Sentiment Analysis of Lithuanian Texts Using Traditional and Deep Learning Approaches



Abstract
:1. Introduction
2. Methodology
2.1. Formal Definition of the Task
2.2. The Dataset
- No pre-processing. The texts were lowercased, numbers and punctuation were eliminated.
- With emoticons. As proved in [39], the emoticon replacement assures the higher classification accuracy. In our experiments we have used 32 groups of emoticons, where each group was mapped into the appropriate sentiment word (presented in its main vocabulary form). For instance, all the emoticons of this group “:(”, “:-(”, “:-c”, “:-[”, etc. have the same meaning liūdnas (sad) and therefore can be replaced with liūdnas in the text. When using this pre-processing technique, all of the words were lowercased; the detected emoticons were replaced with the appropriate sentiment words; numbers and punctuation were eliminated.
- No stop words. Intuitively, such words as acronyms, conjunctions or pronouns appear too often in all types of texts and are too short to carry important sentiment information. However, Spences and Uchyigit in [40] claim that interjections are strong indicators of subjectivity. Due to it, we have used a list of 555 stop words that does not contain interjections. During this text pre-processing step all words were lowercased and stop words, numbers, and punctuation were eliminated.
- Diacritics elimination. The Lithuanian language uses the Latin alphabet supplemented with these diacritics: ą, č, ę, ė, š, ų, ū, ž. However, diacritics in the non-normative Lithuanian texts are sometimes omitted, therefore the same word in the non-normative texts can be found in both cases, i.e., written with or without diacritics. It causes ambiguity problems and increases the data sparseness, which, in turn, negatively affects the accuracy. One of the solutions for decreasing the data sparseness is to distort the data by replacing diacritized letters with their American Standard Code for Information Interchange (ASCII ) equivalent symbols. However, such distortion may cause even more ambiguity problems, which in turn may degrade the performance. Hence, the diacritics elimination is a questionable pre-processing technique, where the effectiveness has to be tested experimentally. Using this pre-processing technique, the words were undiacritized, lowercased and numbers and punctuation were eliminated.
- Diacritics restoration is another direction for decreasing the data sparseness and increasing the text quality. For this purpose, we were using the language modeling method (described in [41]), which was proved to be the best for the Lithuanian diacritization problems. This language modeling method used the bi-gram back-off strategy (having ~58.1 million bigrams and ~2.3 million unigrams) to restore diacritics in our non-normative texts. After diacritization, the words were lowercased and numbers and punctuation were eliminated.
2.3. Traditional Machine Learning Techniques
- Support Vector Machine (SVM) [42] is a discriminative instance-based method, which for the very long time has been the most popular text classification technique. SVM can efficiently cope with the high dimensional feature spaces (e.g., without the feature selection, SVM has to handle ~26 K different features (see a number of distinct tokens in Table 1)); sparseness of the feature vectors (only ~9 words per text); and, it does not perform aggressive feature selection (i.e., does not lose potentially relevant information, which is important not to degrade the accuracy [43]).
- Naïve Bayes Multinomial (NBM) [44] is a generative profile-based approach, which can also outperform popular SVM in the sentiment analysis tasks [16]. It is a simple, but rather fast technique, which performs especially well on a large number of features with equal significance. Besides, this method does not require huge resources for the data storage and it is often selected as a baseline approach.
- Lexical. The token unigrams (a common bag-of-words approach) and both token bigrams + unigrams were extracted from the texts.
- Morphological. These feature types cover unigrams of lemmas and bigrams + unigrams of lemmas. Before feature extraction, the texts had to be lemmatized. For the lemmatization we have used the Lithuanian morphological analyzer-lemmatizer Lemuoklis [45]. Lemuoklis can solve ambiguity problems and transform recognized words into their dictionary form. However, it is only effective on the normative texts, which basically means that all undiacritized, abbreviated, or slang words remain untouched.
- Character. This feature type represents document-level character tetra-grams. Such n = 4 was selected because it demonstrated the best performance over the different n values on the Lithuanian language in the topic classification task [46].
2.4. Deep Learning Methods
- Long Short-Term Memory (LSTM) method [47] is a special type of the artificial neural network. This method analyzes the text word-by-word and stores the captured semantics in the hidden layers. Besides, its main advantage from the recurrent neural networks is that LSTM does not suffer from the vanishing gradient problem when learning long-term dependencies.
- Convolutional Neural Network (CNN) [48] (presented in detail for the text classification in [49]) is a feed-forward artificial neural network (ANN) that contains one or more convolutional layers and the max-pooling. Convolutional layers help the method to go deeper by decreasing the number of parameters and the max-pooling layer helps to effectively determine discriminative phrases in the text. However, the size of the filters in each convolutional layer still remains an issue: too small windows may cause a loss of important information; too large windows may produce an enormous number of parameters.
- Word2Vec. These embeddings were generated with the same deeplearning4j software, the continuous bag-of-words (CBOW) with the negative sampling and 300 dimensions. Under this architecture, a neural network had to predict a focus word by feeding its context words from the surrounding window (the detailed explanation of the method is in [52,53]). Using the corpus of ~234 million running words, it resulted in 687,947 neural word embeddings for the Lithuanian language (more about it can be found in [54]).
- FastText [55]. It is an extension of Word2Vec that is offered by Facebook AI Research Lab. Instead of inputting the whole words into the network (as in Word2Vec case), each word (e.g., network) is split into several word-level character n-grams (netw, etwo, twor, work); the separate vectors are trained for all of these n-grams; and, are then summed to get a single vector for the whole word (network). In our experiments we have used two-million available Lithuanian FastText word embeddings. (The FastText Lithuanian word embeddings were downloaded from https://fasttext.cc/docs/en/crawl-vectors.html).
