1. Introduction
Modern large-scale organizations use enterprise systems as their operational backbone. Enterprise systems integrate various processes, resources, and stakeholders to achieve the objectives of the organization [
1]. However, managing these complex systems poses challenges, including inefficiencies in workflow coordination, resource allocation, and decision making [
2]. The most common way to respond to these challenges is through manual intervention supported by data analysis and visualization tools. However, this introduces additional delays and the potential occurrence of human errors. Both delays and errors increase operational costs [
3].
The integration of AI technologies into enterprise systems offers a promising solution to these challenges. AI models, particularly transformer-based large language models (LLMs), possess unique capabilities that align with the needs of enterprise environments. These models can process vast amounts of both structured and unstructured operational data, identify hidden patterns, and automate decision-making processes. Such automation significantly reduces reliance on human intervention, minimizing errors and improving efficiency. Furthermore, AI systems can provide contextual insights by analyzing interdependencies across different enterprise processes, enabling more informed resource allocation and enhancing overall organizational performance. The proposed EnterpriseAI framework harnesses these AI capabilities, specifically leveraging a transformer model, to address the operational complexities inherent in enterprise systems.
Recent advancements in AI have shown tremendous potential in automating and optimizing system management processes [
4]. Significantly, transformer-based large language models have demonstrated their ability to process and analyze vast amounts of data and make decisions from them [
5]. These can process both structured and unstructured data and draw conclusions with human-like reasoning [
6]. That is why it these models provide promising technologies for integration with enterprise systems, replacing the manual effort of covering operational challenges. This paper introduces
EnterpriseAI, a transformer-based framework specifically designed to address the complexities of enterprise systems. The concepts of NLP and transfer learning have been used in this study to automate routine tasks, minimize manual errors, and optimize resource utilization in enterprise systems. As a result, a substantial amount of expenditure can be saved, and operational efficiency can be improved.
The novelty of this study lies in the successful integration of a transformer model trained on a customized dataset derived from enterprise-specific scenarios. The framework effectively uses the model and optimizes the workflow, performing resource planning and mitigating risks. The model’s architecture enables it to understand and analyze the interdependencies among various components of an enterprise system, delivering contextually relevant insights and solutions. The core contributions of this paper are listed below:
Technology adaptation: The potential of the transformer model has been utilized in the enterprise system and manual efforts have been effectively automated.
Cost optimization: Significant reductions in operational costs have been achieved through automated and accurate system management.
Feasibility analysis: A feasibility analysis has been performed through a scalability test and resource utilization observation for real-world enterprise systems integration.
The remainder of this paper is organized as follows.
Section 2 provides a comprehensive review of related work.
Section 3 outlines the methodology and conceptual framework of EnterpriseAI.
Section 4 presents the use case integration. The implementation details are discussed in
Section 5, followed by performance evaluation and results in
Section 6. The limitations and potential directions for future work are highlighted in
Section 7, and
Section 8 concludes the paper with key insights.
2. Literature Review
A systematic literature review (SLR) has been conducted to identify research gaps and specify the corresponding research objectives upon exploring the current advancements and challenges in enterprise system management and the adaptation of AI in this field. The guidelines established by Kitchenham et al. [
6] have been followed in this study to ensure a comprehensive and structured approach to analyzing the existing literature.
2.1. Research Questions
The literature review has been developed through four research questions (RQs). These questions are directly related to the objectives of this study. The literature review was guided by the following research questions:
RQ1: What are the existing challenges in managing enterprise systems?
RQ2: How is AI being utilized to address these challenges in enterprise systems?
RQ3: What are the limitations of current AI-based approaches in enterprise systems?
RQ4: How can transformer-based models enhance the management of enterprise systems?
2.2. Search Strategy
Reliable and authentic sources have been used in this study to identify relevant papers. These sources are IEEE Xplore, SpringerLink, ACM Digital Library, and Scopus [
7]. With the aid of the Google Scholar search engine, using search key-phrases to explore these sources only, relevant papers were identified [
8]. The search terms were combined as follows:
“enterprise systems” AND “artificial intelligence” AND “transformer models” AND “process optimization” AND “cost reduction”.
Additional filters were applied to include peer-reviewed articles published between 2020 and 2025. However, a few exceptions were made for globally accepted theories, which have been cited multiple times. For these types of papers, the publication time range was relaxed.
2.3. Inclusion and Exclusion Criteria
Not every paper retrieved through the search strategy explained earlier is appropriate for the study conducted in this paper. That is why, even after using a well-developed search strategy, additional inclusion and exclusion criteria have been specified to enhance the quality of the literature review further and ensure relevancy. Both the inclusion and exclusion criteria are presented below:
Inclusion Criteria:
- –
Studies addressing enterprise systems management.
- –
Research involving the application of AI in enterprise systems.
- –
Papers discussing transformer-based models or NLP in enterprise contexts.
- –
Peer-reviewed articles published in reputable journals or conferences.
Exclusion Criteria:
- –
Non-English-language studies.
- –
Studies lacking experimental results or practical implementations.
- –
Duplicate publications or outdated reviews.
The selected studies were analyzed to extract key information, including the challenges addressed, AI techniques employed, and reported outcomes. A total of 72 articles were reviewed after applying the inclusion and exclusion criteria. The findings were synthesized and categorized based on the research questions.
2.4. Findings
2.4.1. Challenges in Enterprise Systems
Jiang et al. [
9] explored the challenges of enterprise systems from a cybersecurity perspective. A similar study was conducted by Shi and Jincheng [
10], which identified the challenges of enterprise systems from a business perspective. According to these studies, inefficient resource allocation, lack of real-time adaptability, and high operational costs are the major challenges facing these systems. These challenges are exacerbated by the complexity of coordinating multiple workflows, stakeholders, and technologies [
11].
