


Bridging the Gap: Limitations of Machine Learning in Real-World Prediction of Heavy Metal Accumulation in Rice in Hunan Province


 ,
,
Abstract

1. Introduction
2. Materials and Methods
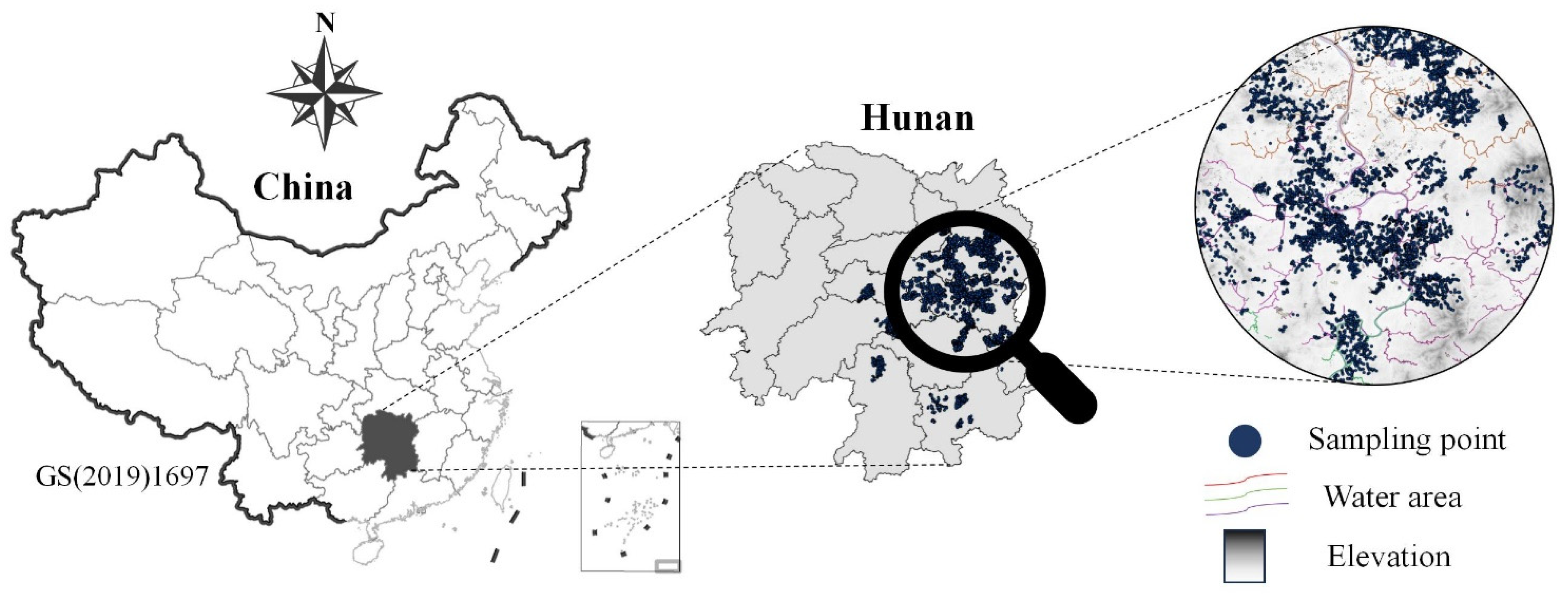
2.1. Study Area
2.2. Soil–Rice Physicochemical Data
2.3. Agricultural Management Data
- (1)
- Low-Cd variety (0/1)
- (2)
- Low-Cd varieties (ordinal encoding)
- (3)
- Water management (0/1)
- (4)
- Application of quicklime (0/1)
- (5)
- Foliar blocker (0/1)
- (6)
- Foliar blockers (ordinal encoding)
- (7)
- Soil conditioner (0/1)
- (8)
- Soil conditioners (ordinal encoding)
- (9)
- Green manure Astragalus (0/1)
- (10)
- Tillage improvement (0/1)
- (11)
- Organic fertilizer (0/1)
- (12)
- Organic fertilizers (ordinal encoding)
- (13)
