1. Introduction
Facial authentication is an innovative biometric authentication method that has seen widespread adoption in mobile devices, such as smartphones and tablets. A preliminary study on FaceCloseup was published as a short paper in ACM AsiaCCS 2019 [
1]. This current version has been substantially revised, expanded, and rewritten, making it significantly different from the conference paper. It includes new and original theoretical frameworks, experimental evaluations, and analyses.Prominent commercial face authentication systems currently available in the market include TrueFaceAI [
2], iProov [
3], Visidon [
4], and Face Unlock [
5].
Compared to traditional password-based user authentication, facial authentication offers several advantages, including higher entropy and no requirement for user memory [
6]. However, many existing facial recognition systems are intrinsically vulnerable to spoofing attacks [
7,
8,
9,
10,
11,
12,
13], where an adversary may replay a photo or video containing the victim’s face or use a 3D virtual model of the victim’s face. This issue is further exacerbated by the vast amount of personal media data published online. Prior research indicates that 53% of facial photos on social networks such as Facebook and Google+ can be used to successfully spoof current facial authentication systems [
14,
15].
To mitigate spoofing attacks, face liveness detection techniques have been developed to enhance facial recognition systems [
16,
17,
18,
19,
20,
21]. These techniques verify the presence of a real user during face authentication by analyzing features such as 3D characteristics, motion patterns, and texture details captured by cameras. Major manufacturers, including Apple, Baidu, Tencent, and Alibaba, have incorporated liveness detection into their face authentication systems [
22,
23,
24].
Previous research on liveness detection has been successful in countering photo-based attacks, where an adversary replays a facial photo of a victim. These liveness detection methods typically require users to perform specific facial motions or expressions during authentication. For example, methods based on eye blinks or head rotations require users to blink or turn their heads (e.g., [
25,
26]). While these techniques are effective against photo-based attacks, they are vulnerable to video-based attacks. In such cases, adversaries can use pre-recorded face videos in which the victim performs the necessary motions or expressions, thereby circumventing the liveness detection system.
Other research on liveness detection aims to counter both photo-based and video-based attacks. For instance, the facial thermogram approach leverages additional data from infrared cameras to analyze thermal characteristics [
27]. Another method, sensor-assisted face recognition, detects liveness by accurately identifying the nose edge under controlled lighting conditions [
28]. However, these approaches face practical challenges on mobile devices due to limited hardware capabilities and diverse usage environments.
More practical liveness detection methods have been developed to combat spoofing attacks on mobile devices. One such method is FaceLive, which requires the user to hold a smartphone with a front-facing camera and move it horizontally over a short distance in front of their face during authentication [
21]. FaceLive detects liveness by analyzing the consistency between a captured facial video and the movement data of the mobile device. This approach is effective in identifying both photo-based and video-based attacks. However, it remains vulnerable to spoofing attacks using 3D virtual face models, as such models can generate facial videos that align with the device’s movements [
11].
Face Flashing is another method aimed at preventing spoofing attacks on mobile devices [
29]. During authentication, the user holds a smartphone facing their face at a close distance. The phone’s screen light is activated, and its color is frequently changed according to a random challenge. A video of the user’s face is recorded under this light and then sent to a cloud server for analysis. The server examines the light reflections to detect 2D surfaces in spoofing attacks. However, Face Flashing demands substantial computational power to analyze facial reflections. Additionally, it generates significant network traffic and raises privacy concerns, as the face video must be transmitted to a remote server for liveness detection. Moreover, Face Flashing relies on precise time synchronization between the screen light and video capture to counter replay attacks. These factors make implementing Face Flashing on current mobile devices challenging.
This study introduces FaceCloseup, an anti-spoofing face authentication solution designed for mobile devices. FaceCloseup effectively detects not only photo-based and video-based attacks, but also those involving 3D virtual face models. The system operates using a standard front-facing camera—commonly available on mobile devices—and requires no specific conditions, such as controlled lighting or the transfer of facial videos to remote servers. These features make FaceCloseup well-suited for on-device liveness detection and practical for deployment on commodity smartphones.
FaceCloseup requires the user to hold and move a mobile device toward or away from their face over a short distance while the front-facing camera captures a video of the user’s face. A live user is identified if the changes in the observed distortions in the facial video correspond to those expected from a live face.
To counter spoofing attacks, FaceCloseup detects the 3D characteristics of a live user’s face by analyzing distortion changes observed in the video frames. Distortion in the facial video is a common phenomenon in photography, particularly when the camera is close to the face. This distortion is primarily due to the uneven 3D surface of the user’s face, causing different facial regions to be displayed at varying scales in the video frames. The scale of specific facial regions depends mainly on the distance between the camera and those regions. Due to the uneven 3D surface of a real face, these scales vary across different facial regions.
To validate the proposed liveness detection mechanism, we conducted a user study, collecting real-world photo and video data from both legitimate authentication requests and face spoofing attacks. In particular, we simulated 3D virtual face model-based attacks using an advanced 3D face reconstruction technique [
30] to generate facial photos with realistic distortions. Our experimental results demonstrate that FaceCloseup can detect face spoofing attacks with an accuracy of 99.48%. Additionally, the results reveal that FaceCloseup can distinguish between different users with an accuracy of 98.44%, effectively capturing the unique 3D characteristics of each user’s face based on the observed distortions in the facial video.
An initial study on FaceCloseup was presented as a short paper at ACM AsiaCCS 2019 [
1]. This version has undergone substantial revisions, expansions, and rewrites, resulting in a significantly enhanced and distinct manuscript. It introduces new theoretical frameworks, experimental evaluations, and analyses that were not included in the original conference paper.
