FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities




Abstract
1. Introduction
2. Microphone Arrays
2.1. Type of Microphones
2.1.1. ECMs
2.1.2. MEMS Microphones
2.1.3. Considerations
- MEMS microphones have less sensitivity to temperature variations than ECMs.
- MEMS microphones’ footprint is around 10 times smaller than ECMs.
- MEMS microphones have a lower sensitivity to vibrations or mechanical shocks than ECMs.
- ECMS have a higher device-to-device variation in their frequency response than MEMS microphones.
- ECMs need a specific soldering process and are unable to be undertaken re-flow soldering, while MEMS can.
- MEMS microphones have a better power supply rejection compared to ECMs, facilitating the reduction of the components’ count of the audio circuit design.
2.2. Microphone Array Processing
- the number of microphones
- the spacing between microphones
- the sound source spectral frequency
- the angle of incidence
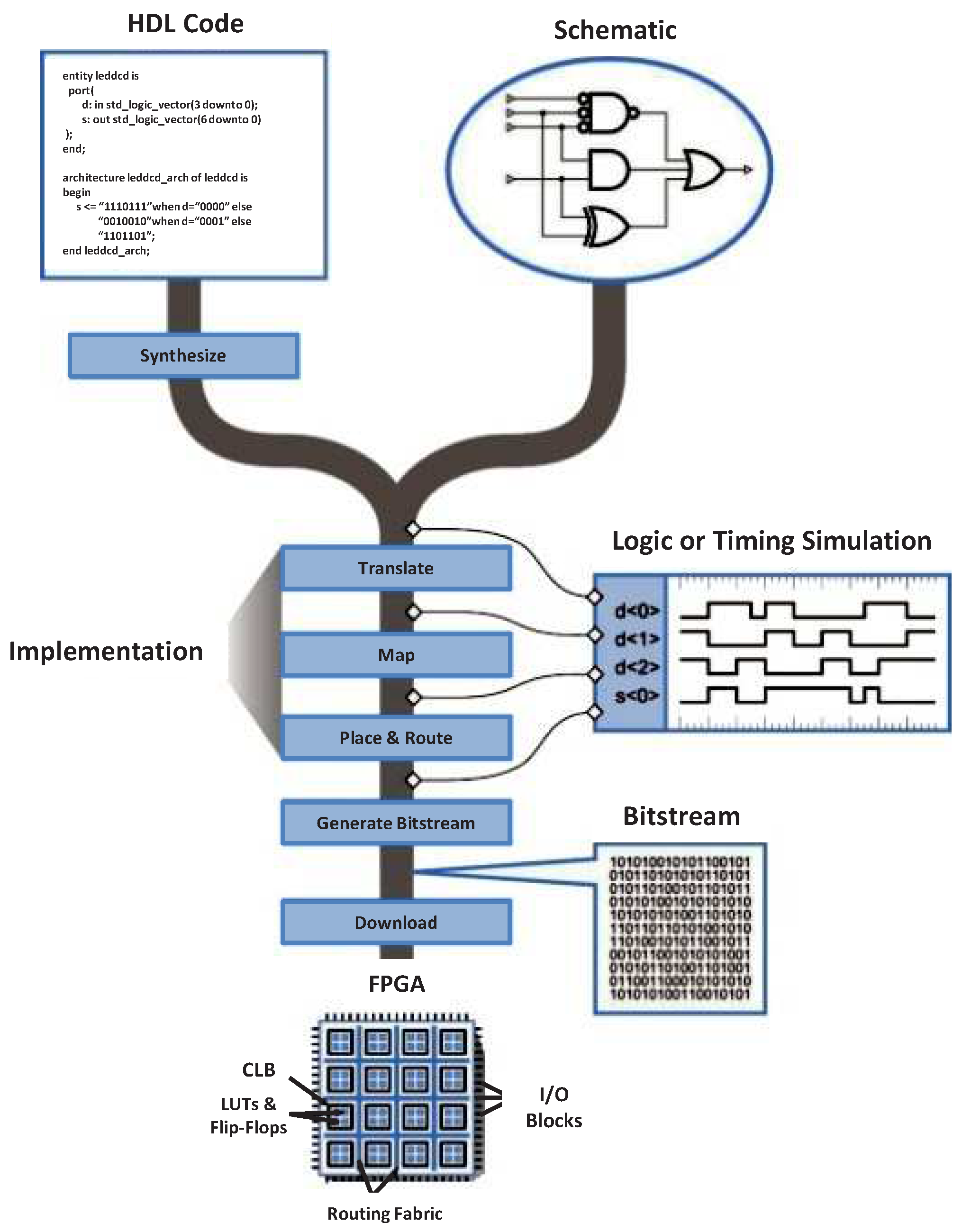
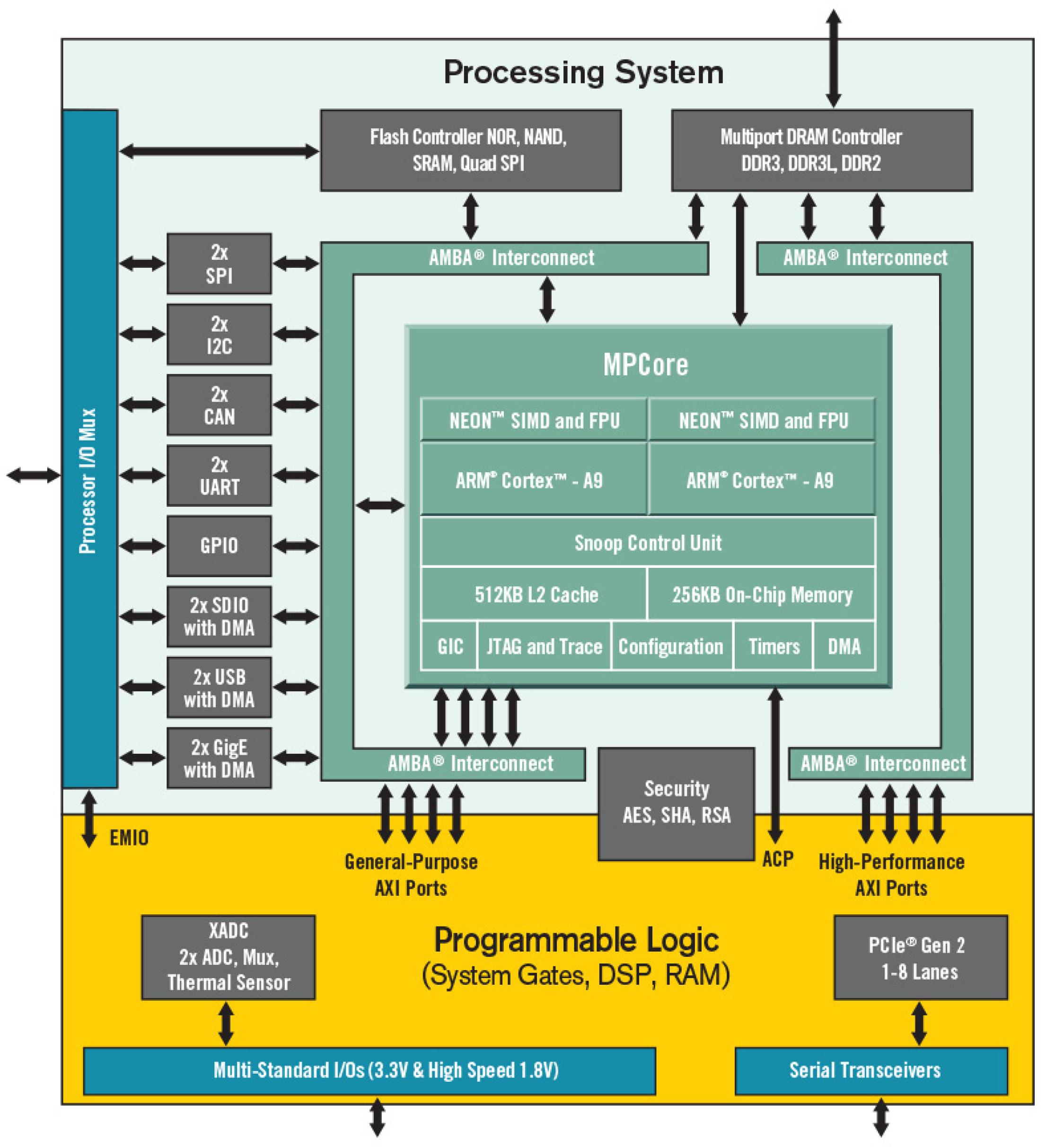
3. FPGA Technology
4. Categorization of FPGA-Based Designs for Microphone Arrays
- FPGAs satisfy the low latency and the deterministic timing required for the management of multiple data streams coming from multiple microphones. In several acoustic applications, FPGAs are used for the audio signal treatment by grouping the multiple data streams in an appropriated format before being processed. A common example is the serialization of the parallel incoming signals from the microphone array.
