Abstract
This paper looks at and describes the potential of using artificial intelligence in smart environments. Various environments such as houses and residential and commercial buildings are becoming smarter through the use of various technologies, i.e., various sensors, smart devices and elements based on artificial intelligence. These technologies are used, for example, to achieve different levels of security in environments, for personalized comfort and control and for ambient assisted living. We investigated the deep learning approach, and, in this paper, describe its use in this context. Accordingly, we developed four deep learning models, which we describe. These are models for hand gesture recognition, emotion recognition, face recognition and gait recognition. These models are intended for use in smart environments for various tasks. In order to present the possible applications of the models, in this paper, a house is used as an example of a smart environment. The models were developed using the TensorFlow platform together with Keras. Four different datasets were used to train and validate the models. The results are promising and are presented in this paper.
1. Introduction
Nowadays, the use of various technologies is unavoidable. Technology is used in different areas of human life and makes life easier in many ways. Some examples are shopping, paying bills, travel planning and navigation. All these things can be done with the help of smartphones and the internet, for example. This was not possible 25 years ago, as smartphones were not as smart and intelligent as they are today and applications for these tasks were not usually available.
Today, all of this can be done from the comfort of your own home. What is more, homes are smarter today. Many environments where people live and work, such as houses, residential and commercial buildings and factories utilize certain technologies—from various sensors to advanced artificial intelligence. The aforementioned technologies are generally used for security purposes, i.e., to implement a security system tailored to the user’s needs, to personalize comfort and to control various elements such as lighting, heating and ventilation systems. In other words, the use of technology makes human life easier, whether for leisure or work.
One technology that has great potential for use in various types of smart environments is artificial intelligence. Artificial intelligence has been on the rise in recent years. There is almost no industry that does not use artificial intelligence in some form. From the manufacturing process to services for customers, artificial intelligence is being used. In the automotive industry, for example, artificial intelligence is part of the manufacturing process and it is also found in vehicles as part of the various safety systems, to support autonomous driving, to improve the in-car driving experience, etc. As already mentioned, artificial intelligence can make environments smarter and more intelligent.
The main aim of this paper was to explore how artificial intelligence can be used in the context of smart environments. In other words, it analyzes the possible use of artificial intelligence in different types of buildings such as houses and residential and commercial buildings. Since neural networks and, generally speaking, the deep learning approach dominate in today’s development and implementation of artificial intelligence, the deep learning approach was used in this paper. More specifically, various deep learning models that have potential applications in smart environments were developed, trained and validated.
The models developed are a model for recognizing hand gestures (hand gesture recognition), a model for recognizing emotions (emotion recognition), a model for recognizing faces (face recognition) and a model for recognizing gait (gait recognition). The TensorFlow platform [1] and Keras [2] were used to develop the aforementioned models, while four different datasets were used to train and validate the models. How the aforementioned models can be used as part of a smart environment is described using the example of a house, i.e., the house represents a smart environment in this context.
The use of deep learning in the context of smart environments has been analyzed in various ways in recent years. In [3], the authors analyzed deep learning for security purposes, i.e., the authors proposed a novel metaheuristic with a deep learning-enabled intrusion detection system. In [4], the authors proposed an intelligent home automation system. This system was designed to control home appliances, monitor environmental factors and detect movements in the home and its surroundings. As the authors state in the paper, a deep learning model was proposed for motion recognition and classification based on the detected movement patterns. In [5], the authors analyzed optical sensors commonly used in smart homes and their operating principles, focusing on the application of optical sensors to detect user behavior. In [6], the authors presented a deep learning approach for attack detection in smart homes. In [7], the authors presented various deep learning models for classifying human activities in smart home scenarios. A deep learning approach was also used in [8] for recognizing human activities in the smart home. The authors in [9] presented a system for recognizing the daily activities of a person in the home environment. An intelligent home security system based on deep learning was presented in [10]. An intelligent security system based on deep learning was also analyzed and described in [11]. This system used face and gait recognition methods to identify people. In [12], the authors analyzed a deep learning approach to recognize faces, silhouettes and human activities in the context of a safe home.
It should be noted that deep learning in the context of smart environments was mainly used to implement some security features in the environments. In this paper, we describe how deep learning is used to implement different methods that can be used for different tasks related to smart environments. With these methods, security functions can be implemented using a different approach. Also, these methods can be used for various tasks such as loading customized settings for specific people in terms of lighting, heating and ventilation, music, etc. The main elements covered in this paper are as follows:
- Analysis and selection of suitable methods that can be used in the context of the smart environments;
- Design of an exemplary smart environment and analysis of the possible applications of the above-mentioned methods for various tasks within the environment;
- Analysis of publicly available datasets that can be used for training and validation of the models;
- Development, adaptation, training and validating of deep learning models for each method.
The paper is structured as follows: After the introduction, Section 2 describes and analyzes the implementation of the developed models in a smart environment. As an example of a smart environment in which the models are implemented, a house is used. Section 3 describes the elements associated with the models. These are the architecture of the models, the settings used and the datasets used to train and validate each model. Taking these points into account, the layers used, the classes associated with the models and the number of images used are listed. In addition, other settings such as the number of epochs and the optimizer used to train and validate the models are described. After Section 3, Section 4 describes the results obtained with each model. The results mentioned refer to the validation accuracy. Section 5 contains a discussion of the results obtained. Concluding remarks can be found at the end of the paper.
2. Application of Deep Learning Models in a Smart Environment
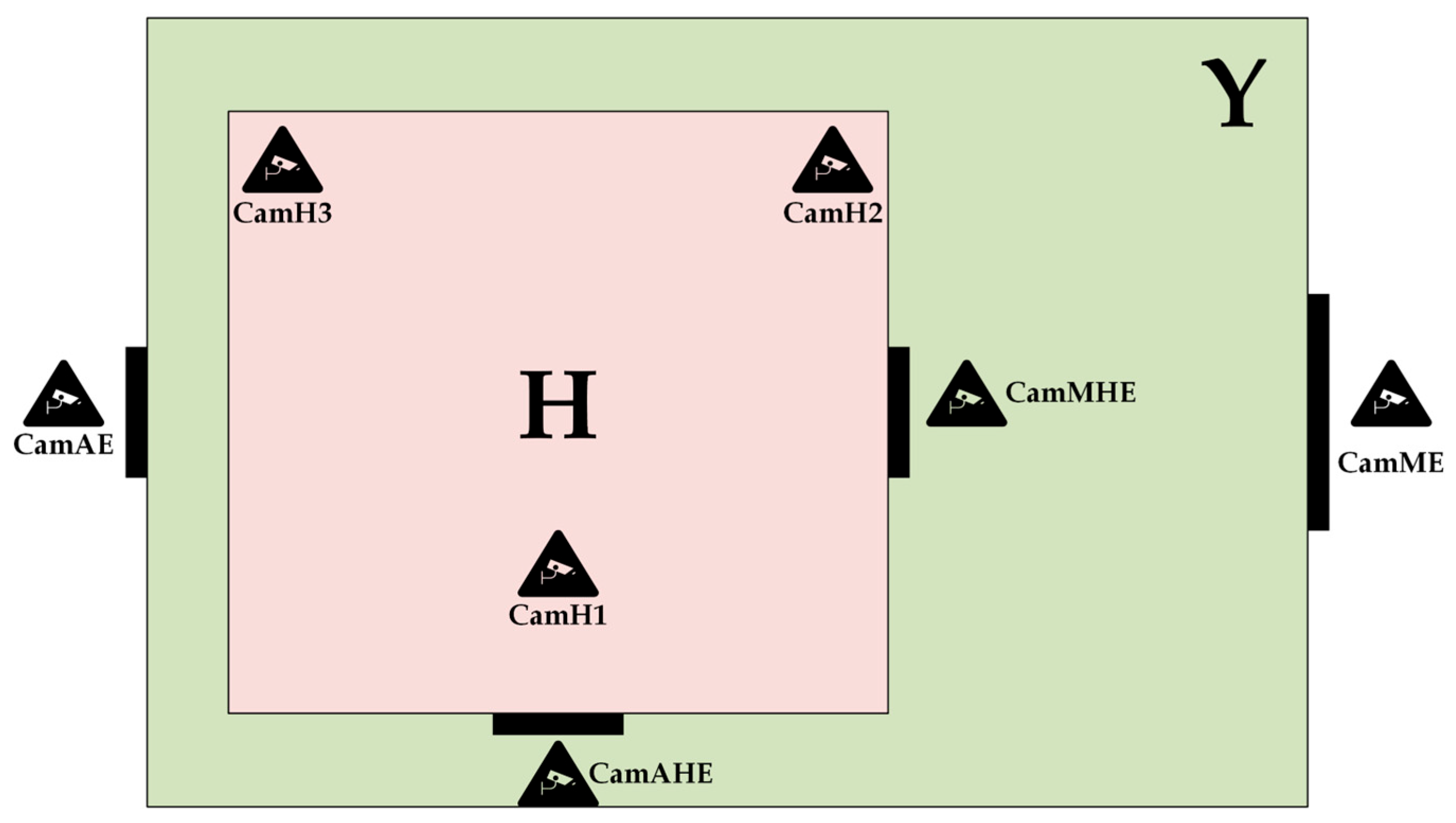
To show how different deep learning models can be used in smart environments, an example of such an environment is shown in Figure 1. In this example, a house is used as a smart environment, as mentioned above. It should be noted that in addition to the house, some examples of residential and commercial buildings can also be used. In the example shown in Figure 1, a plot of land is shown with a yard labeled with the capital letter Y and a house labeled with the capital letter H. The yard has two entrances, a main entrance and an auxiliary entrance. The house also has two entrances, a main entrance and an auxiliary entrance.
