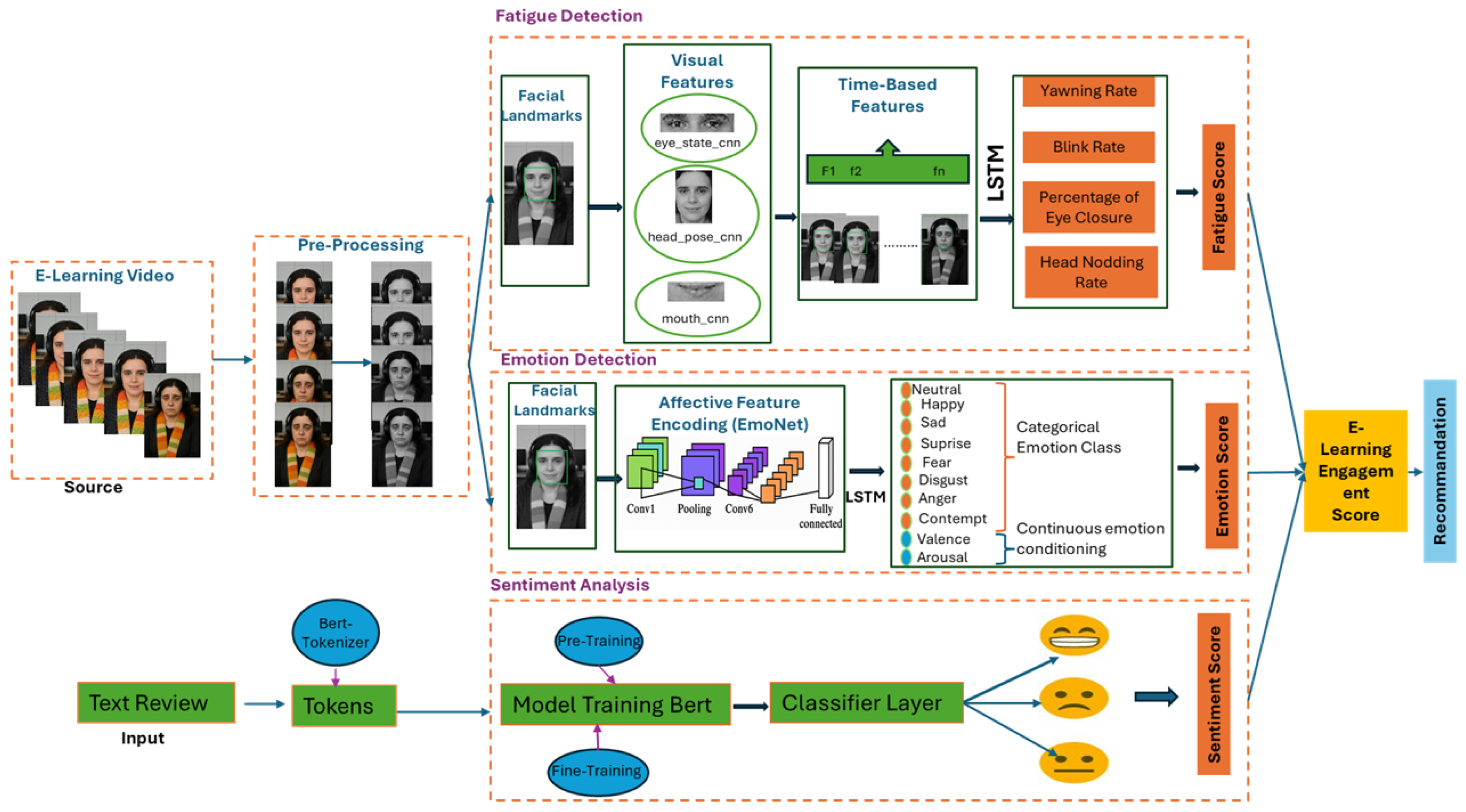
4.1. Work Environment and Datasets
The experiments were conducted in a Python 3.9 environment, using machine learning libraries including TensorFlow 2.13 and Keras 2.13. The Hugging Face Transformers library was used to fine-tune the BERT model. Training was carried out on a workstation equipped with an NVIDIA GPU.
Three main datasets were used for training and evaluating this work:
DAiSEE: This dataset was used to train and evaluate our fatigue detection module. It contains videos of students filmed in a real e-learning environment, annotated frame-by-frame for four affective states: engagement, excitement, frustration, and fatigue. The sequences are resampled at 10 fps, and the labels are binarized into two classes: tired/not tired.
