1. Introduction
China is a traditional agricultural country, and agriculture, as the fundamental industry in China, occupies a dominant position in the national economy [
1]. In 2022, the total grain output reached 1373.06 billion catties, with a year-on-year growth rate of 0.5% [
2]. The sown area of grain crops was 1.775 billion mu, with a year-on-year increase of 0.6%. The grain crop yield per mu was 386.8 kg, with a year-on-year increase of 0.5% [
3]. The level of agricultural production and grain yield directly affects the daily lives of the population [
4]. Pest infestation is a significant factor that causes harm to crops and impacts crop productivity on a global scale [
5]. This, in turn, affects the stability of regional agricultural economies and food security [
6]. Pest and weed infestations exert a substantial impact on global agricultural production, affecting approximately twenty to thirty percent of the total output. Consequently, this predicament leads to a staggering economic loss of an estimated seventy billion US dollars [
7]. In recent years, the Ministry of Agriculture and Rural Affairs has successively deployed major pest control work for autumn grain crops, making every effort to fight against pests and achieve “preventing pests from eating crops” to ensure a good harvest. In response to new situations and characteristics of pests and diseases in autumn grain crops, monitoring and investigation have been strengthened, and the system of reporting and alerting on pest and disease disasters has been strictly implemented. Timely release of early warning information and guidance helps farmers promptly control pests and diseases. Accurate pest identification not only helps reduce the blind use of pesticides and lowers production costs and environmental pollution, but also improves control effectiveness and crop quality [
8,
9,
10,
11]. In order to effectively combat and manage pests and diseases in farmland, the collection and analysis of information pertaining to these issues is imperative [
12]. Traditional monitoring techniques, such as manual observation and statistical analysis, fall short in meeting the demands of modern large-scale agricultural production due to the vast diversity of pests and the complexity of available information sources [
13]. Consequently, the application of deep learning methods in agricultural pest detection has emerged as a prominent area of research [
14].
There are two main types of object detection algorithms based on deep learning [
15,
16,
17]: one-stage target detection algorithms [
18] that rely on regression, and two-stage target detection algorithms [
19] that generate candidate regions. The initial step in two-stage target detection algorithms involves the extraction of potential regions from the input image. These extracted regions are subsequently utilized for target classification and position estimation. Notable algorithms in this domain include R-CNN [
20], Fast R-CNN [
21], Faster R-CNN [
22,
23], and Mask R-CNN [
24]. One-stage target detection algorithms eliminate the step of extracting candidate regions and directly use convolutional neural networks for target classification and position estimation from the input image. YOLO (you only look once) series algorithms [
25,
26,
27,
28] and the SSD (single shot multibox detector) [
29] algorithm are typical one-stage target detection algorithms. These algorithms offer several advantages when compared to two-stage target detection algorithms. Firstly, they significantly reduce the computational cost of the model by eliminating the need to generate candidate regions before target classification and position estimation. Additionally, they demonstrate high real-time performance, making them suitable for rapid detection of agricultural pests. The target detection algorithms mentioned above have demonstrated impressive outcomes on traditional datasets. However, it is important to note that these deep learning models commonly employ sample resizing operations. Consequently, when these models are utilized for pest detection purposes, there is a risk of losing crucial sample features of the pests. Furthermore, the effectiveness of deep learning models heavily relies on the quantity of samples in the dataset. Consequently, for agricultural pest target detection models, the challenges posed by limited sample numbers and datasets containing images that are either too small or too large are undeniably significant.