2. Related Work
Face authentication is increasingly favored over traditional passwords and other biometric methods due to its superior convenience, user-friendliness, and contactless nature, which reduces the risk of forgotten credentials. Recent research on face authentication can be summarized into two primary directions: face recognition and face liveness detection.
Face recognition has been rapidly advancing since the 1990s as a significant component of biometric technologies. With the advent of powerful GPUs and the development of extensive face databases, recent research has focused on the creation of deep neural networks, such as convolutional neural networks (CNNs), for all aspects of face recognition tasks [
31,
32,
33,
34,
35,
36,
37,
38]. Deep learning-based face recognition has achieved remarkable accuracy and robustness [
34,
37], leading to widespread adoption by companies such as Google, Facebook, and Microsoft [
31].
Despite these advancements, face recognition remains vulnerable to various spoofing attacks, including photo-based attacks [
7,
8,
9], video-based attacks [
10], and 3D model-based attacks [
11,
12,
13]. To counter these threats, face liveness detection techniques have been developed to enhance face recognition [
1,
16,
17,
18,
19,
20,
21]. Face liveness detection verifies if a real user is participating in face authentication by analyzing features such as 3D characteristics, motion patterns, and texture details captured by cameras. Additional hardware, such as 3D cameras and infrared lights, may also be used. Many manufacturers, including Apple, Baidu, Tencent, and Alibaba, have integrated liveness detection techniques into their face authentication systems [
22,
23,
24].
Among various face liveness detection methods, the 3D face liveness indicator relies on the understanding that a real face is a three-dimensional object with depth features. Detecting these 3D face characteristics often involves optical flow analysis and changes in facial perspectives. A 3D face exhibits the optical flow characteristic where the central part of the face moves faster than the outer regions [
25]. In this context, Bao et al. proposed a liveness detection method that analyzes the differences and properties of optical flow generated from a holistic 3D face [
39]. In addition to the holistic face, local facial landmarks can also be used for optical flow analysis in liveness detection. Jee et al. introduced a liveness detection algorithm based on the analysis of shape variations in eye blinking, which is utilized for optical flow calculation [
40]. Kollreider et al. developed a liveness detection algorithm that analyzes optical flow by detecting ears, nose, and mouth [
41]. However, approaches based on optical flow analysis typically require high-quality input videos with ideal lighting conditions, which may be challenging to achieve in practice. Unlike these methods, FaceCloseup uses input video from a generic camera, making it more practical for real-world applications.
Conversely, the 3D characteristics of a real face can also be detected through its relative movements. Chen et al. investigated the 3D characteristics of the nose for liveness detection based on the premise that a real face has a three-dimensional nose [
42]. To determine user liveness, their mechanism compares the direction changes of the mobile phone, as measured by the accelerometer, with the changes in the clear nose edge observed in the camera video. However, producing a clear nose edge requires controlled lighting to cast unobstructed shadows, which may be impractical in real-world scenarios. This method is also less effective for individuals with flatter noses.
Li et al. introduced FaceLive, which requires users to move the mobile device in front of their faces and analyzes the consistency between the motion data of the device and the head rotation in the video [
21]. Although these two liveness detection algorithms can identify photo-based and video-based attacks, they remain vulnerable to 3D virtual face model-based attacks, as adversaries can synthesize accurate nose changes and head rotation videos in real-time [
11]. In contrast, FaceCloseup can effectively detect typical face spoofing attacks, including photo-based, video-based, and 3D virtual face model-based attacks.
Texture pattern-based liveness detection techniques are based on the assumption that printed fake faces exhibit detectable texture patterns due to the printing process and the materials used. Maatta et al. assessed user liveness by extracting local binary patterns from a single image [
43]. The IDIAP team utilized facial videos, extracting local binary patterns from each frame to construct a global histogram, which was then used to determine liveness [
9]. Tang et al. introduced Face Flashing, which captures face videos illuminated by random screen light and sends them to remote servers, such as cloud services, for the analysis of light reflections to detect liveness [
29]. These texture pattern-based techniques often require high-quality photos and videos taken under ideal lighting conditions, as well as significant computational power for analysis. This can be challenging to achieve on mobile devices in practice. Moreover, relying on remote servers or cloud services for computation can lead to substantial network traffic and privacy concerns. In contrast, FaceCloseup operates by analyzing closeup facial videos locally on mobile devices, eliminating these issues.
Real-time response-based approaches necessitate user interaction in real-time. For example, Pan et al. required users to blink their eyes to verify liveness [
26], while VeriFace, a popular face authentication software, asked users to rotate their heads for the same purpose [
44]. Unfortunately, these methods are susceptible to video-based and 3D virtual face model-based attacks, where adversaries might replay videos showing the required interactions or use a 3D virtual face model to generate the necessary responses in real time [
5,
45]. In contrast, FaceCloseup effectively detects such video-based attacks.
Finally, multimodal liveness detection approaches incorporate both facial biometrics and other biometric data for user authentication. Rowe et al. proposed a technique that combines face authentication with fingerprint authentication using a camera and a fingerprint scanner [
46]. Similarly, Wilder et al. utilized facial thermograms from an infrared camera alongside facial biometrics from a standard camera during the authentication process [
27,
47]. Unlike these methods, which depend on specialized hardware sensors that are rarely found on mobile devices, our approach leverages the front-facing camera, which is widely available on most mobile devices.
3. Theoretical Background
In this section, we present the theoretical background for developing FaceCloseup, covering face authentication, face spoofing and threat models, as well as distortions in facial images and videos.
3.1. Face Authentication
Face authentication verifies a user’s claimed identity by examining facial features extracted from the user’s photos or videos. A typical face authentication system consists of two subsystems: a face recognition subsystem and a liveness detection subsystem, as illustrated in
Figure 1.
