



TQVGModel: Tomato Quality Visual Grading and Instance Segmentation Deep Learning Model for Complex Scenarios


Abstract
1. Introduction
- (1)
- This study proposes TQVGModel, a novel network based on Mask R-CNN, which incorporates a multi-branch reconstructed IncepConvV2 as the feature extraction network and utilizes the FCMAE self-supervised training strategy. This approach enhances the network’s adaptability to occlusions, improving both instance segmentation accuracy and real-time performance in complex scenarios.
- (2)
- The Class-Balanced Focal Loss [20] function is introduced in the class branch of the network to mitigate the challenges of sparse tomato samples and complex background instance segmentation during training. This enables TQVGModel to focus more on tomato samples that are few in number and difficult to segment, thereby improving overall in-stance segmentation accuracy and reducing missed detections.
- (3)
- In the mask branch, the enhanced E-Sobel (Enhanced Sobel) operator is used to fuse the predicted boundary information of the target, combined with an edge loss function guidance mechanism. This enables TQVGModel to focus more on the edge information of the tomato instance segmentation, improving edge localization accuracy, and providing key discriminative data for evaluating tomato quality in the grading subsystem.
- (4)
- We present a vision-based tomato quality grading subsystem that enables automated quality evaluation, offering decision-making support for subsequent graded harvesting by agricultural robots and crop growth monitoring.
- (5)
- A tomato image instance segmentation dataset for complex scenarios is constructed to provide key data support for research related to tomato grading instance segmentation and harvesting.
