
DeepStego: Privacy-Preserving Natural Language Steganography Using Large Language Models and Advanced Neural Architectures

 ,
,  , and
, and
Abstract
1. Introduction
- A novel steganographic framework leveraging GPT-4-omni for natural text generation and semantic-aware message embedding;
- An adaptive embedding mechanism that maintains strong detection resistance while supporting high-capacity information hiding;
- Comprehensive empirical evaluation demonstrating significant improvements in security and text quality metrics;
- A practical implementation achieving 100% message recovery accuracy with superior scalability.
2. Related Work
2.1. Generation-Based Approaches
2.2. Semantic Preservation Techniques
2.3. Language Model Integration
2.4. Steganalysis Resistance
2.5. Current Challenges
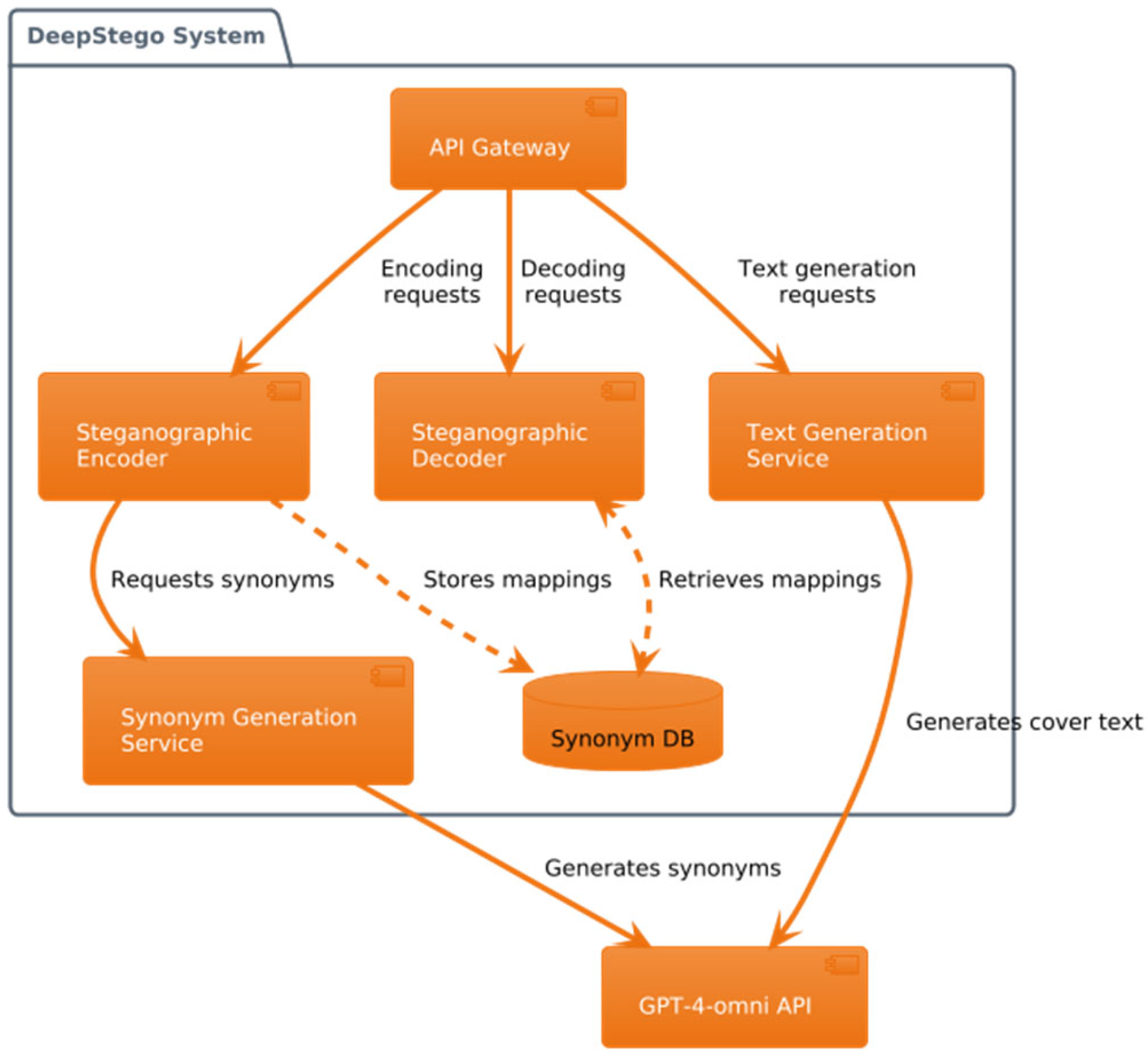
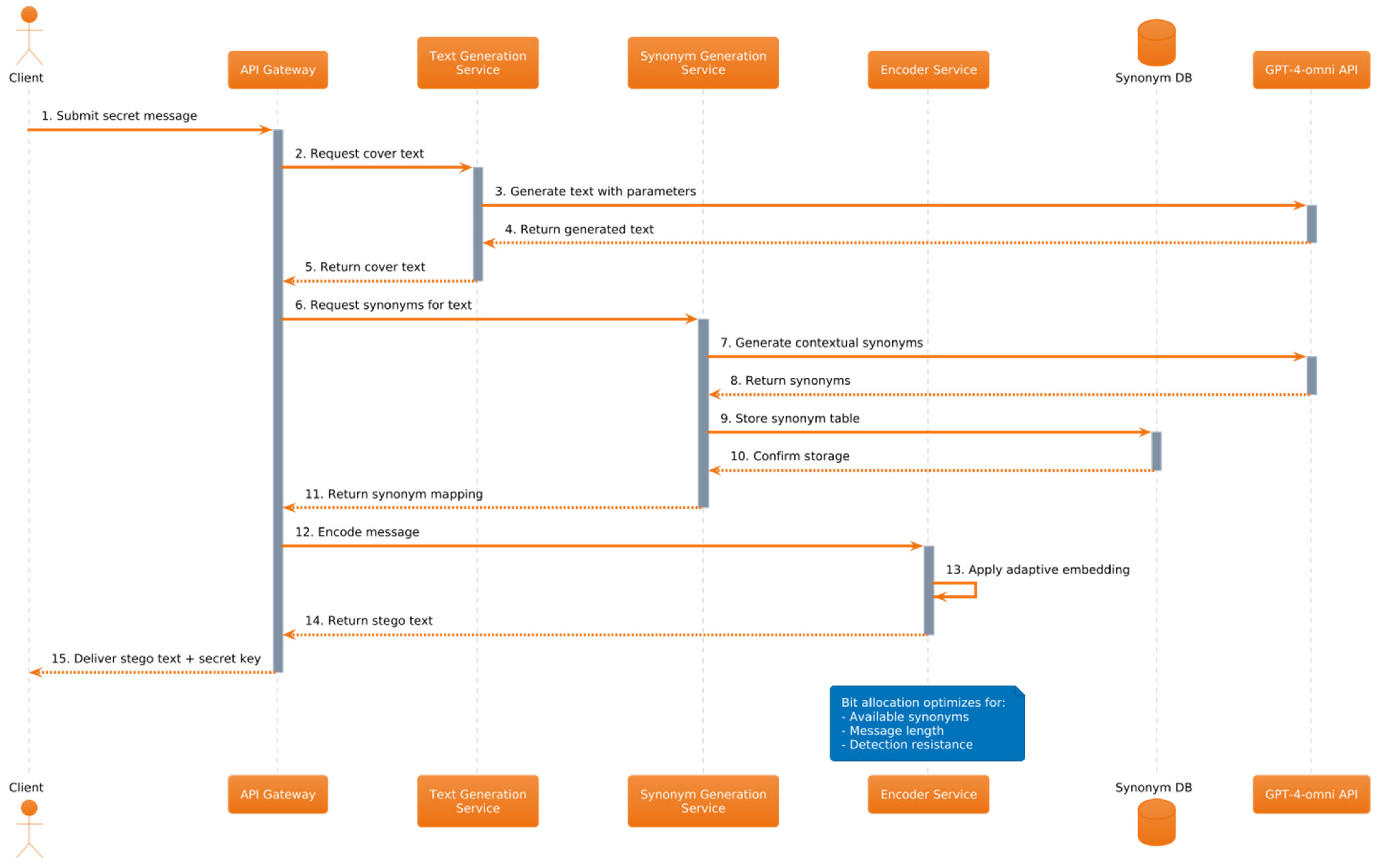
3. System Architecture and Methodology
3.1. System Architecture
3.2. Implementation Methodology
- Container Generation Prompt:
Your task is to generate a plain text on a given topic in English with required number of words. You can generate longer text but not shorter as the number of words in text is important. The style of writing should not include linebreaks characters and paragraphs, just simple plain text. You should always response with generated text only. Do not use special characters in your text like: (){}[]
- 2.
- Synonym Generation Prompt:
Act as a professional linguist with 30 years of experience in this field. You will be given a context (list of words). Your current task is to create a list of synonyms or replacement words for each word... [truncated for brevity]
- 3.
- Prompt Optimization:
- -
- Temperature control (0.7–0.9) based on required text characteristics
- -