- Fallow (0/1)
2.4. Multi-Source Environmental Data Integration
2.4.1. Climate Data
2.4.2. Meteorological Data
2.4.3. Geographic Environmental Data
2.4.4. Anthropogenic Activities
2.5. Data Processing and Machine Learning Models
2.6. Model Simplification and Validation
3. Results
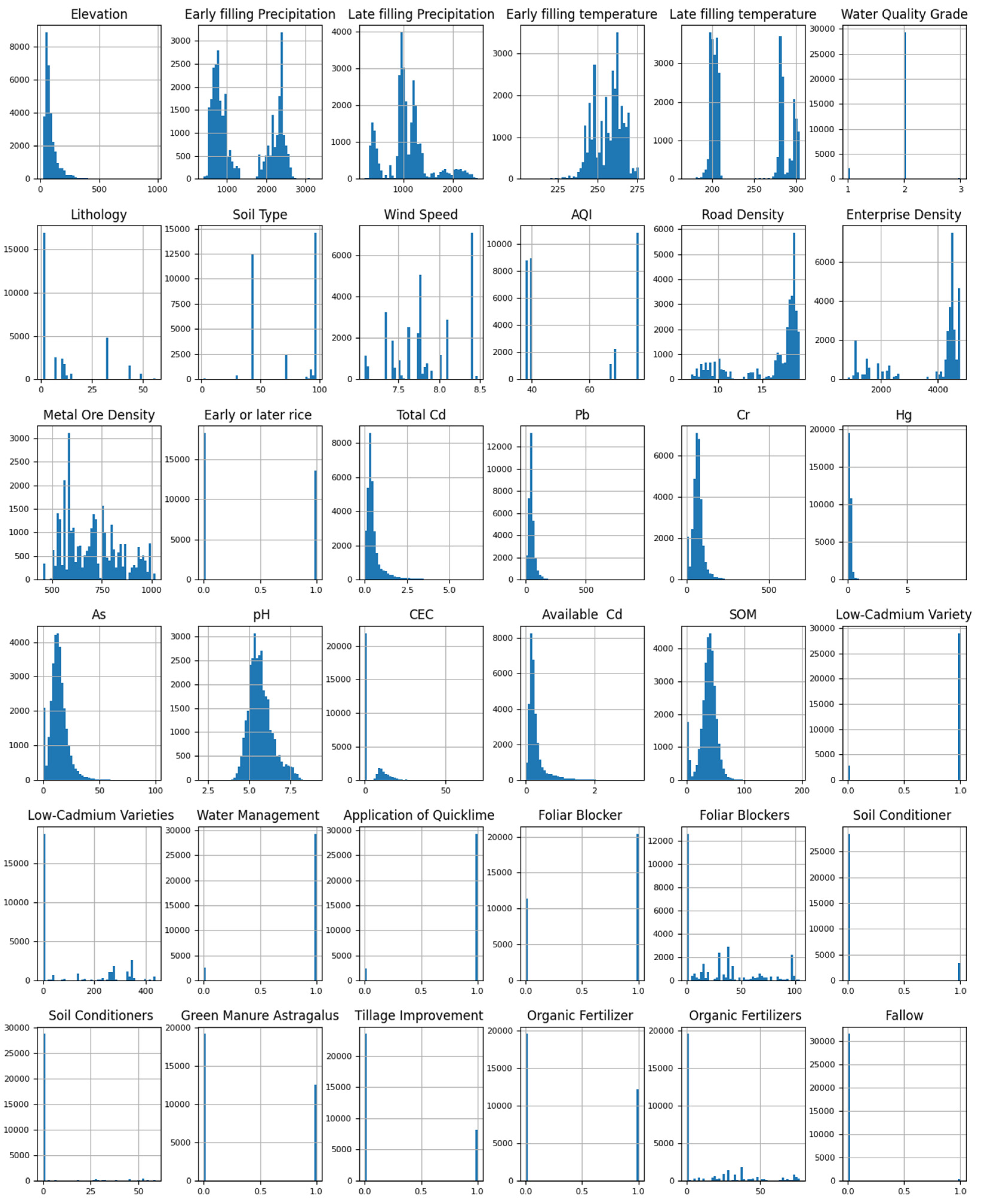
3.1. Primary Data Description
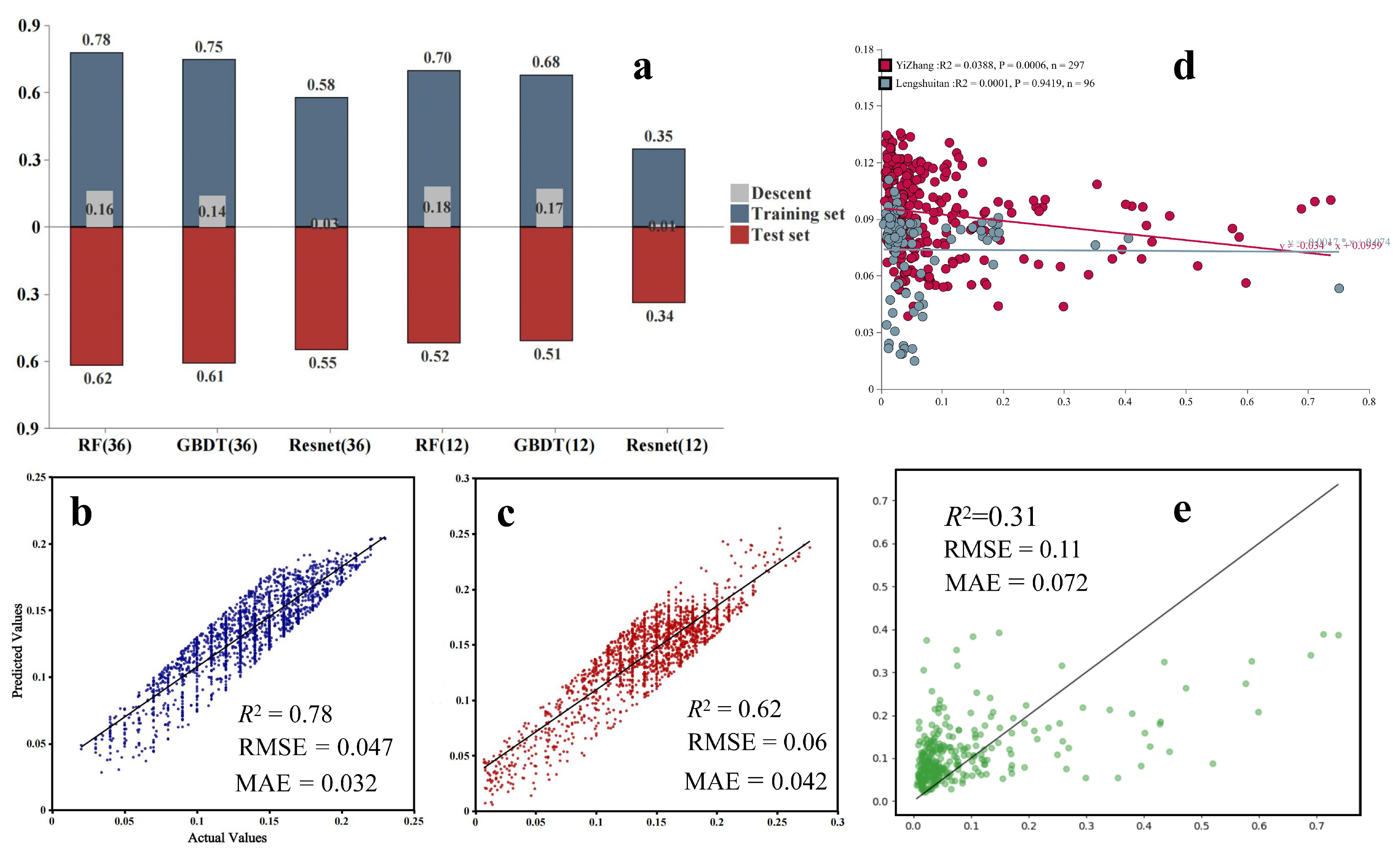
3.2. Feature Importance and Model Performance
3.3. Field Validation Results
4. Discussion
4.1. Heavy Metal Contamination in Study Area
4.2. Feature Importance Analysis
4.3. Model Prediction Outcomes
4.4. Analysis of Field Validation Failure
4.5. Future Perspectives
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karalija, E.; Selović, A.; Bešta-Gajević, R. Thinking for the future: Phytoextraction of cadmium using primed plants for sustainable soil clean-up. Physiol. Plant. 2022, 174, e13739. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Ye, X.; Wang, X. Derivation and validation of thresholds of cadmium, chromium, lead, mercury and arsenic for safe rice production in paddy soil. Ecotoxicol. Environ. Saf. 2021, 220, 112404. [Google Scholar] [CrossRef] [PubMed]
- Mubeen, S.; Ni, W.; He, C. Agricultural strategies to reduce cadmium accumulation in crops for food safety. Agriculture 2023, 13, 471. [Google Scholar] [CrossRef]
- GB 2762-2022; National Food Safety Standard—Maximum Levels of Contaminants in Foods. National Health Commission of the People’s Republic of China and State Administration for Market Regulation: Beijing, China, 2022.
