
Leave as Fast as You Can: Using Generative AI to Automate and Accelerate Hospital Discharge Reports

 ,
, 
 , , , , and
, , , , and
Abstract
1. Introduction
1.1. Hospital Discharge Reports, a Necessary Resource Blackhole
1.2. The Potential of Leveraging AI for HDR Generation
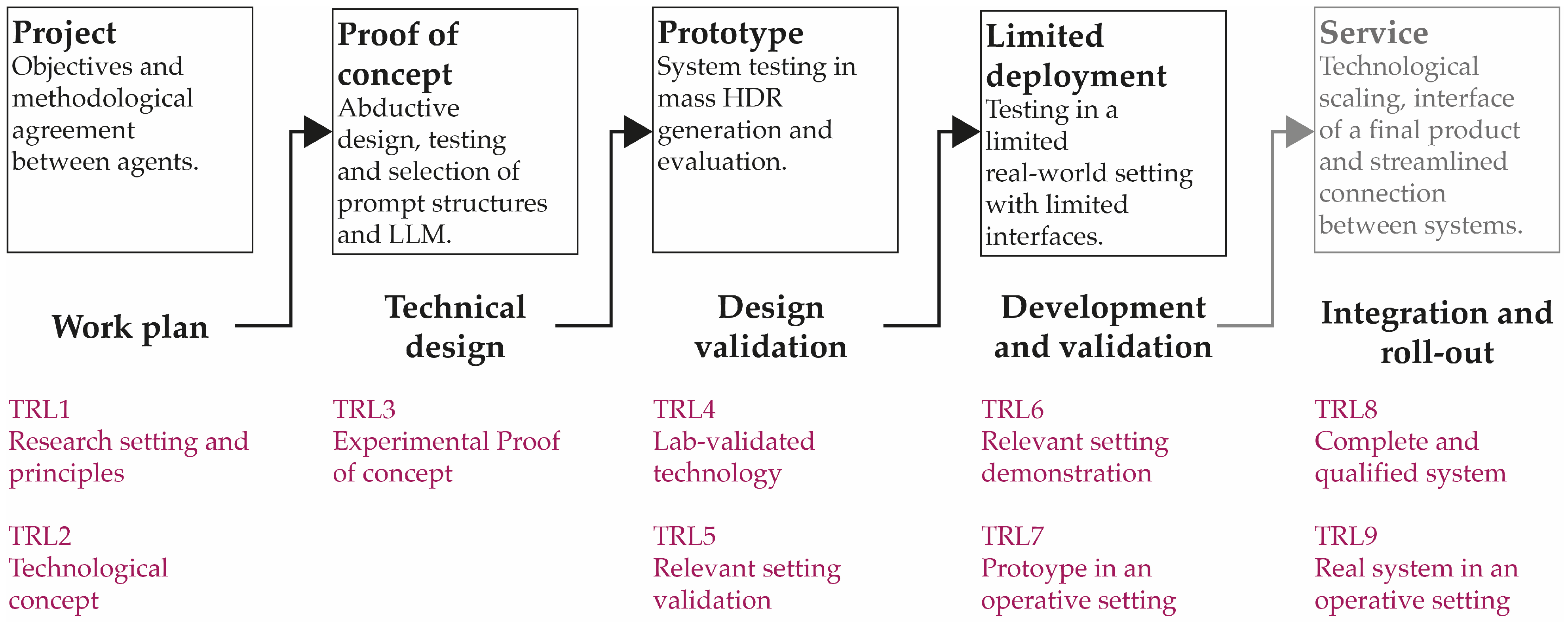
2. Materials and Methods
2.1. Objective
2.2. Solution Development and Implementation
2.2.1. Proof of Concept
- Multilingual support: Given the bilingual nature of the clinical setting (which might include documents in Catalan and Spanish, often mixed in the same clinical course), the system was optimized for both languages. Language-specific adjustments were implemented to ensure effective comprehension and accurate report generation.
- Perceived output quality: The variability in clinical courses and discharge reports necessitated a meticulous analysis to capture the full spectrum of linguistic and contextual nuances inherent in medical documentation. In this initial test, assessments were performed by the developers as medical professionals would intervene later on to improve results.
- Service stability: Continuous availability during testing was a critical operational requirement. Due to recurrent service interruptions, Claude was excluded from further consideration, underscoring the importance of reliability in deploying AI systems in clinical environments.
