
Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Yield Estimation and Yield Prediction in Viticulture
1.2. YOLO (You Only Look Once) and Frameworks
1.3. YOLOv3
1.4. YOLOv4
1.5. YOLOv5
2. Materials and Methods
2.1. Data Collection and Labelling
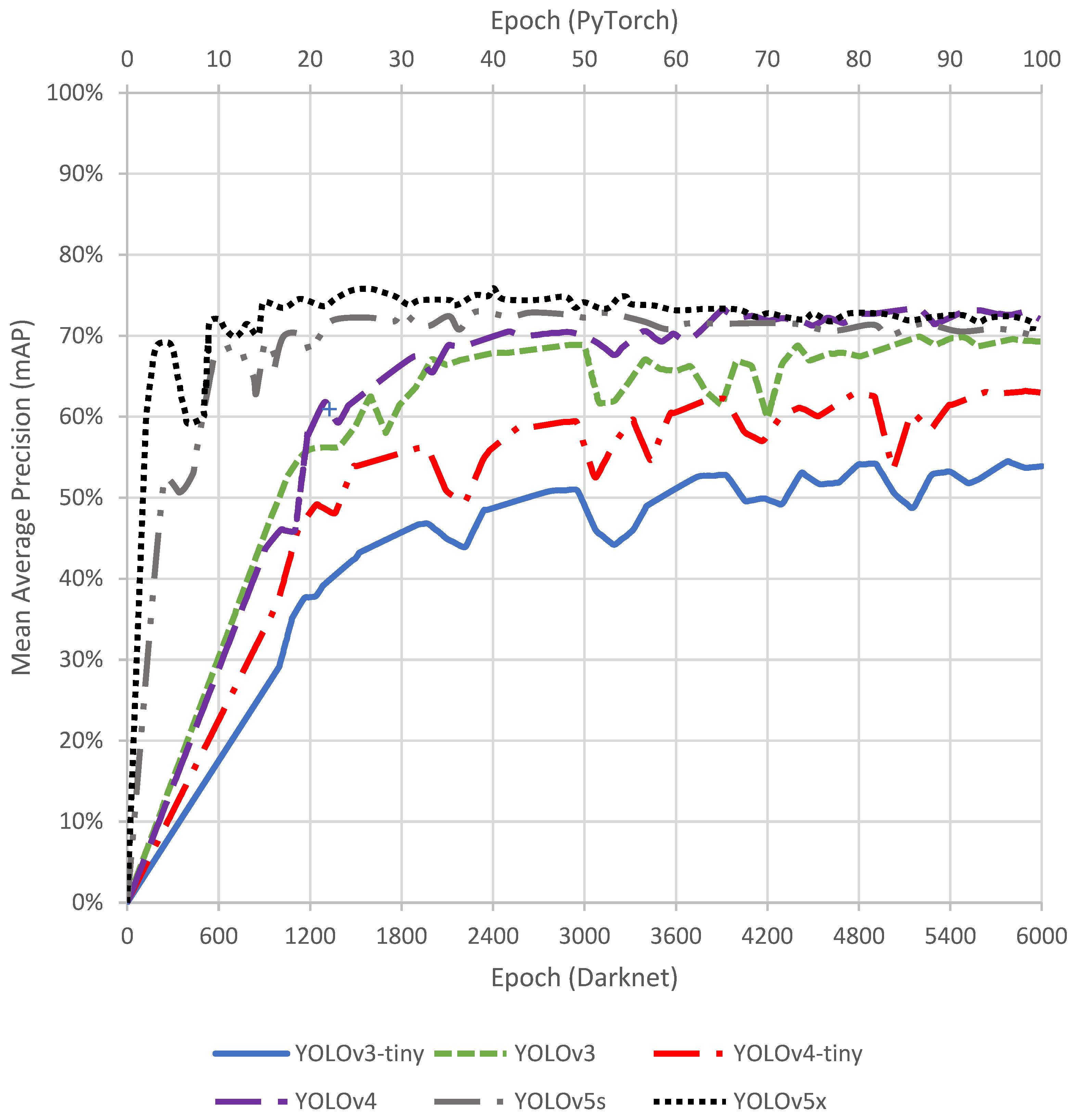
2.2. Training, Test, and Validation
3. Results
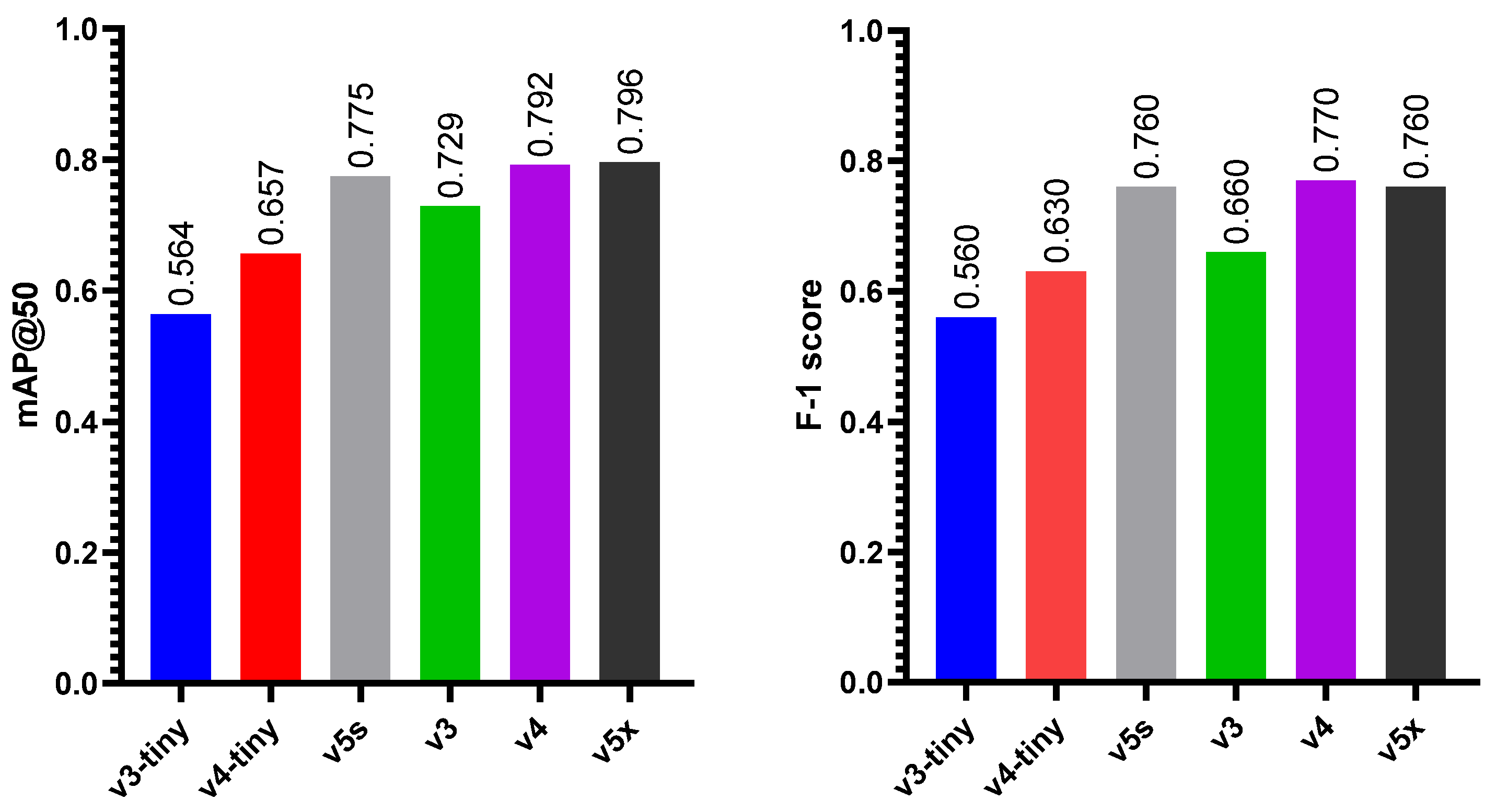
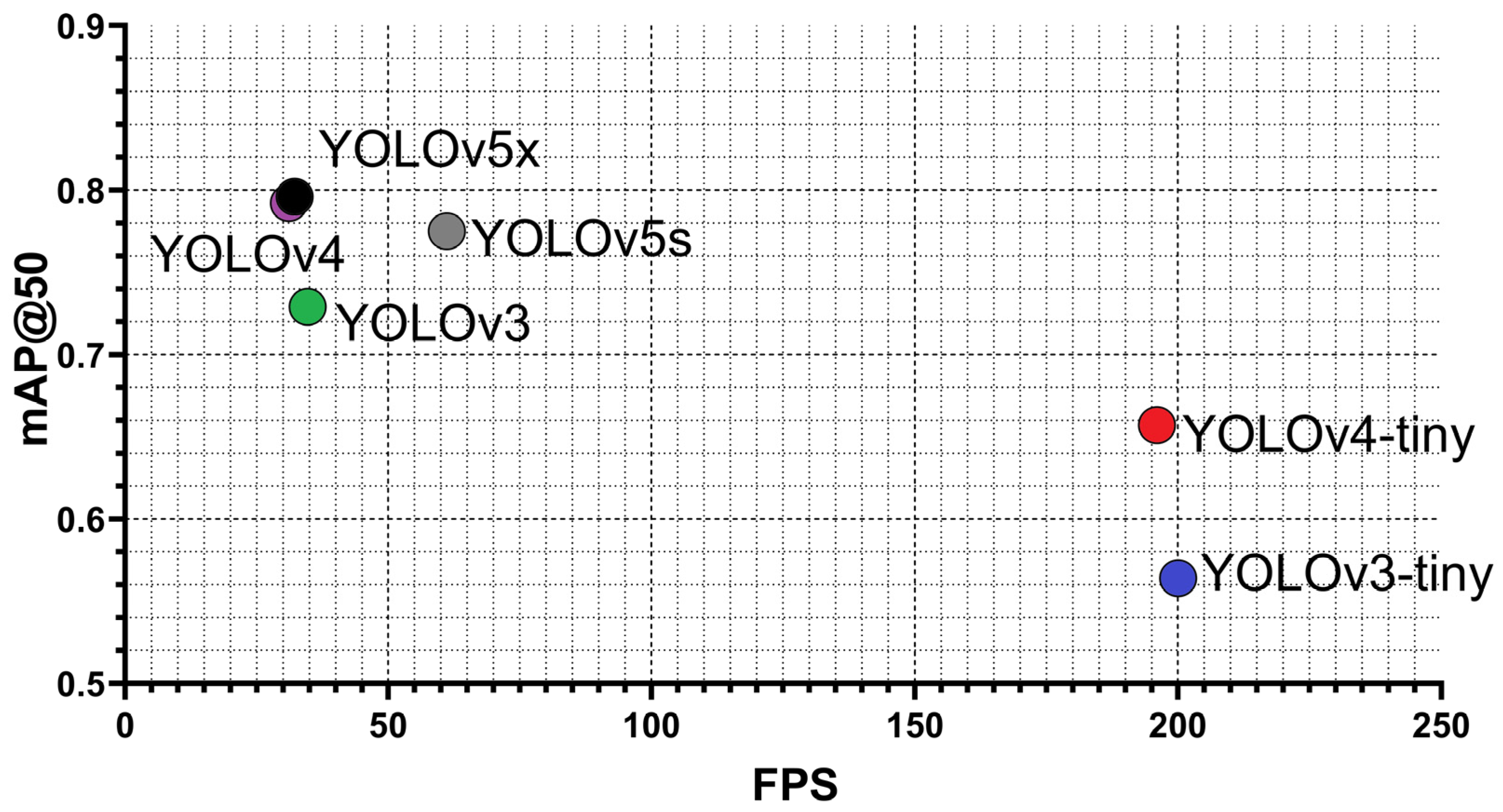
3.1. Accuracy Assessment on the Validation Dataset
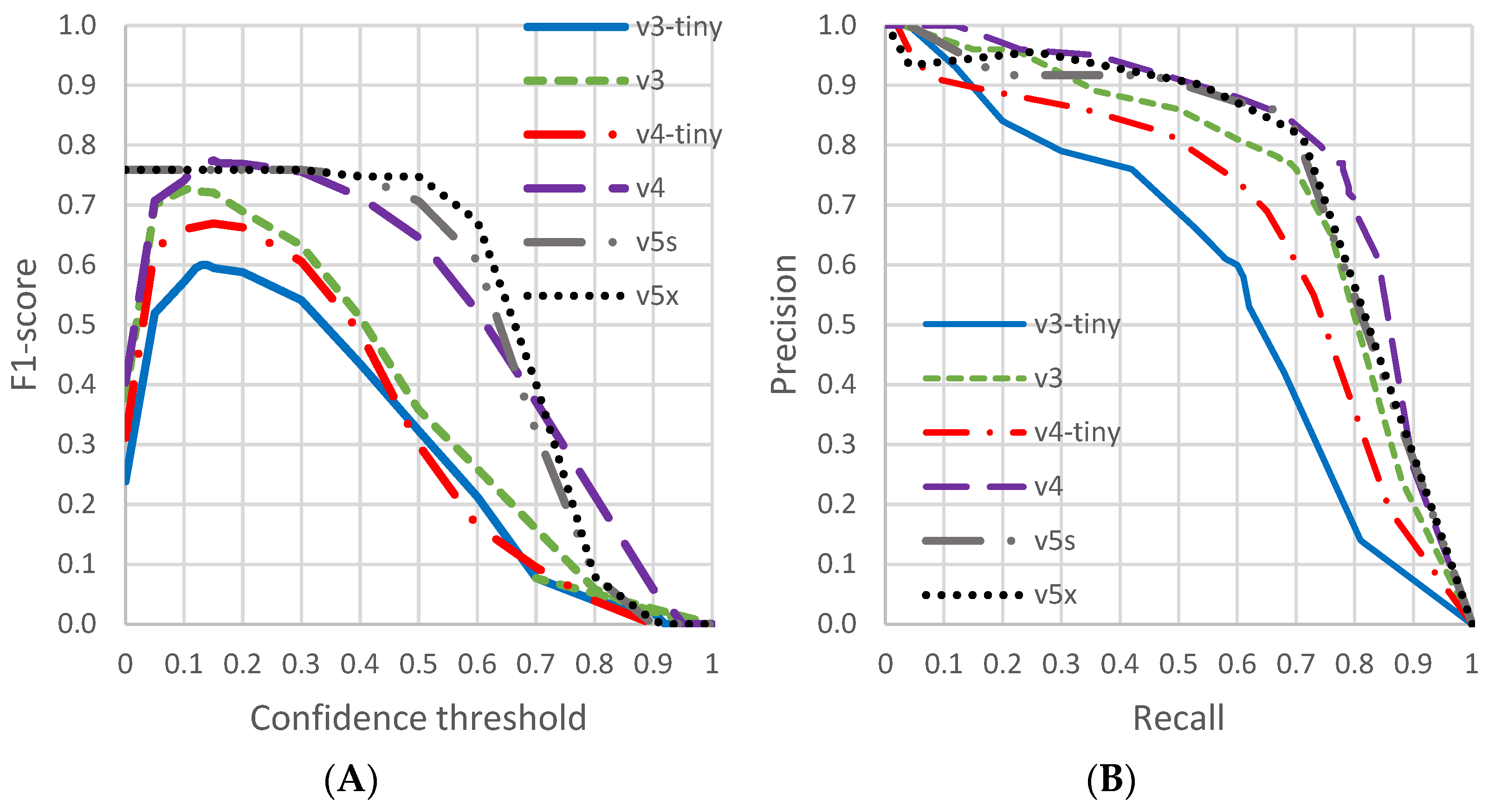
3.2. Precision–Recall Curves and Best Confident Threshold Definition
3.3. Validation to Estimate Real Numbers of Bunches
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Arnó, J.; Casasnovas, J.A.M.; Dasi, M.R.; Rosell, J.R. Review. Precision viticulture. Research topics, challenges and opportunities in site-specific vineyard management. Span. J. Agric. Res. 2009, 7, 779. [Google Scholar] [CrossRef] [Green Version]
- Matese, A.; Di Gennaro, S.F. Technology in precision viticulture: A state of the art review. Int. J. Wine Res. 2015, 7, 69. [Google Scholar] [CrossRef] [Green Version]
- Marinello, F.; Bramley, R.G.V.; Cohen, Y.; Fountas, S.; Guo, H.; Karkee, M.; Martínez-Casasnovas, J.A.; Paraforos, D.S.; Sartori, L.; Sorensen, C.G.; et al. Agriculture and Digital Sustainability: A Digitization Footprint. In Proceedings of the Precision Agriculture ‘21, ECPA 2021, Proceedings of the 13th European Conference on Precision Agriculture, Budapest, Hungary, 18–22 July 2021; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 83–89. [Google Scholar] [CrossRef]
