
YOLOv8-MSP-PD: A Lightweight YOLOv8-Based Detection Method for Jinxiu Malus Fruit in Field Conditions

 ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Construction and Augmentation
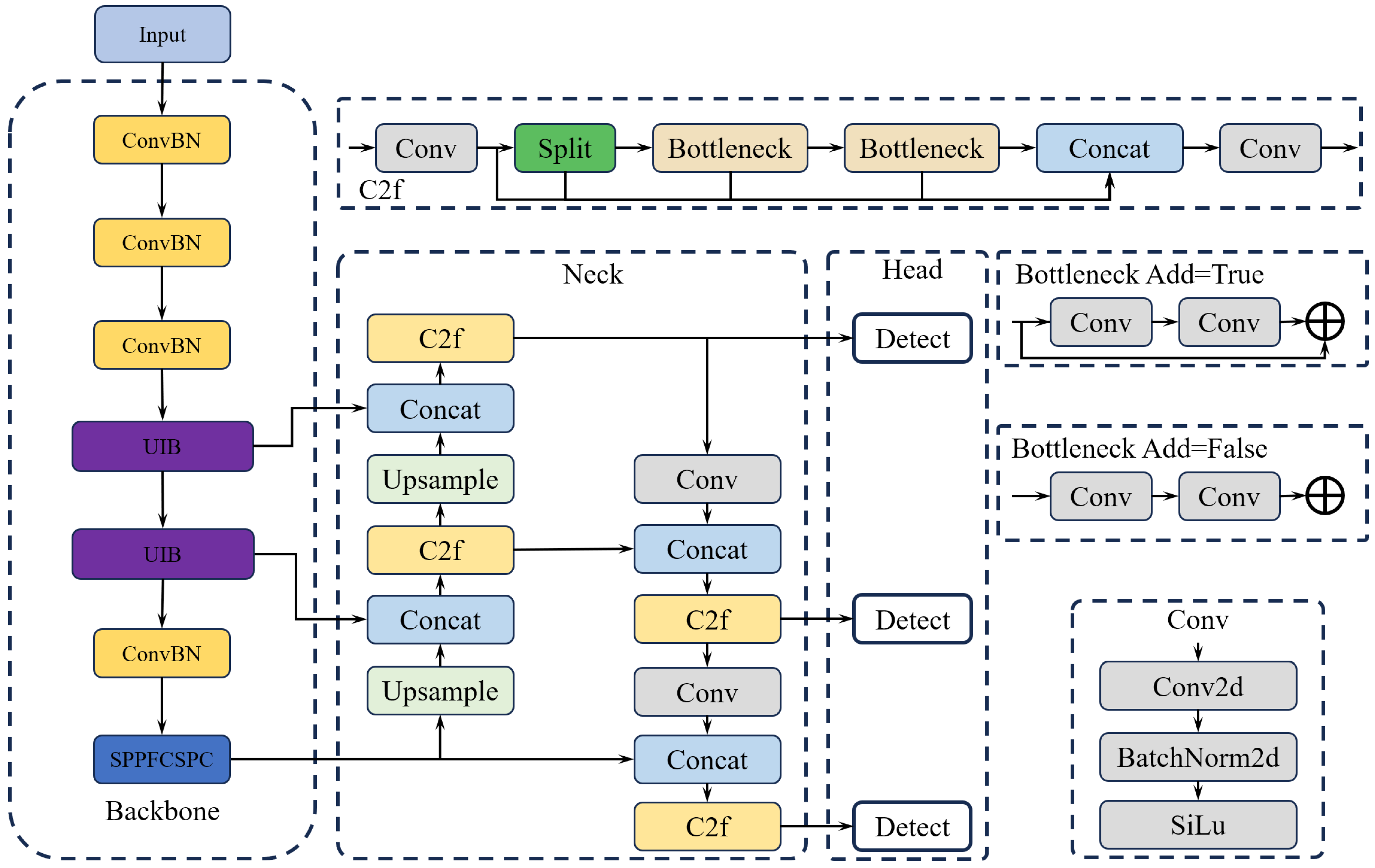
2.2. Field Detection Method for Jinxiu Malus Fruits
2.2.1. Optimization of Backbone Network for Feature Extraction
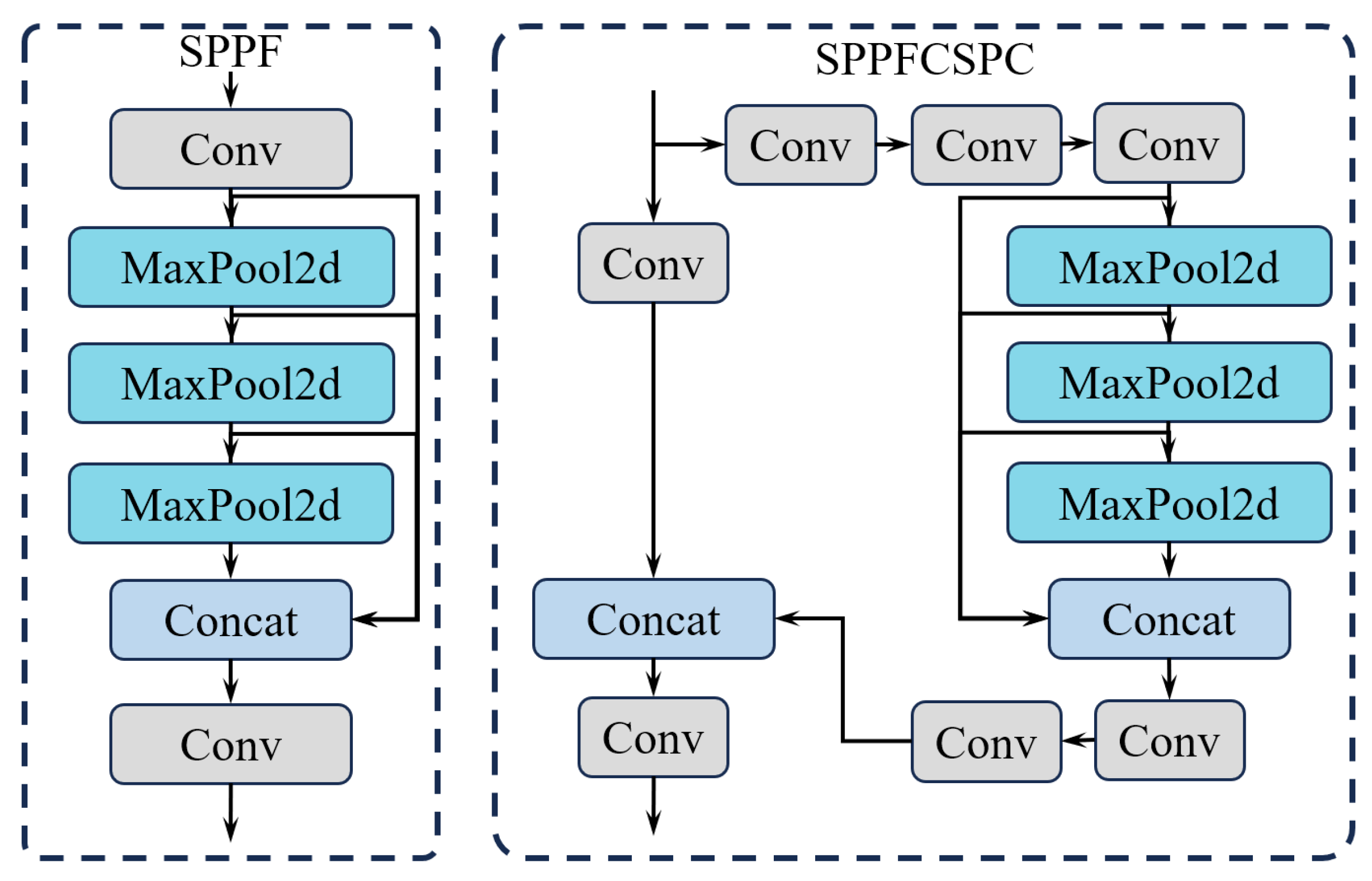
2.2.2. SPPFCSPC Multi-Scale Feature Fusion Module
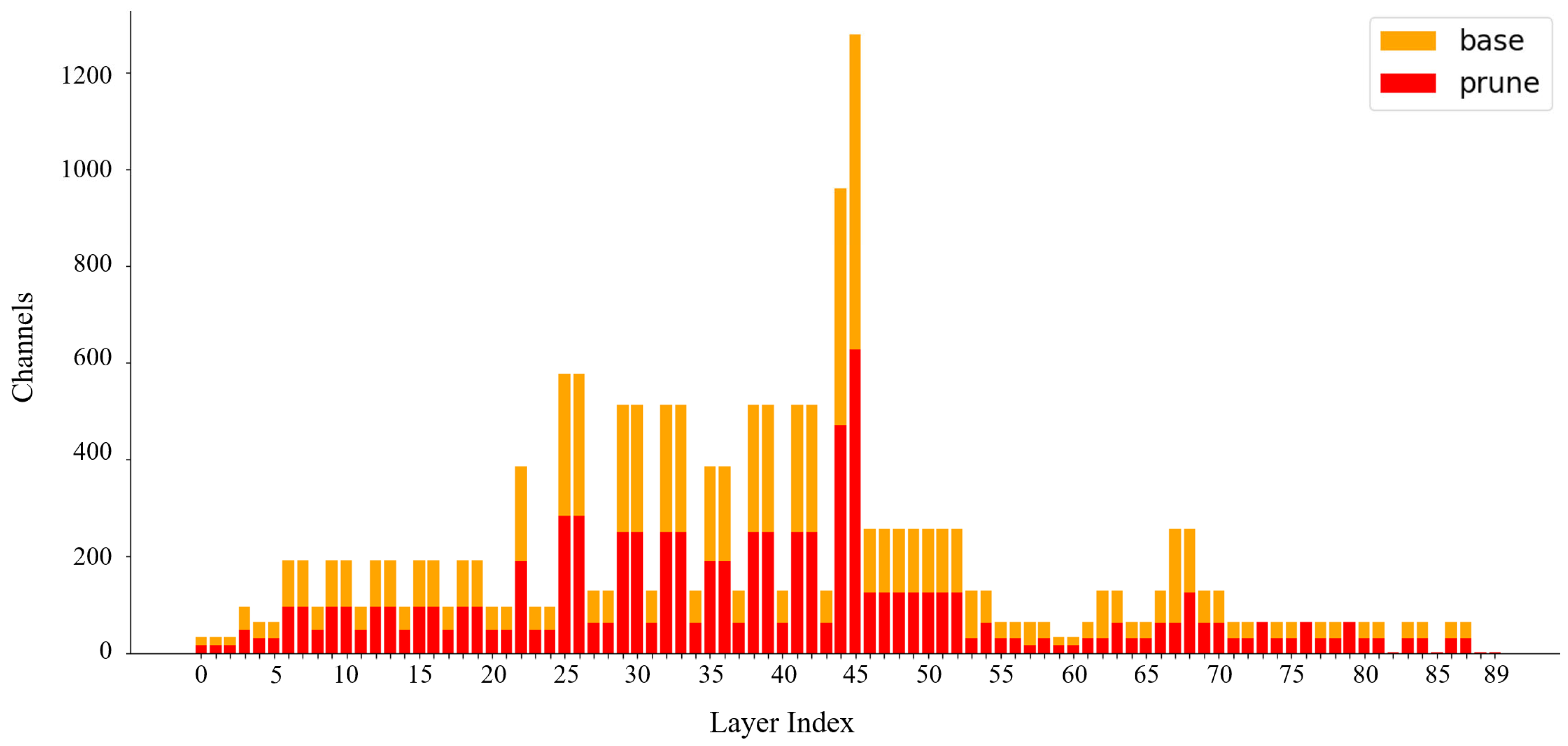
2.2.3. Model Pruning
2.2.4. Model Distillation
2.2.5. MPD-IoU Loss Function
2.3. Model Training and Evaluation Metrics
2.3.1. Experimental Platform
2.3.2. Evaluation Index
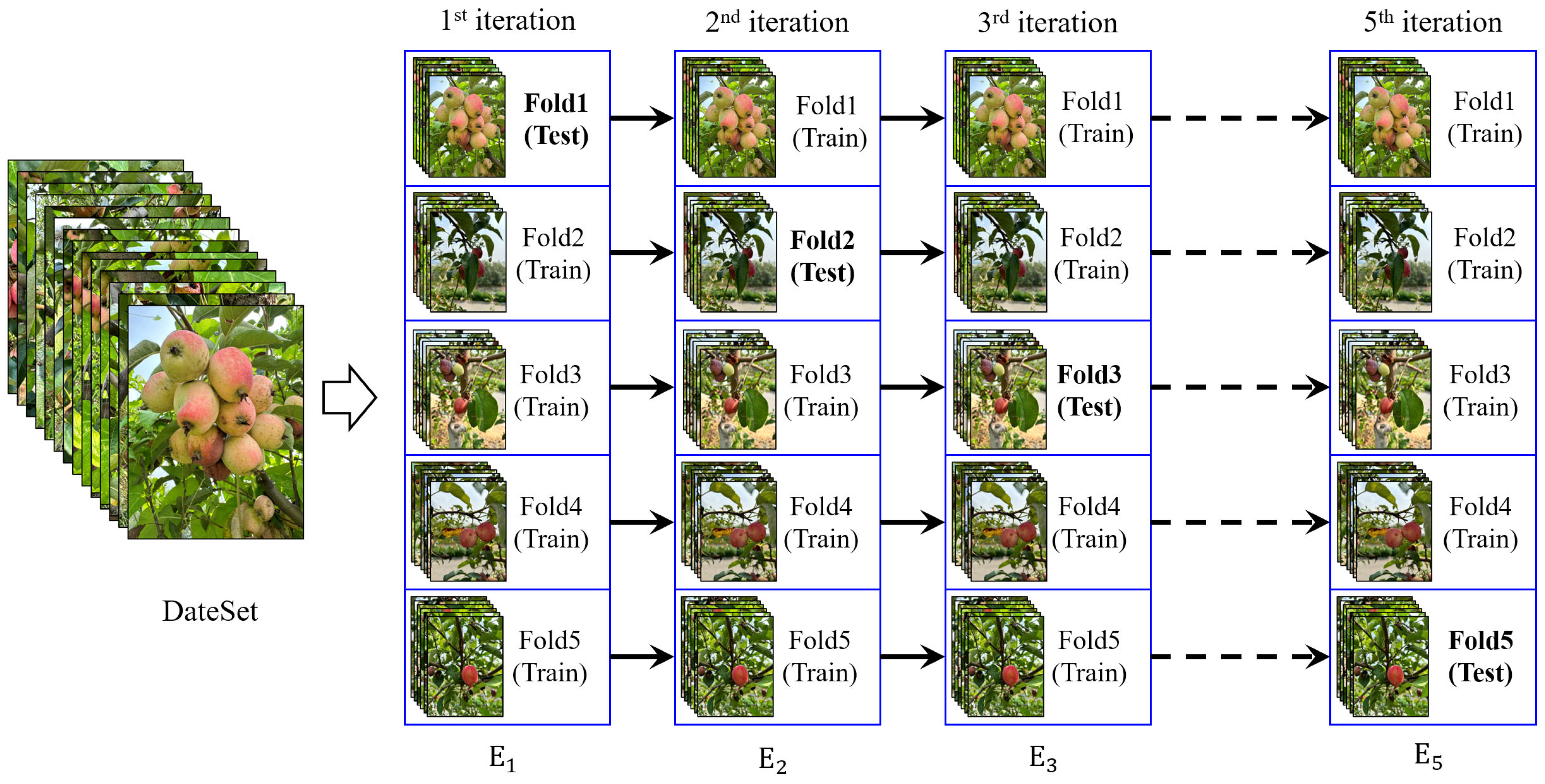
2.3.3. K-Fold Cross-Validation Method
3. Results
3.1. Comparison of Different Backbone Networks
3.2. Ablation Experiments
3.3. Model Lightweight Experiment
3.4. Comparative Experiments with Different Models
3.5. Evaluation of Model Generalization Capability
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, X.; Li, H.; Jiang, W.; Li, Q.; Xi, Y.; Wang, X.; Li, J. Phytochemical compositions, health-promoting properties and food applications of crabapples: A review. Food Chem. 2022, 386, 132789. [Google Scholar] [CrossRef] [PubMed]