- Price: A good balance between cost and effectivity is key in LLM selection; if similar results are obtained with different costs, the cheaper model provides a competitive advantage, while if a high-cost model is perceived to perform more poorly than others, it shall be discarded. Price was calculated based on the average of multiple generations during the testing period.
- Generation time: While AI can generate documentation much faster than humans, considering the time spent by multiple LLMs is relevant in choosing a good balance between price, speed, and quality. Time was calculated based on the average of multiple generations during the testing period.
2.2.2. Prototyping
- Precision: The generated text is considered accurate if it contains only the original information without introducing extraneous content, that is, the amount of AI-generated text that is present in the reference document.
- Recall: A high recall score indicates that the generated text captures nearly all relevant content from the reference, that is, the amount of reference text that is present in the AI-generated text.
- F-score: This measure balances precision and recall, ensuring that the text is both comprehensive and of high quality.
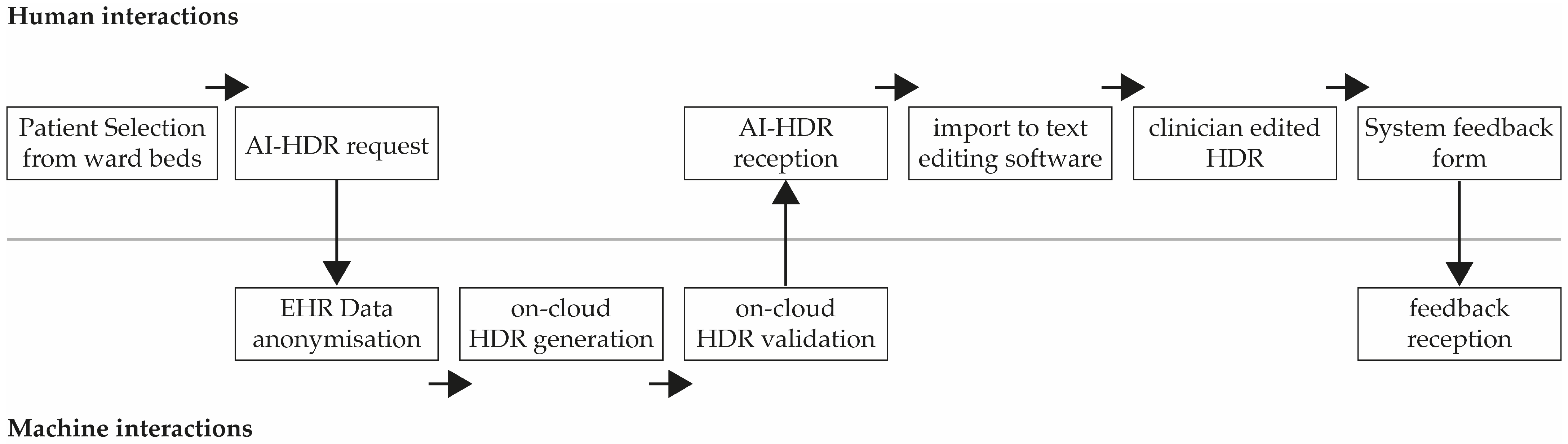
2.2.3. Limited Implementation in a Relevant Setting
- Factual errors;
- Missing information;
- Writing/style issues;
- Correct (only minor edits required).
2.3. Ethical and Legal Framework
- Regulatory Compliance: AI HDR generation will adhere to European (GDPR), national (LOPDGDD and Law 41/2002), and regional (Decree 105/2000 and the CatSalut Security Plan) regulations [43]. This includes measures such as data anonymization, processing agreements, and security protocols.
- Technical Security: High-level protection mechanisms will be deployed, including advanced encryption (TLS 1.3 and AES-256), controlled processing environments, encryption of data at rest, and regular audits to ensure system robustness.
- Ethical Governance: A multidisciplinary committee will oversee the deployment of AI-generated HDRs to ensure alignment with bioethical principles, transparency in informed consent, and the prevention of algorithmic bias [43].
- Post-Market Surveillance: Continuous monitoring of system performance will be conducted through the collection of clinical data, incident management, and iterative reviews to enhance accuracy and adapt to evolving regulations [43].