- Microphone arrays can be used to locate sound sources. Several FPGA-based designs embed not only the acquisition, demodulation and filtering of the data stream from the microphones, but also the required algorithms to locate sound sources. Further classification can be done based on the level of complexity of such algorithms, and the consequent computational demand.
- Highly constraint acoustic imaging applications have been developed on FPGAs in order to satisfy real-time demands and high computational requirements. The real-time computation of tens of microphones used for acoustic imaging applications demands a highly efficient performance architecture to properly exploit and achieve the performance that FPGAs offer nowadays.
4.1. FPGA-Based Audio Acquisition Systems
4.2. FPGA-Based Sound Locators
- Time-Difference of Arrival (TDOA)
- Steered Response Power (SRP)
- High-Resolution Spectral Estimation (HRSE)
4.2.1. FPGA-Based Designs of TDOA-Based Sound Locators
4.2.2. FPGA-Based Designs of SRP-Based Sound Locators
4.2.3. FPGA-Based Designs of HRSE-Based Sound Locators
4.3. FPGA-Based Acoustic Imaging
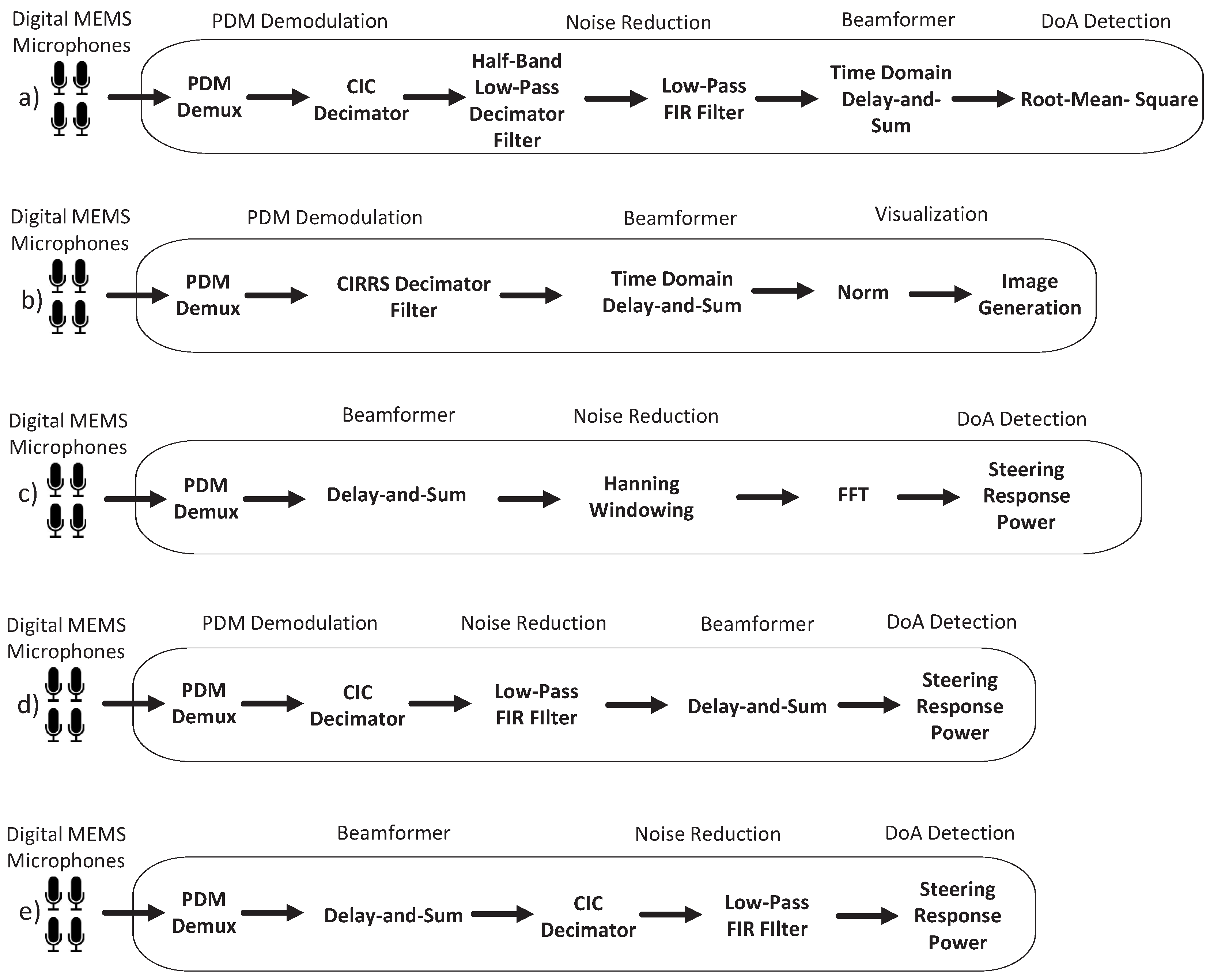
5. FPGA-Based Architectures for Acoustic Beamforming
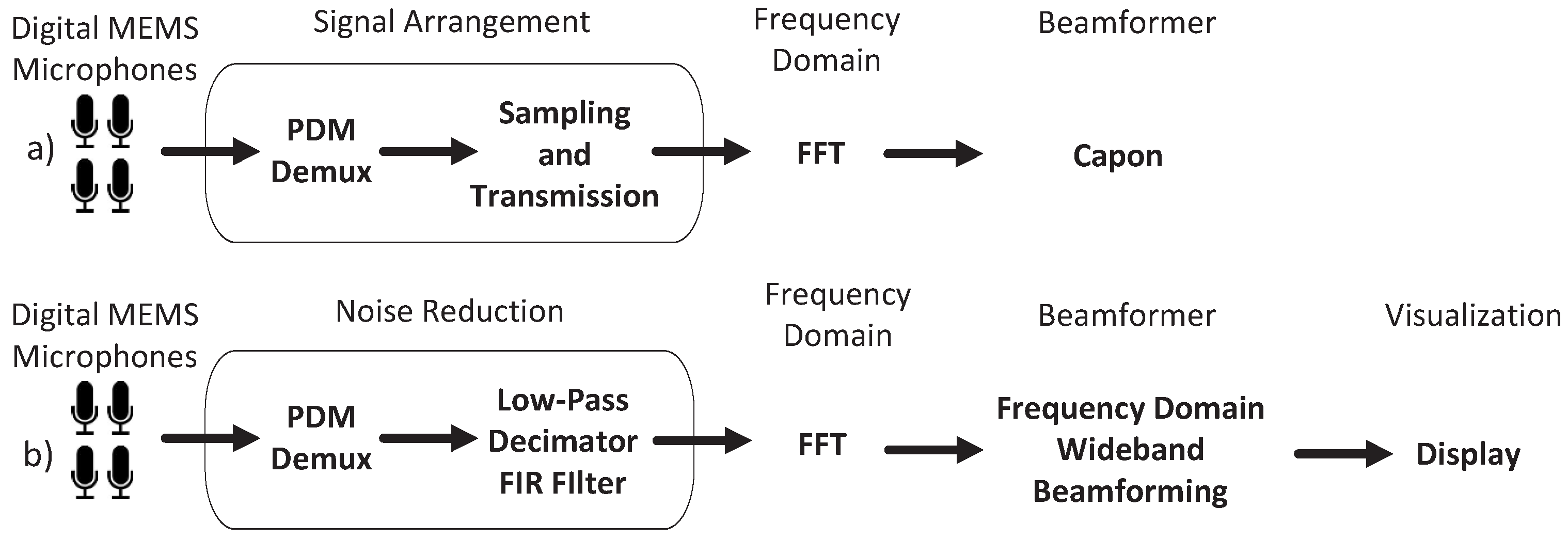
5.1. FPGA-Based Audio Signal Demodulators for Acoustic Beamforming
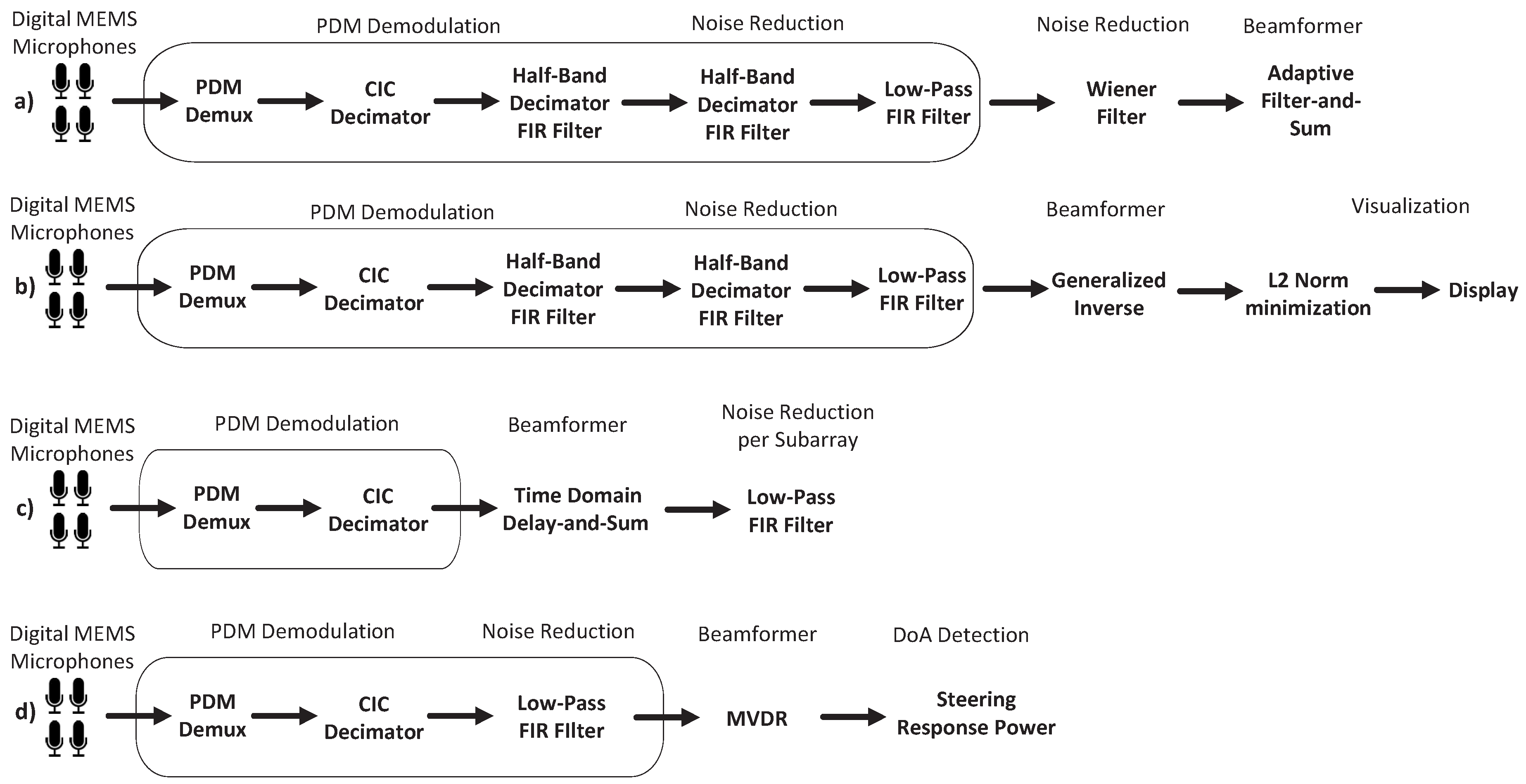
5.2. Partially Embedded FPGA-Based Acoustic Beamformers
5.3. Embedded FPGA-Based Acoustic Beamformers
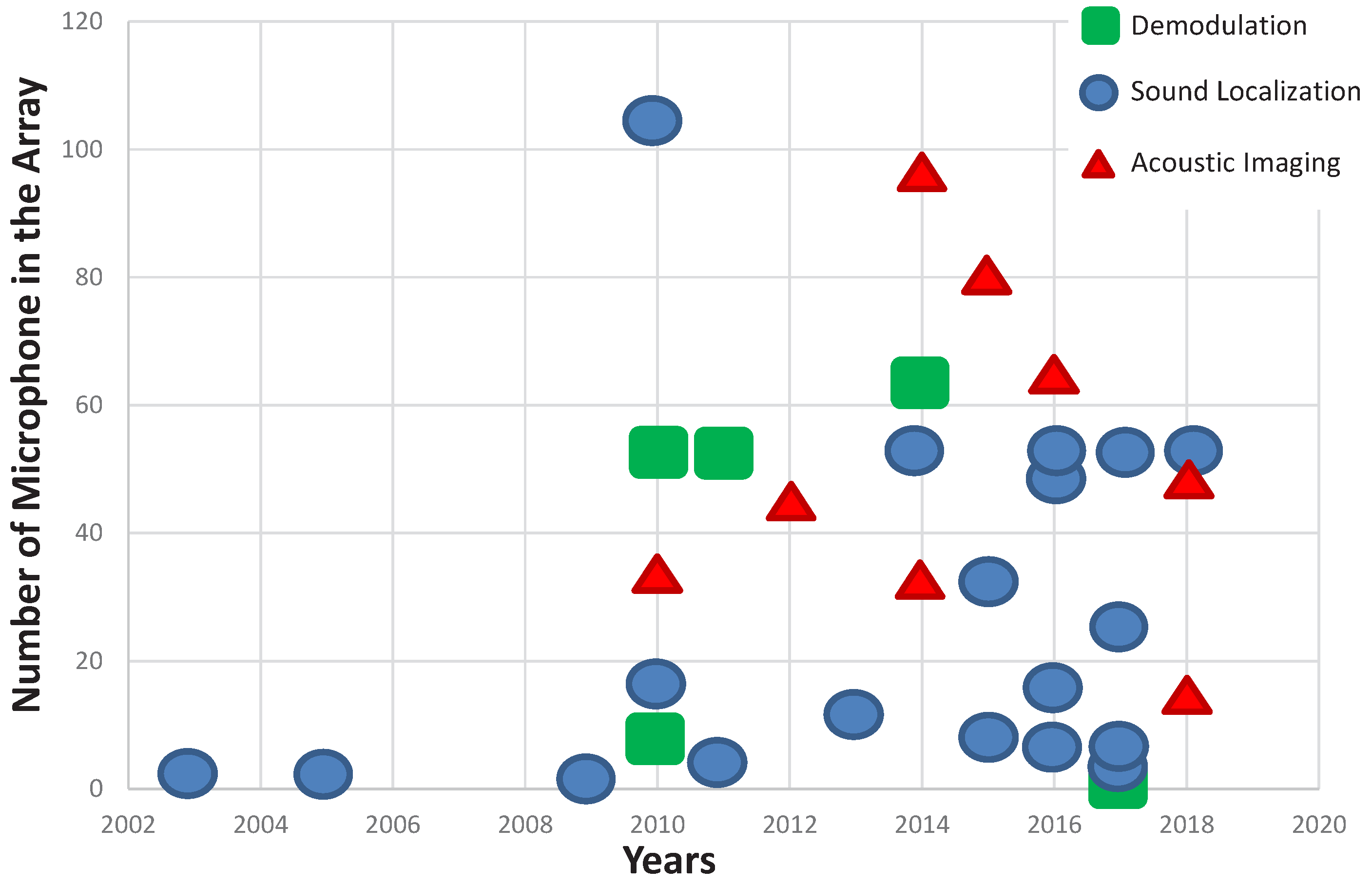
6. Trends
- Cheaper, smaller and fully integrated microphones, like digital MEMS microphones [102], facilitate the construction of larger arrays, increasing the computational demands beyond of what microprocessors or DSPs can deliver.
