1. Introduction
Rice, one of the most important staple crops globally, especially in Asia, is a primary food source for billions of people. The increase in rice yield is of significant importance for global food security. Rice panicles are key factors in both rice yield and quality, and their quantity and quality directly influence the final yield. Therefore, accurately assessing the number, morphology, and development status of rice panicles is not only of great value for improving rice yield, but also provides a scientific basis for optimizing agricultural management decisions.
Traditional methods for estimating rice yield usually rely on manually collecting the number of rice panicles and the number of grains per panicle in a given area, which are then used to estimate the total yield. However, with the expanding scale of agricultural production, manual panicle counting methods struggle to achieve high-frequency, wide-range data collection, making it difficult to provide real-time support for production decisions. This traditional estimation method is often time-consuming, costly, and particularly prone to labor shortages during seasonal peak farming periods, further limiting its application in large-field environments.
In recent years, machine learning technologies have opened new possibilities for automating crop detection [
1,
2,
3]. Introducing automation in rice panicle detection improves the accuracy of yield estimation, reduces human error and lowers labor costs, offering better support for agricultural management decisions [
4]. Through the automated detection of rice panicles, accurate yield estimation data can be obtained, offering a basis for dynamic adjustments in agricultural management measures such as irrigation, fertilization, and weed control. This enhances the precision and efficiency of management, further promoting the sustainable development of rice production [
5].
Currently, some studies are dedicated to using deep learning algorithms for the precise detection and counting of rice panicles. One study proposed a rice panicle detection model using rotated bounding boxes to achieve accurate detection and counting of rice panicles, and validated the model’s effectiveness in rice field estimation [
6]. Another study introduced an algorithm for automatically recognizing rice panicles at multiple developmental stages. Through a rice panicle target detection algorithm, effective and efficient identification of rice panicle development stages was achieved [
7]. Additionally, research has transformed the automatic observation of the rice heading stage into a process of rice panicle detection using computer vision, realizing automatic observation of the rice heading stage [
8].
Current mainstream research typically relies on high-resolution images captured from the ground or from close distances as data sources [
9]. Close-range photography captures rich details, such as clear rice panicle morphology and texture information, making it easier to achieve precise detection of rice panicles. However, this approach has a limited coverage area and is unable to meet the need for rapid detection in large-scale farmlands.
Using field images captured by UAVs allows for rapid acquisition of large-scale farmland information, providing a more convenient means for rice yield estimation and agricultural management. Although progress has been made in this field, there is still significant room for development: (1) Image capture height is usually fixed, which limits the model’s generalizability and its ability to adapt to targets or scenes of varying scales and diversity. (2) Due to the relatively small size and lack of detail in rice panicles in UAV-captured images, the difficulty of detection is increased. (3) In large-area images, there are complex background factors, such as field weeds, soil, and shadows, which make it difficult to clearly segment the boundaries of rice panicles.
Addressing issues related to large-scale, complex backgrounds and occlusion is crucial for improving the accuracy and stability of UAV-based detection systems. This has become a key research focus in agricultural remote sensing and intelligent detection.
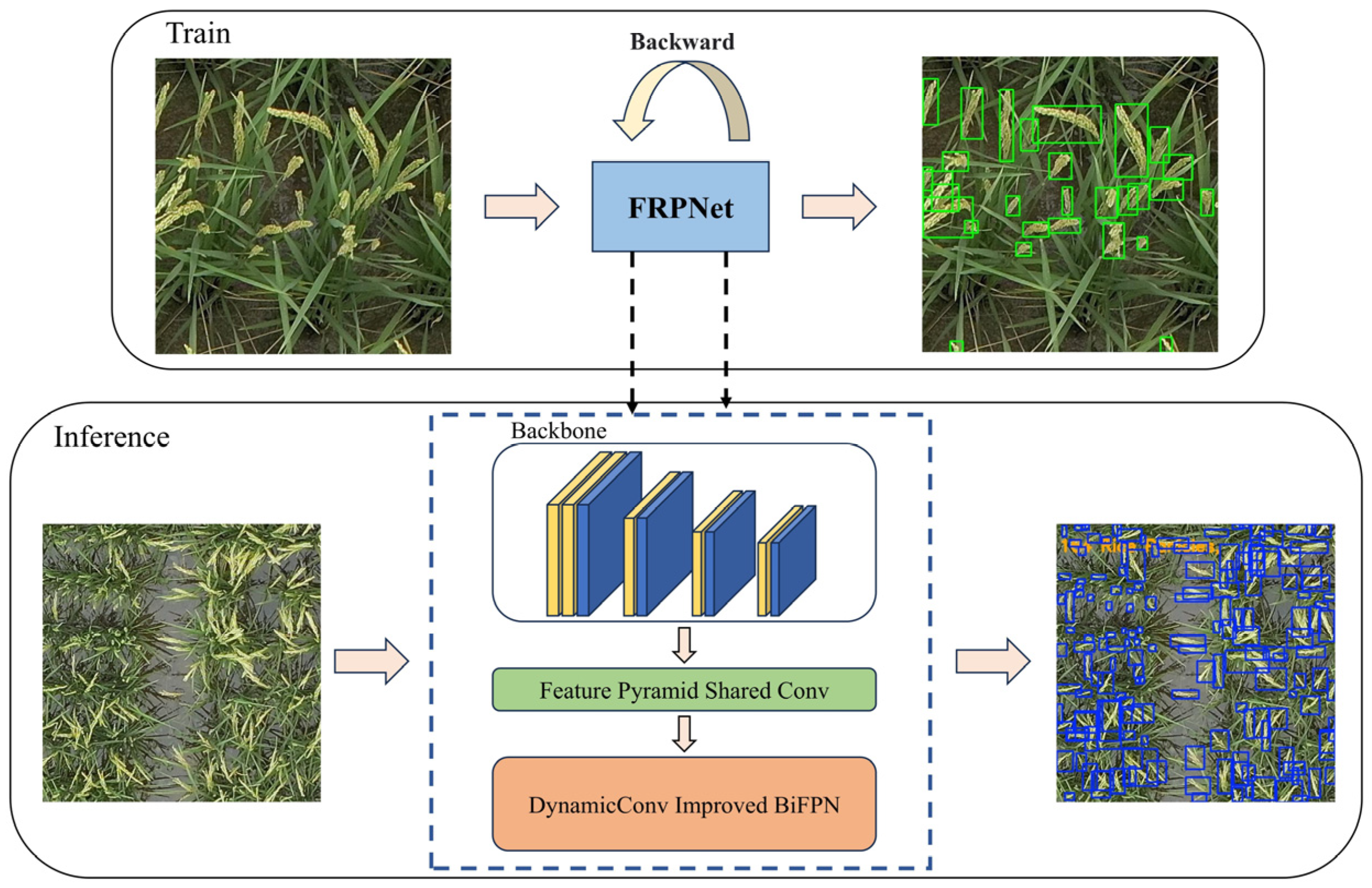
This paper proposes a multi-altitude field rice panicle detection and counting network, FRPNet, based on the Ultralytics object detection framework. Its structure is shown in
Figure 1 below. This study utilizes the open-source DRPD rice panicle dataset to recognize rice panicles in the field. The goal is to improve the performance of rice panicle recognition models and promote the application of artificial intelligence technology in agricultural production practices. By integrating an optimized lightweight backbone, the Feature Pyramid Shared Convolution (FPSC) module, and a Bidirectional Feature Pyramid Network (BiFPN), FRPNet significantly enhances detection performance under challenging conditions such as complex backgrounds and occlusions. To further improve accuracy in detecting small and densely distributed targets, we design a lightweight backbone that leverages the CSP architecture and a self-calibrating convolution module (ScConv) for efficient multi-scale feature extraction. Moreover, the FPSC module replaces traditional pooling operations with convolutional operations, enabling the precise capture of fine-grained and contextual information. This facilitates more stable and robust detection by strengthening the model’s ability to handle multi-scale feature representation.
