Utilizing Transfer Learning and Homomorphic Encryption in a Privacy Preserving and Secure Biometric Recognition System



Abstract
1. Introduction
- Proposing DeepZeroID system, which makes a bridge between deep features, homomorphic encryption, and biometric security. Moreover, the running protocol among all parties within the system that takes an encrypted and masked data for query computations has been demonstrated. In this way, accessing, computing, and storing the data by the agents and parties inside the framework become more secure. This system has the capability of having zero information leakage for two reasons. Firstly biometric data stays encrypted in the system. The encryption prevents the attackers from gaining access to any sensitive data or the contents of the individual queries. Secondly the neural network used as a feature extractor is not trained on biometric data and has no knowledge of the data distribution. This lack of knowledge enables the scalability of the proposed system as well, since new user can be added without the need for changing the feature extractor.
- Development of CNNOptLayer, which is an algorithm that performs an exhaustive search operation among all layers of the convolutional neural network under process. It is capable of finding the optimal layer for feature extraction.
- Inclusion of a single Convolutional Neural network (CNN) as the feature extractor for multiple tasks within the system (namely iris/fingerprint recognition and true/fake detection). The feature extraction is performed based on leveraging the CNNOptLayer algorithm.
- Improving the encryption speed of a CNN-based privacy preserving biometric recognition system by utilization of Paillier Chunkwise.
- Presentation of new attacks and malicious scenarios for deep learning-based biometric recognition system and demonstrating the weaknesses and deficiencies of the system under these attacks.
2. Background
2.1. Transfer Learning
2.2. Homomorphic Encryption
2.3. Leveraged Deep Neural Networks: DenseNet and AlexNet
2.4. True/Fake Detection of Biometric Data
3. Related Work
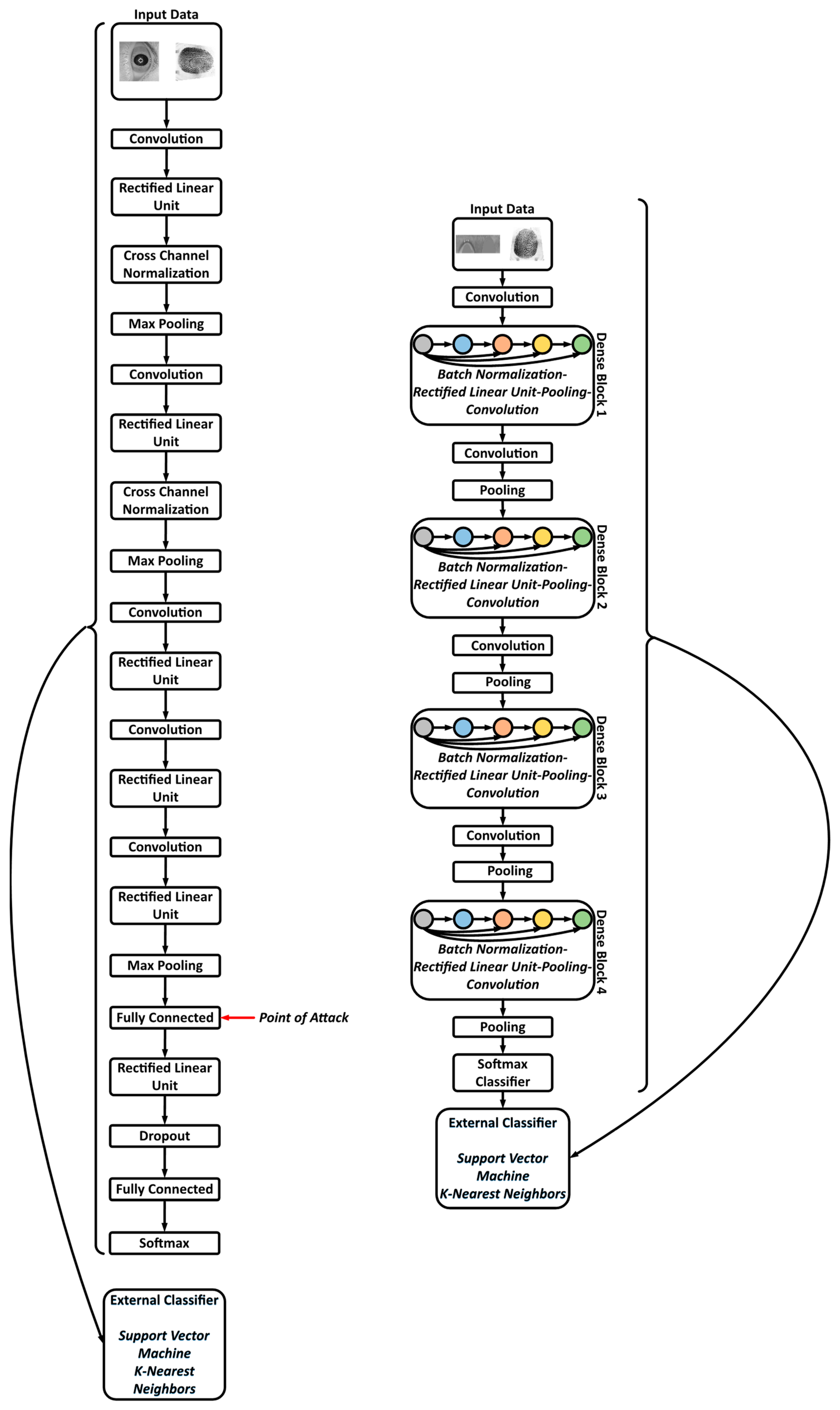
4. Methodology of the Proposed System
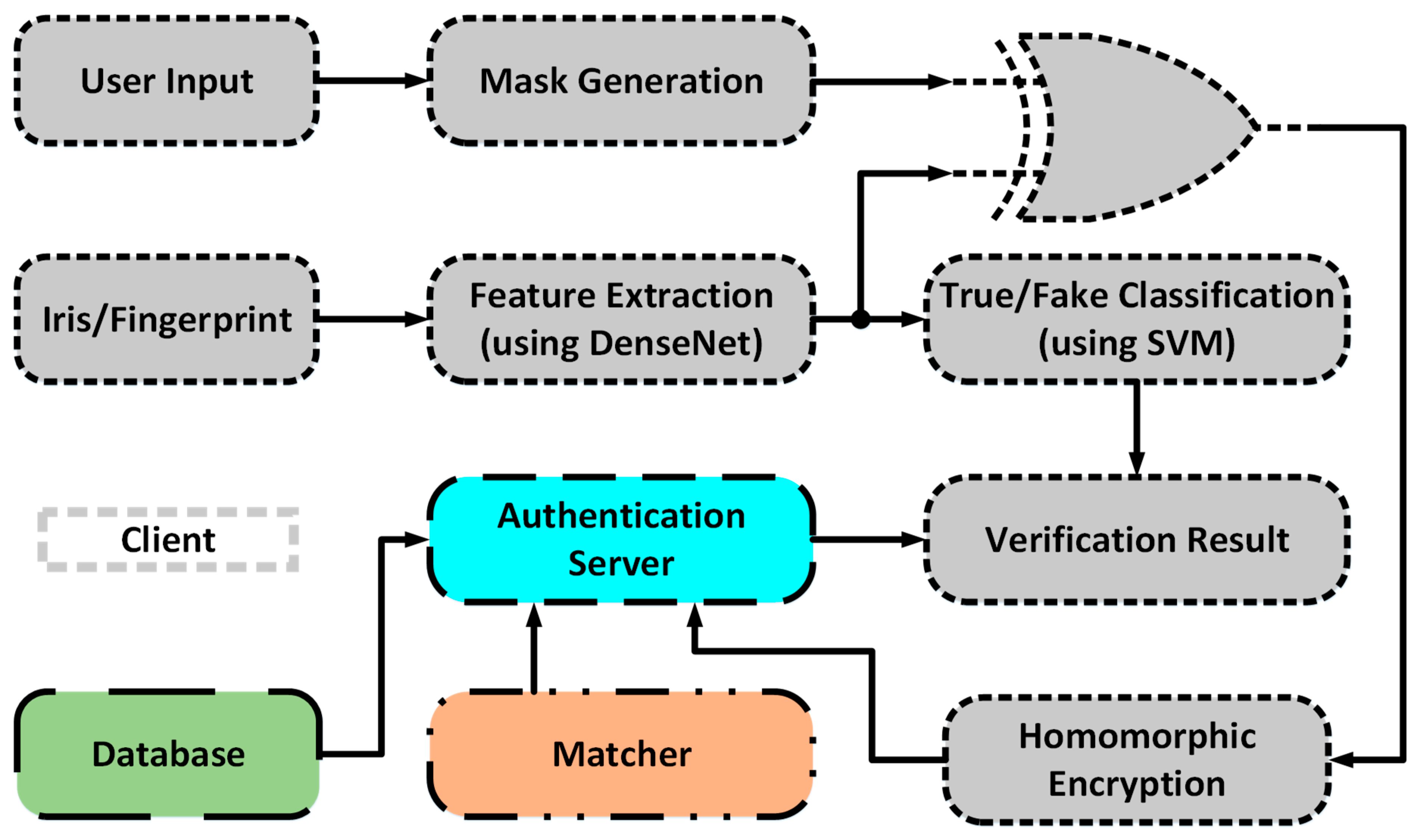
4.1. General Overview of Privacy-Preserving Biometric Recognition System
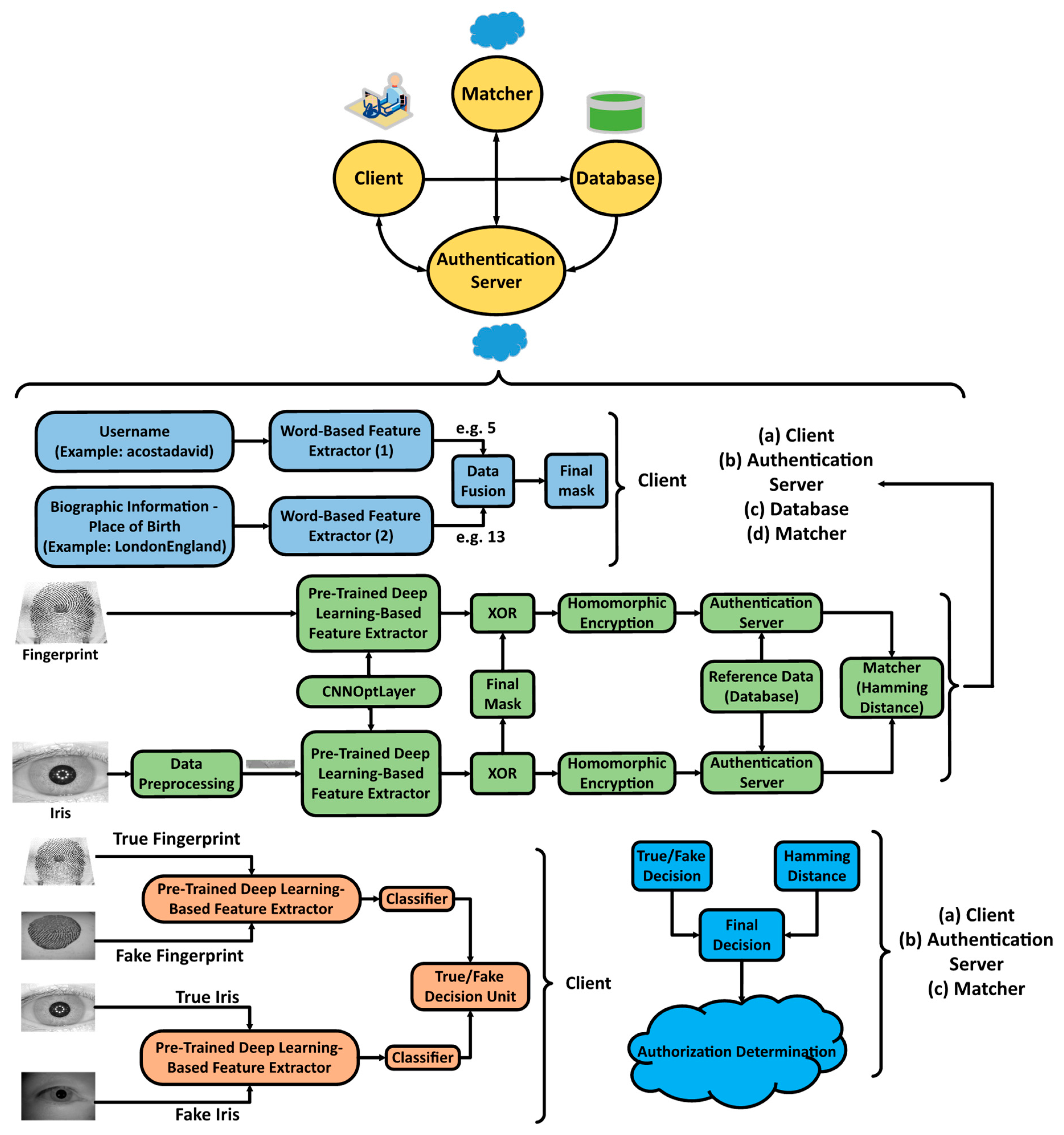
| Algorithm 1: The protocol and overall scheme of deep learning-based privacy preserving bi-modal biometric recognition system. |
