
Champ versus Chump: Viewing an Opponent’s Face Engages Attention but Not Reward Systems

 , , and
, , and
Abstract
1. Introduction
2. Method
2.1. Participants
2.2. Stimuli & Procedure
2.3. Data Collection
2.4. Data Analysis
2.4.1. Behavioral
2.4.2. EEG
2.4.3. Inferential Statistics
3. Results
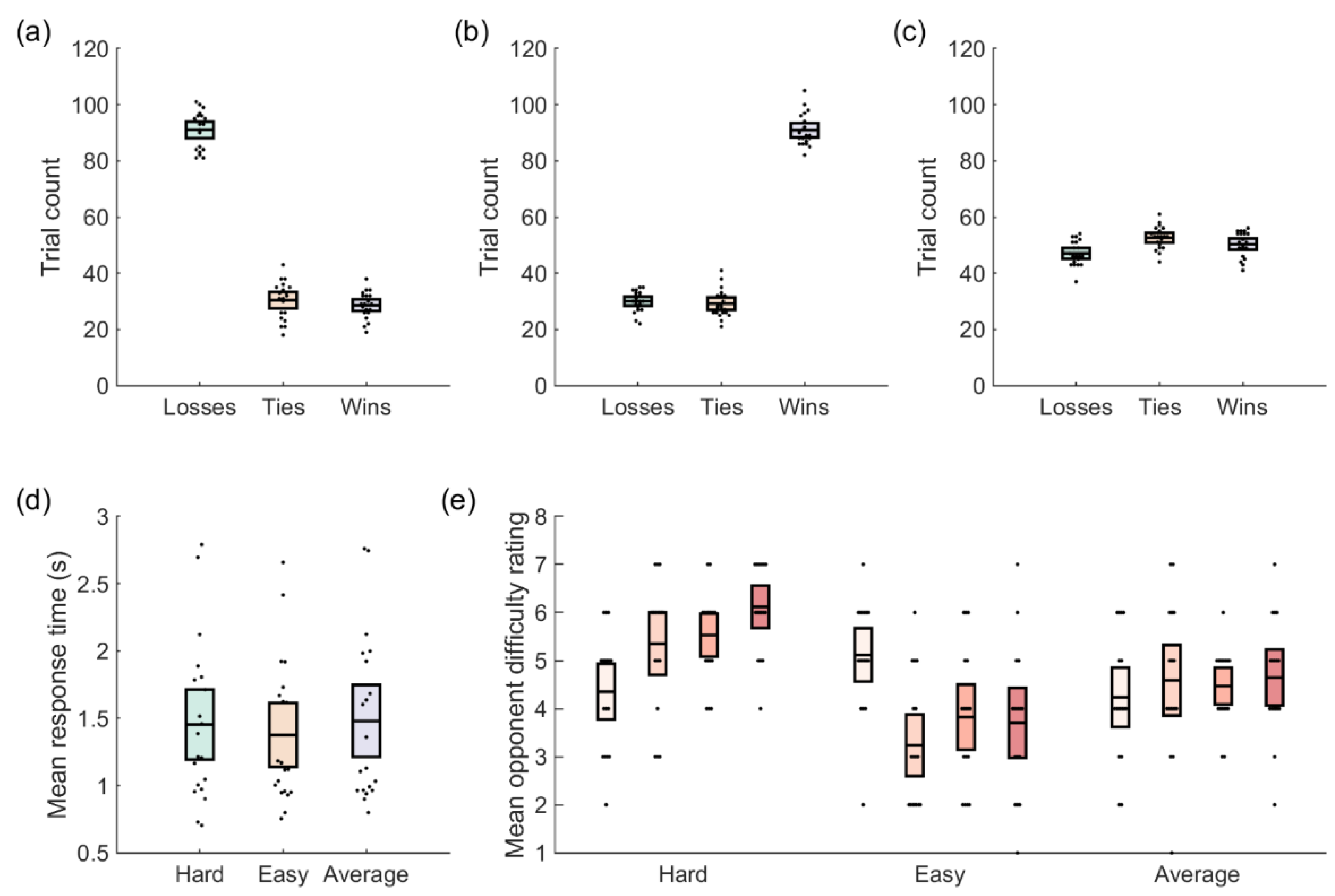
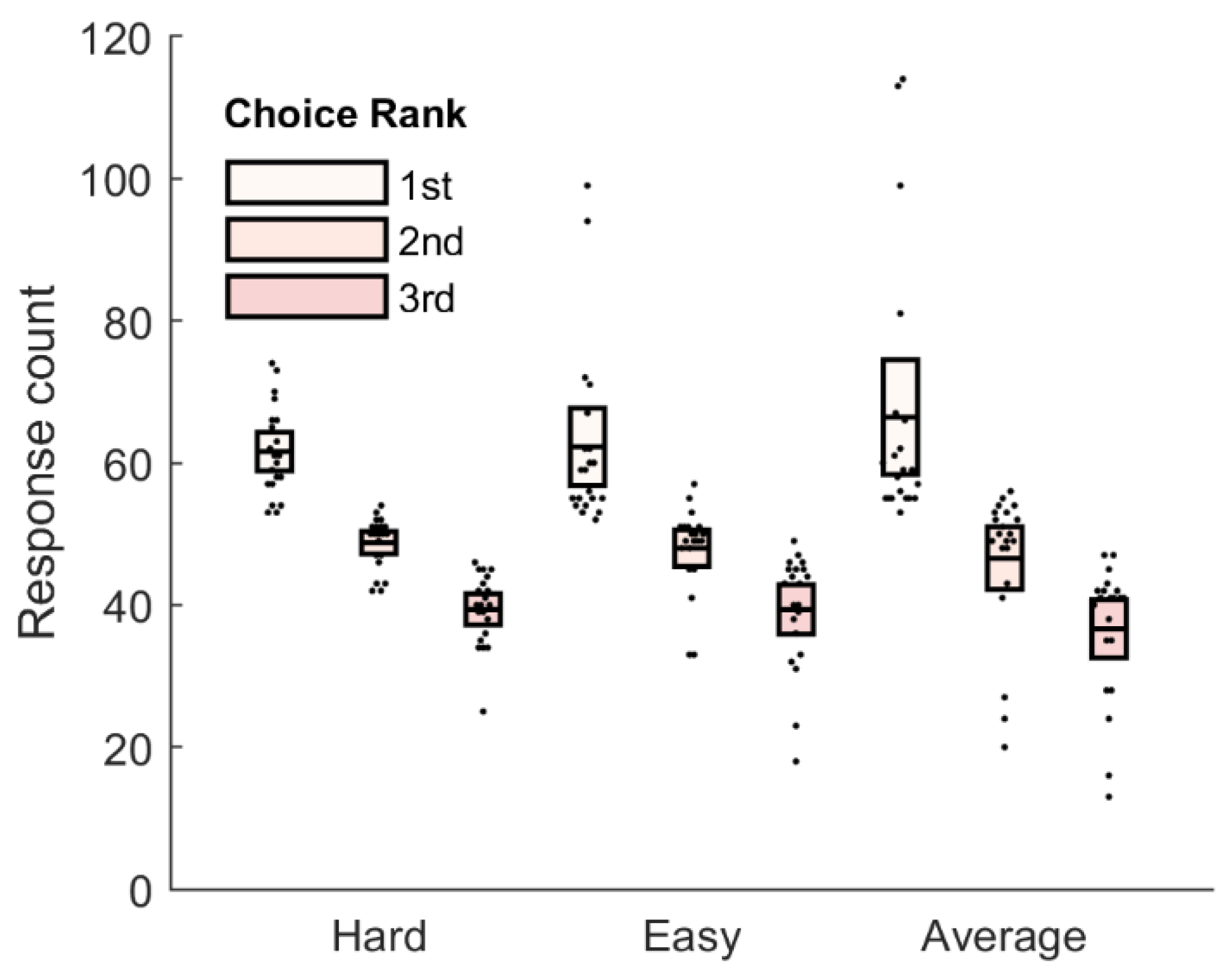
3.1. Behavioral Results
3.2. Electroencephalographic Results
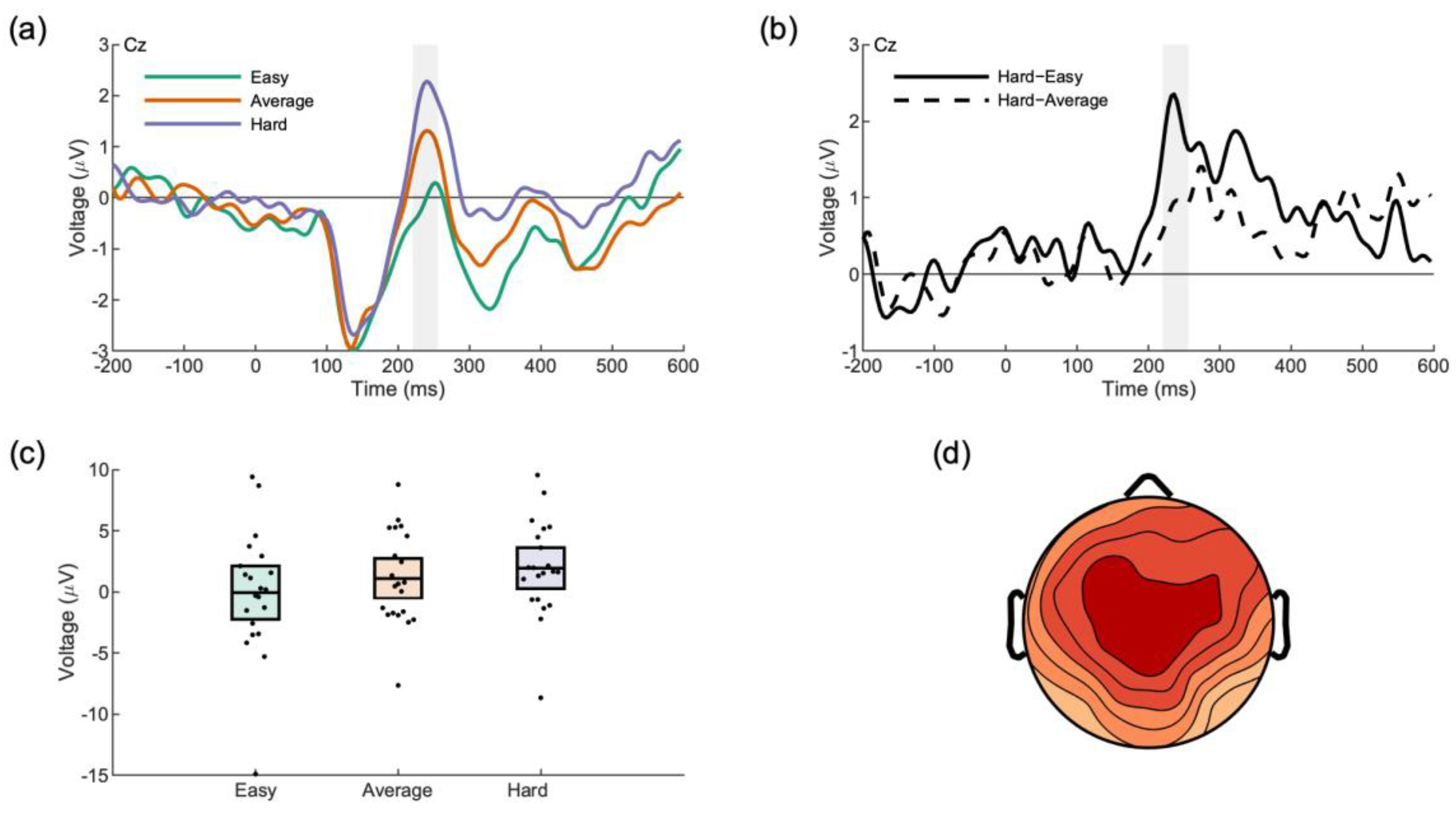
3.2.1. Feedback Processing: Tie, Lose, Win
3.2.2. Feedback Processing: Expectancy
3.2.3. Face Processing
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Klein, R.M.; Vallis, E.H.; Chisholm, J.D. A Comparison of Engagement between the Attention Network Test and a Videogame-Like Version, Called the AttentionTrip. Int. J. Hum. Comput. Interact. 2019, 35, 1813–1819. [Google Scholar] [CrossRef]
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior (Commemorative Edition); Princeton University Press: Princeton, NJ, USA, 2007; ISBN 978-0-691-13061-3. [Google Scholar]
- Smith, J.M. Evolution and the Theory of Games; Cambridge University Press: Cambridge, UK, 1982; ISBN 978-0-521-28884-2. [Google Scholar]
- Mobbs, D.; Trimmer, P.C.; Blumstein, D.T.; Dayan, P. Foraging for foundations in decision neuroscience: Insights from ethology. Nat. Rev. Neurosci. 2018, 19, 419–427. [Google Scholar] [CrossRef]
- Schultz, W.; Dayan, P.; Montague, P.R. A Neural Substrate of Prediction and Reward. Science 1997, 275, 1593–1599. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Coles, M.G. The neural basis of human error processing: Reinforcement learning, dopamine, and the error-related negativity. Psychol. Rev. 2002, 109, 679–709. [Google Scholar] [CrossRef]
- Proudfit, G.H. The reward positivity: From basic research on reward to a biomarker for depression. Psychophysiology 2015, 52, 449–459. [Google Scholar] [CrossRef]
