1. Introduction
With the rise in population and growing urbanization, infrastructure planning is increasing day by day. This demand has resulted in a significant increase in the construction industry’s growth. Concrete is a common building material that is composed of cement, fine aggregate, coarse aggregate, and water [
1]. Because of its durability, increased strength, ease of use, and other advantageous features, concrete is widely employed as a construction material [
2]. It has served as the foundation of modern existence. A rise in population can cause an increase in urbanization demand which results in high concrete demand in construction industry [
3]. Humanity has been willing to overlook concrete’s environmental disadvantages for many years in exchange for concrete’s obvious advantages. Having a strong foundation is appealing in these times of rapid change, but it may also create more problems than it solves if used to its full potential.
After water, concrete is the second most commonly used substance on the earth [
4]. There are numerous environmental and human health hazards associated with concrete. Carbon dioxide emissions from concrete-making accounted for 7% of worldwide carbon dioxide emissions in 2018, which is a major contributor to climate change, as it destroys the ozone layer, which raises the global temperature [
5]. Calcination, the process of heating raw materials, such as limestone and clay, to temperatures greater than 1500 °C, results in the release of CO
2 [
6]. Cement production releases around 0.9 pounds of CO
2 into the environment for every pound of cement produced [
7]. Since the cement is only a fraction of the constituents in concrete, manufacturing a cubic yard of concrete is responsible for emitting about 400 lbs of CO
2. The focus of reductions in CO
2 emissions during cement manufacturing is on energy use, and the cement industry is striving to continuously reduce its CO
2 contribution.
Consequently, each year, around 0.28 billion tonnes of plastic waste is produced worldwide [
8]. A lot of it ends up in landfills, contaminating the environment and endangering aquatic life. Because of its durability and inexpensive cost, plastic is widely used but it has major environmental effects [
9]. New ways for recycling plastic waste are being used nowadays. Plastic recycling saves 7.4 cubic yards of landfill area every tonne [
10]. Recycling is on the rise because of greater environmental awareness and financial reasons. As a result of rapid industrial growth and urbanization, the amount of waste plastics produced each year has expanded uncontrolled. The environment suffers greatly as a result of this plastic waste. To reduce pollution, many products are produced from reusable waste plastics. Plastic waste is now recycled, but only a small percentage of it is recycled in comparison to manufacturing; the rest ends up in landfills, causing major environmental dangers. After being buried, plastic might take up to 1000 years to decompose. When it is burned to get rid of it, toxic chemicals like sulphur dioxide and carbon dioxide are emitted, harming both the environment and human health [
11]. Plastic waste has become a major environmental concern in modern society. The increased use of numerous types of plastic objects is one of the most major environmental concerns. Plastic waste in large quantities, as well as its low biodegradability, has a negative influence on the environment [
12]. To store such large influxes of plastic garbage, which demand vast tracts of land, and which cannot be recycled in their entirety, humans use a variety of plastic products throughout their daily lives. Plastic recycling is an environmentally friendly approach to limit the amount of waste burnt in landfills in the materials sector. As a result, adopting a strategy for utilizing plastic in the construction industry could be quite advantageous in the current situation. Concrete is a crucial input in the construction industry, and it is made up of cement, fine aggregates, and coarse aggregates. Due to high demand and limited supply, these basic resources are becoming increasingly difficult to obtain. As a result, using waste plastics as raw material in concrete may partially resolve both concerns. To accomplish sustainable development, plastic can be crushed and used as a concrete component, this sort of material has become a significant research topic in recent years. Some positive aspects of using plastic in concrete includes enhanced tensile and compressive strengths. Plastic in concrete also provides dense packing, thus reducing the deal weight of concrete. It also provides better resistance against chemical attack. Utilizing plastic in concrete is associated with less cement demand, resulting in less cement production. Moreover, plastic is recycled instead of being dumped in land-fills or being burnt. Hence, emission of harmful gases will be reduced.
Many laboratory tests have been conducted to examine the effect of partial replacement of concrete inputs by plastic waste on various properties of concrete. From the literature review, it is observed that using the plastic waste in concrete as an additive reduces the carbon emission but a decrease in some of the mechanical properties of concrete is also examined [
13,
14,
15,
16]. A detailed literature review is performed to discover the best grade polymer and its optimal quantities and additives for enhanced high strength [
13]. We attempted to replace the fine aggregate with granulated plastic waste at different percentages. The test conducted on hardened concrete revealed a steady decrease in concrete strength as more plastic granules were added to the concrete mix [
14]. The effects of replacing natural aggregate with non-biodegradable plastic aggregate made consisting of mixed plastic waste in concrete were studied. In the range of 9 to 17% at all curing ages, the decline in compressive strength (f
c’) is mainly attributable to the weak adhesion of waste plastic to the cement paste. Compressive strength was increased by 23% when fine aggregate was replaced with irradiated plastic waste up to 5% [
17]. Similarly, with a water–cement ratio of 0.52 and a water–cement ratio of 0.42, the f
c’ increased by 8.86% and 11.97%, respectively, using fine aggregate as a 5% replacement for polyethylene terephthalate waste [
15]. Similarly, it was studied that by replacing the natural coarse aggregate from 0 to 15% with waste plastic bottle caps, an increasing trend in f
c’ was noticed but the course was reversed when the percentage was increased beyond 15% [
16]. At varied mix ratios, the mechanical properties of plastic concrete display aberrant behaviour. A correlation among the properties of plastic waste and quantity of constituents used in concrete is necessary for altering this behaviour and promoting the widespread use of plastic in concrete. To achieve this, several artificial intelligence (AI) modelling techniques are utilized, as well as empirical models to support long progress. For plastic concrete design, basic mechanical parameters including f
c’ and split tensile strength (f
sts) should be considered.
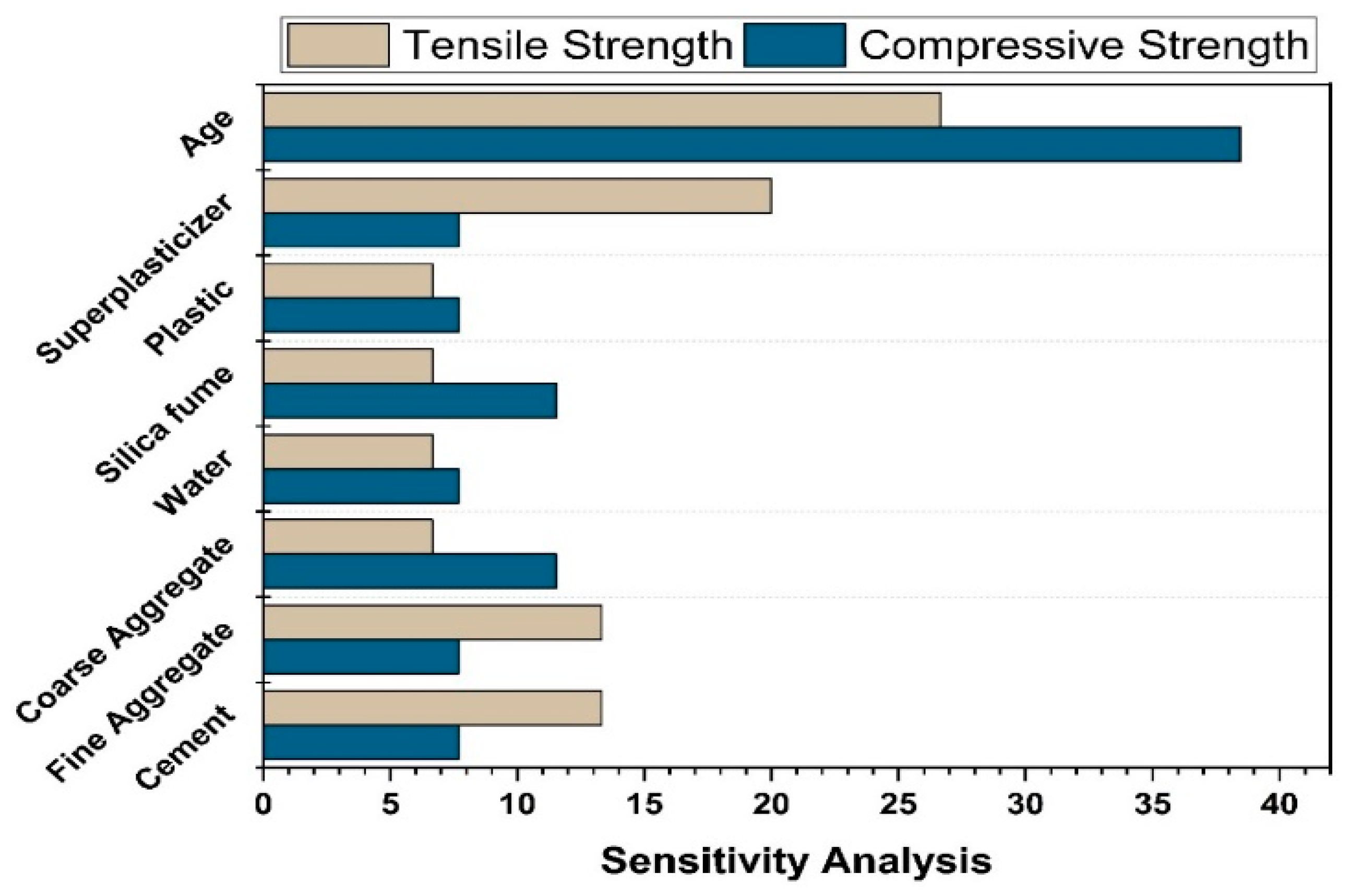
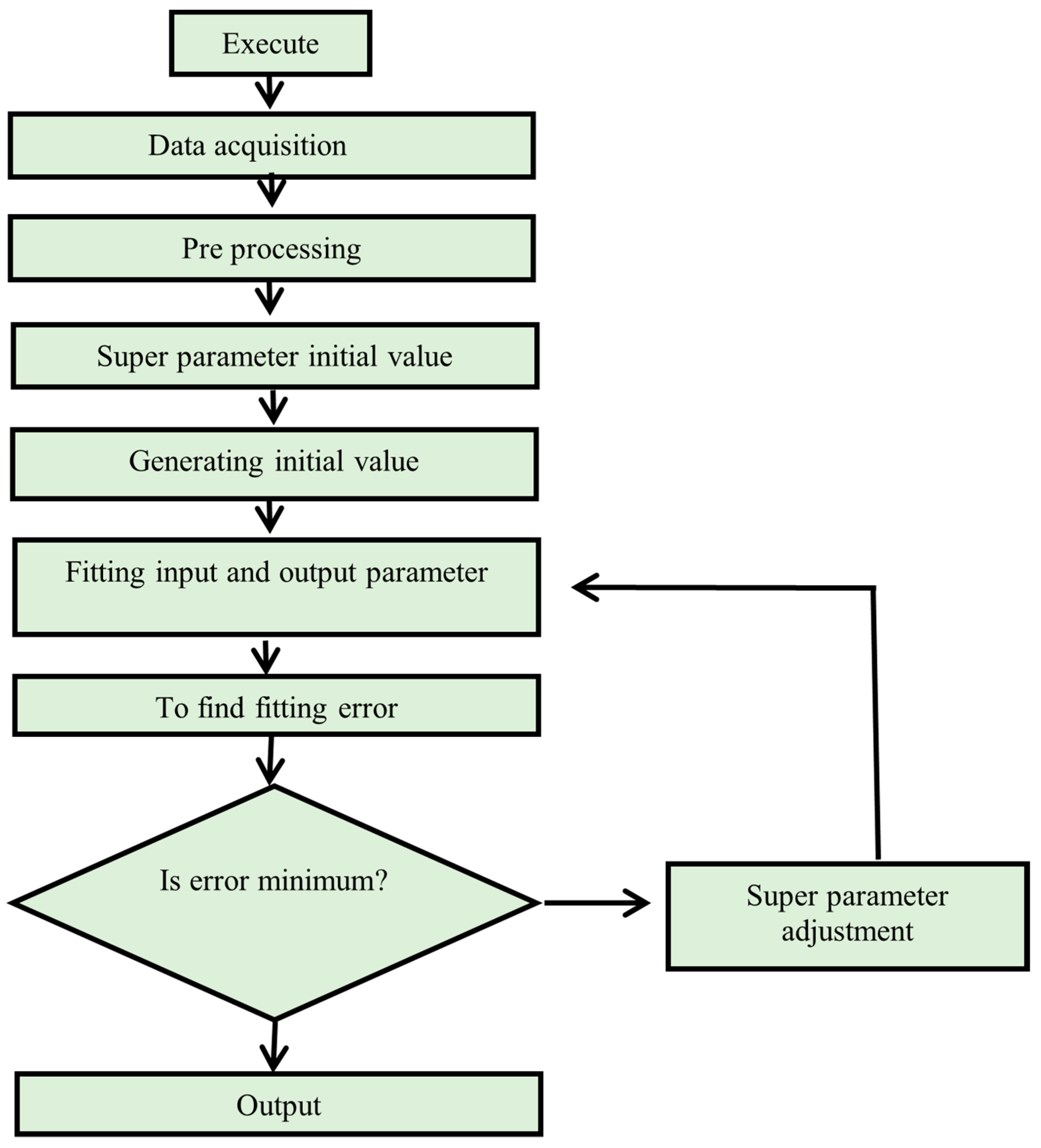
Computational modelling approaches could be a viable alternative to the time-consuming complexity of laboratory-based mixture optimization [
18]. To establish the optimal concrete mixes, these methods create objective functions from the concrete elements and their attributes and then identify the ideal concrete mixes using optimization methods. In the past, objective functions for linear and nonlinear models were designed separately. However, because of the considerably nonlinear correlations among concrete attributes and input parameters, the relations of such models cannot be established accurately. Consequently, researchers are utilizing machine learning (ML) techniques for forecasting concrete characteristics. Previously, a variety of ML techniques were utilized to forecast properties of concrete including f
c’, elasticity modulus, and f
sts. The most often used machine learning approaches were multi-layer perceptron neural networks (MLPNN), artificial neural networks (ANN), support vector machines (SVM), decision trees (DT), and genetic engineering programming (GEP) [
19,
20,
21]. Researchers have used supervised machine learning and its algorithm to handle complicated issues in a variety of domains, including the prediction of concrete’s mechanical properties.