| 01: Input Parameters: True and Fake Biometric Data, Username, and Biographic Information 02: Output Parameters: Output: Authorization Determination 03: Client: 04: BiometricData ← DenseNet Features & CNNOptLayer (TrueFingerprint or Preprocessed Iris) 05: BioInfoData1 ← WordBasedFeatureExtractor1 (Username) 06: BiolnfoData2 ← WordBasedFeatureExtractor2 (Biolnfo) 07: FinalMask ← WordDataFusion(BioInfoDatal1, BioInfoData2) 08: Client-AuthenticationServer-Database-Matcher: 09: PlainData ← XOR (BiometricData, Final Mask) 10: Ref / TestEncryptedData ← Homomorphic Encryption Scheme (PlainData) 11: Matcher ← XOR (Ref EncryptedDatal, TestEncryptedData) 12: MatchingDecision ← Hamming Distance Threshold (Matcher) 13: TrueFakeBiometricData ← DenseNet Features (TrueFakeFingerprint/Iris) 14: DetectedTrueFakeData ← SVM (TrueFakeBiometricData) 15: Client-AuthenticationServer-Matcher: 16: AuthorizationDetermination ← FinalDecisionUnit (Matching Decision, Detected TrueFakeData) |
4.2. Flow of Biometric Data at the Client-Side
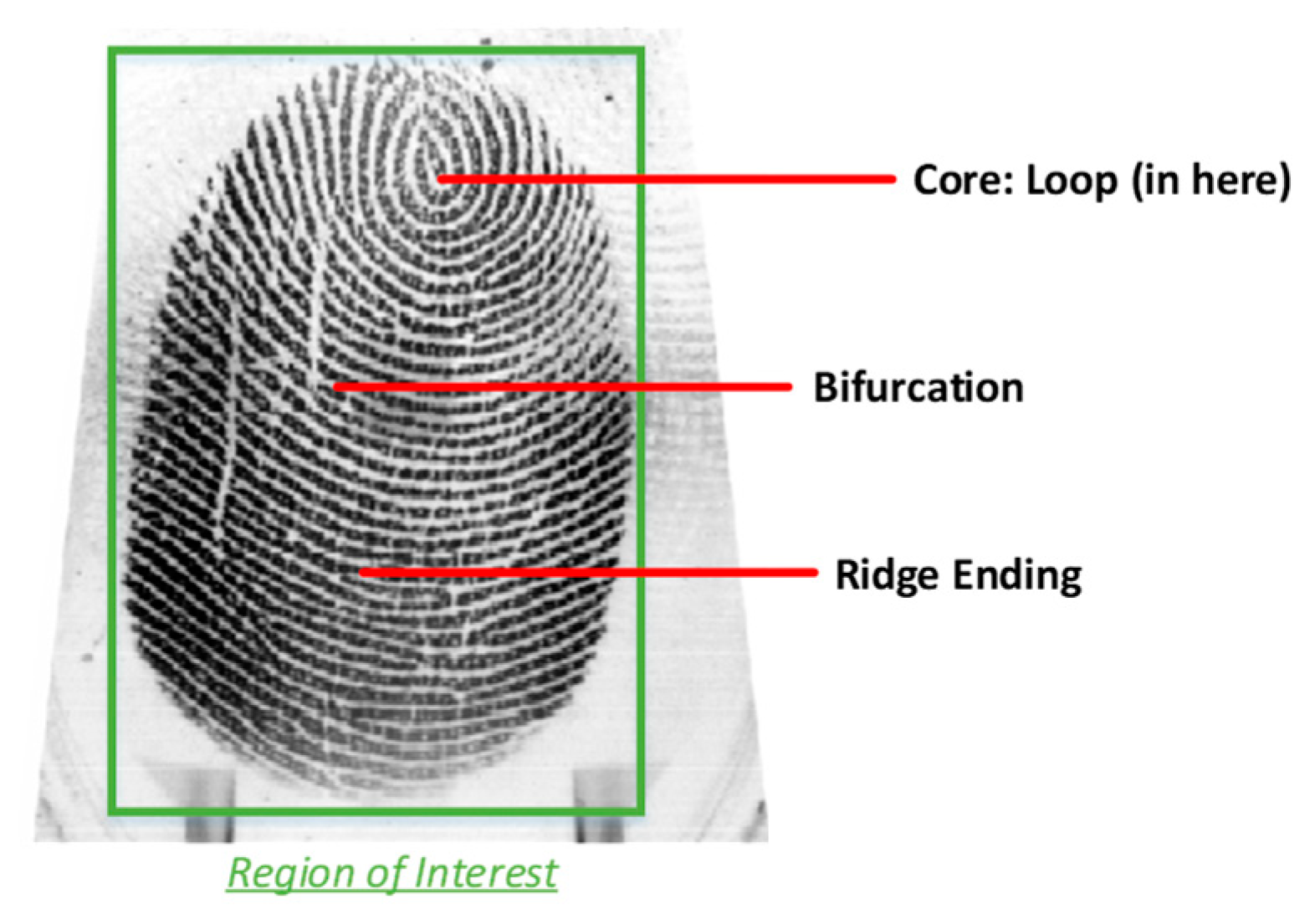
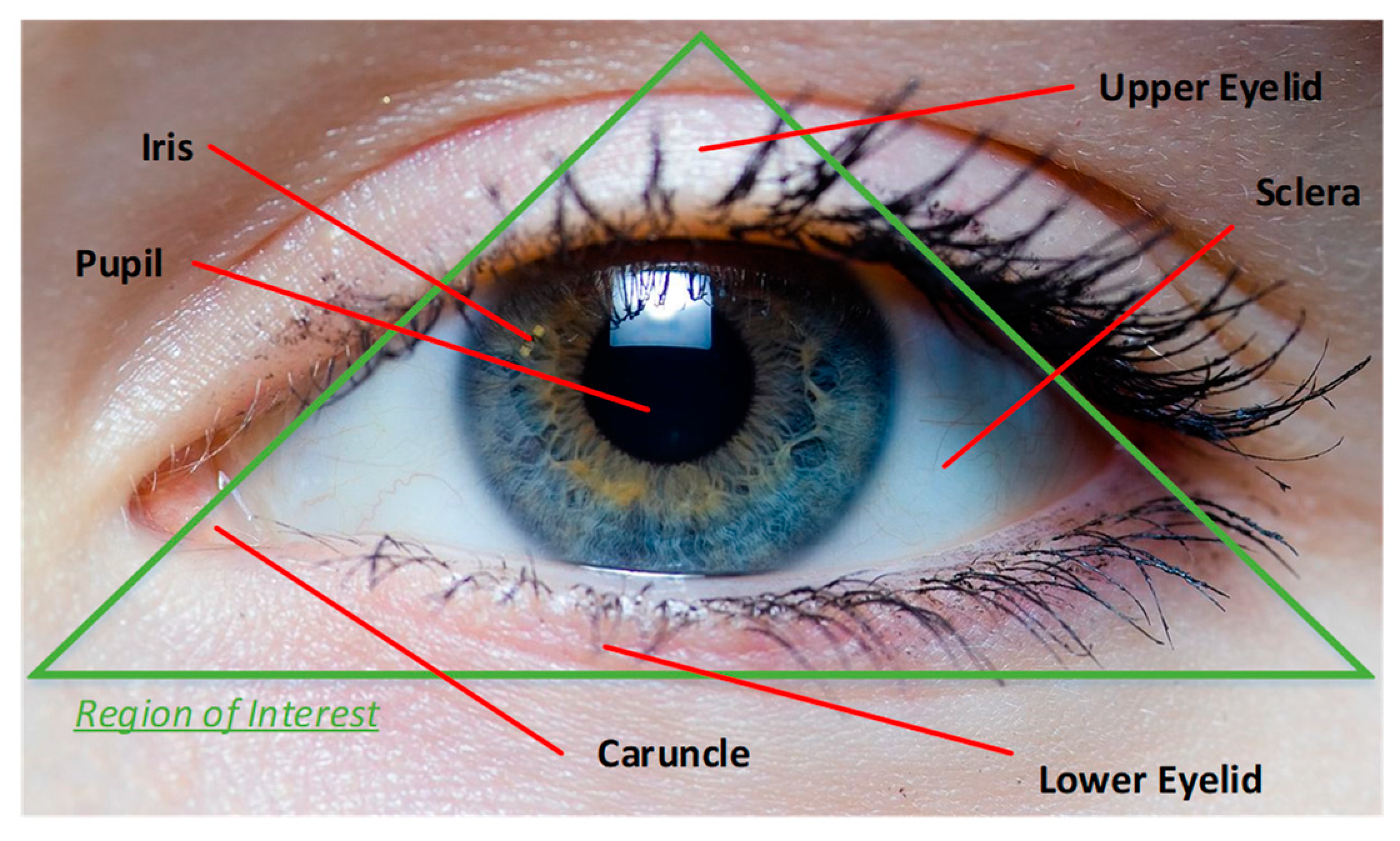
- Data Preprocessing: The area of interest inside the image taken from the eye, i.e., the iris, needs to be extracted. In this work circular Hough transformation is used to localize the iris and extract it. The segmented iris is then normalized. Fingerprint images remain unchanged.