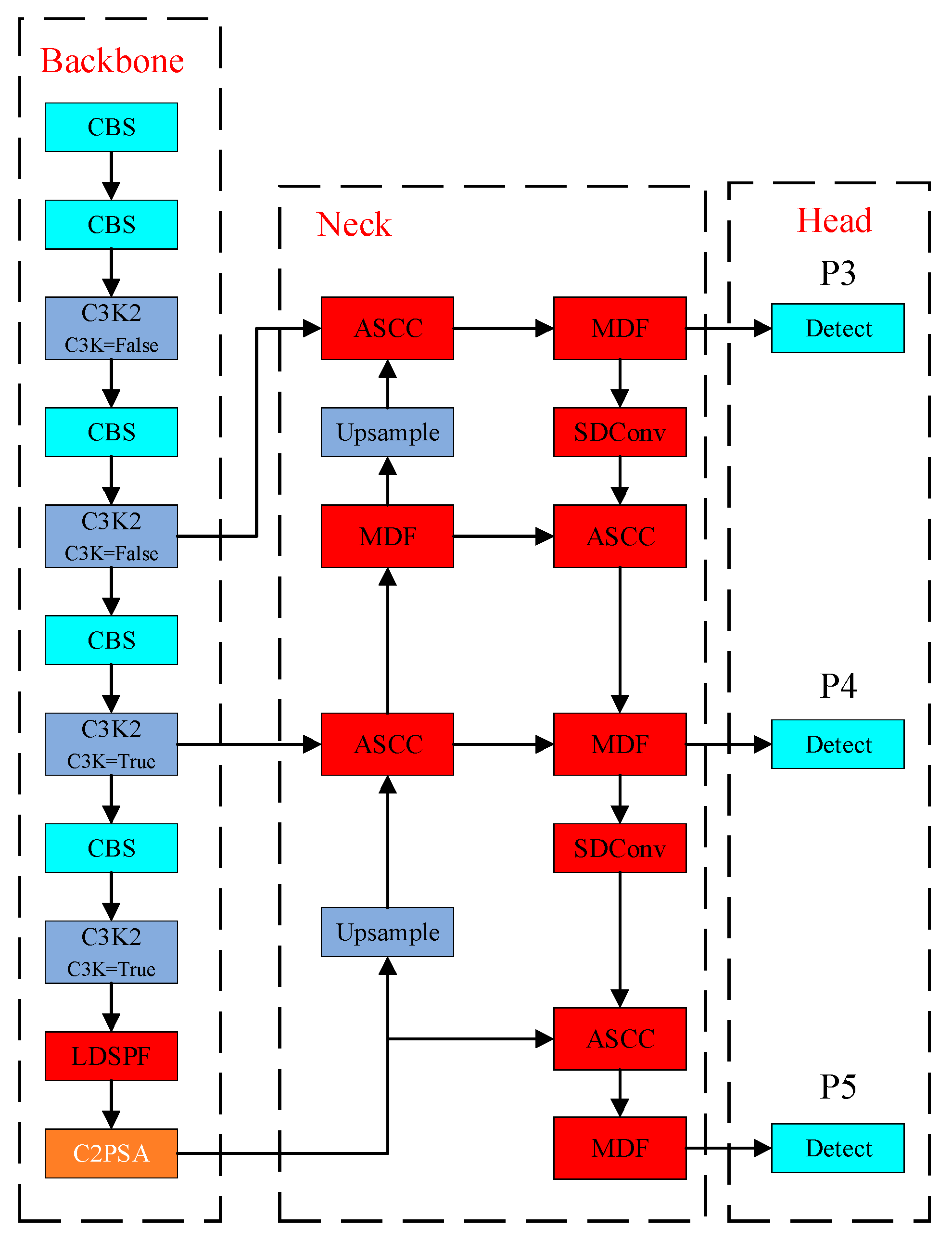
Currently, the existing pest detection methods have the following limitations. The pest dataset exhibits extremely imbalanced class distribution, with some classes contributing to the majority of training samples while others are severely underrepresented in the dataset. The detection model in question experiences a decline in accuracy due to the overlapping presence of multiple pest targets, resulting in the occurrence of numerous redundant detection boxes. This, in turn, poses a challenge when attempting to detect and differentiate between similar and finely detailed pest species. To address these issues, this paper proposed a novel agricultural pest detection model incorporating multi-scale feature fusion and attention mechanisms. Specifically, the proposed model integrated various custom modules into the YOLOv11s network, including the symmetric dual-path convolution (SDConv) module, lightweight dynamic spatial-aware pyramid fusion (LDSPF) module, adaptive spatial-channel concat (ASCC) module, and multiscale dynamic fusion (MDF) module. This amalgamation of components led to the development of an agricultural pest object detection algorithm that enhanced detection accuracy while reducing model parameters and computational costs.
3. Materials and Methods
To improve the detection accuracy of agricultural pest detection models and address the issues of high computational complexity and insufficient feature extraction in existing object detection models, this study proposed a novel agricultural pest detection algorithm (MA-YOLO). Based on the YOLOv11s network, MA-YOLO enhanced detection performance in complex agricultural pest scenarios through four lightweight and efficient modules. First, the SDConv module was designed by combining depthwise separable and group convolution to replace the traditional convolution. Second, the LDSPF module employed parallel dilated convolutions to capture multi-scale information, integrated dynamic weighting with a spatial attention mechanism, and introduced dual residual connections to achieve synergistic optimization of multi-scale perception and spatial enhancement. Third, the ASCC module utilized a ternary weighting system (global, channel, spatial) to adaptively concatenate multi-source feature maps, reinforcing semantic responses in target regions and significantly improving feature discriminability and robustness. Fourth, the MDF module extracted multi-scale features using multi-branch depthwise separable convolution, combined dynamic weighting via soft attention with cross-channel interaction through 1 × 1 convolution, balancing lightweight design and feature enhancement. The architecture of the proposed MA-YOLO agricultural pest detection algorithm is illustrated in
Figure 1.
3.1. YOLOv11s Model
Considering the real-time requirements and detection accuracy for agricultural pest detection, this study selected the YOLOv11s model [
64] as the base model for improvement. YOLOv11, released by Ultralytics in 2024 as part of the YOLO series, underwent refined architectural adjustments compared to YOLOv5 and YOLOv8, adopting a more efficient feature extraction network to enhance small-object detection capability. Additionally, YOLOv11 introduced an adaptive anchor mechanism and advanced data augmentation techniques, further improving model robustness and generalization.
