
Research and Implementation of Agronomic Entity and Attribute Extraction Based on Target Localization

Abstract
1. Introduction
2. Materials and Methods
2.1. Schema Layer of Wheat Agronomic Knowledge Graph
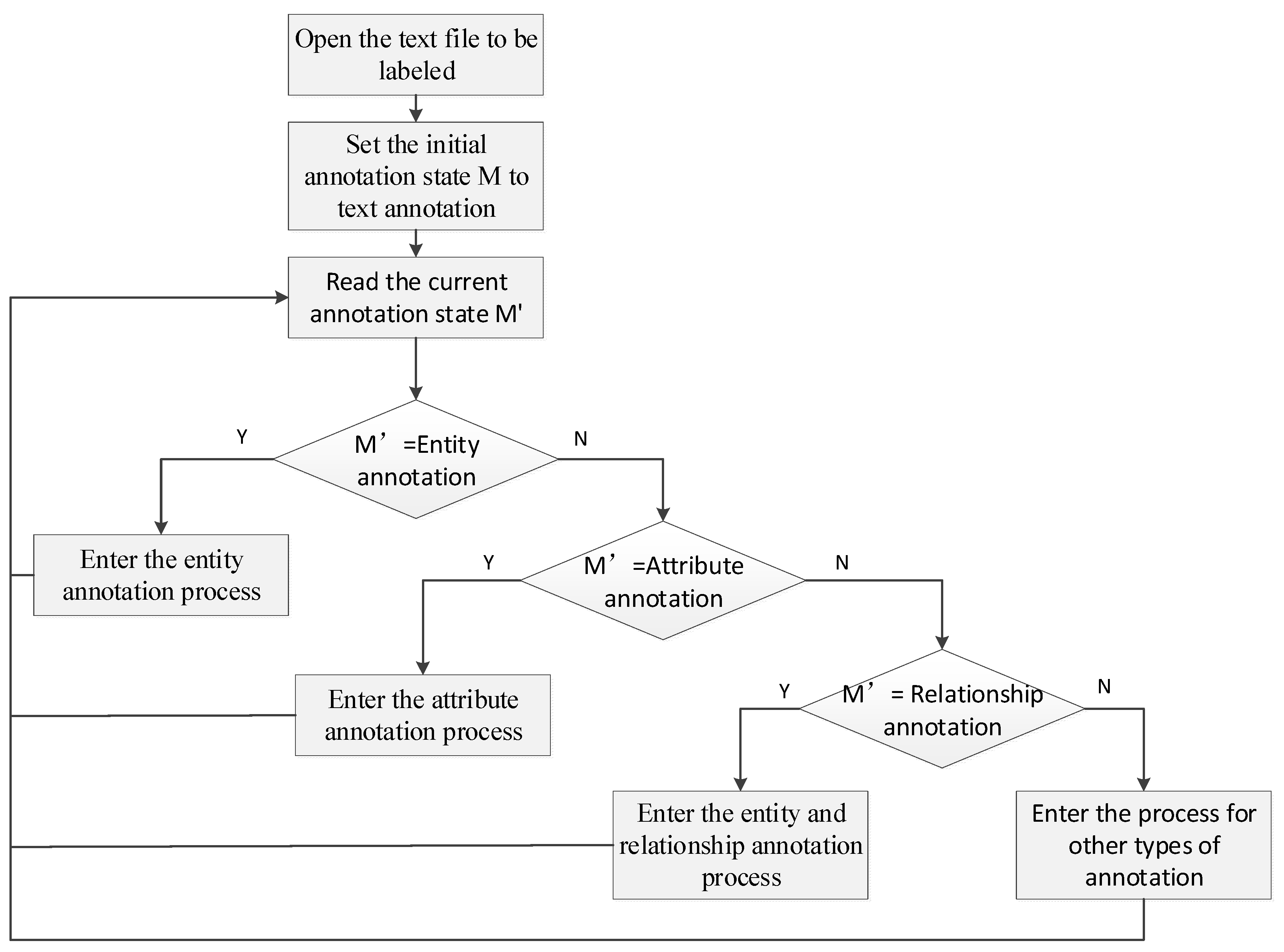
2.2. Natural Language Annotation Method
- Entity annotation process:
- (a)
- If corresponding entity record file does not exist, create entity record file and go to (c).
