1. Introduction
Retrieving the precise corn position and dimensions is essential for expanding the use of smart and precision agriculture in corn cultivation [
1], as corn is one of the three primary grain crops in the world [
2]. Under ideal conditions without occlusion, the information about the pose and shape of corn fruit with their dimensions can be directly obtained from its point cloud using an oriented bounding box (OBB). However, in real agricultural environments, the acquisition of corn point cloud data is often affected by occlusion from leaves, leading to fragmented point clouds. This incompleteness negatively impacts subsequent pose estimation and shape measurements. Compared to classical 6D pose estimation [
3], corn exhibits consistent width and height, eliminating the need for roll angle estimation. Consequently, there are two fewer detection parameters—height and rotation angle.
With this information, several agricultural applications become feasible as follows:
- (1)
Precise spraying [
4]: Pose estimation enables targeted pesticide application for common corn diseases such as kernel rot and corn smut. Leveraging spatial data improves the dosage estimation, ensuring efficiency and accuracy.
- (2)
Precision harvesting [
5]: Pose estimation determines corn’s position relative to the camera and mechanical equipment. Through incorporating its specific shape and position, robotic arms can execute precise harvesting.
- (3)
Phenotypic measurement [
6]: Pose estimation streamlines the extraction of phenotypic traits, eliminating the need for manual measurements or 3D reconstruction. Deep learning models directly obtain phenotype data with greater speed and accuracy.
- (4)
Field monitoring: Integrating camera positioning, pose estimation accurately maps each corn plant’s location, enhancing the monitoring of overall growth conditions.
Thus, 3D information acquisition is crucial for advancing precision agriculture in corn cultivation.
To address the occlusion problem, mature image segmentation techniques, such as the Segment Anything Model (SAM) [
7] and Mask R-CNN [
8], have been developed to extract corn images from corn farmland data effectively. These deep learning-based segmentation methods have been extensively studied in smart agriculture and have achieved promising results. Semantic segmentation has mature and diverse application scenarios in agriculture. Lei [
9], Luo [
10], and Charisis [
11] conducted detailed research on these applications. Semantic segmentation based on deep learning can be applied to crop growth monitoring and plant health analysis. There has been a great deal of research into weed segmentation [
12] and fruit segmentation [
13].
In the existing literature, deep learning-based segmentation techniques have been widely adopted for extracting crop images from occluded scenes, achieving high accuracy in handling leaf occlusion. In particular, utilizing the SAM pre-trained model, the corn body can be efficiently extracted with minimal background prompts, enabling precise segmentation.
However, research on the point cloud completion of corn from fragmented point clouds remains limited. Most existing studies have focused on public datasets for common object completion, while related research on point cloud completion [
14] for specific agricultural crops remains insufficient.
In the domain of agriculture, point cloud-related technologies are primarily employed in phenotype extraction. For example, Gené-Mola [
15] generated 3D point clouds via visual technology to estimate the size of apples in the field under different occlusion conditions; Guo [
16] accomplished precise phenotypic analysis of cabbages based on 3D point cloud segmentation methods; Magistri [
17] predicted the three-dimensional shape of fruit by using RGB-D data to complete the point cloud complementation; and Chen [
18] realized the 3D reconstruction of leaf point clouds utilizing deep learning technology, thereby extracting leaf phenotypes.
This work comprehensively investigates the task of corn point cloud completion. Data generation is first carried out. High-quality corn point cloud data are collected under occlusion-free conditions and detailed 3D corn models are constructed. To enhance the data diversity and simulate the morphological variations encountered in real-world scenarios, we generate 3D corn point cloud models of varying scales and structures through random transformations. Furthermore, we use a random occlusion strategy to create a large-scale dataset of incomplete corn point clouds, which serves as the training data for subsequent algorithm development.
In terms of algorithms, to meet the requirements for the precise localization and measurement of corn in 3D space, Shape Coding PointAttN (SCPAN) is proposed. This begins by simplifying the original model architecture to reduce the number of parameters, as dense point clouds are not required for capturing the overall shape. Consequently, the simplified model is designed to directly output sparse point clouds. A gated multilayer perceptron (MLP) with 3D position encoding [
19] is incorporated into the completion network to enhance spatial feature perception. Additionally, given that this study focuses on a single-class point cloud completion task for corn and primarily aims at overall shape completion, a shape prior encoder [
20] is trained using the original 3D corn models and is incorporated into the model.
The main contributions of this study are as follows:
- (1)
This work develops an efficient method, SCPAN, for completing fragmented corn point clouds to obtain the pose and shape information about corn, helping the precise phenotypic analysis of corn and providing technical support for intelligent perception and decision making in smart agriculture.
