
Machine Learning Techniques for Uncertainty Estimation in Dynamic Aperture Prediction

 , , , , ,
, , , , ,
Abstract
1. Introduction
2. Dynamic Aperture Prediction and Machine Learning Inference
2.1. DA Evaluation via Simulation
2.2. Composition of the Dynamic Aperture Data Set
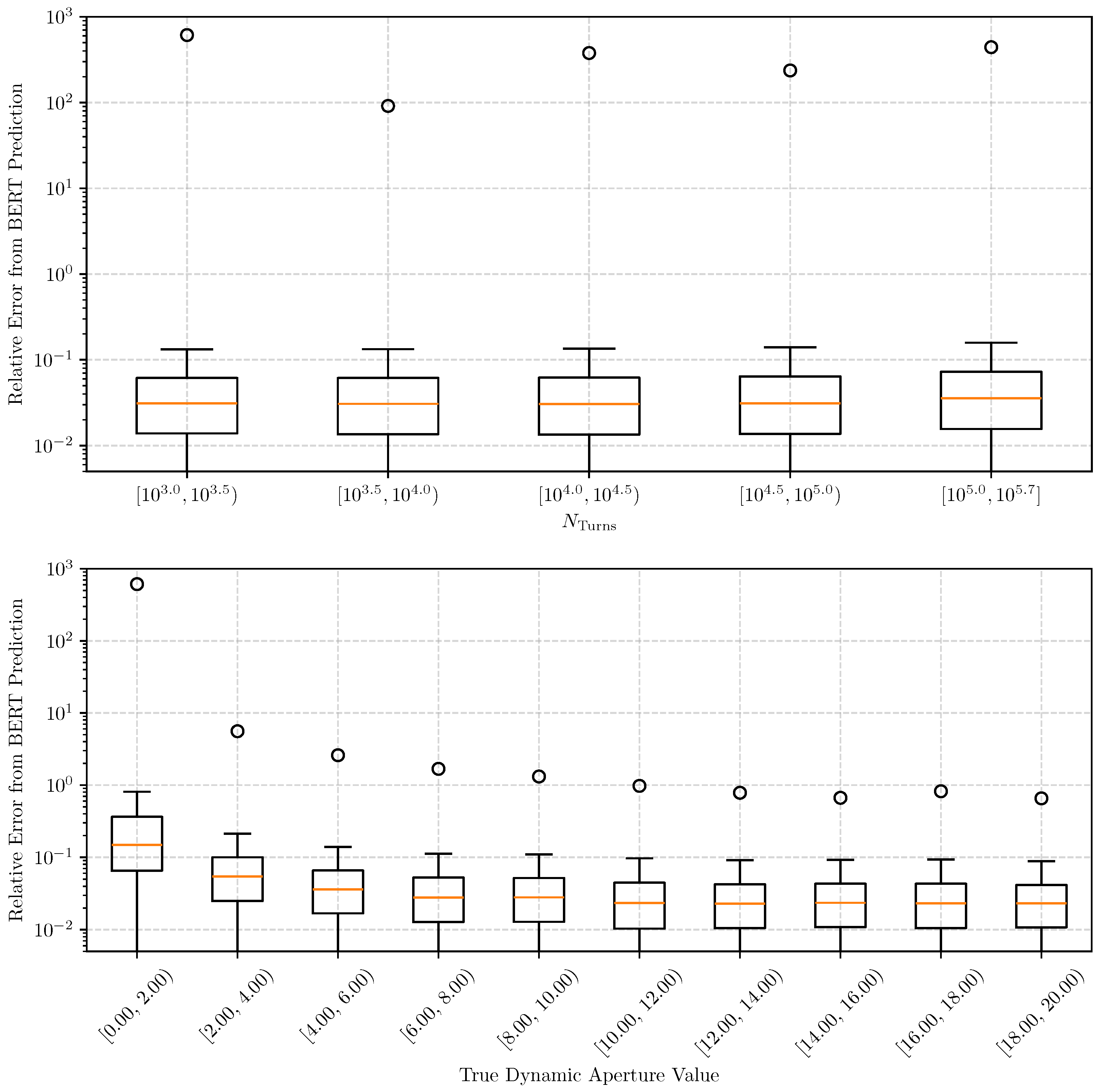
2.3. Machine Learning for Fast DA Prediction
3. Techniques of Epistemic Error Estimation
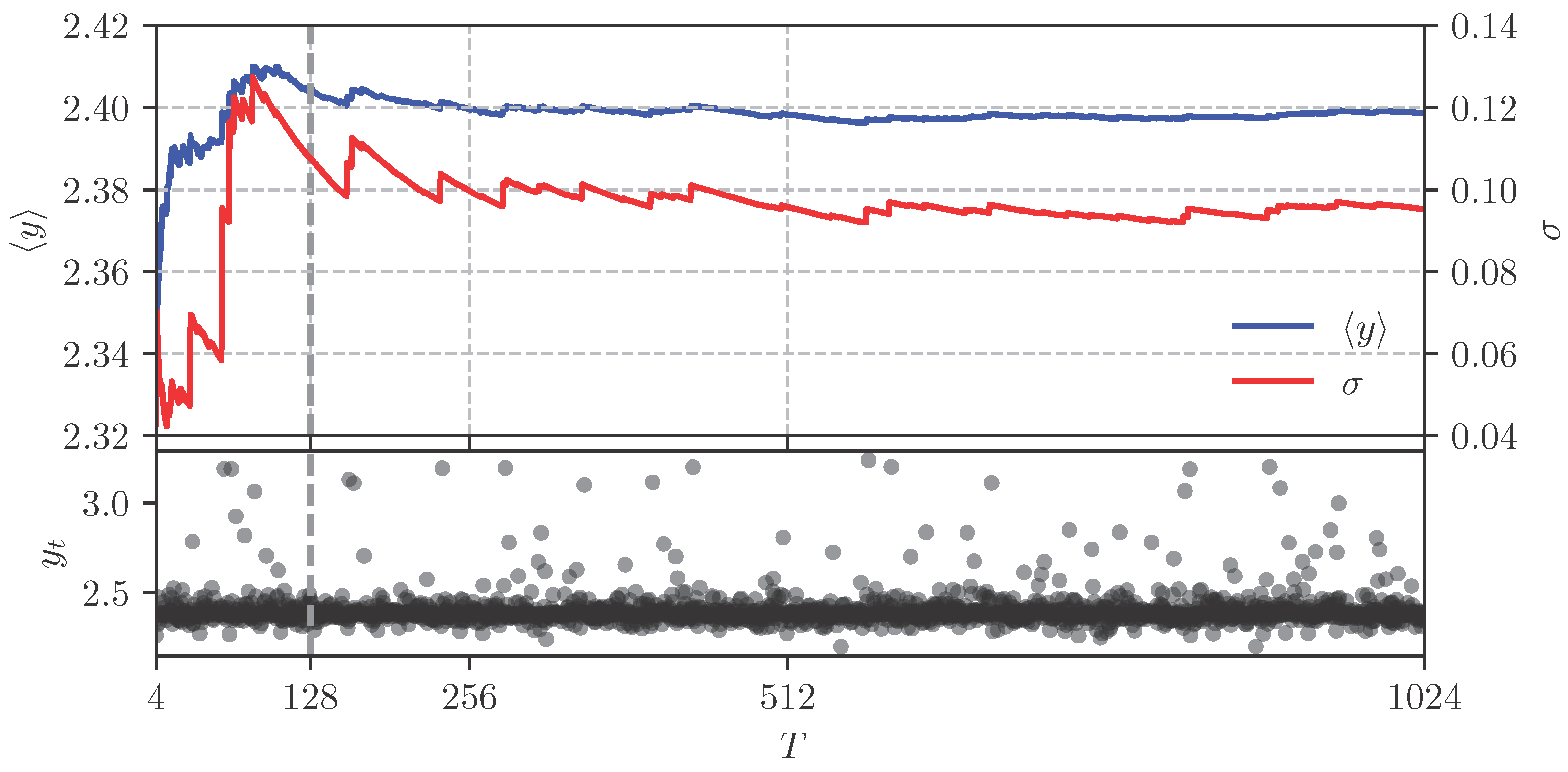
3.1. Monte Carlo Dropout
3.2. Bootstrap Aggregation (Bagging)
3.3. Mixed Technique
4. Results of the Comparative Analysis
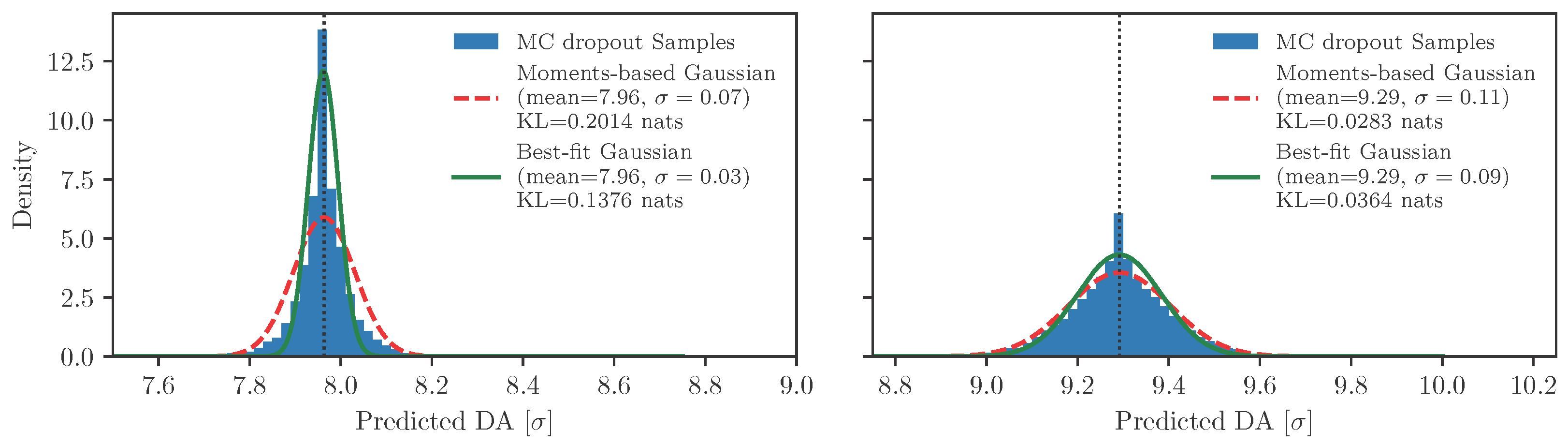
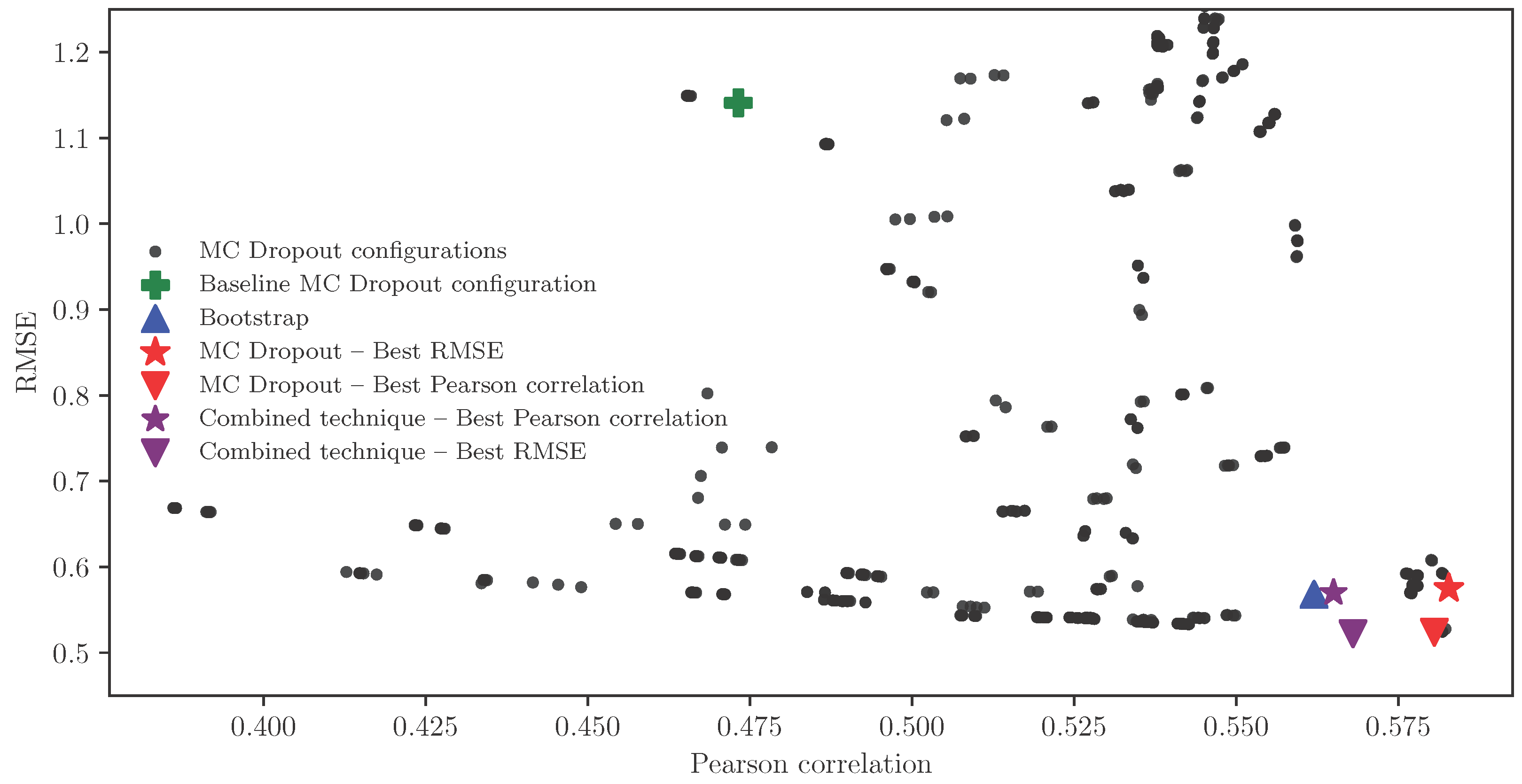
4.1. Uncertainty Evaluation and Benchmarking
4.2. Results of Uncertainty Estimation
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Dependence of the Angular DA on the Beam Emittance
References
- Bazzani, A.; Giovannozzi, M.; Maclean, E.H.; Montanari, C.E.; Van der Veken, F.F.; Van Goethem, W. Advances on the modeling of the time evolution of dynamic aperture of hadron circular accelerators. Phys. Rev. Accel. Beams 2019, 22, 104003. [Google Scholar] [CrossRef]
- Giovannozzi, M. A proposed scaling law for intensity evolution in hadron storage rings based on dynamic aperture variation with time. Phys. Rev. Spec. Top. Accel. Beams 2012, 15, 024001. [Google Scholar] [CrossRef]
- Maclean, E.; Giovannozzi, M.; Appleby, R. Innovative method to measure the extent of the stable phase-space region of proton synchrotrons. Phys. Rev. Accel. Beams 2019, 22, 034002. [Google Scholar] [CrossRef]
- Giovannozzi, M.; Van der Veken, F.F. Description of the luminosity evolution for the CERN LHC including dynamic aperture effects. Part I: The model. Nucl. Instrum. Methods Phys. Res. 2018, A905, 171–179, Erratum in Nucl. Instrum. Methods Phys. Res. 2019, 927, 471. [Google Scholar] [CrossRef]