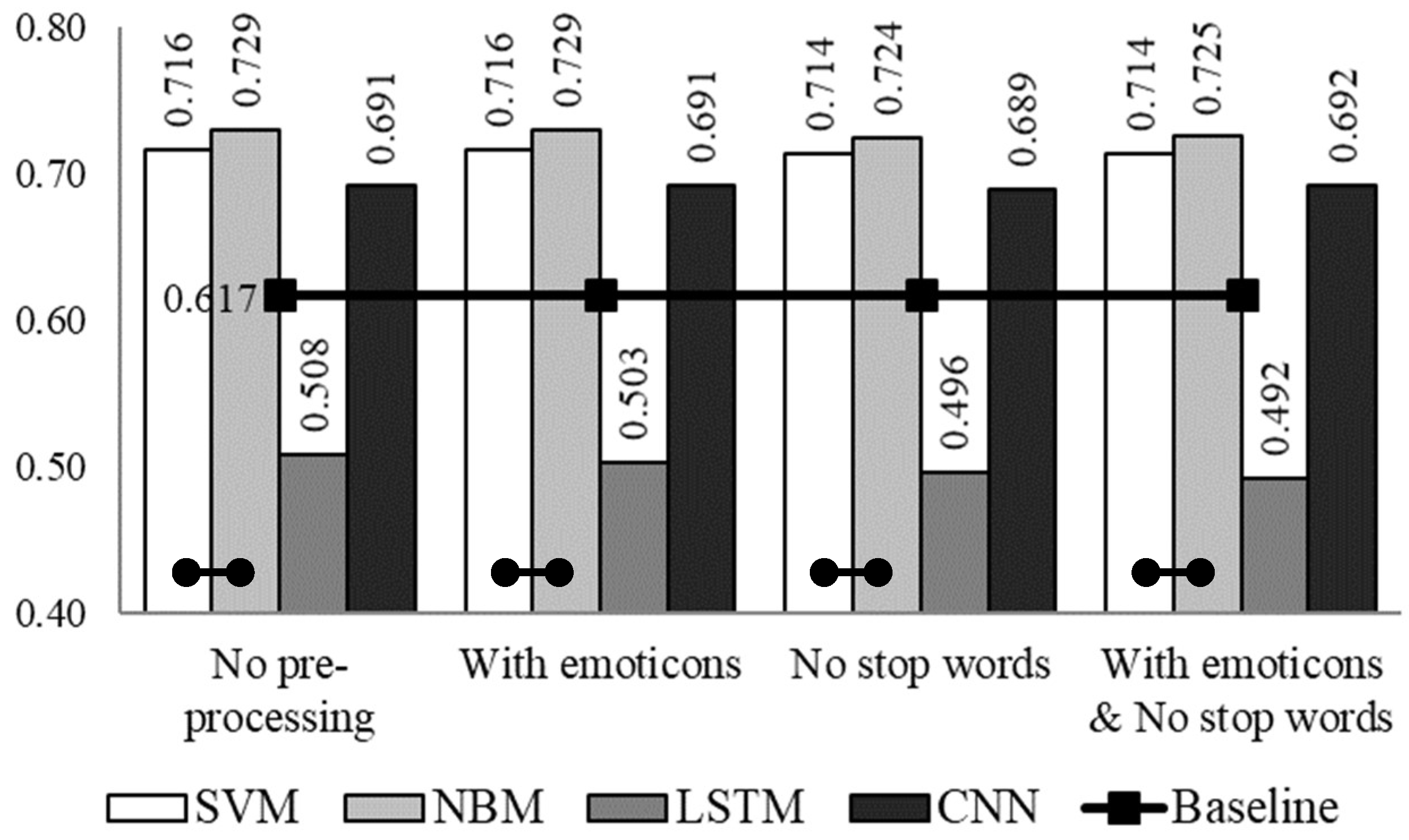
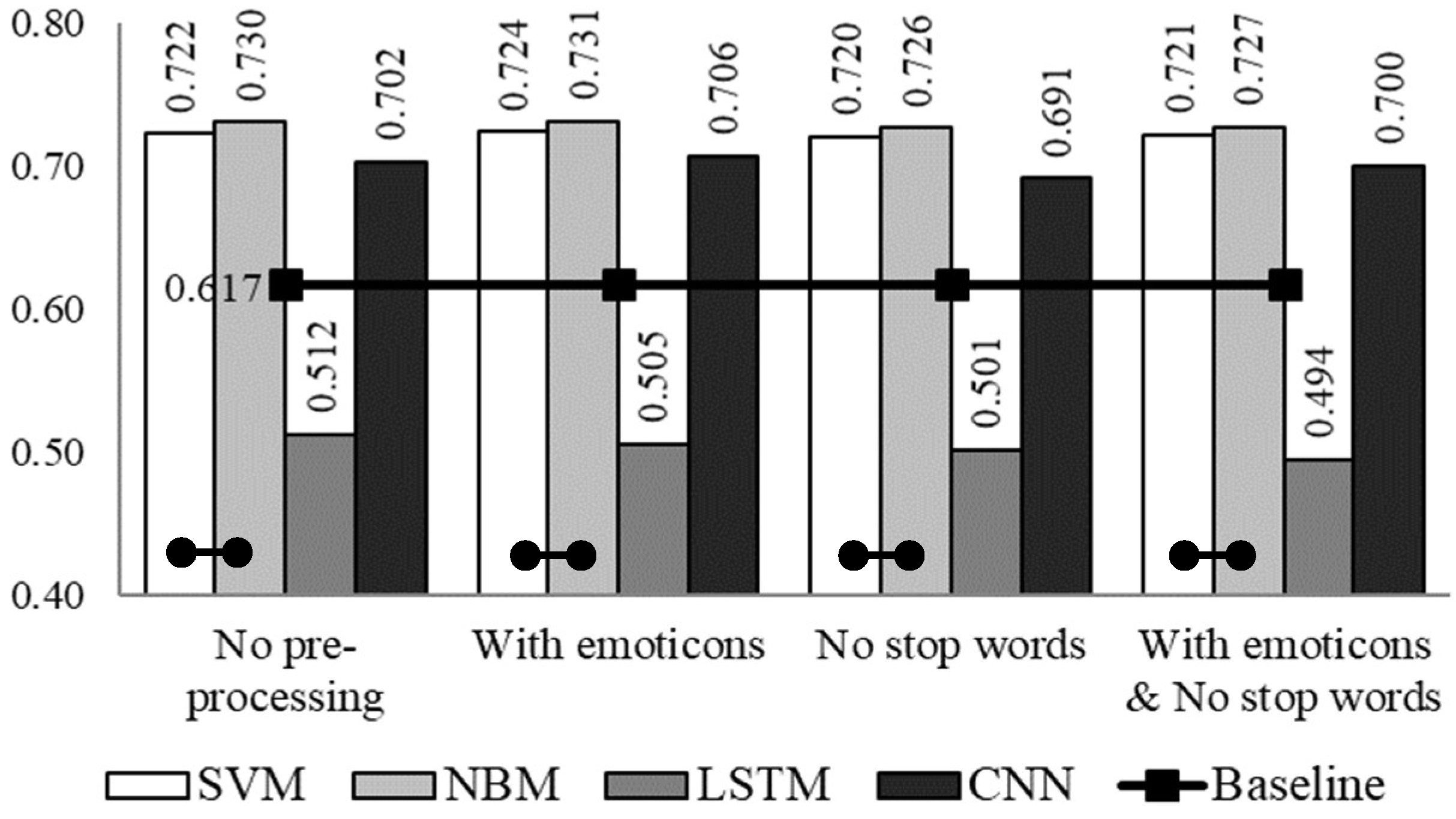
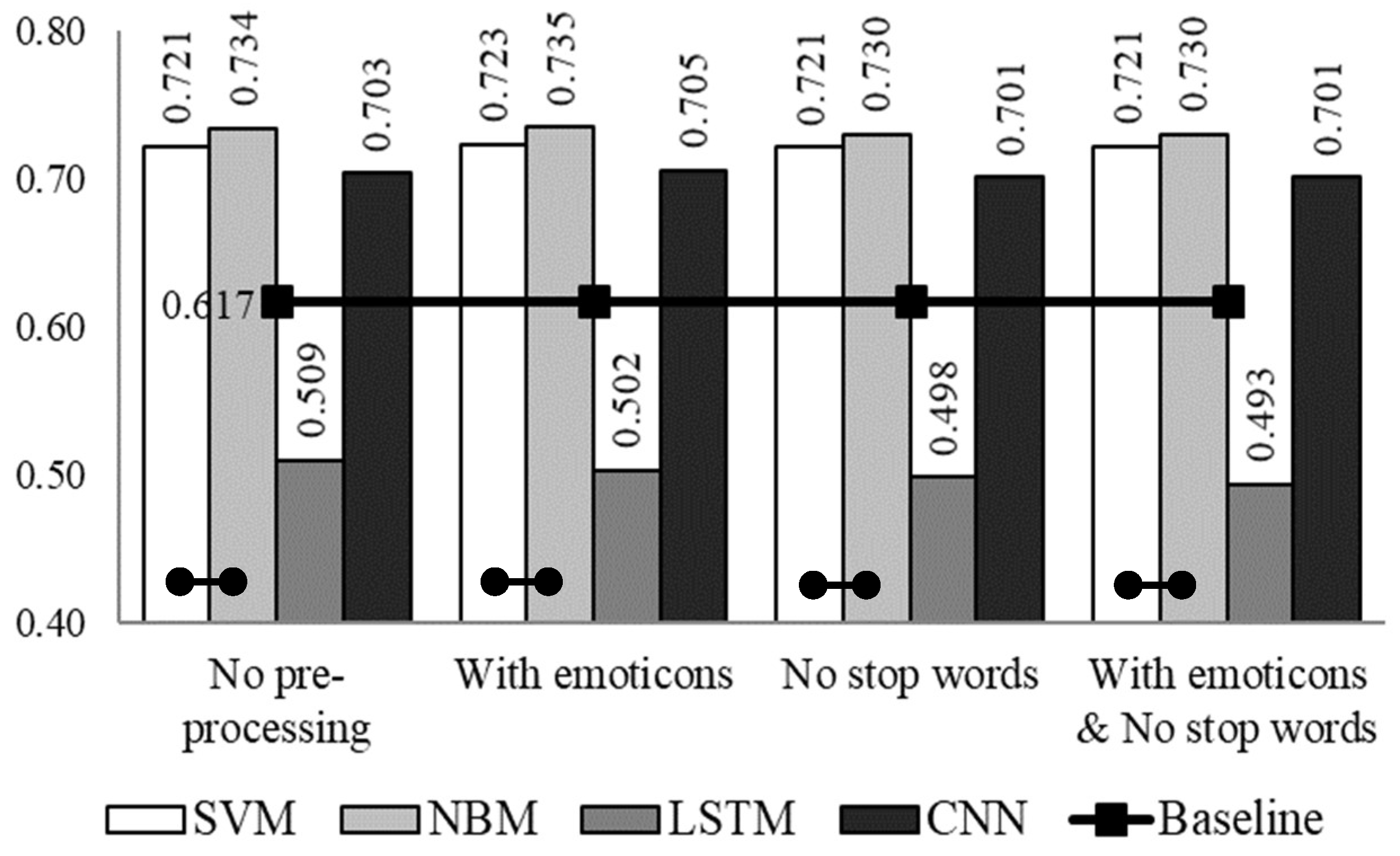
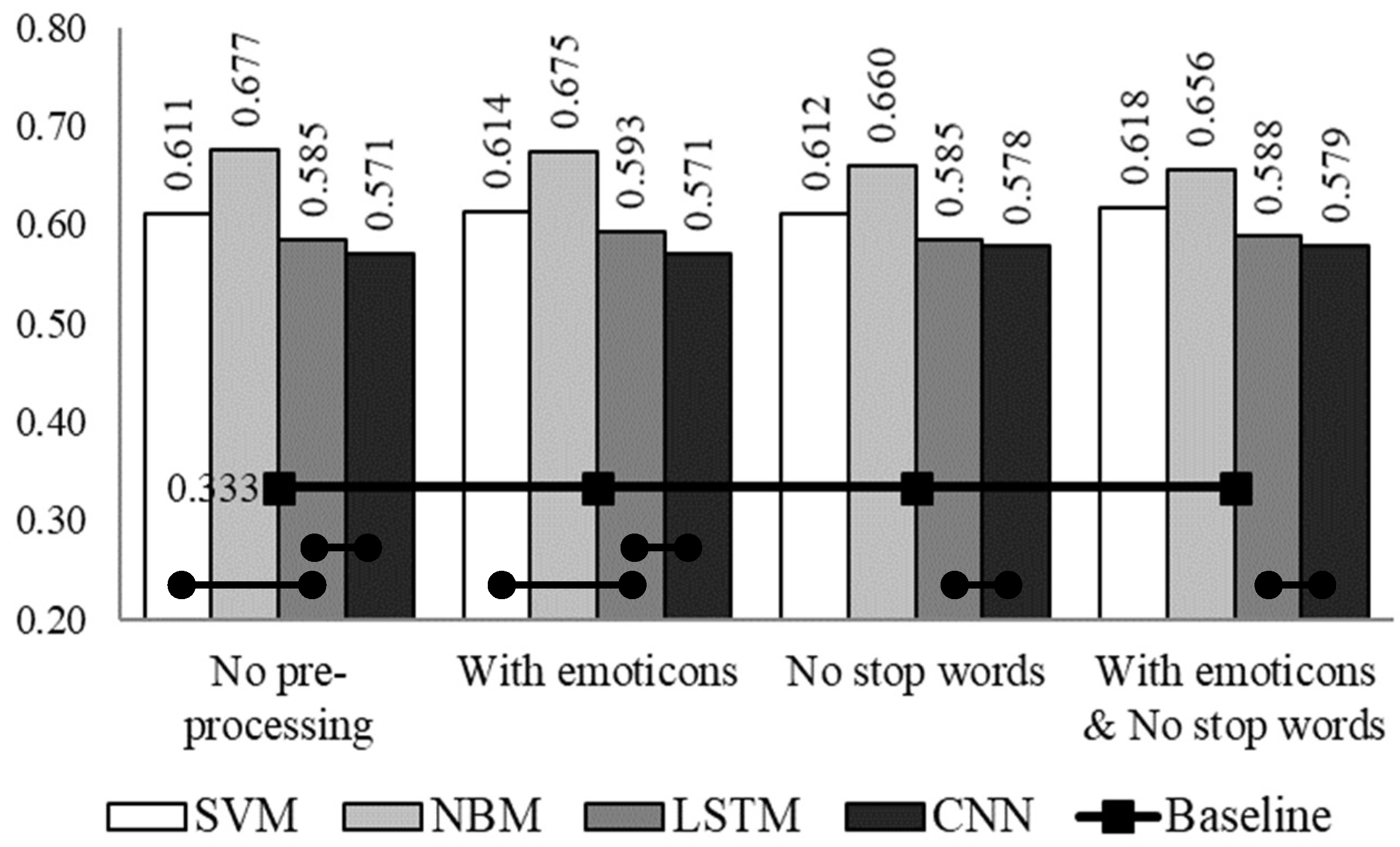
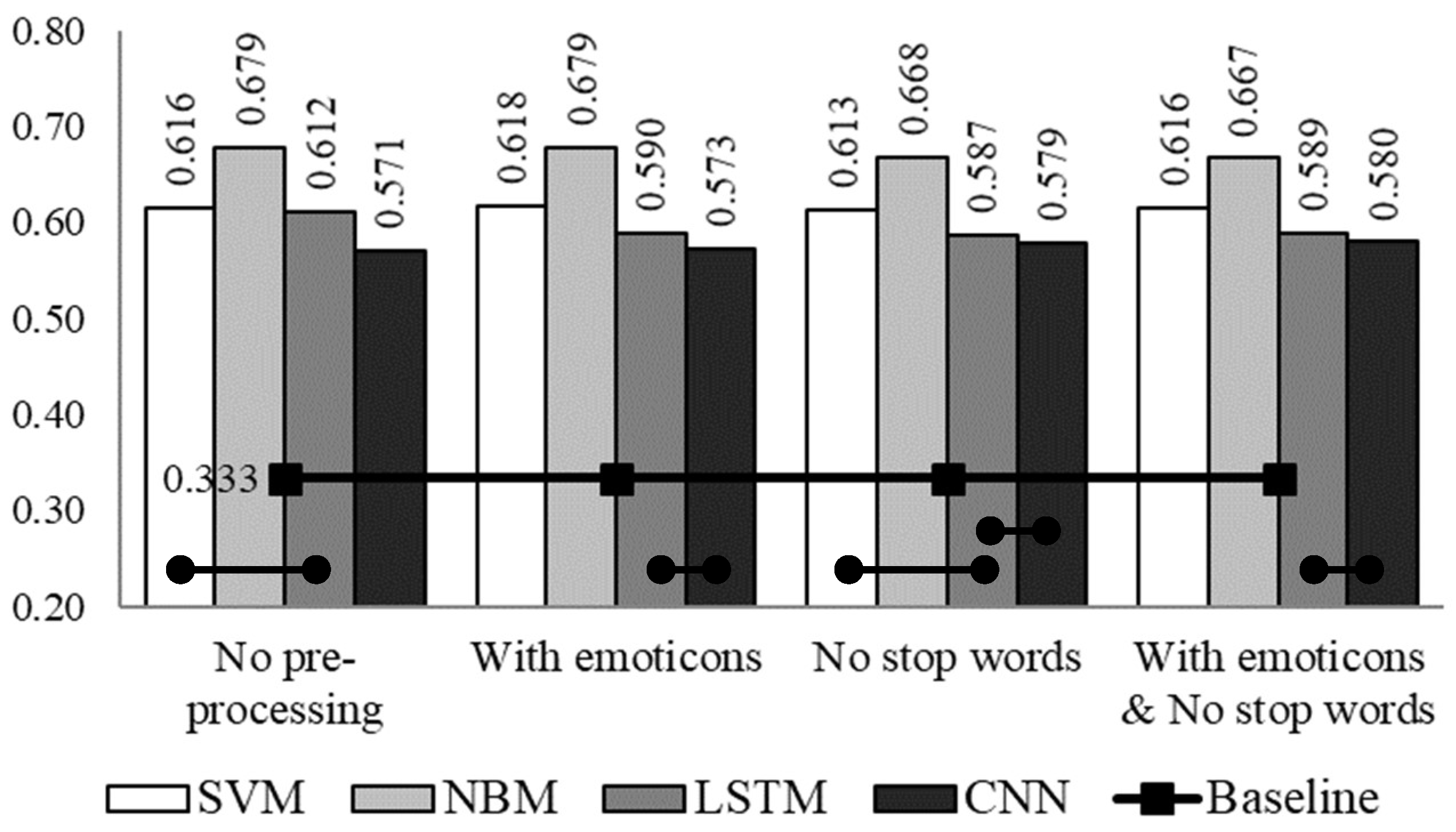
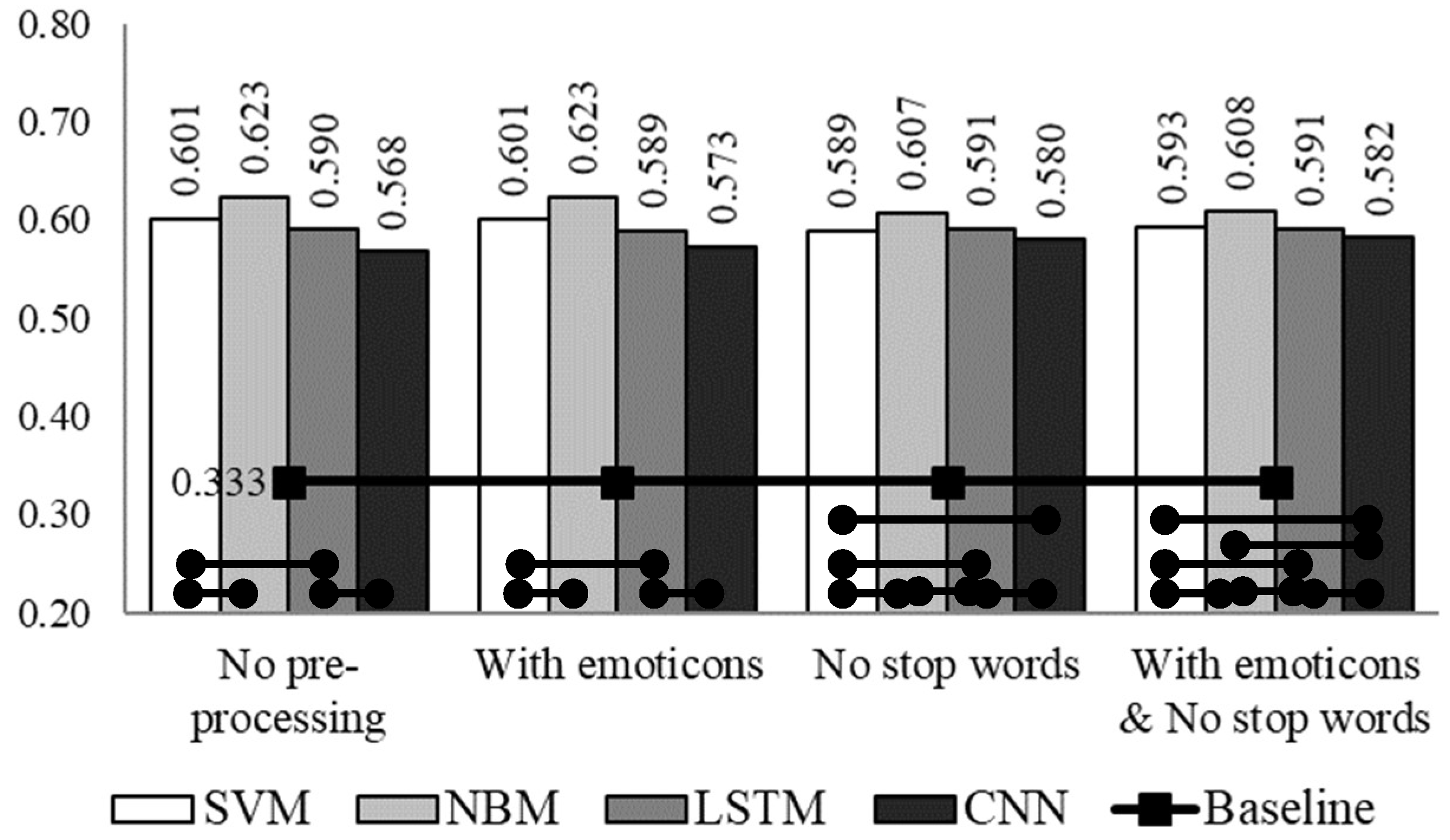
3. Experimental Set-Up and Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Htet, H.; Khaing, S.S.; Myint, Y.Y. Tweets sentiment analysis for healthcare on big data processing and IoT architecture using maximum entropy classifier. In Proceedings of the International Conference on Big Data Analysis and Deep Learning Applications, Miyazaki, Japan, 14–15 May 2018; Zin, T., Lin, J.W., Eds.; Springer: Singapore, 2019; Volume 744, pp. 28–38. [Google Scholar] [CrossRef]
- Moe, Z.H.; San, T.; Tin, H.M.; Hlaing, N.Y.; Tin, M.M. Evaluation for teacher’s ability and forecasting student’s career based on big data. In Big Data Analysis and Deep Learning Applications; Springer: Singapore, 2019. [Google Scholar] [CrossRef]
- Agarwal, B.; Mittal, N.; Bansal, P.; Garg, S. Sentiment Analysis Using Common-Sense and Context Information. Comput. Intell. Neurosci. 2015, 2015. [Google Scholar] [CrossRef] [PubMed]
