1. Introduction
Making databases (DBs) accessible through natural language (NL) has become essential, allowing individuals to query and retrieve information without specialised technical expertise. Across many sectors, data-driven decision-making is fundamental, yet formal query languages often pose significant barriers due to their technical complexity. Furthermore, users frequently require immediate and seamless access to information stored in DBs to perform their tasks effectively, highlighting the need for intuitive systems that simplify the process of data retrieval.
Conventional data retrieval methods often require proficiency in formal query languages, like SQL, SPARQL, or Cypher, creating a barrier for those without specialized training [
1,
2]. Natural Language Interfaces (NLIs) aim to bridge this gap by translating unstructured user questions into executable queries. By simplifying the interaction between humans and machines, NLIs can enhance accessibility, improve user experience, and enable more efficient data exploration. The development of NLIs for querying Knowledge Graphs (KGs) has evolved significantly over the past decade from rule-based systems to hybrid architectures integrating Machine Learning (ML). However, achieving this translation is challenging, because NL is often ambiguous and flexible, whereas database (DB) queries must be precise and structured [
2].
For decades, researchers have strived to bridge this gap by developing Natural Language Interfaces to Databases (NLIDBs). Early seminal work by Adroutsopoulos et al. (1995) [
3] provided a comprehensive overview of NLIDBs, covering their architectures, strengths, limitations, and challenges in translating NL to formal queries. Since then, numerous efforts have focused on text-to-SQL translation for relational DBs and on converting NL into SPARQL for querying KGs.
The evolution of text-to-SQL systems has seen significant advancements over the years, moving from rigid rule-based approaches to more flexible and powerful ML techniques [
2]. Modern approaches use neural semantic parsing, treating query translation as a learning task. Sequence-to-sequence models, adapted from machine translation, generate SQL from questions with improved accuracy by capturing the complexities of both natural and formal language, enabling more flexible and robust NLIDBs [
4]. Recently, large pre-trained language models (LLMs) have improved NL2SQL by better handling subtle language details and leveraging broad world knowledge [
1]. On the dataset side, benchmarks like WikiSQL (2017) [
5] and Spider (2018) [
6] spurred progress by providing large collections of natural questions and matching SQL queries.
In parallel with advancements in relational DBs, similar developments have occurred in the field of KGs. KGs are structured networks of entities and relationships that enable rich representations of knowledge in various domains [
7]. They power applications from search engines to recommender systems by providing a semantic backbone for organizing information. Querying a Knowledge Graph (KG) typically requires using a formal query language (such as SPARQL for RDF graphs or Cypher for Property Graphs), which allows users to retrieve and manipulate graph data with precise patterns. Large-scale Knowledge Bases (KBs), such as Freebase, DBpedia, and Wikidata, contain facts as relational triples (subject–predicate–object), which can be queried with formal languages. Translating a question into a formal query (often SPARQL for RDF graphs) is the goal of Knowledge Base Question Answering (KBQA).
Recent work in KBQA has shifted from simple factoid questions to complex queries requiring multi-hop reasoning, aggregation, or constraints using two main approaches: semantic parsing, which maps natural language to formal queries like SPARQL, and retrieval-based methods, which search and rank relevant subgraphs [
8]. Modern systems often combine both strategies and increasingly leverage LLMs to assist with tasks like entity disambiguation and query generation. However, because KGs often include unseen real-world data, pure LLM-based methods can struggle with factual accuracy, leading to hybrid approaches that integrate LLMs with graph querying [
9].
Property Graphs offer a more flexible model than RDF-based KGs by allowing rich attributes on nodes and edges [
10], supporting more complex querying and representation strategies. Despite their growing adoption in areas like social networks and bioinformatics, translating natural language to Cypher, the query language for graph databases (GDBs) like Neo4j [
11], has received less attention. Cypher’s pattern-oriented syntax aligns well with how people conceptualize graph traversals. While some NL2SPARQL techniques can be adapted to NL2Cypher, differences in structure required new datasets, tools, and methods. Recently, progress has accelerated with the development of specialized benchmarks [
12], LLM-based query generation, and architectures that combine language understanding with graph structure.
The development of NLIDBs has produced a variety of approaches, each with strengths and limitations: (a) Rule-based systems offer high interpretability and precise control in narrow domains but are inflexible, labour-intensive to adapt, and brittle when faced with complex or ambiguous queries [
13,
14,
15]. (b) ML-based methods have improved adaptability and accuracy but depend heavily on large, annotated datasets [
16,
17], suffer from biases [
18], and often act as “black boxes”, making it difficult to diagnose why a generated query might be syntactically valid yet semantically misaligned with the user’s intent. They also require significant computational resources for training and tend to struggle with complex queries. (c) LLM-based approaches bring new opportunities by leveraging broad language knowledge but face challenges with hallucinated queries, sensitivity to prompt phrasing, schema drift, and high computational costs, while still lacking full robustness and explainability [
17].
As NLIDBs evolve, their effectiveness remains strongly linked to the availability of linguistic resources. In high-resource languages, like English, the abundance of datasets, pre-trained models, and Natural Language Processing (NLP) tools has enabled the development of accurate and reliable interfaces. In contrast, for medium- and low-resource languages, like Greek, the scarcity of linguistic data and tools poses significant challenges, slowing progress and hindering model training [
19]. Developing NLP tools for the Greek language presents additional difficulties due to its flexible word order, complex morphology, and limited annotated corpora [
20], all of which complicate tasks such as syntactic parsing and mapping to KGs. The lack of standardized benchmarks further impedes the evaluation and comparison of system performance. Moreover, NL querying of KGs presents intrinsic challenges due to the complexity of mapping unstructured user input to structured queries, even in high-resource languages.
To address the limitations across existing approaches, our proposed system introduces a flexible, modular architecture which overcomes the rigidity of rule-based systems, the data dependence of ML models, and both the computational overhead and hallucination issues associated with LLMs. We employ a schema-agnostic design and leverage syntactic dependencies alongside semantic mapping to reduce ambiguity and computational complexity and facilitate query generation without extensive training data or a complex configuration. The main goal of the system is to translate simple and complex user queries to Cypher queries, requiring minimal resources, user effort, and technical expertise while being adaptable across different languages and domains.
Our approach is based on identifying pairs of entities that are syntactically connected in the Dependency Tree (DT), either directly or indirectly through other tokens. Each entity pair is validated by checking if their types exist and are connected in the extracted Schema Graph. If a corresponding relationship also exists, a triple is formed, consisting of the two entities and the relationship that connects them. These triples are used to build MATCH-WHERE segments, which together define the main Cypher query structure, while the RETURN clause is determined by the question classification process.
The method follows a structured, sequential approach, with each stage implemented by a distinct module. The modules and their respective functions are as follows: (a) preprocessing and dependency parsing, (b) entity and relationship extraction, (c) NER, semantic mapping and classification, (d) relationship validation and triple creation, and (e) Cypher query construction, refinement, and validation. The query construction process is fully transparent, ensuring for each stage and its role in forming the final Cypher query to be clearly explainable. The explainability of the system is particularly valuable when handling complex multi-hop queries and aggregation functions, as it allows for the verification of how NL queries are interpreted and translated into executable Cypher queries. Our contribution in this paper is as follows:
We present a novel NLP method that translates user queries into Cypher queries, enabling querying of KGs within Neo4j DBs. Unlike conventional approaches, our method operates without requiring system training, labelled datasets, predefined templates, user-defined rules, LLMs for query translation, or candidate query and answer ranking. Furthermore, it does not depend on a predefined schema or ontology and is adaptable to diverse domains and languages, including medium- and low-resource languages.
We present a method that semantically processes user queries by extracting entities, entity types, and relationships based on the syntactic dependencies of tokens, which are subsequently aligned with an automatically constructed Schema Graph. This alignment facilitates the generation of Cypher queries without reliance on templates. The method leverages a KG to perform DT traversal and enables the handling of complex queries, including multi-hop queries and aggregation functions, while maintaining full transparency through explainable intermediate representations.
We evaluated the system using real-world user queries in the educational domain, focusing specifically on academic courses and faculty, and our results show that the system reliably translates diverse NL inputs into executable Cypher queries.
To the best of our knowledge, this is the first training-free Question Answering System (QAS) for Property Graphs using a Cypher query language that is adaptable across diverse domains and languages without the need of LLMs for query translation, making it a scalable solution for both high-resource and medium-/low-resource linguistic environments.
This paper is structured as follows:
Section 2 reviews the related work, positioning our approach within the existing research landscape.
Section 3 outlines the key challenges that our study aims to address.
Section 4 provides the necessary preliminaries to establish a foundational understanding.
Section 5 describes the system architecture, detailing the initial setup and the process of Cypher query construction.
Section 6 presents the evaluation, discussing the performance and effectiveness of the proposed system.
Section 7 presents a discussion of our findings and insights.
Section 8 explores future work, suggesting possible enhancements and directions for further research. Finally,
Section 9 offers the conclusions, summarizing our contributions and key insights.
2. Related Work
In the field of Natural Language Question Answering (NLQA) over KGs, existing methodologies are broadly categorised into ML-driven and rule-based approaches. ML approaches, often trained on datasets such as LC-QuAD and QALD, necessitate extensive training corpora to convert NL queries into structured queries [
21]. However, these datasets predominantly target open-domain sources, like DBpedia, and struggle with domain-specific KGs that lack rich question–answer pairs. More recent approaches leverage Neural Machine Translation (NMT) frameworks to generate query statements directly from user input, relying on computationally intensive LLMs. Conversely, rule-based systems demonstrate effectiveness in specialized domains, like biomedical question answering, but require extensive manual rule crafting, making it hard to adapt to broader applications [
21].
Liang et al. [
22] propose a modular QAS that translates NL questions into SPARQL queries for querying large-scale KGs. It tackles the challenges of needing specialized query languages and deep domain knowledge by decomposing the task into five distinct components: question analysis (including syntactic parsing and DT generation); question-type classification (distinguishing between list, count, and Boolean queries using ML); phrase mapping (leveraging an ensemble of state-of-the-art entity and relation-linking tools); query generation (constructing candidate SPARQL queries from identified triple patterns); and query ranking (using Tree-LSTM models to measure the similarity between the input question and generated queries). This design implements semantic parsing and the disambiguation of ambiguous terms and decouples the semantic interpretation from the underlying physical data layout.
