
GYS-RT-DETR: A Lightweight Citrus Disease Detection Model Based on Integrated Adaptive Pruning and Dynamic Knowledge Distillation

Abstract
1. Introduction
- Model innovation: An innovative, GYS-RT-DETR, first-order object detection model is proposed. By introducing the GD mechanism and the SSFF mechanism, the Neck network structure of the original model is greatly improved. By using the Focaler-shapeIoU loss function, the recognition performance of the model is improved, and the problem of an unbalanced sample size during model training is solved.
- Lightweight model: Compared with the original model, the proposed GYS-RT-DETR model has improved memory usage and computational complexity. The Group_taylor pruning strategy greatly reduces the memory footprint and computational complexity of the GYS-RT-DETR model, which makes it easy to deploy edge devices.
- Knowledge distillation framework: A knowledge framework combining feature-logic distillation is proposed, which takes the pruning optimization model as the student model and RT-DETR-r50 as the teacher model, which can effectively solve the problem of information loss caused by the structural difference between the teacher and the students, and ensure a good detection performance, while realizing making the model lightweight.
2. Experiment Materials
2.1. Data Collection
2.2. Dataset Creation and Operating Environment
3. Research Methods
3.1. Model Design
3.1.1. GYS-RT-DETR Network Structure
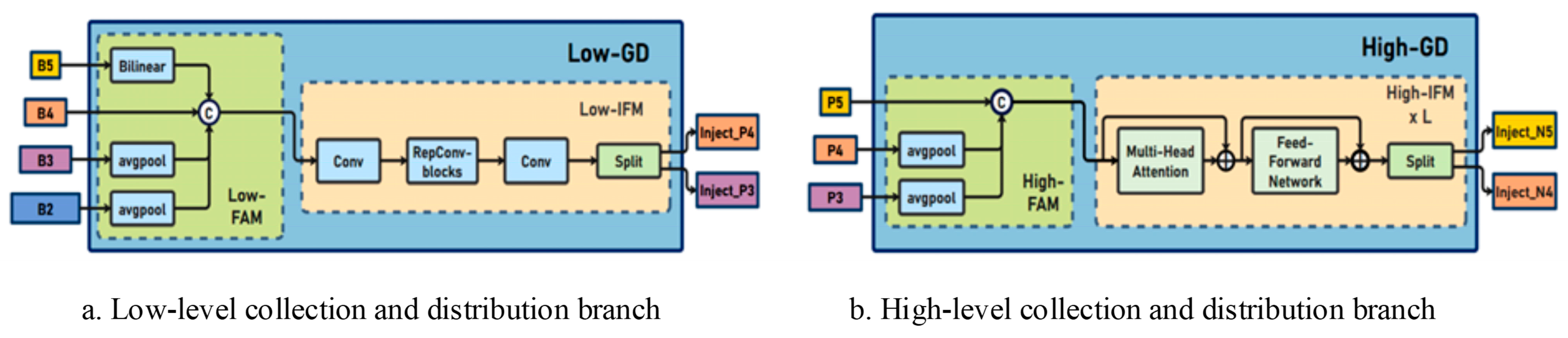
3.1.2. GD Collection and Distribution Mechanism
- (1)
- As shown in Figure 3a, the low-level GD structure is mainly composed of two key modules: the low-level feature alignment module (Low-FAM) and the low-level information fusion module (Low-IFM). The input features are downsampled by using the average pooling operation in the low-level feature alignment module to unify the feature size to the minimum size of the group, so as to obtain accurate low-level feature alignment information. The low-level information fusion module consists of multi-layer reparametrized convolutional blocks (RepBlocks) and segmentation operations. In order to improve the effective integration of global information between different levels, the attention mechanism is introduced, and the deep integration of information is realized.