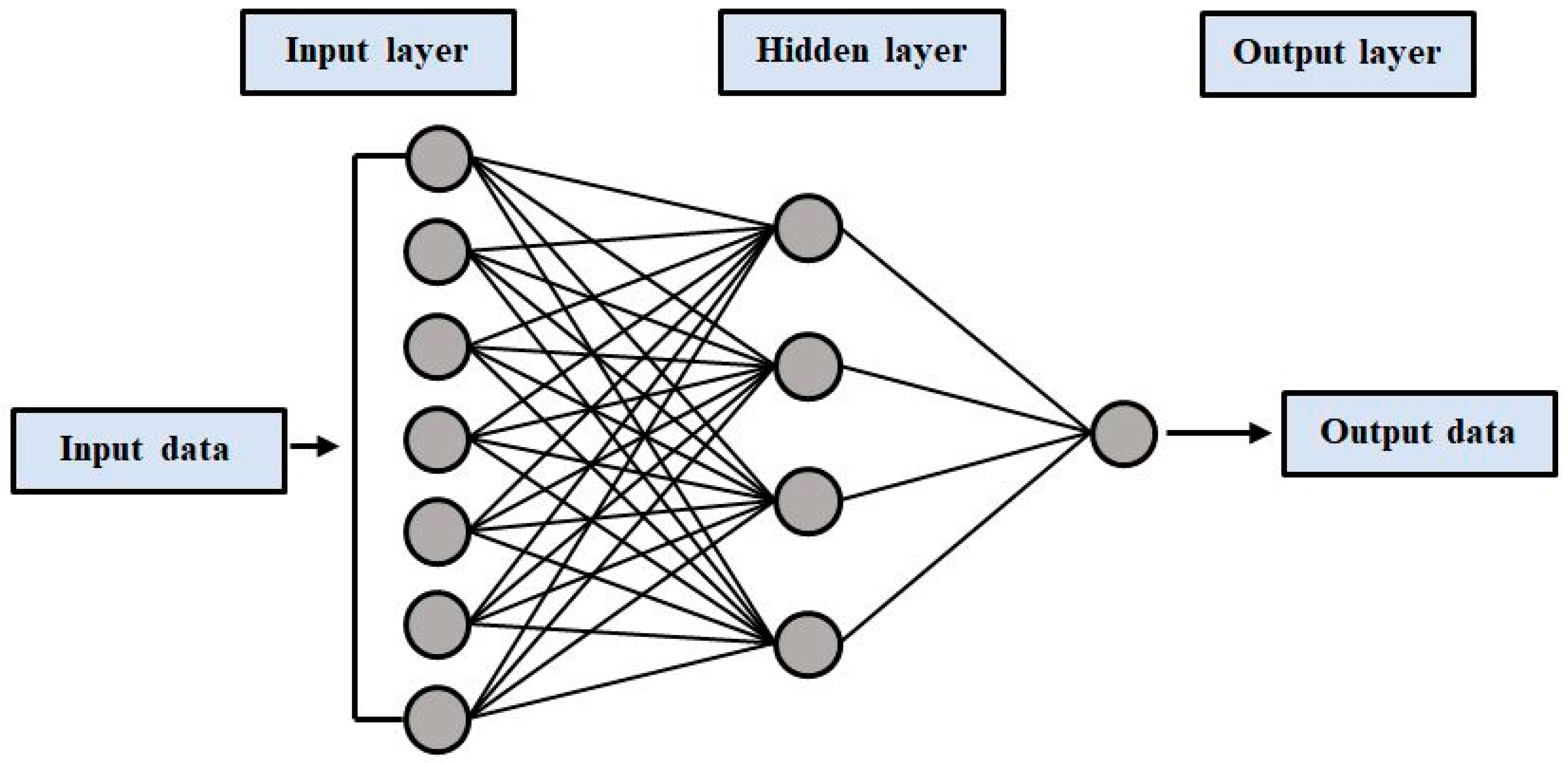
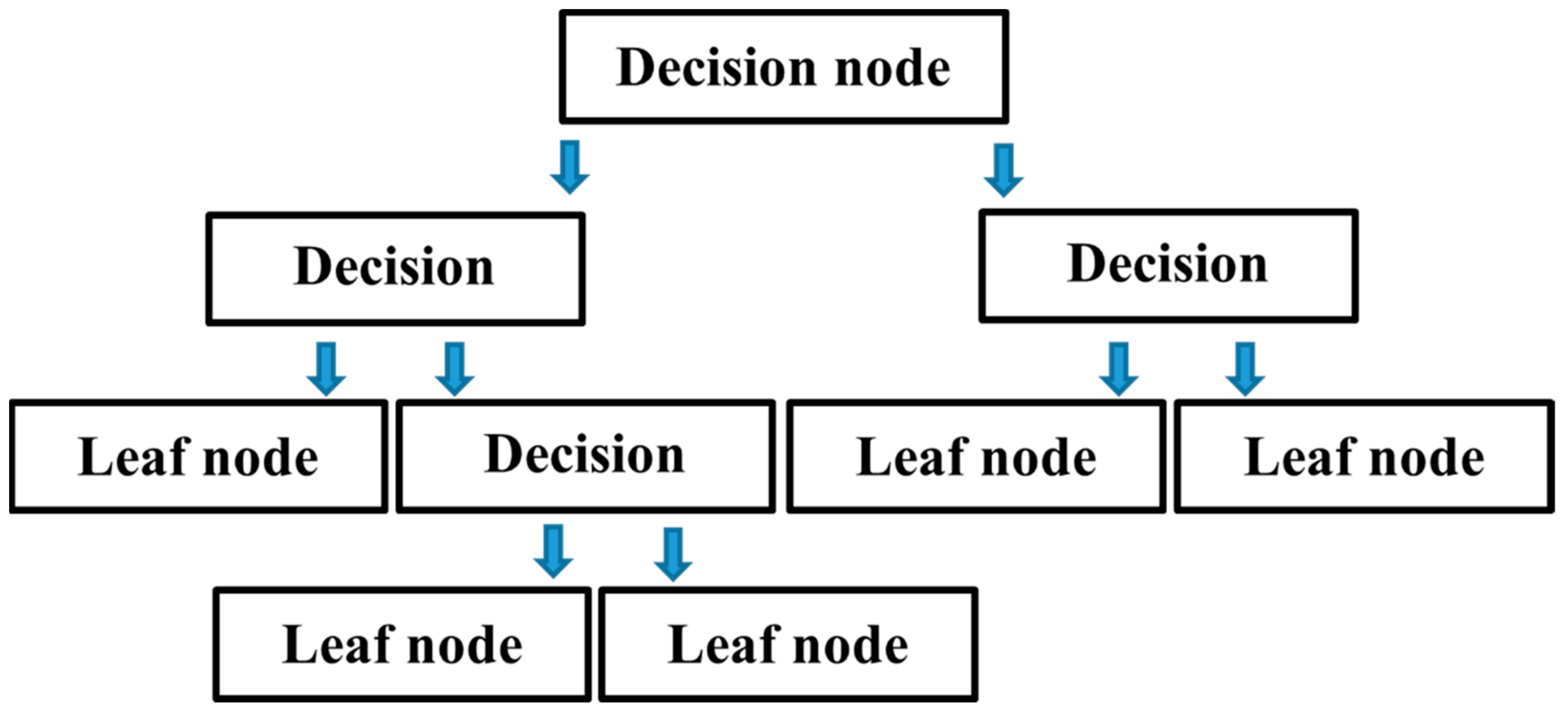
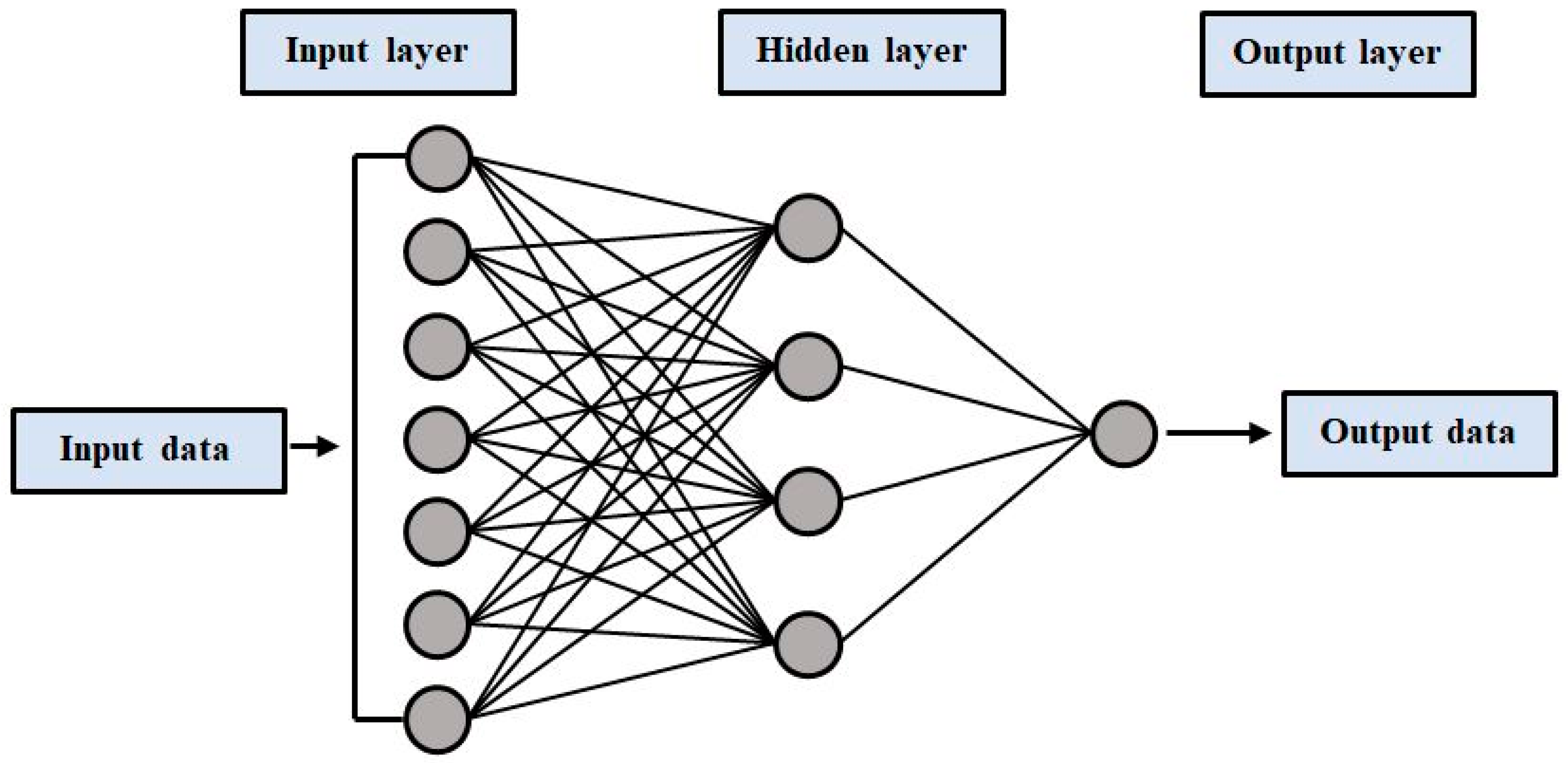
The multi-layer perceptron neural network (MLPNN) is a class of artificial neural network (ANN), which is a non-linear computer modelling method capable of establishing input–output relations for complex issues. SVM models are trained to find a global solution during training because model complexity is considered a structural risk in SVM training [
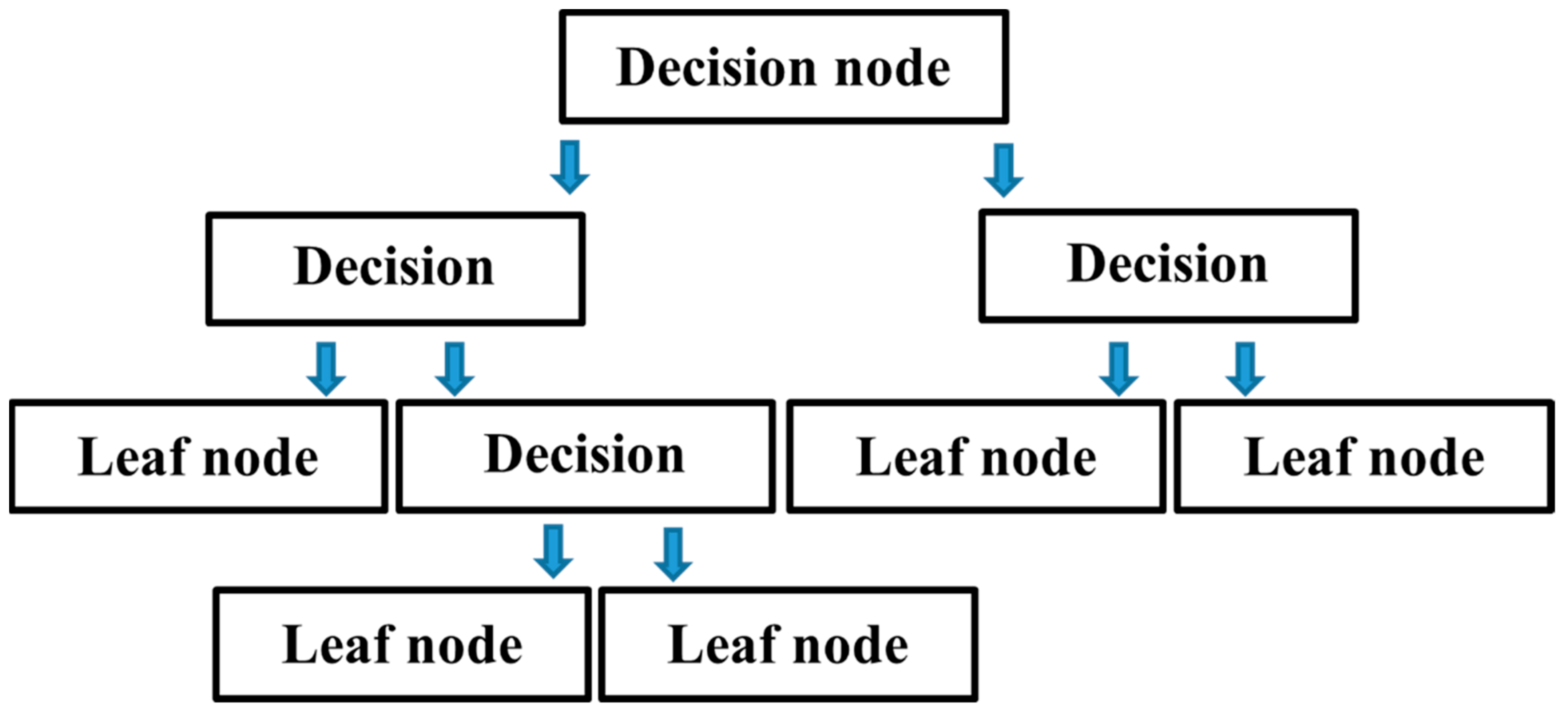
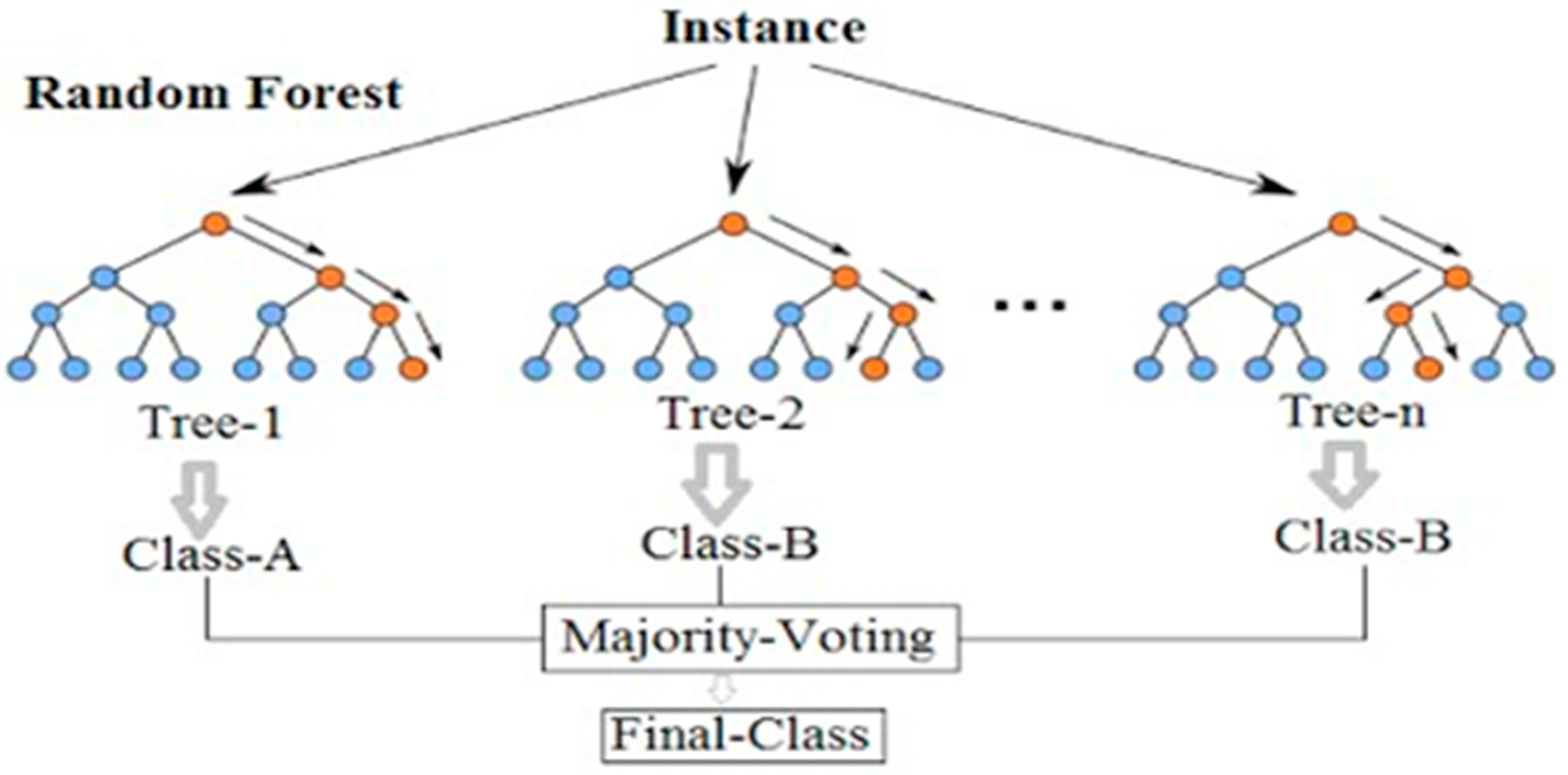
22]. Classification problems are best solved using the decision tree, a supervised learning technique. In a tree-structured classifier, each leaf node represents a classification result, with internal nodes corresponding to dataset features, branching corresponding to decision rules. In the field of computational intelligence, the GEP is one of the most recent methodologies. Advanced genetic algorithms use an expression tree to express non-linear relationships. The robust architecture of deep learning (DL) algorithms, in contrast to previous ML techniques, allows researchers to better predict results. Because of the enormous amount of data collected over the past decade, DL is becoming increasingly popular. Thus, neural networks have been able to demonstrate their potential since they improve with an increasing amount of input data. When compared to typical machine learning techniques, more data will not necessarily lead to better results. When it comes to machine learning algorithms, ensemble approaches have a significant advantage over the competition [
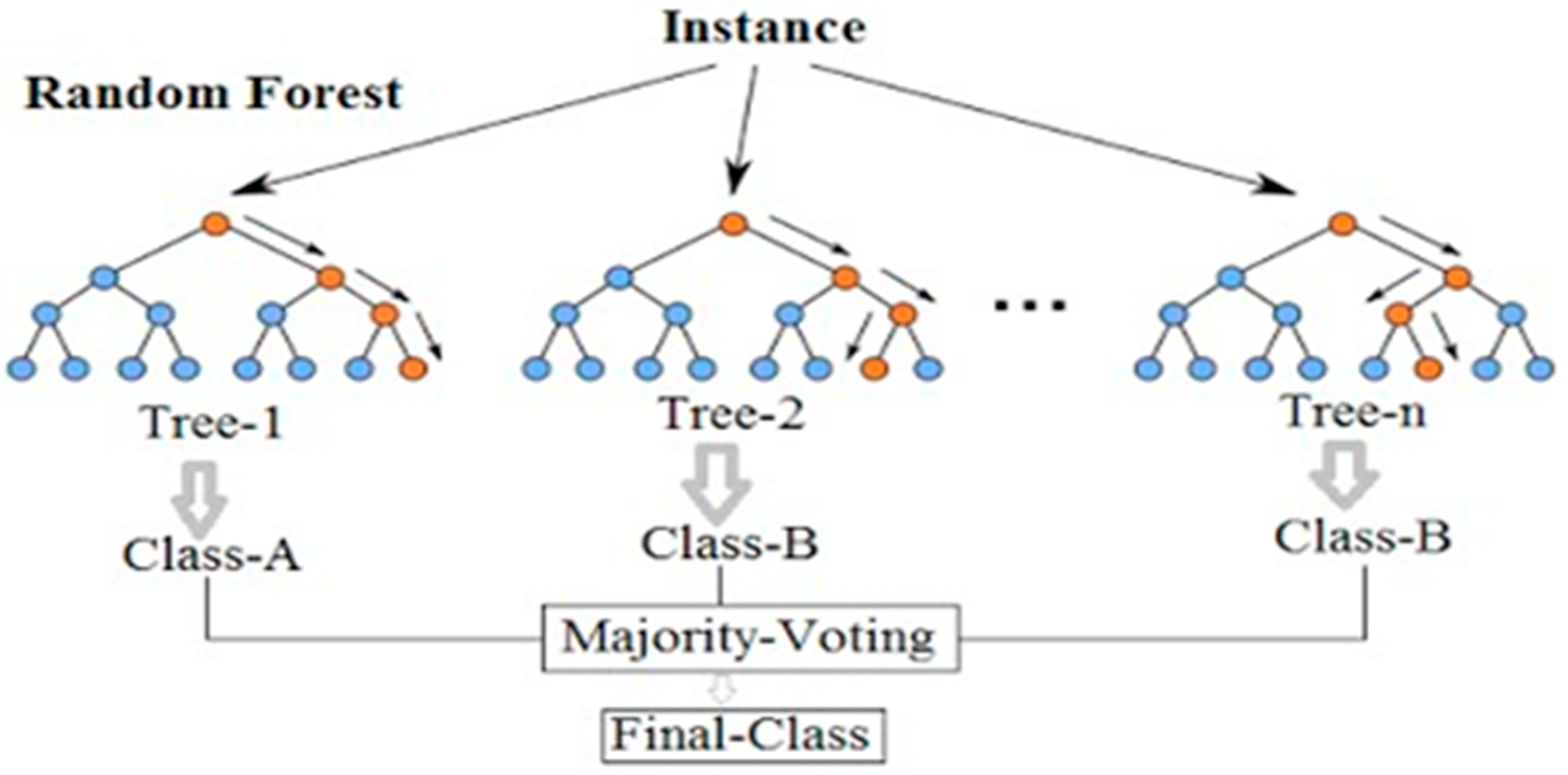
23]. Due to its capacity to tackle complicated and tough issues with exceptional precision, the DL technique has helped to promote the use of machine learning algorithms across a wide range of industries. The random forest (RF) technique was utilized to predict the mechanical properties of high-strength concrete, and statistical analyses, such as mean absolute error (MAE), relative root mean squared error (RRMSE), root mean square error (RMSE), and were employed to evaluate the models’ performance. This model outperformed all others since it relies on a weak base learner decision tree and provides a more accurate coefficient of determination (R
2) = 0.96 [
24]. A study was conducted by [
20] for estimating the uniaxial f
c’ of rubberized concrete by using RF with an optimization technique. The authors claimed that the model was accurate and had a high correlation. Moreover, f
c’ was predicted using SVM, ANN, DT, and linear regression approaches by [
25]. The DT approach was found to predict f
c’ with minimum error and to perform better than other methods, the correlation coefficient (R
2) was 0.86, and the best mean absolute error was 2.59 using the DT algorithm. For the purpose of forecasting the strength of self-compacting geopolymer concrete generated from raw ingredients, ANN and GEP models were developed. Using empirical relationships to predict output parameters, the authors observed that the GEP model performed better than the ANN model [
26]. MLPNN, SVM, DT, and random forest (RF) algorithms were used to evaluate the performance of ensemble techniques in predicting the f
c’ of high-performance concrete. The results suggested that using the bagging and boosting learners improved the individual model performance. In general, the random forest and decision tree with bagging models performed quite well, with R
2 = 0.92. On average, the ensemble model in machine learning enhanced the performance of the model [
24]. Ref. [
25] declared that GEP and ANN are effective and efficient methodologies for estimating swell pressure and unconfined compression strength of expansive soils, according to the comparison results. The mathematical GP-based equations that were created represent the uniqueness of the GEP model and are relatively simple and efficient. The R
2 values for both swell pressure and unconfined compression strength of expansive soils lie in the acceptable range of 0.80. In terms of accuracy, the order followed by the techniques is ANN > GEP > ANFIS. The GEP model outperformed the other two models in terms of closeness of training, validation, and testing dataset with the ideal fit slope.