- (b)
- Read the record file and highlight the text and its type based on the record.
- (c)
- Read entity configuration file and obtain entity type set E.
- (d)
- Select target text w.
- (e)
- If w is not target object, then display the selected text normally, delete the annotated entity type, and delete its record information in the entity record file, go to (i).
- (f)
- Display all entity types in E, and suppose w’s type is c.
- (g)
- If , then add a new entity type c and modify the entity configuration file.
- (h)
- Set the selected text type to c and highlight it, and record the location and type of target text to complete the annotation for w.
- (i)
- If there exist any unlabeled entities, then go to (d).
- (j)
- Complete the annotation for all entities.
- Entity attribute annotation process:
- (a)
- If corresponding entity attribute record file does not exist, then create a new entity attribute record file.
- (b)
- Extract the annotated entity set S and its corresponding type F from the entity annotation record file.
- (c)
- If S is empty, go to (j).
- (d)
- Read the entity attribute record file, highlight the attribute and its corresponding entity, and annotate the type of attribute.
- (e)
- Select target attribute text a to be annotated. If a is not an attribute of any entity in S, go to (k).
- (f)
- a is an attribute of entity b, if , complete the entity annotation to which the attribute belongs, go to (j).
- (g)
- Let the entity type of b be el and b be of type sl, read the attribute set of el from the configuration file, denoted by at. If , add a new attribute type sl and modify the entity attribute configuration file.
- (h)
- Set the selected text type to sl and highlight it, pointing to the entity it belongs to. Modify the entity attribute record file to record a’s location and attribute type and the entity b a belongs to, and complete the annotation for a.
- (i)
- If there exists any unlabeled entity attribute, go to (e), otherwise go to (k).
- (j)
- Display the selected text normally, delete the annotated entity attribute type, and delete its record in the entity attribute record file.
- (k)
- Complete the annotation of all entity attributes.
- Entity relation annotation process:
- (a)
- If corresponding entity relation record file does not exist, create a new entity relation record file.
- (b)
- Extract the annotated entity set S and its corresponding type F from the entity annotation record file.
- (c)
- If S is empty, no entities exist for relationship annotation, prompt to complete entity annotation first, go to (l).
- (d)
- Read the entity relation record file, highlight the relations and their corresponding entities, the type of entity, and the type of relation.
- (e)
- Select an entity pair text that has a relation to be annotated ra and rb. If , complete entity annotation for ra and rb, go to (j).
- (f)
- If no relations exist between ra and rb, go to (j).
- (g)
- Suppose the entity type of ra and rb was la and lb, respectively, and their relation type is lr. Read the entity relationship configuration file and search for the relationship type set lx between la and lb.
- (h)
- If , then add a new entity relation type <la,lr,lb>, modify the entity relation configuration file, and go to (l).
- (i)
- Annotate the relationship between ra and rb as lr, and write the location information of ra and rb and lr into the relationship record file to complete the relation annotation between ra and rb. Go to (k).
- (j)
- Remove the relationship connection and relationship type label between ra and rb, delete its record in the entity relation record file.
- (k)
- If there exist any unlabeled entity relations, go to (e).
- (l)
- Complete annotation of all entity relationships.