- Context window of 5 words for coherent synonym generation
- -
- JSON response formatting for reliable parsing
3.2.1. Custom Refinement Algorithm for Synonym Selection
- Initial synonym generation using GPT-4-omni’s semantic understanding:
- -
- For each word in the container text, request N synonym candidates (where N = 2bits_per_word)
- -
- Apply temperature control (0.7) to balance creativity and contextual relevance
- Semantic similarity evaluation:
- -
- For each candidate synonym, compute contextual embedding
- -
- Calculate cosine similarity between original word and synonym embeddings
- -
- Filter candidates using a dynamic threshold based on bits_per_word parameter
# Pseudocode for synonym refinement algorithm function refine_synonyms(base_token, candidates, context, bits_per_word): refined_candidates = [] similarity_threshold = 0.85 - (bits_per_word * 0.05) # Dynamic threshold for candidate in candidates: embedding_original = compute_embedding(base_token, context) embedding_candidate = compute_embedding(candidate, context) similarity = cosine_similarity(embedding_original, embedding_candidate) if similarity > similarity_threshold: refined_candidates.append(candidate) # Ensure we have enough candidates to encode bits_per_word if len(refined_candidates) < 2^bits_per_word: refined_candidates = candidates[:2^bits_per_word] return refined_candidates
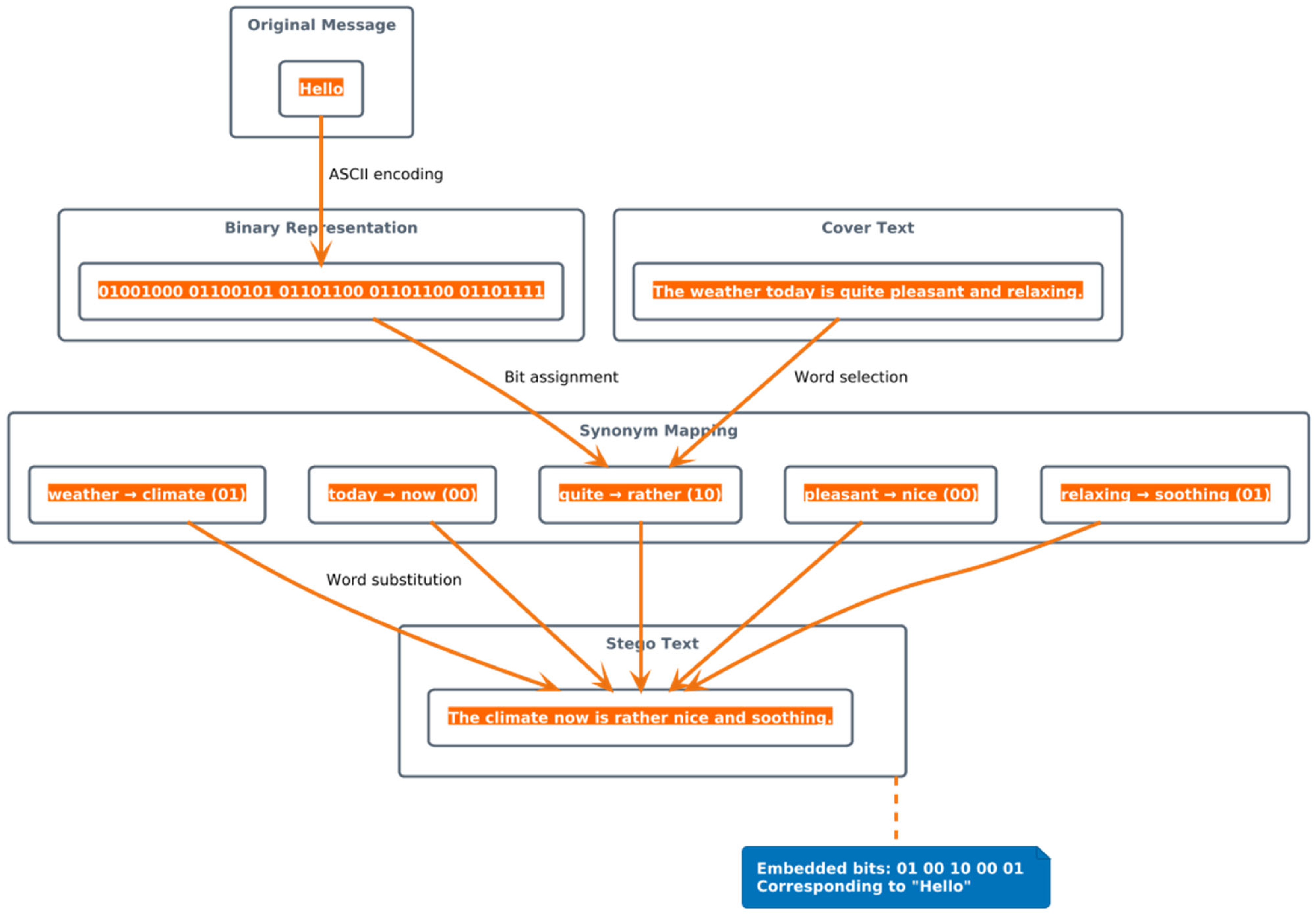
3.2.2. Adaptive Embedding Algorithm
- Message preparation and optimization:
- -
- Convert the input message to binary representation
- -
- Segment the binary message into chunks of size (bits_per_word + additional_bits)
- Adaptive bit allocation:
- -
- Analyze available synonym space for each token
- -
- Dynamically adjust bit allocation based on synonym availability
