
Kinetics of the Direct DME Synthesis: State of the Art and Comprehensive Comparison of Semi-Mechanistic, Data-Based and Hybrid Modeling Approaches

 , , , and
, , , and
Abstract
:
1. Introduction
2. Available Models for the Direct Synthesis of DME—An Overview
2.1. Semi-Mechanistic (Lumped) Models
2.2. Data-Based Models
2.3. Hybrid Models
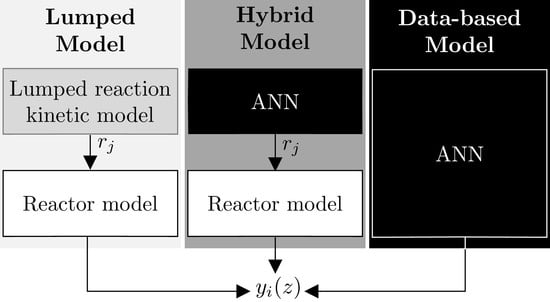
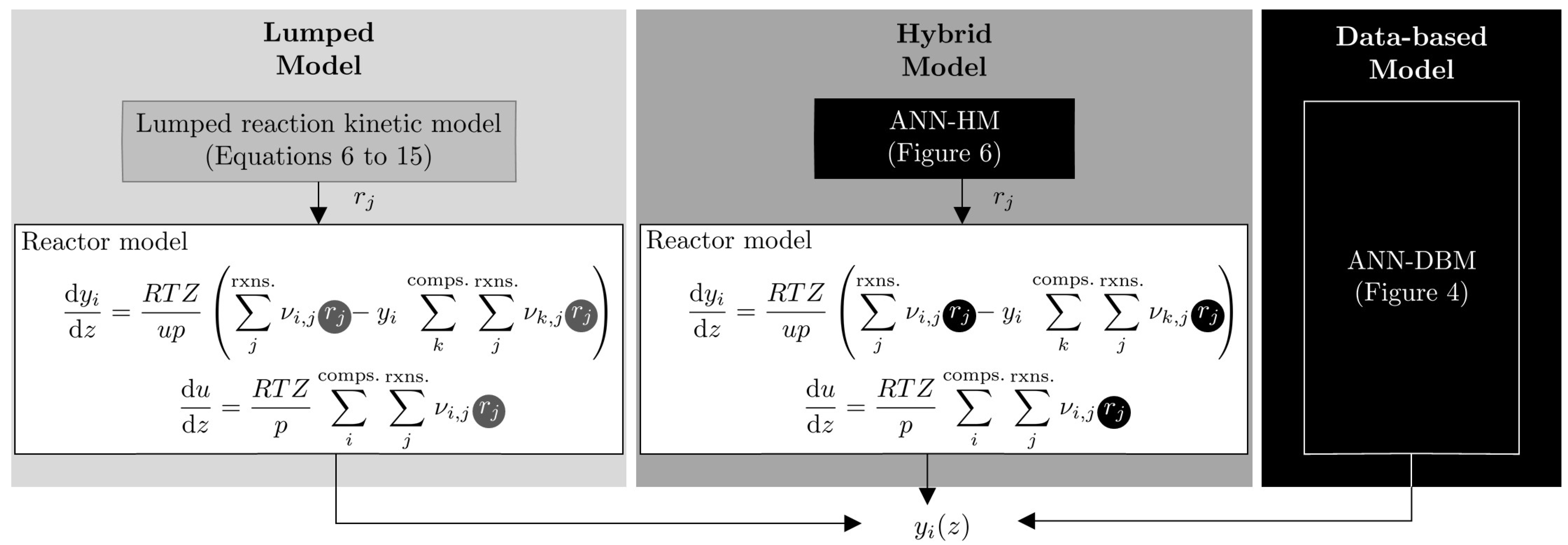
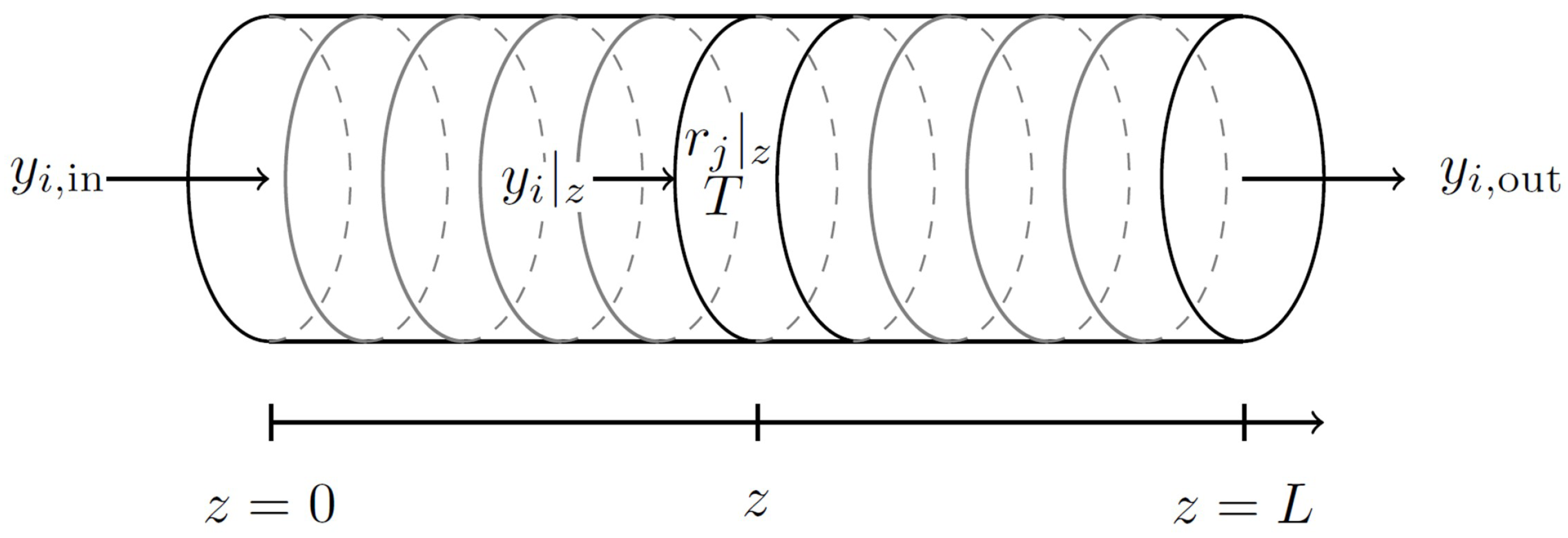
3. Models’ Structures, Modeling and Experimental Methodology
3.1. Lumped Model
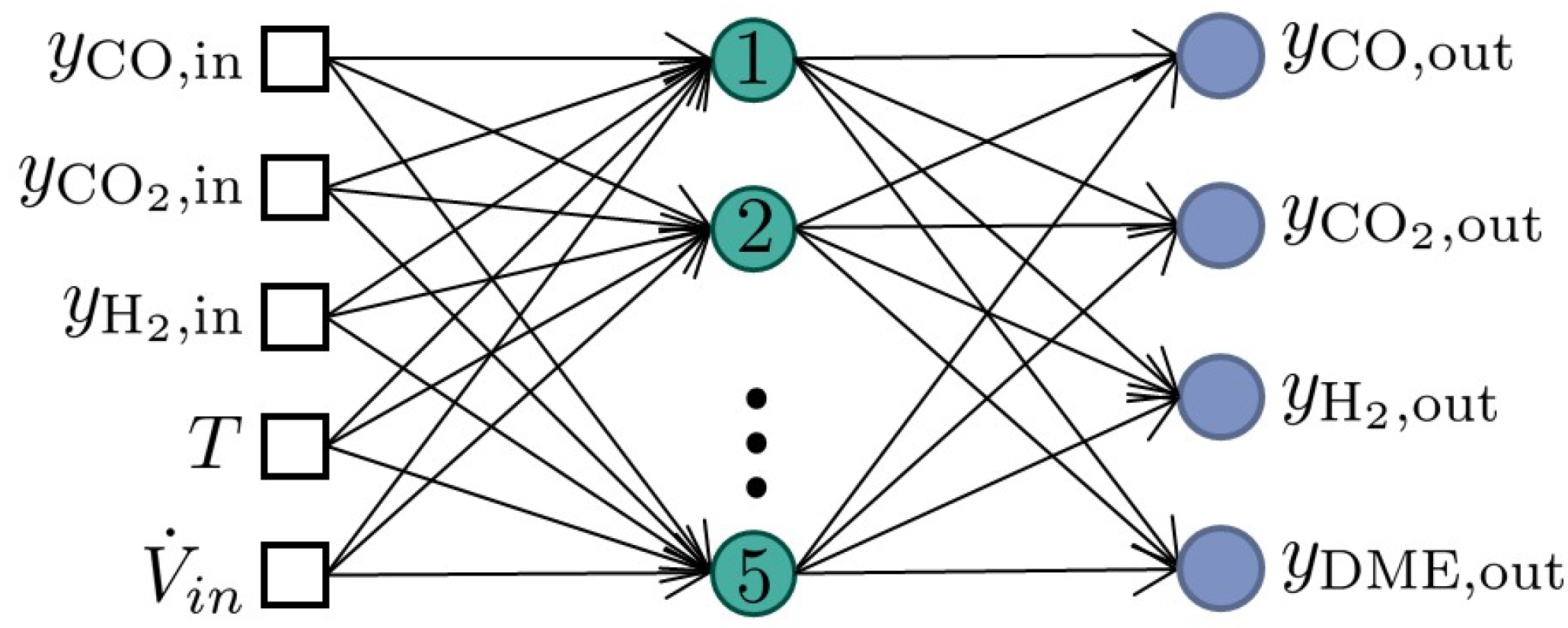
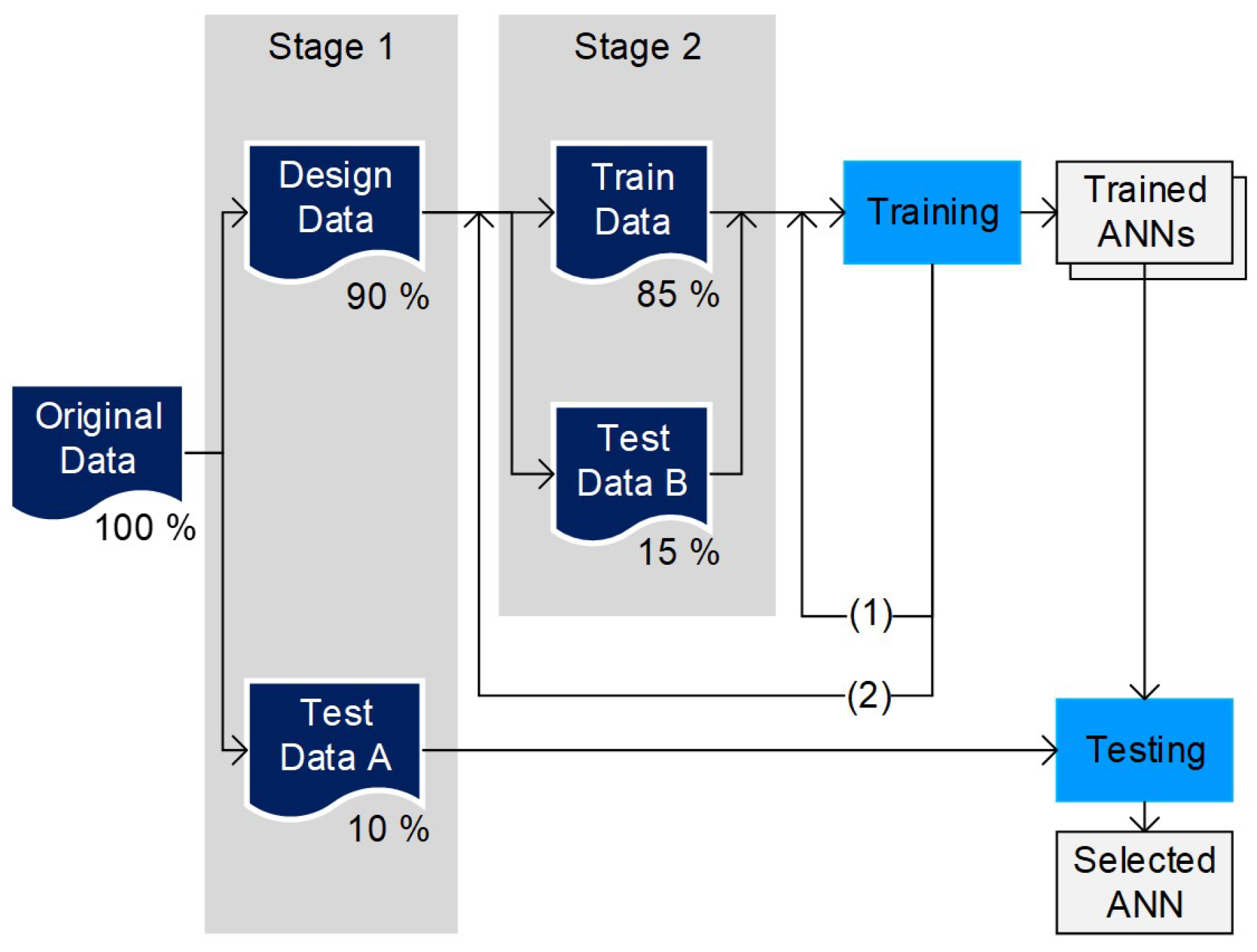
3.2. Data-Based Model and ANN Training Strategy
3.3. Hybrid Model