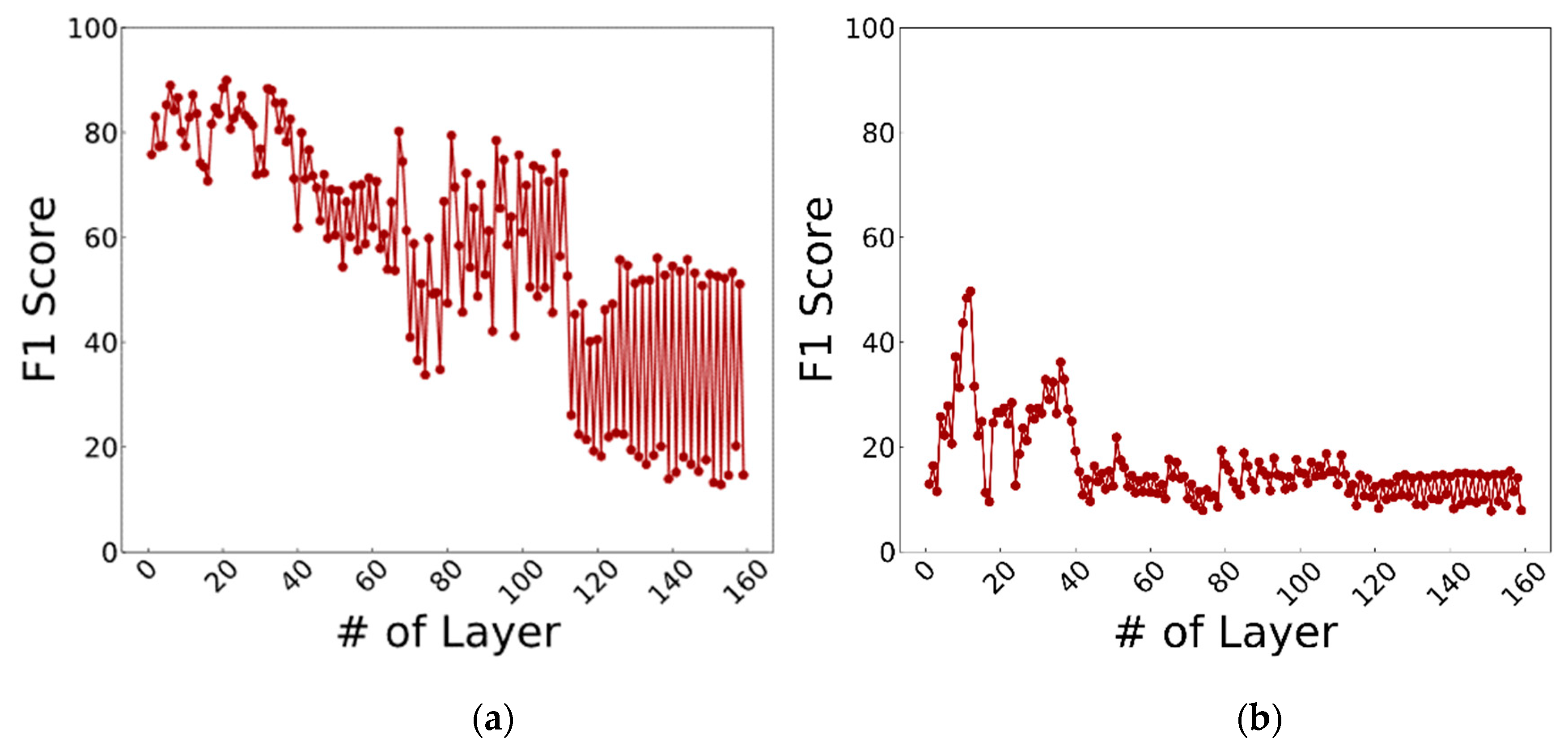
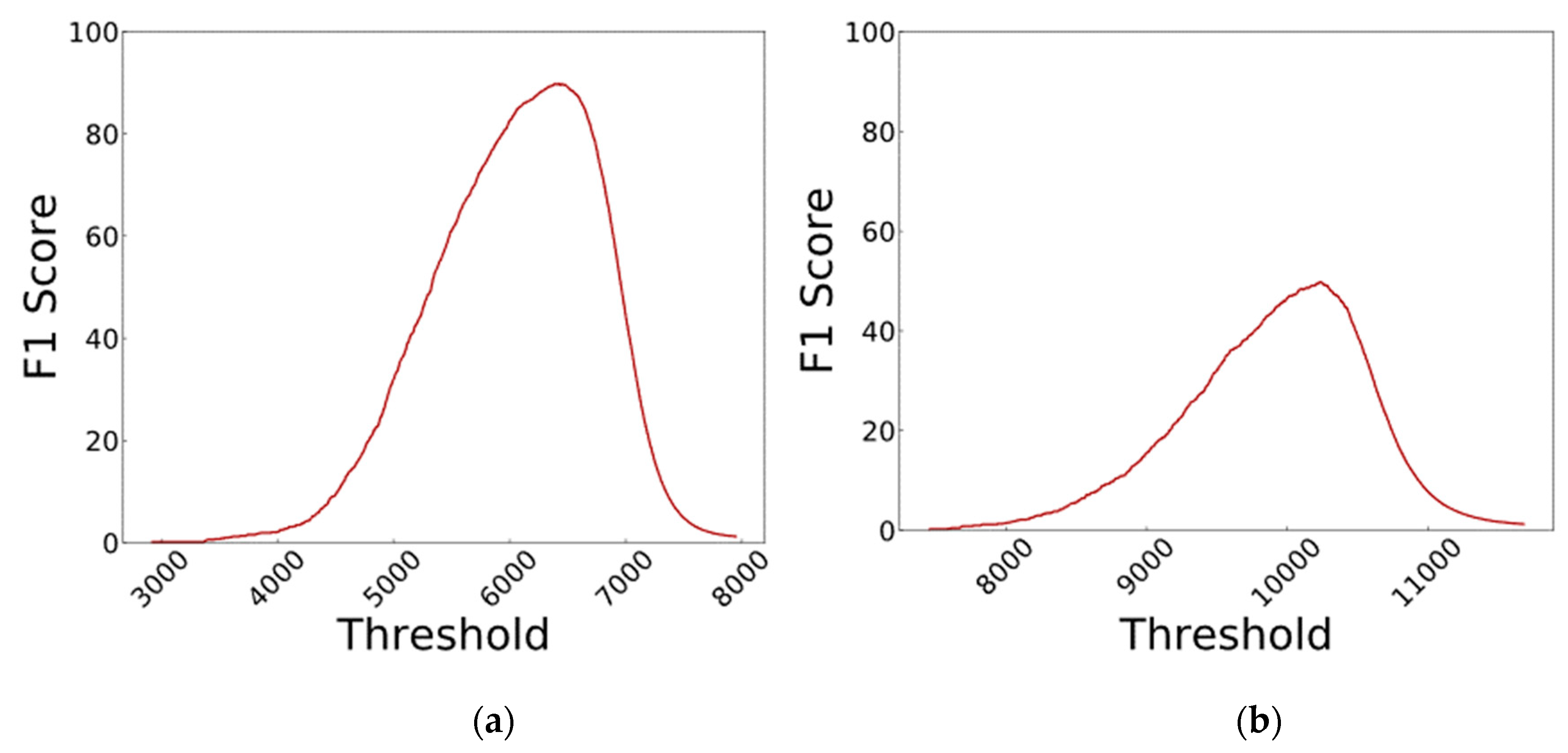
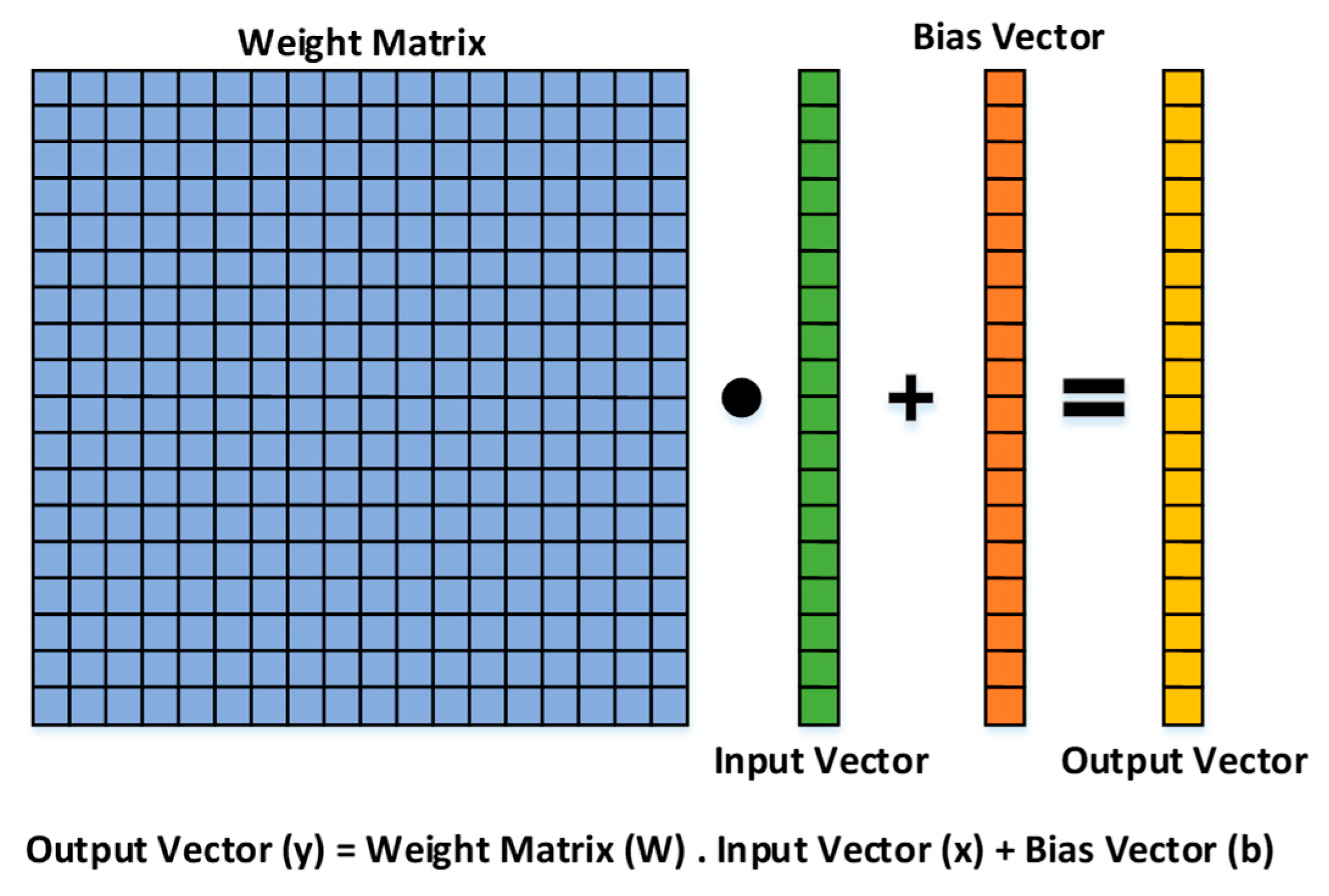
- Feature Extraction: The images are fed to a DenseNet that is pre-trained on millions of images from the ImageNet dataset. This massive amount of images included a thousand various classes such as chairs, zebras, apples, monitors, and etc. The concept of transfer learning aids us to use the patterns learnt from these images for the task of biometric verification. Each layer within this deep network contains many patterns that might be useful in representing the inputted image. The output of these layers, also known as off-the-shelf features [22], is taken as the representation of the input, i.e., the feature vector. However, the task of finding the right layer to extract the features from can be arduous. In [23], layers are chosen randomly in order to extract features. In this work the pre-trained DenseNet is coupled with the CNNOptLayer algorithm to find the most optimal layer for feature extraction for each task. This algorithm performs an exhaustive search on the convolutional layers within the network, and uses their output as features. The acquired features result in a verification output and their performance can be measured using the F1 score. The layer with the highest F1 score is chosen as the optimal layer for that specific task. After extraction, the feature vectors are binarized based on the mean of each feature. This binarization allows us to perform hamming distance and use the encryption scheme.