2. Related Work
Over the past decade, researchers have explored various techniques for rice panicle recognition. Early machine learning methods rely on time-series images and clustering information labels for panicle detection [
10,
11]. However, these methods often struggle to generalize under varying lighting conditions or in the presence of occlusion. With the rapid development of artificial intelligence technologies, particularly deep learning, object detection methods have shown significant advantages in the agricultural field, offering new possibilities for detecting various crops, such as rice [
12], wheat [
13], and maize [
14]. In terms of panicle counting, existing research mainly focuses on two methods: image segmentation and object detection.
Image Segmentation-based Methods
Image segmentation relies on phenotypic features such as color and texture. In the task of panicle counting, image segmentation techniques no longer serve solely to separate panicles from the background but are used for fine segmentation and labeling of the panicles, allowing for more accurate estimation of their number. Xiong et al. [
15] proposed a rice panicle segmentation algorithm, Panicle-SEG, based on Simple Linear Iterative Clustering (SLIC) superpixels and entropy rate superpixel optimization. The segmentation result achieved an F-measure score of 76.73%. Hayat et al. [
16] applied an unsupervised Bayesian learning algorithm to segment rice panicles in images captured by UAVs over rice fields, achieving an F1 score of 82.10%. Hong et al. [
17] proposed a Mask R-CNN rice panicle segmentation model, which incorporated Otsu preprocessing and other techniques. This model significantly improved panicle detection efficiency, addressing issues such as long training times, low detection accuracy, and blurry boundaries in previous methods. Xiao et al. [
18] introduced weighted skip connection feature fusion to improve UAV-based rice panicle segmentation, showing better results compared to traditional methods. Gao et al. [
19] explored the use of self-supervised strategies for deep learning semantic segmentation of rice and wheat field images, enhancing the estimation of green fraction in crops.
Furthermore, image segmentation can be combined with other technologies, such as point cloud reconstruction and 3D modeling, to further enhance the ability to recognize and count rice panicles in complex scenarios. Gong et al. proposed Panicle-3D, which provides an effective phenotypic analysis tool for the accurate semantic segmentation of rice panicle point clouds, showcasing advancements in crop analysis technology [
20].
A weakly supervised vegetation segmentation approach was introduced by integrating spectral reconstruction and vegetation index theory, significantly improving segmentation accuracy while reducing labeling effort. Pei et al. [
21] proposed SRCNet and SRANet architectures reconstructed multispectral images from RGB UAV images, achieving a mean IoU of 0.853. This highlights the potential of spectral-based segmentation in field phenotyping under limited annotations and low-cost sensors.
The datasets used in these studies are limited in size and may not reflect the true complexity of outdoor environments. Images taken at different times and under varying weather conditions can lead to changes in phenotypic features such as color and texture, thereby affecting the accuracy of segmentation results. Especially in outdoor agricultural applications, where environmental lighting changes significantly, the segmentation results may be unstable.
Object Detection-based Methods
Object detection involves extracting image features for detection. In the task of panicle counting, it not only identifies the presence of rice panicles but also accurately locates each panicle’s position, marking it with a bounding box for automated panicle counting. Zhou et al. [
22] implemented a region-based fully convolutional network for panicle detection and counting, achieving an accuracy of 0.868 on the test set. Ji et al. [
23] proposed a maize panicle detection method that uses the Itti visual attention detection algorithm to identify regions of interest and combines feature extraction with an LS-SVM classifier to eliminate errors. The method achieved an F1 score of 88.36%. Lyu et al. [
24] captured rice panicle images using lightweight consumer-grade UAVs and then employed Mask R-CNN for panicle detection. The experimental results showed that the F1 score was 79.66%, with an average error of 33.98%, making it suitable for field detection of rice panicles. Sun et al. [
25] explored the detection of bent rice panicles in complex environments, proposing the use of the Yolov4 algorithm to accurately classify and count different types of rice panicles. Tan et al. [
26] introduced a new network, RiceRes2Net, based on an enhanced Cascade R-CNN, which supports the classification of rice panicle images captured by smartphones in the field. The MAR-Yolov9 model, based on Yolov9 with a redesigned lightweight backbone and hybrid connection strategies, achieved a 39.18% mAP@0.5 gain over existing detection algorithms across multiple datasets while reducing model size and computational cost [
27]. This suggests the growing emphasis on balancing accuracy and efficiency in large-scale agricultural deployment.
In addition, in order to improve the positioning and accuracy of small target panicles in high-density fields, Liu et al. [
28] explored orthophoto map fusion with original UAV images. A SAHI-Yolov10-based pipeline effectively addressed ghosting and seamline distortion issues, achieving an mAP of 0.864 and high-speed inference, with a novel CCOD dataset supporting the study. As rice panicles grow in the field, they often become occluded and overlap due to the high growth density between crops. This makes it challenging for object detection algorithms to accurately identify and separate overlapping panicles, leading to missed or misidentified panicles. Additionally, other surrounding plants, such as weeds or different crops, have similar colors, shapes, and textures, which increase the complexity of the detection algorithms.
To address the shortcomings in existing research, this paper introduces rice panicle data captured at different heights. By mixing multi-scale images from different heights, the model can capture rich features from coarse to fine granularities, which helps enhance the accuracy of object recognition and improve the model’s generalizability. We propose the FRPNet network, which significantly improves the accuracy and error rates in field rice panicle detection. This method aims to provide more accurate, robust, and interpretable results for counting rice panicles under multi-scale data conditions.
3. Materials and Methods
3.1. Datasets
This study utilizes the open-source DRPD (Dense Rice Panicle Detection) dataset, collected by the Crop Research Institute of the Ningxia Academy of Agricultural and Forestry Sciences, China (38°23′9″ N, 106°16′12″ E) during the 2021–2022 rice growing seasons. The dataset includes image data from 229 rice varieties across two seasonal field trials [
29]. The trials were conducted using a small-area sowing method, with each small area planted with 10 rows of 2 columns, totaling 20 plants per plot, and a spacing of 25 cm between plots. Each rice variety was replicated at least three times, covering a total of 1374 small plots. To verify the model’s accuracy and guide rice breeding practices, two different planting densities were used: A (10 × 18 cm) and B (20 × 32 cm).