- Brüning, O.S.; Collier, P.; Lebrun, P.; Myers, S.; Ostojic, R.; Poole, J.; Proudlock, P. LHC Design Report; CERN Yellow Reports: Monographs; CERN: Geneva, Switzerland, 2004. [Google Scholar] [CrossRef]
- Apollinari, G.; Béjar Alonso, I.; Brüning, O.; Fessia, P.; Lamont, M.; Rossi, L.; Tavian, L. High-Luminosity Large Hadron Collider (HL–LHC); CERN Yellow Reports: Monographs; CERN: Geneva, Switzerland, 2017; Volume 4. [Google Scholar] [CrossRef]
- Abada, A.; Abbrescia, M.; AbdusSalam, S.S.; Abdyukhanov, I.; Abelleira Fernandez, J.; Abramov, A.; Aburaia, M.; Acar, A.O.; Adzic, P.R.; Agrawal, P.; et al. FCC-ee: The Lepton Collider. Eur. Phys. J. Spec. Top. 2019, 228, 261–623. [Google Scholar] [CrossRef]
- Abada, A.; Abbrescia, M.; AbdusSalam, S.S.; Abdyukhanov, I.; Abelleira Fernandez, J.; Abramov, A.; Aburaia, M.; Acar, A.O.; Adzic, P.R.; Agrawal, P.; et al. FCC-hh: The Hadron Collider: Future Circular Collider Conceptual Design Report Volume 3. Eur. Phys. J. Spec. Top. 2019, 228, 755–1107. [Google Scholar] [CrossRef]
- Skoufaris, K.; Fartoukh, S.; Papaphilippou, Y.; Poyet, A.; Rossi, A.; Sterbini, G.; Kaltchev, D. Numerical optimization of dc wire parameters for mitigation of the long range beam-beam interactions in High Luminosity Large Hadron Collider. Phys. Rev. Accel. Beams 2021, 24, 074001. [Google Scholar] [CrossRef]
- Droin, C.; Sterbini, G.; Efthymiopoulos, I.; Mounet, N.; De Maria, R.; Tomas, R.; Kostoglou, S.; European Organization for Nuclear Research. Status of beam-beam studies for the high-luminosity LHC. In Proceedings of the IPAC’24—15th International Particle Accelerator Conference, Nashville, TN, USA, 19–24 May 2024; JACoW Publishing: Geneva, Switzerland, 2024; pp. 3213–3216. [Google Scholar] [CrossRef]
- Assmann, R.W.; Jeanneret, J.B.; Kaltchev, D.I. Efficiency for the imperfect LHC collimation system. In Proceedings of the 8th European Particle Accelerator Conference (EPAC 2002), Paris, France, 3–7 June 2002; p. 293. [Google Scholar]