- Masking the Data: The username and the biographic information (or place of birth) are given to two word based feature extractors. The first extractor finds the index of the first, the middle, and the last element of its word from the dictionary of letters. Then, the ceiling of the index of the first element to the power of the index of the third element is divided by the multiplication of the index of the second element to the power of two on one side and the addition of the index of the first element and the index of the second element on the other side. The output of this function is BioInfoData1. The other feature extractor finds three elements: the length of the birth place word, the frequency of the most repeated character, and the difference between the highest and the lowest indices among the characters in the word. The operation to be performed on these elements is described as the round of the addition of the first element, the second, and the third element divided by three as the base and the ceiling of the first element divided by the third element as the power. The output of this unit is BioInfoData2. These two data are concatenated and repeated until the lengths of the image feature vectors are reached. After getting the final mask, it is XORed with the biometric feature vectors to create the plain data for the encryption. The reason for XORing the mask with the feature vector lies within the fact that feature vectors are binarized and later XORed for comparison. Since the mask generation outputs the same mask for the same individual each time they request for verification, the result of comparing two masked feature vectors of the same individual is equal to that of the comparison of two plain feature vectors. Therefore, masking the binary feature vectors does not change the results of the comparison unit for the same individuals, but highly affects the cases where the vectors come from different individuals.