- (2)
- As shown in Figure 3b, the high-level GD structure is mainly composed of two key modules: the high-level feature alignment module (High-FAM) and the high-level information fusion module (High-IFM). The advanced feature alignment module consists of an average pooling layer that maps the dimensions of the input features to a uniform size. The advanced information fusion module mainly includes the Transformer module and the splitting operation. Each Transformer module includes a multi-head attention block, a feedforward network (FFN), and a residual connection, and since the Transformer module extracts high-level information, the pooling operation facilitates information aggregation and reduces the subsequent computational complexity in the Transformer module. This not only ensures that the model inference is not affected by the multi-head attention mechanism, which leads to performance degradation, but also improves the effective integration of global information between different levels.
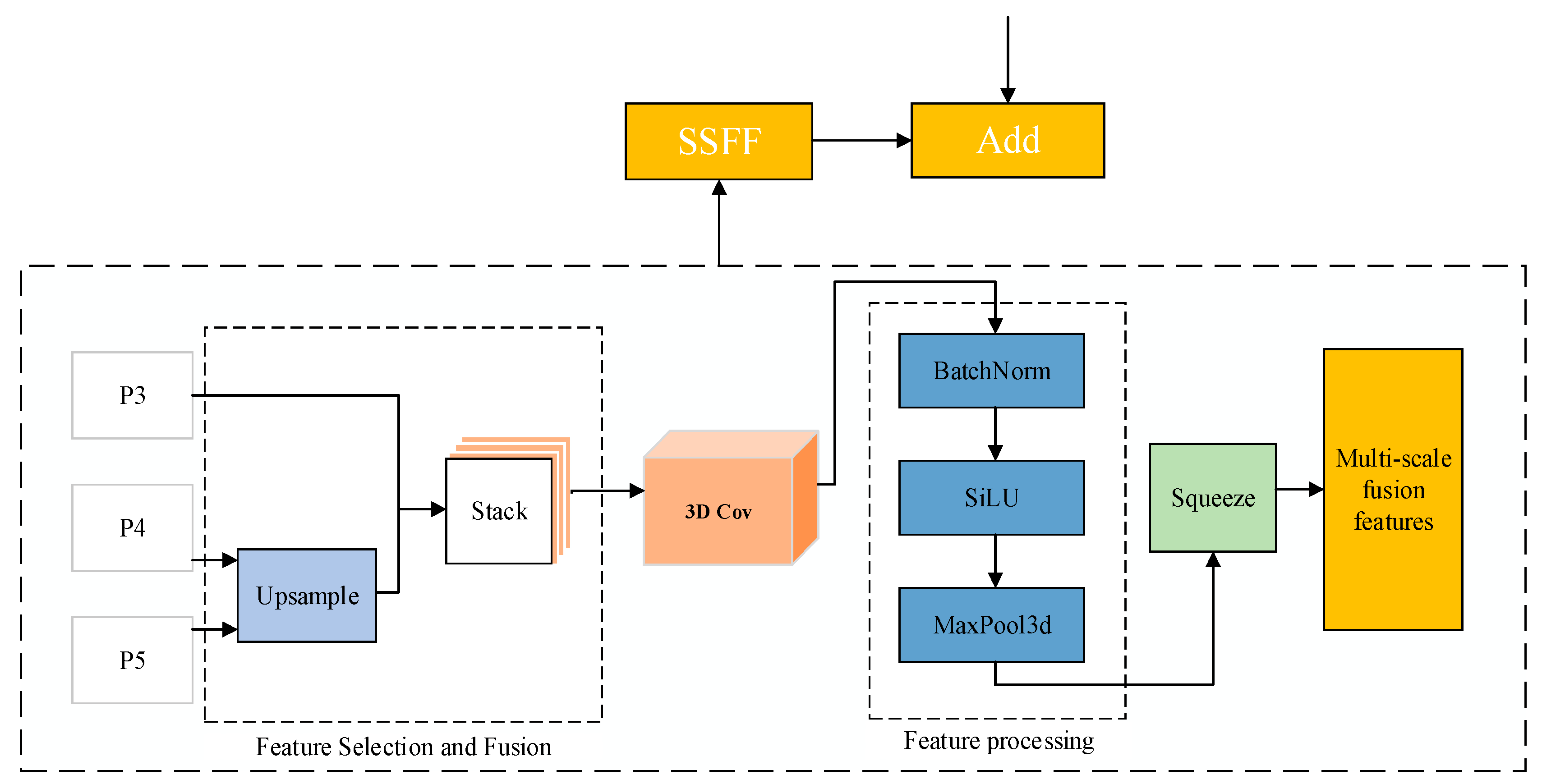
3.1.3. SSFF Module
3.1.4. Neck Network Structure Design
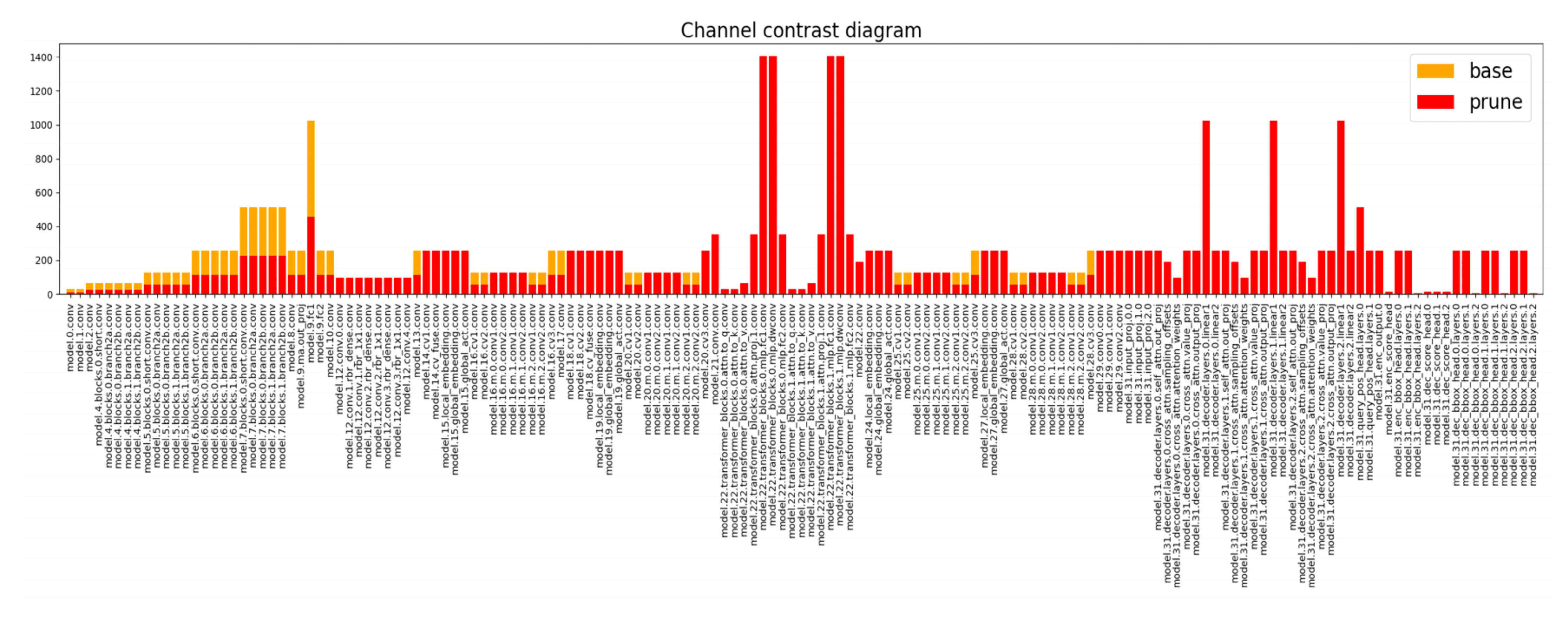
3.2. Group_Taylor Pruning Strategy
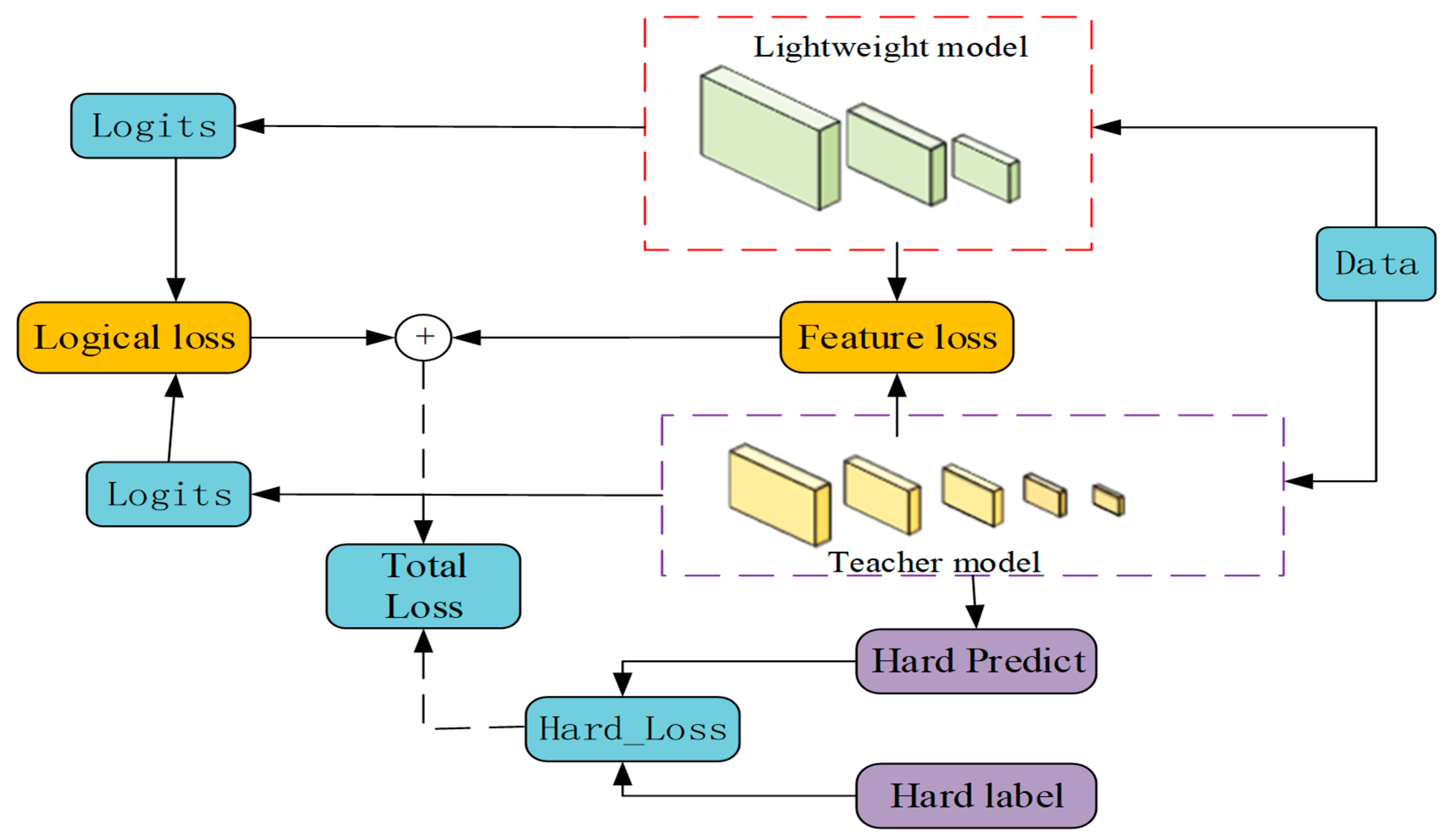
3.3. Feature-Logic Distillation Framework
3.4. Focaler-ShapeIoU Loss Function
3.5. Comparison with Existing Models
3.6. Model Training and Model Evaluation Metrics
- TP is a true positive, predicted to be a positive sample, and the actual sample is also a positive sample.
- FP is a false positive, predicted to be a positive sample, and actually a negative sample.
- FN is a false negative, predicted to be a negative sample, and the actual sample is positive.
- TN is a true negative, predicted to be a negative sample, and actually a negative sample.
