1. Introduction
According to the latest statistics from China’s Ministry of Agriculture and Rural Development, China’s total agricultural area is about 1.35 billion mu (approximately 90 million hectares) [
1,
2,
3,
4,
5]. Among the many crops grown, apples, citrus (e.g., oranges and tangerines), pears, peaches, and walnuts have the largest acreage, with apple orchards covering about 2.2 million hectares with an annual output of about 41 million tons and citrus fruits growing on about 2.3 million hectares [
6,
7]. This data highlights the importance of fruit tree cultivation in China’s agricultural industry [
1,
8,
9,
10]. However, current robotic technologies still face challenges in their application on large-scale farms, mainly due to their over-reliance on manual control, which is inefficient and labor-intensive [
11]. If an autonomous vehicle seeks to navigate independently across diverse orchard types, such as unmanned and precision agriculture orchards, a significant bottleneck hindering robotic autonomy and automation within these settings is their lack of human-like intuition in understanding and perceiving objects within point cloud maps [
12,
13]. Consequently, there is a pressing need to devise methodologies that enhance robots’ perceptual capabilities in orchard point cloud maps [
14,
15,
16].
In tree instance detection methods, there are primarily three approaches: analysis based on remote sensing technology, machine vision recognition methods, and LiDAR technology. In recent years, hyperspectral imaging technology has been widely applied in tree detection. For instance, Jane [
17] successfully differentiated trees from other land cover types by analyzing hyperspectral images and identifying the high reflectance characteristics of vegetation in the near-infrared band. However, these methods often require complex preprocessing steps, cannot meet the requirements of real-time mapping in autonomous driving, and are limited by data availability. With the advancement in computer vision technology, deep learning methods, particularly convolutional neural networks (CNNs), have become powerful tools for detecting objects in images. Object detection models like YOLO have been applied by Chen [
18] and Wang [
19] to directly detect the positions of trees from aerial images. Cao [
20] used YOLOv7 for tree-shaped object detection and achieved semantic segmentation of trees. Kenta [
21] employed a 360° camera and YOLOv2 for tree detection and real-time digital mapping. These deep learning methods have demonstrated superior performance in handling large-scale datasets but training these models requires a significant amount of annotated data. Additionally, visual recognition is susceptible to various environmental interferences such as lighting conditions, visibility, and blurring during platform movement, leading to weak generalization ability [
22,
23,
24,
25,
26,
27].
LiDAR technology provides an effective means of capturing three-dimensional information of the Earth’s surface and objects [
28,
29,
30,
31,
32]. Currently, there are two main types of classification networks specialized in using point cloud data for object detection.
The first method directly utilizes three-dimensional point cloud data. Although this method does not suffer from information loss, the computational cost is often high due to the complexity of 3D data [
33]. For example, Luke [
34] identified trees from LiDAR data by constructing a canopy height model (CHM), which accurately measures tree height and volume. Point cloud classification further expands the application of LiDAR data. John [
35] classified point clouds, accurately distinguishing trees from building roof models. Guan [
36] achieved accurate tree classification by combining LiDAR data with deep learning. LiDAR data analysis provides high-precision tree detection capabilities but direct processing of 3D point clouds is computationally complex and cannot be effectively used on mobile platforms with limited computing power.
The second type of method reduces computational complexity by processing point clouds into two-dimensional data. There are several methods for processing point clouds into two-dimensional data. The method of Jansen [
37] is to represent the 3D point cloud by using several 2D perspective views. In the data preprocessing stage, point cloud images are captured from 64 different angles with the image center as the origin, rotating at a fixed radius. This approach helps reduce information loss to some extent by introducing additional rotations to the scene and utilizing multiple instances in the classification process. Others, like Li [
38], project the point cloud onto a cylinder and represent it as a two-dimensional point map to retain as much information as possible. They utilize a single two-dimensional end-to-end fully convolutional network to simultaneously predict object confidence and bounding boxes.
Similar to the approach described in this article, BirdNet+ [
39] is an enhancement of the object detection framework BirdNet [
40]. BirdNet+ offers an end-to-end solution for 3D object detection based on LiDAR data. It utilizes a bird’s-eye view representation, a 2D structure with three channels converted from LiDAR point clouds, and employs a two-stage architecture to obtain 3D-oriented boxes.