- Kayad, A.; Sozzi, M.; Gatto, S.; Whelan, B.; Sartori, L.; Marinello, F. Ten years of corn yield dynamics at field scale under digital agriculture solutions: A case study from North Italy. Comput. Electron. Agric. 2021, 185, 106126. [Google Scholar] [CrossRef]
- Seng, K.P.; Ang, L.M.; Schmidtke, L.M.; Rogiers, S.Y. Computer vision and machine learning for viticulture technology. IEEE Access 2018, 6, 67494–67510. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks; IEEE Computer Society: Washington, DC, USA, 2017; Volume 39, pp. 1137–1149. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Laurent, C.; Oger, B.; Taylor, J.A.; Scholasch, T.; Metay, A.; Tisseyre, B. A review of the issues, methods and perspectives for yield estimation, prediction and forecasting in viticulture. Eur. J. Agron. 2021, 130, 126339. [Google Scholar] [CrossRef]
- Sabbatini, P.; Dami, I.; Howell, G.S. Predicting Harvest Yield in Juice and Wine Grape Vineyards. Mich. State Univ. Ext. 2012, 1–12. [Google Scholar]
- De La Fuente, M.; Linares, R.; Baeza, P.; Miranda, C.; Lissarrague, J.R. Comparison of different methods of grapevine yield prediction in the time window between fruitset and veraison. OENO One 2015, 49, 27–35. [Google Scholar] [CrossRef]
- Coombe, B.G.; McCarthy, M.G. Dynamics of grape berry growth and physiology of ripening. Aust. J. Grape Wine Res. 2000, 6, 131–135. [Google Scholar] [CrossRef]
- Taylor, J.A.; Sanchez, L.; Sams, B.; Haggerty, L.; Jakubowski, R.; Djafour, S.; Bates, T.R. Evaluation of a commercial grape yield monitor for use mid-season and at-harvest. OENO One 2016, 50, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Sozzi, M.; Kayad, A.; Tomasi, D.; Lovat, L.; Marinello, F.; Sartori, L. Assessment