- Han, M.; Li, G.; Liu, X.; Li, A.; Mao, P.; Liu, P.; Li, H. Phenolic profile, antioxidant activity and anti-proliferative activity of crabapple fruits. Hortic. Plant J. 2019, 5, 155–163. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Li, J.; Xiong, J. In-field citrus detection and localization based on RGB-D image analysis. Biosyst. Eng. 2019, 186, 34–44. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based three-dimensional fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Sun, Y. A detection method for apple fruits based on color and shape features. IEEE Access 2019, 7, 67923–67933. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Part I, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tu, S.; Pang, J.; Liu, H.; Zhuang, N.; Chen, Y.; Zheng, C.; Wan, H.; Xue, Y. Passion fruit detection and counting based on multi-scale Faster R-CNN using RGB-D images. Precis. Agric. 2020, 21, 1072–1091. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Tang, Y.; Qiu, J.; Zhang, Y.; Wu, D.; Cao, Y.; Zhao, K.; Zhu, L. Optimization strategies of fruit detection to overcome the challenge of unstructured background in field orchard environment: A review. Precis. Agric. 2023, 24, 1183–1219. [Google Scholar] [CrossRef]
- Du, X.; Cheng, H.; Ma, Z.; Lu, W.; Wang, M.; Meng, Z.; Jiang, C.; Hong, F. DSW-YOLO: A detection method for ground-planted strawberry fruits under different occlusion levels. Comput. Electron. Agric. 2023, 214, 108304. [Google Scholar] [CrossRef]