However, this method is designed for detecting single-frame LiDAR point clouds. Single-frame LiDAR point clouds are sparse and cover a large range, resulting in numerous empty pixels and few target pixels in the extracted two-dimensional feature view. Consequently, the second-stage network detection component may encounter unnecessary performance losses while processing empty pixels. Moreover, sparse target pixels may lead to reduced accuracy in detecting small objects. These limitations render this method unsuitable for testing on tree objects in orchard point cloud maps.
In our previous work [
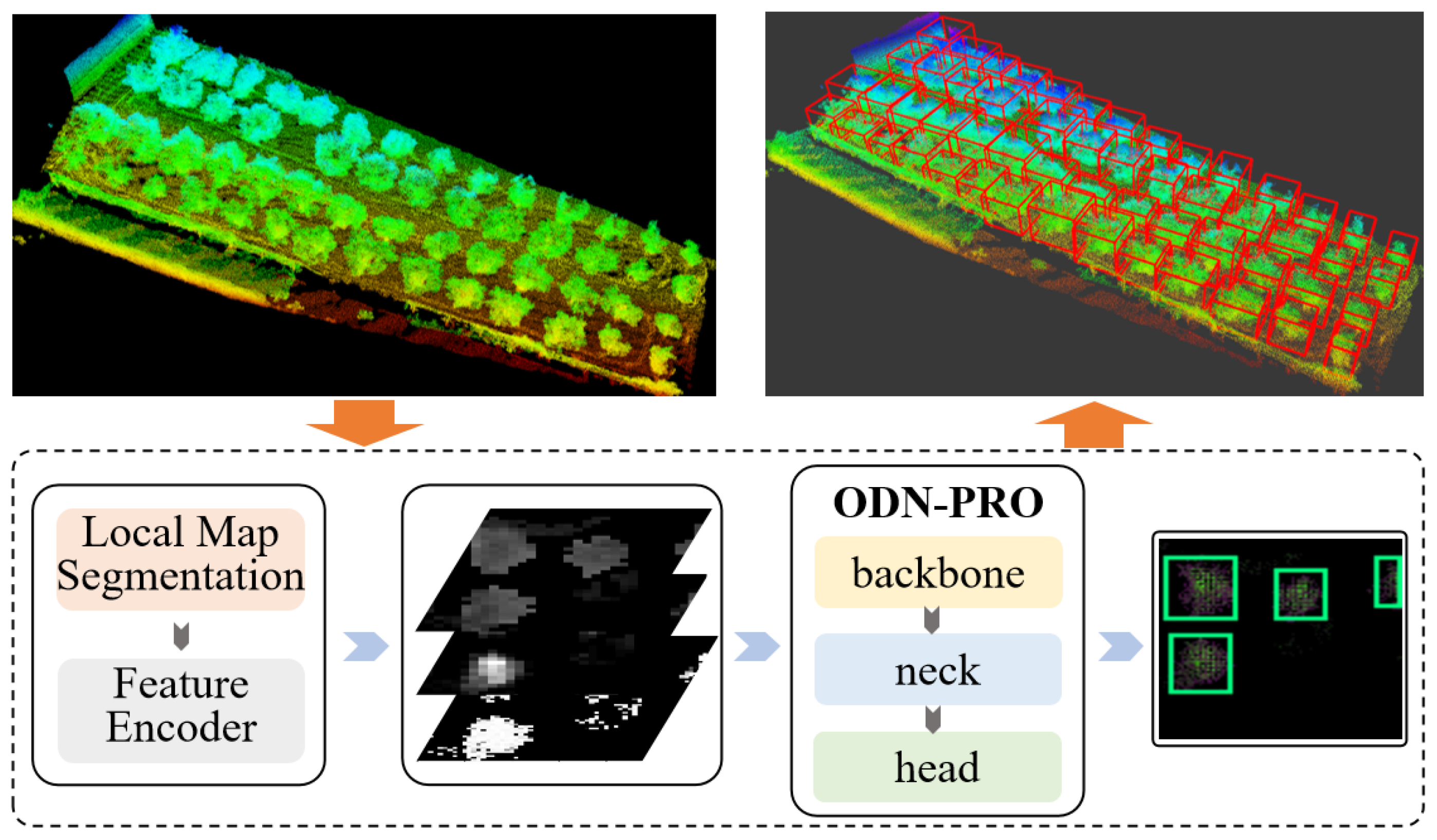
41], we introduced a method for detecting modeled point cloud maps. To further enhance the robot’s ability to perceive tree instances in orchard maps, this study proposes an improved method. Our method focuses on