3.3.1. Architecture
3.3.2. Training Data
3.4. Experimental Equipment and Procedures
4. Hybrid Model Results
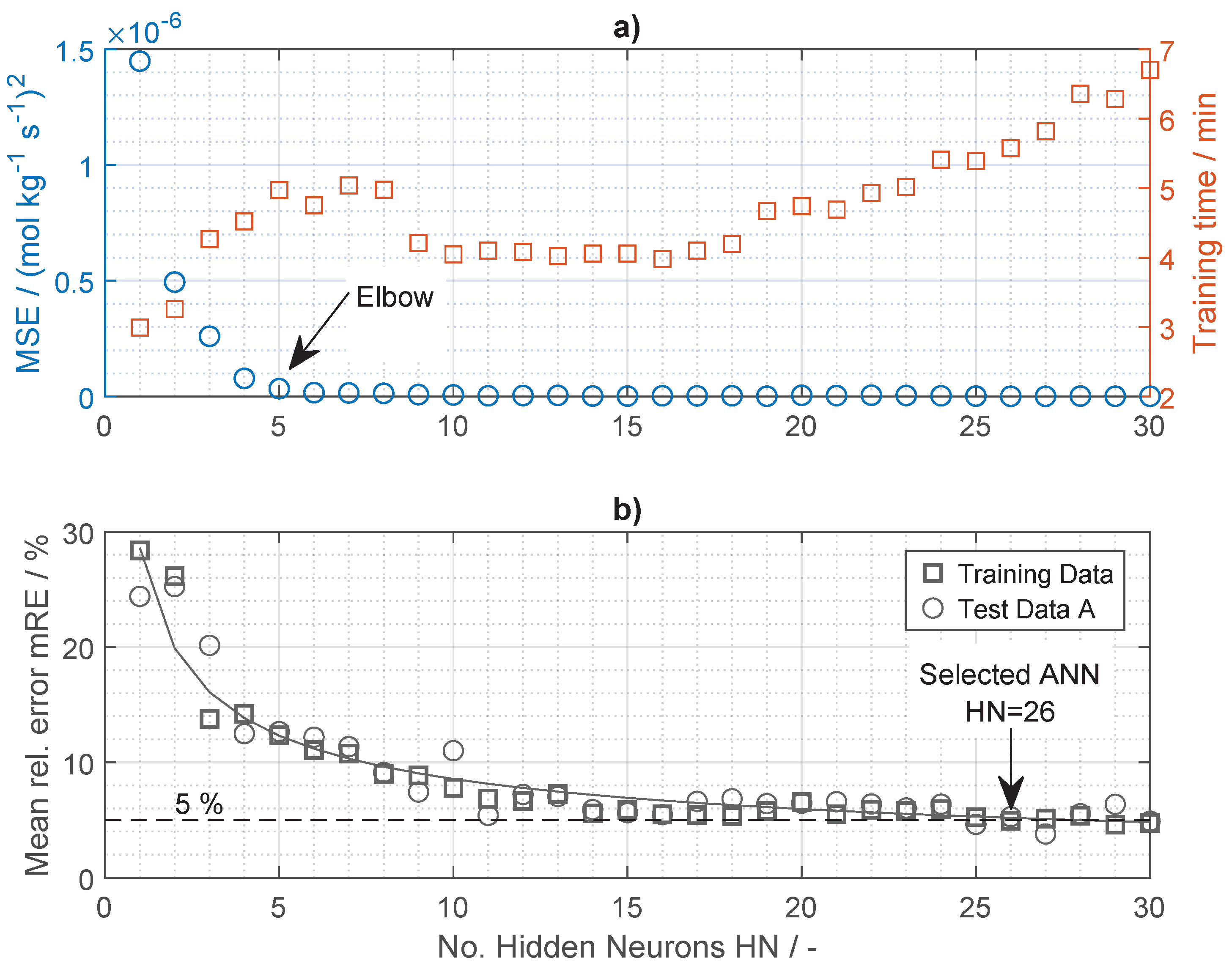
4.1. ANN-HM Training Results
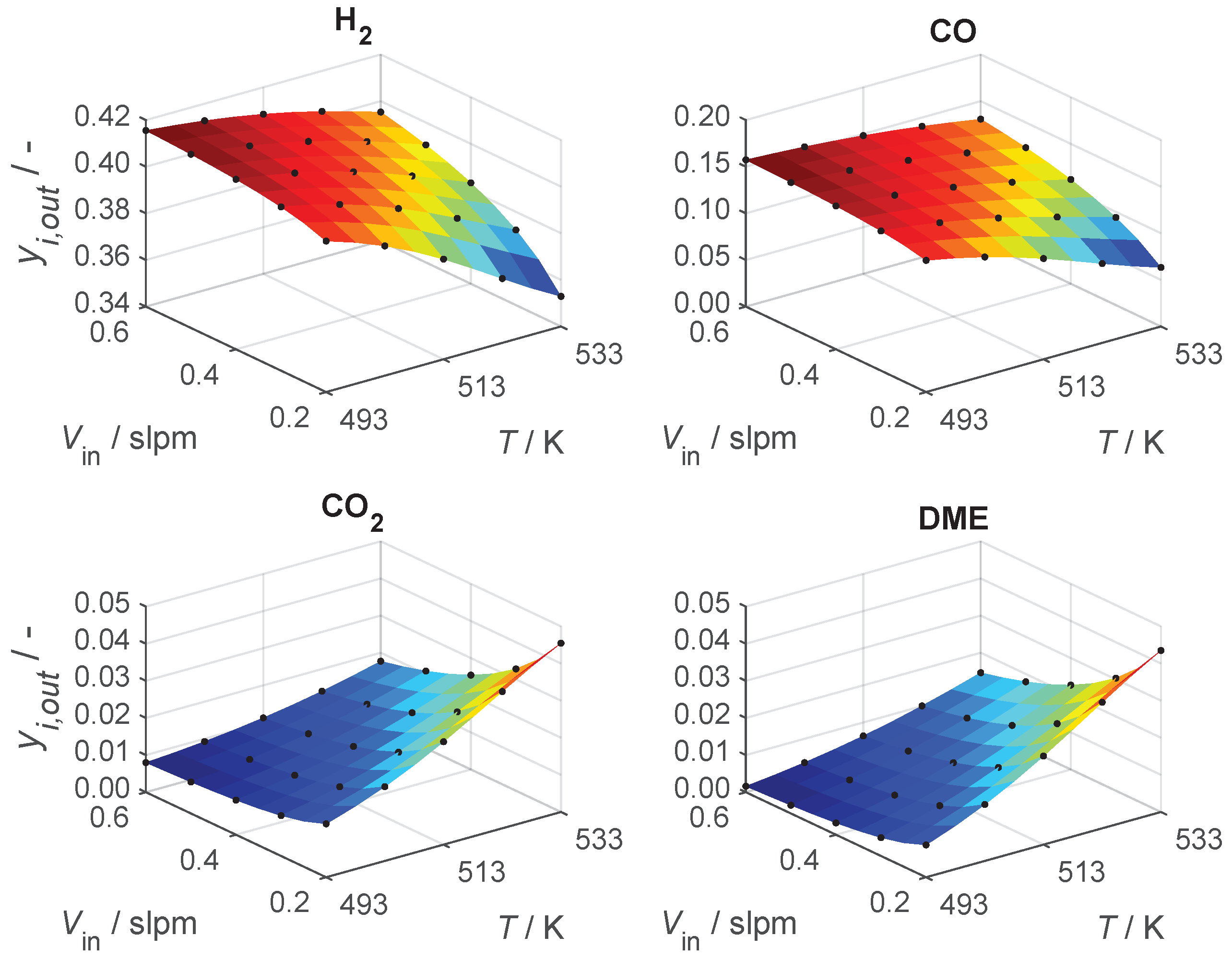
4.2. Hybrid Model Performance and Interpolation Ability
- Data-Based: 0.0798 s;
- Hybrid: 4.2432 s;
- Lumped: 16.4095 s.
