1. Introduction
Vegetation productivity, a crucial quantitative metric of terrestrial vegetation communities, is essential for ecosystem monitoring and assessment. This measure accurately represents the dynamic alterations of regional biological settings and serves a vital function in ecological processes, including biodiversity conservation, carbon sink maintenance, climate control, and hydrological cycles [
1]. A recent study reveals that the ongoing decline in global vegetation acreage has led terrestrial systems to surpass critical ecological thresholds, resulting in substantial adverse effects on biogeochemical cycles [
2]. Enhancing vegetation resource conservation is crucial for reducing biodiversity loss and preserving ecosystem services. Accurate time-series monitoring and predictive technologies for vegetation productivity provide scientific evidence for the sustainable management of vegetation resources. They also create a foundational database for understanding future regional ecosystem changes. This information is valuable for developing ecological protection policies.
Heuristic optimization algorithms provide innovative methods for addressing multi-factor prediction challenges, especially in high-dimensional data environments, enhancing prediction accuracy [
3]. In conventional machine learning models, the selection of network architecture and node placements frequently relies on manual configurations, potentially resulting in model bias [
4]. Traditional techniques often encounter difficulties in managing vegetation cover parameters characterized by intricate linear connections, particularly when confronted with complicated and changing climatic conditions [
5]. Moreover, various data formats frequently exhibit unique time-series patterns and geographic distribution characteristics, complicating the ability of conventional models to capture intricate trend elements accurately [
6]. Due to the high-dimensional nature of multi-factor data, especially in the presence of outliers, conventional models are more susceptible to overfitting problems. Traditional machine learning algorithms often struggle to capture complex patterns in data. This is especially true when forecasting vegetation productivity, which is influenced by various factors [
7]. Additionally, as layers are deeper over time, information tends to deteriorate, resulting in diminished accuracy in managing long-term relationships. Optimization methods successfully resolve challenges in conventional machine learning models, including high-dimensional data processing, outlier impact, and model resilience [
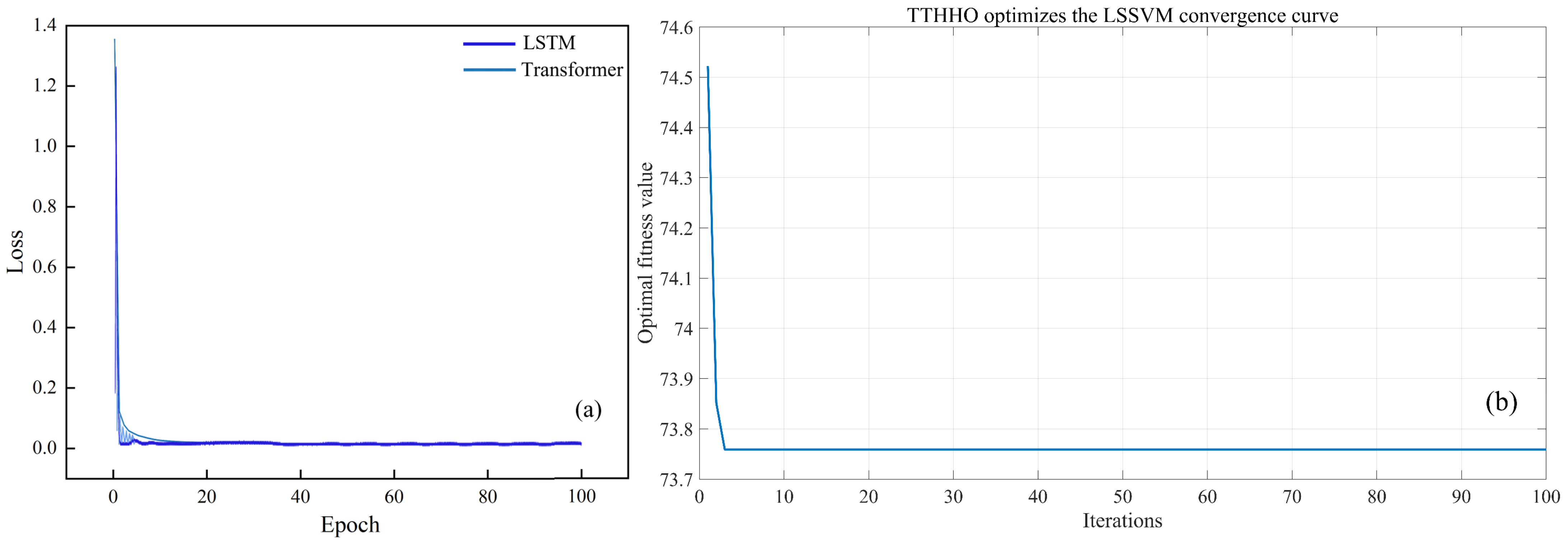
8]. The TTHHO (Transient Trigonometric Harris Hawks Optimizer) method provides an efficient approach for modifying the search strategy in high-dimensional data, circumventing local optima, and systematically identifying the global optimum [
9]. Moreover, conventional machine learning models frequently demonstrate prediction bias when confronted with substantial outliers and noise, impairing effectiveness [