Data collection was carried out by a DJI M300 drone (DJI Technology, Shenzhen, China) equipped with a DJI Zenmuse P1 camera (35 mm focal length lens, maximum resolution of 8192 × 5460 pixels). Aerial images were captured at altitudes of 7 m, 12 m, and 20 m, resulting in a total of 5372 RGB sub-images, as shown in
Figure 2A. The sub-images cover four critical growth stages: booting stage (1903 images), flowering stage (1676 images), early filling stage (1235 images), and middle filling stage (558 images), with a total of 259,498 labeled rice panicles. To increase the diversity and complexity of the dataset, images were captured under various lighting conditions, including sunny, cloudy, and morning/evening settings, reflecting natural field environment variations. This diversity effectively enhanced the robustness and generalizability of the dataset.
The data annotation was carried out manually by experienced staff, who labeled the position and boundaries of each rice panicle in the images, as shown in
Figure 2B. To ensure the scientific accuracy and consistency of the annotations, the results were rigorously reviewed by agricultural experts, and the annotation standards were repeatedly verified and optimized. The high-precision annotation process significantly improved the reliability of the dataset, providing a solid foundation for the training and evaluation of object detection models.
Overall, the 7 m height images consist of 3810 images, each covering 27 to 30 rice plants, with a total of 106,878 labeled panicles. The 12 m height images consist of 1004 images, each covering 65 to 70 rice plants, with 71,404 labeled panicles. The 20 m height images consist of 558 images, each covering 140 to 150 rice plants, with 81,216 labeled panicles. In this study, 70% of the dataset was used for training, 20% for validation, and 10% for testing.
3.2. Preliminary Data Inspection
Before training the proposed model architecture, we first conducted a comprehensive review and curation of the raw dataset to ensure its suitability for the rice panicle detection task.
We manually checked all images to eliminate low-quality samples exhibiting motion blur, overexposure, underexposure, or missing annotations. This initial filtering step was essential to avoid propagating noise into the model training pipeline.
Following manual inspection, all images were resized to a fixed resolution of 512 × 512 pixels, maintaining consistency with input dimension constraints and ensuring compatibility with its convolutional downsampling operations. Pixel values were then normalized to a [0, 1] range to facilitate stable gradient updates during backpropagation.
In addition, we performed stratified sampling to balance data across the three UAV altitudes, ensuring each subset (training, validation, and testing) maintained proportional representation of each flight height. This step mitigates altitude-induced distributional bias and improves the model’s generalization across varying spatial perspectives.
Finally, prior to inputting the data into the training pipeline, augmentation strategies such as horizontal flipping, color jittering, and mosaic augmentation were applied to increase dataset diversity and simulate complex field conditions. This helped reduce overfitting and improved the model’s ability to handle variations in object scale, illumination, and background clutter.
These preliminary inspection and preprocessing steps formed a critical foundation for reliable model development, ensuring that subsequent training was based on high-quality, representative, and well-structured data.
3.3. Field Rice Panicle Network (FRPNet)
3.3.1. Overview of Field Rice Panicle Network (FRPNet)
FRPNet (
Field
Rice
Panicle
Network) is a novel network architecture designed to enhance feature extraction and multi-scale feature fusion in rice panicle detection (as shown in
Figure 3). The core concept of FRPNet is to achieve a balance between computational efficiency and feature richness through an optimized lightweight backbone network, a feature pyramid shared convolution module, and a bidirectional feature pyramid structure. These components work together to improve the model’s ability to capture fine-grained details and contextual information across different scales, thereby enhancing detection accuracy and robustness in complex agricultural environments.
FRPNet is specifically designed to tackle the challenge of detecting small and dense objects. The architecture’s combination of feature extraction, multi-scale fusion, and bidirectional processing enables it to achieve high levels of detection accuracy while remaining computationally efficient. Its modular design makes it easy to integrate into various object detection frameworks, offering strong adaptability and versatility, which makes it suitable for a wide range of agricultural applications.
3.3.2. Constructing Feature Extraction Backbone
Designing a robust feature extraction network is crucial for achieving high-performance object detection tasks. In this study, a novel feature extraction backbone network was designed using different convolutional layers (as shown in
Figure 4). This network plays a key role in effectively capturing the multi-scale features of the input images. The backbone architecture is optimized to balance computational complexity and feature richness, ensuring the optimal performance of downstream tasks.
The first two layers of the backbone network are standard convolutional layers, each using a kernel size of 3 and a stride of 2, which halves the input resolution at each step. This gradual dimensional reduction lays the foundation for multi-scale feature extraction, enabling the model to process images at different resolutions and capture cross-scale features.
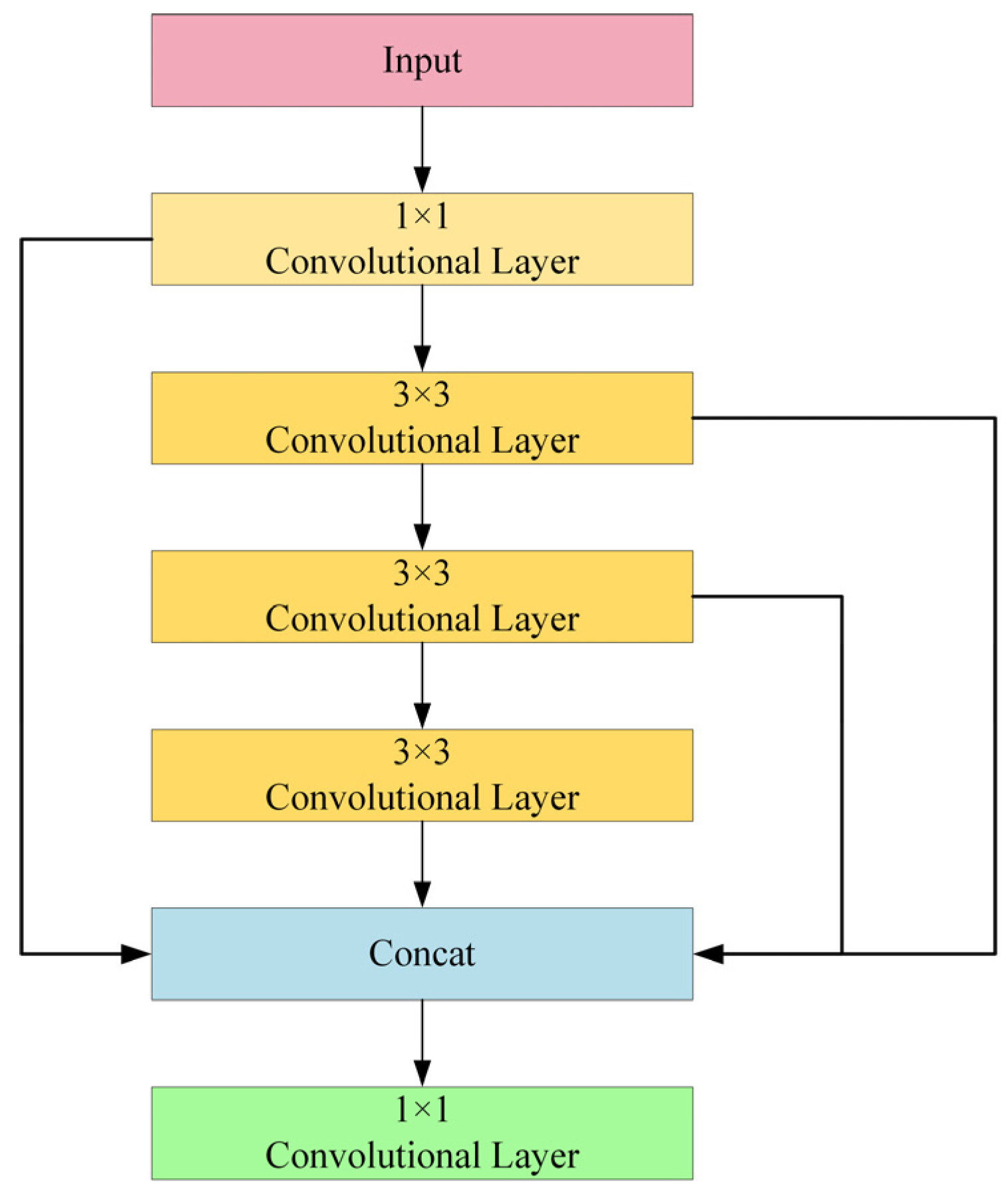
To enhance the backbone network’s ability to capture complex patterns, this study designs a feature extraction module named CSP_ScConv, as shown in
Figure 5. The core design idea is to integrate a self-calibration mechanism (ScConv) into the convolution operations of the Bottleneck within the Cross-Stage Partial (CSP) architecture. CSP is a well -known architecture that improves network efficiency by allowing partial feature sharing across layers, resulting in better computational performance and information flow. The input feature maps are split into two parts. One part passes through convolutional layers (residual blocks), while the other bypasses processing and is directly recombined at the output. This structure allows the network to focus on learning complex features from one part, while preserving the raw features from the other part. CSP reduces the total computational load, speeding up both training and inference, which is especially useful for real-time tasks such as object detection.