4. Experiment Analysis
4.1. Experiment Environment Configuration
4.1.1. Conventional Experimental Parameter Settings
4.1.2. Model Pruning Experiment Parameter Settings
4.1.3. Knowledge Distillation Experiment Parameter Settings
4.2. Ablation Test
4.3. Comparison of Different Loss Functions
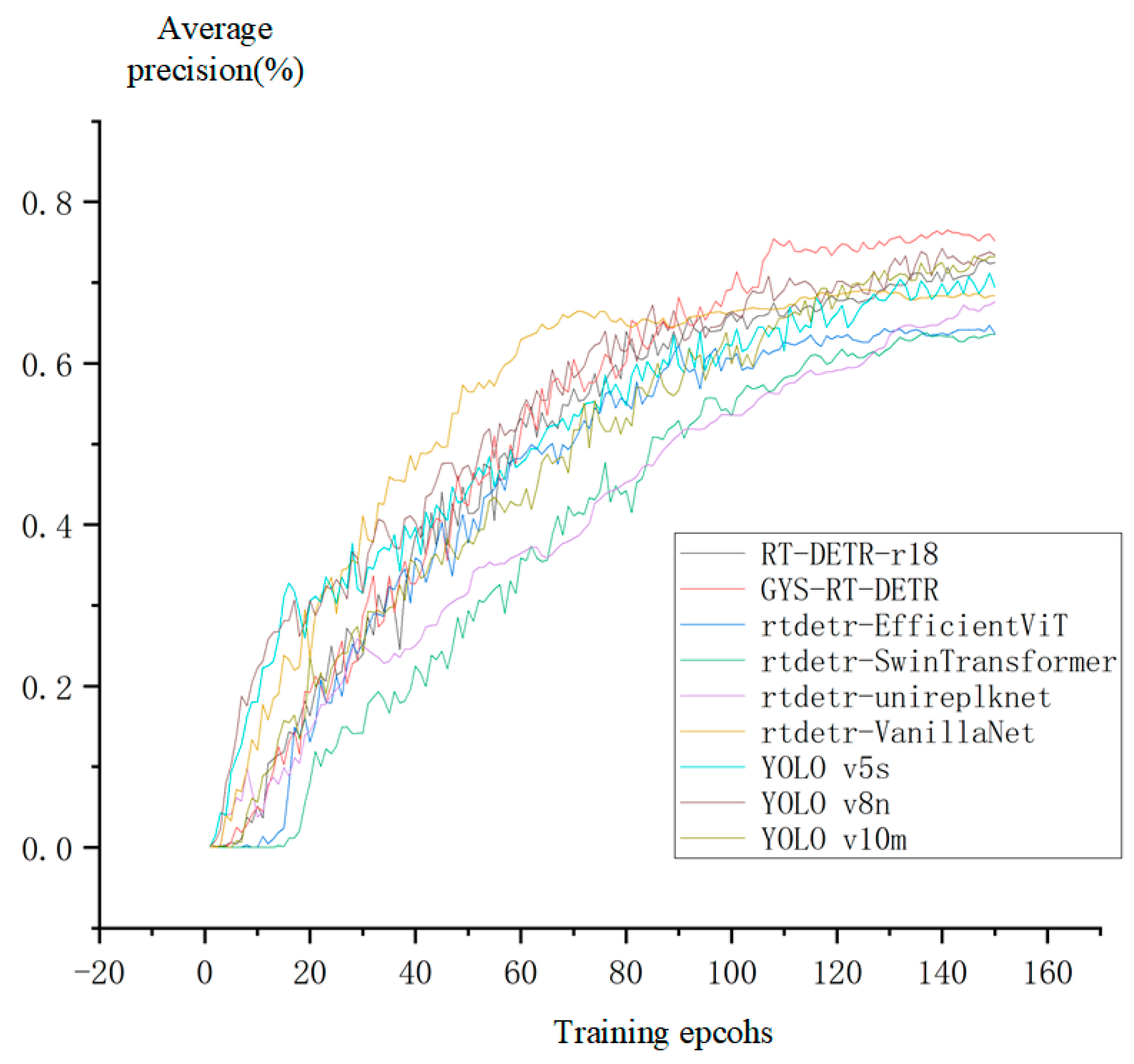
4.4. Comparison and Analysis of Different Models
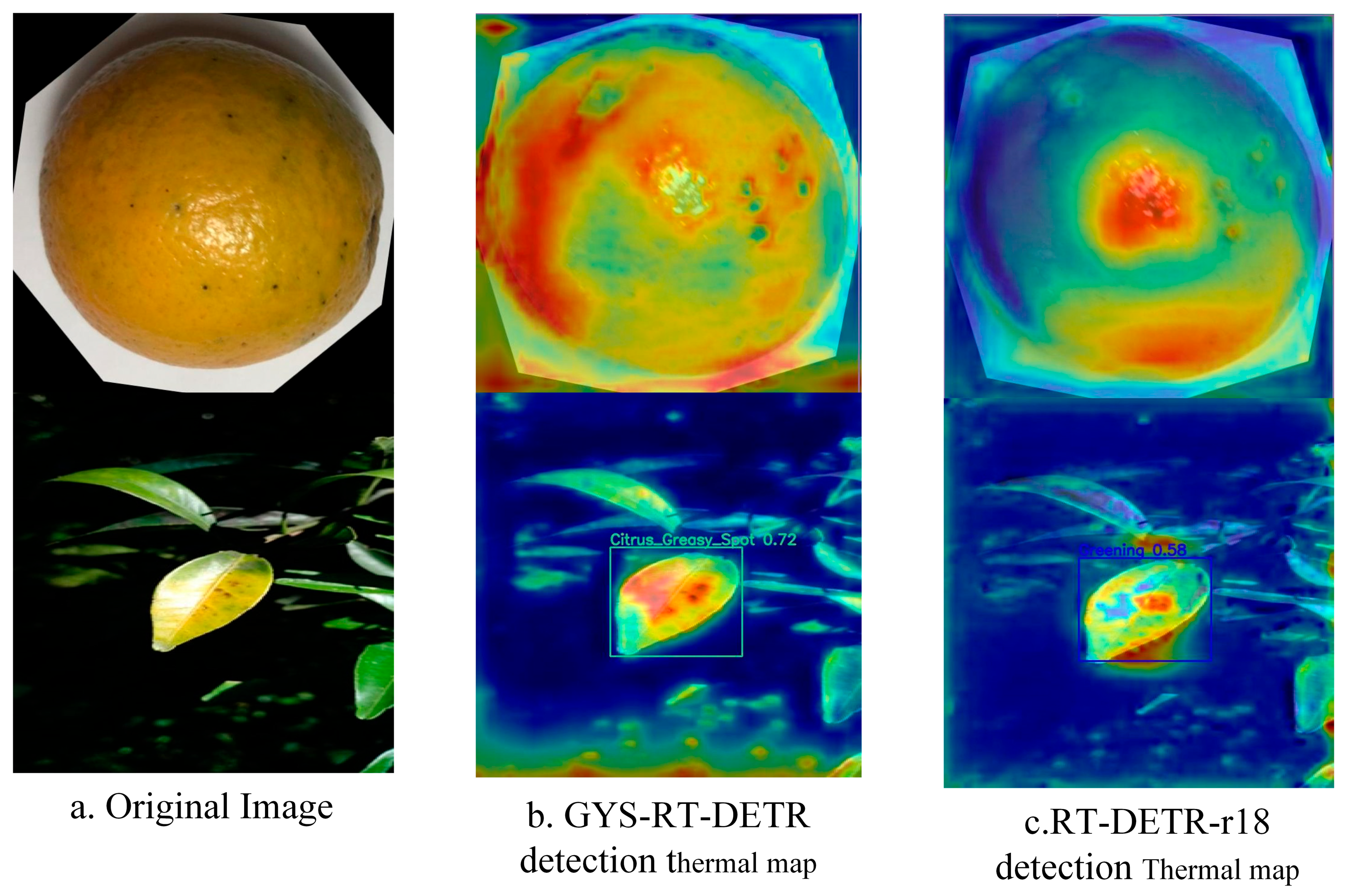
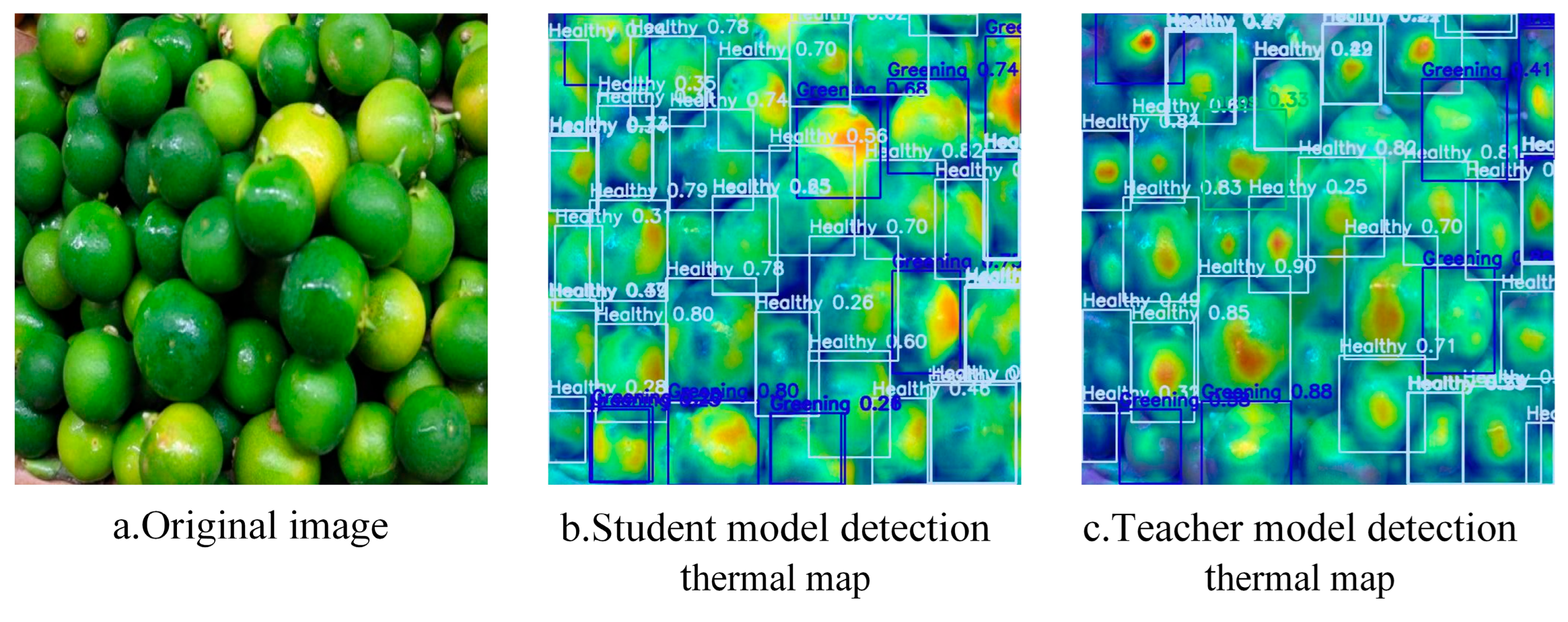
4.5. Global Contextual Information Utilization Capability Analysis
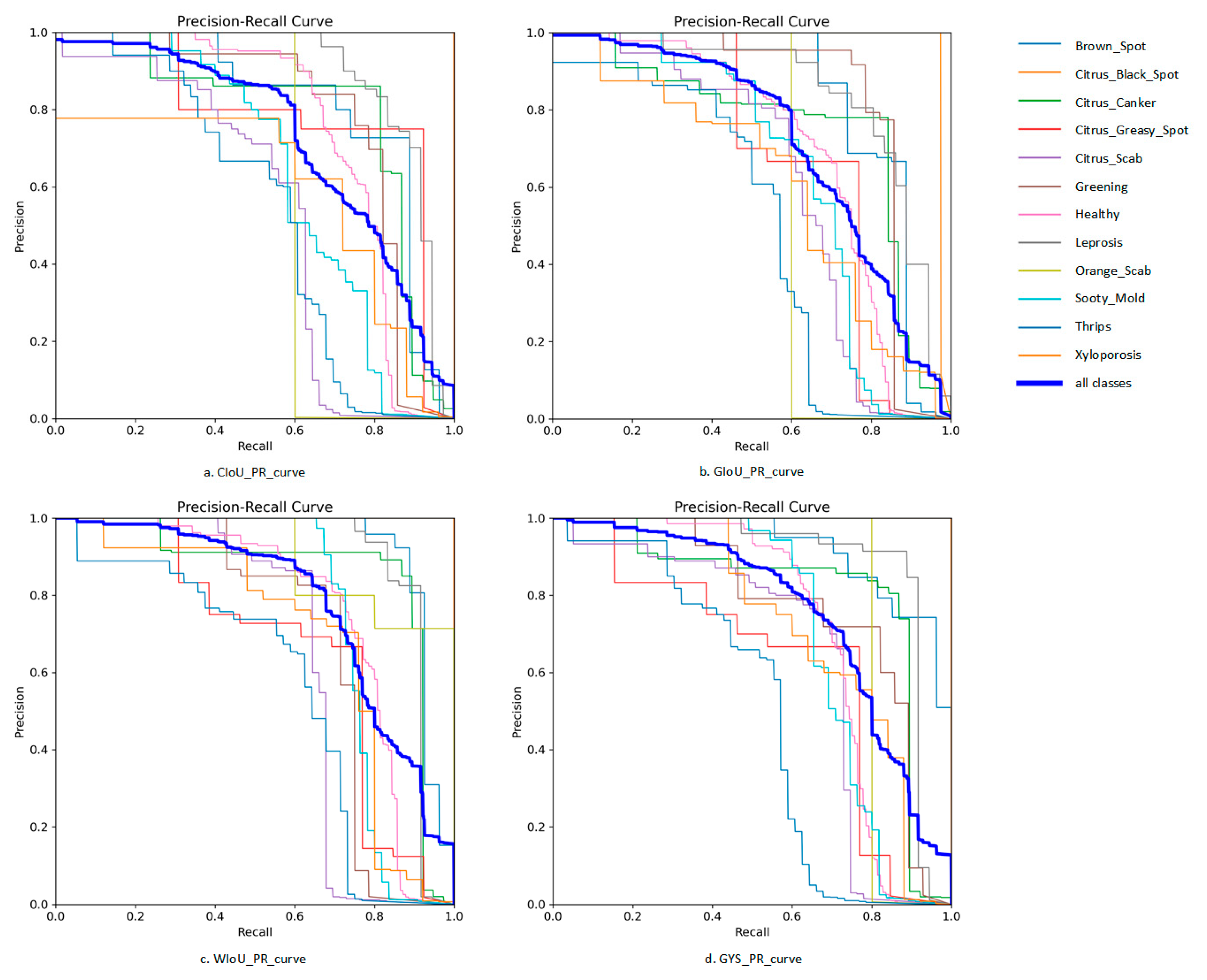
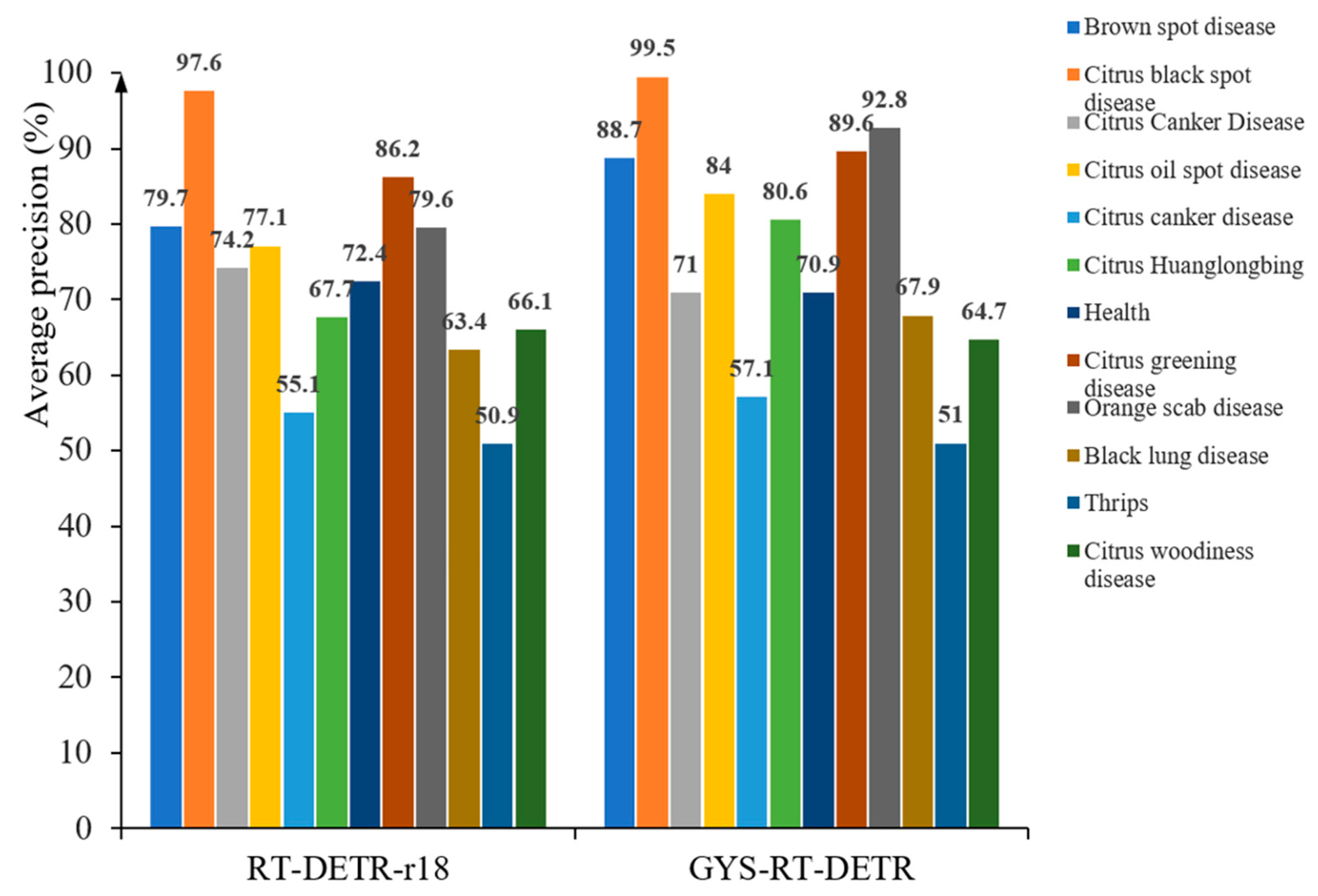
4.6. Comparison of Accuracy in Identifying Different Diseases
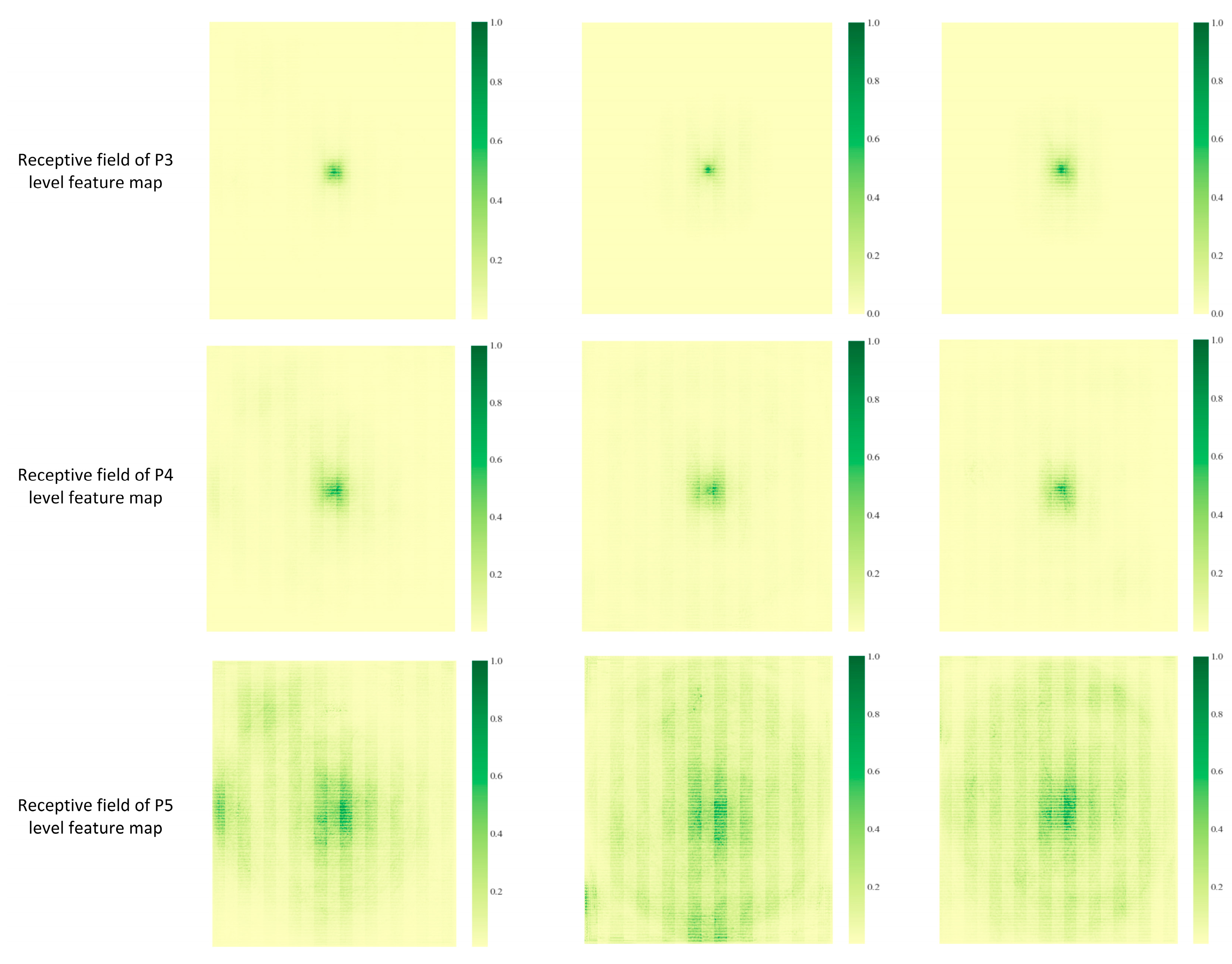
4.7. Comparison of Receptive Fields with Different Network Feature Extraction Capabilities
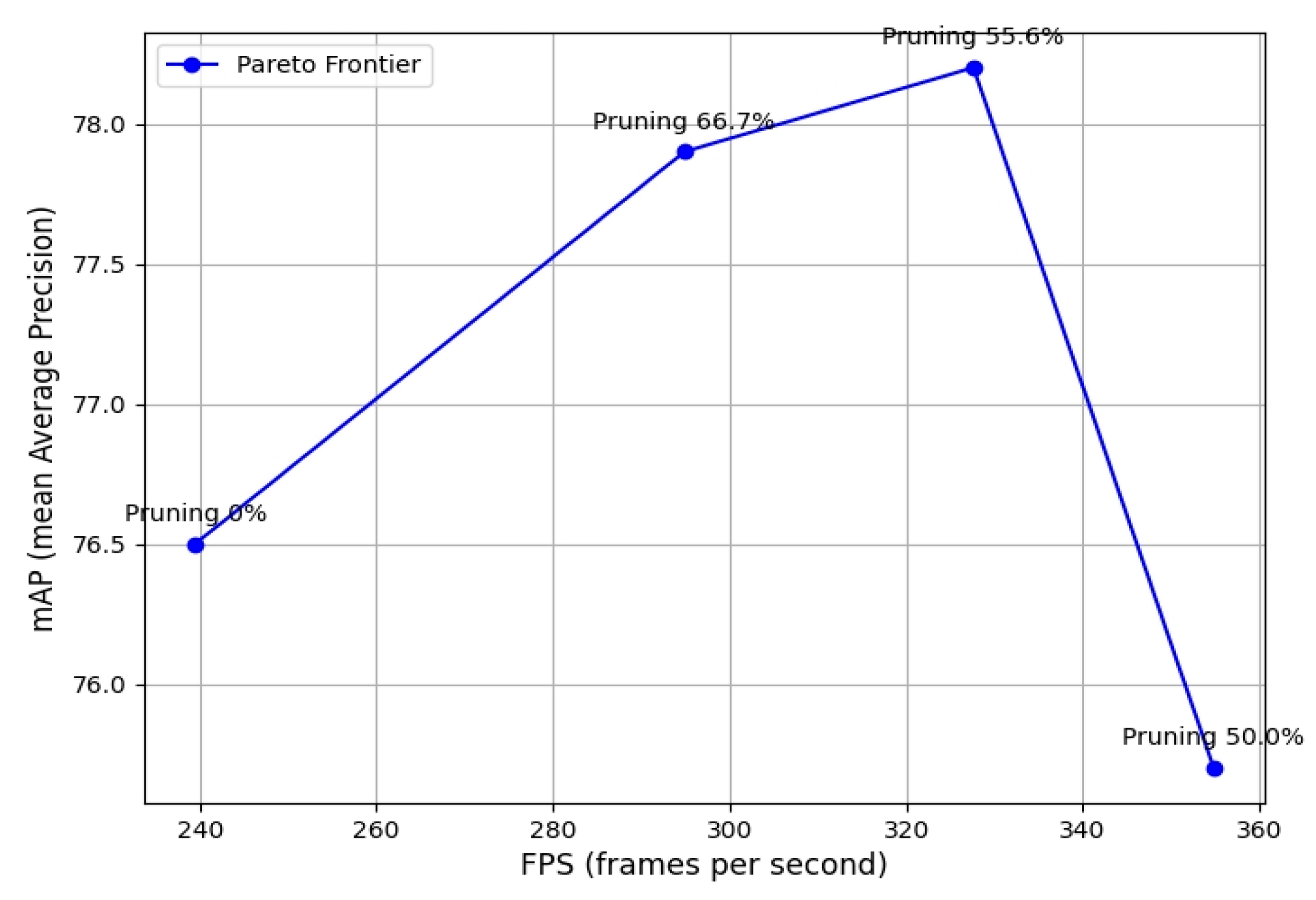
4.8. Experiments with Different Pruning Rates Based on the Group_Taylor Pruning Strategy
4.9. Comparative Analysis of Different Feature Loss Functions
4.10. Comparative Analysis of Model Performance Evaluation Indexes at Different Stages
- (1)
- Compared with the original model RT-DETR-r18, the improved GYS-RT-DETR model has an improvement of 4%, 3.7%, 2.4%, 1.2% of F1-scores, mAP0.5, mAP0.5:0.95, precision, recall and F1-score, respectively, which proves that the improved model has stronger generalization ability. At the same time, compared with RT-DETR-r18, the number of parameters and FLOPs of the GYS-RT-DETR