AffectNet: This dataset is used for facial emotion analysis with the EmoNet model. It contains over 1 million images extracted from the web, labeled with 8 discrete emotions (joy, sadness, fear, anger, surprise, disgust, contempt, neutral), and continuous scores for valence and arousal on a scale of [−1, 1].
Course Reviews on Coursera: This dataset was used for sentiment analysis of learner feedback. It includes textual reviews on various courses offered on Coursera, labeled as positive, neutral, or negative. This dataset was used to fine-tune the BERT model for sentiment classification.
Experimental Results of the Fatigue Detection Layer
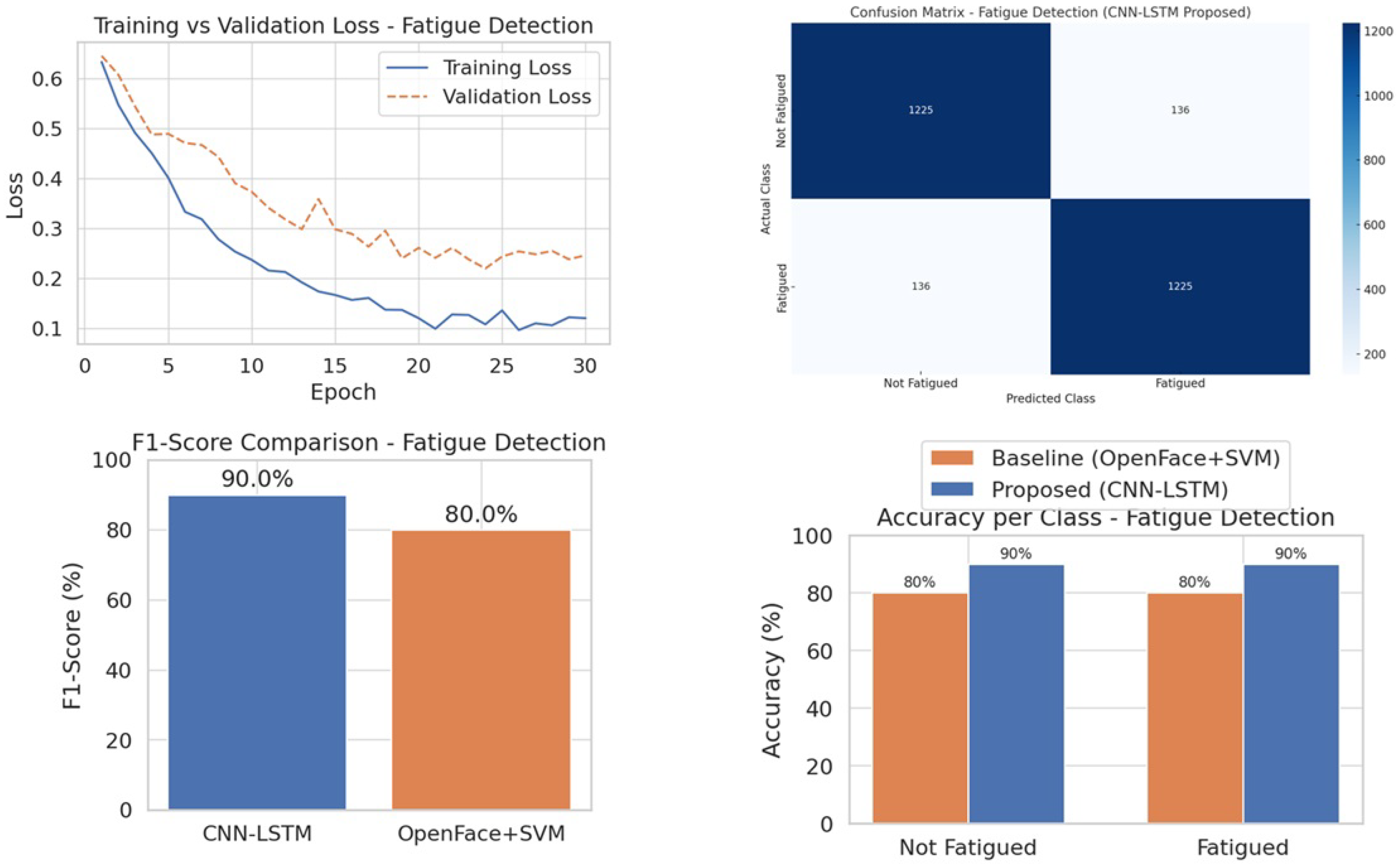
The performance of the CNN-LSTM model for fatigue detection was evaluated on a data set divided into Training (70%), Validation (15%), and Test (15%). The model was trained using the training set and both the validation and test sets were used to evaluate performance.