By introducing the self-calibration mechanism into standard convolution operations, features are dynamically adjusted in both the spatial and channel domains, enhancing the network’s focus on important features while maintaining efficiency and lightweight architecture. The pseudocode is shown in Algorithm 1. For the path in the CSP architecture processed by the convolutional layer, the input feature map
is downsampled through average pooling to generate a low-dimensional embedding
, as shown in the following formula:
where
represents the average pooling operation using a
pooling kernel and stride
The downsampled low-dimensional embedding
is transformed based on
through a convolution operation:
where
is the convolution filter,
represents the convolution operation, and
is a bilinear interpolation operator that maps the intermediate feature from a smaller scale to the original feature space. The calibration operation is as follows:
where
,
represents the sigmoid activation, and
denotes element-wise multiplication. We use
as the residual to form the weight for calibration, which is expressed as follows:
For the path in the CSP architecture that directly connects without processing, we perform a simple convolution operation on the input feature map
to obtain the result
as shown below:
The goal here is to preserve the original spatial information. We then concatenate the results of the residual block operation
with the result
as the final output
:
The introduction of the self-calibration mechanism enables the network to dynamically adjust its features. Traditional convolution layers process input feature maps statically, while ScConv can dynamically adjust spatial and channel weights based on the content of the input features, allowing the network to intelligently focus on the important features.
| Algorithm 1: CSP_ScConv |
| Input: Number of input channels C1, Number of output channels C2, Number of bottleneck layers n, Boolean indicating whether to include shortcut connections shortcut, Group size for group convolution g, Expansion ratio for hidden channels e. |
| Output: Processed feature maps Y. |
| 1. c_hidden = int(C2 ∗ e) //Initialize the number of hidden channels |
| 2. cv1 = Conv(C1, 2 ∗ c_hidden, kernel_size=1, stride=1) //Define the convolutional layers |
| 3. cv2 = Conv((2 + n) ∗ c_hidden, C2, kernel_size=1, stride=1) |
| 4. modules = [] //Initialize a list to hold Bottleneck_ScConv modules |
| 5. for i in range(n): |
| 6. modules.append(Bottleneck_ScConv(c_hidden, c_hidden, shortcut, g)) |
| 7. def forward(x): // Define the forward function |
| 8. y1, y2 = split(cv1(x), [c_hidden, c_hidden], axis = 1) |
| 9. outputs = [y1] //Pass the second part through the series of bottleneck layers |
| 10. for module in modules: |
| 11. y2 = module(y2) |
| 12. outputs.append(y2) |
| 13. return cv2(concat(outputs, axis = 1) |
Each CSP_ScConv module contains multiple repeated units, allowing the network to learn increasingly abstract features at each stage. After the first two convolution layers, the CSP_ScConv module is combined with three additional convolution layers to further downsample the feature maps, refining the extracted information before passing it to the next stage. The addition of these extra convolution layers ensures that the network retains key features while gradually reducing the spatial dimensions, which is crucial for achieving high detection accuracy without introducing excessive computational overhead.
3.3.3. Feature Pyramid Shared Convolution
In the field of deep learning, feature extraction is one of the core components of object detection and image understanding tasks. To address the balance issue between multi-scale feature integration and fine-grained information capture, this study proposes a novel feature pyramid shared convolution module called Feature Pyramid Shared Conv (FPSC), as shown in
Figure 6. In contrast to traditional feature pyramid networks (such as FPN and PANet), which rely on fixed pooling operations and linear feature fusion strategies, FPSC aims to improve the balance between context modeling and detail preservation. Instead of using pooling operations like SPPF, the FPSC module employs convolution operations, enabling more precise capture of fine details and complex patterns. This enhances both the model’s feature representation capability and computational efficiency.
Traditional pooling operations aggregate features using fixed rules (such as maximum or average), which, while computationally efficient, often lead to the loss of some detailed information. In contrast, convolution operations, with learnable weight adjustments and higher-order feature extraction capabilities, are better at capturing the details of the target region and complex contextual patterns, thereby significantly improving detection performance. The FPSC module first performs channel compression on the input feature map using a
convolution, as shown in the following formula:
where
is the feature map after initial processing, and
denotes a
convolution operation. The goal of this step is to reduce computational overhead while enhancing the non-linear transformation capability of feature representation.
The channel-compressed feature map is then fed into a multi-scale convolution path, using convolutions with different receptive fields to capture information at multiple levels. Specifically, the first path uses a single
convolution to extract fine-grained feature information, typically including edges, textures, and other local details of the target. The second path stacks two
convolutions, with the dilation rate of the second convolution set to 3, increasing the receptive field to capture mid-scale contextual information. The third path stacks three
convolutions, with the dilation rate of the final convolution set to 5, to capture global contextual features over a larger range. This design efficiently extracts multi-scale features, resulting in output features with richer semantic information. The multi-scale feature extraction process can be expressed by the following formula:
where
is the output feature map for each path, and
i represents the path number.
denotes the i-th path convolution operation with the specified dilation rate.