The face recognition subsystem captures a user’s facial image or video using a camera and compares it with the user’s enrolled facial biometrics [
31,
32,
33,
34,
35,
36,
37,
38]. This subsystem accepts the user if the input facial image or video matches the enrolled biometrics, otherwise, it rejects the user. The subsystem consists of two key modules: a face detection module and a face matching module. The face detection module identifies the face region and eliminates irrelevant parts of the image, then passes the detected face region to the face matching module. The face matching module compares the input image with the enrolled face template to determine if they belong to the same individual. As the face recognition subsystem is designed to identify a user from an input facial image or video, but not to detect forged biometrics, it is inherently vulnerable to face spoofing attacks [
7,
8,
9,
10,
11,
12,
13]. In such attacks, an adversary may replay a pre-recorded facial image or video or display a 3D virtual face model of a victim.
The liveness detection subsystem is designed to mitigate spoofing attacks by distinguishing between live and forged faces based on facial images or videos [
1,
16,
17,
18,
19,
20,
21]. This subsystem typically employs a camera and/or other sensors to capture information about a live user during face authentication. It comprises two key modules: the liveness feature extraction module and the forgery detection module. The liveness feature extraction module derives features from the input data, while the forgery detection module calculates a liveness score from these features and determines whether the input is from a live user. Based on the outputs from both the face recognition subsystem and the liveness detection subsystem, the face authentication system makes a final decision regarding the authentication claim.
3.2. Face Spoofing and Threat Model
Face spoofing attacks allow an adversary to forge a user’s facial biometrics using photos or videos of the user’s face [
7,
8,
9,
10,
11,
12,
13]. The adversary can then present these forged biometrics to deceive face authentication systems, posing a significant threat to their security.
The face authentication system is inherently susceptible to face spoofing attacks during the recognition process. As illustrated in
Figure 1, the face recognition subsystem identifies a user based on an input facial photo or video but is unable to determine whether the input is from a live user or a pre-recorded or synthesized image or video. To counter these vulnerabilities, a liveness detection subsystem is implemented to prevent face spoofing attacks, including those based on photos, videos, and 3D virtual face models.
Specifically, photo-based and video-based attacks involve an adversary deceiving face authentication systems by replaying pre-recorded facial photos and videos of a user, which can be sourced online, such as from social networks [
7,
8,
9,
10]. More sophisticated and potent are the 3D virtual face model-based attacks, where an adversary constructs a 3D virtual face model of a user using their photos and videos [
11]. This 3D model allows the adversary to generate realistic facial videos with necessary motions and expressions in real-time, effectively bypassing face authentication systems.
The liveness detection subsystem is designed to distinguish between genuine face biometrics captured from a live user and those fabricated by adversaries using the user’s photos, videos, or a 3D virtual face model. This detection relies on indicators derived from human physiological activities, which can be categorized into several types: 3D facial structure, texture patterns, real-time responses, and multimodal approaches [
25].
The 3D face-based liveness indicators are derived from the inherent depth characteristics of a real face, which is an uneven three-dimensional object, as opposed to a fake face in a photo or video, or a 3D virtual face displayed on a flat (2D) plane. Texture pattern-based liveness indicators are based on the assumption that forged faces exhibit certain texture patterns that real faces do not, and vice versa. Real-time response-based liveness indicators rely on the premise that genuine users can interact with an authentication system in real time, a feat that is challenging for fake faces to achieve.
Typical real-time response liveness indicators include eye blinks and head rotations, which have been implemented in popular face authentication systems such as Google’s FaceUnlock [
5]. These indicators are effective in detecting photo-based attacks. However, they remain susceptible to video-based and 3D virtual face model-based attacks. In these scenarios, an adversary could use pre-recorded videos of the victim containing necessary facial movements and expressions, or construct a 3D virtual face model from the victim’s photos or videos to generate the required facial movements and expressions in real-time.
Finally, multimodal-based liveness indicators can be derived from both facial biometrics and additional biometric traits, which are difficult for an adversary to simultaneously obtain. These liveness detection mechanisms require no extra hardware, need only moderate image quality, and impose relatively low usability costs. Among the four types of liveness indicators, FaceCloseup employs the 3D face-based liveness indicator to counter face spoofing attacks due to its moderate usability cost, robustness in varied environments, and reliance on commonly available hardware.
In this work, it is assumed that adversaries lack access to a victim’s facial photos or videos exhibiting significant perspective distortions. User preference data (see
Section 6.2.4) suggests that most individuals are reluctant to share closeup facial imagery—particularly those captured at approximately 20 cm—due to the pronounced and often unflattering distortions. Users typically avoid positioning a smartphone within 20 cm of their faces during video calls, as this results in noticeable image distortion. Additionally, minor hand movements at such short distances frequently cause incomplete or blurred facial regions in video frames.
In contrast, facial photos and videos captured at longer distances (e.g., beyond 20 cm) are more likely to be shared on social media, used in video chats, or transmitted via conferencing platforms such as Zoom or Microsoft Teams. Adversaries may acquire such content through online platforms or by recording remote sessions. However, obtaining close-up facial imagery captured within 20 cm—without the user’s awareness—is substantially more difficult.
We also exclude real 3D attacks, such as 3D-printed faces, from our scope. The effectiveness of a 3D-printed face largely depends on the quality of the surface texture, which can be compromised due to inherent material defects. This vulnerability can be addressed using texture analysis-based methods that differentiate between the surface texture of a real face and that of a printed counterfeit face.
3.3. Distortion in Facial Images and Videos
The liveness indicator in FaceCloseup is grounded in the geometric principle of perspective distortion, a well-known phenomenon in photography and computer vision. When a camera captures a three-dimensional object at close range, regions closer to the lens appear disproportionately larger than those farther away. This effect, distinct from lens aberrations like barrel distortion, is purely a function of spatial geometry and has been studied in both biometric imaging and photographic modeling.