YOLOv11 incorporated two core modules: the C3K2 and the C2PSA module. The C3K2 module, an improved version of the C3 module, adjusted its behavior through parameter tuning in C3K, enabling flexible feature extraction tailored to different scenarios. The C2PSA module integrated stacked PSA blocks, leveraging attention mechanisms to enhance feature representation while efficiently processing feature information, significantly boosting detection performance. In the detection head, YOLOv11 added two depthwise separable convolutions for classification tasks. Compared to standard convolutions, depthwise separable convolutions reduced computational cost and parameter count in large-scale data processing and real-time detection tasks. Through pointwise convolution, they maintained performance close to standard convolutions with lower computational overhead.
3.2. SDConv Module
During convolution operations on input feature maps, conventional convolutions typically employ fixed-size kernels for feature extraction. However, fixed-size kernels struggled to simultaneously capture both local details and global contextual information. Small kernels (e.g., 3 × 3) effectively extracted local features but were limited by their restricted receptive fields in capturing large-scale global information. Conversely, large kernels (e.g., 7 × 7) expanded the receptive field but performed poorly in extracting fine-grained local details while significantly increasing parameter counts and computational costs. Moreover, as network depth increased, conventional convolutions exhibited a substantial rise in both parameter size and computational complexity. This not only prolonged model training and inference time but also led to excessive GPU memory consumption, restricting practical deployment, particularly on edge devices with limited computational resources. Reducing model parameters and computational overhead thus became a critical challenge for real-world applications.
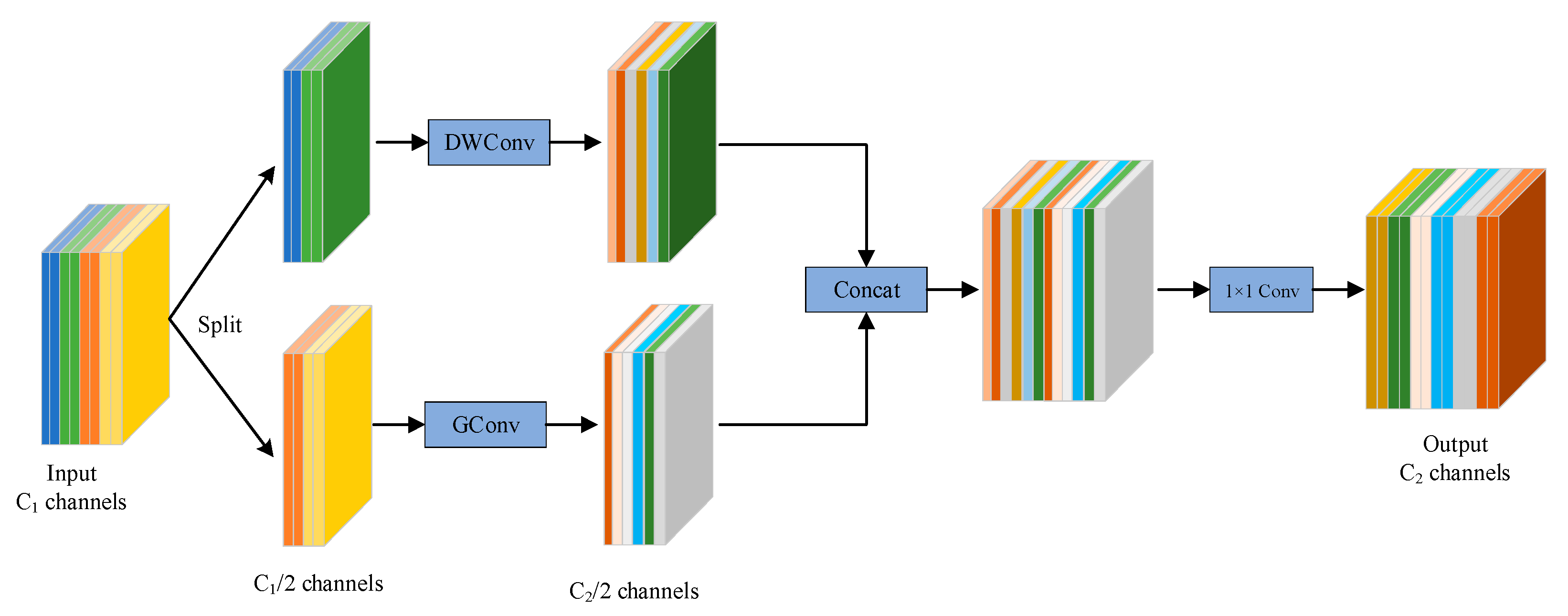
Depthwise separable convolution reduced the number of parameters and computational cost through depthwise convolution and pointwise convolution, while group convolution divided the convolutional kernels into different groups, with each group performing convolution operations on corresponding input channels before merging the results. This effectively decreased network parameters to improve model inference speed. Based on the combination of depthwise separable convolution and group convolution, this study constructed the SDConv module, whose network architecture is illustrated in
Figure 2.
The workflow of the SDConv module was as follows:
Feature Grouping: Given an input feature map , this step evenly split it into two groups along the channel dimension, .