2.4.2. AI Applications in Enterprise Systems
Application of AI in enterprise systems is not a new concept [
12]. Industry 4.0 technologies [
13], utilization of Internet of Things (IoT) data [
14], and automatic resource planning [
15] are a few of the applications of AI in enterprise systems. A comprehensive review conducted by Rehman et al. [
16] shows the challenges of using machine learning and IoT in enterprise systems. It summarized a set of solutions as well. Jawad et al. [
17] studied various optimization techniques for enterprise resource planning (ERP) systems using machine learning. The existing literature review indicates the growing adoption of AI in enterprise systems. However, the application of AI is confined to non-generative AI approaches, where the AI module is dedicated to making predictions about certain variables.
2.4.3. Limitations of Current AI Approaches
The primary limitation of the current AI approaches in the enterprise system is the dependence on discriminative and analytical AI [
18]. The existing AI solutions are focused on making predictions, performing classification, or making small-scale decisions based on pattern recognition [
19]. The adaptation of generative AI-based solutions is underexplored. At the same time, technologies presented in the recent literature related to AI are concentrated on the development of the AI model instead of presenting feasible ways of incorporating them into enterprise systems. As a result, most of these solutions seem promising as potential solutions, whereas the real-world feasibility is yet to be explored [
20].
2.4.4. Potential of Transformer Models in Enterprise Systems
Transformer models have revolutionized the NLP sector. The large language models (LLMs) developed using transformers as the core technologies are capable of human-like reasoning if trained properly [
5]. They are capable of processing large-scale and complex data and establishing logical and syntactical relations among them [
21]. Transformer models are also efficient in data analysis and draw logical conclusions from there [
22]. Such models can handle both structured and unstructured data, combine multiple contexts, including both numerical and descriptive data, and make decisions [
23]. These properties make transformer models an appropriate tool for enterprise system automation.
2.5. Research Gaps
The findings from the literature review reveal a set of research gaps. The primary objective of this study is to fill these gaps. The gaps identified in this study are listed as follows:
Lack of efficient adaptation of transformer models in enterprise systems to automate manual efforts.
Underexplored scope of cost minimization through process optimization in enterprise systems.
Absence of a feasibility analysis through real-world exploration of the transformer model as a substitute for manual efforts in enterprise systems.
The findings from the systematic literature review presented in this section play a foundational role in this study. The contributions presented in the introduction are justified through the relevant research gaps discovered in the literature review. The proposed EnterpriseAI framework aims to address these gaps by leveraging advanced NLP techniques and scalable design principles.
3. Methodology
3.1. Dataset Preparation and Preprocessing
Enterprise systems involve multiple different types of processes. The dynamic workflow associated with the systems usually produces a massive volume of structured and unstructured data [
24]. However, these data vary from system to system. This study has been conducted on an enterprise system associated with a manufacturing industry located in different geographical locations that operate in harmony through the enterprise system. To enable the proposed
EnterpriseAI framework, it is essential to develop a dataset that reflects the complex nature of the enterprise system’s operational process. A specialized dataset has been prepared and preprocessed to ensure this issue is addressed and maintains relevance and applicability.
3.1.1. Dataset Formation
The dataset was constructed from enterprise-specific scenarios, including workflow descriptions, resource allocation plans, and risk mitigation strategies. Data were collected from publicly available enterprise case studies, anonymized internal reports, and industry white papers. All of these documents are related to manufacturing enterprise systems. The collected content was categorized into three categories, which are presented in the list below.
Workflow data (): detailed descriptions of enterprise workflows.
Resource data (): information on resource allocation and usage.
Risk dat (): case studies addressing risk factors and mitigation strategies.
These can be used to produce an initial informed dataset, and the categories have been merged together. The merging process follows the mathematical principle provided in Equation (
1). Here,
,
, and
denote individual entries in the workflow, resource, and risk datasets, respectively [
25].
Training a transformer model through a transfer learning approach requires the dataset to be in a query–response format. The initial unified dataset prepared using Equation (
1) does not have this structure. Later, in the preprocessing steps, the dataset was further transformed into query–response format through semi-manual intervention by following the concept presented in Equation (
2) [
26].
In Equation (
2),
,
, and
represent the annotations or responses associated with
,
, and
, respectively. This structured dataset allows the transformer model to effectively learn enterprise-specific contextual relationships.
Table 1 summarizes the key properties of the dataset, including the number of documents in each category, document types, structure, and word counts.
Table 1 shows that the dataset includes a total of 750 documents categorized into workflow, resource, and risk data. The documents vary in structure, ranging from structured reports to unstructured case studies, ensuring a diverse dataset suitable for training the EnterpriseAI framework. The total word count of the dataset is 904,000, providing a comprehensive knowledge base for the model.
3.1.2. Data Normalization and Cleaning
To standardize the data, all text entries were normalized to lowercase using Unicode transformation rules, ensuring uniformity without affecting semantic meaning [
27]. The normalization process is expressed in Equation (
3), where
denotes the normalized text, and
is the transformation value applied to convert uppercase characters into lowercase.
After normalization, irrelevant characters and noise were removed using Equation (
4), where
represents the set of irrelevant elements excluded from the text.
3.1.3. Tokenization and Embedding Formation
To prepare the data for input into the transformer model, tokens were generated using a hybrid byte-pair encoding method. The tokenization process is expressed in Equation (
5).
The dataset contains a total of 904,000 words spread across 1808 pages. With an average word length of 4.5 characters and an estimated token length of 3.0 characters, the dataset comprises approximately 1,356,000 tokens. On average, each page contributes around 750 tokens, ensuring an even distribution of data. The tokens were subsequently embedded into dense vector representations, defined in Equation (
6).
In Equation (
6),
maps tokens
into a continuous vector space. This transformation facilitates efficient processing by the transformer model, enabling it to capture semantic and contextual relationships effectively.
