
CSGD-YOLO: A Corn Seed Germination Status Detection Model Based on YOLOv8n
 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
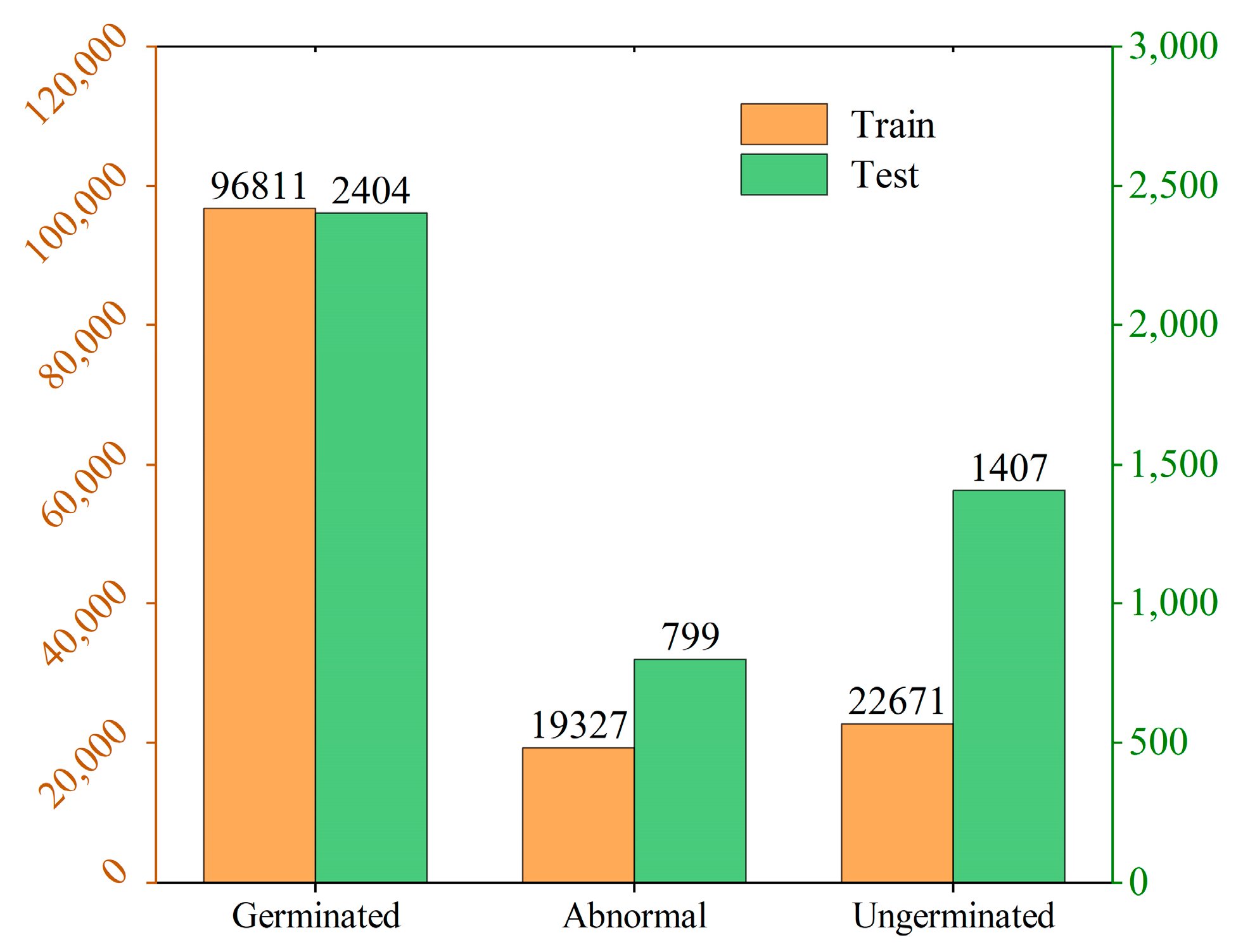
2.1. Construction of Corn Seed Germination Dataset
2.1.1. Corn Seed Material
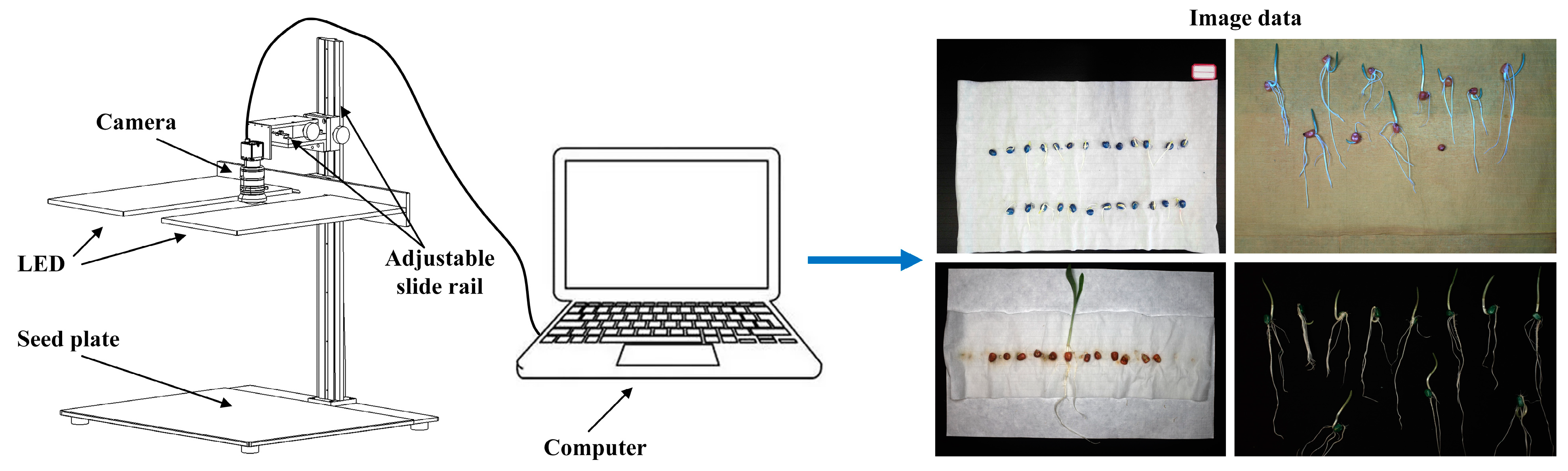
2.1.2. Image Acquisition
2.1.3. Data Preprocessing
2.1.4. Data Enhancement
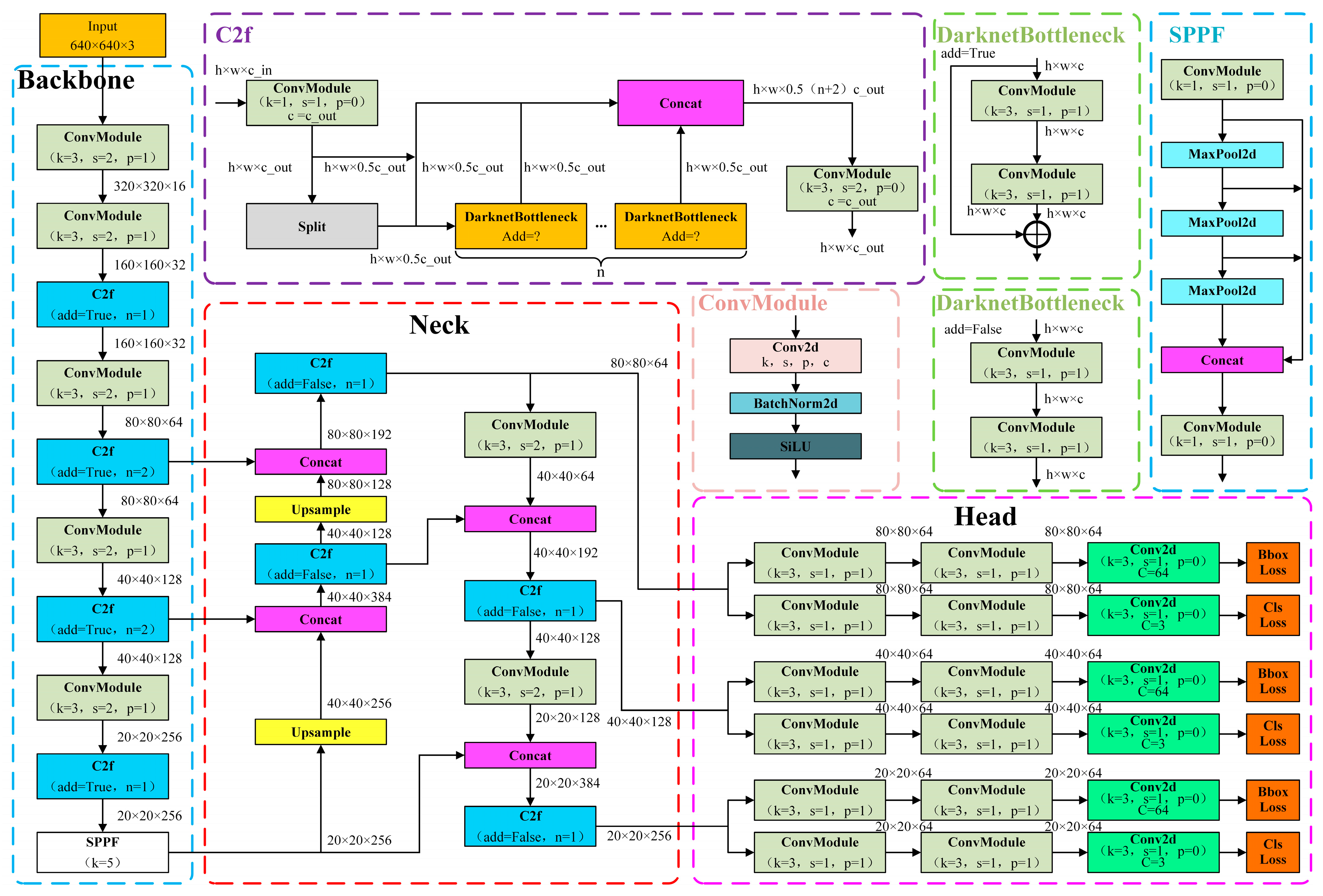
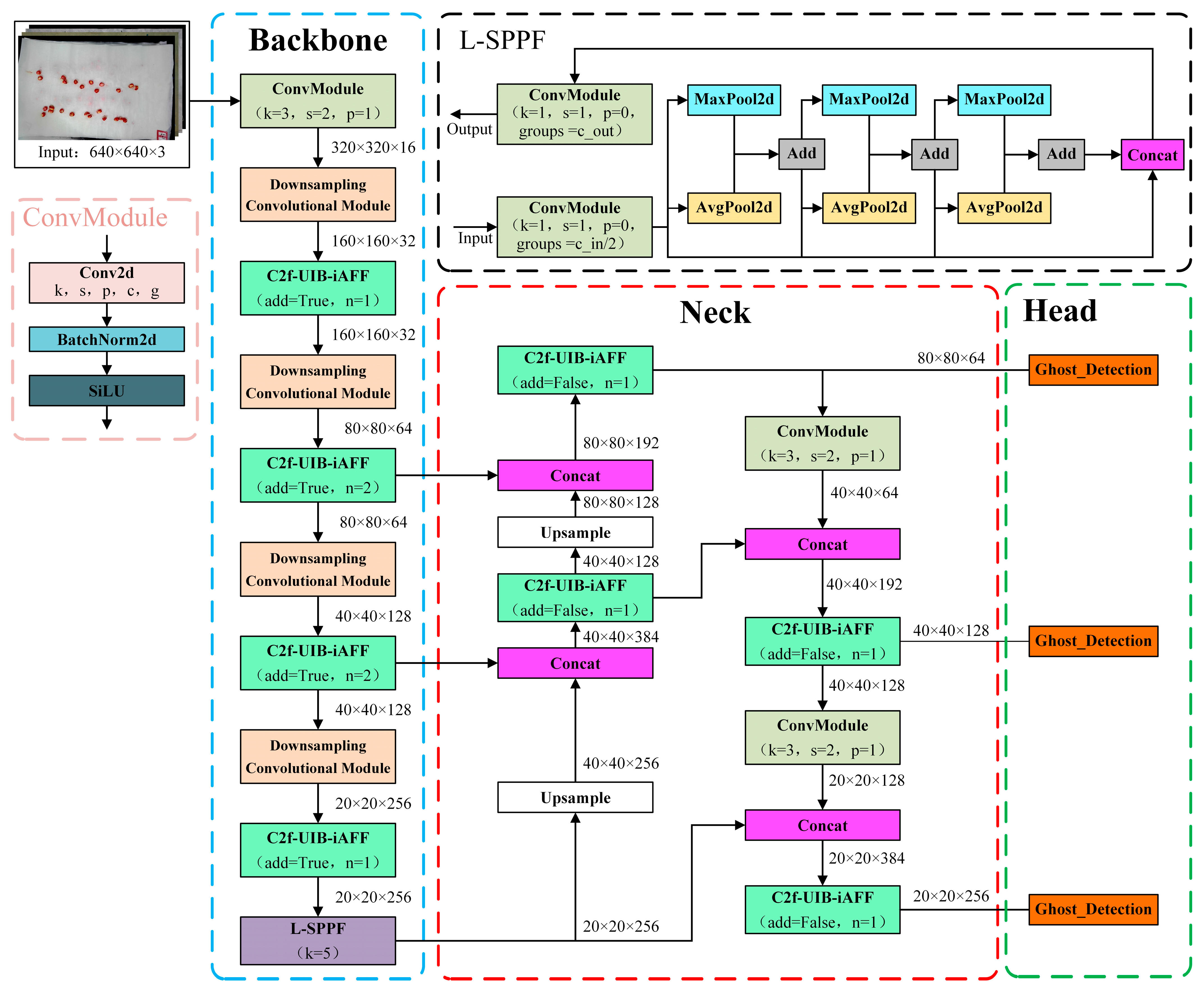
2.2. The Network Structure of CSGD-YOLO
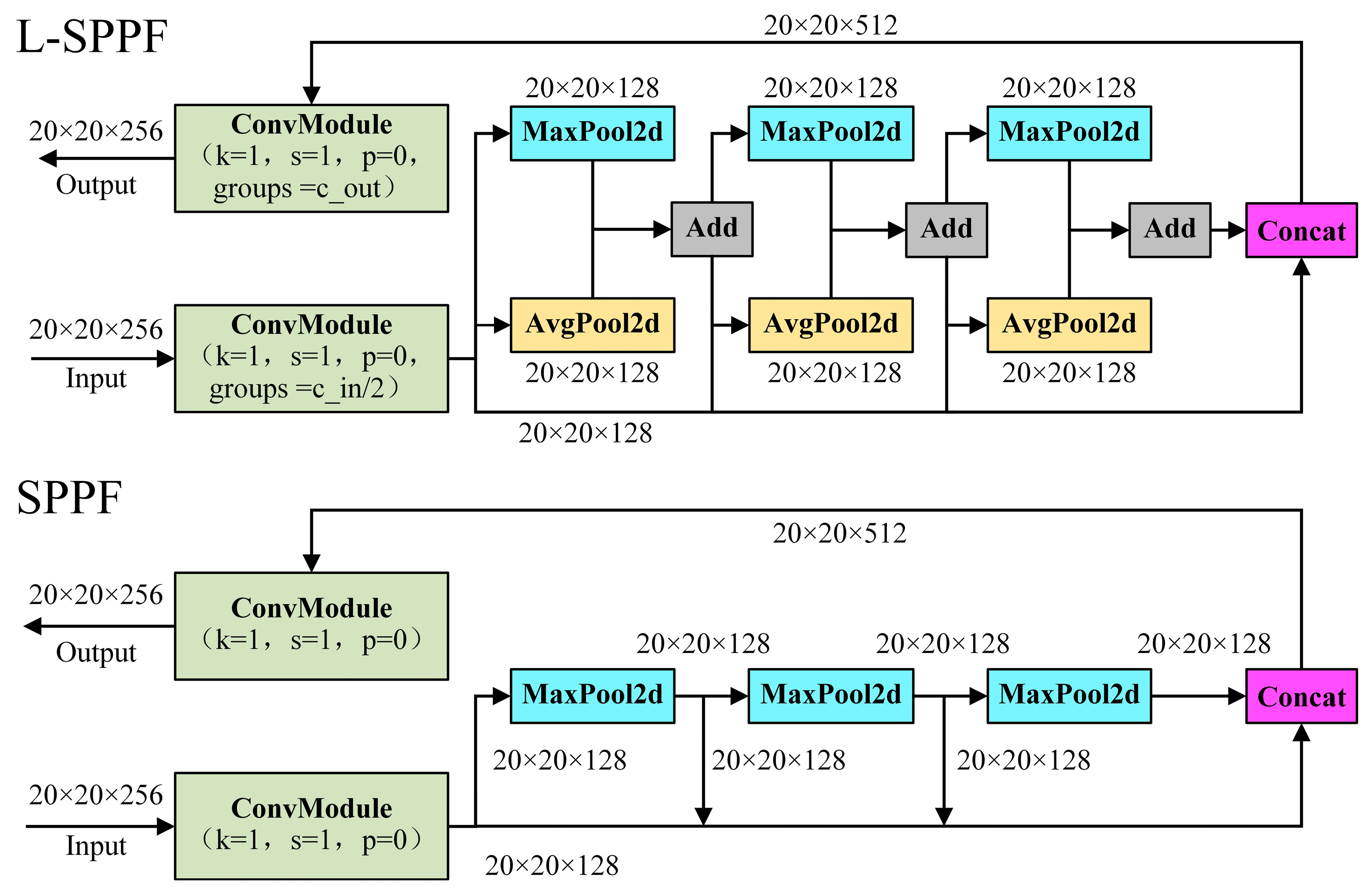
2.2.1. L-SPPF Module
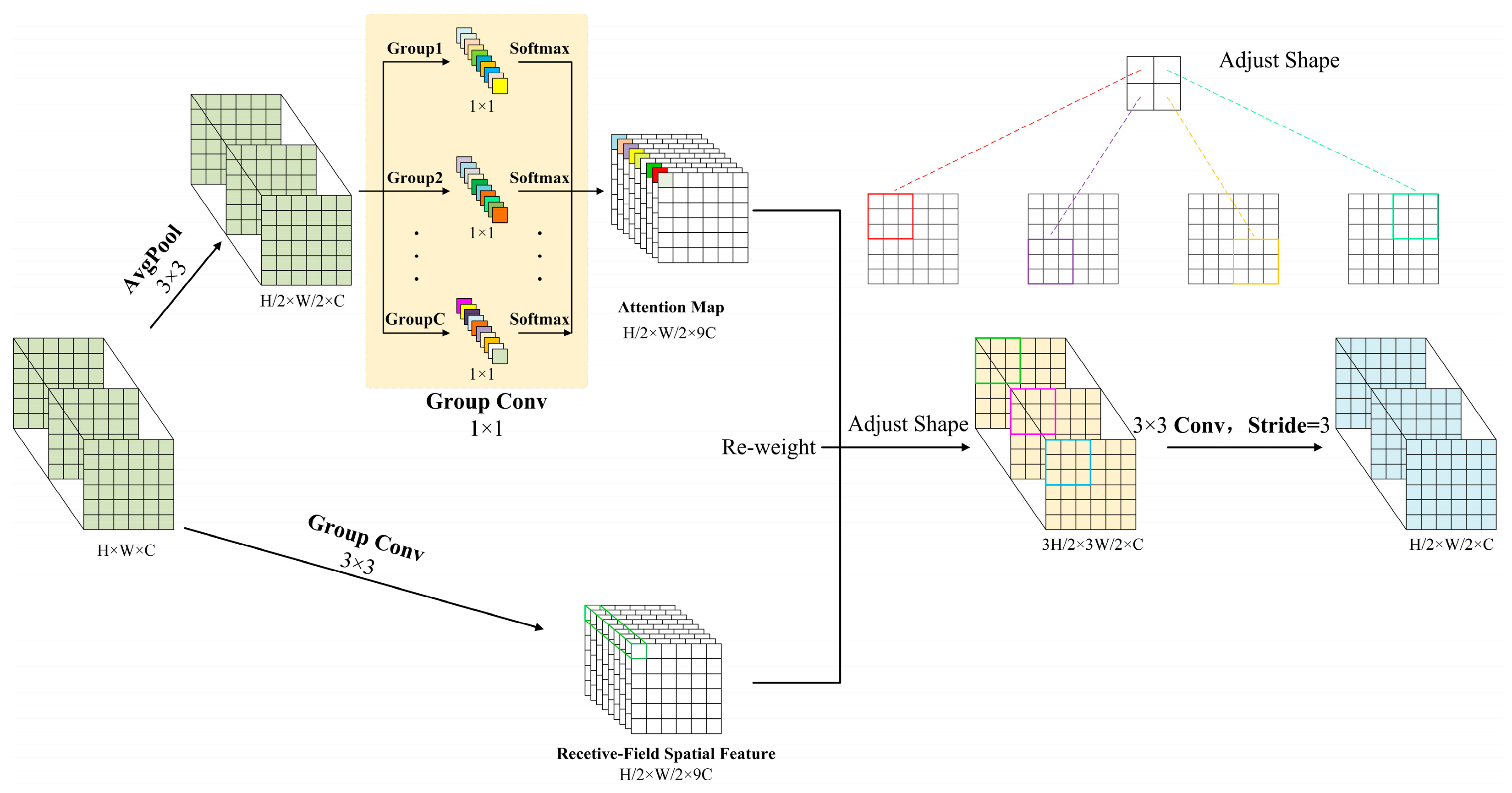
2.2.2. C2f-UIB-iAFF Module
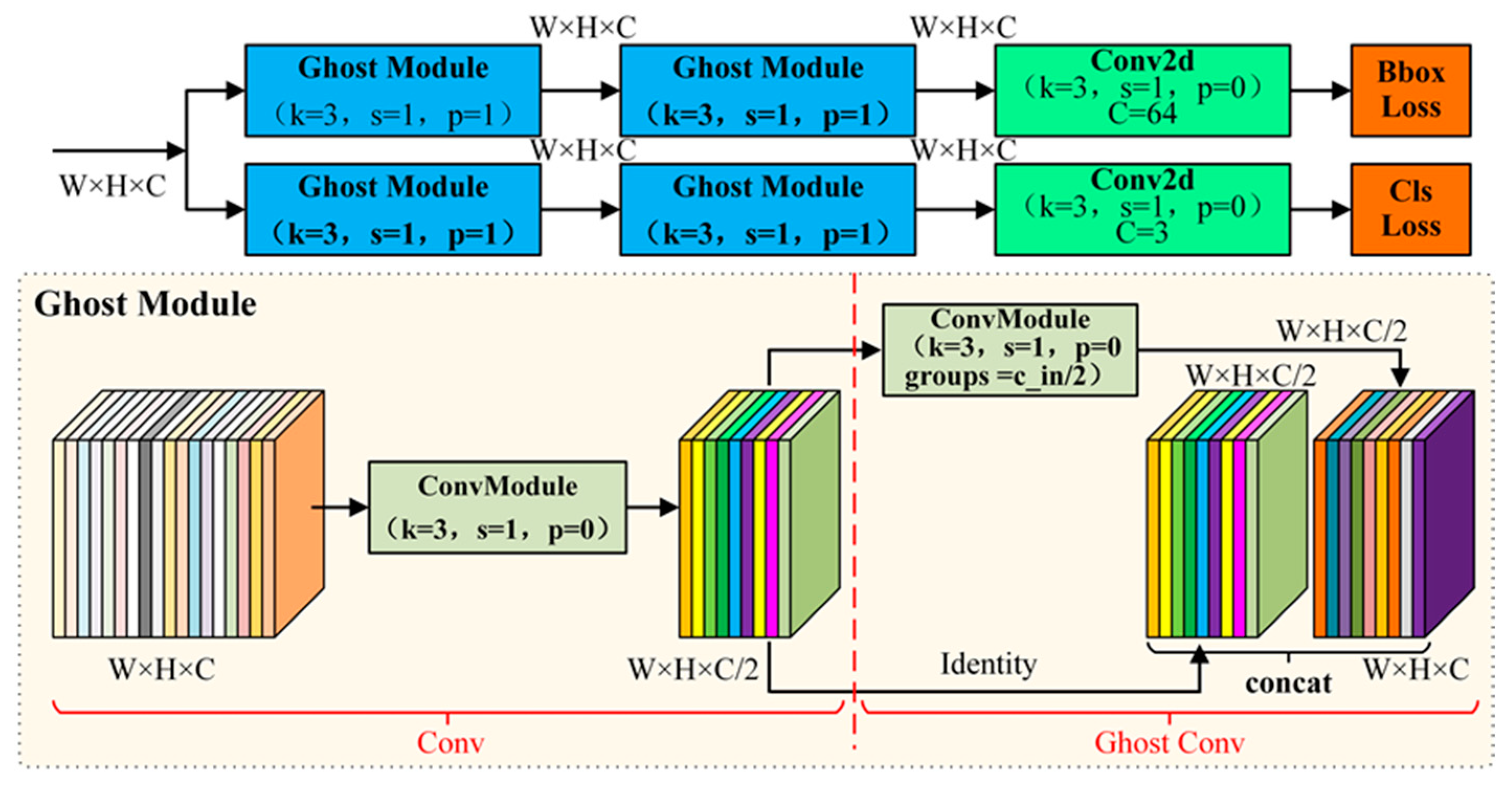
2.2.3. Ghost_Detection Module
2.2.4. Downsampling Convolutional Module
3. Experiment
3.1. Experimental Configuration
3.2. Experiment Parameters Setting
3.3. Evaluation Metrics
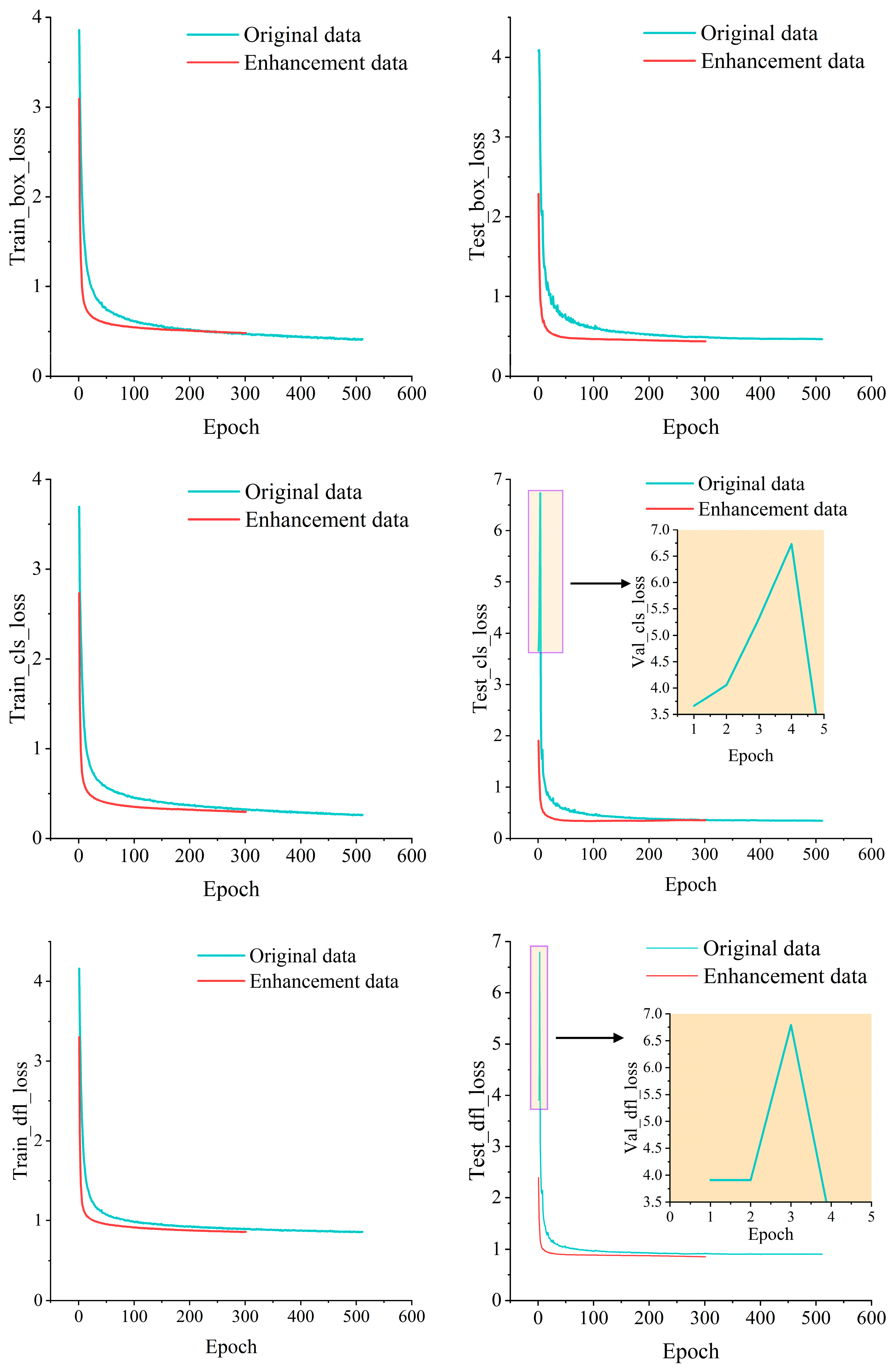
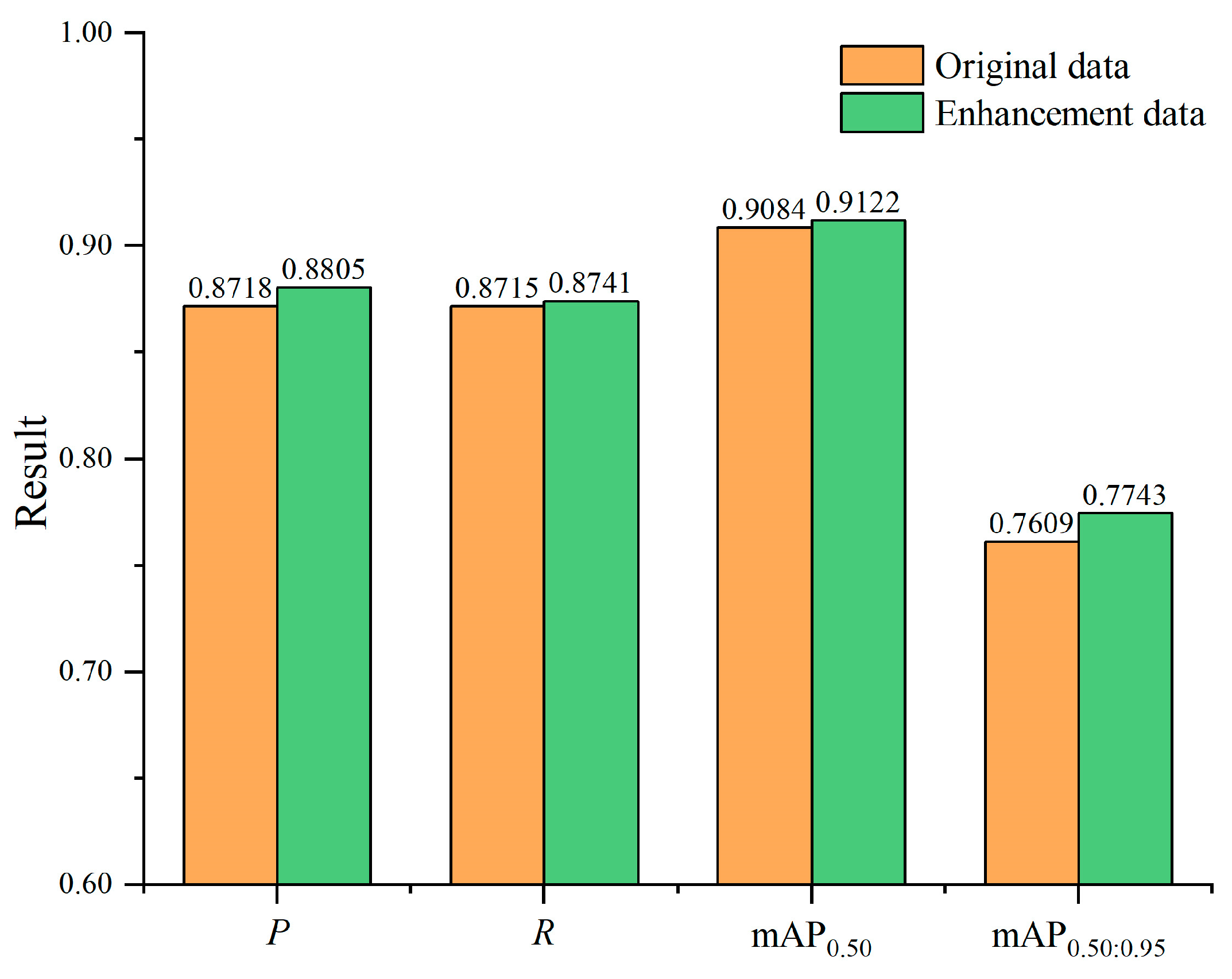
3.4. Data Augmentation Experiments
4. Results
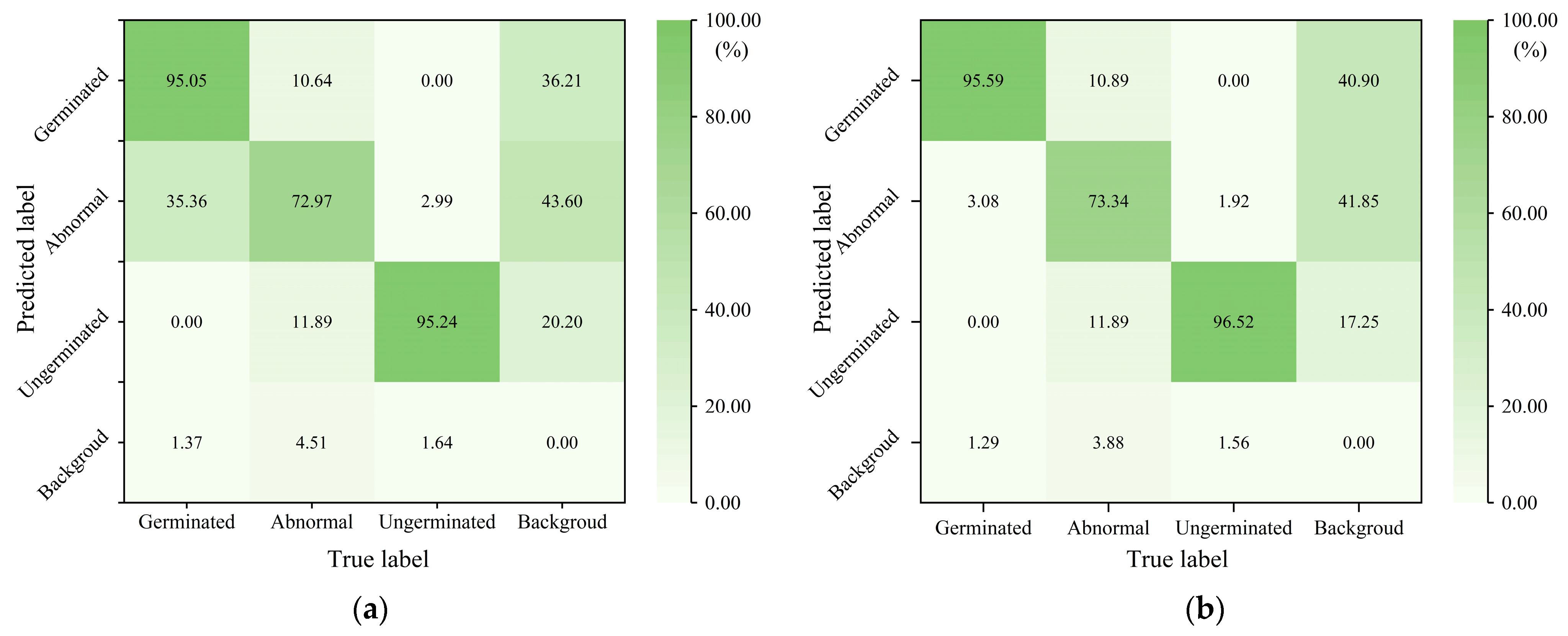
4.1. CSGD-YOLO Test Results and Analysis
4.2. Ablation Experiment Results of Proposed Model
4.3. Performance Comparison of the State-of-the-Art Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Song, P.; Yue, X.; Gu, Y.; Yang, T. Assessment of maize seed vigor under saline-alkali and drought stress based on low field nuclear magnetic resonance. Biosyst. Eng. 2022, 220, 135–145. [Google Scholar] [CrossRef]