of grapevine yield and quality using a canopy spectral index in white grape variety. In Proceedings of the Precision Agriculture ‘19, ECPA 2019, Proceedings of the 12th European Conference on Precision Agriculture, Montpellier, France, 8–11 July 2019; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 181–186. [Google Scholar] [CrossRef]
- Hall, A. Remote sensing applications for viticultural terroir analysis. Elements 2018, 14, 185–190. [Google Scholar] [CrossRef]
- Cogato, A.; Meggio, F.; Collins, C.; Marinello, F. Medium-Resolution Multispectral Data from Sentinel-2 to Assess the Damage and the Recovery Time of Late Frost on Vineyards. Remote Sens. 2020, 12, 1896. [Google Scholar] [CrossRef]
- Sozzi, M.; Kayad, A.; Giora, D.; Sartori, L.; Marinello, F. Cost-effectiveness and performance of optical satellites constellation for Precision Agriculture. In Proceedings of the Precision Agriculture ‘19, ECPA 2019, Proceedings of the 12th European Conference on Precision Agriculture, Montpellier, France, 8–11 July 2019; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 501–507. [Google Scholar] [CrossRef]
- Sozzi, M.; Kayad, A.; Gobbo, S.; Cogato, A.; Sartori, L.; Marinello, F.; Singh, V.; Huang, Y. Economic Comparison of Satellite, Plane and UAV-Acquired NDVI Images for Site-Specific Nitrogen Application: Observations from Italy. Agronomy 2021, 11, 2098. [Google Scholar] [CrossRef]
- Cogato, A.; Wu, L.; Jewan, S.Y.Y.; Meggio, F.; Marinello, F.; Sozzi, M.; Pagay, V. Evaluating the Spectral and Physiological Responses of Grapevines (Vitis vinifera L.) to Heat and Water Stresses under Different Vineyard Cooling and Irrigation Strategies. Agronomy 2021, 11, 1940. [Google Scholar] [CrossRef]
