

High Accuracy Classification of Developmental Toxicants by In Vitro Tests of Human Neuroepithelial and Cardiomyoblast Differentiation

 , , , , , , ,
, , , , , , ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Test Compounds, Teratogenicity Information, and Tested Concentrations
2.2. Cultivation of hiPSCs
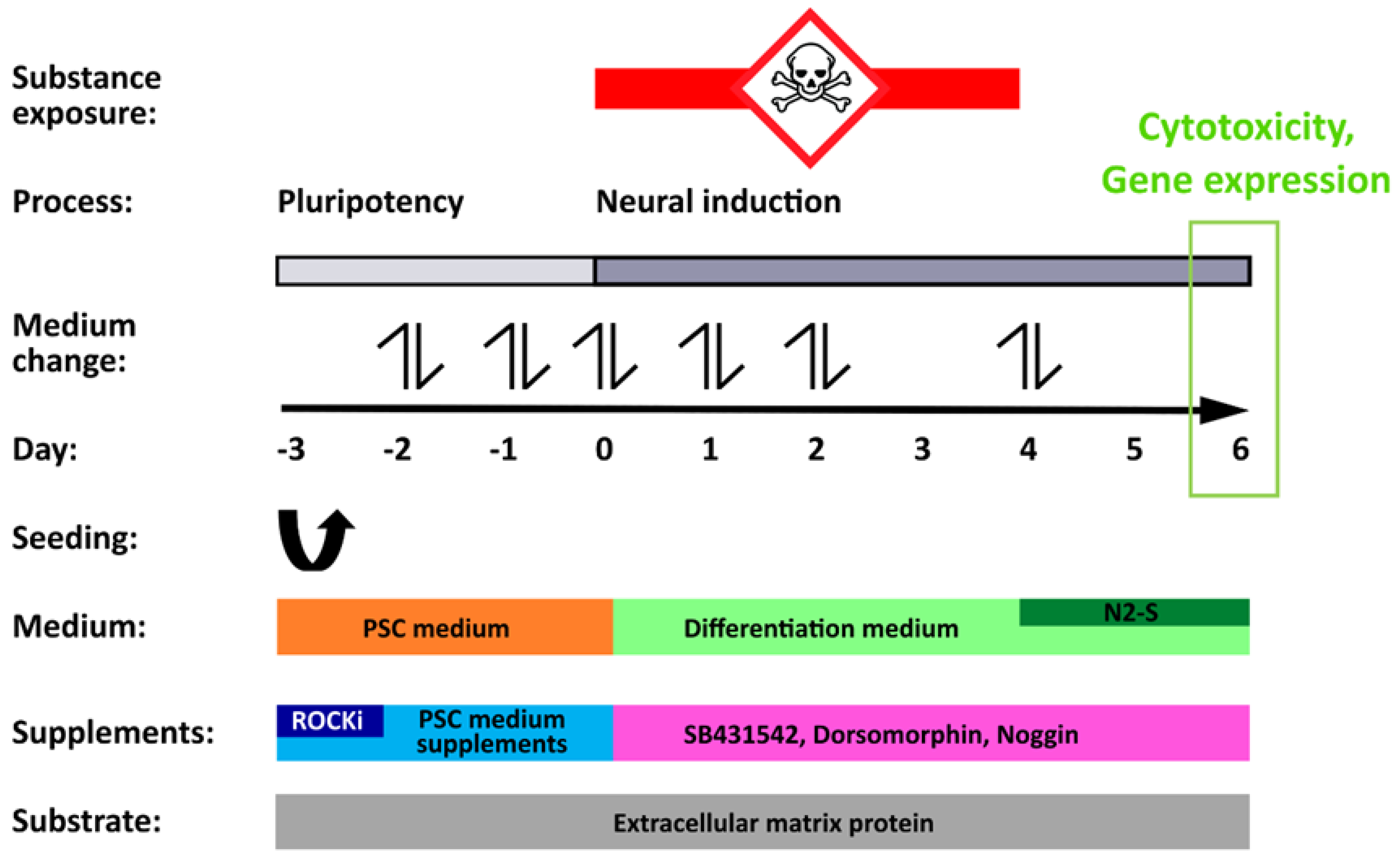
2.3. Neuroepithelial Differentiation of hiPSCs and Compound Exposure
2.4. Affymetrix Microarray Analysis
2.5. Data Pre-Processing
2.6. PCA Plots
2.7. Limma Analysis
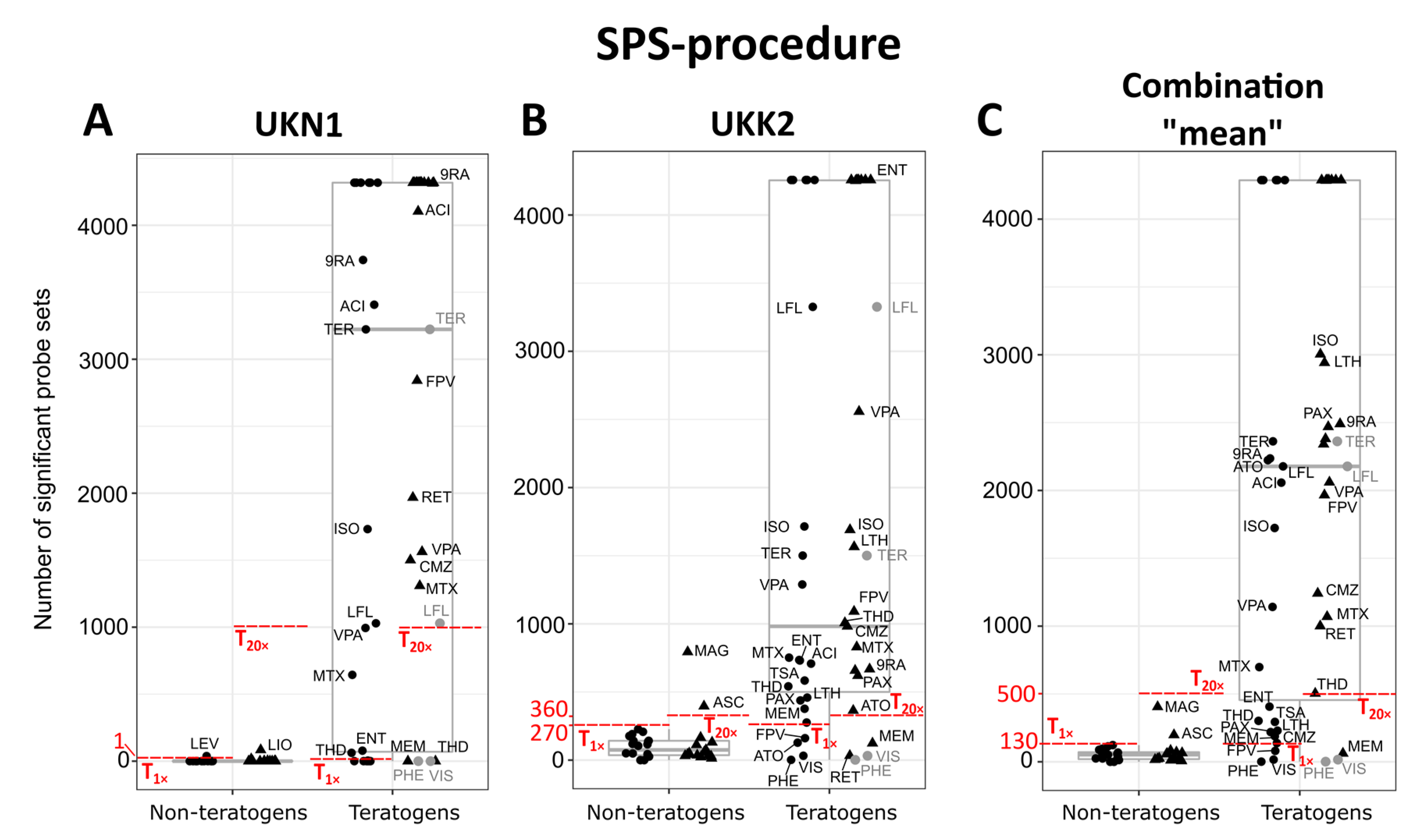
2.8. Classification Based on the Number of Significant Probe Sets (SPS-Procedure)
2.9. Classification Based on Penalized Logistic Regression (Top-1000-Procedure)
2.10. Combination of the UKN1 and UKK2 Test Systems
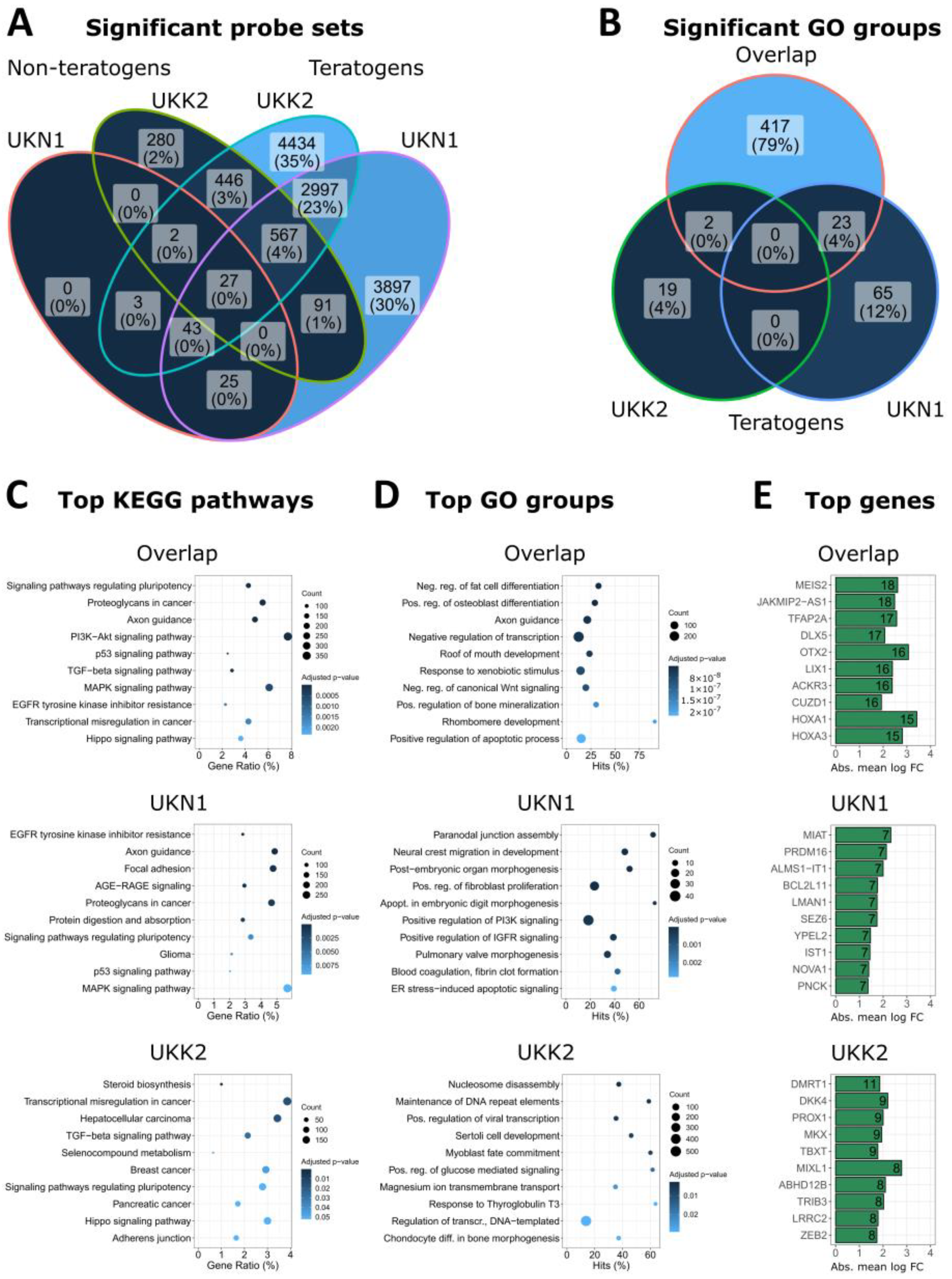
2.11. Venn Diagrams, Top Genes, GO Group Overrepresentation and KEGG Pathway Enrichment
2.12. Classification Based on Seven Significantly Deregulated Top Genes in RT-qPCR
3. Results
3.1. Gene Expression Profiling
3.2. Gene Expression-Based Classification to Identify Teratogens and Non-Teratogens by the UKN1 Test
3.3. Biological Interpretation of Genes Differentially Expressed in the UKN1 Test
3.4. Comparing the UKN1 Test with UKK2 for the Classification of Developmental Toxicity
3.5. Overlap of Teratogen-Induced Expression Patterns in UKN1 and UKK2
3.6. Combining UKN1 and UKK2 Improves the Classification Performance
3.7. Top Genes-Based Classification in UKN1 by RT-qPCR
4. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| hiPSC | Human induced pluripotent stem cell |
| NEP | Neuroepithelial precursors |
| Cmax | Maximal plasma concentration |
| PS | Probe set |
| SPS | Significant probe set |
| AUC | Area-under-the-(receiver operator characteristic)-curve |
| GO | Gene Ontology |
| KEGG | Kyoto Encyclopedia of Genes and Genomes |
References
- Seiler, A.; Oelgeschläger, M.; Liebsch, M.; Pirow, R.; Riebeling, C.; Tralau, T.; Luch, A. Developmental toxicity testing in the 21st century: The sword of Damocles shattered by embryonic stem cell assays? Arch. Toxicol. 2011, 85, 1361–1372. [Google Scholar] [CrossRef] [PubMed]
- Meigs, L.; Smirnova, L.; Rovida, C.; Leist, M.; Hartung, T. Animal testing and its alternatives—The most important omics is economics. ALTEX 2018, 35, 275–305. [Google Scholar] [CrossRef] [PubMed]