3.1.4. Dataset Splitting
The dataset was divided into training, validation, and testing subsets to train the transformer model used in the EnterpriseAI framework and evaluate its performance. The splitting was performed following the widely used ratio of 70:15:15 for training, validation, and testing, respectively, as recommended in machine learning best practices [
28]. During preliminary experiments, alternative splitting ratios, such as 60:20:20 and 80:10:10, were considered. However, the 70:15:15 ratio yielded the most stable performance in terms of convergence speed and evaluation metrics, making it the optimal choice for this study. The dataset comprises 750 documents, categorized into three main groups: workflow data (
), resource data (
), and risk data (
). These documents span a total of 1808 pages, containing 904,000 words and approximately 1,356,000 tokens.
Table 2 summarizes the number of documents and tokens allocated to each subset.
This thoroughly prepared dataset ensures that the EnterpriseAI framework can learn and adapt to the complex requirements of enterprise systems.
3.2. Transformer Model Architecture
The core of the proposed EnterpriseAI framework is a custom transformer model designed to handle the complexities and interdependencies of enterprise systems. The model architecture has been optimized to ensure scalability, efficiency, and adaptability to diverse enterprise scenarios.
3.2.1. Model Design
The transformer model presented in this study has been developed through a series of comparative analyses. The finalized version summarized in
Table 3 is the optimal architecture that produces the most reliable output with the least computational resources [
29].
3.2.2. Input Embedding Layer
The dimension of the input embedding layer is 15,000 × 128. It has been designed to map the input tokens to the dense vectors. That means it converts tokenized sequences into dense vector representations. The embedding process is expressed in Equation (
7) [
30].
Here,
is the embedding matrix, and
represents the
z-th token in the input sequence
. The output of the embedding layer is a matrix
, where
L is the sequence length, defined in Equation (
8).
3.2.3. Positional Encoding Layer
It is essential to preserve the position of the tokens to maintain the meaning of the features. This responsibility is taken care of by the positional encoding layer. To preserve token sequence order, a positional encoding vector is added to each token embedding. The positional encoding process is defined in Equation (
9) [
31], where
represents the
k-th dimension of the positional vector for the
z-th token, and
is the model’s embedding dimension [
31].
3.2.4. Transformer Encoder Block
Each encoder block contains a multi-head attention mechanism, layer normalization, and a feed-forward network (FFN). The multi-head attention mechanism aggregates contextual information from the input sequence by computing attention scores. For each token
, the query (
), key (
), and value (
) vectors are computed as
. The attention score
is then calculated using the scaled dot product expressed in Equation (
10) [
31].
The output from the attention mechanism is a weighted sum. The value of the weighted sum is calculated using Equation (
11).
The feed-forward neural network used in the transformer model applies two linear transformations with a ReLU activation in between which is governed by Equation (
12), where
,
,
, and
are the trainable parameters of the FFN.
3.2.5. Output Layer
The output layer is responsible for delivering the output generated by the transformer model. It is another embedding layer that maps the encoder’s output to logits, which are converted into probabilities using the Softmax function. The process follows the mathematical principle presented in Equation (
13), where
is the logit for token
, and
V is the vocabulary size.
3.3. Training the EnterpriseAI Transformer
The training process of the
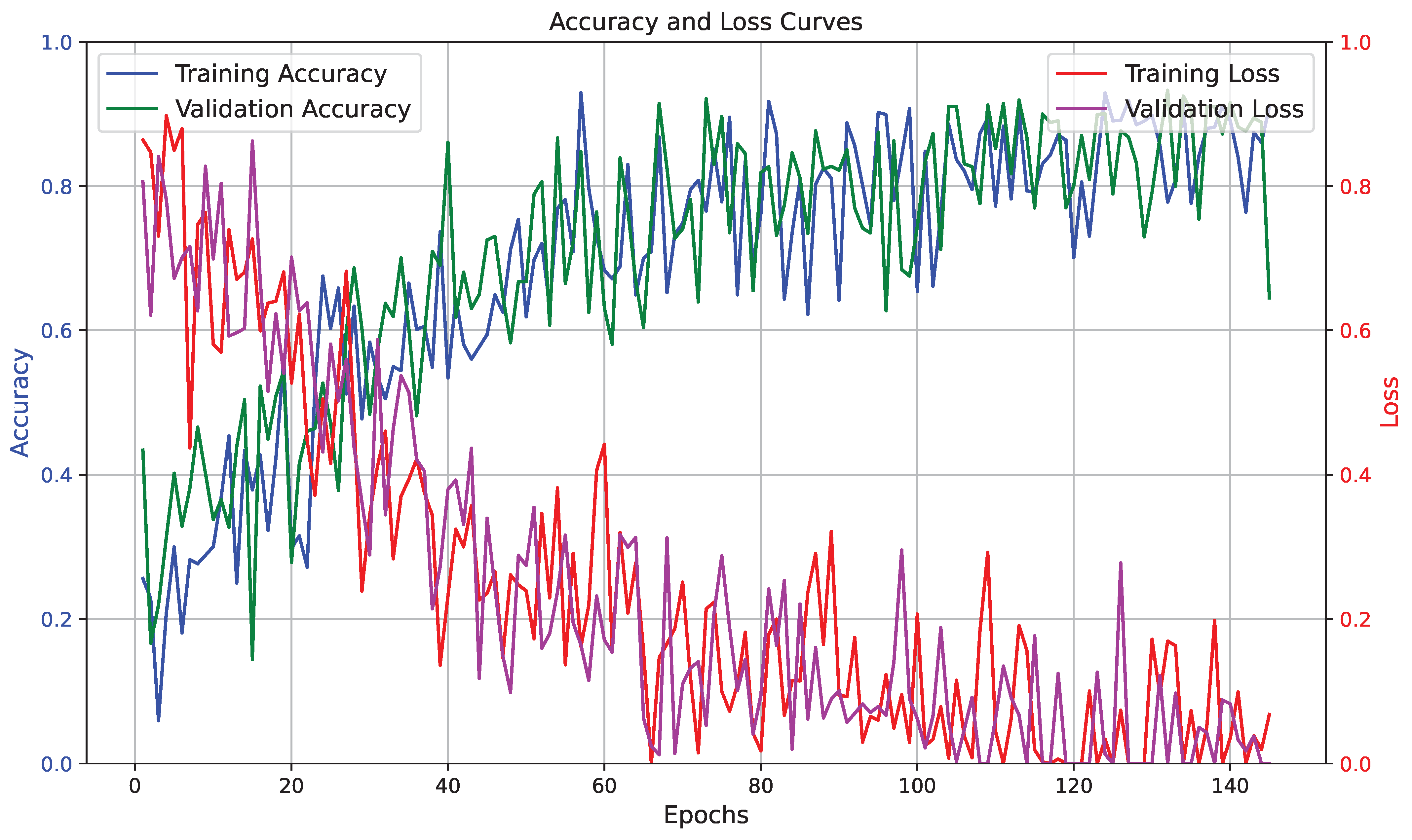
EnterpriseAI transformer model focused on fine-tuning a pre-trained transformer architecture to adapt it to enterprise-specific tasks. The training leveraged transfer learning to expedite the process and enhance the model’s performance on the prepared dataset. The learning curve illustrated in
Figure 1 shows how effectively the transformer model learned from the dataset during the training process [
32].