- Asghar, M.Z.; Khan, A.; Ahmad, Sh.; Qasim, M.; Khan, I.A. Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLoS ONE 2017, 12, e0171649. [Google Scholar] [CrossRef] [PubMed]
- Augustyniak, Ł.; Szymański, P.; Kajdanowicz, T.; Tuligłowicz, W. Comprehensive study on lexicon-based ensemble classification sentiment analysis. Entropy 2016, 18, 4. [Google Scholar] [CrossRef]
- Dilawar, N.; Majeed, H.; Beg, M.O.; Ejaz, N.; Muhammad, K.; Mehmood, I.; Nam, Y. Understanding citizen issues through reviews: A step towards data informed planning in smart cities. Appl. Sci. 2018, 8, 1589. [Google Scholar] [CrossRef]
- Ravichandran, M.; Kulanthaivel, G.; Chellatamilan, T. Intelligent Topical Sentiment Analysis for the Classification of E-Learners and Their Topics of Interest. Sci. World J. 2015, 2015, 617358. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, E.; Yang, Z. Quantifying the Effect of Sentiment on Information Diffusion in Social Media. PeerJ Comput. Sci. 2015, 1, e26. [Google Scholar] [CrossRef]
- Martinčić-Ipšić, S.; Močibob, E.; Perc, M. Link prediction on Twitter. PLoS ONE 2017, 12, e0181079. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, H.; Yuan, S.; Wang, J.; Zhou, Y. Sentiment processing of social media information from both wireless and wired network. Eur. J. Wirel. Commun. Netw. 2016, 164. [Google Scholar] [CrossRef]