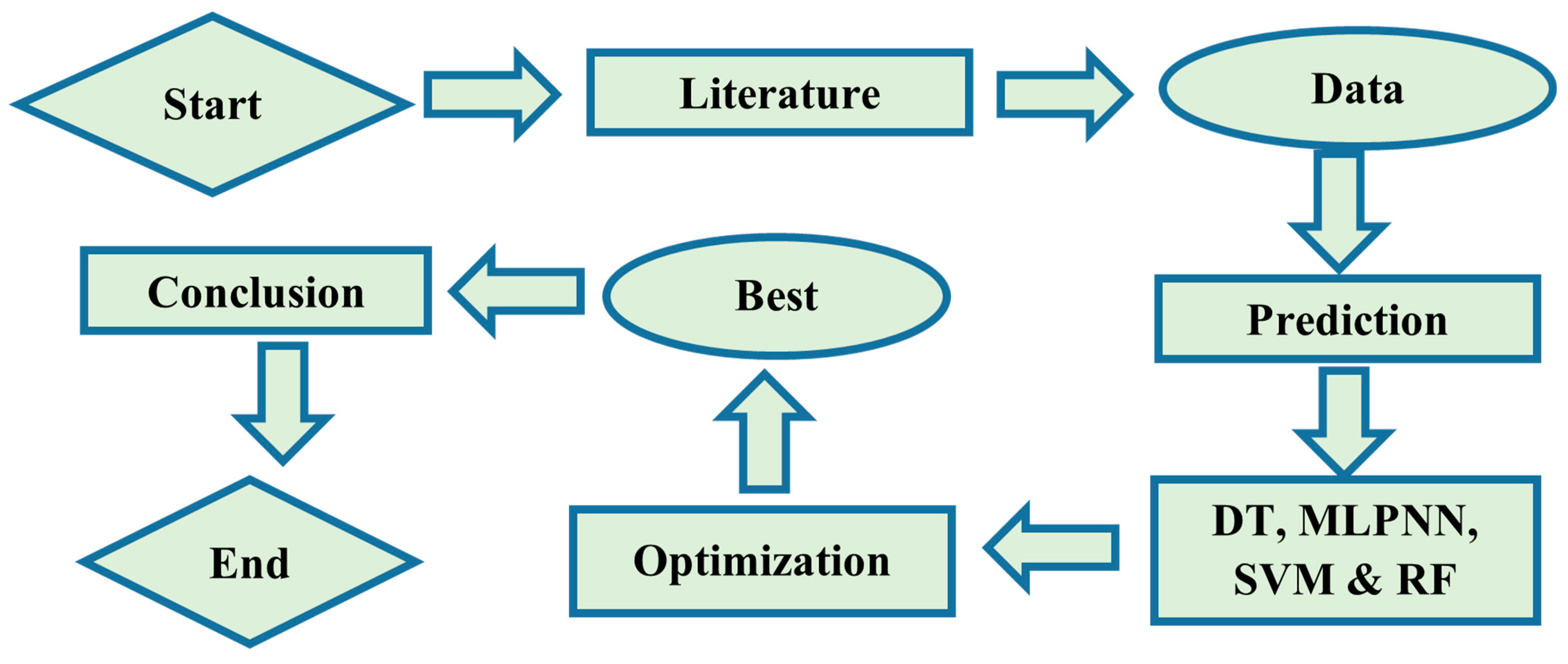
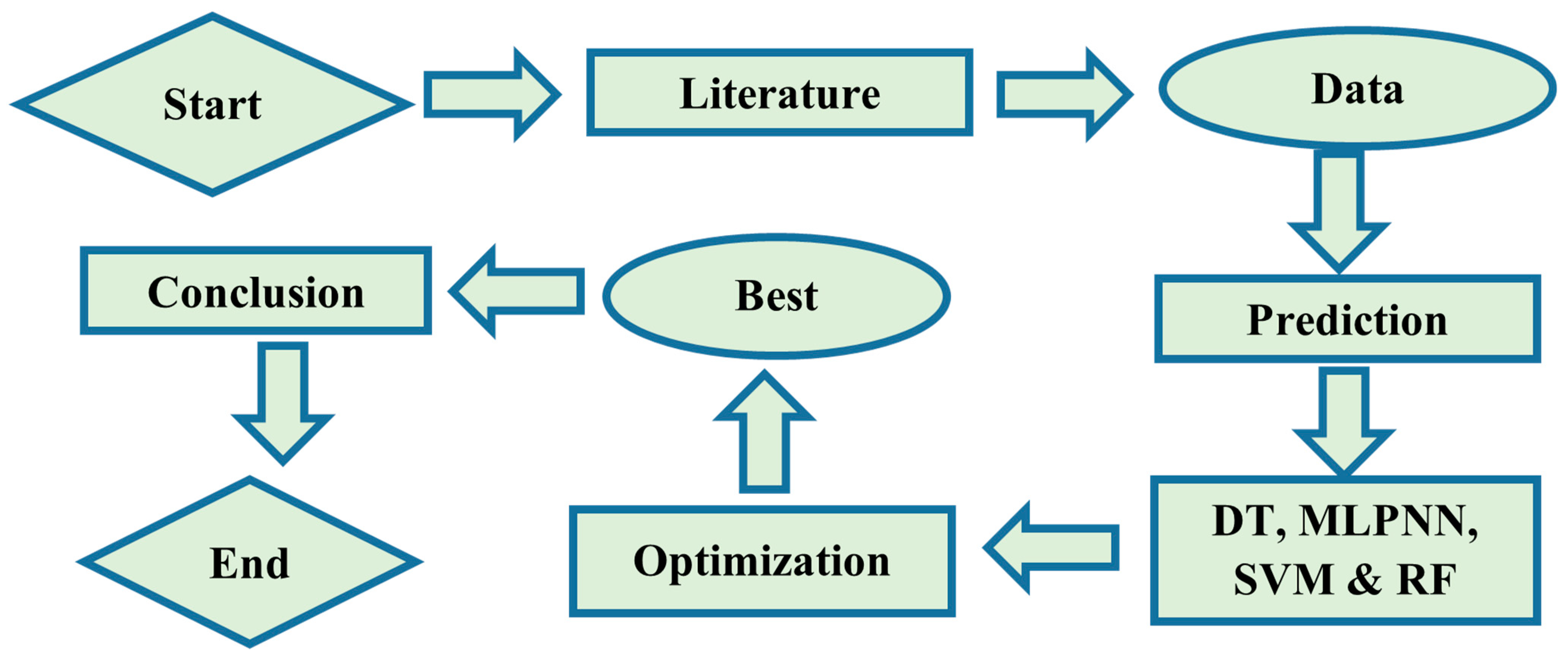
An effort has been made in this study to encourage plastic waste use in concrete, and studies have been undertaken to focus on carbon footprint reduction by employing ensemble ML techniques to use plastic waste as an additive or a replacement in concrete for greater long-term sustainability. The purpose of this research is to evaluate and use ensemble learning methodologies over individual learning models to predict the strength of PC. According to the authors, there is no previous study that employs ensemble machine learning modelling for plastic concrete.
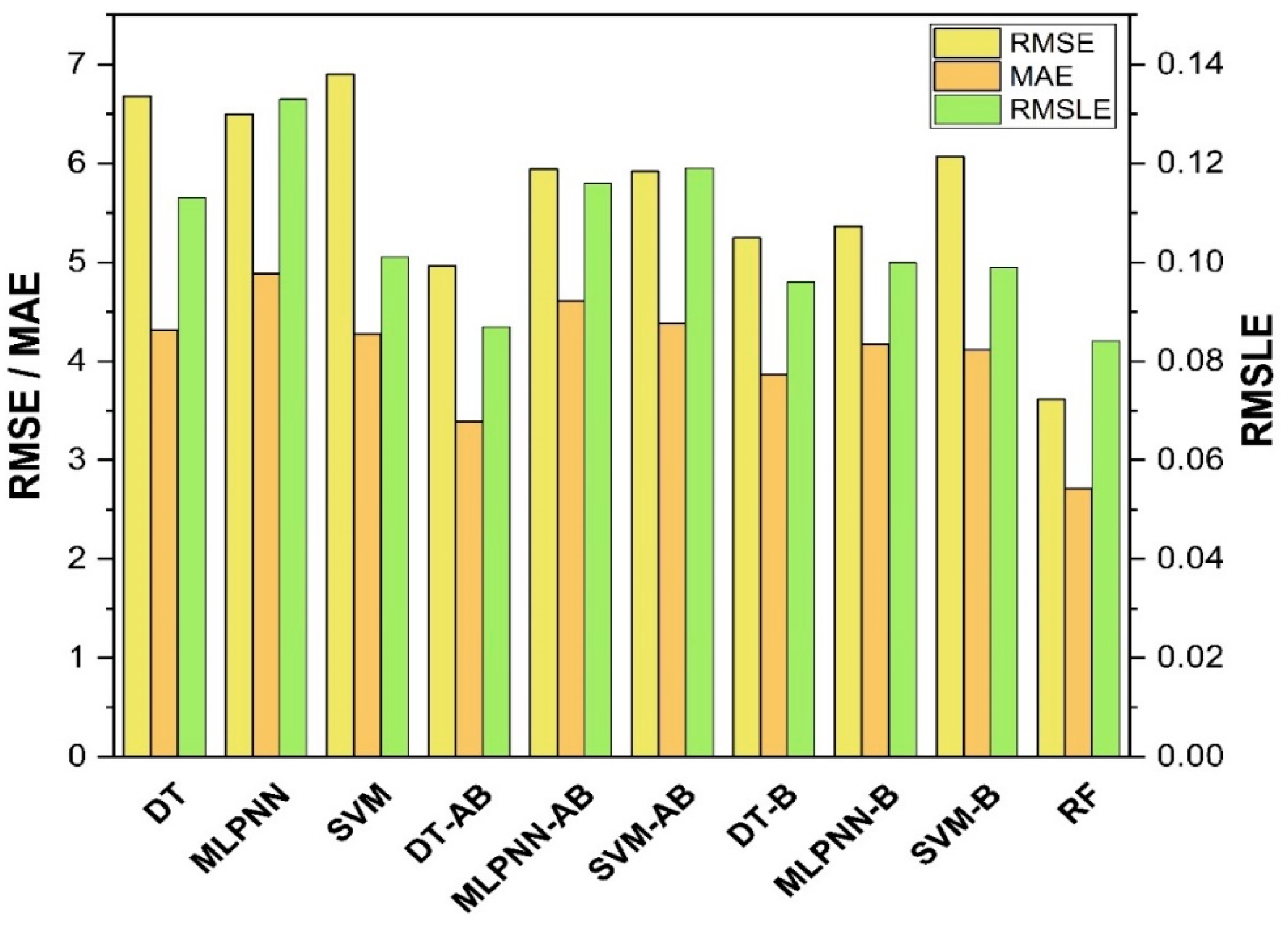
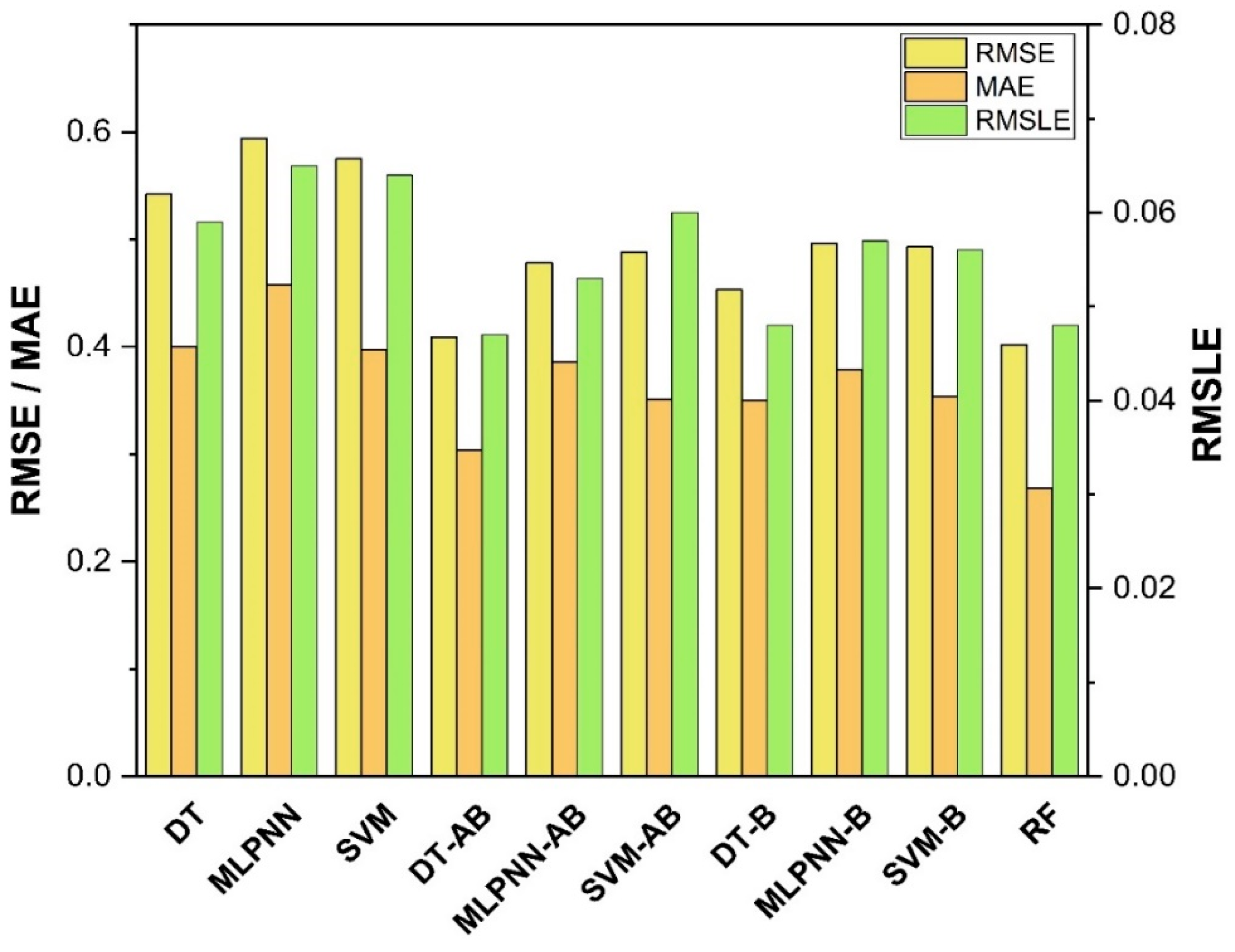
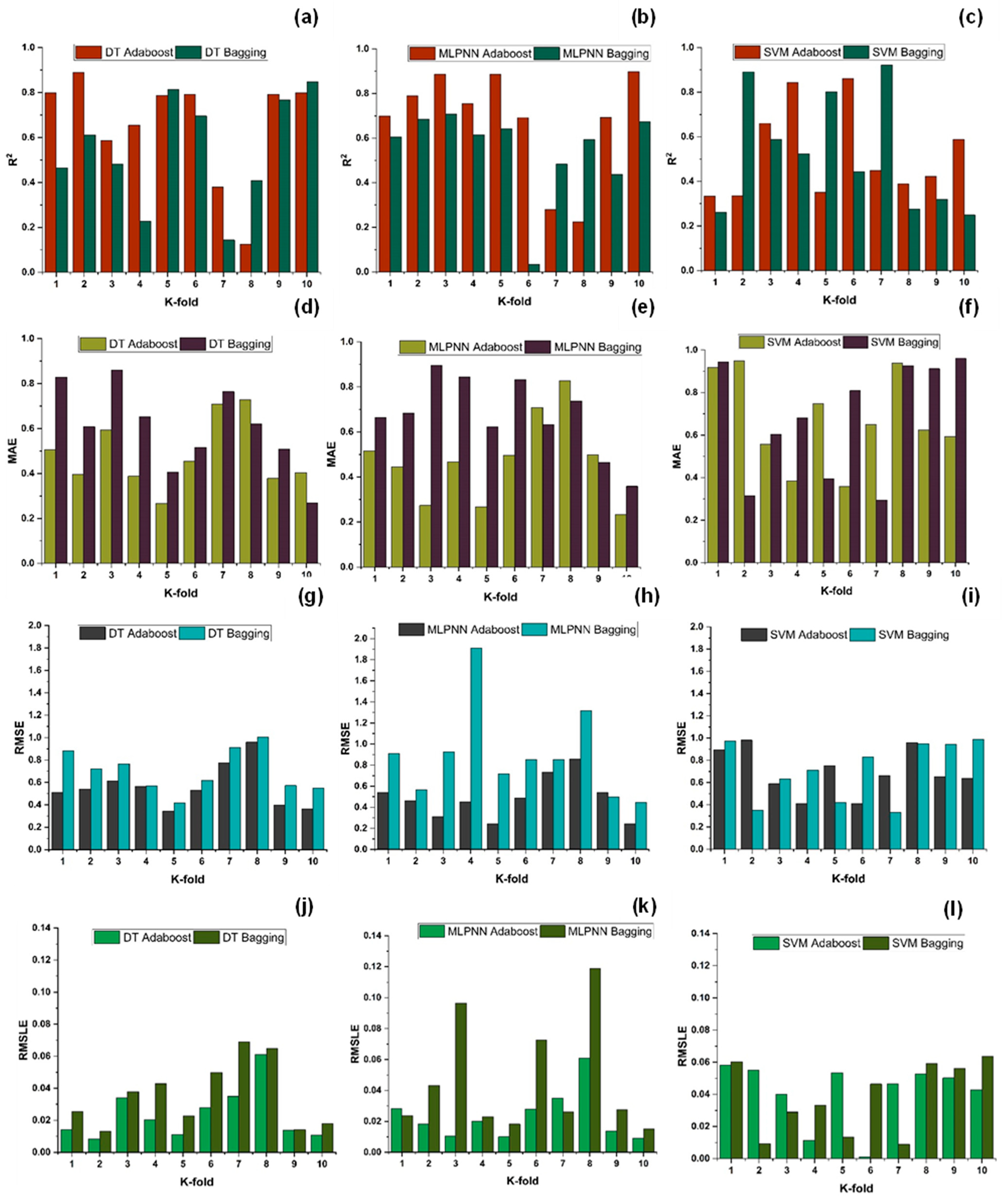