Depthwise Separable Convolution: The main branch employed depthwise separable convolution to achieve spatial–channel decoupled feature extraction, reducing computational complexity while preserving spatial perception.
Group Convolution: The auxiliary branch enhanced local feature representation through dynamic group convolution.
Aggregation: After performing depthwise separable convolution and group convolution, the feature maps from both branches were concatenated. To facilitate information fusion between different sub-feature maps, a 1 × 1 convolution was applied to the aggregated feature map to generate the final output.
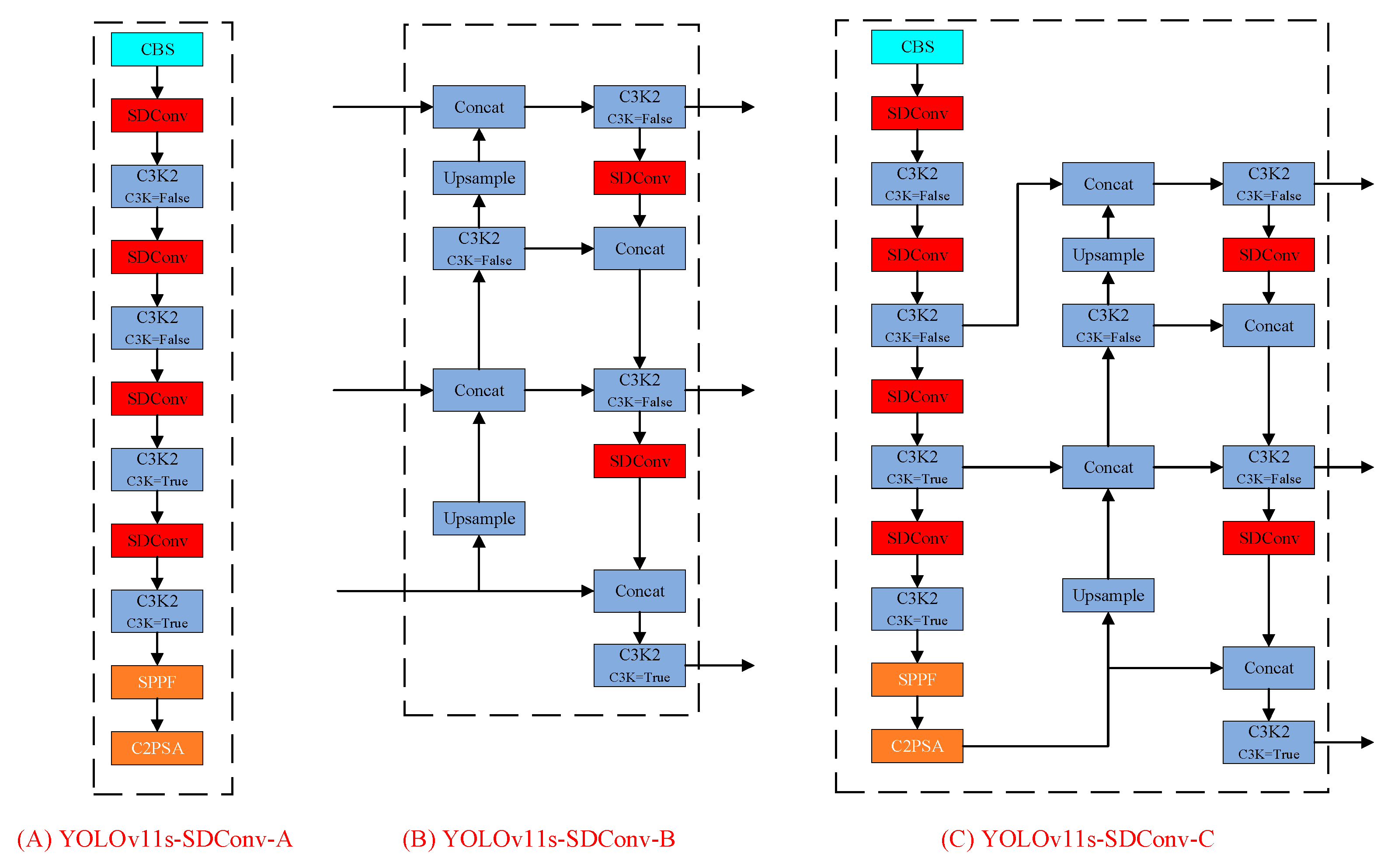
The input module of the YOLOv11s network primarily handled preprocessing tasks such as image scaling rather than feature extraction from images. On the other hand, the output module utilized detection heads to predict objects of varying sizes based on the extracted multi-scale feature maps. In this study, the constructed SDConv module was embedded into the backbone network, the neck network, and both the backbone and neck networks. The corresponding network variants were named YOLOv11s-SDConv-A, YOLOv11s-SDConv-B, and YOLOv11s-SDConv-C, respectively. Their network architecture is illustrated in
Figure 3.