- Luz, A.L.; Tokar, E.J. Pluripotent Stem Cells in Developmental Toxicity Testing: A Review of Methodological Advances. Toxicol. Sci. 2018, 165, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Sachinidis, A.; Albrecht, W.; Nell, P.; Cherianidou, A.; Hewitt, N.J.; Edlund, K.; Hengstler, J.G. Road Map for Development of Stem Cell-Based Alternative Test Methods. Trends Mol. Med. 2019, 25, 470–481. [Google Scholar] [CrossRef]
- Horzmann, K.A.; Freeman, J.L. Making Waves: New Developments in Toxicology With the Zebrafish. Toxicol. Sci. 2018, 163, 5–12. [Google Scholar] [CrossRef]
- Ryan, K.R.; Sirenko, O.; Parham, F.; Hsieh, J.-H.; Cromwell, E.F.; Tice, R.R.; Behl, M. Neurite outgrowth in human induced pluripotent stem cell-derived neurons as a high-throughput screen for developmental neurotoxicity or neurotoxicity. NeuroToxicology 2016, 53, 271–281. [Google Scholar] [CrossRef]
- Hofrichter, M.; Nimtz, L.; Tigges, J.; Kabiri, Y.; Schröter, F.; Royer-Pokora, B.; Hildebrandt, B.; Schmuck, M.; Epanchintsev, A.; Theiss, S.; et al. Comparative performance analysis of human iPSC-derived and primary neural progenitor cells (NPC) grown as neurospheres in vitro. Stem Cell Res. 2017, 25, 72–82. [Google Scholar] [CrossRef]
- Palmer, J.A.; Smith, A.M.; Egnash, L.A.; Conard, K.R.; West, P.R.; Burrier, R.E.; Donley, E.L.; Kirchner, F.R. Establishment and assessment of a new human embryonic stem cell-based biomarker assay for developmental toxicity screening. Birth Defects Res. Part B Dev. Reprod. Toxicol. 2013, 98, 343–363. [Google Scholar] [CrossRef]
- Palmer, J.A.; Smith, A.M.; Egnash, L.A.; Colwell, M.R.; Donley, E.L.; Kirchner, F.R.; Burrier, R.E. A human induced pluripotent stem cell-based in vitro assay predicts developmental toxicity through a retinoic acid receptor-mediated pathway for a series of related retinoid analogues. Reprod. Toxicol. 2017, 73, 350–361. [Google Scholar] [CrossRef]
- Pallocca, G.; Grinberg, M.; Henry, M.; Frickey, T.; Hengstler, J.G.; Waldmann, T.; Sachinidis, A.; Rahnenführer, J.; Leist, M. Identification of transcriptome signatures and biomarkers specific for potential developmental toxicants inhibiting human neural crest cell migration. Arch. Toxicol. 2016, 90, 159–180. [Google Scholar] [CrossRef]