- Bramley, R.G.V.; Le Moigne, M.; Evain, S.; Ouzman, J.; Florin, L.; Fadaili, E.M.; Hinze, C.J.; Cerovic, Z.G. On-the-go sensing of grape berry anthocyanins during commercial harvest: Development and prospects. Aust. J. Grape Wine Res. 2011, 17, 316–326. [Google Scholar] [CrossRef]
- Henry, D.; Aubert, H.; Veronese, T. Proximal Radar Sensors for Precision Viticulture. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4624–4635. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Aquino, A.; Millan, B.; Diago, M.P.; Tardaguila, J. Automated early yield prediction in vineyards from on-the-go image acquisition. Comput. Electron. Agric. 2018, 144, 26–36. [Google Scholar] [CrossRef]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; IEEE: Manhattan, NY, USA, 2011; pp. 2352–2358. [Google Scholar]
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Singh, S. Automated visual yield estimation in vineyards. J. Field Robot. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Di Gennaro, S.F.; Toscano, P.; Cinat, P.; Berton, A.; Matese, A. A precision viticulture UAV-based approach for early yield prediction in vineyard. In Proceedings of the Precision Agriculture ‘19, ECPA 2019, Proceedings of the 12th European Conference on Precision Agriculture, Montpellier, France, 8–11 July 2019; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 373–379. [Google Scholar] [CrossRef]
- Comba, L.; Biglia, A.; Aimonino, D.R.; Gay, P. Unsupervised detection of vineyards by 3D point-cloud UAV photogrammetry for precision agriculture. Comput. Electron. Agric. 2018, 155, 84–95. [Google Scholar] [CrossRef]
