1. Introduction
Citrus is one of the most important economic crops around the world, holding a significant position in international agriculture [
1]. China possesses abundant citrus resources with diverse varieties, leading the world in both cultivation area and production volume. The citrus industry has become a key role in promoting rural economic development in China [
2]. During the growth period, the number of fruits on trees is an important indicator for revealing the tree’s health [
3,
4,
5]. During citrus cultivation, various extreme natural disasters (such as strong winds and heavy rains) can easily cause fruit drop, resulting in significant losses for farmers. Therefore, citrus breeders have been seeking superior varieties that possess certain resistance to natural disasters and are less prone to fruit drop, which is of great significance for the development of China’s citrus industry. Currently, breeders and farmers count the on-tree or dropped fruit after natural disasters manually, which inevitably involves problems such as high costs, low efficiency, and poor accuracy. This deficiency limits the selection of superior citrus varieties and has become a bottleneck of the citrus industries. Therefore, how to achieve precise detection and count on-tree or dropped fruits automatically in natural environments is an urgent problem that needs to be solved.
Although morphology-based methods have previously achieved acceptable results, their generalizability remains unsatisfactory. Furthermore, these methods need manually designed features, and are easily affected by lighting and the environmental background, making them unfavorable for practical applications in different environments. Recently, deep learning algorithms represented by convolutional neural networks have been widely applied in agricultural fruit recognition, disease detection, yield estimation, and achieving good results in crops such as navel oranges, citrus, and pomelos. Based on different model structures, deep-learning-based object detection algorithms can be mainly divided into two categories. One is the two-stage object detection methods represented by R-CNN, Fast R-CNN, and Faster R-CNN; these approaches obtain proposal regions firstly and then perform classification within the current region [
6,
7,
8]. For example, Yan et al. [
9] proposed an improved Faster R-CNN-based rosa roxburghii fruit recognition method, achieving a recall rate, precision, and recognition speed of 96.93%, 95.53%, and 0.2 s/image, respectively. Xiong et al. [
10] proposed a green citrus visual detection method based on Faster R-CNN that could accurately identify green citrus under different lighting conditions and sizes, achieving a mean average precision (mAP) of 85.49%. While these algorithms have high accuracy, the region proposal step consumes substantial computational resources and requires a longer detection time, making it difficult to meet real-time requirements. The other category is single-stage object detection algorithms, represented by SSD and the YOLO (You Only Look Once) series [
11,
12,
13,
14,
15,
16,
17]. These algorithms do not need to generate candidate boxes but instead transform the bounding box problem into a regression problem, featuring high accuracy, a fast speed, a short training time, and a low computational cost. For example, Zhang et al. [
18] proposed an improved YOLOv4-LITE lightweight neural network detection algorithm for highly dense and severely adhered cherry tomato targets. The model used MobileNet-v3 as the feature extraction network, modified the pyramid network, and introduced small target detection layers, achieving a significant reduction in model weights and an average precision of 99.74%. Wang et al. [
19] introduced MPDIoU to replace the original CIoU as the loss function based on the YOLOV8 network, accelerated model convergence, added small target detection layers to improve small target recognition ability, and used SCConv as the feature extraction network. The test results showed that the improved network model achieved a precision, recall, and mean average precision of 97.7%, 97%, and 99%, respectively.
In terms of citrus detection, the YOLO-GC model proposed by Lv et al. [
20], based on improved YOLOv5s, successfully achieved the real-time precise detection of fruits in complex natural environments. The model obtained excellent results, showing a precision, recall, and mean average precision (mAP) of 96.5%, 89.4%, and 96.6%, respectively. Lv et al. [
21] optimized the YOLOv3 network architecture, achieving both an improved detection speed and accuracy while reducing the model size. The improved YOLOv5 detection method proposed by Gao et al. [
22] made a breakthrough: while reducing the model parameters to one-seventh of the original network, it still achieved 98.8% precision and 99.1% average precision, effectively resolving the inherent contradiction between accuracy and model complexity in traditional algorithms.
From the existing research, it is evident that although significant progress has been made in fruit target detection technology based on deep learning, current studies are predominantly confined to the detection of single fruit categories, revealing limitations in model generalization capabilities. Particularly for citrus fruits, their wide variety and significant inter-individual differences further complicate the detection process. Furthermore, earlier versions of the YOLO algorithm, such as YOLOv8, often suffer from complex model architectures and high computational demands, making them less suitable for lightweight application scenarios. To address these issues and meet the practical needs of citrus breeders and orchard managers, this paper takes both on-tree fruits and dropped fruits as objects and proposes a citrus detection and counting method based on improved YOLOv11. The main contributions of this paper are as follows:
(1) Replaced the C2PSA attention mechanism after the SPPF layer with the EMA (efficient multi-scale attention) attention mechanism, enhancing the model’s ability to extract citrus fruit feature information and thereby improving detection accuracy.
(2) Introduced the CSPPC module to replace the original C3K2 module in the model, reducing redundant computations and optimizing memory access while improving citrus fruit detection accuracy.
(3) Replaced the original CIoU (complete intersection over union loss) loss function with the MPDIoU (minimum point distance intersection over union) loss function, both improving bounding box accuracy and accelerating model convergence speed.
(4) The architecture of the original network detection layer was modified in the backbone network, which significantly decreased the parameter count while simultaneously enhancing the detection capability for citrus fruits.