- Krigolson, O.E. Event-related brain potentials and the study of reward processing: Methodological considerations. Int. J. Psychophysiol. 2017, 132, 175–183. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Krigolson, O.E. Reward prediction error signals associated with a modified time estimation task. Psychophysiology 2007, 44, 913–917. [Google Scholar] [CrossRef]
- Williams, C.C.; Hassall, C.D.; Trska, R.; Holroyd, C.B.; Krigolson, O.E. When theory and biology differ: The relationship between reward prediction errors and expectancy. Biol. Psychol. 2017, 129, 265–272. [Google Scholar] [CrossRef]
- Krigolson, O.E.; Hassall, C.D.; Handy, T.C. How We Learn to Make Decisions: Rapid Propagation of Reinforcement Learning Prediction Errors in Humans. J. Cogn. Neurosci. 2014, 26, 635–644. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Krigolson, O.E.; Lee, S. Reward positivity elicited by predictive cues. NeuroReport 2011, 22, 249–252. [Google Scholar] [CrossRef]
- Kaltwasser, L.; Hildebrandt, A.; Wilhelm, O.; Sommer, W. Behavioral and neuronal determinants of negative reciprocity in the ultimatum game. Soc. Cogn. Affect. Neurosci. 2016, 11, 1608–1617. [Google Scholar] [CrossRef]
- Li, D.; Meng, L.; Ma, Q. Who Deserves My Trust? Cue-Elicited Feedback Negativity Tracks Reputation Learning in Repeated Social Interactions. Front. Hum. Neurosci. 2017, 11, 307. [Google Scholar] [CrossRef]
- Osinsky, R.; Mussel, P.; Öhrlein, L.; Hewig, J. A neural signature of the creation of social evaluation. Soc. Cogn. Affect. Neurosci. 2014, 9, 731–736. [Google Scholar] [CrossRef][Green Version]
- Dyson, B.J.; Wilbiks, J.M.P.; Sandhu, R.; Papanicolaou, G.; Lintag, J. Negative outcomes evoke cyclic irrational decisions in Rock, Paper, Scissors. Sci. Rep. 2016, 6, 20479. [Google Scholar] [CrossRef]
