Developing a POS Tagged Corpus of Urdu Tweets


Abstract
:1. Introduction
2. Related Work
3. Urdu Tweet Part-of-Speech Tagset
3.1. ADJ: Adjective
3.2. ADP: Adposition
3.3. ADV: Adverb
3.4. AUX: Auxiliary Verb
3.5. CONJ: Coordinating Conjunction
3.6. DET: Determiner
3.7. INTJ: Interjection
3.8. NOUN: Noun
3.9. NUM: Numeral
3.10. PART: Particle
3.11. PRON: Pronoun
3.12. PROPN: Proper Noun
3.13. PUNCT: Punctuation
3.14. SCONJ: Subordinating Conjunction
3.15. SYM: Symbol
3.16. VERB: Verb
3.17. RET: Retweet
3.18. ICO: Icon
3.19. LINK: Link
3.20. REP: Reply
3.21. HASH: Hash
3.22. X: Others
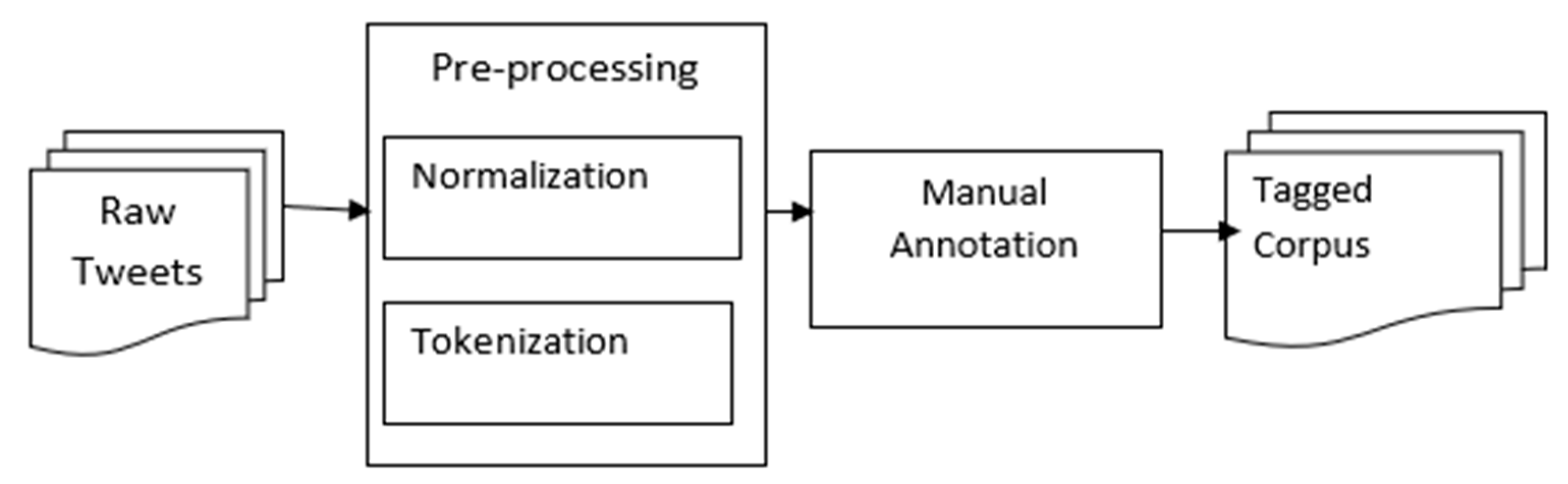
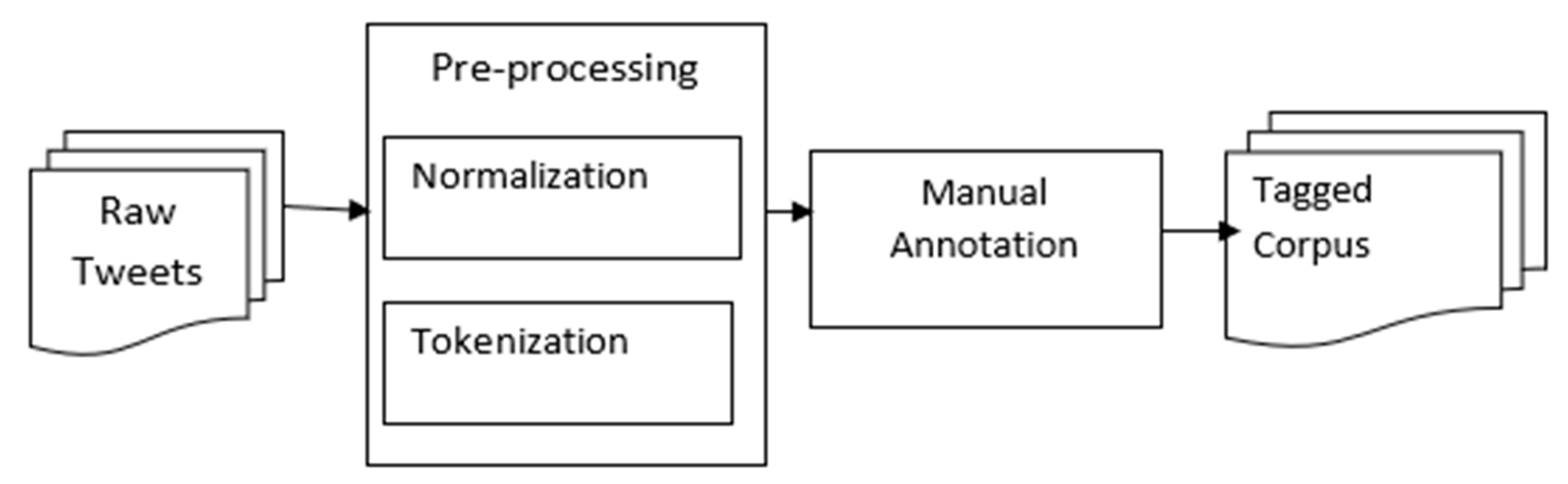
4. Urdu Tweet Corpus
4.1. Dataset for Corpus Creation
4.2. Pre-Processing
4.3. Manual Annotation
5. Bootstrapping
- Divide the manually tagged gold standard corpus of 500 sentences into training (300 sentences), development (100 sentences) and test set (100 sentences).
- On the training set, train the initial Stanford tagger model and evaluate its accuracy against the development set.
- Use the baseline model of step 2 to parse 100 sentences and correct the output manually.
- Train the new tagger model by adding 100 automatically tagged and manually rectified sentences to the training set.
- Use the new tagger model to tag an additional 100 sentences and check model accuracy against the development set.
- Repeat steps 4 and 5 for five iterations.
- At the end of fifth iteration, check final model’s accuracy against the test set.
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Urdu Noisy Text Part-of-Speech Tagset (UNTPOS) | ||
|---|---|---|
| S.No | Tag Name | Example |
| 1 | ADJ | اچھا، بھاری، عمر رسیدہ |
| 2 | ADP | از، تا |
| 3 | ADPT | پر، سے، کو |
| 4 | ADV | بہت، فی الحال |
| 5 | NEG | نہ، نہیں |
| 6 | AUX | ہیں تھا، گی، |
| 7 | CONJ | اور، نیز، تاہم |