As shown in
Figure 2, the train-validation loss curve indicates a steady reduction in loss over approximately 30 epochs. Initially, the loss was high (0.65), but by epoch 30, the training loss converged to 0.12 and the validation loss to 0.42, with minimal overfitting—evidenced by the small gap between the two curves.
The confusion matrix in
Figure 2 further shows that the CNN-LSTM model correctly classifies 90% of both fatigued and non-fatigued instances, with only 10% misclassified in each category.
As illustrated in the F1 score comparison in
Figure 2, CNN-LSTM outperforms the OpenFace + SVM baseline, achieving a significantly higher F1 score of 90% versus 80% for OpenFace+SVM. This indicates that the CNN-LSTM model provides a better balance between precision and recall.
To estimate performance variability, we trained the CNN-LSTM model three times using the same architecture and dataset but with different random initializations (default seed behavior). The average F1-score obtained was 90% with a standard deviation of ±1.2%, indicating stable model performance across runs.
The effectiveness of the CNN-LSTM model was further evaluated using real-world tests on the DAiSEE dataset, simulating an e-learning environment. We selected a sample of sequences and manually annotated key events such as blinks, prolonged eye closures (PERCLOS), and yawning. The annotation was performed using the CVAT (Computer Vision Annotation Tool), which allows precise marking of moments when the eyes are closed, when the learner yawns, and to identify head movements. These manual annotations were then compared to the model’s predictions. We measured the accuracy of detecting each behavior by calculating the percentage of agreement between the model’s predictions and the actual annotations.
The
Table 4 below presents the results obtained from five test sequences, comparing the number of blinks and prolonged eye closures detected by our system against the real observations. The accuracy was calculated as the percentage of agreement between the automatic detections and the manual annotations.
The results indicate that our model achieves an average precision of 95.4% for blink detection and 92.2% for prolonged eye closures (PERCLOS), thus validating the robustness of the EAR + PERCLOS module combined with CNN-LSTM processing.
Similarly, the precision of yawning detection was evaluated using the Mouth Aspect Ratio (MAR) on the same video sequences. The
Table 5 below summarizes the results obtained:
All annotated yawns were correctly identified in most cases, but some errors were observed, particularly a slight mismatch in predictions for certain test sequences. While this confirms the effectiveness of the dynamic MAR threshold integrated into our facial fatigue monitoring algorithm, it also highlights areas for potential improvement. Some critical detection failures, such as undetected yawns, may result from technical limitations like low-resolution frames, partial face occlusion, or suboptimal lighting conditions. Addressing these issues could further enhance the robustness of the system in real-world settings.
The
Table 6 shows the results obtained experimentally for the composite fatigue index, combining eye closures, yawning, head nods, and the PERCLOS value. The 0- to 1-dimensioned composite fatigue index represents the degree of fatigue in the subject. With a corresponding rise in eye closures, yawning, and head nods, the composite measure also rises to indicate more fatigue. For instance, in Test 5 with 7 eye closures and 4 head nods, the composite index is 0.598, representing an extreme degree of fatigue, while in Test 1 with only 3 eye closures and 2 yawns, the index is 0.248, showing lower fatigue.
The metrics, along with the test evaluations, demonstrate the strong performance of the CNN-LSTM model in fatigue detection.
