
Frequency-Domain Collaborative Lightweight Super-Resolution for Fine Texture Enhancement in Rice Imagery

Abstract
1. Introduction
- We propose an efficient LHFB module that divides the super-resolution processing of an image into two branches: the low-frequency branch is used to capture the overall structural information of the image, while the high-frequency branch focuses on reconstructing the details for more accurate image restoration.
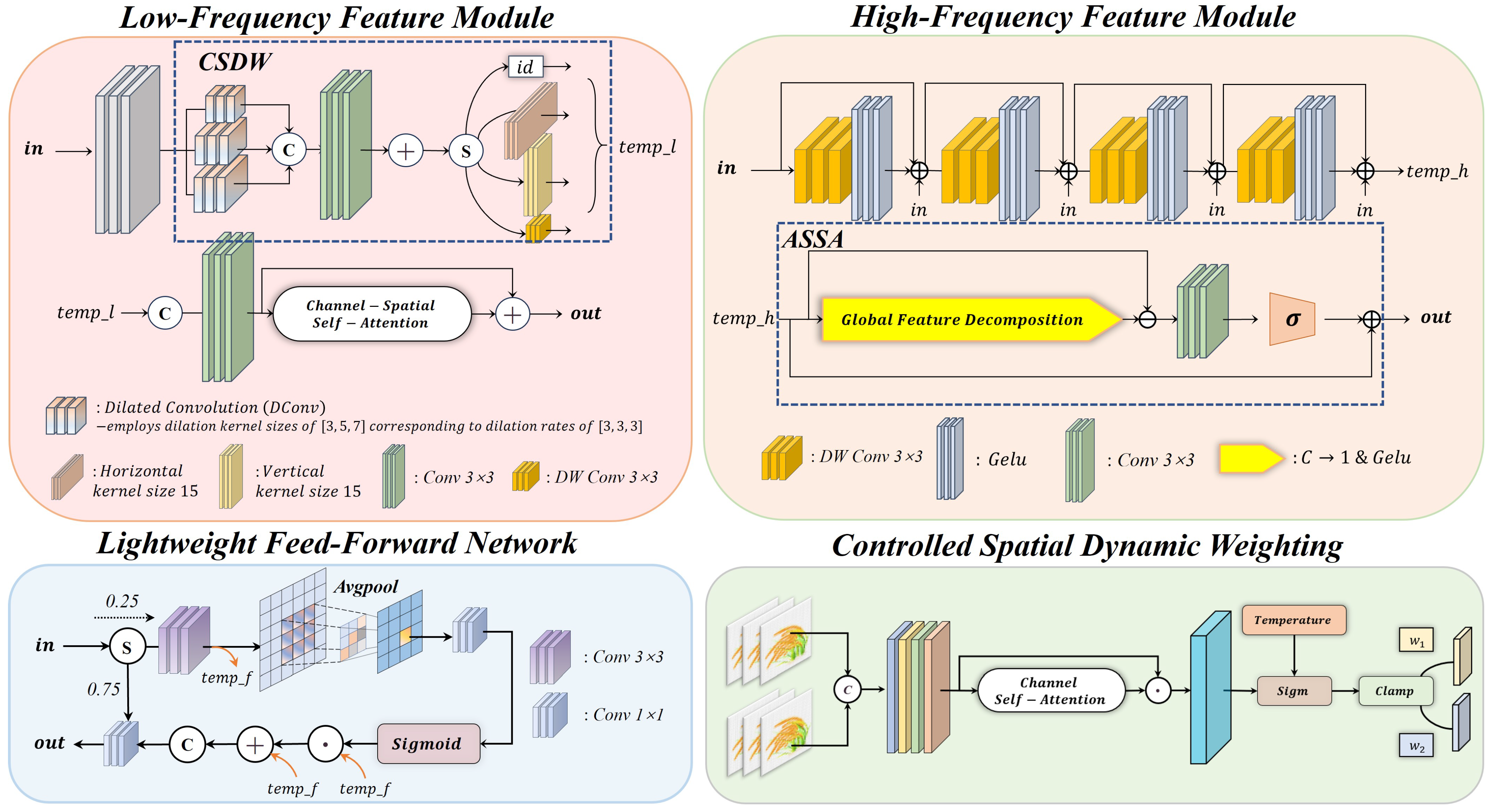
- We propose the degradation-aware dynamic weight fusion module (CSDW) and lightweight feedforward network (LFFN) to adaptively adjust the high-frequency and low-frequency fusion ratios based on the degradation characteristics.