| 8 | DET | یہ، کئی، چند |
| 9 | INTJ | واہ، اوہ، ارے |
| 10 | INTJE | 😢 ، 🤔 ، 😒 |
| 11 | NOUN | آدمی، کمپیوٹر، گھر |
| 12 | NUM | ہزار، 7 جون، بارہ |
| 13 | NUMQ | کچھ، کم، |
| 14 | NUMO | دوسرا، یکم |
| 15 | NUMF | آدھا، چوتھائی |
| 16 | NUMY | دگنا، تہرا |
| 17 | PART | والا، والے، ہی، بھی |
| 18 | PRON | میں، وہ |
| 19 | PRONP | تیرا، میرا، تمہارے |
| 20 | PRONR | خود، آپ |
| 21 | PROND | وہی، وہ، کس |
| 22 | PRONRD | جس، جیسا، جو |
| 23 | PROPN | ، پاکستان، فردوس جمال @mshaanshahid |
| 24 | PUNCT | ۔ ، ؛ ‘ “ |
| 25 | SCONJ | کہ، اگر، کیونکہ |
| 26 | SYM | $ ٪ & |
| 27 | VERB | رکھ، کہا، یاد |
| 28 | RET | RT@faheemabbasii: |
| 29 | ICO | 🏃 🍵 🐅 |
| 30 | LINK | https://youtu.be/oqW6IWVAYSg |
| 31 | REP | RP @SulemanZartasha: |
| 32 | HASH | #StopKillingsOnLOC #خاموشی، |
| 33 | X | ﷺ, DP, اکثراوقات |
References
- Nawaz, M.S.; Bilal, M.; Lali, M.I.; Ul Mustafa, R.; Aslam, W.; Jajja, S. Effectiveness of social media data in healthcare communication. J. Med Imaging Health Inform. 2017, 7, 1365–1371. [Google Scholar]
- Eisenstein, J. What to do about bad language on the internet. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 359–369. [Google Scholar]
- Lynn, T.; Scannell, K.; Maguire, E. Minority language twitter: Part-of-speech tagging and analysis of Irish tweets. In Proceedings of the ACL 2015 Workshop on Noisy User-generated Text, Bejing, China, 31 July 2015; pp. 1–8. [Google Scholar]
- AlKhwiter, W.; Al-Twairesh, N. Part-of-speech Tagging for Arabic Tweets using CRF and BiLSTM. Comput. Speech Lang. 2020, 65, 101138. [Google Scholar]
- Foster, J.; Cetinoglu, O.; Wagner, J.; Le Roux, J.; Hogan, S.; Nivre, J.; Hogan, D.; Van Genabith, J. # hardtoparse: POS Tagging and Parsing the Twitterverse. Available online: https://hal.archives-ouvertes.fr/hal-00702445/file/aaai_mt_2011.pdf (accessed on 5 November 2020).