4.2. Evaluation Emotion Detection
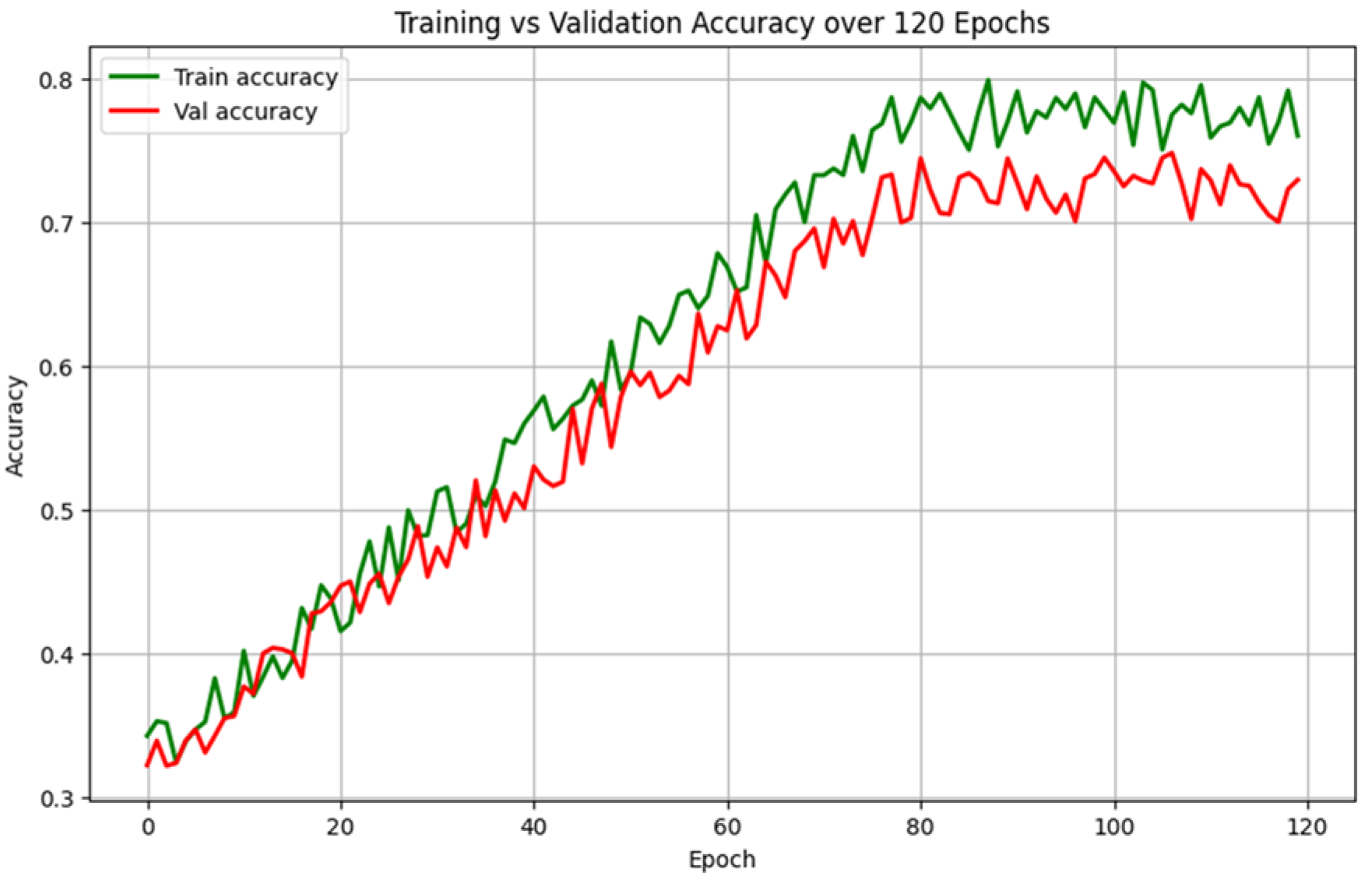
To evaluate our emotion detection pipeline, we used the AffectNet dataset. We used a CNN-LSTM-based model (EmoNet) to predict both discrete emotions and continuous values of valence and arousal for each facial frame. The model was trained over 120 epochs, with a batch size of 16. As shown in
Figure 3, the EmoNet model achieved 0.8 accuracy on the training set, with 0.7 accuracy on the validation set, demonstrating good generalization across unseen data. The accuracy gap between training and validation is typical for deep learning models and indicates the model’s ability to learn robust features while maintaining generalizability. After epoch 80, the model’s performance became stable
Figure 3.
For testing, we used 8 selected video sequences from the DAiSEE dataset, which were re-annotated for facial emotion recognition. Each video was analyzed frame-by-frame at a rate of 6 frames per second (fps). For each video frame, we predicted a discrete emotion and generated a valence-arousal pair. The valence-arousal values were then aggregated using the arousal-weighted valence method to calculate the global emotion score (Semo), which was normalized to fall within the [0, 1] range.