- Wu, H.; Mo, X.; Wen, S.; Wu, K.; Ye, Y.; Wang, Y.; Zhang, Y. DNE-YOLO: A method for apple fruit detection in diverse natural environments. J. King Saud Univ.—Comput. Inf. Sci. 2024, 36, 102220. [Google Scholar] [CrossRef]
- Sun, H.; Ren, R.; Zhang, S.; Tan, C.; Jing, J. Maturity detection of ‘Huping’ jujube fruits in natural environment using YOLO-FHLD. Smart Agric. Technol. 2024, 9, 100670. [Google Scholar] [CrossRef]
- Yang, H.; Yang, L.; Wu, T.; Yuan, Y.; Li, J.; Li, P. MFD-YOLO: A fast and lightweight model for strawberry growth state detection. Comput. Electron. Agric. 2025, 234, 110177. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal models for the mobile ecosystem. In Computer Vision—ECCV 2024, 18th European Conference, Milan, Italy, 29 September–4 October 2024, Proceedings, Part XL; Springer Nature: Cham, Switzerland, 2024; pp. 78–96. [Google Scholar]
- Zhang, H.; Li, G.; Wan, D.; Wang, Z.; Dong, J.; Lin, S.; Deng, L.; Liu, H. DS-YOLO: A dense small object detection algorithm based on inverted bottleneck and multi-scale fusion network. Biomim. Intell. Robot. 2024, 4, 100190. [Google Scholar] [CrossRef]