2. Materials and Methods
2.1. Image Acquisition
The citrus images were collected at the Garden of Jiangxi Agricultural University (115.8° E, 28.7° N) in Nanchang City, Jiangxi Province, during October to November 2024. The images were captured using a Honor 70 camera (Honor Device Co., Ltd., Shenzhen, China). Due to adverse weather conditions in the earlier period, each fruit tree experienced varying degrees of fruit drop. To enhance the model’s applicability in real-world scenarios, a total of 1200 images were captured under different conditions, including varying distances, weather conditions, lighting conditions, occlusion situations, viewing angles, and fruit density levels, with 4096 × 3072 pixels resolution. Each image contains both citrus fruits on the tree and those that had fallen on the ground. Some sample images are shown in
Figure 1.
2.2. Dataset Annotation and Construction
Two categories were established: the on-tree fruit (named “orange_T”) and those that had fallen to the ground (named “orange_G”). The dataset annotation process was executed utilizing LabelImg image annotation software (1.8.0). The dataset was divided into training, validation, and test subsets at a ratio of 8:1:1. To strengthen the robustness and generalization capability of the network model, we deployed a comprehensive data augmentation process, encompassing six transformation techniques: spatial translation, rotation variation, geometric flipping, strategic cropping, brightness adjustment, and Gaussian noise injection. This series of measures effectively enhanced the model’s robustness, enabling it to better cope with complex and varied data environments [
23,
24].
2.3. Data Analysis
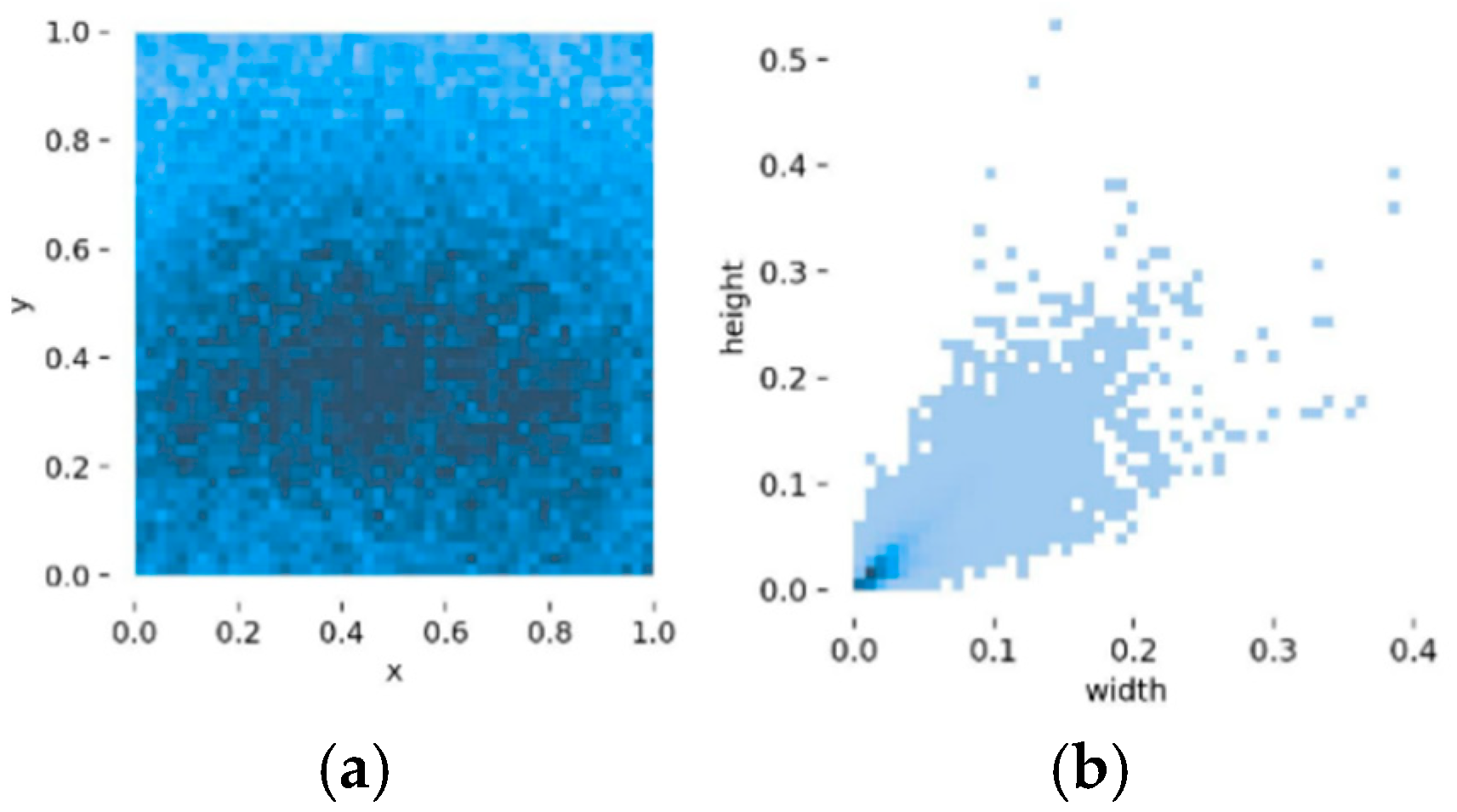
Quantitative analysis of the spatial characteristics reveals several significant findings.
Figure 2a presents the spatial distribution analysis of citrus bounding boxes, demonstrating a predominantly uniform distributional pattern with no significant clustering phenomena.