model increased by 2.7 M and 6.2 G, respectively, which proved that the model memory occupation and model inference prediction speed of the improved GYS-RT-DETR model decreased significantly. This result shows that although the detection performance of GYS-RT-DETR is better than that of the original RT-DETR-r18 model, its deployment difficulty on edge devices is significantly increased.
- (2)
- After multiple experiments with different channel pruning strategies and pruning rates, the pruned model showed a decrease of 0.8% in mAP0.5 and 0.4% in mAP0.5:0.95 compared to the GYS-RT-DETR model. This demonstrates that models based on coarse-grained channel pruning strategies often experience a decline in detection performance due to excessively high pruning rates. Although the precision of the pruned model decreased by 2.9% compared to the GYS-RT-DETR model, the former’s F1-score and recall rate increased by 1% and 1.7%, respectively. This improvement in recall rate led to an increase in the F1-score. Finally, since the model pruning algorithm primarily focuses on the model’s memory usage and inference prediction speed, a comparison between the pruned model and the GYS-RT-DETR model shows that the FLOPs and parameter count decreased by 35.5 G and 11.5 M, respectively, indicating that the model’s computational complexity and memory usage were nearly reduced by 50%. This indicates that the pruned model addresses the deployment challenges of the GYS-RT-DETR model on edge devices, while the overall performance evaluation metrics of the pruned model only show a slight loss compared to the GYS-RT-DETR model.