The Bio-SODA system [
21] introduces a training-free KG QAS approach that automatically translates NL into SPARQL queries using graph-based query generation and a ranking algorithm leveraging node centrality. The system preprocesses the Knowledge Base (KB) by building an Inverted Index of searchable keywords and automatically extracting a Schema Graph that enriches and integrates incomplete or heterogeneous RDF schemas. When a user submits a query, Bio-SODA retrieves candidate matches through token lookup, ranks these candidates using a combination of string and semantic similarity measures alongside node centrality (PageRank), and constructs candidate query graphs by solving an approximate Steiner tree problem over the Schema Graph.
The paper AskNow [
23] introduces the concept of a Normalized Query Structure (NQS), which standardizes diverse linguistic inputs into a canonical syntactic form, thereby facilitating the identification of query intents, inputs, and their interdependencies. The authors detail a multi-stage pipeline that encompasses preprocessing, syntactic parsing, and dependency analysis, followed by intent and entity recognition using tools such as DBpedia Spotlight enhanced with WordNet and the BOA pattern library for improved semantic mapping. This structured approach allows for the automatic translation of normalized queries into SPARQL, mitigating lexical and schematic mismatches. The framework is further validated through empirical evaluation on benchmark datasets, demonstrating high syntactic robustness and semantic accuracy. AskNow offers an explainable, modular, and training-data-independent solution.
PAROT [
24] is a dependency-based framework that translates NL queries into SPARQL queries for ontology-based KBs. It leverages a series of syntactic heuristics and a lexicon constructed using the lemon model to map user language to the underlying ontology. By employing a dependency parser, PAROT identifies key target words and decomposes compound sentences into simpler structures, allowing it to extract user triples that capture the relational semantics of the query. These triples are then mapped to ontology triples via the lexicon, which resolves ambiguities and handles complex query elements, such as scalar adjectives, negation, and numbered lists. The result is an SPARQL query that represents the user’s intent while conforming to the structure of the underlying KB.
Mishra et al. [
25] present a comprehensive NL query formalization framework that transforms user questions into SPARQL queries for querying KBs, leveraging the Rasa framework. This approach begins with the creation of a closed-domain ontology for a hostel management system, designed using Protégé, which captures the key concepts and relationships within the domain. The system then employs Rasa’s NLP pipeline using components such as the WhiteSpaceTokenizer, multiple featurizers, and the DIET classifier to preprocess input queries, identify intents and extract entities, and classify queries. These recognized intents trigger pre-designed skeleton SPARQL queries, where the extracted entities are slotted in to generate formal queries that are executed against the RDF-based KB.
The paper ATHENA [
26] describes an ontology-driven system that decouples query semantics from the underlying data schema. The system employs a two-stage approach that first translates a natural language query (NLQ) into an intermediate, Object Query Language (OQL) using domain-specific ontologies and then converts the OQL into executable SQL queries. This intermediate representation captures rich semantic information, including inheritance and membership relationships, that is typically lost when relying solely on Schema Graphs. ATHENA uses an ontology evidence annotator to match tokens in the NLQ with potential ontology elements, such as concepts, properties, and relations, while employing syntactic parsing and dependency analysis to extract meaningful relationships between them. By abstracting the query’s semantics from the physical DB layout, ATHENA provides physical independence, enabling the same logical query to be executed over different relational schemas without modification. A modified Steiner tree algorithm is then used to generate ranked interpretation trees that satisfy constraints such as evidence cover, inheritance, and relationship consistency. This framework supports both normalized and denormalized relational schemas through a robust ontology-to-DB mapping and achieves high precision and recall across multiple workloads.
The paper SQLizer [
27] introduces a framework that automatically synthesizes SQL queries from NL descriptions by combining techniques from semantic parsing, type-directed program synthesis, and automated program repair. The core methodology relies on converting user queries into structured query sketches, identifying essential components, like entities and relationships, through semantic parsing techniques. Subsequent steps in the pipeline link these components to the target Schema Graph via type-directed synthesis, ensuring that completion and validation of the query align with schema constraints. The framework extends traditional query generation techniques by incorporating an iterative refinement process, improving query accuracy when initial attempts fail. The system validates generated queries through execution to ensure that the results reflect the user’s intent. This approach minimizes training data dependency and enhances adaptability across various Schema Graphs.
Kobeissi et al. [
28] present an NLI designed to facilitate the querying of process execution data for domain analysts lacking technical expertise in DB technologies. The system employs a hybrid pipeline combining ML for Natural Language Understanding (NLU) and rule-based logic for Cypher query construction. The process begins with intent detection and entity and relation extraction using a trained ML model. The detected intents, extracted entities, and relations are then used for Cypher query construction based on predefined templates. Finally, the generated query undergoes verification for syntactic correctness and completeness.
Text2Cypher [
12] presents an approach to bridging NL and GDBs by automatically translating plain language queries into executable Cypher queries. The methodology centres on fine-tuning LLMs using a comprehensive NL to Cypher paired datasets assembled from multiple publicly available sources. They compiled and refined a large dataset of 40 K instances by aggregating publicly available resources, which they use to train and evaluate their models. The fine-tuned models outperform existing baselines, as demonstrated by improvements in Google-BLEU and exact match scores.
Jung et al. [
29] detail a multi-step process for processing Korean NL queries that begins with a morphological analysis and resource mapping, progresses through conceptual graph generation, and culminates in a pathfinding-based query graph construction that is scored to best reflect user intent. Evaluated on a K-pop music ontology, the system demonstrated high precision and recall. The study highlights the strength of using weighted pathfinding on ontology schemas while addressing challenges such as ambiguous token mapping and dependency on ontology design quality.
Chen et al. [
30] introduce Light-QAWizard, a low-cost, high-accuracy system for SPARQL query generation in QA systems. Unlike traditional approaches that generate numerous expensive queries, Light-QAWizard employs a multi-label classification model using RNNs (BiLSTM-CRF) and a template classifier to directly predict the required query types. This design reduces query overhead while improving precision, recall, and F1 scores on the QALD datasets. The system efficiently maps natural language questions to SPARQL without overloading the database with unnecessary requests.
Hornsteiner et al. [
31] present a modular chatbot system that integrates LLMs to convert natural language queries into real-time Cypher queries for Neo4j and other graph databases. Leveraging GPT-4 Turbo, the system supports error correction, database selection, and chat history referencing to enhance the accuracy of query generation. Unlike template-based approaches, it enables fully dynamic query construction, allowing the system to handle complex questions over rich graph structures. A key contribution is its modular pipeline architecture, designed for extensibility across different databases and LLMs.
Recent work on NLIs has largely shifted toward neural approaches, with limited reliance on dependency parsing, making direct comparisons to our method less straightforward. Nonetheless, specific components and design choices from earlier pipeline-based systems remain relevant for comparison. Shivamurthy et al. [
32] propose a system that translates structured textual requirements, written in the EARS (Easy Approach to Requirements Syntax) template, into a Neo4j graph database—targeting formalized input rather than free-form user queries. Their method employs the Stanza NLP toolkit and a rule-based extraction framework to identify triggers, actions, and conditions, making it well-suited for safety-critical domains where structured language is standard. In contrast, their approach is limited by its reliance on template-based input, rendering it unsuitable for handling natural, unstructured queries. Furthermore, their system depends entirely on syntactic dependency parsing, using hardcoded rules to map components to predefined node and relation types. As a result, both the Graph Schema and semantic roles are rigid and closely tied to the input format. Conversely, our system dynamically constructs the semantic structure from free-form text, offering greater flexibility and generalizability across domains.
Hur et al. [
10] present a comprehensive pipeline for domain-agnostic text representations using Labeled Property Graphs (LPGs). Their system applies multi-stage linguistic processing, beginning with a morphological analysis (lemmatization and POS tagging), followed by deep syntactic parsing, and culminating in extensive semantic enrichment—including event detection, temporal and causal link extraction, coreference resolution, and pragmatic context modelling. While their method yields fine-grained contextual graphs that support downstream NLP tasks, such as semantic search and summarization, it is not designed for executable query construction. Our system shares with Hur et al.’s the domain-agnostic design philosophy, reliance on syntactic analysis, and the dynamic construction of graph-based structures. Both emphasize modular processing and the preservation of linguistic relationships within the resulting representations. However, our system prioritizes efficient, real-time Cypher query generation aligned with database schemas in contrast to Hur et al., who focus on comprehensive semantic modelling. We maintain lower computational complexity, targeting real-time interaction through the construction of targeted semantic structures optimized for schema-aware querying, rather than broad linguistic representations.
Skandan et al. [
33] propose a Knowledge Graph Question Answering (KGQA) system that constructs a simple KG by extracting subject-predicate-object (SPO) triples from input paragraphs using part-of-speech tagging and dependency parsing. These entity–relation pairs are stored in a JSON-based graph without schema modelling, relying solely on syntactic patterns and lacking deeper semantic interpretation. Question answering is achieved through basic question classification (e.g., who, what, and where) and keyword-based triple matching, allowing for single-hop and limited multi-hop traversal over the extracted graph. However, the system lacks key features required for complex graph querying: it does not perform semantic mapping or schema validation or generate formal executable queries, such as Cypher. Its interaction remains limited to surface-level factual retrieval, without support for advanced operations, like multi-condition filtering, aggregation, or schema-aligned multi-hop reasoning. These limitations confine the system to basic QA functionality, in contrast to more flexible and execution-oriented natural language query frameworks.
Research on Question Answering Systems (QASs) in the Greek language is limited [
34,
35,
36,
37,
38,
39]. To the best of our knowledge, there is no other implemented and evaluated NLI for querying Property Graphs in Greek.
Our system translates user queries into KG queries, specifically targeting Property Graphs [
10] using the Cypher query language as utilized by the Neo4j DB as in [
12,
28,
31,
32]. It employs a multimodal pipeline similar to the approaches in [
10,
22,
26,
29,
31]. The system preprocesses the KB by constructing a Dictionary of searchable keywords as in [
24] and automatically extracts a Schema Graph as in [
21]. It performs token-to-DB entity mapping as in [
10,
22,
23,
24]. The query construction process leverages the underlying schema structure, aligning with the approaches in [
12,
21]. Furthermore, it extracts triples from user-submitted queries, as outlined in [
24,
33].