3.3. LDSPF Module
Although the SPPF module enhanced the multi-scale object recognition capability of the target detection network through its pyramid pooling structure, the three cascaded 5 × 5 pooling operations significantly increased the module’s parameter count and computational cost. Additionally, the SPPF module employed channel concatenation and convolution operations for multi-scale feature fusion, failing to adaptively account for the varying importance of features across different scenarios. Moreover, its fixed structure and parameters lacked the ability to dynamically adjust feature extraction strategies, leading to insufficient feature representation in complex scenes, particularly at object edges or texture regions, which adversely affected detection accuracy. Finally, the SPPF module did not perform feature channel dimensionality reduction, resulting in redundant high-dimensional features that further increased computational overhead during fusion and hindered the model’s deployment efficiency on edge computing devices.
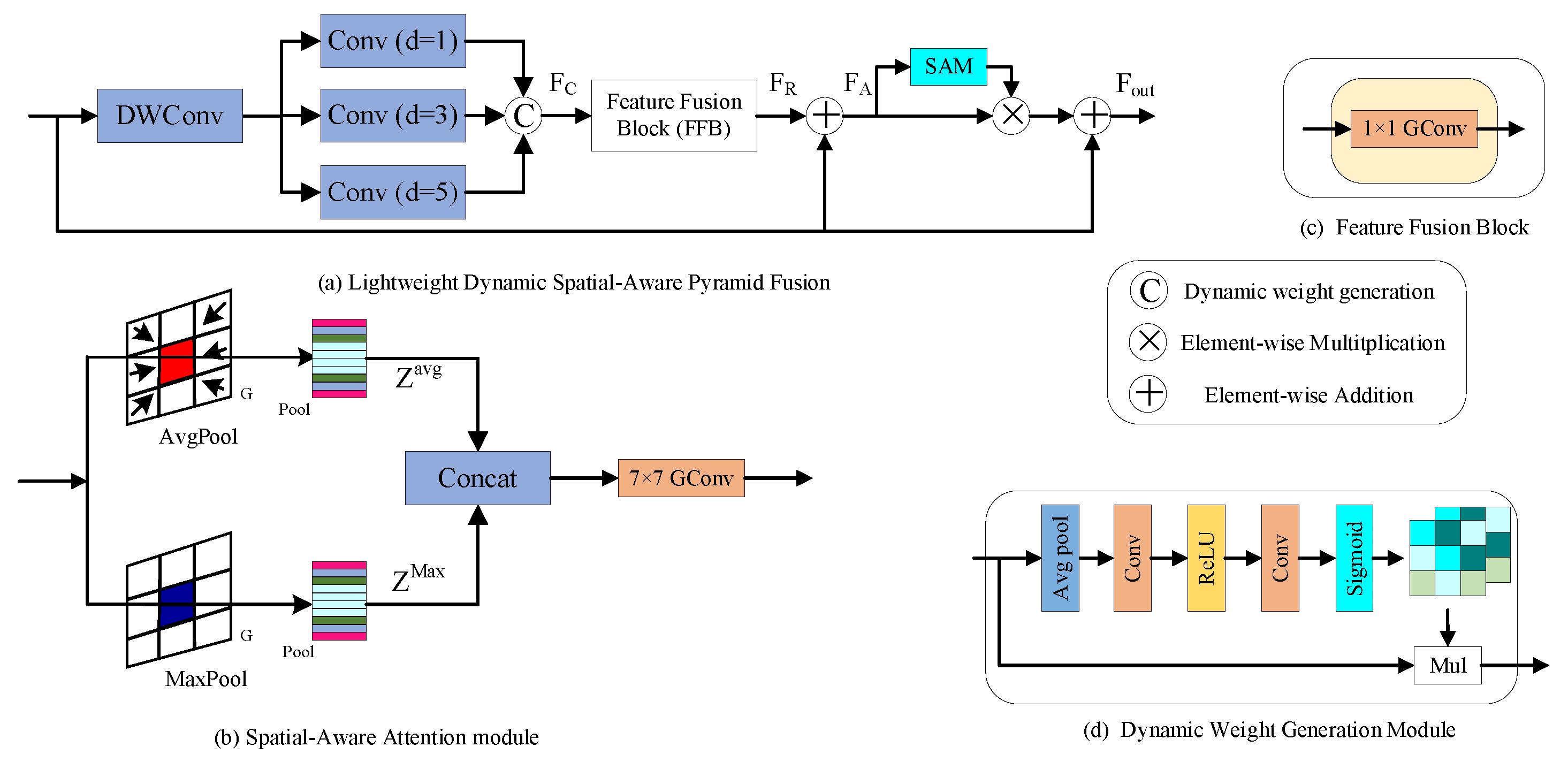
This study integrated the concepts of residual modules, depthwise separable convolution, and dynamic weighted multi-scale fusion to design the LDSPF module, whose architecture is illustrated in
Figure 4.