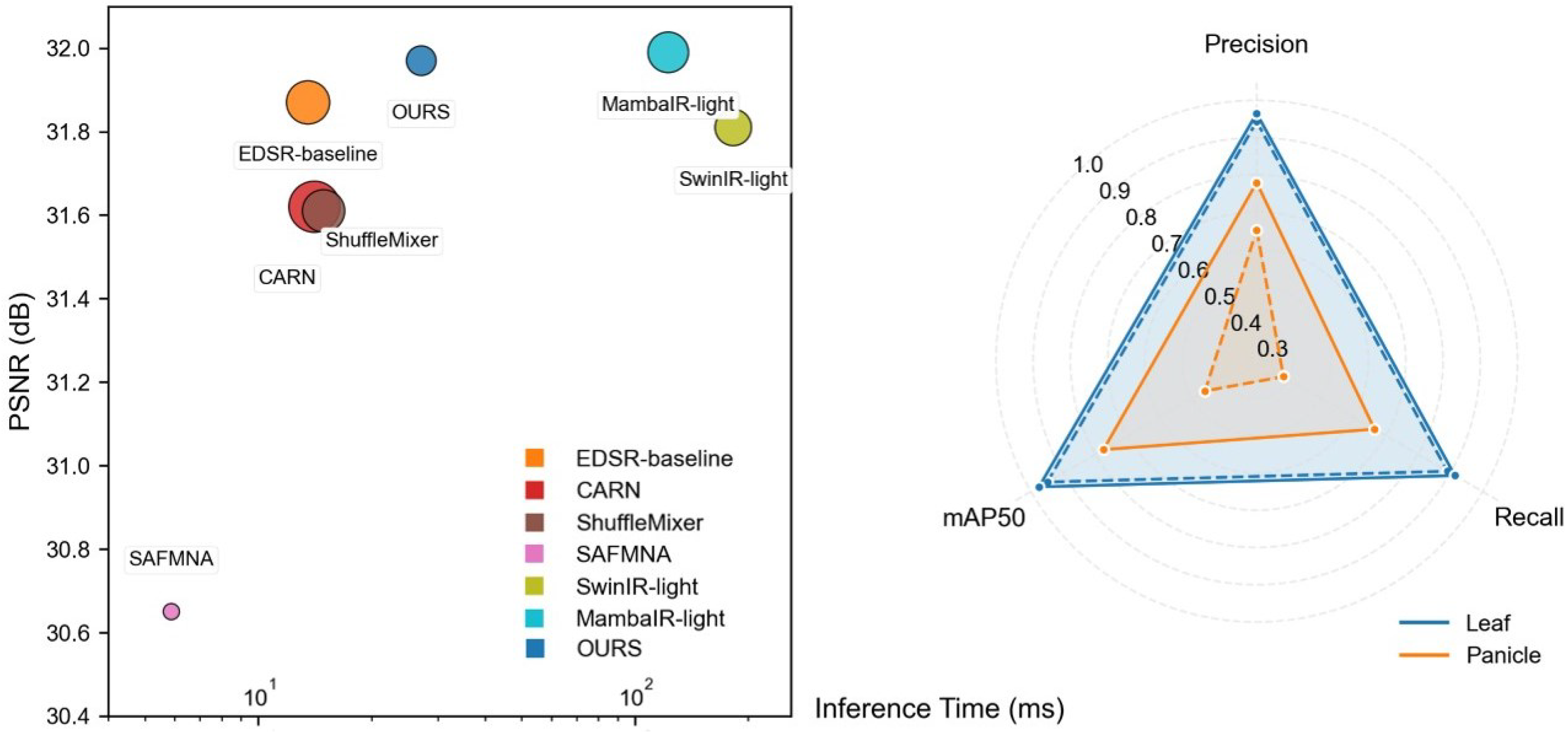
- We quantitatively and qualitatively evaluate our proposed ADFSR on datasets and show that our approach strikes a good balance between model complexity and reconstruction performance. The good performance in the downstream inspection task can be observed, as shown by Figure 3.
2. Materials and Methods
2.1. Degenerate Modeling Training Set Design
2.2. Downstream Mission Datasets Description
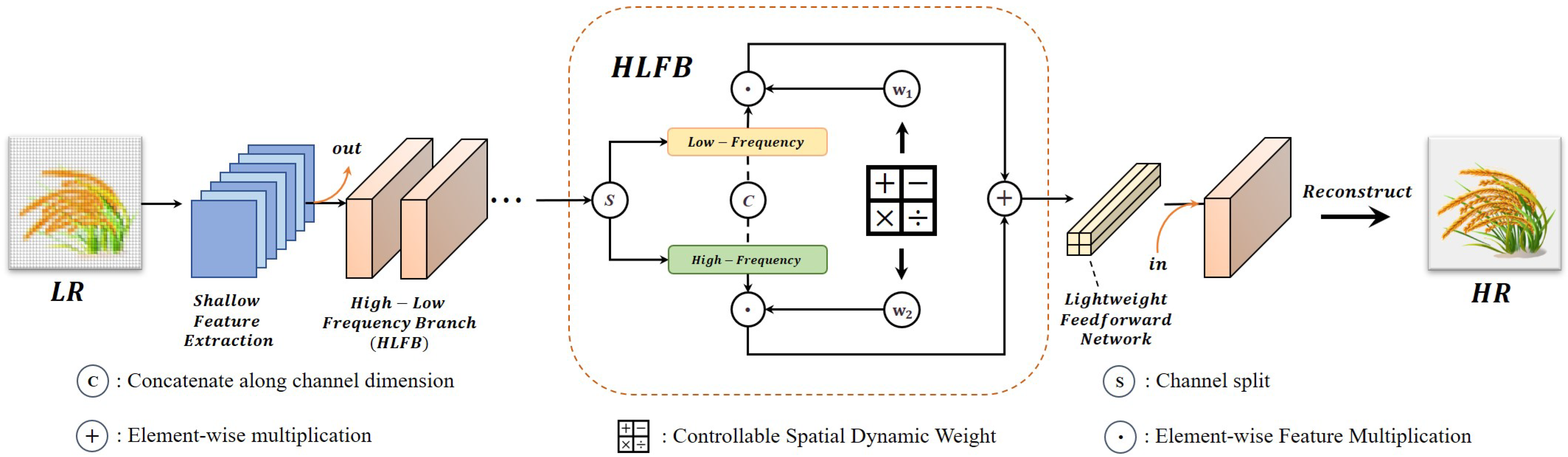
3. Proposed Method
3.1. Degeneration-Aware Image Restoration Analysis
3.2. Low-Frequency Feature Module
3.3. High-Frequency Feature Module
3.4. Dynamic Weight Generation and Lightweight Feedforward Networks
4. Experimental Results
4.1. Assessment of Indicators
4.1.1. Quantitative Comparison with Other Methods
4.1.2. Memory and Runtime Comparison
4.1.3. Image Denoising Performance Analysis
4.1.4. Comparison of Subjective Visual Indicators
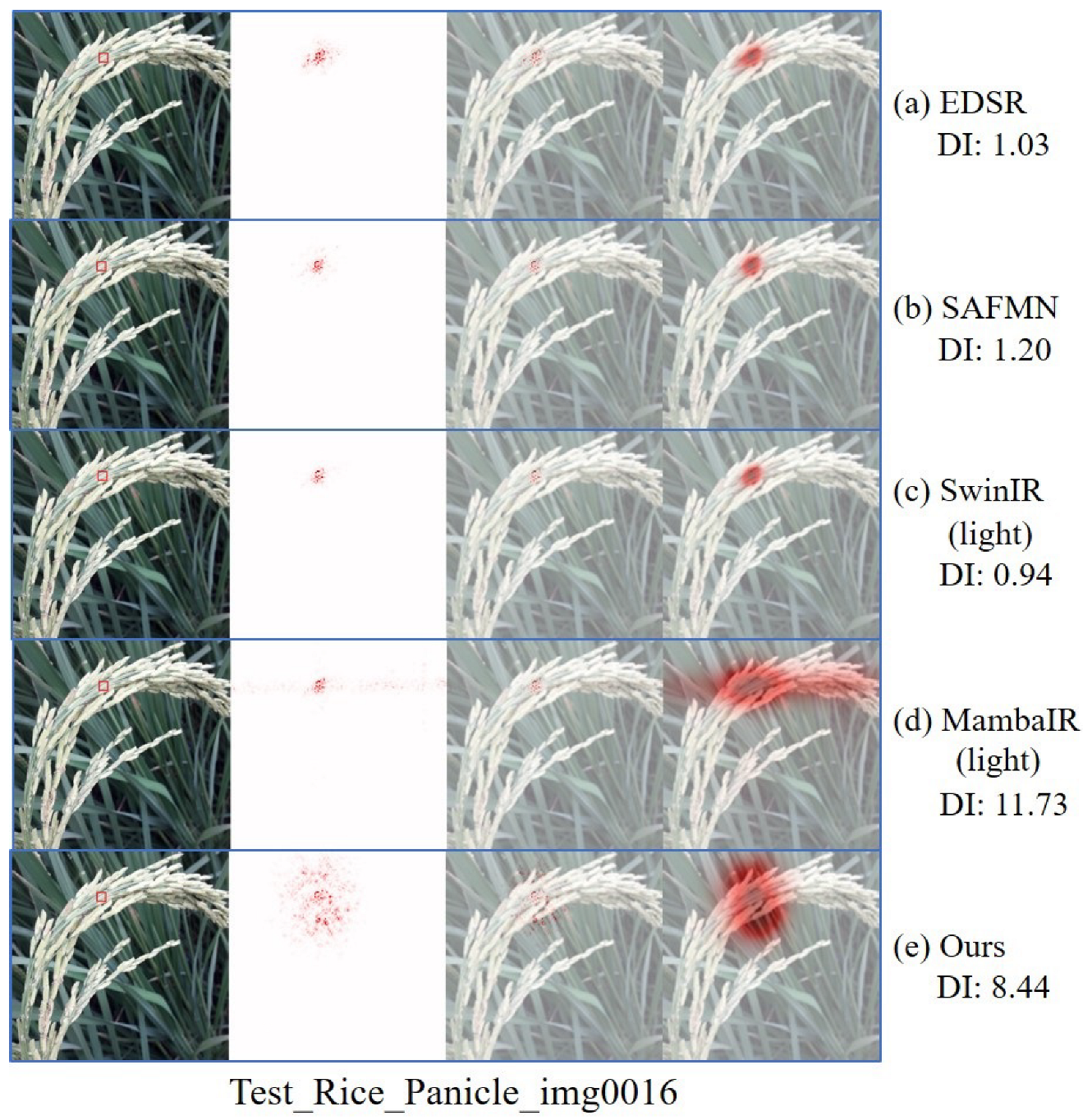
4.1.5. Comparison of Diffusivity
4.1.6. Qualitative Comparison on the DF2K Dataset
4.2. Downstream Task Analysis
4.2.1. Image-Enhancement-Based Ripeness Detection and Analysis of Rice Spikes
4.2.2. Image-Enhancement-Based Detection and Analysis of Rice Leaf Pests and Diseases
4.3. Ablation Experiment
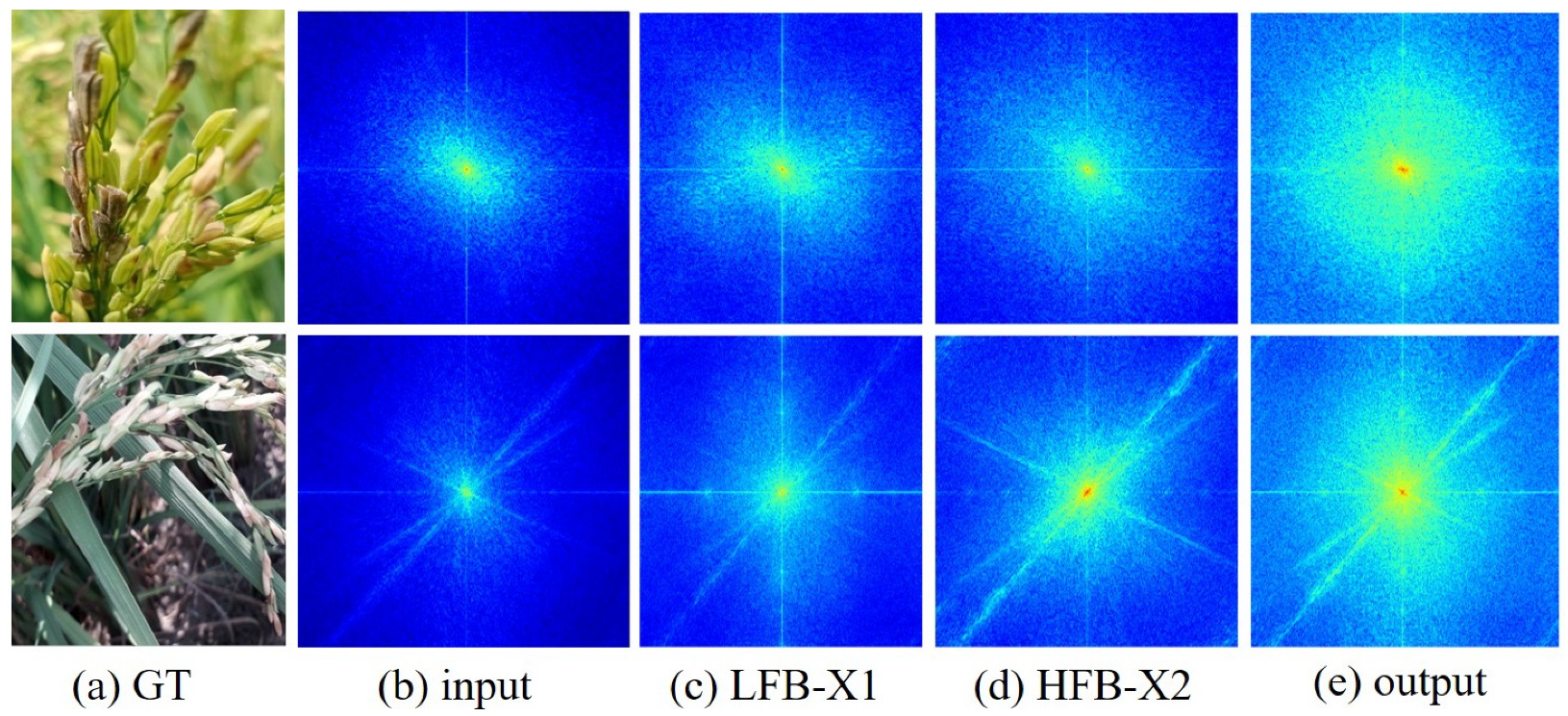
4.3.1. Complementary Effectiveness Analysis of High and Low Frequencies
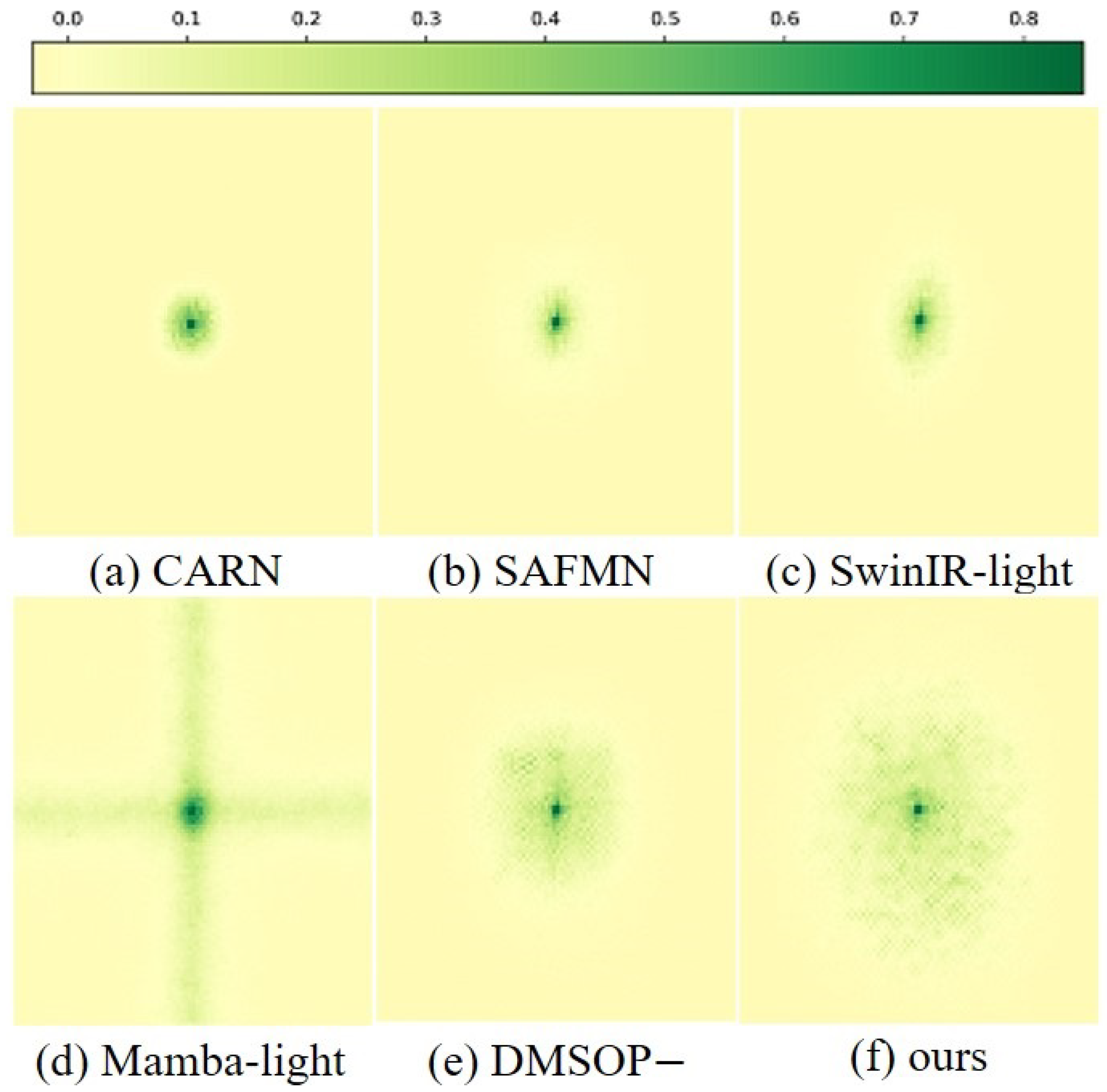
4.3.2. Directional Feature Decoupling and Sensory Field Optimization
4.3.3. ASSA Dynamic Scaling Mechanism Enhanced High-Frequency Detail Analysis
4.3.4. Impact of LFFN on Algorithm Performance
4.3.5. Impact of CSDW on Algorithm Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Ma, S.; Wang, Z.; Ma, X.; Yang, C.; Chen, G.; Wang, Y. Improved Lightweight YOLOv8 Model for Rice Disease Detection in Multi-Scale Scenarios. Agronomy 2025, 15, 445. [Google Scholar] [CrossRef]
- Deng, J.; Yang, C.; Huang, K.; Lei, L.; Ye, J.; Zeng, W.; Zhang, J.; Lan, Y.; Zhang, Y. Deep-Learning-Based Rice Disease and Insect Pest Detection on a Mobile Phone. Agronomy 2023, 13, 2139. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, Q.; Xu, W.; Huang, A.; Yan, C.; Zheng, B. Enhanced local distribution learning for real image super-resolution. Comput. Vis. Image Underst. 2024, 247, 104092. [Google Scholar] [CrossRef]
