1. Introduction
In modern digital infrastructure, websites and web-based applications play a crucial role in facilitating economic, educational, recreational, and political activities. However, as the reliance on these platforms increases, so does the risk of security threats, including unauthorized access, data breaches, and service disruptions. One of the primary attack vectors involves manipulating web requests, where adversaries masquerade as legitimate users to exploit vulnerabilities. Consequently, the detection and mitigation of malicious web requests have become vital for ensuring the security of any online service, including websites, web applications, and Content Delivery Networks (CDNs).
To counter such threats, various security mechanisms, including Web Application Firewalls (WAFs) and blacklisting techniques, have been deployed. While these methods offer some level of protection, they remain ineffective against zero-day attacks and novel exploits that lack predefined security signatures [
1]. The primary challenge associated with zero-day attacks lies in their unpredictability, as they introduce previously unseen patterns that traditional rule-based detection systems fail to recognize. Addressing these challenges through deep learning-based anomaly detection presents a promising approach, leveraging neural networks to autonomously identify deviations indicative of malicious activity.
Conventional methods for preventing web-based attacks, such as WAFs [
2] and blacklisting, exhibit several limitations. For instance, maintaining a blacklist of prohibited keywords within web requests is both time-consuming and insufficient for addressing evolving attack patterns [
3]. Moreover, none of these existing approaches is capable of detecting zero-day attacks, as the strategies and obfuscation techniques employed in these attacks remain unknown. WAFs remain limited in addressing zero-day and obfuscated web attacks. Studies have shown that even modern WAFs such as ModSecurity can fail to detect novel attack patterns, depending on their rule sets and update frequency [
4]. These shortcomings highlight the urgent need for more adaptive and intelligent detection mechanisms capable of identifying unknown threats without relying on predefined signatures.
A critical advantage of anomaly detection models is that they do not require prior exposure to zero-day attacks to effectively detect them. In this study, we aim to address the limitations of existing detection systems by developing an ensemble-based anomaly detection model that can effectively detect zero-day web attacks without prior exposure to attack patterns. The model integrates multiple sub-models designed to detect zero-day attacks. Given that the patterns of zero-day attacks are inherently unknown, the model is trained exclusively on normal web request data. By learning the distribution of normal web traffic, the model becomes proficient in identifying deviations, thereby flagging both known and previously unseen attacks as anomalous. This approach ensures that malicious requests, whether originating from known attack types or zero-day exploits, are effectively classified as security threats.
To evaluate the proposed model, various web attacks such as SQL injection (SQLi), Cross-Site Scripting (XSS), and Buffer Overflow [
5] are treated as zero-day attacks within the dataset. The model classifies any request with an anomaly score exceeding a predefined threshold as a potential zero-day attack. While the proposed approach does not explicitly categorize different types of attacks, it demonstrates the capability to reliably detect anomalous activities, ensuring a high level of security against emerging threats. The primary objective of this model is to simultaneously address both known and zero-day attacks while maintaining a high detection rate and minimizing false positives.
The rest of this paper is structured as follows:
Section 2 presents the foundational concepts and research background.
Section 3 provides a review of existing literature on web attack detection. The methodology and architectural design of the proposed model are discussed in
Section 4, followed by a performance evaluation in
Section 5.
Section 6 elaborates on the broader implications of the findings, and
Section 7 concludes the paper with final remarks.
Our ensemble method differs from conventional ensemble approaches by combining and compressing latent features rather than relying on simple output aggregation (such as majority voting), significantly enhancing detection performance. The key contributions of this research are as follows:
Innovative Ensemble Model Architecture: This study introduces a novel ensemble approach by integrating LSTM, GRU, and stacked autoencoders for anomaly detection in web requests. Unlike conventional ensemble methods that use simple averaging or majority voting, our approach uniquely concatenates and compresses the latent representations from each autoencoder. This technique significantly improves anomaly detection performance and computational efficiency.
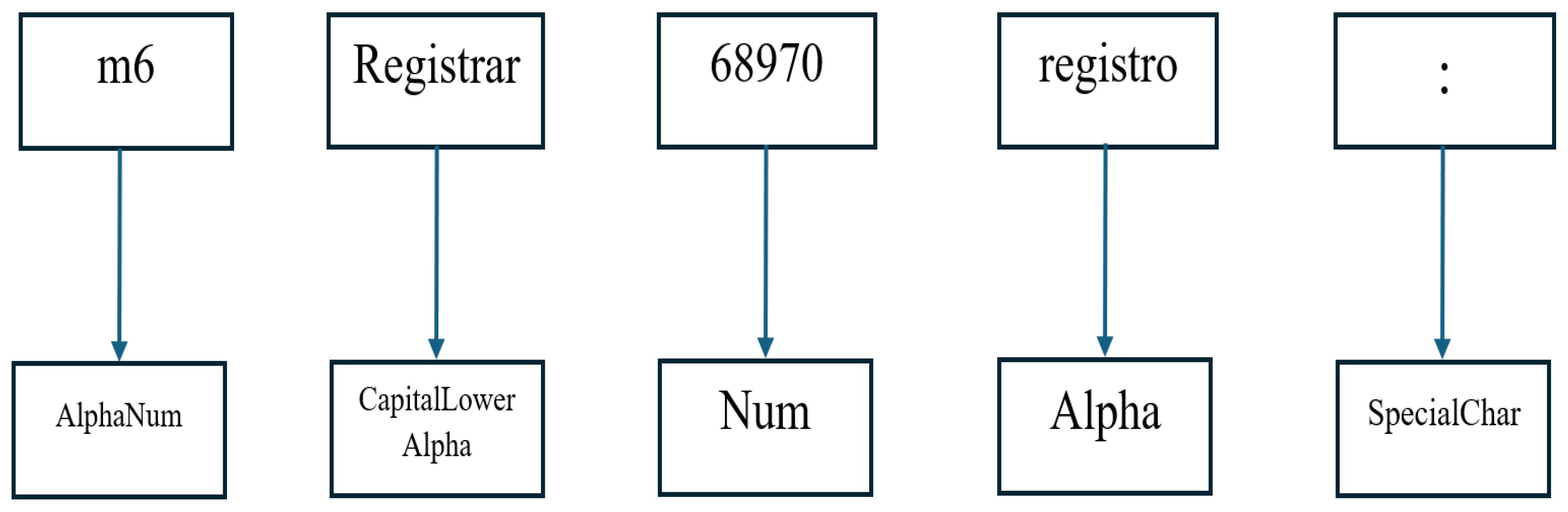
Advanced Tokenization and Feature Mapping: We propose a novel tokenization strategy that classifies tokens based on their character composition (numeric, lowercase, uppercase, and special characters). This structured approach effectively reduces input dimensionality, ensures greater consistency in data representation, and significantly enhances the detection capability of our anomaly detection system.
Zero-Day Attack Detection: Our model is trained exclusively on normal web requests, enabling it to effectively identify and detect previously unseen zero-day attacks by capturing deviations from established normal request patterns.
Comprehensive Evaluation Metrics with Emphasis on False Positive Rate (FPR): Unlike many existing studies, we explicitly evaluate and report the false positive rate, achieving a significantly lower FPR of 0.2%. This comprehensive evaluation underscores the practical applicability of our model, addressing an essential aspect often overlooked in anomaly detection research.
By addressing the limitations of traditional detection systems and leveraging anomaly detection through deep learning, this research contributes to advancing cybersecurity measures against evolving web-based threats.
3. Related Work
Numerous methods and models have been proposed to counter web attacks, including zero-day attacks. Models by researchers like Pu et al. [
9], Ingham et al. [
11], Sivri et al. [
12], Jung et al. [
13], Vartouni et al. [
14], Ariu et al. [
15], Liang et al. [
16], Kuang et al. [
17], Tang et al. [
18], Indrasiri et al. [
19], Gong et al. [
20], Tekerek et al. [
21], Jemal et al. [
22], Alaoui et al. [
23], Moarref et al. [
24], Yatagha et al. [
25], Katbi et al. [
26], Tokmak et al. [
27], Alqhwazi et al. [
28], Thalji et al. [
29], Yao et al. [
30], Mohamed et al. [
31], Shahid et al. [
32], Bedi et al. [
33], Milosevic et al. [
34], Abdelkhalek et al. [
35], Yuan et al. [
36], Vorobyov et al. [
37], Su et al. [
38], and Silvestre et al. [
39] are notable.
Pu et al. [
9] proposed an unsupervised anomaly detection method that combines Sub-Space Clustering (SSC) with a One-Class Support Vector Machine (OCSVM) to detect cyber intrusions, including zero-day attacks, without requiring labeled data. Evaluated on the NSL-KDD dataset, their model achieved a detection rate of 89% with a false alarm rate of 8%, though its performance dropped on low-frequency attack types (e.g., R2L with 52% DR and 8.95% FAR). Additionally, the reliance on Sub-Space Clustering led to increased computational overhead, limiting real-time deployment.