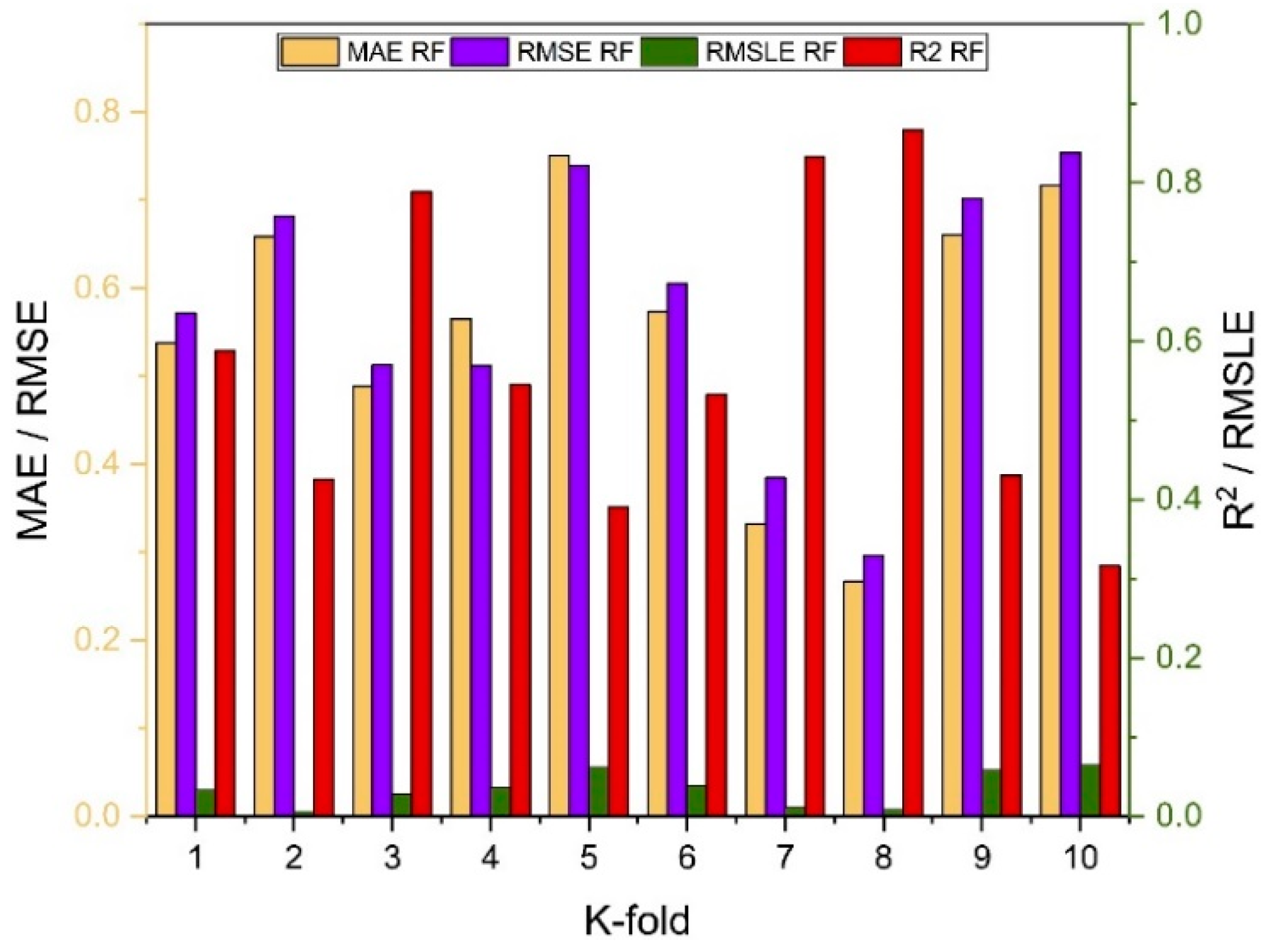
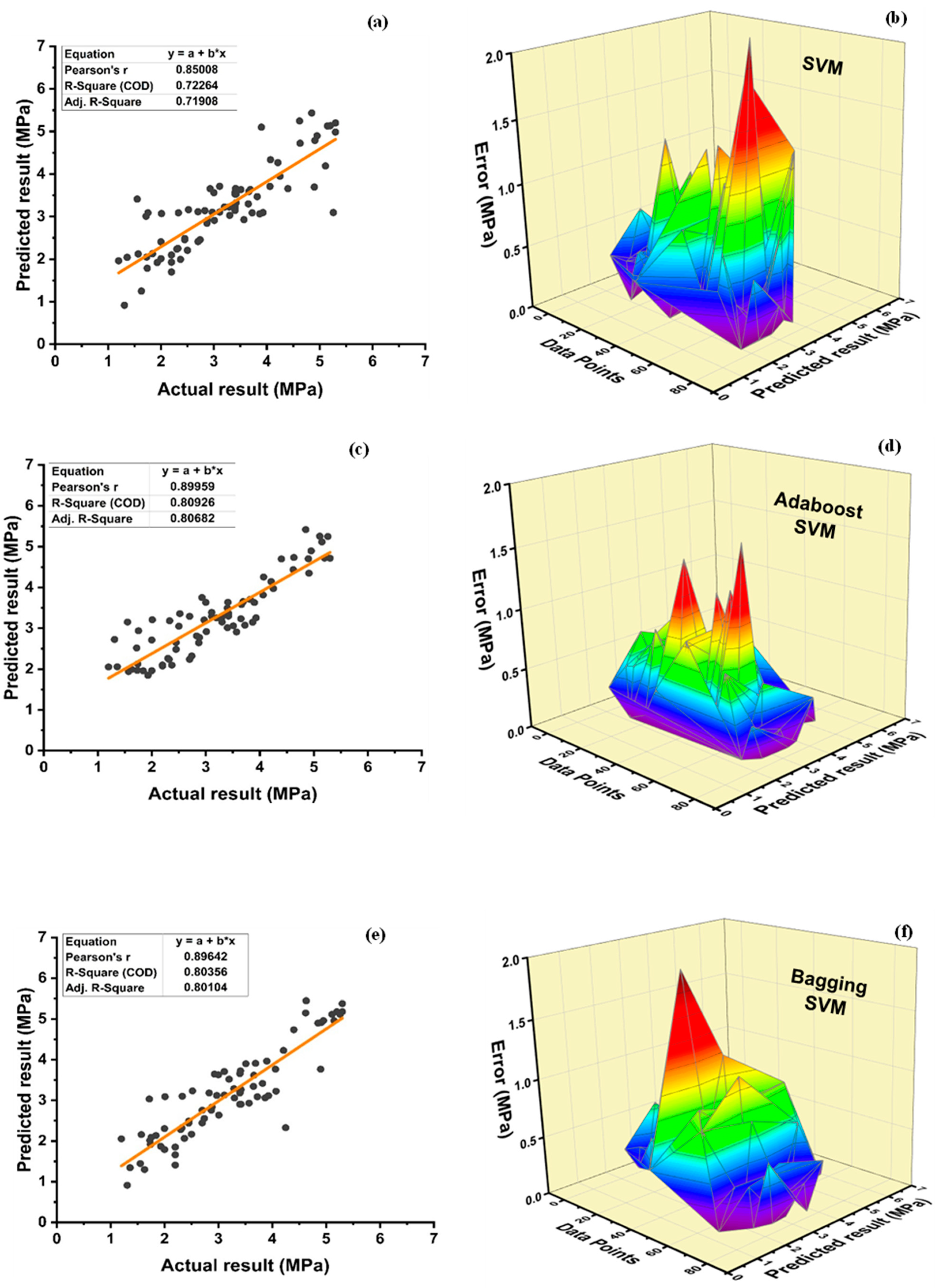
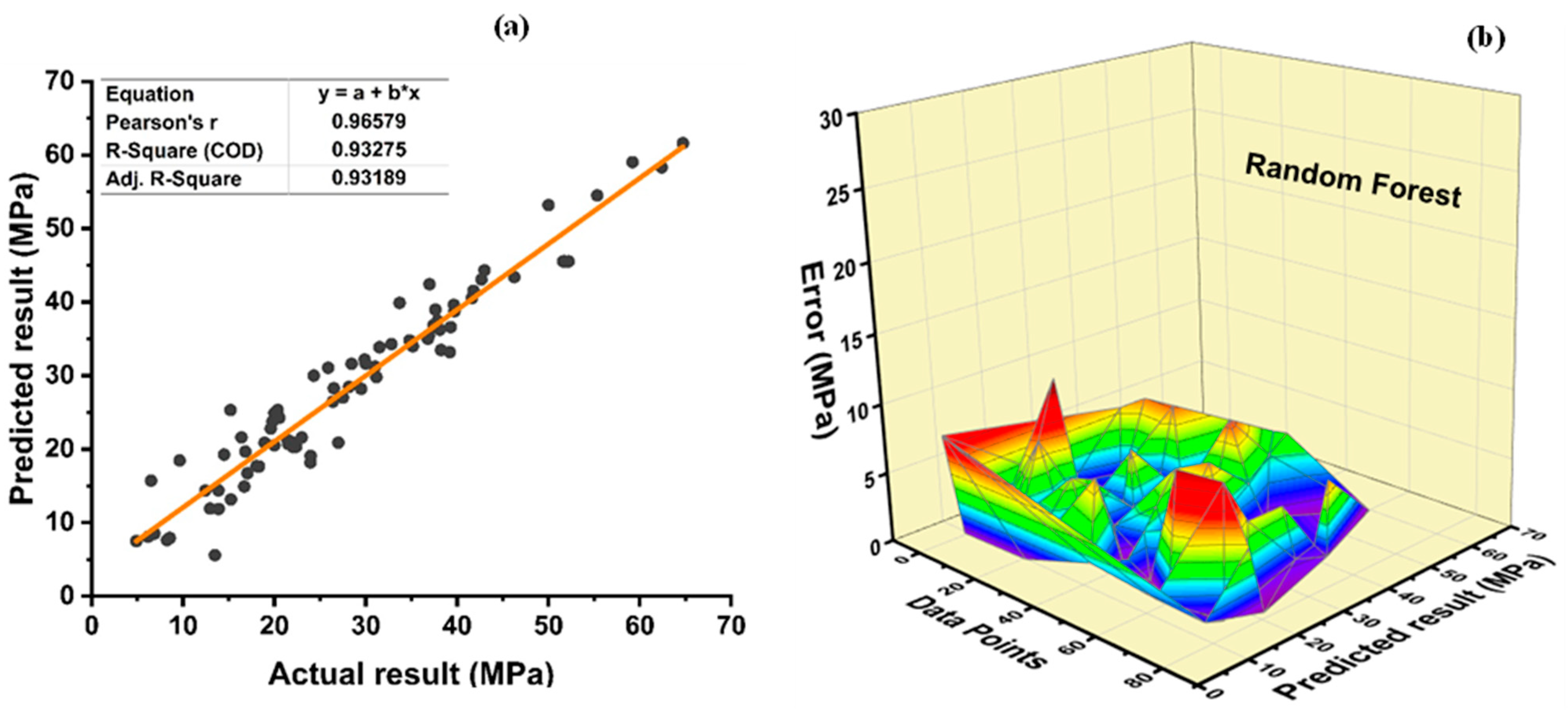
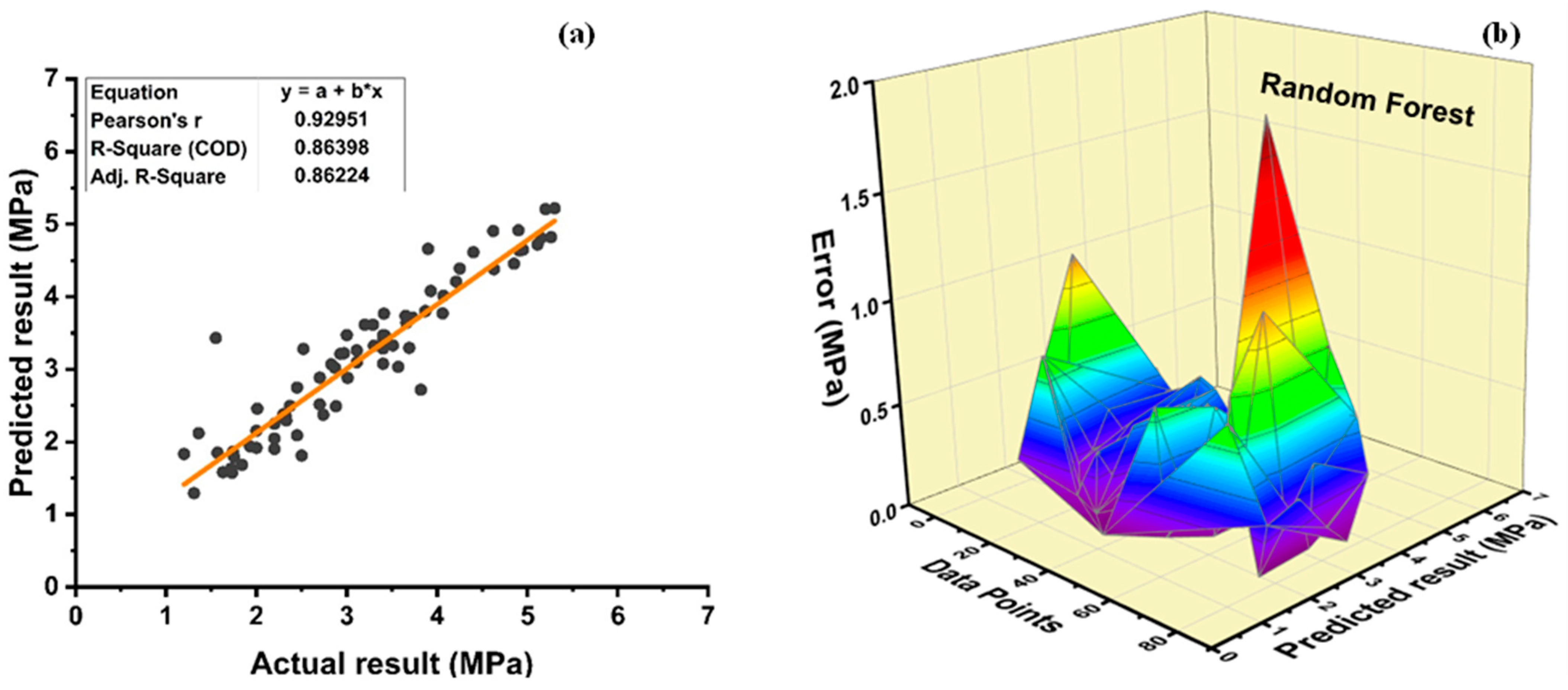
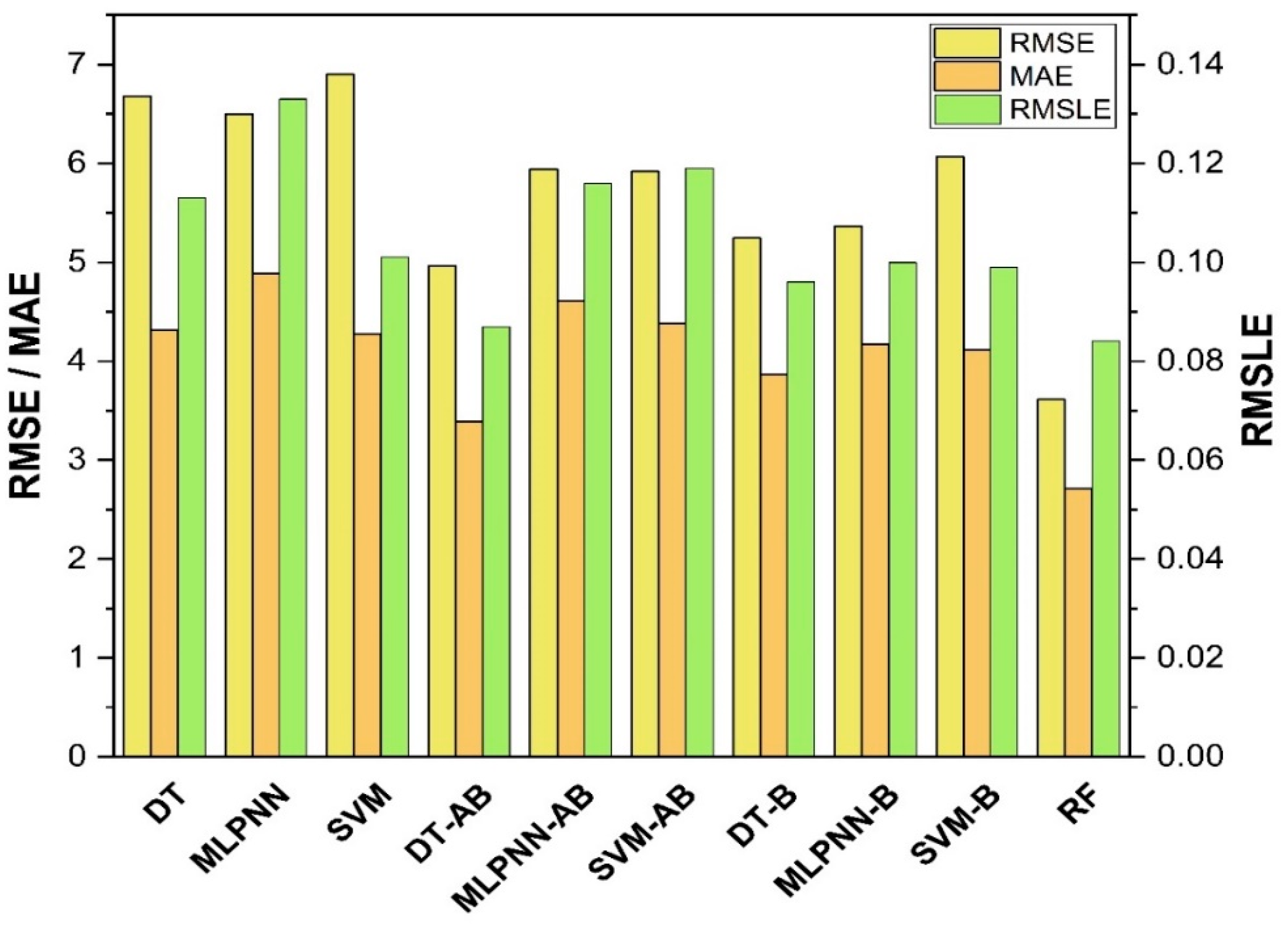
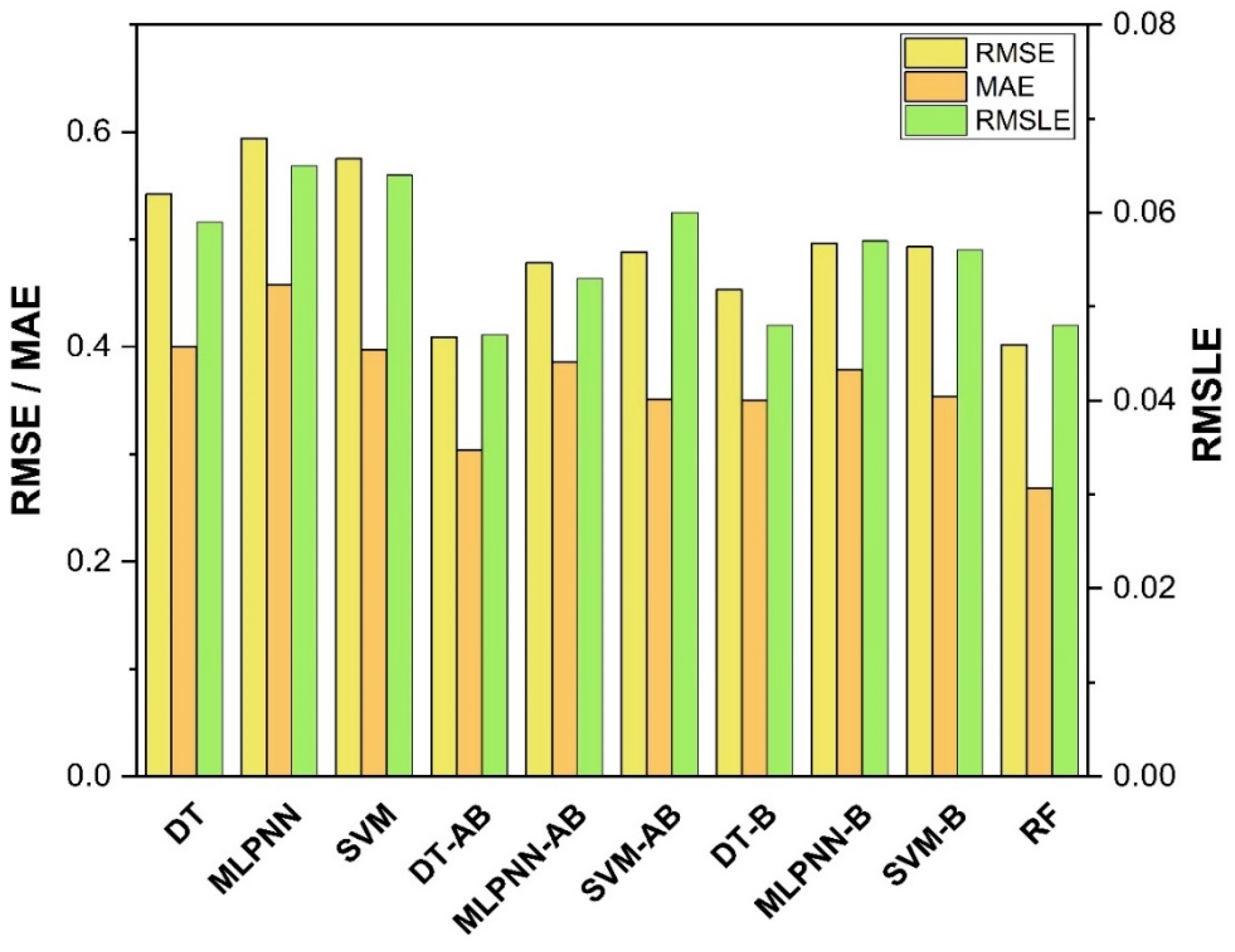
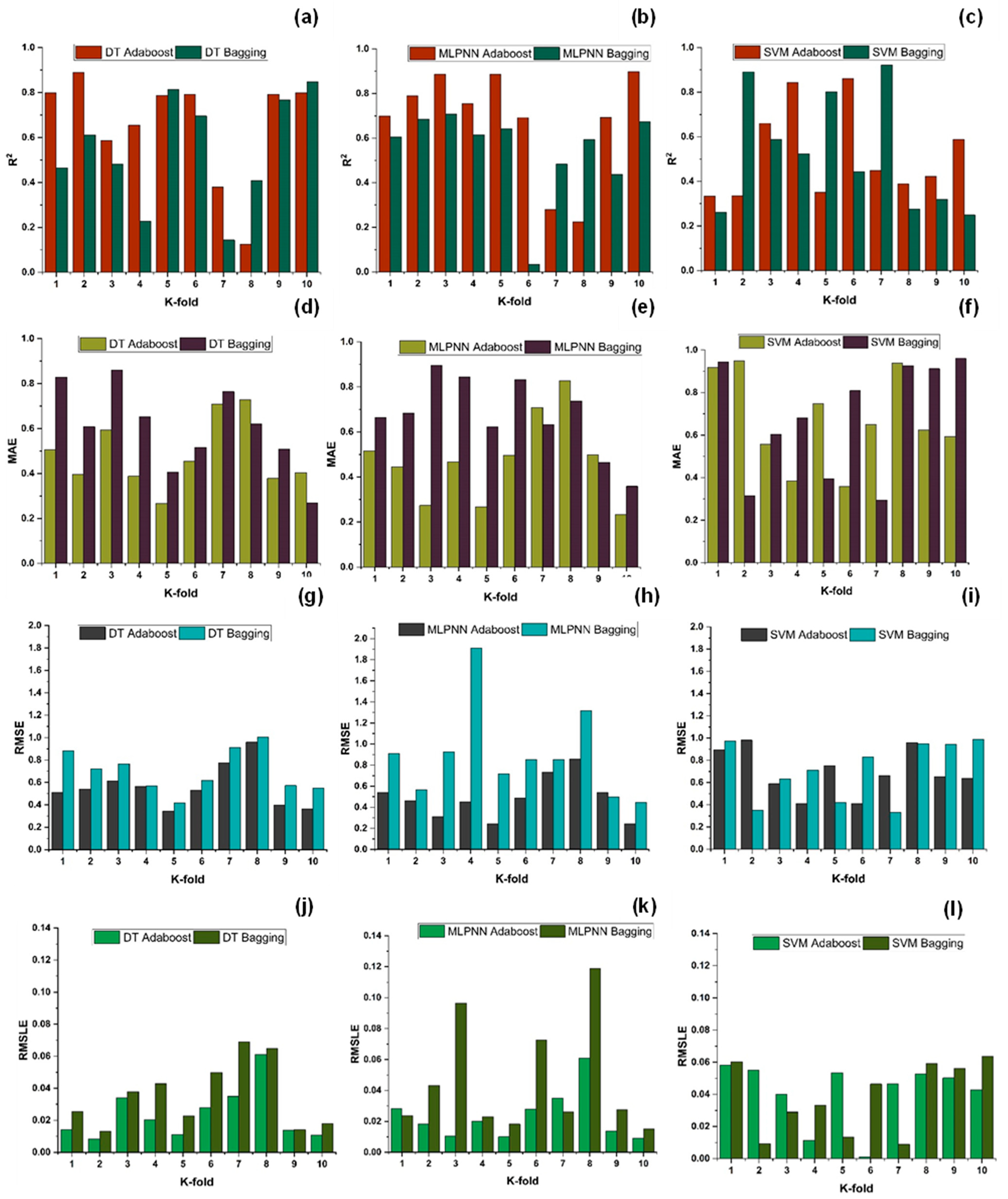
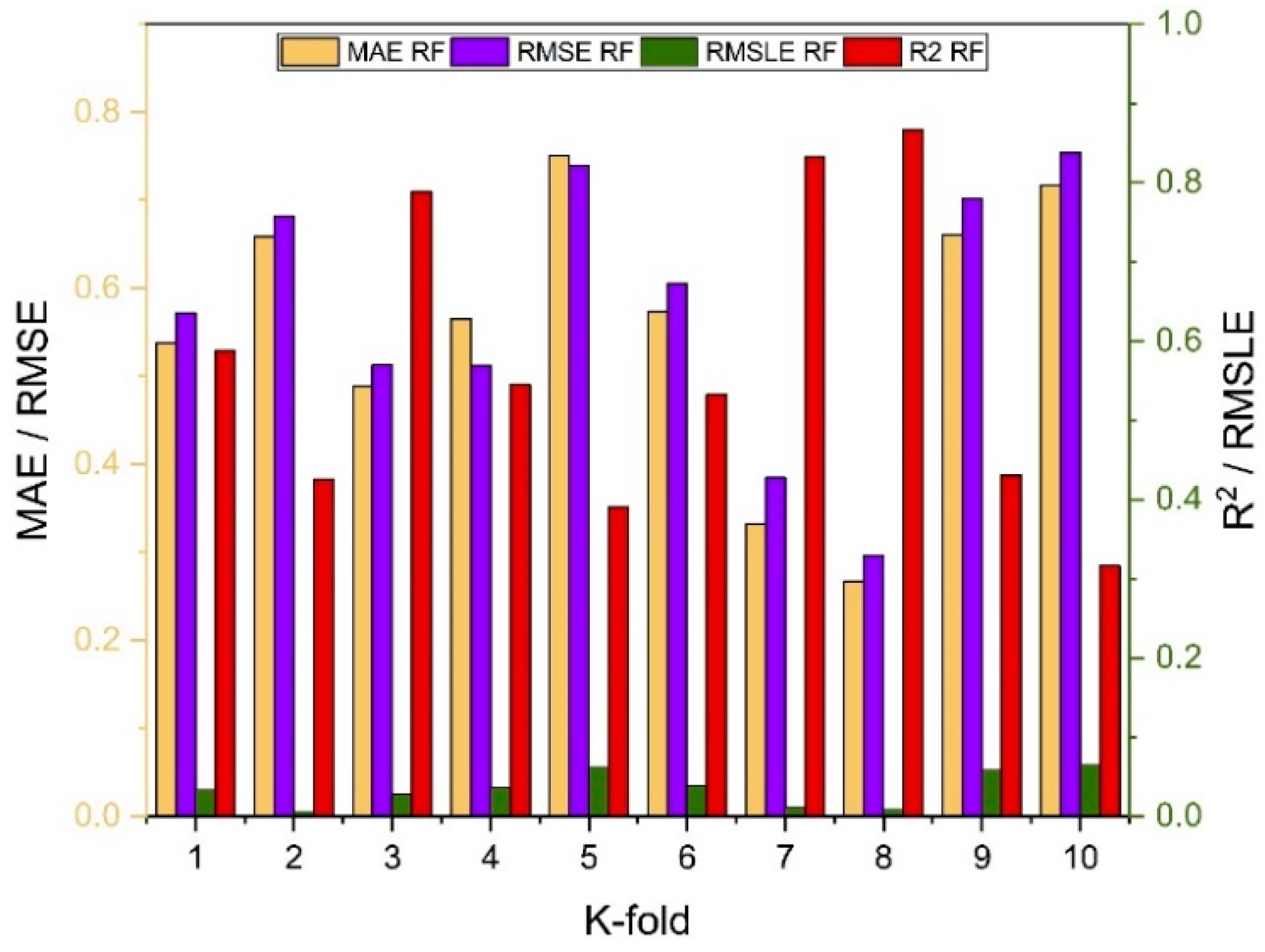
7. Evaluation of Models
The results of individual, ensemble bagging, ensemble boosting, and modified ensemble models are evaluated by different errors including correlation coefficient (R
2), RMSLE, MAE, and RMSE, as shown in
Figure 20 for f
c’ models and
Figure 21 and f
sts models, and their values are tabulated in
Table 15.
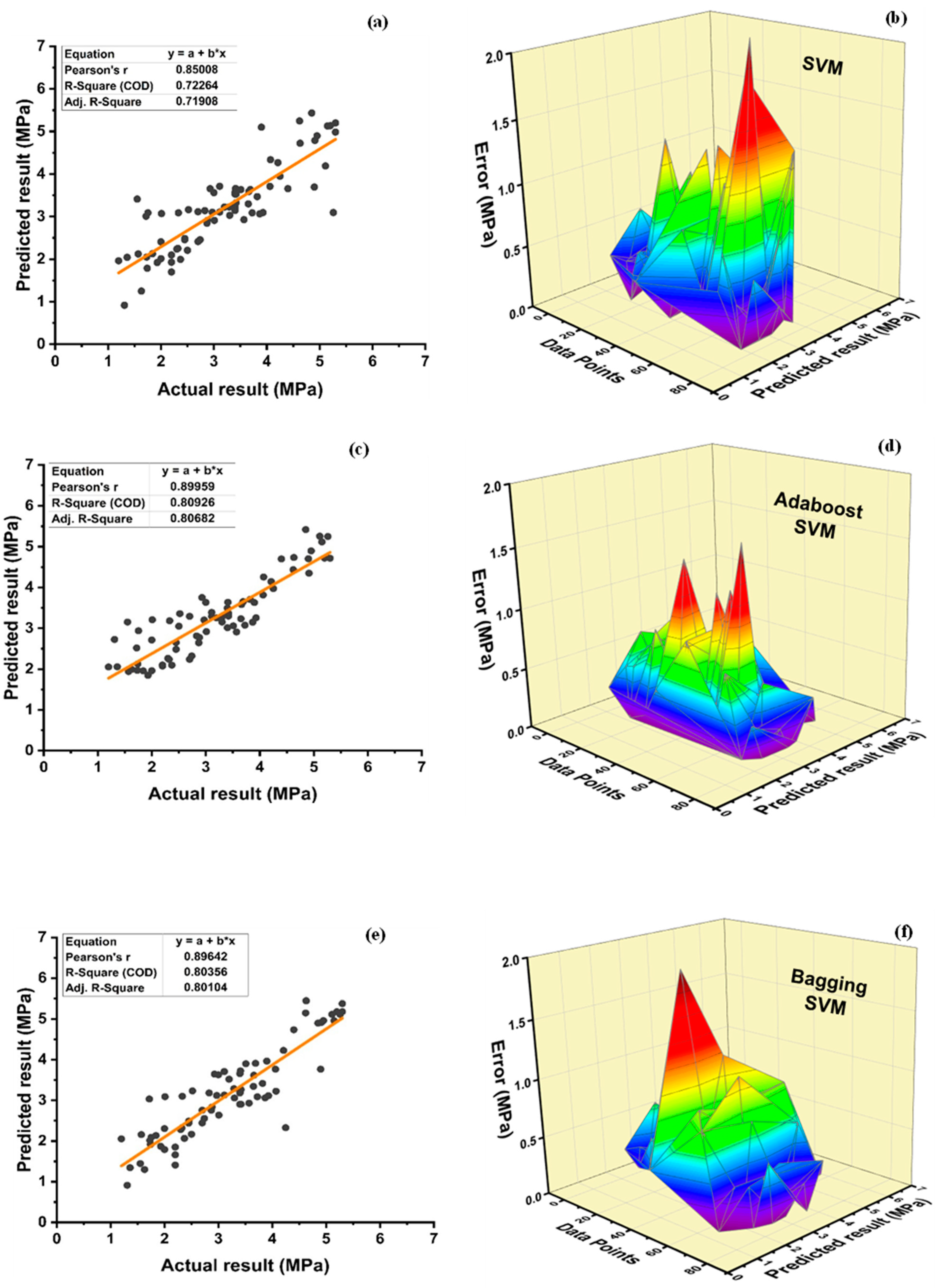
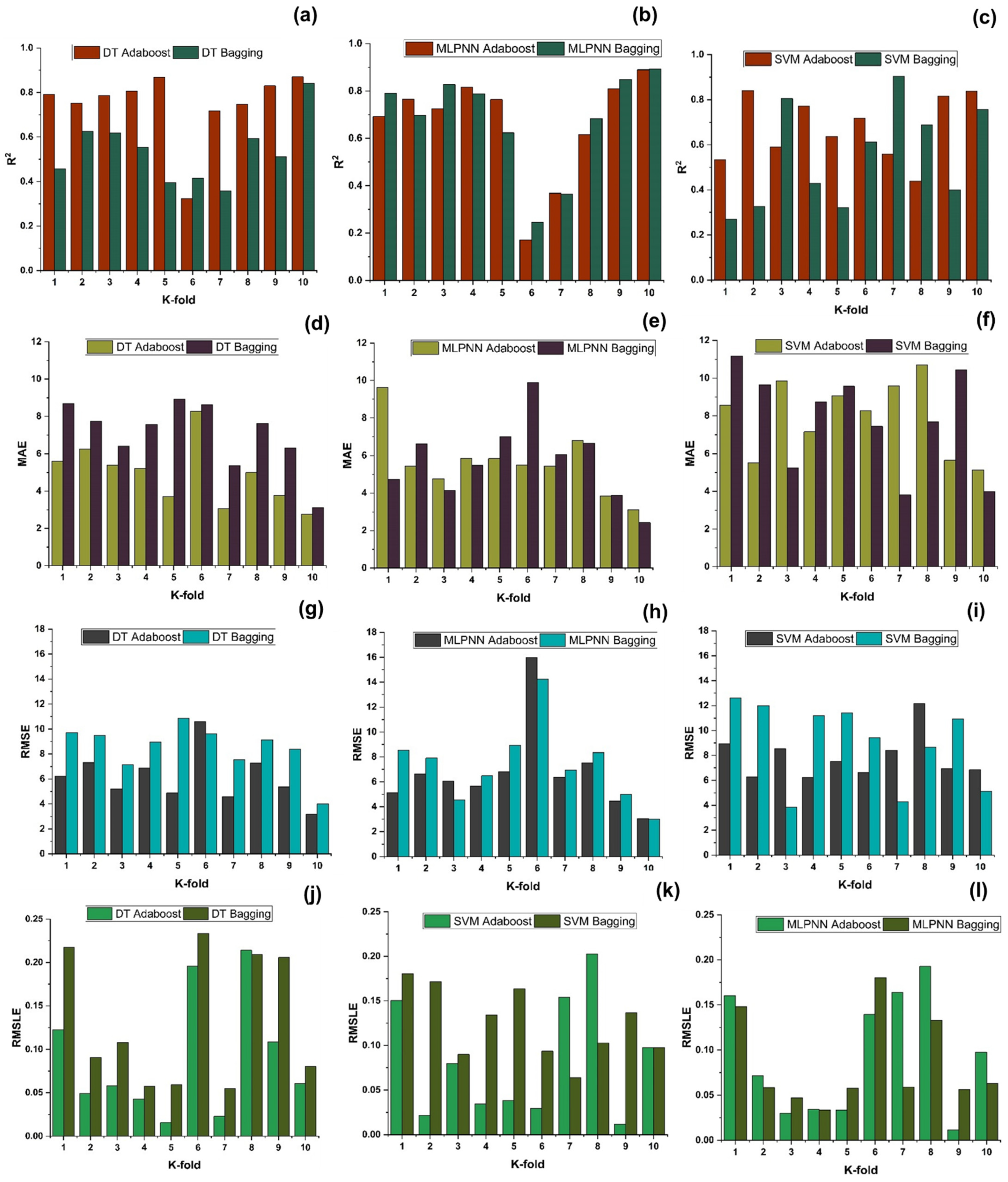
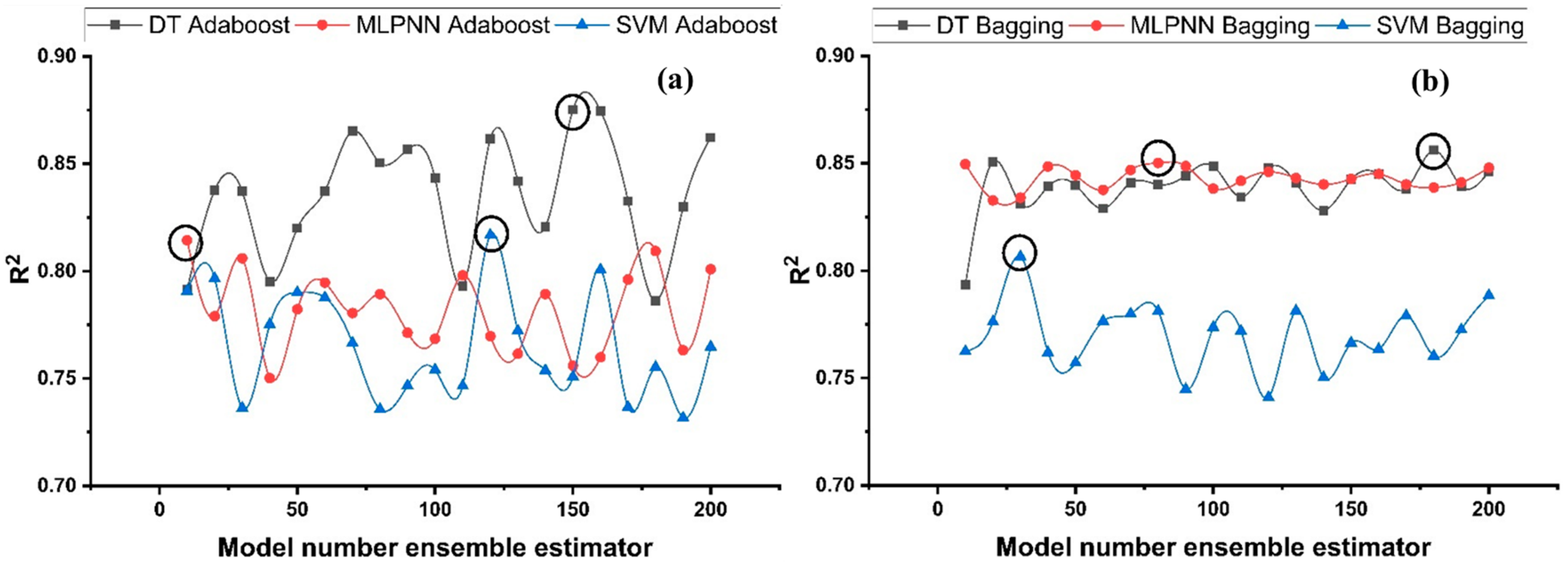
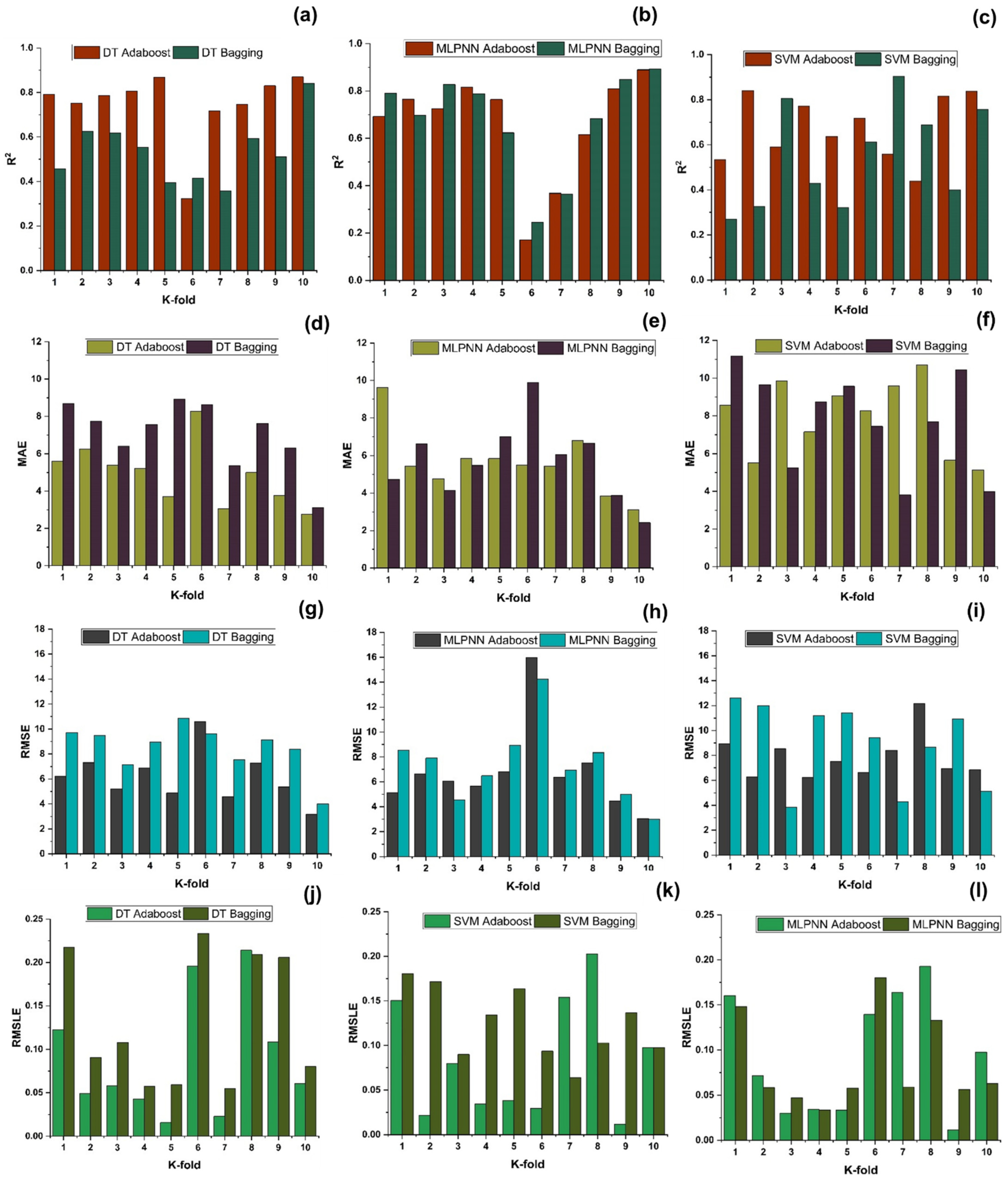
