1. Introduction
A deterministic one-dimensional two-player linear-quadratic (nonzero-sum) difference game can be defined as follows (see, for example, [
1]):
for
, where
,
and
are deterministic functions, the control
(respectively,
) gives the decision of player 1 (respectively, player 2) at time
n. Each player has a general quadratic cost function that he/she tries to minimize.
The difference game can be made stochastic by adding the random variable
in Equation (
1). The random variables
are assumed to be independent and identically distributed.
The final time
T can be finite or infinite. Reddy and Zaccour [
2] considered a class of non-cooperative
N-player finite-horizon linear-quadratic dynamic games with linear constraints. Lin [
3] studied the Stackelberg strategies in the infinite horizon LQ mean-field stochastic difference game. Liu et al. [
4] used an adaptive dynamic programming approach to solve the infinite horizon linear quadratic Stackelberg game problem for unknown stochastic discrete-time systems with multiple decision makers. Ju et al. [
5] used dynamic programming to obtain an optimal linear strategy profile for a class of two-player finite-horizon linear-quadratic difference games.
In this paper, we consider the one-dimensional controlled Markov chain
defined by
where
with probability 1/2 and the random variables
are independent, so that
is a (controlled) symmetric random walk. The chain starts at
.
We define the first-passage time
Our aim is to find the controls
and
that minimize the expected value of the cost function
where
is a positive constant. This parameter gives the penalty incurred for survival in the continuation region
. It is needed to obtain a well-defined problem. Indeed, if we set
, then the optimal solution for the first (respectively, second) player is trivially to choose
(respectively,
).
Thus, there are two optimizers. The first one, using , would like the Markov chain to hit the origin as soon as possible. Therefore, he/she would like to choose , but this generates a cost. On the other hand, the second optimizer wants the Markov chain to remain positive as long as possible. Hence, he/she would prefer to choose , which however generates no costs. Both optimizers, and especially the second one, must also take into account the value of the constant .
Remark 1. We could, in theory, assume that the parameter λ is negative. Then, it is mainly the first optimizer who would need to consider the value of λ. See, however, Remark 3.
The main difference between the current paper and the related ones found in the literature is the fact that, in our case, the final time is neither finite or infinite; it is rather a random variable.
The above problem is a particular
homing problem, in which a stochastic process is controlled until a certain event occurs. This type of problem was introduced by Whittle ([
6] p. 289) for
n-dimensional diffusion processes. He also considered the case when we take the risk-sensitivity of the optimizer into account; see [
7], as well as [
8,
9].
The author has written numerous papers on homing problems. In [
10,
11], these problems where extended to the case of discrete-time Markov chains, whereas in [
12] the case of autoregressive processes was treated; see also [
13].
In [
10,
11], the authors considered a problem related to the one defined above, but with only one optimizer. Thus, they treated a stochastic optimal control problem, whereas the problem in the current paper is a stochastic difference game.
To solve our problem, we will use dynamic programming. Let
be the value function defined by
In the next section, the dynamic programming equation satisfied by the function will be derived.
2. Dynamic Programming
In theory, we must determine the optimal value of for . However, using dynamic programming, the problem is reduced to finding the optimal solution at the initial time only.
Indeed, we can write, making use of Bellman’s principle of optimality, that
We can now state the following proposition.
Proposition 1. The value function satisfies the dynamic programming equationThe equation is subject to the boundary condition Remark 2. The usefulness of the value function is that it enables us to determine the optimal controls and .
Since
, we deduce from Equation (
7) that
Now, let
be the random variable that corresponds to
when
. Using the well-known results on the
gambler’s ruin problem (see, for instance, ([
14] p. 349), we can state that
Hence, we would also have
Since the objective is to minimize the expected value of
, we must conclude that the optimal solution is not
.
Remark 3. (i) We deduce from what precedes that we cannot choose a value of the parameter λ in the interval , otherwise we obtain an infinite expected reward by choosing .
(ii) If , then there is no penalty (or reward) for survival in the continuation region . The optimal solution is obviously . As will be seen below, the optimal value of is 1 for any value of .
(iii) If we definethen, when , we find that (see, again, ([14] p. 349))so thatTherefore, we could take in that case. (iv) If and and is defined as in (12), then (see ([14] p. 348))andThus, we could consider the case when if . Next, notice that and yield the same expected value of . However, the choice generates a cost of 1, while with a reward of 1 is obtained. Hence, taking is surely a better decision than choosing . Thus, we must determine whether the optimal solution is or .
Proposition 2. We deduce from what precedes that the second optimizer should choose , independently of the value of .