2. Materials and Methods
2.1. Dataset Sample Composition and Creation
2.2. Challenges of Mask R-CNN for Tomato Instance Segmentation in Complex Scenes
2.3. Network Design
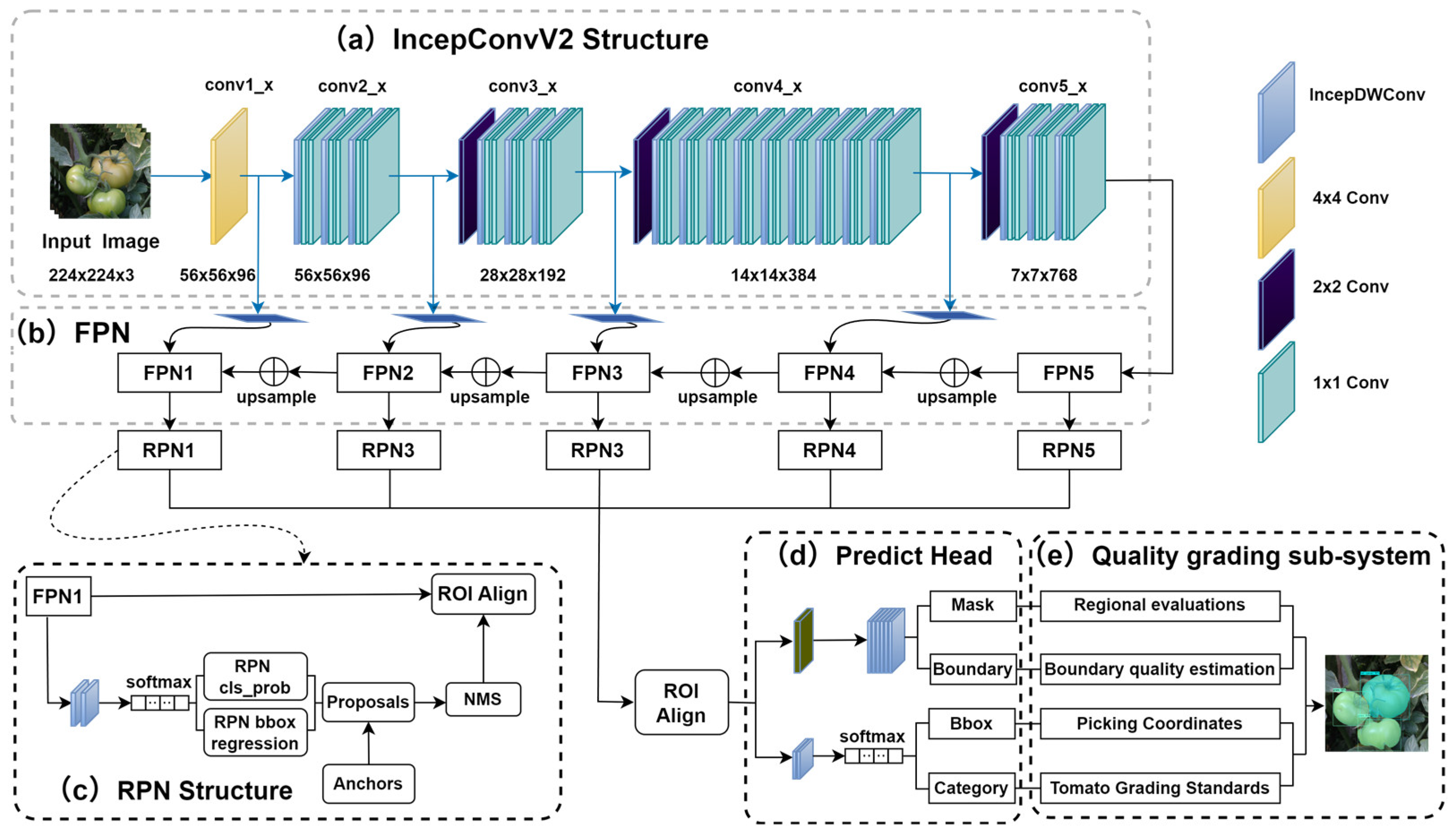
2.3.1. TQVGModel Overall Structure
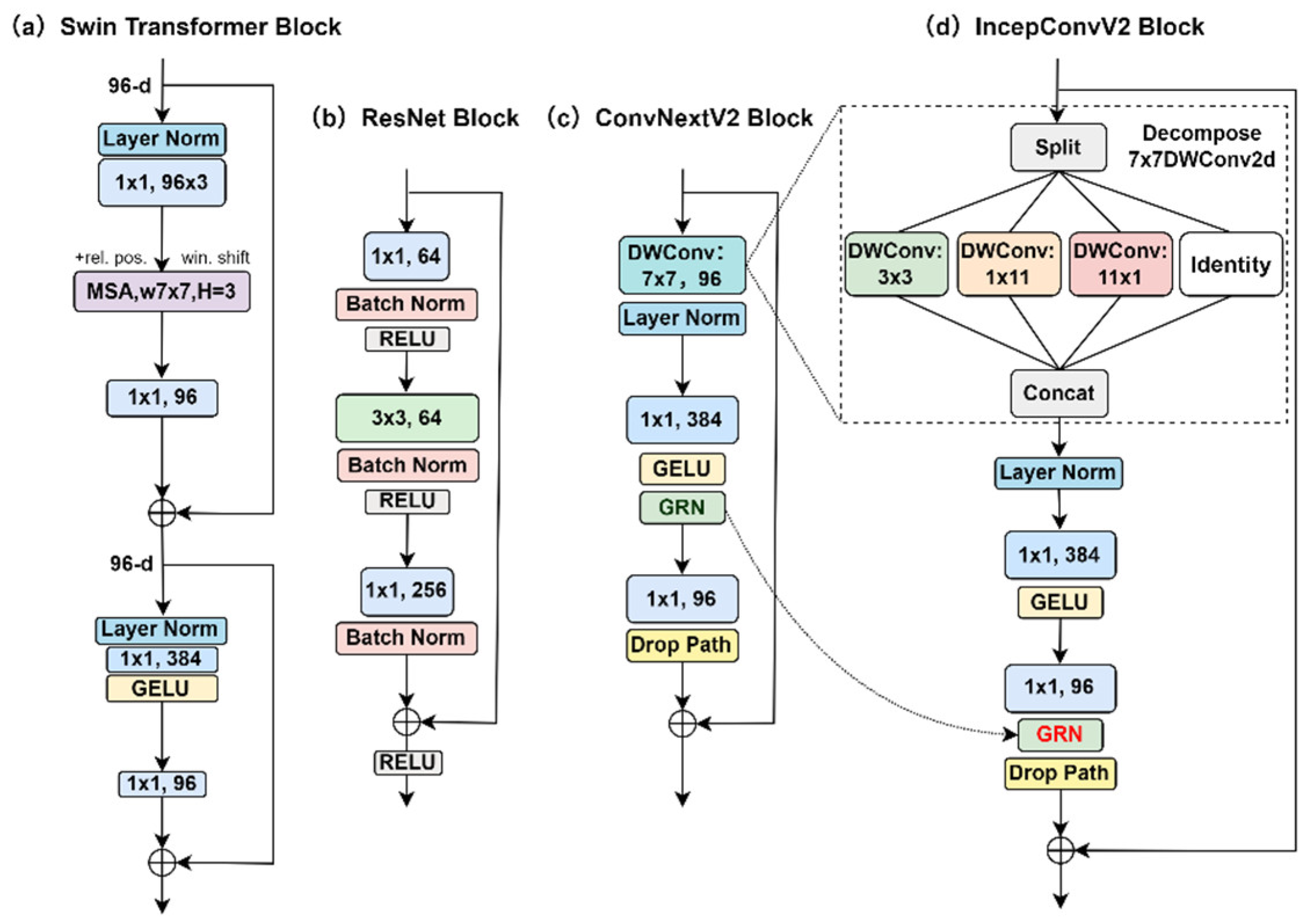
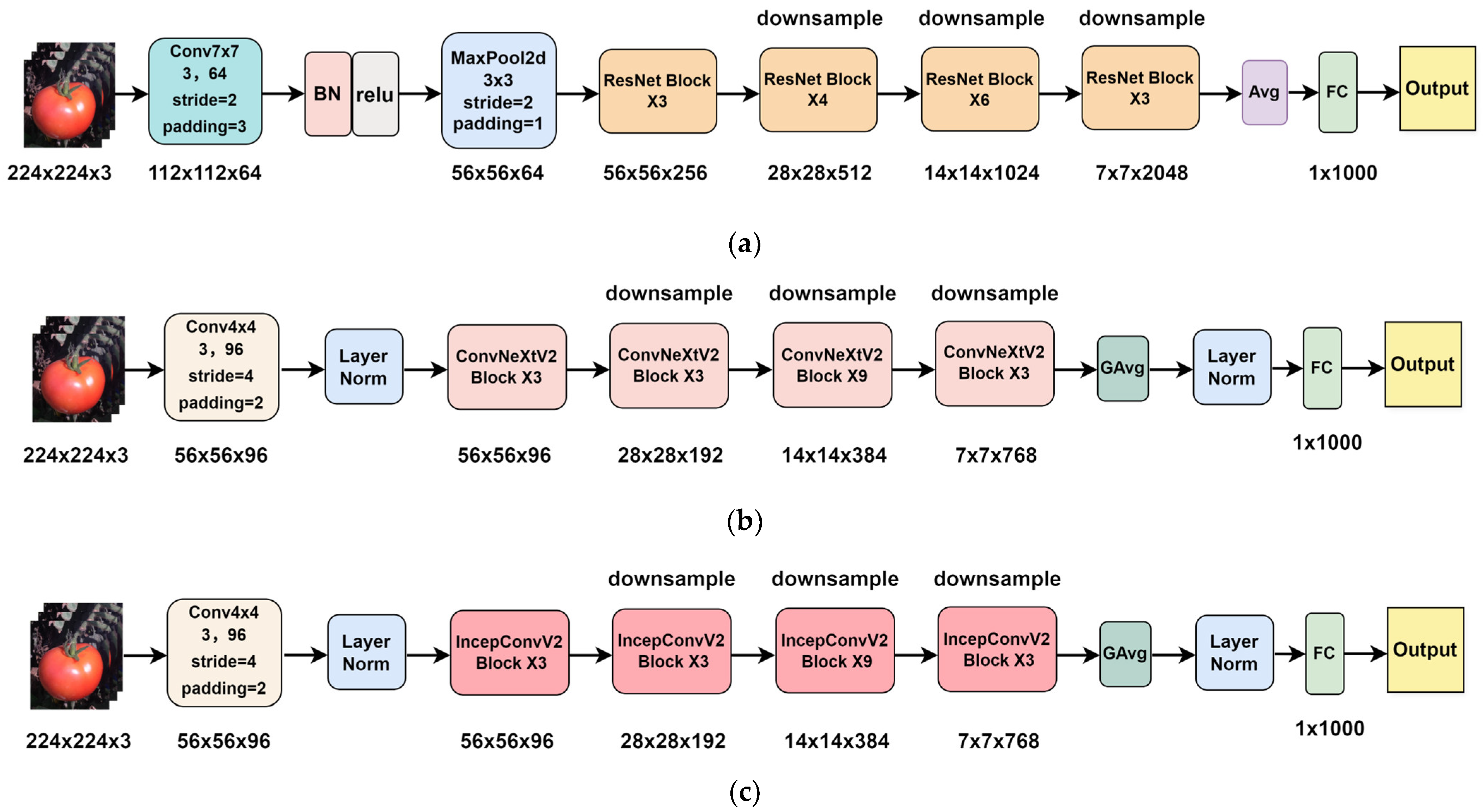
2.3.2. IncepConvV2 Network Structure
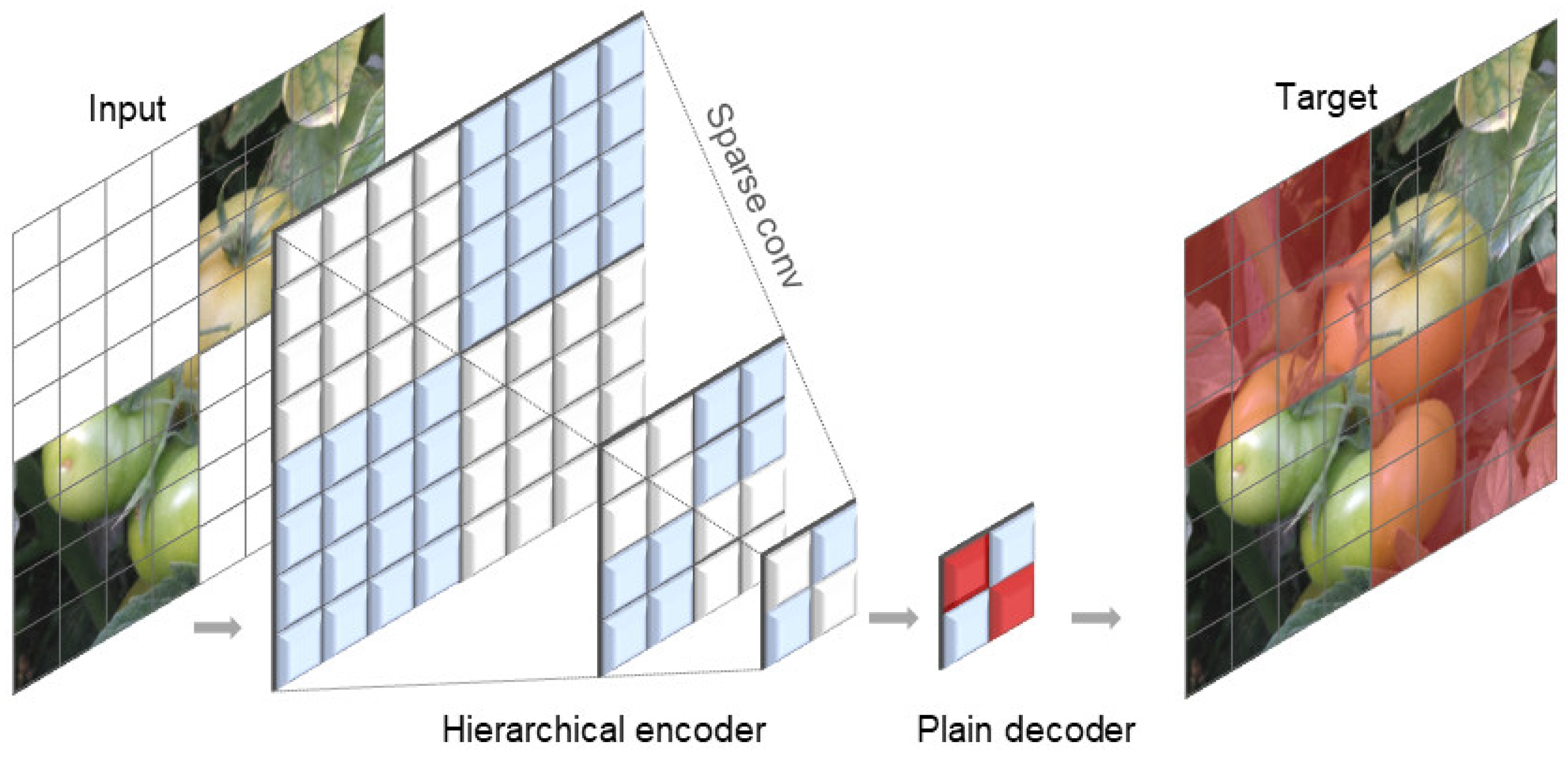
2.3.3. FCMAE Structure
2.3.4. Network Loss Function
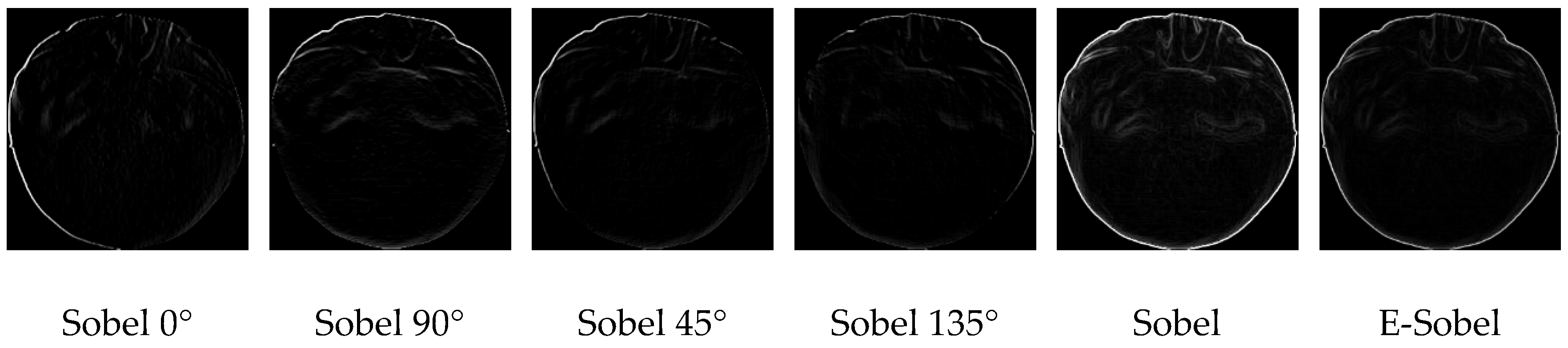
2.3.5. E-Sobel Operator
2.3.6. Grading Subsystem
2.4. Experimental Design
2.4.1. Network Training
2.4.2. Network Evaluation
3. Results
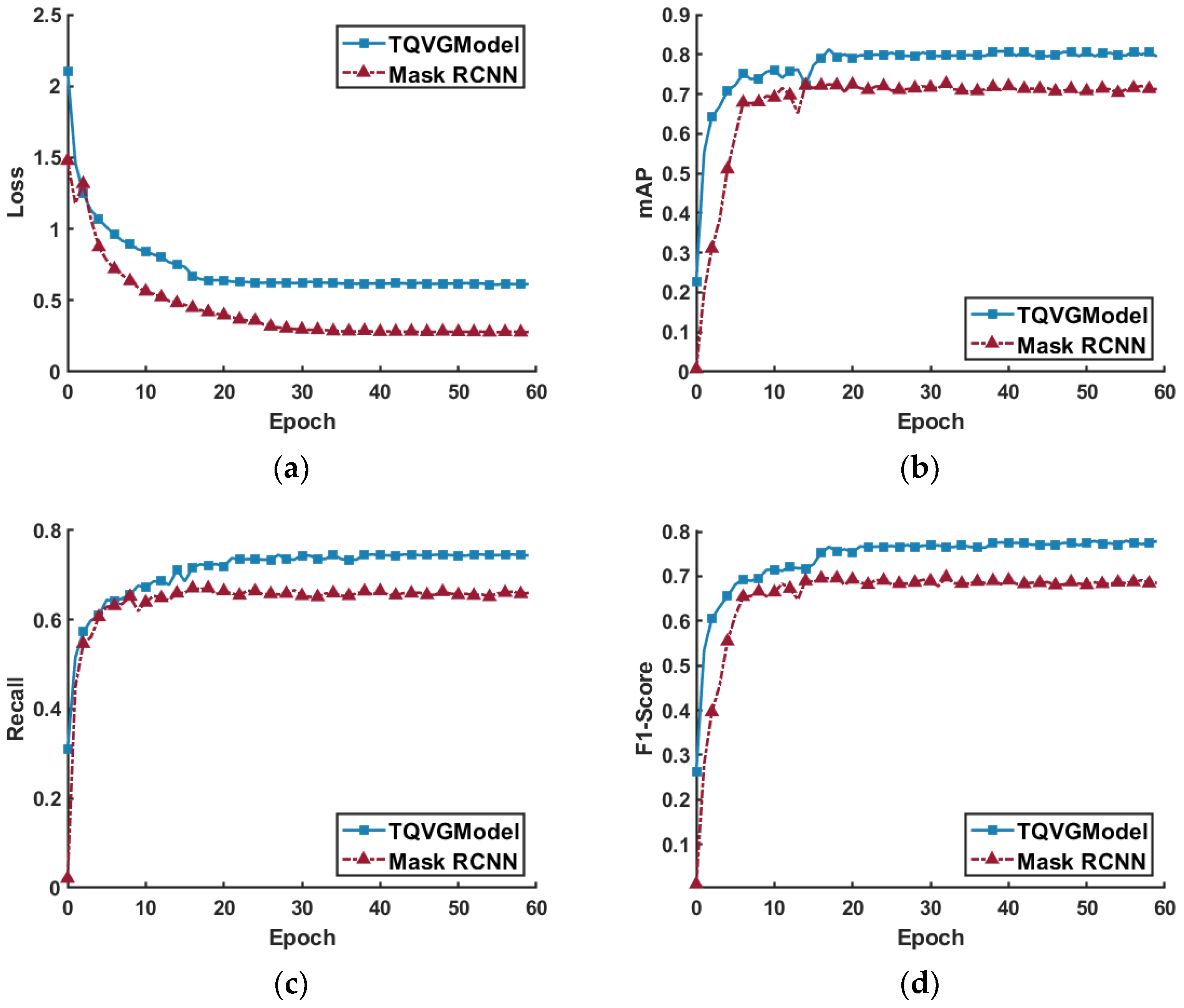
3.1. Experimental Results
3.2. Ablation Experiment Results
3.3. Experimental Result Analysis
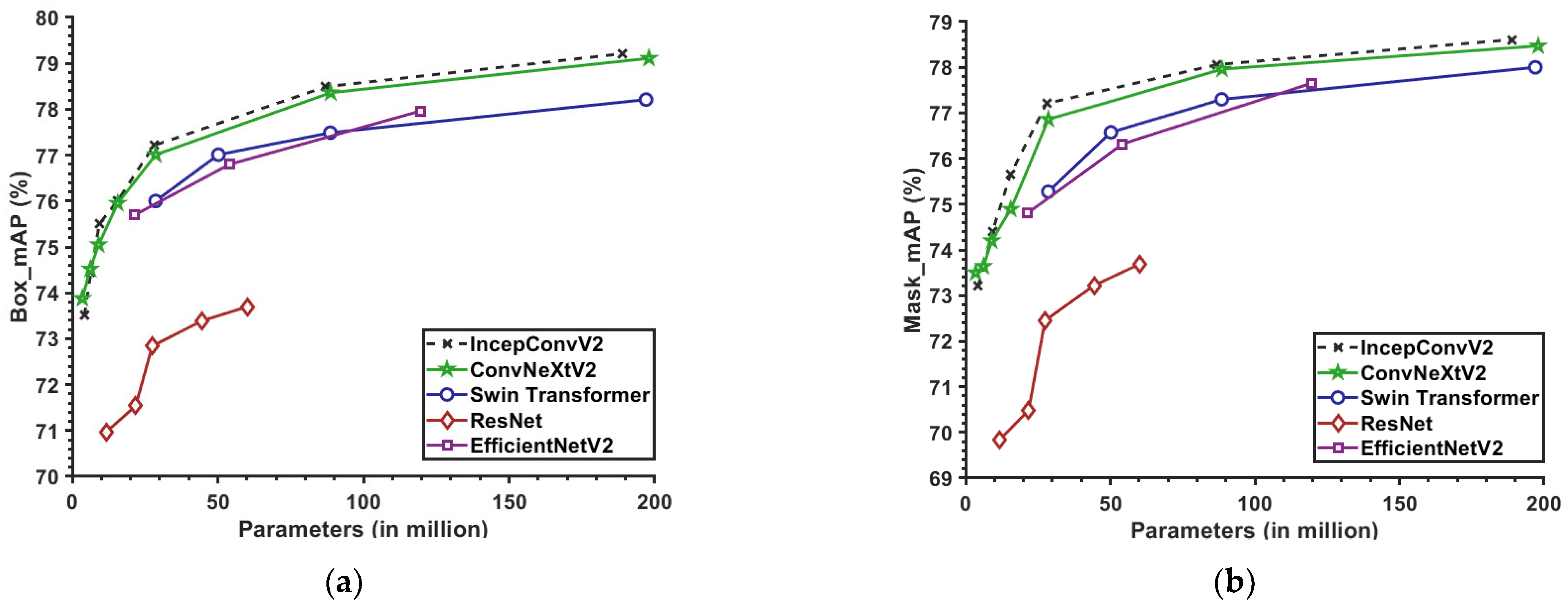
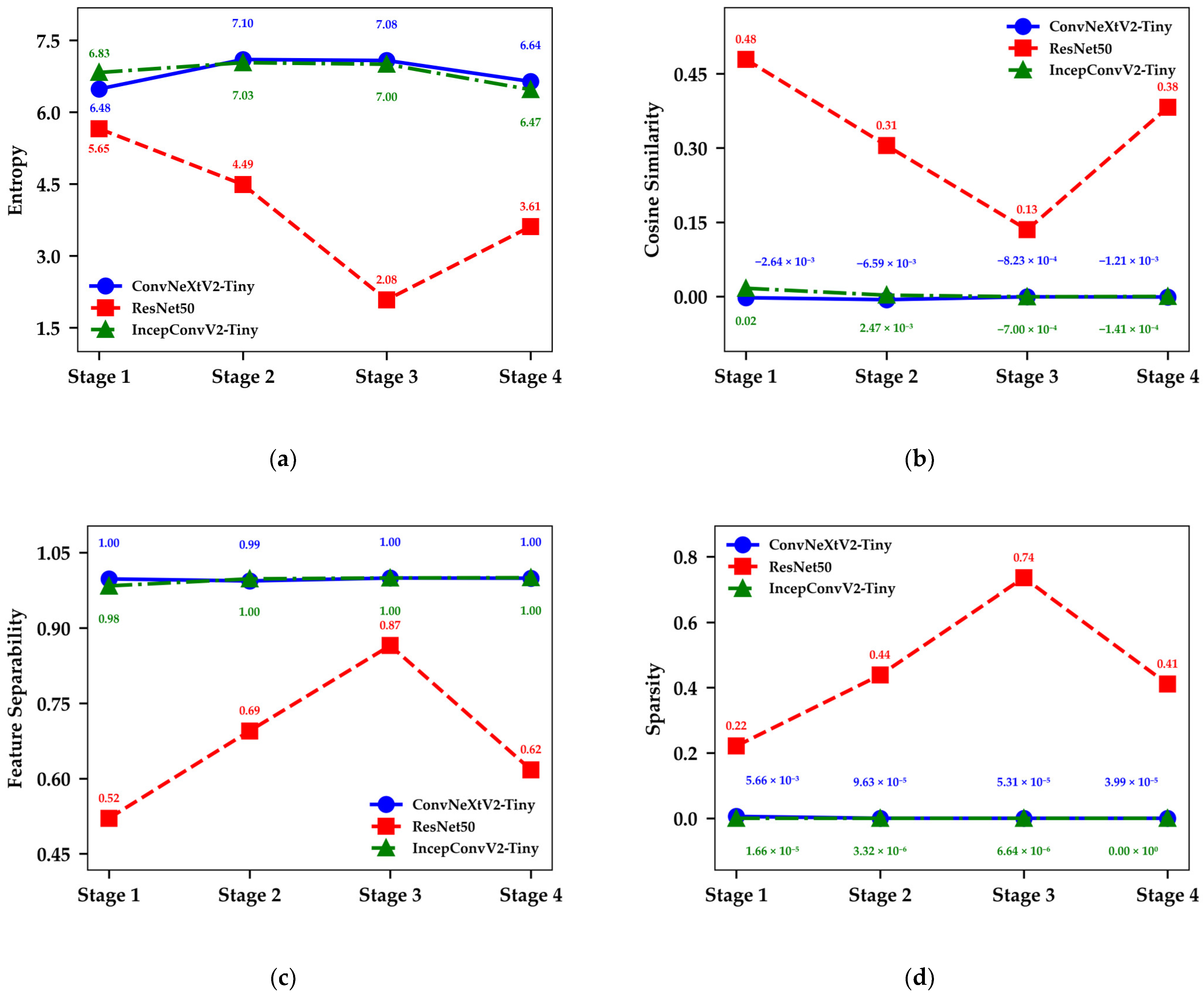
3.3.1. Performance Analysis of the IncepConvV2 Backbone Network
3.3.2. Effectiveness Analysis of Class-Balanced Focal Loss
3.3.3. Analysis of Enhanced Sobel Operator Performance
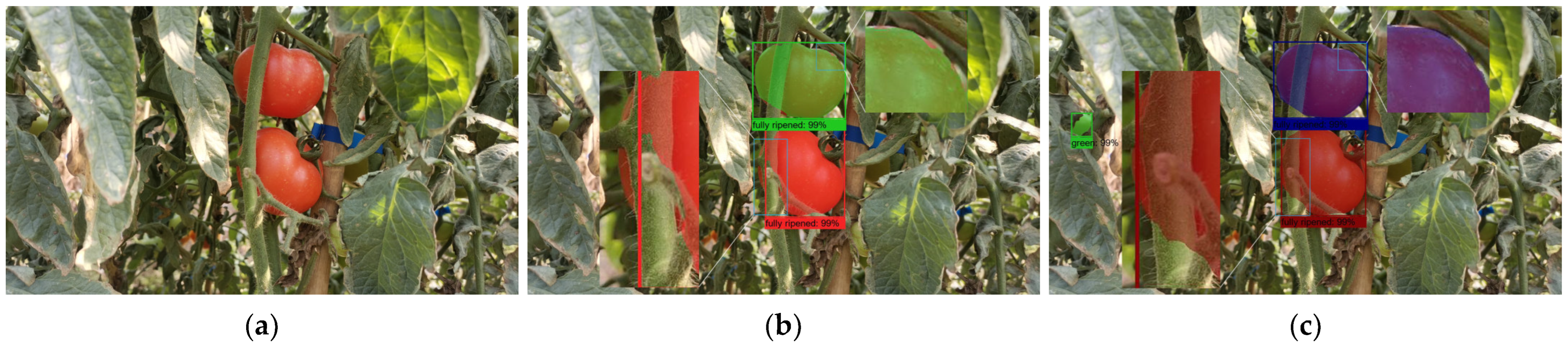
3.4. Multi-Scenario Application Analysis
4. Discussion
4.1. Interpretation of Results in Context
4.2. Training Efficiency and Computational Cost Analysis
4.3. Implications for Robotic Harvesting Systems
4.4. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saha, K.K.; Weltzien, C.; Bookhagen, B.; Zude-Sasse, M. Chlorophyll Content Estimation and Ripeness Detection in Tomato Fruit Based on NDVI from Dual Wavelength LiDAR Point Cloud Data. J. Food Eng. 2024, 383, 112218. [Google Scholar] [CrossRef]