Ingham et al. [
11] proposed an anomaly detection system for web servers that models normal HTTP requests using Deterministic Finite Automata (DFA) induction. Their approach uses heuristics to reduce variability in request tokens before feeding them to the DFA learner, enabling the system to detect anomalous web requests without requiring labeled attack data. While effective in identifying various types of web attacks, the method suffers from scalability issues due to large DFA sizes and exhibits high false positive rates in complex environments (e.g., 21 false alarms/day on cs.unm.edu).
Sivri et al. [
12] evaluated various machine learning and deep learning models on the CSIC 2012 dataset for web attack detection. They explored character-level representations of HTTP requests and applied classifiers such as LSTM, Convolutional Neural Network (CNN), Extreme Gradient Boosting (XGBoost), and Light Gradient Boosting Machine (LightGBM). For the CSIC 2012 portion of the dataset, the LSTM model achieved the highest performance, with an accuracy of 98.15%, F1-score of 98.16%, and false positive rate of approximately 0.008 (0.8%). Despite strong results, their models were trained in a supervised fashion using both normal and malicious samples, which limits adaptability to zero-day threats. Additionally, their best-performing models required extensive training time (e.g., over 5600 s for LSTM), making them less practical for real-time systems. In contrast, our unsupervised ensemble model operates solely on normal request data, detects zero-day attacks and achieves comparable accuracy with a significantly lower false positive rate of 0.2%, while also offering more efficient training.
Jung et al. [
13] proposed a payload feature-based transfer learning (PF-TL) framework to address the problem of insufficient labeled training data in intrusion detection. Their approach enhances feature extraction by combining traditional signature-based features with text vectorization over both the header and payload, aiming to improve representation of domain-specific attack patterns. The transfer process optimizes latent feature sub-spaces between labeled source domains and unlabeled target domains using Principal Component Analysis (PCA) and similarity-aware projection. They evaluated the method across public datasets including CSIC 2012, showing that payload feature-based transfer learning (PF-TL) significantly outperforms baseline transfer learning (HeTL) and non-transfer baselines, achieving 99.88% accuracy and 99.80% F1-score in detecting attacks like SQLi, XSS, and LDAP injection on the CSIC dataset. However, the approach depends on domain similarity assumptions and requires prior knowledge for effective source–target alignment, limiting its flexibility. Unlike our model, which operates fully unsupervised and does not require labeled data or domain pairing, PF-TL still relies on pre-labeled source domains and structured sub-space mapping.
Vartouni et al. [
14] proposed an anomaly detection method using a stacked autoencoder (SAE) for feature extraction combined with an Isolation Forest classifier to detect web attacks in HTTP traffic. Features were constructed using a character-level n-gram model, and experiments were conducted on the CSIC 2010 dataset. Their best-performing configuration, using bigram features and SAE with Sigmoid activation and Adam optimizer, achieved 88.32% accuracy, 88.34% detection rate, and 80.79% precision, with specificity of 90.20% and an F1-score of 84.12%. While the approach effectively leveraged unsupervised learning, it suffered from high-dimensional feature vectors (e.g., 2572 features for bigrams), which may introduce computational overhead and noise. In contrast, our model achieves superior precision (99.99%) by combining latent representations from multiple autoencoders, reducing reliance on sparse token-based features and enhancing both efficiency and generalization.
Ariu et al. [
15] proposed HMMPayl, an anomaly-based intrusion detection system that uses Hidden Markov Models (HMMs) to model HTTP payloads as sequences of bytes. Their approach offers the expressive power of n-gram analysis while mitigating its computational complexity by processing variable-length payloads through sliding windows and extracting sequence features efficiently. HMMPayl combines multiple HMMs using ensemble techniques like max, min, and mean rules to improve accuracy and robustness. It was evaluated on datasets containing real HTTP traffic and attacks such as SQL injection and XSS, achieving high AUC scores often above 0.97 for shell-code and polymorphic attacks. However, its effectiveness heavily depends on proper tuning of HMM parameters and the window size n, and the system struggles when payloads are short or similar to normal traffic, which can lead to false positives. Unlike our model, which uses high-level semantic tokenization and compresses multi-autoencoder latent representations, HMMPayl operates directly on raw bytes, making it sensitive to payload noise and potentially less adaptable to structural anomalies in web requests.
Liang et al. [
16] proposed a deep learning approach for anomaly-based web attack detection using a two-stage model. First, two Recurrent Neural Networks (RNNs), one for the URL path and another for query parameters, are trained in an unsupervised manner using normal GET requests to learn request structure patterns. Then, a supervised Multilayer Perceptron (MLP) classifier is trained on the outputs of the RNNs to distinguish between normal and anomalous requests. Evaluated on a trimmed version of the CSIC 2010 dataset, their model with LSTM achieved 98.42% accuracy, 0.79% false alarm rate and 99.21% specificity, outperforming other approaches like SOM and C4.5. However, the model depends on labeled attack data during the second (supervised) phase, which may hinder generalization to zero-day attacks.
Kuang et al. [
17] proposed DeepWAF, a deep learning-based Web Application Firewall that integrates multiple neural network architectures, including CNN, LSTM, CNN-LSTM, and LSTM-CNN, to detect malicious HTTP requests. Their models were evaluated on the CSIC 2010 dataset and achieved a detection rate of approximately 95% with a false alarm rate of around 2%. While DeepWAF demonstrated the effectiveness of deep learning in web attack detection, its performance still resulted in a noticeable number of false positives, and the approach was trained in a supervised fashion using both normal and attack data. In contrast, our unsupervised ensemble model operates solely on normal traffic, enabling it to detect zero-day attacks while maintaining a significantly lower false positive rate of 0.2%, with higher detection precision and efficiency.
Tang et al. [
18] proposed ZeroWall, an unsupervised deep learning model for detecting zero-day web attacks. The system operates alongside traditional Web Application Firewalls (WAFs) and uses an encoder–decoder Recurrent Neural Network to model benign HTTP requests as sequences in a “request language”. It is trained exclusively on benign traffic filtered through an existing WAF, then detects anomalies in real time by assessing how well the model can reconstruct incoming requests. A poor reconstruction, measured using the BLEU score, signals potential malicious behavior. The approach was evaluated on eight large-scale real-world HTTP traces and achieved F1-scores above 0.98, outperforming both supervised and other unsupervised baselines.
Indrasiri et al. [
19] proposed a robust ensemble learning model called Expandable Random Gradient Stacked Voting Classifier (ERG-SVC) to detect phishing URLs. Their approach utilizes a combination of seven classification algorithms, two ensemble methods, and a clustering algorithm. The system was evaluated on two large datasets with 73,575 and 100,000 URLs, incorporating techniques like heuristic thresholding, extensive feature engineering, and hyperparameter tuning. The ensemble model achieved a high prediction accuracy of 98.27%, and the authors also proposed a lightweight preprocessor for efficiency. However, this work focuses exclusively on phishing URL detection, not full HTTP request analysis, and relies on URL-based features—some of which depend on third-party services like WHOIS and PageRank.
Gong et al. [
20] proposed a deep learning-based web attack detection system that introduces model uncertainty to address annotation errors in training data. Their model uses character-level CNNs combined with dropout-based Bayesian inference to quantify uncertainty in predictions. By measuring the variance of the model’s output—rather than relying solely on Softmax confidence, they identified mislabeled training samples that could otherwise degrade detection accuracy. The system was evaluated on three datasets, including CSIC 2010, and demonstrated strong performance, with F1-scores up to 94.25%, 97.64% accuracy, 91.11% recall and 97.62% precision. However, their method depends on labeled attack and normal traffic for supervised training and focuses more on correcting label noise than detecting zero-day attacks.
Tekerek et al. [
21] proposed a CNN-based deep learning model for anomaly detection in HTTP web traffic. Their system focused on identifying malicious patterns in URLs and payloads extracted from HTTP requests in the CSIC2010v2 dataset. The method uses bag-of-words (BoW) encoding to convert segmented URL and payload parameters into matrix representations, which are then used as grayscale input images to train a CNN. Evaluated over 400 epochs, their model achieved a best accuracy of 97.07%, F1-score of 97.51%, and a false positive rate (FPR) of 3.68%. While the approach effectively detects web attacks through CNN’s automatic feature extraction, its reliance on BoW leads to large sparse matrices, and the model may be sensitive to input structure variations. In contrast, our method avoids token sparsity by applying semantic-level tokenization and learning compressed latent representations through an ensemble of autoencoders, achieving comparable detection accuracy with a significantly lower FPR of 0.2%.
Jemal et al. [
22] introduced SWAF, a smart Web Application Firewall based on a 5-layer Convolutional Neural Network (CNN) trained using the CSIC 2010 dataset. Their system processes HTTP requests using an ASCII embedding method, which maps each character in the request to its ASCII code, avoiding issues with unseen tokens found in word or character embedding. SWAF was evaluated using 5-fold cross-validation and achieved an accuracy of 98.1%, with a detection time of just 2.3 ms per request—a notable improvement over earlier CNN-based methods. While effective, the model relies entirely on labeled attack data for supervised training and does not target zero-day attacks directly.