- Shinde, V.; Hoelting, L.; Srinivasan, S.P.; Meisig, J.; Meganathan, K.; Jagtap, S.; Grinberg, M.; Liebing, J.; Bluethgen, N.; Rahnenführer, J.; et al. Definition of transcriptome-based indices for quantitative characterization of chemically disturbed stem cell development: Introduction of the STOP-Toxukn and STOP-Toxukk tests. Arch. Toxicol. 2017, 91, 839–864. [Google Scholar] [CrossRef]
- Rempel, E.; Hoelting, L.; Waldmann, T.; Balmer, N.V.; Schildknecht, S.; Grinberg, M.; Das Gaspar, J.A.; Shinde, V.; Stöber, R.; Marchan, R.; et al. A transcriptome-based classifier to identify developmental toxicants by stem cell testing: Design, validation and optimization for histone deacetylase inhibitors. Arch. Toxicol. 2015, 89, 1599–1618. [Google Scholar] [CrossRef] [PubMed]
- Waldmann, T.; Grinberg, M.; König, A.; Rempel, E.; Schildknecht, S.; Henry, M.; Holzer, A.-K.; Dreser, N.; Shinde, V.; Sachinidis, A.; et al. Stem Cell Transcriptome Responses and Corresponding Biomarkers That Indicate the Transition from Adaptive Responses to Cytotoxicity. Chem. Res. Toxicol. 2017, 30, 905–922. [Google Scholar] [CrossRef] [PubMed]
- Cherianidou, A.; Seidel, F.; Kappenberg, F.; Dreser, N.; Blum, J.; Waldmann, T.; Blüthgen, N.; Meisig, J.; Madjar, K.; Henry, M.; et al. Classification of Developmental Toxicants in a Human iPSC Transcriptomics-Based Test. Chem. Res. Toxicol. 2022, 35, 760–773. [Google Scholar] [CrossRef]
- Nemade, H.; Acharya, A.; Chaudhari, U.; Nembo, E.; Nguemo, F.; Riet, N.; Abken, H.; Hescheler, J.; Papadopoulos, S.; Sachinidis, A. Cyclooxygenases Inhibitors Efficiently Induce Cardiomyogenesis in Human Pluripotent Stem Cells. Cells 2020, 9, 554. [Google Scholar] [CrossRef] [PubMed]
- Lian, X.; Hsiao, C.; Wilson, G.; Zhu, K.; Hazeltine, L.B.; Azarin, S.M.; Raval, K.K.; Zhang, J.; Kamp, T.J.; Palecek, S.P. Cozzarelli Prize Winner: Robust cardiomyocyte differentiation from human pluripotent stem cells via temporal modulation of canonical Wnt signaling. Proc. Natl. Acad. Sci. USA 2012, 109, E1848–E1857. [Google Scholar] [CrossRef]
- Ornoy, A. Valproic acid in pregnancy: How much are we endangering the embryo and fetus? Reprod. Toxicol. 2009, 28, 1–10. [Google Scholar] [CrossRef]
- Vargesson, N. Thalidomide-induced teratogenesis: History and mechanisms. Birth Defects Res. Part C Embryo Today Rev. 2015, 105, 140–156. [Google Scholar] [CrossRef]