- Chen, C.; Bai, M.; Wang, T.; Zhang, W.; Yu, H.; Pang, T.; Wu, J.; Li, Z.; Wang, X. An RGB image dataset for seed germination prediction and vigor detection-maize. Front. Plant Sci. 2024, 15, 1341335. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Tsuchikawa, S.; Inagaki, T. Rapid and non-destructive seed viability prediction using near-infrared hyperspectral imaging coupled with a deep learning approach. Comput. Electron. Agric. 2020, 177, 105683. [Google Scholar] [CrossRef]
- Ali, F.; Qanmber, G.; Li, F.; Wang, Z. Updated role of ABA in seed maturation, dormancy, and germination. J. Adv. Res. 2022, 35, 199–214. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, X.; Zhang, W.; Liu, F.; Wang, C.; Liu, Y.; Dirk, L.M.A.; Downie, A.B.; Zhao, T. Maize PIMT2 repairs damaged 3-METHYLCROTONYL COA CARBOXYLASE in mitochondria, affecting seed vigor. Plant J. 2023, 115, 220–235. [Google Scholar] [CrossRef]
- Škrubej, U.; Rozman, Č.; Stajnko, D. The accuracy of the germination rate of seeds based on image processing and artificial neural networks. Agricultura 2015, 12, 19–24. [Google Scholar] [CrossRef]