- Li, T.; Sun, M.; He, Q.; Zhang, G.; Shi, G.; Ding, X.; Lin, S. Tomato Recognition and Location Algorithm Based on Improved YOLOv5. Comput. Electron. Agric. 2023, 208, 107759. [Google Scholar] [CrossRef]
- Zheng, S.; Liu, Y.; Weng, W.; Jia, X.; Yu, S.; Wu, Z. Tomato Recognition and Localization Method Based on Improved YOLOv5n-Seg Model and Binocular Stereo Vision. Agronomy 2023, 13, 2339. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Fruits and Vegetables Quality Evaluation Using Computer Vision: A Review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Guo, F.; Qin, W.; Fu, X.; Tao, D.; Zhao, C.; Li, G. A Novel Method for Online Sex Sorting of Silkworm Pupae (Bombyx mori) Using Computer Vision Combined with Deep Learning. J. Sci. Food Agric. 2025, 105, 4232–4240. [Google Scholar] [CrossRef]
- Liu, L.; Li, Z.; Lan, Y.; Shi, Y.; Cui, Y. Design of a Tomato Classifier Based on Machine Vision. PLoS ONE 2019, 14, e0219803. [Google Scholar] [CrossRef]
- Li, Y. Research and Application of Deep Learning in Image Recognition. In Proceedings of the 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 21–23 January 2022; pp. 994–999. [Google Scholar]
- Chuquimarca, L.E.; Vintimilla, B.X.; Velastin, S.A. A Review of External Quality Inspection for Fruit Grading Using CNN Models. Artif. Intell. Agric. 2024, 14, 1–20. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Sapkota, R.; Ahmed, D.; Karkee, M. Comparing YOLOv8 and Mask R-CNN for Instance Segmentation in Complex Orchard Environments. Artif. Intell. Agric. 2024, 13, 84–99. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Wang, C.; Ding, F.; Wang, Y.; Wu, R.; Yao, X.; Jiang, C.; Ling, L. Real-Time Detection and Instance Segmentation of Strawberry in Unstructured Environment. Comput. Mater. Contin. 2024, 78, 1481–1501. [Google Scholar] [CrossRef]