- Sun, J.; Shao, Y.; He, G. Statement on establishment of a provisional health-based guidance value for dietary exposure to cadmium in China. China CDC Weekl. 2023, 5, 499. [Google Scholar] [CrossRef]
- Li, X.; Du, J.; Sun, L. Derivation of soil criteria of cadmium for safe rice production applying soil–plant transfer model and species sensitivity distribution. Int. J. Environ. Res. Public Health 2022, 19, 8854. [Google Scholar] [CrossRef]
- Mamun, S.A.; Sultana, N.; Hasan, M. Phytoaccumulation of cadmium in leafy vegetables grown in contaminated soil under varying rates of compost and phosphate fertilizer application. Commun. Soil Sci. Plant Anal. 2021, 52, 2161–2176. [Google Scholar] [CrossRef]
- Majeed, A.; Niaz, A.; Rizwan, M. Effects of biochar, farm manure, and pressmud on mineral nutrients and cadmium availability to wheat (Triticum aestivum L.) in Cd-contaminated soil. Physiol. Plant. 2021, 173, 191–200. [Google Scholar] [CrossRef]
- Zhao, X.; Lei, M.; Gu, R. Knowledge mapping of the phytoremediation of cadmium-contaminated soil: A bibliometric analysis from 1994 to 2021. Int. J. Environ. Res. Public Health 2022, 19, 6987. [Google Scholar] [CrossRef]
- Al Mamun, S.; Saha, S.; Ferdush, J. Cadmium contamination in agricultural soils of Bangladesh and management by application of organic amendments: Evaluation of field assessment and pot experiments. Environ. Geochem. Health 2021, 43, 3557–3582. [Google Scholar] [CrossRef]
- Subašić, M.; Šamec, D.; Selović, A. Phytoremediation of cadmium polluted soils: Current status and approaches for enhancing. Soil Syst. 2022, 6, 3. [Google Scholar] [CrossRef]
- Dai, Z.W.; Fang, C.; Sun, B. Cadmium accumulation characteristics and impacting factors of different rice varieties under paddy soils with high geological backgrounds. Huanjing Kexue 2021, 42, 2016–2023. [Google Scholar] [PubMed]
- Li, L.; Ma, L.; Tang, L. Key factors controlling cadmium and lead contents in rice grains of plants grown in soil with different cadmium levels from an area with typical karst geology. Agronomy 2024, 14, 2076. [Google Scholar] [CrossRef]
- Zhou, J.; Xia, R.; Landis, J.D. Isotope evidence for rice accumulation of newly deposited and soil legacy cadmium: A three-year field study. Environ. Sci. Technol. 2024, 58, 17283–17294. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Fu, T.; Chen, X. Modeling cadmium contents in a soil–rice system and identifying potential controls. Land 2022, 11, 617. [Google Scholar] [CrossRef]
- Niu, S.; Li, Y.L.; Yang, Y. Prediction of cadmium uptake factor in wheat based on machine learning. Huanjing Kexue 2023, 44, 3619–3626. [Google Scholar]
- Keçeci, M.; Gökmen, F.; Usul, M. Prediction of cadmium content using machine learning methods. Environ. Earth Sci. 2024, 83, 362. [Google Scholar] [CrossRef]
- Miao, X.; Miao, Y.; Gong, H. NIR spectroscopy coupled with chemometric algorithms for the prediction of cadmium content in rice samples. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 257, 119700. [Google Scholar] [CrossRef]
- Chen, R.; Cheng, N.; Ding, G. Predictive model for cadmium uptake by maize and rice grains on the basis of bioconcentration factor and the diffusive gradients in thin-films technique. Environ. Pollut. 2021, 289, 117841. [Google Scholar] [CrossRef]
- Yang, Y.; Li, C.; Yang, Z. Application of cadmium prediction models for rice and maize in the safe utilization of farmland associated with tin mining in Hezhou, Guangxi, China. Environ. Pollut. 2021, 285, 117202. [Google Scholar] [CrossRef]