- -
- Apply binary mapping that optimizes for both security and capacity
- Context-aware replacement strategy:
- -
- Evaluate both local context (surrounding words) and global context (document theme)
- -
- Select replacements that maintain natural language patterns
- -
- Preserve statistical properties to resist detection
# Pseudocode for adaptive embedding algorithm function adaptive_embed(binary_message, container, secret_key, bits_per_word, additional_bits): encoded_message = [] current_bit_index = 0 for token, replacement_options in zip(container.split(), secret_key): # Check if token can be replaced and there are bits left to encode if is_replaceable(token, replacement_options) and current_bit_index < len(binary_message): # Dynamic bit allocation available_bits = log2(len(replacement_options[token])) bits_to_encode = min(available_bits, remaining_bits(binary_message, current_bit_index)) # Extract message segment message_segment = binary_message[current_bit_index:current_bit_index + bits_to_encode] # Apply context-aware replacement if len(message_segment) != bits_to_encode: # Adjust container size for last segment replacement_options = adjust_container_size(replacement_options, len(message_segment)) # Select appropriate replacement maintaining capitalization replacement = replacement_options[token][message_segment] replacement = preserve_capitalization(replacement, token) encoded_message.append(replacement) current_bit_index += bits_to_encode else: # Skip token if not replaceable encoded_message.append(token) return “ “.join(encoded_message)
- Binary Message Encoding:
def binarize_message(message: str) -> str: “““Binarize an ASCII-encoded message.””” return ″.join([bin(x)[2:].zfill(N_ASCII_BITS) for x in list(message.encode(‘ascii’))])
- 2.