- Haggag, S.; Veres, M.; Tarry, C.; Moussa, M. Object Detection in Tomato Greenhouses: A Study on Model Generalization. Agriculture 2024, 14, 173. [Google Scholar] [CrossRef]
- Chowdhury, M.; Reza, M.N.; Jin, H.; Islam, S.; Lee, G.-J.; Chung, S.-O. Defective Pennywort Leaf Detection Using Machine Vision and Mask R-CNN Model. Agronomy 2024, 14, 2313. [Google Scholar] [CrossRef]
- Cong, P.; Li, S.; Zhou, J.; Lv, K.; Feng, H. Research on Instance Segmentation Algorithm of Greenhouse Sweet Pepper Detection Based on Improved Mask RCNN. Agronomy 2023, 13, 196. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, G.; Meng, Q.; Yao, T.; Han, J.; Zhang, B. DSE-YOLO: Detail Semantics Enhancement YOLO for Multi-Stage Strawberry Detection. Comput. Electron. Agric. 2022, 198, 107057. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An Attribution-Based Pruning Method for Real-Time Mango Detection with YOLO Network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.-Y.; Song, Y.; Belongie, S. Class-Balanced Loss Based on Effective Number of Samples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9260–9269. [Google Scholar]
- Li, H.; Gu, Z.; He, D.; Wang, X.; Huang, J.; Mo, Y.; Li, P.; Huang, Z.; Wu, F. A Lightweight Improved YOLOv5s Model and Its Deployment for Detecting Pitaya Fruits in Daytime and Nighttime Light-Supplement Environments. Comput. Electron. Agric. 2024, 220, 108914. [Google Scholar] [CrossRef]
- Camacho, J.; Morocho-Cayamcela, M.E. Mask R-CNN and YOLOv8 Comparison to Perform Tomato Maturity Recognition Task. In TICEC 2023, Proceedings of the Conference on Information and Communication Technologies of Ecuador, Cuenca, Ecuador, 18–20 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 382–396. ISBN 978-3-031-45437-0. [Google Scholar]