A comparison was conducted between the ensemble algorithm and the other individual machine learning algorithms to further demonstrate the ensemble algorithm’s capacity. The model parameter determinations are comparable to ensemble models, for example, setting initial values and then optimizing these values using ensemble algorithm. Ensemble algorithms are widely recognised to contain multiple weak-learners created by individual learning algorithms, weak-learners with excellent performance gain weight, while weak-learners with poor performance lose weight. As a result, it can provide exact projections. As indicated in
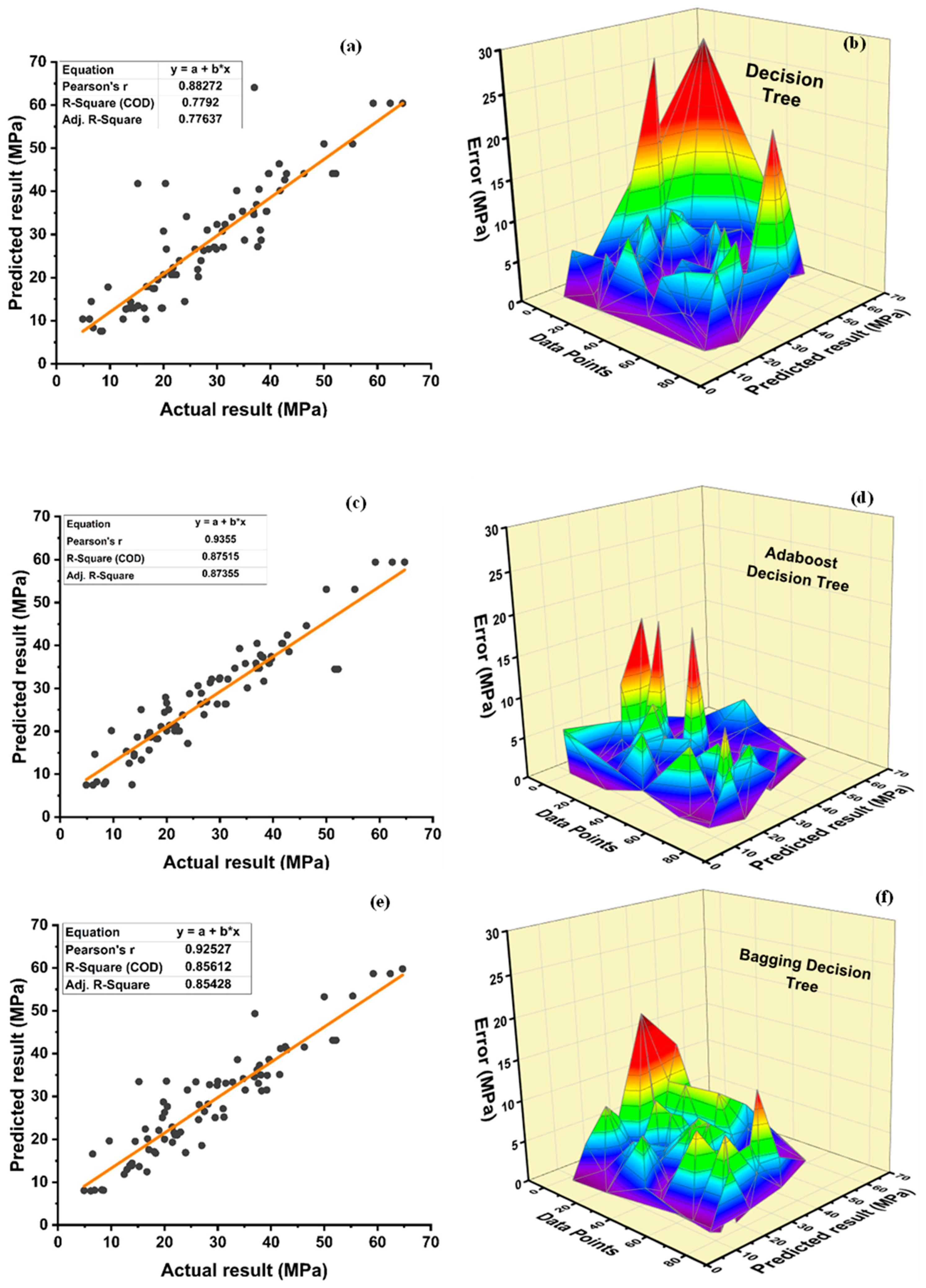
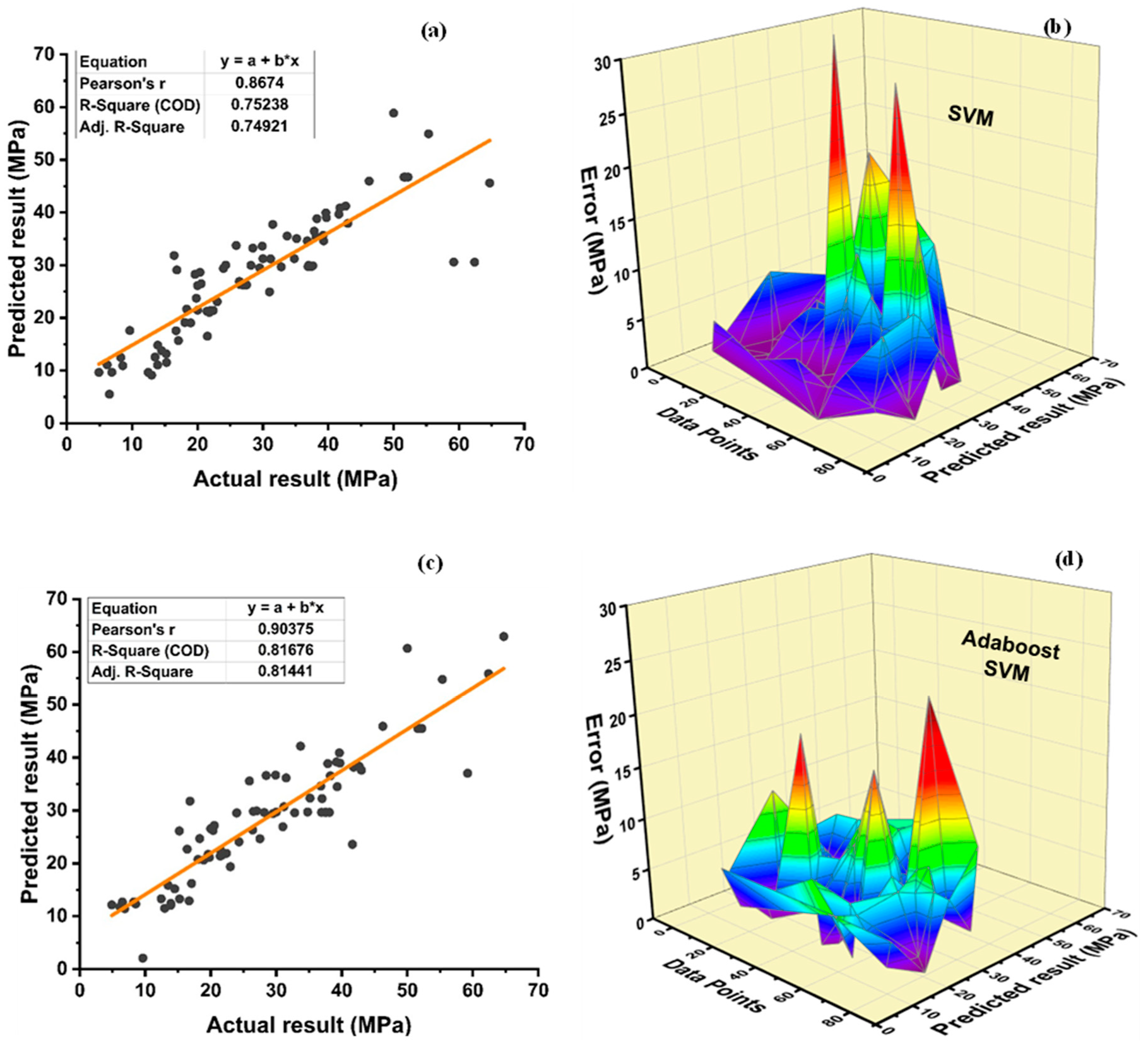
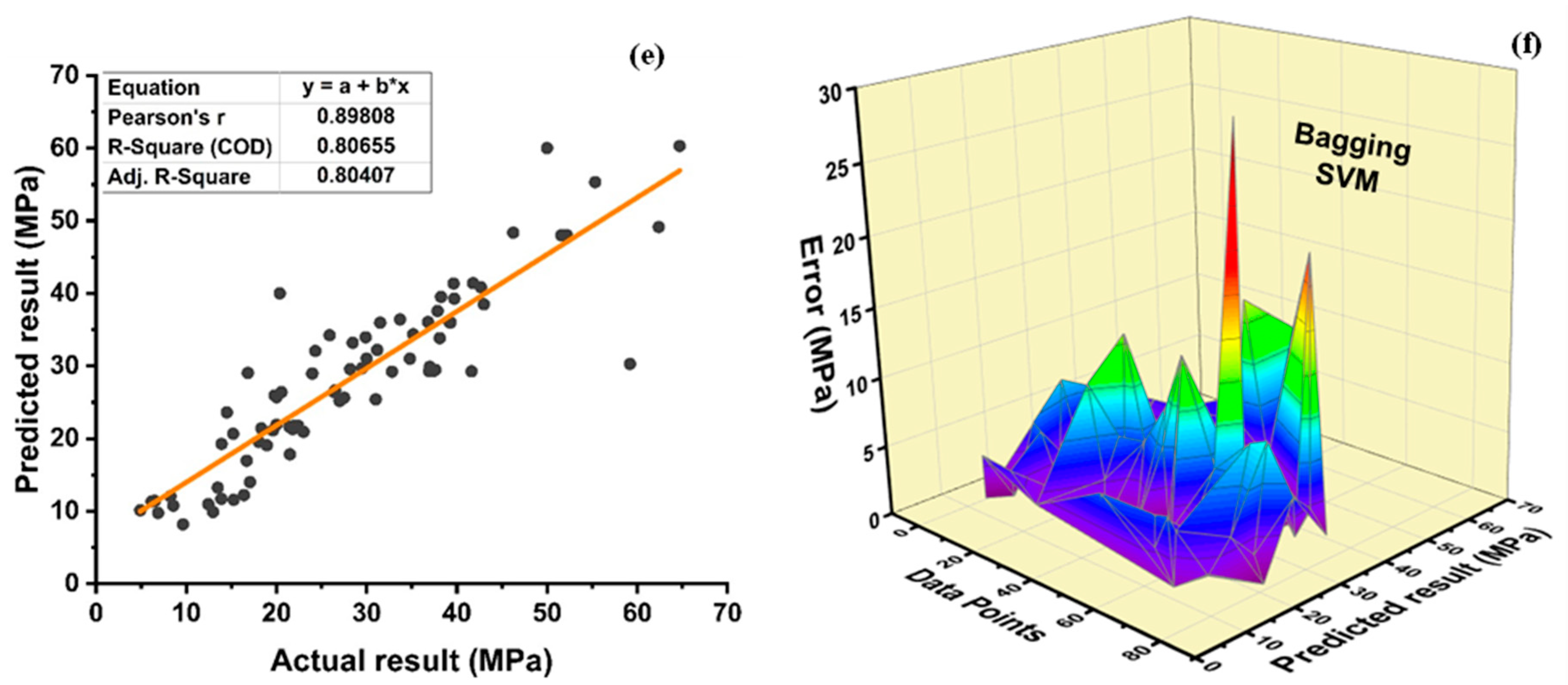