The following
Table 7 summarizes the results of our valence-Arousal prediction for each test sample:
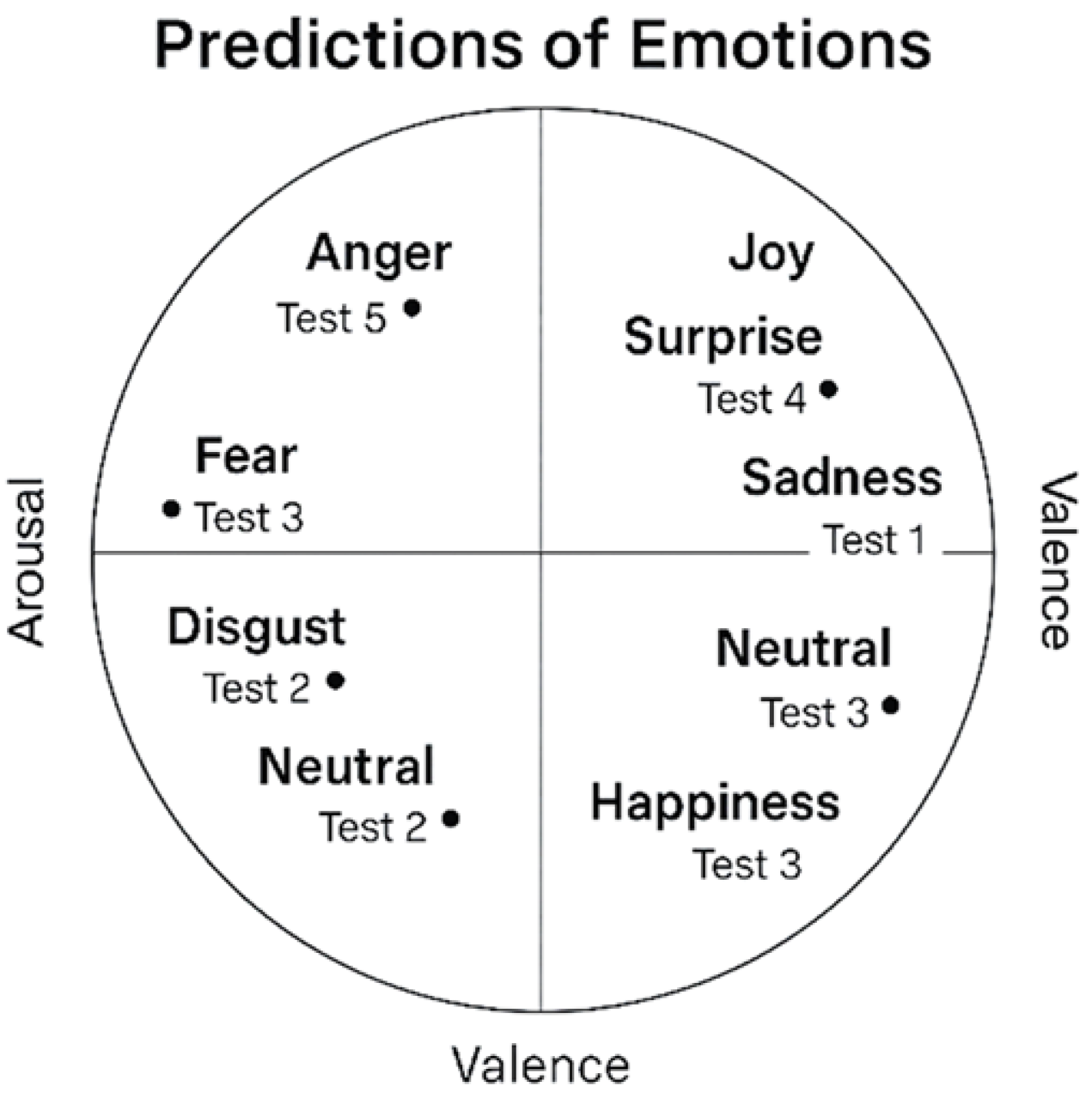
The following
Figure 4 illustrates the prediction of emotions based on the valence-arousal pair for the test set, showing how the predicted emotions are distributed within the valence-arousal circle. This visualization helps to understand the mapping of the predicted emotions in the emotion space:
The results indicate that the model achieves a reliable match between predicted and real valence–arousal pairs, with low Euclidean errors across all cases. Emotion scores span the full spectrum of affective engagement, ranging from deep disengagement (e.g., anger and fear) to high positive engagement (e.g., joy and happiness). This confirms the model’s ability to accurately capture both the polarity and intensity of learners’ emotional states.