- Bracco, C. Commissioning Scenarios and Tests for the LHC Collimation System. Ph.D. Thesis, EPFL, Lausanne, Switzerland, 2008. [Google Scholar]
- Schenk, M.; Coyle, L.; Pieloni, T.; Giovannozzi, M.; Mereghetti, A.; Krymova, E.; Obozinski, G. Modeling Particle Stability Plots for Accelerator Optimization Using Adaptive Sampling. In Proceedings of the IPAC’21, Campinas, Brazil, 24–28 May 2021; JACoW Publishing: Geneva, Switzerland, 2021; pp. 1923–1926. [Google Scholar] [CrossRef]
- Casanova, M.; Dalena, B.; Bonaventura, L.; Giovannozzi, M. Ensemble reservoir computing for dynamical systems: Prediction of phase-space stable region for hadron storage rings. Eur. Phys. J. Plus 2023, 138, 559. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Aftan, S.; Shah, H. A Survey on BERT and Its Applications. In Proceedings of the 2023 20th Learning and Technology Conference, Jeddah, Saudi Arabia, 26 January 2023; pp. 161–166. [Google Scholar] [CrossRef]
- Di Croce, D.; Giovannozzi, M.; Montanari, C.E.; Pieloni, T.; Redaelli, S.; Van der Veken, F.F. Assessing the Performance of Deep Learning Predictions for Dynamic Aperture of a Hadron Circular Particle Accelerator. Instruments 2024, 8, 50. [Google Scholar] [CrossRef]
- Alizadeh, R.; Allen, J.K.; Mistree, F. Managing computational complexity using surrogate models: A critical review. Res. Eng. Des. 2020, 31, 275–298. [Google Scholar] [CrossRef]
- Sudret, B.; Marelli, S.; Wiart, J. Surrogate models for uncertainty quantification: An overview. In Proceedings of the 2017 11th European Conference on Antennas and Propagation (EUCAP), Paris, France, 19–24 March 2017; pp. 793–797. [Google Scholar] [CrossRef]