- Krug, A.K.; Kolde, R.; Gaspar, J.A.; Rempel, E.; Balmer, N.V.; Meganathan, K.; Vojnits, K.; Baquié, M.; Waldmann, T.; Ensenat-Waser, R.; et al. Human embryonic stem cell-derived test systems for developmental neurotoxicity: A transcriptomics approach. Arch. Toxicol. 2013, 87, 123–143. [Google Scholar] [CrossRef]
- Balmer, N.V.; Weng, M.K.; Zimmer, B.; Ivanova, V.N.; Chambers, S.M.; Nikolaeva, E.; Jagtap, S.; Sachinidis, A.; Hescheler, J.; Waldmann, T.; et al. Epigenetic changes and disturbed neural development in a human embryonic stem cell-based model relating to the fetal valproate syndrome. Hum. Mol. Genet. 2012, 21, 4104–4114. [Google Scholar] [CrossRef]
- Dreser, N.; Madjar, K.; Holzer, A.-K.; Kapitza, M.; Scholz, C.; Kranaster, P.; Gutbier, S.; Klima, S.; Kolb, D.; Dietz, C.; et al. Development of a neural rosette formation assay (RoFA) to identify neurodevelopmental toxicants and to characterize their transcriptome disturbances. Arch. Toxicol. 2020, 94, 151–171. [Google Scholar] [CrossRef] [PubMed]
- Meisig, J.; Dreser, N.; Kapitza, M.; Henry, M.; Rotshteyn, T.; Rahnenführer, J.; Hengstler, J.G.; Sachinidis, A.; Waldmann, T.; Leist, M.; et al. Kinetic modeling of stem cell transcriptome dynamics to identify regulatory modules of normal and disturbed neuroectodermal differentiation. Nucleic Acids Res. 2020, 48, 12577–12592. [Google Scholar] [CrossRef] [PubMed]
- Morrison, M.; Klein, C.; Clemann, N.; Collier, D.A.; Hardy, J.; Heiβerer, B.; Cader, Z.; Graf, M.R.; Kaye, J. StemBANCC: Governing Access to Material and Data in a Large Stem Cell Research Consortium. Stem Cell Rev. Rep. 2015, 11, 681–687. [Google Scholar] [CrossRef] [PubMed]
- Chambers, S.M.; Fasano, C.A.; Papapetrou, E.P.; Tomishima, M.; Sadelain, M.; Studer, L. Highly efficient neural conversion of human ES and iPS cells by dual inhibition of SMAD signaling. Nat. Biotechnol. 2009, 27, 275–280. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 25 October 2022).
- Gautier, L.; Cope, L.; Bolstad, B.M.; Irizarry, R.A. Affy--analysis of Affymetrix GeneChip data at the probe level. Bioinformatics 2004, 20, 307–315. [Google Scholar] [CrossRef]
- McCall, M.N.; Bolstad, B.M.; Irizarry, R.A. Frozen robust multiarray analysis (fRMA). Biostatistics 2010, 11, 242–253. [Google Scholar] [CrossRef]
- McCall, M.N.; Irizarry, R.A. hgu133plus2frmavecs: Vectors Used by Frma for Microarrays of Type hgu133plus2. R Package Version 1.5.0. 2017. Available online: https://doi.org/10.18129/B9.bioc.hgu133plus2frmavecs (accessed on 25 October 2022).