Alaoui et al. [
23] proposed a deep learning-based approach for web attack detection using Word2vec embeddings and a stacked generalization ensemble of LSTM networks. The system processes HTTP requests from the CSIC 2010 dataset, applying decoding, generalization, and tokenization to prepare input for embedding. Multiple Word2vec models with different training configurations were used to produce diverse word representations, which were fed into base LSTM models. A shallow neural network was then used as a meta-classifier to combine sub-model predictions. The best configuration of their stacked LSTM ensemble achieved 78.95% accuracy, 81.54% precision, 78.41% recall, and an F1-score of 77.57%. While the model benefits from ensemble diversity and word-level semantics, it remains a supervised approach reliant on labeled attack data.
Moarref et al. [
24] proposed a character-level multichannel multilayer dilated Convolutional Neural Network (MC-MLDCNN) for detecting web attacks. Their model processes the entire HTTP request text and applies dilated CNNs across multiple channels to capture both short- and long-term dependencies in character sequences. This structure eliminates the need for handcrafted feature engineering, enhancing adaptability to novel attack patterns. Experiments conducted on the CSIC 2010 dataset demonstrated strong performance with 99.36% accuracy, 99.65% precision, 98.80% recall, and an F1-score of 99.22%. However, the approach is supervised and relies on both normal and labeled attack data, limiting its zero-day detection capability in comparison to unsupervised methods.
Yatagha et al. [
25] proposed a hybrid anomaly detection framework combining Variational Autoencoders (VAEs), Long Short-Term Memory (LSTM) networks, and a One-Class SVM (OCSVM) to detect zero-day anomalies in cyber–physical systems. The model is trained exclusively on normal time-series data and leverages both reconstruction error and latent space deviation to flag contextual and temporal anomalies. To ensure continual adaptation without catastrophic forgetting, the authors introduced an Adaptive Loss Weight Adjustment Algorithm (ALWAA) aligned with ISO/IEC 42001:2023 standards. Deployed in a real-time industrial setting on a Raspberry Pi 400, the system successfully detected subtle anomalies such as valve failures and pump delays, outperforming baseline methods. While effective for low-dimensional physical sensor data, the model is not tailored for web-based request structures like HTTP traffic.
Katbi et al. [
26] proposed IDSVDD, a one-class anomaly detection framework tailored for IoT security, which combines Deep Support Vector Data Description (SVDD) with an interpolated adversarial autoencoder. The model constructs a convex and regularized latent space by enforcing adversarial interpolation constraints, enabling better separation between normal and anomalous behaviors. Trained only on benign data, IDSVDD learns a compact hypersphere that tightly encloses normal samples while rejecting outliers. It was evaluated on multiple benchmark IoT datasets, demonstrating strong zero-day detection performance with minimal computational overhead suitable for resource-constrained devices like Raspberry Pi. However, the system is designed for sensor-driven IoT data and does not address the structure, complexity, or variability of HTTP web requests.
Tokmak et al. [
27] proposed a hybrid deep learning framework that combines stacked autoencoders (SAEs) for unsupervised feature extraction with a Long Short-Term Memory (LSTM) classifier for detecting zero-day cyber threats. The model was trained and evaluated using the UGRansome dataset, which includes labeled samples of signature, synthetic signature, and anomaly attacks. The SAE extracts a low-dimensional latent feature set from raw input, which is then passed to the LSTM for supervised temporal classification. The proposed system achieved a high accuracy of 98.49%, with precision, recall, and F1-score all around 0.985, demonstrating strong generalization to diverse attack categories. However, its reliance on labeled attack data during LSTM training limits its applicability to true zero-day detection. In contrast, our proposed ensemble model operates in a fully unsupervised setting trained solely on normal web requests, enabling it to detect zero-day web attacks without prior exposure to malicious samples, while maintaining a lower false positive rate (0.2%) and higher precision (99.99%).
Alqhwazi et al. [
28] proposed a deep learning architecture for detecting SQL injection attacks using a Recurrent Neural Network (RNN) autoencoder. The model was trained on a public Kaggle SQL injection dataset, consisting of over 30,000 SQL queries labeled as benign or malicious. Their architecture includes an autoencoder for dimensionality reduction followed by an LSTM classifier for binary classification. The proposed system achieved 94% accuracy, 95% precision, 90% recall, and an F1-score of 92%, outperforming traditional machine learning models such as SVM, decision tree, random forest, and logistic regression. However, the approach is tailored specifically for SQL injection patterns and depends on labeled data for supervised classification. In contrast, our ensemble model is designed for detecting a wide range of web-based attacks (e.g., XSS, SQLi, Buffer Overflow) using only normal web requests.
Thalji et al. [
29] proposed AE-Net, a novel autoencoder-based deep feature extraction approach for detecting SQL injection (SQLi) attacks. The model uses an unsupervised autoencoder to extract high-level semantic features from SQL queries, which are then fed into traditional machine learning models for classification. Evaluated on a public dataset of 46,392 labeled SQL queries, the framework was benchmarked using k-fold cross-validation, with XGBoost achieving the highest performance—an accuracy of 99%, outperforming BoW and TF-IDF-based feature extraction techniques. While the AE-Net successfully enhances feature representation quality, the detection model still depends on labeled attack data and is limited to SQLi detection only, not general web attacks.
Yao et al. [
30] proposed a lightweight intrusion detection system for IoT that combines a One-Class Bidirectional GRU Autoencoder with Soft-Voting Ensemble Learning. The autoencoder is trained on only normal data to detect anomalies—including zero-day attacks—based on reconstruction loss. Detected anomalies are then classified using an ensemble of Random Forest, XGBoost, and LightGBM to identify the closest known attack type. The system demonstrated high accuracy and adaptability across three benchmark datasets: WSN-DS, UNSW-NB15, and KDD99.
Mohamed et al. [
31] proposed a deep learning-based multi-class intrusion detection system that automatically classifies various types of web attacks using LSTM, Bi-LSTM, CNN, and RNN models. Their system uses tokenization and sequence padding to convert HTTP request payloads into numerical input for deep models, avoiding traditional feature engineering. The model was evaluated on three benchmark datasets, CSIC 2012, HTTPPARAM, and ECML-PKDD, demonstrating high classification accuracy. The CNN model achieved 99.28% accuracy, 99.18% precision, 99.28% recall, and 99.22% F1-score on CSIC-2012, while Bi-LSTM achieved 99.66% on HTTPPARAM and 90.6% on ECML-PKDD. While this approach achieves excellent detection and multi-class labeling performance, it requires labeled attack data for supervised training and may struggle with detecting zero-day attacks without retraining. In contrast, our proposed model operates in a fully unsupervised manner using only normal traffic for training, and it leverages latent feature compression across multiple autoencoders to detect unknown web attacks with higher precision (99.99%) and lower false positive rates (0.2%).
Shahid et al. [
32] proposed a hybrid deep learning framework for real-time web attack detection and attacker profiling, which nests a Convolutional Neural Network (CNN) classifier with a custom Cookie Analysis Engine (CAE). The CNN is trained on HTTP request parameters, while the CAE performs integrity and sanitization checks on cookies to enhance profiling and reduce false positives. Their model achieves high accuracy (99.94% on their own dataset and 98.73% on the CSIC 2010 dataset) and claims to reduce classifier invocations through intelligent profiling. However, the framework’s real-time efficiency is largely dependent on the CAE’s effectiveness, and the approach still triggers deep learning analysis for many cases, raising concerns about scalability.
Bedi et al. [
33] addressed the well-known class imbalance problem in intrusion detection systems (IDSs), particularly in datasets like NSL-KDD where classes such as Remote to Local (R2L) and User to Root (U2R) are underrepresented. To overcome the limitations of traditional class balancing methods—such as oversampling (which may cause overfitting), undersampling (which may discard valuable data), and SMOTE (which may introduce synthetic noise)—the authors proposed Siam-IDS, a novel anomaly detection framework based on Siamese Neural Networks. By leveraging few-shot learning, Siam-IDS learns similarity-based representations and avoids reliance on class distribution altogether. Experimental results demonstrated that this approach significantly improved the recall values of minority attack classes compared to deep neural network (DNN) and Convolutional Neural Network (CNN) baselines, highlighting the potential of similarity-based learning in imbalanced intrusion scenarios.
Milosevic et al. [
34] addressed the challenge of extreme class imbalance in network intrusion detection using deep learning. Rather than employing typical resampling techniques, they retained the original imbalanced distribution of the CICIDS-2017 and CICIDS-2018 datasets, which include several classes with extremely low instance counts. Their approach focuses on designing a deep neural network (DNN) architecture and leveraging statistical and correlation-based feature selection methods to enhance the model’s sensitivity to minority classes. Notably, their analysis reveals that even classes with as few as three instances can be detected accurately when relevant coarse-grained features are preserved. This work demonstrates that careful feature selection and model tuning can partially mitigate the effects of imbalance without modifying the dataset distribution.