3.3.1. Fine-Tuning Objective
The fine-tuning objective was to minimize the discrepancy between the model’s predicted output and the true output from the dataset. This was achieved by optimizing the cross-entropy loss function, as defined in Equation (
14) [
33].
In Equation (
14),
represents the true probability of token
, given the preceding tokens, and
is the model’s predicted probability.
3.3.2. Optimization Strategy
The Adaptive Moment Estimation (ADAM) optimizer with weight decay was used to minimize the loss. The update rule for the model’s parameters
at step
t is given by Equation (
15) [
34].
Here, is the learning rate, and are the first and second moment estimates of the gradient, respectively, and is a small constant to prevent division by zero.
3.3.3. Learning Rate Scheduler
A learning rate scheduler was employed to adjust the learning rate dynamically during training. The scheduler followed a warm-up phase, gradually increasing the learning rate for the initial steps before decaying it. The learning rate at step
t is defined in Equation (
16) [
35].
In Equation (
16),
is the initial learning rate,
is the number of warm-up steps, and
t is the current training step.
3.3.4. Evaluation During Training
During training, the model’s performance was evaluated on the validation set after every epoch. Metrics such as accuracy, precision, recall, and perplexity were computed to monitor progress. The perplexity metric, a measure of the model’s uncertainty in generating predictions, is defined in Equation (
17) [
36].
Here, is the cross-entropy between the true probability distribution and the predicted distribution .
4. Enterprise Use Case Integration
The
EnterpriseAI framework is designed to seamlessly integrate the transformer model trained on enterprise-related data into existing enterprise systems and address real-world use cases. The literature review in
Section 2 shows that the utilization of AI models in real-world applications for enterprise systems is a significant research gap. This section fills up this gap by seamlessly integrating the transformer model into enterprise systems.
4.1. Integration Architecture
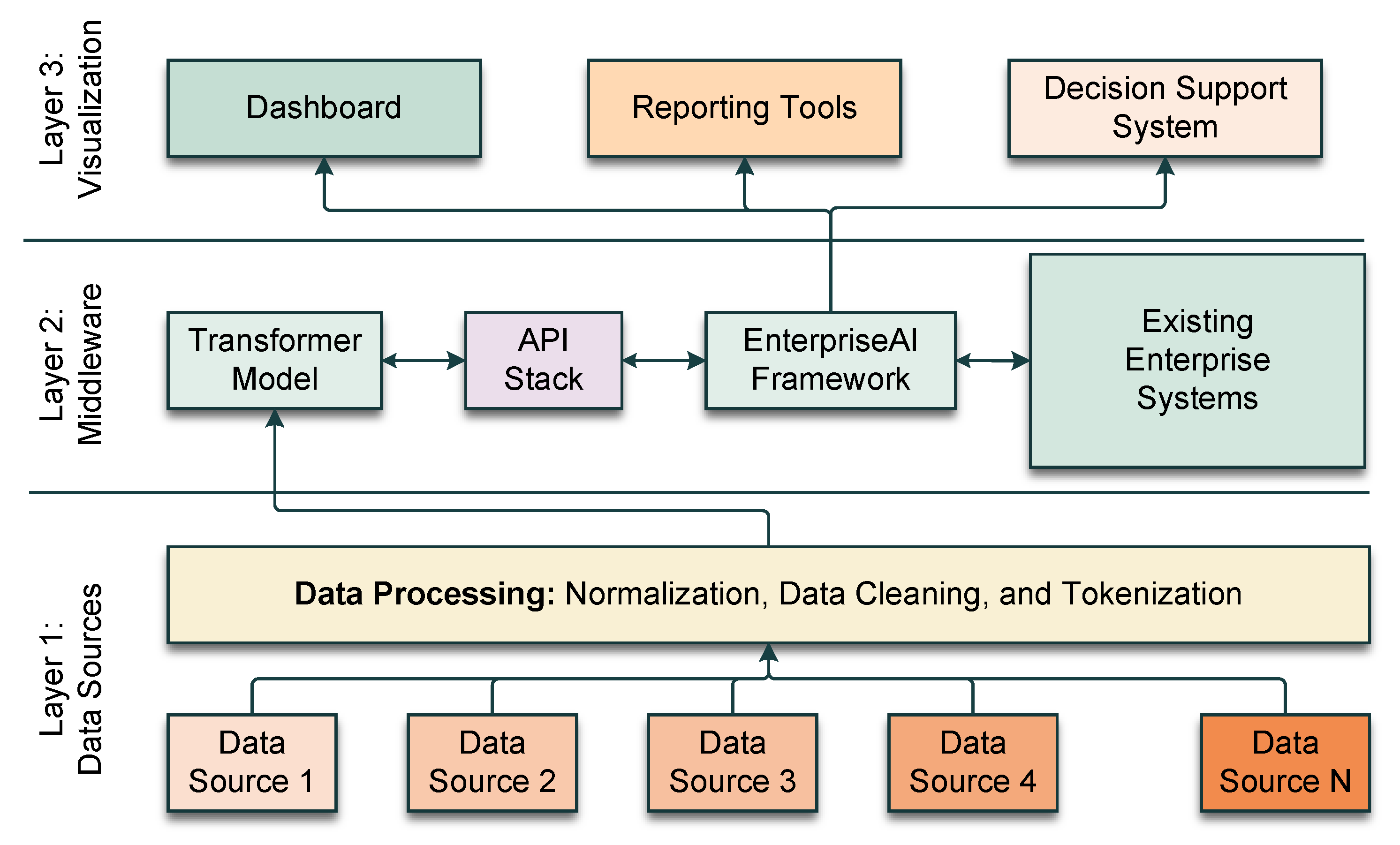
The integration architecture has been developed using layered and modular approaches. A transformer model trained for one enterprise system may not be suitable for another, so it will need to be retrained using the relevant data. The integration architecture has been developed to accept any trained transformer model that starts working immediately. The integration architecture has been developed with three layers, as illustrated in
Figure 2.