Figure 4a shows the overall structure of the LDSPF module,
Figure 4b depicts the spatial-aware attention module,
Figure 4c presents the feature fusion module, and
Figure 4d illustrates the dynamic weight generation module. The LDSPF module employed depthwise separable convolution for feature extraction from the input feature maps, effectively reducing model parameters and computational costs while preserving the receptive field. Subsequently, the feature maps were fed into three parallel dilated convolutions with dilation rates of 1, 3, and 5, respectively. This design was inspired by the multi-resolution perception mechanism of biological vision systems, enabling the network to capture contextual information at different scales. The dynamic weight generation module extracted channel statistics via global average pooling and generated fusion weights for each branch through two convolutional layers and a sigmoid function. This allowed the network to adaptively adjust the importance weights of features at different scales based on the input. The weighted multi-scale features were fused using a 1 × 1 convolutional layer and combined with the original input features through residual connections. This design, integrating multi-scale feature fusion and residual connections, preserved the initial feature information while capturing multi-scale contextual details.
Based on the aforementioned module, a spatial attention enhancement mechanism was incorporated to develop the spatial-aware attention module. The spatial-aware module applied both max pooling and average pooling operations along the channel dimension of the input feature maps to capture high-response features (such as object edges) and global distribution characteristics. The resulting feature maps were concatenated and processed through a 7 × 7 large-kernel convolution to generate a spatial attention map. This attention map was then element-wise multiplied with the input feature maps to enhance the network’s focus on target regions. Finally, a secondary residual connection was established with the original input features to balance feature intensity levels. Through the integration of multi-scale perception, dynamic fusion, and spatial enhancement strategies, the LDSPF module enabled the network to simultaneously capture long-range dependencies and concentrate on local detail features, while maintaining robust discriminative capability even under complex background interference.
3.4. ASCC Module
The concat module fused low-level positional information with high-level semantic features through channel-wise concatenation, preserving the original distribution characteristics of different branches. This operation required no additional learnable parameters, demonstrating significant advantages in lightweight network design. In multi-scale object detection tasks, integrating semantic features from different levels effectively enhanced the model’s adaptability to complex scenes. However, the concat module simply concatenated feature maps from different levels along the channel dimension without dynamic perception of feature importance. Consequently, both noisy and effective features were assigned equal weights, leading to semantic confusion in challenging scenarios such as occlusion and illumination variations. During gradient propagation, the distribution discrepancy among hierarchical features caused imbalanced gradient magnitudes, potentially hindering the consistency of network optimization and affecting model convergence stability.
The BiFPN module improved upon the concat module by introducing learnable global weighting parameters, which dynamically adjusted fusion weights based on the semantic importance of input features while preserving the advantages of multi-scale feature concatenation. This approach mitigated channel redundancy and gradient imbalance caused by direct channel-wise concatenation, with weight normalization strategies enhancing the stability of weight allocation. However, the BiFPN module relied solely on scalar weights for global feature modulation without modeling the channel characteristics and spatial distribution variations across different-scale feature maps. Consequently, when detecting targets with significant channel sensitivity or spatial bias, this coarse-grained weighting mechanism struggled to adequately capture feature responses in critical regions. To address this limitation, this study integrated an adaptive weight allocation mechanism with channel-wise concatenation, enhancing fusion robustness through dynamic feature selection.
The ASCC module achieved cross-modal information fusion through a dual-path feature joint perception mechanism. By constructing a differentiable ternary weighting system, it first retained the global scale weights of the BiFPN module as the basic fusion coefficients, while introducing channel sensitivity weight and spatial attention weight to capture the semantic importance of input feature maps in the channel dimension and the regional response intensity in the spatial dimension, respectively. The channel weight compressed spatial information through global average pooling to obtain channel-wise statistical features, while the spatial weights generated spatial response heatmaps through channel squeezing. Finally, the channel and spatial weights were nonlinearly coupled with trainable base weights, forming a feature enhancement mechanism with dual-domain adaptability in both spatial and channel dimensions. Through parameterization, the ASCC module realized progressive feature fusion with multi-dimensional perception, organically integrating channel sensitivity analysis and spatial attention modeling into the feature concatenation process. This enabled the multi-scale information fusion to focus more precisely on the feature regions of detection targets.