The average Euclidean error across the 8 test videos was 0.067, with a standard deviation of ±0.018, computed over three inference runs using different random seeds.
4.3. Sentiment Analysis and Evaluation on Course Reviews
The fine-tuned BERT model on the Course Reviews on Coursera dataset was evaluated using standard metrics such as accuracy, macro F1-score, as well as precision and recall for each class. The batch size was set to 16, with a learning rate of
, and a total of 30 epochs. The model achieved an accuracy of 88.1% and a macro F1-score of 84.9%, outperforming the reference models such as Naive Bayes (79.8%) and CNN-GRU (83.2%) [
39,
40]. The results suggest that BERT excels in capturing emotional nuances in educational feedback, with high precision for the “positive” class and relatively lower results for the “neutral” class.
To assess the accuracy of the predicted sentiment, we computed
for a sample from the dataset and compared it to the real annotations. We used metrics like Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). The results obtained are summarized in
Table 8.
While the model performed reliably overall, we observed higher error margins in the “neutral” class (e.g., MAE = 0.17 in Test 5 and 0.28 in Test 4), confirming that this category remains harder to classify. This can be attributed to the inherent ambiguity and semantic overlap in neutral reviews. Future improvements could include the integration of enhanced contextual embeddings to better disambiguate neutral expressions, and the enrichment of the dataset with more representative and balanced samples for this class. Such strategies have been shown to reduce misclassification of neutral sentiment in similar educational domains. Overall, the BERT model has demonstrated robustness in emotion classification and provided accurate sentiment scores, contributing to the overall engagement evaluation of learners.
4.4. Learner Engagement Detection Evaluation
To evaluate our engagement detection pipeline, we built a dedicated subset of the public DAiSEE dataset. To ensure both validity and diversity of the video sequences, we selected 30 videos using an automatic filtering process based on the following criteria:
Confidence score (provided in DAiSEE official annotations), ensuring reliable engagement labels (“Engaged”, “At Risk”, “Disengaged”).
Inter-individual diversity by selecting videos from 10 different users using the user_id attribute, to minimize intra-subject bias.
Class balance: 10 videos per engagement class, allowing a symmetric evaluation of predictions.
Although DAiSEE provides validated engagement annotations, we reinforced their robustness with an additional manual annotation procedure. Two independent raters reviewed each video sequence and assigned an engagement label. The inter-rater agreement, measured using Cohen’s Kappa coefficient, was 0.81, indicating strong consistency between annotators.
Each video was processed at 6 frames per second to extract behavioral fatigue indicators (eye closures, yawns, head nods). In parallel, valence and arousal scores were computed using the EmoNet model to estimate facial emotional state. To complete this multimodal analysis, we manually associated a textual comment from the Coursera Reviews corpus with each video.
This manual pairing was based on the following criteria:
Semantic consistency: the comment content had to match the visible emotional state in the video (positive, neutral, or negative).
Balanced polarity: each engagement class was associated with textual comments reflecting a coherent satisfaction level.
Cross-checking by two annotators to ensure subjective validity of the pairing.
Although this manual process does not reflect a truly co-localized learning context, it was used for exploratory purposes to evaluate the benefit of fusing heterogeneous modalities for engagement prediction.
Each extracted score—fatigue
, emotion
, and sentiment
—was normalized to the range
. We then computed a global engagement score
using a weighted fusion of the three modalities as described in Equation (
17).