- Roussel, R.; Edelen, A.L.; Boltz, T.; Kennedy, D.; Zhang, Z.; Ji, F.; Huang, X.; Ratner, D.; Garcia, A.S.; Xu, C.; et al. Bayesian optimization algorithms for accelerator physics. Phys. Rev. Accel. Beams 2024, 27, 084801. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A review of predictive uncertainty estimation with machine learning. Artif. Intell. Rev. 2024, 57, 94. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference. arXiv 2016, arXiv:1506.02158. [Google Scholar] [CrossRef]
- Gal, Y.; Hron, J.; Kendall, A. Concrete Dropout. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—ICML’16, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Information Science and Statistics; Springer: New York, NY, USA, 2006; Volume IV, p. 778. [Google Scholar]
- Di Croce, D.; Giovannozzi, M.; Krymova, E.; Pieloni, T.; Redaelli, S.; Seidel, M.; Tomás, R.; Van der Veken, F.F. Optimizing dynamic aperture studies with active learning. J. Instrum. 2024, 19, P04004. [Google Scholar] [CrossRef]
- Kaplan, L.; Cerutti, F.; Sensoy, M.; Preece, A.; Sullivan, P. Uncertainty Aware AI ML: Why and How. arXiv 2018, arXiv:1809.07882. [Google Scholar] [CrossRef]
- Kabir, H.D.; Mondal, S.K.; Khanam, S.; Khosravi, A.; Rahman, S.; Qazani, M.R.C.; Alizadehsani, R.; Asadi, H.; Mohamed, S.; Nahavandi, S.; et al. Uncertainty aware neural network from similarity and sensitivity. Appl. Soft Comput. 2023, 149, 111027. [Google Scholar] [CrossRef]
- Tabarisaadi, P.; Khosravi, A.; Nahavandi, S.; Shafie-Khah, M.; Catalão, J.P.S. An Optimized Uncertainty-Aware Training Framework for Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 6928–6935. [Google Scholar] [CrossRef]
- Giovannozzi, M.; Scandale, W.; Todesco, E. Dynamic aperture extrapolation in presence of tune modulation. Phys. Rev. 1998, E57, 3432. [Google Scholar] [CrossRef]
- Pellegrini, D.; Fartoukh, S.; Karastathis, N.; Papaphilippou, Y. Multiparametric response of the HL-LHC Dynamic Aperture in presence of beam-beam effects. J. Phys. Conf. Ser. 2017, 874, 012007. [Google Scholar] [CrossRef]