- Ritchie, M.E.; Belinda, P.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Society. Ser. B (Methodol.) 1995, 57, 289–300. Available online: http://www.jstor.org/stable/2346101 (accessed on 25 October 2022). [CrossRef]
- Bischl, B.; Lang, M.; Kotthoff, L.; Schiffner, J.; Richter, J.; Studerus, E.; Casalicchio, G.; Jones, Z.M. Mlr: Machine Learning in R. J. Mach. Learn. Res. 2016, 17, 1–5. Available online: http://jmlr.org/papers/v17/15-066.html (accessed on 25 October 2022).
- Friedman, J.H.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Alexa, A.; Rahnenfuhrer, J.; Lengauer, T. Improved scoring of functional groups from gene expression data by decorrelating GO graph structure. Bioinformatics 2006, 22, 1600–1607. [Google Scholar] [CrossRef] [PubMed]
- Alexa, A.; Rahnenführer, J.; topGO: Enrichment Analysis for Gene Ontology. R Package Version 2.46.0; 2021. Available online: https://bioc.ism.ac.jp/packages/3.14/bioc/manuals/topGO/man/topGO.pdf (accessed on 25 October 2022).
- Wu, T.; Hu, E.; Xu, S.; Chen, M.; Guo, P.; Dai, Z.; Feng, T.; Zhou, L.; Tang, W.; Zhan, L.; et al. clusterProfiler 4.0: A universal enrichment tool for interpreting omics data. Innovation 2021, 2, 100141. [Google Scholar] [CrossRef]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef]
- Balmer, N.V.; Klima, S.; Rempel, E.; Ivanova, V.N.; Kolde, R.; Weng, M.K.; Meganathan, K.; Henry, M.; Sachinidis, A.; Berthold, M.R.; et al. From transient transcriptome responses to disturbed neurodevelopment: Role of histone acetylation and methylation as epigenetic switch between reversible and irreversible drug effects. Arch. Toxicol. 2014, 88, 1451–1468. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.; Janssen, B.; Malinauskas, T.; Vangoor, V.; Coles, C.; Kaufmann, R.; Ni, T.; Gilbert, R.; Padilla-Parra, S.; Pasterkamp, R.J.; et al. Structural Basis for Plexin Activation and Regulation. Neuron 2016, 91, 548–560. [Google Scholar] [CrossRef] [PubMed]
- Janssen, B.; Malinauskas, T.; Weir, G.; Cader, Z.; Siebold, C.; Jones, E.Y. Neuropilins lock secreted semaphorins onto plexins in a ternary signaling complex. Nat. Struct. Mol. Biol. 2012, 19, 1293–1299. [Google Scholar] [CrossRef]
- Sone, M.; Hayashi, T.; Tarui, H.; Agata, K.; Takeichi, M.; Nakagawa, S. The mRNA-like noncoding RNA Gomafu constitutes a novel nuclear domain in a subset of neurons. J. Cell Sci. 2007, 120 Pt 15, 2498–2506. [Google Scholar] [CrossRef]
- Rapicavoli, N.A.; Poth, E.M.; Blackshaw, S. The long noncoding RNA RNCR2 directs mouse retinal cell specification. BMC Dev. Biol. 2010, 10, 49. [Google Scholar] [CrossRef]
- Fricker, L.D. Carboxypeptidase E. Annu. Rev. Physiol. 1988, 50, 309–321. [Google Scholar] [CrossRef]
- Radovanovic, D.; Meier, P.J.; Guirguis, M.; Lorent, J.-P.; Kupferschmidt, H. Dose-dependent toxicity of diphenhydramine overdose. Hum. Exp. Toxicol. 2000, 19, 489–495. [Google Scholar] [CrossRef]
- Kundu, N.; Domingues, C.C.; Patel, J.; Aljishi, M.; Ahmadi, N.; Fakhri, M.; Sylvetsky, A.C.; Sen, S. Sucralose promotes accumulation of reactive oxygen species (ROS) and adipogenesis in mesenchymal stromal cells. Stem Cell Res. Ther. 2020, 11, 250. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.-W.; Chi, L.; Tu, P.; Xue, J.; Ru, H.; Lu, K. Quantitative proteomics reveals systematic dysregulations of liver protein metabolism in sucralose-treated mice. J. Proteom. 2019, 196, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Guo, Z.; Chen, D.; Li, L.; Song, X.; Liu, T.; Jin, G.; Li, Y.; Liu, Y.; Ajiguli, A.; et al. Maternal sucralose intake alters gut microbiota of offspring and exacerbates hepatic steatosis in adulthood. Gut Microbes 2020, 11, 1043–1063. [Google Scholar] [CrossRef] [PubMed]
- Sklan, D.; Shalit, I.; Lasebnik, N.; Spirer, Z.; Weisman, Y. Retinol transport proteins and concentrations in human amniotic fluid, placenta, and fetal and maternal sera. Br. J. Nutr. 1985, 54, 577–583. [Google Scholar] [CrossRef]
- Manolescu, D.C.; El-Kares, R.; Lakhal-Chaieb, L.; Montpetit, A.; Bhat, P.V.; Goodyer, P. Newborn serum retinoic acid level is associated with variants of genes in the retinol metabolism pathway. Pediatr. Res. 2010, 67, 598–602. [Google Scholar] [CrossRef]