- Petrov, S.; McDonald, R. Overview of the 2012 shared task on parsing the web. Available online: https://www.petrovi.de/data/sancl12.pdf (accessed on 5 November 2020).
- Owoputi, O.; O’Connor, B.; Dyer, C.; Gimpel, K.; Schneider, N.; Smith, N.A. Improved part-of-speech tagging for online conversational text with word clusters. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 380–390. [Google Scholar]
- Gimpel, K.; Schneider, N.; O’Connor, B.; Das, D.; Mills, D.; Eisenstein, J.; Heilman, M.; Yogatama, D.; Flanigan, J.; Smith, N.A. Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers-Volume 2, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Florence, Italy, 2011; pp. 1524–1534. [Google Scholar]
- Seddah, D.; Sagot, B.; Candito, M.; Mouilleron, V.; Combet, V. The French Social Media Bank: A Treebank of Noisy User Generated Content. Available online: https://www.aclweb.org/anthology/C12-1149.pdf (accessed on 5 November 2020).
- Kong, L.; Schneider, N.; Swayamdipta, S.; Bhatia, A.; Dyer, C.; Smith, N.A. A dependency parser for tweets. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1001–1012. [Google Scholar]
- Albogamy, F.; Ramsay, A. Fast and robust POS tagger for Arabic tweets using agreement-based bootstrapping. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1500–1506. [Google Scholar]
- Jamatia, A.; Das, A. Part-of-speech tagging system for indian social media text on twitter. In Proceedings of the Social-India 2014, First Workshop on Language Technologies for Indian Social Media Text, at the Eleventh International Conference on Natural Language Processing (ICON-2014), Goa, India, 21 December 2014; pp. 21–28. [Google Scholar]
- Rehbein, I. Fine-grained pos tagging of german tweets. In Language Processing and Knowledge in the Web; Springer: Berlin/Heidelberg, Germany, 2013; pp. 162–175. [Google Scholar]
- Raza, A.A.; Habib, A.; Ashraf, J.; Javed, M. A review on Urdu language parsing. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 93–97. [Google Scholar]
- Adeeba, F.; Hussain, S. Experiences in building urdu wordnet. In Proceedings of the 9th Workshop on Asian Language Resources 2011, Chiang Mai, Thailand, 12–13 November 2011; pp. 31–35. [Google Scholar]
- Ali, M.; Khalid, S.; Aslam, M.H. Pattern based comprehensive urdu stemmer and short text classification. IEEE Access 2017, 6, 7374–7389. [Google Scholar]
- Ali, M.; Khalid, S.; Saleemi, M. Comprehensive stemmer for morphologically rich urdu language. Int. Arab J. Inf. Technol. 2019, 16, 138–147. [Google Scholar]
- Anwar, W.; Wang, X.; Li, L.; Wang, X.-L. A statistical based part of speech tagger for Urdu language. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; pp. 3418–3424. [Google Scholar]
- Ehsan, T.; Butt, M. Dependency Parsing for Urdu: Resources, Conversions and Learning. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5202–5207. [Google Scholar]
- Ehsan, T.; Hussain, S. Development and evaluation of an Urdu treebank (CLE-UTB) and a statistical parser. Lang. Resour. Eval. 2020, 1–40. [Google Scholar] [CrossRef]
- Avontuur, T.; Balemans, I.; Elshof, L.; Van Noord, N.; Van Zaanen, M. Developing a part-of-speech tagger for Dutch tweets. Comput. Linguist. Neth. J. 2012, 2, 34–51. [Google Scholar]
- Toutanova, K.; Klein, D.; Manning, C.D.; Singer, Y. Feature-rich part-of-speech tagging with a cyclic dependency network. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Edmonton, AB, Canada, 27 May–1 June 2003; Volume 1, pp. 173–180. [Google Scholar]
- Suryawati, E.; Munandar, D.; Riswantini, D.; Abka, A.F.; Arisal, A. POS-Tagging for informal language (study in Indonesian tweets). In Proceedings of the International Conference on Data and Information Science, Nantes, France, 29–31 May 2018. [Google Scholar]
- Abka, A.F. Evaluating the use of word embeddings for part-of-speech tagging in Bahasa Indonesia. In Proceedings of the 2016 International Conference on Computer, Control, Informatics and Its Applications (IC3INA), Jakarta, Indonesia, 3–5 October 2016; pp. 209–214. [Google Scholar]
- Hardie, A. Developing a Tagset for Automated Part-of-Speech Tagging in Urdu. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.218.513&rep=rep1&type=pdf (accessed on 5 November 2020).