Figure 2b illustrates the dimensional analysis of bounding box relative sizes within the image space, revealing a notable concentration of dimensions within the 0–0.01 range. This distribution pattern indicates a predominance of small-scale target objects within our dataset, a characteristic that potentially introduces challenges for detection accuracy. These observed distributional characteristics can be attributed to multiple interconnected factors, including, but not limited to, established citrus cultivation methodologies, inherent growth patterns, and viewpoint constraints during data acquisition, all of which contribute to the complexity of the model’s detection parameters.
2.4. YOLOv11 Network Architecture
YOLOv11 represents the latest evolution in the YOLO (You Only Look Once) object detection algorithm series. In comparison to its antecedents, it introduces sophisticated architectural paradigms and technological innovations, demonstrating substantial enhancements in both model accuracy and computational efficiency [
25,
26]. The YOLOv11 framework encompasses five distinct model variants—n, s, l, m, and x—characterized by incrementally increasing network depth and detection precision, strategically designed to accommodate diverse application scenarios. Based on a comprehensive consideration of factors such as detection accuracy, model complexity, and hardware compatibility, we selected YOLO11s from these variants as the foundational architecture for our research [
27].
The framework of YOLOv11 comprises three fundamental components: the backbone, neck, and head. The backbone, responsible for feature extraction, implements the classical Darknet-53 deep residual network architecture, incorporating strategically designed convolutional layers with diverse kernel scales to facilitate comprehensive multi-scale feature capture. Notably, the C3k2 module has been integrated, leveraging its demonstrated capability in synthesizing high-level features with contextual information to enhance detection precision. Consequently, YOLOv11 implements a sophisticated modification to the CSPLayer, substituting the conventional C2f module with the more advanced C3k2 module. Following multiple convolutional operations, YOLOv11 incorporates the SPPF module to expand the receptive field and capture hierarchical features in complex environmental scenarios.
The neck component orchestrates sophisticated feature fusion, utilizing path aggregation networks and C3k2 modules to integrate multi-scale feature maps generated across various stages of the backbone, thereby enhancing the network’s capability to capture features across diverse spatial scales. The head component maintains a meticulously designed decoupled architecture, bifurcating into classification and localization prediction branches to effectively mitigate inherent task conflicts between classification and localization objectives. Furthermore, the classification detection head implements an innovative substitution of the conventional dual 3 × 3 convolutions with two depth-separable convolutions comprising DWConv and 1 × 1 convolutions, resulting in substantial optimizations in both model parameterization and computational requirements.
2.5. YOLO-MECD Model
Although YOLOv11 is designed as a general-purpose object detection model and demonstrates excellent performance, it can still be further optimized for citrus detection tasks by addressing specific target characteristics, such as the significant variation in fruit size, complex occlusion, and similar color and texture patterns, to enhance detection accuracy and adaptability. Consequently, YOLO-MECD, an enhanced derivative of YOLOv11s, was proposed by us. This novel model improved detection precision at a small size. The specific architectural enhancements encompass the following modifications:
(1) Implementation of the EMA attention mechanism to supersede the original C2PSA attention mechanism, facilitating enhanced network feature extraction capabilities while reducing model parameters.
(2) Substitution of the conventional CIoU loss function with the MPDIoU loss function, resulting in improved model detection precision and accelerated convergence rates.
(3) Integration of the CSPPC architecture to replace the C3K2 structure in YOLOv11, effectively reducing the model’s parametric complexity.
(4) Optimization of convolution operations in the backbone component, simultaneously achieving significant parameter reduction while enhancing small object detection capabilities.
The architectural framework of the YOLO-MECD model is illustrated in
Figure 3.
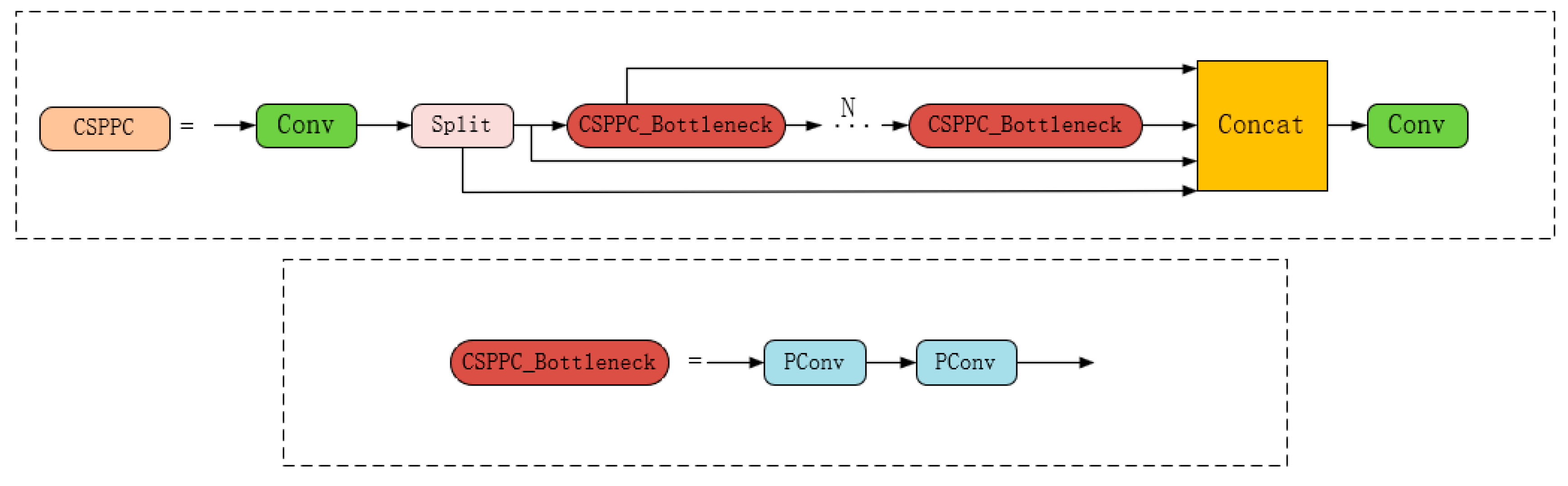
2.5.1. CSPPC Module
While reducing convolution operations in the backbone effectively diminishes model parameters and volume, it potentially results in increased GFLOPs. To enhance model efficiency without compromising detection precision, numerous researchers have implemented depth-wise convolution for feature extraction. Although this approach effectively reduces computational complexity, it simultaneously increases memory access requirements, resulting in diminished GFLOP efficiency. The C3K2 module in YOLOv11, incorporating multiple bottleneck modules, extracts comprehensive features but introduces excessive channel information redundancy. Consequently, certain channels may exhibit high similarity with others, resulting in redundant processing during forward propagation without contributing additional effective information, thereby increasing both computation and memory overhead.