- Zhao, B.; Zhu, W.; Hao, S. Prediction of heavy metals accumulation risk in rice using machine learning and mapping pollution risk. J. Hazard. Mater. 2023, 448, 130879. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Z.; Zhang, J. The effect of terrain factors on rice production: A case study in Hunan Province. J. Geogr. Sci. 2019, 29, 287–305. [Google Scholar] [CrossRef]
- Hu, Z.; Zheng, W.W.; Liu, P.L. The forms and structures of traditional landscape genome maps: A case study of Hunan Province. Acta Geogr. Sin. 2018, 73, 317–332. [Google Scholar]
- Nelson, D.W.; Sommers, L.E. Total carbon, organic carbon, and organic matter. Methods Soil Anal. Part 3 Chem. Methods 1996, 5, 961–1010. [Google Scholar]
- Kahr, G.; Madsen, F.T. Determination of the cation exchange capacity and the surface area of bentonite, illite and kaolinite by methylene blue adsorption. Appl. Clay Sci. 1995, 9, 327–336. [Google Scholar] [CrossRef]
- Zeng, P.; Wei, B.; Zhou, H. Co-application of water management and foliar spraying silicon to reduce cadmium and arsenic uptake in rice: A two-year field experiment. Sci. Total Environ. 2022, 818, 151801. [Google Scholar] [CrossRef]
- Gómez-Ariza, J.L.; Sánchez-Rodas, D.; Giráldez, I. A comparison between ICP-MS and AFS detection for arsenic speciation in environmental samples. Talanta 2000, 51, 257–268. [Google Scholar] [CrossRef]
- Han, L.; Zhao, Z.; Li, J. Application of humic acid and hydroxyapatite in Cd-contaminated alkaline maize cropland: A field trial. Sci. Total Environ. 2023, 859, 160315. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Peng, S.; Gang, C.; Cao, Y. Assessment of climate change trends over the Loess Plateau in China from 1901 to 2100. Int. J. Climatol. 2018, 38, 2250–2264. [Google Scholar] [CrossRef]
- Peng, S.; Ding, Y.; Liu, W. 1 km monthly temperature and precipitation dataset for China from 1901 to 2017. Earth Syst. Sci. Data 2019, 11, 1931–1946. [Google Scholar] [CrossRef]
- Dong, M.; Yao, L.; Wang, X. Gradient boosted neural decision forest. IEEE Trans. Serv. Comput. 2021, 16, 330–342. [Google Scholar] [CrossRef]
- Yunianta, A.; Wulandhari, L.A.; Desnelita, Y. Enhancing rice production prediction in Indonesia using advanced machine learning models. IEEE Access 2024, 12, 151161–151177. [Google Scholar]
- Lingwal, S.; Bhatia, K.K.; Singh, M. A novel machine learning approach for rice yield estimation. J. Exp. Theor. Artif. Intell. 2024, 36, 337–356. [Google Scholar] [CrossRef]
- Sinha, D.; Dasmandal, T.; Yeasin, M. GB5mCPred: Cross-species 5mc site predictor based on bootstrap-based stochastic gradient boosting method for Poaceae. Curr. Bioinform. 2025, 20, 139–148. [Google Scholar] [CrossRef]
- Dangi, S.L.; Karaliūtė, V.; Maurya, N.K. Predicting flow in porous media: A comparison of physics-driven neural network approaches. Math. Model. Eng. 2023, 9, 52–71. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhu, X.; Liu, D. Model of gradient boosting random forest prediction. In Proceedings of the 2022 IEEE International Conference on Networking, Sensing and Control (ICNSC), Shanghai, China, 15–18 December 2022; pp. 1–6. [Google Scholar]
- Khan, R.U.; Zhang, X.; Kumar, R. Evaluating the performance of ResNet model based on image recognition. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence, Chengdu, China, 12–14 March 2018; pp. 86–90. [Google Scholar]
- Liang, J. Image classification based on ResNet. J. Phys. Conf. Ser. 2020, 1634, 012110. [Google Scholar] [CrossRef]
- GB 15618-2018; Soil Environment Quality—Risk Control Standard for Soil Contamination of Agricultural Land. Ministry of Environmental Protection of China: Beijing, China, 2018.