3. Results
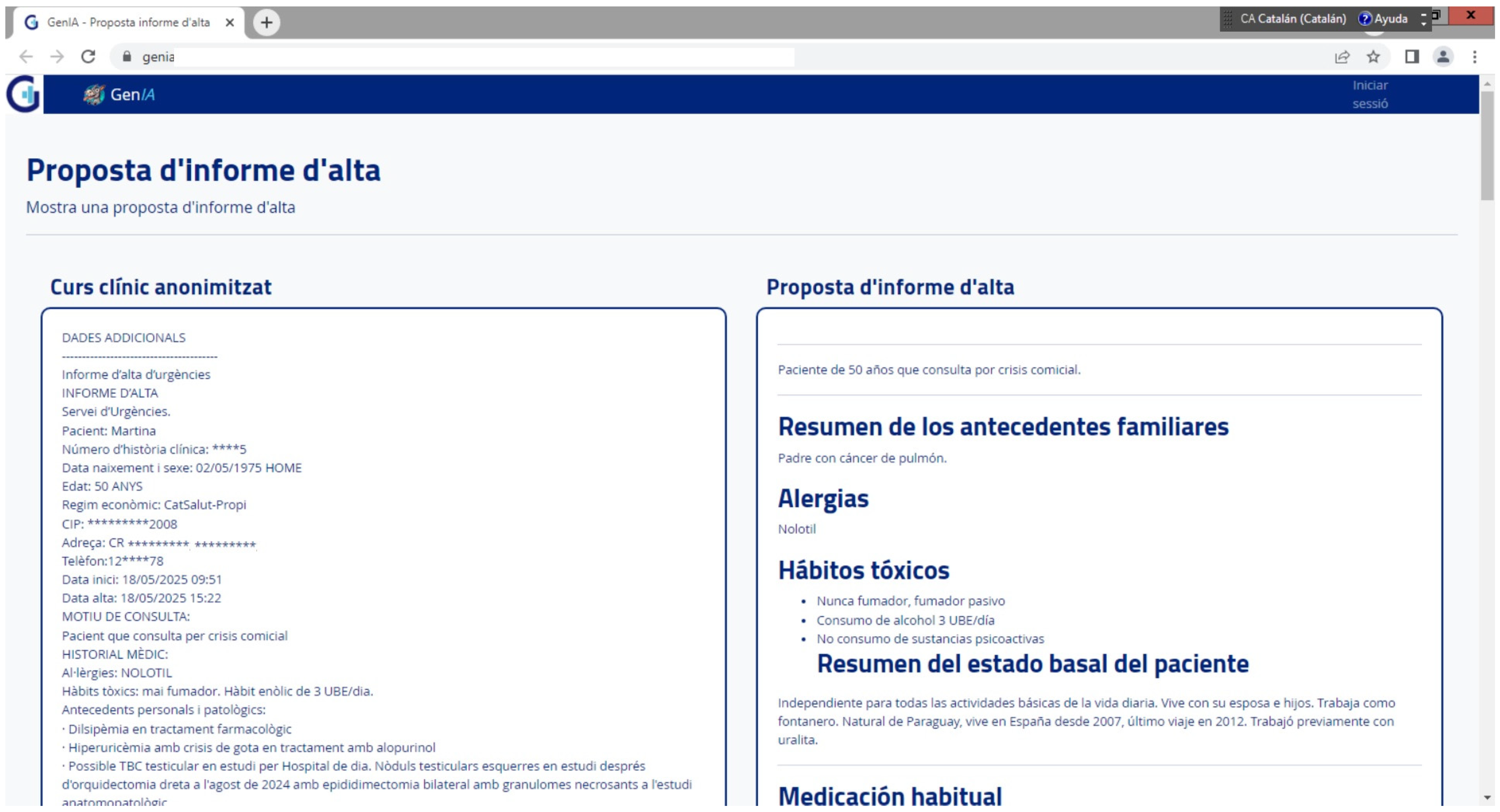
3.1. Proof of Concept
3.2. Prototype
3.3. Limited Implementation in a Relevant Setting
4. Discussion
4.1. Analysis of ROUGE Evaluation and Its Limitations
- Stylistic heterogeneity in clinical notes: Clinical course notes oscillate between terse, checklist-like phrasing and richer narrative prose, often within the same service; these affect the AI-generated contents, while humans have better training at extracting the actually useful information and standardizing its format in a concise manner. Moreover, each physician has their own preferences when it comes to HDR writing styles, which affects the reference documents against which the AI-generated reports are compared. When the reference is highly narrative and the AI output is concise, recall drops and precision rises; the reverse occurs when the AI is more expansive than the reference. Our results with overall higher scores on recall suggest that reference texts are more succinct while AI-generated texts are more detailed in the explanations. This analysis is in fact substantiated by the qualitative evaluation of 27 HDRs performed along with the ROUGE tests. Generally, doctors’ HDRs were more telegraphic and factual, whereas the model tended to elaborate, especially around the daily evolution narrative of the patient, which is an expected behavior of general LLM models when they are provided with superfluous information—as can be the case in hospital clinical courses.