- Ranco, G.; Bordino, I.; Bormetti, G.; Caldarelli, G.; Lillo, F.; Treccani, M. Coupling News Sentiment with Web Browsing Data Improves Prediction of Intra-Day Price Dynamics. PLoS ONE 2016, 11, e0146576. [Google Scholar] [CrossRef] [PubMed]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-Based Methods for Sentiment Analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Turney, P.D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002, ACL’02, Philadelphia, PA, USA, 7–12 July 2002; pp. 417–424. [Google Scholar] [CrossRef]
- De Diego, I.M.; Fernández-Isabel, A.; Ortega, F.; Moguerza, J.M. A visual framework for dynamic emotional web analysis. Knowl. Based Syst. 2018, 145, 264–273. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, Washington, DC, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Pak, A.; Paroubek, P. Twitter for Sentiment Analysis: When Language Resources are Not Available. In Proceedings of the Database and Expert Systems Applications (DEXA 2011), Toulouse, France, 29 August–2 September 2011; pp. 111–115. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP, Honolulu, HI, USA, 25–27 October 2002; pp. 79–86. [Google Scholar] [CrossRef]
- Nogueira dos Santos, C.; Maira, G. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the 25th International Conference on Computational Linguistics (COLING), Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the Association for Computational Linguistics (ACL), Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar] [CrossRef]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification using Distant Supervision. Available online: https://cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf (accessed on 30 December 2018).
- Katoh, K.; Ninomiya, T. Deep Learning for Large-Scale Sentiment Analysis Using Distributed Representations. In Proceedings of the SEMAPRO 2015: The 9th International Conference on Advances in Semantic Processing, Nice, France, 19–24 July 2015; pp. 92–96. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter Sentiment Analysis with Deep Convolutional Neural Networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’15, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar] [CrossRef]
- Guan, Z.; Chen, L.; Zhao, W.; Zheng, Y.; Tan, S.; Cai, D. Weakly-Supervised Deep Learning for Customer Review Sentiment Classification. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3719–3725. [Google Scholar]