- (2)
It proposes a novel data generation process for the fragmented corn point cloud. In this way, we construct a corn point cloud completion dataset through data collection, segmentation, modeling, transformation, and occlusion simulation, providing high-quality training data for point cloud completion.
- (3)
It examines the architecture of the baseline model PointAttN and explores our task’s goal. The structure of the original model is simplified to output sparse point clouds and fit the single-class point cloud completion task.
- (4)
A prior shape encoder is trained and incorporated into SCPAN, which helps the model to focus on the overall shape. A novel gated MLP with spatial feature enhancement is also incorporated into SCPAN. Three-dimensional position encoding is introduced into the gated MLP to improve the model’s spatial awareness, thereby enhancing its point cloud completion ability.
2. Materials and Methods
2.1. Data Acquisition
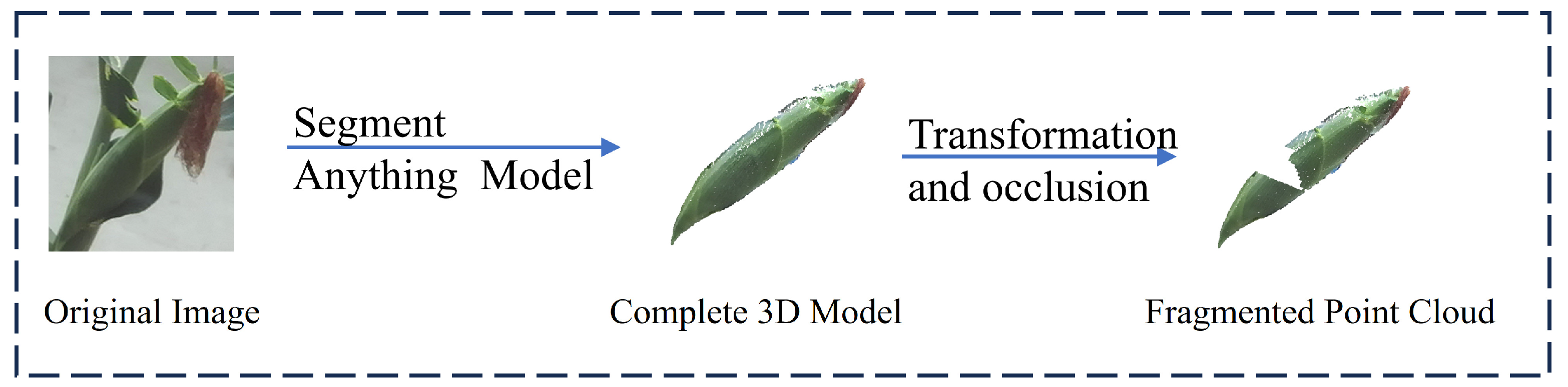
The core objective of this study is to complete fragmented corn point clouds with varying positions and sizes under occlusion conditions. Therefore, obtaining high-quality data is a crucial step. In this work, unoccluded corn data were first collected from multiple perspectives and the segmented corn converted into 3D models. Considering the natural variations in corn size during growth, a point cloud transformation algorithm was applied to adjust the scale, thereby expanding the dataset and enhancing the model’s robustness. Finally, a random occlusion strategy was introduced to generate a large set of incomplete point clouds, which serve as training data for point cloud completion. The process of producing data is shown in
Figure 1.
2.1.1. Original Data Collection
The data collection process was conducted in the experimental fields of Yangzhou University, Jiangsu Province. To address the challenges posed by outdoor strong light conditions, a ZED2i stereo depth camera(Stereolabs, San Francisco, CA, USA) [
21] was used for depth data acquisition as shown in
Figure 2. In total, 100 unoccluded corn RGB-D images with different orientations were captured. The RGB images had a resolution of 1080 × 720 pixels, and the corresponding depth maps shared the same resolution. All images were saved in PNG format. To extract corn from the background, we utilized the SAM and converted the segmented corn data into point cloud models based on the depth data.
2.1.2. Model Transformation and Random Occlusion
To introduce variability and simulate real-world conditions, the length and width of the point cloud models were randomly scaled within a transformation range of 0.8–1.2. After transformation, the transformed models obtained were randomly occluded to obtain a large amount of data. The sample data changes are shown in
Figure 3.
Table 1 shows the composition of the dataset for this work. This work divides the dataset in a 9:1 ratio for training and testing.