10]. TTHHO possesses robust global search capabilities, allowing the model to adaptively modify parameters during optimization adaptively, hence reducing the influence of outliers [
11]. By modifying LSSVM settings (penalty factor and kernel width), TTHHO may significantly mitigate the impact of outliers on training and prediction, enhancing the predictive accuracy [
12]. TTHHO’s global search capabilities allow the model to handle high-noise and incomplete data. It optimizes parameter selection, improving the model’s stability and resilience to interference [
13]. When dealing with multifactorial variations and ambient noise, TTHHO can adjust the model parameters carefully. This helps avoid predictive biases found in conventional approaches and ensures accurate forecasts in complex data settings [
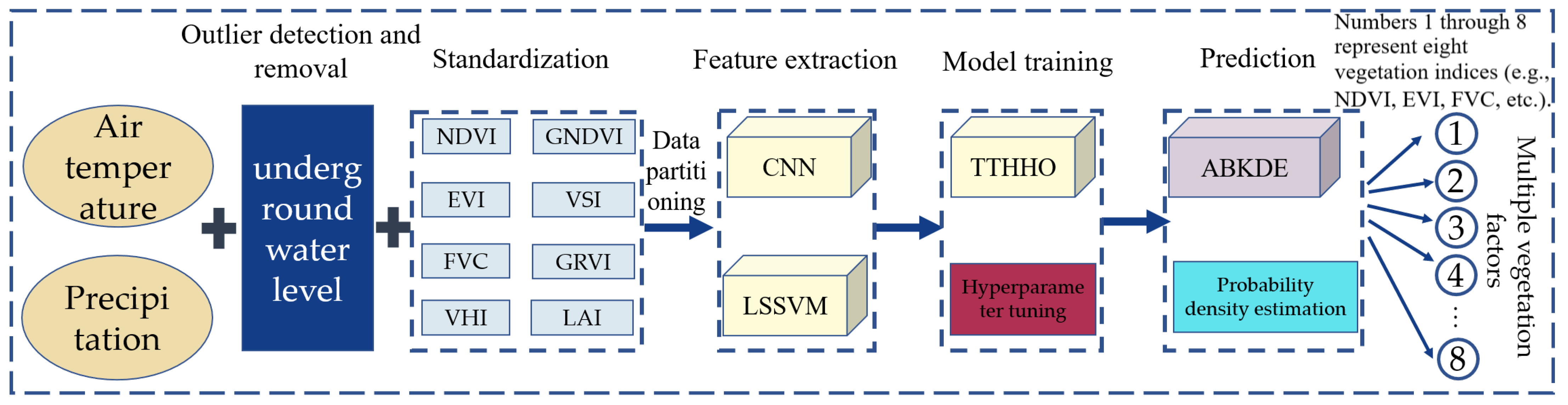
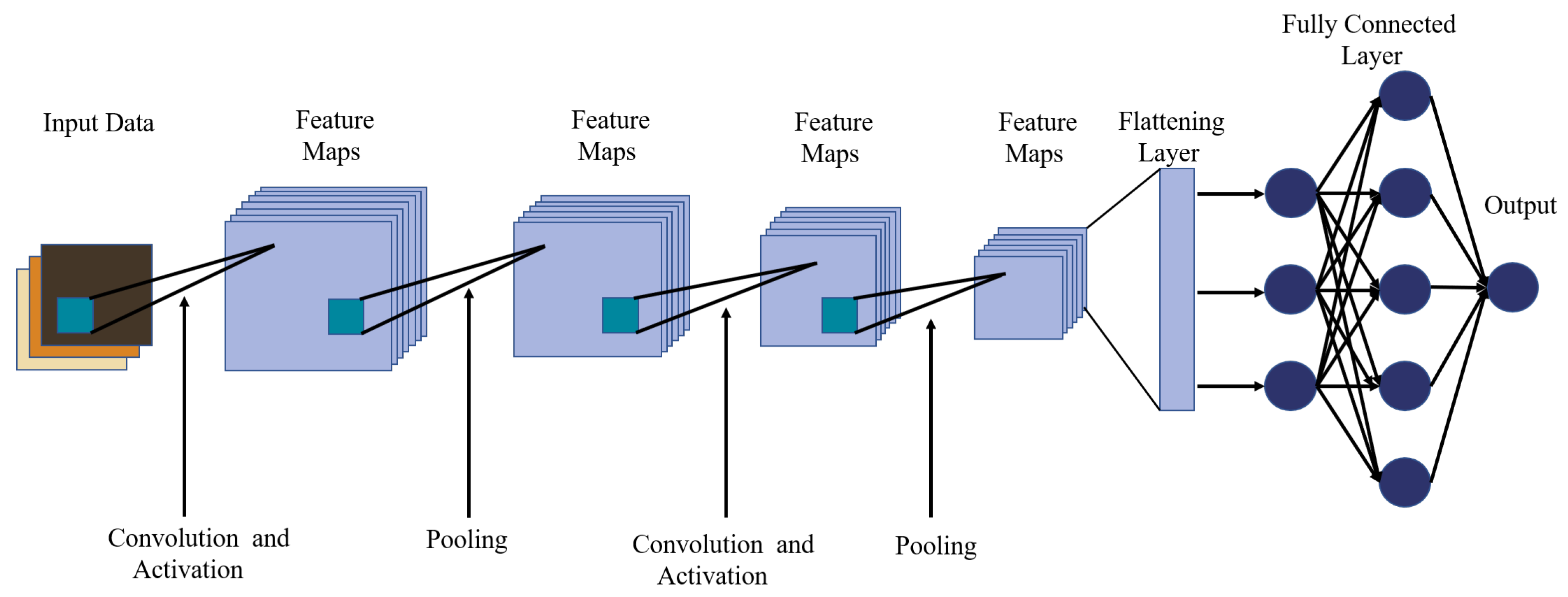
14]. To tackle the prevalent issues of multimodal data processing in vegetation productivity prediction, we suggest integrating TTHHO with a regression model with parallel computing capabilities and efficient optimization, namely CNN-LSSVM. Utilizing CNN to process spatially correlated data, LSSVM can proficiently execute regression analysis based on features derived from various data sources, markedly improving the multi-factor predictive performance.
Conventional point prediction techniques frequently neglect the uncertainty inherent in forecasts, particularly when addressing extremely dynamic data [
15]. A solitary prediction of vegetation cover frequently inadequately represents the actual data conditions [
16]. Using confidence intervals for interval probability prediction helps to clearly show the uncertainty in the predicted outcomes. In contrast to conventional point prediction, interval probability prediction offers not only the expected value but also its confidence interval, which signifies the likelihood of the prediction residing within a designated range, thus more thoroughly representing the potential variability of the data [
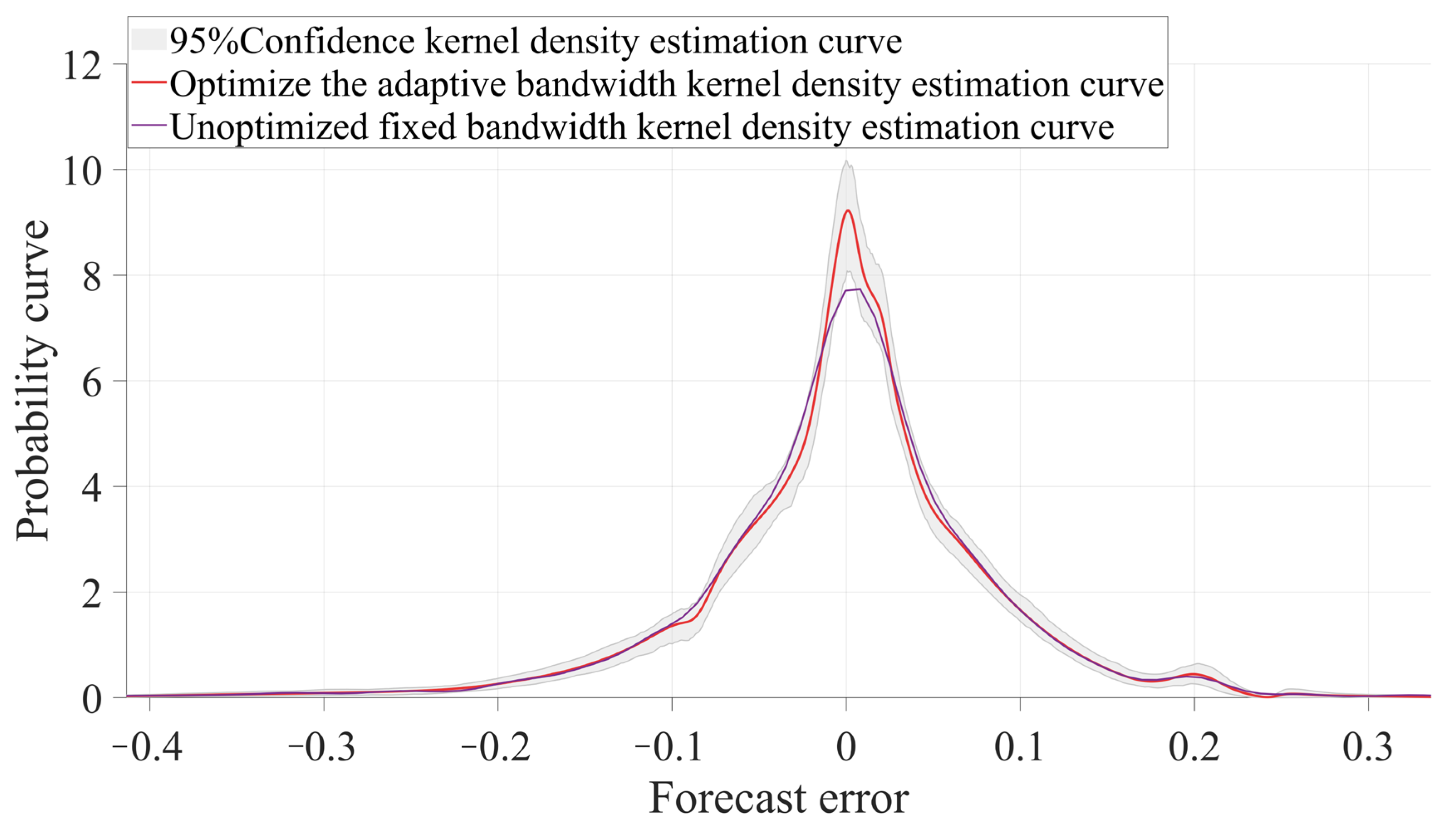
17]. Adaptive Bandwidth Kernel Density Estimation (ABKDE) offers a novel method for evaluating the probability density function of prediction errors, facilitating the accurate identification of data instability [
18]. When the data include outliers, interval prediction can accommodate data variability, offering an expanded range for the predicted value and diminishing dependence on a singular value, thereby improving the model’s resilience and stability [
19]. Recent studies show that integrating ABKDE with machine learning models helps to improve distribution estimates. This approach better handles outliers and noise, reduces data interference, and enhances model resilience [
20]. In multi-factor prediction tasks for vegetation productivity, ABKDE-based interval prediction uses probability density estimates to represent the data’s variance and uncertainty. While ABKDE shows promise in predicting multi-factor interval probabilities for vegetation productivity, further optimization is needed to address issues with high-dimensional data and outlier prediction.