Another recent study by Abdelkhalek et al. [
35] directly addressed the class imbalance problem in intrusion detection by proposing a hybrid resampling approach combining Adaptive Synthetic Sampling (ADASYN) with Tomek Links undersampling. Using the NSL-KDD dataset, the authors first applied ADASYN to generate synthetic minority class samples based on difficulty of learning, followed by Tomek Links to remove overlapping or noisy instances near class boundaries. This strategy was shown to significantly enhance the detection of minority attack types (such as U2R and R2L), which are typically underrepresented in intrusion datasets. Their method was tested across multiple deep learning models including MLP, DNN, CNN, and CNN-BLSTM, achieving a maximum binary classification accuracy of 99.8% and a multi-class classification accuracy of 99.98%, clearly demonstrating the impact of well-designed data balancing techniques in improving NIDS performance.
Apart from machine learning techniques, various heuristic-based approaches have been proposed to detect web-based attacks, such as Yuan et al. [
36], who proposed a static SQL injection detection technique based on program transformation to address the limitations of existing tools in handling object-oriented database extensions (OODBEs) in PHP applications. Their method, OODBE-SCAN, first transforms object-oriented constructs into semantically equivalent procedural code, enabling accurate identification of source and sink points. The method then performs control flow graph construction and taint analysis to detect vulnerabilities. Compared to tools like RIPS and Seay, OODBE-SCAN demonstrated superior precision and recall in detecting real-world vulnerabilities in OODBE-based web applications. Its effectiveness is also limited when dealing with complex semantic constructs in modern web applications, which may hinder accurate transformation and lead to missed vulnerabilities.
Vorobyov et al. [
37] introduced a novel runtime protection mechanism against SQL injection attacks based on synthesizing fine-grained allowlists from benign SQL queries. Their approach uses an information flow model to decompose SQL queries into semantic units called information tuples, which capture disclosed columns, accessed fields, and related predicates. By generalizing these tuples across a set of safe queries, they create a context-sensitive allowlist that permits future queries only if they disclose no more information than allowed. This method outperforms syntax-based detectors by focusing on semantic disclosure rather than structural similarity, thus reducing false positives and better preventing data exfiltration. However, the model relies heavily on the completeness of the training set. This can result in false positives when encountering legitimate but unseen query patterns, and performance bottlenecks when comparing incoming queries against large allowlists at runtime.
Su et al. [
38] proposed Splendor, a static analysis framework for detecting stored Cross-Site Scripting (XSS) vulnerabilities in modern PHP web applications, especially those using Data Access Layers (DAL). The approach introduces a fuzzy token-matching technique to identify database operation triples (table, column, and operation type) from code fragments, even when SQL queries are dynamically constructed or obscured through encapsulation. Splendor then performs a two-phase taint analysis, tracing tainted data from sources to the database writes and from the database reads to sinks. The framework demonstrated strong scalability, identifying 17 real-world zero-day vulnerabilities and outperforming both static (RIPS) and dynamic (Black Widow) tools.
Silvestre et al. [
39] introduced FreeSQLi, a novel static analysis tool that detects SQL injection vulnerabilities in PHP applications using session types. Their approach translates PHP code into the FreeST programming language, which supports rich type systems modeling communication protocols. By interpreting interactions between the application and the database as typed communication sessions, FreeSQLi checks for type mismatches—such as sending unsanitized user input (typed as Unsafe) to sensitive sinks—and flags these inconsistencies as SQLi vulnerabilities. This method offers formal guarantees and reduces false positives by leveraging strong type checking rather than heuristics or machine learning.
A recurring limitation among the reviewed studies is the lack of emphasis on one of the most critical evaluation metrics in real-world deployment: the false positive rate (FPR), which quantifies how often benign web requests are incorrectly flagged as malicious. Despite high accuracy or F1-scores, many models fail to report or sufficiently optimize FPR, leading to increased friction for legitimate users and reduced system trustworthiness. This omission makes it difficult to assess a model’s practical effectiveness, especially for zero-day detection scenarios where avoiding false alarms is crucial. In contrast, our proposed model explicitly prioritizes FPR and achieves a significantly lower rate of 0.2%, outperforming even those models that do report this metric. Additionally, unlike many supervised approaches that rely on labeled attack data, our method is trained solely on normal traffic, ensuring greater generalization to unseen attacks while maintaining high precision (99.99%) and efficient inference time. These qualities collectively position our model as a more practical and robust solution for real-world web attack detection.
5. Evaluation and Results
This section presents the evaluation of the proposed model and its sub-models based on multiple performance metrics, including accuracy, detection rate, sensitivity, precision, and false positive rate. To assess the effectiveness of the proposed approach, a threshold-based evaluation is conducted using the Mean Absolute Error (MAE), which quantifies the difference between the reconstructed request and the original input (prior to encoding).
In machine learning, MAE is a widely used metric for measuring the absolute difference between predicted values and their actual counterparts. It is computed by averaging the absolute errors across all predictions. MAE was selected as the primary evaluation metric due to its interpretability, robustness, and alignment with the model’s objectives. Specifically, MAE measures the average absolute deviation between the original and reconstructed web requests, providing a clear and intuitive indicator of reconstruction accuracy.
Unlike the Mean Squared Error (MSE), which disproportionately amplifies the effect of outliers due to its squared loss formulation, MAE is less sensitive to extreme deviations. This stability makes MAE particularly well-suited for anomaly detection, as it emphasizes individual discrepancies without being overly influenced by rare, extreme variations. By leveraging linear reconstruction errors, MAE effectively differentiates between benign and malicious web requests while ensuring an optimal balance between detection rates and false positives. This makes it an appropriate choice for evaluating the performance of web attack detection models.
The Mean Absolute Error (MAE) is formally defined as
In Formula (7),
represents the reconstructed value, while
denotes the actual value. The classification criterion is based on the computed MAE for each web request. To determine the optimal threshold for distinguishing between benign and malicious requests, we analyzed the distribution of MAE scores across normal training requests, as visualized in
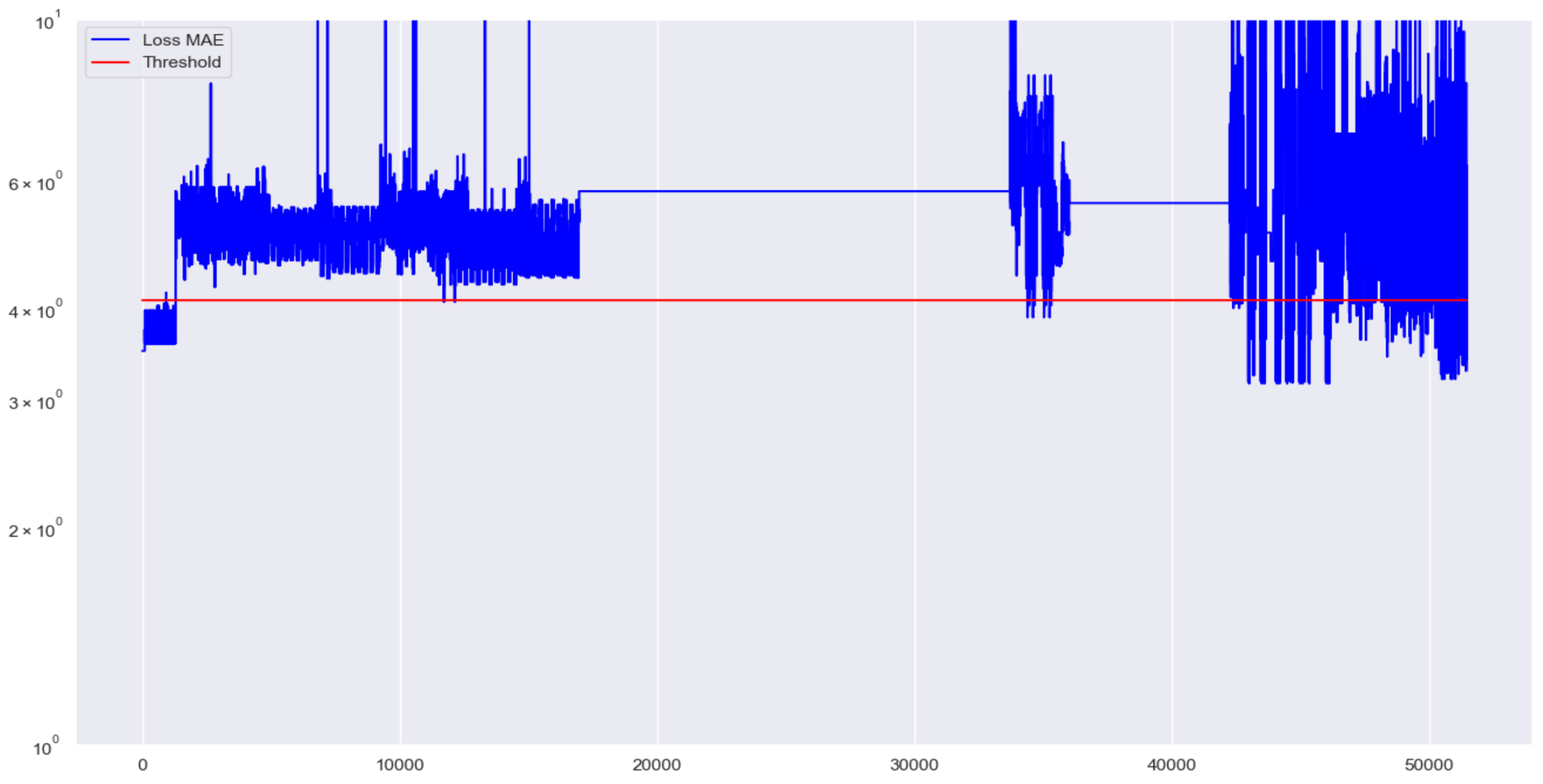
Figure 6. Based on this distribution, we observed that MAE values greater than approximately 4 were uncommon among normal requests, suggesting that these higher values represent potential anomalies. Consequently, we selected a threshold of 4.09, just above this observed point, as our decision boundary. Additional experiments with alternative threshold values around 4 confirmed that this selection offered a balanced trade-off between sensitivity to malicious requests and avoiding excessive false positives. Although this approach is heuristic, future work could systematically evaluate the threshold using techniques such as percentile-based analysis or automated hyperparameter tuning methods to further refine the detection performance.