After feature extraction from the three paths, all feature maps are concatenated along the channel dimension, thus integrating the multi-scale information. The fused feature map contains both local details and global semantics, providing a more comprehensive feature representation for subsequent object detection tasks. The fusion process is expressed by the following formula:
where
denotes the concatenation operation along the channel dimension, and
contains multi-scale information from different receptive fields:
and
.
Finally, a
convolution is applied to the fused feature map for channel compression, generating the final output feature, as shown in the following formula:
The FPSC module employs convolutional operations with different receptive fields to capture features from various scales. It preserves fine-grained details while aggregating broader contextual information. This allows FRPNet to accurately detect rice panicles regardless of their size, ensuring that both small and large targets are detected effectively.
3.3.4. The Structure of Feature Pyramid Network (FPN)
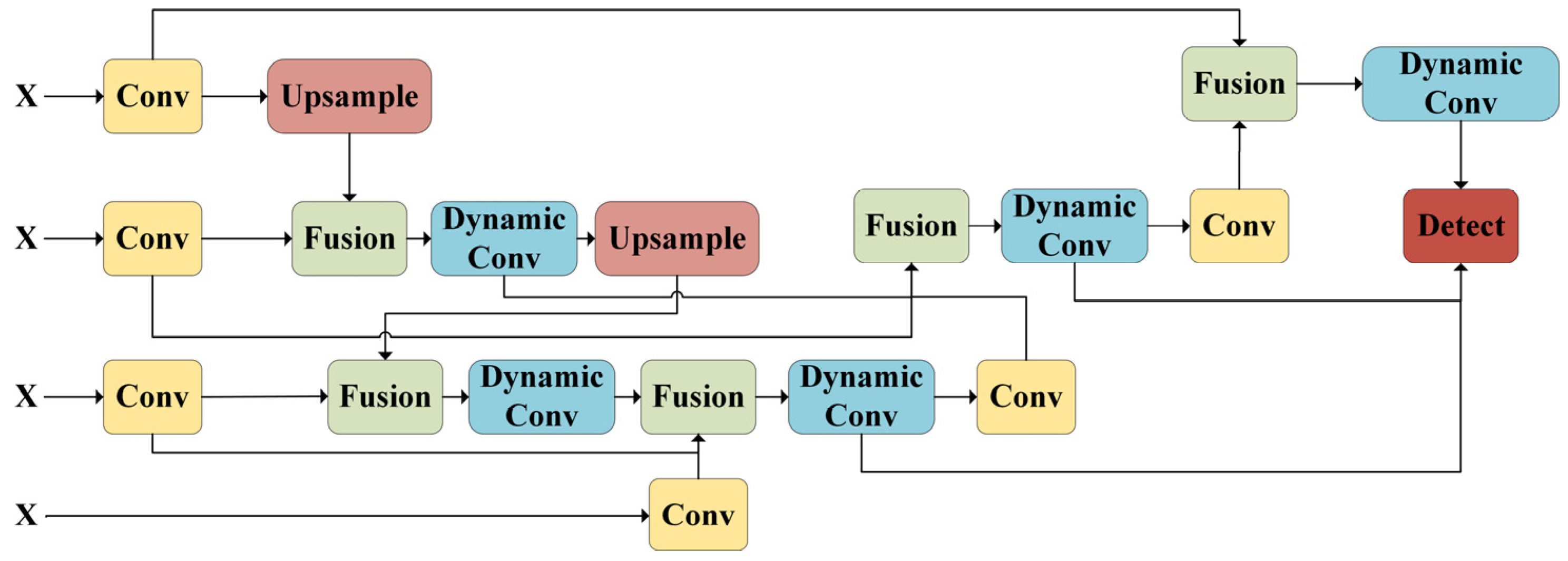
Traditional Feature Pyramid Networks (FPNs) have been widely used in object detection and image segmentation tasks due to their ability to effectively integrate low-level spatial details and high-level semantic information. However, the unidirectional information flow limits interaction and fusion between features at different scales, reducing the model’s feature extraction capability. To address this limitation, the Bi-directional Feature Pyramid Network (BiFPN) introduces a bidirectional information flow mechanism and enhances the network’s representation power through dynamic convolutions.
BiFPN improves the efficiency and effectiveness of feature pyramid construction by incorporating key strategies such as bidirectional connections, adaptive weighted fusion, and structural simplification. In contrast to the traditional top-down path, the BiFPN bidirectional connection mechanism allows feature maps to flow in both directions across scales, enabling each level to access rich contextual information from both higher and lower layers. This enhanced information flow strengthens feature aggregation, improving performance in object detection and segmentation tasks.
BiFPN performs feature fusion across different scales using learnable weights, and proposes a weighted feature fusion mechanism. In this mechanism, the network can adaptively prioritize features with higher information content, thus improving the quality of the fused features. The weighted feature fusion process can be expressed as the following formula:
where
represents feature maps at different scales, and
is the learnable weight, which is automatically adjusted during the optimization process. Compared to simple average or max pooling operations, this weighted fusion method handles the importance differences between features at different scales more flexibly.
To further enhance the network’s feature extraction capability, we replace the standard convolutional layers in BiFPN with Dynamic Convolutions, and propose DynamicBiFPN (as shown in
Figure 7). Dynamic convolution is a technique that adaptively adjusts convolution kernel weights based on the input features, giving the network greater flexibility and robustness during feature extraction. Its core advantage lies in the input-dependent weight mechanism, which enhances the network’s representation power. In contrast to traditional convolution with fixed weights, dynamic convolution generates weights based on the input, enabling the network to focus on more relevant patterns in the data. This adaptability greatly improves the model’s generalization. The operation of dynamic convolution can be expressed as follows:
where
represents the input feature map,
is the
k-th convolution kernel, and
is the attention weight assigned to the
k-th convolution kernel based on the input
. This mechanism enables dynamic convolution to adaptively adjust on different input data, thereby capturing spatial and contextual information more effectively.
In the proposed DynamicBiFPN, the combination of BiFPN and dynamic convolution is achieved through a series of optimization processes. The process from feature extraction to output generation significantly enhances multi-scale feature fusion and adaptive feature extraction. BiFPN enables efficient interaction across different scales through bidirectional connections and weighted feature fusion, while the dynamic convolution layers adapt their operations based on input features, enhancing feature representation The optimized feature maps are then passed to task-specific head modules to generate the final predictions.
The core advantages of this structure include enhanced feature fusion, adaptive feature extraction, and strong scalability. The bidirectional connections and weighted fusion mechanism ensure efficient aggregation of multi-scale features, allowing the model to fully leverage information from each layer’s features. The introduction of dynamic convolution enhances the network’s robustness and flexibility across different data patterns. With input-dependent weight adjustments, it effectively improves the quality of feature representation.