- Jing, Y.C.; Litvinenko, V.; Trbojevic, D. Optimization of Dynamic Aperture for Hadron Lattices in eRHIC. In Proceedings of the 6th International Particle Accelerator Conference (IPAC’15), Richmond, VA, USA, 4 May 2015; p. 757. [Google Scholar] [CrossRef]
- Cruz Alaniz, E.; Abelleira, J.L.; van Riesen-Hauptpresenter, L.; Seryi, A.; Martin, R.; Tomás, R. Methods to Increase the Dynamic Aperture of the FCC-hh Lattice. In Proceedings of the 9th International Particle Accelerator Conference (IPAC’18), Vancouver, BC, Canada, 3 May 2018; p. 3593. [Google Scholar] [CrossRef]
- Iadarola, G.; Latina, A.; Abramov, A.; Droin, C.; Demetriadou, D.; Soubelet, F.; Van der Veken, F.; Sterbini, G.; Dilly, J.; Paraschou, K.; et al. Xsuite: An integrated beam physics simulation framework. In Proceedings of the IPAC’24—15th International Particle Accelerator Conference, Nashville, TN, USA, 19–24 May 2024; JACoW Publishing: Geneva, Switzerland, 2024; pp. 2623–2626. [Google Scholar] [CrossRef]
- Grote, H.; Schmidt, F. MAD-X—An Upgrade from MAD8. In Proceedings of the PAC’03, Portland, OR, USA, 12–16 May 2003; JACoW Publishing: Geneva, Switzerland, 2003; pp. 3497–3499. [Google Scholar] [CrossRef]
- Deniau, L.; Burkhardt, H.; Maria, R.D.; Giovannozzi, M.; Jowett, J.M.; Latina, A.; Persson, T.; Schmidt, F.; Shreyber, I.S.; Skowroński, P.K.; et al. Upgrade of MAD-X for HL-LHC Project and FCC Studies. In Proceedings of the ICAP’18, Key West, FL, USA, 20–24 October 2018; JACoW Publishing: Geneva, Switzerland, 2018; pp. 165–171. [Google Scholar] [CrossRef]
- Maria, R.D.; Latina, A.; Schmidt, F.; Dilly, J.; Deniau, L.; Skowronski, P.; Berg, J.; Gläßle, T. Status of MAD-X V5.09. In Proceedings of the IPAC’23—International Particle Accelerator Conference, Venice, Italy, 7–12 May 2023; JACoW Publishing: Geneva, Switzerland, 2023; pp. 3340–3343. [Google Scholar] [CrossRef]
- MAD—Methodical Accelerator Design. Available online: https://mad.web.cern.ch/mad/ (accessed on 17 July 2025).