- Wu, M.; Yang, X.; Yun, L.; Yang, C.; Chen, Z.; Xia, Y. A General Image Super-Resolution Reconstruction Technique for Walnut Object Detection Model. Agriculture 2024, 14, 1279. [Google Scholar] [CrossRef]
- Martínez-Ruedas, C.; Yanes-Luis, S.; Díaz-Cabrera, J.M.; Gutiérrez-Reina, D.; Linares-Burgos, R.; Castillejo-González, I.L. Detection of Planting Systems in Olive Groves Based on Open-Source, High-Resolution Images and Convolutional Neural Networks. Agronomy 2022, 12, 2700. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Ma, Z.; Liu, Z.; Wang, K.; Lian, S. Hybrid attention transformer with re-parameterized large kernel convolution for image super-resolution. Image Vis. Comput. 2024, 149, 105162. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Y.; Li, J.; Wang, J.; Lai, X. TCSR: Self-attention with time and category for session-based recommendation. Comput. Intell. 2024, 40, e12695. [Google Scholar] [CrossRef]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 3247–3258. [Google Scholar]
- Sun, L.; Dong, J.; Tang, J.; Pan, J. Spatially-adaptive feature modulation for efficient image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13190–13199. [Google Scholar]
- Sun, L.; Pan, J.; Tang, J. Shufflemixer: An efficient convnet for image super-resolution. Adv. Neural Inf. Process. Syst. 2022, 35, 17314–17326. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Lv, N.; Yuan, M.; Xie, Y.; Zhan, K.; Lu, F. Non-local sparse attention based swin transformer V2 for image super-resolution. Signal Process. 2024, 222, 109542. [Google Scholar] [CrossRef]
- Huang, S.; Deng, W.; Li, G.; Yang, Y.; Wang, J. RTEN-SR: A reference-based texture enhancement network for single image super-resolution. Displays 2024, 83, 102684. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Yang, J. Video super-resolution with inverse recurrent net and hybrid local fusion. Neurocomputing 2022, 489, 40–51. [Google Scholar] [CrossRef]