- Awty-Carroll, D.; Clifton-Brown, J.; Robson, P. Using k-NN to analyse images of diverse germination phenotypes and detect single seed germination in Miscanthus sinensis. Plant Methods 2018, 14, 5. [Google Scholar] [CrossRef]
- Bai, W.W.; Zhao, X.N.; Luo, B.; Zhao, W.; Huang, S.; Zhang, H. Study of YOLOv5-based germination detection method for wheat seeds. Acta Agric. Zhejiangensis 2023, 35, 445–454. [Google Scholar] [CrossRef]
- Genze, N.; Bharti, R.; Grieb, M.; Schultheiss, S.J.; Grimm, D.G. Accurate machine learning-based germination detection, prediction and quality assessment of three grain crops. Plant Methods 2020, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- Ma, Q.L.; Yang, X.M.; Hu, S.X.; Huang, Z.H.; Qi, H.N. Automatic detection method of corn seed germination based on Mask RCNN and vision technology. Acta Agric. Zhejiangensis 2023, 35, 1927–1936. [Google Scholar] [CrossRef]
- Zhao, J.; Ma, Y.; Yong, K.; Zhu, M.; Wang, Y.; Luo, Z.; Wei, X.; Huang, X. Deep-learning-based automatic evaluation of rice seed germination rate. J. Sci. Food Agric. 2023, 103, 1912–1924. [Google Scholar] [CrossRef] [PubMed]
- Yao, Q.; Zheng, X.; Zhou, G.; Zhang, J. SGR-YOLO: A method for detecting seed germination rate in wild rice. Front. Plant Sci. 2024, 14, 1305081. [Google Scholar] [CrossRef]