- Hostiadi, D.P.; Atmojo, Y.P.; Huizen, R.R.; Susila, I.M.D.; Pradipta, G.A.; Liandana, I.M. A New Approach Feature Selection for Intrusion Detection System Using Correlation Analysis. In Proceedings of the 2022 4th International Conference on Cybernetics and Intelligent System (ICORIS), Prapat, Indonesia, 8–9 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Parsaei, M.; Taheri, R.; Javidan, R. Perusing The Effect of Discretization of Data on Accuracy of Predicting Naïve Bayes Algorithm. J. Curr. Res. Sci. 2016, 1, 457–462. [Google Scholar]
- Schmidt, F.; Forest, E.; McIntosh, E. Introduction to the Polymorphic Tracking Code: Fibre Bundles, Polymorphic Taylor Types and “Exact Tracking”; Technical Report CERN-SL-2002-044-AP, KEK-REPORT-2002-3; CERN: Geneva, Switzerland, 2002; Available online: https://cds.cern.ch/record/573082 (accessed on 17 July 2025).
- Schmidt, F.; Chiu, C.Y.; Goddard, B.; Jacquet, D.; Kain, V.; Lamont, M.; Mertens, V.; Uythoven, J.; Wenninger, J. MAD-X PTC Integration. In Proceedings of the 21st IEEE Particle Accelerator Conference (PAC 2005), Knoxville, TN, USA, 16–20 May 2005; p. 1272. [Google Scholar]
- Bazzani, A.; Servizi, G.; Todesco, E.; Turchetti, G. A Normal Form Approach to the Theory of Nonlinear Betatronic Motion; CERN Yellow Reports: Monographs; CERN: Geneva, Switzerland, 1994. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 17 July 2025).