Table 15, individual learners have higher error-values than ensemble learners with boosting and bagging. This demonstrates that ensemble algorithms besides minimizing the range of error between experimental and predicted results provide precise forecasts.
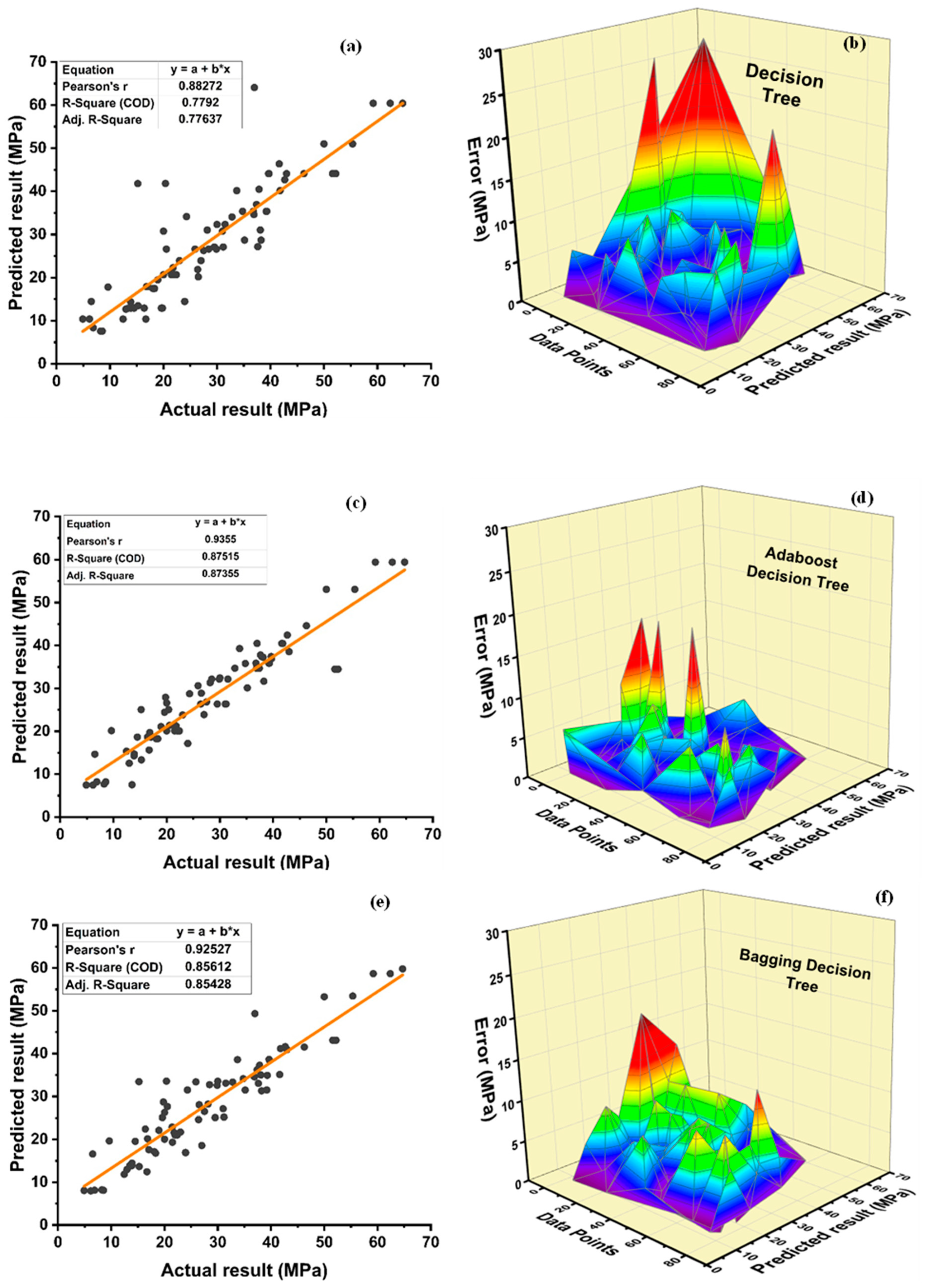
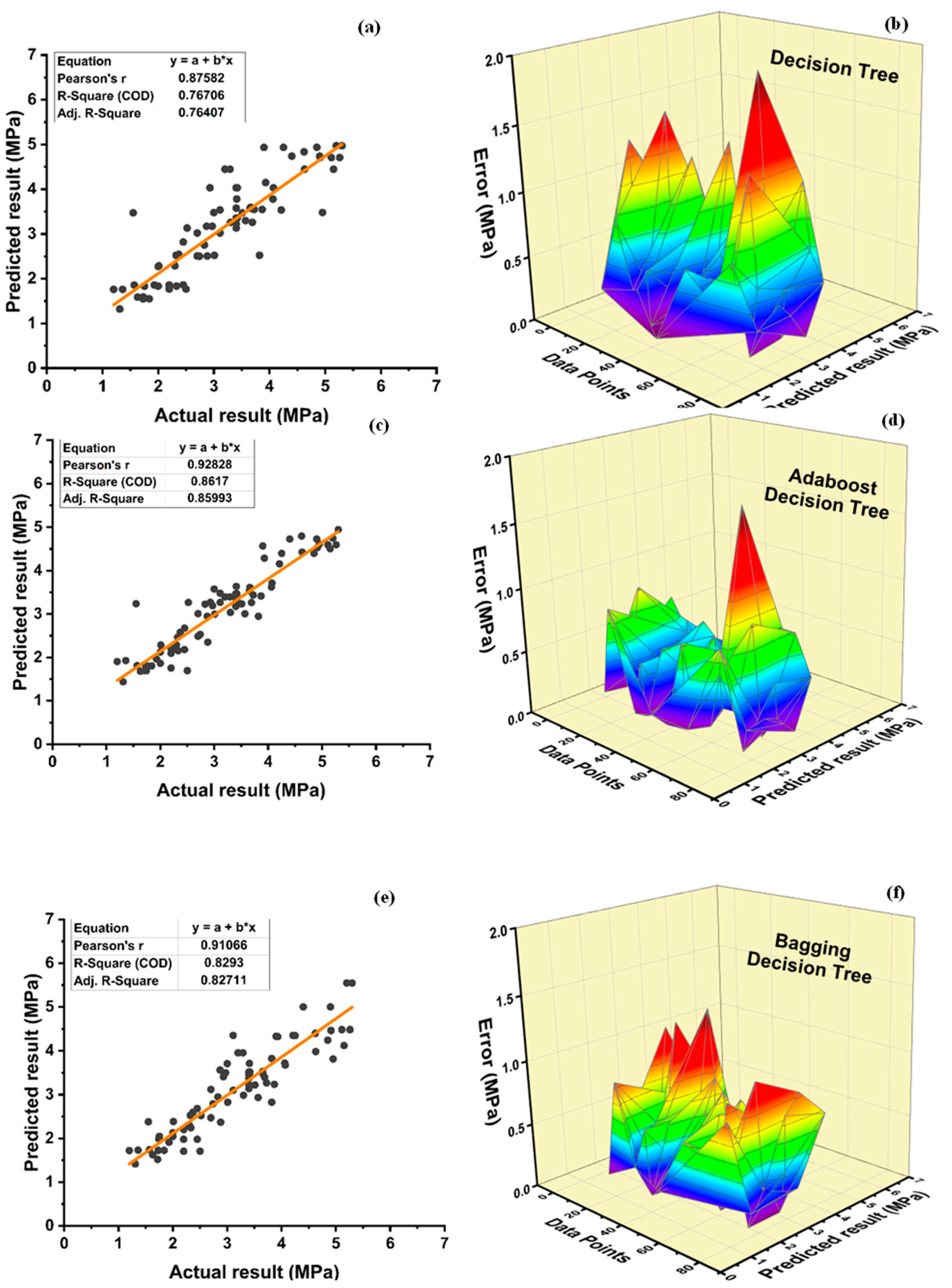
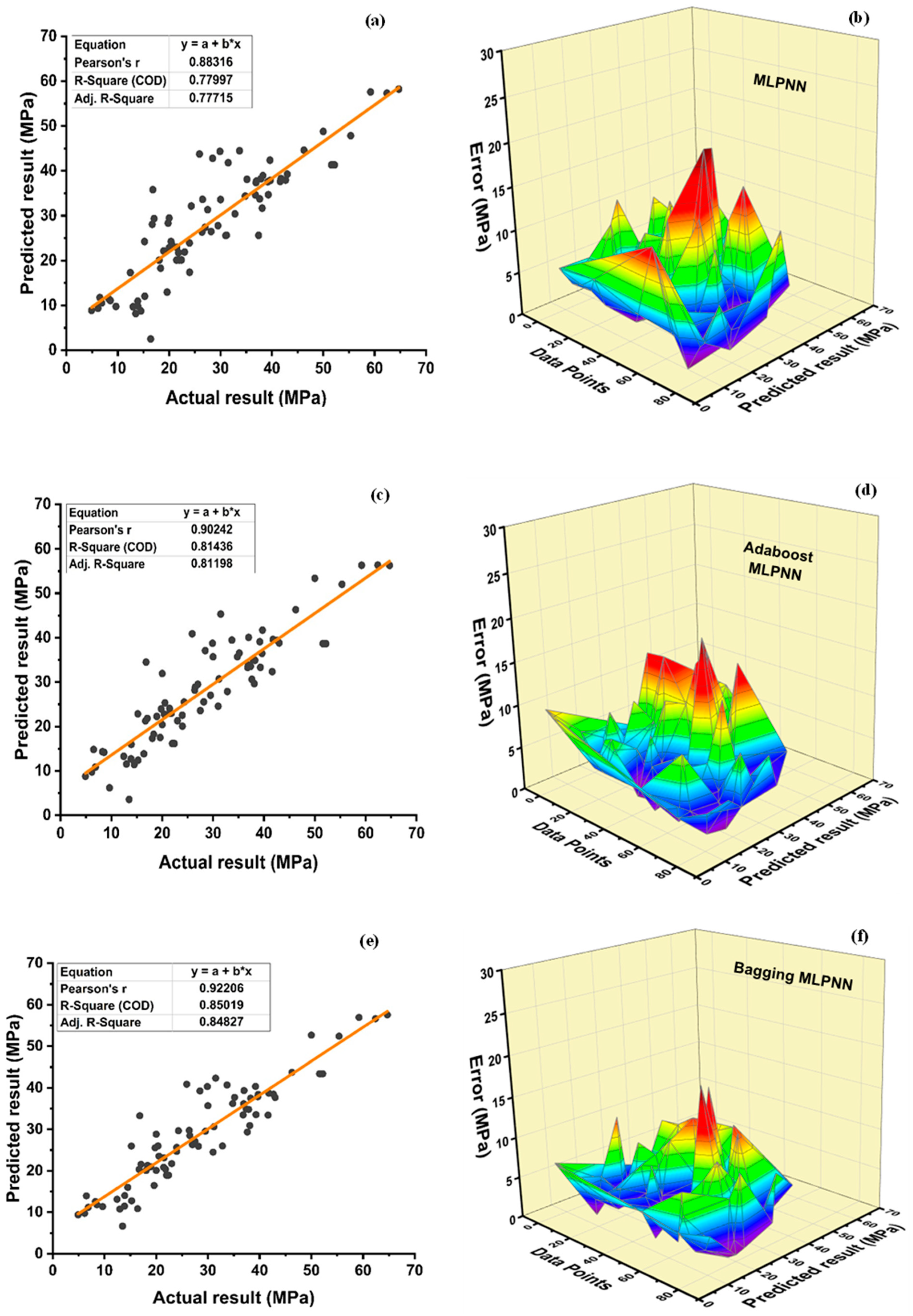
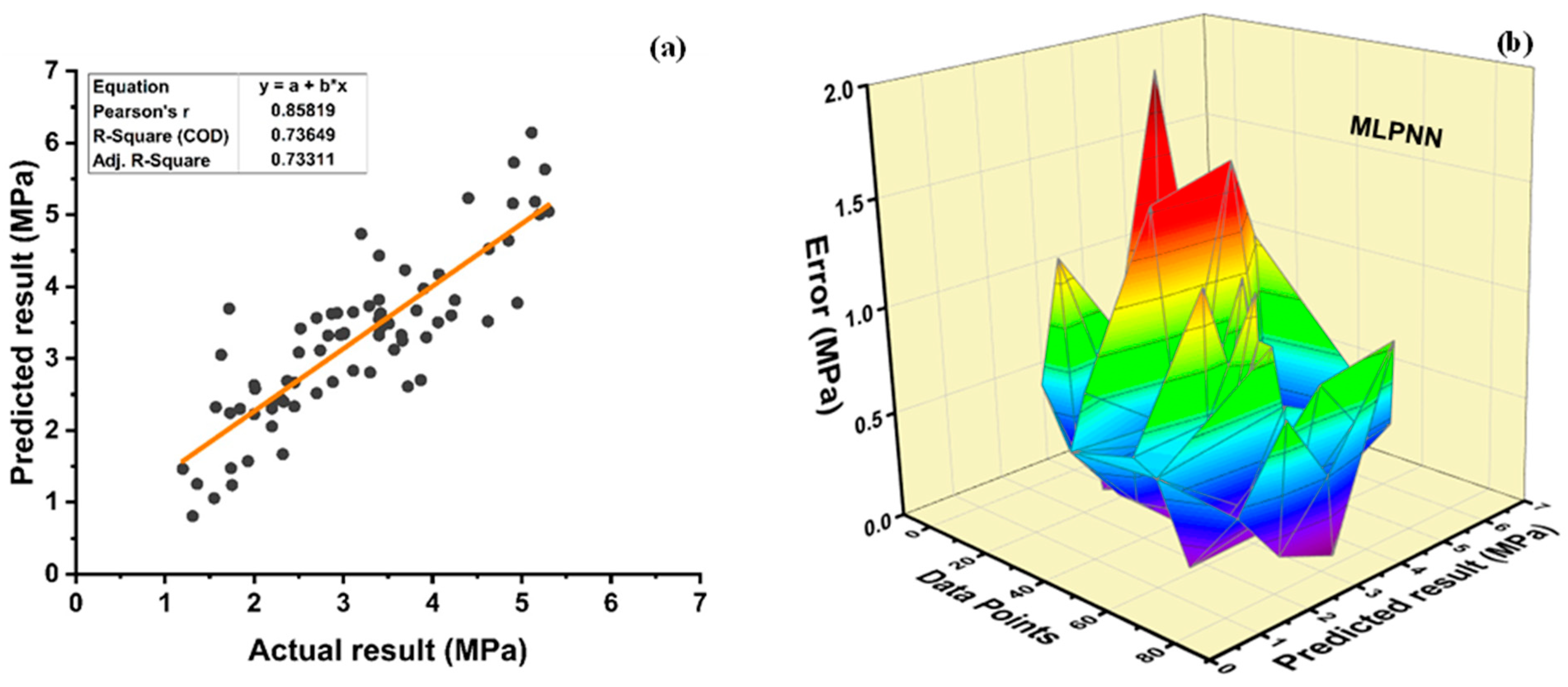
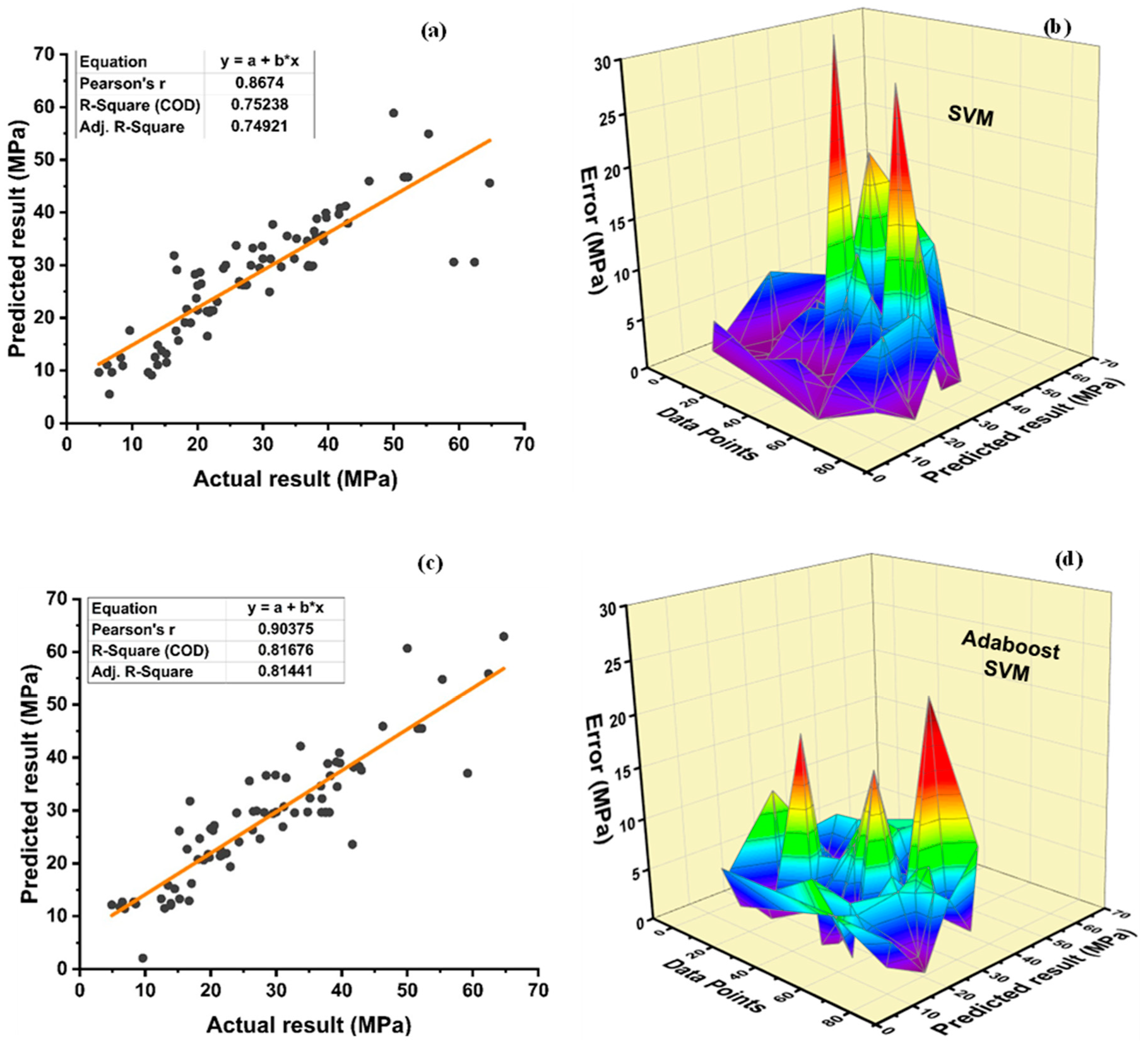
Among Individual learner models for f
c’, R
2 value of 0.780 for MLPNN overrule DT and SVM representing the accuracy of model up to 78%, whereas DT model surpasses the other two model in terms of coefficient of determination (R
2) for f
sts. SVM is shown to have the least accurate method in predicting both outcomes. Values of the statistical errors for each method are shown in