- Chunking and Distribution:
def divide_chunks(text: str | list, chunk_size: int) -> list[str]: “““Split string into chunks with specified chunk_size””” for i in range(0, len(text), chunk_size): yield text[i:i + chunk_size]
- 3.
- Synonym-Binary Mapping:
def binarize_synonyms(base_token: str, synonyms: list[str]) -> dict[str, str]:
“““Binarize a base token by assigning binary indices to synonyms.”””
if not len(synonyms):
return {“0”: base_token, “1”: base_token}
return {
““.join(index): synonym
for index, synonym in zip(product(“01”, repeat=int(math.log2(len(synonyms)))), synonyms)
}
- 4.
- Enhanced Capacity Mapping:
def binarize_synonyms_partially(synonyms: list[str], include_sequence: str): “““Binarize synonyms to include a specific binary sequence.””” # Implementation ensures include_sequence will be represented in the mapping
3.3. Edge Case Management
3.3.1. Text Length Constraints
- -
- Minimum viable length of 13 words for standard embedding
- -
- Automatic container regeneration when text is insufficient
- -
- Bit allocation adaptation based on available synonym space
3.3.2. Special Token Handling
# Pseudocode for special token handling function handle_special_tokens(token): # Check for special characters and punctuation if token ends with punctuation: special_suffix = extract_suffix(token) clean_token = remove_suffix(token) return special_suffix, clean_token return ‘’, token
3.3.3. Message Recovery Robustness
- -
- Perfect alignment between container and secret key through the align_container_and_secret_key function
- -
- Token size adaptation for partial message chunks
- -
- Capitalization preservation during token replacement
3.4. System Deployment
3.4.1. Deployment Architecture
- Frontend:
- Streamlit-based web interface for encoding/decoding operations
- Secure authentication via SHA-512 password hashing
- Backend:
- Containerized Python (version 3.7) services using Docker
- MongoDB document storage for operation logs and reports
- OpenAI API integration for GPT-4-omni access
version: ‘3.7’ services: synsteg: build: . ports: - “80:8501” volumes: - .:/synsteg networks: - net
3.4.2. Resource Management
- Multiprocessing:
- Parallel synonym generation via Pool implementation
- Efficient API utilization with backoff retry mechanisms
- Data Persistence:
- MongoDB integration for report storage
- Configurable database connection parameters
- Secure credential management
3.4.3. User Interaction
- Encoding Interface:
- Text input for message content
- Immediate binary length feedback
- Downloadable results with UUID identification
- Decoding Interface:
- File upload for stego text and secret key
- Automatic validation of uploaded files
- Message recovery with timing metrics
4. Experimental Results and Analysis
4.1. Evaluation Methodology