- Pang, B.; Nijkamp, E.; Wu, Y.N. Deep Learning with TensorFlow: A Review. J. Educ. Behav. Stat. 2020, 45, 227–248. [Google Scholar] [CrossRef]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding Deep Neural Networks with Rectified Linear Units. arXiv 2018, arXiv:1611.01491. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2019, arXiv:1803.08375. [Google Scholar] [CrossRef]
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. KerasTuner. 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 17 July 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Nguyen, S.; Nguyen, D.; Nguyen, K.; Than, K.; Bui, H.; Ho, N. Structured Dropout Variational Inference for Bayesian Neural Networks. arXiv 2021, arXiv:1909.00719. [Google Scholar] [CrossRef]
- Foong, A.Y.K.; Burt, D.R.; Li, Y.; Turner, R.E. On the Expressiveness of Approximate Inference in Bayesian Neural Networks. arXiv 2020, arXiv:1909.00719. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
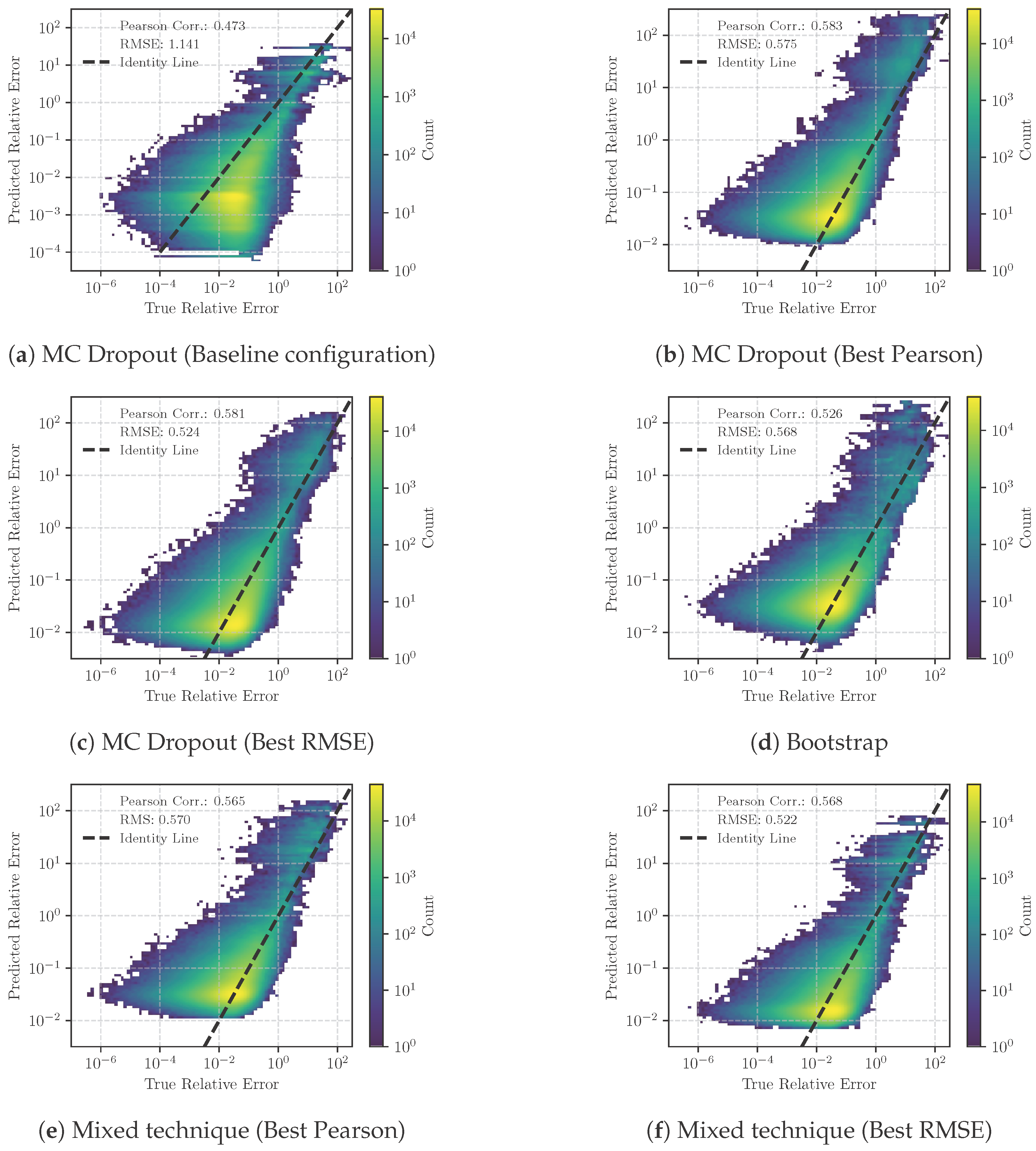
| Technique | Validation | Test | ||
|---|---|---|---|---|
| Pearson Correlation | RMSE | Pearson Correlation | RMSE | |
| MC Dropout (Baseline) | 0.473 | 1.141 | 0.381 | 0.92 |
| MC Dropout (Best Pearson) | 0.583 | 0.575 | 0.581 | 0.575 |
| MC Dropout (Best RMSE) | 0.581 | 0.524 | 0.579 | 0.525 |
| Bootstrap Aggregation | 0.562 | 0.568 | 0.518 | 0.581 |
| Combined Technique (Best Pearson) | 0.565 | 0.570 | 0.557 | 0.574 |
| Combined Technique (Best RMSE) | 0.568 | 0.522 | 0.560 | 0.523 |
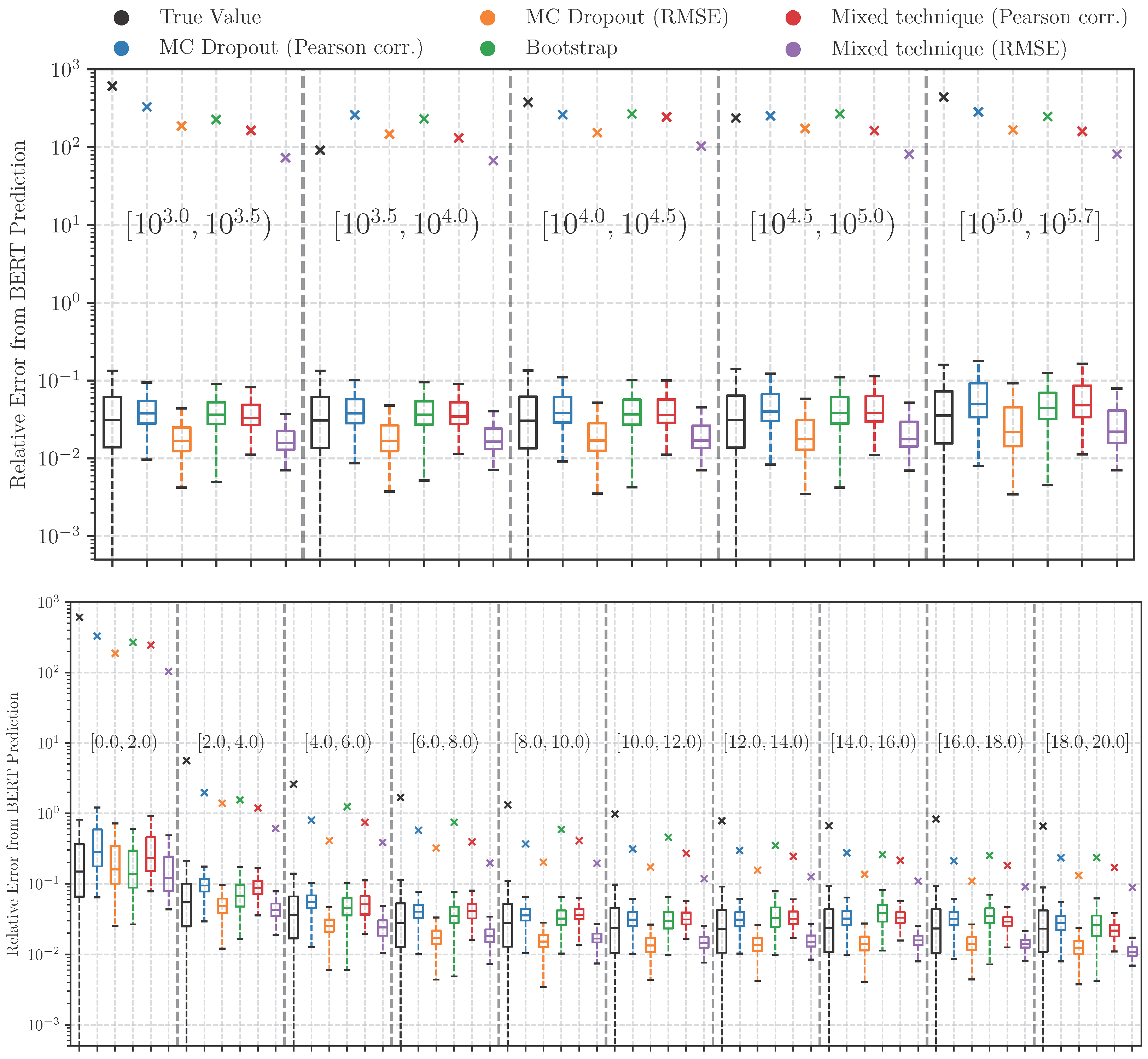
| Technique | 68% CI (%) | 90% CI (%) | 95% CI (%) |