Unlike other systems [
25,
28], our approach does not require predefined intents and entities [
10]. In contrast to ontology-driven methods [
24,
25,
26], it operates without relying on domain-specific ontologies. While some methods rely on ML models trained on predefined intents and entities [
22,
25,
28] our system operates without such dependencies. Instead of employing query templates [
25], it dynamically constructs queries based on extracted information [
10]. Likewise, approaches that incorporate intermediate syntactic representations [
23,
26] or implement query-ranking mechanisms [
21,
22,
26,
27] are avoided [
30] for a more adaptable and schema-driven query construction process. Our system has been evaluated on an educational domain real-world application, similar to [
25], in a medium-/low-resource language like [
29].
3. Challenges
NL querying of KGs presents several complex challenges that significantly affect the effectiveness of NLQA systems [
21]. These include the fundamental challenge of translating unstructured NL input into structured DB queries, a problem that becomes even more pronounced in medium- and low-resource languages due to linguistic variability, limited NLP tools, and frequent parsing errors. The main challenges are the following:
Ambiguity, Polysemy, Synonym Handling, and Variability in Natural Language.
Ambiguity arises when a term or phrase has multiple interpretations. For example, in the query,
“What courses are being held in the room ‘John Smith’?” and
“What courses are being taught by Mr. John Smith?”, the term
John Smith refers to a classroom name in the first query and an instructor in the second one. Resolving such ambiguities requires external knowledge sources or advanced semantic similarity measures to interpret user intent and map it to the correct entities and relationships within the KG [
21].
Polysemy involves a single word with multiple related meanings. For example, the noun level has different meanings in the phrases “Show all courses available for undergraduate level” and “What offices are available in level 2”. In the first query, level denotes the undergraduate tier of study, while in the second, it denotes the second floor of a building.
Synonym handling addresses different words with similar meanings. For example, in the phrase
“Which lecturers are conducting the Programming course?”, the word
conducting is a synonym of
teaching, and it must be mapped to the
TEACHES relationship in the KG. Without proper lexical normalization, queries may fail due to mismatched entity labels, leading to incorrect or missing connections within the KG. Implementing effective disambiguation and synonym handling techniques is essential for accurate information retrieval [
21].
Variability pertains to the diverse ways users can phrase the same query. For example,
“Who teaches Statistics?” and
“Which instructor is responsible for the Statistics course?” have the same intent but different structures. This diversity necessitates advanced NLU to accurately capture user intent [
28].
Complex Query Structures. Real-world queries frequently involve multi-hop relationships across various entity types, adding layers of complexity to the query structure. For example, answering
“On which floor is located the office of the professor who teaches Statistics?” entails traversing multiple relationships through entities such as
floor,
office, and
Statistics. Many existing KGQA models struggle with such complex queries, especially those involving more than two or three hops due to limitations in their ability to navigate and interpret complex graph structures [
21].
Handling Aggregations, Comparisons, and Ordering. Queries involving counts, comparisons, and superlatives, such as
“How many courses have 4 ECTS?”, “Which course in Spring semester has the most ECTS credits?”, or
“Which courses are held in the classroom where the course A-123 is conducted?”, require aggregation functions, constraints, and filtering that many KGQA systems do not support effectively. Some solutions either lack aggregation handling or rely on manual rule-based configurations, limiting their ability to process such queries accurately [
21,
28].
Explainability and User Interaction. Users need to understand how a system interprets their query, but many systems function as “black boxes”, making it difficult to debug incorrect results. This lack of transparency can reduce user trust and hinder the adoption of NLQA systems.
Inference of Implicit Graph Elements. Users often omit specific details in their queries, requiring the system to infer missing graph elements. For example, in the query
“What are the emails of the Special Teaching Staff?”, the system must deduce that
emails pertains to the
email property of
Person entities which belong to
Special Teaching Staff [
28].
Extraction of correct triples. Generating accurate Cypher queries requires adherence to the database schema. Missing or wrong relationships can lead to incorrect results.
4. Preliminaries
Property Graph: A Property Graph is a directed labelled multigraph with the special characteristic that each node or edge could maintain a set of property–value pairs where a node represents an entity, an edge represents a relationship between entities, and a property represents a specific feature of an entity or relationship. In Property Graphs, both edges and nodes can be labelled [
40].
Entity: An entity is a distinct, identifiable unit in a system or dataset that represents a real-world object, concept, or instance. Entities have unique identities and can have properties (also called attributes).
Entity Type: An entity type is a category or classification that defines a group of entities with common properties. It acts as a blueprint, specifying the structure of entities but not individual instances.
Path: a path in a Property Graph refers to a sequence of nodes/vertices connected by edges (relationships), representing a traversal from one entity to another.
Named Entity Recognition (NER): NER is the task of automatically identifying and classifying spans of text that refer to real-world entities into predefined categories.
Neo4j: Neo4j is a Graph Database Management System (GDBMS). It is designed to store, manage, and query data structured as Property Graphs, consisting of nodes, relationships, and properties in nodes and in relationships.
Cypher: Cypher is a declarative query language designed for querying and managing Property Graphs. The language is built around clauses that define query logic, such as retrieving data, filtering results, ordering outputs, and modifying the graph structure. MATCH is used to find specific elements in the graph, WHERE filters based on conditions, and RETURN specifies the output. Additional clauses allow sorting, limiting, aggregating, and modifying data. Patterns define the input structure for these clauses.
In the context of Property Graphs, particularly within Neo4j, the concept of a relationship label directly corresponds to the relationship type. Unlike nodes, which can possess multiple labels for categorization, a relationship in Neo4j is characterized by a single, specific type that defines the nature of the connection between the two connected nodes. This relationship type acts as a label, indicating the kind of interaction or association that exists, such as TEACHES and TAUGHT_AT. Therefore, when discussing the classification or categorization of connections between entities in a Neo4j graph database (GDB), the relationship type serves the same role as a relationship label would in a more general Property Graph model.
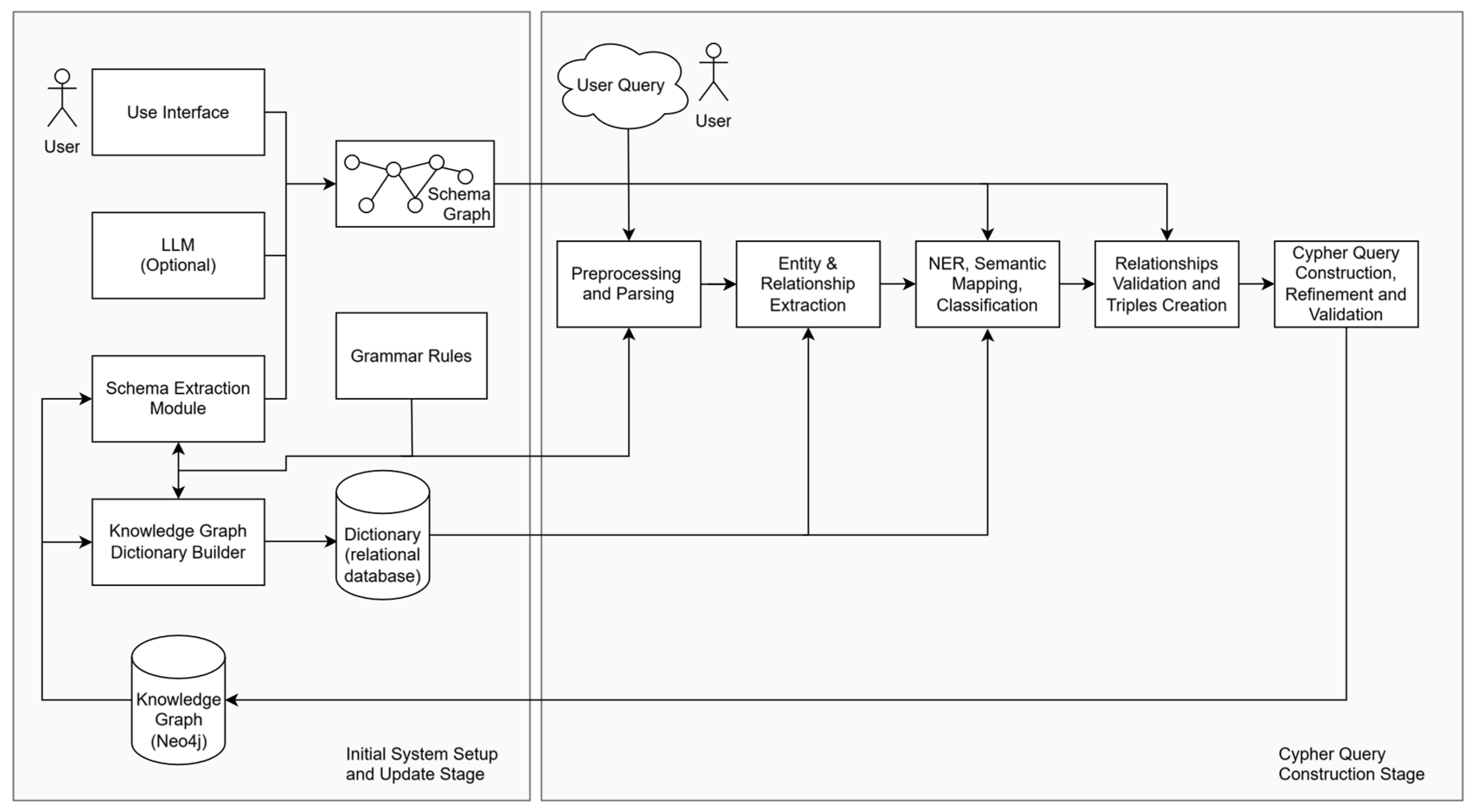
5. System Architecture
The implementation of our system involves two distinct stages:
Initial System Setup and Update and
Cypher query construction. During the system setup stage, a Schema Graph and a Dictionary of entities are constructed. In the
Cypher query construction stage, NL queries are transformed into Cypher queries. The overall system architecture, including the two stages, i.e., the
Initial System Setup and Update Stage and the
Cypher query construction stage, is illustrated in
Figure 1.
5.1. Initial System Setup and Update
During the Initial System Setup, the Schema Graph of the KG and a Dictionary are automatically generated. The Schema Graph is extracted as a subgraph of the KG by executing a DB library process. After extraction, the schema’s data literals are created and enriched through a set of grammatical rules. Additionally, user annotations and alternative token expressions generated by an LLM can be used to further enhance the matching literals. The Schema Graph is automatically updated whenever new node labels, new relationships, or new property keys are introduced.
Additionally, a Dictionary is created during the Initial System Setup and used during user query processing. It stores entities and their lexical variations, such as course codes and the names of persons, offices, courses, and rooms, and it is updated whenever the database changes.