extracting local graphs from orchard point cloud maps to tackle challenges arising from the abundance of empty pixels and sparse target pixels in the two-dimensional feature views derived from large-scale laser point cloud frames. By directly detecting tree point clouds following orchard modeling, we mitigate clustering errors in target prediction frames generated from single-frame laser point clouds. The contributions of this study are outlined as follows:
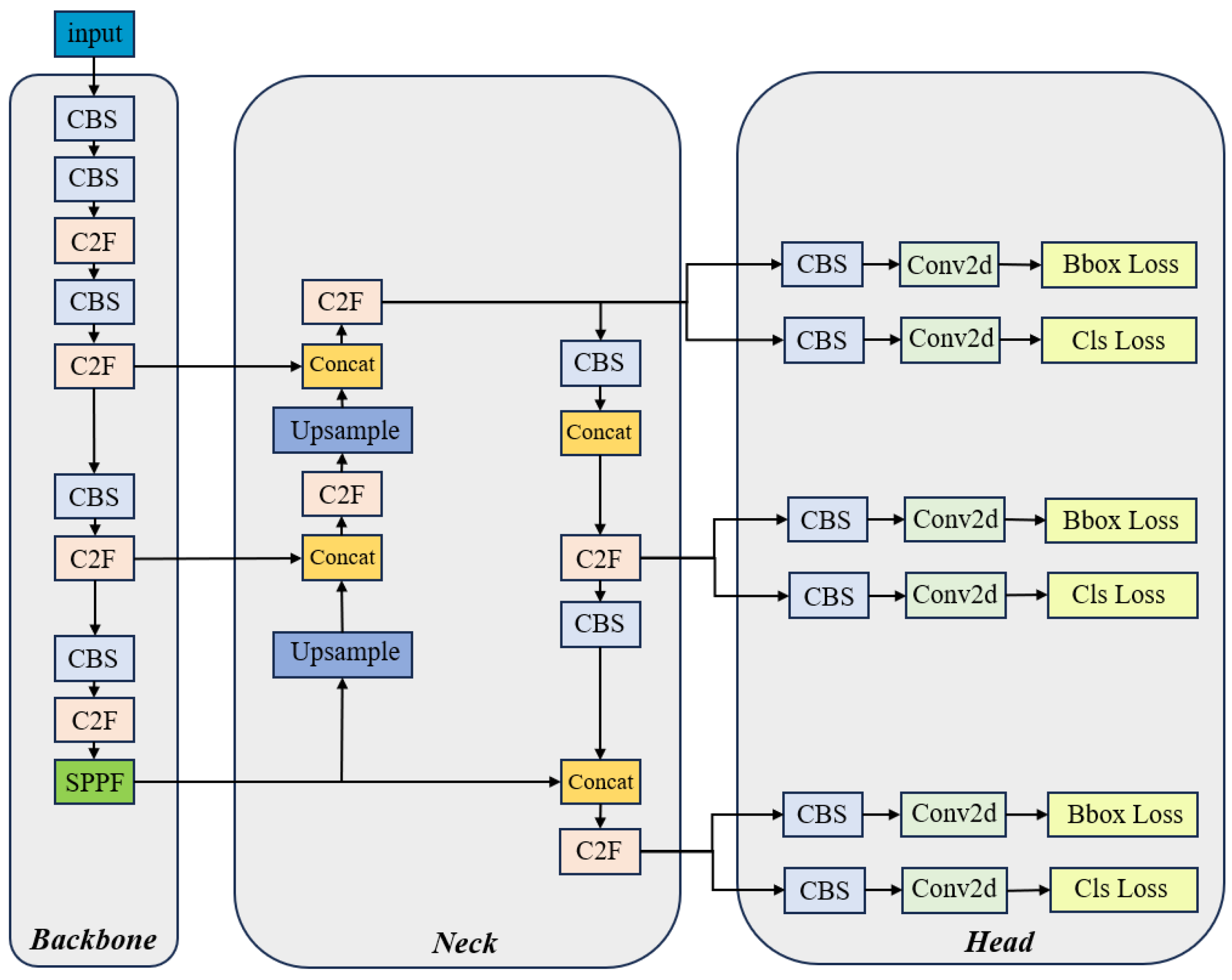
An improved end-to-end orchard point cloud object detection framework called ODN-Pro has been proposed;
Testing of multiple feature extraction methods to determine which feature extraction layer is best for network detection;
Testing of multiple deep learning network components for the optimal feature extraction method to obtain the optimal detection effect.