- Guo, H.; Li, J.; Dai, T.; Ouyang, Z.; Ren, X.; Xia, S.T. Mambair: A simple baseline for image restoration with state-space model. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2024; pp. 222–241. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Zang, C.; Song, G.; Li, L.; Zhao, G.; Lu, W.; Jiang, G.; Sun, Q. DB-MFENet: A Dual-Branch Multi-Frequency Feature Enhancement Network for Hyperspectral Image Classification. Remote Sens. 2025, 17, 1458. [Google Scholar] [CrossRef]
- Zheng, M.; Sun, L.; Dong, J.; Pan, J. SMFANet: A lightweight self-modulation feature aggregation network for efficient image super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2024; pp. 359–375. [Google Scholar]
- Prajapati, H.B.; Shah, J.P.; Dabh, V.K. Detection and classification of rice plant diseases. Intell. Decis. Technol. 2017, 11, 357–373. [Google Scholar] [CrossRef]
- Kumar, R. Rice Plant Dataset. 2020. Available online: https://www.kaggle.com/datasets/rajkumar898/rice-plant-dataset (accessed on 24 April 2025).
- Xiao, R.; Wang, L.; Yuan, H. Rice Disease Detection Dataset of 6715 Images. 2024. Available online: https://www.kaggle.com/datasets/hiramscud/rice-disease-detection-dataset-of-6000-images (accessed on 24 April 2025).
- Ma, X.; Tan, S.; Lu, H. In-Field Rice Panicles Detection of Different Growth Stages. 2022. Available online: https://data.mendeley.com/datasets/m3pvzxfd7v/1 (accessed on 24 April 2025).
- Wijayanto, A.K.; Prasetyo, L.B.; Hudjimartsu, S.A.; Sigit, G.; Hongo, C. Textural features for BLB disease damage assessment in paddy fields using drone data and machine learning: Enhancing disease detection accuracy. Smart Agric. Technol. 2024, 8, 100498. [Google Scholar] [CrossRef]
- Chen, G.; Dai, K.; Yang, K.; Hu, T.; Chen, X.; Yang, Y.; Dong, W.; Wu, P.; Zhang, Y.; Yan, Q. Bracketing image restoration and enhancement with high-low frequency decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6097–6107. [Google Scholar]