The first layer of the integration architecture is the data sources, which can accommodate multiple data sources simultaneously. This layer cleans the data, normalizes them, and covers them into tokens, making them suitable for the second layer. The second layer is the middleware layer, which maintains communication between the transformer and the framework. The third and final layer is the visualization layer, which consists of the dashboards, reporting tools, and decision-making workflows.
4.2. Key Enterprise Applications
The proposed EnterpriseAI has been applied in four different applications. The first application is financial forecasting and risk analysis, the second one is supply chain optimization, the third application is customer experience enhancement, and the fourth application is human resource management. Each application involves different operational variables that the model processes to generate cost-optimized decisions. For example, in supply chain optimization, the key variables are supplier reliability (), inventory levels (), logistics cost (), and demand variability (). The EnterpriseAI framework processes historical financial data and real-time market trends to generate accurate forecasts and identify potential risks. The transformer model captures intricate patterns in the data, providing actionable insights for financial planning and risk mitigation. EnterpriseAI enables real-time analysis of supply chain operations, identifying bottlenecks and optimizing logistics. The model analyzes shipment data, inventory levels, and supplier performance, suggesting cost-effective strategies to enhance operational efficiency. By analyzing customer feedback, support tickets, and interaction histories, the framework generates insights into customer sentiment and behavior. Enterprises use these insights to personalize customer experiences, improve satisfaction, and drive loyalty. The framework assists in workforce planning, recruitment, and retention strategies. It analyzes employee performance data, attrition rates, and industry benchmarks to recommend optimal HR strategies.
4.3. Implementation in Real-World Scenarios
The EnterpriseAI framework has been deployed in a pilot project within a manufacturing multinational corporation. The deployment focused on supply chain optimization and financial forecasting.
Table 4 summarizes the outcomes achieved.
4.4. Input Variables and Relationship Identification
The effectiveness of the EnterpriseAI framework relies on identifying relationships between various enterprise data variables. The transformer model processes structured and unstructured data from multiple sources to derive meaningful cost-saving strategies. The following categories of input variables have been utilized in the cost optimization process:
Operational costs (): Employee workload, task complexity, and automation impact.
Resource utilization (): Labor allocation, equipment downtime, and material usage.
Supply chain factors (): Vendor performance, transportation logistics, and procurement efficiency.
Financial metrics(): Revenue projections, risk exposure, and investment efficiency.
Customer experience (): User satisfaction, service response time, and feedback trends.
These variables are analyzed through transformer attention layers, enabling EnterpriseAI to make cost-optimized recommendations dynamically.
4.5. Challenges and Benefits
The deployment of EnterpriseAI faced several challenges that were effectively addressed to ensure seamless integration and optimal performance. Data inconsistencies, such as missing or erroneous information within enterprise systems, were resolved using preprocessing and imputation techniques. System integration barriers with legacy systems were mitigated by developing custom APIs and middleware components, enabling smooth communication between EnterpriseAI and the existing infrastructure. Performance bottlenecks were addressed by optimizing inference pipelines through batching and asynchronous processing, ensuring the system could meet enterprise-scale demands. Despite these challenges, the deployment yielded significant benefits, including substantial cost savings in supply chain and financial operations, enhanced decision making through real-time analytics and accurate forecasts, improved customer satisfaction and employee retention rates, and remarkable scalability and adaptability across various departments and workflows.