- Encryption: The two plain vectors data go into a Paillier Chunkwise encryption scheme [24]. This scheme first up-samples the data, and then encrypts chunks of it using Paillier Encryption. This scheme has two advantages; firstly, Paillier encryption is partially homomorphic and supports addition, which enables us to perform the XOR operation on the authentication server. Secondly, the up-sampling allows the matcher to calculate the hamming distance and recognize if the two feature vectors match or not.
- True/Fake Detection: The last operation on the client-side to identify the liveness of the presented biometric data. The CNNOptLayer is used to find the optimal layer for feature extraction for this task and a SVM, which is trained on these feature vectors from true and fake datasets, identifies the liveness of the data.
4.3. Decision Making Process
5. Experimental Approach and Results
5.1. Experimental Setup
5.2. Dataset Selection
5.3. Final Results
5.4. Security Analysis
5.5. Discussion and Future Research
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gentry, C.; Boneh, D. A Fully Homomorphic Encryption Scheme; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Khan, M.A.; Akram, T.; Sharif, M.; Javed, M.Y.; Muhammad, N.; Yasmin, M. An implementation of optimized framework for action classification using multilayers neural network on selected fused features. Pattern Anal. Appl. 2018. Available online: https://doi.org/10.1007/s10044-018-0688-1 (accessed on 30 November 2018). [CrossRef]
- Mahmood, Z.; Muhammad, N.; Bibi, N.; Ali, T. A Review on State-of-the-Art Face Recognition Approaches. Fractals 2017, 25, 1750025. [Google Scholar] [CrossRef]
- Ene, A.; Togan, M.I.; Tom, S.-A. Privacy Preserving Vector Quantization Based Speaker Recognition System. Proc. Rom. Acad. Ser. A 2017, 158, 371–380. [Google Scholar]
- Bommagani, A.S.; Valenti, M.C.; Ross, A. A Framework for Secure Cloud-Empowered Mobile Biometrics. In Proceedings of the 2014 IEEE Military Communications Conference, Baltimore, MD, USA, 6–8 October 2014; pp. 255–261. [Google Scholar]
- Toli, C.-A.; Aly, A.; Preneel, B. Privacy-Preserving Multibiometric Authentication in Cloud with Untrusted Database Providers. undefined 2018. Available online: https://www.semanticscholar.org/paper/Privacy-Preserving-Multibiometric-Authentication-in-Toli-Aly/d37472309ba3a28b66646e92d239ffedb85f2abb (accessed on 30 November 2018).
- Weng, L.; Amsaleg, L.; Morton, A.; Marchand-Maillet, S. A Privacy-Preserving Framework for Large-Scale Content-Based Information Retrieval. IEEE Trans. Inf. Forensics Secur. 2015, 10, 152–167. [Google Scholar] [CrossRef]
- Talreja, V.; Valenti, M.C.; Nasrabadi, N.M. Multibiometric secure system based on deep learning. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 298–302. [Google Scholar]
- Zhou, K.; Ren, J. PassBio: Privacy-Preserving User-Centric Biometric Authentication. IEEE Trans. Inf. Forensics Secur. 2018, 13, 3050–3063. [Google Scholar] [CrossRef]
- Toli, C.-A.; Preneel, B. Privacy-preserving Biometric Authentication Model for e-Finance Applications. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; pp. 353–360. [Google Scholar]
- Toli, C.-A.; Aly, A.; Preneel, B. A Privacy-Preserving Model for Biometric Fusion. In International Conference on Cryptology and Network Security; Springer: Cham, Switzerland, 2016; pp. 743–748. [Google Scholar]
- Abidin, A. On Privacy-Preserving Biometric Authentication. In International Conference on Information Security and Cryptology; Springer: Cham, Switzerland, 2017; pp. 169–186. [Google Scholar]
- Taheri, S.; Yuan, J.-S. A Cross-Layer Biometric Recognition System for Mobile IoT Devices. Electronics 2018, 7, 26. [Google Scholar] [CrossRef]
- Erkin, Z.; Franz, M.; Guajardo, J.; Katzenbeisser, S.; Lagendijk, I.; Toft, T. Privacy-Preserving Face Recognition. In International Symposium on Privacy Enhancing Technologies Symposium; Springer: Berlin/Heidelberg, Germany, 2009; pp. 235–253. [Google Scholar]
- Huang, Y.; Malka, L.; Evans, D.; Katz, J. Efficient Privacy-Preserving Biometric Identification. Available online: http://mightbeevil.com/secure-biometrics/ndss-talk.pdf (accessed on 30 November 2018).
- Osadchy, M.; Pinkas, B.; Jarrous, A.; Moskovich, B. SCiFI—A System for Secure Face Identification. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Berkeley/Oakland, CA, USA, 16–19 May 2010; pp. 239–254. [Google Scholar]
- Yuan, J.; Yu, S. Efficient privacy-preserving biometric identification in cloud computing. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2652–2660. [Google Scholar]
- Wang, Q.; Du, M.; Chen, X.; Chen, Y.; Zhou, P.; Chen, X.; Huang, X. Privacy-Preserving Collaborative Model Learning: The Case of Word Vector Training. IEEE Trans. Knowl. Data Eng. 2018, 30, 2381–2393. [Google Scholar] [CrossRef]
- Niu, X.; Ye, Q.; Zhang, Y.; Ye, D. A Privacy-Preserving Identification Mechanism for Mobile Sensing Systems. IEEE Access 2018, 6, 15457–15467. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, C.; Xu, C.; Liu, X.; Huang, C. An Efficient and Privacy-Preserving Biometric Identification Scheme in Cloud Computing. IEEE Access 2018, 6, 19025–19033. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, L.; Gu, X.; He, J.; Yang, Z. A Secure Face-Verification Scheme Based on Homomorphic Encryption and Deep Neural Networks. IEEE Access 2017, 5, 16532–16538. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features off-the-shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 24–27 June 2014; pp. 806–813. [Google Scholar]
- Nguyen, K.; Fookes, C.; Ross, A.; Sridharan, S. Iris Recognition with off-the-Shelf CNN Features: A Deep Learning Perspective. IEEE Access 2018, 6, 18848–18855. [Google Scholar] [CrossRef]
- Penn, G.M.; Pötzelsberger, G.; Rohde, M.; Uhl, A. Customisation of Paillier homomorphic encryption for efficient binary biometric feature vector matching. In Proceedings of the 2014 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 10–12 September 2014. [Google Scholar]
- Biometrics Ideal Test. Available online: http://biometrics.idealtest.org/dbDetailForUser.do?id=7 (accessed on 4 December 2018).
- Popa, D.; Simion, E. Enhancing security by combining biometrics and cryptography. In Proceedings of the 2017 9th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Targoviste, Romania, 29 June–1 July 2017; pp. 1–7. [Google Scholar]
- Tams, B. Attacks and Countermeasures in Fingerprint Based Biometric Cryptosystems. arXiv, 2013; arXiv:1304.7386. [Google Scholar]
- Roberts, C. Biometric attack vectors and defences. Comput. Secur. 2007, 26, 14–25. [Google Scholar] [CrossRef]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. arXiv, 2018; arXiv:1805.12185. [Google Scholar]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Molloy, I.; Srivastava, B. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering. arXiv, 2018; arXiv:1811.03728. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. Available online: https://people.cs.vt.edu/vbimal/publications/backdoor-sp19.pdf (accessed on 30 November 2018).