4. Discussion
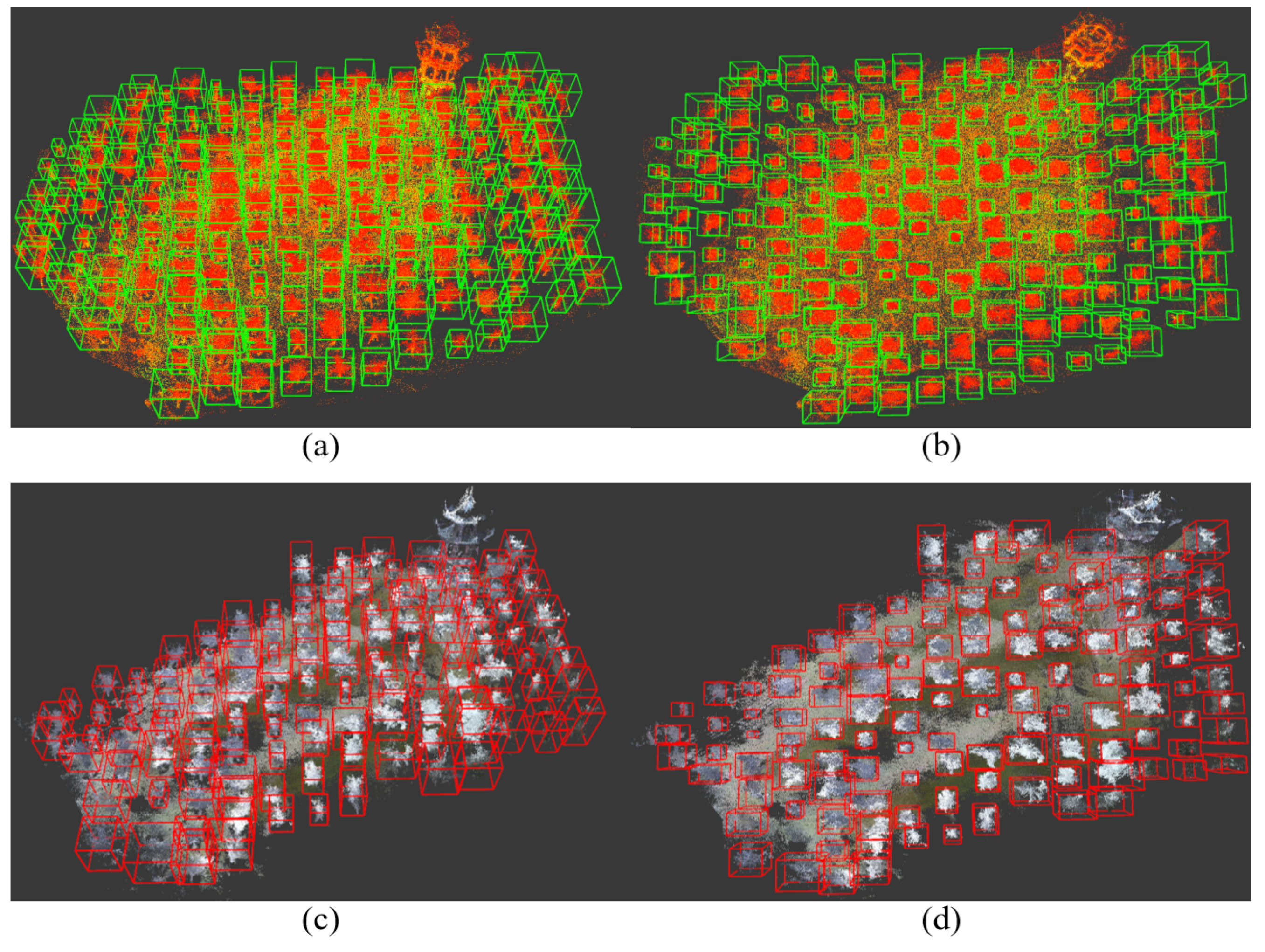
Our study demonstrates that the proposed method can effectively detect fruit trees in point cloud maps generated by different LiDAR sensors with varying point cloud densities. Despite the differences in point cloud densities, our method accurately identifies tree objects in the maps, providing robust assurance for safe navigation of autonomous vehicles in orchards. By effectively recognizing trees, our method enables autonomous vehicles to plan reliable paths within orchards, autonomously navigate through them, and avoid collisions with trees while performing tasks such as planting, irrigation, monitoring, and harvesting. This significantly enhances the efficiency of autonomous vehicle operations in orchards and reduces the risk of accidents, further promoting the development of intelligent and automated orchard management.