- FPGAs have also benefited from the Moore’s law [103], and due to a higher transistor integration in the same die, FPGAs offer larger reconfigurable resources.
7. Challenges and Research Opportunities
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Silverman, H.F.; Patterson, W.; Flanagan, J.L.; Rabinkin, D. A digital processing system for source location and sound capture by large microphone arrays. In Proceedings of the 1997 IEEE International Conference on IEEE 1997 ICASSP-97 Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 1, pp. 251–254. [Google Scholar]
- Silverman, H.F.; Patterson, W.R.; Flanagan, J.L. The huge microphone array. IEEE Concurr. 1998, 6, 36–46. [Google Scholar] [CrossRef]
- Weinstein, E.; Steele, K.; Agarwal, A.; Glass, J. Loud: A 1020-Node Modular Microphone Array and Beamformer for Intelligent Computing Spaces; Technical Report; Massachusetts Institute of Technology: Cambridge, MA, USA, 2004. [Google Scholar]
- Tiete, J.; Domínguez, F.; da Silva, B.; Touhafi, A.; Steenhaut, K. MEMS microphones for wireless applications. In Wireless MEMS Networks and Applications; Elsevier: New York, NY, USA, 2017; pp. 177–195. [Google Scholar]
- Moore, D.C.; McCowan, I.A. Microphone array speech recognition: Experiments on overlapping speech in meetings. In Proceedings of the 2003 IEEE International Conference on (ICASSP’03) IEEE Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Volume 5, p. 497. [Google Scholar]
- Microsemi, Alexa Voice Service Development Kit (ZLK38AVS2). Available online: https://www.microsemi.com/product-directory/connected-home/4628-zlk38avs (accessed on 15 July 2018).
- Widrow, B.; Luo, F.L. Microphone arrays for hearing aids: An overview. Speech Commun. 2003, 39, 139–146. [Google Scholar] [CrossRef]
- Kellermann, W. Strategies for combining acoustic echo cancellation and adaptive beamforming microphone arrays. In Proceedings of the IEEE International Conference on ICASSP-97 1997, Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 1, pp. 219–222. [Google Scholar]
- Villacorta, J.J.; Jiménez, M.I.; Val, L.D.; Izquierdo, A. A configurable sensor network applied to ambient assisted living. Sensors 2011, 11, 10724–10737. [Google Scholar] [CrossRef] [PubMed]
- Grenier, Y. A Microphone Array for Car Environments; IEEE: Piscataway, NJ, USA, 1992; pp. 305–308. [Google Scholar]
- Fuchs, M.; Haulick, T.; Schmidt, G. Noise suppression for automotive applications based on directional information. In Proceedings of the (ICASSP’04) IEEE International Conference on IEEE Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. I–237. [Google Scholar]
- Izquierdo-Fuente, A.; Del Val, L.; Jiménez, M.I.; Villacorta, J.J. Performance evaluation of a biometric system based on acoustic images. Sensors 2011, 11, 9499–9519. [Google Scholar] [CrossRef] [PubMed]
- Del Val, L.; Izquierdo-Fuente, A.; Villacorta, J.J.; Raboso, M. Acoustic biometric system based on preprocessing techniques and linear support vector machines. Sensors 2015, 15, 14241–14260. [Google Scholar] [CrossRef] [PubMed]
- Blumstein, D.T.; Mennill, D.J.; Clemins, P.; Girod, L.; Yao, K.; Patricelli, G.; Deppe, J.L.; Krakauer, A.H.; Clark, C.; Cortopassi, K.A.; et al. Acoustic monitoring in terrestrial environments using microphone arrays: Applications, technological considerations and prospectus. J. Appl. Ecol. 2011, 48, 758–767. [Google Scholar] [CrossRef]
- Nakadai, K.; Kumon, M.; Okuno, H.G.; Hoshiba, K.; Wakabayashi, M.; Washizaki, K.; Ishiki, T.; Gabriel, D.; Bando, Y.; Morito, T.; et al. Development of microphone-array-embedded UAV for search and rescue task. In Proceedings of the 2017 IEEE/RSJ International Conference on IEEE Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5985–5990. [Google Scholar]
- Case, E.E.; Zelnio, A.M.; Rigling, B.D. Low-cost acoustic array for small UAV detection and tracking. In Proceedings of the IEEE National, NAECON 2008 Aerospace and Electronics Conference, Dayton, OH, USA, 16–18 July 2008; pp. 110–113. [Google Scholar]
- Hoshiba, K.; Washizaki, K.; Wakabayashi, M.; Ishiki, T.; Kumon, M.; Bando, Y.; Gabriel, D.; Nakadai, K.; Okuno, H.G. Design of UAV-embedded microphone array system for sound source localization in outdoor environments. Sensors 2017, 17, 2535. [Google Scholar] [CrossRef] [PubMed]
- Doclo, S.; Moonen, M. GSVD-based optimal filtering for single and multimicrophone speech enhancement. IEEE Trans. Signal Process. 2002, 50, 2230–2244. [Google Scholar] [CrossRef]
- Brandstein, M.; Ward, D. Microphone Arrays: Signal Processing Techniques and Applications; Springer Science & Business Media: Berlin/Heidelberger, Germany, 2013. [Google Scholar]
- Stetron, Stetron Electret Condenser Microphones (ECM) Catalog. Available online: https://www.stetron.com/category/microphones/ (accessed on 15 July 2018).
- Hosiden, Guide for Electret Condenser Microphones. Available online: http://www.es.co.th/Schemetic/PDF/KUC.PDF (accessed on 15 July 2018).
- Neumann, J.; Gabriel, K. A fully-integrated CMOS-MEMS audio microphone. In Proceedings of the 12th International Conference on Solid-State Sensors, Actuators and Microsystems, Boston, MA, USA, 8–12 June 2003; Volume 1, pp. 230–233. [Google Scholar]
- Lewis, J. Analog and Digital MEMS Microphone Design Considerations. Available online: http://www.analog.com/media/en/technical-documentation/technical-articles/Analog-and-Digital-MEMS-Microphone-Design-Considerations-MS-2472.pdf (accessed on 15 July 2018).
- Lewis, J.; Moss, B. MEMS microphone: The future for hearing aids. Analog Dialog. 2013, 47, 3–5. [Google Scholar]
- Song, Y. Design, Analysis and Characterization of Silicon Microphones; State University of New York: Binghamton, NY, USA, 2008. [Google Scholar]
- Fairchild, FAN3850A Microphone Pre-Amplifier with Digital Output. Available online: http://www.onsemi.com/PowerSolutions/product.do?id=FAN3850A (accessed on 15 July 2018).
- Philips Semiconductors, I2S Bus Specification. Available online: https://www.sparkfun.com/datasheets/BreakoutBoards/I2SBUS.pdf (accessed on 15 July 2018).
- MEMS Analog and Digital Microphones, ST Microelectronics. Available online: http://www.st.com/content/ccc/resource/sales_and_marketing/promotional_material/flyer/83/e5/0d/ba/f0/40/4b/a3/flmemsmic.pdf/files/flmemsmic.pdf/jcr:content/translations/en.flmemsmic.pdf (accessed on 1 June 2018).
- Lewis, J. Understanding Microphone Sensitivity. Available online: http://www.analog.com/en/analog-dialogue/articles/understanding-microphone-sensitivity.html (accessed on 31 July 2018).
