1. Introduction
Information technology has revolutionized many aspects of everyday life. One major new technology, which facilitated the goal of delivering computing as a utility, is cloud computing. It is envisioned that cloud computing will play a pivotal role in storage, social networking and delivery of multimedia systems. However, cloud computing brings along many challenges, specifically in terms of security [
1]. The growth rate of data stored on the cloud is huge. Client-side encryption has been used to provide security to the data stored in the cloud. However, client-side encryption alone is not enough to provide security to data stored on the cloud, since an adversary can observe the access pattern to the stored data and can discover a lot of information from this access pattern [
2]. Fortunately, there is a cryptographic primitive that hides the access pattern. This cryptographic primitive is called Oblivious Random Access Memory (ORAM) [
3].
ORAM was initially developed by Goldreich and Ostrovsky [
3,
4,
5]. The basic idea of ORAM is to randomly permute and shuffle the data stored in memory, so that no data block is stored in the same position again and no relation between the accessed data blocks can be deduced by the adversary. Any ORAM scheme must use probabilistic encryption to encrypt the data before it is stored on the server. Then when the data is either read or written by the user, the user must decrypt it first, perform a task with it, then the data must be encrypted again with probabilistic encryption before it is sent back to the server again.
The first (obvious) ORAM had to read the whole memory to perform a single read or write, and write the whole memory back again. Moreover, when the user receives the whole content of the memory they must decrypt it then encrypt it again before it can be written back to the server. This ORAM incurs an enormous overhead in bandwidth and processing time, which prevents any practical use of it. Fortunately, this first trivial ORAM was followed up by many ORAM constructions and improvements [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]. The basic idea in these new ORAMs, to make the data access oblivious, is to introduce an extra storage at the server and continuously and obliviously shuffle the data so that no data block is saved in its same previous location. The continuous shuffling ensures the obliviousness of the access pattern.
Current ORAM constructions can be grouped into two main groups: Hierarchical ORAM and Tree ORAM [
18]. There are many ORAM constructions and variants in each group. However, Tree ORAMs are the most recent and have better performance than Hierarchical ORAM. This is essentially due to the fact that Hierarchical ORAMs require expensive oblivious shuffling and sorting operations.
There is a number of tree ORAM constructions among them are: Path ORAM [
12,
19], Ring ORAM [
15], XOR Ring ORAM [
15,
20] and Onion ORAM [
16]. However, Path ORAM is the most practical as a result of its simplicity [
19]. In this paper, we will concentrate on Path ORAM and try to further enhance its performance and implementation to take advantages of any popularity in the requested data.
ORAMs in general do not protect against a kind of information leakage that can be obtained by observing the timing of operations generally referred to as the timing channel attack [
19,
21]. Path ORAM like most ORAMs tacitly ignores the timing channel attack [
19].
Most of real-world applications show an immense rate of data locality and popularity. Accessing outsourced data is no exception. The popularity of a data document in a collection of documents is the number of times the document is requested compared to the number of times the rest of the documents in the collection are requested in a certain period of time [
22]. On the other hand, data locality may also refer to data parts or segments within the same document. Some parts of a document are accessed much more often than other parts of the same document. For example, the abstract of a research paper has data locality higher than other parts of a research paper. This kind of data locality is referred to as temporal data locality. Spatial locality, that is accessing data blocks close to each other, is very important in the secure processor setting [
23,
24,
25]. However, the ORAM literature has overlooked data locality and popularity. Using ORAM inherently destroys any spatial data locality, since ORAM depends on storing the data in random locations. As such, we will only concentrate on temporal locality and popularity to enhance the performance of Path ORAM.
Path ORAM has gained popularity in the research community due to its good performance and its simple and elegant algorithm. Many work have tried to enhance its performance specially in the secure processor domain. However, to the best of our knowledge, there is no work in the secure storage outsourcing domain that has improved the Path ORAM performance using the popularity or locality of the requested data. Data accessed by the user tend to exhibit some form of popularity and locality that can be used to enhance the performance of any ORAM. We show in this paper that the addition of some small storage at the client side allows to take advantage of the existence of any data popularity and locality. This will amount to a much better response time compared to that of the original Path ORAM.
Our contributions are the following:
Enhancing the implementation of Path ORAM by integrating the necessary awareness about any existent popularity within the sequence of requested data blocks
Showing the superiority of the enhanced implementation even for a small additional storage and a reduced data locality
Developing a mathematical model providing adequate closed form solutions for the size of the extra storage as well as the hit ratio for any given non-null popularity parameter
Validating our proposed mathematical model using the conducted experimental results.
The rest of the paper is organized as follows. We present a detailed description of Path ORAM in
Section 2. In
Section 3, we present the relevant related work to our research. Then in
Section 4, we present the enhancement and modification we propose to get advantage of data popularity. In
Section 5, we first describe the test bed used for the experiments, then we present and interpret the results of our conducted experiments. In
Section 6, we present the mathematical model based on the Zipf distribution. This provides closed form approximated solutions for the cache size and cache hit. Our proposed mathematical model is then validated using the results obtained from the conducted experiments. Finally, in
Section 7, we present some concluding remarks.