- Solawetz, J.; Francesco. What is YOLOv8? The Ultimate Guide. 2023. Available online: https://roboflow.com/ (accessed on 15 August 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B. MobileNetV4-Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Goswami, S.; Ashwini, K.; Dash, R. Grading of Diabetic Retinopathy using iterative Attentional Feature Fusion (iAFF). In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; IEEE: New Jersey, NJ, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Ma, X.; Ji, Z.; Niu, S.; Leng, T.; Rubin, D.L.; Chen, Q. MS-CAM: Multi-scale class activation maps for weakly-supervised segmentation of geographic atrophy lesions in SD-OCT images. IEEE J. Biomed. Health Inform. 2020, 24, 3443–3455. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating spatial attention and standard convolutional operation. arXiv 2023, arXiv:2304.03198. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Tao, X.; Fang, J.; Lorna; Zeng, Y.; et al. Ultralytics YOLOv5. 2020. Available online: https://zenodo.org/records/7347926 (accessed on 15 August 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725v1. [Google Scholar]
- Badgujar, C.M.; Armstrong, P.R.; Gerken, A.R.; Pordesimo, L.O.; Campbell, J.F. Real-time stored product insect detection and identification using deep learning: System integration and extensibility to mobile platforms. J. Stored Prod. Res. 2023, 104, 102196. [Google Scholar] [CrossRef]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Bazame, H.; Molin, J.P.; Althoff, D.; Martello, M. Detection, classification, and mapping of coffee fruits during harvest with computer vision. Comput. Electron. Agric. 2021, 183, 106066. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Wilczek, U.; Hensel, O. Sugar beet damage detection during harvesting using different convolutional neural network models. Agriculture 2021, 11, 1111. [Google Scholar] [CrossRef]
- Fan, X.; Sun, T.; Chai, X.; Zhou, J. YOLO-WDNet: A lightweight and accurate model for weeds detection in cotton field. Comput. Electron. Agric. 2024, 225, 109317. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Growth Days | Train | Test | Total | Total | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Background Color | Background Color | Background Color | |||||||||
| White | Black | Yellow | White | Black | Yellow | White | Black | Yellow | |||
| Original Data | 4 days | 142 | 126 | 114 | 38 | 34 | 31 | 180 | 160 | 145 | 485 |
| 5 days | 159 | 118 | 100 | 46 | 31 | 26 | 205 | 149 | 126 | 480 | |