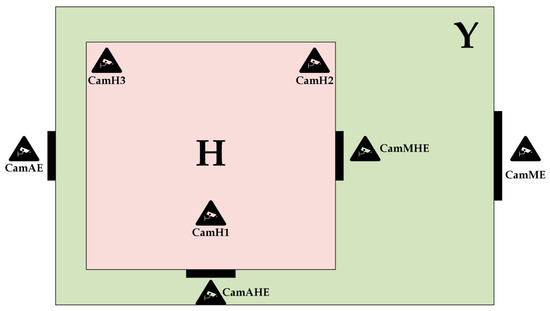
Figure 1.
Example of a smart environment.
All entrances to the yard and the house are monitored by cameras. There are four cameras in total. There is a camera labeled CamME at the main entrance to the yard. The auxiliary entrance is monitored by a camera labeled CamAE. The same applies to the house. The main entrance is covered by the CamMHE camera, while the auxiliary entrance is covered by the CamAHE camera. There are three cameras inside the house, labeled CamH1, CamH2 and CamH3.
The purpose of the cameras at the entrances is to detect and track people who want to enter the yard or house. The cameras also have the task of capturing images of the people in order to identify them and allow them access to the yard and the house. These images should be forwarded to the deep learning models developed so that they can be identified. Different deep learning models should be implemented in relation to the entrances. To gain access to the yard or house, a specific person should make a specific hand gesture in the first step. These hand gestures are used to start the identification process. To gain access to the yard at the main entrance, a specific person should show an open hand, i.e., a palm. At the main entrance to the house, a specific person should show a closed fist. To gain access to the yard at the auxiliary entrance, a specific person should show a hand with a joined thumb and first finger, i.e., the sign OK. On the other hand, to gain access to the house at the auxiliary entrance, a specific person should show a thumb, i.e., the like sign.
The hand gesture recognition model is used to recognize a specific hand gesture. Once the gesture has been recognized, the process of identifying the person begins. Two models are used to identify people. There are models for gait recognition and for face recognition. The standard model for the main entrances (yard and house) is the gait recognition model. If the gait recognition model cannot identify a specific person, the face recognition model is used. The standard model for the auxiliary entrances (yard and house) is the face recognition model. In all cases, regardless of which model is used, the certainty of identification of a particular person must be above 90%.
The cameras inside the house are used to detect and track people living in the house. These cameras also have the task of capturing images of people in order to identify them. The purpose of identification in this case is to load customized settings related to that person. These individual settings can relate to lighting, heating and ventilation, music, etc. A face recognition model is used for identification within the house.
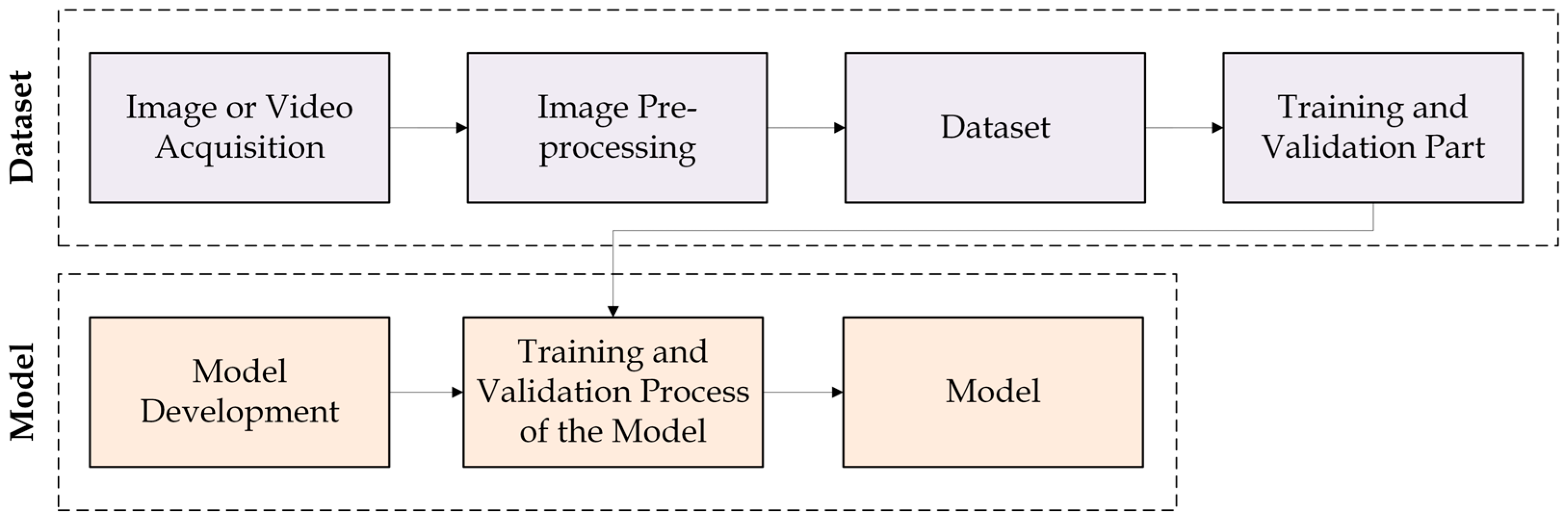
In addition to this model, another model is used within the house. The model mentioned is a model for recognizing emotions, i.e., an emotion recognition model. The purpose of this model is to recognize the current emotions of a specific person in order to make additional individual adjustments. For example, if the person is sad, specific music can be played. The entire process of developing deep learning models can be roughly described as shown in Figure 2.
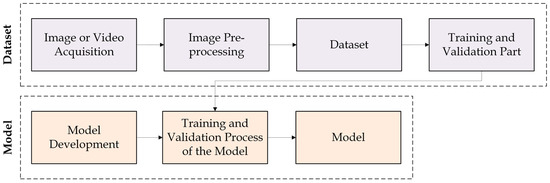
Figure 2.
Steps in the development of a deep learning model.
In general, the whole process of developing a specific model can be roughly divided into two parts (Figure 2). The first part is the creation of the dataset. This part includes the acquisition of images related to a specific dataset to be used with a specific model. A video can also be used instead. Once the images have been captured, they usually need to be pre-processed in some way before they can be used as a dataset. If all images are suitable for the training and validation process of the model, the respective dataset should be split into a training part and a validation part before it is used with a specific model. There is also a frequent and a test part. The second part is the model development part. In this part, each model should be developed, trained and validated. The development of the models can be done on different platforms. Popular platforms nowadays are TensorFlow [1], PyTorch [13], OpenVINO [14], etc.