- Dong, J.; Pan, J.; Yang, Z.; Tang, J. Multi-scale residual low-pass filter network for image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12345–12354. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Run, D.W. Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Jocher, G. YOLOv8: Real-Time Object Detection. 2023. Available online: https://docs.ultralytics.com/zh/models/yolov8/ (accessed on 24 April 2025).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; BMVA Press: Durham, UK, 2012. [Google Scholar] [CrossRef]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In International Conference on Curves and Surfaces; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference On Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4917–4926. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 649–667. [Google Scholar]
- Liu, J.; Chen, C.; Tang, J.; Wu, G. From coarse to fine: Hierarchical pixel integration for lightweight image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1666–1674. [Google Scholar]
- Zhang, A.; Ren, W.; Liu, Y.; Cao, X. Lightweight image super-resolution with superpixel token interaction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12728–12737. [Google Scholar]
- Liu, C.; Gao, G.; Wu, F.; Guo, Z.; Yu, Y. An efficient feature reuse distillation network for lightweight image super-resolution. Comput. Vis. Image Underst. 2024, 249, 104178. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, Z.; Guo, C.L.; Bai, S.; Cheng, M.M.; Hou, Q. Srformer: Permuted self-attention for single image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12780–12791. [Google Scholar]
- Guo, H.; Guo, Y.; Zha, Y.; Zhang, Y.; Li, W.; Dai, T.; Xia, S.T.; Li, Y. Mambairv2: Attentive state space restoration. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 10–17 June 2025; pp. 28124–28133. [Google Scholar]
- Hu, T.; Liu, Z.; Hu, R.; Zeng, L.; Deng, K.; Dong, H.; Li, M.; Deng, Y.J. Yield prediction method for regenerated rice based on hyperspectral image and attention mechanisms. Smart Agric. Technol. 2025, 10, 100804. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | #Params (K) | #FLOPs (G) | Rice_Panicle PSNR/SSIM | Rice_Healthy PSNR/SSIM | Rice_Leaf PSNR/SSIM |
|---|---|---|---|---|---|---|