|---|---|---|---|
| MC Dropout (Baseline) | 0.3 | 0.3 | 0.3 |
| MC Dropout (Best Pearson) | 67.1 | 85.7 | 90.5 |
| MC Dropout (Best RMSE) | 37.1 | 55.3 | 62.4 |
| Bootstrap Aggregation | 60.8 | 79.5 | 84.9 |
| Combined Technique (Best Pearson) | 65.3 | 83.8 | 88.7 |
| Combined Technique (Best RMSE) | 36.7 | 55.3 | 62.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montanari, C.E.; Appleby, R.B.; Di Croce, D.; Giovannozzi, M.; Pieloni, T.; Redaelli, S.; Van der Veken, F.F. Machine Learning Techniques for Uncertainty Estimation in Dynamic Aperture Prediction. Computers 2025, 14, 287. https://doi.org/10.3390/computers14070287
Montanari CE, Appleby RB, Di Croce D, Giovannozzi M, Pieloni T, Redaelli S, Van der Veken FF. Machine Learning Techniques for Uncertainty Estimation in Dynamic Aperture Prediction. Computers. 2025; 14(7):287. https://doi.org/10.3390/computers14070287
Chicago/Turabian StyleMontanari, Carlo Emilio, Robert B. Appleby, Davide Di Croce, Massimo Giovannozzi, Tatiana Pieloni, Stefano Redaelli, and Frederik F. Van der Veken. 2025. "Machine Learning Techniques for Uncertainty Estimation in Dynamic Aperture Prediction" Computers 14, no. 7: 287. https://doi.org/10.3390/computers14070287
APA StyleMontanari, C. E., Appleby, R. B., Di Croce, D., Giovannozzi, M., Pieloni, T., Redaelli, S., & Van der Veken, F. F. (2025). Machine Learning Techniques for Uncertainty Estimation in Dynamic Aperture Prediction. Computers, 14(7), 287. https://doi.org/10.3390/computers14070287