- (3)
- Compared with the pruning model, the FLOPs and parameters of the student model KDP-GYS-RT-DETR model after feature-logic distillation remain unchanged, which proves that the attention of the KD distillation algorithm mainly focuses on the deep feature learning of the network layer between the student-teacher model, without changing the number of model parameters and the computational complexity of the model. At the same time, the distillation optimization model increased the mAP0.5, mAP0.5:0.95, precision, recall and F1-score by 2.0%, 1.7%, 3.5%, 0.8% and 1.0%, respectively, compared with the pruning model. This proves that the feature-logic distillation framework proposed in this paper makes the pruning model effectively learn the deep features and output decision-making ability of the RT-DETR-r50 model.
5. Discussion
- (1)
- Network Improvement: After improvements to the network structure and loss function, the GYS-RT-DETR model shows an increase of 4%, 3.7%, 2.4%, 1.2%, and 2% in mAP0.5, mAP0.5:0.95, precision, recall, and F1-score, respectively, compared to the original model RT-DETR-r18. At the same time, the parameter count and FLOPs of the GYS-RT-DETR model increased by 2.7 M and 6.2 G, respectively, compared to RT-DETR-r18, indicating that the memory usage and inference prediction speed of the GYS-RT-DETR improved model have significantly decreased. This result suggests that the increase in computational parameters for GYS-RT-DETR is not conducive to the model’s lightweight goals.
- (2)
- Model Pruning: The pruned model obtained using the Group_taylor pruning strategy shows a reduction of 35.5 G in FLOPs and 11.5 M in parameter count compared to the GYS-RT-DETR model, resulting in nearly a 50% decrease in computational complexity and memory usage. This result demonstrates that the pruned model addresses the deployment challenges of the GYS-RT-DETR model on edge devices, while the overall performance evaluation parameters of the pruned model only incur a slight loss compared to the GYS-RT-DETR model.
- (3)
- Knowledge Distillation: This article optimizes lightweight pruned models through a feature-logic distillation framework. Compared to the pruned models before distillation, the pruned models after distillation show improvements of 2.0% in mAP0.5, 1.7% in mAP0.5:0.95, 3.5% in precision, 0.8% in recall, and 1.0% in F1-score. Additionally, the knowledge distillation framework proposed in this article shows differences in the feature learning network layers between the student model and the teacher model. This demonstrates that the feature-logic distillation framework enables the pruned model to effectively learn the deep features and output decision-making capabilities of the RT-DETR-r50 model.