| 6 days | 126 | 155 | 168 | 33 | 40 | 45 | 159 | 195 | 213 | 567 | |
| 7 days | 78 | 257 | 0 | 20 | 66 | 0 | 98 | 323 | 0 | 421 | |
| 7 days (Cold Soaking) | 71 | 0 | 0 | 72 | 0 | 0 | 143 | 0 | 0 | 143 | |
| Total | 576 | 656 | 382 | 209 | 171 | 102 | 785 | 827 | 484 | 2096 | |
| 1614 | 482 | 2096 | / | ||||||||
| Layers | Module | Params | Layers | Module | Params | Layers | Module | Params |
|---|---|---|---|---|---|---|---|---|
| 1 | ConvModule | 464 | 9 | C2f | 460,288 | 17 | ConvModule | 36,992 |
| 2 | ConvModule | 4672 | 10 | SPPF | 164,608 | 18 | Concat | 0 |
| 3 | C2f | 7360 | 11 | Upsample | 0 | 19 | C2f | 123,648 |
| 4 | ConvModule | 18,560 | 12 | Concat | 0 | 20 | ConvModule | 147,712 |
| 5 | C2f | 49,664 | 13 | C2f | 14,824 | 21 | Concat | 0 |
| 6 | ConvModule | 73,984 | 14 | Upsample | 0 | 22 | C2f | 493,056 |
| 7 | C2f | 197,632 | 15 | Concat | 0 | 23 | Head (n = 3) | 751,897 |
| 8 | ConvModule | 295,424 | 16 | C2f | 37,248 | / | / | / |
| Method | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) | Weight Size (MB) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLO v8n | 88.05 | 87.41 | 91.22 | 77.43 | 6.1 | 3.01 | 8.09 |
| CSGD-YOLO | 89.44 | 88.82 | 92.99 | 80.38 | 4.4 | 1.91 | 5.21 |