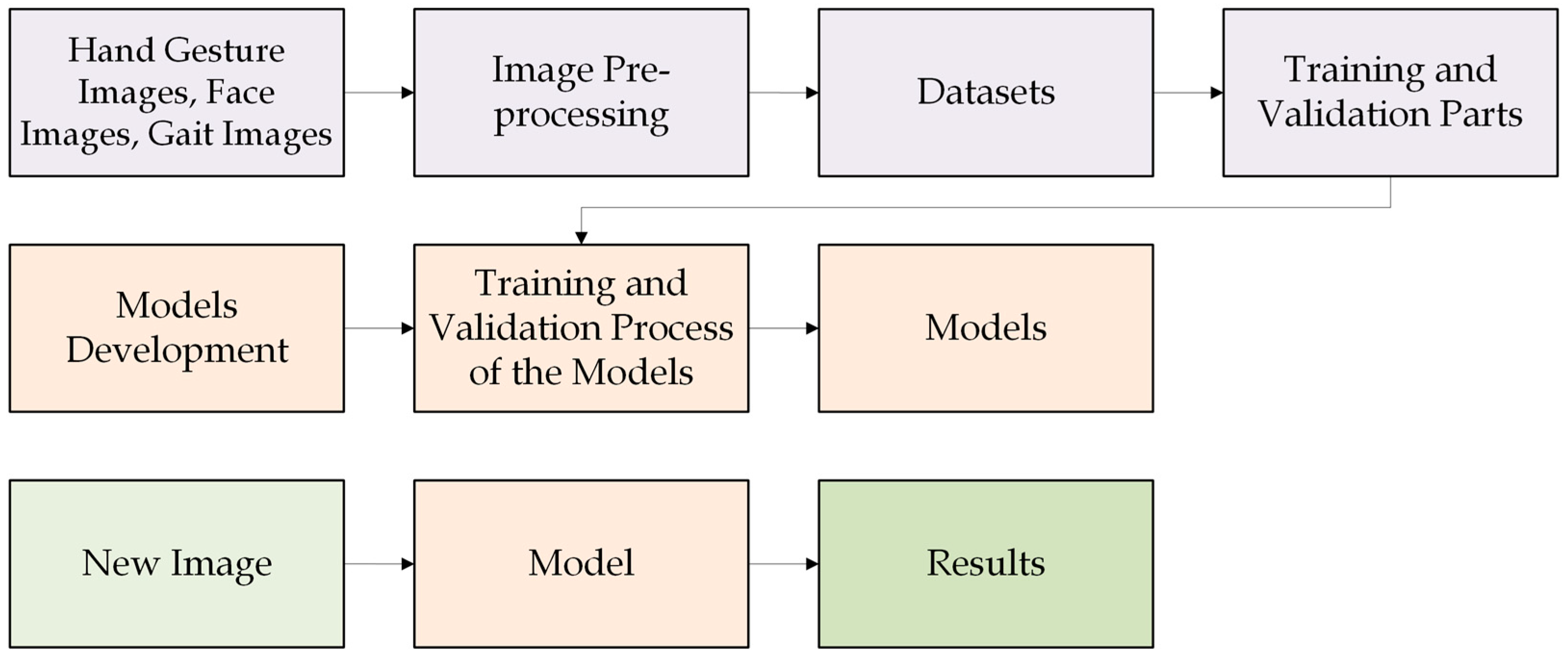
In the case of the four models developed and described in this paper, the whole process is the same (Figure 3) and can be described as follows: For the hand gesture model, it is necessary to capture images of different hand gestures. For example, images of the open hand, the fist and the like sign. In the case of the face recognition model, it is necessary to obtain images of the faces of all persons. For the emotion recognition model, images of faces with different grimaces, i.e., face expressions representing different emotions, should be captured. It should be noted that the dataset for the face recognition model and the emotion recognition model can be the same in many cases.
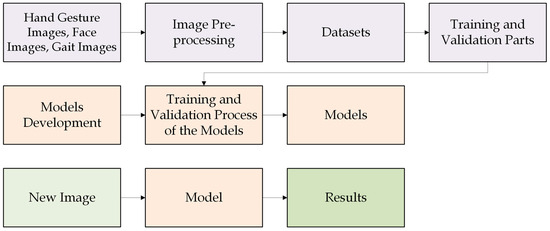
Figure 3.
Steps in the development of the four described deep learning models.
In the case of the gait recognition model, images with a person walking, i.e., during gait, should be available. Depending on the method of gait recognition, different images may be required. For example, silhouette images may be required to implement a particular method of gait recognition. It should be noted that, as already mentioned, the images belonging to the dataset should usually be additionally processed in order to have the best images available. If all images are suitable for the training and validation process of the models, the datasets are divided into a training part and a validation part.
The second part is the model development part. In this part, each model (in this case four models) should be developed, trained and validated. For the development of the four models described in this paper, the TensorFlow platform was used together with Keras.
In a real-world scenario, once the models have been developed and the final versions are available, they should be hosted on private servers or using cloud solutions. In the practical application of the models, it is now necessary to capture a new image in relation to a specific model, for example, to recognize a hand gesture or identify a person by their face. For example, if a face recognition model is used to identify a specific person, a new face image of the person should be captured and then passed to the model.
3. Architecture of the Models, Settings and Datasets
As mentioned in the previous text, four models were developed. These models are the hand gesture recognition model, the emotion recognition model, the face recognition model and the gait recognition model. All four models were developed using the TensorFlow platform and Keras, i.e., the Keras Sequential model was used. The models for gesture recognition, emotion recognition and face recognition consist of a preprocessing layer, convolution layers, pooling layers, a reshaping layer, core layers and a regularization layer. More precisely, Rescaling, Conv2D, MaxPooling2D, Conv2D, MaxPooling2D, Conv2D, MaxPooling2D, Dropout, Flatten, Dense and Dense are used.
The model for gait recognition consists of preprocessing layer, convolution layers, pooling layers, a reshaping layer and core layers. More precisely, Rescaling, Conv2D, MaxPooling2D, Conv2D, MaxPooling2D, Conv2D, MaxPooling2D, Flatten, Dense and Dense are used.
The dataset in [15] was used to train and validate the hand gesture recognition model. This dataset contains 10 different hand gestures performed by 10 different people, of which 5 are men and 5 are women. Only five gestures were used in this study, i.e., there were five different classes. The gestures mentioned were palm, fist, thumb (i.e., like), OK and C-shaped hand. There were 2000 images for each class, so a total of 10,000 images. Of this number of images, 8000 were used for training and 2000 for validation, i.e., the images were divided so that 80 percent of the images were used for training and 20 percent for validation.
The dataset Facial Expression Recognition 2013 (FER 2013) [16] was used to train and validate the emotion recognition model. This dataset consists of over 30,000 grayscale face images, which are divided into a training part and a test part. There are seven facial expressions, namely anger, disgust, fear, happy, sad, surprise and neutral. In other words, there are seven classes. In this study, only three facial expressions were used. These three expressions were happy, sad and neutral. The happy class consists of 7215 images, the sad class consists of 4830 images and the neutral class consists of 4965 images. A total of 17,010 images were used. Of these, 13,608 were used for training and 3402 for validation. The images were also divided so that 80 percent of the images were used for training and 20 percent for validation.
The Amsterdam Dynamic Facial Expression Set (ADFES) [17] was used to train and validate the face recognition model. This dataset consists of Northern European and Mediterranean models (male and female) with nine emotions, namely joy, anger, fear, sadness, surprise, disgust, contempt, pride and embarrassment. From the aforementioned dataset, 19 people were used in this study, which means that there were 19 classes. A total of 190 images were used, i.e., 10 images for each person, including images with the nine emotions mentioned above, as well as neutral images. The images were divided so that 80 percent of the images were used for training and 20 percent for validation. This means that out of 190 images, 152 images were used for training and 38 images for validation.