To validate the effectiveness of the proposed method, we compared it with the PointNet++ deep learning network for point cloud semantic segmentation. Experimental results show that our method achieves both accuracy and speed without compromising on either aspect.
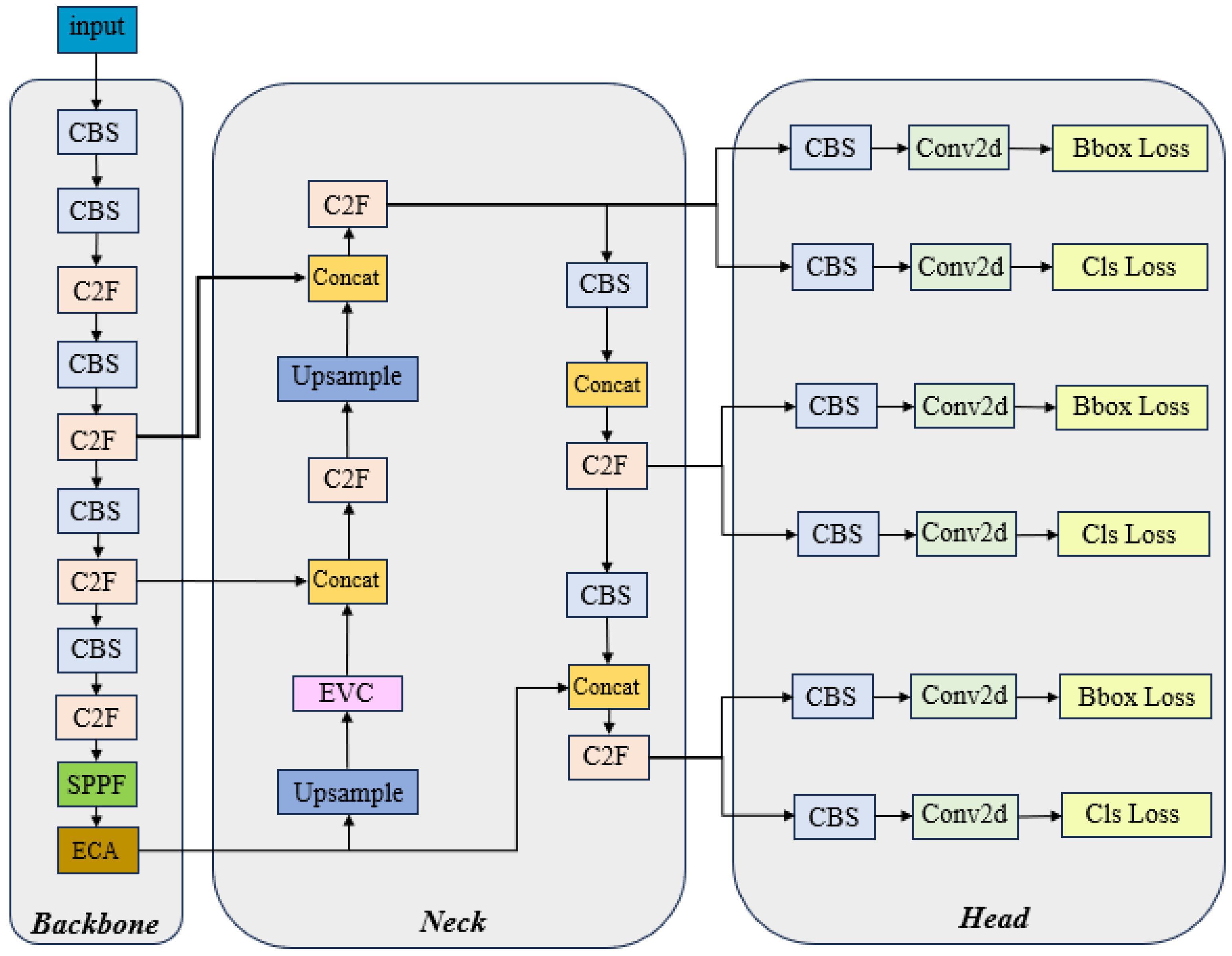
Furthermore, this study introduces a network architecture called ODN-Pro for tree point cloud detection, which utilizes a 3 × 3 sliding window for feature extraction and employs an encoding method to transform three-dimensional point clouds into two-dimensional feature representations. We also conducted K-fold cross-validation on ODN-Pro and its associated dataset. The results demonstrate that these methods contribute to stable and accurate tree object detection across different types of maps.