2.2. Acquisition of the Pose and Shape Information
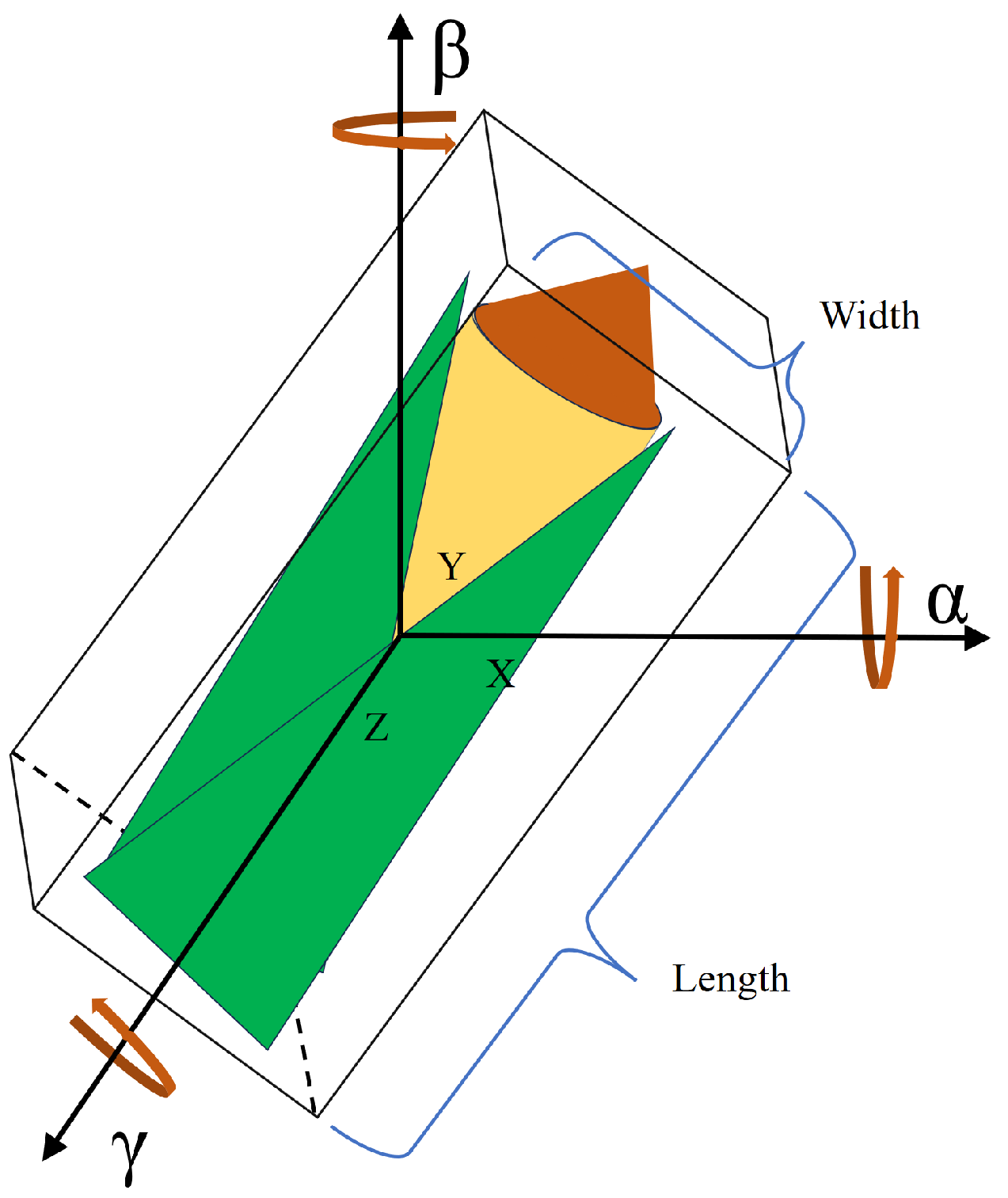
Through the information about the completed point cloud’s OBB, the information about the pose and shape with their dimensions can be obtained.
- (1)
Dimensions: These indicate the OBB’s width and length, respectively. They explain the properties of the corn as they are shown in
Figure 4.
- (2)
Three-dimensional coordinates of the center: These indicate the 3D coordinates of the object center in the camera coordinate system. As shown in
Figure 4, they specify the object’s location along the
x-,
y-, and
z-axes.
- (3)
Rotation matrix: The rotation matrix that transforms the local OBB axes to world coordinates. Each column of the rotation matrix represents the direction of one of the OBB’s local axes in world coordinates.
Figure 4 illustrates the connection between these rotation angles.
2.3. Point Cloud Completion Algorithm
In this work, a method for estimating the position and pose of occluded corn using point cloud completion is proposed. SCPAN, an enhanced version of PointAttN [
22] in the point cloud completion network, is introduced. PointAttN is one of the best point cloud completion algorithms, achieving better results in the PCN dataset [
23] than PCN [
24] and SnowflakeNet [
25].