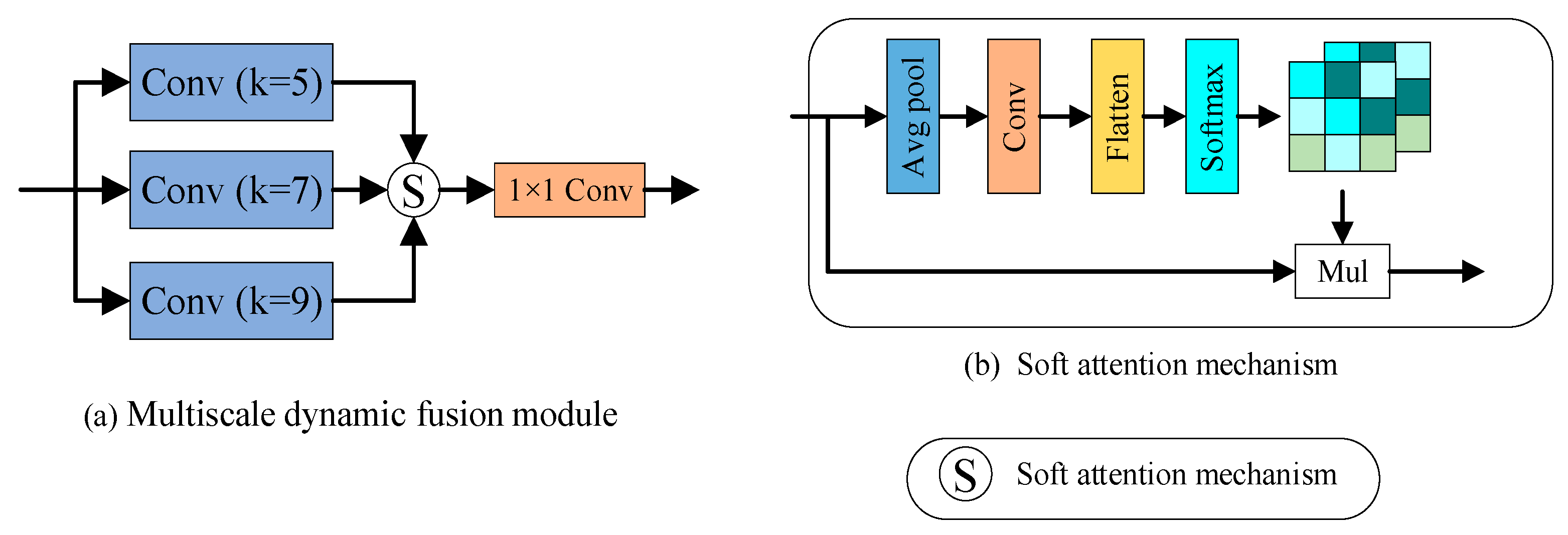
3.5. MDF Module
The C3K2 module in the YOLOv11s network was an improved structure based on the Cross Stage Partial (CSP) architecture, which inherited the C2f structure and incorporated an optional C3K module for feature fusion. The C3K2 module utilized either bottleneck or C3K modules to extract high-level features and fused shallow and deep features through concatenation operations. However, the C3K2 module employed convolution kernels of the same size, lacking adaptive processing for multi-scale features, which limited its ability to capture objects of varying sizes. Particularly in complex scenes, the fixed receptive field struggled to adaptively match target features of different scales, leading to the loss of fine-grained details or insufficient contextual associations. Additionally, the C3K2 module relied on simple channel-wise concatenation for feature fusion without a dynamic weight allocation mechanism, making it difficult to emphasize critical information in the feature maps.
Similarly to the design concept of the LDSPF module, this study also integrated depthwise separable convolution and dynamic weighted multi-scale fusion to construct the MDF module, whose network architecture is illustrated in
Figure 5.
Figure 5a shows the architecture of the multiscale dynamic fusion module, while
Figure 5b depicts the soft attention module. The MDF module first extracted multi-scale features using multiple parallel depthwise separable convolutions with different kernel sizes. The soft attention mechanism learned spatial attention through global average pooling and 1 × 1 convolutions, automatically computing the weights of each feature extraction branch and normalizing them via the softmax function to achieve dynamic fusion. Finally, a 1 × 1 convolution was applied to the fused feature maps for information interaction.
The MDF module expanded the receptive field coverage through multi-scale convolutional kernels, enhancing both local detail perception and large-scale contextual modeling capabilities. Secondly, the soft attention mechanism adaptively optimized multi-scale features in a learnable manner, enabling the network to dynamically adjust weights based on multi-scale feature information. Meanwhile, the MDF module employed depthwise separable convolutions to reduce parameter count and computational overhead, achieving dual benefits of lightweight design and high accuracy through efficient feature reuse.
In this study, the constructed MDF module was embedded into the backbone network, the neck network, and both the backbone and neck networks. The corresponding networks were named YOLOv11s-MDF-A, YOLOv11s-MDF-B, and YOLOv11s-MDF-C, with their architectures illustrated in
Figure 6.
3.6. Experimental Dataset
The dataset used in this study is the IP102 dataset [
65] and Pest24 dataset [
66]. Both datasets are specifically designed for pest detection in precision agriculture and can effectively support deep learning-based pest identification and detection research.
The IP102 dataset is a large-scale benchmark dataset for insect pest recognition released in June 2019, specifically designed for pest identification tasks in agricultural production. This dataset contains 75,222 high-quality images covering 102 different pest categories, including important pest species that affect major crops such as rice, maize, wheat, and soybeans. Examples include rice pests such as rice leaf roller, rice leaf caterpillar, white-backed planthoppe, and grain spreader thrips, as well as maize pests such as corn borer and armyworm. The dataset exhibits a natural long-tailed distribution, accurately reflecting the realistic occurrence patterns of pests in agricultural production, where some pest species have abundant samples while rare pest species have relatively fewer samples. The dataset contains 18,981 images with precise bounding box annotations supporting object detection tasks. Notably, small inter-class differences (similar features) and large intra-class differences (multiple stages in the lifecycle of pests) exist among pest species, fully reflecting the technical challenges faced in pest identification for practical agricultural applications.