In facial imagery, perspective distortion causes features such as the nose or chin to appear enlarged relative to more recessed areas like the ears or temples. This distortion becomes more pronounced as the camera-to-subject distance decreases. While prior work has explored image distortion for spoof detection—such as the Image Distortion Analysis (IDA) framework by Wen et al., which uses features like specular reflection and blurriness to detect spoofing attacks [
48]—FaceCloseup introduces a geometric modeling approach that explicitly quantifies distortion scaling across facial regions using the Gaussian thin lens model.
Let
denote the distance from the lens to the image plane,
the distance from a facial region to the lens, and
f the focal length. The Gaussian lens formula for thin lens [
49] is as follows:
With Equation (
1), we compare ratio
between the size of a facial region in the image and the size of the facial region on 3D face as follows:
The change rate
of the size of the facial region in the image with respect to the change of
can be calculated as follows:
Equation (
3) reveals that as the camera approaches the face, the magnification of nearer regions increases rapidly, amplifying perspective distortion. This geometric insight enables FaceCloseup to infer depth cues from single images or videos without requiring stereo vision or active sensors.
Unlike prior distortion-based spoof detection methods that rely on texture or frequency-domain features [
48], FaceCloseup leverages region-specific geometric scaling to distinguish real 3D faces from flat 2D spoof media. Empirical observations show that selfie images taken at 20 cm exhibit significant distortion, while those at 50 cm do not. Since spoofing artifacts (e.g., printed photos or screen replays) lack true 3D structure, they fail to replicate the depth-dependent distortion patterns of a live face. FaceCloseup exploits this discrepancy by analyzing the relative scaling of facial regions to detect liveness.
4. FaceCloseup Design
FaceCloseup authenticates facial liveness against spoofing attacks by examining the 3D characteristics of the face, based on distortion changes across various facial regions in close-up videos. This 3D face detection serves as a liveness indicator, as utilized by many existing detection mechanisms outlined in
Section 3.2. The facial video is recorded using a front-facing camera, which is standard hardware on current mobile devices.
When a live user initiates an authentication request, the distortion variations in different facial regions captured in the video should align with the 3D characteristics of the user’s actual face. For successful face authentication, the user must hold and move a mobile device over a short distance towards or away from their face. As this movement occurs, the front-facing camera on the mobile device captures the user’s face at varying distances. If it is a genuine 3D face in front of the camera, the resulting facial video will display corresponding distortion changes in various facial regions.
FaceCloseup comprises three primary modules: the Video Frame Selector (VFS), the Distortion Feature Extractor (DFE), and the Liveness Classifier (LC), as illustrated in
Figure 2. Specifically, the VFS module processes the input facial video, extracting and selecting multiple frames based on the detected facial size in each frame. Using these frames, the DFE module identifies numerous facial landmarks and calculates features related to the distortion changes across the frames. Finally, the LC module applies a classification algorithm to differentiate a genuine face from a forged face during spoofing attacks.
4.1. Video Frame Selector
As a mobile device is moved towards or away from a user’s face, the device’s camera captures a video comprising multiple frames of the user’s face, each taken at varying distances between the camera and the face. Consequently, the size of the faces in the video frames fluctuates due to this movement. The Video Frame Selector (VFS) extracts and selects a series of frames from the video based on the detected face size in each frame. The VFS employs the Viola–Jones face detection algorithm, a robust real-time face detection method that achieves 98.7% accuracy on widely-used face datasets such as LFPW and LFW-A&C [
50,
51].
The face detection algorithm comprises several sub-techniques, including integral image, AdaBoost, and attentional cascade. The integral image technique extracts rectangular features from each frame by computing the sum of values within rectangle subsets of grids in the frame. The AdaBoost algorithm selects these features and trains a strong classifier based on a combination of sub-classifiers. The attentional cascade structure for these sub-classifiers significantly accelerates the face detection process.
Once faces are detected in the video frames, the Video Frame Selector (VFS) selects K frames based on the size of the detected faces, where K is a parameter of the FaceCloseup system. The face size is determined by the number of pixels in the detected face within a frame. VFS selects K frames by categorizing face sizes into K ranges, , where each size range corresponds to the i-th frame selection, ensuring that the face size in the i-th selected frame falls within , where denotes the lower bound, and the upper bound, both in terms of mega-pixels. If multiple frames fall within a particular size range , VFS randomly selects one among them. The sequence of selected frames is denoted as . Without loss of generality, we assume that the user moves their mobile device away from their face during liveness detection, causing the face size to decrease as the frame index increases.
4.2. Distortion Feature Extractor
Due to the three-dimensional characteristics of the human face, distortions in various facial regions can be observed in facial images, as discussed in
Section 3.3. As a mobile device moves closer to or further from a user’s face, the distortion of facial regions in different video frames varies according to the distance between the camera and the user’s face at the time the frames are captured. These distortion changes are correlated with changes in distance. Given a sequence of frames
selected by the Video Frame Selector (VFS), the Distortion Feature Extractor (DFE) calculates the geometric distances between various facial landmarks in each frame and uses these measurements as features to detect distortion changes in the facial video.
To detect facial landmarks on 2D facial images, we employ the supervised descent method (SDM) due to its ability to identify facial landmarks under various poses and achieve a median alignment error of 2.7 pixels [
51]. The SDM method identifies 66 facial landmarks in each frame. These landmarks are distributed across different facial regions, including the chin (17), eyebrows (10), nose stem (4), area below the nose (5), eyes (12), and lips (18). A comprehensive review of facial landmark detection algorithms, including those utilizing 66 facial landmarks, is available in the literature survey on facial landmark detection [
52].