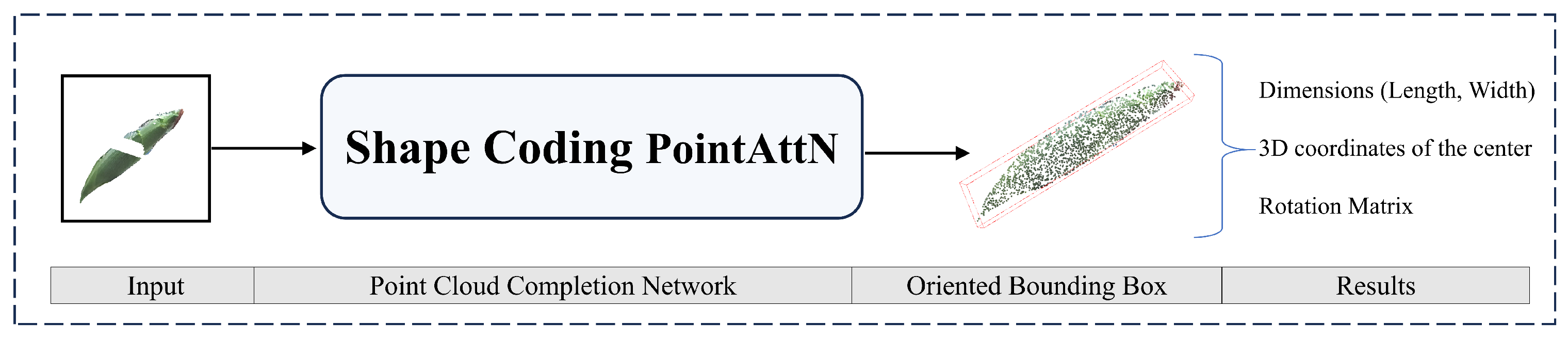
The proposed SCPAN model simplifies the original structure, while also incorporating a gated MLP that integrates 3D positional encoding and a prior shape encoder to improve the model’s performance. The model is capable of completing fragmented point clouds, and the pose information of the corn can be extracted by calculating the OBB of the completed point cloud using Open3D. The process proposed in this work is shown in
Figure 5.
2.3.1. Standard PointAttN Model
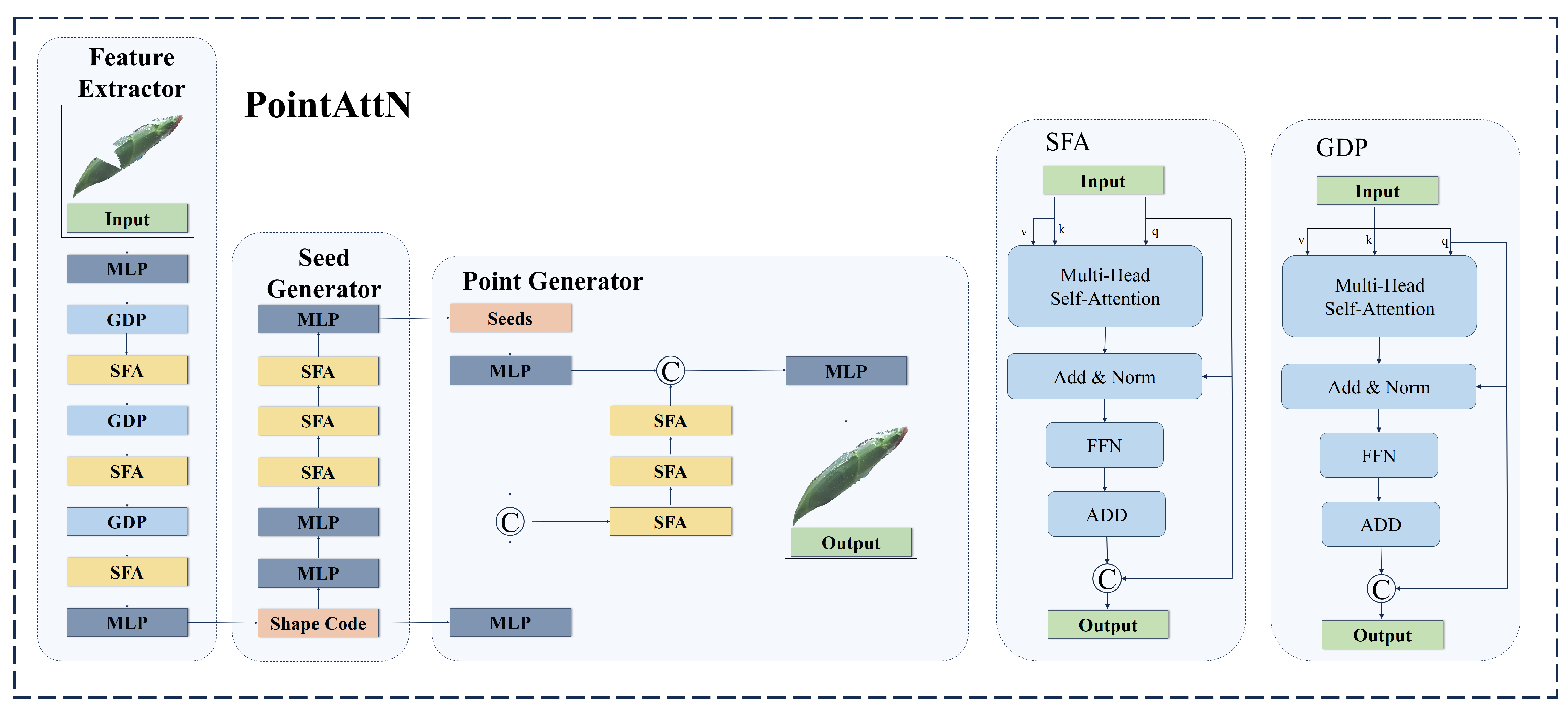
PointAttN is a point cloud completion framework designed to predict a complete 3D shape from an incomplete point cloud. It addresses the limitations of k-nearest neighbors (KNNs), which struggle to describe local geometric structures. Its key innovation is the elimination of explicit local region partitioning and the introduction of cross-attention and self-attention mechanisms to capture both short-range and long-range structural relationships among points. PointAttN consists of the following three main modules: the feature extractor, seed generator, and point generator. The feature extractor adaptively captures both local structural details and the global context of an object to generate a shape code. The seed generator takes the shape code as input to produce a sparse yet complete point cloud. Finally, the point generator refines this output by taking both the sparse point cloud and shape code as input. To achieve these, two key blocks are integrated within these modules as follows: the Geometric Details Perception (GDP) block, which facilitates information aggregation, and the Self-Feature Augmentation (SFA) block, which captures intricate geometric details about 3D shapes. The original PointAttN structure is illustrated in
Figure 6.
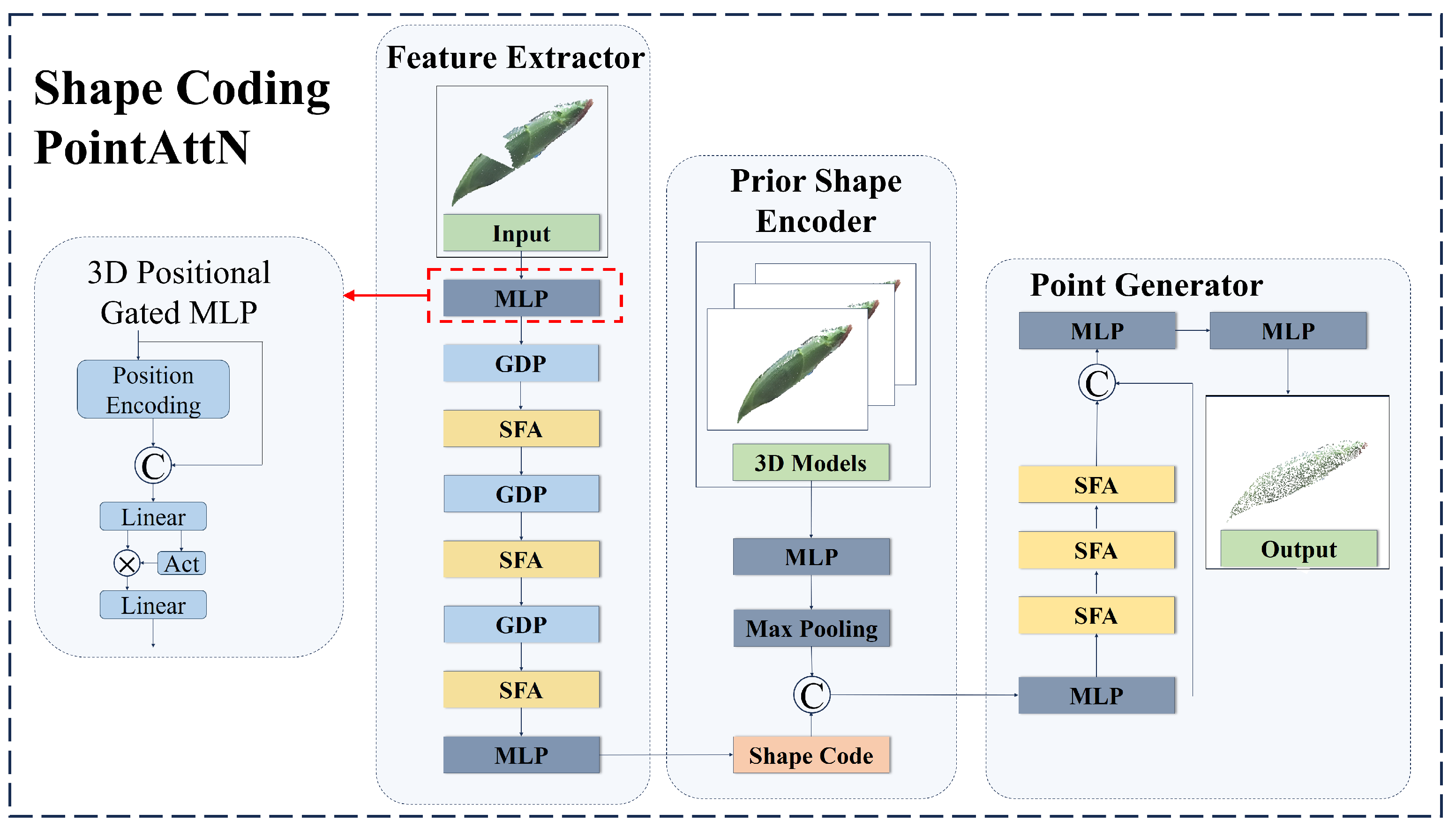
2.3.2. Shape Coding PointAttN
The standard PointAttN demonstrates excellent performance in completing point clouds. However, when it comes to achieving shape and pose estimation through the completion of corn point clouds, there is still room for improvement. Firstly, the results of this work do not need to be generated by dense point clouds. Secondly, the original model excessively