4. Results
4.1. Experimental Environment
The hardware configuration for model training is as follows: CPU Intel (R) Core (TM) i9-12900K, 64 GB of RAM, GPU RTX 4090 with 24 GB of VRAM. The software configuration is as follows: Ubuntu 22.04, Python 3.11, PyTorch 2.1.0, CUDA 12.1.
The hardware configuration for inference on the test set is as follows: CPU AMD Ryzen 9 9900X, 64 GB of RAM, GPU RTX 2080 Ti with 11 GB of VRAM. The software configuration is as follows: Windows 11 24H2, Python 3.11, PyTorch 2.1.0, CUDA 12.1.
4.2. Selection of Training Parameters
In the experimental design, standardizing the experimental parameters significantly reduces the interference of external variables on the results, allowing for a more accurate reflection of the core factors’ actual effects. This enhances the reliability and reproducibility of the experiment. When comparing the performance of multiple models, using consistent parameter settings ensures that all methods are tested under the same conditions, providing a fair basis for performance evaluation.
The fixed parameters used in the experiment are shown in
Table 1. This setup aims to minimize the potential impact of non-network factors on the experimental results. By precisely recording and controlling the parameters, the experimental conditions remain consistent, significantly enhancing the credibility and reproducibility of the results. This approach not only strengthens the robustness of the research findings, but also provides a reliable foundation for subsequent validation and reference.
During the model training process, we employed early stopping techniques to prevent overfitting. Specifically, we monitored the loss value on the validation set and set the patience value to 100. If the validation loss does not improve over 100 consecutive epochs, the training process is terminated early. This technique helps reduce unnecessary training iterations, saving computational resources without sacrificing model performance.
4.3. Evaluation Metrics
This study utilizes various evaluation metrics, including Precision, Recall, AP, AP50, and AP75, to assess the model’s performance with the goal of achieving optimal results.
Precision refers to the proportion of correctly predicted positive samples out of all samples predicted as positive. Its calculation formula is as follows:
Recall represents the proportion of correctly predicted positive samples out of all actual positive samples. The formula for Recall is as follows:
In the task of rice panicle detection, missed detections may imply that some panicles are not recognized, which could affect yield prediction and farm management. To minimize missed detections, this study places greater emphasis on Recall. The F2 score, which assigns higher weight to Recall, is particularly suitable for this case. The formula for the F2 score is as follows:
IoU (Intersection over Union) is a commonly used evaluation metric for object detection, which measures the overlap between the predicted bounding box and the ground truth bounding box. It is defined as the ratio of the intersection area to the union area of the predicted and ground truth boxes. The higher the IoU, the better the prediction box overlaps with the ground truth, indicating better detection performance. In detection tasks, since the intersecting bounding boxes form a rectangular shape, IoU can be efficiently calculated based on the center coordinates, width, and height of the bounding boxes. Given the coordinates of the top-left and bottom-right corners of the predicted bounding box as
and
, and the ground truth bounding box as
and
, the IoU calculation formula is as follows:
AP (Average Precision) is a global evaluation metric obtained by integrating the Precision-Recall curve at various IoU thresholds. In standard object detection tasks, AP is calculated by evaluating Precision and Recall at different IoU thresholds. At each threshold, the detection results are classified as TP (True Positive), FP (False Positive), or FN (False Negative), and Precision and Recall are computed accordingly. The average precision (AP) is then obtained by integrating these values. The formula for AP is as follows:
where
is the
point and
is the precision corresponding to that recall point.
This study uses three main evaluation metrics to assess the model’s performance:
AP (AP50:95): This metric measures the model’s detection ability by calculating the average precision over the range of IoU thresholds from 0.5 to 0.95 (with a step size of 0.05). A higher AP indicates better detection accuracy.
AP50: This represents the average precision at an IoU threshold of 0.5, reflecting the model’s performance under a lower matching standard.
AP75: This represents the average precision at an IoU threshold of 0.75, evaluating the model’s performance under a more stringent matching standard.
When evaluating the generalizability of the model, we used the False Positive Rate and Error Rate to analyze the test set results in-depth. These two metrics assess the model’s performance in terms of missed and false detections, providing a comprehensive reflection of the model’s real-world performance.
The False Positive Rate primarily evaluates the model’s false detection rate, i.e., the proportion of actual targets that were not correctly detected. This metric directly reflects the model’s sensitivity to the targets. A lower False Positive Rate indicates that the model can more accurately identify the actual targets, reducing the likelihood of missing detections. The calculation formula is as follows:
The Error Rate measures the model’s error detection rate, i.e., the proportion of incorrectly detected targets among the total detected targets. The formula for Error Rate is as follows:
In analyzing the test set data, we recorded the detection results for each image, including the counts of True Positives (TPs), False Negatives (FNs), and False Positives (FPs). Based on these statistics, we calculated the overall False Positive Rate and Error Rate for the test set.
4.4. Comparative Analysis with Existing Advanced Networks
To validate the advantages of the proposed model, it is compared with three categories of mainstream object detection models, including advanced convolutional neural networks, Vision Transformer (ViT)-based networks, and YOLO (You Only Look Once)-type single-object detection models. The neck and head components proposed in PANet are applied to advanced convolutional neural networks and ViT-based networks to enable object detection capabilities. These models represent different technological approaches in the field of object detection and provide a comprehensive comparison of the performance differences across various architectures.
Specifically, the convolutional neural networks selected for comparison include ConvNext v2 [
30], RevCol [
31], and Starnet [
32]. For the Vision Transformer-based networks, we chose EfficientViT [
33] and SwinTransformer [
34], while the YOLO-based detection models include Yolov8 [
35], Yolov9 [
36], and Yolov10 [
37]. By comparing these models, this study thoroughly explores the relative advantages and performance differences of the proposed model.