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, Y.; Shen, Y.; Zhang, J. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Hendry; Chen, R.C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar] [CrossRef]
- Zhou, J.; Jing, J.; Zhang, H.; Zhen, W.; Wang, Z.; Huang, H. Real-time fabric defect detection algorithm based on s-yolov3 model. Laser Optoelectron. Prog. 2020, 57, 161001. [Google Scholar] [CrossRef]
- Bresilla, K.; Perulli, G.D.; Boini, A.; Morandi, B.; Grappadelli, L.C.; Manfrini, L. Single-Shot Convolution Neural Networks for Real-Time Fruit Detection Within the Tree. Front. Plant Sci. 2019, 10, 611. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Li, X.; Qin, Y.; Wang, F.; Guo, F.; Yeow, J.T.W. Pitaya detection in orchards using the MobileNet-YOLO model. In Proceedings of the Chinese Control Conference, CCC, Shenyang, China, 27–30 July 2020; IEEE Computer Society: Washington, DC, USA, 2020; Volume 2020, pp. 6274–6278. [Google Scholar]
- Morbekar, A.; Parihar, A.; Jadhav, R. Crop disease detection using YOLO. In Proceedings of the 2020 International Conference for Emerging Technology, INCET 2020, Belgaum, India, 5–7 June 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020. [Google Scholar]
- Ponnusamy, V.; Coumaran, A.; Shunmugam, A.S.; Rajaram, K.; Senthilvelavan, S. Smart Glass: Real-Time Leaf Disease Detection using YOLO Transfer Learning. In Proceedings of the 2020 IEEE International Conference on Communication and Signal Processing, ICCSP 2020, Chennai, India, 28–30 July 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 1150–1154. [Google Scholar]
