amplicons for mixtures with minor contribution ≥ 5%. The new software provides a user-friendly interface and reduces confounding features such as NUMTs and noise, reducing traditionally prohibitive processing times. Based on this study, processing times can be further diminished through random reduction of samples to 20 K fragments while maintaining the ability to successfully identify contributor haplogroups and reducing the time to run a sample by approximately 60%.
A challenge of mixture deconvolution using small amplicon sequencing is the generation of spurious haplogroups resulting from private mutations that differ from Phylotree but these additional haplogroups can be resolved by including known haplotype/s in the evaluation. The inclusion of known haplotypes can also help to resolve trace contributors (minor contribution 1–2%), which remain challenging to resolve even with deep sequencing. The outcomes of this work will help to increase the effectiveness of forensic mtDNA analysis, decrease the time and cost of data analysis compared to current standard practices, and allow for separation of components of a mitogenome mixture.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}