- Semantic adequacy beyond surface overlap: As ROUGE compares groups of letters (tokens) rather than factual information, harmless synonyms or equivalent expressions (abbreviations or differing descriptive wording) are penalized as false positives/negatives. Complementary semantic metrics such as BERTScore [44] or domain-adapted COMET [45] are recommended for future iterations, and the multilingual FRESA framework has already demonstrated a better correlation with human judgment in Spanish and Catalan [46]. In our case, we opted for a complementary human qualitative review.
4.2. Context of Qualitative Evaluations
4.3. Overall Study Limitations and Expansion of the Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- European Commission. Guidelines on Hospital Discharge Report; European Commission: Budapest, Hungary, 2024. [Google Scholar]
- Kripalani, S.; LeFevre, F.; Phillips, C.O.; Williams, M.V.; Basaviah, P.; Baker, D.W. Deficits in Communication and Information Transfer Between Hospital-Based and Primary Care Physicians: Implications for Patient Safety and Continuity of Care. JAMA 2007, 297, 831. [Google Scholar] [CrossRef] [PubMed]
- Walraven, C.; Seth, R.; Austin, P.C.; Laupacis, A. Effect of Discharge Summary Availability during Post-Discharge Visits on Hospital Readmission. J. Gen. Intern. Med. 2002, 17, 186–192. [Google Scholar] [CrossRef] [PubMed]
- Sakaguchi, F.H.; Lenert, L.A. Improving Continuity of Care via the Discharge Summary. AMIA Annu. Symp. Proc. 2015, 2015, 1111–1120. [Google Scholar]
- Pal, K.; Bahrainian, S.A.; Mercurio, L.; Eickhoff, C. Neural Summarization of Electronic Health Records. arXiv 2023, arXiv:2305.15222. [Google Scholar]
- Al-Damluji, M.S.; Dzara, K.; Hodshon, B.; Punnanithinont, N.; Krumholz, H.M.; Chaudhry, S.I.; Horwitz, L.I. Hospital Variation in Quality of Discharge Summaries for Patients Hospitalized With Heart Failure Exacerbation. Circ. Cardiovasc. Qual. Outcomes 2015, 8, 77–86. [Google Scholar] [CrossRef]
- Were, M.C.; Li, X.; Kesterson, J.; Cadwallader, J.; Asirwa, C.; Khan, B.; Rosenman, M.B. Adequacy of Hospital Discharge Summaries in Documenting Tests with Pending Results and Outpatient Follow-up Providers. J. Gen. Intern. Med. 2009, 24, 1002–1006. [Google Scholar] [CrossRef]
- Hartman, V.C.; Bapat, S.S.; Weiner, M.G.; Navi, B.B.; Sholle, E.T.; Campion, T.R. A Method to Automate the Discharge Summary Hospital Course for Neurology Patients. J. Am. Med. Inform. Assoc. 2023, 30, 1995–2003. [Google Scholar] [CrossRef]
- Sinsky, C.; Colligan, L.; Li, L.; Prgomet, M.; Reynolds, S.; Goeders, L.; Westbrook, J.; Tutty, M.; Blike, G. Allocation of Physician Time in Ambulatory Practice: A Time and Motion Study in 4 Specialties. Ann. Intern. Med. 2016, 165, 753–760. [Google Scholar] [CrossRef]
- Downing, N.L.; Bates, D.W.; Longhurst, C.A. Physician Burnout in the Electronic Health Record Era: Are We Ignoring the Real Cause? Ann. Intern. Med. 2018, 169, 50–51. [Google Scholar] [CrossRef]
- Sloss, E.A.; Abdul, S.; Aboagyewah, M.A.; Beebe, A.; Kendle, K.; Marshall, K.; Rosenbloom, S.T.; Rossetti, S.; Grigg, A.; Smith, K.D.; et al. Toward Alleviating Clinician Documentation Burden: A Scoping Review of Burden Reduction Efforts. Appl. Clin. Inform. 2024, 15, 446–455. [Google Scholar] [CrossRef]
- Rosenbloom, S.T.; Denny, J.C.; Xu, H.; Lorenzi, N.; Stead, W.W.; Johnson, K.B. Data from Clinical Notes: A Perspective on the Tension between Structure and Flexible Documentation. J. Am. Med. Inform. Assoc. 2011, 18, 181–186. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.T.; Pincock, D.; Baumgart, D.C.; Sadowski, D.C.; Fedorak, R.N.; Kroeker, K.I. An Overview of Clinical Decision Support Systems: Benefits, Risks, and Strategies for Success. Npj Digit. Med. 2020, 3, 17. [Google Scholar] [CrossRef] [PubMed]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT Makes Medicine Easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports. Eur. Radiol. 2023, 34, 2817–2825. [Google Scholar] [CrossRef]
- Spotnitz, M.; Idnay, B.; Gordon, E.R.; Shyu, R.; Zhang, G.; Liu, C.; Cimino, J.J.; Weng, C. A Survey of Clinicians’ Views of the Utility of Large Language Models. Appl. Clin. Inform. 2024, 15, 306–312. [Google Scholar] [CrossRef]
- Sahota, P. How We’re Using Generative AI to Support Outpatient Care in Peru. Front. Tech Hub. Available online: https://www.frontiertechhub.org/insights/avatr-generative-ai-learnings-in-project-empatia (accessed on 1 March 2025).