- Wang, B.; Li, M.; Wang, Y.; Li, Y.; Xiong, Z. A Smart Fruit Size Measuring Method and System in Natural Environment. J. Food Eng. 2024, 373, 112020. [Google Scholar] [CrossRef]
- Kaur, P.; Khehra, B.S.; Mavi, E.B.S. Data Augmentation for Object Detection: A Review. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 8–11 August 2021; pp. 537–543. [Google Scholar]
- Fang, S.; Zhang, B.; Hu, J. Improved Mask R-CNN Multi-Target Detection and Segmentation for Autonomous Driving in Complex Scenes. Sensors 2023, 23, 3853. [Google Scholar] [CrossRef]
- Chu, P.; Li, Z.; Lammers, K.; Lu, R.; Liu, X. Deep Learning-Based Apple Detection Using a Suppression Mask R-CNN. Pattern Recognit. Lett. 2021, 147, 206–211. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit Detection for Strawberry Harvesting Robot in Non-Structural Environment Based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Wu, J.; Song, L.; Wang, T.; Zhang, Q.; Yuan, J. Forest R-CNN: Large-Vocabulary Long-Tailed Object Detection and Instance Segmentation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1570–1578. [Google Scholar]
- Wang, D.; He, D. Fusion of Mask RCNN and Attention Mechanism for Instance Segmentation of Apples under Complex Background. Comput. Electron. Agric. 2022, 196, 106864. [Google Scholar] [CrossRef]
- Jia, W.; Wei, J.; Zhang, Q.; Pan, N.; Niu, Y.; Yin, X.; Ding, Y.; Ge, X. Accurate Segmentation of Green Fruit Based on Optimized Mask RCNN Application in Complex Orchard. Front. Plant Sci. 2022, 13, 955256. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Chen, H.; Li, X.; Li, J.; Zhang, Z.; Hu, X. Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13921–13930. [Google Scholar]