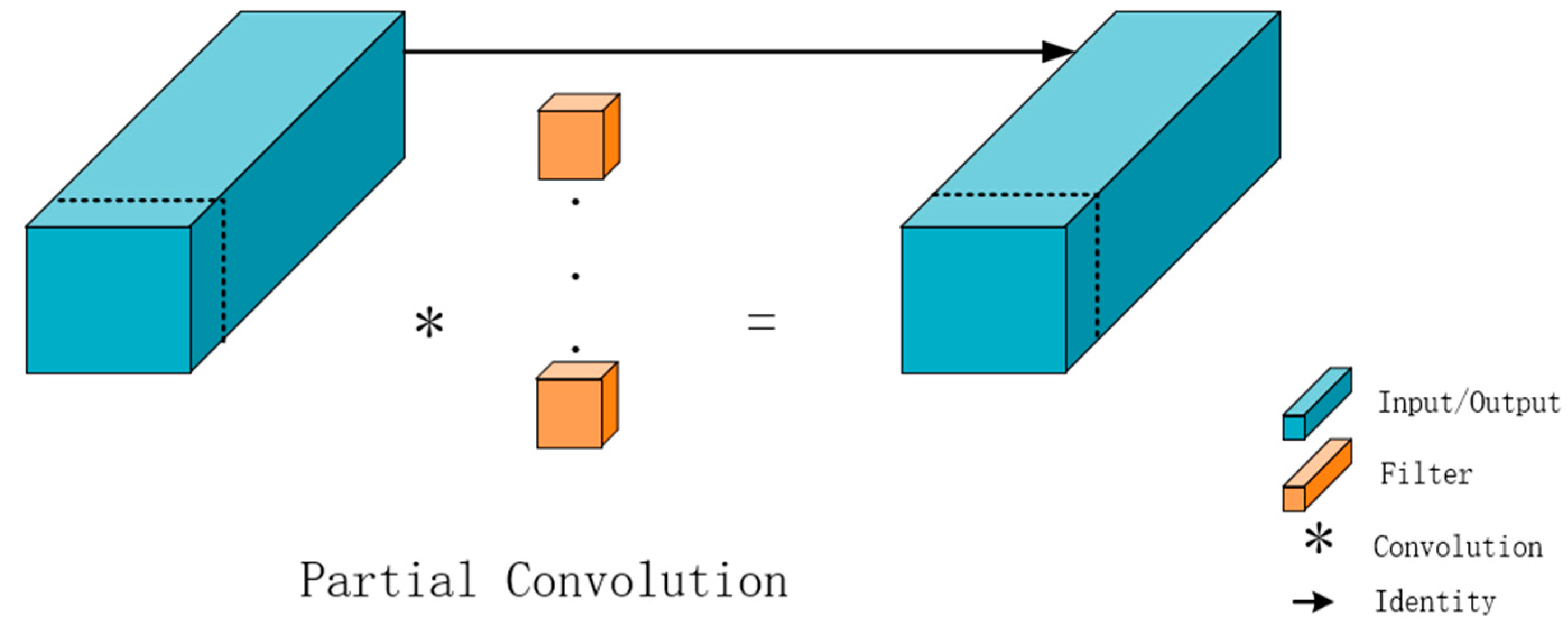
To conquer these limitations, this investigation implements PConv (partial convolution), a lightweight convolution structure characterized by high-speed inference capabilities [
28]. Based on this architecture, we have developed the CSPPC structure to supersede the C3K2 module in YOLOv11. The architectural framework of the CSPPC structure is illustrated in
Figure 4.
The fundamental architecture of PConv is predicated on the selective processing of a subset of input channels during convolution operations while maintaining channel integrity for non-processed channels. This innovative design paradigm achieves significant computational optimization through the elimination of redundant channel-wise calculations, facilitating enhanced spatial feature extraction efficiency while simultaneously improving real-time performance and model efficiency metrics without compromising operational capabilities.
In quantitative terms, given feature map dimensions
h and
w, total channel count
c, participating convolution channels
, and convolution kernel dimension
k, the computational complexity (FLOP) of the PConv module can be formally expressed through Equations (1) and (2). The architectural schema is presented in
Figure 5.
The implementation of PConv with a 1/4 convolution ratio demonstrates a remarkable reduction in computational complexity, achieving GFLOPs equivalent to 1/16 of conventional convolution operations, thereby substantially optimizing the detection model’s FLOP efficiency. Moreover, the selective engagement of cp channels in spatial feature extraction, while maintaining downstream feature channel integrity, facilitates substantial optimization of both computational requirements and memory access patterns.