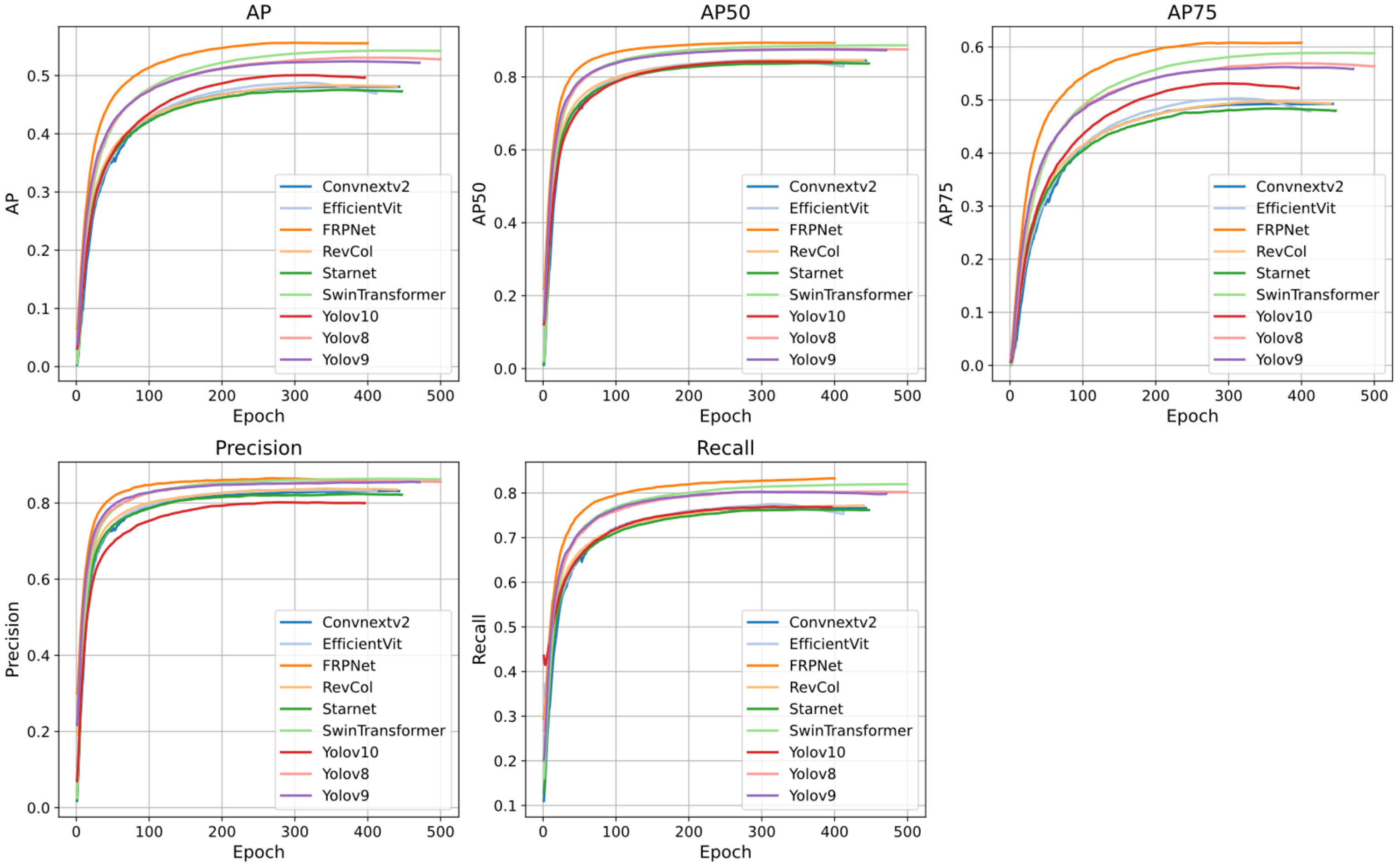
Figure 8 illustrates how the validation set metrics of each model change over time. As shown in
Table 2, we compared these methods across various evaluation metrics. Yolov8 and Yolov9 perform similarly, but overall, they lag behind the Proposed model and SwinTransformer. Yolov10 performs the worst, with its metrics lower than all other models. EfficientViT, Starnet, RevCol, and ConvNeXt v2 exhibit relatively weak performance, particularly in key metrics such as AP and F2 Score.
FRPNet achieved a Precision of 0.856, Recall of 0.8329, AP of 0.5553, AP50 of 0.8931, AP75 of 0.6072, and an F2 score of 0.8377. Most of these metrics significantly outperform the current state-of-the-art methods. The only exception is Precision, where SwinTransformer slightly outperforms FRPNet by 0.0048 (Precision: 0.8624). However, FRPNet surpasses SwinTransformer in all other metrics. Compared to advanced convolutional neural network models, FRPNet’s F2 score improves by 5.94%, 5.35%, and 6.48%, respectively. When compared to Vision Transformers, the F2 score improves by 7.2% and 1%. Compared to the latest YOLO models, the F2 score improves by 2.52%, 2.92%, and 6.29%, respectively.
As shown in
Table 3, FRPNet demonstrates a balanced performance compared to other models, with a parameter count of 4.65 M. This is moderate and provides an advantage over models with significantly higher parameter counts, such as SwinTransformer (close to 30 M).
In terms of computational complexity, measured in GFLOPs, FRPNet operates at 14.6 GFLOPs, which is more efficient than models like SwinTransformer but slightly higher than some models such as RevCol and Starnet. Its inference time of 2.6 milliseconds is moderate, faster than ConvNext v2 and SwinTransformer, but slower than Yolov10 and RevCol. Additionally, the total processing time of 4.5 milliseconds further highlights its efficiency, although it still lags behind the fastest models like Yolov10. The depth of 274 layers in FRPNet strikes a good balance, avoiding the computational overhead of deeper models.
Although FRPNet demonstrates high resource efficiency in resource-constrained applications, a comprehensive evaluation requires accuracy and performance data specific to the task at hand. Overall, FRPNet offers a good balance between computational efficiency and potential performance, making it a feasible choice for a variety of applications.
4.5. Ablation Experiments
Ablation experiment results indicate that each core component of the FRPNet model plays a crucial role in improving performance and optimizing computational efficiency. As shown in
Table 4 and
Table 5, removing the FPSC module resulted in a 2.41% drop in recall rate, a 1.51% decrease in the AP metric, and a particularly significant 1.78% drop in AP75, indicating the critical role of this module in enhancing high-precision localization.
The removal of the DynamicBiFPN module led to a 12.0% reduction in the number of model parameters, but an 8.2% increase in GFLOPs, while the AP75 metric decreased by 3.05%. This confirms the module’s balance between feature fusion efficiency and detection accuracy. When both FPSC and DynamicBiFPN were removed simultaneously, the model’s parameters were compressed by 31.4%, but AP75 dropped drastically by 8.76%, highlighting the synergistic optimization effect of these two modules.
It is noteworthy that removing the SCConv module, while reducing computational load by 5.5%, resulted in a 38.5% increase in inference time, and a 2.18% decrease in the AP metric. This demonstrates that the SCConv module, through structured feature reconstruction, effectively enhances computational efficiency.
Overall, the complete FRPNet, with 4.65 M parameters, achieves the optimal AP50 and F2 scores. Its multi-stage feature enhancement architecture significantly improves detection robustness in complex scenarios while maintaining real-time performance.
4.6. Generalizability Testing
Generalizability Testing aims to evaluate the model’s performance on unseen data, especially in different scenarios and data distributions that may be encountered in real-world applications. To assess the model’s generalization, this study uses the pre-trained model to perform inference on the test set data. By using the test set, we can examine the model’s accuracy and robustness in a real-world environment, ensuring that it not only performs well on the training set but also maintains efficient performance on different, unknown data. This test is crucial for evaluating the model’s practicality and reliability, as it helps identify the risk of overfitting and provides a basis for further optimization.
The analysis in
Figure 9 shows that FRPNet exhibits a lower frequency of missed targets (red boxes) and false predictions (blue boxes) compared to other models, indicating a better balance between accuracy and completeness. In contrast, while the YOLO series models have an advantage in real-time performance, they may involve certain trade-offs in accuracy, showing a higher number of false predictions. Although ConvNeXtV2 and SwinTransformer models offer higher accuracy, they suffer from higher missed targets due to computational constraints or architectural limitations. The FRPNet advantage comes from its stronger feature extraction capabilities and better performance in handling occlusion and small objects.