- Forder, L.; Dyson, B.J. Behavioural and neural modulation of win-stay but not lose-shift strategies as a function of outcome value in Rock, Paper, Scissors. Sci. Rep. 2016, 6, 33809. [Google Scholar] [CrossRef] [PubMed]
- Polich, J. Updating P300: An integrative theory of P3a and P3b. Clin. Neurophysiol. 2007, 118, 2128–2148. [Google Scholar] [CrossRef]
- Fisher, D.J.; Labelle, A.; Knott, V.J. Auditory hallucinations and the P3a: Attention-switching to speech in schizophrenia. Biol. Psychol. 2010, 85, 417–423. [Google Scholar] [CrossRef]
- Hartikainen, K.M.; Ogawa, K.H.; Knight, R.T. Orbitofrontal cortex biases attention to emotional events. J. Clin. Exp. Neuropsychol. 2012, 34, 588–597. [Google Scholar] [CrossRef]
- Treleaven-Hassard, S.; Gold, J.; Bellman, S.; Schweda, A.; Ciorciari, J.; Critchley, C.; Varan, D. Using the P3a to gauge automatic attention to interactive television advertising. J. Econ. Psychol. 2010, 31, 777–784. [Google Scholar] [CrossRef]
- Wang, J.; Liu, L.; Yan, J.H. Implicit power motive effects on the ERP processing of emotional intensity in anger faces. J. Res. Pers. 2014, 50, 90–97. [Google Scholar] [CrossRef]
- Campanella, S.; Gaspard, C.; Debatisse, D.; Bruyer, R.; Crommelinck, M.; Guerit, J.-M. Discrimination of emotional facial expressions in a visual oddball task: An ERP study. Biol. Psychol. 2002, 59, 171–186. [Google Scholar] [CrossRef]
- Milivojevic, B.; Clapp, W.C.; Johnson, B.W.; Corballis, M.C. Turn that frown upside down: ERP effects of thatcherization of misorientated faces. Psychophysiology 2003, 40, 967–978. [Google Scholar] [CrossRef]
- Halit, H.; De Haan, M.; Johnson, M.H. Modulation of event-related potentials by prototypical and atypical faces. NeuroReport 2000, 11, 1871–1875. [Google Scholar] [CrossRef]