- Shi, J.; Sun, D.; Kieu, M.; Guo, B.; Gao, M. An enhanced detector for vulnerable road users using infrastructure-sensors-enabled device. Sensors 2023, 24, 59. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.; Zhou, Z.; Zhou, D.; Su, B.; Xuanyuan, Z.; Tang, J.; Lai, Y.; Chen, J.; Liang, W. Underwater object detection algorithm based on attention mechanism and cross-stage partial fast spatial pyramidal pooling. Front. Mar. Sci. 2022, 9, 1056300. [Google Scholar] [CrossRef]
- Xu, K.; Wang, Z.; Geng, X.; Wu, M.; Li, X.; Lin, W. Efficient joint optimization of layer-adaptive weight pruning in deep neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023), Paris, France, 1–8 October 2023; pp. 17447–17457. [Google Scholar]
- Wang, D.; He, D. Channel-pruned YOLOv5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Nie, Y.; Lai, H.; Gao, G. DSOD-YOLO: A lightweight dual feature extraction method for small target detection. Digit. Signal Process. 2025, 164, 105268. [Google Scholar] [CrossRef]
- Liao, H.; Wang, G.; Jin, S.; Liu, Y.; Sun, W.; Yang, S.; Wang, L. HCRP-YOLO: A lightweight algorithm for potato defect detection. Smart Agric. Technol. 2025, 10, 100849. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, G.; Ge, Y.; Shi, J.; Wang, Y.; Li, J. Multi-scale plastic lunch box surface defect detection based on dynamic convolution. IEEE Access 2024, 12, 120064–120076. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Zhang, L.; Wan, Y.; Chen, Z.; Xu, Y.; Cao, R.; Zhao, L.; Yang, Y.; Yu, X. A feature enhancement network based on image partitioning in a multi-branch encoder–decoder architecture. Knowl.-Based Syst. 2025, 311, 113120. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | R/% | mAP/% | FLOPs/G | Parameters | Model Size/MB |
|---|---|---|---|---|---|---|
| YOLOv8 | 90.9% | 88.7% | 90.6% | 9.4 | 3.0 × 106 | 6.3 |
| YOLOv8-EfficientFormerV2 | 88.7% | 87.2% | 89.5% | 9.4 | 4.0 × 106 | 8.8 |
| YOLOv8-FasterNet | 86.3% | 84.5% | 87.8% | 8.2 | 3.5 × 106 | 7.2 |
| YOLOv8-StarNet | 89.1% | 86.7% | 89.0% | 18.5 | 6.0 × 106 | 10.8 |
| YOLOv8-MobileNetV3 | 88.2% | 86.8% | 89.3% | 12.5 | 5.5 × 106 | 10.5 |
| YOLOv8-MobileNetV4 | 91.5% | 89.1% | 91.2% | 22.5 | 5.0 × 106 | 11.7 |
| Improvements | P/% | R/% | mAP/% | FLOPs/G | Parameters | Model Size/MB | ||
|---|---|---|---|---|---|---|---|---|
| MobileNetV4 | SPPFCSPC | MPD-IoU | ||||||
| ✗ | ✗ | ✗ | 90.9% | 88.7% | 90.6% | 9.4 | 3.0 × 106 | 6.3 |
| ✔ | ✗ | ✗ | 91.5% | 89.1% | 91.2% | 22.5 | 5.0 × 106 | 11.7 |
| ✗ | ✔ | ✗ | 85.9% | 85.1% | 90.9% | 10.1 | 4.6 × 106 | 9.5 |
| ✗ | ✗ | ✔ | 91.3% | 89.0% | 93.1% | 9.4 | 3.0 × 105 | 6.3 |
| ✔ | ✔ | ✗ | 90.7% | 87.8% | 92.2% | 23.2 | 6.5 × 106 | 13.4 |
| ✗ | ✔ | ✔ | 92.4% | 89.1% | 91.5% | 10.1 | 4.6 × 106 | 9.5 |