focuses on the recovery of local details. Thirdly, for a single category (such as corn), in order to enhance the overall performance of the model, it is necessary to further strengthen its 3D modeling ability of point clouds. Based on the above analysis, the model structure of PointAttN is simplified to output sparse point clouds. The model’s attention to local details is appropriately reduced and instead focuses on the completion of the overall shape and the processing of sparse point clouds. Therefore, we propose a gated MLP combined with 3D position encoding and introduce a prior shape encoder to enhance the model’s shape regression ability. The overall architecture is shown in
Figure 7.
The improvements proposed in this work are as follows:
- (1)
Model structure simplification:
The original PointAttN model consists of two main stages—the generation of a sparse point cloud in the first stage, followed by densification in the second stage. However, in this work, the final output is derived through the generation of an OBB, which is independent of point cloud density. Therefore, the model structure is simplified accordingly, as illustrated in
Figure 7.
- (2)
Three-dimensional positional gated MLP:
The MLP is an important component of PointAttN. However, traditional MLPs present the following problem: they rely on a single activation function, which restricts their ability to model complex features. In contrast, gated MLP utilizes the activation function to regulate the information flow, enhancing feature representation and making it more suitable for point cloud tasks with complex geometric structures. However, conventional gated MLP lacks spatial feature modeling, making it less effective for spatial tasks. To address this limitation, we introduce a 3D position encoding structure into the gated MLP to propose a 3D positional gated MLP, improving the model’s spatial awareness as shown in
Figure 7.
- (3)
Prior shape encoder:
This work primarily focuses on the point cloud completion of single-crop corn, given that the shape of corn is relatively consistent. A prior shape encoder is constructed by encoding 3D corn models to capture their geometric characteristics. As illustrated in