Remark 4. The optimal choice for will depend on the value of the parameter λ, which, as mentioned above, gives the penalty incurred for survival in the continuation region.
It follows from Proposition 2 that Equation (
9) can be simplified to
Proposition 3. The value function satisfies the non-linear third-order difference equationfor The boundary condition is Proof. Making use of the formula
we deduce from Equation (
17) that
By squaring both sides of the above equation and simplifying, we obtain Equation (
18). □
Solving a boundary value problem for a non-linear difference equation of order 3 is not easy. Instead of trying to solve Equation (
18) directly, we will proceed as in [
10].
3. Optimal Choice for
We must determine whether the first optimizer should take or . The control variable (as well as ) is actually a function of .
Suppose that we set
. Then, denoting the function
by
, Equation (
17) implies that
that we rewrite as follows:
where
. The equation is valid for
and is subject to the boundary condition
Making use of the mathematical software program
Maple, we find that the solution of Equation (
23) that satisfies the boundary conditions
is
for
, so that
for
.
Remark 5. (i) The function is real, even if it contains the imaginary constant i.
(ii) Because Equation (23) is a third-order linear difference equation, we need three boundary conditions to solve it uniquely. Therefore, we used Equation (24) for and . Next, let us denote the function
by
if we set
. We then deduce from Equation (
17) that the function
satisfies the second-order difference equation
The unique solution that is such that
is
Every time the value of
changes, the (first) optimizer must make a new decision. It then follows from Equation (
17) that we can express the value function
in terms of
and
as in the following proposition.
Proposition 4. The value function is given byfor . To determine the value function, and hence the optimal value of