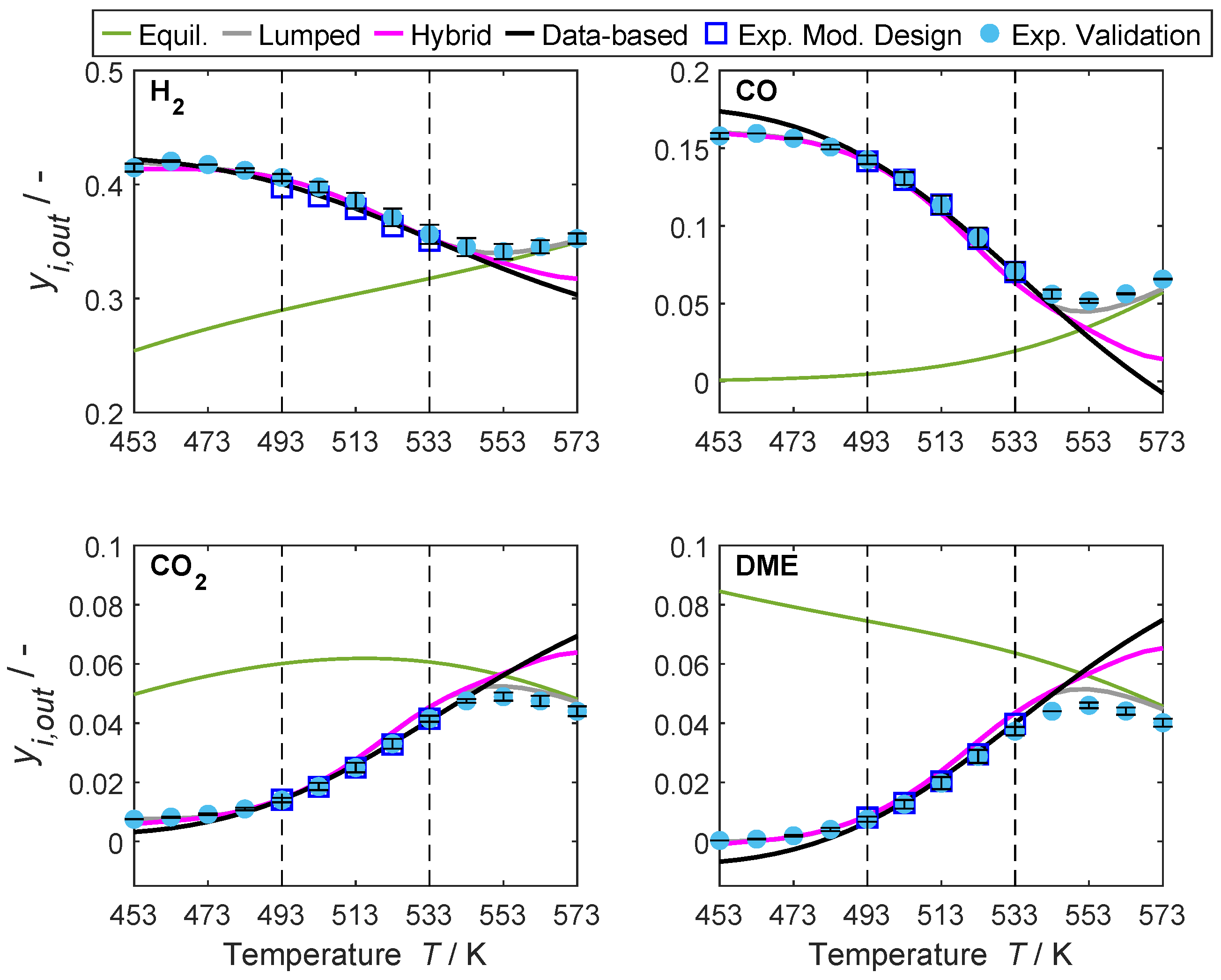
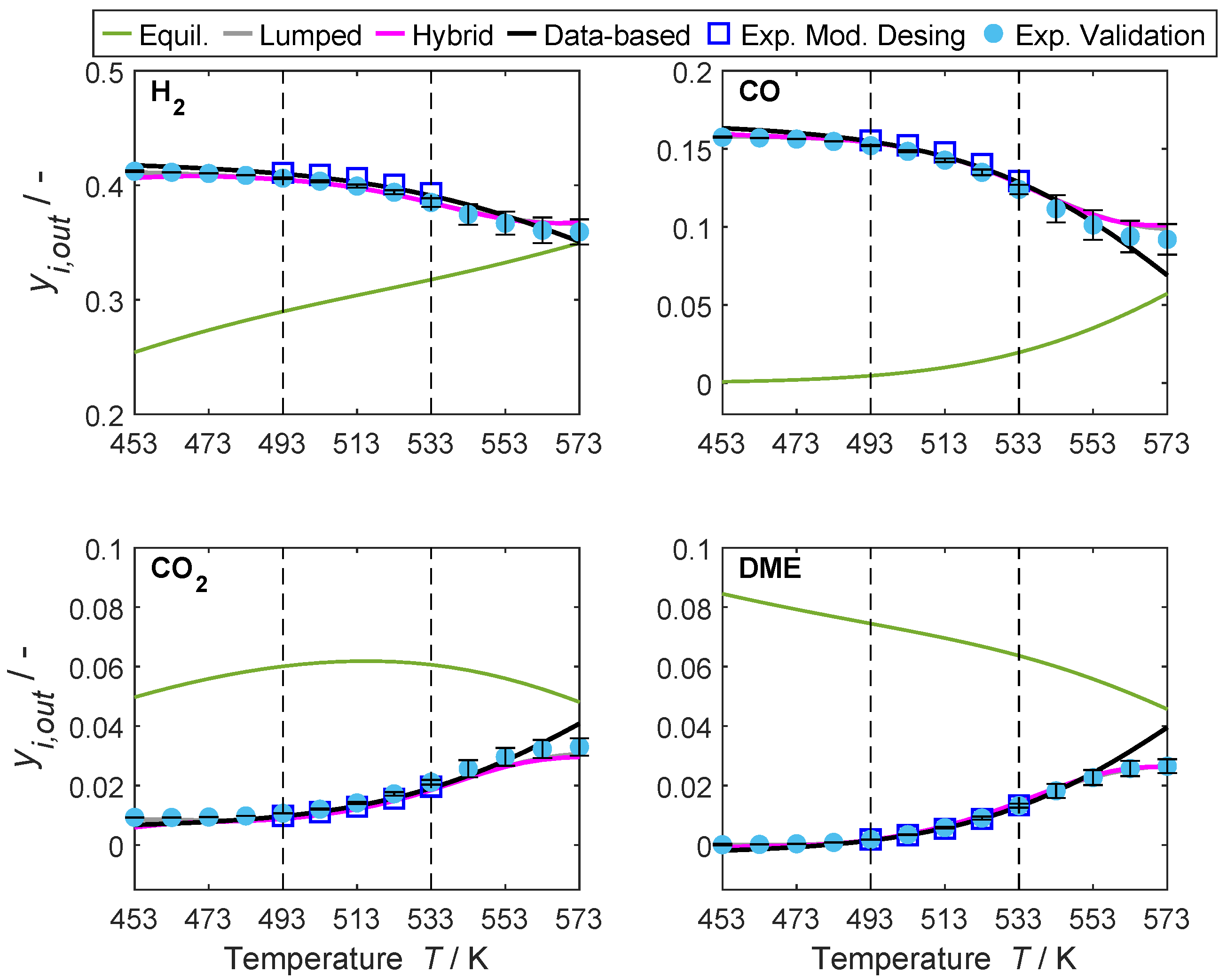
4.3. Models’ Extrapolation Ability
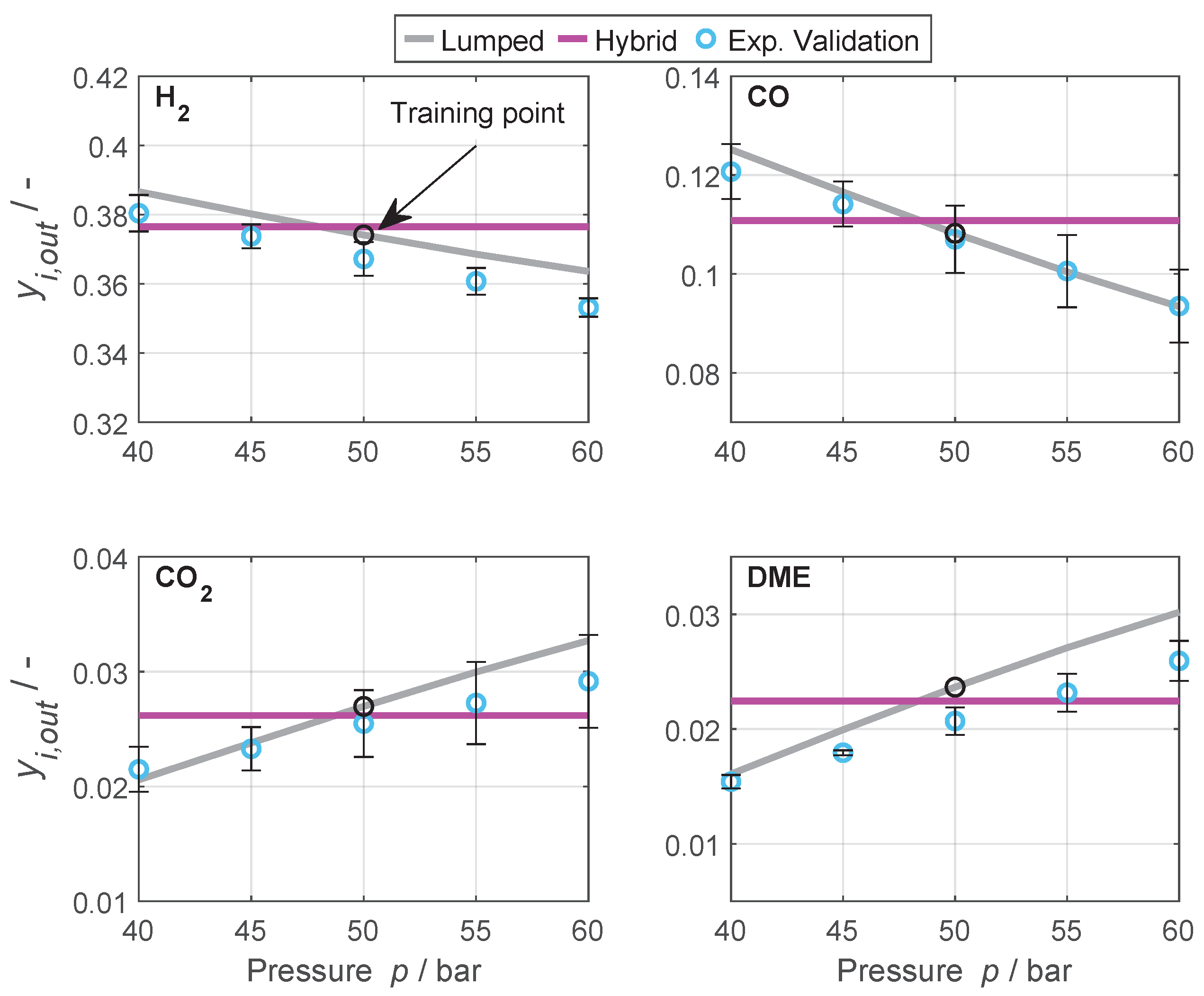
4.3.1. Dimension Extrapolation
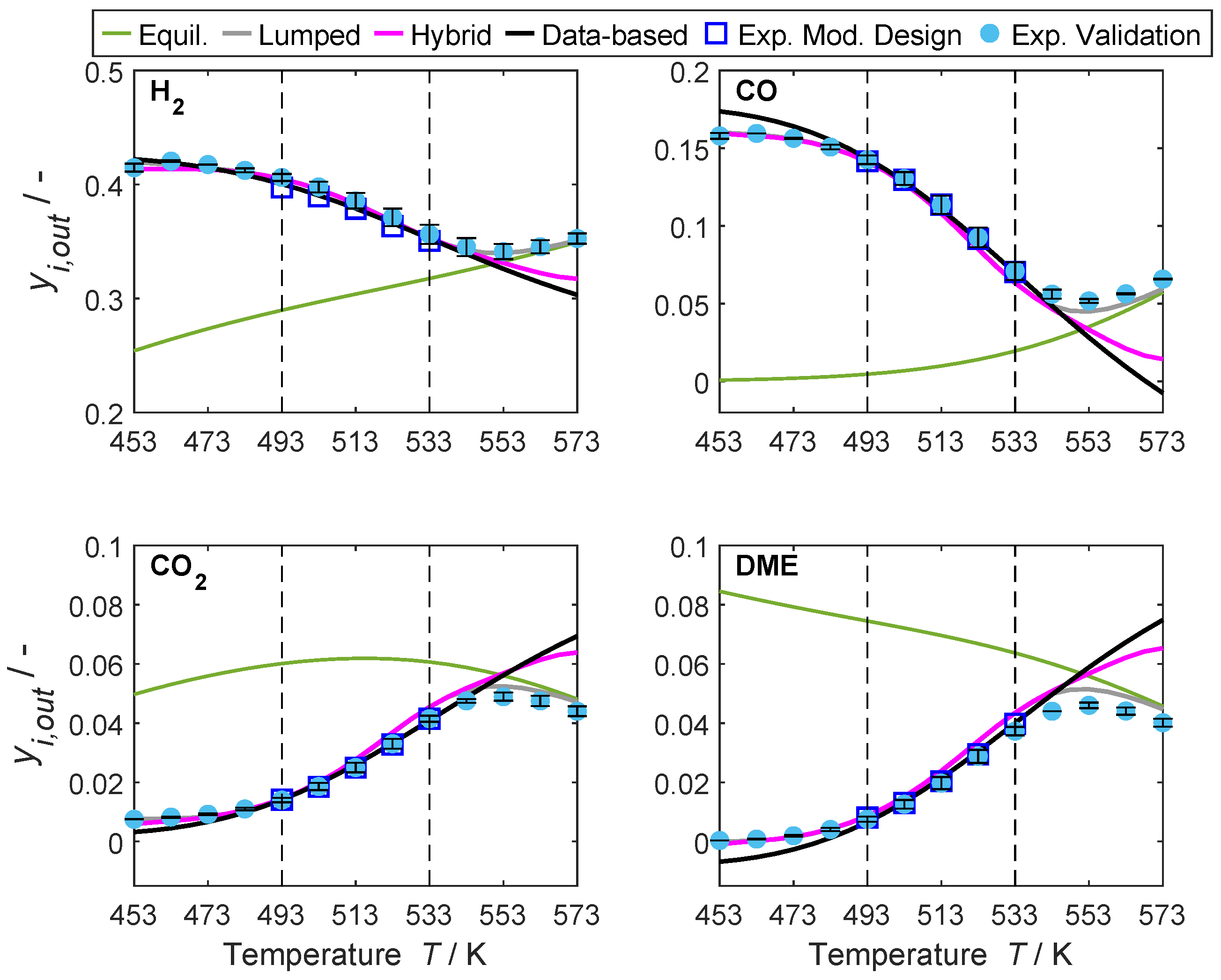
4.3.2. Range Extrapolation
5. Summary and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dahmen, N.; Arnold, U.; Djordjevic, N.; Henrich, T.; Kolb, T.; Leibold, H.; Sauer, J. High pressure in synthetic fuels production. J. Supercrit. Fluids 2015, 96, 124–132. [Google Scholar] [CrossRef]
- Niethammer, B.; Wodarz, S.; Betz, M.; Haltenort, P.; Oestreich, D.; Hackbarth, K.; Arnold, U.; Otto, T.; Sauer, J. Alternative Liquid Fuels from Renewable Resources. Chem. Ing. Tech. 2018, 90, 99–112. [Google Scholar] [CrossRef] [Green Version]
- Semelsberger, T.A.; Borup, R.L.; Greene, H.L. Dimethyl ether (DME) as an alternative fuel. J. Power Sources 2006, 156, 497–511. [Google Scholar] [CrossRef]
- Azizi, Z.; Rezaeimanesh, M.; Tohidian, T.; Rahimpour, M.R. Dimethyl ether: A review of technologies and production challenges. Chem. Eng. Process. Process Intensif. 2014, 82, 150–172. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, S.; Ge, X.; Liu, Q.; Luo, Z.; Cen, K. Experimental study of improved two step synthesis for DME production. Fuel Process. Technol. 2010, 91, 424–429. [Google Scholar] [CrossRef]
- Polierer, S.; Guse, D.; Wild, S.; Herrera Delgado, K.; Otto, T.N.; Zevaco, T.A.; Kind, M.; Sauer, J.; Studt, F.; Pitter, S. Enhanced Direct Dimethyl Ether Synthesis from CO2-Rich Syngas with Cu/ZnO/ZrO2 Catalysts Prepared by Continuous Co-Precipitation. Catalysts 2020, 10, 816. [Google Scholar] [CrossRef]
- Joint News Release: BASF and Lutianhua Plan to Pilot a New Production Process that Significantly Reduces CO2 Emissions. 2019. Available online: https://www.basf.com/global/en/media/news-releases/2019/06/p-19-249.html (accessed on 1 April 2021).