- Long, C.-F.; Yang, Y.-J.; Liu, H.-M.; Su, F.; Deng, Y.-J. An Approach for Detecting Tomato Under a Complicated Environment. Agronomy 2025, 15, 667. [Google Scholar] [CrossRef]
- Arakeri, M.P.; Lakshmana. Computer Vision Based Fruit Grading System for Quality Evaluation of Tomato in Agriculture Industry. Procedia Comput. Sci. 2016, 79, 426–433. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. ConvNeXt V2: Co-Designing and Scaling ConvNets with Masked Autoencoders. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. InceptionNeXt: When Inception Meets ConvNeXt. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 5672–5683. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-Preserving Mask R-CNN. In Computer Vision–ECCV 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Wang, S.; Sun, G.; Zheng, B.; Du, Y. A Crop Image Segmentation and Extraction Algorithm Based on Mask RCNN. Entropy 2021, 23, 1160. [Google Scholar] [CrossRef]
- Zimmermann, R.S.; Siems, J.N. Faster Training of Mask R-CNN by Focusing on Instance Boundaries. Comput. Vis. Image Underst. 2019, 188, 102795. [Google Scholar] [CrossRef]
- Tian, R.; Sun, G.; Liu, X.; Zheng, B. Sobel Edge Detection Based on Weighted Nuclear Norm Minimization Image Denoising. Electronics 2021, 10, 655. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 17721–17732. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2024, arXiv:2305.09972v2. [Google Scholar]
- Miao, Z.; Yu, X.; Li, N.; Zhang, Z.; He, C.; Li, Z.; Deng, C.; Sun, T. Efficient Tomato Harvesting Robot Based on Image Processing and Deep Learning. Precis. Agric. 2023, 24, 254–287. [Google Scholar] [CrossRef]