The CSPPC module’s architectural innovation, characterized by the substitution of conventional convolution operations with PConv within the C3K2 framework and the integration of a dual-branch structural paradigm, achieves enhanced feature extraction capabilities while simultaneously implementing significant reductions in both parametric complexity and GFLOPs, culminating in a more efficient lightweight model architecture.
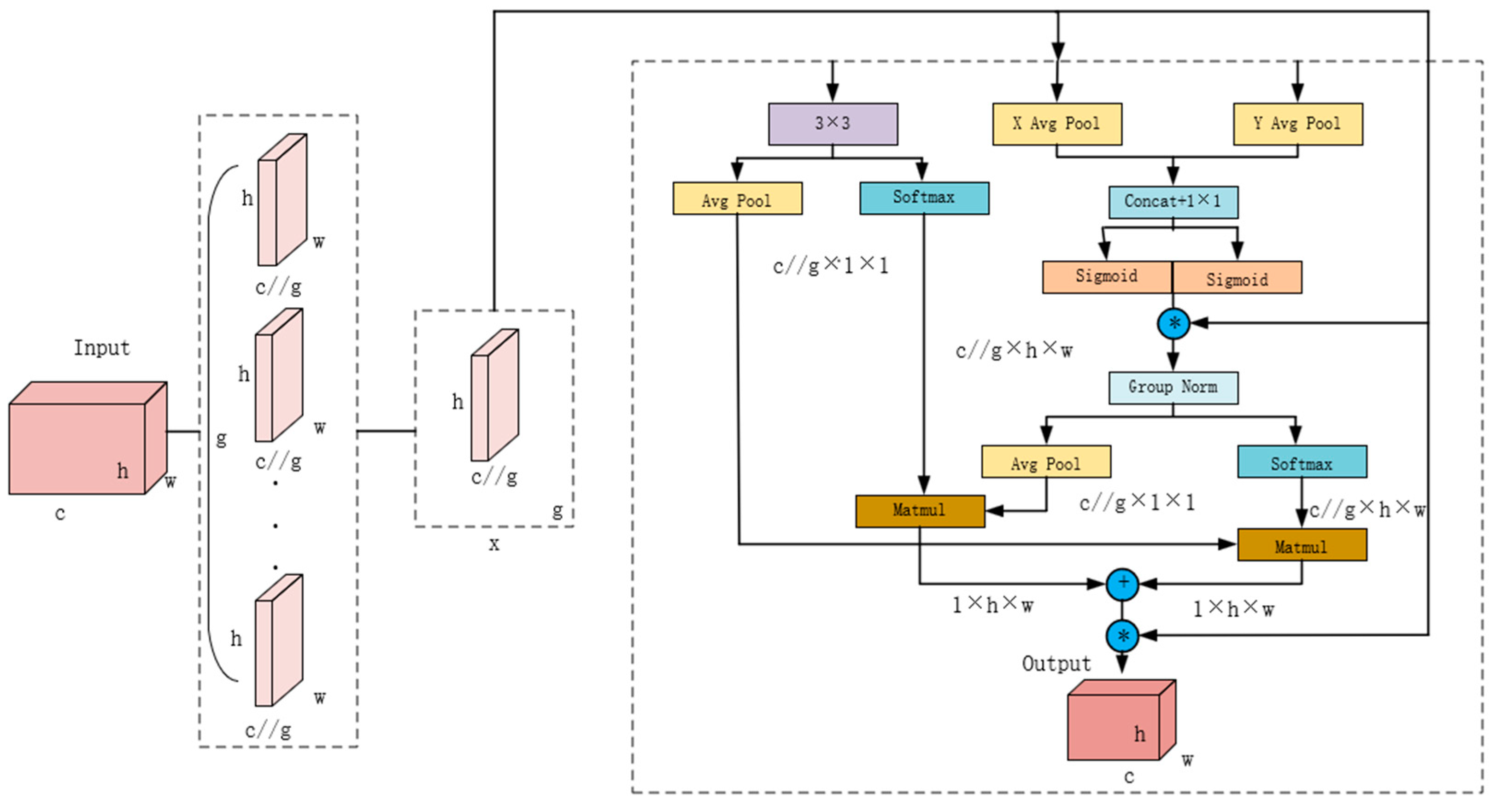
2.5.2. EMA Attention Mechanism
The attention mechanism serves as a critical architectural component facilitating selective feature emphasis, enabling the model to prioritize salient image characteristics while attenuating non-pertinent background information, thereby enhancing both detection performance metrics and generalization capabilities. EMA (efficient multi-scale attention) represents an optimized multi-scale attention module whose foundational principle is predicated on achieving efficient cross-channel learning through strategic channel reorganization and grouping methodologies while maintaining model complexity constraints [
29]. The architecture of the EMA attention mechanism is shown in
Figure 6.
The architectural framework incorporates multiple operational components: “X Avg Pool” and “Y Avg Pool” denoting one-dimensional horizontal and vertical global pooling operations, respectively; Conv representing convolutional operations; Matmul indicating matrix multiplication; GroupNorm signifying normalization procedures; Reweight representing weight redistribution; Groups denoting grouped convolution operations; and Sigmoid and Softmax functioning as activation functions. The asterisk * denotes the fusion of inputs directed towards the asterisk *.