- Wang, Z.; He, T.; Li, J.; Wu, J.; Qin, J.; Liu, G.; Han, D.; Zi, Z.; Li, Z.; Wu, J. Design and operation of a pilot plant for biomass to liquid fuels by integrating gasification, DME synthesis and DME to gasoline. Fuel 2016, 186, 587–596. [Google Scholar] [CrossRef]
- Park, J.; Kim, H.S.; Lee, W.B.; Park, M.J. Trends and Outlook of Computational Chemistry and Microkinetic Modeling for Catalytic Synthesis of Methanol and DME. Catalysts 2020, 10, 655. [Google Scholar] [CrossRef]
- Grunwaldt, J.D.; Molenbroek, A.M.; Topsøe, N.Y.; Topsøe, H.; Clausen, B.S. In situ investigations of structural changes in Cu/ZnO catalysts. J. Catal. 2000, 194, 452–460. [Google Scholar] [CrossRef]
- Gaikwad, R.; Reymond, H.; Phongprueksathat, N.; Rudolf von Rohr, P.; Urakawa, A. From CO or CO2?: Space-resolved insights into high-pressure CO2 hydrogenation to methanol over Cu/ZnO/Al2O3. Catal. Sci. Technol. 2020, 10, 2763–2768. [Google Scholar] [CrossRef] [Green Version]
- Martin, O.; Mondelli, C.; Cervellino, A.; Ferri, D.; Curulla-Ferré, D.; Pérez-Ramírez, J. Operando Synchrotron X-ray Powder Diffraction and Modulated-Excitation Infrared Spectroscopy Elucidate the CO2 Promotion on a Commercial Methanol Synthesis Catalyst. Angew. Chem. Int. Ed. 2016, 55, 11031–11036. [Google Scholar] [CrossRef] [PubMed]
- Miletto, I.; Catizzone, E.; Bonura, G.; Ivaldi, C.; Migliori, M.; Gianotti, E.; Marchese, L.; Frusteri, F.; Giordano, G. In situ FT-IR characterization of CuZnZr/ferrierite hybrid catalysts for one-pot CO2-to-DME conversion. Materials 2018, 11, 2275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, W.H.; Hsu, C.L.; Wang, X.D. Thermodynamic approach and comparison of two-step and single step DME (dimethyl ether) syntheses with carbon dioxide utilization. Energy 2016, 109, 326–340. [Google Scholar] [CrossRef]
- Delgado Otalvaro, N.; Kaiser, M.; Herrera Delgado, K.; Wild, S.; Sauer, J.; Freund, H. Optimization of the direct synthesis of dimethyl ether from CO2 rich synthesis gas: Closing the loop between experimental investigations and model-based reactor design. React. Chem. Eng. 2020, 5, 949–960. [Google Scholar] [CrossRef] [Green Version]
- Peláez, R.; Marín, P.; Ordóñez, S. Direct synthesis of dimethyl ether from syngas over mechanical mixtures of CuO/ZnO/Al2O3 and Γ-Al2O3: Process optimization and kinetic modelling. Fuel Process. Technol. 2017, 168, 40–49. [Google Scholar] [CrossRef] [Green Version]
- Delgado Otalvaro, N.; Sogne, G.; Herrera Delgado, K.; Wild, S.; Pitter, S.; Sauer, J. Kinetics of the direct DME synthesis from CO2 rich syngas under variation of the CZA-to-γ-Al2O3 ratio of a mixed catalyst bed. RSC Adv. 2021, 11, 24556–24569. [Google Scholar] [CrossRef]
- Ereña, J.; Sierra, I.; Aguayo, A.T.; Ateka, A.; Olazar, M.; Bilbao, J. Kinetic modelling of dimethyl ether synthesis from (H2+CO2) by considering catalyst deactivation. Chem. Eng. J. 2011, 174, 660–667. [Google Scholar] [CrossRef]
- Cheng, C.; Zhang, H.; Ying, W.; Fang, D. Intrinsic kinetics of one-step dimethyl ether synthesis from hydrogen-rich synthesis gas over bi-functional catalyst. Korean J. Chem. Eng. 2011, 28, 1511–1517. [Google Scholar] [CrossRef]
- Sierra, I.; Ereña, J.; Aguayo, A.T.; Olazar, M.; Bilbao, J. Deactivation kinetics for direct dimethyl ether synthesis on a CuO-ZnO-Al2O3/γ-Al2O3 Catalyst. Ind. Eng. Chem. Res. 2010, 49, 481–489. [Google Scholar] [CrossRef]
- Pyatnitskii, Y.I.; Strizhak, P.E.; Lunev, N.K. Kinetic modeling for the conversion of synthesis gas to dimethyl ether on a mixed Cu-ZnO-Al2O3 catalyst with γ-Al2O3. Theor. Exp. Chem. 2009, 45, 325–330. [Google Scholar] [CrossRef]
- Renk, C.P. Die Einstufige Dimethylether-Synthese aus Synthesegas: Experimentelle und Theoretische Betrachtungen zur Einstufigen DME-Synthese mit Synthesegas aus der Flugstrom-Druckvergasung von Biomasse. Ph.D. Thesis. 2009. Available online: https://publikationen.bibliothek.kit.edu/1000012461/3815570 (accessed on 31 October 2009).