Casia Dataset B [18,19,20] was used for the gait recognition model. Casia Dataset B contains images of 124 people from 11 views, in which various conditions were taken into account, such as normal gait, clothing and carrying condition changes. It should be noted that a well-known method called Gait Energy Image [21] was used as a gait recognition method. GEI is essentially an image containing extracted silhouettes of a person during a gait cycle that are aligned, normalized and averaged.
The process of obtaining GEI images may roughly be described as shown in Figure 4. Images are taken of a person during a gait cycle. An RGB (red, green, blue) or RGB-D (red, green, blue-depth) sensor can be used for this purpose. Put simply, an ordinary camera, for example, can be used to obtain images of a person during a gait cycle. Subsequently, the obtained images can be additionally processed to obtain the best possible silhouettes of a person.

Figure 4.
Steps in creating GEI images.
It should be noted that silhouette images can be obtained from both RGB images and depth images. Once the silhouette images of a person during a gait cycle are available, they should be aligned, normalized and averaged. The result is a GEI image.
Examples of the GEI images from the Casia Dataset B are shown in Figure 5. Some other methods of gait recognition can also be considered as a substitute for GEI. In recent decades, various methods have been presented for gait recognition. In general, there are two types of gait recognition approaches. These approaches are appearance-based and model-based. The appearance-based approach and the methods based on it are usually based on the silhouette of a person. Model-based approaches, on the other hand, are based on a model that is based on certain characteristics. For example, the length of the legs or arms or the height of a person. Interesting work related to gait recognition can be found in [22,23,24,25,26,27,28,29].

Figure 5.
Examples of the GEI images from Casia Dataset B.
A total of 19 people were used in this study, i.e., there were 19 classes. The people were randomly selected and for each person, all available images were used, i.e., all angles and conditions were considered. There were 110 GEI images for each person, resulting in a total of 2090 GEI images. In this case too, the images were divided in the ratio 80–20 percent, which means that 80 percent were used for training and 20 percent for validation. Expressed in figures, 1672 images were used for training and 418 for validation.
Other settings for the models were as follows: Adaptive Moment Estimation Optimizer (Adam) [30] was used in all cases and 30 epochs for the hand gesture recognition, emotion recognition and gait recognition models. In the case of the face recognition model, 50 epochs were defined.
Various settings and parameters were tested during the training and validation process. This means that in addition to the number of epochs, different batch sizes were also tested. The best results for the developed models were achieved with the following settings: For the hand gesture recognition and gait recognition models, the batch size was 32. For the emotion and face recognition models, the batch size was 12. For the optimizer Adam, a default learning rate of 0.001 was used. In addition to Adam, several other optimizers such as Stochastic Gradient Descent (SGD) and Root Mean Square Propagation (RMSprop) were also tested.
4. Results
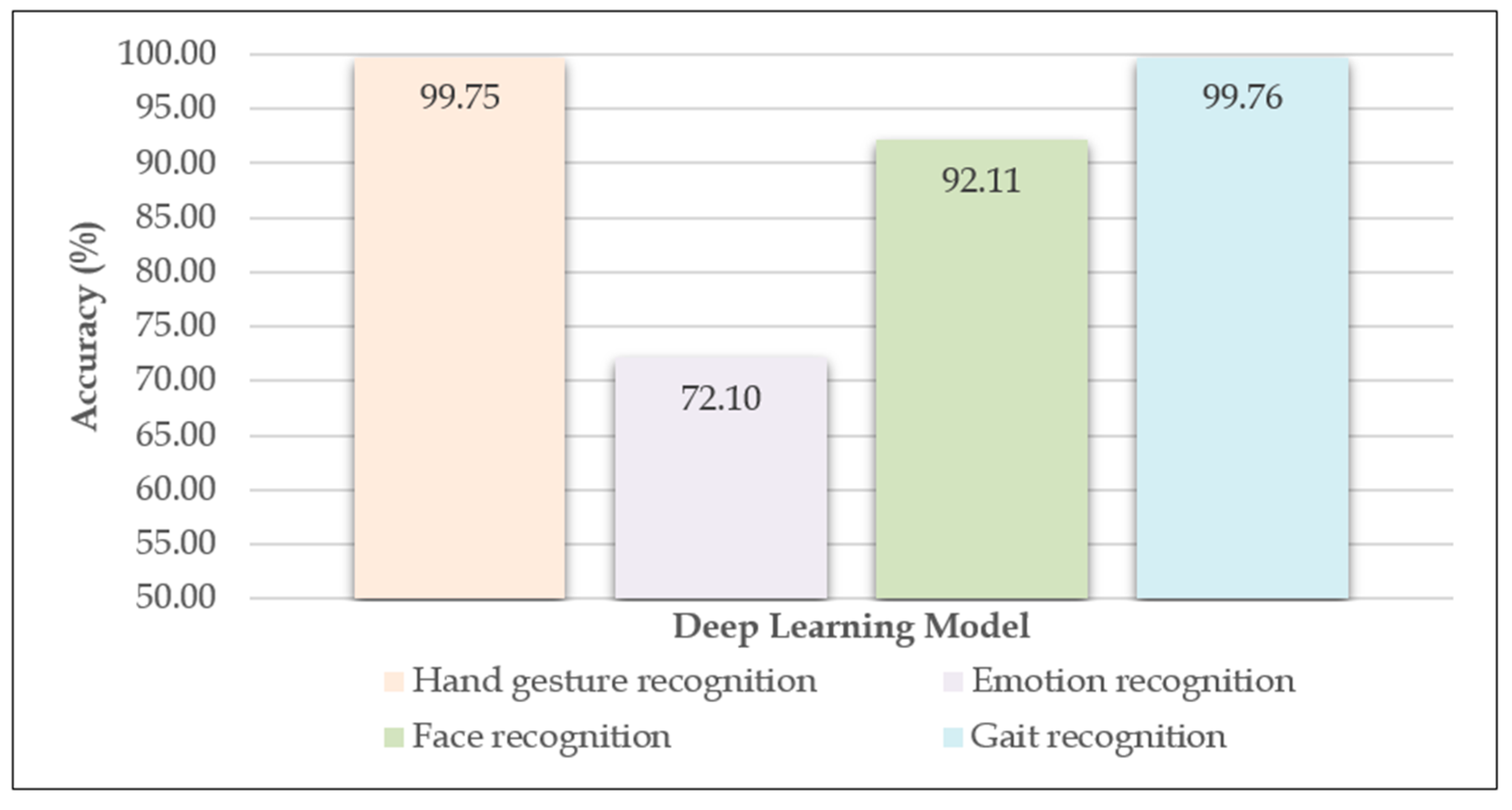
The results obtained, in terms of validation accuracy, with the defined settings and datasets used, were as follows: In the case of the hand gesture recognition model, the validation accuracy was 99.75%. For the emotion recognition model, the validation accuracy was 72.10%. The model for face recognition had a validation accuracy of 92.11% and the model for gait recognition, 99.76%. The results obtained are shown in Table 1 and illustrated in Figure 6.

Table 1.
Validation accuracy of the four developed models.
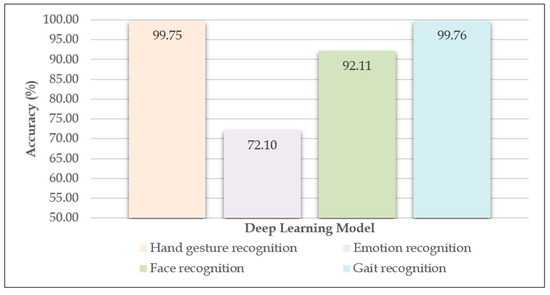
Figure 6.
Validation accuracy of the four developed models.