We maintain consistent indices
for the 66 facial landmarks across all video frames, with the coordinate of each landmark represented as
. Consequently, we establish a matrix for the facial landmarks in the
K selected frames as follows:
where each row
i represents frame
, and each column
j represents the
j-th facial landmark.
Facial distortion impacts both the geometric positions of facial landmarks and the overall size of the face in different frames. To capture this distortion, we calculate the distance between any two facial landmarks, and , as , where and represent the coordinates of and , respectively, with and . The 66 facial landmarks in each frame generate 2145 pairwise distances, . Assuming the detected face size in a frame is w in width and h in height, a geometric vector describing the face is formed as .
According to Equation (
3), facial distortion becomes increasingly pronounced as the camera moves closer to a real 3D face. Instead of utilizing the absolute distances in the geometric vector, we compute relative distances by normalizing the geometric vector of each frame against a base facial image, which the user registers during a registration phase. It is required that the user’s face in this base image fall within a predefined pixel range,
. The geometric vector for the base image is calculated as
. For each selected frame
, we compute a relative geometric vector
, where
for
,
, and
. The facial distortion in
K selected frames is represented by a
matrix FD:
where each row
i corresponds to the relative geometric vector for frame
.
4.3. Liveness Classifier
Following the extraction of the
feature matrix FD by the Distortion Feature Extractor (DFE), the Liveness Classifier (LC) module processes FD using a classification algorithm to ascertain whether the features originate from a genuine face or a counterfeit one in spoofing attacks. Given that the input matrix FD resides in a high-dimensional space, traditional classification algorithms may encounter issues such as overfitting and high variance gradients [
53]. Deep learning-based classification algorithms, however, typically perform more effectively with high-dimensional data [
54,
55]. Specifically, we have implemented a convolutional neural network (CNN) tailored to our classification needs within the LC module. Comprehensive evaluations indicate that CNN yields highly accurate classification results in distinguishing genuine user faces from spoofed ones.
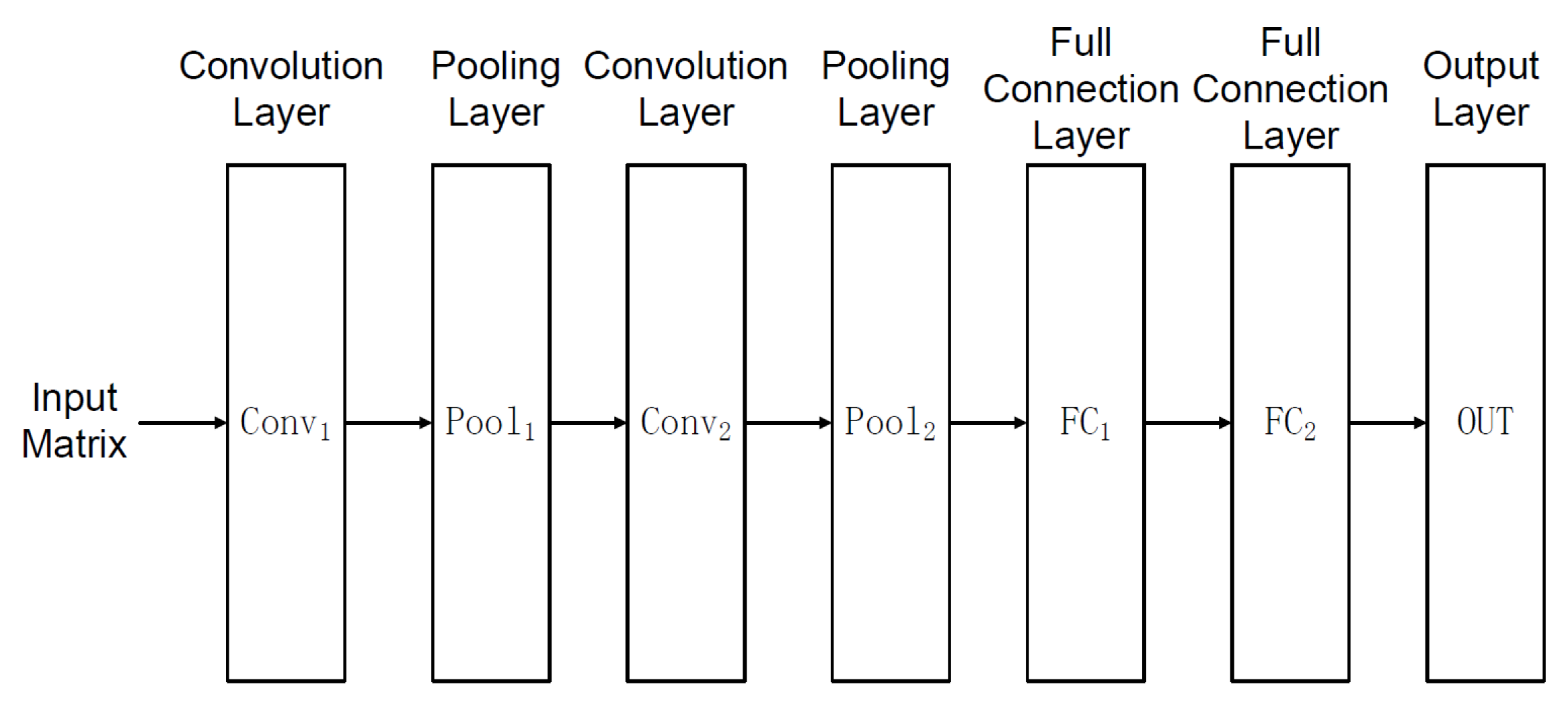
The CNN-based classification algorithm within the LC module comprises seven layers: two convolution layers, two pooling layers, two fully connected layers, and one output layer, as illustrated in
Figure 3. Given an input
feature matrix (FD), the first convolution layer (
) computes a tensor matrix (
). To achieve non-linear properties while maintaining the receptive fields within
, a rectified linear unit (ReLU) activation function is applied to
, resulting in the tensor matrix
. The ReLU function is defined as
. The first pooling layer (
) then performs non-linear downsampling on
. Subsequently, the second convolution layer (
) and the second pooling layer (
) execute the same operations as
and
, respectively, in the third and fourth steps.