- Xiao, H.; Xiao, H.; Eckert, C. Adversarial label flips attack on support vector machines. In Proceedings of the 20th European Conference on Artificial Intelligence, Montpellier, France, 27–31 August 2012; pp. 870–875. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Support Vector Machines Under Adversarial Label Noise. In Proceedings of the Asian Conference on Machine Learning, Taoyuan, Taiwan, 13–15 November 2011; pp. 97–112. [Google Scholar]
- Biggio, B.; Corona, I.; Nelson, B.; Rubinstein, B.I.; Maiorca, D.; Fumera, G.; Giacinto, G.; Roli, F. Security Evaluation of Support Vector Machines in Adversarial Environments. In Support Vector Machines Applications; Springer International Publishing: Cham, Switzerlane, 2014; pp. 105–153. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting Classifiers against Adversarial Attacks Using Generative Models. arXiv, 2018; arXiv:1805.06605. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Masked | Layer | Threshold | TP | TN | FP | FN | F-Score |
|---|---|---|---|---|---|---|---|---|
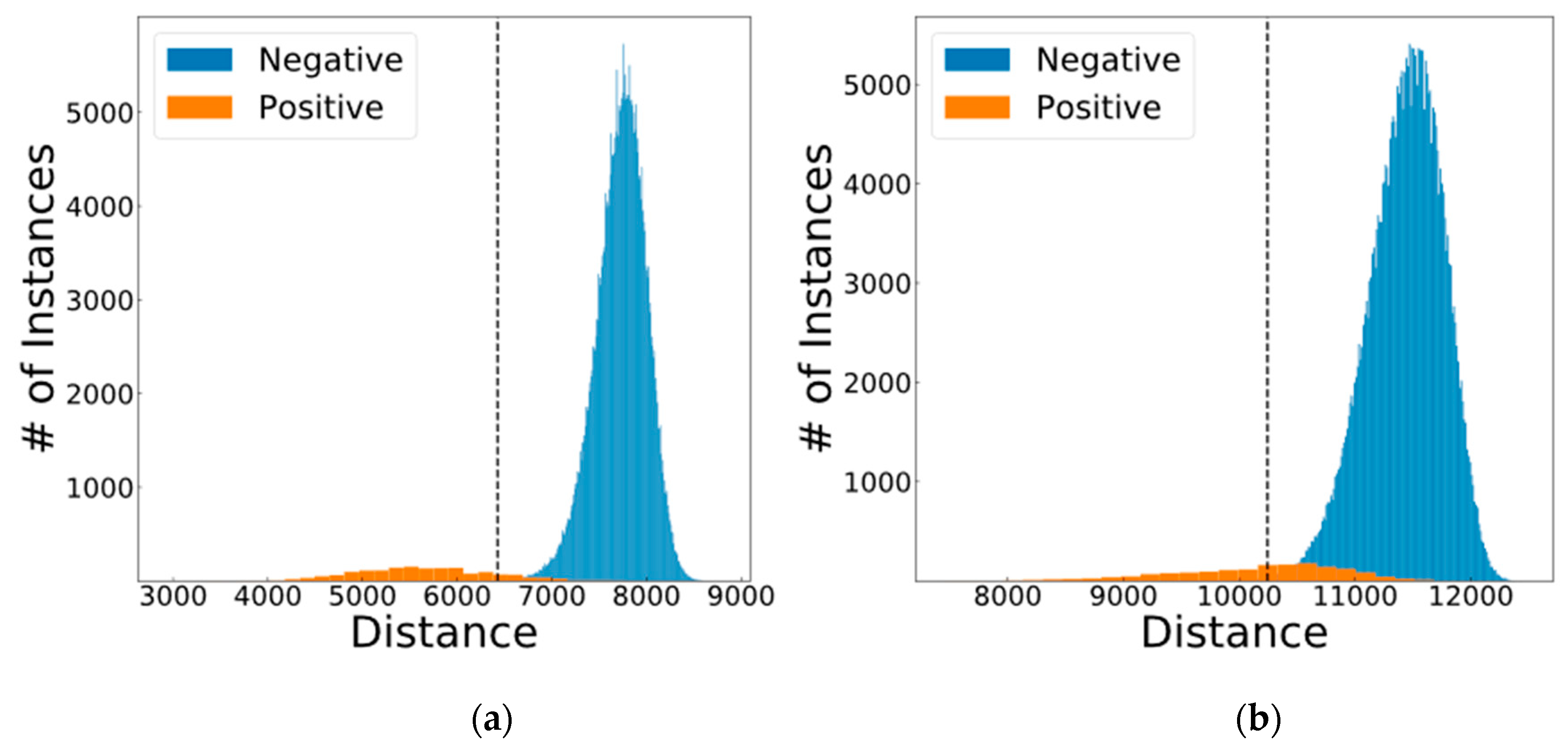
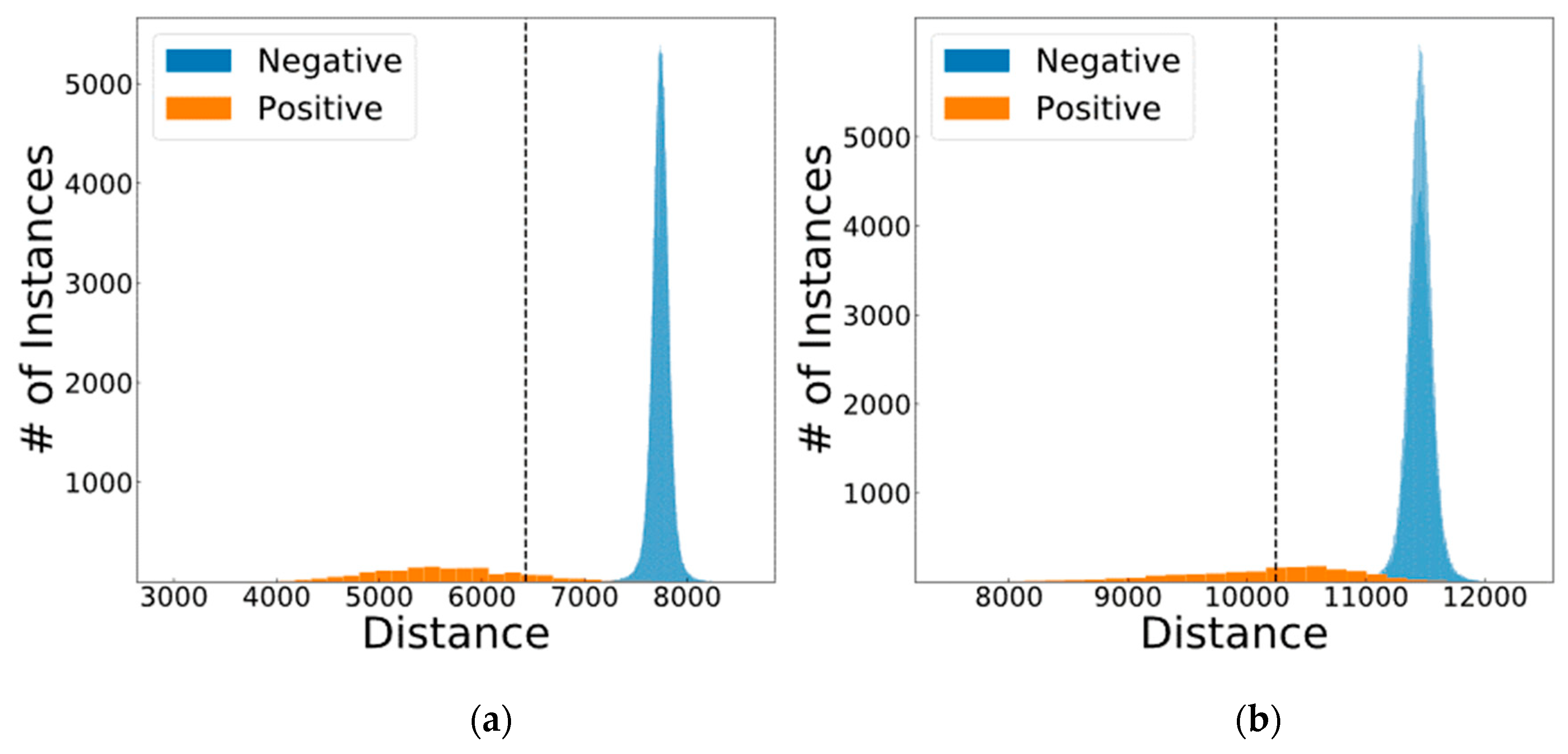
| Fingerprint | No | 12 | 10,243 | 812 | 337,450 | 800 | 838 | 49.79 |
| Fingerprint | Yes | 12 | 10,243 | 812 | 338,246 | 4 | 838 | 65.86 |