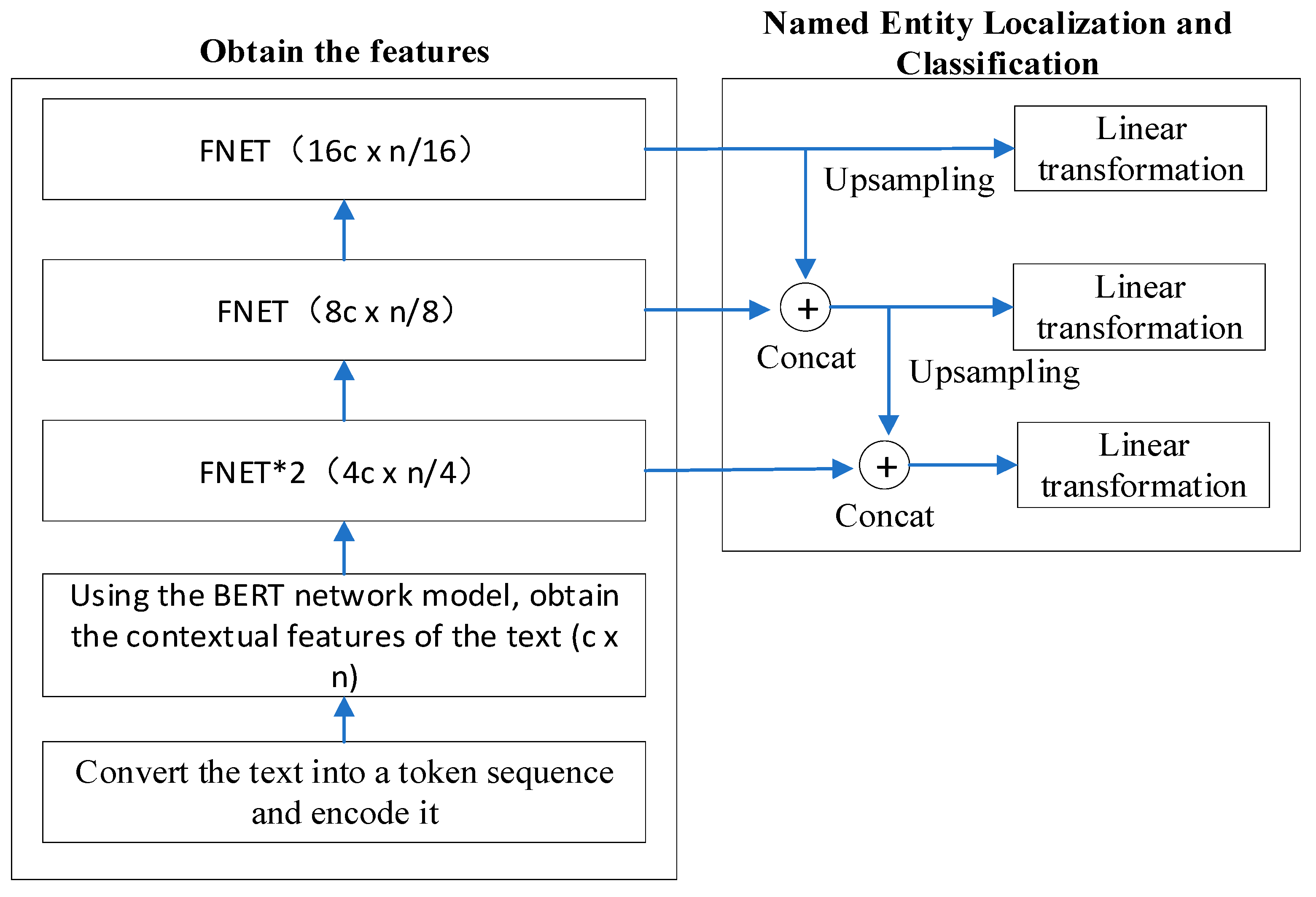
2.3. Named Entity Recognition
2.3.1. Network Structure for EntityDetectModel
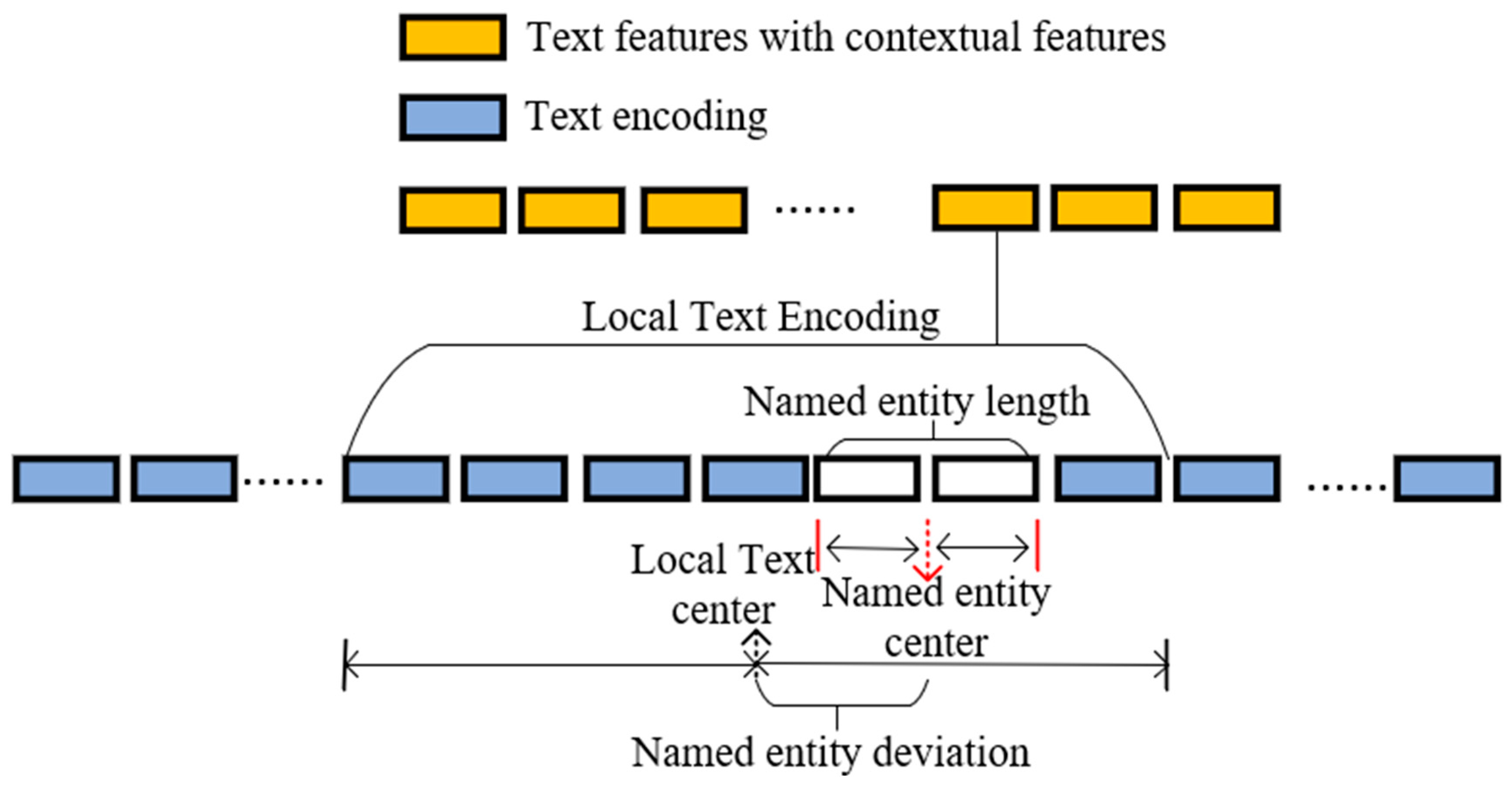
2.3.2. Positive and Negative Sample Determination and Loss Function
- (1)
- Set the positive sample list to z = [], the actual named entity list for positive sample predictions to zm = [], and the negative sample list to f = [].
- (2)
- Given the input Bert feature length as bw and the final feature length as fw, the text interval length is set to interval = Γbw/fw˥.
- (3)
- Using interval as the spacing, divide the input text length into fw intervals, and form a set QT with all intervals as elements: QT = {[0, interval-1], [interval, 2*interval-1], …}.
- (4)
- Form a range from the start and end position indices of the actual named entities, form a set GT consisting of the ranges of all named entities, and obtain DT by taking the Cartesian product of GT and QT.
- (5)
- For each element in DT, calculate the intersection-over-union (the ratio of intersection length to the total length, abbreviated as IOU in the following text) between the two intervals to form a set DT1. Set a positive sample selection threshold α and set the values in DT1 with an IOU value less than α to 0.
- (6)
- For each element g in GT, select the element p in QT with the highest IOU value as the positive sample, remove p from QT, add it to z, and add g to zm.
- (7)
- For each element q in QT, let the element in GT with the highest IOU value be g1. If the corresponding IOU value o > α, then remove q from QT, add it to z, and add g1 to zm.
- (8)
- Treat the remaining elements in QT as negative samples and add them to f.