| CARN [7] | 2 | 1592 | 223 | 35.60/0.9499 | 34.42/0.9364 | 36.15/0.9293 |
| EDSR [15] | 2 | 1370 | 316 | 35.89/0.9529 | 35.86/0.9408 | 36.46/0.9333 |
| SAFMN [13] | 2 | 228 | 52 | 35.57/0.9492 | 35.52/0.9364 | 36.16/0.9294 |
| ShuffleMixer [14] | 2 | 394 | 91 | 35.61/0.9495 | 35.51/0.9364 | 36.14/0.9293 |
| SwinIR-light [9] | 2 | 910 | 244 | 35.86/0.9524 | 35.83/0.9404 | 36.43/0.9329 |
| MambaIR-light [19] | 2 | 859 | 198 | 35.99/0.9539 | 35.99/0.9424 | 36.55/0.9347 |
| Ours | 2 | 558 | 116 | 35.99/0.9542 | 35.93/0.9415 | 36.48/0.9335 |
| CARN [7] | 3 | 1592 | 119 | 32.23/0.9017 | 32.44/0.8843 | 33.50/0.8784 |
| EDSR [15] | 3 | 1555 | 160 | 32.42/0.9060 | 32.68/0.8899 | 33.75/0.8840 |
| SAFMN [13] | 3 | 233 | 23 | 32.31/0.9035 | 32.54/0.8867 | 33.62/0.8812 |
| ShuffleMixer [14] | 3 | 415 | 43 | 32.24/0.9018 | 32.45/0.8846 | 33.51/0.8789 |
| SwinIR-light [9] | 3 | 918 | 114 | 32.36/0.9044 | 32.61/0.8881 | 33.67/0.8872 |
| MambaIR-light [19] | 3 | 867 | 89 | 30.56/0.9084 | 30.86/0.8939 | 33.90/0.8877 |
| Ours | 3 | 566 | 52 | 32.58/0.9089 | 32.84/0.8934 | 33.87/0.8870 |
| CARN [7] | 4 | 1592 | 91 | 29.98/0.8518 | 30.33/0.8315 | 31.61/0.8270 |
| EDSR [15] | 4 | 1518 | 114 | 30.18/0.8581 | 30.58/0.8392 | 31.87/0.8344 |
| SAFMN [13] | 4 | 240 | 14 | 30.06/0.8545 | 30.45/0.8351 | 31.72/0.8301 |
| ShuffleMixer [14] | 4 | 411 | 28 | 30.00/0.8528 | 30.37/0.8330 | 31.61/0.8274 |
| SwinIR-light [9] | 4 | 930 | 65 | 30.14/0.8571 | 30.55/0.8383 | 31.81/0.8330 |
| MambaIR-light [19] | 4 | 879 | 51 | 30.27/0.8609 | 30.73/0.8437 | 31.99/0.8380 |
| Ours | 4 | 575 | 30 | 30.31/0.8617 | 30.73/0.8432 | 31.97/0.8369 |
| Methods | #GPU Mem. [M] | #Avg. Time [ms] |
|---|---|---|
| EDSR | 487 | 13.56 |
| CARN | 684 | 14.10 |
| SAFMN | 65 | 5.88 |
| ShuffleMixer | 468 | 14.91 |
| SwinIR-light | 345 | 182.53 |
| MambaIR-light | 430 | 122.65 |
| Ours | 227 | 27.10 |
| Method | Rice_Healthy PSNR/SSIM | Rice_Leaf PSNR/SSIM |
|---|---|---|
| MambaIR | 36.93/0.9607 | 36.97/0.9499 |
| ADFSR | 37.88/0.9620 | 38.10/0.9537 |
| Methods | #Params (K) | #FLOPs (G) | Set5 | Set14 | B100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|