- Hegde, N. Seamlessly Interfacing MEMS Microphones with Blackfin Processors. EE-350 Engineer-to-Engineer Note. 2010. Available online: http://www.analog.com/media/en/technical-documentation/application-notes/EE-350rev1.pdf (accessed on 31 July 2018).
- TDK Invensense, ICS-43434 Datasheet. Available online: https://www.invensense.com/wp-content/uploads/2016/02/DS-000069-ICS-43434-v1.2.pdf (accessed on 15 July 2018).
- da Silva, B.; Braeken, A.; Steenhaut, K.; Touhafi, A. Design Considerations When Accelerating an FPGA-Based Digital Microphone Array for Sound-Source Localization. J. Sens. 2017, 2017, 6782176:1–6782176:20. [Google Scholar] [CrossRef]
- Seltzer, M.L. Microphone Array Processing for Robust Speech Recognition. Ph.D. Thesis, CMU, Pittsburgh, PA, USA, 2003. [Google Scholar]
- Tiete, J.; Domínguez, F.; da Silva, B.; Segers, L.; Steenhaut, K.; Touhafi, A. SoundCompass: A Distributed MEMS Microphone Array-Based Sensor for Sound Source Localization. Sensors 2014, 14, 1918–1949. [Google Scholar] [CrossRef] [PubMed]
- Petersen, D.; Howard, C. Simulation and design of a microphone array for beamforming on a moving acoustic source. In Proceedings of the Acoustics 2013, Victor Harbor, Australia, 9–11 November 2013. [Google Scholar]
- Sarradj, E. A generic approach to synthesize optimal array microphone arrangements. In Proceedings of the 6th Berlin Beamforming Conference, BeBeC-2016-S4, Senftenberg, Germany, 5–6 March 2016. [Google Scholar]
- Krim, H.; Viberg, M. Two decades of array signal processing research: the parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Van Veen, B.D.; Buckley, K.M. Beamforming: A versatile approach to spatial filtering. IEEE ASSP Mag. 1988, 5, 4–24. [Google Scholar] [CrossRef]
- Mucci, R. A comparison of efficient beamforming algorithms. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 548–558. [Google Scholar] [CrossRef]
- Xilinx Vivado High-Level Synthesis. Available online: https://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html (accessed on 1 June 2018).
- Intel/Altera HLS Compiler. Available online: https://www.altera.com/products/design-software/high-level-design/intel-hls-compiler/overview.html (accessed on 15 July 2018).
- Intel/Altera FPGA SDK for OpenCL. Available online: https://www.altera.com/products/design-software/embedded-software-developers/opencl/overview.html (accessed on 15 July 2018).
- OpenRISC Project: Open processor for Embedded Systems. Available online: https://openrisc.io/ (accessed on 30 July 2018).
- RISC-V Foundation. Available online: https://riscv.org/ (accessed on 30 July 2018).
- Xilinx MicroBlaze Soft Processor Core. Available online: https://www.xilinx.com/products/design-tools/microblaze.html (accessed on 30 July 2018).
- Intel/Altera Nios-II Soft Processor. Available online: https://www.intel.la/content/www/xl/es/products/programmable/processor/nios-ii.html (accessed on 30 July 2018).
- Xilinx Zynq-7000 SoC. Available online: https://www.xilinx.com/products/silicon-devices/soc/zynq-7000.html (accessed on 1 June 2018).
- Turqueti, M.; Saniie, J.; Oruklu, E. MEMS acoustic array embedded in an FPGA based data acquisition and signal processing system. In Proceedings of the 2010 53rd IEEE International Midwest Symposium on IEEE Circuits and Systems (MWSCAS), Seattle, WA, USA, 1–4 August 2010; pp. 1161–1164. [Google Scholar]
- Turqueti, M.; Rivera, R.A.; Prosser, A.; Andresen, J.; Chramowicz, J. CAPTAN: A hardware architecture for integrated data acquisition, control, and analysis for detector development. In Proceedings of the 2008 NSS’08 IEEE Nuclear Science Symposium Conference Record, Piscataway, NJ, USA, 25–28 October 2008; pp. 3546–3552. [Google Scholar]
- Turqueti, M.; Kunin, V.; Cardoso, B.; Saniie, J.; Oruklu, E. Acoustic sensor array for sonic imaging in air. In Proceedings of the 2010 IEEE Ultrasonics Symposium (IUS), San Diego, CA, USA, 11–14 October 2010; pp. 1833–1836. [Google Scholar]
- Kunin, V.; Turqueti, M.; Saniie, J.; Oruklu, E. Direction of arrival estimation and localization using acoustic sensor arrays. J. Sens. Technol. 2011, 1, 71–80. [Google Scholar] [CrossRef]
- Havránek, Z.; Beneš, P.; Klusáček, S. Free-field calibration of MEMS microphone array used for acoustic holography. In Proceedings of the 21st International Congress on Sound and Vibration, Beijing, China, 13–17 July 2014. [Google Scholar]
- Akay, M.; Dragomir, A.; Akay, Y.M.; Chen, F.; Post, A.; Jneid, H.; Paniagua, D.; Denktas, A.; Bozkurt, B. The Assessment of Stent Effectiveness Using a Wearable Beamforming MEMS Microphone Array System. IEEE J. Transl. Eng. Health Med. 2016, 4, 1–10. [Google Scholar] [CrossRef]
- DiBiase, J.H.; Silverman, H.F.; Brandstein, M.S. Robust localization in reverberant rooms. In Microphone Arrays; Springer: Berlin, Germany, 2001; pp. 157–180. [Google Scholar]
- Nguyen, D.; Aarabi, P.; Sheikholeslami, A. Real-time sound localization using field-programmable gate arrays. In Proceedings of the 2003 (ICASSP’03) IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Volume 2, p. 573. [Google Scholar]
- Wang, J.F.; Jiang, Y.C.; Sun, Z.W. FPGA implementation of a novel far-field sound localization system. In Proceedings of the TENCON 2009 IEEE Region 10 Conference, Singapore, 23–26 November 2009; pp. 1–4. [Google Scholar]
- Simon, G.; Maróti, M.; Lédeczi, Á.; Balogh, G.; Kusy, B.; Nádas, A.; Pap, G.; Sallai, J.; Frampton, K. Sensor network-based countersniper system. In Proceedings of the 2nd International Conference on Embedded Networked Sensor Systems, Baltimore, MD, USA, 3–5 November 2004; pp. 1–12. [Google Scholar]
- Lédeczi, Á.; Nádas, A.; Völgyesi, P.; Balogh, G.; Kusy, B.; Sallai, J.; Pap, G.; Dóra, S.; Molnár, K.; Maróti, M.; et al. Countersniper system for urban warfare. ACM Trans. Sens. Netw. 2005, 1, 153–177. [Google Scholar] [CrossRef]
- Aleksi, I.; Hocenski, Ž.; Horvat, P. Acoustic Localization based on FPGA. In Proceedings of the 33rd International Convention MIPRO, Opatija, Croatia, 24–28 May 2010; pp. 656–658. [Google Scholar]
- Faraji, M.M.; Shouraki, S.B.; Iranmehr, E. Spiking neural network for sound localization using microphone array. In Proceedings of the 2015 23rd Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 10–14 May 2015; pp. 1260–1265. [Google Scholar]
- Biswas, T.; Mandal, S.B.; Saha, D.; Chakrabarti, A. Coherence based dual microphone speech enhancement technique using FPGA. Microprocess. Microsyst. 2017, 55, 111–118. [Google Scholar] [CrossRef]
- Sledevič, T.; Laptik, R. An evaluation of hardware-software design for sound source localization based on SoC. In Proceedings of the 2017 Open Conference of IEEE, Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 27 April 2017; pp. 1–4. [Google Scholar]
- Đurišić, M.P.; Tafa, Z.; Dimić, G.; Milutinović, V. A survey of military applications of wireless sensor networks. In Proceedings of the 2012 Mediterranean Conference on, IEEE, Embedded Computing (MECO), Bar, Montenegro, 19–21 June 2012; pp. 196–199. [Google Scholar]
- Sallai, J.; Hedgecock, W.; Volgyesi, P.; Nadas, A.; Balogh, G.; Ledeczi, A. Weapon classification and shooter localization using distributed multichannel acoustic sensors. J. Syst. Archit. 2011, 57, 869–885. [Google Scholar] [CrossRef]