Despite several significant achievements, it is essential to acknowledge the limitations of our study. For instance, in complex forest scenes, our method may encounter issues such as detection omissions or false alarms due to the challenging structures of point clouds in dense environments. Additionally, when there are significant differences in tree structures, such as between trees with large and small canopies, the network’s performance may degrade. This may require targeted data collection and retraining of the network. Furthermore, like all deep learning networks, our method may face computational complexity issues when processing high-density point clouds. Therefore, in future work, further algorithm optimization is needed to improve detection performance and efficiency, especially in dense forest scenarios, to achieve real-time tree detection.
5. Conclusions
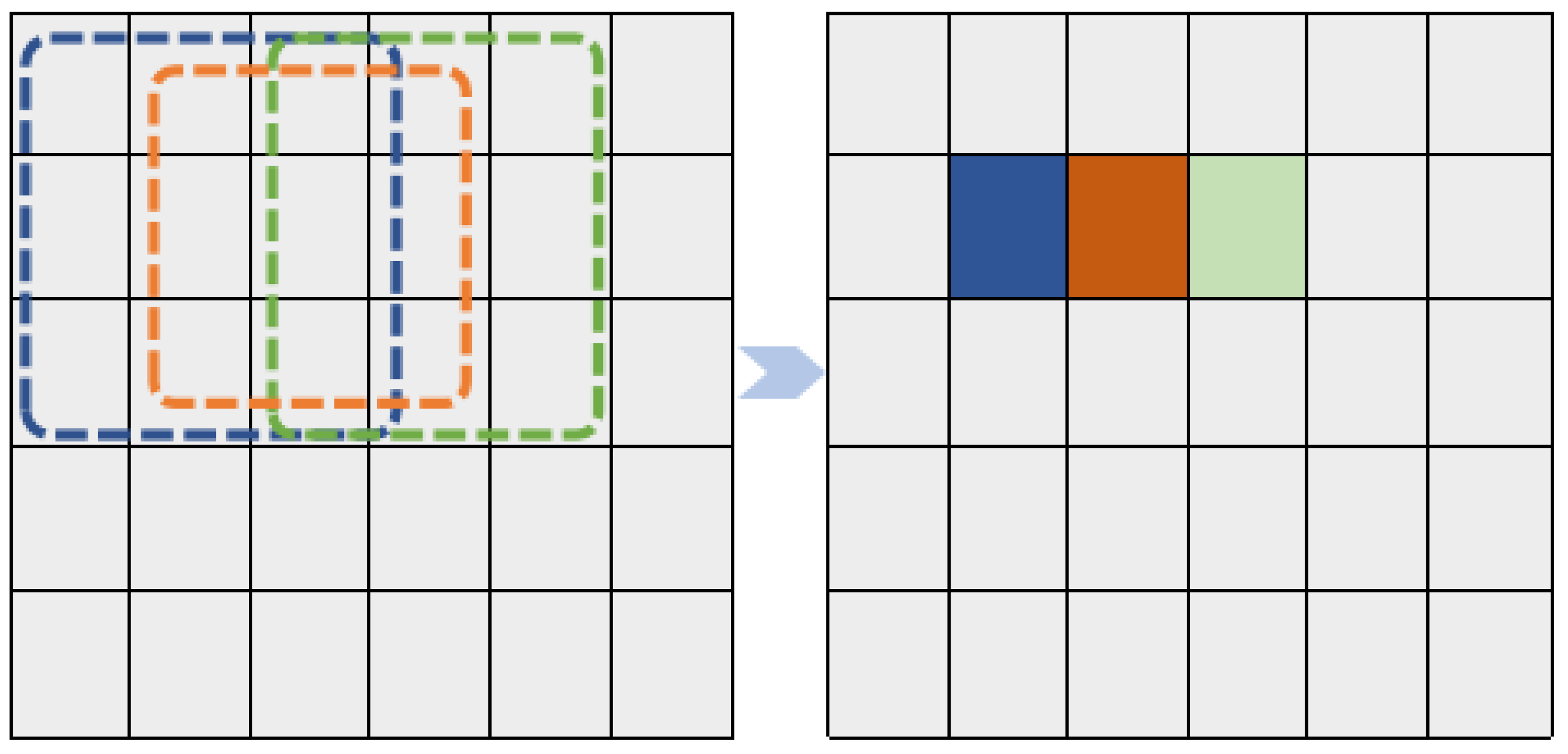