5.1. Data Collection
Previous research on detecting malicious and zero-day web requests has primarily relied on two well-established datasets: CSIC [
48] and HTTPPARAMS [
48]. These datasets provide a comprehensive representation of both normal and malicious web requests, making them widely used benchmarks in web security research. Additionally, a project hosted on GitHub [
49], which employs Convolutional Neural Networks (CNNs), utilized the CSIC 2012 dataset. Accordingly, the proposed model leverages this dataset for training and evaluation.
The dataset utilized in this study is significant due to the following characteristics:
It encompasses a diverse range of malicious requests, including SQL injection (SQLi), Cross-Site Scripting (XSS), and Buffer Overflow attacks.
It contains normal (benign) web requests, ensuring a balanced distribution of data for effective training and evaluation.
A key consideration in dataset selection is ensuring that malicious requests accurately reflect real-world attack scenarios. The dataset comprises approximately 16,000 instances labeled as anomalous. However, certain anomalies may arise from factors unrelated to direct cyberattacks, such as unusual user behavior, malformed requests, or suspicious data entry attempts. These cases, while indicative of potential security threats, do not strictly conform to defined attack patterns. To maintain data integrity and ensure the model is trained on well-defined attack and normal request samples, such ambiguous anomalies are removed from the dataset prior to training.
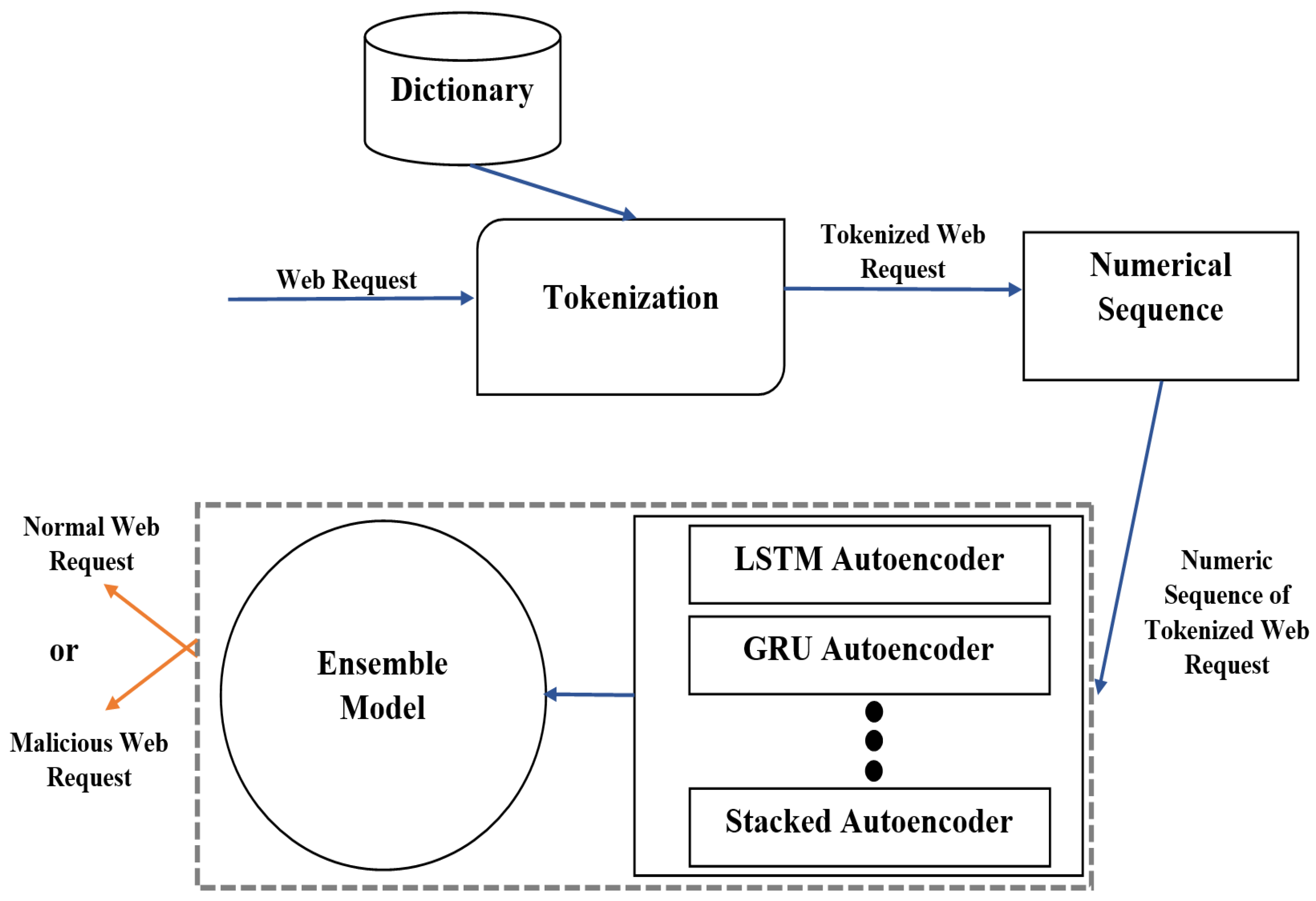
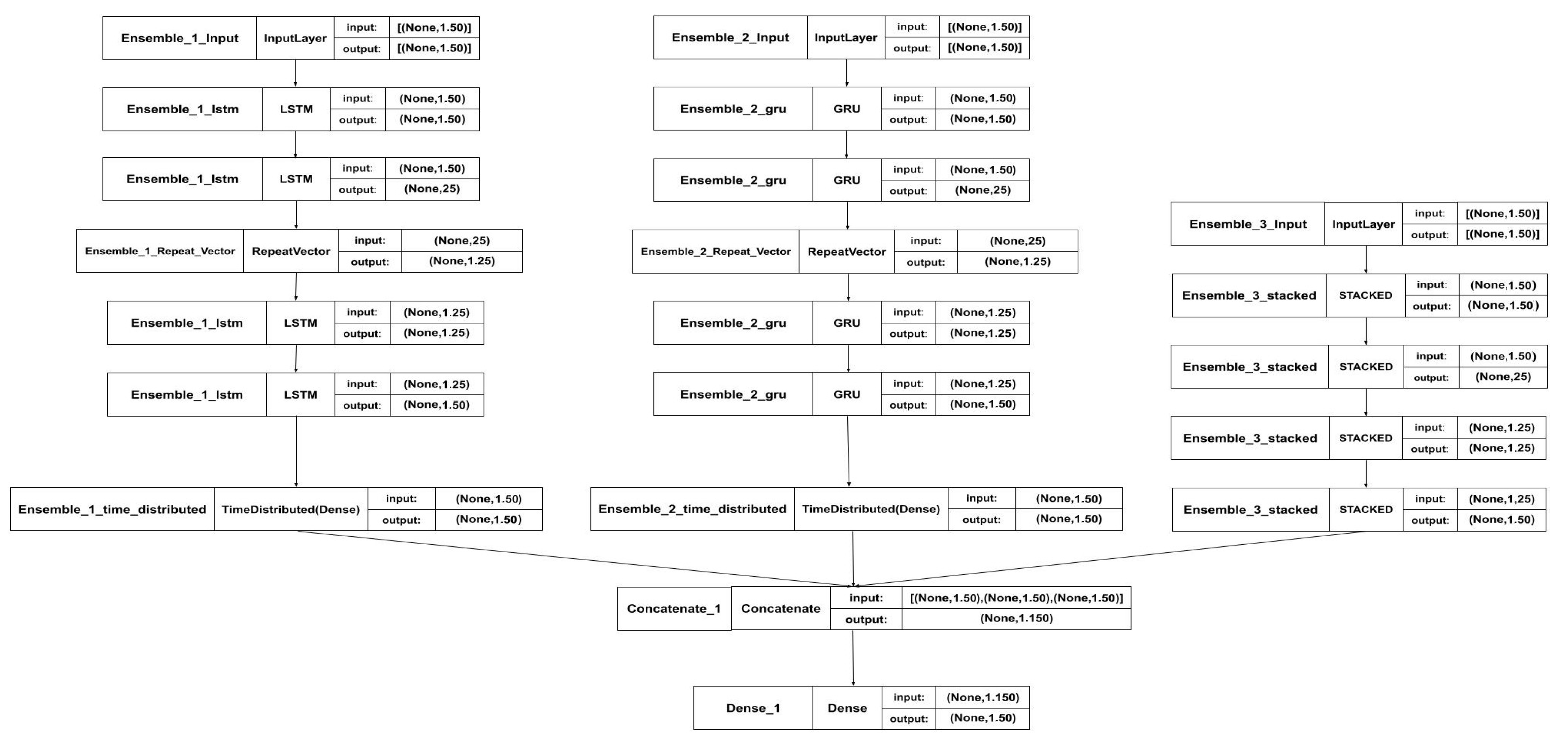
