The key properties of the model are analysed at compile time. This analysis includes checking the boundedness, the ability to avoid the deadlock, finding the schedule and computing the buffer size. A model is bounded if it can be executed infinitely using finite FIFO buffers. Like in the SDF model, the SDF-AP boundedness exists if there is a finite non-zero number of firings for each actor such that executing the model the number of times as specified in the repetition vector (i.e., ) takes it back to its original state. The SDF-AP model is deadlock-free if each actor can fire without interruption for the number of times specified in the repetition vector. However, the deadlock-free property for an SDF-AP model is sufficient but not a necessary condition as often times the actor is fired before all the tokens are available in the input FIFO buffer.
The PASS schedule is followed by another schedule of a bounded SDF-AP model execution which is referred to as a
1-periodic schedule [
11]. The 1-periodic schedule is defined as
where
is the actor schedule at iteration index
and actor instance index
,
is a start time (scheduling offset) of the first actor instance, iteration period (or iteration/schedule initiation interval)
, and
is the actor scheduling period (i.e., interval between successive actor instances in one iteration). The buffer computation for SDF-AP is briefly explained in [
13,
14] whereby the constraint formulation is used to iteratively explore the buffer sizes for FIFO channels to the specified throughput. Wang et al. [
11] generalize this approach and introduce an optimization technique that is based on Integer Linear Programming (ILP) to minimize communication buffers. In this work, we present in
Section 3.2, a method to formally compute a buffer size using a 1-periodic schedule which can easily be automated in high-level synthesis tool.
Moreover, an actor is associated with the
execution pattern (
) which is a sequence of binary elements of an
access pattern (
) on the port of actor
where it is active (i.e., firing state) and idle (i.e., non-firing state) for a duration of iteration latency (
) which will be explained in
Section 3.1. The order of the
elements is determined by a 1-periodic schedule where the actor idleness (i.e.,
) in the schedule is denoted by 0’s. The
(resp.
) is used to access the
i-th element of
on source (resp. sink) port
q (resp.
p) of channel
c. For example, in
Figure 2 the execution pattern of a source port is
and that of the sink port is
The asterisk (*) represents the whole vector
where the individual elements are for example accessed as follows, the element of
at
i = 1 is
and the element of
at
i = 1 is
. Please note that the elements in bold represent locations where an actor is idle hence its neither producing nor consuming a token. We also define a
token counter (
) as the sequence of length
which represents the total number of tokens that are produced (resp. consumed) (i.e.,
(resp.
)) to (resp. from) the channel up to the
i-th clock cycle. The
computation is a trivial cumulative sum of
and using the same example of
vectors above, the token counters for a channel can be determined as
and
3.2. Buffer Size Computation
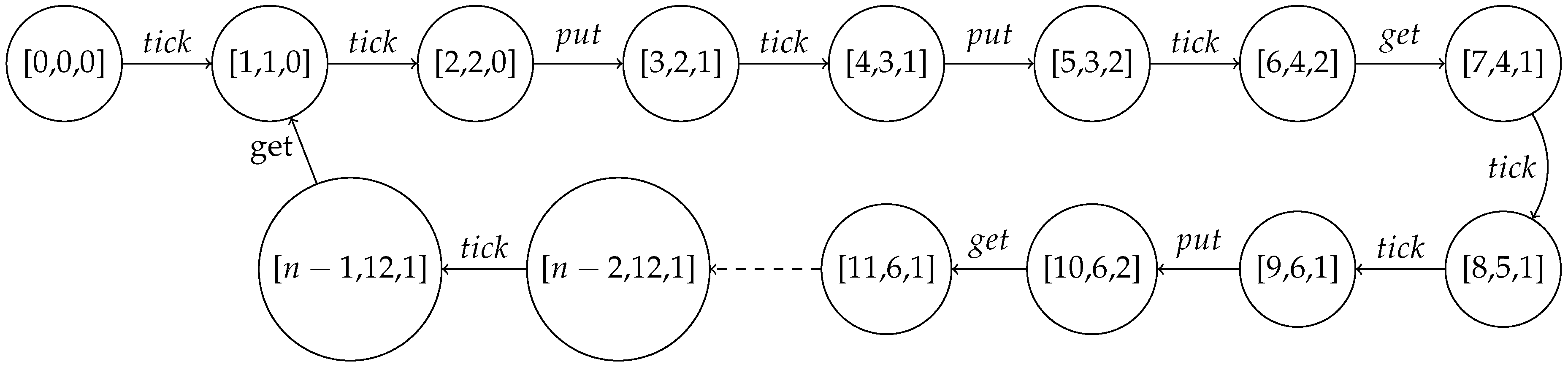
To compute the minimal buffer size from a given throughput constraint, the 1-periodic schedule is determined as in
Figure 2 under the throughput constraint of 6 samples per 12 cycles (i.e.,
) where
and
. We use rectangles to represent actor firings and the holes inside the rectangles are access patterns. A black hole denotes a single token consumption or production by an actor while the white whole indicates that token consumption or production does not occur. Each SDF-AP model iteration is represented by a sequence of actor firing with similar filled colour, hence the alternating white and shaded firing sequences correspond to individual iterations. The schedule has actor
x which executes once every four clock cycles (i.e.,
) whereas actor
y executes once in five or more clock cycles (
). The initiation interval of the model execution is 12 cycles (i.e.,
), and the iteration latency is 13 cycles (i.e.,
).