Subsequently, the fully connected layers
and
execute high-level reasoning. Assuming
comprises
M neurons, it generates a vector
, which is then passed to the output layer
. The output layer calculates the probabilities for
C classes, with the probability of each class
c determined using the following multinomial distribution:
where
C represents the number of classes,
is the
c-th row of a learnable weighting matrix
, and
is a bias term. The output layer generates the classification result by selecting the class with the highest probability among the
C classes. Since liveness detection aims to differentiate between a real face and a forged face,
C is set to 2.
To train the CNN-based classification model, we utilize a cross-entropy loss function, which evaluates the performance of a classification model with probabilistic output values ranging between 0 and 1 [
56]. For each input training sample
i, we define the loss as follows:
where
represents the predicted probability for the correct class
, based on the sample’s actual observation label.
During the model training, we apply mini-batch to split the training dataset into small batches that are used to calculate model error and update model coefficients. Training the model with mini-batch can allow for robust convergence, avoid local minima, and provide a computationally efficient update process [
56]. To mitigate the overfitting problem, we add regularization loss to the loss function for each mini-batch as follows:
where
represents the average prediction loss for
N samples within the mini-batch, and
denotes the regularization loss for
l weighting factors across
k layers in the CNN-based classification model. Here,
acts as the regularization strength factor. Hence, our objective function is to minimize
L.
5. Data Collection and Dataset Generation
An IRB-approved user study was conducted to gather users’ data for both legitimate requests and face spoofing attacks, including photo-based attacks, video-based attacks, and 3D virtual face model-based attacks.
5.1. Data Collection
Our user study comprises 71 participants, consisting of 43 males and 28 females, aged between 18 and 35. Each participant spent approximately 50 min in a quiet room during the study. The study was divided into three parts, with participants taking a short break of about 3 min after completing each part. Detailed descriptions of the study follow below.
In the first part, we collected multiple selfie facial videos of participants at various device positions. Each participant was instructed to hold a mobile phone and take three frontal facial video clips over a controlled distance (DFD) between their face and the phone. The mobile device used in our experiments was a Google Nexus 6P smartphone, equipped with an 8-megapixel front-facing camera, a 5.7-inch screen, and operating on Android 7.1.1. The front-facing camera captured 1080p HD video at 30 fps. Each video clip lasted for 3 s, with each frame measuring
pixels and the face centered in the frame. These facial videos later guided the frame selection by the Video Frame Selector (VFS) as outlined in
Section 4.1 and provided facial photos for photo-based attacks.
The controlled distance (DFD) between the face and the smartphone was set at 20 cm, 30 cm, 40 cm, and 50 cm. These distances were selected based on common participant behaviors and the capabilities of the smartphone’s front-facing camera. According to our pilot study, over 65% of participants faced challenges in capturing clear and complete frontal selfie videos at DFD < 20 cm, as the camera was either too close to focus on partial facial regions or too close to capture entire faces. Conversely, more than 70% of participants experienced difficulties holding the smartphone at DFD > 50 cm due to the limited length of their arms. Consequently, we collected 12 frontal selfie video clips at these controlled distances from each participant.
In the second part of our study, we collected facial videos of participants performing FaceCloseup trials. Each participant was instructed to conduct these trials using the provided Google Nexus 6P smartphone, with controlled device movement distances. For the FaceCloseup trials, participants held and moved the smartphone away from their face from a distance of
20 cm to
50 cm, from
30 cm to
50 cm, and from
40 cm to
50 cm. Each participant completed 10 trials for each controlled movement setting. Prior to each set of trials, a researcher demonstrated the required movements, and participants were given time to practice. During the movement, the participant’s facial video, captured by the front-facing camera, was displayed on the screen in real time, allowing participants to adjust the smartphone to ensure their face was always fully captured. To control the moving distance, the required distance was marked along a horizontal line on the wall. We ensured that no significant head rotation occurred during the smartphone movement, as per the method described in [
57]. In this part of the study, we collected facial video data from 30 trials per participant, which was later used to simulate both legitimate requests and video-based attacks.
In the third part of the study, each participant was asked to complete a questionnaire utilizing a 5-point Likert scale. This segment aimed to gather participants’ perceptions regarding the use of FaceCloseup and their preferences for online sharing behaviors.
5.2. Dataset Generation
To simulate legitimate requests and face spoofing attacks, we generated several datasets: a legitimate dataset, a photo-based attack dataset, a video-based attack dataset, and a 3D virtual face model-based attack dataset. These datasets were derived from the frontal facial videos collected during our user study.
5.2.1. Legitimate Dataset
Since FaceCloseup performs liveness checks by analyzing distortion changes across various facial regions in closeup videos, the facial videos for this purpose must exhibit clear facial distortion. Consequently, the legitimate dataset consists of the closeup facial videos recorded during FaceCloseup trials, with smartphone movements ranging from a distance of
20 cm to
50 cm, as detailed in
Section 5.1. In total, the legitimate dataset comprises 710 trials.