| Experiment Number | Models | P (%) | R (%) | mAP0.50 (%) | mAP0.50:0.95 (%) | Weight Size (MB) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| 1 | Base | 88.05 | 87.41 | 91.22 | 77.43 | 6.3 | 3.01 | 8.09 |
| 2 | Base+UIB | 88.40 | 85.47 | 90.08 | 76.37 | 4.7 | 2.18 | 6.13 |
| 3 | Base+L-SPPF | 87.42 | 88.30 | 91.72 | 78.08 | 5.9 | 2.84 | 7.96 |
| 4 | Base+Ghost_Detection | 88.47 | 87.49 | 92.00 | 77.34 | 5.6 | 2.65 | 6.69 |
| 5 | Base+C2f_UIB_iAFF | 87.29 | 86.94 | 90.28 | 76.89 | 5.1 | 2.33 | 6.47 |
| 6 | Base+ Downsampling Convolutional Module | 89.13 | 88.93 | 92.07 | 78.36 | 6.3 | 3.03 | 8.29 |
| 7 | Base+UIB+L-SPPF+ Ghost_Detection | 88.53 | 87.23 | 91.40 | 77.17 | 3.7 | 1.66 | 4.61 |
| 8 | Base+C2f_UIB+L-SPPF+Ghost_head+ Downsampling Convolutional Module | 87.74 | 89.91 | 92.51 | 79.31 | 3.7 | 1.69 | 4.82 |
| 9 | Base+C2f_UIB_iAFF+L-SPPF+Ghost_Detection | 89.95 | 87.57 | 91.84 | 78.22 | 4.3 | 1.88 | 5.00 |
| 10 | CSGD-YOLO | 89.44 | 88.82 | 92.99 | 80.38 | 4.4 | 1.91 | 5.21 |
| Models | P (%) | R (%) | mAP0.5 (%) | mAP0.50:0.95 (%) | Weight Size (MB) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLO v5n | 88.41 | 86.27 | 90.88 | 77.37 | 5.3 | 2.50 | 7.07 |
| YOLO v6n | 89.68 | 87.55 | 92.25 | 77.40 | 8.7 | 4.23 | 11.78 |