5.2. The Ensemble Model Structure
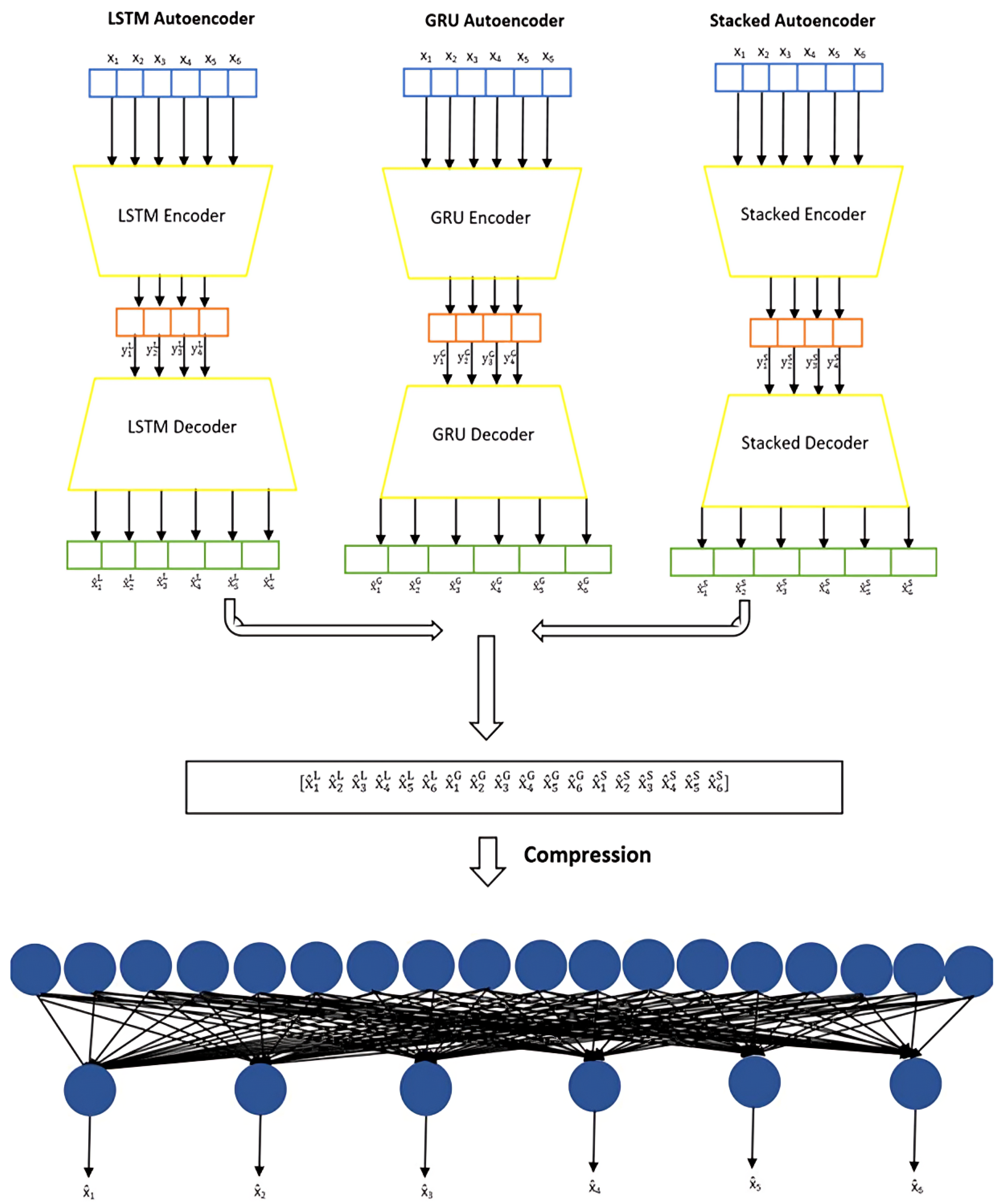
According to
Figure 7, the LSTM autoencoder and GRU autoencoder each consist of four layers (two encoder layers of 50 and 25 units, respectively, and two symmetric decoder layers of 25 and 50 units), using the default tanh activation function. The stacked autoencoder comprises four dense layers (50, 25, 25, and 50 units) with linear activation. The ensemble model concatenates outputs from these autoencoders into a unified latent vector, which is further compressed via a dense layer (50 units). All models are trained using the Mean Absolute Error (MAE) loss function, the Nadam optimizer, and evaluated based on accuracy metrics.
The specific number of layers and units was primarily chosen to match the dimensionality of our input features (50 features). Additional experiments with alternative configurations (e.g., different layer sizes) confirmed that this selection provided the optimal balance between accuracy, computational efficiency, and effective representation of the structured input data.
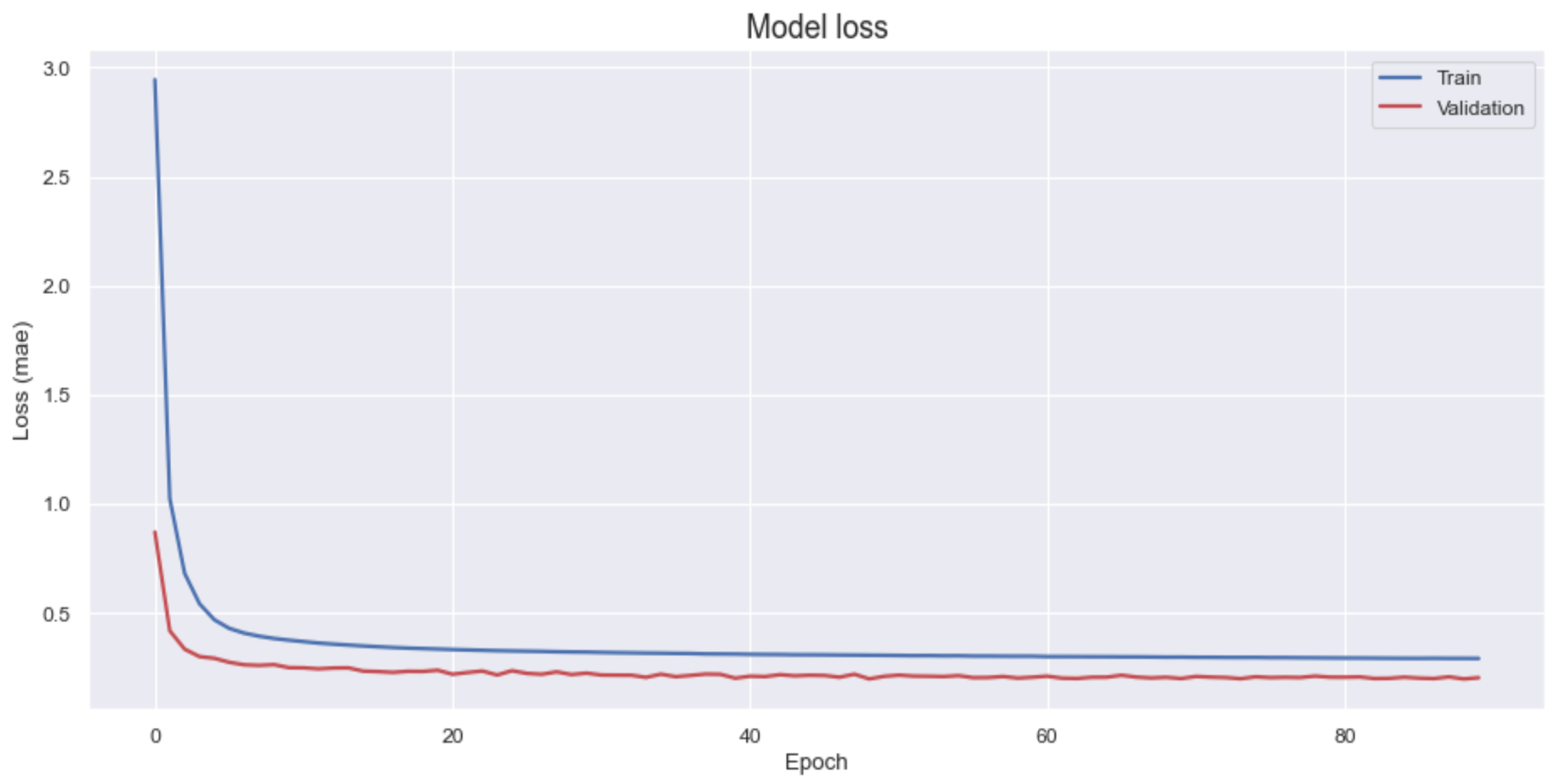
Figure 8 shows the learning behavior of the proposed model across 90 epochs. Both the training and validation MAE decrease rapidly during early epochs and converge to low, stable values, indicating effective learning of the normal request distribution. The gap between the training and validation curves remains small throughout, suggesting minimal overfitting. This result confirms that the ensemble model generalizes well to unseen data while preserving low reconstruction error, which is critical for robust anomaly detection.