- Verk, J.; Hernavs, J.; Klančnik, S. Using a Region-Based Convolutional Neural Network (R-CNN) for Potato Segmentation in a Sorting Process. Foods 2025, 14, 1131. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A Review of Object Detection Based on Deep Learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Ruiz-Santaquiteria, J.; Bueno, G.; Deniz, O.; Vallez, N.; Cristobal, G. Semantic versus Instance Segmentation in Microscopic Algae Detection. Eng. Appl. Artif. Intell. 2020, 87, 103271. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Depths | Dims | Parameters (M) |
|---|---|---|---|
| IncepConvV2-Atto | (2, 2, 6, 2) | (40, 80, 160, 320) | 3.7 M |
| IncepConvV2-Femto | (2, 2, 6, 2) | (48, 96, 192, 384) | 6.4 M |
| IncepConvV2-Pico | (2, 2, 6, 2) | (64, 128, 256, 512) | 9.3 M |
| IncepConvV2-Nano | (2, 2, 8, 2) | (80, 160, 320, 640) | 15.5 M |
| IncepConvV2-Tiny | (3, 3, 9, 3) | (96, 192, 384, 768) | 28 M |
| IncepConvV2-base | (3, 3, 27, 3) | (128, 256, 512, 1024) | 87 M |
| IncepConvV2-Large | (3, 3, 27, 3) | (192, 384, 768, 1536) | 189 M |
| IncepConvV2-huge | (3, 3, 27, 3) | (256, 512, 1024, 2048) | 650 M |
| Hardware or Software | Configuration |
|---|---|
| CPU | Intel i9-10900K |
| RAM | 24 GB |
| SSD | 1024 GB |
| GPU | NVIDIA GeForce GTX 3090Ti 24 GB |
| Development environment | Python3.8, Pytorch2.0.1, CUDA12.6 |
| Model | IncepConvV2 | CB Loss | E-Sobel | mAP | Recall | F1-Score | Params |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | × | × | × | 72.45% | 66.05% | 69.10% | 44.18 M |
| Mask R-CNN-A | √ | × | × | 76.36% | 71.04% | 73.60% | 33.88 M |
| Mask R-CNN-B | √ | √ | × | 78.03% | 74.83% | 76.40% | 33.88 M |
| TQVGModel | √ | √ | √ | 80.51% | 75.81% | 78.09% | 33.98 M |
| Experiment Number | γ Value | mAP (%) | Recall (%) | F1-Score (%) | Training Time (h) |