2.4. Data Collection and Processing
3. Results and Discussion
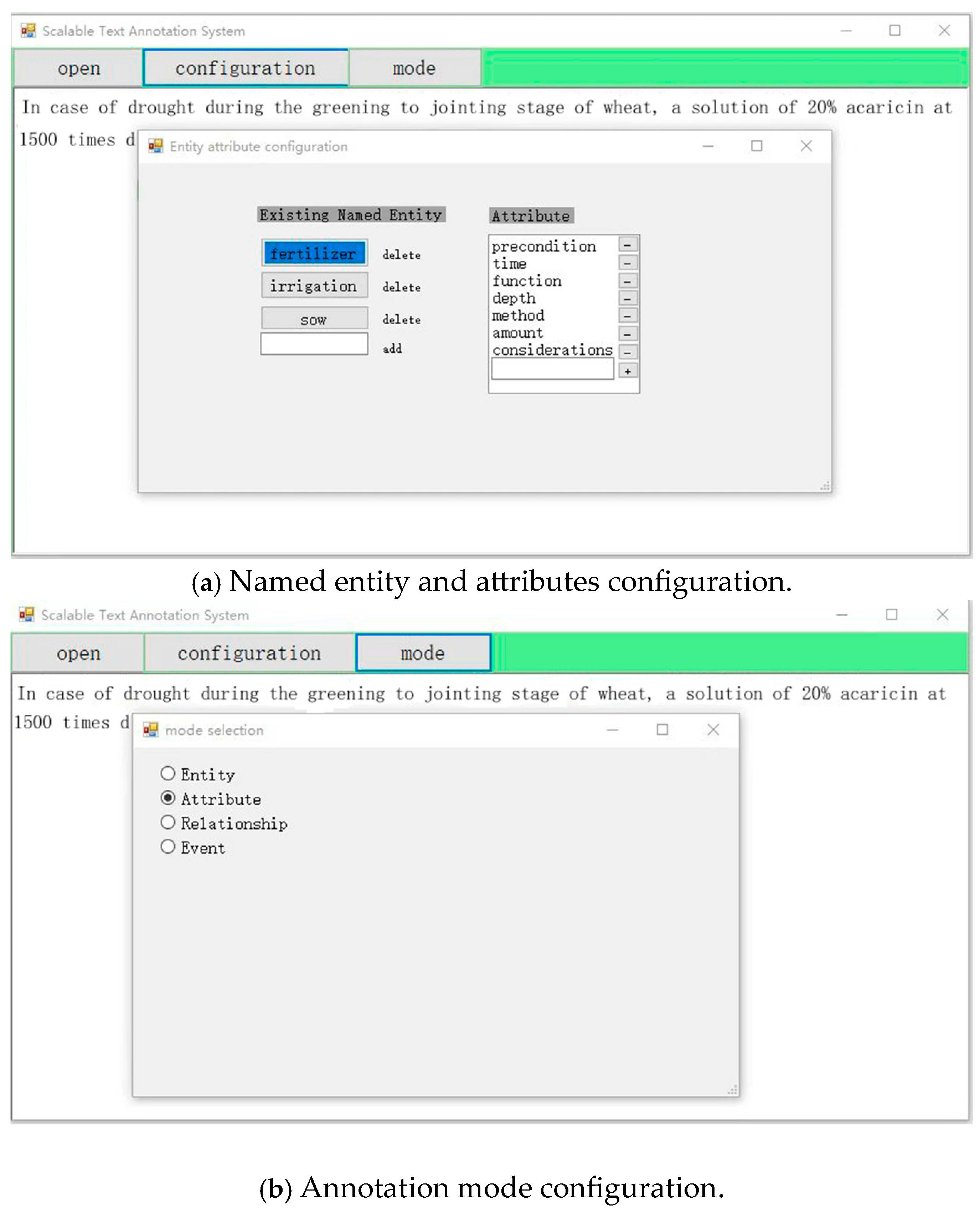
3.1. Scalable Text Annotation System
3.2. Performance Analysis for EntityDetectModel
- (1)
- Count the types and quantities of named entities and attributes of different categories in the training dataset;
- (2)
- Sort them in descending order of quantity, and label their category list as Clist and quantity list as Alist;
- (3)
- Train the model in pre-set quantity of epochs to obtain model weights;
- (4)
- Validate the trained model on the training set and set the set of correctly predicted entities as U;
- (5)
- Take the first category from Clist and record it as Cm;
- (6)
- Take the first number from Alist and record it as Af, and take the last number and record it as Al;
- (7)
- If Af/Al < 2, go to 11;
- (8)
- Extract all predictions of category Cm from U and arrange them in descending order of prediction probability, denoted as list P with length Pl;
- (9)
- Compute d = Af − Al, if Pl < d, then PG = P; otherwise, take the first d ground truths from P and denote them as Pd, PG = Pd;
- (10)
- Modify the training set and remove the ground truth annotation in PG from the training set;
- (11)
- The end.