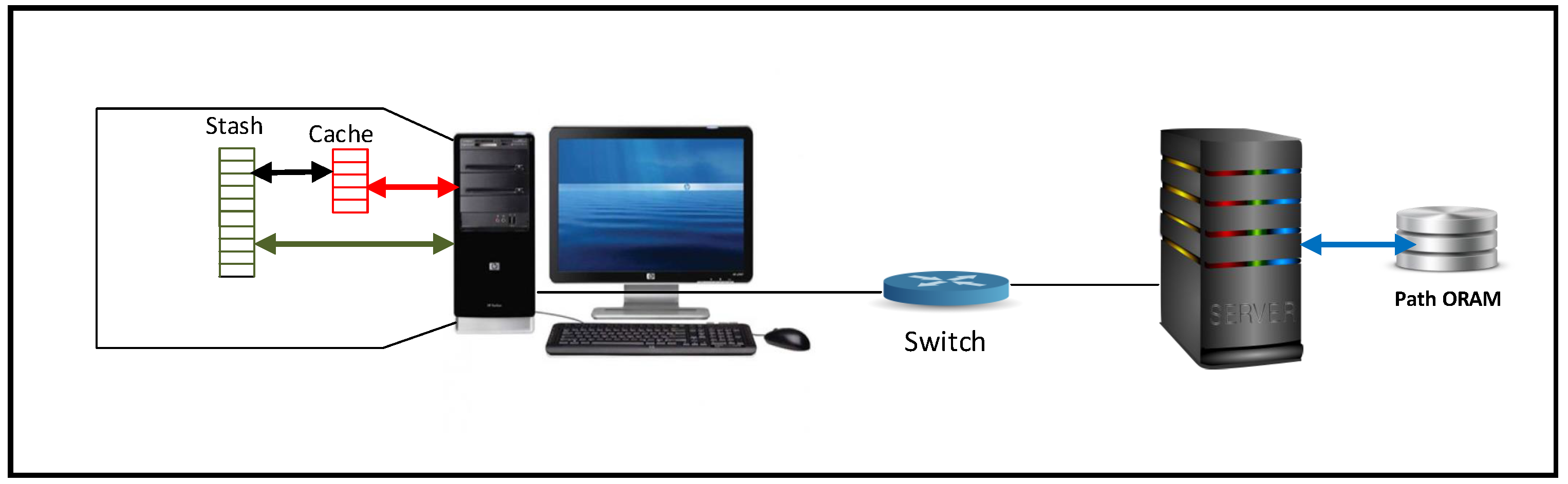
2. Path ORAM
Stefanov et al. [
12] introduced a very simple and elegant ORAM, named Path ORAM. Path ORAM uses a binary tree structure just like the initial Tree ORAM proposed by Shi et al. [
9] to store the data on the server. The binary tree is composed of constant size nodes called buckets. To store N data blocks the tree has to have N buckets. Each bucket can store up to some constant number
z of data blocks [
12,
26,
27]. If the number of data blocks in a bucket is lower than the constant number
z then the bucket must be filled up with dummy blocks until the total number of blocks in the bucket reaches
z.
Every data block in Path ORAM is mapped to a random leaf; this information is stored in a position map stored at the client. When a data block is mapped to a leaf it means that it must be stored in a bucket residing on the path from the root of the tree to that leaf. The leaves are numbered starting from zero. The client also has a buffer reserved to store the read data blocks. This buffer is named a stash. The stash must be able to hold at least a complete path read from root to leaf. Thus, the size of the stash must be at least , where N is the number of buckets in the binary tree. Path Oram has the following invariant: a data block must be stored on the path it is mapped to or be in the stash.
The notations used for Path ORAM are displayed in
Table 1 and the read-write algorithm is displayed in Algorithm 1. To read/write a data block, the position map has to be looked up first to find the leaf the data block is mapped to and stored in the variable x line 1 in the algorithm. Following that, the data block must be mapped to a new random leaf and the position map has to be updated to reflect this change line 2 in the algorithm. Then all the blocks residing in the buckets along the path from the root to leaf x are read and decrypted then stored into the stash lines 3, 4 and 5 in the algorithm. Storing only real data blocks and discarding any dummy blocks. If the operation is a write the content of the data block will be changed to the new content lines 6, 7 and 8 in the algorithm. Then the path just read has to be written back to the server. This step is done using a greedy filling strategy starting from the leaf and filling up buckets on the path with data blocks from the stash that satisfy the invariant of Path ORAM. Each bucket on the path must hold
z blocks if there are not enough blocks in the stash to fill up the bucket, then the bucket will be filled up with dummy blocks lines 9–15 in the algorithm. Finally the data is returned to the user line 16 in the algorithm.
We must here note that before sending any block whether a data block or a dummy block, it must be encrypted first [
12,
28].
| Algorithm 1 Algorithm for data access of Path ORAM |
Input: operation, a, data*
- 1:
- 2:
- 3:
for to L do - 4:
- 5:
end for - 6:
if () then - 7:
- 8:
end if - 9:
for downto 0 do - 10:
- 11:
- 12:
blocks from St′ - 13:
- 14:
- 15:
end for - 16:
return data
|
3. Related Work
Ren et al. [
29] introduced three techniques to optimize the performance of Path ORAM in the secure processor setting. The first technique is background eviction that allows to decrease the number of blocks
z stored in each bucket. This amounts in decreasing the overhead as well as lowering the failure probability. When the number of blocks in the stash reach a certain threshold, background evictions are performed by issuing dummy read requests. Background evictions are kept oblivious and cannot be distinguished from normal ORAM access. The second technique in the secure processor setting is static super block. In this technique, blocks that exhibit some form of locality are grouped into a super block and assigned to the same leaf in the Path ORAM tree. Thus, when one block is read, all the other blocks belonging to the same super block are also read. Furthermore, after reading a block in a super block, not only that block gets assigned to a new random leaf but all the blocks belonging to the same super block get assigned to the same random leaf. In their work, they used address space locality to group the blocks of a program into super blocks, and this grouping had to be done before loading the ORAM tree and was static. As such, their work is limited to program locality and not data locality. The third technique is subtree layout where they proposed packing subtrees with k levels together. These subtrees are handled as the buckets of a new tree [
29].
Fletcher et al. developed a secure processor that uses Path ORAM and defeats the timing channel attack by imposing the access to the Path ORAM at a fixed predetermined rate. This rate is determined offline. Thus, if a request is present before the next allowed request time, it must wait. Moreover, if there is no request at the allowed request time, a dummy request must be sent. This solution clearly degrades the performance of the ORAM and introduces a large amount of overhead. Fletchery et al. [
30] showed that this secure processor has more than 50% overhead in power and performance. They proposed a dynamic scheme that allows a small amount of leakage. This scheme reduces the performance deterioration by 30% [
30].