Given a throughput constraint, a valid buffer-size for each model channel can be computed from the 1-periodic schedule [
11] model provided that the system is bounded and deadlock-free. The throughput
of an actor
a is defined as the average number of firings per unit time and is determined using
or
. It can also be defined as how often the schedule
executes, in this case, the throughput formula
is used where
T is an iteration period. The maximum throughput of the SDF-AP model is only bounded by an actor with the longest execution time (
) and calculated as
where
is a model sink actor (i.e.,
),
is a model sink channel (i.e.,
) and
denotes the maximum execution time of the model actor (i.e., actor
with the longest
). For example, the maximum throughput of SDF-AP model in
Figure 1 is
We address the problem of buffer size computation of a bounded SDF-AP model execution under a 1-periodic schedule and a throughput constraint by implementing a buffer sizing algorithm shown in Algorithm 2. To explain this algorithm, we use the model example in
Figure 1. Generally, the algorithm accepts the throughput constraint
of the model and returns a set
of channel-buffer size pairs. First the iteration period
T is determined in line 2 as
with respect to model sink actor
and model sink channel
(where
and
). The algorithm continues iteratively (line 3) to find the channel buffer size of each channel of the SDF-AP model
where there is only one channel (i.e.,
) in this example. To compute the buffer size for each channel, the initial source actor scheduling period
is initialized to 0 (line 4). The source actor scheduling period
remains set (line 5) to the scheduling period
of a sink actor from the predecessor channel if the two conditions (lines 6 and 8) of Algorithm 2 do not hold. The first condition ensures that
does not fall below the
while the second one applies when the source actor of the channel (i.e.,
u) is also a root actor in a model (i.e.,
).
| Algorithm 2: Compute the buffer size for SDF-AP channels |
| Input: An SDF-AP graph |
| Input: A throughput |
| Result: A set D of pairs (channel c, buffer size ) |
| 1: procedure ComputeBufferSize () |
| 2: | ▹ iteration period T |
| 3: for each channel c in do | ▹ traverse a set of channels of graph |
| 4: | ▹ source actor initial schedule |
| 5: | ▹ source scheduling period |
| 6: if then |
| 7: |
| 8: else if then |
| 9: | ▹ source scheduling period |
| 10: end if |
| 11: | ▹ sink actor initial schedule |
| 12: If then |
| 13: |
| 14: else if and then |
| 15: |
| 16: end if |
| 17: | ▹ sink second schedule |
| 18: | ▹ Sink scheduling period |
| 19: if or then |
| 20: | ▹ Sink scheduling period |
| 21: end if |
| 22: an element-wise difference between and |
| 23: maximum element of set |
| 24: end for |
| 25: return D |
| 26: end procedure |
Next, the algorithm determines the initial schedule of the first sink actor instance
, calculated in line 11 as
and this value remains unchanged as the conditions in lines 12 and 14 do not hold. The initial schedule of the second sink actor instance
is calculated in line 17 as
and a sink actor scheduling period
is computed in line 18 as
To allocate the buffer size
in a channel
c at clock cycle
, the number of tokens consumed prior to
t is subtracted from the sum of number of produced tokens up to
t and initial delay
. Given
that is computed from
as explained in
Section 3, the vector
is extended to length
by appending the last element in line 17 as
and the vector
is extended to
by prepending 0 in line 17 as
The element-wise difference (line 17) of the two vectors above becomes
This resulting vector contains the buffer sizes at time t over one iteration period . The optimal buffer size of a channel c is then determined by finding the maximum element of which in this case is 2. Generally, the variation in buffer size between successive throughput values largely depends on the structure of the access pattern and the average number of tokens produced and consumed over a period of iteration latency . The are three possibilities regarding the buffer size results of the FIFO channel/s as the throughput () increases; the buffer size either remains constant, increases or decreases with the increased throughput. Given the two throughput values , such that and their respective computed buffer sizes , for channel c, the buffer size values () computed in the range are constant if ratio of the last elements of token counters (i.e., ) at is respectively equal to the ratio of last elements of token counters at , otherwise the buffer size from to increases or decreases. Our reason for why there is an increase or decrease when throughput goes high is attributable to the access patterns as well as the source and sink scheduling periods. Calculating the impact on buffering is not a straightforward operation due to needing to know these implementation-dependent aspects on these parameters. This aspect is out of the scope of this paper, but we do plan to take this study on buffer size further in our future research.