Figure 7, the prior shape encoder takes the 3D point cloud of the corn models as input, extracts global features via the MLP, and subsequently obtains high-dimensional feature vectors through a pooling-based prior encoder. During model training, these high-dimensional feature vectors are embedded into the model to enhance its shape perception capabilities.
2.4. Experimental Setting
Table 2 lists the hardware and software setups used for model testing and training in this study. With a batch size of nine, the training epochs are set to 400. The Adam optimizer with a momentum of 0.9 is used to carry out the optimization. Every 100 rounds, the learning rate is modified from the starting setting of 0.0001.
2.5. Training Loss
In order to define the loss function during training, we use the Chamfer Distance (
) as the measure for point cloud similarity. The seed point cloud and the output point cloud from the two cascaded point generators are denoted by
, respectively. Three sub-clouds,
, and
, are obtained by downsampling the ground truth point cloud using FPS. These sub-clouds have the same density as
, and
, respectively. The definition of the model loss is shown in Equation (
1), expressed as follows:
where
is the Chamfer Distance loss, which is defined by Equation (
2), expressed as follows:
In the implementation, each is set to 1.
2.6. Evaluation Metrics
To evaluate the quality of the completed point clouds, we adopt the Chamfer Distance, a widely used metric in point cloud generation and completion tasks. The measures the average closest-point distances between the predicted point cloud and the ground truth and effectively captures both the accuracy and completeness of the reconstructed shape. Let denote the predicted point cloud and denote the ground truth point cloud. We compute the in both directions as follows:
The
from the predicted point cloud to the ground truth is defined as shown in Equation (
3), expressed as follows:
The
from the ground truth to the prediction is defined as shown in Equation (
4), expressed as follows:
Here, evaluates how accurately the predicted points approximate the ground truth surface, while reflects the completeness of the predicted shape with respect to the ground truth.