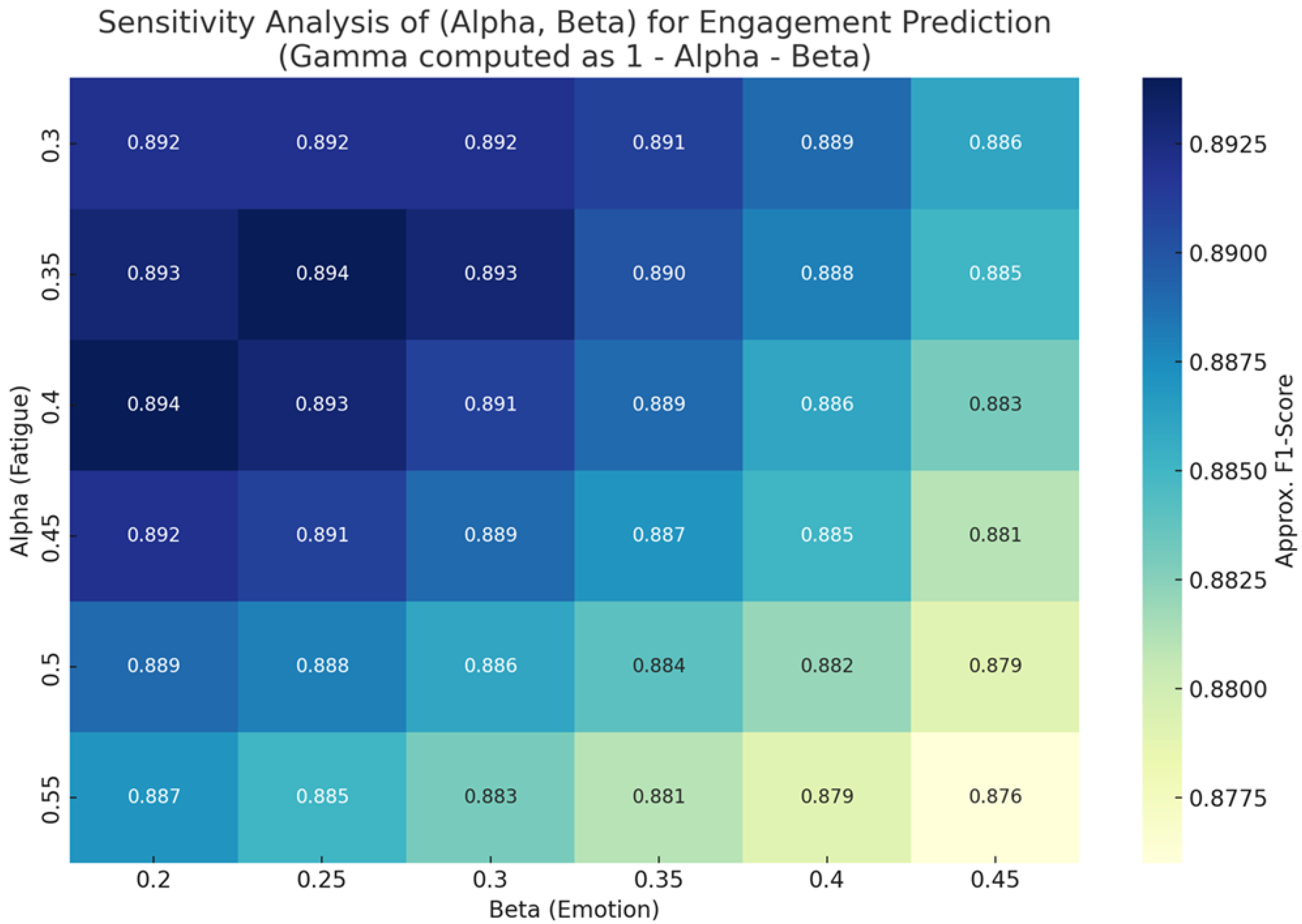
To determine the optimal combination of coefficients for the engagement fusion formula, we conducted a sensitivity analysis by testing various weighted configurations. The F1-score, which balances precision and recall, was used as the primary evaluation metric to identify the most effective weighting strategy.
As shown in
Figure 5, the combination
produced the highest F1-score. This indicates that prioritizing the fatigue dimension—while still accounting for emotional and sentiment cues—results in a more accurate engagement prediction. These findings are consistent with prior research emphasizing the complementary roles of affective and cognitive signals in learner state detection [
41].