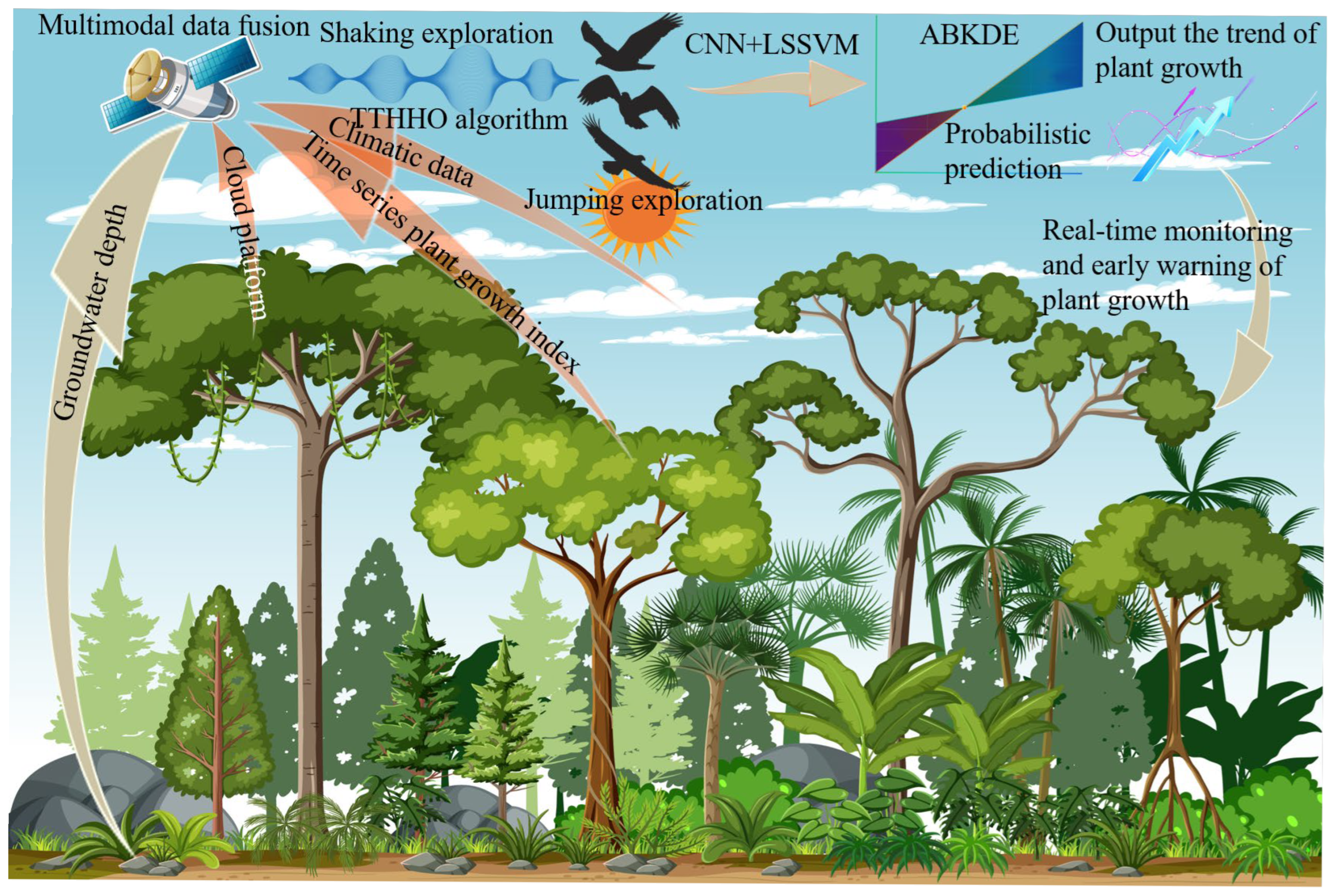
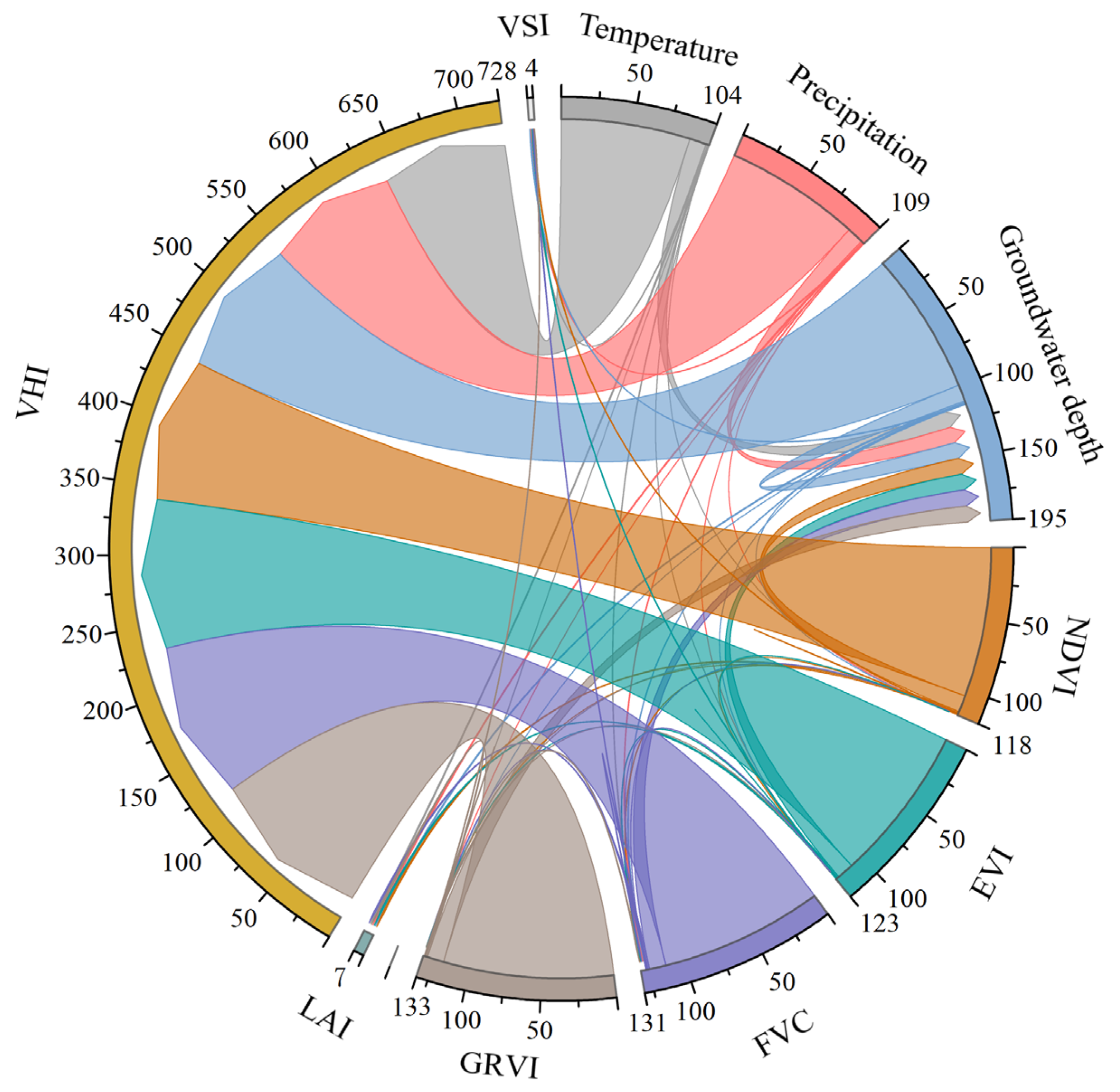
This paper introduces the TCLA technique, which integrates the TTHHO algorithm, CNN-LSSVM, and ABKDE model, to address two fundamental issues in conventional machine learning: the accuracy of regional probability predictions and resilience against interference. We chose the Hetao Irrigation District, China’s most significant irrigation region, as the research site to assess the model’s efficacy. The TTHHO algorithm navigates the search space and optimizes network node placements using multimodal data, including climate data, groundwater levels, and vegetation indices. The model’s robustness is improved by integrating CNN-LSSVM for feature extraction and regression analysis. ABKDE is also introduced to estimate the probability density function and identify outliers. This technique effectively performs region-specific probability prediction