Algorithm 1 presents the procedure for the Initial System Setup.
| Algorithm 1: The Algorithm of the Initial System Setup |
function systemInitialization (KG, GrammarRules):
// 1. Extract the schema subgraph from Neo4j using APOC
SchemaKG: = extractSchemaFromDB (KG)
store SchemaKG in KG_DB
// 2. Enrich schema nodes with property keys
NodeLabelsAndProperties: = extractNodeDataFromDB (KG, GrammarRules)
foreach (Label, PropertySet) in NodeLabelsAndProperties do
SchemaKG.node(Label).extraproperty: = makeList(PropertySet)
endfor
// 3. Enrich schema relationships with property keys
RelationshipTypesAndProperties: = extractRealationshipDataFromDB (KG)
foreach (RelType, PropertySet) in RelationshipTypesAndProperties do
SchemaKG. relationship (RelType).extraproperty: = makeList(PropertySet)
endfor
// 4. Create and enrich literals in the schema
foreach NodeOrRel in schemaKG do
BaseLiteralsSet: = generateLiteralsFromName (NodeOrRel)
EnrichedLiteralsSet: = applyGrammaticalRules (BaseLiteralsSet, GrammarRules)
AdditionalLiteralsSet: = getLiteralsFromLLMorUser (NodeOrRel)
AllLiteralsSet: = union (EnrichedLiteralsSet, AdditionalLiteralsSet)
add AllLiteralsSet to NodeOrRel.literals
endfor
foreach Node in SchemaKG.node do
Node.pronouns: = interrogativePronouns (Node)
//(e.g., “who”,”what”)
endfor
// 5. Create the Dictionary
Dictionary: = emptyTable
AllEntRelSet: = extractAllEntitiesAndRelationships (KG)
// e.g., node names, relationship types, property keys, property values
foreach Element in AllEntRelSet do
LexicalVariationsSet: = generateLexicalVariations (Element)
// morphological forms, synonyms, alternate spellings, etc.
Dictionary.add (Element, LexicalVariationsSet)
endfor
store Dictionary in RELATIONAL_DB
end function |
5.1.1. Schema Creation
Extraction of Nodes, Relationships, and Properties
The domain’s data in the DB are represented as a Property Graph of interconnected nodes. Nodes representing the same entity type share a common label. During the schema creation process, all labels are extracted and used to create a new subgraph in the DB that forms the nodes of the schema. These nodes are connected by one or more edges, reflecting how their corresponding entity nodes are linked in the KG DB.
Figure 2 depicts the extracted Schema Graph, which abstracts the structure of the KG by representing node labels (entity types) and their valid relationship types. This Schema Graph is automatically generated and used for validating relationships and guiding query construction.
In order to create the Schema Graph, the APOC (Awesome Procedures on Cypher) library of Neo4j is used, which offers utilities for tasks such as graph analytics, data import/export, and schema handling. Executing the command “CALL apoc.meta.graph()” returns a subgraph representation of the KG Schema, where each node represents a node label in the DB and each edge represents a relationship type between the respective nodes. This resulting Schema Graph illustrates the structure of the DB by showing how different node labels and relationship types are interconnected, providing a high-level meta-structure of the data. The extracted subgraph is stored in the DB as a persistent representation of the schema.
In addition to their labels, KG nodes contain various properties that provide specific information about the entities they represent. Each node is associated with a set of properties. For example, nodes labelled Person may include properties such as lastname and email. To enrich the schema, the keys of these properties are extracted and incorporated into the corresponding schema nodes. The properties of each group of nodes sharing the same label are stored as a list-type property in the schema node corresponding to that label.
The following Cypher query retrieves information about node labels and their associated properties in a Neo4j GDB:
MATCH (n)
WITH labels (n) AS label, keys (n) AS properties
UNWIND label AS singleLabel
RETURN singleLabel AS NodeLabel, collect (distinct properties) AS Properties
Similar to nodes, relationships also contain properties that provide additional context about the connections they represent. Each relationship type is associated with a specific set of properties that describe its characteristics. For instance, a relationship of type TAUGHT_AT includes properties such as day and time. To enrich the schema, the keys of these properties are extracted and added to the corresponding schema relationships. The properties associated with each group of relationship types in the KG are stored as a list-type property within the corresponding schema relationship.
The following Cypher query retrieves information about relationship types and their associated properties:
MATCH ()-[r]->()
WITH type (r) AS RelationshipType, keys (r) AS propertyKeys
RETURN RelationshipType, collect (distinct propertyKeys) AS Properties
The extracted and enriched schema represents a high-level abstraction of the underlying data, which provides a comprehensive blueprint of the database’s structure.
Literals and Pronounces Creation
Literals are words or phrases that describe specific entities and relationships that are expected to appear in users’ queries. Literals represent different ways a user might refer to a specific entity or relationship in an NL query. Schema literals correspond to node label names, relationship-type names, and property key names. They are stored as list-type properties within the schema’s nodes and edges. The initial values of literals are derived from corresponding node and property names, along with common syntactic variations. Additional literals can be added manually by the user through a graphical interface or, alternatively, generated by an LLM. For example, the verb teaches might also be posed as lectures or conducts. These literals encompass different words or phrases associated with a specific concept, along with their potential variations.
In addition to literal properties, each node also includes relevant interrogative pronouns as part of its properties. For example, the Person node contains as a property the pronouns who and whom. These pronouns are later used to identify candidate entity types during the query interpretation process. Pronouns can be assigned either manually through the user interface or automatically with the assistance of an LLM.
5.1.2. Dictionary Creation
During the system setup, a Dictionary is generated to store the system’s vocabulary. The Dictionary is stored in a relational DB for efficient retrieval and enables fast searches and literal matching against KG data. All entities in the KG, including node names, node labels, relationship types, and property keys and values, are stored and indexed in a relational DB. These stored literals can consist of multiple words. For example, a person’s full name may contain two or three words, while a course’s name could range from two to twenty words. For each literal string, corresponding lexical variations are generated based on grammatical rules, synonyms, and alternate spellings. For instance, the genitive forms of Greek words, including proper names, are automatically created and indexed. In addition, the associated nodes and relationships are also stored and used in the NER process. For example, a person’s name is stored alongside its corresponding node label, Person. The Dictionary is dynamically updated whenever modifications occur in the KG.
Both the Schema Graph and the Dictionary play an important role in processing user queries by supporting token matching, semantic role labelling, NER, and relationship validation. They are used to map query tokens to the corresponding DB entities and relationships. Incorporating lexical variations enhances entity recognition, while the structured representation of the schema supports relationship validation and reduces invalid query constructions. Together, the Schema Graph and the Dictionary are essential for translating NL queries into structured DB queries.
5.2. Cypher Query Construction
Upon acceptance of a user’s query, the system executes a series of processes to extract its semantics and translate it into a Cypher query. These processes, as outlined in the query construction algorithm presented in Algorithm 2, include text preprocessing, syntactic analysis, DT-to-GDB mapping, question classification, entity extraction, NER, semantic mapping, semantic relationship validation, and query construction. The following paragraphs discuss each process in detail.
| Algorithm 2: The Algorithm of the Query Construction |
function ProcessUserQuery (UserQuery, SchemaKG, GrammarRules, Dictionary)
// 1. Text Preprocessing
TokensList: = tokenize (UserQuery)
NormalizedTokensList: = normalize (TokensList) // lowercasing, diacritics removal, etc.
// 2. Syntactic Analysis
(PosTags, DependencyTree): = syntacticAnalysis (NormalizedTokensList, GrammarRules)
// spaCy to get POS and dependency parse
// 3. Dependency Tree to Graph Mapping
DT_KG: = buildDependencyTreeGraph (DependencyTree)
// store each token as a node, each dep as an edge
// 4. Question Classification
QuestionType: = determineQuestionType (DT_KG)
// QuestionType values: “list”, “count”, or “boolean”
// 5. Entity and Relation Extraction
(CandidateEntities, CandidateRelationships): = extractEntitiesAndRelations (DT_KG, Dictionary)
// The function extractEntitiesAndRelations performs exact match, fuzzy match, regex, etc.
// 6. Named Entity Recognition (NER)
RecognizedEntities: = assignEntityTypes (CandidateEntities, Dictionary)
// 7. Semantic Mapping
SemanticMap: = mapEntitiesToSchema (RecognizedEntities, DT_KG, schemaKG)
// find valid node-node, node-property, property-property alignments
// identify intermediary nodes from the schema if needed
// 8. Schema Validation
ValidatedPairs: = []
foreach CandidatePair in SemanticMap do
if CandidatePair.containsProperty then
// Distinguish between node-property and property-property pairs.
if CandidatePair.entityA.isNode and CandidatePair.entityB.isProperty then
NodeLabel: = getLabel (CandidatePair.entityA)
PropertyKey: = getPropertyKey (CandidatePair.entityB)
// Check that the property is valid for the node.
if schemaHasProperty (SchemaKG, NodeLabel, PropertyKey) then
ValidatedPairs.append (CandidatePair)
endif
elseif CandidatePair.entityA.isProperty and CandidatePair.entityB.isNode then
NodeLabel: = getLabel (CandidatePair.entityB)
PropertyKey: = getPropertyKey (CandidatePair.entityA)
if schemaHasProperty (SchemaKG, NodeLabel, PropertyKey) then
ValidatedPairs.append (CandidatePair)
endif
elseif CandidatePair.entityA.isProperty and CandidatePair.entityB.isProperty then
NodeLabelA: = getNodeLabelForProperty (CandidatePair.entityA)
PropertyKeyA: = getPropertyKey (CandidatePair.entityA)
NodeLabelB: = getNodeLabelForProperty (CandidatePair.entityB)
PropertyKeyB: = getPropertyKey (CandidatePair.entityB)
if schemaHasProperty (SchemaKG, NodeLabelA, PropertyKeyA) and
schemaHasProperty (SchemaKG, NodeLabelB, PropertyKeyB) then
// If both properties belong to the same node label, no connectivity check is needed.
if NodeLabelA = NodeLabelB then
ValidatedPairs.append (CandidatePair)
else
Paths: = findPathsInSchema (SchemaKG, NodeLabelA, NodeLabelB)
if notEmpty (Paths) then
CandidatePair.paths: = Paths
ValidatedPairs.append (CandidatePair)
endif
endif
endif
endif
else
// Handle simple Node-Node candidate pairs.