- Hadipour, A.; Sohrabi, M. Synthesis of some bifunctional catalysts and determination of kinetic parameters for direct conversion of syngas to dimethyl ether. Chem. Eng. J. 2008, 137, 294–301. [Google Scholar] [CrossRef]
- Aguayo, A.T.; Ereña, J.; Mier, D.; Arandes, J.M.; Olazar, M.; Bilbao, J. Kinetic Modeling of Dimethyl Ether Synthesis in a Single Step on a CuO/ZnO/Al2O3/Γ-Al2O3 Catalyst. Ind. Eng. Chem. Res. 2007, 46, 5522–5530. [Google Scholar] [CrossRef]
- Nie, Z.; Liu, H.; Liu, D.; Ying, W.; Fang, D. Intrinsic kinetics of dimethyl ether synthesis from syngas. J. Nat. Gas Chem. 2005, 14, 22–28. [Google Scholar] [CrossRef]
- Ng, K.L.; Chadwick, D.; Toseland, B.A. Kinetics and modelling of dimethyl ether synthesis from synthesis gas. Chem. Eng. Sci. 1999, 54, 3587–3592. [Google Scholar] [CrossRef]
- Strieth-Kalthoff, F.; Sandfort, F.; Segler, M.H.S.; Glorius, F. Machine learning the ropes: Principles, applications and directions in synthetic chemistry. Chem. Soc. Rev. 2020, 49, 6154–6168. [Google Scholar] [CrossRef]
- Jha, S.K.; Bilalovic, J.; Jha, A.; Patel, N.; Zhang, H. Renewable energy: Present research and future scope of Artificial Intelligence. Renew. Sustain. Energy Rev. 2017, 77, 297–317. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Z.; Liu, Z. Application of Artificial Neural Networks for Catalysis: A Review. Catalysts 2017, 7, 306. [Google Scholar] [CrossRef]
- Goncalves, V.; Maria, K.; da Silv, A.B.F. Applications of Artificial Neural Networks in Chemical Problems. In Artificial Neural Networks—Architectures and Applications; Suzuki, K., Ed.; InTech: London, UK, 2013; Chapter 10; pp. 203–223. [Google Scholar] [CrossRef] [Green Version]
- Basheer, I.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Zendehboudi, S.; Rezaei, N.; Lohi, A. Applications of hybrid models in chemical, petroleum, and energy systems: A systematic review. Appl. Energy 2018, 228, 2539–2566. [Google Scholar] [CrossRef]
- Sansana, J.; Joswiak, M.N.; Castillo, I.; Wang, Z.; Rendall, R.; Chiang, L.H.; Reis, M.S. Recent trends on hybrid modeling for Industry 4.0. Comput. Chem. Eng. 2021, 151, 107365. [Google Scholar] [CrossRef]
- Hein, J.E. Machine learning made easy for optimizing chemical reactions. Nature 2021, 590, 40–41. [Google Scholar] [CrossRef] [PubMed]
- von Stosch, M.; Oliveira, R.; Peres, J.; Feyo de Azevedo, S. Hybrid semi-parametric modeling in process systems engineering: Past, present and future. Comput. Chem. Eng. 2014, 60, 86–101. [Google Scholar] [CrossRef] [Green Version]
- McBride, K.; Sundmacher, K. Overview of Surrogate Modeling in Chemical Process Engineering. Chem. Ing. Tech. 2019, 91, 228–239. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Hontoir, Y.; Huang, D.; Zhang, J.; Morris, A. Combining first principles with black-box techniques for reaction systems. Control Eng. Pract. 2004, 12, 819–826. [Google Scholar] [CrossRef]
- Mondal, U.; Yadav, G.D. Perspective of dimethyl ether as fuel: Part I. Catalysis. J. CO2 Util. 2019, 32, 299–320. [Google Scholar] [CrossRef]
- Behr, A.; Agar, D.W.; Jörissen, J.; Vorholt, A.J. Einführung in Die Technische Chemie, 2nd ed.; Springer: Berlin, Germany, 2016. [Google Scholar]
- Aguayo, A.T.; Ereña, J.; Sierra, I.; Olazar, M.; Bilbao, J. Deactivation and regeneration of hybrid catalysts in the single-step synthesis of dimethyl ether from syngas and CO2. Catal. Today 2005, 106, 265–270. [Google Scholar] [CrossRef]
- Ateka, A.; Pérez-Uriarte, P.; Gamero, M.; Ereña, J.; Aguayo, A.T.; Bilbao, J. A comparative thermodynamic study on the CO2 conversion in the synthesis of methanol and of DME. Energy 2017, 120, 796–804. [Google Scholar] [CrossRef]
- Luu, M.T.; Milani, D.; Wake, M.; Abbas, A. Analysis of di-methyl ether production routes: Process performance evaluations at various syngas compositions. Chem. Eng. Sci. 2016, 149, 143–155. [Google Scholar] [CrossRef]
- Catizzone, E.; Bonura, G.; Migliori, M.; Frusteri, F.; Giordano, G. CO2 Recycling to Dimethyl Ether: State-of-the-Art and Perspectives. Molecules 2017, 23, 31. [Google Scholar] [CrossRef] [Green Version]
- Nestler, F.; Krüger, M.; Full, J.; Hadrich, M.J.; White, R.J.; Schaadt, A. Methanol Synthesis—Industrial Challenges within a Changing Raw Material Landscape. Chem. Ing. Tech. 2018, 90, 1409–1418. [Google Scholar] [CrossRef]
- Centi, G.; Perathoner, S. Opportunities and prospects in the chemical recycling of carbon dioxide to fuels. Catal. Today 2009, 148, 191–205. [Google Scholar] [CrossRef]
- Dalena, F.; Senatore, A.; Marino, A.; Gordano, A.; Basile, M.; Basile, A. Methanol Production and Applications: An Overview. In Methanol; Elsevier: Amsterdam, The Netherlands, 2018; pp. 3–28. [Google Scholar] [CrossRef]
- Mohd Ali, J.; Hussain, M.A.; Tade, M.O.; Zhang, J. Artificial Intelligence techniques applied as estimator in chemical process systems—A literature survey. Expert Syst. Appl. 2015, 42, 5915–5931. [Google Scholar] [CrossRef]
- Panerati, J.; Schnellmann, M.A.; Patience, C.; Beltrame, G.; Patience, G.S. Experimental methods in chemical engineering: Artificial neural networks—ANNs. Can. J. Chem. Eng. 2019, 97, 2372–2382. [Google Scholar] [CrossRef]
- Cybenko, G. Mathematics of Control, Signals, and Systems Approximation by Superpositions of a Sigmoidal Function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchconbe, M.; White, H. Multilayer Feedforward Networks are Universal Approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Delgado Otalvaro, N.; Bilir, P.G.; Herrera Delgado, K.; Pitter, S.; Sauer, J. Modeling the Direct Synthesis of Dimethyl Ether using Artificial Neural Networks. Chem. Ing. Tech. 2021, 93, 754–761. [Google Scholar] [CrossRef]
- Moradi, G.R.; Parvizian, F. An expert model for estimation of the performance of direct dimethyl ether synthesis from synthesis gas. Can. J. Chem. Eng. 2011, 89, 1266–1273. [Google Scholar] [CrossRef]
- Alamolhoda, S.; Kazemeini, M.; Zaherian, A.; Zakerinasab, M.R. Reaction kinetics determination and neural networks modeling of methanol dehydration over nano γ-Al2O3 catalyst. J. Ind. Eng. Chem. 2012, 18, 2059–2068. [Google Scholar] [CrossRef]
- Blanco, M.; Coello, J.; Iturriaga, H.; Maspoch, S.; Redón, M. Artificial Neural Networks for Multicomponent Kinetic Determinations. Anal. Chem. 1995, 67, 4477–4483. [Google Scholar] [CrossRef]
- Omata, K.; Ozaki, T.; Umegaki, T.; Watanabe, Y.; Nukui, N.; Yamada, M. Optimization of the temperature profile of a temperature gradient reactor for DME synthesis using a simple genetic algorithm assisted by a neural network. Energy Fuels 2003, 17, 836–841. [Google Scholar] [CrossRef]