for several vegetation productivity parameters (NDVI (Normalized Difference Vegetation Index), EVI (Enhanced Vegetation Index), FVC (Fractional Vegetation Cover), VHI (Vegetation Health Index), GNDVI (Green Normalized Difference Vegetation Index), VSI (Vegetation Stress Index), GRVI (Green-Red Vegetation Index), and LAI (Leaf Area Index)) and demonstrates considerable resilience to interference. The principal advances of this work are as follows:
- (1)
TTHHO intelligently explores the search space and adaptively optimizes network node placements, improving the model’s capacity to manage multimodal data. Compared to conventional approaches, TTHHO can more precisely analyze multi-factor data and enhance the network architecture, substantially increasing the accuracy of vegetation productivity forecasts. This study uses TTHHO as outlined in
Section 2.4.2, differing from Abdulrab H’s original proposal of the TTHHO algorithm [
12], which primarily assessed the algorithm’s advantages relative to conventional approaches. We present the inaugural application of TTHHO to a machine learning model, incorporating targeted enhancements and optimizations to its hyperparameters. It has been effectively utilized in the development of a practical model to improve the accuracy of vegetation productivity forecasts.
- (2)
This research presents ABKDE for estimating probability density functions and detecting outliers. This invention successfully mitigates prediction bias in conventional models when encountering outliers. This study uses ABKDE as outlined in
Section 2.5.3. In contrast to Liu et al.’s CBGRU-ABKDE-WT model [
20], we innovatively incorporate the bootstrap method to generate prediction intervals, providing upper and lower bounds for forecasts and thereby enhancing the model’s credibility.
- (3)
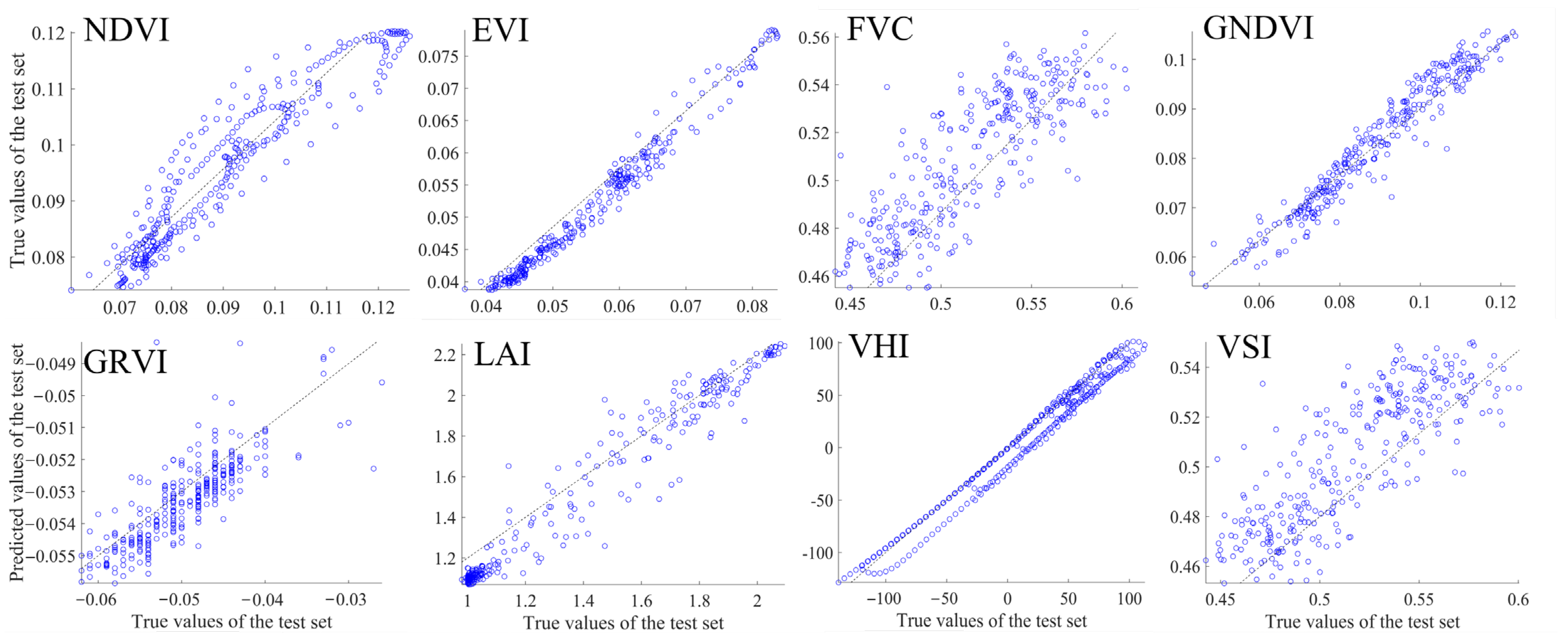