LabelA: = getLabel (CandidatePair.entityA)
LabelB: = getLabel (CandidatePair.entityB)
Paths: = findPathsInSchema(SchemaKG, LabelA, LabelB)
if notEmpty (Paths) then
CandidatePair.paths: = Paths
ValidatedPairs.append (CandidatePair)
endif
endif
endfor
// 9. Semantic Relationship Validation
ValidatedTriples: = validateRelationships (ValidatedPairs, DT_KG, SchemaKG)
// confirm that extracted relationships exist in the user’s query
// 10. Query Construction
InitialCypherQuery: = constructCypherQuery (ValidatedTriples, QuestionType)
// build MATCH-WHERE segments + RETURN/ORDER BY
// 11. Query Refinement
RefinedCypherQuery: = removeRedundancies (InitialCypherQuery)
// omit duplicate MATCH or WHERE conditions
// 12. Query Validation
IsQueryValid: = validateQueryEntities (RefinedCypherQuery, RecognizedEntities)
if not IsQueryValid then
return “Query Invalid or Incomplete”
endif
// 13. Execute the Cypher query
Result: = executeCypher(RefinedCypherQuery)
// 14. Return the Result
return result
endfunction |
5.2.1. Dependency Parsing
User queries are first preprocessed to apply basic normalization by converting uppercase letters to lowercase ones, unifying diacritics, and correcting common spelling errors using spaCy and grammar rules. The system applies POS tagging to assign grammatical roles to individual tokens and constructs a DT that represents the syntactic structure of the user’s input. The DT is generated using spaCy’s dependency parser for the Greek language, which captures syntactic relationships between tokens, such as subjects, objects, and modifiers.
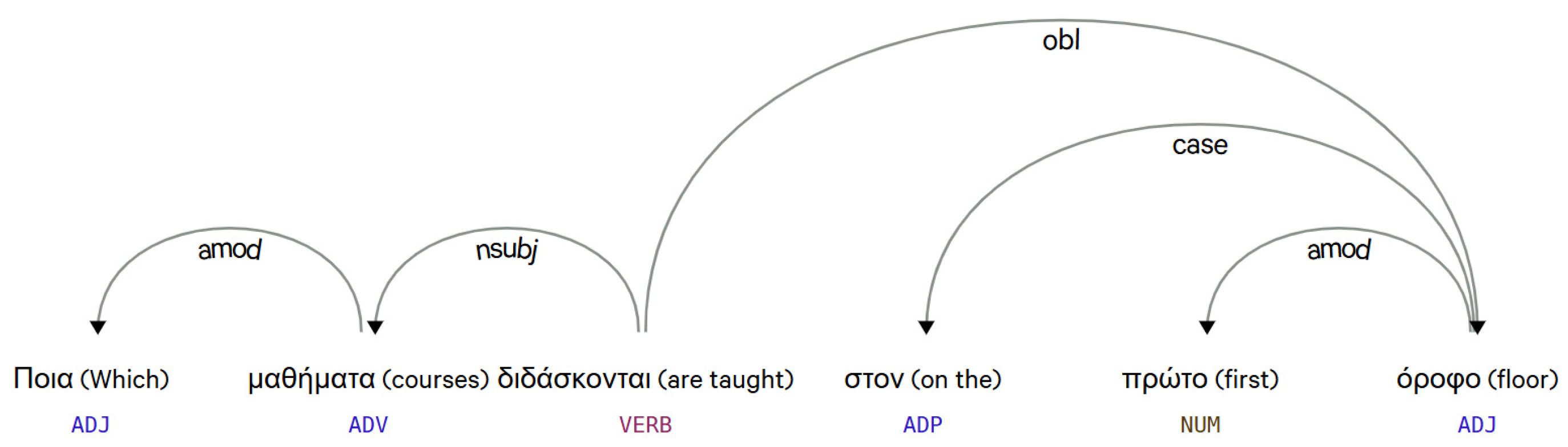
For example, in the question
“Ποια μαθήματα διδάσκονται στον πρώτο όροφο;” (Which courses are taught on the first floor?), the DT identifies
μαθήματα (
courses) as the subject (nsubj),
διδάσκονται (
are taught) as the main verb (ROOT), and
πρώτο όροφο (
first floor) as an oblique modifier (obl) (
Figure 3). The system also recognizes adjective modifiers (amod), such as
ποια (
which) describing
μαθήματα (
courses). By parsing these relationships, the system clarifies the grammatical hierarchy within the sentence.
This structured analysis forms the basis for subsequent steps like entity recognition and mapping.
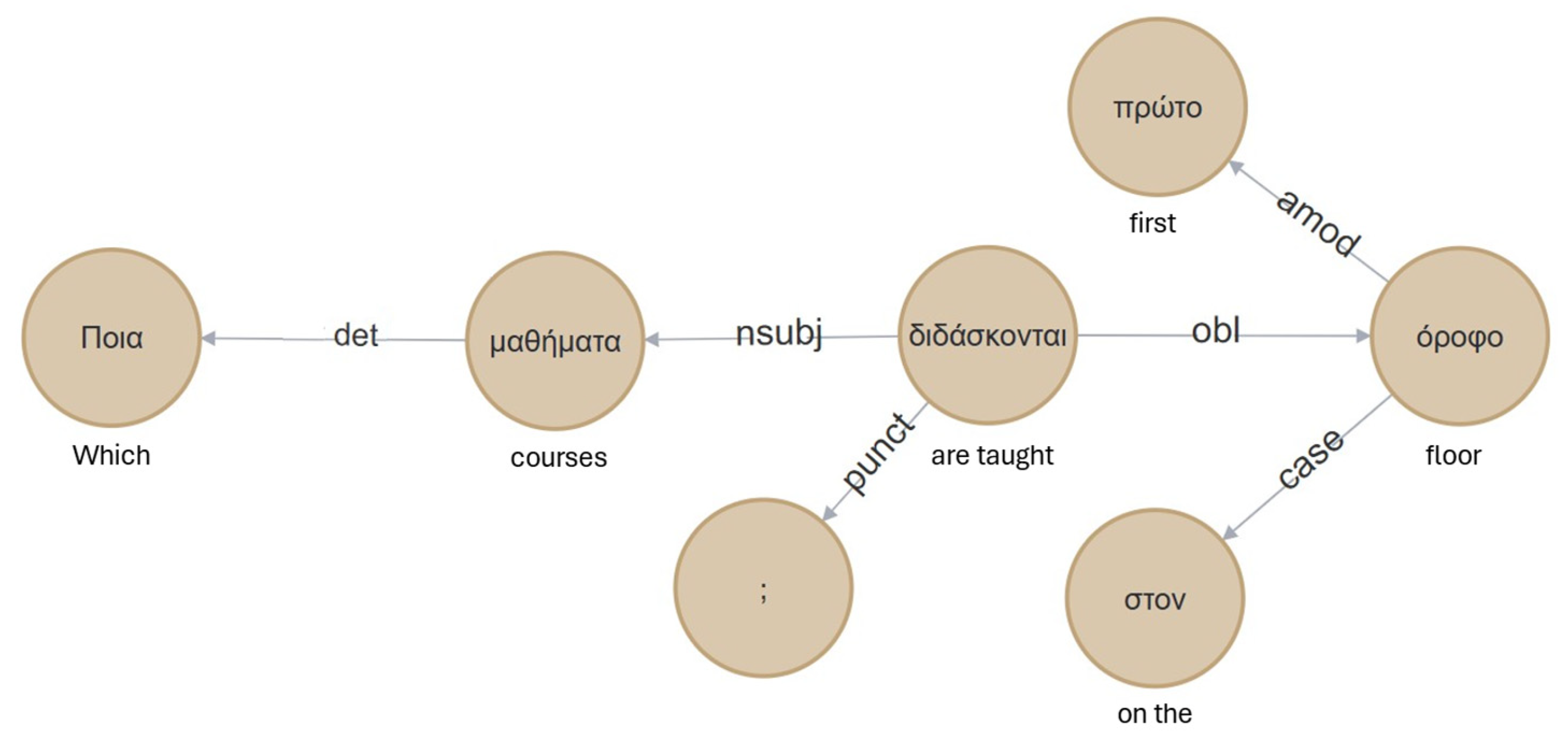
5.2.2. Dependency Tree-to-Graph Database Mapping
The extracted DT is mapped into the Neo4j GDB as a KG, forming a DT KG. In this structure, each token from the user’s query is represented as a node, while the syntactic dependencies between tokens are modelled as edges. This representation of Greek-language DTs was introduced in [
36] and later used in [
41]. The specific representation offers several advantages. First, reasoning over the DT becomes independent of edge direction and more efficient compared to using spaCy’s native functions—particularly for path-related tasks, such as identifying the shortest path between two tokens. Second, it enables the automatic correction of extraction errors within the DT. For example, when a sentence is incorrectly split into multiple Dependency Trees (DTs), additional relations can be introduced to restore structural integrity. Third, this approach facilitates a clear visualization of the question’s syntactic structure, which proves useful during both development and debugging.
Figure 4 illustrates the DT KG of the sentence
“Ποια μαθήματα διδάσκονται στον πρώτο όροφο;” (
“Which courses are taught on the first floor?”).
5.2.3. Question Classification
During the question classification process, the intent of the user’s query is determined and used in the resulting Cypher query construction. By analysing the linguistic features of the input, the system identifies the type of the question—such as list, count, or Boolean.
The system examines specific indicators in the input, such as interrogative pronouns and syntactic structures. For instance, questions starting with “Who/Which/What” are typically classified as list questions, where the user seeks one or more entities that satisfy certain conditions. Queries involving quantifiers or numerical constraints, such as “How many”, are typically categorized as count questions, requiring the system to return a numerical result. Questions beginning with auxiliary verbs, like Is or Does, are classified as Boolean questions, prompting the system to evaluate whether specific conditions are met in the KG and return a simple yes or no answer.
For example, in the query “Ποια μαθήματα διδάσκονται στον πρώτο όροφο;” (Which courses are taught on the first floor?), the presence of Which signals a list-type question. The query “Πόσα μαθήματα είναι υποχρεωτικά;” (How many courses are compulsory?) is classified as a count question. The query “Είναι το μάθημα υποχρεωτικό;” (Is the course compulsory?) is classified as a Boolean question.
This classification determines the construction of the Cypher query’s RETURN clause that should correspond to the user’s intent.