Maas et al. [
31] introduced the first Path ORAM implementation on hardware. They named it Parallel Hardware to make Applications Non-leaky Through Oblivious Memory (Phantom). Two techniques were used to enhance the performance of Path ORAM in Phantom. The first technique is, treetop caching. In tree top caching the first k levels of the tree are saved in the stash so that when reading/writing to the ORAM only the lower layers are updated reducing the latency and overhead. The second technique used in Phantom is min-heap eviction where the stash is stored as a min-heap evicting the blocks that are least recently used first.
Yu et al. [
32] improved on the previous work of Ren et al. [
29] that used static super block and proposed a dynamic super block approach that allows the contents and size of the super block to change during the run of the ORAM taking into consideration the programs locality. They called their new approach Dynamic Prefetcher for ORAM (PrORAM). However, this PrORAM is only for secure processor and programs and not for outsourced data.
Ren et al. [
33] introduced Unified ORAM. Basically, Unified ORAM, is a recursive Path ORAM that has been updated to allow for the use of locality in the position map and pseudorandom compression to store the position map. Recursion is used in ORAMs to reduce the storage needed for the position map at the client. It is more important for ORAMs implemented on hardware due the constraints of on-chip area. The main objective of their work was to reduce the overhead introduced by recursive Path ORAM. They did so by using the locality in the position map. Moreover, they were able to reduce the size of the position map to be stored on-chip by using some pseudorandom compression. However, their work only takes into consideration the locality of the position map and not the locality of the data itself.
Fletcher et al. [
34] developed three techniques to improve the performance of any recursive ORAM. Their work is an enhancement to the work of Ren et al. [
33]. They proposed a Position map Lookaside Buffer (PLB) that uses the locality of the position map, in addition to using compression methods for storing the position map. Moreover, they introduced a Position map Message Authentication Code (PMAC) to ensure integrity and verification. However, their work is restricted to recursive ORAM and is more important for ORAMs implemented in hardware. Furthermore, the locality used is only the locality of the position map and not the locality of the data itself.
Zhang et al. [
35] introduced Fork Path ORAM. Fork Path ORAM merges two consecutive ORAM requests together. They tried to make use of the fact that two consecutive requests might have overlapping buckets in their paths. Thus, they suggested when a read/write request is performed and the whole path of the desired data block is read from the server and loaded into the stash, to wait and postpone the writing back of the complete path until having the subsequent request. When the subsequent request comes, the buckets that overlap in the two paths are not written back, and only the buckets that are in the path of the first request are written back. Moreover, to process the second request only the buckets in the second path that do not intersect with the path of the first request are read into the stash. Since the overlapping buckets have been fetched and read previously by the first request. Then the process is continued with the second request and third request and so on. They further suggested the rescheduling of pending ORAM requests. However, all their work was with the secure processor setting, yet the benefit of the merging of the requests is minimal as showed by Sanchez [
36]. Sanchez showed that grouping requests of size two can achieve a saving of one bucket (i.e., only one bucket does not have to be re-read, which is the root). While increasing the grouping of requests from two to five can only achieve a saving of 2.25 buckets.
Sanchez [
36] proposed merging requests in groups of more than two and working in batches. Furthermore, he proposed to dynamically reorder the batch requests to achieve the maximum overlap between paths of a batch. Unfortunately, this work depends on a very hard assumption of having all the requests in advance. This assumption is not practical at all for outsourced data. They showed in their experiments that grouping five requests together can only achieve a saving of 2.25 buckets. This saving is in the top levels of the tree (i.e., the root and the two levels below it.) These top three levels only contain seven buckets. We could have just read the first three levels and saved them in the stash by using the tree-top caching technique proposed by Maas et al. [
31]. Moreover, the problem was formulated as a partition problem making it an NP-hard problem.
Asharov et al. [
18] stated that previous work on ORAMs ignored locality and that they are the first to take locality into consideration when designing ORAMs in the context of secure processors. They argue that in many reasonable applications a user accessing neighboring memory locations is not kept a secret. Like in applications where the user asks for information between specific dates.
Chakraborti et al. [
37] designed a hierarchical ORAM that uses locality however, this ORAM is a write-only ORAM based on the work done by Li et al. [
38]. A write only ORAM preserves only the security of write operations and not that of read operations. Read operations are treated normally and their obliviousness is not preserved.
4. Path ORAM Enhancement
In the quest to improve the performance of Path ORAM and make it able to take advantage of data popularity/locality, we propose using a cache of reduced size at the client side to capture any eventual popularity/locality in the sequence of requested data blocks. As such, for each read request issued to the ORAM, we first check the cache if it contains the requested data block. In the affirmative, this will free the ORAM from having to fetch the data from the server. All write requests, on the other hand, have to be fetched from the server and then written back, but they are also stored in the cache according to their level of popularity/locality. A cache replacement policy must be used to manage our extra storage and segregate between stored data blocks according to their level of popularity. Cache replacement policies have been extensively studied in the context of the web caching. There are many replacement policies that have been proposed. Different policies suite different environments [
39]. However, it is well known that three policies in general outperform the rest of the policies. The first policy is Greedy Dual Size Frequency (GDSF). Unfortunately, this policy works only for variable block size [
40], and is consequently not applicable in our case of fixed size data blocks. The second policy is the Least Frequently Used (LFU) replacement policy where the least frequently accessed data blocks are replaced first. The third replacement policy is the Least Recently Used (LRU) where the least recently accessed data blocks are replaced first [
41]. It should be stressed here that our main objective is to extend Path ORAM to make it capable of taking advantage of any eventually data popularity and not to propose the best replacement strategy. However, it remains important to be able to lower at most the extra storage (i.e., the size of the local cache) to be added locally at the client. To this end, we shall develop a mathematical model to ascertain the minimum capacity of our extra storage to satisfy a certain hit ratio; and this independently of the used replacement strategy.