- Brown, C.R.; Clarke, A.R.; Barry, R.J. Inter-modal attention: ERPs to auditory targets in an inter-modal oddball task. Int. J. Psychophysiol. 2006, 62, 77–86. [Google Scholar] [CrossRef]
- García-Larrea, L.; Lukaszewicz, A.-C.; Mauguiére, F. Revisiting the oddball paradigm. Non-target vs neutral stimuli and the evaluation of ERP attentional effects. Neuropsychologia 1992, 30, 723–741. [Google Scholar] [CrossRef]
- Brainard, D.H. The Psychophysics Toolbox. Spat. Vis. 1997, 10, 433–436. [Google Scholar] [CrossRef]
- Pelli, D.G. The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spat. Vis. 1997, 10, 437–442. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An Open Source Toolbox for Analysis of Single-Trial EEG Dynamics Including Independ-ent Component Analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef]
- Sambrook, T.D.; Goslin, J. A Neural Reward Prediction Error Revealed by a Meta-Analysis of ERPs Using Great Grand Aver-ages. Psychol. Bull. 2015, 141, 213–235. [Google Scholar] [CrossRef]
- Luck, S.J.; Gaspelin, N. How to get statistically significant effects in any ERP experiment (and why you shouldn’t). Psychophysiology 2017, 54, 146–157. [Google Scholar] [CrossRef]
- Lee, M.J.C.; Tidman, S.J.; Lay, B.S.; Bourke, P.D.; Lloyd, D.G.; Alderson, J.A. Visual Search Differs But Not Reaction Time When Intercepting a 3D Versus 2D Videoed Opponent. J. Mot. Behav. 2013, 45, 107–115. [Google Scholar] [CrossRef]
- Slezak, D.F.; Sigman, M. Do not fear your opponent: Suboptimal changes of a prevention strategy when facing stronger opponents. J. Exp. Psychol. Gen. 2012, 141, 527–538. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Hajcak, G.; Larsen, J.T. The good, the bad and the neutral: Electrophysiological responses to feedback stimuli. Brain Res. 2006, 1105, 93–101. [Google Scholar] [CrossRef]