- Blomhoff, R. Vitamin A and Carotenoid Toxicity. Food Nutr. Bull. 2001, 22, 320–334. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Compound | Abbreviation | Pregnancy Category a | Drug Class | Concentration [µM] | |
|---|---|---|---|---|---|
| 1-Fold Cmax b | 20-Fold Cmax b | ||||
| Non-teratogens | |||||
| Ampicillin | AMP | A, B | Antibiotic | 107 | 2140 |
| Ascorbic acid | ASC | A | Vitamin | 200 | 4000 |
| Buspirone | BSP | B | Anxiolytic, serotonin 5-HT1A receptor agonist | 0.0244 | 0.488 |
| Chlorpheniramine | CPA | B | Antihistamine, histamine H1 receptor antagonist | 0.0304 | 0.608 |
| Dextromethorphan | DEX | A | Antitussive and psychoactive agent | 0.15 | 3 |
| Diphenhydramine | DPH | A, B | Antihistamine, histamine H1 receptor antagonist | 0.3 | 6 |
| Doxylamine | DOA | A | Antihistamine, histamine H1 receptor antagonist | 0.38 | 7.6 |
| Famotidine | FAM | B | Antihistamine, histamine H2 receptor antagonist | 1.06 | 21.2 |
| Folic acid | FOA | A | Vitamin | 0.38 | 7.6 |
| Levothyroxine | LEV | A | Synthetic thyroid hormone | 0.077 | 1.54 |
| Liothyronine | LIO | A | Synthetic thyroid hormone | 0.00307 | 0.06145 |
| Magnesium (chloride) | MAG | n/a | Dietary supplement | 1200 | 24,000 |
| Methicillin | MET | B | Antibiotic | 140 | 2800 |
| Ranitidine | RAN | B | Antihistamine, histamine H2 receptor antagonist | 0.8 | 16 |
| Retinol d | RET | n/a | Vitamin and retinoid | 1 d | -- d |
| Sucralose | SUC | n/a | Artificial sweetener | 2.5 | 50 |
| Teratogens | |||||
| 9-cis-Retinoic acid | 9RA | D | Retinoid, RAR and RXR ligand | 1 | 20 |
| Acitretin | ACI | X | Retinoid, RAR activator | 1.2 | 24 |
| Actinomycin D | ACD | D | Antineoplastic agent, RNA synthesis inhibitor | 0.1 | 2 |
| Atorvastatin | ATO | X | Antilipemic agent, HMG-CoA reductase inhibitor | 0.54 | 10.8 |
| Carbamazepine | CMZ | D | Anticonvulsant, voltage-gated sodium channel blocker | 19 | 10-fold Cmax: 190 c |
| Doxorubicin | DXR | D | Antineoplastic agent, affects DNA and related proteins; produces ROS | 1.84 | 36.8 |
| Entinostat | ENT | n/a | Potential antineoplastic agent, HDAC inhibitor | 0.2 | 4 |
| Favipiravir | FPV | n/a | Antiviral drug, selective inhibitor of RNA polymerase of influenza virus | 382 | 7600 |
| Isotretinoin | ISO | X | Retinoid, RAR ligand | 1.7 | 34 |
| Leflunomide | LFL | X | Anti-inflammatory agent, DHODH inhibitor | 370 | -- c |
| Lithium (chloride) | LTH | D | Mood stabilizer | 1000 | 20,000 |
| Methotrexate | MTX | D/X | Antineoplastic, dihydrofolate reductase inhibitor | 1 | 20 |
| Methylmercury | MEM | n/a | Bioaccumulative environmental toxicant, hypothesized ROS production | 0.020 | 0.4 |
| Panobinostat | PAN | n/a, (D) | Antineoplastic agent, HDAC inhibitor | 0.06 | 1.2 |
| Paroxetine | PAX | D | Antidepressant, SSR inhibitor | 1.2 | 24 |
| Phenytoin | PHE | D | Anticonvulsant, voltage-gated sodium channel blocker | 20 | --- c |
| Retinol d | RET | n/a | Vitamin and retinoid | -- d | 20 d |
| Teriflunomide | TER | X | Anti-inflammatory agent, DHODH inhibitor | 370 | --- c |
| Thalidomide | THD | X | Antiangiogenic | 3.9 | 78 |
| Trichostatin A | TSA | n/a | Antifungal antibiotic, HDAC inhibitor | 0.01 | 0.2 |
| Valproic acid | VPA | D, X | Anticonvulsant, voltage-gated sodium channel blocker, antifolate agent, HDAC inhibitor | 600 | 1.67-fold Cmax: 1000 c |
| Vinblastine | VIN | D | Antimitotic agent, affects microtubule dynamics | 0.0247 | 0.494 |
| Vismodegib | VIS | X | Antineoplastic agent, hedgehog pathway inhibitor | 20 | -- c |
| Vorinostat | VST | D | Antineoplastic agent, HDAC inhibitor | 3 | 60 |
| Compounds | Abbreviation | Cytotoxicity b | Number of Up-/Downregulated Probe Sets c | ||||
|---|---|---|---|---|---|---|---|
| 1-Fold Cmax a | 20-Fold Cmax a | ||||||
| 1-Fold Cmax a | 20-Fold Cmax a | Up | Down | Up | Down | ||
| Non-teratogens | |||||||
| Ampicillin | AMP | No | No | 0 | 0 | 0 | 0 |
| Ascorbic acid | ASC | No | No | 0 | 0 | 0 | 0 |
| Buspirone | BSP | No | No | 0 | 0 | 0 | 0 |
| Chlorpheniramine | CPA | No | No | 0 | 0 | 0 | 0 |