4.1.1. Performance Metrics
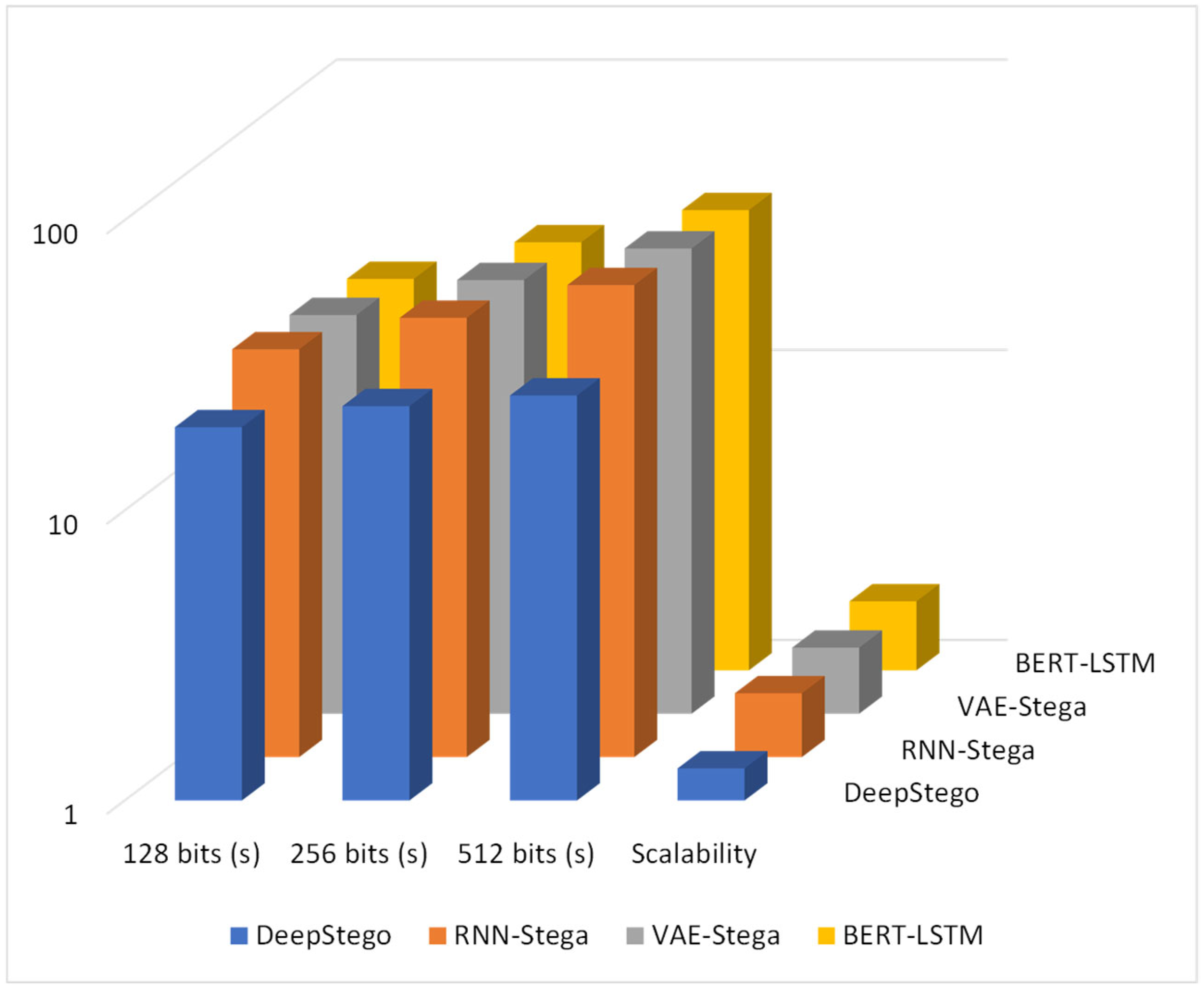
- Processing Time: We measured the time required for each stage of the steganographic process:
- Container Generation: Time to generate appropriate cover text using GPT-4-omni
- Secret Key Generation: Time to generate and refine synonym sets
- Message Encoding: Time to embed the binary message within the cover text
- Message Decoding: Time to extract the hidden message from stego text
- Resource Utilization:
- Memory Usage: Peak memory consumption during encoding/decoding operations
- API Efficiency: Number of API calls to GPT-4-omni per kilobyte of message
- Token Consumption: Total tokens consumed for container and synonym generation
4.1.2. Effectiveness Metrics
- Security Metrics:
- Detection Resistance: Measured by detection accuracy of state-of-the-art steganalysis methods
- Statistical Preservation: Evaluated using statistical tests comparing original and stego texts
- Confusion Rate: Proximity to optimal 0.5 detection rate (complete undetectability)
- Message Integrity:
- Bit Error Rate: Percentage of incorrectly decoded bits
- Message Recovery Accuracy: Percentage of messages perfectly recovered
- Maximum Reliable Capacity: Highest bits-per-word rate with 100% recovery accuracy
- Text Quality Preservation:
- Readability Scores: Using Flesch-Kincaid and other standard readability metrics
- Natural Language Score: Calculated using GPT-4-omni’s perplexity on generated texts
- Semantic Coherence: Measured using embedding-based semantic similarity metrics
4.2. Experimental Environment and Dataset Composition
- Cover Text Sources:
- -
- GPT-4-omni generated texts on 50 diverse topics from science, technology, culture, and society
- -
- Text lengths ranging from 13 to 125 words (mean: 68.3, std: 22.7)
- -
- Linguistic complexity varied to represent real-world use cases (average Flesch-Kincaid grade level: 11.2)
- Secret Message Types:
- -
- Random binary sequences: Generated using cryptographically secure random number generators
- -
- Structured binary data: Encrypted text messages converted to binary representation
- -
- Message lengths: Three categories (128, 256, and 512 bits) with equal representation
- Embedding Parameters:
- -
- Standard mode: Fixed embedding capacity of 5 bits per word
- -
- Enhanced mode: Advanced embedding technique with 10 bits per word capacity
- -
- Mixed capacity mode: Variable bit allocation based on contextual factors
4.3. Results Analysis
4.4. Key Findings
- The enhanced embedding mode doubles capacity without proportional security degradation, representing a significant advancement over previous approaches.
- DeepStego achieves complete undetectability against certain advanced steganalysis methods, particularly deep-learning-based approaches.