| ✔ | ✗ | ✔ | 91.1% | 84.1% | 91.7% | 22.5 | 5.0 × 106 | 11.7 |
| ✔ | ✔ | ✔ | 92.9% | 91.2% | 93.5% | 23.2 | 6.5 × 106 | 13.4 |
| Model | P/% | R/% | mAP/% | FLOPs/G | Parameters | Model Size/MB |
|---|---|---|---|---|---|---|
| Original | 92.9% | 91.2% | 93.5% | 23.2 | 6.5 × 106 | 13.4 |
| Speed_up 1.5 | 91.2% | 89.1% | 90.8% | 14.2 | 2.3 × 106 | 5.0 |
| Speed_up 2.0 | 91.8% | 90.3% | 91.0% | 9.3 | 1.2 × 106 | 2.9 |
| Speed_up 2.5 | 90.1% | 89.5% | 90.6% | 7.9 | 0.9 × 106 | 2.2 |
| Speed_up 3.0 | 87.6% | 85.6% | 86.2% | 7.1 | 0.7 × 106 | 1.9 |
| Knowledge Distillation | 92.5% | 90.8% | 92.2% | 7.9 | 0.9 × 106 | 2.2 |
| Model | P/% | R/% | mAP/% | FLOPs/G | Parameters | Model Size/MB |
|---|---|---|---|---|---|---|
| Faster R-CNN | 78.8% | 71.4% | 82.6% | 23.2 | 6.5 × 107 | 260.0 |
| SSD | 88.6% | 80.1% | 79.3% | 14.2 | 2.3 × 107 | 92.0 |
| YOLOv5 | 90.1% | 88.2% | 90.3% | 12.3 | 1.2 × 106 | 4.8 |
| YOLOv8 | 90.9% | 88.7% | 90.6% | 9.4 | 3.0 × 106 | 6.3 |
| YOLOv8-MSP-PD | 92.5% | 90.8% | 92.2% | 7.9 | 1.2 × 106 | 2.2 |
| YOLOv9 | 91.8% | 89.5% | 91.7% | 102.4 | 2.5 × 107 | 48.0 |
| DETR | 92.1% | 89.2% | 92.5% | 280.7 | 6.7 × 107 | 130.0 |
| RTMDet | 89.3% | 87.6% | 89.9% | 28.6 | 1.1 × 107 | 22.1 |
| Validation Fold | P/% | R/% | mAP/% |
|---|---|---|---|
| 1st iteration | 89.8 | 88.9 | 91.3 |
| 2nd iteration | 90.6 | 89.7 | 92.1 |