- Akhtar, M.S.; Kumar, A.; Ekbal, A.; Bhattacharyya, P. A Hybrid Deep Learning Architecture for Sentiment Analysis. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 482–493. [Google Scholar]
- Yousif, A.; Niu, Z.; Nyamawe, A.S.; Hu, Y. Improving citation sentiment and purpose classification using hybrid deep neural network model. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, AISI 2018, Cairo, Egypt, 1–3 September 2018; pp. 327–336. [Google Scholar] [CrossRef]
- Yun, W.; An, W.X.; Jindan, Z.; Yu, C. Combining vector space features and convolution neural network for text sentiment analysis. In Proceedings of the CISIS 2018: Complex, Intelligent, and Software Intensive Systems, Osaka, Japan, 4–6 July 2018; pp. 780–790. [Google Scholar] [CrossRef]
- Stojanovski, D.; Strezoski, G.; Madjarov, G.; Dimitrovski, I. Finki at SemEval-2016 Task 4: Deep Learning Architecture for Twitter Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 149–154. [Google Scholar]
- Lu, Y.; Sakamoto, K.; Shibuki, H.; Mori, T. Are Deep Learning Methods Better for Twitter Sentiment Analysis? Available online: http://www.anlp.jp/proceedings/annual_meeting/2017/pdf_dir/C5-1.pdf (accessed on 30 December 2018).