Furthermore, the SDF-AP model example illustrated in
Figure 1 is based on a simple acyclic graph whose analysis, scheduling and buffer computation are straight-forward. For a model with a cyclic graph, the same methodology for analysis, scheduling, and buffer computation can be used in the same way as for a model in
Figure 1. However, this can only be possible on condition that the model source (
) and sink actors (
) are not a subset of cyclic sub-graphs of the model graph. The limitation of a modeled source and sink actors that are not part of a cycle can be lifted by connecting these actors to virtual actors with infinite FIFOs. While this limitation aspect is out of the scope of this paper it will, however, be considered in the more complex examples that will be presented in our future work.

























{kind=link}
{kind=link}
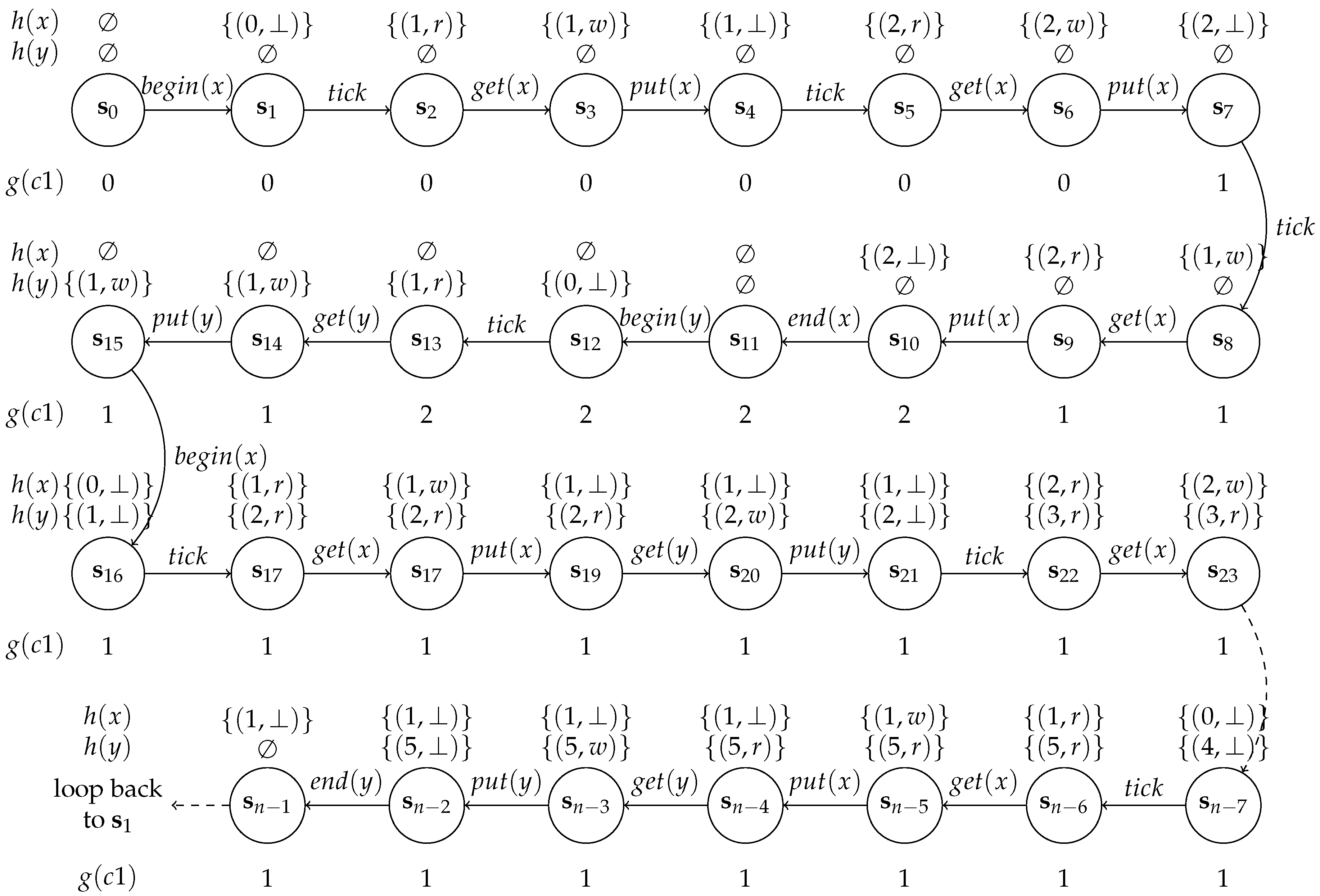{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
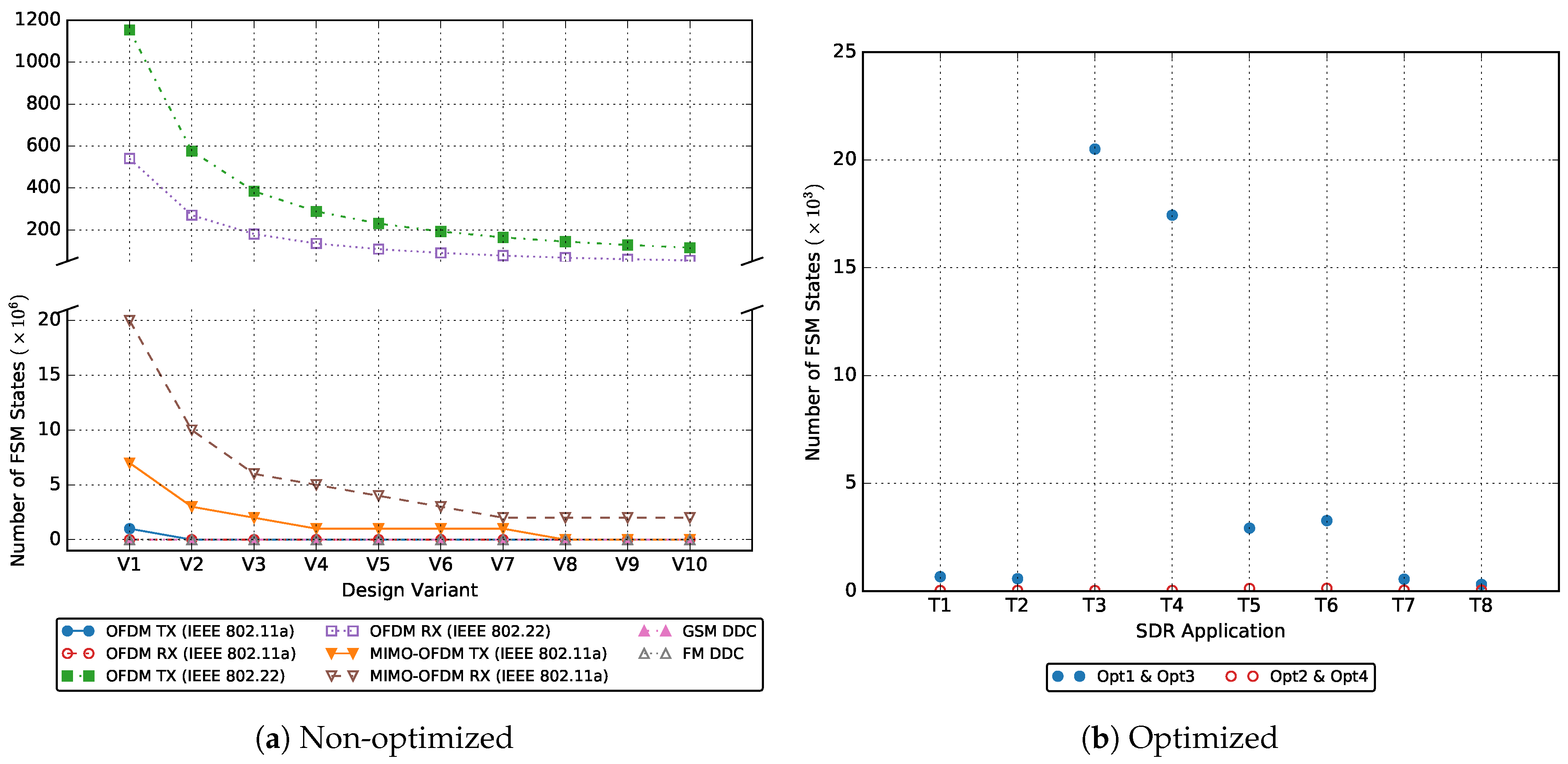{kind=link}
{kind=link}
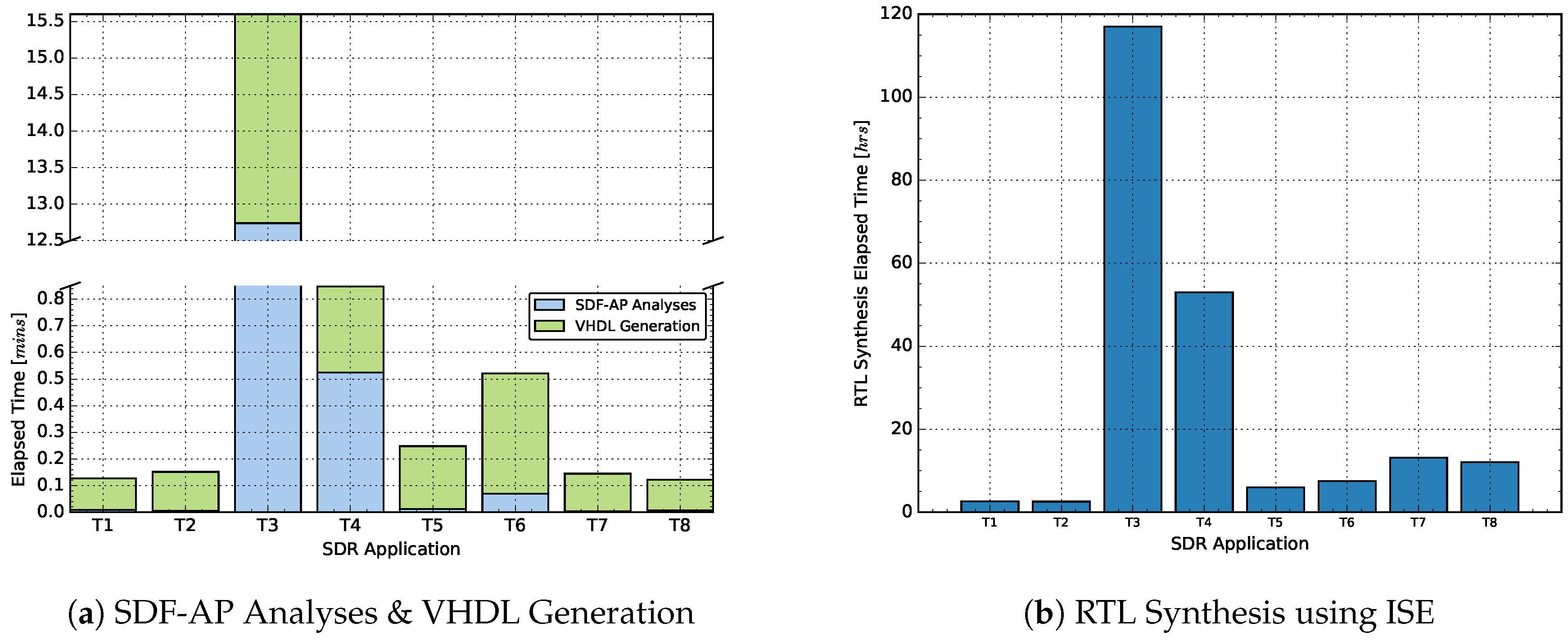{kind=link}
{kind=link}
{kind=link}