| 3rd iteration | 89.4 | 88.2 | 90.7 |
| 4th iteration | 90.3 | 89.4 | 91.8 |
| 5th iteration | 90.1 | 89.2 | 91.5 |
| Mean ± Std | 90.04 ± 0.46 | 89.08 ± 0.58 | 91.48 ± 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Han, X.; Zhang, H.; Liu, S.; Ma, W.; Yan, Y.; Sun, L.; Jing, L.; Wang, Y.; Wang, J. YOLOv8-MSP-PD: A Lightweight YOLOv8-Based Detection Method for Jinxiu Malus Fruit in Field Conditions. Agronomy 2025, 15, 1581. https://doi.org/10.3390/agronomy15071581
Liu Y, Han X, Zhang H, Liu S, Ma W, Yan Y, Sun L, Jing L, Wang Y, Wang J. YOLOv8-MSP-PD: A Lightweight YOLOv8-Based Detection Method for Jinxiu Malus Fruit in Field Conditions. Agronomy. 2025; 15(7):1581. https://doi.org/10.3390/agronomy15071581
Chicago/Turabian StyleLiu, Yi, Xiang Han, Hongjian Zhang, Shuangxi Liu, Wei Ma, Yinfa Yan, Linlin Sun, Linlong Jing, Yongxian Wang, and Jinxing Wang. 2025. "YOLOv8-MSP-PD: A Lightweight YOLOv8-Based Detection Method for Jinxiu Malus Fruit in Field Conditions" Agronomy 15, no. 7: 1581. https://doi.org/10.3390/agronomy15071581
APA StyleLiu, Y., Han, X., Zhang, H., Liu, S., Ma, W., Yan, Y., Sun, L., Jing, L., Wang, Y., & Wang, J. (2025). YOLOv8-MSP-PD: A Lightweight YOLOv8-Based Detection Method for Jinxiu Malus Fruit in Field Conditions. Agronomy, 15(7), 1581. https://doi.org/10.3390/agronomy15071581