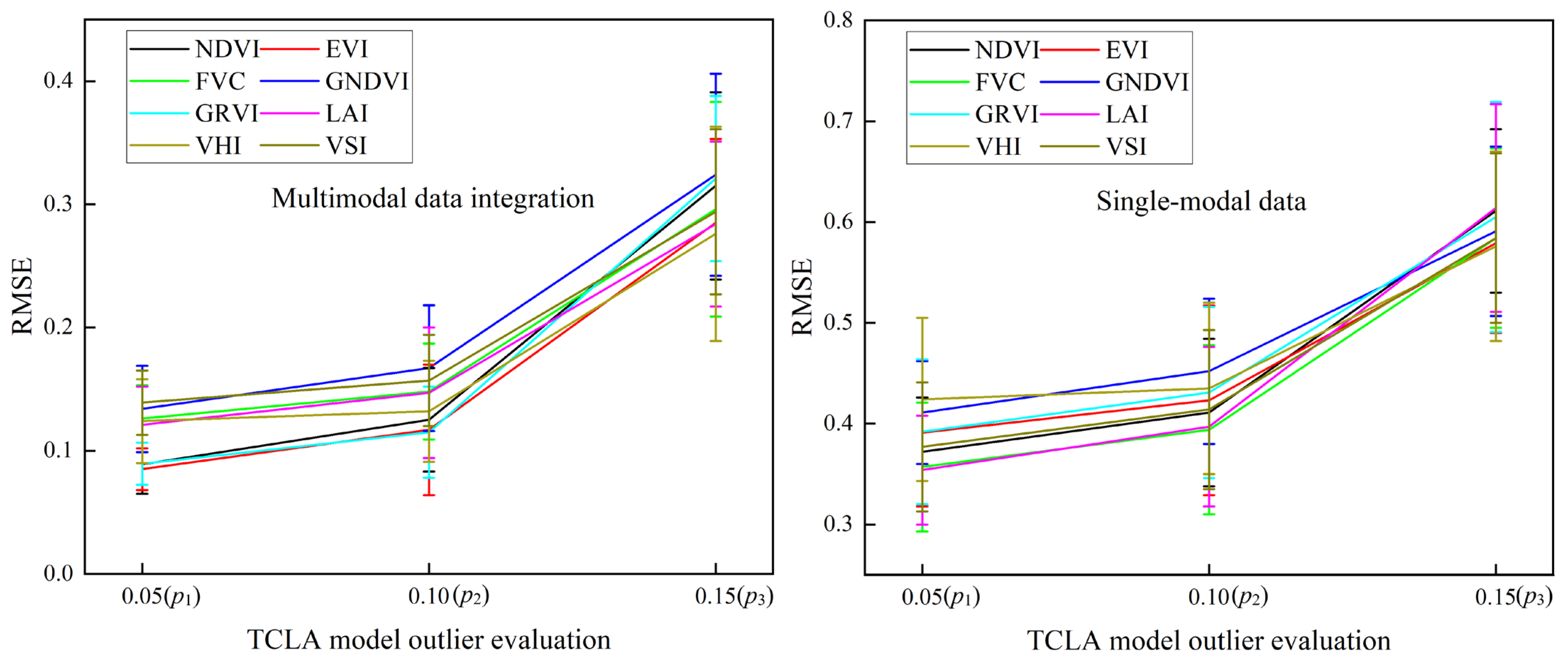
This research effectively combines TTHHO, CNN-LSSVM, and ABKDE to provide multi-factor regional probability forecasting for vegetation productivity. The model exhibits enhanced resilience to interference, considerably improving its robustness and precision in real applications, particularly when confronted with 5–15% outliers.
5. Conclusions
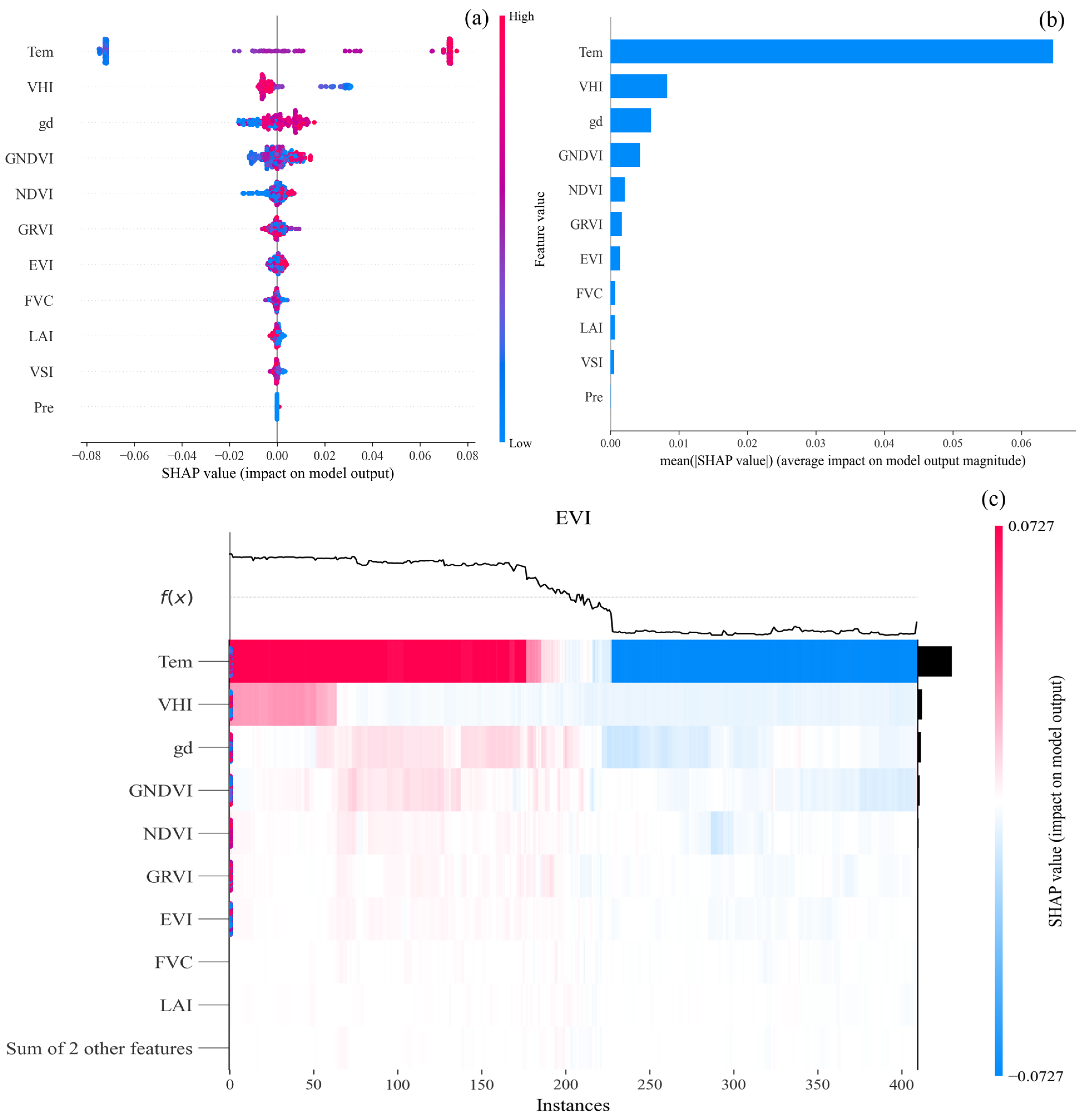
This research introduces a deep learning model, TCLA, founded on multimodal data fusion, which creatively amalgamates TTHHO, CNN, LSSVM, and ABKDE to achieve precise predictions of the future three years of forest cover multi-factor time series. The Hetao Irrigation District in China serves as the study area, where the model adeptly captures nonlinear relationships among diverse factors by incorporating multi-source information, including climate data, vegetation parameters, and groundwater depth, while exhibiting remarkable robustness in managing outliers. The principal research findings are as follows:
- (1)
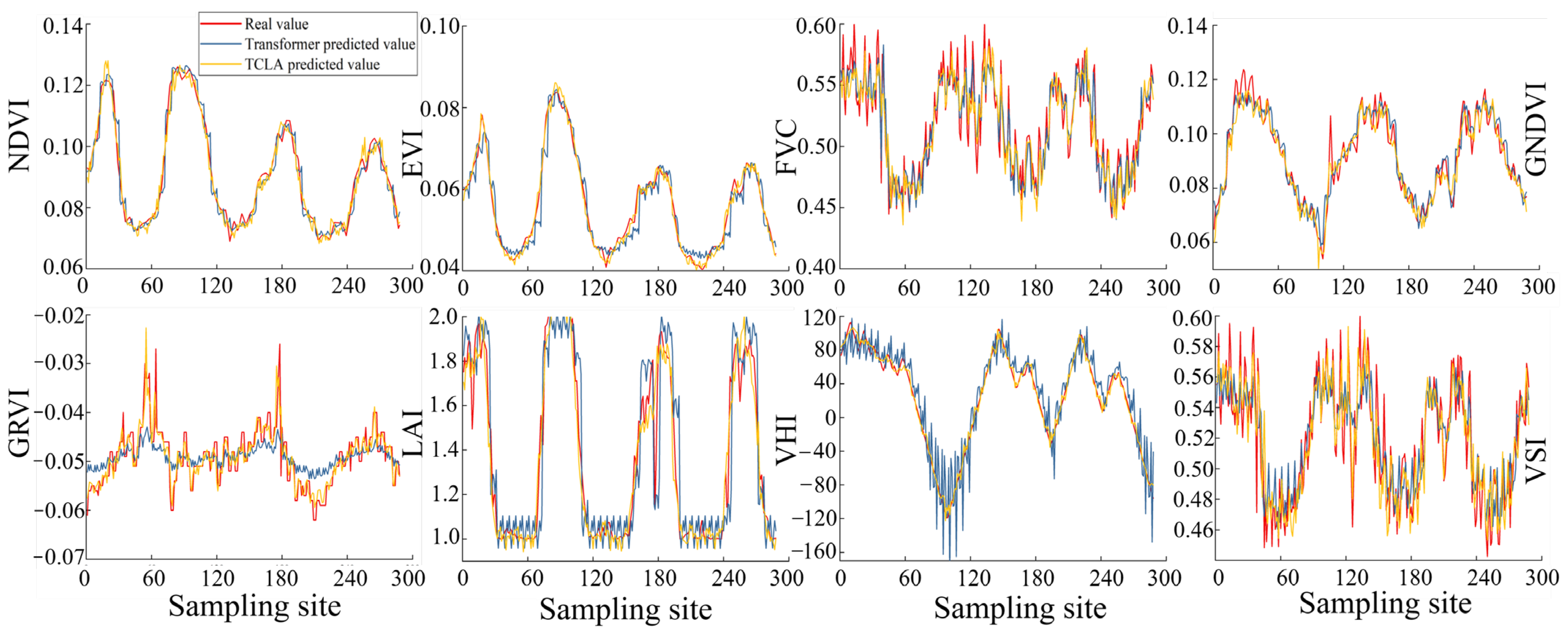
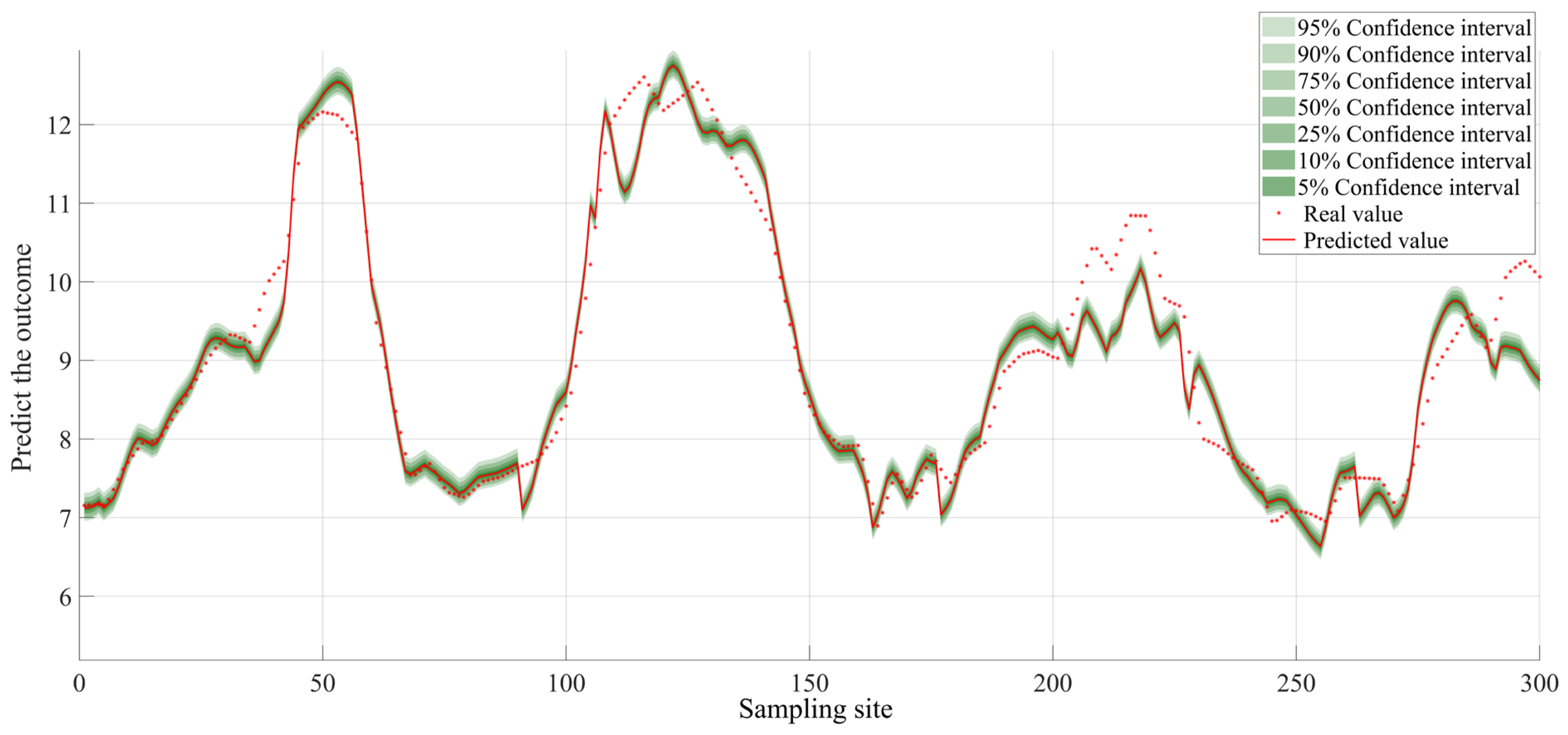
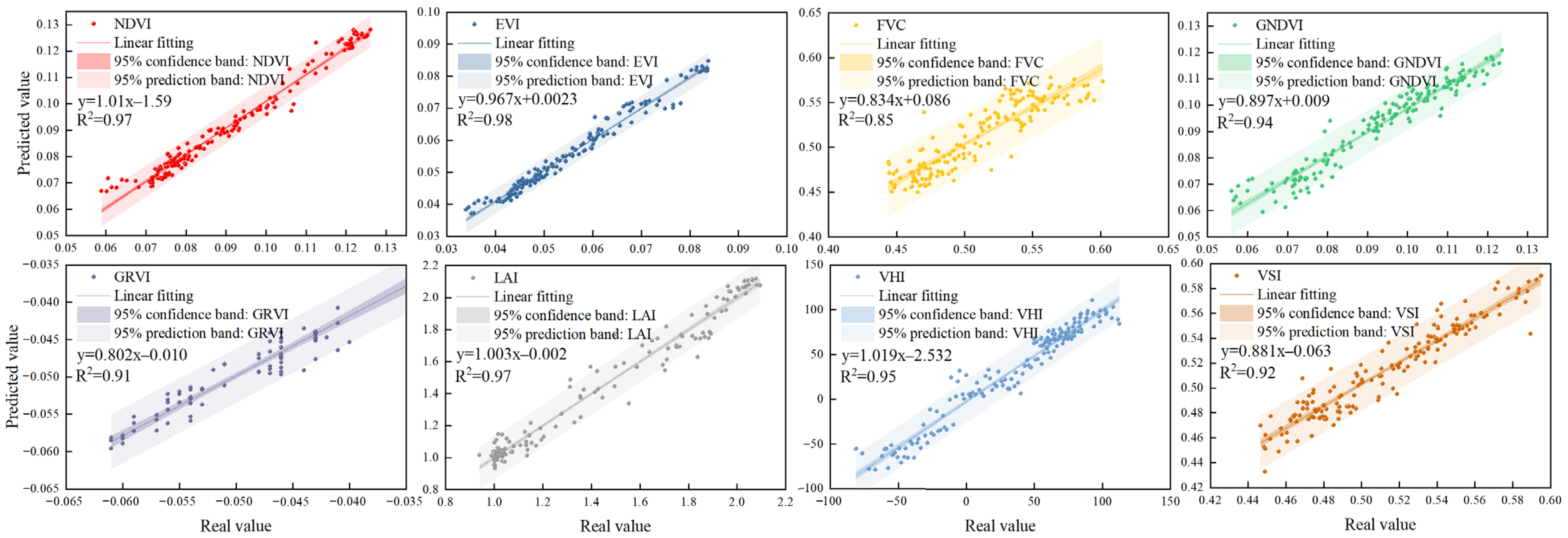
The TCLA model enhances prediction accuracy by 10.57% to 26.47% relative to traditional models (LSTM, Transformer), demonstrating superior generalization ability in managing complex datasets and effectively resolving the limitations of LSTM and Transformer models in high-dimensional and non-stationary data.
- (2)
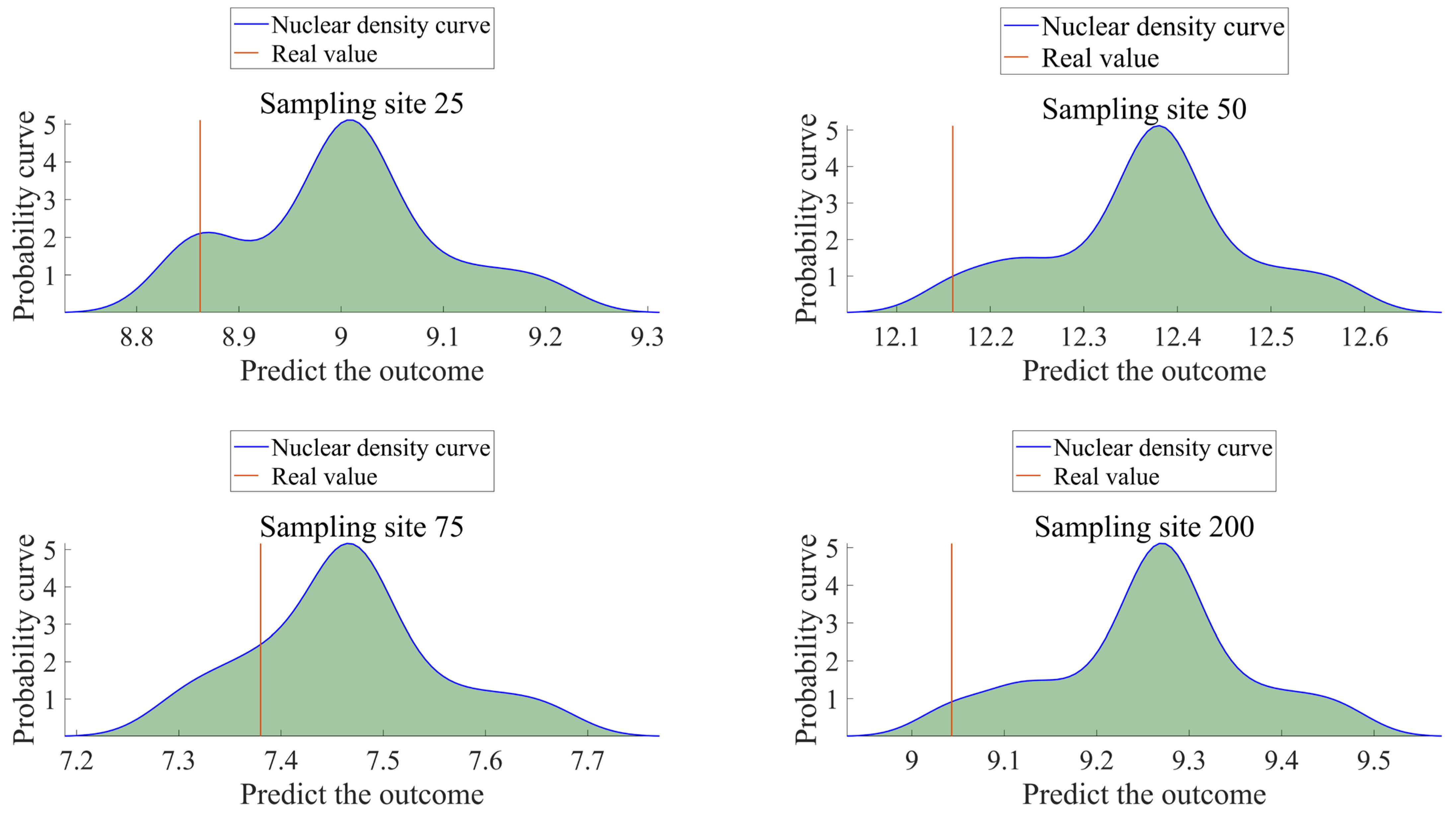
The multimodal TCLA model exhibits an overall accuracy enhancement of 3.57 ± 2.13% compared to single-modality models. The model exhibits optimal PINAW and PICP values performance, with negligible CRPS and CWC value variations. TCLA offers exact prediction intervals, a robust prediction distribution, and calibration stability.