5.2.4. Entity and Relation Extraction
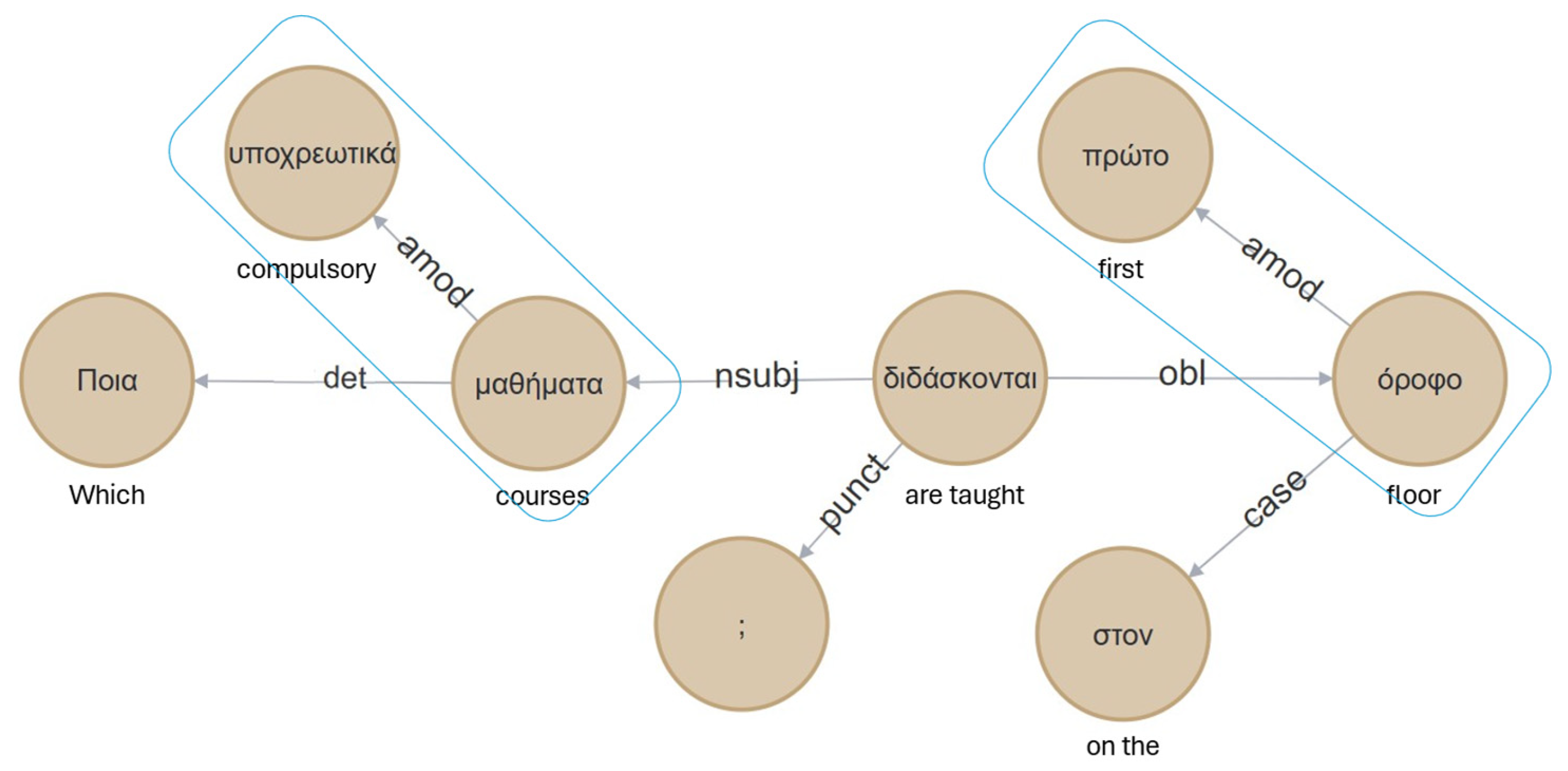
The entity and relation extraction process involves analysing the input text using syntactic techniques to identify key entities and determine the relationships between them. The system leverages the Dictionary, and it uses a combination of exact matches, fuzzy logic, and regular expressions to associate tokens and phrases with the indexed entities and relationships. For example, in the query
“Ποια υποχρεωτικά μαθήματα διδάσκονται στον πρώτο όροφο;” (
Which compulsory courses are taught on the first floor?), the entities
compulsory courses and
first floor, along with the relationship
taught, are extracted. The DT KG representation of this query is illustrated in
Figure 5. In this graph, the noun phrases
“υποχρεωτικά μαθήματα” (
compulsory courses) and
“πρώτο όροφο” (
first floor) are treated as unified entity phrases. These groupings are formed based on syntactic dependencies such as amod (adjectival modifier), which links adjectives to their corresponding nouns. The boxed areas in the figure highlight these adjective–noun pairs.
To account for phrasing variations, query tokens are compared against the literal alternatives stored in the Dictionary. Fuzzy logic matching is employed to assess the similarity between input tokens and schema-defined entities, allowing the system to accommodate minor spelling errors. However, fuzzy matching is restricted for the numeric components of entities to prevent incorrect associations between distinct entities with similar numeric strings, such as “Statistics I” and “Statistics II”. Regular expressions are used to capture entities that follow specific patterns, such as course codes or predefined formats, like dates. If two candidate entities share overlapping words, the system retains the one composed of the greatest number of words. For example, in the question “Which compulsory courses are taught on the first floor?”, the candidate entities floor and first floor are both identified. In this case, first floor is recognized as a single entity, as it represents the more specific match.
5.2.5. Named Entity Recognition
The NER process assigns identified entities within the user’s query to their corresponding entity types, such as Person, Course, or Room. The Dictionary is used for entity extraction, with each entity record linked to its respective entity type. If an entity can be associated with multiple types (e.g., “Level—Course Category” or “Level—Floor”), all possible alternatives are retained and further evaluated and filtered in subsequent steps. Additionally, interrogative pronouns (e.g., who, what, and how many) are mapped to their respective entity.
The extracted entities, along with metadata, such as their tokens’ position in the sentence and corresponding literals, are used in the Semantic Mapping process.
5.2.6. Semantic Mapping
Semantic Mapping refers to the process of aligning entity types extracted from NL queries with those defined within a DB Schema. Building upon NER, this step involves associating each identified entity type with the appropriate schema node. For example, the phrase πρώτο όροφο (first floor) is mapped to the Floor entity type, and μαθήματα (courses) is mapped to the Course entity type. Following entity alignment, relevant relationships between nodes are identified and subsequently validated in the next stage of the pipeline.
In the DT KG, tokens identified as entities are replaced with their corresponding entity type, producing a transformed KG that consists of the following:
Entity Types: tokens representing identified entities are substituted with their respective entity types.
Tokens: the remaining tokens, primarily verbs, that were not identified as entities.
Dependencies: syntactic relationships connecting entity types and remaining tokens, representing the grammatical structure of the original query.
After entity-type incorporation into the DT KG, each entity type is paired with its nearest neighbour based on the shortest dependency path, so that the resulting connections represent the most direct syntactic relationships in the query. These pairs are used for Schema Graph alignment validation, which involves the following:
Node–Property matching: validate that two entity types can be matched as a node and its property (e.g., a person’s email address), ensuring the property belongs to the specific node.
Property–Property matching within a Node: validate that two entity types can be matched as two properties of the same node (e.g., a Person’s first name and last name), ensuring that a node exists which owns both properties.
Node–Node Relationship matching: validate that two nodes are connected by one relationship (e.g., a Person and a Course) or path, ensuring that at least one relationship exists between the two nodes.
Node–Property-to-Connected Node matching: validate whether a node’s property can be associated with another connected node (e.g., matching a Person’s email address to a Course) by confirming that the property exists on a node and that there is at least one relationship or path linking it to the target node.
Property–Property across Connected Nodes matching: validate that a node’s property can be matched with another connected node’s property (e.g., a Person’s email address with a Course’s code), ensuring that two nodes own the respective properties and that at least one relationship or path exists between them.
During the validation phase, the extracted entity types are mapped to the Schema Graph. Missing nodes, such as those that hold the identified entities as properties, are detected and added, and relevant relationships between nodes are retrieved. Nodes that possess the required properties, even if not explicitly mentioned in the query, are also incorporated into the subsequent query construction. For example, in the question “Who teaches Statistics?”, the term “Statistics” corresponds to the title property of a Course node, which is not explicitly referenced in the query but is inferred during validation. At this stage, entity pairs, whether representing nodes or node properties, are also checked for connectivity via valid paths. A simple path involves a direct relationship between two nodes, while a composite path includes at least two relationships and an intermediary node. These extracted paths are subsequently validated against the DT during the semantic relationship validation process.
In the following example, the user inputs the query
“Ποιοι διδάσκουν μάθημα στον όροφο που διεξάγεται το μάθημα Γενική Φυσική;” (“Who teaches courses on the floor where the course General Physics is held”). The entity and relation extraction module outputs the following entities:
who, course, floor, course, and
title (
Table 1). Concurrently, the NER process assigns the corresponding entity types:
Who, Course, Floor, Course, and
Course.title.
After replacing the corresponding tokens with the extracted entity types in the DT KG, all entity-type pairs are examined to identify those connected by the shortest dependency path. In other words, the process involves locating the nearest syntactic neighbour for each entity type. This task is significantly simplified within the DT KG compared to the original DT. The result is retrieved through the execution of a Cypher query.
Figure 6 illustrates the entity types, the tokens, and the syntactic dependencies of the query.
If multiple entity-type pairs include a common entity type and have identical minimum dependency path lengths, selection is determined based on an empirically defined dependency priority list. For instance, consider the following dependency paths:
Both paths include the entity type Who and have a dependency length of 2. However, since the relation obj holds higher priority than obl in the dependency order, the first pair is selected.
The entity pairs with the shortest dependency paths, along with their corresponding dependencies (as shown in
Table 2), map to nodes in the schema—except for the final pair, where Entity B refers to a
title property of a node.
In the DT KG, when two or more entities are linked by a conjunction (typically indicated by a conj relation), they are merged into a single consolidated entity. Instead of treating the conjoined entities separately, the system combines them to represent a unified entity within the graph structure. This approach simplifies both semantic mapping and query generation. For example, consider the following query: “What is the name and phone number of the professor who teaches Statistics?”. During semantic mapping, the system recognizes this relationship and merges both properties (name and phone) into one. In practical implementations, when the dependency graph reveals a conjoined relation between name and phone with both pointing to the same Person node, the system treats them as grouped properties of that single node. The merged entities are subsequently separated and used in the formulation of the RETURN clause. As a result, the final query is constructed to retrieve both the name and phone of the professor as properties of the same Person node.