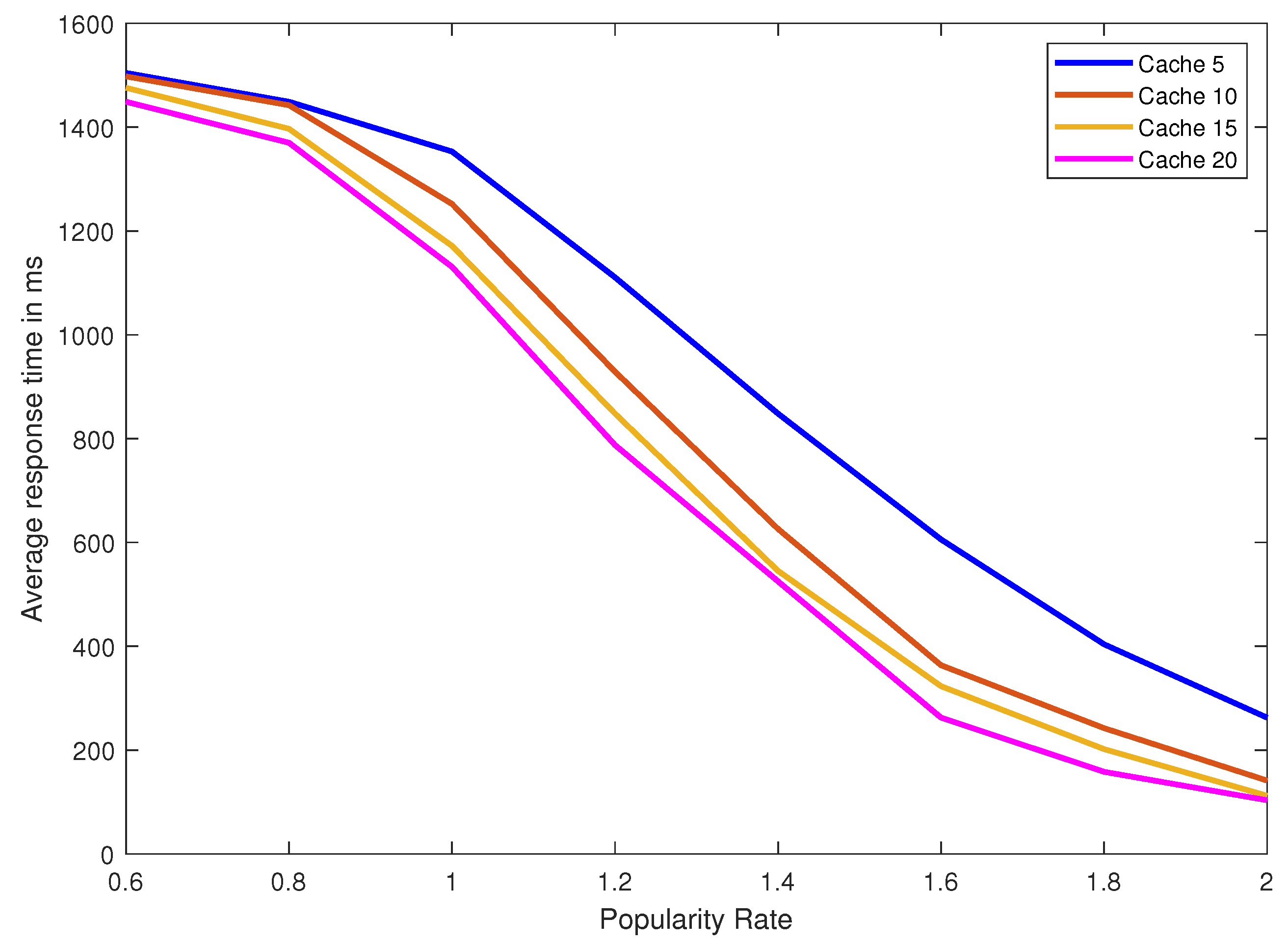
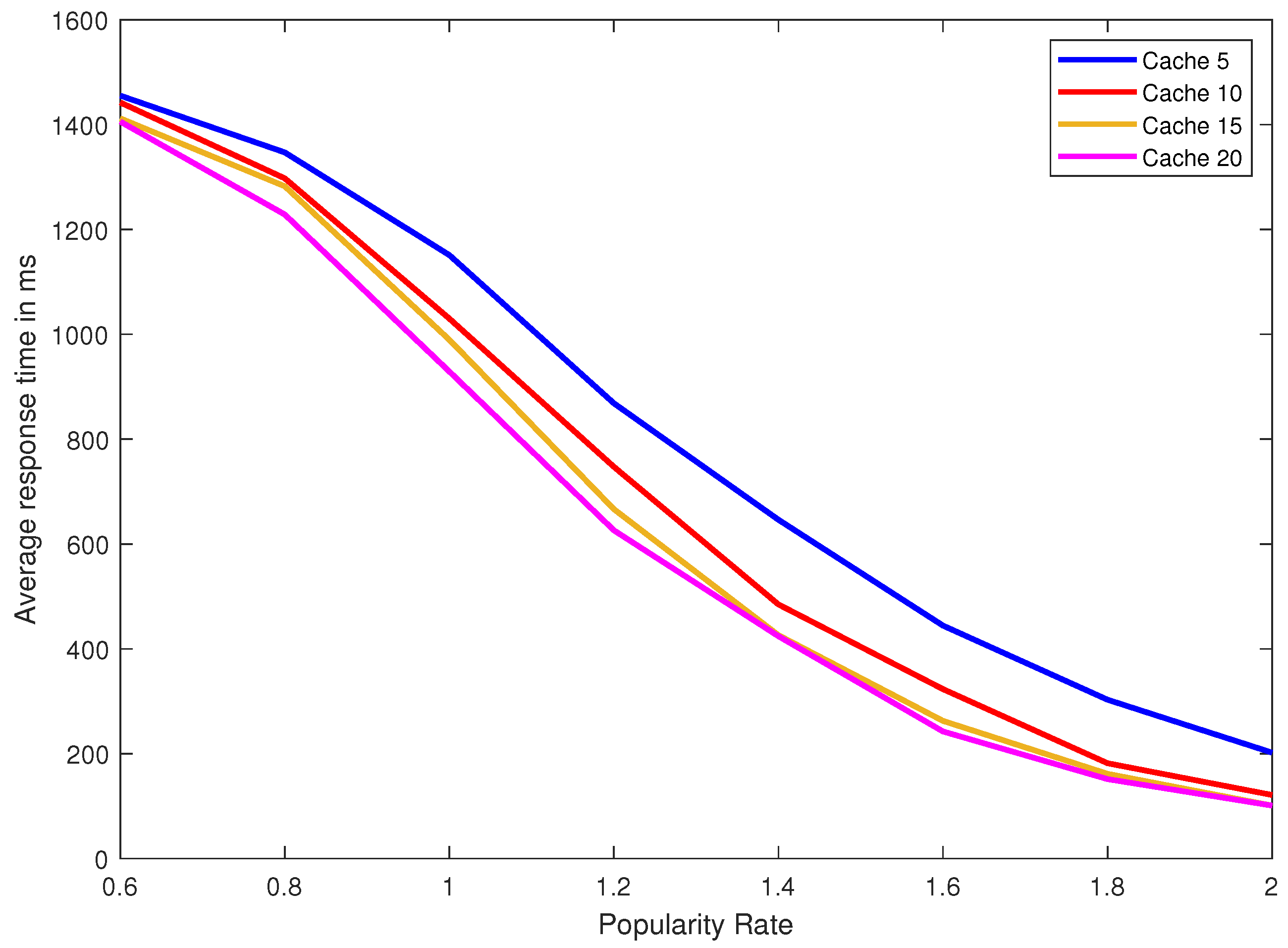
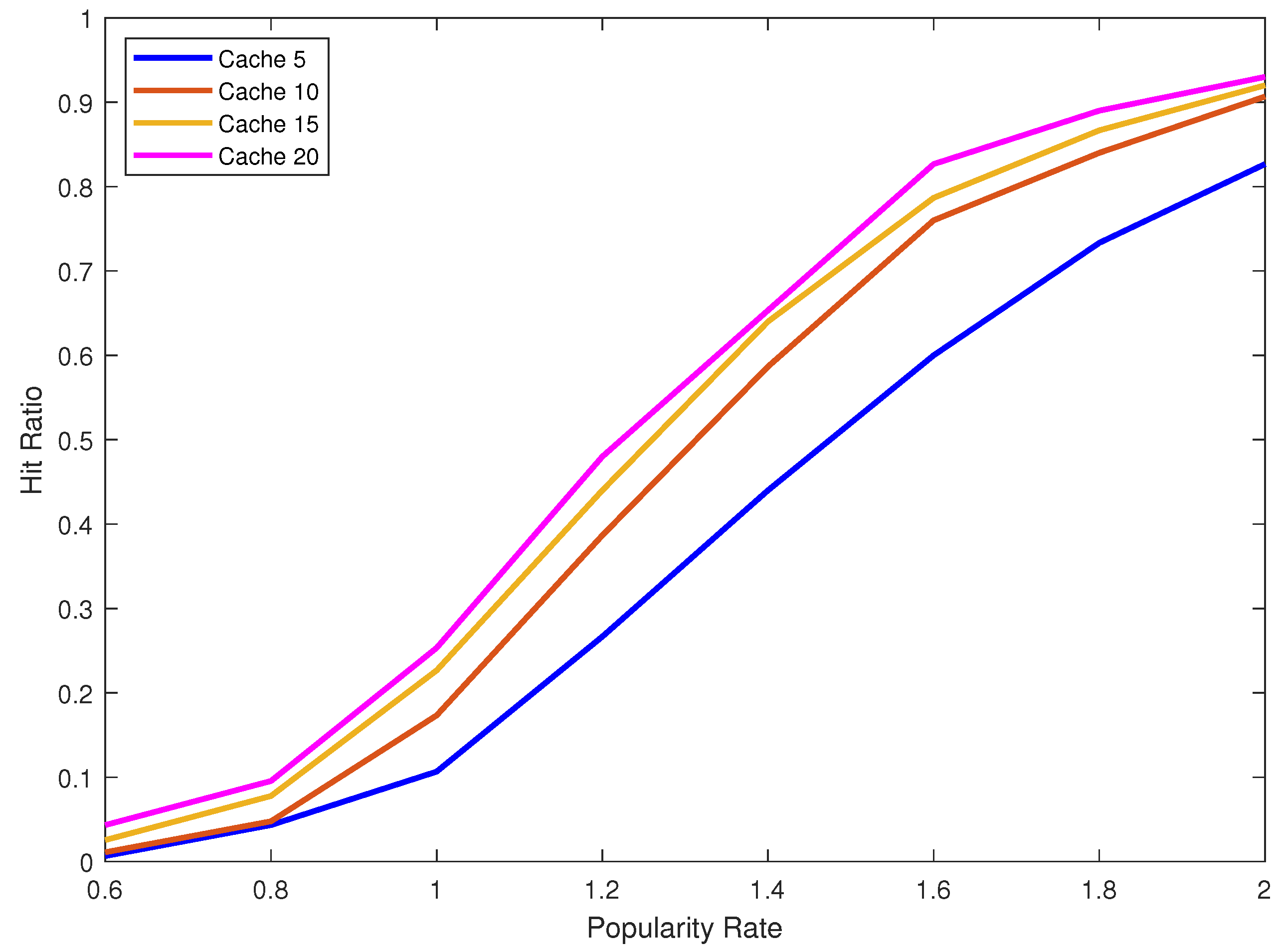
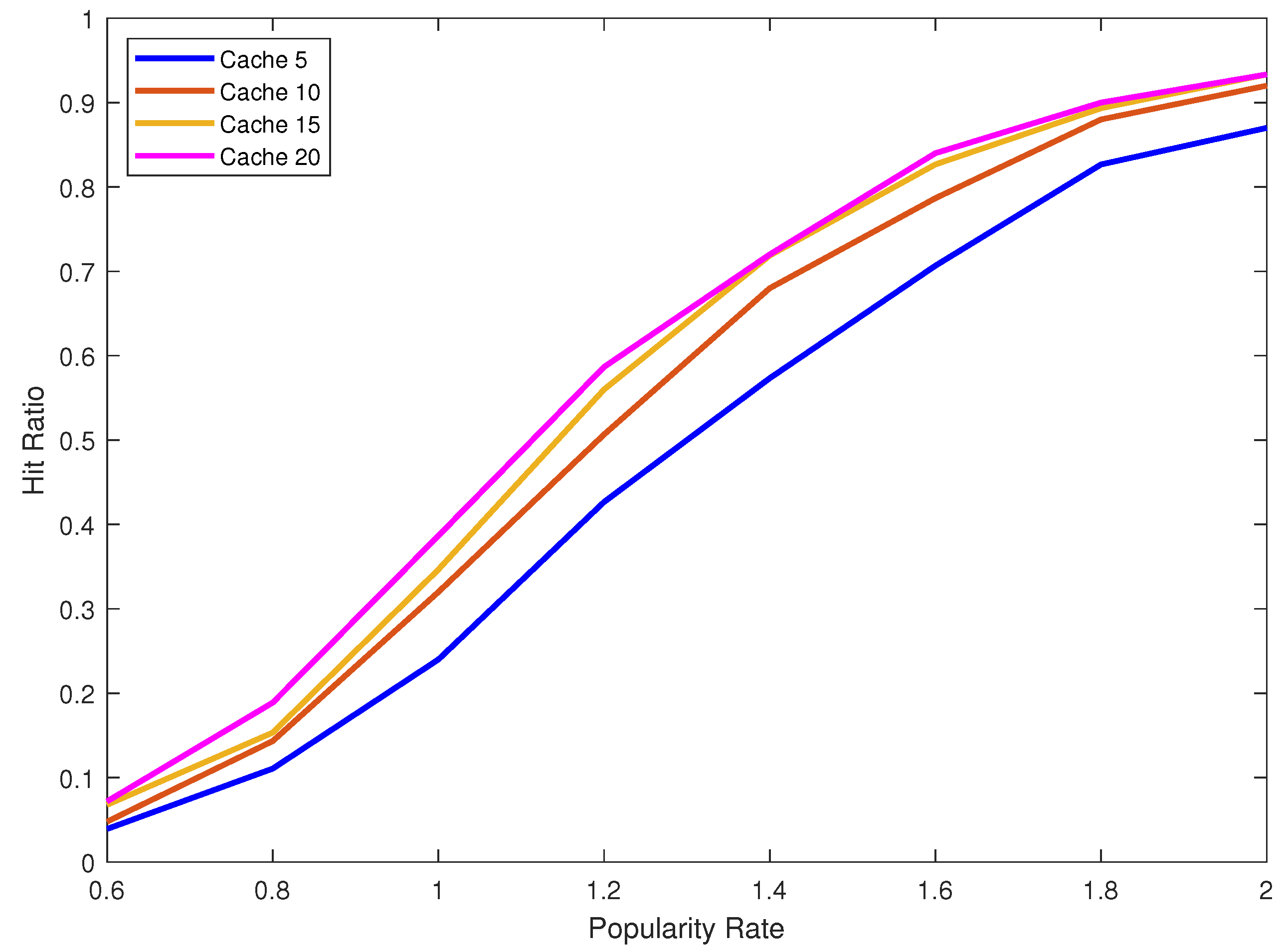
The cache used does not have to be big in fact it can be the size of five data blocks. With the current advance in technology this is very affordable, even in mobile phones and personnel devices. We show the performance gain is huge and we implement this addition to Path ORAM in real experiments using varying cache sizes of five, ten, fifteen and twenty data blocks. Moreover, we vary the popularity/locality rate of the distribution of the requested data blocks. We show that even for data with a low popularity/locality rate the gain is still good. The gain can be measured using the hit ratio defined as the percentage of client requests satisfied by the cache without the need to access the server. The higher is the hit ratio the larger is the gain and the lower is the response time of our ORAM.
Usually data blocks accessed by the user are not uniformly distributed over the set of data blocks outsourced at the server. The Zipf distribution is often used to model a non-uniform access to a database [
42,
43,
44,