- (4)
- Comparison with Other Studies: Compared with the ASF-YOLO model proposed by Kang et al. [18], the GYS-RT-DETR model, with the addition of the GD mechanism, outperforms ASF-YOLO in the detection capability of medium and large targets. When compared with the Gold-YOLO model proposed by Wang et al. [17], both Gold-YOLO and GYS-RT-DETR enhance the detection of multi-scale targets through the introduction of the global feature fusion mechanism (GD). However, GYS-RT-DETR further improves the detection performance of small targets by incorporating the Scale Sequence Feature Fusion (SSFF) mechanism. Compared with the Focaler-IoU method proposed in reference [20], the GYS-RT-DETR model adopts a different strategy to address the issues of sample imbalance and localization accuracy in disease detection tasks. It introduces the Focaler-ShapeIoU loss function, which combines shape and scale information to optimize the detection capability for occluded and small targets. Moreover, the GYS-RT-DETR model achieves model lightweighting and is more suitable for deployment on edge devices compared to the two aforementioned models.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Below is the complete code of the GYS-RT-DETR model |
| # Parameters |
| nc: 80 # number of classes |
| scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n' |
| # [depth, width, max_channels] |
| l: [1.00, 1.00, 1024] |
| backbone: |
| # [from, repeats, module, args] |
| - [-1, 1, ConvNormLayer, [32, 3, 2, None, False, 'relu']] # 0-P1/2 |
| - [-1, 1, ConvNormLayer, [32, 3, 1, None, False, 'relu']] # 1 |
| - [-1, 1, ConvNormLayer, [64, 3, 1, None, False, 'relu']] # 2 |
| - [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2/4 |
| # [ch_out, block_type, block_nums, stage_num, act, variant] |
| - [-1, 1, Blocks, [64, BasicBlock, 2, 2, 'relu']] # 4 |
| - [-1, 1, Blocks, [128, BasicBlock, 2, 3, 'relu']] # 5-P3/8 |
| - [-1, 1, Blocks, [256, BasicBlock, 2, 4, 'relu']] # 6-P4/16 |
| - [-1, 1, Blocks, [512, BasicBlock, 2, 5, 'relu']] # 7-P5/32 |
| head: |
| - [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2 |
| - [-1, 1, AIFI, [1024, 8]] # 9 |
| - [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0 |
| - [[4, 5, 6, 7], 1, SimFusion_4in, []] # 11 |
| - [-1, 1, IFM, [[64, 32]]] # 12 |
| - [10, 1, Conv, [256, 1, 1]] # 13 |
| - [[5, 6, -1], 1, SimFusion_3in, [256]] # 14 |
| - [[-1, 12], 1, InjectionMultiSum_Auto_pool, [256, [64, 32], 0]] # 15 |
| - [-1, 3, RepC3, [256, 0.5]] # 16 |
| - [6, 1, Conv, [256, 1, 1]] # 17 |
| - [[4, 5, -1], 1, SimFusion_3in, [256]] # 18 |
| - [[-1, 12], 1, InjectionMultiSum_Auto_pool, [256, [64, 32], 1]] # 19 |
| - [-1, 3, RepC3, [256, 0.5]] # 20 |
| - [[20, 16, 10], 1, PyramidPoolAgg, [352, 2]] # 21 |
| - [-1, 1, TopBasicLayer, [352, [64, 128]]] # 22 |
| - [[20, 17], 1, AdvPoolFusion, []] # 23 |
| - [[-1, 22], 1, InjectionMultiSum_Auto_pool, [256, [64, 128], 0]] # 24 |
| - [-1, 3, RepC3, [256, 0.5]] # 25 |
| - [[-1, 13], 1, AdvPoolFusion, []] # 26 |
| - [[-1, 22], 1, InjectionMultiSum_Auto_pool, [256, [64, 128], 1]] # 27 |
| - [-1, 3, RepC3, [256, 0.5]] # 28 |
| - [[5, 6, 8], 1, ScalSeq, [256]] # 29 |
| - [[20, -1], 1, Add, []] # 30 |
| # - [[20, -1], 1, asf_attention_model, []] # 30 |
| - [[30, 25, 28], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # 29 |
References
- Deng, X. A Review and Perspective for Citrus Breeding in China During the Last SixDecades. Acta Hortic. Sin. 2022, 49, 2063–2074. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, Y.; Feng, Z.; Li, R.; Li, M.; Li, Y. Analysis of Competitive Advantages in the Development of the Citrus Industry in Yunnan Province. Yunnan Agric. 2018, 40–41. [Google Scholar]
- Nie, R.; Sun, M.; Feng, D.; Song, X.; Gao, J.; Guo, L.; Deng, X.; Chai, L.; Xie, Z.; Ye, J. An Investigation on Occurrence and Distribution Patterns of Five Common Citrus Diseases in Yunnan. Acta Hortic. Sin. 2024, 51, 2685–2700. [Google Scholar] [CrossRef]
- Tan, B. Research on Citrus Disease Identification Based on Convolutional Neural Networks. Master’s Thesis, Jiangsu University, Zhenjiang, China, 2023. [Google Scholar]
- Zeng, W.; Chen, Y.; Hu, G.; Bao, W.; Liang, D. Detection of citrus Huanglongbing in natural background by SMS and two-way feature fusion. Trans. Chin. Soc. Agric. Mach. 2022, 53, 1. [Google Scholar]
- He, C. Rapid Detection Citrus HLB by Developing a Handheld Device Based on Spectral Imaging Technology. Master’s Thesis, Fujian Agriculture and Forestry University, Fuzhou, China, 2022. [Google Scholar]
- Dai, Z. Research on Citrus Huanglongbing Diagnosis System Based on Edge Computing. Master’s Thesis, Southwestern University, Georgetown, TX, USA, 2022. [Google Scholar]
- Lian, B. Research on Online Diagnostic Technology and System of Citrus Huanglongbing Based on MobileNet. Master’s Thesis, South China Agricultural University, Guangzhou, China, 2019. [Google Scholar]
- Liu, Y.; Xiao, H.; Sun, X.; Zhu, D.; Han, R.; Ye, L.; Wang, J.; Ma, K. Spectral feature selection and discriminant model building for citrus leaf Huanglongbing. Trans. Chin. Soc. Agric. Eng. 2018, 34, 180–187. [Google Scholar]
- Qing, D. Rapid Nondestructive Detection of Citrus Greening (HLB) Using Hyperspectral Imaging Technology. Ph.D. Dissertation, East China Jiaotong University, Nanchang, China, 2016. [Google Scholar]
- Bové, J.; Chau, N.M.; Trung, H.M.; Bourdeaut, J.; Garnier, M. Huanglongbing (greening) in Vietnam: Detection of Liberobacter asiaticum by DNA-hybridization with probe in 2.6 and PCR-amplification of 16S ribosomal DNA. In Proceedings of the International Organization of Citrus Virologists Conference Proceedings (1957–2010), Fuzhou, China, 16–23 November 1996. [Google Scholar]
- Weng, H.; Liu, Y.; Captoline, I.; Li, X.; Ye, D.; Wu, R. Citrus Huanglongbing detection based on polyphasic chlorophyll a fluorescence coupled with machine learning and model transfer in two citrus cultivars. Comput. Electron. Agric. 2021, 187, 106289. [Google Scholar] [CrossRef]
- He, C.; Li, X.; Liu, Y.; Yang, B.; Wu, Z.; Tan, S.; Ye, D.; Weng, H. Combining multicolor fluorescence imaging with multispectral reflectance imaging for rapid citrus Huanglongbing detection based on lightweight convolutional neural network using a handheld device. Comput. Electron. Agric. 2022, 194, 106808. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Linlin, L.; Hailong, S. Forest Pedestrian Detection Based on Improved YOLOv8. For. Eng. 2025, 41, 138–150. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient transfer learning. arXiv 2016, arXiv:1611.06440. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2023, 36, 51094–51112. [Google Scholar]