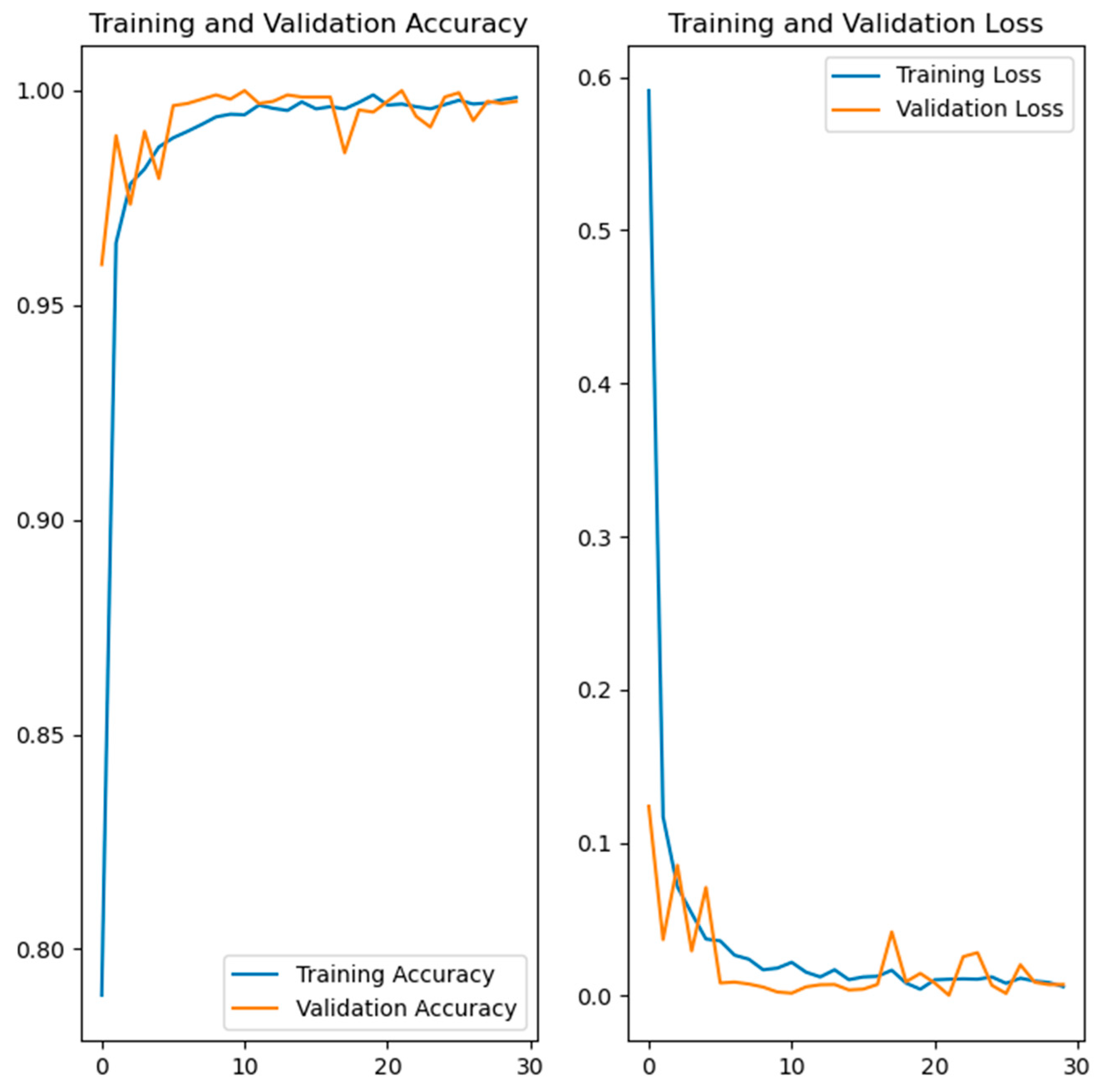
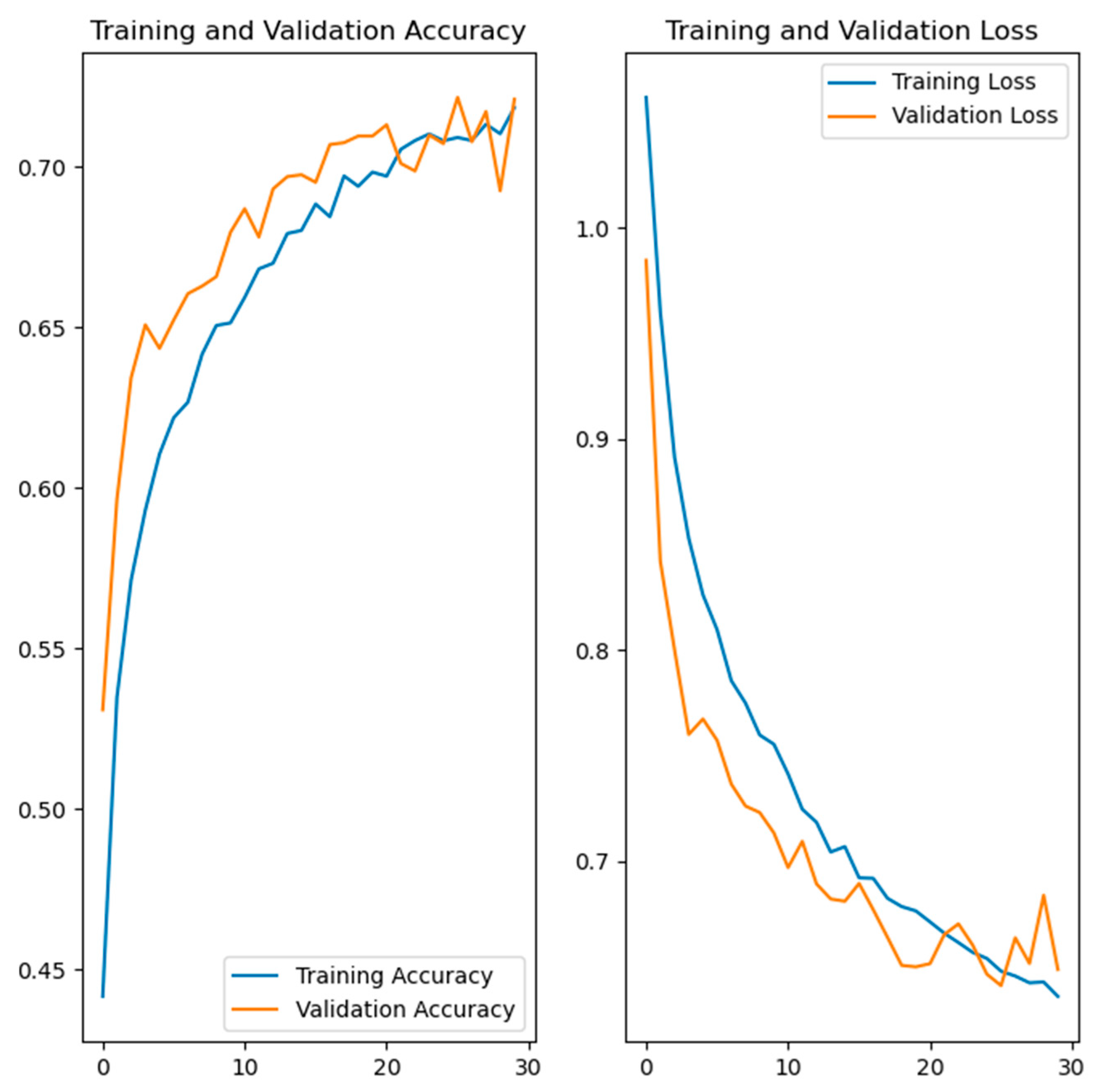
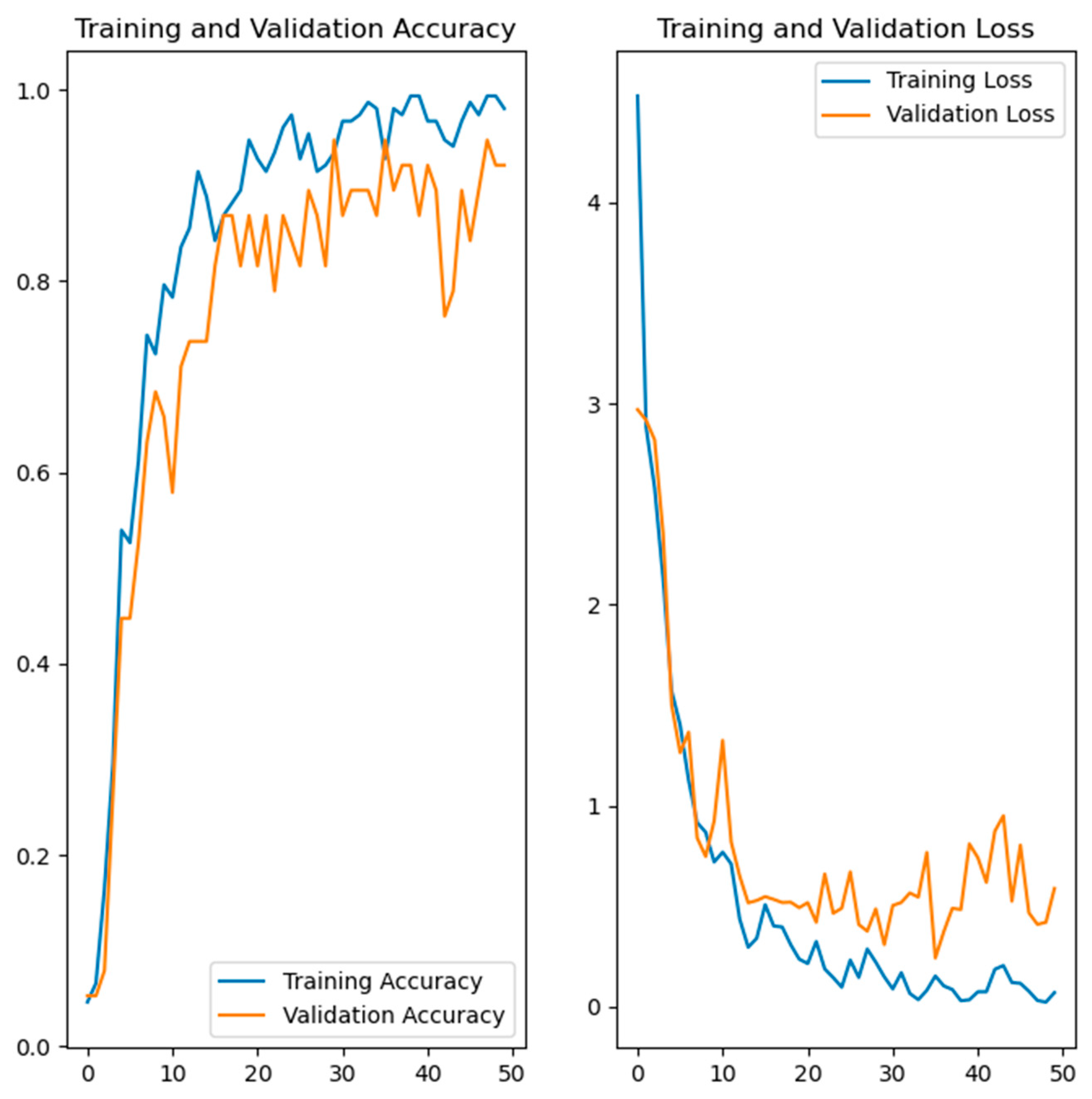
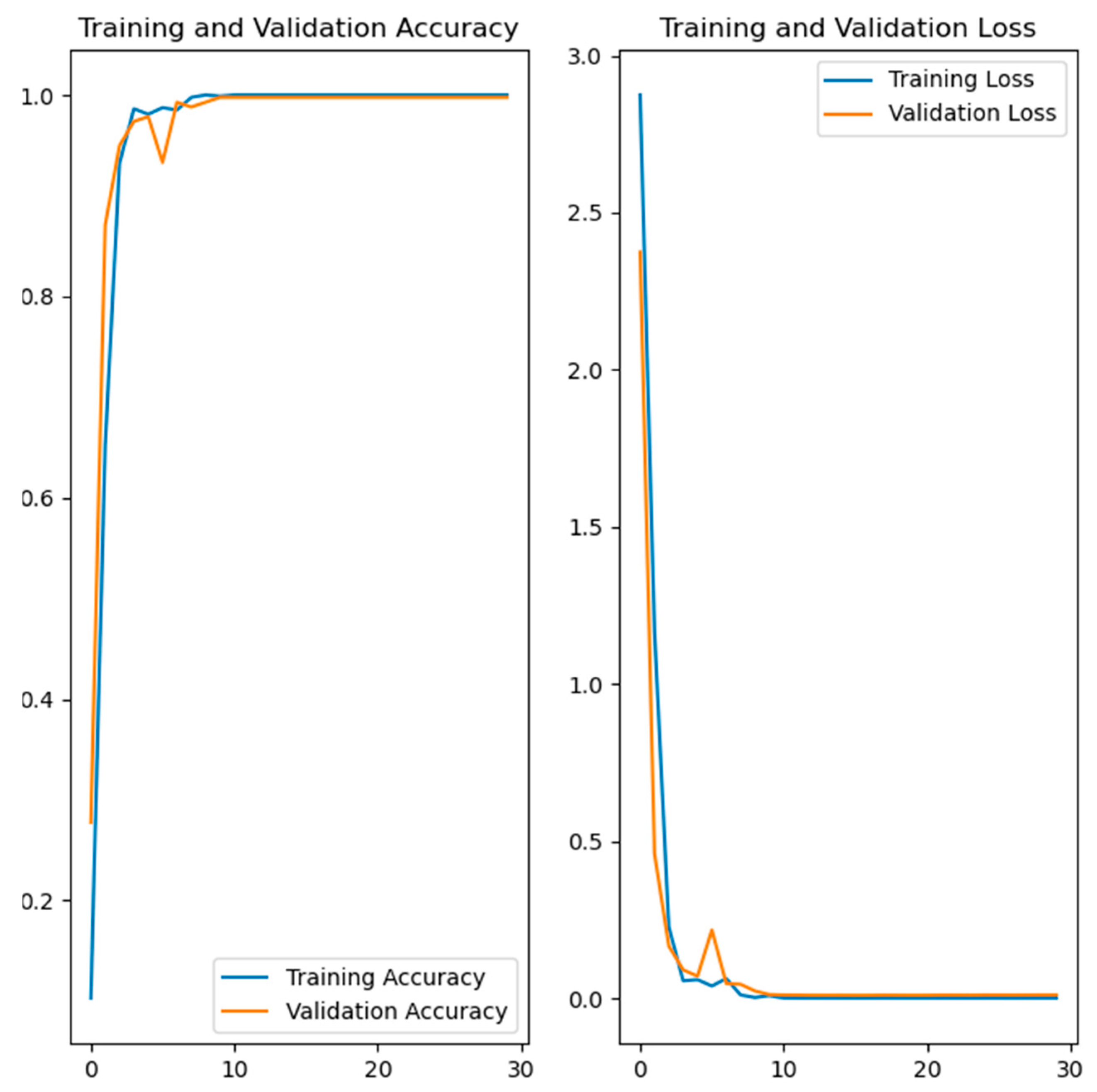
Figure 7, Figure 8, Figure 9 and Figure 10 show the training and validation accuracy and loss for the developed deep learning models. Figure 7 shows the training and validation accuracy and the loss of the hand gesture model, while Figure 8 shows the training and validation accuracy and the loss of the emotion recognition model. The training and validation accuracy and loss for the face recognition model are shown in Figure 9. Figure 10 shows the training and validation accuracy and loss for the gait recognition model.
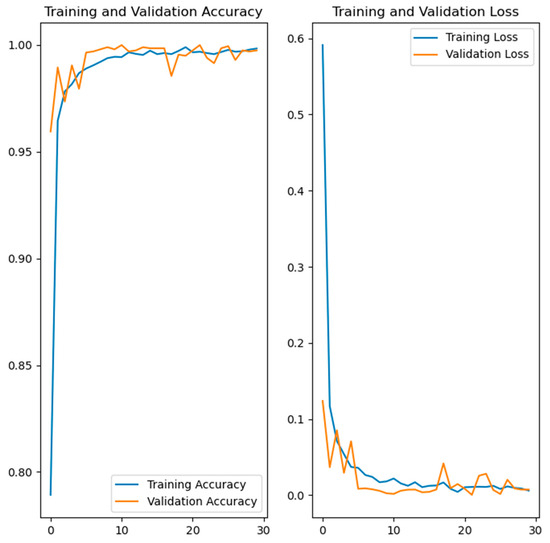
Figure 7.