- Sajjad, H.; Schmid, H. Tagging Urdu text with parts of speech: A tagger comparison. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 692–700. [Google Scholar]
- Ahmed, T.; Urooj, S.; Hussain, S.; Mustafa, A.; Parveen, R.; Adeeba, F.; Hautli, A.; Butt, M. The CLE urdu POS tagset. In Proceedings of the LREC 2014, Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 2920–2925. [Google Scholar]
- Urdu Shallow Parser. Available online: http://ltrc.iiit.ac.in/analyzer/urdu/index.cgi (accessed on 5 November 2020).
- Center for Language Engineering. Available online: http://www.cle.org.pk/software/langproc/POS_tagger.htm (accessed on 5 November 2020).
- Petrov, S.; Das, D.; McDonald, R. A universal part-of-speech tagset. arXiv 2011, arXiv:1104.2086. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar]
- Urduhack: A Python NlP Library for Urdu Language. Available online: https://pypi.org/project/urduhack/ (accessed on 5 November 2020).
- Albogamy, F.; Ramsay, A. POS tagging for Arabic tweets. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Varna, Bulgaria, 2–4 September 2019; pp. 1–8. [Google Scholar]
- Urdu-Noisy-Text. Available online: https://github.com/amberbaig/Urdu-Noisy-Text (accessed on 5 November 2020).


| Tagger | Evaluation Metrics | News Text | Urdu Tweets |
|---|---|---|---|
| IIIT Urdu Shallow Tagger | Precision | 95.4% | 66.6% |
| Recall | 96.7% | 64.7% | |
| F-Measure | 96.1% | 65.6% | |
| CLE Statistical POS Tagger | Precision | 93.4% | 60.6% |
| Recall | 94.6% | 62.2% | |
| F-Measure | 94% | 61.5% |
| Metric | Folds | Average % | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| Precision | 82 | 80.2 | 83.6 | 82.7 | 84.6 | 82.6 |
| Recall | 80.8 | 82.7 | 86.1 | 88.8 | 78.5 | 83.3 |
| F-Measure | 81.4 | 81.4 | 84.8 | 85.7 | 81.4 | 82.9 |
| Metric | Initial Evaluation % | Iterations and Results | Final Evaluation % | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| Precision | 84.3 | 86.6 | 87.9 | 89 | 90.3 | 92.5 | 93.8 |
| Recall | 80.4 | 88.6 | 89.8 | 90 | 92.3 | 93.5 | 92.9 |
| F-Measure | 82.3 | 87.6 | 88.8 | 89.5 | 91.3 | 93 | 93.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baig, A.; Rahman, M.U.; Kazi, H.; Baloch, A. Developing a POS Tagged Corpus of Urdu Tweets. Computers 2020, 9, 90. https://doi.org/10.3390/computers9040090
Baig A, Rahman MU, Kazi H, Baloch A. Developing a POS Tagged Corpus of Urdu Tweets. Computers. 2020; 9(4):90. https://doi.org/10.3390/computers9040090
Chicago/Turabian StyleBaig, Amber, Mutee U Rahman, Hameedullah Kazi, and Ahsanullah Baloch. 2020. "Developing a POS Tagged Corpus of Urdu Tweets" Computers 9, no. 4: 90. https://doi.org/10.3390/computers9040090
APA StyleBaig, A., Rahman, M. U., Kazi, H., & Baloch, A. (2020). Developing a POS Tagged Corpus of Urdu Tweets. Computers, 9(4), 90. https://doi.org/10.3390/computers9040090