45]. The Zipf distribution is also known as the 80:20 or 90:10 law. This law states that most of (from 80 to 90%) the requests address a small batch (from 10 to 20%) of the population. With the Zipf law, the object with the highest frequency is selected twice as often as the object with the second highest frequency, then the object with the second highest frequency is requested twice as often as the object with the third highest frequency and so on.
Formally the truncated version of the Zeta distribution (i.e., the Zipf law) is:
where
r represents the rank of the requested data block,
N the total number of data blocks, and
the Zipf parameter (also called the popularity parameter).
is then the probability of the requested block to be of rank
r given the parameter
, it also represents the frequency of blocks of rank
r. We denote the harmonic number of order
N and
by
; that is:
The parameter
(
> 0) plays a major role in the Zipf distribution as it determines the shape of the cumulative probability function and regulates the deterioration in requests frequencies [
42,
45,
46,
47,
48]. This parameter
can have different values for different applications. When
takes a different value than 1, the distribution is usually called Zipf-like distribution. Virtually in all previous research studies on web caching,
was considered to be less or equal to one [
49,
50,
51].
Recently new evidence showed that popularity has become more important than before, and values of
> 1 are becoming more common due to the proliferation of the Internet of Things and social networking [
40,
52,
53]. The popularity is more concentrated than before, and therefore, caching becomes a more profitable approach. In [
52], the authors analyzed 14 websites and showed that all of them provided a value
.
The modification to the Path ORAM algorithm can be done in a very simple manner. When a read request is submitted by the user the algorithm first checks to see if the block is already in the cache. If the data block is in the cache, then there is no need to proceed with the Path ORAM algorithm and just return the data block to the user. However, if the block was not present in the cache the block needs to be fetched from the server using the Path ORAM algorithm. In either case, the cache will be updated using the selected replacement strategy.
It is important to note that the invariant of Path ORAM remains unchanged since any block is either in the tree or in the stash. The copy we are keeping in the cache is an extra copy that is local to the user and does not affect the Path ORAM algorithm or violate its security.