- Abdeen, A.; Ray, L. Design and performance of a real-time acoustic beamforming system. In Proceedings of the 2013 SENSORS, Baltimore, MD, USA, 3–6 November 2013; pp. 1–4. [Google Scholar]
- Zwyssig, E.; Lincoln, M.; Renals, S. A digital microphone array for distant speech recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 5106–5109. [Google Scholar]
- Hafizovic, I.; Nilsen, C.I.C.; Kjølerbakken, M. Acoustic tracking of aircraft using a circular microphone array sensor. In Proceedings of the 2010 IEEE International Symposium on Phased Array Systems and Technology (ARRAY), Waltham, MA, USA, 12–15 October 2010; pp. 1025–1032. [Google Scholar]
- Hafizovic, I.; Nilsen, C.I.C.; Kjølerbakken, M.; Jahr, V. Design and implementation of a MEMS microphone array system for real-time speech acquisition. Appl. Acoust. 2012, 73, 132–143. [Google Scholar] [CrossRef]
- Salom, I.; Celebic, V.; Milanovic, M.; Todorovic, D.; Prezelj, J. An implementation of beamforming algorithm on FPGA platform with digital microphone array. In Proceedings of the Audio Engineering Society Convention 138, Audio Engineering Society, Warsaw, Poland, 7–10 May 2015. [Google Scholar]
- Todorović, D.; Salom, I.; Čelebić, V.; Prezelj, J. Implementation and Application of FPGA Platform with Digital MEMS Microphone Array. In Proceedings of the Proceedings of 4th International Conference on Electrical, Electronics and Computing Engineering, Kladovo, Serbia, 5–8 June 2017; pp. 1–6. [Google Scholar]
- Petrica, L.; Stefan, G. Energy-Efficient WSN Architecture for Illegal Deforestation Detection. Int. J. Sens. Sens. Netw. 2015, 3, 24–30. [Google Scholar]
- Petrica, L. An evaluation of low-power microphone array sound source localization for deforestation detection. Appl. Acoust. 2016, 113, 162–169. [Google Scholar] [CrossRef]
- Kowalczyk, K.; Wozniak, S.; Chyrowicz, T.; Rumian, R. Embedded system for acquisition and enhancement of audio signals. In Proceedings of the 2016 IEEE, Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 21–23 September 2016; pp. 68–71. [Google Scholar]
- Azcarreta Ortiz, J. Pyramic Array: An FPGA Based Platform for Many-Channel Audio Acquisition. Master’s Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2016. [Google Scholar]
- Bezzam, E.; Scheibler, R.; Azcarreta, J.; Pan, H.; Simeoni, M.; Beuchat, R.; Hurley, P.; Bruneau, B.; Ferry, C.; Kashani, S. Hardware and software for reproducible research in audio array signal processing. In Proceedings of the 2017 IEEE International Conference on IEEE, Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 6591–6592. [Google Scholar]
- da Silva, B.; Segers, L.; Braeken, A.; Touhafi, A. Runtime reconfigurable beamforming architecture for real-time sound-source localization. In Proceedings of the 26th International Conference on Field Programmable Logic and Applications, FPL 2016, Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar]
- Samtani, K.; Thomas, J.; Varma, G.A.; Sumam, D.S.; Deepu, S.P. FPGA implementation of adaptive beamforming in hearing aids. In Proceedings of the 2017 39th Annual International Conference of the IEEE, Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; pp. 2239–2242. [Google Scholar]
- Inoue, T.; Ikeda, Y.; Oikawa, Y. Hat-type hearing aid system with flexible sound directivity pattern. Acoust. Sci. Technol. 2018, 39, 22–29. [Google Scholar] [CrossRef]
- da Silva, B.; Segers, L.; Braeken, A.; Steenhaut, K.; Touhafi, A. A Low-Power FPGA-Based Architecture for Microphone Arrays in Wireless Sensor Networks. In Proceedings of the 14th International Symposium, Applied Reconfigurable Computing. Architectures, Tools, and Applications 2018, Santorini, Greece, 2–4 May 2018; pp. 281–293. [Google Scholar]
- Luo, F.L.; Yang, J.; Pavlovic, C.; Nehorai, A. Adaptive null-forming scheme in digital hearing aids. IEEE Trans. Signal Process. 2002, 50, 1583–1590. [Google Scholar]
- Takagi, T.; Noguchi, H.; Kugata, K.; Yoshimoto, M.; Kawaguchi, H. Microphone array network for ubiquitous sound acquisition. In Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 1474–1477. [Google Scholar]
- Kugata, K.; Takagi, T.; Noguchi, H.; Yoshimoto, M.; Kawaguchi, H. Intelligent ubiquitous sensor network for sound acquisition. In Proceedings of the 2010 IEEE International Symposium on IEEE, 2010 Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; pp. 1414–1417. [Google Scholar]
- Izumi, S.; Noguchi, H.; Takagi, T.; Kugata, K.; Soda, S.; Yoshimoto, M.; Kawaguchi, H. Data aggregation protocol for multiple sound sources acquisition with microphone array network. In Proceedings of the 20th International Conference on IEEE Computer Communications and Networks (ICCCN), Lahaina, HI, USA, 31 July–4 August 2011; pp. 1–6. [Google Scholar]
- Zimmermann, B.; Studer, C. FPGA-based real-time acoustic camera prototype. In Proceedings of the 2010 IEEE International Symposium on IEEE, Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; p. 1419. [Google Scholar]
- Sanchez-Hevia, H.; Gil-Pita, R.; Rosa-Zurera, M. FPGA-based real-time acoustic camera using pdm mems microphones with a custom demodulation filter. In Proceedings of the 2014 IEEE 8th IEEE, Sensor Array and Multichannel Signal Processing Workshop (SAM), A Coruna, Spain, 22–25 June 2014; pp. 181–184. [Google Scholar]
- Sánchez-Hevia, H.A.; Mohino-Herranz, I.; Gil-Pita, R.; Rosa-Zurera, M. Memory Requirements Reduction Technique for Delay Storage in Real Time Acoustic Cameras; Audio Engineering Society Convention 136; Audio Engineering Society: New York, NY, USA, 2014. [Google Scholar]
- Kim, Y.; Kang, J.; Lee, M. Developing beam-forming devices to detect squeak and rattle sources by using FPGA. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings. Institute of Noise Control Engineering, Melbourne, Australia, 16–19 November 2014; Volume 249, pp. 4582–4587. [Google Scholar]
- Perrodin, F.; Nikolic, J.; Busset, J.; Siegwart, R. Design and calibration of large microphone arrays for robotic applications. In Proceedings of the 2012 IEEE/RSJ International Conference on IEEE, Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 4596–4601. [Google Scholar]
- Suzuki, T. L1 generalized inverse beam-forming algorithm resolving coherent/incoherent, distributed and multipole sources. J. Sound Vib. 2011, 330, 5835–5851. [Google Scholar] [CrossRef]
- Netti, A.; Diodati, G.; Camastra, F.; Quaranta, V. FPGA implementation of a real-time filter and sum beamformer for acoustic antenna. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings. Institute of Noise Control Engineering, San Francisco, CA, USA, 9–12 August 2015; Volume 250, pp. 3458–3469. [Google Scholar]
- Bourgeois, J.; Minker, W. (Eds.) Linearly Constrained Minimum Variance Beamforming. In Time-Domain Beamforming and Blind Source Separation: Speech Input in the Car Environment; Springer: Boston, MA, USA, 2009; pp. 27–38. [Google Scholar]
- Diodati, G.; Quaranta, V. Acoustic Sensors Array for Pass-by-Noise Measurements: Antenna Design. In Proceedings of the International Congress on Sound and Vibration ICSV22, Athens, Greece, 10–14 July 2015. [Google Scholar]
- Izquierdo, A.; Villacorta, J.J.; del Val Puente, L.; Suárez, L. Design and evaluation of a scalable and reconfigurable multi-platform system for acoustic imaging. Sensors 2016, 16, 1671. [Google Scholar] [CrossRef] [PubMed]
- LabVIEW FPGA Module. Available online: http://www.ni.com/labview/fpga/ (accessed on 1 June 2018).