Combining the quantitative analysis results from
Table 6, FRPNet stands out in terms of missed target rate (10.25%) and error rate (18.09%), showing clear advantages over other models. Specifically, FRPNet has a lower missed target rate than all other models, particularly when compared to CNN-based models and YOLO series models, where FRPNet demonstrates higher accuracy and completeness in reducing missed targets and false predictions. Additionally, the SwinTransformer model, as a ViTs-based model, has a missed target rate of 9.56%, slightly better than FRPNet, but its error rate remains relatively high.
4.7. Heatmap Analysis
To further evaluate the model’s detection accuracy for rice panicle targets, this study used Grad-CAM heatmaps for visual analysis of detection results. Grad-CAM heatmaps show the model’s attention to different areas of the image through varying color intensities, providing an intuitive reflection of the model’s focus during the detection process.
By observing the heatmap, we can effectively assess the model’s ability to recognize the distribution and position of rice panicle targets, and analyze its detection performance and local accuracy in different scenarios. The heatmap analysis not only reveals potential false positives or missed detections in certain regions, but also provides targeted guidance for model optimization, contributing to improved detection performance in practical applications.
From the experimental results shown in
Figure 10, it is evident that the proposed FRPNet network demonstrates excellent rice panicle detection performance at different flight altitudes (20 m, 12 m, and 7 m). Compared to other mainstream detection models, the heatmap of FRPNet shows more concentrated feature activation areas, especially exhibiting higher detection accuracy and sensitivity in the rice panicle target areas.
Specifically, the FRPNet highlighted activation areas are primarily concentrated in key parts of the rice panicle, indicating that the model effectively captures the prominent features of the rice panicle. Although other detection models also show strong detection responses, their activation areas are more dispersed and contain excessive redundancy. This phenomenon is particularly evident in long-range images (20 m), further verifying the FRPNet advantage in feature focusing.
From the perspective of multi-scale stability, FRPNet maintains high feature focusing ability at 20 m, 12 m, and 7 m altitudes, and there is no significant drift or blurring of the feature response area with scale variation. This indicates that FRPNet exhibits strong robustness and adaptability in multi-scale rice panicle detection tasks.
Moreover, FRPNet shows significant advantages in background noise suppression. Specifically, the FRPNet heatmap appears overall deep blue in non-target areas, indicating effective suppression of background noise and reduced irrelevant activations in non-rice panicle regions. Other networks such as Yolov10 and Yolov9, show more irrelevant responses in background areas, which leads to a decrease in detection accuracy.
In summary, the Grad-CAM heatmap analysis demonstrates that FRPNet outperforms existing mainstream detection models in feature extraction capability, background noise suppression, and multi-scale detection stability. This further validates the effectiveness and superiority of FRPNet in rice panicle detection in complex scenarios, providing a higher-accuracy solution for rice panicle detection tasks.
5. Conclusions
This paper proposes FRPNet, an efficient network for rice panicle detection, addressing the issues of small and dense targets. Through an optimized lightweight backbone network, Feature Pyramid Shared Convolution Module (FPSC), and Bidirectional Feature Pyramid Network (BiFPN), FRPNet significantly improves detection accuracy and computational efficiency. The backbone network enhances feature extraction through the CSP architecture and self-calibration convolution module (ScConv), improving the robustness of multi-scale features. The FPSC module replaces traditional pooling operations and efficiently captures fine-grained features through convolution, strengthening multi-scale information fusion. BiFPN introduces bidirectional feature flow and dynamic convolution, further optimizing feature fusion and adaptive feature extraction.
Experimental results show that FRPNet performs excellently in rice panicle detection tasks, achieving a Precision of 0.856, Recall of 0.8329, AP of 0.5553, AP50 of 0.8931, AP75 of 0.6072, and an F2 score of 0.8377.
FRPNet highlights the potential of deep learning methods in agricultural applications, especially in precision agriculture. The practical significance of this study lies in its direct applicability to real-world agricultural scenarios, particularly in the context of large-scale, data-driven crop management. Traditional rice panicle counting methods are labor-intensive, time-consuming, and often infeasible in expansive farmlands, especially under time-sensitive conditions such as peak growing periods. By leveraging UAV image and a lightweight, high-accuracy detection network, FRPNet enables rapid, automated, and non-invasive monitoring of rice panicle development across multiple altitudes and environmental conditions. This contributes not only to improving the precision of yield estimation, but also to enhancing decision-making in irrigation, fertilization, and field management. The model’s robustness in handling occlusions, complex backgrounds, and scale variations makes it particularly suitable for deployment in dynamic field environments, bridging the gap between advanced computer vision technologies and practical agricultural needs. Therefore, this research offers a scalable and cost-effective solution that supports the digital transformation of precision agriculture.
The model’s ability to handle multi-scale data and its efficient feature extraction make it a promising tool for rice yield estimation and agricultural management. However, several limitations must be acknowledged, particularly when considering deployment in diverse real-world agricultural contexts:
- (1)
Dataset Size Limitations and Annotation Costs
Deep learning-based object detection models require large-scale, high-quality labeled datasets for optimal performance. However, in the context of rice panicle detection, the annotation process is particularly challenging due to the dense distribution of panicles and the complex backgrounds typical of field environments. A single high-resolution UAV image can contain hundreds of small, overlapping panicles, making manual annotation labor-intensive, error-prone, and prohibitively costly at scale. This restricts the availability of sufficient annotated data for model training and evaluation. At present, there have been some studies in the field of agronomy, using Few-Shot related technology to detect and count crops [
38,
39]. Future work should refer to these semi-supervised learning framework ensembles to exploit unlabeled data and reduce reliance on exhaustive manual annotations.
- (2)
Detection and Counting Under High-Density Conditions
While FRPNet demonstrates strong performance across multiple evaluation metrics, its effectiveness tends to decline when applied to images featuring extremely dense and overlapping rice panicles. In such cases, occlusion between adjacent panicles can obscure visual boundaries, leading to false negatives or double counting. This limitation is inherent to many object detection architectures, where performance degrades as inter-object spacing decreases. Addressing this challenge may require the incorporation of instance segmentation techniques, adaptive density-aware post-processing, or temporal fusion methods if time-sequenced UAV images are available.
- (3)
Sensitivity to Extreme Lighting Conditions
The variability in natural illumination, such as overexposure at midday and inconsistent cloud cover, poses a significant challenge to the generalization of detection models. Although FRPNet was trained with data collected under various lighting conditions, its performance may still degrade under extreme or uncommon lighting scenarios. Future research can explore the use of advanced photometric augmentation strategies, domain adaptation, or the fusion of multispectral or hyperspectral data to enhance model robustness against lighting-induced variance. Such techniques would be particularly valuable in extending the usability of FRPNet across diverse geographic regions and weather conditions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}