6. Mathematical Assessment
The fundamental question here is how to approximate in a closed form solution the harmonic number
given by Formula (
2). For
,
is readily given by expression 0.131 in [
54]; that is:
where
is the Euler’s constant and is given by
= 0.5772156649. As the total number of data blocks,
N, is suppose to be very large, we consider the following approximation instead:
and consequently we obtain:
For
, the integral approximation provides a rather accurate and useful closed form approximation of
.
and consequently we get:
Formula (
6) has been very successfully used in several work on caching that assumed a Zipf parameter (a popularity index) less than 1. However Formula (
6) cannot be used for a Zipf parameter larger than 1 as it yields an unacceptable large relative error. The relative error of the use of Formula (
6) instead of the original Formula (
1) grows very quickly with
and attains more than 60% for
[
55].
In [
55], the author noticed that approximate Formula (
5) is always smaller than the actual sum of Formula (
2), as it is an integral from below. Consequently, he proposed to approximate Formula (
2) by taking the average of the integrals from above and from below, which yields:
which once replaced in Formula (
1) yields the so-called average integral approximation:
As N, the total number of data blocks is very large, we may tacitly simplify Formula (
7) to give:
which provides a much better closed form expression for the truncated Zeta function for our considered range of
(
and
) given by:
In fact, the relative error
is given by:
which yields for the case
by using Formulas (
1) and (
4):
and yield for the case of
by using Formulas (
1) and (
10):
Table 6 provides the relative errors for the considered values of
and for
N = 2048, 10,240 and 20,480. We clearly notice that our approximation of the truncated Zeta function given by Formula (
10) is excellent when
is less than 1. For
, the approximation given by Formula (
4) is also excellent. Our approximation as per Formula (
10) for
> 1, is still a good approximation but not as excellent as in the cases using lower values of
. We notice that even for a very high value of
, the relative error is still under 10%. We also notice that the relative error is not that sensitive to the value of
N especially for large values of
;
N = 2048 seems to be large enough.
6.1. Cache Size and Caching Hit Ratio
Let
be the cumulative probability of accessing the
k most frequent (i.e., popular) data blocks. Then:
Now using our approximations of the harmonic number of order
N and
, we obtain for the case