- del Val, L.; Izquierdo, A.; Villacorta, J.J.; Suárez, L. Using a Planar Array of MEMS Microphones to Obtain Acoustic Images of a Fan Matrix. J. Sens. 2017, 2017. [Google Scholar] [CrossRef]
- Izquierdo, A.; Villacorta, J.J.; del Val, L.; Suárez, L.; Suárez, D. Implementation of a Virtual Microphone Array to Obtain High Resolution Acoustic Images. Sensors 2017, 18, 25. [Google Scholar] [CrossRef] [PubMed]
- Seo, S.W.; Kim, M. Estimation of 3D ball motion using an infrared and acoustic vector sensor. In Proceedings of the 2017 International Conference on IEEE, Information and Communication Technology Convergence (ICTC), Jeju, Korea, 18–20 October 2017; pp. 1047–1049. [Google Scholar]
- Seo, S.W.; Kim, M. 3D Impulsive Sound-Source Localization Method through a 2D MEMS Microphone Array using Delay-and-Sum Beamforming. In Proceedings of the 9th International Conference on Signal Processing Systems, Auckland, New Zealand, 27–30 November 2017; pp. 170–174. [Google Scholar]
- da Silva, B.; Segers, L.; Rasschaert, Y.; Quevy, Q.; Braeken, A.; Touhafi, A. A Multimode SoC FPGA-Based Acoustic Camera for Wireless Sensor Networks. In Proceedings of the 13th International Symposium on Reconfigurable Communication-centric Systems-on-Chip, ReCoSoC 2018, Lille, France, 9–11 July 2018; pp. 1–8. [Google Scholar]
- Hogenauer, E. An economical class of digital filters for decimation and interpolation. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 155–162. [Google Scholar] [CrossRef]
- Garrido, M.; Acevedo, M.; Ehliar, A.; Gustafsson, O. Challenging the limits of FFT performance on FPGAs. In Proceedings of the 2014 14th International Symposium on Integrated Circuits (ISIC), Saint-Malo, France, 13–16 September 2014; pp. 172–175. [Google Scholar]
- Bogue, R. Recent developments in MEMS sensors: A review of applications, markets and technologies. Sens. Rev. 2013, 33, 300–304. [Google Scholar] [CrossRef]
- Underwood, K. FPGAs vs. CPUs: trends in peak floating-point performance. In Proceedings of the 2004 ACM/SIGDA 12th International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2004; pp. 171–180. [Google Scholar]
- Xilinx System Generator for DSP. Available online: https://www.xilinx.com/products/design-tools/vivado/integration/sysgen.html (accessed on 1 June 2018).
- Dusan, S.V.; Lindahl, A.; Andersen, E.B. System and Method of Mixing Accelerometer and Microphone Signals to Improve Voice Quality in a Mobile Device. U.S. Patent 9,363,596, 7 June 2016. [Google Scholar]
- Mathworks HDL Coder Toolbox. Available online: https://www.mathworks.com/products/hdl-coder.html (accessed on 1 June 2018).
- Nordholm, S.; Claesson, I.; Dahl, M. Adaptive microphone array employing calibration signals: an analytical evaluation. IEEE Trans. Speech Audio Process. 1999, 7, 241–252. [Google Scholar] [CrossRef]
- Zynq Ultrascale+ SoC. Available online: https://www.xilinx.com/products/silicon-devices/soc/zynq-ultrascale-mpsoc.html (accessed on 1 June 2018).
- Greene, J.; Kaptanoglu, S.; Feng, W.; Hecht, V.; Landry, J.; Li, F.; Krouglyanskiy, A.; Morosan, M.; Pevzner, V. A 65nm flash-based FPGA fabric optimized for low cost and power. In Proceedings of the 19th ACM/SIGDA iNternational Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 27 February–1 March 2011; pp. 87–96. [Google Scholar]
- Cowling, M.; Sitte, R. Comparison of techniques for environmental sound recognition. Pattern Recognit. Lett. 2003, 24, 2895–2907. [Google Scholar] [CrossRef]
- Heittola, T.; Mesaros, A.; Virtanen, T.; Eronen, A. Sound Event Detection in Multisource Environments Using Source Separation. Machine Listening in Multisource Environments. 2011. Available online: https://www.isca-speech.org/archive/chime_2011/cm11_036.html (accessed on 31 July 2018).
- Kao, C. Benefits of partial reconfiguration. Xcell J. 2005, 55, 65–67. [Google Scholar]
- Wang, L.; Wu, F.-Y. Dynamic partial reconfiguration in FPGAs. In Proceedings of the 2009 Third International Symposium on Intelligent Information Technology Application, Nanchang, China, 21–22 November 2009; Volume 2, pp. 445–448. [Google Scholar]
- Llamocca, D.; Aloi, D.N. Self-reconfigurable implementation for a switched beam smart antenna. Microprocess. Microsyst. 2018, 60, 1–14. [Google Scholar] [CrossRef]
- Degnan, B.; Marr, B.; Hasler, J. Assessing trends in performance per Watt for signal processing applications. IEEE Trans. Very Large Scale Integr. Syst. 2016, 24, 58–66. [Google Scholar] [CrossRef]
- Betkaoui, B.; Thomas, D.B.; Luk, W. Comparing performance and energy efficiency of FPGAs and GPUs for high productivity computing. In Proceedings of the 2010 International Conference on Field-Programmable Technology, Beijing, China, 8–10 December 2010; pp. 94–101. [Google Scholar]
- GPU vs. FPGA Performance Comparison, White Paper. Available online: http://www.bertendsp.com/pdf/whitepaper/BWP001_GPU_vs_FPGA_Performance_Comparison_v1.0.pdf (accessed on 1 June 2018).
- Dai, W. Acoustic Scene Recognition with Deep Learning. 2016. Available online: https://www.ml.cmu.edu/research/dap-papers/DAP_Dai_Wei.pdf (accessed on 31 July 2018).