| FSRCNN [6] | 12 | 5 | 30.71/0.8657 | 27.59/0.7535 | 26.98/0.7150 | 24.62/0.7280 | 27.90/0.8517 |
| CARN [7] | 1592 | 91 | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.47/0.9084 |
| EDSR-baseline [15] | 1518 | 114 | 32.09/0.8938 | 28.58/0.7813 | 27.57/0.7357 | 26.04/0.7849 | 30.35/0.9067 |
| IMDN [40] | 715 | 41 | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 |
| LAPAR-A [41] | 659 | 94 | 32.15/0.8944 | 28.61/0.7818 | 27.61/0.7366 | 26.14/0.7871 | 30.42/0.9074 |
| SMSR [42] | 1006 | 42 | 32.12/0.8932 | 28.55/0.7808 | 27.55/0.7351 | 26.11/0.7868 | 30.54/0.9085 |
| ShuffleMixer [14] | 411 | 28 | 32.21/0.8953 | 28.66/0.7827 | 27.61/0.7366 | 26.08/0.7835 | 30.65/0.9093 |
| SAFMN [13] | 240 | 14 | 32.18/0.8948 | 28.60/0.7813 | 27.58/0.7359 | 25.97/0.7809 | 30.43/0.9063 |
| SMFANet [22] | 197 | 11 | 32.25/0.8956 | 28.71/0.7833 | 27.64/0.7377 | 26.18/0.7862 | 30.82/0.9104 |
| ESRT [43] | 752 | 298 | 32.19/0.8947 | 28.69/0.7833 | 27.69/0.7379 | 26.39/0.7962 | 30.75/0.9100 |
| SwinIR-light [9] | 930 | 65 | 32.44/0.8976 | 28.77/0.7858 | 27.69/0.7406 | 26.47/0.7980 | 30.92/0.9151 |
| ELAN-light [44] | 640 | 54 | 32.43/0.8975 | 28.78/0.7858 | 27.69/0.7406 | 26.54/0.7982 | 30.92/0.9150 |
| NGswin [45] | 1019 | 40 | 32.33/0.8963 | 28.78/0.7859 | 27.66/0.7396 | 26.45/0.7963 | 30.80/0.9128 |
| SPIN [46] | 555 | 42 | 32.48/0.8983 | 28.80/0.7862 | 27.70/0.7415 | 26.55/0.7998 | 30.980.9156 |
| EFRDN [47] | 767 | 30 | 32.33/0.8964 | 28.67/0.7833 | 27.63/0.7384 | 26.37/0.7939 | 30.76/0.9113 |
| SRFormer-light [48] | 873 | 63 | 32.51/0.8988 | 28.82/0.7872 | 27.73/0.7422 | 26.67/0.7422 | 31.17/0.9165 |
| MambaIRv2-light [49] | 790 | 76 | 32.51/0.8992 | 28.84/0.7878 | 27.75/0.7426 | 26.82/0.7426 | 31.24/0.9182 |
| Ours | 575 | 30 | 32.44/0.8983 | 28.86/0.7867 | 27.74/0.7407 | 26.49/0.7959 | 31.20/0.9159 |
| Method | Stage | P | R | mAP50 |
|---|---|---|---|---|
| Early | 0.836 | 0.317 | 0.480 | |
| Before | Middle | 0.556 | 0.493 | 0.517 |
| Restoration | Late | 0.564 | 0.339 | 0.382 |
| Average | 0.652 | 0.383 | 0.460 | |
| Early | 0.865 | 0.663 | 0.829 | |
| After | Middle | 0.755 | 0.751 | 0.819 |
| Restoration | Late | 0.716 | 0.581 | 0.678 |