In the feature grouping domain, input feature maps undergo strategic partitioning into g sub-features for diverse semantic information extraction, maintaining the relationship g<<C.
In the parallel sub-network section, EMA extracts attention weights of grouped feature maps through three parallel paths, where two paths adopt 1 × 1 convolution branches while the third path employs a 3 × 3 convolution branch. To capture cross-channel dependencies and alleviate the computational burden, EMA models the interaction of cross-channel information along the channel dimension. Specifically, in the 1 × 1 branches, two one-dimensional global average pooling operations are utilized, aggregating two channel attention maps within each group through multiplication to achieve cross-channel feature interaction. In the 3 × 3 branch, a 3 × 3 convolution is employed to capture local cross-channel interaction information, further expanding the feature space.
Additionally, the EMA architecture integrates cross-spatial learning mechanisms, facilitating the aggregation of multi-dimensional cross-spatial information to achieve comprehensive feature integration and enhanced network feature extraction capabilities.
2.5.3. MPDIoU Loss Function
The loss function represents an integral architectural component in detection model frameworks, serving as a critical metric for the quantitative assessment of prediction effectiveness. The function exhibits inverse proportionality between its magnitude and the spatial proximity of predicted bounding boxes to their corresponding ground truth coordinates. YOLOv11 employs the CIoU (complete intersection over union) boundary loss function, which can be formally expressed through the following mathematical formulation:
where
W and
H represent the width and height of the predicted citrus bounding box,
Wt and
Ht denote the width and height of the ground truth bounding box,
Bprd and
Bgt represent the centroids of the predicted and ground truth bounding boxes, respectively; ρ indicates the Euclidean distance between
Bprd and
Bgt; c represents the diagonal distance of the smallest enclosing box containing both predicted and ground truth boxes;
IoU (intersection over union) quantifies their degree of overlap.
LCIoU represents the CIoU loss function. As evident from Equations (3)–(5), when the aspect ratios of predicted and ground truth boxes are identical, ν equals zero. Under these conditions, the effectiveness of the CIoU loss function is compromised, resulting in varying sensitivities to objects of different scales, particularly disadvantageous for small object localization. However, given the prevalence of small objects in our custom citrus dataset, utilizing this loss function frequently results in detection omissions.
To effectively address this limitation, we introduce the MPDIoU loss function [
30]. The MPDIoU loss function encompasses all relevant factors typically considered in other loss functions, providing a more comprehensive approach to object detection boundary refinement. MPDIoU simplifies similarity comparisons between two detection boxes, applicable to both overlapping and non-overlapping boundary box regression. The computational principles of MPDIoU are illustrated in
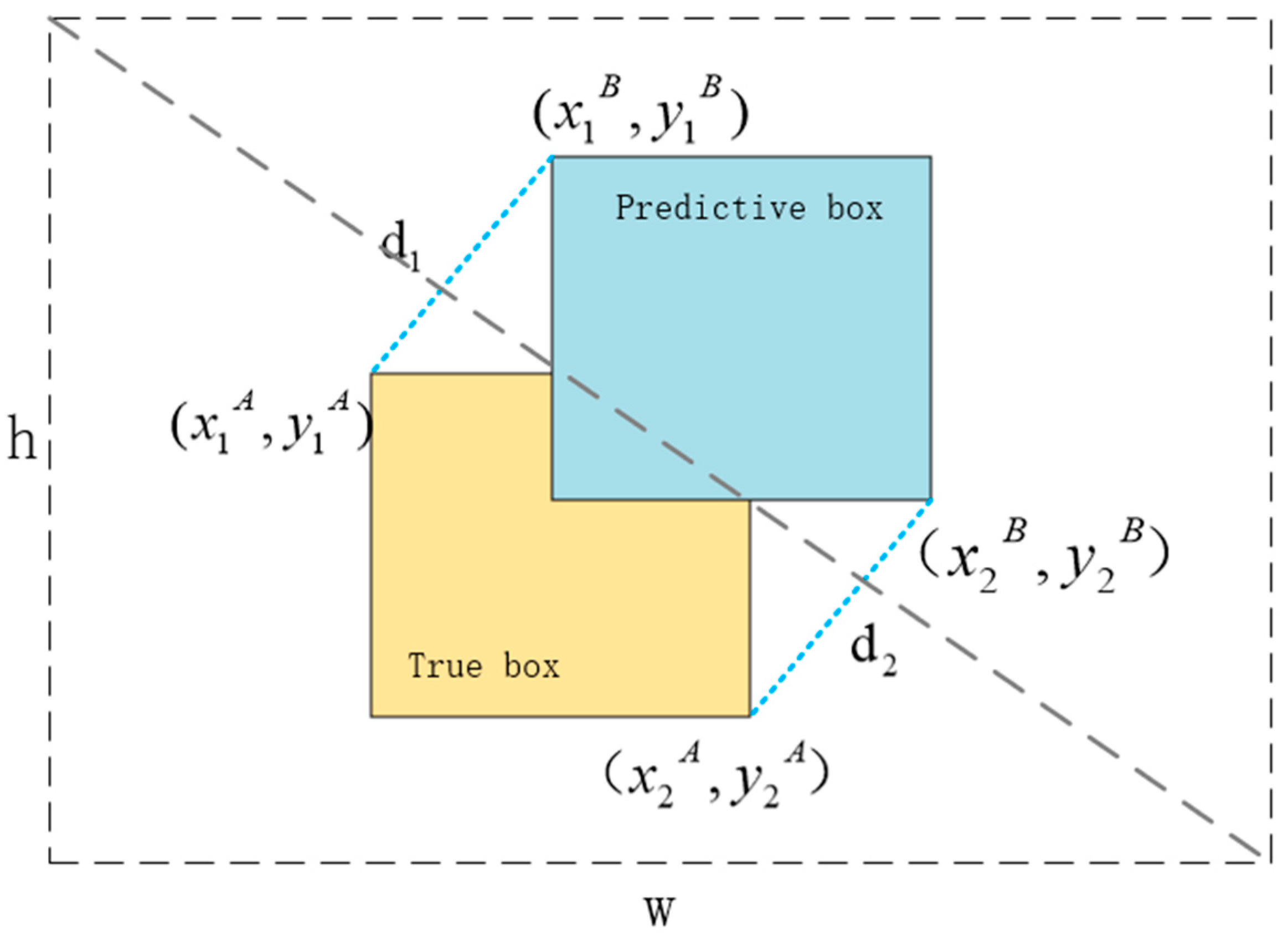
Figure 7. It enhances prediction accuracy and accelerates model regression convergence by calculating the minimum point distance between predicted and actual boxes as a similarity metric. The mathematical formulation of MPDIoU is expressed as follows:
where variables
d1 and
d2 represent the distances between the top-left and bottom-right corners of ground truth box
A and the predicted box
B, respectively. w and h denote the width and height of the input image. (x1B, y1B) and (x2B, y2B) represent the coordinates of the top-left and bottom-right corners of the predicted box, respectively.