A similar process is applied to the following query: “When does a class take place in Room 3 during the winter semester, and which one?”. In this case, the conjunction and linking the interrogatives when and which triggers a unification step, where the entities When and Which are merged into a single composite entity. As a result, the generated Cypher query retrieves both the day/time and the course associated with Room 3.
5.2.7. Schema Validation
The entity type pairs are validated by executing the corresponding Cypher queries against the database schema. This validation step confirms both valid node–property associations and valid node-to-node paths. The results of the queries for each selected pair from
Table 2 are presented in
Table 3.
Entity Pair 1: This pair identifies a node containing the interrogative entity Who linked to a node labelled Course. According to the schema, this corresponds to a node labelled Person (which stores the interrogative pronoun who in its properties) that is associated with a node labelled Course via the relationship TEACHES.
Entity Pair 2: This pair comprises a node named course1 labelled Course and a node named floor1 labelled Floor. Schema validation confirms that these entities are linked through the following path: :TAUGHT_AT → :Room → :LOCATED_AT.
Entity Pair 3: Similarly, this pair comprises nodes labelled floor1 and course2 and follows the same path as the second pair: :TAUGHT_AT → :Room → :LOCATED_AT. It is important to note that instances of the intermediary node labelled Room may vary in the DB.
Entity Pair 4: The final pair links a node named course2 labelled Course (represented as course2:Course) to the property title of a temporary node designated as Course. Schema validation confirms that the property title is associated with the node labelled Course.
Using the schema mapping, the following relationships are verified:
(who1:Person)-[:TEACHES]-(course1:Course)
(course1:Course)-[:TAUGHT_AT]-(:Room)-[:LOCATED_AT]-(floor1:Floor)
(course2:Course)-[:TAUGHT_AT]-(:Room)-[:LOCATED_AT]-(floor1:Floor)
(course2.title)
Note that the path connecting the courses to the floor includes an extra node labelled Room. In this example, this intermediary node does not need to be included in the construction or the RETURN results. However, in other cases, intermediate nodes may be explicitly named in the MATCH clause and included in subsequent clauses as required.
The output of semantic mapping is a structured representation that aligns recognized entities with their corresponding schema elements, generating candidate node-to-node and node-to-property associations. It includes intermediary nodes where necessary and forms a foundation for subsequent validation and query construction.
Semantic mapping addresses ambiguity by validating entity pairs against the schema and retaining only those that align with the graph’s structure.
5.2.8. Semantic Relationship Validation
Semantic relationship validation evaluates the extracted relationships to confirm their existence in the DT. This is performed by comparing the literals of the extracted relationships from the Schema Graph with the verb tokens from the DT. When a match is found, the corresponding entity-type pair and their relationship or path constitute a triple that is used in the query creation process. This process also resolves ambiguities in relationships.
5.2.9. Query Construction
The process of query construction translates the mapped triples into Cypher query clauses. This step utilizes the triples along with metadata to generate a query reflecting the user’s intent. The construction of Cypher queries involves three primary components: MATCH, WHERE, and RETURN clauses.
Each one of the created triples, along with the corresponding properties, is used to construct a set of MATCH-WHERE clause segments in the Cypher query. The number of MATCH-WHERE clause segments is the number of the extracted triples plus the validated node–property pairs. Each MATCH clause defines the graph pattern by specifying the entity types and their relationships, while the WHERE clause applies constraints derived from the DT. The Cypher query is composed through chained MATCH-WHERE clauses. This approach is used to incrementally build a query through entity matching and filtering.
The MATCH clause captures the structural patterns of nodes and relationships, constructed from validated entity relationships or paths. The WHERE clause is constructed to apply constraints that refine the results returned by the query based on conditions derived from the extracted entities. For example, if the query is “What courses are taught in Room 2?”, the extracted entities are Course and Room 2, and the resulting Cypher query will include a WHERE clause, such as WHERE room.name = ‘Room 2’, to filter courses associated with that specific room.
The RETURN clause of the Cypher query includes nodes and their properties related to the data extracted during the question classification process and specifies what information the query should retrieve and present to the user. Its creation is guided by the type of question (list, count, or Boolean) and the identified entities relevant to the query’s intent. By default, if no specific property is requested, the returned property is name. For example, if the user’s query begins with “Who teaches”, the Cypher query identifies a Person node and returns its name property. Alternatively, if the query starts with “What is the phone number”, the Cypher query similarly identifies a Person node but returns the phone property instead. For merged entities resulting from conjunctions, the RETURN clause is structured to include all relevant properties from the unified entity. In queries like “What is the name and phone number of the professor who teaches Statistics?”, this translates to a RETURN statement, such as RETURN person.name, person.phone, retrieving both merged entities. Furthermore, in a query like “In how many rooms on the first floor are classes held?”, the RETURN clause should implement aggregation to count and return the number of distinct rooms that meet the specified criteria, using aggregation functions, such as COUNT, to provide numerical answers.
The ORDER BY clause is also determined by the question classification process. If the question implies a ranking or sorting criterion, the relevant property is used for ordering the results. For instance, if the query asks, “Which course has the most ECTS?” the Cypher query will include an ORDER BY clause sorting courses by the ECTS property in descending order.
Consider the query “Ποια υποχρεωτικά μαθήματα διδάσκονται στον πρώτο όροφο;” (Which compulsory courses are taught on the first floor?). The extracted triples are as follows:
- (a)
(Course, TAUGHT_AT, Room).
- (b)
(Room, LOCATED_AT, Floor (first floor)).
- (c)
(Course, IS_CATEGORY, Category (compulsory)).
These relationships are mapped to MATCH clauses as follows:
- (a)
MATCH (course:Course)-[:TAUGHT_AT]-(room:Room)
- (b)
MATCH (room:Room)-[:LOCATED_AT]-(floor:Floor)
- (c)
MATCH (course:Course)-[:IS_CATEGORY]-(category:Category)
From the example query, constraints for the respective MATCH clause are as follows:
- (a)
No constraint.
- (b)
Filtering floors identified as 1st floor.
- (c)
Filtering courses categorized as compulsory.
These constraints are added to the query as follows:
- (a)
None
- (b)
WHERE floor.literal = ‘1st floor’
- (c)
WHERE category.literal = ‘compulsory’
The final query for the example question is built by combining the respective MATCH, WHERE, and RETURN clauses:
- (a)
MATCH (course:Course)-[:TAUGHT_AT]-(room:Room)
- (b)
MATCH (room:Room)-[:LOCATED_AT]-(floor:Floor)
WHERE floor.literal = ‘1st floor’
- (c)
MATCH (course:Course)-[:IS_CATEGORY]-(category:Category)
WHERE category.literal = ‘compulsory’
RETURN course.name.
5.2.10. Query Refinement
The query creation algorithm is flexible enough to transform a user’s query into a Cypher query without relying on predefined templates. However, the generated queries are not optimized, particularly due to overlapping paths extracted during semantic mapping process. After query creation, each MATCH-WHERE clause is checked for redundancy within another MATCH-WHERE clause. For example, a MATCH clause within a MATCH-WHERE clause may be identical to another MATCH clause that lacks a WHERE condition. In such cases, the second MATCH clause is omitted to reduce redundancy. On the other hand, identical WHERE clauses may appear in different MATCH-WHERE clauses. In such cases, the duplicate WHERE clauses are removed.
After the query refinement process, the final Cypher queries are simplified by reducing redundancy, which improves efficiency and optimizes execution.
5.2.11. Query Validation
After query construction and refinement, all extracted entities are checked for their presence in the constructed query. If one or more extracted entities from the user’s query are missing, the query is considered invalid. Additionally, for each node present in the RETURN clause, its existence in the MATCH clause is verified. Query validation is the last process before running the Cypher query to the Neo4j GDB.
6. Evaluation and Results
To evaluate the system using real-world queries, we conducted a questionnaire targeting students and personnel from a physics university department, asking them to submit NL questions related to courses, faculty, and the academic program. The collected questions reflected authentic user inquiries and covered a range of complexity levels. After gathering the dataset, we manually reviewed and categorized the questions into two groups: those that could be answered using information available in the system’s DB, and those that fell outside its scope. Additionally, we performed corrections for spelling errors to ensure that linguistic inconsistencies did not affect the system’s ability to process and interpret the queries accurately. We also identified and removed duplicate questions to maintain a diverse and representative dataset. This dataset formed the basis for evaluating the system’s performance in translating Greek NL questions into structured Cypher queries.
To evaluate the system’s accuracy, we manually reviewed the Cypher queries generated for each input question. A query was deemed correct if it met two key criteria: (a) executing the query successfully retrieved the intended information from the DB, and (b) the generated query accurately reflected the logical intent of the user’s question in terms of data retrieval [
27]. The evaluation process ensured that the system retrieved the correct information using a generated query that accurately aligned with the user’s intent. User queries were posed on a KG that consists of 276 nodes spanning 10 unique labels and are interconnected by 1718 relationships of 10 different relationship types.
To assess the effectiveness of the proposed system, we categorized the collected queries into six distinct types: (1) Simple Queries (SQ), (2) Simple Queries with Conjunctions (SQCs), (3) multi-hop queries (MHQs), (4) Multi-Hop Queries with Conjunctions (MHQCs), (5) simple aggregation queries (SAQs), and (6) Multi-Hop Aggregation Queries (MHAQs). Additionally, queries that were beyond the system’s capabilities due to missing data or unsupported query structures were categorized as Out-of-Scope Queries (OSQs).
Simple Queries (SQs): These involve retrieving a single piece of information based on direct relationships in the KG. An example query would be, “Who teaches the course Algorithms?”, which requires a direct relationship match in the DB.
Simple Queries with Conjunctions (SQCs): These include multiple conditions applied to a single entity type. An example would be, “What is the name and email of Professor X”.
Multi-Hop Queries (MHQs): these require traversing multiple relationships in the graph, for instance, “Who teaches in Room 4 every Monday during the winter semester?”
Multi-Hop Queries with Conjunctions (MHQCs): These combine multi-hop traversal with multiple return entities. An example would be, “Which professors teach in the third semester and which courses?”.