| Average | 0.779 | 0.665 | 0.775 |
| Method | Type | P | R | mAP50 |
|---|---|---|---|---|
| Leaf_Blight | 0.962 | 0.944 | 0.971 | |
| Before | Brown_Spot | 0.930 | 0.774 | 0.896 |
| Restoration | Leaf_smut | 0.937 | 0.956 | 0.979 |
| Average | 0.943 | 0.891 | 0.949 | |
| Leaf_Blight | 0.977 | 0.935 | 0.989 | |
| After | Brown_Spot | 0.948 | 0.843 | 0.945 |
| Restoration | Leaf_smut | 0.971 | 0.966 | 0.991 |
| Average | 0.965 | 0.914 | 0.975 |
| Ablation | Variant | Rice_Panicle PSNR/SSIM | Rice_Healthy PSNR/SSIM |
|---|---|---|---|
| Baseline | ADFSR | 30.31/0.8617 | 30.73/0.8432 |
| HLFB | HFB− | 30.14/0.8569 | 30.53/0.8375 |
| LFB− | 30.10/0.8569 | 30.50/0.8362 | |
| HFB × 2 | 30.20/0.8585 | 30.58/0.8391 | |
| LFB × 2 | 30.58/0.8391 | 30.64/0.8402 | |
| Module Variables | DMSOP− | 30.31/0.8615 | 30.72/0.8430 |
| ASSA− | 30.29/0.8610 | 30.70/0.8424 | |
| LFFN− | 30.28/0.8606 | 30.68/0.8420 | |
| Weight modulation | No weight | 30.28/0.8612 | 30.72/0.8428 |
| Competitive weight1 | 30.30/0.8616 | 30.70/0.8426 | |
| Competitive weight2 | 30.30/0.8611 | 30.72/0.8428 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhang, J.; Du, J.; Chen, X.; Zhang, W.; Peng, C. Frequency-Domain Collaborative Lightweight Super-Resolution for Fine Texture Enhancement in Rice Imagery. Agronomy 2025, 15, 1729. https://doi.org/10.3390/agronomy15071729
Zhang Z, Zhang J, Du J, Chen X, Zhang W, Peng C. Frequency-Domain Collaborative Lightweight Super-Resolution for Fine Texture Enhancement in Rice Imagery. Agronomy. 2025; 15(7):1729. https://doi.org/10.3390/agronomy15071729
Chicago/Turabian StyleZhang, Zexiao, Jie Zhang, Jinyang Du, Xiangdong Chen, Wenjing Zhang, and Changmeng Peng. 2025. "Frequency-Domain Collaborative Lightweight Super-Resolution for Fine Texture Enhancement in Rice Imagery" Agronomy 15, no. 7: 1729. https://doi.org/10.3390/agronomy15071729
APA StyleZhang, Z., Zhang, J., Du, J., Chen, X., Zhang, W., & Peng, C. (2025). Frequency-Domain Collaborative Lightweight Super-Resolution for Fine Texture Enhancement in Rice Imagery. Agronomy, 15(7), 1729. https://doi.org/10.3390/agronomy15071729