Table 15.
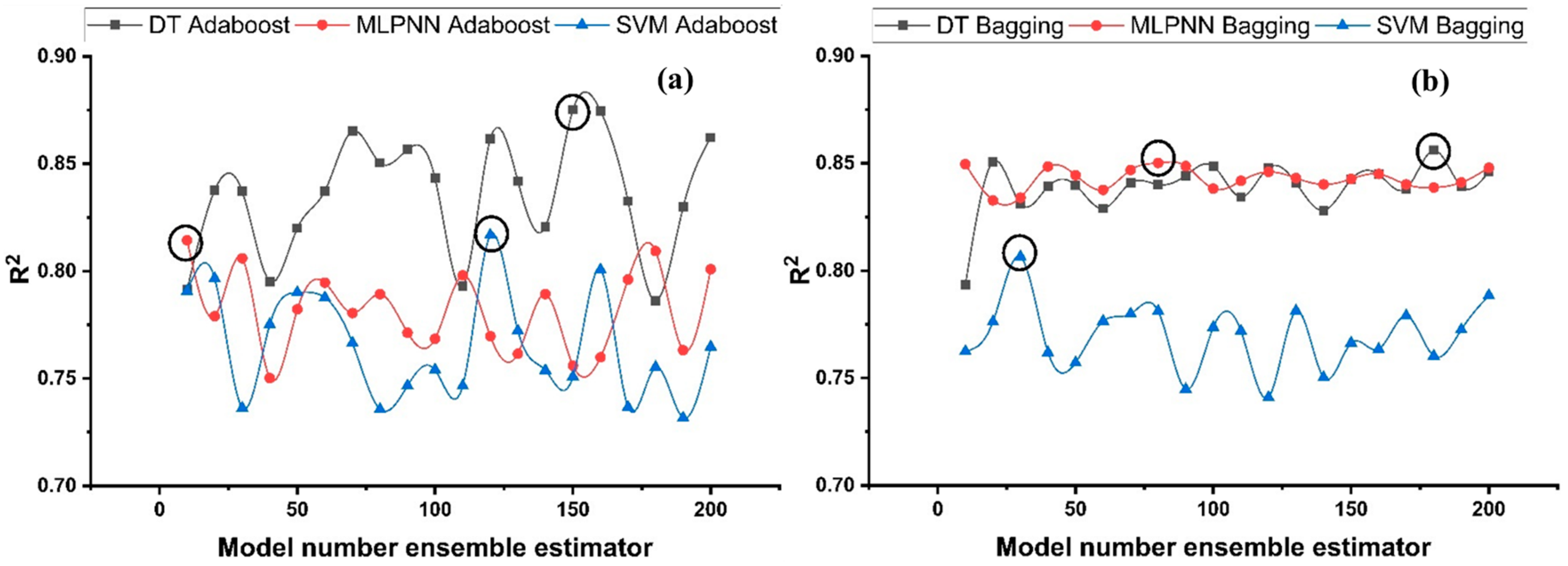
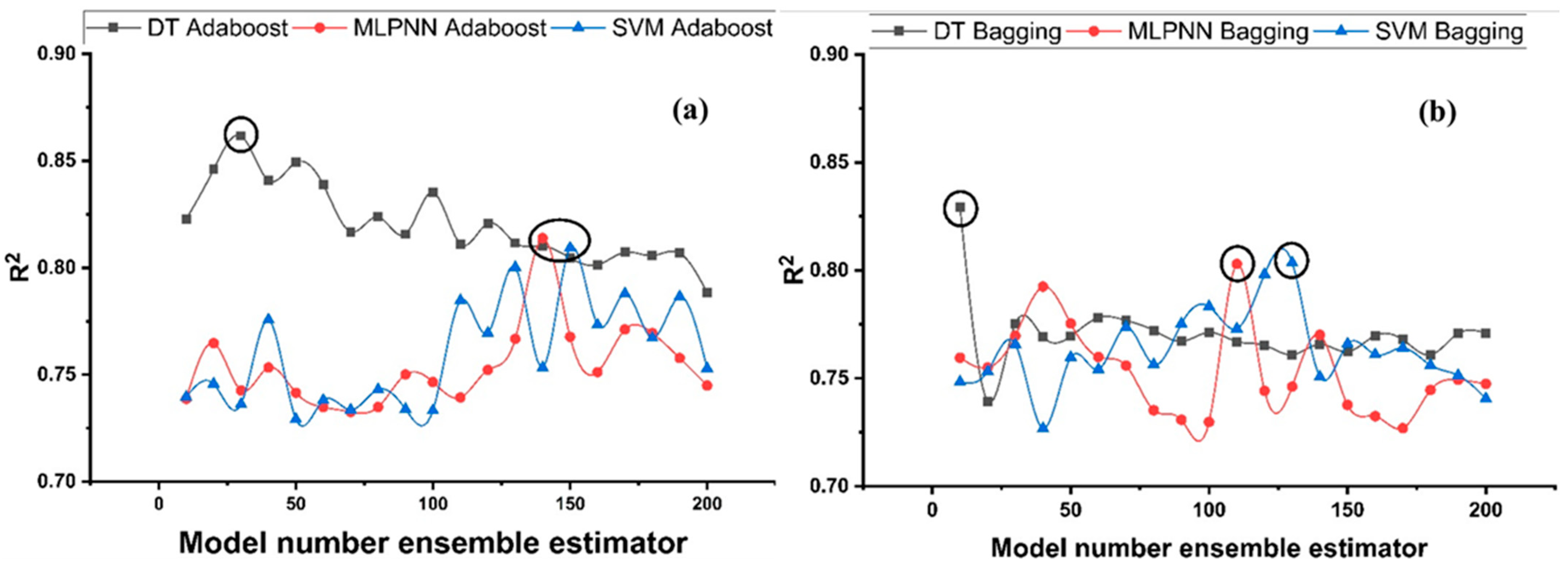
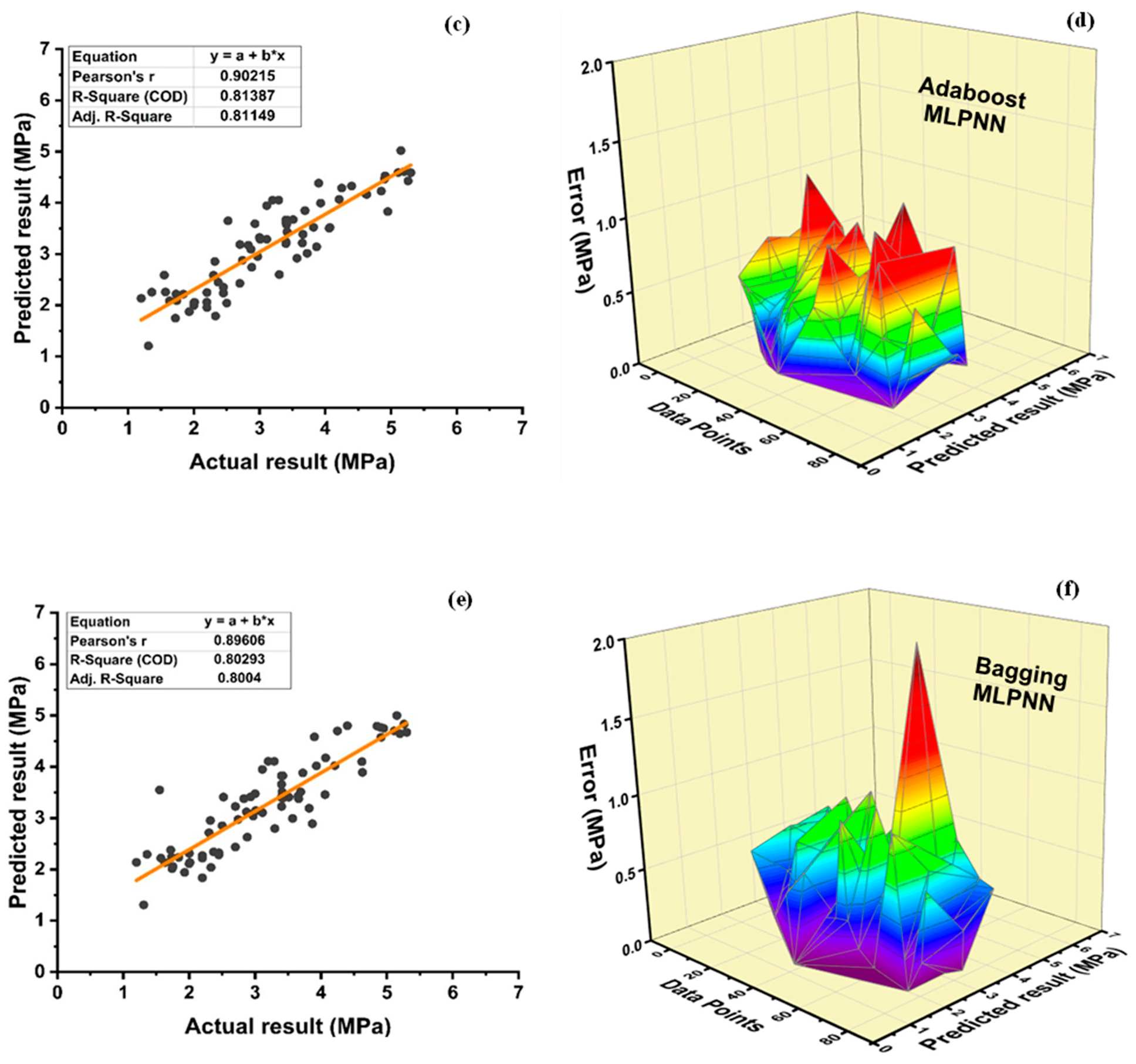
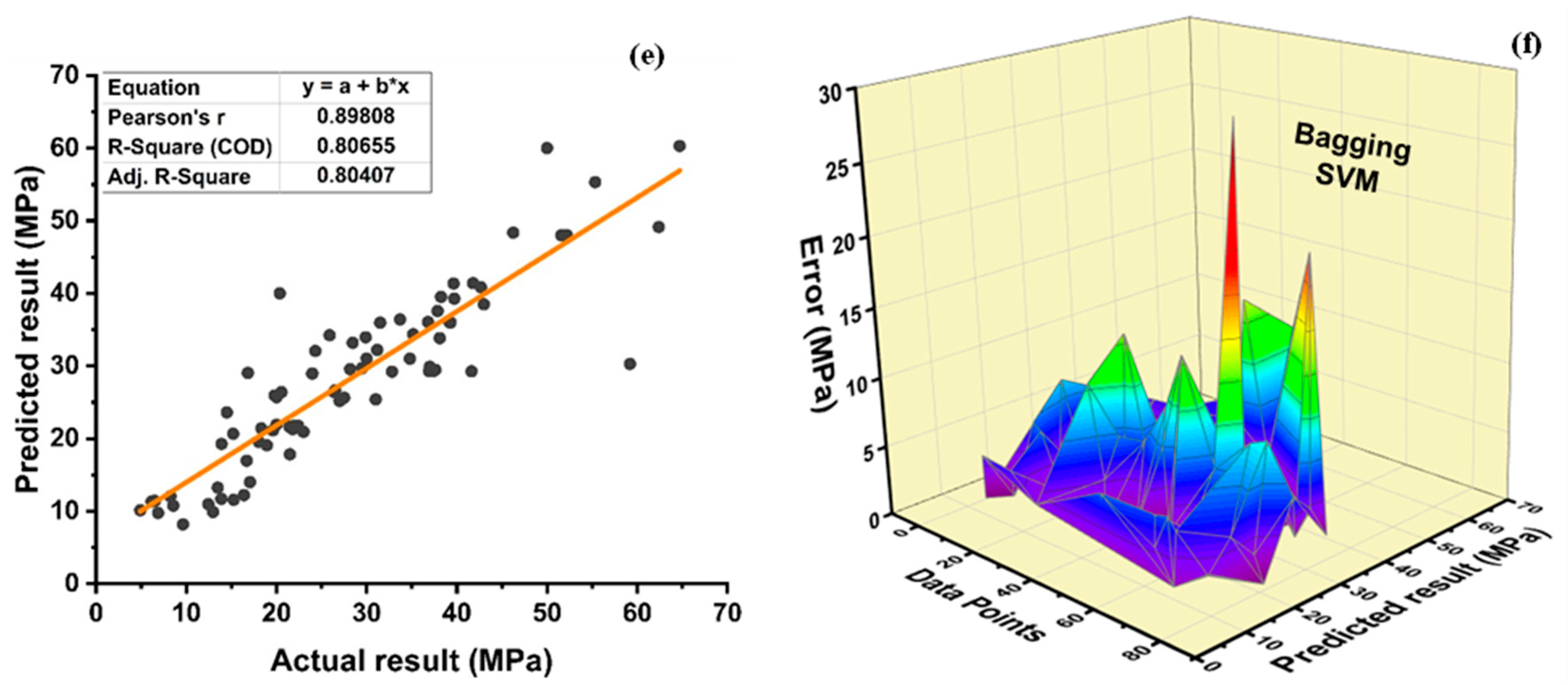
DT-Adaboost stands out among ensemble learning models with boosting having R2 values of 0.875 for fc’ model and 0.862 for fsts models, demonstrating the model’s accuracy of about 87%. The prediction accuracy of DT-Adaboost model outperforms the MLPNN model by 26.49%, 16.47%, and 25% for fc’ and 21.24%, 14.44%, and 11.32% for fsts in terms of MAE, RMSE, and RMSLE, respectively. Similarly, in terms of MAE, RMSE, and RMSLE, DT-Adaboost model beats SVM model with model accuracy of 22.5%, 16.2%, and 26.89% for fc’ and 13.39%, 16.19%, and 21.67% for fsts, respectively.