2.5.4. Reconstruction of Detection Layer
The YOLOv11 network detection layer architecture is illustrated in
Figure 8a. Following feature fusion, the feature maps output by detection heads p3, p4, and p5 exhibit dimensions of 80 × 80, 40 × 40, and 20 × 20 pixels, respectively, corresponding to small, medium, and large targets. In the feature maps output by detection heads p3, p4, and p5, each pixel represents information from 32 × 32, 16 × 16, and 8 × 8 pixel regions of the input network image, respectively. However, numerous target objects in the image possess dimensions smaller than 8 × 8 pixels, resulting in relatively limited detail information in the output feature maps, consequently leading to suboptimal detection accuracy for small targets and significant detection omissions.
To enhance small target detection capabilities, numerous researchers have implemented additional P2 detection heads specifically for small targets, as illustrated in
Figure 8b. Through this approach, the output feature map dimensions are 160 × 160, 80 × 80, 40 × 40, and 20 × 20 pixels, respectively, enabling the effective detection of targets larger than 4 × 4 pixels in the input image, thereby significantly improving detection accuracy and reducing omission incidents. Although this methodology demonstrates substantial improvements in detection performance, it results in significant increases in both parameter count and computational complexity, unfavorable for model deployment on embedded devices and mobile platforms.
Based on these considerations, this investigation implements network structure optimization by reducing downsampling operations in the backbone network to decrease network layers, resulting in feature map dimensions of 160 × 160, 80 × 80, and 40 × 40 for P3, P4, and P5 detection heads, respectively, facilitating enhanced small target detection. The detection layer architecture is illustrated in
Figure 8c. Compared to methods incorporating additional small target detection heads, this optimization achieves significant reductions in network layers, computational complexity, and parameter count, better aligning with practical application requirements.
2.6. Experimental Configuration
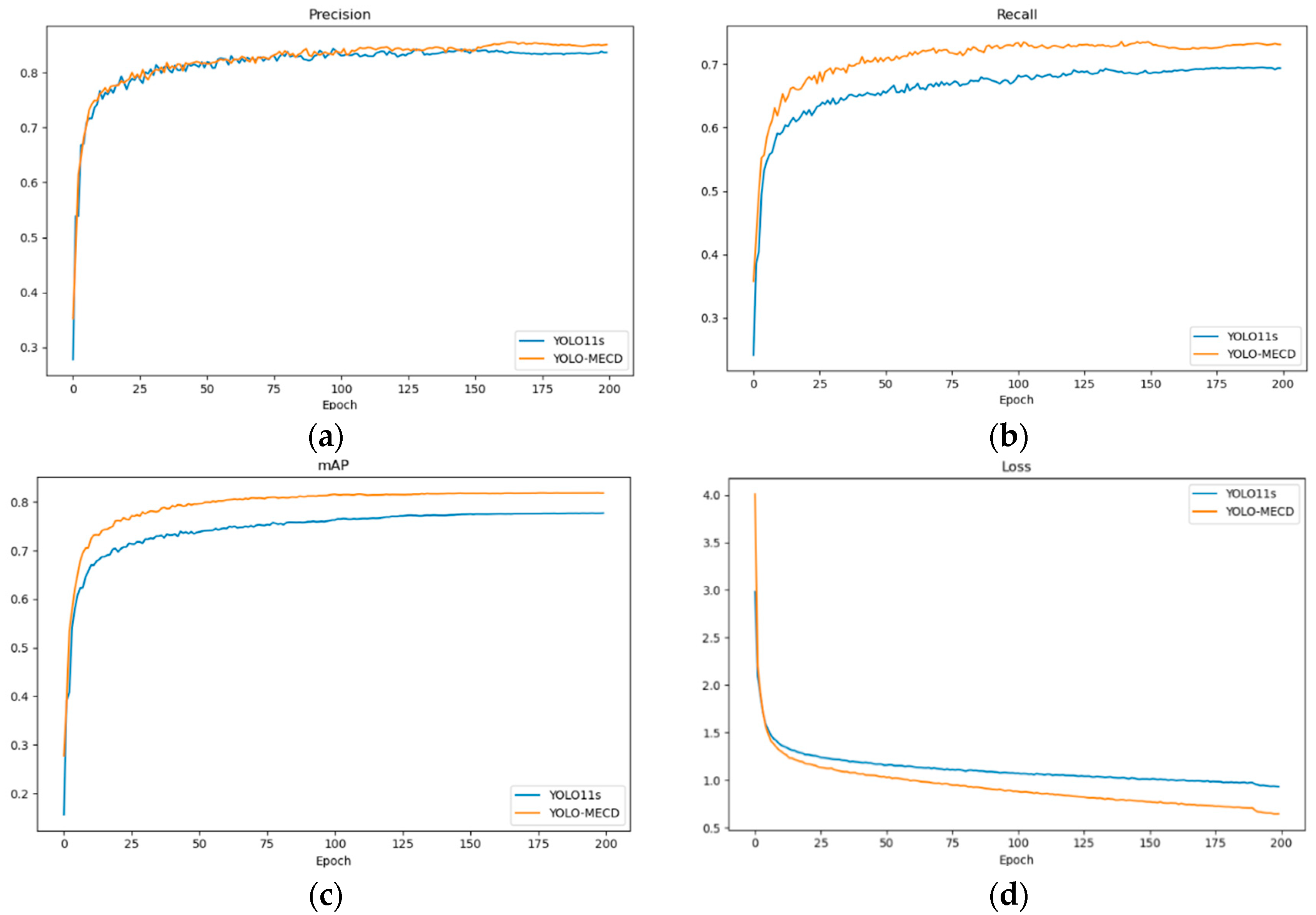
The experimental framework is implemented on a Windows 10 (Professional Edition) operating system, utilizing an Nvidia GeForce RTX 3060Ti (NVIDIA Corporation, Santa Clara, CA, USA) graphics processing unit with 12 GB VRAM capacity. The software infrastructure comprises CUDA 12.1, Python 3.12, and the PyTorch 2.3 deep learning framework. Training hyperparameters are configured with the following specifications: learning rate initialized at 0.0001, batch size of 16, weight decay coefficient of 0.0005, momentum parameter of 0.937, iteration count of 200, and SGD optimization algorithm. Consistency in dataset utilization and training configurations is maintained across all model implementations.
2.7. Evaluation Metrics
The precision (
P), recall (
R), mean average precision (mAP), F1 score, model size, parameter count, and GFLOPs were utilized to evaluate the result in this paper. Precision (
P), a fundamental metric, quantifies the ratio of true positive predictions to total positive predictions, with higher values indicating enhanced model discrimination against false positive identifications. The mathematical formulation for precision computation is expressed as follows:
Recall (
R) quantifies the ratio of correctly identified positive samples to the total number of actual positive samples in the dataset. An elevated recall value indicates enhanced model proficiency in comprehensive target object detection. This metric can be mathematically formulated as:
mAP (mean average precision) quantifies the arithmetic mean of precision values across multiple categories, while the F1 score serves as a harmonized metric that integrates both precision and recall. Parameter count serves as a metric for architectural complexity, where reduced parameterization enables enhanced deployment capabilities on computationally constrained platforms. FLOPs provide a quantitative measure of computational complexity, where optimization of this metric facilitates efficient model execution in edge computing environments.
Within the context of the presented mathematical formulations, TP (true positive) denotes the cardinality of correctly classified positive instances, FP (false positive) represents the quantity of negative instances erroneously classified as positive, and FN (false negative) indicates the number of positive instances incorrectly classified as negative.
5. Conclusions
To achieve the rapid and accurate detection of on-tree and fallen citrus fruits in complex environments, this paper proposes an improved citrus detection model named YOLO-MECD. The model enhances feature extraction and detection accuracy by introducing the EMA (efficient multi-scale attention) module to replace the C2PSA module. Simultaneously, the CSPPC module, designed based on partial convolution, replaces the C3K2 module, effectively reducing the model’s parameter count and computational complexity. To further optimize performance, the model adopts the MPDIoU loss function instead of the CIoU loss function, which not only improves detection accuracy but also accelerates convergence speed. Additionally, by streamlining the number of convolutional layers in the backbone network, the model significantly enhances small target detection capability while substantially reducing the number of parameters, laying a solid foundation for mobile deployment. The experimental results demonstrate that, compared to the original YOLOv11 model, YOLO-MECD achieved improvements of 0.2, 4.1, and 3.9 percentage points in precision (P), recall (R), and mean average precision (mAP), respectively, while significantly enhancing feature extraction capabilities and effectively reducing the occurrence of missed detections, false detections, and repeated detections. Under the condition of substantially optimized model complexity (with a 75.6% reduction in parameter count), YOLO-MECD achieved P, R, and mAP values of 84.4%, 73.3%, and 81.6%, respectively. Compared to YOLOv8, YOLOv9, and YOLOv10, YOLO-MECD improved mAP by 3.8, 3.2, and 5.5 percentage points, demonstrating significant performance advantages. Furthermore, the method exhibited excellent adaptability in detection tasks for citrus fruits such as lingonberries, fully validating the model’s strong generalization capability and practical application value. It is worth noting that the issue of duplicate counting that may arise during multi-angle shooting will be addressed in future research. In the future, techniques such as knowledge distillation and network pruning can be employed to further optimize the model structure, significantly reducing computational complexity while improving detection accuracy. Additionally, we plan to deploy this model on edge devices for practical application verification, assessing its performance and feasibility in real-world environments.




 represents modified components.
represents modified components.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}