- Cortis, K.; Freitas, A.; Daudert, T.; Hürlimann, M.; Zarrouk, M.; Handschuh, S.; Davis, B. SemEval-2017 Task 5: Fine-Grained Sentiment Analysis on Financial Microblogs and News. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 519–535. [Google Scholar]
- Jiang, M.; Lan, M.; Wu, Y. ECNU at SemEval-2017 Task 5: An Ensemble of Regression Algorithms with Effective Features for Fine-Grained Sentiment Analysis in Financial Domain. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 888–893. [Google Scholar]
- Ghosal, D.; Bhatnagar, S.; Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. IITP at SemEval-2017 Task 5: An Ensemble of Deep Learning and Feature Based Models for Financial Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 899–903. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 502–518. [Google Scholar]
- Cliché, M. BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 573–580. [Google Scholar]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-level and Topic-based Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 747–754. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Krupavičius, A.; Krilavičius, T. A Comparison of Approaches for Sentiment Classification on Lithuanian Internet Comments. In Proceedings of the 4th Biennial International Workshop on Balto-Slavic Natural Language Processing, Sofia, Bulgaria, 8–9 August 2013; pp. 2–11. [Google Scholar]
- Naktinienė, G.; Paulauskas, J.; Petrokienė, R.; Vitkauskas, V.; Zabarskaitė, J. (Eds.) Lietuvių Kalbos Žodynas (t. 1-20, 1941–2002): Elektroninis Variantas [Lithuanian Language Dictionary (Vol. 1-20, 1941–2002): Electronic version]; Lietuvių Kalbos Institutas: Vilnius, Lithuania, 2005. (In Lithuanian) [Google Scholar]
- Stevenson, A. (Ed.) Oxford Dictionary of English, 3th ed.; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Urbutis, U. Žodžių Darybos Teorija [Word Derivation Theory]; Mokslo ir Enciklopedijų Leidybos Institutas: Vilnius, Lithuania, 2009. (In Lithuanian) [Google Scholar]
- Read, J. Using Emoticons to Reduce Dependency in Machine Learning Techniques for Sentiment Classification. In Proceedings of the ACL Student Research Workshop, ACL’05, Ann Arbor, MI, USA, 27 June 2005; pp. 43–48. [Google Scholar]
- Spencer, J.; Uchyigit, G. Sentimentor: Sentiment Analysis on Twitter Data. In Proceedings of the 1st International Workshop on Sentiment Discovery from Affective Data, Bristol, UK, 28 September 2012; pp. 56–66. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Davidsonas, A.; Vidugirienė, A. Character-Based Machine Learning vs. Language Modeling for Diacritics Restoration. Inf. Technol. Control 2017, 46, 508–520. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1997, 20, 273–297. [Google Scholar] [CrossRef]
- Joachims, T. Text Categorization with Support Vector Machines: Learning with many Relevant Features. In Proceedings of the 10th European Conference on Machine Learning, ECML-98, Chemnitz, Germany, 21–23 April 1998; Volume 1398, pp. 137–142. [Google Scholar] [CrossRef]
- Lewis, D.D.; Gale, W.A. A sequential algorithm for training text classifiers. In Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, SIGIR-94, Dublin, Ireland, 3–6 July 1994; pp. 3–12. [Google Scholar]
- Zinkevičius, V. Lemuoklis—Morfologinei analizei [Morphological analysis with Lemuoklis]. In Darbai ir Dienos; Gudaitis, L., Ed.; VDU Leidykla: Kaunas, Lithuania, 2000; Volume 24, pp. 246–273. (In Lithuanian) [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Vaassen, F.; Daelemans, W.; Krupavičius, A. Improving topic classification for highly inflective languages. In Proceedings of the 24th International Conference on Computational Linguistics (COLING 2012), Mumbai, India, 8–15 December 2012; pp. 1393–1410. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 2278–2324. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the Empirical Methods in Natural Language Processing, EMNLP, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 11–31. ISBN 978-3-642-24796-5. [Google Scholar]
- Open-Source, Distributed, Deep Learning Library for the JVM. Available online: https://deeplearning4j.org/ (accessed on 30 December 2018).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R. Intrinsic evaluation of Lithuanian word embeddings using WordNet. In Proceedings of the CSOC 2018: 7th Computer Science On-Line Conference, Zlin, Czech Republic, 25–28 April 2018; pp. 394–404. [Google Scholar] [CrossRef]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. In Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Wozniak, M. Sentiment analysis of Lithuanian texts using deep learning methods. In Proceedings of the 24th international conference on Information and Software Technologies, (ICIST 2018), Vilnius, Lithuania, 4–6 October 2018; pp. 521–532. [Google Scholar] [CrossRef]