- Omata, K.; Hashimoto, M.; Sutarto; Yamada, M. Artificial neural network and grid search aided optimization of temperature profile of temperature gradient reactor for dimethyl ether synthesis from syngas. Ind. Eng. Chem. Res. 2009, 48, 844–849. [Google Scholar] [CrossRef]
- Omata, K.; Sutarto; Hashimoto, M.; Ishiguro, G.; Watanabe, Y.; Umegaki, T.; Yamada, M. Design and development of Cu-Zn oxide catalyst for direct dimethyl ether synthesis using an artificial neural network and physicochemical properties of elements. Ind. Eng. Chem. Res. 2006, 45, 4905–4910. [Google Scholar] [CrossRef]
- Svitnic, T.; Do, N.T.Q.; Schuhmann, T.; Renner, T.; Haag, S.; Örs, E. Data-driven approach for predicitive modeling of by-product formation in methanol synthesis. In Proceedings of the 30th European Symposium on Computer Aided Process Engineering, Milan, Italy, 24–27 May 2020; pp. 505–510. [Google Scholar] [CrossRef]
- Valeh-E-Sheyda, P.; Yaripour, F.; Moradi, G.; Saber, M. Application of artificial neural networks for estimation of the reaction rate in methanol dehydration. Ind. Eng. Chem. Res. 2010, 49, 4620–4626. [Google Scholar] [CrossRef]
- Ye, J. Artificial neural network modeling of methanol production from syngas. Pet. Sci. Technol. 2019, 37, 629–632. [Google Scholar] [CrossRef]
- Din, I.U.; Shaharun, M.S.; Naeem, A.; Alotaibi, M.A.; Alharthi, A.I.; Nasir, Q. CO2 Conversion to Methanol over Novel Carbon Nanofiber-Based Cu/ZrO2 Catalysts—A Kinetics Study. Catalysts 2020, 10, 567. [Google Scholar] [CrossRef]
- Zahedi, G.; Elkamel, A.; Lohi, A.; Jahanmiri, A.; Rahimpor, M.R. Hybrid artificial neural network—First principle model formulation for the unsteady state simulation and analysis of a packed bed reactor for CO2 hydrogenation to methanol. Chem. Eng. J. 2005, 115, 113–120. [Google Scholar] [CrossRef]
- Potočnik, P.; Grabec, I.; Šetinc, M.; Levec, J. Neural net based hybrid modeling of the methanol synthesis process. Neural Process. Lett. 2000, 11, 219–228. [Google Scholar] [CrossRef]
- Alavi, M.; Jazayeri-Rad, H.; Behbahani, R.M. Optimizing the Feed Conditions in a Dimethyl Ether Production Process To Maximize Methanol Conversion Using a Hybrid First Principle Neural Network Approach. Chem. Eng. Commun. 2014, 201, 650–673. [Google Scholar] [CrossRef]
- Peng, D.Y.; Robinson, D.B. A new two-constant equation of state. Ind. Eng. Chem. Fundam. 1976, 15, 59–64. [Google Scholar] [CrossRef]
- Lu, W.Z.; Teng, L.H.; Xiao, W.D. Simulation and experiment study of dimethyl ether synthesis from syngas in a fluidized-bed reactor. Chem. Eng. Sci. 2004, 59, 5455–5464. [Google Scholar] [CrossRef]
- Hameed, A.A.; Karlik, B.; Salman, M.S. Back-propagation algorithm with variable adaptive momentum. Knowl.-Based Syst. 2016, 114, 79–87. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Okut, H. Bayesian Regularized Neural Networks for Small n Big p Data. In Artificial Neural Networks—Models and Applications; InTech: London, UK, 2016; Chapter 2. [Google Scholar] [CrossRef] [Green Version]
- Burden, F.; Winkler, D. Bayesian Regularization of Neural Networks. Methods Mol. Biol. 2009, 458, 23–42. [Google Scholar] [CrossRef]
- Kalogirou, S.A.; Bojic, M. Artificial neural networks for the prediction of the energy consumption of a passive solar building. Energy 2000, 25, 479–491. [Google Scholar] [CrossRef]
- Lachtermacher, G.; Fuller, J.D. Back propagation in time-series forecasting. J. Forecast. 1995, 14, 381–393. [Google Scholar] [CrossRef]
- Jadid, M.N.; Fairbairn, D.R. Neural-network applications in predicting moment-curvature parameters from experimental data. Eng. Appl. Artif. Intell. 1996, 9, 309–319. [Google Scholar] [CrossRef]
- Amato, F.; González-Hernández, J.L.; Havel, J. Artificial neural networks combined with experimental design: A “soft” approach for chemical kinetics. Talanta 2012, 93, 72–78. [Google Scholar] [CrossRef]
- Zahedi, G.; Lohi, A.; Mahdi, K. Hybrid modeling of ethylene to ethylene oxide heterogeneous reactor. Fuel Process. Technol. 2011, 92, 1725–1732. [Google Scholar] [CrossRef]
- Van Can, H.J.L.; Te Braake, H.A.B.; Dubbelman, S.; Hellinga, C.; Luyben, K.C.A.M.; Heijnen, J.J. Understanding and applying the extrapolation properties of serial gray-box models. AIChE J. 1998, 44, 1071–1089. [Google Scholar] [CrossRef]
- Pérez-Ramírez, J.; Berger, R.J.; Mul, G.; Kapteijn, F.; Moulijn, J.A. Six-flow reactor technology a review on fast catalyst screening and kinetic studies. Catal. Today 2000, 60, 93–109. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reaction | Equation (13) | Equation (14) | Adsorbate | Equation (15) | |||
|---|---|---|---|---|---|---|---|
| A | B | ln() | ln() | ||||
| 1 | 3014.4029 | 10.3857 | −6.94 | 21.81 | CO | −15.32 | −14.03 |
| 2 | 1143.9494 | 0.9925 | −2.07 | 42.77 | CO2 | −0.57 | 0 |
| 3 | 2076.2131 | 2.0101 | −2.75 | 10.82 | H2 | −19.51 | −14.68 |
| Param. | Value | Unit |
|---|---|---|
| T | 220, 230, 240, 250, 260 | °C |
| 0.2, 0.3, 0.4, 0.5, 0.6, 0.7 | slpm * | |
| 0, 1, 3 | % | |
| 4, 8, 15 | % | |
| % |
| Model | mRE | mRE | mRE | mRE |
|---|---|---|---|---|
| Lumped | 1.49% | 5.49% | 6.02% | 28.89% |
| Hybrid | 1.49% | 5.45% | 6.08% | 28.36% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delgado Otalvaro, N.; Bilir, P.G.; Herrera Delgado, K.; Pitter, S.; Sauer, J. Kinetics of the Direct DME Synthesis: State of the Art and Comprehensive Comparison of Semi-Mechanistic, Data-Based and Hybrid Modeling Approaches. Catalysts 2022, 12, 347. https://doi.org/10.3390/catal12030347
Delgado Otalvaro N, Bilir PG, Herrera Delgado K, Pitter S, Sauer J. Kinetics of the Direct DME Synthesis: State of the Art and Comprehensive Comparison of Semi-Mechanistic, Data-Based and Hybrid Modeling Approaches. Catalysts. 2022; 12(3):347. https://doi.org/10.3390/catal12030347
Chicago/Turabian StyleDelgado Otalvaro, Nirvana, Pembe Gül Bilir, Karla Herrera Delgado, Stephan Pitter, and Jörg Sauer. 2022. "Kinetics of the Direct DME Synthesis: State of the Art and Comprehensive Comparison of Semi-Mechanistic, Data-Based and Hybrid Modeling Approaches" Catalysts 12, no. 3: 347. https://doi.org/10.3390/catal12030347
APA StyleDelgado Otalvaro, N., Bilir, P. G., Herrera Delgado, K., Pitter, S., & Sauer, J. (2022). Kinetics of the Direct DME Synthesis: State of the Art and Comprehensive Comparison of Semi-Mechanistic, Data-Based and Hybrid Modeling Approaches. Catalysts, 12(3), 347. https://doi.org/10.3390/catal12030347