- Zhong, Y.; Gao, J.; Lei, Q.; Zhou, Y. A Vision-Based Counting and Recognition System for Flying Insects in Intelligent Agriculture. Sensors 2018, 18, 1489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdulsalam, M.; Aouf, N. Deep Weed Detector/Classifier Network for Precision Agriculture; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 1087–1092. [Google Scholar]
- Yin, Y.; Li, H.; Fu, W. Faster-YOLO: An accurate and faster object detection method. Digit. Signal Process. 2020, 102, 102756. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; IEEE Computer Society: Washington, DC, USA, 2020; Volume 2020, pp. 1571–1580. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Christopher, S.T.A.N.; Laughing, L.C. ultralytics/yolov5: v4.0-nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration. Zenodo 2021. [Google Scholar] [CrossRef]
- Iyer, R.; Shashikant Ringe, P.; Varadharajan Iyer, R.; Prabhulal Bhensdadiya, K. Comparison of YOLOv3, YOLOv5s and MobileNet-SSD V2 for Real-Time Mask Detection. Artic. Int. J. Res. Eng. Technol. 2021, 8, 1156–1160. [Google Scholar]
- Yang, G.; Feng, W.; Jin, J.; Lei, Q.; Li, X.; Gui, G.; Wang, W. Face Mask Recognition System with YOLOV5 Based on Image Recognition. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; Volume 1, pp. 1398–1404. [Google Scholar] [CrossRef]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cuDNN: Efficient Primitives for Deep Learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Kwon, Y.; Choi, W.; Marrable, D.; Abdulatipov, R.; Loïck, J. Yolo_label 2020. Available online: https://github.com/developer0hye/Yolo_Label (accessed on 23 January 2022).