- Rotim, L.; Snajder, J. Comparison of Short-Text Sentiment Analysis Methods for Croatian. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, Valencia, Spain, 4 April 2017; pp. 69–75. [Google Scholar]
- Habernal, I.; Ptácek, T.; Steinberger, J. Sentiment Analysis in Czech Social Media Using Supervised Machine Learning. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, GA, USA, 14 June 2013; pp. 65–74. [Google Scholar]
- Rogers, A.; Romanov, A.; Rumshisky, A.; Volkova, S.; Gronas, M.; Gribov, A. RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. In Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018), Santa Fe, NM, USA, 20–26 August 2018; pp. 755–763. [Google Scholar]
- Ma, Y.; Peng, H.; Khan, T.; Cambria, E.; Hussain, A. Sentic LSTM: A Hybrid Network for Targeted Aspect-Based Sentiment Analysis. Cogn. Comput. 2018, 10, 639–650. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Label | Numb. of Texts | Avg. Text Length | Numb. of Tokens | Tokens with Emoticons | Tokens without Stop Words |
|---|---|---|---|---|---|
| positive | 2176 | 7.62 | 16,576 4976 | 16,818 4977 | 14,609 4902 |
| negative | 6521 | 9.94 | 64,832 20,365 | 65,159 20,368 | 54,162 20,307 |
| neutral | 1873 | 8.98 | 16,824 6551 | 16,884 6552 | 13,831 6544 |
| total | 10,570 | 9.29 | 98,232 25,942 | 98,861 25,945 | 82,602 25,491 |
| Class Label | Numb. of Texts | Avg. Text Length | Numb. of Tokens | Tokens with Emoticons | Tokens without Stop Words |
|---|---|---|---|---|---|
| positive | 1500 | 6.97 | 10,455 3177 | 10,664 4027 | 8982 3941 |
| negative | 1500 | 10.00 | 15,000 6475 | 15,107 7811 | 11,945 7716 |
| neutral | 1500 | 8.77 | 13,165 5134 | 13,226 6391 | 10,427 6276 |
| total | 4500 | 8.58 | 38,621 11,669 | 38,997 14,966 | 31,354 14,923 |
| SVM | NBM | LSTM | CNN | |
|---|---|---|---|---|
| Original | ||||
| No pre-processing | lem1 | lem1 | Word2Vec | FastText |
| With emoticons | lem1 | lem1 | Word2Vec | FastText |
| No stop words | lex1 | lex1 | Word2Vec | FastText |
| With emoticons & No stop words | lem1 | lem1 | Word2Vec | FastText |
| Eliminated Diacrtics | ||||
| No pre-processing | lex1 | lem1 | Word2Vec_d | FastText |
| With emoticons | lem1 | lem1 | Word2Vec | FastText |
| No stop words | lex1 | lex1 | Word2Vec | FastText |
| With emoticons & No stop words | lem1 | lem1 | Word2Vec | FastText |
| Restored diacritics | ||||
| No pre-processing | lex1 | lem1 | Word2Vec | FastText |
| With emoticons | lex1 | lem1 | Word2Vec | FastText |
| No stop words | lex1 | lem1 | Word2Vec | FastText |
| With emoticons & No stop words | lex1 | lem1 | Word2Vec | FastText |
| SVM | NBM | LSTM | CNN | |
|---|---|---|---|---|
| Original | ||||
| No pre-processing | lex1 | lex2 | FastText | FastText |
| With emoticons | lem1 | lex2 | FastText | FastText |
| No stop words | lex1 | lex2 | FastText | FastText |
| With emoticons & No stop words | lem1 | lex2 | FastText | FastText |
| Eliminated Diacrtics | ||||
| No pre-processing | lex1 | lex2 | Word2Vec | FastText |
| With emoticons | lex1 | lex2 | FastText | FastText |
| No stop words | lex1 | lex2 | FastText | FastText |
| With emoticons & No stop words | lex1 | lex2 | FastText | FastText |
| Restored diacritics | ||||
| No pre-processing | lem1 | lem1 | Word2Vec | FastText |
| With emoticons | lem1 | lem1 | FastText | FastText |
| No stop words | lem1 | lem1 | FastText | FastText |
| With emoticons & No stop words | lem1 | lem1 | FastText | FastText |
| Pre-Processing Technique | Compared Methods | |||
|---|---|---|---|---|
| CNN & SVM | CNN & NBM | SVM & NBM | ||
| Original | No pre-processing With emoticons No stop words With emoticons & No stop words | 0.001 0.001 0.001 0.003 | 0.000 0.000 0.000 0.000 | 0.069 0.071 0.165 0.135 |
| Eliminated diacritics | No pre-processing With emoticons No stop words With emoticons & No stop words | 0.007 0.018 0.000 0.004 | 0.000 0.001 0.000 0.000 | 0.264 0.330 0.418 0.432 |
| Restored diacritics | No pre-processing With emoticons No stop words With emoticons & No stop words | 0.015 0.015 0.007 0.005 | 0.000 0.000 0.000 0.000 | 0.089 0.107 0.222 0.217 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment Analysis of Lithuanian Texts Using Traditional and Deep Learning Approaches. Computers 2019, 8, 4. https://doi.org/10.3390/computers8010004
Kapočiūtė-Dzikienė J, Damaševičius R, Woźniak M. Sentiment Analysis of Lithuanian Texts Using Traditional and Deep Learning Approaches. Computers. 2019; 8(1):4. https://doi.org/10.3390/computers8010004
Chicago/Turabian StyleKapočiūtė-Dzikienė, Jurgita, Robertas Damaševičius, and Marcin Woźniak. 2019. "Sentiment Analysis of Lithuanian Texts Using Traditional and Deep Learning Approaches" Computers 8, no. 1: 4. https://doi.org/10.3390/computers8010004
APA StyleKapočiūtė-Dzikienė, J., Damaševičius, R., & Woźniak, M. (2019). Sentiment Analysis of Lithuanian Texts Using Traditional and Deep Learning Approaches. Computers, 8(1), 4. https://doi.org/10.3390/computers8010004