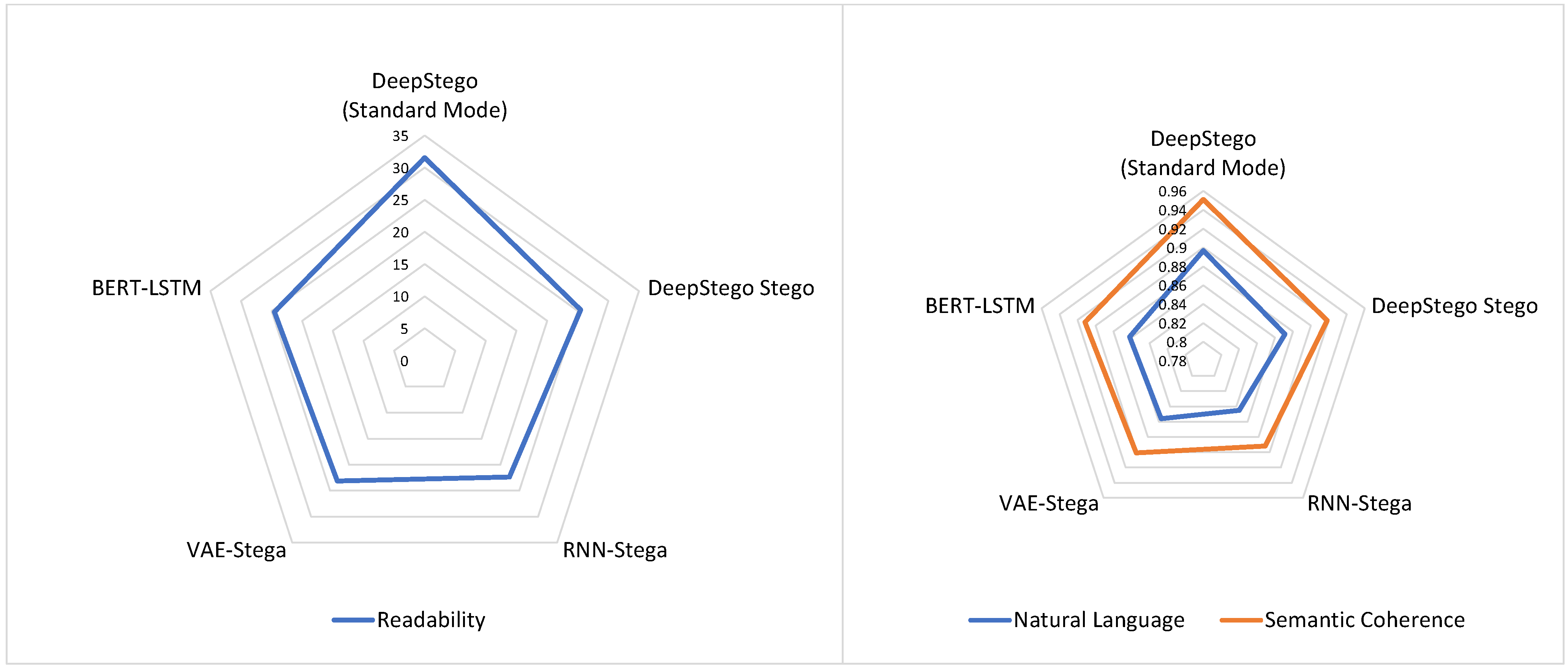
- The system maintains text quality even at high embedding rates, with semantic coherence scores remaining above 0.91 across all test conditions.
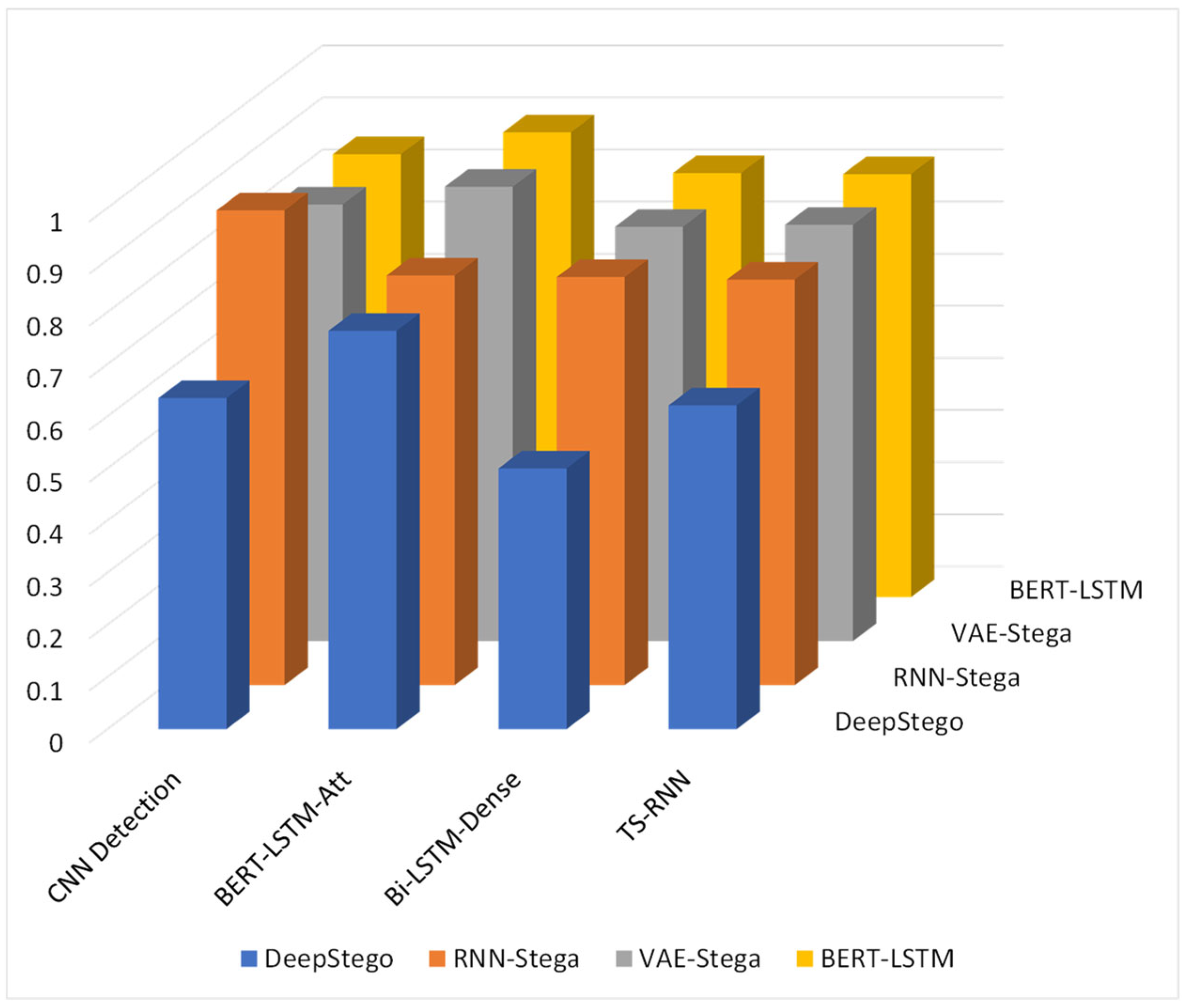
4.5. Comparative Analysis
5. Discussion
5.1. Detection Resistance
5.2. Text Quality Preservation
5.3. Computational Efficiency
5.4. Limitations and Future Work
- Reducing perplexity while maintaining detection resistance;
- Extending the approach to support multiple languages;
- Developing more sophisticated prompt engineering strategies;
- Investigating the impact of different GPT model architectures.