| Iris | No | 21 | 6427 | 1414 | 338,165 | 85 | 236 | 89.81 |
| Iris | Yes | 21 | 6427 | 1414 | 338,248 | 2 | 236 | 92.24 |
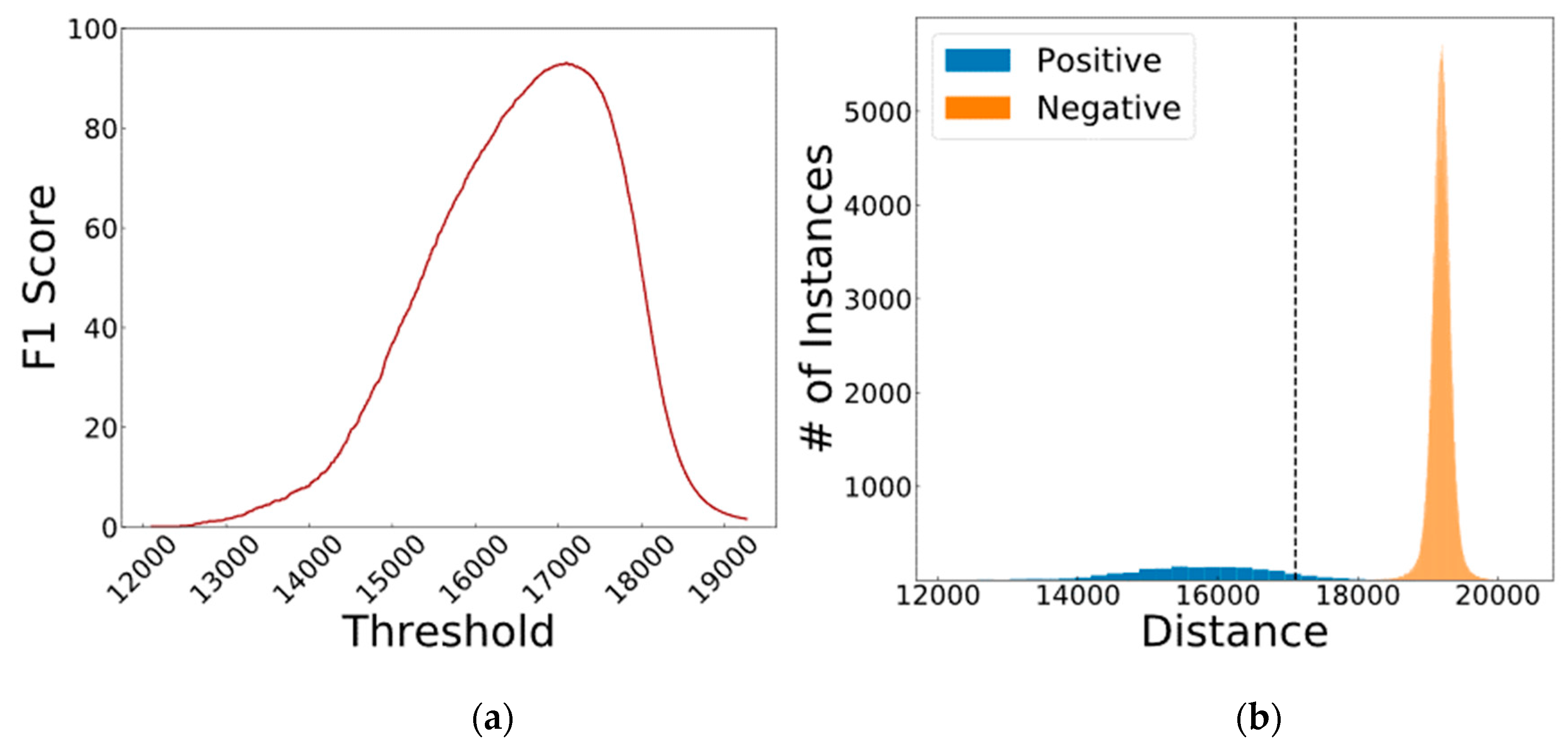
| Combined | No | 12 + 21 | 17,108 | 1507 | 338,168 | 82 | 143 | 93.05 |
| Combined | Yes | 12 + 21 | 17,108 | 1507 | 338,250 | 0 | 143 | 95.47 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salem, M.; Taheri, S.; Yuan, J.-S. Utilizing Transfer Learning and Homomorphic Encryption in a Privacy Preserving and Secure Biometric Recognition System. Computers 2019, 8, 3. https://doi.org/10.3390/computers8010003
Salem M, Taheri S, Yuan J-S. Utilizing Transfer Learning and Homomorphic Encryption in a Privacy Preserving and Secure Biometric Recognition System. Computers. 2019; 8(1):3. https://doi.org/10.3390/computers8010003
Chicago/Turabian StyleSalem, Milad, Shayan Taheri, and Jiann-Shiun Yuan. 2019. "Utilizing Transfer Learning and Homomorphic Encryption in a Privacy Preserving and Secure Biometric Recognition System" Computers 8, no. 1: 3. https://doi.org/10.3390/computers8010003
APA StyleSalem, M., Taheri, S., & Yuan, J.-S. (2019). Utilizing Transfer Learning and Homomorphic Encryption in a Privacy Preserving and Secure Biometric Recognition System. Computers, 8(1), 3. https://doi.org/10.3390/computers8010003