- Chaillou, A.-C.; Giersch, A.; Hoonakker, M.; Capa, R.L.; Bonnefond, A. Differentiating Motivational from Affective Influence of Performance-contingent Reward on Cognitive Control: The Wanting Component Enhances Both Proactive and Reactive Control. Biol. Psychol. 2017, 125, 146–153. [Google Scholar] [CrossRef]
- Morales, J.; Yudes, C.; Gómez-Ariza, C.J.; Bajo, M.T. Bilingualism modulates dual mechanisms of cognitive control: Evidence from ERPs. Neuropsychologia 2015, 66, 157–169. [Google Scholar] [CrossRef]
- Barceló, F.; Periáñez, J.A.; Knight, R.T. Think differently: A brain orienting response to task novelty. NeuroReport 2002, 13, 1887–1892. [Google Scholar] [CrossRef]
- Barcelo, F.; Escera, C.; Corral, M.J.; Periáñez, J.A. Task Switching and Novelty Processing Activate a Common Neural Network for Cognitive Control. J. Cogn. Neurosci. 2006, 18, 1734–1748. [Google Scholar] [CrossRef]
- Hampton, A.N.; Bossaerts, P.; O’Doherty, J.P. Neural correlates of mentalizing-related computations during strategic interactions in humans. Proc. Natl. Acad. Sci. USA 2008, 105, 6741–6746. [Google Scholar] [CrossRef]
- Donchin, E. Surprise!? Surprise? Psychophysiology 1981, 18, 493–513. [Google Scholar] [CrossRef]
- Daw, N.D.; Gershman, S.J.; Seymour, B.; Dayan, P.; Dolan, R.J. Model-Based Influences on Humans’ Choices and Striatal Prediction Errors. Neuron 2011, 69, 1204–1215. [Google Scholar] [CrossRef]
- Collins, A.G.E.; Cockburn, J. Beyond dichotomies in reinforcement learning. Nat. Rev. Neurosci. 2020, 21, 576–586. [Google Scholar] [CrossRef]
- Cohen, M.X.; Elger, C.E.; Ranganath, C. Reward expectation modulates feedback-related negativity and EEG spectra. NeuroImage 2007, 35, 968–978. [Google Scholar] [CrossRef] [PubMed]
- Dyson, B.J.; Musgrave, C.; Rowe, C.; Sandhur, R. Behavioural and neural interactions between objective and subjective performance in a Matching Pennies game. Int. J. Psychophysiol. 2020, 147, 128–136. [Google Scholar] [CrossRef]