5.2.2. Photo-Based Attack Dataset
To simulate photo-based attacks, we manually extracted 10 facial frames from each participant’s selfie frontal video clips, recorded at fixed distances
as detailed in
Section 5.1. The selected fixed distances were 30 cm, 40 cm, and 50 cm. These distances were chosen because participants typically published their selfie photos/videos or made video calls while holding their mobile phones at these distances. The majority of participants did not share selfie photos/videos taken at distances shorter than 30 cm due to noticeable facial distortion. Further details regarding participants’ sharing preferences and video call behaviors will be presented in the following section.
Secondly, for each extracted facial frame, we displayed the frame on an iPad HD Retina screen to simulate photo-based attacks, in a manner similar to the approach detailed in [
28]. The facial region in the frame was adjusted to full screen to closely match the size of a real face. The smartphone was fixed on a table with its front-facing camera consistently aimed at the iPad screen. We then moved the iPad from
20 cm to
50 cm. During this movement, the smartphone’s front-facing camera recorded a video of the face displayed on the iPad screen. This process resulted in a photo-based attack dataset comprising 1420 attack videos.
5.2.3. Video-Based Attack Dataset
To simulate video-based attacks, we utilized the videos recorded during trials where participants moved the smartphone from 30 cm to 50 cm and from 40 cm to 50 cm. Each video was displayed on an iPad screen, while the smartphone remained fixed on a table with its front-facing camera continuously recording the screen. The video frames were scaled appropriately so that the face in the initial frame was displayed in full screen. The distance between the iPad and the smartphone was kept constant at 20 cm, as the displayed video included movements similar to those in legitimate requests. Consequently, we generated a total of 1420 attacking videos for the video-based attacks.
5.2.4. 3D Virtual Face Model-Based Attack Dataset
The effectiveness of photo-based and video-based attacks is often constrained, as it can be challenging for an adversary to obtain suitable facial photos and pre-recorded videos featuring the necessary facial expressions (e.g., smiles) and deformations (e.g., head rotations). In contrast, a 3D virtual face model-based attack can create a real-time 3D virtual face model of a victim, producing facial photos and videos with the required expressions and deformations. This form of attack presents a significant threat to most existing liveness detection techniques, such as FaceLive.
In 3D virtual face model-based attacks, an adversary may reconstruct a 3D virtual face model of the victim using one or more standard facial photos/videos, typically taken from a distance of at least 40 cm and possibly shared by the victim. A variety of 3D face reconstruction algorithms are available [
11,
58,
59,
60]. Most existing 3D face reconstruction algorithms process one or multiple standard facial photos of the victim to extract facial landmarks. The 3D virtual face model is then estimated by optimizing the geometry of a 3D morphable face model to align with the observed 2D landmarks. This optimization assumes that a virtual camera is positioned at a predefined distance from the face (usually considered infinite). Subsequently, image-based texturing and gaze correction techniques are applied to refine the 3D face model. The textured 3D face model can then be used to generate various facial expressions and head movements in real time.
FaceCloseup verifies the liveness of a face by analyzing changes in facial distortion as the camera-to-face distance varies. The aforementioned 3D virtual face model is unable to circumvent FaceCloseup’s detection, as its reconstruction relies on a virtual camera fixed at a predefined distance. Consequently, this 3D virtual face model cannot replicate the requisite facial distortions resulting from changes in camera distance, particularly when the camera is in close proximity to the face.
To emulate a sophisticated adversary in the context of 3D virtual face model-based attacks, we employ the perspective-aware 3D face reconstruction algorithm [
30]. This algorithm is capable of generating facial distortions in accordance with changes in virtual camera distance, as well as alterations in facial expressions and head poses. For reconstructing a perspective-aware 3D face model of a victim, the algorithm initially extracts 69 facial landmarks from a provided facial photo. Among these, 66 landmarks are automatically identified using the SDM-based landmark detection algorithm [
51], as detailed in
Section 4.2. The remaining three facial landmarks, located on the top of the head and ears, are manually labeled to ensure higher accuracy.
Secondly, the 3D face model is associated with an identity vector , an expression vector , an upper-triangular intrinsic matrix , a rotation matrix , and a translation matrix . The facial photo and the 69 facial landmark locations are employed to fit a 3D head model by identifying the optimal parameters that minimize the Euclidean distance between the facial landmarks and their projections on the 3D head model.
Thirdly, once a good fit is achieved between the input facial photo and the 3D head model, the 3D head model can be manipulated to generate a new projected head shape by altering the virtual camera distance and head poses. Specifically, the virtual camera can be moved closer to or farther from the face by adjusting the translation matrix
T, and the head can be rotated by modifying both the translation matrix
T and the rotation matrix
R. Ultimately, the manipulated 3D head model produces a 2D facial photo with distortions that correspond to the changes in camera distance. For further details on this perspective-aware 3D face reconstruction algorithm, please refer to [
30].
To conduct the 3D virtual face model-based attacks, we first extracted 10 facial photos from the selfie videos taken by each participant at controlled distances
of 30 cm, 40 cm, and 50 cm, as detailed in
Section 5.1. Using these facial photos as inputs, we employed the perspective-aware 3D face reconstruction algorithm to generate photos with facial distortions by manually varying the virtual camera distances, which included 20 cm, 25 cm, 30 cm, 35 cm, 40 cm, 45 cm, and 50 cm. We adjusted the scale of the manipulated photos to match the size of the facial region in the original photos taken at similar distances. Consequently, we generated a sequence of seven manipulated facial photos from each extracted photo. The resulting dataset for the 3D virtual face model-based attack comprises 2130 sequences of manipulated facial photos.
7. Discussion
In this section, we discuss the integration of FaceCloseup in existing face authentication systems and the limitations of FaceCloseup.
7.1. Integration of FaceCloseup
FaceCloseup can be seamlessly integrated into most existing mobile face authentication systems without significant modifications.