- Hartman, V.; Campion, T.R. A Day-to-Day Approach for Automating the Hospital Course Section of the Discharge Summary. AMIA Summits Transl. Sci. Proc. 2022, 2022, 216–225. [Google Scholar]
- Zaretsky, J.; Kim, J.M.; Baskharoun, S.; Zhao, Y.; Austrian, J.; Aphinyanaphongs, Y.; Gupta, R.; Blecker, S.B.; Feldman, J. Generative Artificial Intelligence to Transform Inpatient Discharge Summaries to Patient-Friendly Language and Format. JAMA Netw. Open 2024, 7, e240357. [Google Scholar] [CrossRef]
- Janota, B.; Janota, K. Application of AI in the Creation of Discharge Summaries in Psychiatric Clinics. Int. J. Psychiatry Med. 2025, 60, 330–337. [Google Scholar] [CrossRef]
- Clough, R.A.J.; Sparkes, W.A.; Clough, O.T.; Sykes, J.T.; Steventon, A.T.; King, K. Transforming Healthcare Documentation: Harnessing the Potential of AI to Generate Discharge Summaries. BJGP Open 2024, 8, BJGPO.2023.0116. [Google Scholar] [CrossRef]
- Rosenberg, G.S.; Magnéli, M.; Barle, N.; Kontakis, M.G.; Müller, A.M.; Wittauer, M.; Gordon, M.; Brodén, C. ChatGPT-4 Generates Orthopedic Discharge Documents Faster than Humans Maintaining Comparable Quality: A Pilot Study of 6 Cases. Acta Orthop. 2024, 95, 152–156. [Google Scholar] [CrossRef]
- Ruinelli, L.; Colombo, A.; Rochat, M.; Popeskou, S.G.; Franchini, A.; Mitrović, S.; Lithgow, O.W.; Cornelius, J.; Rinaldi, F. Experiments in Automated Generation of Discharge Summaries in Italian. In Proceedings of the First Workshop on Patient-Oriented Language Processing (CL4Health) @ LREC-COLING 2024, Turin, Italy, 20 May 2024; Demner-Fushman, D., Ananiadou, S., Thompson, P., Ondov, B., Eds.; ELRA and ICCL: Turin, Italy, 2024; pp. 137–144. [Google Scholar]
- de Salut, D. Implantació del Conjunt Mínim Bàsic de Dades d’Atenció Primària (CMBD-AP) i d’Urgències (CMBD-UR)(06/2012); Scientia: Bristol, UK, 2012. [Google Scholar]
- Kind, A.J.; Smith, M.A. Documentation of Mandated Discharge Summary Components in Transitions from Acute to Subacute Care. In Advances in Patient Safety: New Directions and Alternative Approaches (Vol. 2: Culture and Redesign); Henriksen, K., Battles, J.B., Keyes, M.A., Grady, M.L., Eds.; Agency for Healthcare Research and Quality (US): Fishers Lane Rockville, MD, USA, 2008. [Google Scholar]
- Xiong, Y.; Tang, B.; Chen, Q.; Wang, X.; Yan, J. A Study on Automatic Generation of Chinese Discharge Summary. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 1681–1687. [Google Scholar]
- Taylor, A. How Real-World Businesses Are Transforming with AI—with More than 140 New Stories. Off. Microsoft Blog. 2025. Available online: https://blogs.microsoft.com/blog/2025/04/22/https-blogs-microsoft-com-blog-2024-11-12-how-real-world-businesses-are-transforming-with-ai/ (accessed on 1 March 2025).