Among ensemble learning models with bagging, DT out-performs the other two methods with R2 value of 0.856 for fc’ model and 0.829 for fsts model. From evaluation of MAE, RMSE, and RMSLE, again the prediction accuracy of DT-bagging overrule MLPNN by 7.31%, 2.29%, and 4% for fc’ and 1.1%, 8.67%, and 15.79% for fsts model, respectively. DT-bagging model tops SVM Bagging models by 6.03%, 13.55%, and 3.03% for fc’ and 1.13%, 8.11%, and 14.26% for fsts model in terms of MAE, RMSE, and RMSLE, respectively.
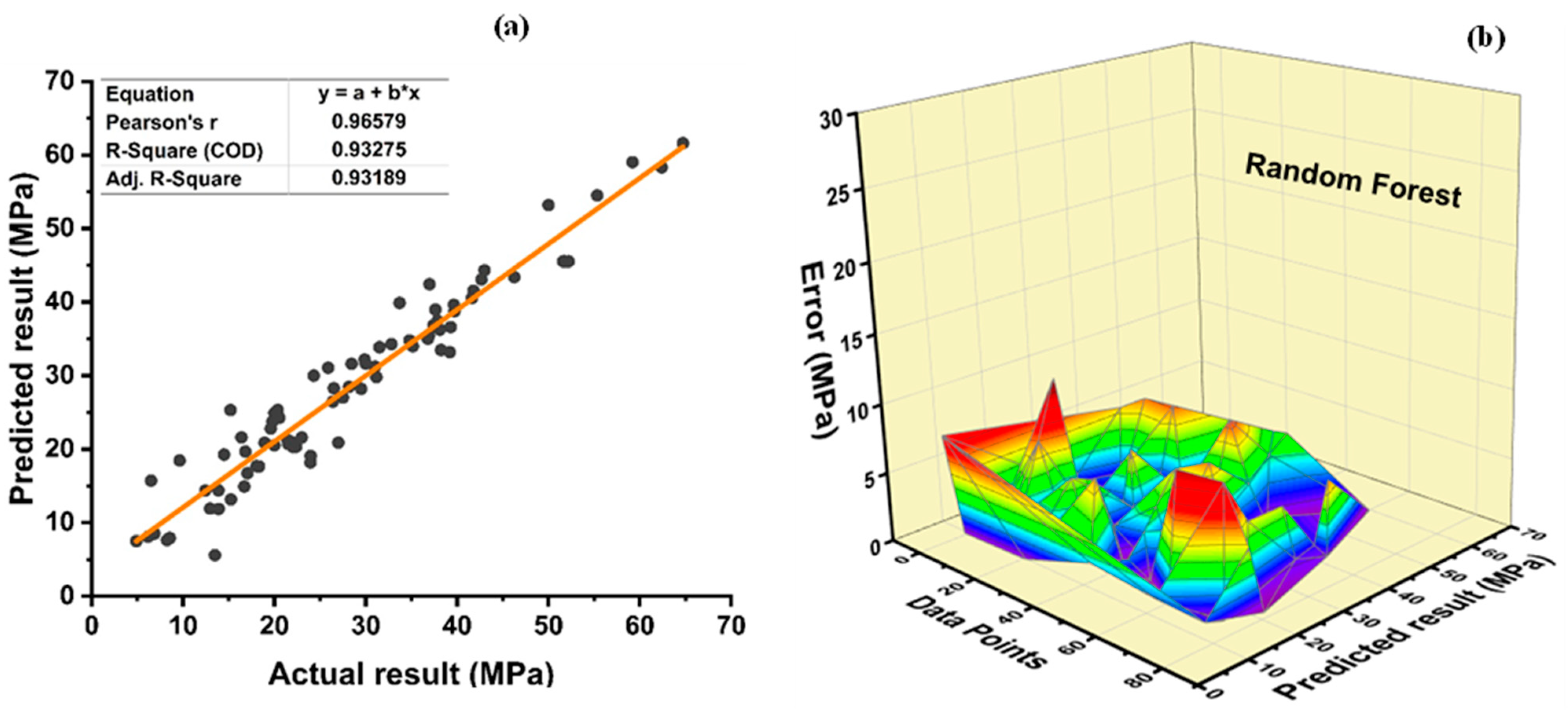
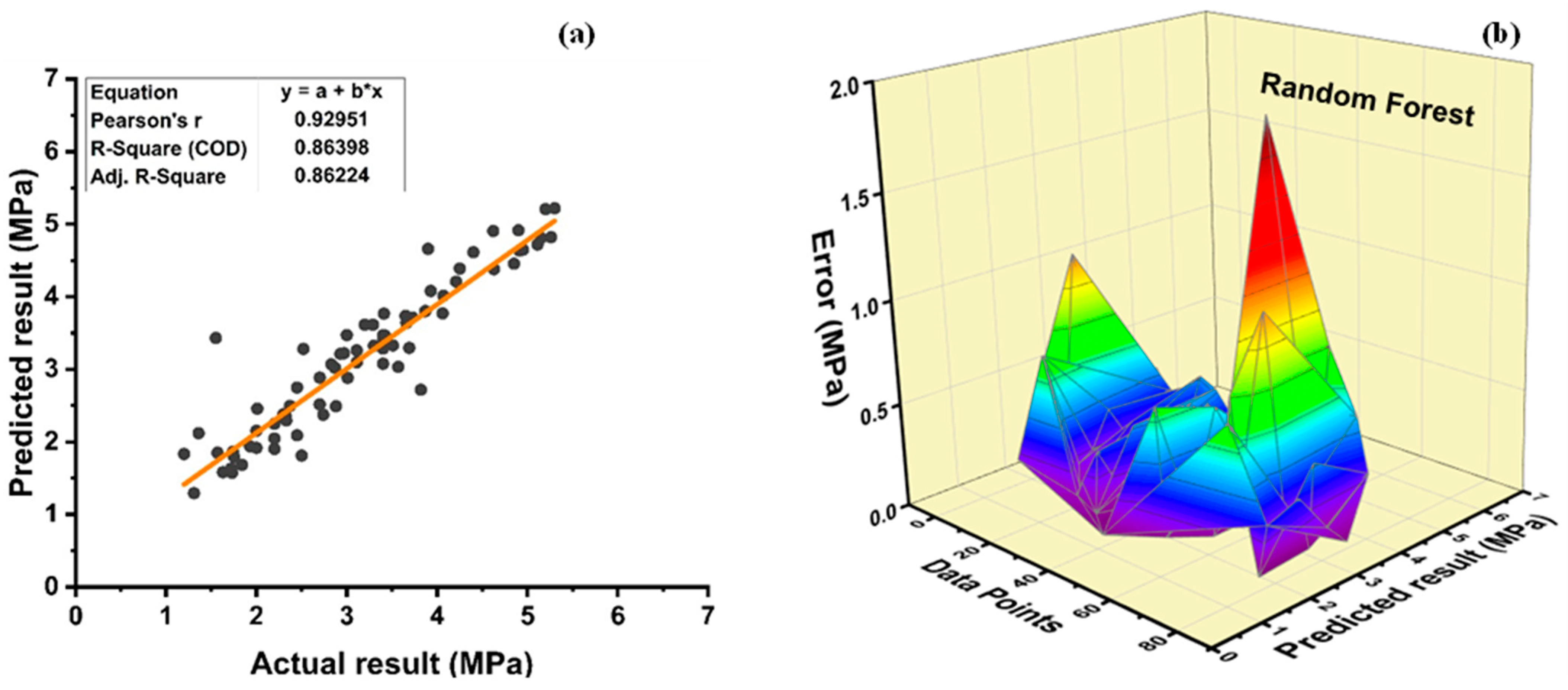
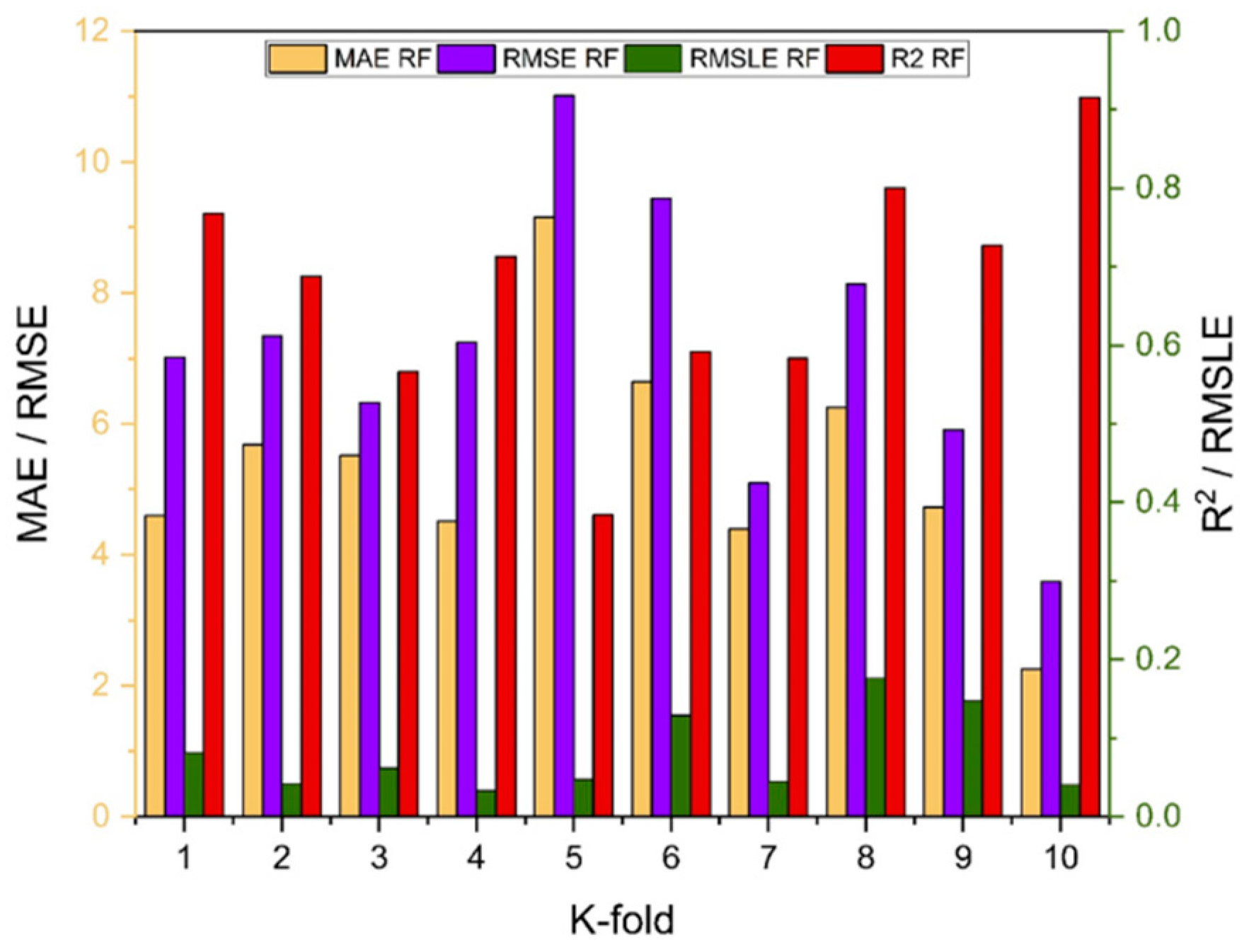
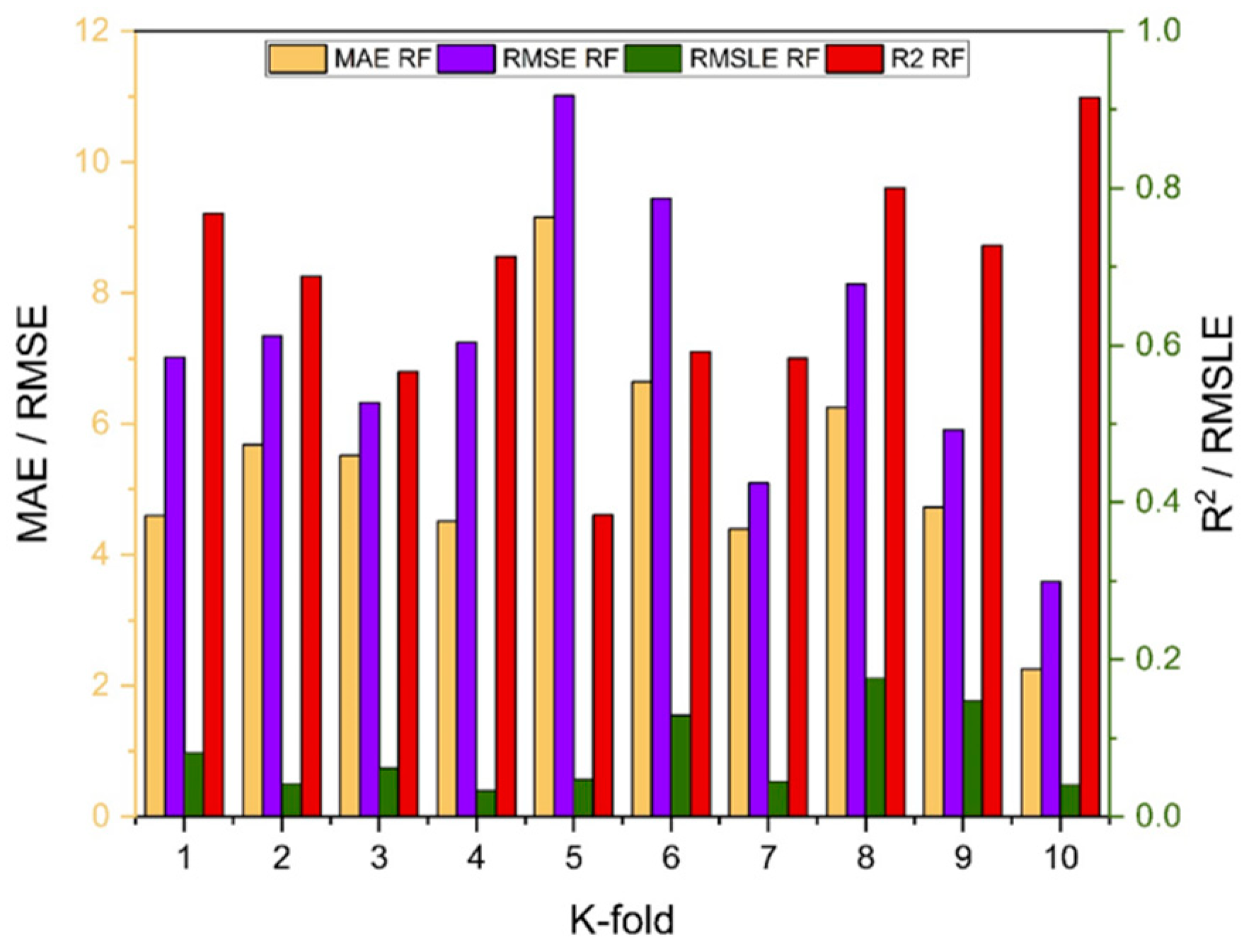
Random forest is classified as modified ensemble learner model, the prediction accuracy of modified ensemble outperforms individual, bagging, and boosting models based on correlation coefficient R2 with model accuracy of 93% for fc’ model and 86% for fsts model.
Comparing all the models based on the coefficient of determination R2 value the prediction accuracy follows the following order, modified ensemble > ensemble-adaboosting > ensemble-Bagging > individual learner.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}