| Dextromethorphan | DEX | No | No | 0 | 0 | 0 | 0 |
| Diphenhydramine | DPH | No | No | 0 | 0 | 0 | 0 |
| Doxylamine | DOA | No | No | 0 | 0 | 0 | 0 |
| Famotidine | FAM | No | No | 0 | 0 | 0 | 0 |
| Folic acid | FOA | No | No | 0 | 0 | 0 | 0 |
| Levothyroxine | LEV | No | No | 18 | 20 | 0 | 0 |
| Liothyronine | LIO | No | No | 0 | 0 | 27 | 57 |
| Magnesium chloride | MAG | No | No | 0 | 0 | 13 | 3 |
| Methicillin | MET | No | No | 0 | 0 | 0 | 2 |
| Ranitidine | RAN | No | No | 0 | 0 | 0 | 0 |
| Retinol e | RET | No | -- e | 0 e | 0 e | -- e | -- e |
| Sucralose | SUC | No | No | 0 | 0 | 0 | 0 |
| Teratogens | |||||||
| 9-cis-retinoic acid | 9RA | No | No | 1956 | 1785 | 2426 | 1887 |
| Acitretin | ACI | No | No | 1803 | 1604 | 2309 | 1795 |
| Actinomycin D | ACD | Yes | Yes | toxic | toxic | toxic | toxic |
| Atorvastatin | ATO | Yes | Yes | toxic | toxic | toxic | toxic |
| Carbamazepine | CMZ | No | No d | 0 | 0 | 910 d | 591 d |
| Doxorubicin | DXR | Yes | Yes | toxic | toxic | toxic | toxic |
| Entinostat | ENT | No | Yes | 48 | 30 | toxic | toxic |
| Favipiravir | FPV | No | No | 0 | 0 | 1551 | 1290 |
| Isotretinoin | ISO | No | Yes | 1029 | 703 | toxic | toxic |
| Leflunomide | LFL | No | --- d | 614 | 415 | --- d | --- d |
| Lithium chloride | LTH | No | Yes | 0 | 0 | toxic | toxic |
| Methotrexate | MTX | No | No | 435 | 209 | 687 | 622 |
| Methylmercury | MEM | No | No | 0 | 0 | 0 | 0 |
| Panobinostat | PAN | Yes | Yes | toxic | toxic | toxic | toxic |
| Paroxetine | PAX | No | Yes | 0 | 0 | toxic | toxic |
| Phenytoin | PHE | No | --- d | 0 | 0 | --- d | --- d |
| Retinol e | RET | -- e | No | -- e | -- e | 1032 e | 936 e |
| Teriflunomide | TER | No | --- d | 1829 | 1394 | --- d | --- d |
| Thalidomide | THD | No | No | 41 | 21 | 0 | 0 |
| Trichostatin A | TSA | No | Yes | 4 | 0 | toxic | toxic |
| Valproic acid | VPA | No | No d | 630 | 364 | 878 d | 685 d |
| Vinblastine | VIN | Yes | Yes | toxic | toxic | toxic | toxic |
| Vismodegib | VIS | No | --- d | 0 | 0 | --- d | --- d |
| Vorinostat | VST | Yes | Yes | toxic | toxic | toxic | toxic |
| 1-Fold Cmax | 20-Fold Cmax a | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Test | Data | Procedure | AUC | Accuracy | Sensitivity | Specificity | AUC | Accuracy | Sensitivity | Specificity |
| UKN1 | Cytotoxicity | 0.63 | 0.56 | 0.26 | 1 | 0.73 | 0.67 | 0.46 | 1 | |
| Gene expression | SPS | 0.78 | 0.64 | 0.43 | 0.94 | 0.82 | 0.62 | 0.38 | 1 | |
| Top-1000 | 0.84 | 0.69 | 0.70 | 0.69 | 0.90 | 0.59 | 0.46 | 0.8 | ||
| Cytotoxicity and gene expression | SPS | 0.84 | 0.79 | 0.70 | 0.94 | 0.90 | 0.90 | 0.83 | 1 | |
| Top-1000 | 0.88 | 0.85 | 0.96 | 0.69 | 0.95 | 0.87 | 0.92 | 0.8 | ||
| RT-qPCR (SPS-like) | Not calculated | 0.74 | 0.57 | 1 | Not calculated | 0.90 | 0.83 | 1 | ||
| RT-qPCR (Top-1000-like) | 0.76 | 0.77 | 0.74 | 0.81 | 0.91 | 0.87 | 0.88 | 0.87 | ||
| UKK2 | Cytotoxicity | 0.61 | 0.54 | 0.22 | 1 | 0.63 | 0.54 | 0.25 | 1 | |
| Gene expression | SPS | 0.87 | 0.77 | 0.61 | 1 | 0.83 | 0.69 | 0.58 | 0.87 | |
| Top-1000 | 0.93 | 0.79 | 0.74 | 0.88 | 0.92 | 0.77 | 0.71 | 0.87 | ||
| Cytotoxicity and gene expression | SPS | 0.9 | 0.9 | 0.83 | 1 | 0.87 | 0.85 | 0.83 | 0.87 | |
| Top-1000 | 0.95 | 0.92 | 0.96 | 0.88 | 0.94 | 0.92 | 0.96 | 0.87 | ||
| Combination ‘mean’ | Cytotoxicity | 0.63 | 0.56 | 0.26 | 1 | 0.73 | 0.67 | 0.46 | 1 | |
| Gene expression | SPS | 0.89 | 0.77 | 0.61 | 1 | 0.84 | 0.64 | 0.42 | 1 | |
| Top-1000 | 0.94 | 0.79 | 0.74 | 0.88 | 0.96 | 0.79 | 0.75 | 0.87 | ||
| Cytotoxicity and gene expression | SPS | 0.92 | 0.92 | 0.87 | 1 | 0.91 | 0.92 | 0.88 | 1 | |
| Top-1000 | 0.95 | 0.92 | 0.96 | 0.88 | 0.98 | 0.95 | 1 | 0.87 | ||
| Compounds | Abbreviation | SPS-Procedure | Top-1000-Procedure | RT-qPCR (SPS-Like) | RT-qPCR (Top-1000-Like) | ||||
|---|---|---|---|---|---|---|---|---|---|
| UKN1 20-Fold Cmax a | UKK2 1-Fold Cmax a | Mean 20-Fold Cmax a | UKN1 20-Fold Cmax a | UKK2 1-Fold Cmax a | Mean 20-Fold Cmax a | UKN1 20-Fold Cmax a | UKN1 20-Fold Cmax a | ||
| Non-teratogens | |||||||||
| Ampicillin | AMP | TN | TN | TN | TN | TN | TN | TN | TN |
| Ascorbic acid | ASC | TN | TN | TN | FP | TN | TN | TN | FP |