In the case of multi-stage completion frameworks, we further report the
at the coarse prediction stage, denoted as
. The coarse-level metrics are defined as in Equation (
5) as follows:
All values are reported in squared Euclidean distance. Lower values of each metric indicate a better reconstruction performance. In our experiments, we report all four metrics—, , and —to comprehensively assess the quality of both the final and coarse predictions.
The accuracy of the pose estimates is gauged by the
. The formula for its computation is shown in Equation (
6), expressed as follows:
where the model’s predicted values are shown by
, whereas the associated ground truth values are denoted by
.
4. Discussion
4.1. Main Work
Within a complex agricultural environment, due to the occlusion of corn leaves, obtaining the complete three-dimensional structure of corn plants and their precise pose encounters considerable challenges. To tackle this problem, this work puts forward a method based on point cloud completion to detect the pose and shape of corn from the OBBs of complete corn models, aimed at completing the fragmented point cloud resulting from occlusion and accurately obtaining information about the pose and shape of the corn in three dimensions. For the purpose of effectively training the point cloud completion model, this work generates data systematically in batches. It utilizes high-quality 3D models of corn, in combination with a random occlusion strategy, to construct a large-scale point cloud completion dataset, thereby enhancing the generalization ability of the model.
To further improve the accuracy and stability of point cloud completion, this work proposes a point cloud completion algorithm, which we call SCPAN, based on PointAttN. SCPAN is a transformer-based network architecture that generally involves more parameters; it offers higher accuracy and improved robustness when dealing with corn of varying sizes during different growth stages. SCPAN first simplifies the structure of the model to reduce the number of model parameters and outputs a sparse point cloud as the result. This work also proposes a gated MLP incorporating 3D position encoding to enhance the model’s awareness of spatial features. Simultaneously, in order to reduce the parameters of the model, we utilize 3D corn models to train a prior shape encoder and introduce it into the model training.
The experimental outcomes indicate that, on the occluded point cloud dataset constructed in this study, the point cloud completion algorithm proposed in this work is capable of achieving a completion effect equivalent to the baseline with fewer parameters, verifying the effectiveness of the proposed method.
4.2. Comparison with Existing Research
Table 8 shows the comparison between this work and previous related work. This work is the first in the field of smart agriculture to employ the point cloud completion technique to obtain the pose and shape information about corn under occlusion. It can detect a single corn plant with a speed of up to 50 ms. In terms of speed, this work is better than those of Chen [
18] and Gené-Mola [
15] in completing shape estimation using 3D modeling. In terms of the speed and simplicity of the method, it is superior to that of Guo [
16] in using point cloud segmentation.
Compared with our previous work [
26], as the results show in
Table 7, this work can better solve the occlusion problem, updating the data generation method to improve the robustness of the algorithm.
The idea of this work is similar to that of Magistri [
17], which uses the existing 3D models for supervision, which is not conducive to expanding to data that have not been collected. In this work, the dataset can be expanded in batches through the random transformation of 3D models, so that the model is suitable for completing the corn plants without 3D model collection, and it is more suitable for large-scale farmland environments.
4.3. Limitations
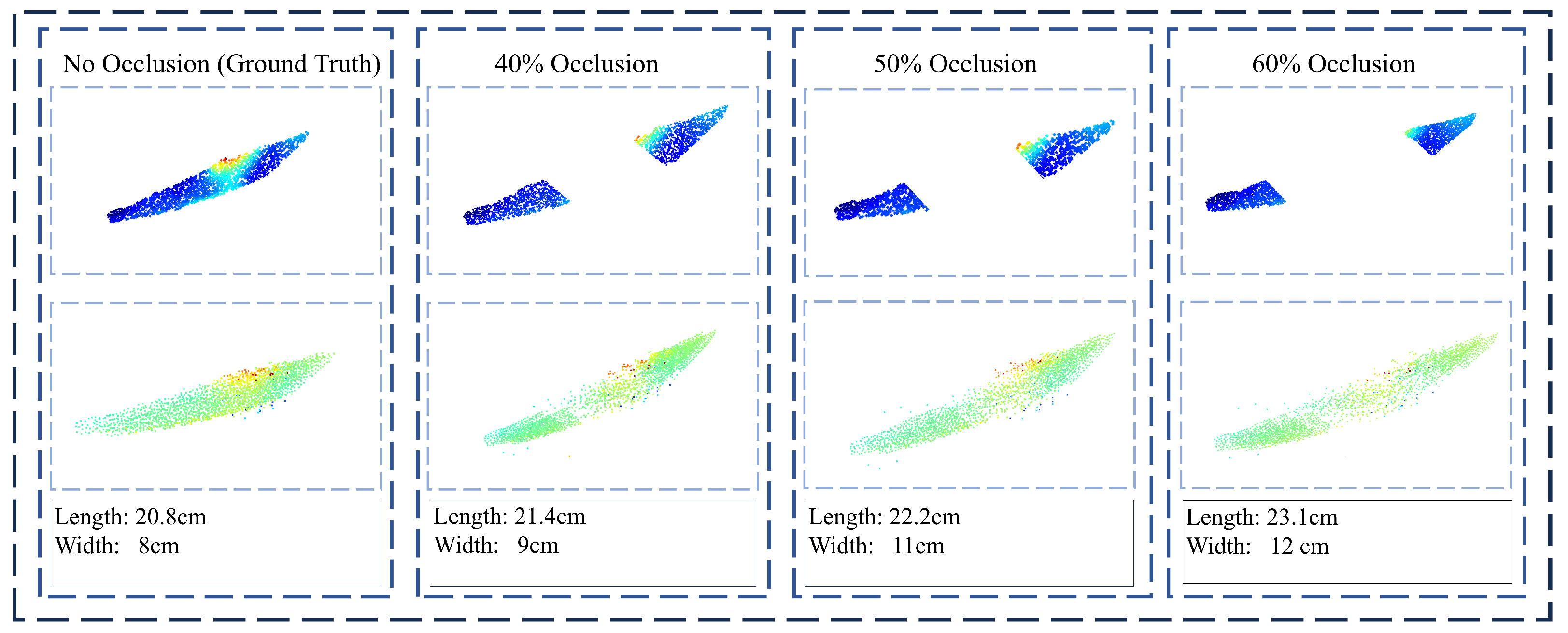
The results in the test set were presented in