5. Implementation
The proposed
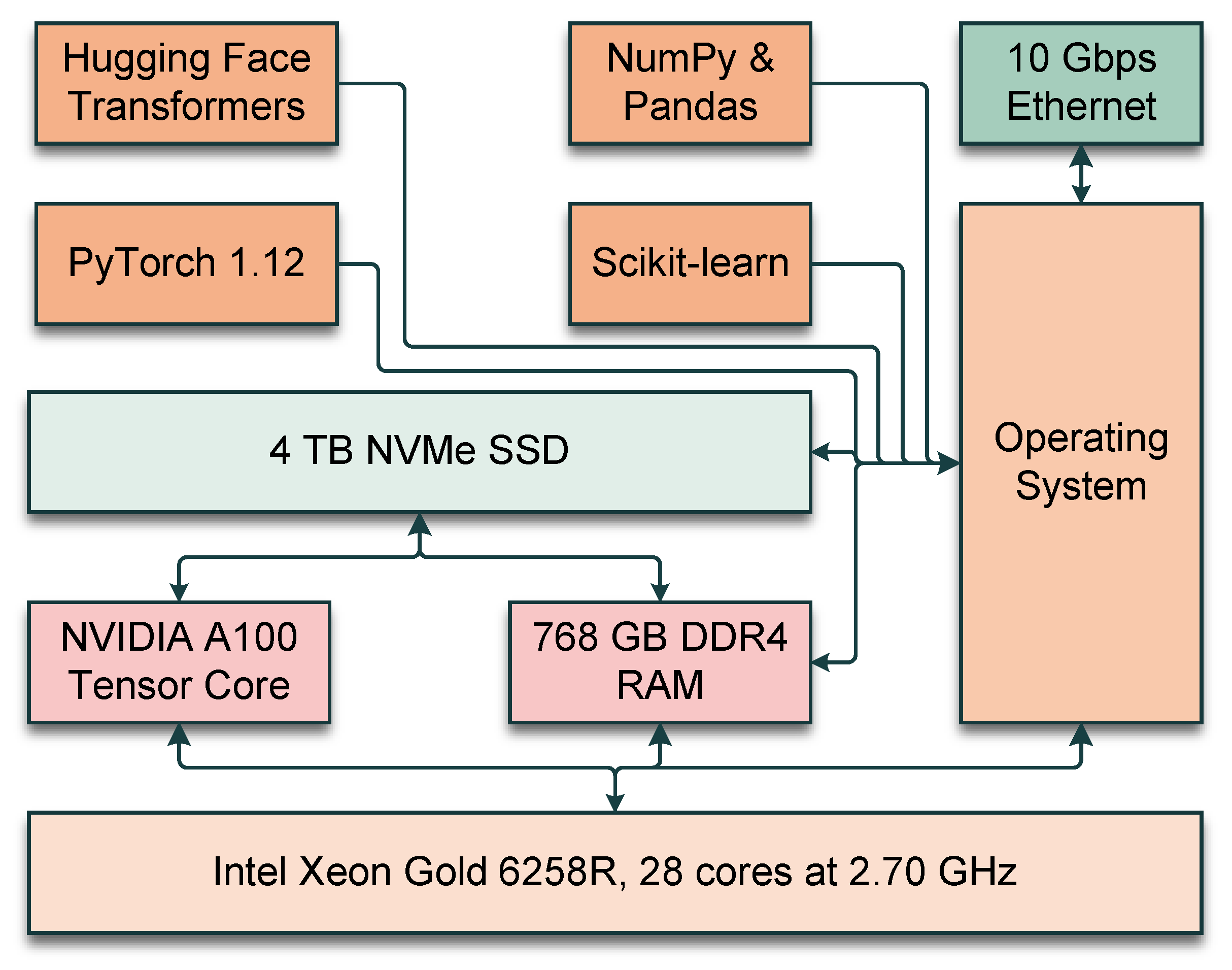
EnterpriseAI framework has been implemented on a robust computational infrastructure so that multiple experiments can be conducted. Moreover, the training requires high computational resources. The hardware used in this study and the software stack utilized have been illustrated in
Figure 3.
5.1. Hardware Configuration and Software Stack
The hardware configuration for this project has been carefully selected to process a massive volume of data for the training and train the transformer model efficiently. Training a transformer model is time-consuming, and the model presented in this paper has been trained after multiple trials and error attempts. That is why hardware configuration with very high computational capability has been selected for this paper. The software stack has been carefully selected, which offers the flexibility to modify the transformer model as necessary. A list of the hardware configurations and software stacks is presented in
Table 5.
5.2. Implementation Workflow
The implementation of EnterpriseAI followed a structured workflow to ensure efficient development and deployment. It has been presented in
Figure 4. It starts with the data preprocessing. After that, the processed data are used to train the model. Before deployment, the inference pipeline has been developed. Finally, the model is deployed using Docker container on Kubernetes clusters.
5.3. Training and Inference Time
The training process for the EnterpriseAI model took approximately 29 h for 145 epochs on the specified hardware. The average inference time for a single query was 95 ms, demonstrating the framework’s suitability for real-time applications. The training and inference time along with other relevant data are presented in
Table 6.
6. Performance Evaluation and Results
The performance analysis of the proposed EnterposeAI framework is categorized into two broad categories. The first category is related to the machine learning performance evaluation. At the heart of this framework is the transformer model, and the transformer model makes every intelligent decision the system makes. That is why the performance of it has been evaluated from the machine learning performance evaluation perspective. The second category is the performance evaluation, which involves the feasibility of the approach.
6.1. Evaluation Metrics
To evaluate the performance of the transformer model from the machine learning performance perspective, the accuracy, precision, recall, and F1-score were used. These performance metrics are defined in Equations (
18), (
19) and (
20), respectively. These metrics are dependent on true positive (TP), true negative (TN), false positive (FP), and false negative (FN). These values have been obtained from the confusion metrics analysis [
37,
38].
Along with other evaluation metrics, the perplexity score has been used to evaluate the ability of the transformer model to generate meaningful results, which is defined in Equation (
22), where
represents the cross-entropy between the true distribution
P and the predicted distribution
.