- (3)
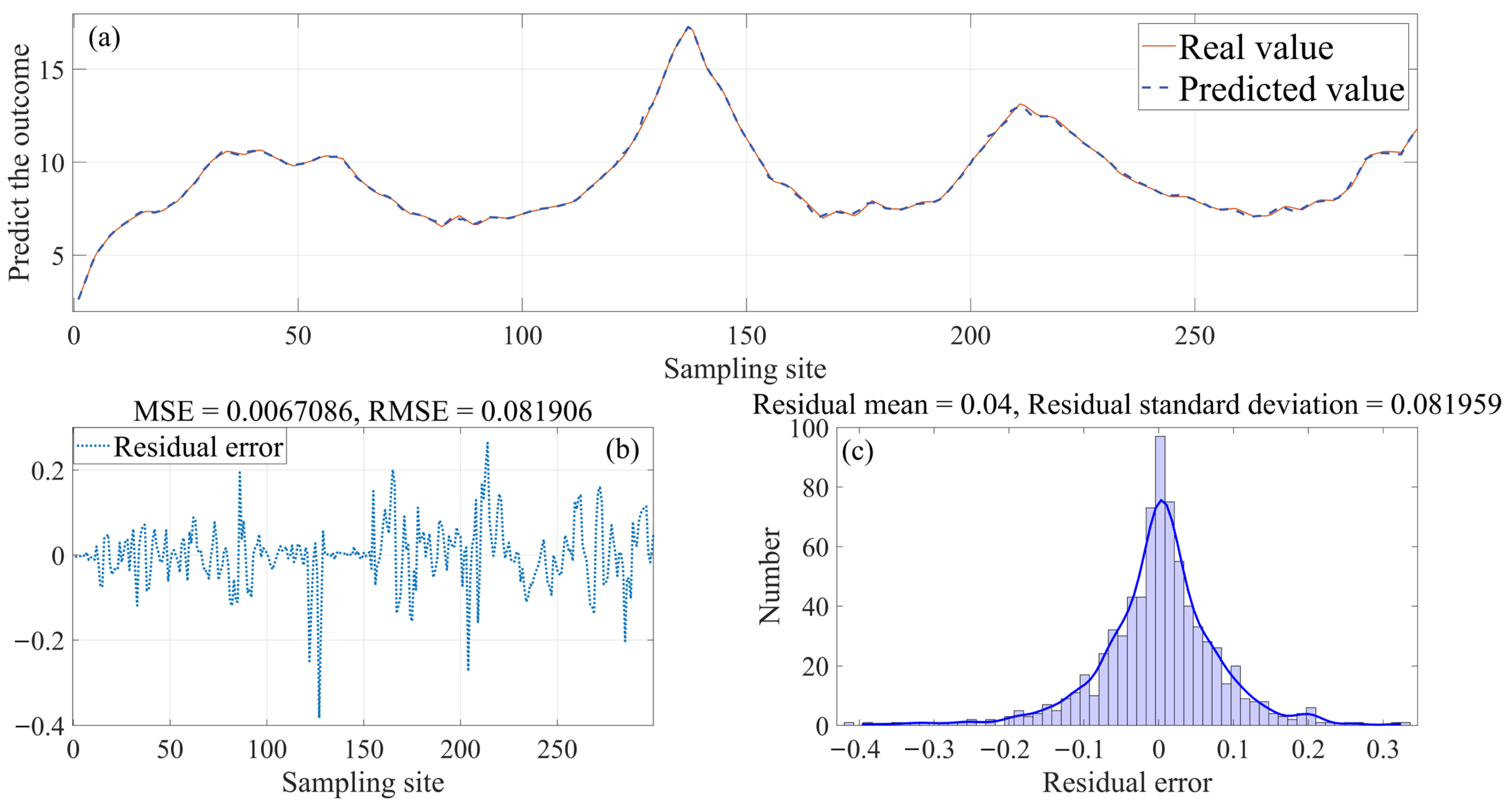
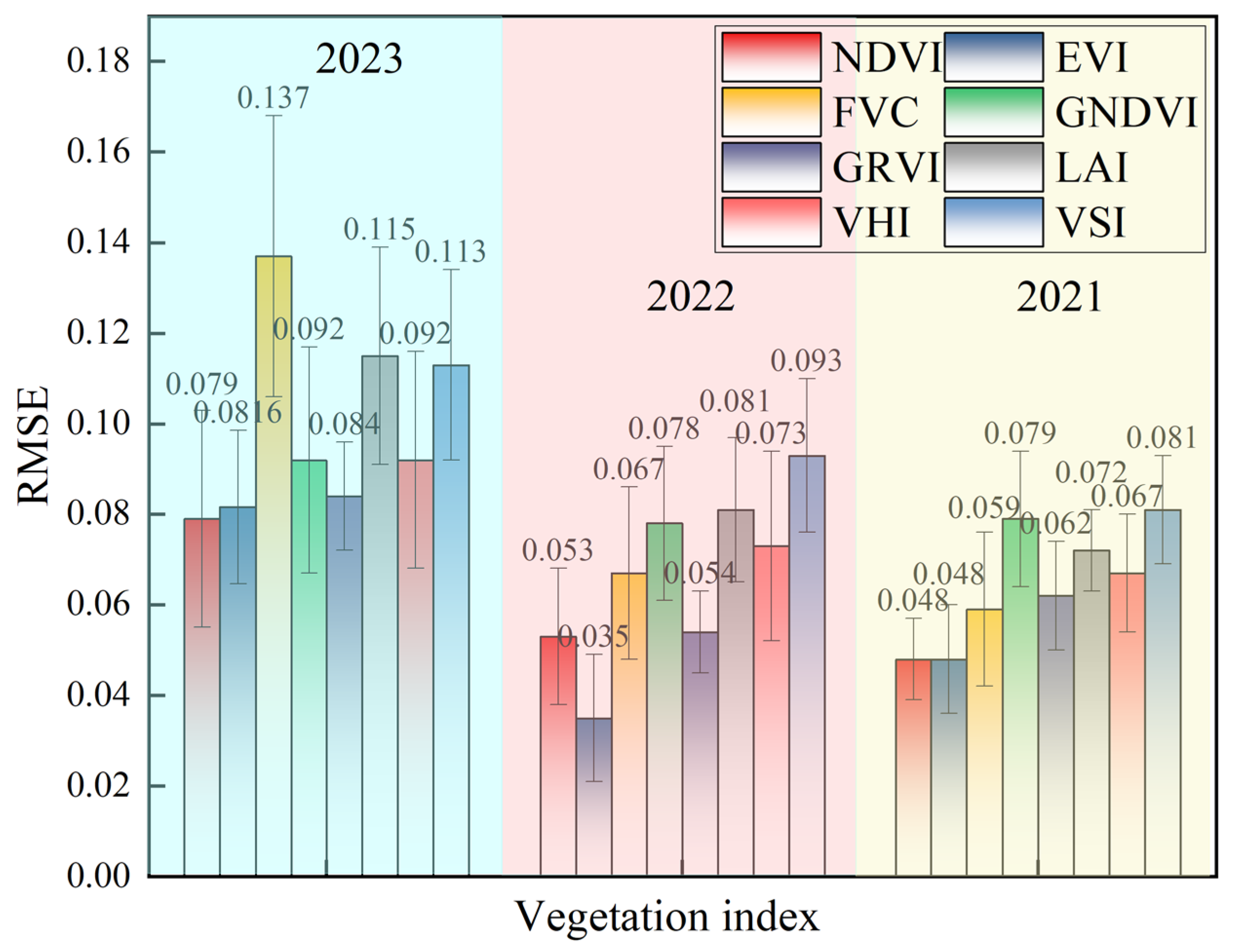
In the presence of outlier proportions between p1 and p3, the RMSE of the TCLA model diminishes by 45.18% to 69.66%, within a range of 0.079 to 0.137, thereby mitigating the influence of single-modality data and markedly enhancing the predictive accuracy.
Despite TCLA’s exceptional performance in accuracy and durability, its comparatively large computational complexity requires optimization. Future research will resolve critical challenges such as model complexity regulation, automated hyperparameter optimization, and enhancing interpretability to broaden the model’s application and significance, offering scientific backing for worldwide vegetation productivity monitoring.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}