by using Formula (
3):
and for the case
that is using Formula (
9):
Let
denotes the total number of user requests;
is supposedly very large. The number of accesses made to the k most frequent data blocks, denoted by
, is then given by:
that is:
and by using Formula (
13), we obtain:
Now, if the
k most frequent data blocks are always cached independently from the specifics of any used caching scheme, then the cache hit ratio
is given by:
which yields for the case
by using Formula (
14):
and for the general case of
by using approximation (
15):
Given
k, this is the best cache hit ration that can be accomplished by any caching scheme subject to the relative error of our approximations. Finally (
20) yields the following approximations of the cache size, denoted by
, for a given cache hit ratio
:
6.2. Validation of the Mathematical Model
To validate our mathematical model, we used our experimental results.
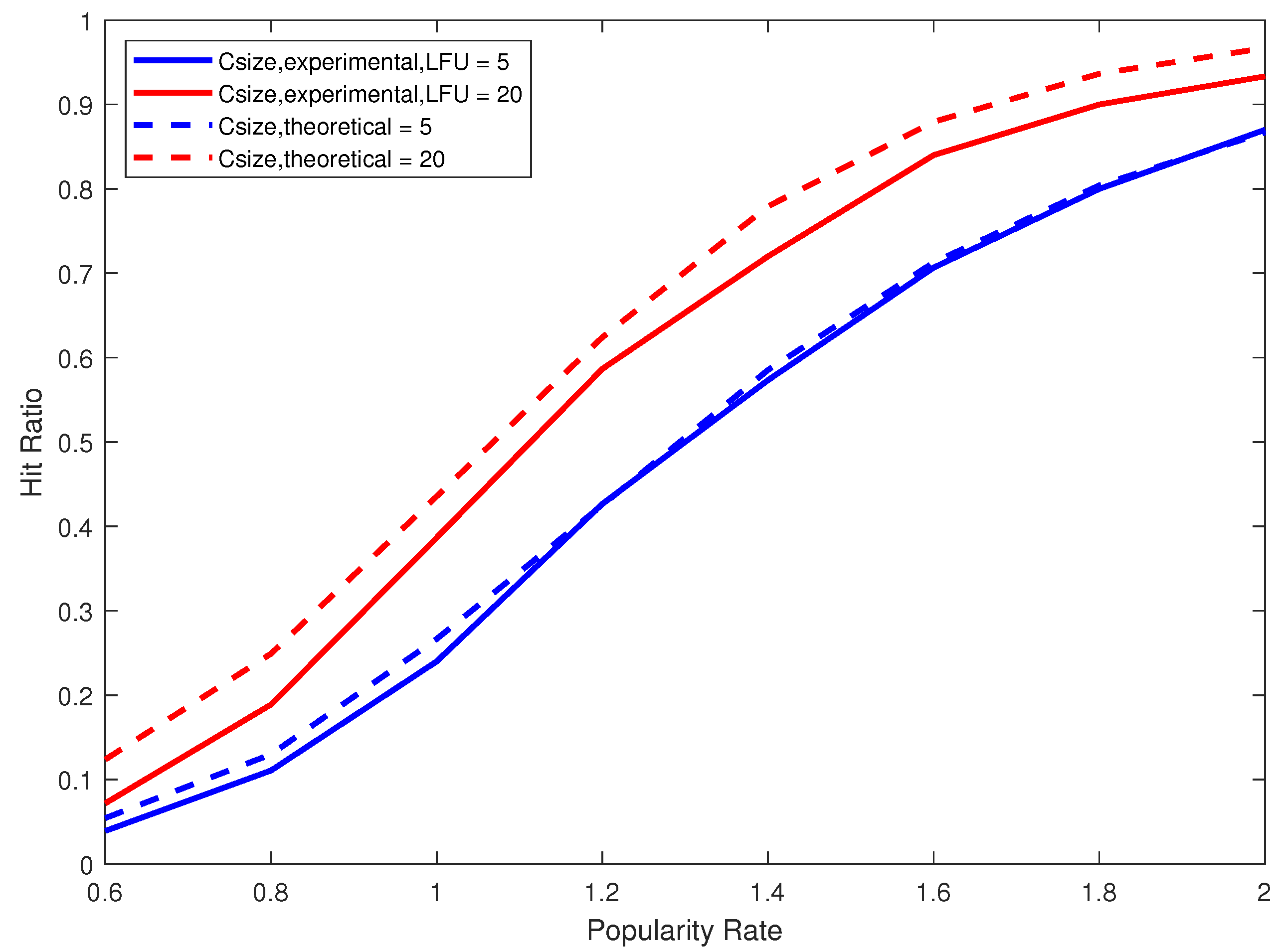
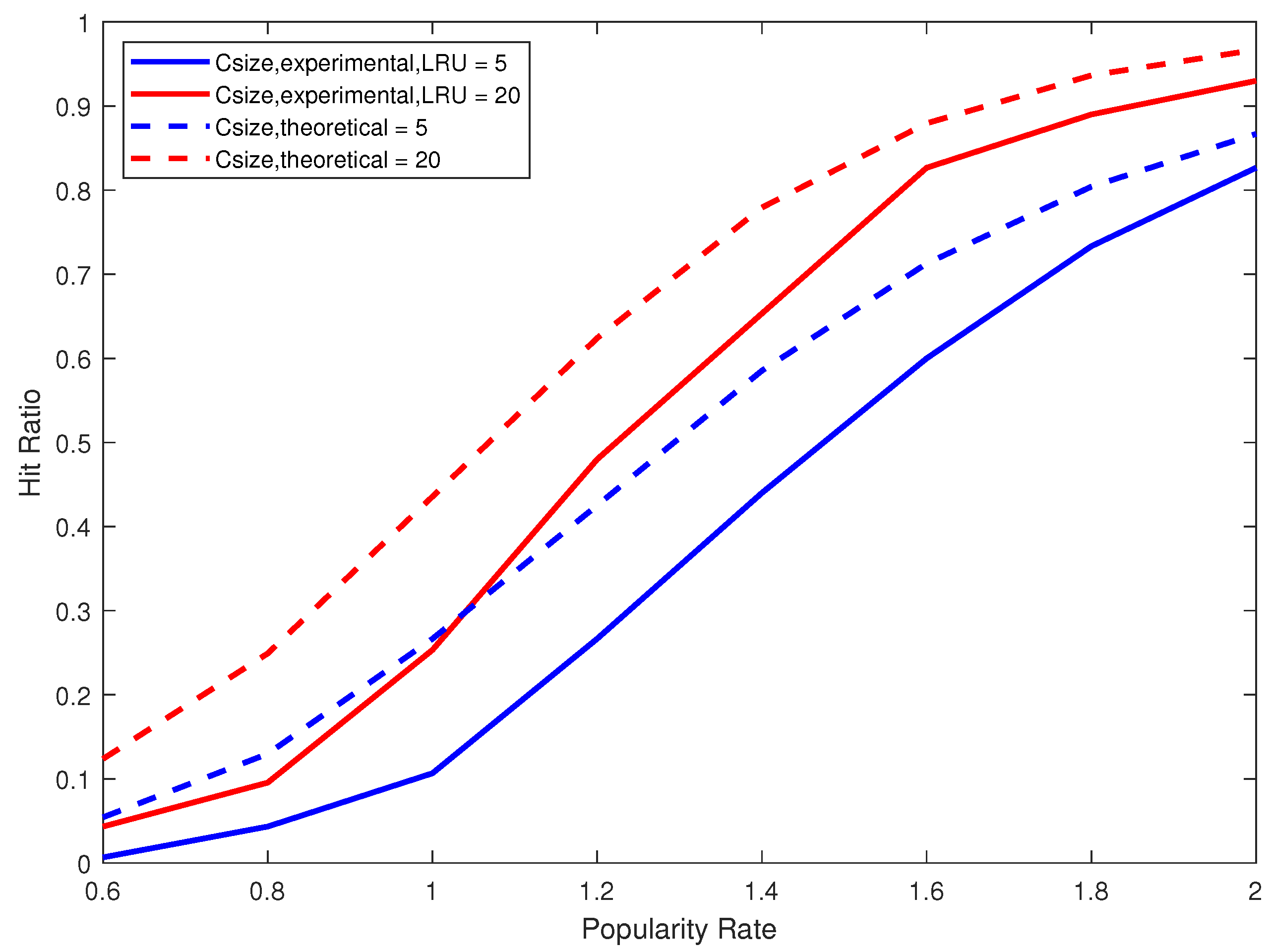
Figure 6 and
Figure 7 compare the theoretical and experimental hit ratios for cache sizes five and 20 when using LFU and LRU respectively. We clearly observe on
Figure 6 the close match between the theoretical results given by Formulas (
19) and (
20) and the experimental results using the replacement strategy LFU. On
Figure 7, we remarkably notice that both theoretical and experimental curves have the exact shape (behavior) but with almost 10% difference. This is essentially due to the use of the replacement strategy LRU that cannot accomplish as much as the theoretical case which provides the optimal (within the relative error) hit ratio. Recall that the theoretical model assumes that the k most frequent data blocks are always cached, and consequently it tacitly provides an upper bound on the value of the hit ratio.
Figure 6 clearly shows that LFU leads to a hit ratio very close to this upper bound.
Figure 7 shows, however, that LRU is not as efficient as LFU. To sum up, the experimental results are in complete synergy with our theoretical results and the mathematical model is very well validated.
Finally,
Figure 8 portrays the required cache size for the different considered values of the popularity parameter
and for a hit ration of 60%. First of all, we observe that for values of
larger than one, we only need a very small cache. However, for a small value of
, the required cache size is much bigger. Notice also that for large popularity rates, the cache size becomes much less sensitive to the total number
N of real blocks.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}