6.2. Confusion Matrix Analysis
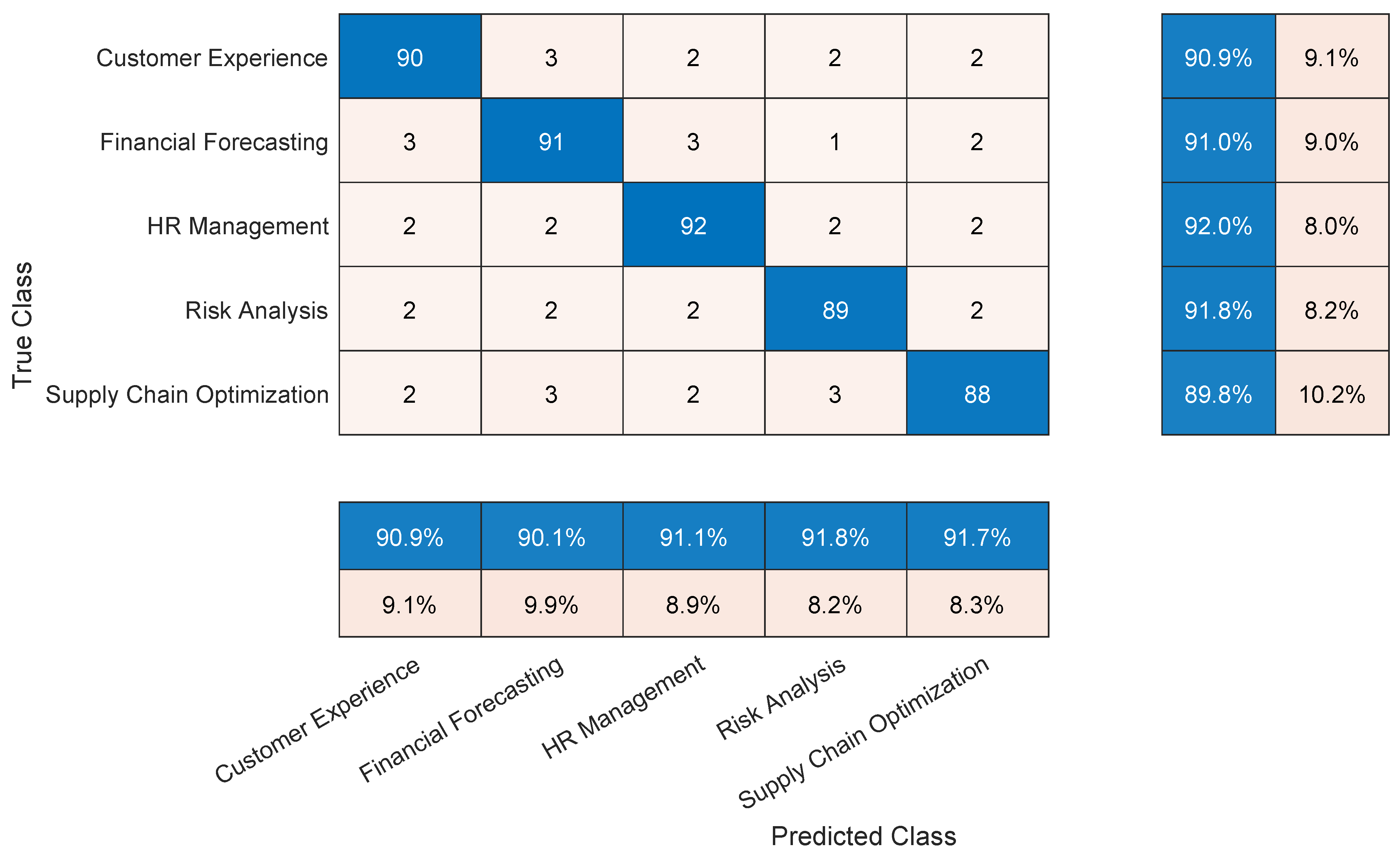
There are a total of 271 pages in the test dataset, which consists of 135,600 words. To evaluate the performance of the proposed transformer model, 400 paragraphs were randomly picked from the testing dataset. After that, these paragraphs were manually labeled according to their subject into one of the following categories: Financial Forecasting, Risk Analysis, Supply Chain Optimization, Customer Experience, and Human Resource Management. After that, the ability of the transformer model to accurately classify the paragraphs was evaluated. The confusion matrix illustrated in
Figure 5 shows the classification performance of the transformer model. According to the confusion matrix analysis, the overall accuracy, precision, recall, and F1-score are 91.09%, 91.10%, 91.09%, and 91.09%. These values indicate that the transformer model is well-trained and capable of understanding the content correctly.
6.3. k-Fold Cross-Validation
To further validate the performance of the transformer model,
cross-validation has been performed with
. The cross-validation has been performed on the test dataset. The findings have been presented in
Table 7. The
cross-validation further validates the performance and consistency of the transformer model trained in this paper.
The consistency in performance discovered through the k-fold cross-validation has been visually presented in
Figure 6 to explore the variations in performance at different folds. The value range in this figure is from around 90% to 91.8%. That means the variation is marginal, which again suggests that the proposed transformer model is capable of maintaining consistent performance.
6.4. Scalability and Resource Utilization
Depending on the demand and number of users, queries made by the enterprise systems can significantly vary. That is why the framework must be scalable. It is a mandatory requirement to consider the proposed framework as a feasible solution. The scalability is directly associated with the resource utilization. A scalability test has been performed that relates to resource utilization as well. The results obtained from the test have been presented in
Table 8.
Figure 7 demonstrates the scalability range. The maximum response time of the system is 350 milliseconds, which is for the maximum number of queries. This is the threshold, and beyond it, the system fails to maintain acceptable performance. The system utilizes a moderate volume of computational resources to process 100 simultaneous queries. Although no significant performance deviation is noticeable for 101 to 200 queries, the GPU utilization touches 85% at this level. Going beyond it occupies 80% CPU and 90% of the GPU, leaving limited resources for the other core operations. That means the proposed system is scalable for up to 200 queries at a time.
6.5. Workflow Optimization
The EnterpriseAI framework significantly improved workflow efficiency across various enterprise functions. By automating repetitive tasks, streamlining resource allocation, and providing data-driven insights, the system optimized key performance indicators (KPIs) for workflow efficiency.
Table 9 presents a comparison of workflow metrics before and after implementing the EnterpriseAI framework.
Figure 8 highlights substantial improvements in workflow metrics. Task completion time was reduced by 33.3%, while resource utilization efficiency increased by 30.8%. Furthermore, the error rate decreased significantly by 66.7%, contributing to a 50.0% improvement in project delivery rate. The customer satisfaction score also increased by 15.4%, demonstrating the positive impact of EnterpriseAI on overall workflow performance. By automating data processing and leveraging intelligent recommendations, EnterpriseAI allowed enterprise systems to operate more efficiently, reduce manual interventions, and achieve higher operational excellence.