- Dice, L.R. Measures of the Amount of Ecologic Association between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Li, S.; Gu, X.; Xu, X.; Xu, D.; Zhang, T.; Liu, Z.; Dong, Q. Detection of concealed cracks from ground penetrating radar images based on deep learning algorithm. Constr. Build. Mater. 2021, 273, 121949. [Google Scholar] [CrossRef]
- Lema, D.G.; Pedrayes, O.D.; Usamentiaga, R.; García, D.F.; Alonso, Á. Cost-performance evaluation of a recognition service of livestock activity using aerial images. Remote Sens. 2021, 13, 2318. [Google Scholar] [CrossRef]
- Aguiar, A.S.; Magalhães, S.A.; Dos Santos, F.N.; Castro, L.; Pinho, T.; Valente, J.; Martins, R.; Boaventura-Cunha, J. Grape Bunch Detection at Different Growth Stages Using Deep Learning Quantized Models. Agronomy 2021, 11, 1890. [Google Scholar] [CrossRef]
- Taylor, J.A.; Dresser, J.L.; Hickey, C.C.; Nuske, S.T.; Bates, T.R. Considerations on spatial crop load mapping. Aust. J. Grape Wine Res. 2019, 25, 144–155. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Grape Yield Spatial Variability Assessment Using YOLOv4 Object Detection Algorithm. In Proceedings of the Precision Agriculture ‘21, ECPA 2021, Proceedings of the 13th European Conference on Precision Agriculture, Budapest, Hungary, 18–22 July 2021; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 193–198. [Google Scholar] [CrossRef]
- Pollock, K.H. A Capture-Recapture Design Robust to Unequal Probability of Capture. J. Wildl. Manag. 1982, 46, 752. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | Number of Images |
|---|---|
| Train | 1954 |
| Test | 977 |
| Validation | 54 |
| Total | 2985 |
| Models | Epoch | Framework | Augmentation | Billions of FLOPs | ||||
|---|---|---|---|---|---|---|---|---|