| Buspirone | BSP | TN | TN | TN | TN | TN | TN | TN | TN |
| Chlorpheniramine | CPA | TN | TN | TN | TN | TN | TN | TN | TN |
| Dextromethorphan | DEX | TN | TN | TN | TN | TN | TN | TN | TN |
| Diphenhydramine | DPH | TN | TN | TN | FP | FP | FP | TN | TN |
| Doxylamine | DOA | TN | TN | TN | TN | TN | TN | TN | TN |
| Famotidine | FAM | TN | TN | TN | TN | TN | TN | TN | TN |
| Folic acid | FOA | TN | TN | TN | TN | TN | TN | TN | TN |
| Levothyroxine | LEV | TN | TN | TN | TN | TN | TN | TN e | TN e |
| Liothyronine | LIO | TN | TN | TN | TN | TN | TN | TN | FP |
| Magnesium chloride | MAG | TN | TN | TN | TN | TN | TN | TN | TN |
| Methicillin | MET | TN | TN | TN | TN | TN | TN | TN | TN |
| Ranitidine | RAN | TN | TN | TN | TN | TN | TN | TN | TN |
| Retinol d | RET | -- d | TN d | -- d | -- d | TN d | -- d | -- d | -- d |
| Sucralose | SUC | TN | TN | TN | FP | FP | FP | TN | TN |
| Teratogens | |||||||||
| 9-cis-retinoic acid | 9RA | TP | TP | TP | TP | TP | TP | TP | TP |
| Acitretin | ACI | TP | TP | TP | TP | TP | TP | TP | TP |
| Actinomycin D | ACD | TP | TP | TP | TP | TP | TP | TP | TP |
| Atorvastatin | ATO | TP | FN | TP | TP | FN | TP | TP | TP |
| Carbamazepine | CMZ | TP b | TP | TP b | TP b | TP | TP b | TP b | TP b |
| Doxorubicin | DXR | TP | TP | TP | TP | TP | TP | TP | TP |
| Entinostat | ENT | TP | TP | TP | TP | TP | TP | TP | TP |
| Favipiravir | FPV | TP | FN | TP | TP | TP | TP | TP | TP |
| Isotretinoin | ISO | TP | TP | TP | TP | TP | TP | TP | TP |
| Leflunomide | LFL | TP c | TP | TP c | TP c | TP | TP c | TP c | TP c |
| Lithium chloride | LTH | TP | TP | TP | TP | TP | TP | TP | TP |
| Methotrexate | MTX | TP | TP | TP | TP | TP | TP | TP | TP |
| Methylmercury | MEM | FN | TP | FN | TP | TP | TP | FN | FN |
| Panobinostat | PAN | TP | TP | TP | TP | TP | TP | TP | TP |
| Paroxetine | PAX | TP | TP | TP | TP | TP | TP | TP | TP |
| Phenytoin | PHE | FN c | FN | FN c | TP c | TP | TP c | FN c | FN c |
| Retinol d | RET | TP d | -- d | TP d | TP d | -- d | TP d | TP d | TP d |
| Teriflunomide | TER | TP c | TP | TP c | TP c | TP | TP c | TP c | TP c |
| Thalidomide | THD | FN | TP | TP | FN | TP | TP | FN | TP |
| Trichostatin A | TSA | TP | TP | TP | TP | TP | TP | TP | TP |
| Valproic acid | VPA | TP b | TP | TP b | TP b | TP | TP b | TP b | TP b |
| Vinblastine | VIN | TP | TP | TP | TP | TP | TP | TP | TP |
| Vismodegib | VIS | FN c | FN | FN c | FN c | TP | TP c | FN c | FN c |
| Vorinostat | VST | TP | TP | TP | TP | TP | TP | TP | TP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seidel, F.; Cherianidou, A.; Kappenberg, F.; Marta, M.; Dreser, N.; Blum, J.; Waldmann, T.; Blüthgen, N.; Meisig, J.; Madjar, K.; et al. High Accuracy Classification of Developmental Toxicants by In Vitro Tests of Human Neuroepithelial and Cardiomyoblast Differentiation. Cells 2022, 11, 3404. https://doi.org/10.3390/cells11213404
Seidel F, Cherianidou A, Kappenberg F, Marta M, Dreser N, Blum J, Waldmann T, Blüthgen N, Meisig J, Madjar K, et al. High Accuracy Classification of Developmental Toxicants by In Vitro Tests of Human Neuroepithelial and Cardiomyoblast Differentiation. Cells. 2022; 11(21):3404. https://doi.org/10.3390/cells11213404
Chicago/Turabian StyleSeidel, Florian, Anna Cherianidou, Franziska Kappenberg, Miriam Marta, Nadine Dreser, Jonathan Blum, Tanja Waldmann, Nils Blüthgen, Johannes Meisig, Katrin Madjar, and et al. 2022. "High Accuracy Classification of Developmental Toxicants by In Vitro Tests of Human Neuroepithelial and Cardiomyoblast Differentiation" Cells 11, no. 21: 3404. https://doi.org/10.3390/cells11213404
APA StyleSeidel, F., Cherianidou, A., Kappenberg, F., Marta, M., Dreser, N., Blum, J., Waldmann, T., Blüthgen, N., Meisig, J., Madjar, K., Henry, M., Rotshteyn, T., Scholtz-Illigens, A., Marchan, R., Edlund, K., Leist, M., Rahnenführer, J., Sachinidis, A., & Hengstler, J. G. (2022). High Accuracy Classification of Developmental Toxicants by In Vitro Tests of Human Neuroepithelial and Cardiomyoblast Differentiation. Cells, 11(21), 3404. https://doi.org/10.3390/cells11213404