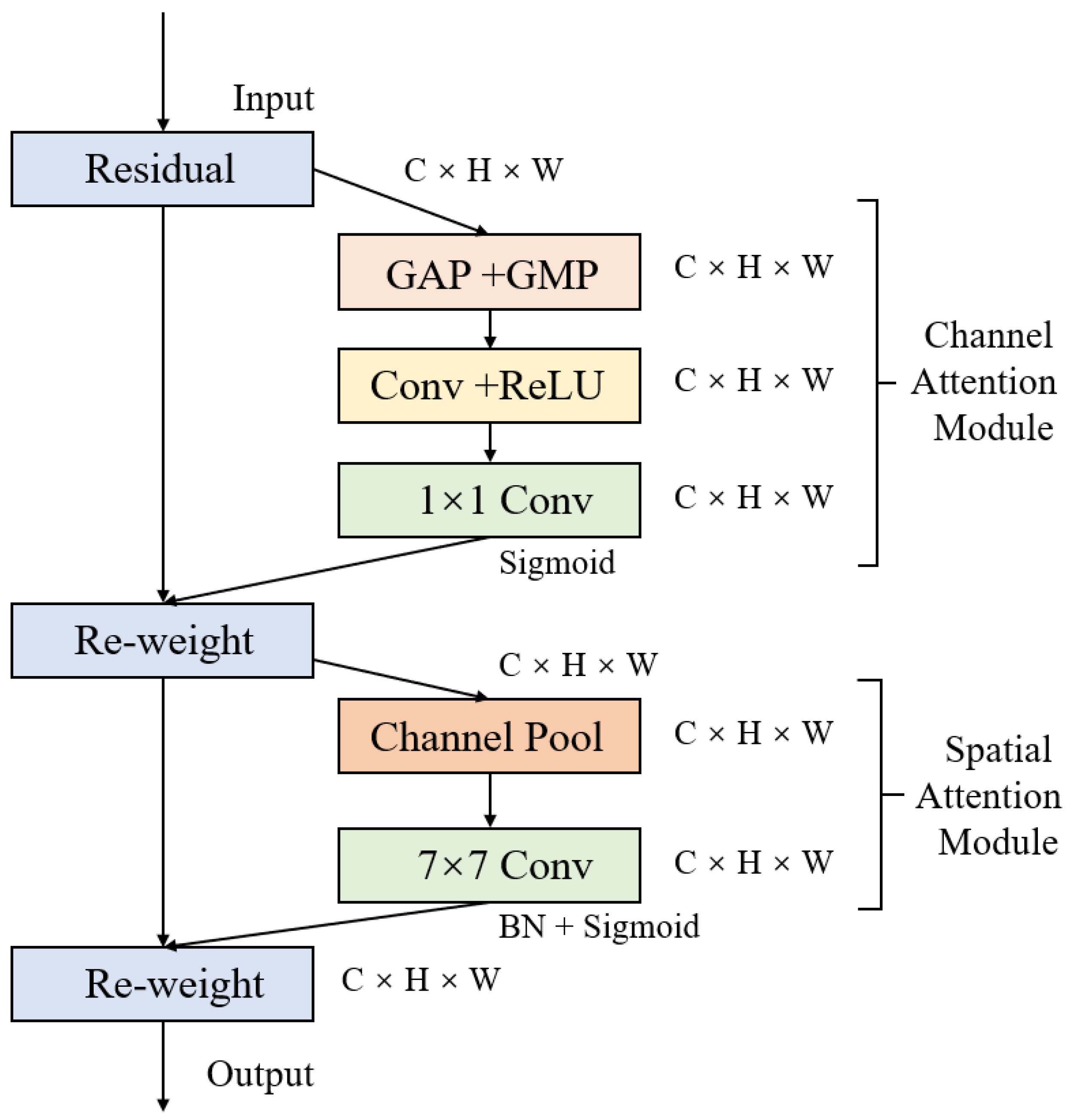
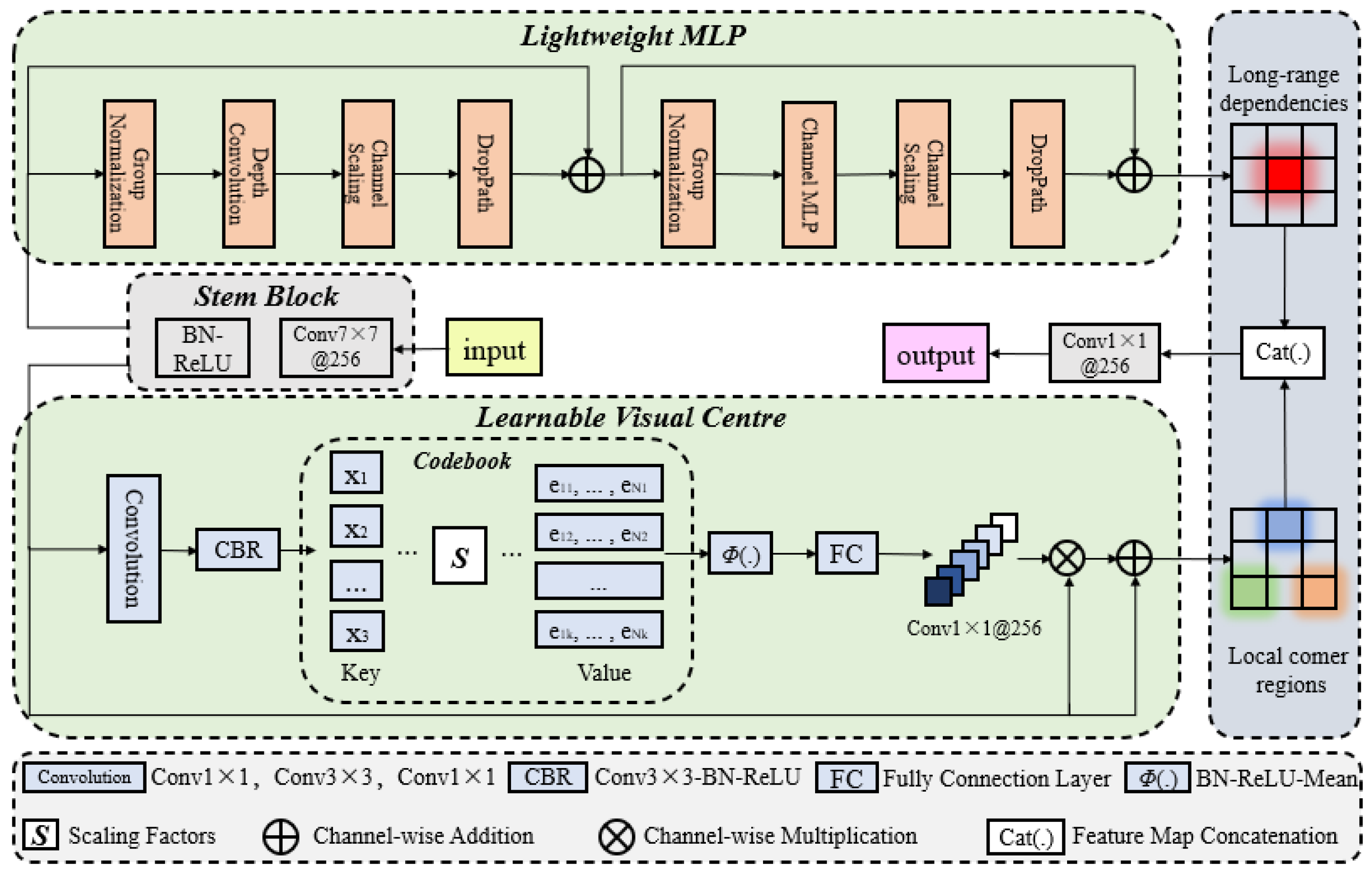
This study proposes a detection method named ODN-Pro, which aims to extract two-dimensional feature vectors containing more accurate three-dimensional point cloud information. We employ various data augmentation techniques on the collected point cloud maps, including random point sampling, random point cloud transformation, point cloud clipping, and noise addition. These augmentation methods help diversify the dataset, thereby enhancing the effectiveness of the learning process and improving the model’s robustness and generalization capability. Our method segments local maps from global point cloud maps, uniformly divides the local maps into grids in the x and y directions, and performs statistical operations on the point clouds within the grids. After comparing with feature extraction operators such as VFH and CVFH, we select the barycenter height (), density (), and the angle () between the main vector and the z-axis as point cloud features and construct a three-channel two-dimensional feature map. After comparing different window sizes for grid selection, we found that a grid resolution of and a sliding window size of in a local map strike a balance between accuracy and speed. The processing time for point cloud features is 0.398 s and the mean average precision (mAP) for network detection is 0.844, achieved using the original version of the YOLOv8 network. Furthermore, we introduce the ECA block in the backbone network and the EVC block in the neck network of ODN-Pro, which results in improved detection performance. This enhancement is evidenced by the observed improvements in precision, recall, and mAP by 1.5%, 0.9%, and 1.2%, respectively.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}