5.5. Practical Implications
5.6. Theoretical Significance
5.7. Security Analysis
5.7.1. Adversarial Model
- Passive Observer:
- -
- Has access to the stego text only
- -
- May apply statistical or ML-based detection methods
- -
- Has no knowledge of DeepStego’s specific implementation
- Active Adversary:
- -
- May have limited knowledge of DeepStego’s methodology
- -
- Can access state-of-the-art steganalysis tools
- -
- Cannot access the secret key or specific GPT parameters
5.7.2. Attack Vectors and Mitigations
- Statistical Steganalysis:
- -
- Mitigation: Semantic-aware embedding preserves natural language statistics
- -
- Effectiveness: Near-optimal confusion rates (0.5000) against Bi-LSTM-Dense detection
- Neural Steganalysis:
- -
- Mitigation: High-quality GPT-4-omni text generation
- -
- Effectiveness: Detection accuracy reduced to 0.635 compared to 0.911 for existing methods
5.7.3. Security Features
- Randomized Mapping:
- -
- Binary sequences mapped to synonyms using cryptographically secure randomization
- -
- Different mapping for each message prevents pattern analysis
- Message Segmentation:
- -
- Secret message divided into chunks using divide_chunks function
- -
- Variable bit allocation across words prevents consistent patterns
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.; Xie, Z.; Chen, T.; Cheng, X.; Wen, H. Image Privacy Protection Scheme Based on High-Quality Reconstruction DCT Compression and Nonlinear Dynamics. Expert Syst. Appl. 2024, 257, 124891. [Google Scholar] [CrossRef]
- Denemark, T.; Fridrich, J.; Holub, V. Further Study on the Security of S-UNIWARD; Binghamton University: Binghamton, NY, USA, 2014; Volume 9028. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- GPT-4. Available online: https://openai.com/research/gpt-4 (accessed on 14 April 2024).
- Scanlon, M.; Breitinger, F.; Hargreaves, C.; Hilgert, J.-N.; Sheppard, J. ChatGPT for Digital Forensic Investigation: The Good, the Bad, and the Unknown. Forensic Sci. Int. Digit. Investig. 2023, 46, 301609. [Google Scholar] [CrossRef]
- Fridrich, J. Steganography in Digital Media: Principles, Algorithms, and Applications; Illustrated Edition; Cambridge University Press: Cambridge, NY, USA; New York, NY, USA, 2009; ISBN 978-0-521-19019-0. [Google Scholar]
- Cox, I.; Miller, M.; Bloom, J.; Fridrich, J.; Kalker, T. Digital Watermarking and Steganography, 2nd ed.; Morgan Kaufmann: Amsterdam, The Netherlands; Boston, MA, USA, 2007; ISBN 978-0-12-372585-1. [Google Scholar]
- Yang, Z.; Wang, K.; Li, J.; Huang, Y.; Zhang, Y.-J. TS-RNN: Text Steganalysis Based on Recurrent Neural Networks. IEEE Signal Process. Lett. 2019, 26, 1743–1747. [Google Scholar] [CrossRef]
- Yang, Z.-L.; Zhang, S.-Y.; Hu, Y.-T.; Hu, Z.-W.; Huang, Y.-F. VAE-Stega: Linguistic Steganography Based on Variational Auto-Encoder. IEEE Trans. Inf. Forensics Secur. 2021, 16, 880–895. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Z.; Yang, J.; Huang, Y. Linguistic Steganography: From Symbolic Space to Semantic Space. IEEE Signal Process. Lett. 2021, 28, 11–15. [Google Scholar] [CrossRef]
- Fang, T.; Jaggi, M.; Argyraki, K. Generating Steganographic Text with LSTMs. In Proceedings of ACL 2017, Student Research Workshop; Ettinger, A., Gella, S., Labeau, M., Alm, C.O., Carpuat, M., Dredze, M., Eds.; Association for Computational Linguistics: Vancouver, DC, Canada, 2017; pp. 100–106. [Google Scholar]
- Yang, Z.; Xiang, L.; Zhang, S.; Sun, X.; Huang, Y. Linguistic Generative Steganography With Enhanced Cognitive-Imperceptibility. IEEE Signal Process. Lett. 2021, 28, 409–413. [Google Scholar] [CrossRef]
- Yan, R.; Yang, Y.; Song, T. A Secure and Disambiguating Approach for Generative Linguistic Steganography. IEEE Signal Process. Lett. 2023, 30, 1047–1051. [Google Scholar] [CrossRef]