- Çakır, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar]
- Brdiczka, O.; Crowley, J.L.; Reignier, P. Learning situation models in a smart home. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 56–63. [Google Scholar] [CrossRef] [PubMed]
- Budkov, V.Y.; Prischepa, M.; Ronzhin, A.; Karpov, A. Multimodal human-robot interaction. In Proceedings of the 2010 International Congress on IEEE Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 18–20 October 2010; pp. 485–488. [Google Scholar]
- Zunino, A.; Crocco, M.; Martelli, S.; Trucco, A.; Del Bue, A.; Murino, V. Seeing the Sound: A New Multimodal Imaging Device for Computer Vision. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 6–14. [Google Scholar]
- Mentens, N.; Vandorpe, J.; Vliegen, J.; Braeken, A.; da Silva, B.; Touhafi, A.; Kern, A.; Knappmann, S.; Rettkowski, J.; Al Kadi, M.S.; et al. DynamIA: Dynamic hardware reconfiguration in industrial applications. In Proceedings of the International Symposium on Applied Reconfigurable Computing (ARC) 2015, Bochum, Germany, 13–17 April 2015; pp. 513–518. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Application | Year | Type of MIC | Model of MIC | MICs Per Array | FPGA | Operations |
|---|---|---|---|---|---|---|---|
| [3] | Acoustic Data Acquisition System | 2004 | Analog ECM | Panasonic WM-54BT | 1020 | Xilinx 3000E | Data formatting and transmission |
| [48,50] | Acoustic Data Acquisition System | 2010 | Analog MEMS | Knowles Acoustics SPM0208 | 52 | Xilinx Virtex-4 XC4VFX12 | Sampling, formatting and transmission |
| [51] | Sound-Source Location | 2011 | Analog MEMS | Knowles Acoustics SPM0208 | 52 | Xilinx Virtex-4 XC4VFX12 | Sampling, formatting and transmission |
| [52] | Calibration for Acoustic Imaging | 2014 | Digital MEMS | Knowles Acoustics SPM0405HD4 | 64 | FPGA array PXI-7854R | Data Acquisition |
| [53] | Evaluation of Stent Effectiveness | 2016 | Digital MEMS | Analog Devices ADMP521 | 4 | Unspecified FPGA | Data acquisition and transmission |
| Reference | Application | Year | Type of MIC | Model of MIC | MICs Per Array | FPGA | Source Location Technique |
|---|---|---|---|---|---|---|---|
| [55] | Sound-Source Localization | 2003 | Not Specified | Not Specified | 2 | Xilinx Virtex-II 2000 | GCC-TDOA |
| [57,58] | Countersniper System | 2005 | Analog ECM | Not Specified | 3 | Xilinx XC2S100 FPGA or ADSP-218x DSP | Shockwave and Muzzle Blast Detectors |
| [56] | Sound-Source Localization | 2009 | Analog | Not Specified | 2 | Altera DE2-70 Cyclone-II | AMDF-based TDOA |
| [59] | Sound-Source Localization | 2010 | Analog ECM | Not Specified | 8 | Xilinx Spartan-3 XC3S200 | MCALD |
| [60] | Sound-Source Localization | 2015 | Analog | Not Specified | 8 | Xilinx Spartan-3E XC3S400 | SNN and TDOA |
| [61] | Speech Enhancement | 2017 | - | MS Kinect microphones | 2 | Xilinx Spartan-6 LX45 | TDOA |
| [62] | Sound-Sources Localization | 2017 | Analog ECM | Not Specified | 4 | Xilinx Zynq 7020 | GCC-TDOA |
| Reference | Application | Year | Type of MIC | Model of MIC | MICs Per Array | FPGA | Source Location Technique |
|---|---|---|---|---|---|---|---|
| [66] | Distant Speech Recognition | 2010 | Digital MEMS | Knowles Acoustics SPM0205HD4 | 8 | Xilinx Spartan-3A | Adaptive Filter-and-Sum |
| [68] | Speech Acquisition | 2012 | Digital MEMS | Not Specified | 300 | Multiple unspecified FPGAs | Time Domain Delay-and-Sum |
| [65] | Sound-Source Localization | 2013 | Analog MEMS | Not Specified | 12 | Xilinx Spartan-3E 1200 | Time Domain Delay-and-Sum |
| [34] | Sound-Source Localization | 2014 | Digital MEMS | Analog Devices ADMP521 | 52 | MicroSemi Igloo | Time Domain Delay-and-Sum |
| [69,70] | Sound-Source Localization | 2015 | Digital MEMS | Analog Devices ADMP621 | 33 | Xilinx Spartan-6 LX25 | Time Domain Delay-and-Sum |
| [71] | Deforestation Detection | 2015 | Digital MEMS | ST Microlectronics MP34DT01 | 8 | MicroSemi Igloo 2 | Time Domain Delay-and-Sum |
| [72] | Deforestation Detection | 2016 | Digital MEMS | ST Microlectronics MP32DB01 | 4, 8 or 16 | Xilinx Spartan 6 FPGA | Time Domain Delay-and-Sum |
| [73] | Enhancement of Audio Signals | 2016 | Digital MEMS | AKUSTIC AKU242 | 7 | Xilinx Zynq 7020 | MVDR |
| [74,75] | Sound-Sources Localization | 2016 | Analog MEMS | InvenSense INMP504 | 48 | Intel/Altera’s DE1-SoC board | Adaptive Filter-and-Sum |
| [76] | Sound-Source Localization | 2017 | Digital MEMS | Analog Devices ADMP521 | 4, 8, 16 or 52 | Xilinx Zynq 7020 | Time Filter-Domain Delay-and-Sum |
| [77] | Hearing Aid System | 2017 | Analog MEMS | Analog Devices ADMP401 | 2 | Xilinx Artix-7 A100 | Adaptive Null-forming |
| [32] | Sound-Source Localization | 2017 | Digital MEMS | Analog Devices ADMP521 | 4, 8, 16 or 52 | Xilinx Zynq 7020 | Time Domain Filter-Delay-and-Sum |
| [78] | Hearing Aid System | 2018 | Digital MEMS | Knowles Acoustics SPM0405HD4H | 48 | Intel/Altera EP4CE15F17C8N | Time Domain Delay-and-Sum |
| [79] | Sound-Sources Localization | 2018 | Digital MEMS | InvenSense ICS-41350 | 4, 8, 16 or 52 | Microsemi SmartFusion2 M2S050 | Time Domain Delay-and-Sum |
| Reference | Application | Year | Type of MIC | Model of MIC | MICs Per Array | FPGA | Source Location Technique |
|---|---|---|---|---|---|---|---|
| [81,82,83] | Sound-Source Localization and Separation | 2010 | Analog ECM | Sony ECM-C10 | 16 | Xilinx Virtex-4 FX (SZ410 Suzaku board) | MUSIC and Delay-and-Sum |
| [67] | Detection and Tracking of Aircrafts | 2010 | Digital MEMS | Not Specified | 105 | Unspecified FPGA | Capon |
| Reference | Application | Year | Type of MIC | Model of MIC | MICs Per Array | Device | Beamforming Algorithm | Resolution | Real-Time | Power |
|---|---|---|---|---|---|---|---|---|---|---|
| [84] | Acoustic Imaging | 2010 | Analog ECM | Ekulit EMY-63M/P | 32 | Xilinx Spartan-3E XC3S500E | Time-Domain Delay-and-Sum | 320 × 240 | 10 FPS | Not Specified |
| [88] | Robotic Applications | 2012 | Digital MEMS | Not Specified | 44 | Xilinx Spartan-6 LX45 | Frequency-Domain Generalized Inverse | Not Specified | 60 FPS | Not Specified |
| [85] | Acoustic Imaging | 2014 | Digital MEMS | Not Specified | 32 | Xilinx Spartan-6 XC6SLX16 | Time-Domain Delay-and-Sum | 128 × 96 | Not Specified | Not Specified |
| [87] | Detection squeak and rattle sources | 2014 | Digital MEMS | Analog Devices ADMP 441 | 30 or 96 | National Instruments sbRIO or FlexRIO (Xilinx Zynq 7020) | Time-Domain Unspecified Beamforming | Not Specified | 25 FPS | Not Specified |
| [90] | Acoustic Imaging | 2015 | Analog MEMS | InvenSense ICS 40720 | 80 | Xilinx Virtex-7 VC707 | Linearly Constrained Minimum Variance | 61 × 61 | 31 FPS | 75 W |
| [93,95,96] | Acoustic Imaging | 2016 | Digital MEMS | ST Microlectronics MP34DT01 | 64 | National Instruments myRIO (Xilinx Zynq 7010) | Frequency-Domain Wideband | 40 × 40 | 33.4 ms to 257.3 ms | Not Specified |
| [97,98] | Acoustic Imaging | 2017 | Analog MEMS | ST Microlectronics MP33AB01 | 25 | Xilinx Artix-7 XC7A100T | Time-Domain Delay-and-Sum | Not Specified | Not Specified | Not Specified |
| [99] | Acoustic Imaging | 2018 | Digital MEMS | Knowles Acoustics SPH0641LU4H | 16 | Xilinx Zynq 7020 | Time-Domain Delay-and-Sum | 160 × 120 up to 640 × 480 | 32.5 FPS | Not Specified |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Da Silva, B.; Braeken, A.; Touhafi, A. FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities. Computers 2018, 7, 41. https://doi.org/10.3390/computers7030041
Da Silva B, Braeken A, Touhafi A. FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities. Computers. 2018; 7(3):41. https://doi.org/10.3390/computers7030041
Chicago/Turabian StyleDa Silva, Bruno, An Braeken, and Abdellah Touhafi. 2018. "FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities" Computers 7, no. 3: 41. https://doi.org/10.3390/computers7030041
APA StyleDa Silva, B., Braeken, A., & Touhafi, A. (2018). FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities. Computers, 7(3), 41. https://doi.org/10.3390/computers7030041