6.6. Business Cost Optimization
The EnterpriseAI framework significantly contributes to optimizing business costs by automating manual tasks, minimizing resource wastage, and reducing error rates. By leveraging intelligent data processing and real-time insights, the system enables enterprises to cut operational expenses while improving overall efficiency.
Table 10 highlights the cost optimization achieved in different operational areas.
Table 10 demonstrates the significant cost savings achieved across various operational areas. Manual effort costs were reduced by 58.3%, error and rework costs decreased by 66.7%, and inefficiencies in resource allocation saw a reduction of 60.0%. Additionally, the system shortened project durations by 30.0% and reduced unforeseen expenses related to risk mitigation by 50.0%.
These improvements highlight the system’s ability to optimize business costs effectively, providing enterprises with a scalable and cost-efficient solution for operational management.
7. Limitations and Future Directions
While the EnterpriseAI framework demonstrates significant potential in optimizing enterprise operations, several limitations and areas for improvement have been identified. This section outlines these limitations and discusses potential future directions to enhance the framework.
7.1. Limitations
7.1.1. Dataset Generalization
The current model relies on a dataset specifically tailored for enterprise use cases; while it is effective for the tested scenarios, the dataset lacks diversity across different industries and regions. This limitation may hinder the framework’s adaptability to niche or highly specialized enterprise domains.
7.1.2. Computational Complexity
The EnterpriseAI framework employs a transformer model with a large number of parameters, making it computationally intensive. The high resource requirements for training and inference may pose challenges for deployment in resource-constrained environments.
7.1.3. Interpretability
Like most transformer-based models, EnterpriseAI functions as a black-box system [
39]. The lack of interpretability limits the ability to understand why specific decisions or predictions were made, which is critical for trust and transparency in enterprise applications.
7.1.4. Real-Time Adaptability
The framework is static in its current form, relying solely on pre-trained knowledge. It cannot dynamically adapt to real-time changes in enterprise operations or rapidly evolving market conditions, which could limit its effectiveness in highly dynamic environments.
7.1.5. Scalability Bottlenecks
While the framework performs well under moderate workloads, scalability to extremely high query loads introduces minor latency increases [
40]. Further optimization is needed to ensure consistent performance in large-scale, high-demand enterprise systems.
7.2. Future Directions
7.2.1. Dataset Expansion and Diversity
Future work will focus on constructing a more diverse and comprehensive dataset that spans multiple industries, geographies, and operational contexts. This will improve the framework’s adaptability and generalization capabilities.
7.2.2. Model Compression and Optimization
To address computational complexity, techniques such as model pruning, quantization, and knowledge distillation will be explored. These techniques can reduce model size and resource requirements while maintaining performance.
7.2.3. Explainable AI (XAI) Integration
Integrating explainable AI techniques into the framework will enhance its interpretability. Approaches such as attention visualization, feature attribution, and decision tracing will be employed to provide insights into the model’s decision-making process.
7.2.4. Real-Time Learning and Adaptation
Incorporating online learning mechanisms will enable the framework to update its knowledge base in real-time. Techniques like incremental learning and continual learning will be explored to allow the model to adapt to dynamic enterprise environments.
7.2.5. Edge Deployment for Resource-Constrained Environments
Future iterations of the framework will explore deployment on edge devices, enabling it to operate efficiently in resource-constrained environments. Lightweight model architectures and optimized inference pipelines will be developed for this purpose.
7.2.6. Enhanced Scalability for High-Demand Applications
Scalability improvements will focus on advanced distributed computing techniques, including sharding, micro-batching, and asynchronous query processing. These enhancements will ensure consistent performance under high-demand scenarios.
7.2.7. Enterprise-Specific Customizations
Future versions of the framework will include customizable modules tailored to specific enterprise needs. This could involve fine-tuning the model for industry-specific terminology, workflows, and regulations.
7.3. Collaborative Research Opportunities
Collaboration with industry partners and academic institutions will be pursued to benchmark the framework against real-world datasets and scenarios. Such partnerships will also provide valuable feedback to refine and extend the system’s capabilities.
7.4. Long-Term Vision
The long-term vision for EnterpriseAI is to create a fully autonomous enterprise assistant that can seamlessly integrate with existing systems, adapt to real-time changes, and provide actionable insights with minimal human intervention. Achieving this vision will involve a combination of AI advancements, robust data pipelines, and close collaboration with stakeholders.
The identified limitations and proposed future directions provide a roadmap for advancing the EnterpriseAI framework, ensuring its continued relevance and effectiveness in addressing the evolving challenges of enterprise operations.
8. Conclusions
The EnterpriseAI framework presented in this paper offers a scalable, efficient, and intelligent solution for enterprise systems, addressing critical challenges in data-driven decision making, resource optimization, and operational efficiency. Built upon a transformer-based architecture, the framework demonstrates exceptional capabilities in handling complex enterprise processes, delivering real-time insights, and significantly reducing operational costs.
The performance evaluation validates the framework’s robustness and reliability, with high accuracy, precision, recall, and F1-scores across various tasks, including phase classification and priority prediction. The successful deployment in enterprise use cases, such as financial forecasting, supply chain optimization, and customer experience enhancement, highlights its practical relevance and business impact. Moreover, the framework’s scalability and efficient resource utilization make it well suited for diverse enterprise environments.
Despite its promising performance, the study acknowledges several limitations, including dataset generalization, computational complexity, and interpretability challenges. These limitations present opportunities for future research and development, focusing on enhancing adaptability, reducing resource requirements, and integrating Explainable AI techniques. Additionally, the proposed directions for real-time learning, edge deployment, and industry-specific customizations will further refine the framework and extend its applicability.
In conclusion, the EnterpriseAI framework represents a significant advancement in the application of AI to enterprise systems. By leveraging state-of-the-art transformer models, it provides a powerful tool for enterprises to optimize operations, improve decision making, and achieve strategic objectives. With continued research and development, this framework has the potential to redefine enterprise processes and contribute to the future of intelligent and autonomous enterprise systems.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}