Simple Aggregation Queries (SAQs): These involve numerical computations, such as counts, averages, or maximum/minimum values. An example would be, “How many courses have 4 ECTS?”.
Multi-Hop Aggregation Queries (MHAQs): these apply aggregation over entities connected through multi-hop paths, such as “How many courses are held in Room 4 during the winter semester?”.
Out-of-Scope Queries (OSQs): these fall outside the system’s current capabilities due to missing schema elements or unsupported structures and were excluded from performance evaluation.
In evaluating the proposed system’s performance, three key metrics were used: true positives (TPs), false positives (FPs), and false negatives (FNs). TPs represent the number of correctly generated Cypher queries that accurately match the user’s intent and successfully retrieve the desired information from the DB. FPs occur when the system generates a Cypher query that executes successfully but does not retrieve the correct information due to incorrect mappings or logical structure. In such cases, the query may produce results, but they are irrelevant or do not align with the user’s query intent. FNs, on the other hand, refer to instances where the system completely fails to generate a valid query or produces a query that retrieves nothing, indicating a breakdown in the entity or relationship recognition process, schema validation, or query construction. Based on these outcomes, precision (P) is defined as the proportion of true positives among all retrieved results and recall (R) as the proportion of true positives among all relevant results. The F1 score, which combines precision and recall, provides a balanced measure of the system’s accuracy by accounting for both the completeness of query generation (recall) and the correctness of the retrieved information (precision). High F1 scores indicate effective handling of various query types, while discrepancies between precision and recall highlight areas where the system’s query generation process can be further refined.
To measure system performance, we calculated the P, R, and F1 for each query type. The following formulas were used:
The evaluation dataset consisted of 147 real-world queries distributed across different query categories.
Table 4 summarizes the system’s performance for each query type, presenting the number of queries along with the corresponding TP, FP, FN, P, R, and F1 score. A set of example queries is shown in
Appendix A.
The results demonstrate that the NL-to-query translation system generally performs well across different query types, achieving an overall precision of 0.89, a recall of 0.91, and an F1 score of 0.90. The system is particularly effective in handling Simple Queries (SQs) and multi-hop queries (MHQs), where the F1 scores are 0.86 and 0.93, respectively. This indicates that the system accurately maps straightforward questions and effectively traverses complex relationships in the KG.
High scores in Simple Queries with Conjunctions (SQCs) and multi-hop queries with Conjunctions (MHQCs) highlight the system’s robustness in handling queries with multiple filtering conditions. However, the precision drop to 0.83 for MHQCs suggests an occasional over-generation of results when dealing with conjunctions in multi-hop scenarios.
Simple aggregation queries (SAQs) are handled well, with a high precision of 1.00 but a slightly lower recall of 0.80, suggesting some difficulty in covering all relevant cases. Similarly, Multi-Hop Aggregation Queries (MHAQs) present balanced performance metrics with a precision and recall of 0.80, indicating that aggregation tasks involving complex relationships require further refinement.
It is important to note that the number of queries for Simple Queries with Conjunctions, Multi-Hop Queries with Conjunctions, and simple aggregation queries categories is relatively small compared to other categories, which may limit the representativeness of their performance metrics. The limited number of examples in these categories may inflate or deflate their scores and may not accurately reflect the system’s true performance. Therefore, further testing with a larger and more diverse set of queries is necessary to draw more reliable conclusions about the system’s ability to handle these types of queries effectively.
Overall, the system effectively translates NL queries to structured queries with minimal errors. However, enhancing the handling of conjunctions and improving the processing of aggregation queries, particularly those involving multi-hop relationships, could further improve the system’s robustness and precision.
Additionally, Out-of-Scope Queries (OSQs) were identified as cases where the system was unable to generate a valid Cypher query due to missing information, unsupported query types, or reasoning requirements beyond basic graph traversal. These queries were not included in the performance metrics but serve as indicators of the system’s limitations.
7. Discussion
In this paper we presented a dependency-based, training-free, modular, multi-stage pipeline for NL queries-to-Cypher queries translation, adaptable to diverse domains and languages. The results show that despite the simplicity and low resource and expertise requirements of the system, it can achieve satisfactory performance in real-world user queries.
Our approach leverages syntactic dependencies and schema validation to reduce the number of candidate triples considered prior to query construction. This filtering eliminates the need for iterative query ranking and extensive template matching. As a result, our method provides an interpretable, modular, and efficient mechanism for bridging the gap between unstructured NL and structured Property Graph queries.
One of the key contributions of our work is the schema-agnostic design. By automatically extracting and enriching the KG Schema and creating a Dictionary of lexical variations, our system dynamically adapts to changes in the underlying graph without requiring predefined ontologies, templates, or extensive training data. This flexibility is particularly valuable for medium- and low-resource languages and specialized domains where data and linguistic resources may be scarce. Our evaluation with real-world queries in Greek, focused on an educational KG, illustrates that even with linguistic nuances and complex query structures, the system is robust and capable of generating executable Cypher queries.
Another significant advantage of our approach is its interpretability. Unlike many ML-based methods, our pipeline produces transparent intermediate representations, such as the DT KG, extracted entities, pairs of related entities, extracted triples, MATCH-WHERE set constructions, and the composed final Cypher query. This explainable workflow facilitates easier debugging, error correction, and further refinement of query generation strategies.
The evaluation results show that the system performs well overall, particularly in handling straightforward and complex queries involving multiple relationships. The system achieves high precision, recall, and F1 scores, demonstrating its effectiveness in accurately mapping NL to structured queries. It excels in simple queries and multi-hop queries, but there are occasional errors when handling complex conditions or aggregation tasks.
While our evaluation with real-world Greek queries demonstrates satisfactory results, standardized benchmark datasets would enable a more objective comparison in terms of accuracy, generalizability, and efficiency. A critical aspect of assessing our approach is benchmarking it against existing systems using common datasets. Such evaluations would highlight our system’s strengths and areas for improvement, ensuring fair performance assessment against state-of-the-art solutions. This benchmarking remains an important direction for future work.
Despite its strengths, our system has certain limitations that warrant further investigation. First, while our syntactic dependency-based approach handles ambiguity, polysemy, and variability, it may still struggle with queries that require advanced reasoning beyond syntactic parsing. Future work could explore hybrid approaches that incorporate embeddings and external knowledge sources. Second, while our system performs well on the selected domain, its generalizability to other domains beyond education remains to be fully evaluated. Expanding our experiments to diverse KG structures, such as those used in healthcare, would further validate our approach’s adaptability. Third, while our schema extraction method dynamically updates based on DB changes, further optimizations could improve efficiency, particularly in large-scale dynamic environments. Future iterations could incorporate incremental schema updates rather than full re-extraction to enhance performance. Finally, although the overall performance is strong, a marginal drop in precision for complex conjunctive queries and lower recall in aggregation queries involving multi-hop relationships highlight areas for improvement. These results point to the need for further development to better handle structurally complex queries.
In summary, our domain and language-adaptable NL-to-Cypher query builder presents an alternative approach to NLIs for GDBs. Its modular, explainable design and low infrastructure requirements make DB querying easy for non-experts.
8. Future Work
While our proposed system demonstrates satisfactory performance in translating NL queries into Cypher, several enhancements can further improve its accuracy, efficiency, and adaptability across domains and languages.
Handling Complex Conjunctive and Aggregation Queries: Improving the system’s handling of queries with multiple combined conditions will require a better interpretation of conjunctive structures during query construction. Similarly, for aggregation queries involving multi-hop relationships, enhancements are needed to ensure more complete and accurate retrievals. These improvements would strengthen the system’s performance on structurally complex Cypher queries, particularly in terms of precision and recall.
Query Optimization: Query optimization is important for improving the efficiency and performance of generated Cypher queries. Currently, the system produces queries in a standardized MATCH-WHERE format. However, further optimizations could be applied to enhance the query execution speed and minimize computational overhead. These optimizations would enhance system performance, making the output more efficient and scalable for large GDBs.
Vector Similarity Matching on Nodes and Relationships: Currently, entity and relationship extraction rely on exact matches, fuzzy matching, and predefined lexical variations. However, integrating vector-based similarity measures, such as word embeddings or contextualized embeddings, can improve entity and relationship mapping. This enhancement would allow the system to identify semantically related terms, improving the handling of synonymy and polysemy while reducing false negatives in entity recognition. Such an approach could also facilitate the resolution of ambiguous queries by ranking potential matches based on similarity scores, leading to more accurate query translations.
Evaluation Using Commonly Used Datasets: Our evaluation thus far has been conducted on a domain-specific KG using real-world user queries. To facilitate broader comparisons with existing NL2Cypher systems and NLIDBs, we aim to assess performance on publicly available datasets. Benchmarking against standard datasets will provide a more comprehensive evaluation of the system’s generalizability and highlight areas requiring further refinement. Additionally, evaluating on diverse datasets with varying schema structures will test the adaptability of our schema-extraction approach.
Leveraging Other NER Methods for Improved Disambiguation: Our current NER approach relies on string matching and lexical variations. Incorporating additional NER techniques, such as transformer-based entity recognition, can enhance entity recognition accuracy, particularly in handling unseen entities.
These enhancements will strengthen the system’s robustness, broaden its applicability across domains, and improve its performance in low-resource languages.
9. Conclusions
The proposed dependency-based NLI system for translating NL queries into Cypher queries demonstrates a robust, schema-agnostic approach that is both domain- and language-adaptable. By leveraging syntactic dependencies and schema validation, we mitigate the common challenges associated with ambiguity and query complexity, making our system a scalable and practical alternative to existing methods. The results indicate strong performance in a real-world educational KG, with promising implications for further applications across various domains and languages. Future research will aim to improve disambiguation, enhance performance, and focus on cross-domain evaluation and schema extraction for large-scale use.



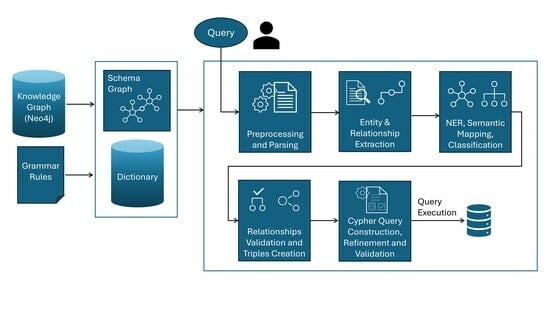

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}