Section 3. To further evaluate the robustness of the proposed method under challenging conditions, we simulate point cloud completion in extreme scenarios with severe occlusion. Specifically, the method was tested on data with 40% to 60% occlusion of the input points. As illustrated in
Figure 10, when the occlusion level exceeds 50%, the completion results begin to degrade significantly. As can be seen from
Figure 10, when the missing portion reaches 50%, SCPAN is still capable of recovering the overall shape of the corn. However, there remains a noticeable discrepancy in the completed corn’s dimensions compared to the ground truth. This deviation hinders the precise estimation of the corn’s physical measurements. In such cases, the predicted point cloud diverges noticeably from the ground truth, indicating failure in recovering the original object shape. This highlights the difficulty in accurate completion under extreme occlusion.
Nevertheless, this study still has certain limitations. Firstly, this work merely investigates point cloud completion under partial occlusion; that is, the occluded area is confined to a portion of the corn and does not encompass more complex occlusion scenarios, such as the completion of point clouds caused by multiple leaves or the corn being in the frontal position to the observer. Moreover, this work did not explore multiple corn plants in one scene simultaneously.
Additionally, the research objectives of this paper mainly pertain to corn at the maturity stage, where the characteristics of the corn are relatively pronounced, and existing deep learning segmentation techniques can extract them from the background with relative ease. However, in practical agricultural applications, the morphological characteristics of corn exhibit significant variations at different growth stages, particularly in the early growth period, when the contrast between the corn and the leaves is low, and traditional segmentation methods might face challenges in extracting the target area effectively. Future research can further explore these challenging occlusion circumstances to enhance the robustness and practicality of the model. Hence, future research could further explore methods for completing and segmenting occluded point clouds of corn at different growth stages and more challenging occlusion circumstances to enhance the model’s adaptability.
5. Conclusions
This work aimed to address the issue of point cloud completion for occluded corn to obtain the pose and shape. A method based on completing the fragmented point cloud after segmentation to obtain the complete corn model was proposed. The information about the pose and shape and their dimensions can be obtained from the OBB of the complete corn model. A better point cloud completion algorithm based on PointAttN, which we call SCPAN, was also proposed in this work. Considering that the task is focused on the completion of the overall shape, SCPAN simplifies the model structure to output a sparse point cloud as the result, thereby significantly reducing the number of model parameters. Furthermore, by introducing a gated MLP with 3D position encoding and a prior shape encoder, the regression of the overall shape of the object by the model is enhanced. The experimental results demonstrated that SCPAN achieves comparable point cloud completion results while having 34% fewer parameters than PointAttN, and the inference time was reduced by 30 ms. Simultaneously, the experimental results also reveal that the 3D positional gated MLP and the prior shape encoder can notably improve the and metrics, indicating that these two proposals can enable the model to better focus on the overall shape of the object. Statistical evaluation further proved the validity of our proposal. The method and algorithm proposed in this work are not only applicable for the estimation of corn poses but also to other crops (e.g., citrus and tomatoes). This work can provide technical support for automatic picking and phenotypic extraction in precision agriculture, promoting the advancement of smart agriculture.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}