Training and validation accuracy and loss of the developed model for hand gesture recognition.
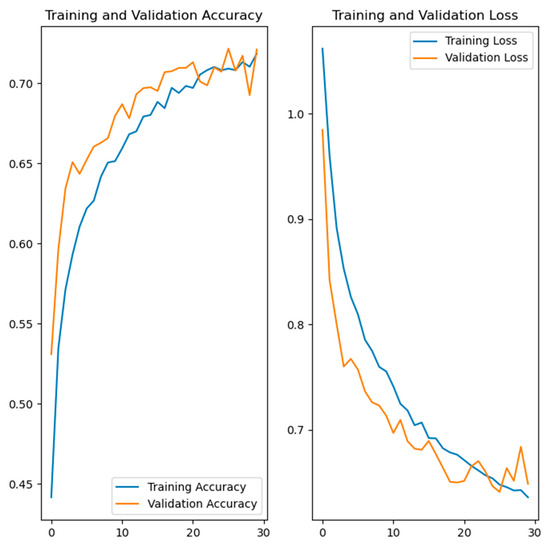
Figure 8.
Training and validation accuracy and loss of the developed model for emotion recognition.
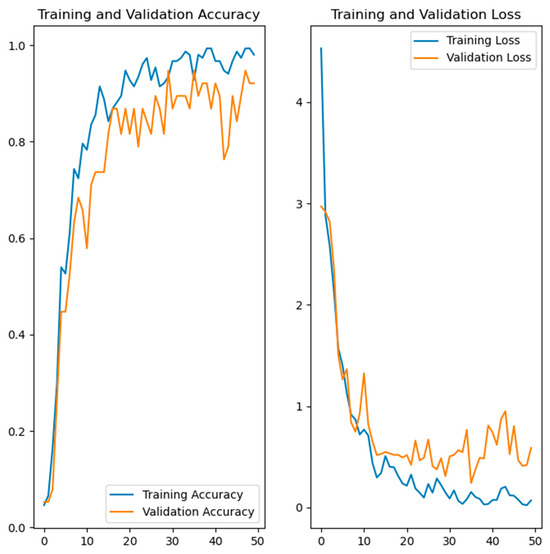
Figure 9.
Training and validation accuracy and loss of the developed model for face recognition.
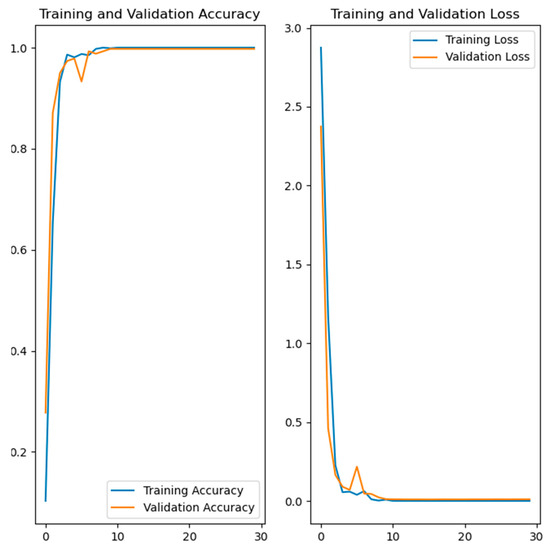
Figure 10.
Training and validation accuracy and loss of the developed model for gait recognition.
The left side in Figure 7, Figure 8, Figure 9 and Figure 10 shows the training and validation accuracy of the four developed models, while the right side shows the training and validation loss. Referring to the left side of the images, the x-axis shows the epochs, while the y-axis shows the accuracy during the training and validation process. On the right side of the images, the x-axis shows the epochs, while the y-axis shows the loss value.
5. Discussion
From the results shown in Table 1 and Figure 6, it can be concluded that three models achieved high results of over 90% in terms of validation accuracy. These models were the hand gesture recognition, face recognition and gait recognition models. Two of these, hand gesture recognition and gait recognition, had a validation accuracy of over 99%, which is very high and promising. In the case of the emotion recognition model, the results were significantly lower compared to the other models developed. To improve these lower results, different settings were tested, but the validation accuracy did not exceed 72–73%. A possible reason for the lower results could be the dataset used. It should be noted that the classes belonging to the mentioned dataset were additionally assumed to be balanced, but the results were similar. The validation accuracy can possibly be improved by using a different dataset with different images or more diverse images, or by additional processing of the images from the dataset. A different dataset containing a smaller number of images, with higher resolution, was also attempted, but the results were below 72%. It should be noted that in the case of the hand gesture recognition, emotion recognition and face recognition models, data augmentation was performed to increase the diversity of the training set.
Based on the results obtained, it can be said that artificial intelligence will be and already is part of many smart environments. From today’s perspective, artificial intelligence is already present in various environments where there are different devices that use artificial intelligence in some way. Examples of these devices include virtual assistants that enable voice control, home automation and personalization devices that control lighting and temperature, lock doors, etc. There are also various AI-powered cameras that have implemented face recognition methods and motion detection and alert systems. There are also various devices that monitor air quality or sleep patterns.
In addition to residential environments such as houses and residential buildings, artificial intelligence will also be used in other environments such as commercial buildings, factories and warehouses, and it is already present there. Many of these environments already use some kind of artificial intelligence, but in the future this will be taken to a higher level.
It should also be noted that various challenges need to be overcome when implementing the models. Firstly, the most modern hardware should be used to process the new images in real time. This means that servers with sufficient computing power should be used, which requires considerable financial resources. In addition, high-resolution cameras should be used to capture images that are suitable for use with the models. When training and validating the models, different images should be used, with different viewing angles of the people, different changes in the face, etc. In the case of gait recognition, it should be kept in mind that this type of method usually requires several steps. In this paper, the GEI method was used as the gait recognition method, and, as already mentioned in the paper, several steps are required to obtain a GEI image. The process of obtaining GEI images is very time consuming, which should not be disregarded.
In addition, the models for hand gesture recognition, face recognition and gait recognition may be used in different types of smart environments. The model for emotion recognition, on the other hand, is not suitable for use in all types of smart environments. With this model, various aspects such as privacy, ethics and acceptance must be taken into account. For this reason, the use of this model is primarily suitable for use within a home, as the data used is only linked to the occupant of the home and their own system. Third parties should not have access to the private data.
6. Conclusions
This paper analyzes and describes the possible use of artificial intelligence in smart environments. In general, the use of technology is inevitable nowadays. One of the technologies that is evolving rapidly today is artificial intelligence. This technology is used in many industries, from medical to automotive. As the various environments are getting smarter day by day and using different sensors and smart devices, artificial intelligence has a great potential to be used in such environments. Accordingly, it can be used in homes, residential and commercial buildings, factories, warehouses, etc. Some kind of artificial intelligence is already in use in many environments, but there is still a lot of room for improvement. In connection with the development and implementation of various elements based on artificial intelligence, neural networks and the deep learning approach dominate today.
The deep learning approach is mostly used in the context of smart environments to realize some security functions. In this work, deep learning was used to implement various methods that can be used for various tasks in addition to security, such as loading customized settings for specific person in terms of lighting, heating and ventilation, music, etc. With this in mind, this paper focused on analyzing and selecting suitable methods that can be used in the context of smart environments. Accordingly, this paper deals with the design of an exemplary smart environment and the analysis of the possible applications of the above-mentioned methods for various tasks. In addition, the development, adaptation, training and validation of deep learning models for each method is also covered.
Against this background, four deep learning models which have potential applications in smart environments were developed, trained and validated in this paper and an example of a house is used as the smart environment. The models developed are:
- The hand gesture recognition model;
- The emotion recognition model;
- The face recognition model;
- The gait recognition model.