- Zou, J.; Yang, Z.; Zhang, S.; Rehman, S.U.; Huang, Y. High-Performance Linguistic Steganalysis, Capacity Estimation and Steganographic Positioning. In Proceedings of the Digital Forensics and Watermarking; Zhao, X., Shi, Y.-Q., Piva, A., Kim, H.J., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 80–93. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS ’22), Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Nice, France, 2022; pp. 27730–27744. [Google Scholar]
- Niu, Y.; Wen, J.; Zhong, P.; Xue, Y. A Hybrid R-BILSTM-C Neural Network Based Text Steganalysis. IEEE Signal Process. Lett. 2019, 26, 1907–1911. [Google Scholar] [CrossRef]
- Wen, J.; Zhou, X.; Zhong, P.; Xue, Y. Convolutional Neural Network Based Text Steganalysis. IEEE Signal Process. Lett. 2019, 26, 460–464. [Google Scholar] [CrossRef]
- Yang, H.; Bao, Y.; Yang, Z.; Liu, S.; Huang, Y.; Jiao, S. Linguistic Steganalysis via Densely Connected LSTM with Feature Pyramid. In Proceedings of the 2020 ACM Workshop on Information Hiding and Multimedia Security; Association for Computing Machinery: New York, NY, USA, 2020; pp. 5–10. [Google Scholar]
- Yang, Z.; Wei, N.; Sheng, J.; Huang, Y.; Zhang, Y. TS-CNN: Text Steganalysis from Semantic Space Based on Convolutional Neural Network. arXiv 2018, arXiv:1810.08136. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Message Size (Bits) | Embedding Mode | Capacity (%) | BPW | Words Required | Processing Time (s) |
|---|---|---|---|---|---|
| 128 | Standard | 8.22 ± 0.12 | 4.34 | 29.55 ± 1.32 | 19.35 ± 3.69 |
| 256 | Standard | 8.54 ± 0.14 | 4.26 | 60.05 ± 2.21 | 22.87 ± 2.62 |
| 512 | Standard | 8.83 ± 0.12 | 4.09 | 124.95 ± 2.84 | 24.89 ± 1.90 |
| 128 | Enhanced | 16.64 ± 0.21 | 9.84 | 13.00 ± 0.00 | 19.35 ± 3.69 |
| 256 | Enhanced | 18.37 ± 0.26 | 9.84 | 52.00 ± 0.00 | 22.87 ± 2.62 |
| 512 | Enhanced | 19.48 ± 0.18 | 9.84 | 29.55 ± 0.00 | 24.89 ± 1.90 |
| Detection Method | Standard Mode (1 Bit/Word) | Enhanced Mode (4 Bits/Word) |
|---|---|---|
| BERT-LSTM-Att [14] | 0.7644/0.5543 (Acc/Rec) | 0.9432/0.8933 (Acc/Rec) |
| CNN-based [19] | 0.6351/0.4503 (Acc/Rec) | 0.6552/0.5415 (Acc/Rec) |
| RNN-based [8] | 0.6212/0.4942 (Acc/Rec) | 0.5538/0.2134 (Acc/Rec) |
| Bi-LSTM-Dense [18] | 0.5000/0.0000 (Acc/Rec) | 0.5000/0.0000 (Acc/Rec) |
| Message Size (Bits) | Mode | Readability Score | Natural Language Score | Semantic Coherence |
|---|---|---|---|---|
| 128 | Original | 29.18 ± 11.49 | 0.892 ± 0.043 | 0.945 ± 0.028 |
| Stego | 23.40 ± 10.51 | 0.863 ± 0.052 | 0.912 ± 0.035 | |
| 256 | Original | 32.74 ± 8.86 | 0.901 ± 0.038 | 0.956 ± 0.024 |
| Stego | 26.99 ± 8.98 | 0.878 ± 0.045 | 0.923 ± 0.031 | |
| 512 | Original | 32.76 ± 8.90 | 0.899 ± 0.041 | 0.951 ± 0.026 |
| Stego | 25.98 ± 7.32 | 0.871 ± 0.047 | 0.918 ± 0.033 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuznetsov, O.; Chernov, K.; Shaikhanova, A.; Iklassova, K.; Kozhakhmetova, D. DeepStego: Privacy-Preserving Natural Language Steganography Using Large Language Models and Advanced Neural Architectures. Computers 2025, 14, 165. https://doi.org/10.3390/computers14050165
Kuznetsov O, Chernov K, Shaikhanova A, Iklassova K, Kozhakhmetova D. DeepStego: Privacy-Preserving Natural Language Steganography Using Large Language Models and Advanced Neural Architectures. Computers. 2025; 14(5):165. https://doi.org/10.3390/computers14050165
Chicago/Turabian StyleKuznetsov, Oleksandr, Kyrylo Chernov, Aigul Shaikhanova, Kainizhamal Iklassova, and Dinara Kozhakhmetova. 2025. "DeepStego: Privacy-Preserving Natural Language Steganography Using Large Language Models and Advanced Neural Architectures" Computers 14, no. 5: 165. https://doi.org/10.3390/computers14050165
APA StyleKuznetsov, O., Chernov, K., Shaikhanova, A., Iklassova, K., & Kozhakhmetova, D. (2025). DeepStego: Privacy-Preserving Natural Language Steganography Using Large Language Models and Advanced Neural Architectures. Computers, 14(5), 165. https://doi.org/10.3390/computers14050165