(
), we can compare the two expressions
and
That is, we can write that
Remark 6. We must set when we compute the function (and ).
In the next section, we will present the results obtained with different values of the parameter to see the effect of this parameter on the optimal control .
5. Conclusions
Homing problems are generally considered for diffusion processes. The author and Kounta [
11] extended these problems to the discrete-time case. In [
10], the author improved the results found in [
11] by finding an explicit expression for the value function.
In the current paper, a homing problem with two optimizers has been defined and solved explicitly. The problem can be interpreted as a stochastic difference game, as one optimizer is trying to minimize the time spent by the controlled stochastic process in the continuation region C, while the second one seeks to maximize the survival time in C.
In
Section 2, the equation satisfied by the value function has been derived. This equation is a non-linear third-order difference equation, which is obviously very difficult to solve explicitly.
The technique that we have used in the paper enables us to obtain an exact expression for the solution of a boundary value problem for a non-linear difference equation. This result is of interest in itself.
For the sake of simplicity, we have considered a symmetric random walk, and it has been assumed that the control variables can take only two values. We could of course generalize the results that have been presented in the paper. However, if there are many possible values for the control variables, obtaining an explicit solution to the homing problem considered can be quite tedious.



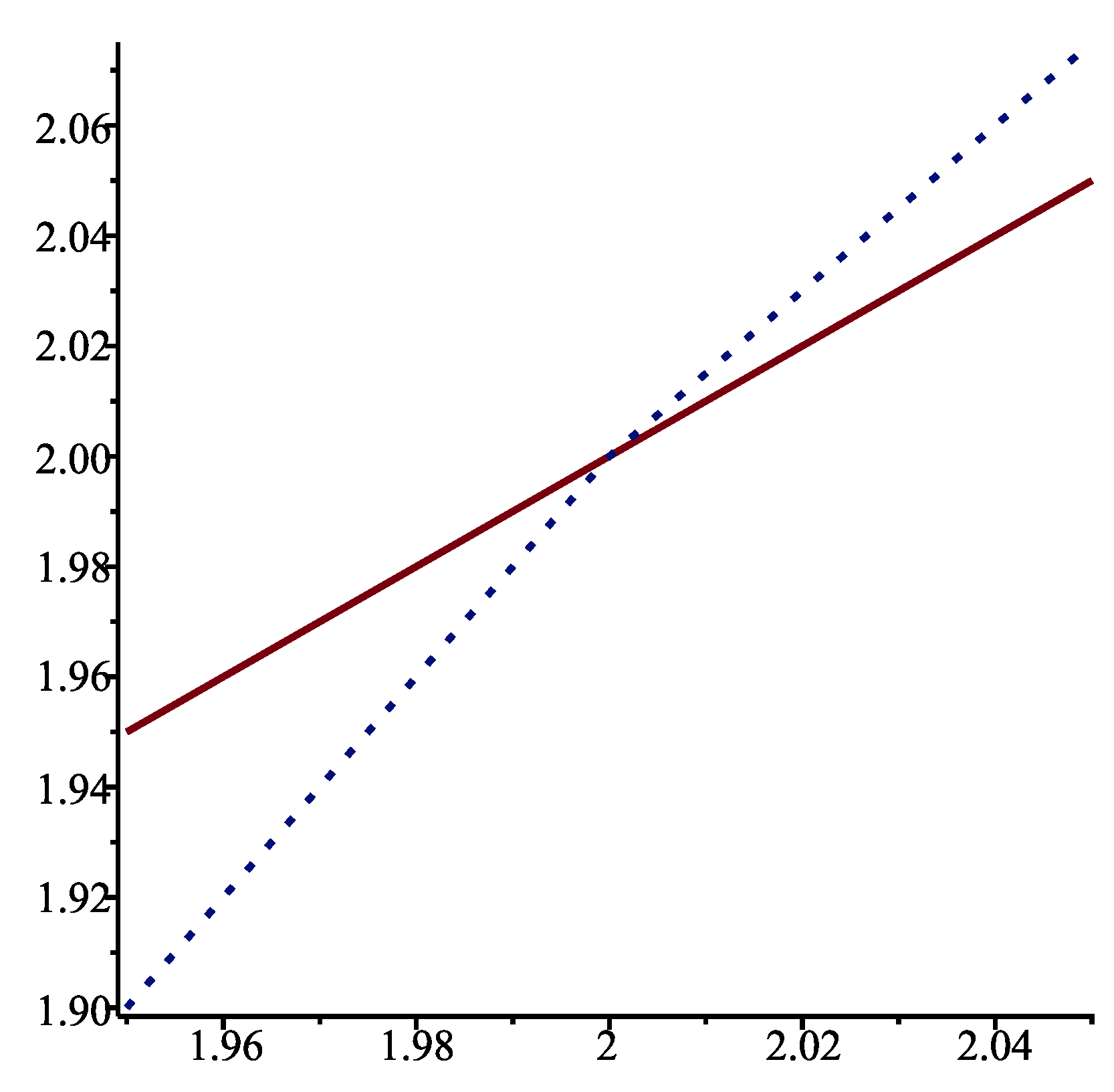
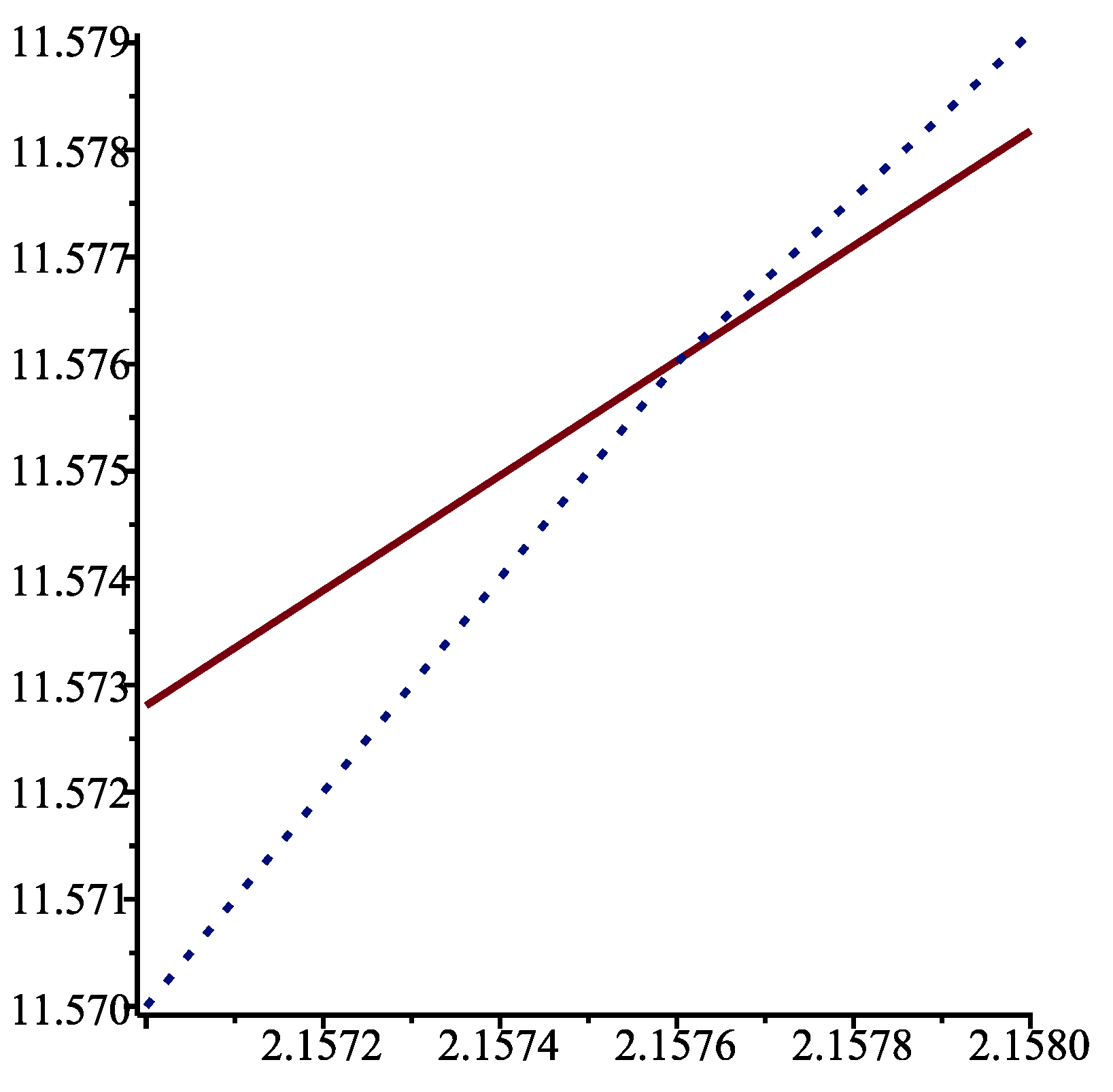

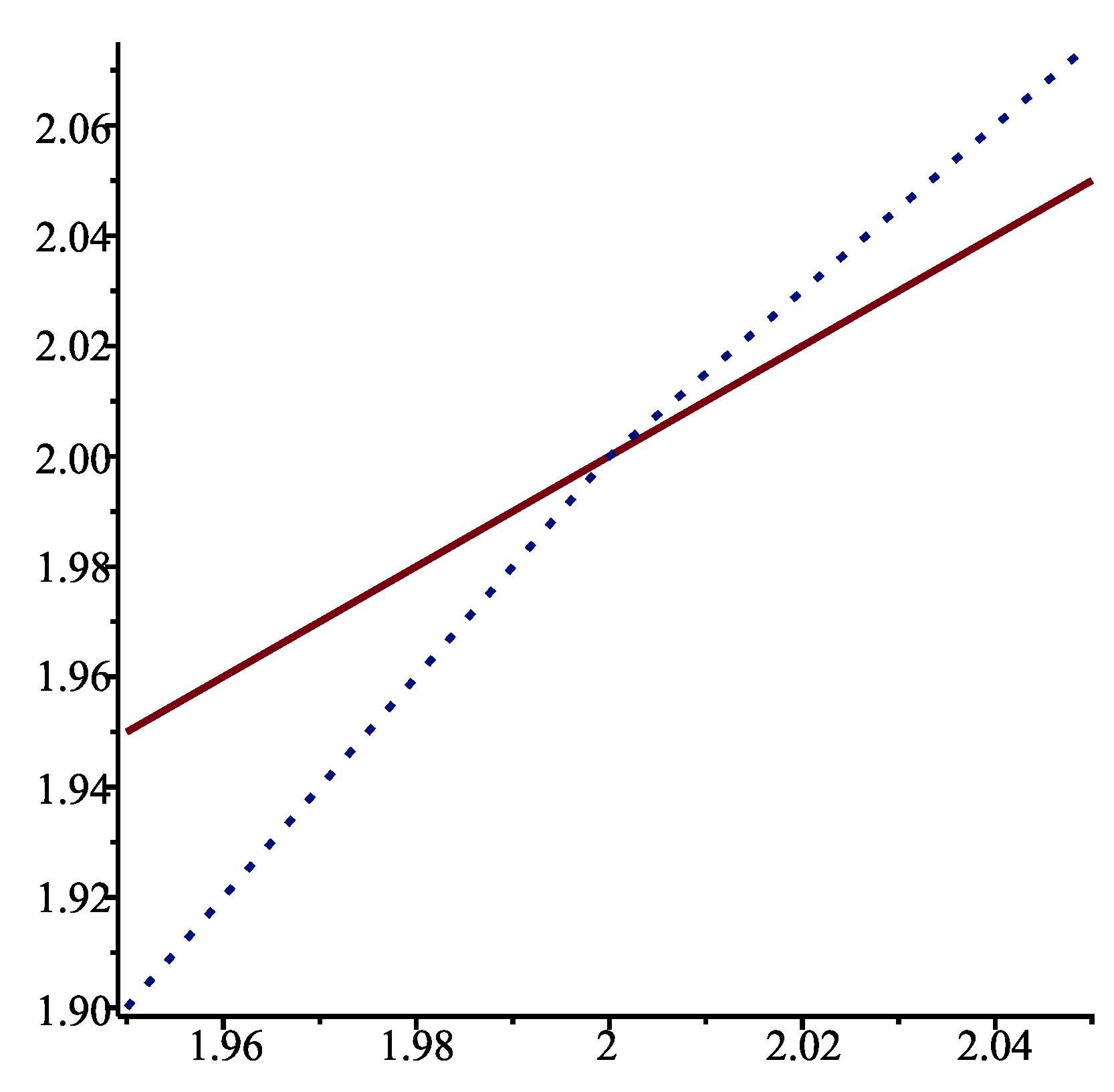{kind=link}
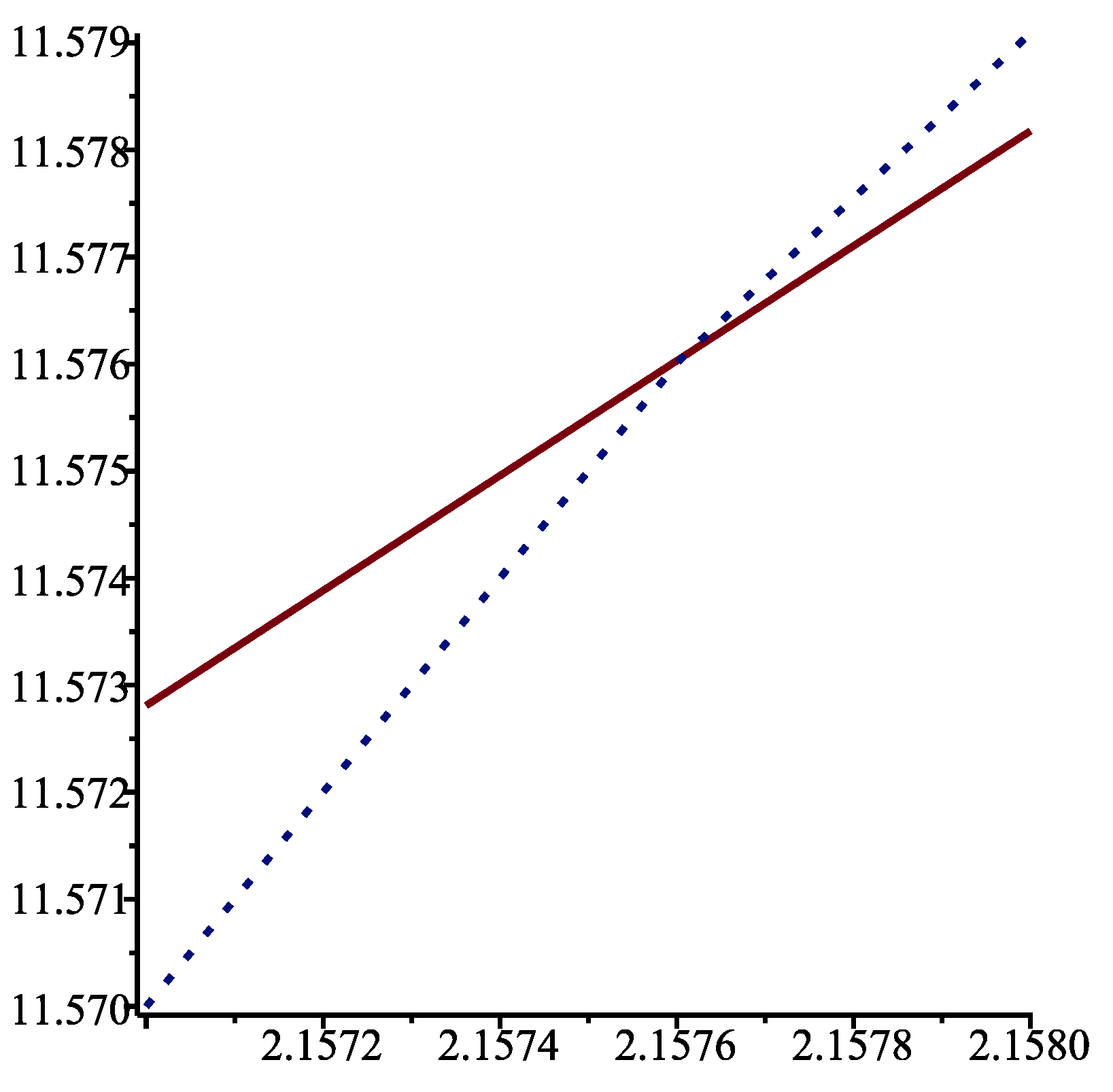{kind=link}