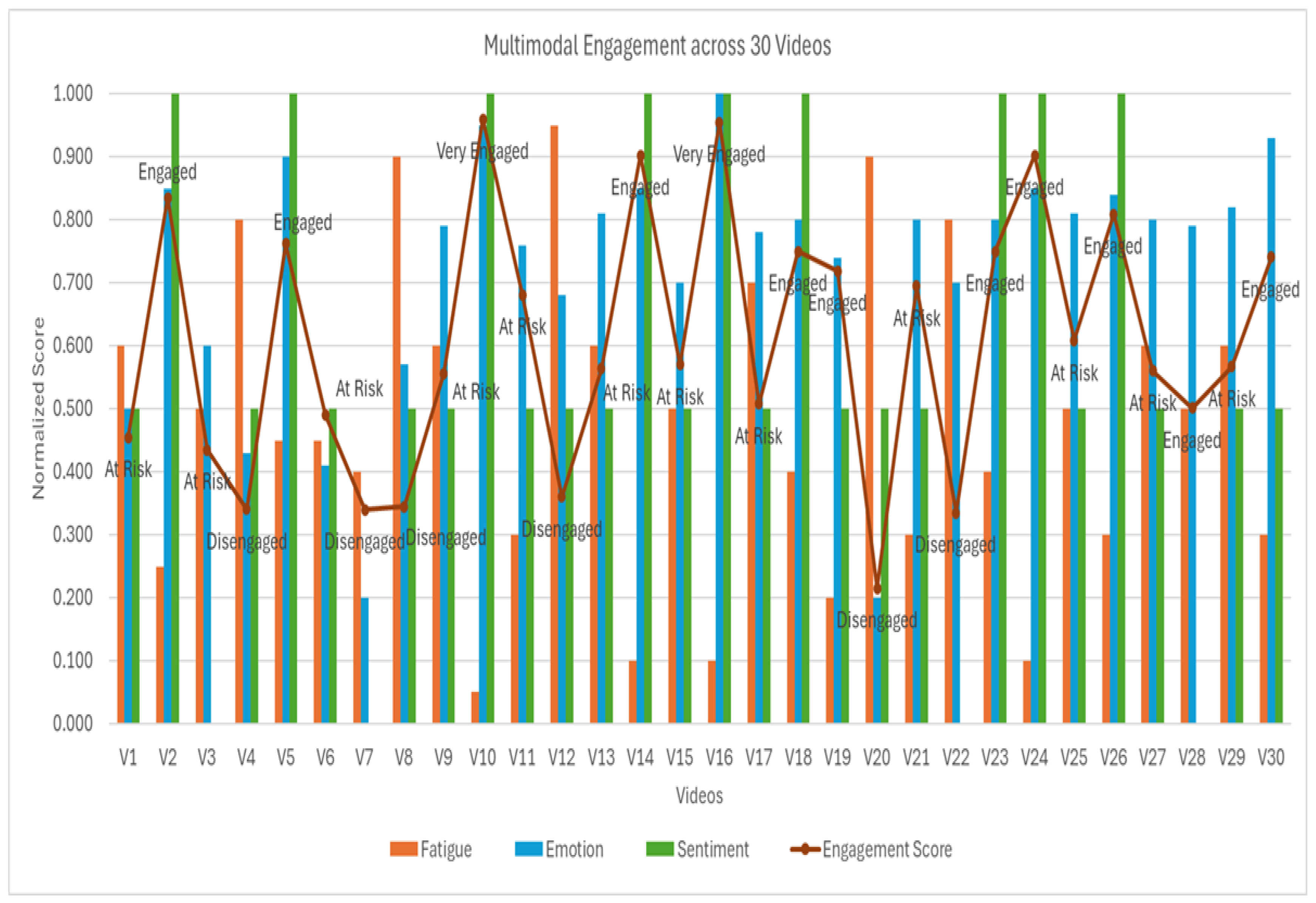
Table 9 presents a representative sample of 8 cases out of the 30 analyzed videos. Each row details the computed fatigue, emotion, and sentiment scores, along with the predicted global engagement score. Pedagogical recommendations are associated with each profile to guide the adaptation of content and pace.
For instance, in video V2, the learner exhibits moderate fatigue but high emotional and semantic scores, resulting in an “Engaged” prediction. In this case, maintaining the current learning rhythm while offering stimulating content is advised to support motivation.
In contrast, video V7 shows all signals pointing to a clear disengagement: high fatigue, low emotion, and neutral sentiment. A temporary interruption of activities, followed by a gradual re-engagement strategy, is recommended.
Figure 6 provides an overview of the 30 selected videos, illustrating normalized scores for each dimension (fatigue, emotion, sentiment) and the corresponding engagement classes (Very Engaged, Engaged, At Risk, Disengaged). This visualization highlights the diversity of learner profiles.
These results confirm that engagement detection requires a combined multimodal analysis. Some learners show signs of “At Risk” engagement despite physiological fatigue (e.g., V3), supported by emotional involvement. When all three dimensions converge toward low engagement scores (as in V4 or V7), the system detects significant cognitive and emotional withdrawal.
This cross-modality perspective supports the relevance of a weighted fusion approach, capable of capturing the complexity of learners’ internal states and fueling personalized recommendations to improve the learning experience. As such, this multimodal and weighted approach constitutes not only a robust framework for diagnosing engagement levels but also opens the door to intelligent systems that can deliver adaptive pedagogical responses tailored to each learner’s profile.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}