The TensorFlow platform was used together with Keras to develop the models. In this context, the Keras Sequential model was used. Four suitable datasets were used to train and validate each of the models. As for the datasets, in the case of the hand gesture recognition model, a total of 10,000 images were used to train and validate the model. Of these, 8000 images were used for training and 2000 for validation. For the emotion recognition model, 17,010 images were used for the training and validation process, i.e., 13,608 images were used for the training process and 3402 images for validation. In the case of the face recognition model, a total of 190 images were used, of which 152 images were used for training and 38 images for validation. For the training and validation process of the gait recognition model, 2090 images were used, i.e., 1672 for training and 418 for validation. As can be seen from the previous text, in all cases the images were divided in a ratio of 80–20 percent.
The results in terms of validation accuracy are promising and exceeded 90% for the hand gesture recognition model, the face recognition model and the gait recognition model. In addition, the hand gesture recognition model and the gait recognition model had a validation accuracy of over 99%.
In the future, it would be interesting to analyze other elements based on artificial intelligence that could be used in smart environments. It would also be interesting to develop, train and validate some other deep learning models that can be used for different tasks in smart environments. Another method of gait recognition would also be interesting for use instead of the GEI.
Author Contributions
Conceptualization, A.R. and Z.B.; methodology, A.R. and Z.B.; software, A.R.; validation, A.R.; formal analysis, A.R.; investigation, A.R. and Z.B.; resources, A.R.; writing—original draft preparation, A.R.; writing—review and editing, A.R. and Z.B.; visualization, A.R.; supervision, Z.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets used in this study are publicly available or can be obtained from the authors of the datasets on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- TensorFlow. Available online: https://www.tensorflow.org (accessed on 25 May 2025).
- Keras. Available online: https://keras.io (accessed on 25 May 2025).
- Malibari, A.A.; Alotaibi, S.S.; Alshahrani, R.; Dhahbi, S.; Alabdan, R.; Al-wesabi, F.N.; Hilal, A.M. A Novel Metaheuristics with Deep Learning Enabled Intrusion Detection System for Secured Smart Environment. Sustain. Energy Technol. Assess. 2022, 52, 102312. [Google Scholar] [CrossRef]
- Taiwo, O.; Ezugwu, A.E.; Oyelade, O.N.; Almutairi, M.S. Enhanced Intelligent Smart Home Control and Security System Based on Deep Learning Model. Wire. Comm. Mob. Comp. 2022, 2022, 9307961. [Google Scholar] [CrossRef]
- Lu, Y.; Zhou, L.; Zhang, A.; Zha, S.; Zhuo, X.; Ge, S. Application of Deep Learning and Intelligent Sensing Analysis in Smart Home. Sensors 2024, 24, 953. [Google Scholar] [CrossRef] [PubMed]
- Bokka, R.; Sadasivam, T. Deep Learning Model for Detection of Attacks in the Internet of Things Based Smart Home Environment. In Proceedings of the International Conference on Recent Trends in Machine Learning, IoT, Smart Cities and Applications (ICMISC), Hyderabad, India, 28–29 March 2020; Springer: Singapore, 2021; pp. 725–735. [Google Scholar]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A Sequential Deep Learning Application for Recognising Human Activities in Smart Homes. Neurocomputing 2020, 396, 501–513. [Google Scholar] [CrossRef]
- Mehr, H.D.; Polat, H. Human Activity Recognition in Smart Home with Deep Learning Approach. In Proceedings of the 7th International Istanbul Smart Grids and Cities Congress and Fair (ICSG), Istanbul, Turkey, 25–26 April 2019; pp. 149–153. [Google Scholar]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; De Munari, I. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Gayathri, P.; Stalin, A.; Anand, S. Intelligent Smart Home Security System: A Deep Learning Approach. In Proceedings of the IEEE 10th Region 10 Humanitarian Technology Conference (R10-HTC), Hyderabad, India, 16–18 September 2022; pp. 438–444. [Google Scholar]
- Ramakić, A.; Bundalo, Z.; Bundalo, D. An Example of Intelligent Security System Based on Deep Learning. J. Circuits Syst. Comput. 2024, 33, 2450208. [Google Scholar] [CrossRef]
- Vardakis, G.; Tsamis, G.; Koutsaki, E.; Haridimos, K.; Papadakis, N. Smart Home: Deep Learning as a Method for Machine Learning in Recognition of Face, Silhouette and Human Activity in the Service of a Safe Home. Electronics 2022, 11, 1622. [Google Scholar] [CrossRef]
- PyTorch. Available online: https://pytorch.org (accessed on 25 May 2025).
- OpenVINO. Available online: https://docs.openvino.ai/2025/index.html (accessed on 26 May 2025).
- Hand Gesture Recognition Database. Available online: https://www.kaggle.com/datasets/gti-upm/leapgestrecog (accessed on 26 April 2025).
- Facial Expression Recognition 2013 Dataset (FER 2013). Available online: https://www.kaggle.com/datasets/msambare/fer2013 (accessed on 26 April 2025).
- Van Der Schalk, J.; Hawk, S.T.; Fischer, A.H.; Doosje, B. Moving Faces, Looking Places: Validation of the Amsterdam Dynamic Facial Expression Set (ADFES). Emotion 2011, 11, 907. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Tan, D.; Tan, T. A Framework for Evaluating the Effect of View Angle, Clothing and Carrying Condition on Gait Recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; pp. 441–444. [Google Scholar]
- Zheng, S.; Zhang, J.; Huang, K.; He, R.; Tan, T. Robust View Transformation Model for Gait Recognition. In Proceedings of the 18th International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2073–2076. [Google Scholar]
- Institute of Automation, Chinese Academy of Sciences. Available online: http://www.cbsr.ia.ac.cn/english/Gait%20Databases.asp (accessed on 25 May 2025).
- Han, J.; Bhanu, B. Individual Recognition Using Gait Energy Image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Arora, P.; Srivastava, S. Gait Recognition Using Gait Gaussian Image. In Proceedings of the 2nd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 19–20 February 2015; pp. 791–794. [Google Scholar]
- Bashir, K.; Xiang, T.; Gong, S. Gait Recognition Using Gait Entropy Image. In Proceedings of the 3rd International Conference on Imaging for Crime Detection and Prevention (ICDP), London, UK, 3 December 2009; pp. 1–6. [Google Scholar]
- Chattopadhyay, P.; Roy, A.; Sural, S.; Mukhopadhyay, J. Pose Depth Volume Extraction from RGB-D Streams for Frontal Gait Recognition. J. Vis. Commun. Image Represent. 2014, 25, 53–63. [Google Scholar] [CrossRef]
- Hofmann, M.; Bachmann, S.; Rigoll, G. 2.5D Gait Biometrics Using the Depth Gradient Histogram Energy Image. In Proceedings of the 5th International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 399–403. [Google Scholar]
- Lenac, K.; Sušanj, D.; Ramakić, A.; Pinčić, D. Extending Appearance Based Gait Recognition with Depth Data. Appl. Sci. 2019, 9, 5529. [Google Scholar] [CrossRef]
- Ramakić, A.; Bundalo, Z.; Bundalo, D. A Method for Human Gait Recognition from Video Streams Using Silhouette, Height and Step Length. J. Circuits Syst. Comput. 2020, 29, 2050101. [Google Scholar] [CrossRef]
- Sivapalan, S.; Chen, D.; Denman, S.; Sridharan, S.; Fookes, C. Gait Energy Volumes and Frontal Gait Recognition Using Depth Images. In Proceedings of the International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–6. [Google Scholar]
- Sivapalan, S.; Chen, D.; Denman, S.; Sridharan, S.; Fookes, C. The Backfilled GEI-A Cross-capture Modality Gait Feature for Frontal and Side-view Gait Recognition. In Proceedings of the International Conference on Digital Image Computing Techniques and Applications (DICTA), Fremantle, WA, Australia, 3–5 December 2012; pp. 1–8. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).