- Du, Y.; Hu, X.F.; Wu, X.H. Effects of mining activities on Cd pollution to the paddy soils and rice grain in Hunan province, Central South China. Environ. Monit. Assess. 2013, 185, 9843–9856. [Google Scholar] [CrossRef]
- Wang, M.; Chen, W.; Peng, C. Risk assessment of Cd-polluted paddy soils in the industrial and township areas in Hunan, Southern China. Chemosphere 2016, 144, 346–351. [Google Scholar] [CrossRef]
- Yu, Y.; Luo, H.; He, L. Level, source, and spatial distribution of potentially toxic elements in agricultural soil of typical mining areas in Xiangjiang River Basin, Hunan Province. Int. J. Environ. Res. Public Health 2020, 17, 5793. [Google Scholar] [CrossRef]
- Fang, X.; Peng, B.; Wang, X. Distribution, contamination and source identification of heavy metals in bed sediments from the lower reaches of the Xiangjiang River in Hunan Province, China. Sci. Total Environ. 2019, 689, 557–570. [Google Scholar] [CrossRef]
- Huang, B.Y.; Lü, Q.X.; Tang, Z.X. Machine learning methods to predict cadmium (Cd) concentration in rice grain and support soil management at a regional scale. Fundam. Res. 2024, 4, 1196–1205. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, C.; Ruan, J.; Zhang, C.; Ge, Y. Cadmium bioavailability and accumulation in rice grain are controlled by pH and Ca in paddy soils with high geological background of transportation and deposition. Bull. Environ. Contam. Toxicol. 2021, 106, 92–98. [Google Scholar]
- Xiao, W.; Ye, X.; Zhu, Z. Evaluation of cadmium (Cd) transfer from paddy soil to rice (Oryza sativa L.) using DGT in comparison with conventional chemical methods: Derivation of models to predict Cd accumulation in rice grains. Environ. Sci. Pollut. Res. 2020, 27, 14953–14962. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.J.; Wang, P. Arsenic and cadmium accumulation in rice and mitigation strategies. Plant Soil 2020, 446, 1–21. [Google Scholar] [CrossRef]
- Hou, D.; Wang, R.; Gao, X. Cultivar-specific response of bacterial community to cadmium contamination in the rhizosphere of rice (Oryza sativa L.). Environ. Pollut. 2018, 241, 63–73. [Google Scholar] [CrossRef]
- Zhao, K.L.; Fu, W.J.; Dai, W.; Ye, Z.Q.; Gao, W. Characteristics and quantitative model of heavy metal transfer in soil-rice systems in typical rice production areas of Zhejiang Province. Chin. J. Eco-Agric. 2016, 24, 226–234. [Google Scholar]
- Hossain, M.Z.; Islam, M.A.; Kibria, K.Q. Effects of soil pH and organic matter on the accumulation of cadmium in the grains of salt-tolerant rice genotypes grown in Cd-contaminated soil. Khulna Univ. Stud. 2024, 1, 120–131. [Google Scholar] [CrossRef]
- Li, B.; Yang, L.; Wang, C.Q. Effects of organic-inorganic amendments on the cadmium fraction in soil and its accumulation in rice (Oryza sativa L.). Environ. Sci. Pollut. Res. 2019, 26, 13762–13772. [Google Scholar] [CrossRef]
- Lin, J.; Du, Z.; Chen, J. Distribution of cadmium and lead in soil and rice along road polluted by traffic exhaust. J. Environ. Health 1992, 9, 1–10. [Google Scholar]
- Zhang, M.; Shan, S.; Chen, Y. Biochar reduces cadmium accumulation in rice grains in a tungsten mining area—Field experiment: Effects of biochar type and dosage, rice variety, and pollution level. Environ. Geochem. Health 2019, 41, 43–52. [Google Scholar] [CrossRef]
- He, F.; Liu, T.; Tao, D. Why resnet works? residuals generalize. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5349–5362. [Google Scholar] [CrossRef]