- O’Brien, M.; Parvini, S. In 2024, Artificial Intelligence Was All About Putting AI Tools to Work. Assoc. Press News. 2024. Available online: https://apnews.com/article/ai-artificial-intelligence-0b6ab89193265c3f60f382bae9bbabc9 (accessed on 1 March 2025).
- Garbuio, M.; Lin, N. Innovative Idea Generation in Problem Finding: Abductive Reasoning, Cognitive Impediments, and the Promise of Artificial Intelligence. J. Prod. Innov. Manag. 2021, 38, 701–725. [Google Scholar] [CrossRef]
- Chun Tie, Y.; Birks, M.; Francis, K. Grounded Theory Research: A Design Framework for Novice Researchers. SAGE Open Med. 2019, 7, 2050312118822927. [Google Scholar] [CrossRef] [PubMed]
- Brown, T. Harvard Business Review. June 2008. Available online: https://readings.design/PDF/Tim%20Brown,%20Design%20Thinking.pdf (accessed on 1 March 2025).
- Brankaert, R.; Ouden, E. The Design-Driven Living Lab: A New Approach to Exploring Solutions to Complex Societal Challenges. Technol. Innov. Manag. Rev. 2017, 7, 44–51. [Google Scholar] [CrossRef]
- Héder, M. From NASA to EU: The Evolution of the TRL Scale in Public Sector Innovation. Innov. J. 2017, 22, 1–23. [Google Scholar]
- Hevner, M.; Park, R. Design Science in Information Systems Research. MIS Q. 2004, 28, 25148625. [Google Scholar] [CrossRef]
- Zhou, D.; Schärli, N.; Hou, L.; Wei, J.; Scales, N.; Wang, X.; Schuurmans, D.; Cui, C.; Bousquet, O.; Le, Q.; et al. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. arXiv 2022, arXiv:2205.10625. [Google Scholar]
- Hao, Y.; Sun, Y.; Dong, L.; Han, Z.; Gu, Y.; Wei, F. Structured Prompting: Scaling In-Context Learning to 1000 Examples. arXiv 2022, arXiv:2212.06713. [Google Scholar]
- Jung, J.; Qin, L.; Welleck, S.; Brahman, F.; Bhagavatula, C.; Bras, R.L.; Choi, Y. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations. arXiv 2022, arXiv:2205.11822. [Google Scholar]
- Shortliffe, E.H.; Cimino, J.J. Biomedical Informatics: Computer Applications in Health Care and Biomedicine; Shortliffe, E.H., Cimino, J.J., Eds.; Springer: London, UK, 2014; ISBN 978-1-4471-4473-1. [Google Scholar]
- Carter, N.; Bryant-Lukosius, D.; DiCenso, A.; Blythe, J.; Neville, A.J. The Use of Triangulation in Qualitative Research. Oncol. Nurs. Forum 2014, 41, 545–547. [Google Scholar] [CrossRef]
- Wang, W.; Duffy, A. A Triangulation Approach for Design Research. In Proceedings of the ICED 09 17th International Conference on Engineering Design, Palo Alto, CA, USA, 24–27 August 2009; The Design Society: Glasgow, Scotland, 2009; Volume 2, pp. 275–286. [Google Scholar]
- Auriemma Citarella, A.; Barbella, M.; Ciobanu, M.G.; De Marco, F.; Di Biasi, L.; Tortora, G. Assessing the effectiveness of ROUGE as unbiased metric in Extractive vs. Abstractive summarization techniques. J. Comput. Sci. 2025, 87, 102571. [Google Scholar] [CrossRef]
- van Zandvoort, D.; Wiersema, L.; Huibers, T.; van Dulmen, S.; Brinkkemper, S. Enhancing Summarization Performance through Transformer-Based Prompt Engineering in Automated Medical Reporting. arXiv 2023, arXiv:2311.13274. [Google Scholar]
- Lin, C.-Y.; Och, F. Looking for a Few Good Metrics: ROUGE and Its Evaluation. In Proceedings of the NTCIR Workshop, Tokyo, Japan, 2–4 June 2004; pp. 1–8. [Google Scholar]