- Hajcak, G.; Holroyd, C.B.; Moser, J.S.; Simons, R.F. Brain potentials associated with expected and unexpected good and bad outcomes. Psychophysiology 2005, 42, 161–170. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Nieuwenhuis, S.; Yeung, N.; Cohen, J.D. Errors in reward prediction are reflected in the event-related brain potential. NeuroReport 2003, 14, 2481–2484. [Google Scholar] [CrossRef]
- Eppinger, B.; Kray, J.; Mock, B.; Mecklinger, A. Better or worse than expected? Aging, learning, and the ERN. Neuropsychologia 2008, 46, 521–539. [Google Scholar] [CrossRef]
- Hajcak, G.; Moser, J.S.; Holroyd, C.B.; Simons, R.F. It’s worse than you thought: The feedback negativity and violations of reward prediction in gambling tasks. Psychophysiology 2007, 44, 905–912. [Google Scholar] [CrossRef]
- Hewig, J.; Trippe, R.; Hecht, H.; Coles, M.G.H.; Holroyd, C.B.; Miltner, W.H.R. Decision-Making in Blackjack: An Electro-physiological Analysis. Cereb. Cortex 2006, 17, 865–877. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Krigolson, O.E.; Baker, R.; Lee, S.; Gibson, J. When is an error not a prediction error? An electrophysiological investigation. Cogn. Affect. Behav. Neurosci. 2009, 9, 59–70. [Google Scholar] [CrossRef] [PubMed]
- KreuSSel, L.; Hewig, J.; Kretschmer, N.; Hecht, H.; Coles, M.G.H.; Miltner, W.H.R. The influence of the magnitude, probability, and valence of potential wins and losses on the amplitude of the feedback negativity. Psychophysiology 2012, 49, 207–219. [Google Scholar] [CrossRef]
- Masaki, H.; Takeuchi, S.; Gehring, W.J.; Takasawa, N.; Yamazaki, K. Affective-motivational influences on feedback-related ERPs in a gambling task. Brain Res. 2006, 1105, 110–121. [Google Scholar] [CrossRef]
- Santesso, D.L.; Dzyundzyak, A.; Segalowitz, S.J. Age, sex and individual differences in punishment sensitivity: Factors influencing the feedback-related negativity. Psychophysiology 2011, 48, 1481–1489. [Google Scholar] [CrossRef]