- Xie, K.; Ou, J.; He, M. Predicting the bioaccessibility of soil Cd, Pb, and As with advanced machine learning for continental-scale soil environmental criteria determination in China. Environ. Health 2024, 2, 631–641. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Fan, G.; Liu, C. Predicting soil available cadmium by machine learning based on soil properties. J. Hazard. Mater. 2023, 460, 132327. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.M.; Long, S.S.; Li, B.Y. Enrichment of cadmium in rice (Oryza sativa L.) grown under different exogenous pollution sources. Environ. Sci. Pollut. Res. 2020, 27, 44249–44256. [Google Scholar] [CrossRef] [PubMed]
- Deng, X.; Chen, Y.; Yang, Y. Cadmium accumulation in rice (Oryza sativa L.) alleviated by basal alkaline fertilizers followed by topdressing of manganese fertilizer. Environ. Pollut. 2020, 262, 114289. [Google Scholar] [CrossRef]
- Hu, K.; Yu, H.; Feng, W.Q. Effects of secondary, micro- and beneficial elements on rice growth and cadmium uptake. Acta Ecol. Sin. 2011, 31, 2341–2348. [Google Scholar]
- Li, X.; Teng, L.; Fu, T. Comparing the effects of calcium and magnesium ions on accumulation and translocation of cadmium in rice. Environ. Sci. Pollut. Res. 2022, 29, 41628–41639. [Google Scholar] [CrossRef]
- Zhang, J.; Kong, F.Y.; Lu, S.G. Remediation effect and mechanism of inorganic passivators on cadmium-contaminated acidic paddy soil. Huanjing Kexue 2022, 43, 4679–4686. [Google Scholar]
- Wu, J.; Li, R.; Lu, Y. Sustainable management of cadmium-contaminated soils as affected by exogenous application of nutrients: A review. J. Environ. Manag. 2021, 295, 113081. [Google Scholar] [CrossRef]
- Li, S.; Huang, X.; Li, G. Effects of mineral-based potassium humate on cadmium accumulation in rice (Oryza sativa L.) under three levels of cadmium-contaminated alkaline soils. Sustainability 2023, 15, 2836. [Google Scholar] [CrossRef]
- Islam, M.S.; Magid, A.S.I.A.; Chen, Y. Effect of calcium and iron-enriched biochar on arsenic and cadmium accumulation from soil to rice paddy tissues. Sci. Total Environ. 2021, 785, 147163. [Google Scholar] [CrossRef]
- Rezaei, A.; Liu, A.; Memarrast, O.; Ziebart, B.D. Robust fairness under covariate shift. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2–9 February 2021; Volume 35, pp. 9419–9427. [Google Scholar]
- Magahud, J.C.; Badayos, R.B.; Sanchez, P.B. Levels and sources of potassium, calcium, sulfur, iron and manganese in major paddy soils of the Philippines. Int. J. Philipp. Sci. Technol. 2015, 8, 1–8. [Google Scholar] [CrossRef]
- Liang, J.; He, R.; Tan, T. A comprehensive survey on test-time adaptation under distribution shifts. Int. J. Comput. Vis. 2025, 133, 31–64. [Google Scholar] [CrossRef]
- Acevedo, N.; Cortez, C.; Brooks, C. Fairness Hub Technical Briefs: Definition and detection of distribution shift. arXiv 2024, arXiv:2405.14186. [Google Scholar]
- Jiang, X.J.; Luo, Y.M.; Liu, Q. Effects of cadmium on nutrient uptake and translocation by Indian mustard. Environ. Geochem. Health 2004, 26, 319–324. [Google Scholar] [CrossRef]
- Zhu, Y.X.; Zhuang, Y.; Sun, X.H. Interactions between cadmium and nutrients and their implications for safe crop production in Cd-contaminated soils. Crit. Rev. Environ. Sci. Technol. 2023, 53, 2071–2091. [Google Scholar] [CrossRef]
- Sarwar, N.; Saifullah; Malhi, S.S. Role of mineral nutrition in minimizing cadmium accumulation by plants. J. Sci. Food Agric. 2010, 90, 925–937. [Google Scholar] [CrossRef]
- Mao, P.; Zhuang, P.; Li, F. Phosphate addition diminishes the efficacy of wollastonite in decreasing Cd uptake by rice (Oryza sativa L.) in paddy soil. Sci. Total Environ. 2019, 687, 441–450. [Google Scholar] [CrossRef]