| YOLO v8n | 88.05 | 87.41 | 91.22 | 77.43 | 6.3 | 3.01 | 8.09 |
| YOLO v9t | 89.85 | 88.23 | 92.82 | 78.62 | 4.6 | 1.97 | 7.60 |
| YOLO v10n | 87.55 | 87.73 | 91.13 | 77.63 | 5.8 | 2.70 | 8.23 |
| YOLO v11n | 87.94 | 88.16 | 91.47 | 77.14 | 5.5 | 2.58 | 6.32 |
| CSGD-YOLO | 89.44 | 88.82 | 92.99 | 80.38 | 4.4 | 1.91 | 5.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Xu, M.; Xu, K.; Chen, D.; Wang, J.; Yang, R.; Chen, Q.; Yang, S. CSGD-YOLO: A Corn Seed Germination Status Detection Model Based on YOLOv8n. Agronomy 2025, 15, 128. https://doi.org/10.3390/agronomy15010128
Sun W, Xu M, Xu K, Chen D, Wang J, Yang R, Chen Q, Yang S. CSGD-YOLO: A Corn Seed Germination Status Detection Model Based on YOLOv8n. Agronomy. 2025; 15(1):128. https://doi.org/10.3390/agronomy15010128
Chicago/Turabian StyleSun, Wenbin, Meihan Xu, Kang Xu, Dongquan Chen, Jianhua Wang, Ranbing Yang, Quanquan Chen, and Songmei Yang. 2025. "CSGD-YOLO: A Corn Seed Germination Status Detection Model Based on YOLOv8n" Agronomy 15, no. 1: 128. https://doi.org/10.3390/agronomy15010128
APA StyleSun, W., Xu, M., Xu, K., Chen, D., Wang, J., Yang, R., Chen, Q., & Yang, S. (2025). CSGD-YOLO: A Corn Seed Germination Status Detection Model Based on YOLOv8n. Agronomy, 15(1), 128. https://doi.org/10.3390/agronomy15010128