|---|---|---|---|---|---|
| 1 | 0.5 | 75.12% | 71.36% | 73.19% | 5.5382 |
| 2 | 1.0 | 77.47% | 72.89% | 75.11% | 5.8567 |
| 3 | 1.5 | 78.03% | 74.83% | 76.40% | 6.1097 |
| 4 | 2.0 | 76.81% | 72.73% | 73.93% | 6.5692 |
| 5 | 2.5 | 75.98% | 72.94% | 74.43% | 6.7776 |
| 6 | 3.0 | 75.05% | 72.29% | 73.64% | 7.3125 |
| Segmentation Algorithm | Total Parameters (M) | Average Inference Time (ms) | mAP% |
|---|---|---|---|
| SOLO V2 | 86.67 M | 60.32 | 72.57% |
| YOLACT | 36.83 M | 31.43 | 71.41% |
| YOLOV8s-Seg | 11.4 M | 25.56 | 73.01% |
| Mask R-CNN | 44.18 M | 69.98 | 73.31% |
| TQVGModel-Atto | 24.78 M | 45.24 | 75.03% |
| TQVGModel-Tiny | 33.98 M | 53.38 | 80.05% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cong, P.; Wang, K.; Liang, J.; Xu, Y.; Li, T.; Xue, B. TQVGModel: Tomato Quality Visual Grading and Instance Segmentation Deep Learning Model for Complex Scenarios. Agronomy 2025, 15, 1273. https://doi.org/10.3390/agronomy15061273
Cong P, Wang K, Liang J, Xu Y, Li T, Xue B. TQVGModel: Tomato Quality Visual Grading and Instance Segmentation Deep Learning Model for Complex Scenarios. Agronomy. 2025; 15(6):1273. https://doi.org/10.3390/agronomy15061273
Chicago/Turabian StyleCong, Peichao, Kun Wang, Ji Liang, Yutao Xu, Tianheng Li, and Bin Xue. 2025. "TQVGModel: Tomato Quality Visual Grading and Instance Segmentation Deep Learning Model for Complex Scenarios" Agronomy 15, no. 6: 1273. https://doi.org/10.3390/agronomy15061273
APA StyleCong, P., Wang, K., Liang, J., Xu, Y., Li, T., & Xue, B. (2025). TQVGModel: Tomato Quality Visual Grading and Instance Segmentation Deep Learning Model for Complex Scenarios. Agronomy, 15(6), 1273. https://doi.org/10.3390/agronomy15061273