- Aussó, S.; Berenguer, A.; Aznar, J.; Raventós, C.; Gómez, V.; Bretones, M. Guia de Bones Pràctiques per al Desenvolupament d’Eines d’IA Generativa en Salut. Grans Models de Llenguatge (LLM); Fundació TIC Salut Social, Generalitat de Ctalunya: Barcelona, Spain, 2025. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Rei, R.; Stewart, C.; Farinha, A.C.; Lavie, A. COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2685–2702. [Google Scholar]
- Saggion, H.; Torres-Moreno, J.-M.; da Cunha, I.; SanJuan, E. Multilingual Summarization Evaluation without Human Models. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 1059–1067. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-Training with Extracted Gap-Sentences for Abstractive Summarization. In Proceedings of the 37th International Conference on Machine Learning, Online, 3–18 July 2020; pp. 11328–11339. [Google Scholar]
- Ahuir, V.; Hurtado, L.-F.; González, J.Á.; Segarra, E. NASca and NASes: Two Monolingual Pre-Trained Models for Abstractive Summarization in Catalan and Spanish. Appl. Sci. 2021, 11, 9872. [Google Scholar] [CrossRef]
- Adams, G.; Alsentzer, E.; Ketenci, M.; Zucker, J.; Elhadad, N. What’s in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4794–4811. [Google Scholar]
- Ando, K.; Komachi, M.; Okumura, T.; Horiguchi, H.; Matsumoto, Y. Is In-Hospital Meta-Information Useful for Abstractive Discharge Summary Generation? In Proceedings of the 2022 International Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taichung, Taiwan, 8–10 December 2022; pp. 143–148. [Google Scholar] [CrossRef]
- Irugalbandara, C.; Mahendra, A.; Daynauth, R.; Arachchige, T.K.; Dantanarayana, J.; Flautner, K.; Tang, L.; Kang, Y.; Mars, J. Scaling Down to Scale Up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production. In Proceedings of the 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Indianapolis, IN, USA, 5–7 May 2024. [Google Scholar]
- Lohn, A.J. Scaling AI. Cost and Perfomance of AI at the Leading Edge; Center for Security and Emerging Technology: Washington, DC, USA, 2023. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Model | Google’s Gemini Pro 1.5 | Anthropic’s Claude 3.5 Sonnet | OpenAI’s GPT-4o | Mistral | Llama 3.1 |
|---|---|---|---|---|---|
| Summaries Performance | +++ | ++ | + | +- | +- |
| Multilingual Support | Yes | Yes | No | No | No |
| Service Stability | Yes | No | |||
| Average Price (EUR) | 0.25 | 0.22 | 0.42 | 0.22 | 0.30 |
| Average Generation Time (s) | 147 | 133 | 215 | >300 | 200 |
| Speciality | R1-Precision | R1-Recall | R1-F1 | R2-Precision | R2-Recall | R2-F2 | RL-Precision | RL-Recall | RL-F |
|---|---|---|---|---|---|---|---|---|---|
| Gynecology | 0.16 | 0.49 | 0.24 | 0.06 | 0.19 | 0.09 | 0.08 | 0.26 | 0.12 |
| Vascular surgery | 0.18 | 0.49 | 0.25 | 0.07 | 0.19 | 0.10 | 0.10 | 0.28 | 0.15 |
| Urology | 0.22 | 0.57 | 0.31 | 0.11 | 0.27 | 0.15 | 0.14 | 0.36 | 0.19 |
| Surgery | 0.31 | 0.60 | 0.40 | 0.13 | 0.26 | 0.17 | 0.14 | 0.29 | 0.18 |
| Cardiology | 0.52 | 0.43 | 0.44 | 0.21 | 0.19 | 0.19 | 0.24 | 0.21 | 0.21 |
| Pneumology | 0.55 | 0.61 | 0.57 | 0.31 | 0.35 | 0.33 | 0.31 | 0.35 | 0.33 |
| Language Pair | R1-Precision | R1-Recall | R1-F1 | R2-Precision | R2-Recall | R2-F2 | RL-Precision | RL-Recall | RL-F | Nº of Cases |
|---|---|---|---|---|---|---|---|---|---|---|
| es-es | 0.39 | 0.57 | 0.43 | 0.20 | 0.28 | 0.22 | 0.22 | 0.33 | 0.24 | 35 |
| ca-es | 0.24 | 0.46 | 0.29 | 0.08 | 0.17 | 0.10 | 0.11 | 0.24 | 0.14 | 16 |
| ca-ca | 0.18 | 0.52 | 0.26 | 0.07 | 0.20 | 0.10 | 0.09 | 0.26 | 0.13 | 9 |
| HDR Domain | Mismatched Cases | Patterns Observed |
|---|---|---|