The Pest24 dataset is a large-scale agricultural pest object detection dataset released in August 2020, specifically targeting key monitored pests in Chinese agricultural production. This dataset is automatically collected through specialized pest trapping and imaging devices deployed in fields, ensuring data authenticity and scene diversity. The dataset selects 24 categories of key pests designated for monitoring by China’s Ministry of Agriculture and Rural Affairs as annotation targets, all of which are important species that pose serious threats to China’s major crops. Specific examples include rice pests such as rice planthopper and rice leaf folder, and vegetable pests such as Plutella xylostella and spodoptera cabbage. The Pest24 dataset contains 25,378 professionally annotated pest images, divided into training and testing sets with a 7:3 ratio. A distinctive feature of this dataset is that pest targets are generally small with high similarity, fully conforming to the technical challenges of pest identification in actual field monitoring. Additionally, non-target pest samples are mixed in the images, realistically simulating complex situations in actual agricultural environments. Since automated pest capture equipment is used for collection, the data collection process is highly standardized, ensuring the authenticity of field environments and reliability of data quality.
The selection of IP102 and Pest24 datasets fully considers the practical needs of agricultural pest monitoring, covering the complete application scenario from pest identification to field detection. The IP102 dataset provides rich pest species information, helping to build comprehensive pest identification models, while the Pest24 dataset focuses on key pest monitoring in agricultural production, providing more targeted training data for practical agricultural applications. The combined use of both datasets ensures both model generalization capability and detection accuracy for key monitored pests, providing reliable technical support for pest control in precision agriculture.
3.7. Experimental Setup
The experimental framework comprised two distinct computational environments: a training server and an embedded testing platform. The training server was equipped with an Intel(R) Xeon(R) Platinum 8358P CPU, Ubuntu 18.04 operating system, and an NVIDIA RTX 3080Ti graphic card. The deep learning environment utilized CUDA framework version 11.1 and PyTorch 1.9.0. Model initialization employed pretrained weights derived from the COCO dataset, and training was conducted over 300 epochs with a batch size of 32 and input image dimensions of 640 × 640 pixels. In this study, all models employed the official default parameters, with an initial learning rate of 0.01, SGD (Stochastic Gradient Descent) optimizer, momentum parameter of 0.937, and weight decay coefficient of 0.0005. Additionally, a fixed random seed was established to further enhance the reproducibility of experiments and the reliability of results.
For embedded system evaluation, a Jetson Xavier AGX development platform was employed (NVIDIA Corporation, Santa Clara, CA, USA), configured with Ubuntu 16.04, Jetpack 4.5.1, CUDA 10.2, and cuDNN 8.0. The embedded testing environment utilized PyTorch 1.10.0 and Torchvision 0.11.1 to ensure compatibility and optimal performance on the edge computing platform. This dual-platform approach enabled comprehensive evaluation of both training efficiency and deployment feasibility across different computational architectures.
5. Conclusions
Currently, the existing pest detection methods suffer from imbalanced class distribution in datasets, small inter-class variations, and large intra-class variations, resulting in poor detection performance of current object detection algorithms on pest datasets and insufficient generalization in real-world scenarios. To address the issues of high computational complexity and inadequate feature representation in traditional convolutional networks, a novel agricultural pest detection model (MA-YOLO) based on multi-scale fusion and attention mechanisms was proposed in this study. The SDConv module reduces computational costs through depthwise separable convolution and dynamic group convolution while enhancing local feature extraction. The LDSPF module captures multi-scale information via parallel dilated convolutions with spatial attention mechanisms and dual residual connections. The ASCC module improves feature discriminability by establishing an adaptive triple-weight system for global, channel, and spatial semantic responses. The MDF module balances efficiency and multi-scale feature extraction using multi-branch depthwise separable convolution and soft attention-based dynamic weighting. Experimental results demonstrated that the proposed modules, through dynamic fusion and lightweight design, significantly enhance multi-scale modeling and spatial optimization capabilities while reducing computational costs, achieving a synergistic improvement in high-precision detection and efficient computation in complex scenarios. The superior performance on public datasets further validated the effectiveness of the proposed method.
Although the MA-YOLO model constructed in this study demonstrates exceptional performance in pest detection tasks, the model’s performance is dependent on the training dataset and can effectively identify known pest species but cannot recognize new or unknown species not represented in the training data. Future research should focus on two directions. First, unknown-species detection should be addressed through continual learning or open-set recognition methods. Second, extensive field trials should be conducted to evaluate the model’s robustness under different agricultural conditions, including varying lighting conditions, weather conditions, and crop growth stages. Furthermore, the pest detection model should be integrated with automated intervention mechanisms, such as real-time warning systems and precision spraying systems, to ultimately establish a comprehensive smart agriculture ecosystem that not only accurately identifies pest threats but also provides automated responses tailored to specific pest categories to effectively reduce crop damage.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}