Following the detection phase, the Mean Absolute Error (MAE) for each web request is computed and compared against the predefined threshold.
Figure 9 provides a detailed view of how the Mean Absolute Error (MAE) for each individual request compares to the detection threshold. The X-axis represents the sequence of requests processed during evaluation, while the Y-axis shows the MAE score on a logarithmic scale. Blue dots above the red threshold line indicate detected anomalies. This visualization demonstrates the model’s ability to sharply distinguish between normal and malicious traffic, validating the appropriateness of the selected MAE threshold (4.09) for anomaly detection.
The ensemble model, incorporating LSTM, GRU, and stacked autoencoder sub-models, demonstrates superior performance across all evaluation metrics compared to each sub-model individually. The reported results represent the average performance obtained over six independent runs of the model.
The system utilized for evaluating the proposed model consists of key components, as shown in
Table 1, including LSTM, GRU, and stacked autoencoder for neural network-based processing, running on Windows 11 with Python v3.12 as the programming language. The implementation leverages Scikit-learn v1.6.0 for machine learning functionalities and WordPunctTokenizer from the Natural Language Toolkit (NLTK) for splitting a text into a sequence of words. Additionally, the Tokenizer class is employed for converting text data into numerical sequences, ensuring compatibility with neural networks. The model’s performance is evaluated using Mean Absolute Error (MAE), as previously defined, to quantify the difference between predicted and actual values, providing an effective measure for anomaly detection. The training phase required approximately 20 s, while the test phase was completed in 5 s. The model itself was implemented using Python version 3.12 with the Keras framework.
5.3. Results
Table 2 defines the key terms used to compute the evaluation metrics. The performance assessment of the proposed model involves the computation of six primary metrics: accuracy, precision, sensitivity, detection rate, false positive rate, and F1-score.
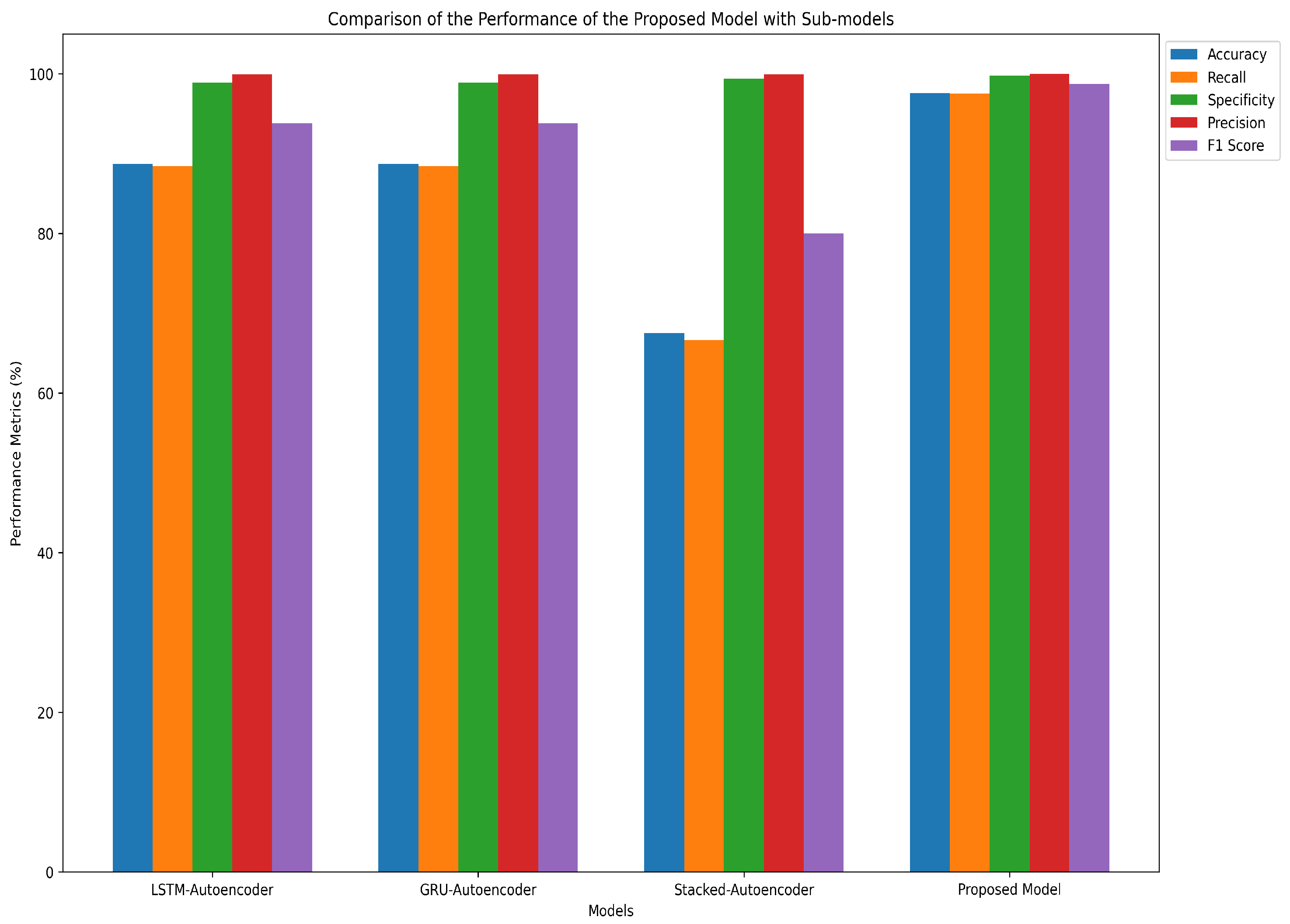
The proposed ensemble model consistently outperforms the individual sub-models across all evaluation metrics. While the LSTM and GRU autoencoders achieve high accuracy, sensitivity, and precision, they exhibit a higher false positive rate, incorrectly classifying several normal requests as malicious. Conversely, the stacked autoencoder reduces the false positive rate effectively but shows comparatively weaker precision and recall. Combining these sub-models into a unified ensemble framework leverages their complementary strengths, thereby significantly improving overall detection performance.
A detailed analysis reveals that both LSTM and GRU sub-models misclassified 14 out of 1299 normal requests as malicious—an undesirable outcome in real-world scenarios. Incorporating the stacked autoencoder into the ensemble mitigates this issue by reducing false positives, albeit at the expense of slightly lower accuracy and recall when used independently.
Table 3 and
Figure 10 provide a detailed comparative analysis of the performance metrics for each individual sub-model—LSTM, GRU, and stacked autoencoder—as well as the overall ensemble model. The ensemble model significantly outperforms all individual components in terms of accuracy (97.58%), recall (97.52%), and F1-score (98.74%), and exhibits a notably low false positive rate of just 0.2%. This improvement reflects the ensemble’s ability to capture diverse latent representations and mitigate the weaknesses of standalone models. The bar chart in
Figure 10 visually reinforces these findings, showing that the proposed model maintains high precision and recall simultaneously—indicating a balanced and effective detection mechanism suitable for real-world deployment.