| Admission chronology | 12/27 (44%) | Date or level-of-care pathway (e.g., ED vs. ward) wrong or missing in AI report. Examples: Case 4 (01-06 vs. 31-05), Case 5 (04-05 vs. 03-05), Case 6 (three different dates documented). |
| Discharge date | 6/27 (22%) | AI usually matched; human had the occasional extra day noted (e.g., Case 11). |
| Social/baseline context | 14/27 (52%) | Human versions added living situation, occupation, or functional status; AI also included some details, but not always the same as the clinician and omitted information (e.g., Case 6 and Case 2), sometimes not found in the course documentation. |
| Diagnostic labels | 11/27 (41%) | Humans frequently added comorbid or situational diagnoses (e.g., SARS-CoV-2, acidosis, and psychiatric history) that AI left out or phrased more broadly (e.g., Cases 3, 14, and 25). |
| Medication and dosage | 15/27 (56%) | Divergences in dose (amoxicillin 1 g q8h vs. 500 mg q12h), omission of gastro-protection, or additional heparin/NSAIDs only in human report (Cases 4, 7, 10). |
| Investigations | 10/27 (37%) | AI gave a list without dates/values, human-specified results, or added studies (extra ECG and sensitivity panel) (Cases 6, 10, 22). |
| Follow-up plans | 12/27 (44%) | Human follow-ups were generally vague while AI added additional details, in some cases hallucinated. (e.g., Case 6, 25) |
| Score | Reports (n) | Percentage of HDR |
|---|---|---|
| Factual errors | 22 | 46.8% |
| Missing information | 25 | 53.2% |
| Writing/style issues | 13 | 27.7% |
| Correct (only minor edits needed) | 2 | 4.3% |
| Score | Reports (n) | Percentage of HDR |
|---|---|---|
| Factual errors | 9 | 19.1% |
| Missing information | 22 | 46.8% |
| Lengthy or too short evolution | 6 | 12.8% |
| Writing/style issues | 5 | 10.6% |
| Duplicated data | 3 | 6.4% |
| Outdated data | 1 | 2.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trejo Omeñaca, A.; Llargués Rocabruna, E.; Sloan, J.; Catta-Preta, M.; Ferrer i Picó, J.; Alfaro Alvarez, J.C.; Alonso Solis, T.; Lloveras Gil, E.; Serrano Vinaixa, X.; Velasquez Villegas, D.; et al. Leave as Fast as You Can: Using Generative AI to Automate and Accelerate Hospital Discharge Reports. Computers 2025, 14, 210. https://doi.org/10.3390/computers14060210
Trejo Omeñaca A, Llargués Rocabruna E, Sloan J, Catta-Preta M, Ferrer i Picó J, Alfaro Alvarez JC, Alonso Solis T, Lloveras Gil E, Serrano Vinaixa X, Velasquez Villegas D, et al. Leave as Fast as You Can: Using Generative AI to Automate and Accelerate Hospital Discharge Reports. Computers. 2025; 14(6):210. https://doi.org/10.3390/computers14060210
Chicago/Turabian StyleTrejo Omeñaca, Alex, Esteve Llargués Rocabruna, Jonny Sloan, Michelle Catta-Preta, Jan Ferrer i Picó, Julio Cesar Alfaro Alvarez, Toni Alonso Solis, Eloy Lloveras Gil, Xavier Serrano Vinaixa, Daniela Velasquez Villegas, and et al. 2025. "Leave as Fast as You Can: Using Generative AI to Automate and Accelerate Hospital Discharge Reports" Computers 14, no. 6: 210. https://doi.org/10.3390/computers14060210
APA StyleTrejo Omeñaca, A., Llargués Rocabruna, E., Sloan, J., Catta-Preta, M., Ferrer i Picó, J., Alfaro Alvarez, J. C., Alonso Solis, T., Lloveras Gil, E., Serrano Vinaixa, X., Velasquez Villegas, D., Romeu Garcia, R., Rubies Feijoo, C., Monguet i Fierro, J. M., & Bayes Genis, B. (2025). Leave as Fast as You Can: Using Generative AI to Automate and Accelerate Hospital Discharge Reports. Computers, 14(6), 210. https://doi.org/10.3390/computers14060210