3.3. Construction of Wheat Agronomy Knowledge Graph Database
4. Conclusions and Prospect
- A scalable natural language annotation method has been proposed, which can annotate multi-level and different objects as needed, solving the problem of diverse annotation functions and lack of attribute annotation in current annotation tools, and developing a corresponding annotation system.
- An entity and attribute recognition model based on target localization, EntityDetectModel, was proposed. Firstly, Bert was used to extract text features with contextual information, and then convolutional neural networks were used to further extract text features at different depths. The high-level semantic features are fused to the low-level to improve the semantic expression ability of the low-level. At each feature layer, the location information of the entity and its corresponding attributes are directly regressed. Comparing EntityDetectModel with some recently published models, our model had the best recognition performance, with recognition precision, recall rate, and F1 values of 91.0%, 83.4%, and 87.0% respectively.
- Taking the wheat variety Gaoyou 2018 as an example, a trained model was used to extract its named entities and attributes. A total of 521 entities and 537 attributes were extracted, forming the Gaoyou 2018 agronomic database.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fensel, D.; Şimşek, U.; Angele, K.; Huaman, E.; Kärle, E.; Panasiuk, O.; Toma, I.; Umbrich, J.; Wahler, A. Introduction: What is a knowledge graph? In Knowledge Graphs: Methodology, Tools and Selected Use Cases; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–10. [Google Scholar]
- Acosta, M.; Zaveri, A.; Simperl, E.; Kontokostas, D.; Auer, S.; Lehmann, J. Crowdsourcing Linked Data Quality Assessment; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Zou, X. A survey on application of knowledge graph. J. Phys. Conf. Ser. 2020, 1487, 012016. [Google Scholar] [CrossRef]
- Peng, Y.N. Development of A Corn Planting Management System Based on Knowledge Graph; Shandong Agricultural University: Tai’an, China, 2023. [Google Scholar]
- Xu, X.; Yue, J.Z.; Zhao, J.P.; Wang, Y.K.; Ma, X.M.; Qian, X.L. Construction and Visualization of Knowledge Map of Wheat Varieties. Comput. Syst. Appl. 2021, 30, 286–292. [Google Scholar] [CrossRef]
- Zhang, S.W.; Wang, Z.; Wang, Z.L. Prediction of wheat stripe rust disease by combining knowledge graph and bidirectional long short term memory network. Trans. Chin. Soc. Agric. Eng. 2020, 36, 172–178. [Google Scholar]
- Li, R.; Su, X.; Zhang, H.; Zhang, X.; Yao, Y.; Zhou, S.; Zhang, B.; Ye, M.; Lv, C. Integration of diffusion transformer and knowledge graph for efficient cucumber disease detection in agriculture. Plants 2024, 13, 2435. [Google Scholar] [CrossRef] [PubMed]
- Ge, W.; Zhou, J.; Zheng, P.; Yuan, L.; Rottok, L.T. A recommendation model of rice fertilization using knowledge graph and case-based reasoning. Comput. Electron. Agric. 2024. [Google Scholar] [CrossRef]
- Wang, J.L. Research on Knowledge Graph Fusion Method for Fields of Wheat Production; Henan Agricultural University: Zhengzhou, China, 2024. [Google Scholar] [CrossRef]
- Syed, M.; Al-Shukri, S.; Syed, S.; Sexton, K.; Greer, M.L.; Zozus, M.; Bhattacharyya, S.; Prior, F. DeIDNER Corpus: Annotation of clinical discharge summary notes for named entity recognition using brat tool. Med. Inform. Eur. Conf. 2021, 281, 432–436. [Google Scholar]
- Lu, G.; Liu, Y.; Wang, J.; Wu, H. CNN-BiLSTM-Attention: A multi-label neural classifier for short texts with a small set of labels. Inf. Process. Manag. 2023, 60, 103320. [Google Scholar] [CrossRef]