Firstly, FaceCloseup analyzes facial distortion changes by calculating the facial geometry ratio changes relative to a base facial photo within a predefined size range (sz) of the face region, as explained in
Section 4.2. During registration, users need to perform a one-time process of registering one or more facial photos with face regions falling within sz, akin to the registration processes of most current face authentication systems. Secondly, during each authentication request, FaceCloseup requires users to capture a closeup selfie video with a front-facing smartphone camera, moving the smartphone towards or away from their face. By analyzing the captured video, FaceCloseup determines whether the request is from a live face or a spoofed face. Simultaneously, the typical face recognition subsystem can extract a frame from the video and compare it with the pre-stored facial biometrics to verify the user’s identity.
According to our experimental results, FaceCloseup can distinguish different users with an accuracy of 99.44%. Therefore, FaceCloseup has the potential to both recognize a user’s face and verify its liveness simultaneously. To enable face recognition, users must complete a one-time registration by capturing a closeup selfie video. This video is taken in the same manner as the videos used for liveness checks, wherein the user moves the smartphone towards or away from their face. The pattern of facial distortion changes extracted from the registered video is stored on the smartphone. For each authentication request, FaceCloseup captures a closeup selfie video of the user, incorporating the required device movements. The captured video is then used to verify the user’s identity and assess the liveness of the face concurrently.
Since FaceCloseup relies on closeup facial videos to analyze the necessary facial distortion changes, it may be vulnerable if an adversary obtains a closeup video taken within 30 cm of a victim’s face. This proximity provides the significant facial distortion changes required by FaceCloseup. However, it is challenging for adversaries to obtain such closeup videos, as users are generally reluctant to capture and share them. Moreover, it is difficult for an adversary to directly capture a closeup video at such a short distance without the victim’s awareness. Even if an adversary manages to stealthily record a closeup facial video while the victim is sleeping, FaceCloseup can easily detect such attempts by analyzing the status of the victim’s eyes. Numerous existing techniques can monitor eye movement and status in real time [
26].
7.2. Limitations of FaceCloseup
Limitations of the Current User Study: Our study primarily recruited university students, who tend to be more active users of mobile devices. While this provides valuable insights into FaceCloseup’s real-world applicability, it introduces limitations in generalizing performance to broader demographics, including older adults, children, and individuals with diverse ethnic and physiological characteristics.
Potential Variations Across Demographics: Facial authentication systems may exhibit performance differences across age groups due to variations in skin texture, facial structure, and device interaction habits. Similarly, ethnic diversity can influence facial recognition algorithms, particularly in how features are detected under different lighting conditions and facial angles. While our study did not include a stratified analysis, the existing literature suggests that these factors can impact the efficacy of spoof detection and user authentication accuracy [
61,
62,
63].
To address these concerns, future studies will involve a larger and more demographically diverse participant pool. A stratified analysis will be conducted to examine performance variations across age groups, ethnic backgrounds, and physiological characteristics. This will help refine FaceCloseup’s robustness and ensure equitable authentication accuracy across a wider range of users.
Environmental Factors and Their Impact on FaceCloseup: While our study considered lighting and movement, additional environmental factors—such as low light conditions, motion blur, outdoor scenes, and differences in camera quality—can also influence facial authentication performance.
Motion Blur and Device Stability: In our user study, participants were instructed to maintain controlled camera distances and regulated hand movements. However, involuntary hand tremors and natural limitations in movement control can introduce motion blur, which may affect facial feature detection. Prior research suggests that motion blur can degrade recognition accuracy, particularly in dynamic environments [
42,
64]. Future work will explore stabilization techniques and adaptive algorithms to mitigate these effects.
Outdoor Scenes and Lighting Variability: While close-up facial videos benefit from screen light when the smartphone is within 30 cm of the user’s face, outdoor environments introduce additional challenges such as variable lighting, shadows, and background complexity [
65]. Studies indicate that facial recognition systems can experience reduced accuracy in uncontrolled lighting conditions [
29]. Future research will incorporate outdoor testing to evaluate FaceCloseup’s robustness across diverse environments.
Camera Quality and Device Variability: Differences in smartphone camera specifications—such as resolution, sensor quality, and frame rate—can impact facial authentication performance. The existing literature highlights that lower-resolution cameras may struggle with fine-grained facial feature extraction [
66]. Expanding our study to include a range of device models will help assess FaceCloseup’s adaptability across different hardware configurations.
To address these concerns, future studies will incorporate a broader range of environmental conditions, including outdoor settings, varied lighting scenarios, and different smartphone models. This will ensure a more comprehensive evaluation of FaceCloseup’s performance and enhance its applicability in real-world use cases.
Usability Considerations in FaceCloseup: While FaceCloseup enhances security by leveraging perspective distortion in close-up facial authentication, we recognize that requiring users to position their devices close to their faces may raise usability concerns, particularly for individuals with mobility limitations or privacy sensitivities.
Accessibility and Mobility Considerations: For users with limited mobility, holding a device at a precise distance may pose challenges. Future iterations of FaceCloseup could incorporate adaptive mechanisms, such as automatic distance calibration or voice-guided positioning, to improve accessibility.
Privacy Considerations: Some users may feel uncomfortable bringing their devices close to their faces due to privacy concerns, particularly in public settings. To mitigate this, FaceCloseup could be enhanced with on-device processing for privacy-preserving face authentication, ensuring that facial data remains private and is not transmitted externally, thereby addressing data security concerns.
Existing privacy-preserving biometric authentication approaches, including fuzzy extractors and fuzzy signatures [
67,
68,
69,
70,
71,
72,
73,
74], could potentially be applied to transform close-up facial biometrics into privacy-protected representations. The integration of FaceCloseup and such approaches would enable authentication servers—if deployed off-device—to verify users without inferring any biometric information.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}