- Patchipala, S. Tackling data and model drift in AI: Strategies for maintaining accuracy during ML model inference. Int. J. Sci. Res. Arch. 2023, 10, 1198–1209. [Google Scholar] [CrossRef]
- Bhindhu, P.S.; Sureshkumar, P.; Abraham, M. Effect of liming on soil properties, nutrient content and yield of wetland rice in acid tropical soils of Kerala. Int. J. Bio-Resour. Stress Manag. 2018, 9, 541–546. [Google Scholar]
- Suksabye, P.; Pimthong, A.; Dhurakit, P. Effect of biochars and microorganisms on cadmium accumulation in rice grains grown in Cd-contaminated soil. Environ. Sci. Pollut. Res. 2016, 23, 962–973. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variables | Data Source | Processing Method | Screening Criteria |
|---|---|---|---|---|
| Soil Properties | pH, SOM, CEC, Total_Cd, Available_Cd (CaCl2/HCl/EDTA/DTPA) | 52,000 paired soil–rice samples (Hunan Province, 2014–2016) | Air-dried, sieved (2 mm/0.149 mm) | Excluded samples with pH > 9 |
| ICP-AES for Cd quantification | Removed outliers (3σ Law) | |||
| Agronomic Practices | Low-Cd variety (binary), Water management (binary), Lime application (binary) | Field surveys and government reports (2014–2016) | Ordinal encoding for categorical variables (e.g., variety types) | Excluded records with >30% missing values |
| Binary (0/1) | Manual verification of farm records | |||
| Environmental Data | Precipitation (early/late-filling), Elevation, Enterprise density | Remote sensing (NOAA, Peng et al. 2019 [30,31]), GIS (ArcGIS), POI mining (Baidu Map) | Z-score normalization | Removed pixels with cloud cover >20% |
| Spatial interpolation (kriging) | Excluded non-agricultural land use | |||
| Geospatial Features | River proximity, Road density, Mining activity intensity | National Geospatial Database (2021), OSM road network | Kernel density estimation | Buffered zones > 5 km from industrial areas excluded |
| Euclidean distance calculation |
| pH | Samples | Cd | Hg | As | Pb | Cr |
|---|---|---|---|---|---|---|
| <5.5 | 44% | 64% | 1.80% | 3.00% | 12% | 0.17% |
| 5.5–6.5 | 44% | 44% | 2.10% | 3.40% | 3.50% | 0.20% |
| 6.5–7.5 | 10% | 34% | 1.40% | 9.10% | 1.00% | 0.00% |
| >7.5 | 2.00% | 28% | 0.70% | 31% | 0.80% | 0.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Q.-Q.; Zhou, X.; Zhou, H.; Liao, Y.; Han, Z.-Y.; Hu, L.; Zeng, P.; Gu, J.-F.; Zhang, R. Bridging the Gap: Limitations of Machine Learning in Real-World Prediction of Heavy Metal Accumulation in Rice in Hunan Province. Agronomy 2025, 15, 1478. https://doi.org/10.3390/agronomy15061478
Peng Q-Q, Zhou X, Zhou H, Liao Y, Han Z-Y, Hu L, Zeng P, Gu J-F, Zhang R. Bridging the Gap: Limitations of Machine Learning in Real-World Prediction of Heavy Metal Accumulation in Rice in Hunan Province. Agronomy. 2025; 15(6):1478. https://doi.org/10.3390/agronomy15061478
Chicago/Turabian StylePeng, Qing-Qian, Xia Zhou, Hang Zhou, Ye Liao, Zi-Yu Han, Lu Hu, Peng Zeng, Jiao-Feng Gu, and Rong Zhang. 2025. "Bridging the Gap: Limitations of Machine Learning in Real-World Prediction of Heavy Metal Accumulation in Rice in Hunan Province" Agronomy 15, no. 6: 1478. https://doi.org/10.3390/agronomy15061478
APA StylePeng, Q.-Q., Zhou, X., Zhou, H., Liao, Y., Han, Z.-Y., Hu, L., Zeng, P., Gu, J.-F., & Zhang, R. (2025). Bridging the Gap: Limitations of Machine Learning in Real-World Prediction of Heavy Metal Accumulation in Rice in Hunan Province. Agronomy, 15(6), 1478. https://doi.org/10.3390/agronomy15061478