- Wang, C.Q.; Zhou, Y.H.; Zhang, S.X.; Yu, Y.H.; Yu, X.L. Aspect-opinion pair extraction of new energy vehicle complaint text based on context enhancement. J. Comput. Appl. 2024, 44, 2430–2436. [Google Scholar]
- Takanobu, R.; Zhang, T.; Liu, J.; Huang, M. A hierarchical framework for relation extraction with reinforcement learning. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7072–7079. [Google Scholar]
- Liu, J.; Chen, S.; Wang, B.; Zhang, J.; Li, N.; Xu, T. Attention as relation: Learning supervised multi-head self-attention for relation extraction. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3787–3793. [Google Scholar]
- Eberts, M.; Ulges, A. Span-based joint entity and relation extraction with transformer pre-training. In Proceedings of the 24th European Conference on Artificial Intelligence (ECAI), Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2006–2013. [Google Scholar]
- Tang, R.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. Boundary regression model for joint entity and relation extraction. Expert Syst. Appl. 2023, 229, 120441. [Google Scholar] [CrossRef]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Tapas, N.; Hwee, T.N. Effective modeling of encoder-decoder architecture for joint entity and relation extraction. CoRR 2019, 34, abs/1911.09886. [Google Scholar] [CrossRef]
- Lu, J.; Yang, W.; He, L.; Feng, Q.; Zhang, T.; Yang, S. A Method for Extracting Fine-Grained Knowledge of the Wheat Production Chain. Agronomy 2024, 14, 1903. [Google Scholar] [CrossRef]
- Huang, Q.; Tao, Y.; Wu, Z.; Marinello, F. Based on BERT-wwm for Agricultural Named Entity Recognition. Agronomy 2024, 14, 1217. [Google Scholar] [CrossRef]
- Cheng, J.R.; Liu, J.X.; Xu, X.B.; Xia, D.; Liu, L.; Sheng, V.S. A review of Chinese named entity recognition. KSII Trans. Internet Inf. Syst. 2021, 15, 2012–2030. [Google Scholar]
- Jiang, H.J. Slot Filling via Deep Learning; Zhejiang University: Hangzhou, China, 2017. [Google Scholar]
- Detroja, K.; Bhensdadia, C.K.; Bhatt, B.S. A survey on relation extraction. Intell. Syst. Appl. 2023, 19, 200244. [Google Scholar] [CrossRef]
- Wang, C.D.; Xu, J.; Zhang, Y. Survey of entity relation extraction. Comput. Eng. Appl. 2020, 56, 25–35. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Prec | Rec | F1 |
|---|---|---|---|
| Reference [13] | 51.5 | 62.4 | 56.4 |
| Reference [14] | 57.7 | 66.7 | 61.9 |
| Reference [15] | 69.1 | 75.9 | 72.3 |
| Reference [16] | 71.3 | 75.2 | 73.2 |
| EntityDetectModel | 91.0 | 83.4 | 87.0 |
| Feature Layer Used for Prediction | Prec | Rec | F1 |
|---|---|---|---|
| The top-level single-layer feature | 52.3 | 45.7 | 48.8 |
| The mid-level single-layer feature | 61.8 | 53.0 | 57.1 |
| The bottom-level single-layer feature | 55.4 | 51.7 | 53.5 |
| Non-fused three-layer features | 85.3 | 79.7 | 82.4 |
| Fused three-layer features | 91.0 | 83.4 | 87.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Zhu, Y.; Li, S.; Wu, S.; E, Y.; Liu, S. Research and Implementation of Agronomic Entity and Attribute Extraction Based on Target Localization. Agronomy 2025, 15, 354. https://doi.org/10.3390/agronomy15020354
Guo X, Zhu Y, Li S, Wu S, E Y, Liu S. Research and Implementation of Agronomic Entity and Attribute Extraction Based on Target Localization. Agronomy. 2025; 15(2):354. https://doi.org/10.3390/agronomy15020354
Chicago/Turabian StyleGuo, Xiuming, Yeping Zhu, Shijuan Li, Sheng Wu, Yue E, and Shengping Liu. 2025. "Research and Implementation of Agronomic Entity and Attribute Extraction Based on Target Localization" Agronomy 15, no. 2: 354. https://doi.org/10.3390/agronomy15020354
APA StyleGuo, X., Zhu, Y., Li, S., Wu, S., E, Y., & Liu, S. (2025). Research and Implementation of Agronomic Entity and Attribute Extraction Based on Target Localization. Agronomy, 15(2), 354. https://doi.org/10.3390/agronomy15020354