- Kang, M.; Ting, C.-M.; Ting, F.F.; Phan, R. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Shape-iou: More accurate metric considering bounding box shape and scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Zhang, H.; Zhang, S. Focaler-iou: More focused intersection over union loss. arXiv 2024, arXiv:2401.10525. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citrus Disease Categories | Number of Images | Collection Time |
|---|---|---|
| Brown spot disease | 63 | 9:00 a.m.~11:00 a.m., 15:00 p.m.~17:00 p.m. |
| Citrus black spot disease | 372 | |
| Citrus canker | 277 | |
| Citrus oil spot disease | 121 | |
| Citrus scab disease | 366 | |
| Citrus huanglongbing | 222 | |
| healthy citrus fruits | 604 | |
| Citrus leprosy | 187 | |
| Orange scab | 72 | |
| Soot disease | 160 | |
| Thrips | 350 | |
| Citrus lignification | 91 |
| Model | Base Model | Mechanisms | Loss Function |
| GYS-RT-DETR | RT-DETR-r18 | Gather-and-Distribute (GD) Scale Sequence Feature Fusion (SSFF) | Focaler-ShapeIoU |
| Gold-YOLO | YOLOv5 | Gather-and-Distribute (GD) Mechanism Lightweight Adjacent Layer Fusion (LAF) Global Context Fusion Module (GCFM) | Traditional IoU loss + classification loss (cross-entropy) |
| ASF-YOLO | YOLOv5 | Scale Sequence Feature Fusion (SSFF) Module Channel and Position Attention Mechanism (CPAM) | EIoU loss function + classification loss (cross-entropy) |
| Evaluation Indicators | Evaluation Formula |
|---|---|
| Precision (P) | |
| Recall (R) | |
| -Scores | |
| Average Precision (AP) | |
| Mean Average Precision (mAP) | |
| Accuracy (Acc) |
| Stage | Parameter Settings | |
|---|---|---|
| Pruning | Pruning rate/% | 50.0~66.7% |
| Global_pruning | False | |
| Image size | ||
| Epochs | 250 | |
| Fine-tuning | Batch size | 16 |
| Optimizer | AdamW | |
| Parameter Type | Parameter Value |
|---|---|
| Image size | |
| Epochs | 200 |
| Batch size | 16 |
| Teacher Network Layer | 3,5,6,7,25,22,19 |
| Student Network Layer | 3,5,6,7,28,25,30 |
| Baseline Model | GD | SSFF | P/% | R/% | mAP/% | /% | FLOPs/G | Params/M | Model Size/MB | FPS(f/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-r18 | × | × | 75.6 | 72.6 | 72.5 | 73.0 | 57.0 | 19.8 | 48.5 | 344.5 |
| RT-DETR-r18 | √ | × | 76.1 | 71.9 | 72.1 | 73.0 | 60.0 | 22.2 | 45.5 | 275.1 |
| RT-DETR-r18 | × | √ | 73.1 | 72.1 | 70.2 | 72.0 | 61.5 | 20.1 | 39.2 | 267.2 |
| RT-DETR-r18 | √ | √ | 78.4 | 73.7 | 73.9 | 75.0 | 63.2 | 22.5 | 45.9 | 239.5 |
| Baseline Model | Focaler-ShapeIoU | WIoU | CIoU | GIoU | P/% | R/% | |||
|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-r18 + GD+SSFF | √ | × | × | × | 78.0 | 73.8 | 76.5 | 49.8 | 75.0 |
| RT-DETR-r18 + GD+SSFF | × | √ | × | × | 78.0 | 73.7 | 73.9 | 46.9 | 75.0 |
| RT-DETR-r18 + GD+SSFF | × | × | √ | × | 73.8 | 72.2 | 72.4 | 46.8 | 73.0 |
| RT-DETR-r18 + GD+SSFF | × | × | × | √ | 75.9 | 69.0 | 71.4 | 45.7 | 72.0 |
| Model | P/% | R/% | mAP/% | F1/% | FLOPs/G | Params/M | Model Size/MB | FPS (f/s) |
|---|---|---|---|---|---|---|---|---|
| GYS-RT-DETR | 78.0 | 73.8 | 76.5 | 75.0 | 63.2 | 22.5 | 43.8 | 239.5 |
| rtdetr-EfficientViT | 70.3 | 63.9 | 64.3 | 64.3 | 23.7 | 10.7 | 22.7 | 255.8 |
| rtdetr-VanillaNet | 74.5 | 65.4 | 68.8 | 69.0 | 110.2 | 21.7 | 55.8 | 182.8 |
| rtdetr-unireplknet | 65.7 | 65.7 | 67.4 | 65.0 | 35.3 | 13.1 | 12.7 | 247.0 |
| rtdetr-SwinTransformer | 66.4 | 64.6 | 63.4 | 64.0 | 98.1 | 36.6 | 26.8 | 129.7 |
| YOLOv8n | 68.3 | 71.4 | 73.9 | 69.0 | 8.1 | 3.0 | 6.3 | 1916.8 |
| YOLO v5n | 68.3 | 65.3 | 71.2 | 66.0 | 7.1 | 2.5 | 5.3 | 1920.9 |
| YOLO v10m | 74.2 | 63.6 | 73.3 | 67.0 | 58.9 | 15.3 | 33.5 | 444.9 |
| RT-DETR-r18 | 75.6 | 72.6 | 72.5 | 73.0 | 57.0 | 19.8 | 48.5 | 344.5 |
| Experiment Serial Number | Model | Params/M | FLOPs/G | Model Size/MB | /% | /% | FPS (f/s) | Pruning Rate/% |
|---|---|---|---|---|---|---|---|---|
| 0 | GYS-RT-DETR | 22.5 | 63.2 | 43.8 | 76.5 | 49.8 | 239.5 | × |
| 1 | Group_taylor exp1 | 15.1 (67.1%) | 39.6 (62.7%) | 31.3 (71.5%) | 77.9 (+1.4) | 51.3 (+1.5) | 294.9 (+55.4) | 66.7 |
| 2 | Group_taylor exp2 | 13.3 (59.1%) | 34.2 (54.1%) | 27.6 (63.0%) | 78.2 (+1.7) | 51.4 (+1.6) | 327.6 (+88.1) | 55.6 |
| 3 | Group_taylor exp3 | 11.0 (48.9%) | 27.7 (43.8%) | 23.0 (52.5%) | 75.7 (−0.8) | 49.4 (−0.4) | 354.8 (+115.3) | 50.0 |
| Parameter Type | Parameter Value |
| kd_loss_decay | Linear |
| kd_loss_epoch | 1.0 |
| logical_loss_type | logical |
| kd_loss_type | all |
| Student Model | FLOPs/G | Params/M | P/% | R/% | /% | |||
|---|---|---|---|---|---|---|---|---|
| Pruning model | x | 75.7 | 49.4 | 27.7 | 11.0 | 75.1 | 75.5 | 76.0 |
| cwd | 77.2 (+1.5) | 50.8 (+1.4) | 27.7 | 11.0 | 75.9 (+0.8) | 75.9 (+0.4) | 77.0 (+1.0) | |
| mimic | 76.4 (+0.7) | 50.4 (+1.0) | 27.7 | 11.0 | 80.6 (+5.5) | 72.3 (−3.2) | 76.0 (+0.0) | |
| mgd | 76.8 (+1.1) | 50.1 (+0.7) | 27.7 | 11.0 | 80.9 (+5.8) | 74.1 (−1.4) | 77.0 (+1.0) | |
| chsim | 76.5 (+0.8) | 50.3 (+0.9) | 27.7 | 11.0 | 76.0 (+0.9) | 74.4 (−1.1) | 75.0 (−1.0) | |
| sp | 77.7 (+2.0) | 51.1 (+1.7) | 27.7 | 11.0 | 78.6 (+3.5) | 76.3 (+0.8) | 77.0 (+1.0) |
| /% | /% | FLOPs/G | Params/M | P/% | |||
|---|---|---|---|---|---|---|---|
| RT-DETR-r18 | 72.5 | 46.1 | 57.0 | 19.8 | 75.6 | 72.6 | 73.0 |
| GYS-RT-DETR | 76.5 | 49.8 | 63.2 | 22.5 | 78.0 | 73.8 | 75.0 |
| Pruning model | 75.7 | 49.4 | 27.7 | 11.0 | 75.1 | 75.5 | 76.0 |
| Distillation optimization model | 77.7 | 51.1 | 27.7 | 11.0 | 78.6 | 76.3 | 77.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Huang, Z.; Huangfu, Y.; Liu, R.; Wang, X.; Pan, Z.; Shi, J. GYS-RT-DETR: A Lightweight Citrus Disease Detection Model Based on Integrated Adaptive Pruning and Dynamic Knowledge Distillation. Agronomy 2025, 15, 1515. https://doi.org/10.3390/agronomy15071515
Yang L, Huang Z, Huangfu Y, Liu R, Wang X, Pan Z, Shi J. GYS-RT-DETR: A Lightweight Citrus Disease Detection Model Based on Integrated Adaptive Pruning and Dynamic Knowledge Distillation. Agronomy. 2025; 15(7):1515. https://doi.org/10.3390/agronomy15071515
Chicago/Turabian StyleYang, Linlin, Zhonghao Huang, Yi Huangfu, Rui Liu, Xuerui Wang, Zhiwei Pan, and Jie Shi. 2025. "GYS-RT-DETR: A Lightweight Citrus Disease Detection Model Based on Integrated Adaptive Pruning and Dynamic Knowledge Distillation" Agronomy 15, no. 7: 1515. https://doi.org/10.3390/agronomy15071515
APA StyleYang, L., Huang, Z., Huangfu, Y., Liu, R., Wang, X., Pan, Z., & Shi, J. (2025). GYS-RT-DETR: A Lightweight Citrus Disease Detection Model Based on Integrated Adaptive Pruning and Dynamic Knowledge Distillation. Agronomy, 15(7), 1515. https://doi.org/10.3390/agronomy15071515