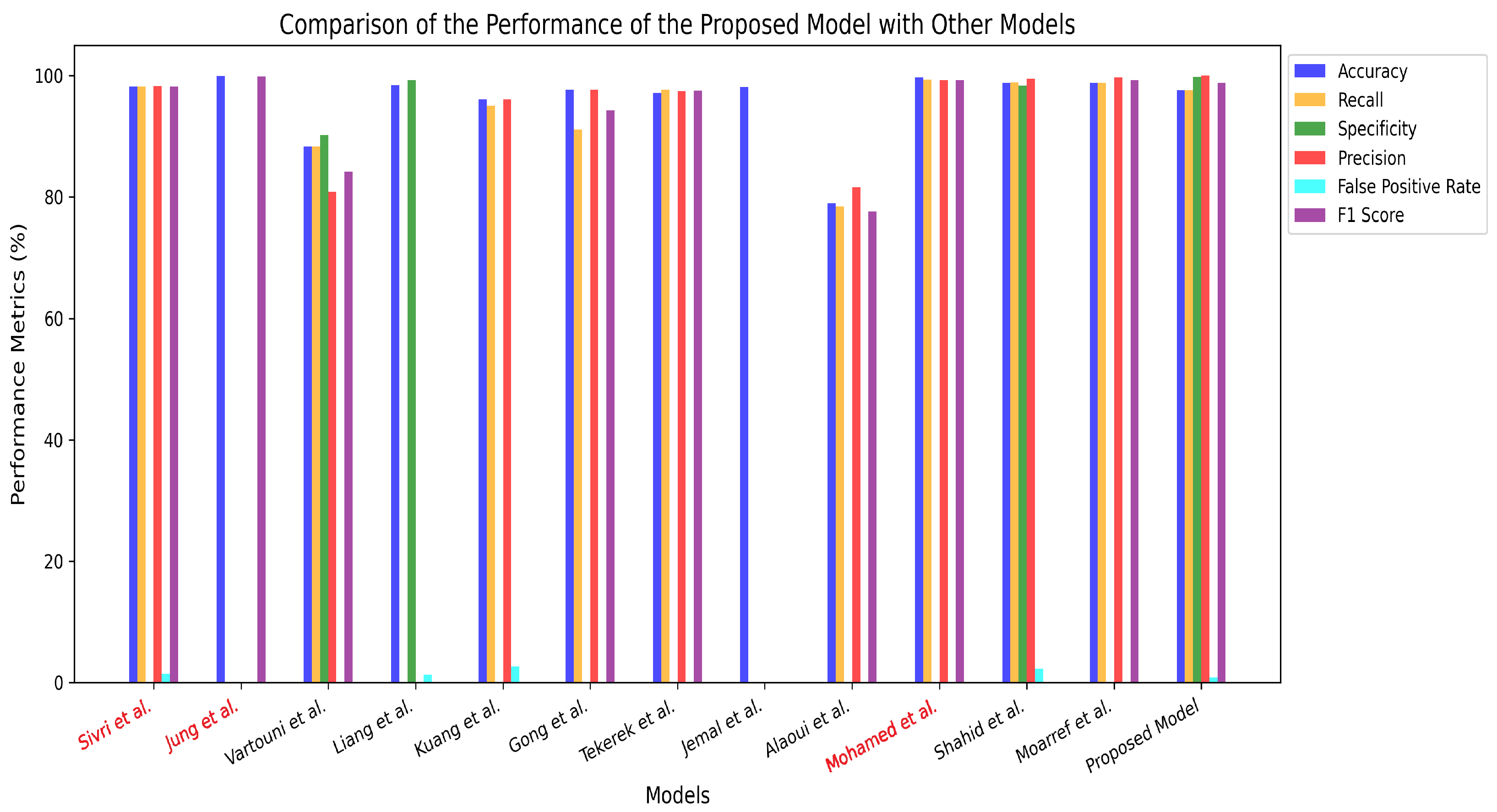
Table 4 presents a comparative analysis of the proposed model’s performance against various models from previous research that have utilized the CSIC2010 and CSIC2012 datasets. This comparison provides insights into the effectiveness of the proposed approach relative to existing solutions in the field. One notable limitation in prior studies is the omission of the false positive rate (FPR) in their evaluation results. This metric is crucial, as it quantifies the number of normal requests misclassified as malicious, directly impacting the practical applicability of detection models. The bar chart in
Figure 11 visually reinforces these findings, illustrating that the proposed model maintains high precision, recall and low FPR simultaneously—showing a balanced among metrics and effective detection mechanism suitable for real-world deployment. In the figure, models that utilized the CSIC2012 dataset are highlighted in red.
The primary comparison focuses on studies that have employed the CSIC2012 dataset [
12,
13,
31], as they provide the most directly comparable benchmark. However, to offer a broader perspective, we also include studies based on the CSIC2010 dataset [
14,
16,
17,
20,
21,
22,
23,
24,
32]. It is important to note that differences in dataset characteristics may influence the comparability of results.
The CSIC2010 and CSIC2012 datasets are widely recognized benchmarks for evaluating web application security models, particularly for detecting SQL injection (SQLi) and other web-based attacks. The CSIC2010 dataset, developed earlier, contains a diverse set of normal and anomalous HTTP requests. While it provides a solid foundation for studying web attack detection, it lacks the complexity and evolving attack patterns characteristic of modern cybersecurity threats.
To address these limitations, the CSIC2012 dataset was designed with more sophisticated and realistic attack scenarios, along with a broader range of normal traffic. This makes CSIC2012 a more representative dataset for contemporary web security challenges. Additionally, CSIC2012 includes refined labeling and a larger volume of data, enhancing its suitability for training and evaluating advanced machine learning models.
These distinctions underscore the importance of selecting CSIC2012 for research targeting modern web application threats, as it serves as a more rigorous and up-to-date evaluation benchmark compared to its predecessor.
7. Conclusions
In this study, each web request was initially segmented into individual words and then tokenized using a predefined vocabulary. This preprocessing step aimed to standardize and simplify web requests while establishing a structured pattern for normal web traffic. In the final stage of preprocessing, each tokenized word was mapped to a unique numerical representation, facilitating its input into the neural network. The proposed model employs an ensemble approach comprising three relatively simple sub-models: LSTM, GRU, and stacked autoencoders. The ensemble operates by independently processing the input data through each sub-model and then outputs are explicitly concatenated into a combined latent feature set, ensuring the ensemble benefits from the diverse representation capabilities of each sub-model. After concatenation, a dedicated dense layer compresses the resulting features into a unified, optimized representation, significantly reducing the dimensionality from a larger combined vector to a manageable size. A novel structured tokenization method significantly enhancing detection performance, and explicit evaluation of critical metrics including false positive rate.
During the training phase, only normal web requests were provided as input to the ensemble model, enabling it to learn the underlying patterns of legitimate requests. Upon completion of training, the model effectively captured and recognized these patterns. In the detection phase, both normal and malicious web requests were introduced for evaluation. The Mean Absolute Error (MAE) was employed as the primary metric to quantify the difference between the reconstructed and original values of each request. The threshold for classification was determined based on the MAE values computed during the training phase. In the detection phase, if the MAE of a web request was below the threshold, it was classified as normal; otherwise, it was identified as malicious.
During evaluation, the ensemble model’s performance was compared against each of its sub-models individually. The results demonstrated that the ensemble approach achieved superior performance, particularly in terms of an increased detection rate and a reduced false positive rate. Additionally, the proposed model was benchmarked against prior research, where it consistently outperformed existing approaches, further validating its effectiveness in detecting web-based threats.
Practical deployment within real-world security frameworks, such as Web Application Firewalls (WAFs) and real-time Intrusion Detection and Prevention Systems (IDS/IPS), is feasible given the computational efficiency of the proposed ensemble approach. Specifically, the pre-trained ensemble model can be integrated as a detection engine within WAF modules or IDS/IPS components, processing web requests in real time to promptly identify anomalous behavior based on reconstruction errors. To optimize performance in real-time scenarios, further efforts should explore model quantization, pruning, or efficient inference methods to ensure minimal latency without compromising detection accuracy.
8. Future Work
One potential direction for future research involves enhancing the tokenization and feature extraction process [
51] across diverse web attack datasets. This improvement can be achieved through the application of Generative AI, leveraging Large Language Models (LLMs) [
52,
53]. Specifically, prompt engineering [
4,
54] can be employed to construct a structured prompt that systematically guides the LLM in preprocessing each dataset sample. To achieve this concretely, the following structured roadmap will be adopted:
In Phase 1, an exploratory pilot study will be conducted using a representative dataset such as HTTPParams [
50]. The goal is to develop and evaluate initial prompt engineering strategies that leverage few-shot learning to guide Large Language Models (LLMs) in generating dataset-specific tokenization rules. During this phase, the performance of the LLM-generated tokenization will be assessed based on consistency with human-crafted rules, semantic accuracy, and overall computational efficiency.
In Phase 2, the experiments will be expanded by incorporating additional datasets, including FWAF and real-world HTTP traffic logs. This phase will focus on systematically comparing LLM-generated tokenization rules to those derived manually. Key performance indicators to be analyzed include generalizability across formats, robustness to variations in input structure, and the computational overhead introduced during preprocessing.
In Phase 3, the aim will be to fully automate the preprocessing pipeline. LLMs will be used to dynamically generate customized preprocessing scripts [
55] based on structured prompts. This phase will focus on evaluating the reliability and consistency of the generated scripts, as well as measuring their runtime efficiency and the downstream impact on anomaly detection accuracy after LLM-driven preprocessing.
In Phase 4, beyond preprocessing improvements, future efforts will explore the implementation of advanced neural architectures and anomaly detection approaches, such as Bidirectional LSTM, GRU, and Convolutional Neural Networks (CNNs) [
56,
57], to develop a more robust ensemble model for web attack detection. Additionally, feature selection techniques will be applied to retain high-information-value features while eliminating less significant ones, effectively reducing input dimensionality and enhancing computational efficiency.
Regarding the adoption of LLMs for tokenization and preprocessing, potential challenges such as robustness against adversarial inputs, model hallucinations, and inconsistent outputs must be considered. Future research should thus include explicit adversarial robustness evaluations and validation protocols to assess and ensure reliability. Moreover, structured reasoning strategies inspired by recent frameworks such as VulnSage [
58], a framework leveraging structured reasoning strategies such as Chain-of-Thought and Think and Verify to improve zero-shot vulnerability detection in software systems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}