- Fuentes-García, J.P.; Villafaina, S.; Collado-Mateo, D.; Cano-Plasencia, R.; Gusi, N. Chess Players Increase the Theta Power Spectrum When the Difficulty of the Opponent Increases: An EEG Study. Int. J. Environ. Res. Public Health 2019, 17, 46. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Analysis | Condition | Voltage (µV) | 95% CI |
|---|---|---|---|
| Outcome Type (Reward Positivity) | Tie | 7.92 | [5.48, 10.36] |
| Lose | 7.55 | [5.58, 9.52] | |
| Win | 9.24 | [6.62, 11.85] | |
| Outcome Expectancy (Reward Positivity) | Low | 0.85 | [−0.61, 2.34] |
| Medium | 1.73 | [0.44, 3.02] | |
| High | 2.07 | [−0.31, 4.45] | |
| Opponent Face (P3a) | Hard | −0.06 | [−2.39, 2.26] |
| Average | 1.10 | [−0.65, 2.84] | |
| Easy | 1.94 | [0.16, 3.72] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Redden, R.S.; Gagliardi, G.A.; Williams, C.C.; Hassall, C.D.; Krigolson, O.E. Champ versus Chump: Viewing an Opponent’s Face Engages Attention but Not Reward Systems. Games 2021, 12, 62. https://doi.org/10.3390/g12030062
Redden RS, Gagliardi GA, Williams CC, Hassall CD, Krigolson OE. Champ versus Chump: Viewing an Opponent’s Face Engages Attention but Not Reward Systems. Games. 2021; 12(3):62. https://doi.org/10.3390/g12030062
Chicago/Turabian StyleRedden, Ralph S., Greg A. Gagliardi, Chad C. Williams, Cameron D. Hassall, and Olave E. Krigolson. 2021. "Champ versus Chump: Viewing an Opponent’s Face Engages Attention but Not Reward Systems" Games 12, no. 3: 62. https://doi.org/10.3390/g12030062
APA StyleRedden, R. S., Gagliardi, G. A., Williams, C. C., Hassall, C. D., & Krigolson, O. E. (2021). Champ versus Chump: Viewing an Opponent’s Face Engages Attention but Not Reward Systems. Games, 12(3), 62. https://doi.org/10.3390/g12030062