| Sat. & Exp. | Hue | Blur | Mosaic | |||||
| V3-tiny | 6000 | Darknet | Online | null | 11.6 | |||
| V3 | 1.5 | 0.05 | yes | no | 140 | |||
| V4-tiny | null | 14.5 | ||||||
| V4 | 1.5 | 0.05 | yes | yes | 127 | |||
| V5s | 100 | PyTorch | 1.5 | 0.05 | yes | no | 16.4 | |
| V5x | 217 | |||||||
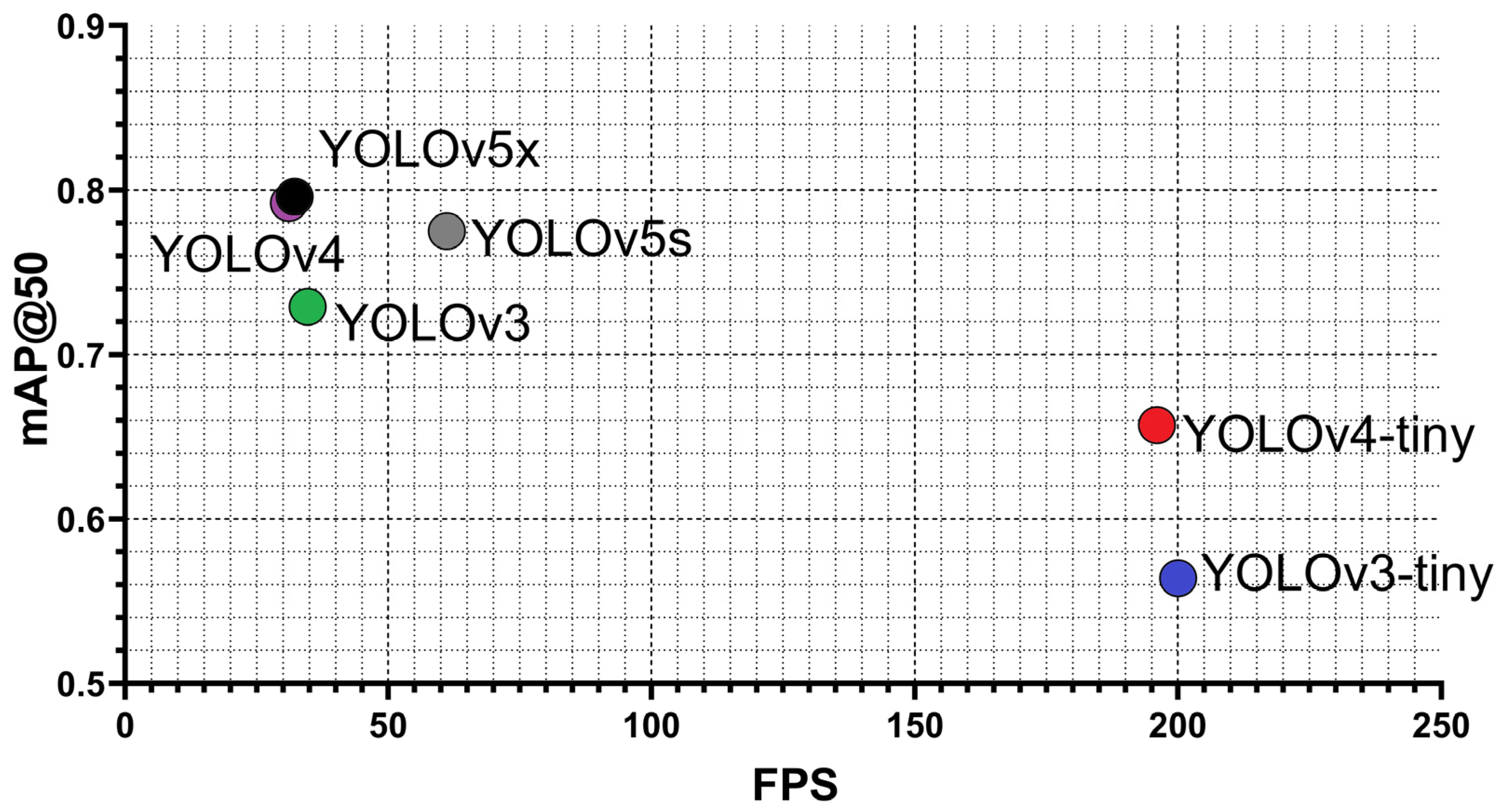
| Models | Training Time (h) | Last mAP@50 | Best mAP@50 | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| V3-tiny | 3.48 | 53.7% | 54.4% | 0.71 | 0.45 | 0.55 |
| V3 | 15.2 | 69.2% | 69.9% | 0.79 | 0.61 | 0.69 |
| V4-tiny | 3.66 | 62.9% | 63.2% | 0.75 | 0.53 | 0.63 |
| V4 | 16.4 | 71.9% | 73.2% | 0.76 | 0.69 | 0.72 |
| V5s | 4.66 | 69.5% | 73.1% | 0.74 | 0.70 | 0.72 |
| V5x | 7.00 | 70.6% | 76.1% | 0.77 | 0.72 | 0.74 |
| v3-Tiny | v4-Tiny | v5s | v3 | v4 | v5x | |
|---|---|---|---|---|---|---|
| Mean percentage of TP bunches on RNoB | 58.0% | 70.2% | 79.0% | 65.3% | 78.7% | 82.6% |
| RMSE | 3.589 | 3.236 | 2.955 | 2.631 | 2.931 | 2.804 |
| MAE | 2.739 | 2.600 | 1.944 | 1.919 | 2.254 | 2.059 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. https://doi.org/10.3390/agronomy12020319
Sozzi M, Cantalamessa S, Cogato A, Kayad A, Marinello F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy. 2022; 12(2):319. https://doi.org/10.3390/agronomy12020319
Chicago/Turabian StyleSozzi, Marco, Silvia Cantalamessa, Alessia Cogato, Ahmed Kayad, and Francesco Marinello. 2022. "Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms" Agronomy 12, no. 2: 319. https://doi.org/10.3390/agronomy12020319
APA StyleSozzi, M., Cantalamessa, S., Cogato, A., Kayad, A., & Marinello, F. (2022). Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy, 12(2), 319. https://doi.org/10.3390/agronomy12020319